
Abstract
In the recruitment process, manually selecting suitable candidates from curriculum vitae (CVs) for a job description (JD) is both time-consuming and expensive. Traditional keyword-based methods struggle to capture skill semantics, prompting the development of more advanced JD-CV matching systems. This paper aims to investigate and construct an ontology-based skills recommendation system, with objectives including creating a skills ontology and developing skills matching methods for JD-CV pairs. The objective of our approach is to enhance the accuracy and contextual relevance of recommendations by utilizing the proposed score. The proposed skills ontology and skills matching strategies are applied to a real dataset in Vietnam. The results of our study can automatically recommend a list of CVs for a given JD. Furthermore, the findings indicate that our proposed model surpasses comparative approaches by a margin of at least 1% to 5%. Overall, the study demonstrates the potential of utilizing ontology-based approaches to offer a practical solution for enhancing hiring practices.
Introduction
Nowadays, the demand for hiring fitting candidates for specific job positions is increasing .1
ManpowerGroup’s 2024 Global Talent Shortage Survey.
LinkedIn Statistics 2023.
The manual selection of candidates during recruitment can be time-consuming and laborious. The conventional method of keyword-based searching fails to capture the semantics (Negi and Kumar, 2014) and complexities of skills, resulting in unsuitable matches. Therefore, many matching systems between JDs and CVs have been developed.
JD-CV matching systems (recommendation systems) are intelligent technologies that help recruit talent by identifying the best candidates for a specific job role. There are four main types of recommendation systems:
Content-based system: A content-based recommendation system focuses on the attributes and characteristics of the CVs and JDs (Francis C. Fernández-Reyes, 2019; Najjar et al., 2022).
Collaborative filtering system: It relies on the behaviour and preferences of multiple users to make recommendations. In JD-CV matching, collaborative filtering can analyze the interactions between CVs and JDs (Cabrera-Diego et al., 2019).
Knowledge-based system: A knowledge-based recommendation system, known for ontology technologies, leverages domain-specific knowledge, such as industry standards, job requirements, and qualifications (Guo et al., 2016).
Hybrid system: A hybrid recommendation system combines multiple recommendation approaches to provide more accurate recommendations (Wang et al., 2022; Huang et al., 2023).
Each method has its merits and there is no one-size-fits-all approach. In this paper, an ontology-based matching system between JDs and CVs is investigated since it offers several benefits:
Ontology-based methods enable semantic understanding of data (Grimm et al., 2011; Embley, 2004), ensuring that matches are not solely based on exact keyword matches but consider the relevance and relatedness of concepts, leading to meaningful matches.
Ontologies are designed to be flexible and extensible (Zhao and Meersman, 2005), allowing for the addition of new skills as the job market evolves. This adaptability ensures that the matching system remains up-to-date and relevant over time.
Ontologies can be developed with input from domain experts, ensuring that the matching process aligns closely with industry-specific requirements (Tang et al., 2023).
The paper is structured as follows: Section 1 provides a broad perspective of the research and outlines the core issue addressed. Section 2 analyzes some related works. Section 3 introduces the conceptualization of ontology and its application in constructing a skills ontology. Additionally, it describes the methods for skills matching. Section 4 is the practical implementation and outcomes of experiments on real datasets. Our conclusion is described in Section 5.
JD-CV matching
Talent acquisition is a significant, intricate, and time-consuming task in human resources (HR) (Derous and De Fruyt, 2016). In addition, there is a substantial number of employees stepping in and out each month. For example, in the United States alone, in April 2024, there were 5.64 million hires and 5.37 million separations, reflecting significant workforce movement.3
Statista’s monthly job hires and separations in the United States.
Summary of previous literature on JD-CV matching and skills matching
There are several JD-CV matching methods. Previous studies have incorporated JD-CV matching systems using a content-based approach. Francis C. Fernández-Reyes (2019) focused on training the hybrid word embedding space to better represent JDs and CVs. To be more specific, they trained a word embedding space and prepared another pre-trained space to make a hybrid word embedding space. Three techniques including word embedding addition, linear combination and selection were utilized to create the hybrid space. Then CVs and JDs were both mapped to the corresponding average word embeddings and then they were used to compute ranking scores, using the cosine similarity. Besides, Najjar et al. (2022) suggested an intelligent decision support system (I-Recruiter) to rank CVs. The recommender system includes (i) a training block to train word embeddings, (ii) a matching block to match between JDs and CVs using cosine similarity, and (iii) an extracting block to retrieve the details of top-ranked CVs. Nevertheless, word embeddings failed to incorporate semantic information and were not considered historical data, potentially leading to adverse effects on the output of the system.
On the other hand, Cabrera-Diego et al. (2019) utilized a collaborative-centered approach and proposed two novel methods for evaluating CVs without relying on job offers or any semantic resources, namely Inter-Résumé proximity and Relevance feedback. Inter-Résumé proximity refers to the lexical similarity observed among CVs for a specific JD, while Relevance feedback is a means to enhance the ranking of CVs. The application of Relevance feedback involves the utilization of techniques that rely on similarity coefficients and vocabulary scoring. Nevertheless, due to the semantic independence of this approach, the ranking of CVs or more specifically, the scores of CVs do not accurately represent the compatibility between CVs and JDs.
Other studies employed a knowledge-based method to address the JD-CV matching process. Guo et al. (2016) introduced RésuMatcher, a personalized job-résumé matching system that extracts information from JDs and CVs and constructs a domain-specific ontology for skills. The system subsequently employs a unique statistical similarity measure to compute the degree of similarity between JDs and CVs. However, the assessment was performed on a limited dataset and only a single-domain ontology was constructed. Hence, numerous domain-specific ontologies are an essential expansion to better and effectively incorporate JDs and CVs from various domains (i.e. other skills and disciplinaries).
Recently, hybrid ontology methods have gained more attention in the science community. Wang et al. (2022) are the pioneers in incorporating graph neural networks into the person-job fit task, thereby introducing a novel approach to modelling the experience of recruiters. They established PJFCANN (Person-Job Fit from candidate profile and related recruitment history with Co-Attention Neural Networks) – a model considering both JDs and CVs content and the successful matches in the past. When provided with a given targetted CV-job post pair, PJFCANN initially generates local semantic representations using a Recurrent Neural Network (RNN). Simultaneously, it generates global experience representations for the pair from historical actual employment records, using a Graph Neural Network (GNN). Consequently, the ultimate matching degree is computed by concatenating these two representations. Though the model is robust, it heavily depends on historical data and more semantic information should be incorporated. Huang et al. (2023) also attempted hybrid methods and used neural networks and integrated historical recruitment data in their model, Attentive Implicit Relationship-Aware Neural Network (AIRANN). ALBERT and TextCNN were used to represent text features while the co-attention mechanism was used to represent non-text features. Additionally, hired CVs also contributed to the overall representation via an implicit relationship mechanism. Three of them were aggregated using an aspect-attention mechanism and then went through a prediction layer to generate a final prediction.
The research on recruitment is always developed with the aim of improving the match between employers’ skills and job requirements quickly and accurately. Recent research in the field of HR has been increasingly developed to improve the match between candidates and job requirements. Research focuses mainly on the quantitative relevance of candidates’ skills, including soft skills (Fareri et al., 2021) and expert-level skills (Fallahnejad and Beigy, 2022).
The above studies focus mainly on the amount of skills included in a candidate’s profile and their compatibility. The approaches are also very diverse such as using text mining (Fareri et al., 2021) to help extract skills, or more complex using deep learning networks combined with attention technology to get similarities between two different CVs (Fallahnejad and Beigy, 2022; Wang et al., 2022).
Fallahnejad et al. approached the issue by leveraging context-aware data to identify semantically related translations for skills or by employing machine translation models to bridge the semantic gap between applicants and skills (Fallahnejad and Beigy, 2022). The models mentioned above have partially solved the issue of locating qualified applicants and have also demonstrated the significance of skill fields in the process in large part due to their vast number of skills and ongoing updates and also specifically identified how appropriate the application is for the position.
Ontology-based approach
The application of the ontology-based approach is widespread across various disciplines due to its provision of a formal representation and semantic lucidity. Zaouga et al. (2019) suggested employing an ontological methodology to construct a unified and shared representation within the field of human resource management (HRM) domain. Following the ontology development process, the authors built a human resource ontology named HR-Ontology. The HR-Ontology provides a structured and universally accepted lexicon of HRM processes and concepts to address the knowledge gap. It also lets us evaluate each offer role based on skills, authority, and other factors. The proposed ontology allows for the development of decision support systems that improve human resource management.
On the other hand, Lv and Peng (2021) focused on ontology matching. The primary contribution of this article lies in the introduction of a novel periodic learning ontology matching model based on an interactive grasshopper optimization algorithm. This model incorporates user engagement and regular feedback to enhance the accuracy of the matching process. The authors additionally present the roulette wheel method, for selecting the most challenging mappings, and mechanisms for rewarding and punishing in order to effectively disseminate user feedback to the evolving population. The model was examined using two interactive tracks from the Ontology Alignment Evaluation Initiative and it is expected to facilitate enterprises in achieving harmonization of product catalogues and enhancing data integration.
Ntioudis et al. (2022) shared the same interest with our research when they developed an ontology-based personalized job recommendation framework for migrants and refugees. The framework uses an ontology to semantically represent the CV of an applicant, which is a migrant or refugee, and the details of a JD. It also includes a matchmaking service that provides relevant job recommendations considering the full CV of a job seeker and the details of the available jobs. They also utilized Simple Protocol and RDF Query Language (SPARQL) (Harris and Seaborne, 2013) to give suitable recommendations. However, the framework was experimented on a limited dataset with only 100 JDs and 30 CVs of migrants and refugees.
Recently, semantic retrieving has received more attention. Sharma and Kumar (2023) devised a semantic knowledge-based retrieval system to overcome challenges encountered in previous approaches, including limited vector dimensions and prolonged execution time. The unique point in this model is using a word2vec model enhanced by Horse Herd Optimization (HHO). This integration was used to support the accuracy level performance of the information retrieval system, which aids in the extraction of vectors as features for classification. Summary of previous literature on ontology-based approach is described in Table 2.
Summary of previous literature on ontology-based approach
Summary of previous literature on ontology-based approach
Skills ontology
Based on a skills taxonomy, a skills ontology can be built. Gallagher et al. (2022) constructed a UK skills taxonomy, extracted from over 100,000 JDs in the UK in 2022 with four levels. Using this result, an ontology for skills is built.
A skills ontology can be defined as the following tuple:
In this part, techniques to match skills between a JD and CVs, namely cosine similarity and semantic similarity are discussed.
Cosine similarity
The most common approach is to use cosine similarity or its variants to evaluate skills in CV and JD. In this paper, a cosine similarity-based approach is introduced. Note that, this approach is the most common, however, it is not an ontology-based approach.
First, the “closeness” between pairs of skills is calculated. The idea is that if two skills are related, it is highly likely to appear in the same JD. Thus, a count matrix is built to record the appearance of every skill in all JDs in the dataset.
Given
From matrix

Constructing matrix of cosine scores between skills
Algorithm 1 describes how to construct matrices
For arbitrary

Cosine similarity
Algorithm 2 shows the cosine similarity approach. In general, it is clear that cosine similarity is easy to implement and not related to
With the aim of using the semantics of skills, the
Before the semantic similarity is introduced, first, the
To find

Dijkstra’s algorithm to find the shortest path

Semantic similarity
Finally, for arbitrary
Algorithm 4 describes the complete semantic similarity approach to calculate the skill score between
Proposed semantic similarity
To better the semantic similarity introduced in 3.2.2, an improved version is suggested. Instead of converting an ontology to a graph and then using Dijkstra’s method, the
First, consider the situation shown in Fig. 1. In this case,
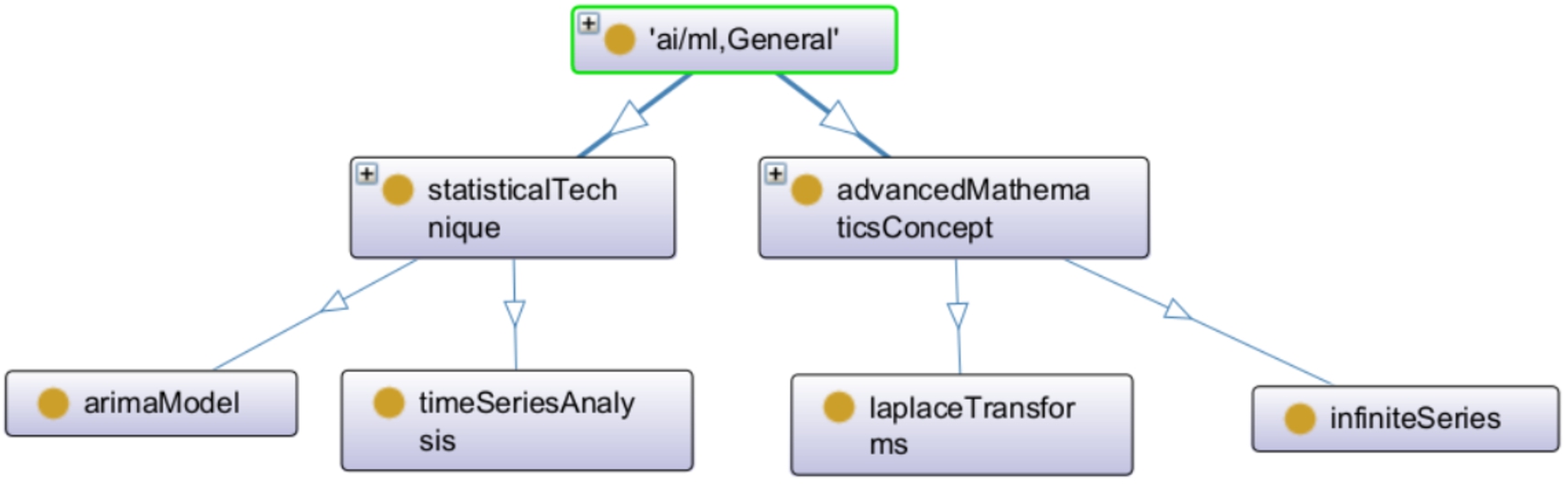
An example leads to the improved semantic similarity.
The proposed version originates from the idea that it only matters if two skills have the relationship
Let
To find
First, as presented in Definition 1, each class has a label corresponding to its exact English name. For example, a class displaying
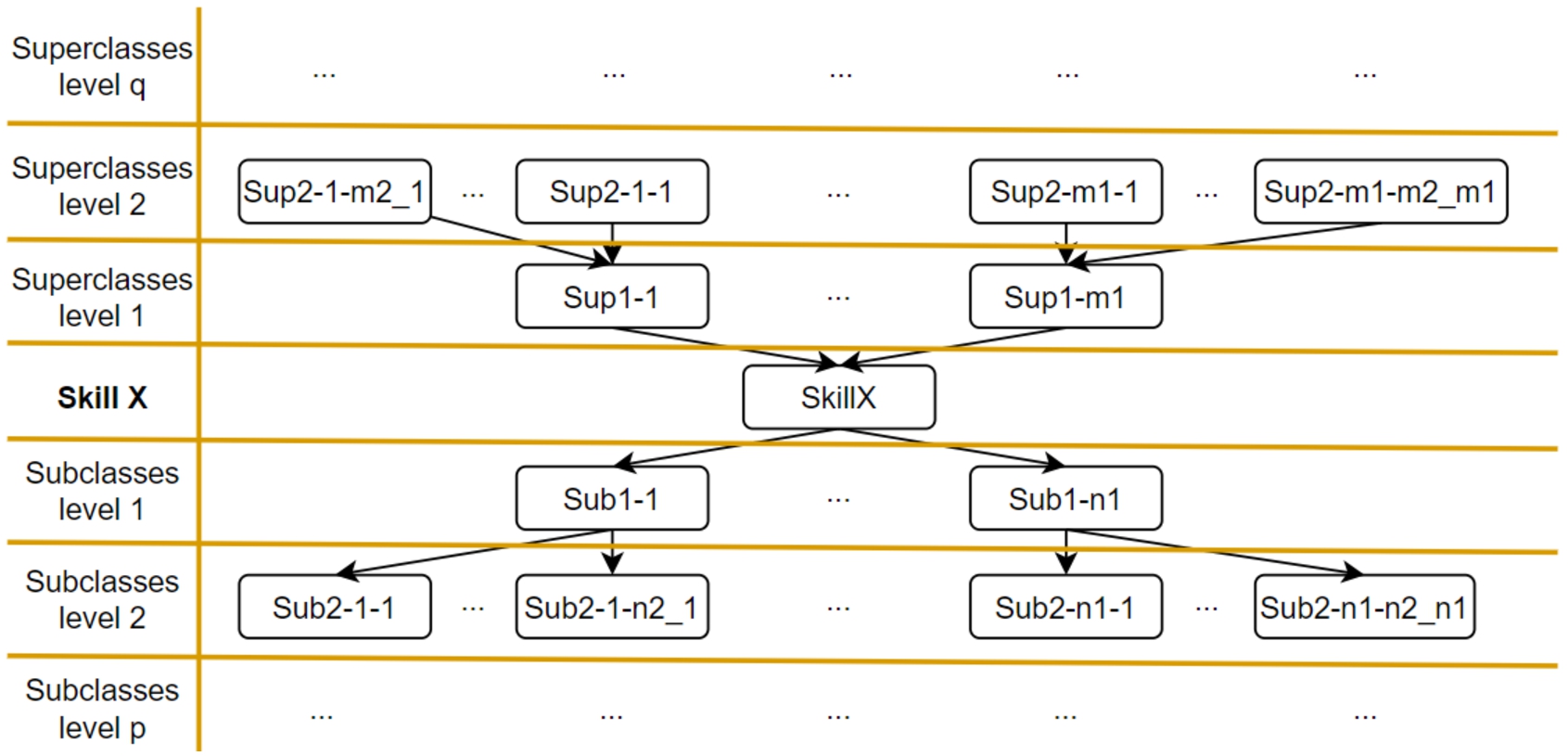
Subclasses and superclasses of
Let QSub_1(“name of skill”) denote the query in SPARQL for finding subclasses (subskills) level 1 of an arbitrary skill. Class
A package for manipulating OWL 2.0 ontologies in Python.
Similarly, QSub_1(“name of skill”), QSub_2(“name of skill”), … are defined and they are queries for finding subskills level 1, 2, … of an arbitrary skill.
The same scenario is applied to find superclasses (superskills) of a random skill. Let QSup_2(“name of skill”) denote the query in SPARQL for finding superskills level 2 of an arbitrary skill. QSup_2(“skill X”) can be shown as:
Consequently, QSup_1(“name of skill”), QSup_2(“name of skill”), … are queries for finding superskills level 1, 2, … of an arbitrary skill.

Finding superskills and subskills in 3 levels using SPARQL
Algorithm 5 computes all superskills and subskills of every skill in a CV and adds them to the corresponding levels, from 1 to 3, as the
For arbitrary
Algorithm 6 displays the complete version of the proposed semantic similarity to calculate the score between

Proposed semantic similarity
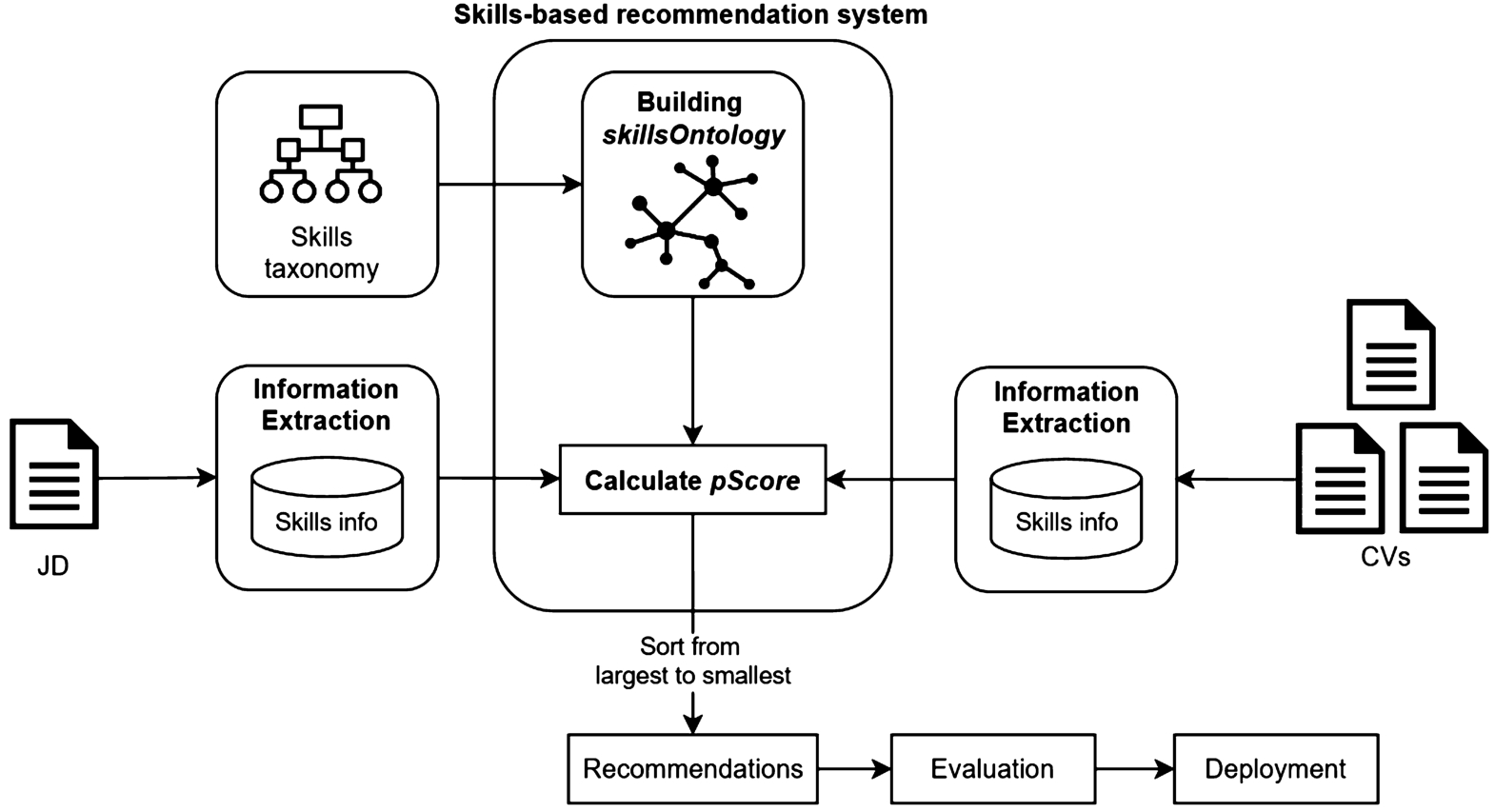
Proposed skills-based recommendation system.
Figure 3 describes the proposed system to recommend CVs for JDs. First, a
Dataset
The dataset includes JDs and CVs collected in Vietnam, available in https://github.com/anhnguyenthingoc/Ontology-based-skills-matching. In each JD, there is “required_skills”, a list of required skills for that position. Each CV includes “skills”, a list of skills that an applicant has. There are 1200 pairs of JD-CV and they are divided into 6 datasets. Each JD-CV pair is labelled with 1 if it is a successful pair and 0 otherwise. For each JD, there is only one successful CV and vice versa, for each CV, only one JD is suitable. Note that for each JD in the dataset, there is only one successful CV and nine failed CVs.
Evaluation metrics
Mean Average Precision@K (MAP@K)
MAP@K calculates the average precision across all JDs. Let
Normalized Discounted Cumulative Gain@K (NDCG@K)
NDCG@K measures the quality of top K recommendation CVs for a given JD by considering both the relevance of the CVs (successful or unsuccessful CVs) and their positions in the ranked list. NDCG@K is calculated based on Discounted Cumulative Gain@K (DCG@K) and Ideal Discounted Cumulative Gain@K (IDCG@K):
Results
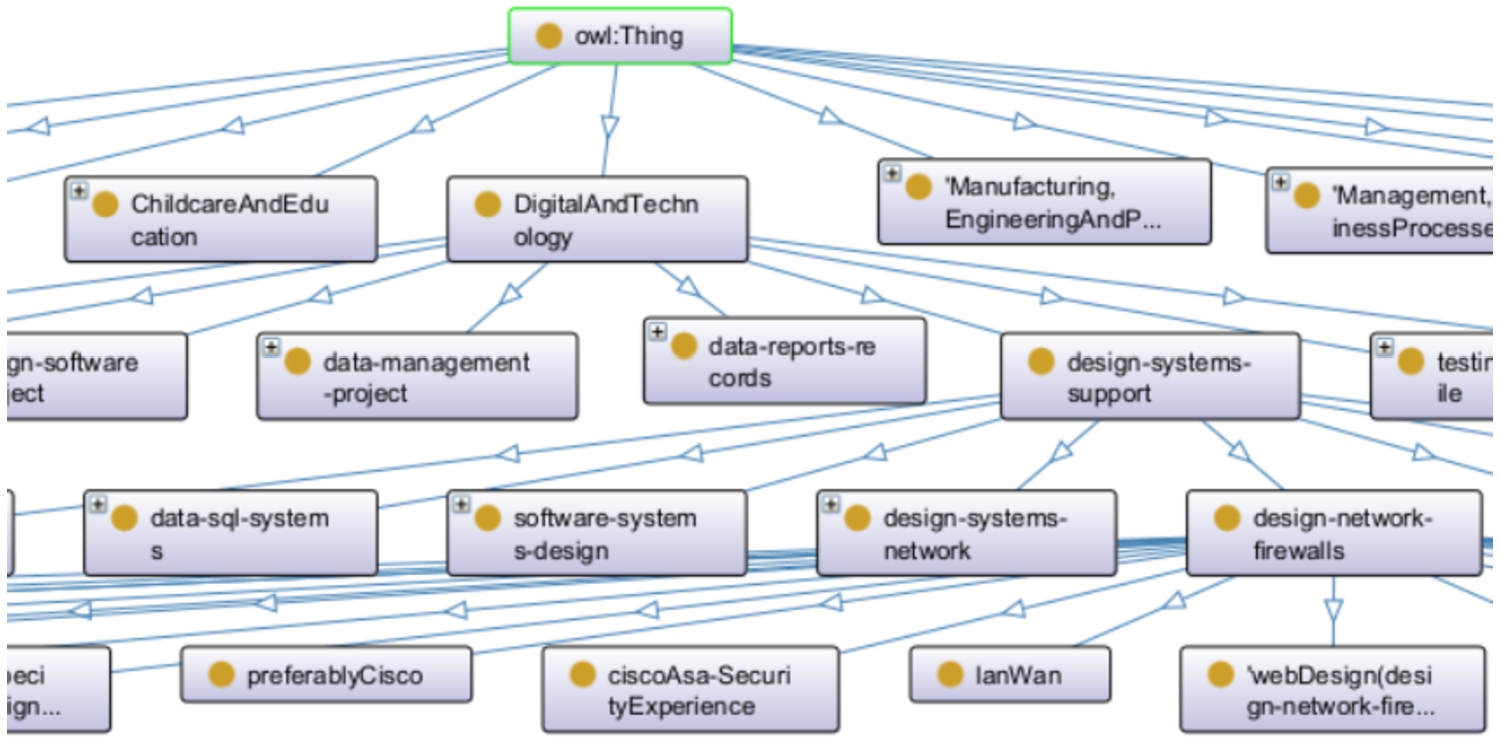
Example of
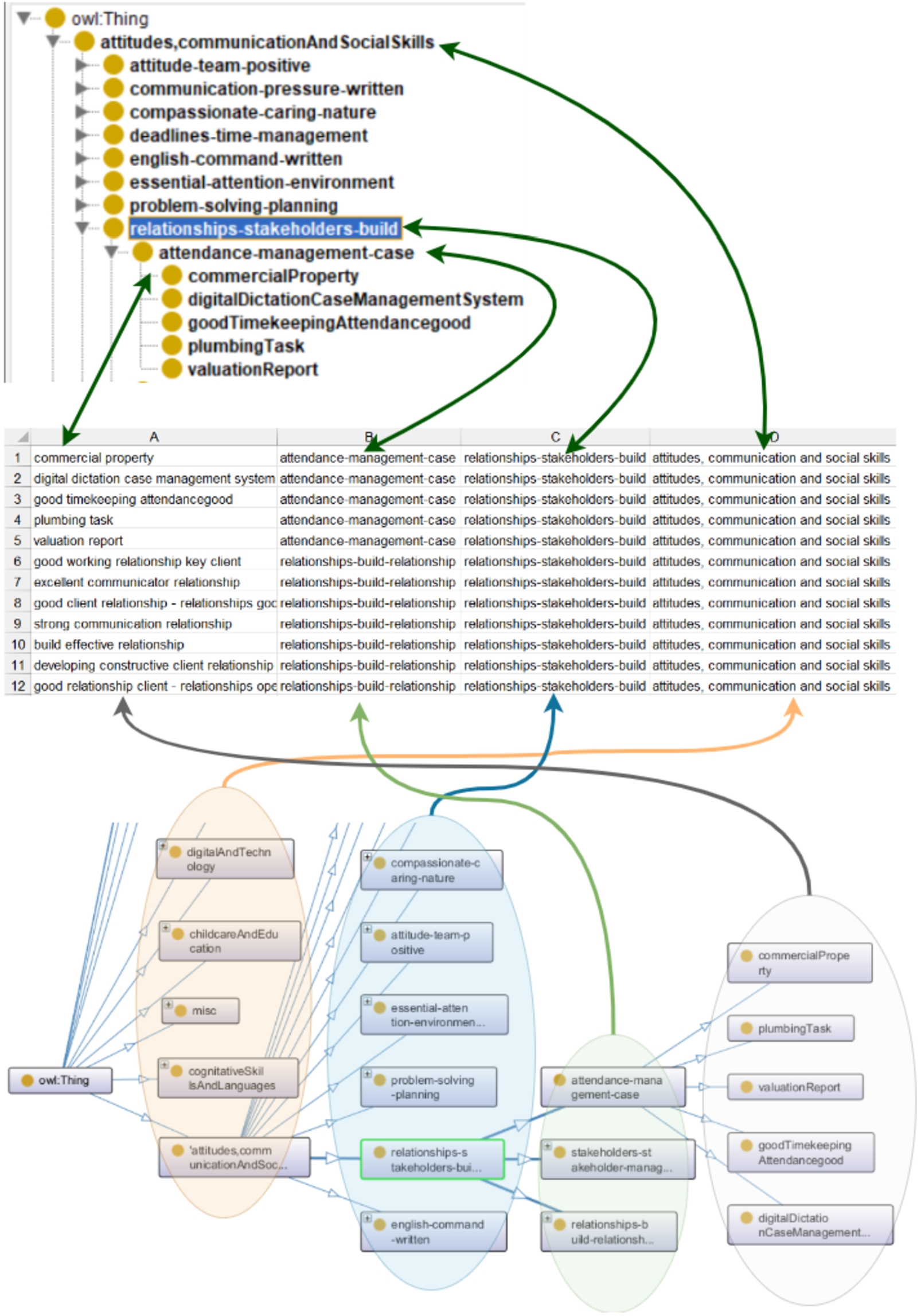
Mapping of the UK skills taxonomy to the
As stated before, the UK skills taxonomy (Gallagher et al., 2022) is used to create
Figure 4 describes the
Figure 5 shows the mapping of the UK skills taxonomy to the
After the
Result conducted in Google Colab with Intel(R) Xeon(R) 2.20 GHz and 16 GB RAM.
The table provided in Table 3 presents a summary of the overall recommendation outcomes, with the most successful metrics emphasized in bold. Despite pScore’s not faster running speed compared to cScore, it is only one-fifth of sScore’s speed and produces the most optimal outcomes. The metrics consist of the mean values of cScore, sScore, and pScore, each accompanied by their respective standard deviations. Additionally, the precision metrics (MAP@1, MAP@3, and MAP@5) and Normalized Discounted Cumulative Gain (NDCG@3, NDCG@5) further confirm the model’s exceptional quality. The precision metric, specifically MAP@5, demonstrates exceptional performance with a value of
Main contributions
Our main contribution is an ontology-based skills-matching system for Job Descriptions (JDs) and Curriculum Vitae (CVs), in which we (i) build a skills ontology and (ii) suggest a semantic skills-matching utilizing SPARQL. This approach has clear benefits, particularly its ability to provide a semantic comprehension of deep knowledge skills that surpass superficial skill keywords. The inherent flexibility of ontology-based skills matching enables the incorporation of a wide range of job requirements and candidate qualities. Moreover, the system’s ability to reason improves the accuracy of matching, leading to more precise and contextually aware outcomes. The outcomes of the proposed model demonstrate outstanding performance across various criteria, showcasing an average improvement ranging from
Overall recommendation result with the best results bold. The proposed model is superior performance on average from 1% to 5 %
Overall recommendation result with the best results bold. The proposed model is superior performance on average from 1% to 5 %
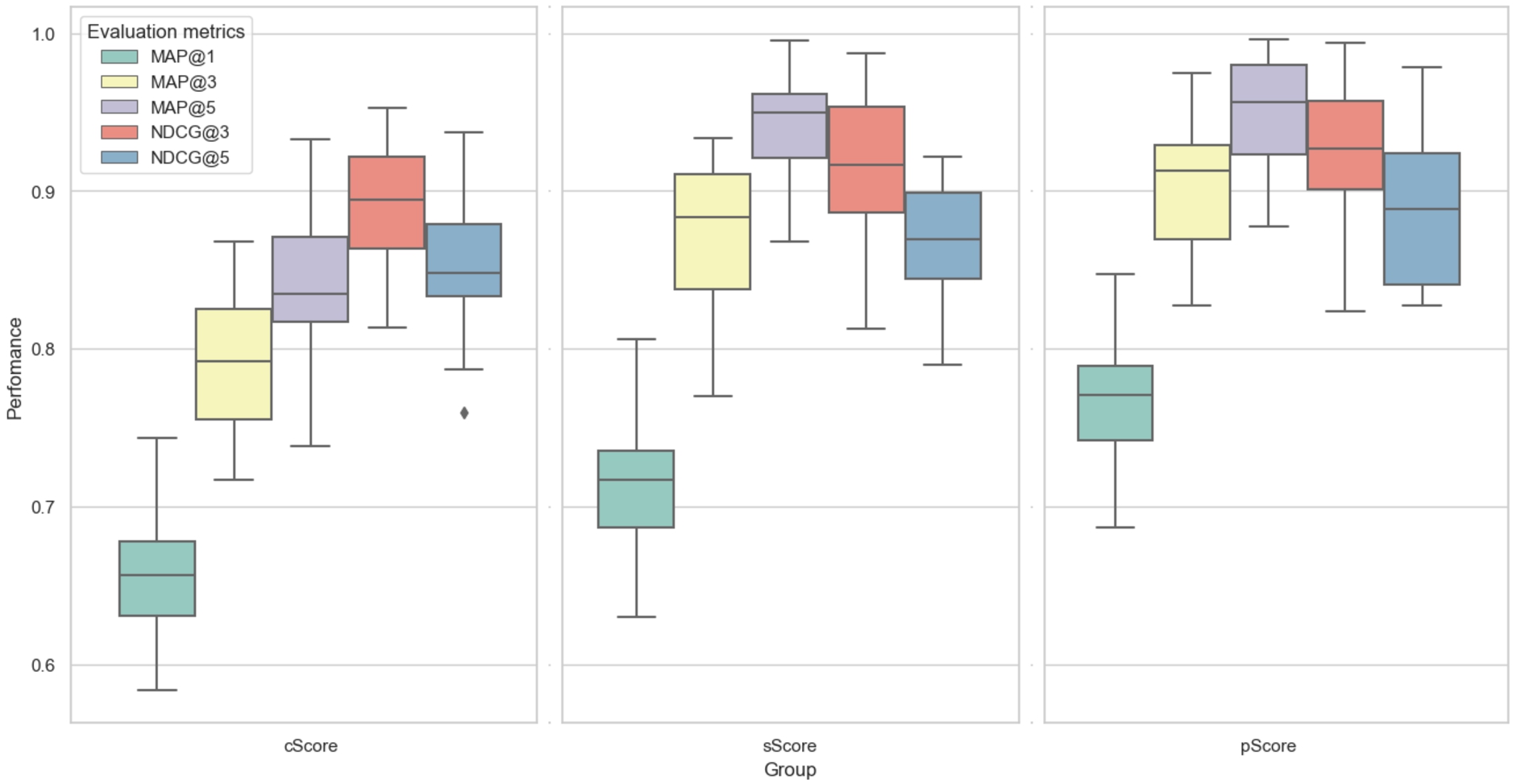
Results of the proposed model and other competitive models.
As the results from the proposed system are promising, it should be implemented for future practical use. To work in practice, the proposed system utilizes RDF stores by Apache Jena Fuseki, specifically designed for efficiently storing and querying large RDF graphs, ensuring the system’s scalability in the real world. In reality, there are a huge number of JDs and CVs, therefore, it is necessary to have a better configuration server than the configuration in the experiment to meet the actual needs. We suggest using a hardware server equipped with an Intel Core i9 processor with 16 cores, 32 GB of RAM, and a 1TB SSD hard drive. Also, a Kubernetes service should be created for container orchestration and load balancing.
Within this context, the approach offers outstanding advantages, particularly its ability to offer a deep comprehension of skills that go beyond conventional keyword searching. Therefore, the ontology-based skills matching system results in more precise and contextually aware results. However, to improve the robustness of the ontology-based skills matching system, it is crucial to conduct future work to address the following issues.
Firstly, it is essential to develop a standardization system for skills extracted from JDs and CVs. Usually, this information lacks organization and is presented in different levels of complexity. For instance, educational qualifications in a CV can provide insight into the skills that a person acquired. Additionally, a skill might have multiple ways of being described (synonyms) in CVs and JDs. Therefore, skill standardization is vital to find all implicit and explicit skills and use unified skill names.
Secondly, we intend to research a more dynamic model which utilizes machine learning and deep learning to build the skills ontology automatically. Existing skills taxonomies are static and require manual updates, making them slow to adapt to evolving job markets. Thus, the research direction will enable the integration of new skills by utilizing real-time job market data, such as data from platforms like LinkedIn. This ensures that the skills acquired are aligned with the evolving demands of the job market in various countries. While relying less on manual work, the dynamic ontology will still capture the core skill relationships.
Finally, skill proficiency and weights for each skill should be included. Certain skills may be indispensable requirements for the job (with significant importance), whereas others may be regarded as less crucial (with lower weight) or capable of being applied from prior experience. Moreover, knowing the desired level of proficiency for each skill (e.g., beginner, advanced) is vital. This allows employers or the recommendation system to evaluate whether a candidate possesses the requisite skills at a sufficiently advanced level. In general, incorporating both skill weights and proficiency levels creates a clearer picture of a candidate’s suitability for the role.
Footnotes
Acknowledgements
This work was supported by the Vietnam Ministry of Education and Training [grant number B2023-BKA-07].