
Abstract
Recommender systems are software tools used to generate and provide suggestions for items and other entities to the users by exploiting various strategies. Hybrid recommender systems combine two or more recommendation strategies in different ways to benefit from their complementary advantages. This systematic literature review presents the state of the art in hybrid recommender systems of the last decade. It is the first quantitative review work completely focused in hybrid recommenders. We address the most relevant problems considered and present the associated data mining and recommendation techniques used to overcome them. We also explore the hybridization classes each hybrid recommender belongs to, the application domains, the evaluation process and proposed future research directions. Based on our findings, most of the studies combine collaborative filtering with another technique often in a weighted way. Also cold-start and data sparsity are the two traditional and top problems being addressed in 23 and 22 studies each, while movies and movie datasets are still widely used by most of the authors. As most of the studies are evaluated by comparisons with similar methods using accuracy metrics, providing more credible and user oriented evaluations remains a typical challenge. Besides this, newer challenges were also identified such as responding to the variation of user context, evolving user tastes or providing cross-domain recommendations. Being a hot topic, hybrid recommenders represent a good basis with which to respond accordingly by exploring newer opportunities such as contextualizing recommendations, involving parallel hybrid algorithms, processing larger datasets, etc.
Introduction
Historically people have relied on their peers or on experts’ suggestions for decision support and recommendations about commodities, news, entertainment, etc. The exponential growth of the digital information in the last 25 years, especially in the web, has created the problem of information overload. Information overload is defined as “stress induced by reception of more information than is necessary to make a decision and by attempts to deal with it with outdated time management practices”.1 This problem limits our capacity to review the specifications and choose between numerous alternatives of items in the online market. On the other hand, information science and technology reacted accordingly by developing information filtering tools to alleviate the problem. Recommender Systems (RSs) are one such tools that emerged in the mid 90s. They are commonly defined as software tools and techniques used to provide suggestions for items and other recommendable entities to users [1]. In the early days (beginning of 90s) RSs were the study subject of other closely related research disciplines such as Human Computer Interaction (HCI) or Information Retrieval (IR) [2]. Today, RSs are found everywhere helping users in searching for various types of items and services. They also serve as sales assistants for businesses increasing their profits.
Technically all RSs employ one or more recommendation strategies such as Content-Based Filtering (CBF), Collaborative Filtering (CF), Demographic Filtering (DF), Knowledge-Based Filtering (KBF), etc. described below:
One of the earliest recommender systems was Tapestry, a manual CF mail system [3]. The first computerized RS prototypes also applied a collaborative filtering approach and emerged in mid 90s [6, 7]. GroupLens was a CF recommendation engine for finding news articles. In [7] the authors present a detailed analysis and evaluation of the Bellcore video recommender algorithm and its implementation embedded in the Mosaic browser interface. Ringo used taste similarities to provide personalized music recommendations. Other prototypes like NewsWeeder and InfoFinder recommended news and documents using CBF, based on item attributes [8, 9]. In late 90s important commercial RS prototypes also came out with Amazon.com recommender being the most popular. Many researchers started to combine the recommendation strategies in different ways building hybrid RSs which we consider in this review. Hybrid RSs put together two or more of the other strategies with the goal of reinforcing their advantages and reducing their disadvantages or limitations. One of the first was Fab, a meta-level recommender (see Section 3.4.6) which was used to suggest websites [10]. It incorporated a combination of CF to find users having similar website preferences, with CBF to find websites with similar content. Other works such as [11] followed shortly and hybrid RSs became a well established recommendation approach.
The continuously growing industrial interest in the recent and promising domains of mobile and social web has been followed by a similar increase of academic interest in RSs. ACM RecSys annual conference2 is now the most significant event for presenting and discussing RS research. The work of Burke in [12] is one of the first qualitative surveys addressing hybrid RSs. The author analyzes advantages and disadvantages of the different recommendation strategies and provides a comprehensive taxonomy for classifying the ways they combine with each other to form hybrid RSs. He also presents several hybrid RS prototypes falling into the 7 hybridization classes of the taxonomy. Another early exploratory work is [13] where several experiments combining personalized agents with opinions of community members in a CF framework are conducted. They conclude that this combination produces high-quality recommendations and that the best results of CF are achieved using large data of user communities. Other review works are more generic and address RSs in general, not focusing in any RS type. They reflect the increasing interest in the field in quantitative terms. In [14] the authors perform a review work of 249 journal and conference RS publications from 1995 to 2013. The peak publication period of the works they consider is between 2007 and 2013 (last one-third of the analyzed period). They emphasize the fact that the current hybrid RSs are incorporating location information into existing recommendation algorithms. They also highlight the proper combination of existing methods using different forms of data, and evaluating other characteristics (e.g., diversity and novelty) besides accuracy as future trends. In [15] the authors review 210 recommender system articles published in 46 journals from 2001 to 2010. They similarly report a rapid increase of publications between 2007 and 2010 and predict an increase interest in mixing existing recommendation methods or using social network analysis to provide recommendations.
In this review paper we summarize the state of the art of hybrid RSs in the last 10 years. We follow a systematic methodology to analyze and interpret the available facts related to the 7 research questions we defined. This methodology defined at [16, 17] provides an unbiased and reproducible way for undertaking a review work. Unlike the other review works not focused in any RS type [14, 15], this systematic literature review is the first quantitative work that is entirely focused in recent hybrid RS publications. For this reason it was not possible for us to have a direct basis with which to compare our results. Nevertheless we provide some comparisons of results for certain aspects in which hybrid RSs do not differ from other types of RSs. To have a general idea about what percentage of total RS publications address hybrid RSs we examined [18], a survey work about RSs in general. Here the authors review the work of 330 papers published in computer science and information systems conferences proceedings and journals from 2006 to 2011. Their results show that hybrid recommendation paradigm is the study object of about 14.5% of their reviewed literature.
We considered the most relevant problems hybrid RSs attempt to solve, the data mining and machine learning methods involved, RS technique combinations the studies utilize and the hybridization classes the proposed systems fall into. We also observed the domains in which the contributions were applied and the evaluation strategies, characteristics and metrics that were used. Based on the suggestions of the authors and the identified challenges we also present some future work directions which seem promising and in concordance with the RS trends. Many primary studies were retrieved from digital libraries and the most relevant papers were selected for more detailed processing (we use the terms paper and study interchangeably to refer to the same object/concept). We hope this work will help anyone working in the field of (hybrid) RSs, especially by providing insights about future trends or opportunities. The remainder of the paper is structured as follows. Section 2 briefly summarizes the methodology we followed, the objectives and research questions defined, the selection of papers and the quality assessment process. Section 3 introduces the results of the review organized in accordance with each research question. Section 4 discusses and summarizes each result whereas Section 5 concludes. Finally we list the selected papers in Appendix.
Methodology
The review work of this paper follows the guidelines that were defined by Kitchenham and Charters [17] for systematic literature reviews in Software Engineering. The purpose of a systematic literature review is to present a verifiable and unbiased treatment of a research topic utilizing a rigorous and reproducible methodology. The guidelines that were followed are high level and do not consider the influence of research questions type on the review procedures. In Fig. 1 we present the protocol of the review. It represents a clear set of steps which assist the management of the review process. The protocol was defined by the first author and verified by the second author. In the following sections we describe each step we summarized in Fig. 1.
Systematic literature review protocol.
The primary goal of this systematic literature review is to understand what challenges hybrid RSs could successfully address, how they are developed and evaluated and in what ways or aspects they could be experimented with. To this end, we defined the following research questions:
Selected sources to search for primary studies
Selected sources to search for primary studies
Keywords and synonyms
Furthermore we picked five scientific digital libraries that represent our primary sources for computer science research publications. They are listed in Table 1. Other similar sources were not considered as they mainly index data from the primary sources. We defined (“Hybrid”, “Recommender”, “Systems”) as the basic set of keywords. Then we added synonyms to extend it and obtain the final set of keywords. The set of keywords and synonyms is listed in Table 2. The search string we defined is: (“Hybrid” OR “Hybridization” OR “Mixed”) AND (“Recommender” OR “Recommendation”) AND (“System” OR “Software” OR “Technique” OR “Technology” OR “Approach” OR “Engine”).
Inclusion and exclusion criteria
Following Step 4 of the protocol, we applied the search string in the search engines of the five digital libraries and found 9673 preliminary primary studies (see Table 4). The digital libraries return different numbers of papers because of the dissimilar filtering settings they use in their search engines. This retrieval process was conducted during May 2015. To objectively decide whether to select each preliminary primary study for further processing or not, we defined a set of inclusion/exclusion criteria listed in Table 3. The inclusion/exclusion criteria are considered as a basis of concentrating in the most relevant studies with which to achieve the objectives of the review. Duplicate papers were removed and a coarse selection phase followed. Processing all of them strictly was not practical. Therefore we decided to include journal and conference papers only, leaving out gray literature, workshop presentations or papers that report abstracts or presentation slides. We initially analyzed title, publication year and publication type (journal, conference, workshop, etc.). In many cases abstract or even more parts of each paper were examined for deciding to keep it or not. Our focus in this review work is on hybrid recommender systems. Thus we selected papers presenting mixed or combined RSs dropping out any paper addressing single recommendation strategies or papers not addressing RSs at all. Hybrid RSs represent a somehow newer family of recommender systems compared to other well known and widely used families such as CF or CBF. Therefore the last decade (2005–2015) was considered an appropriate publication period. Using inclusion/exclusion and this coarse selection step we reached to a list of 240 papers. In the next step we performed a more detailed analysis and selection of the papers reviewing abstract and other parts of every paper. Besides relevance based on the inclusion/exclusion criteria, completeness (in terms of problem definition, description of the proposed method/technique/algorithm and evaluation of results) of each study was also taken into account. Finally we reached to our set of 76 included papers. The full list is presented in Appendix together with the publication details.
Number of papers after each selection step
Number of papers after each selection step
Quality assessment questions
We also defined 6 questions listed in Table 5 for the quality estimation of the selected studies. Each of the question receives score values of 0, 0.5 and 1 which represent answers “no”, “partly” and “yes” correspondingly. The questions we defined do not reflect equal level of importance in the overall quality of the studies. For this reason we decided to weight them with coefficients of 0.5 (low importance) 1 (medium importance) and 1.5 (high importance). We set higher weight to the quality questions that address the components/architecture of the system/solution (QQ4) and the empirical evaluation (QQ5). Quality questions that address problem description (QQ1) and statement of results (QQ6) got medium importance. We set a low importance weight to the two questions that address the related studies (QQ2) and future work (QQ3). The papers were split in two disjoint subsets. Each subset of papers was evaluated by one of the authors. In cases of indecision the quality score was set after a discussion between the authors. At the end, the final weighted quality score of each study was computed using the following formula:
After this evaluation, cross-checking of the assessment was done on arbitrary studies (about 40% of included papers) by the second author. At the end, an agreement on differences was reached by discussion.
Data extraction form
Data extraction form
Data extraction was carried on the final set of selected primary studies. We collected both paper meta-data (i.e., author, title, year, etc.) and content data important to answer our research questions like problems, application domains, etc. Table 6 presents our data extraction form. In the first column we list the extracted data, in the second column we provide an explanation for some of the extracted data which may seem unclear and in the third column the research question with which the data is related. All the extracted information was stored in Nvivo3 which was used to manage data extraction and synthesis process. Nvivo is a data analysis software tool that helps in automating the identification and the labeling of the initial segments of text from the selected studies.
Synthesis
For the synthesis step we followed Cruzes and Dyba methodology for the thematic synthesis [19]. Their methodology uses the concept of codes which are labeled segments of text to organize and aggregate the extracted information. Following the methodology we defined some initial codes which reflected the research questions. Some examples include the first research problems found, hybrid recommendation classes, first application domains, data mining techniques, recommendation approaches and evaluation methodologies. After completing the reading we had refined or detailed each of the initial codes with more precise sub-codes (leaf nodes in NVivo) which were even closer to the content of the selected papers, covering all the problems found, all the datasets used, and similar detailed data we found. We finished assigning codes to all the highlighted text segments of the papers and then the codes were aggregated in themes (of different levels if necessary) by which the papers were grouped. Afterwards a model of higher-order themes was created to have an overall picture. The research questions were mapped with the corresponding themes. Finally, the extracted data were summarized in categories which are reported in the results section (in pictures or tables) associated with the research questions they belong to.
Results
In this section we present the results we found from the selected studies to answer each research question. We illustrate the different categories of problems, techniques, hybridization classes, evaluation methodologies, etc. with examples from the included studies. The results are further discussed in the next section.
RQ1: Included studies
Distribution of studies per publication year.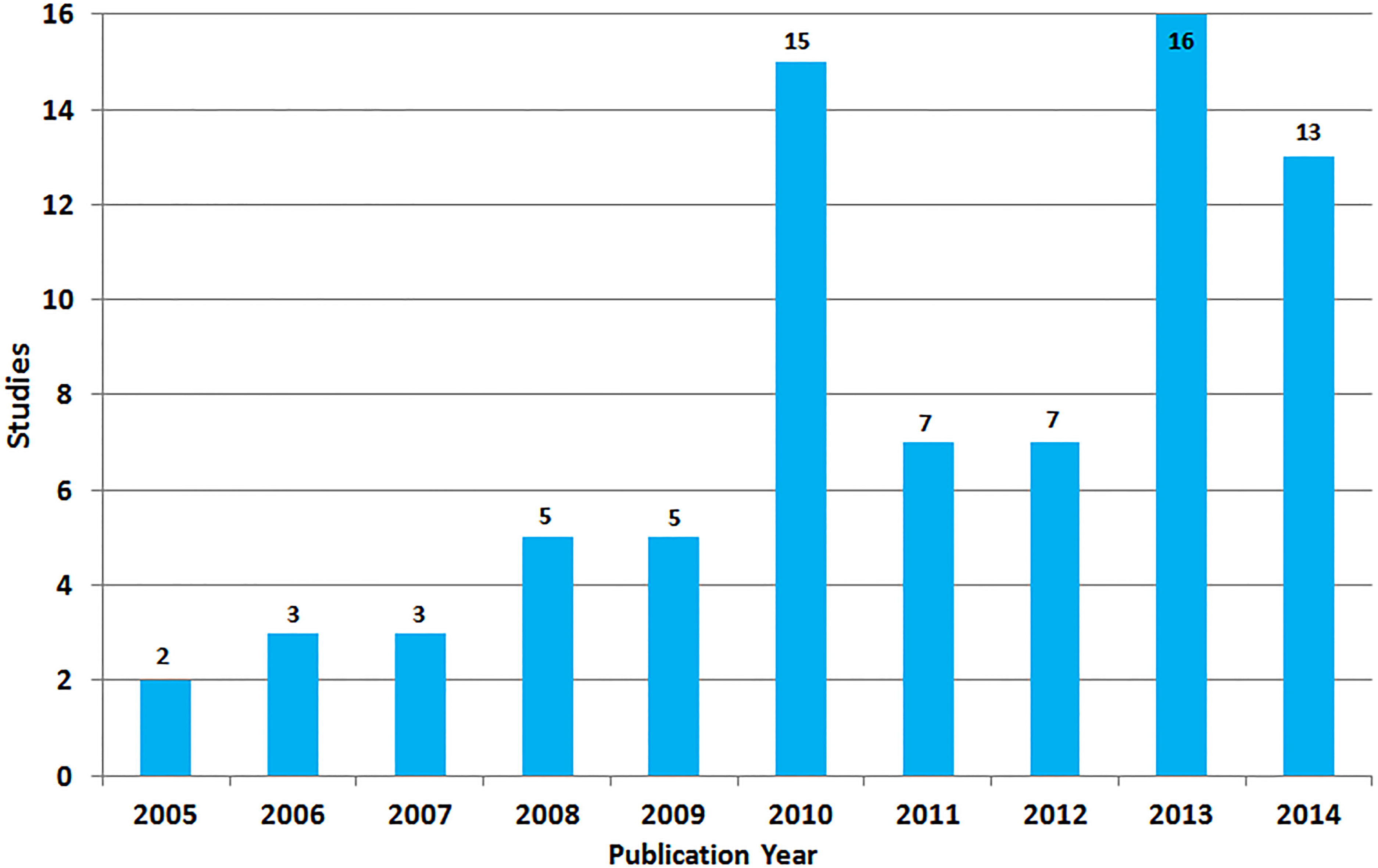
RQ1 addresses the most relevant studies that present Hybrid RSs. We selected 76 papers as the final ones for further processing. They were published in conference proceedings and journals from 2005 to 2015. The publication year distribution of the papers is presented in Fig. 2. It shows that most of the hybrid RS papers we selected were published in the last 5 years.
For the quality assessment process we used the quality questions listed in Table 5. In Fig. 3, the box plots of quality score distributions per study type (conference or journal) are shown. We see that about 75% of journal studies have quality score higher than 0.9. Same is true for about 35% of conference studies. In Fig. 4 we present the average quality score about each quality question. QQ4 (Did the study describe the components or architecture of the proposed system?) has the highest average score (0.947) wheres QQ3 (Did the study suggest further research?) has the lowest (0.651). The weighted quality score is higher than 0.81 for any included paper. Only one journal study got a weighted average score of 1.0 (highest possible).
Boxplot of quality score per publication type.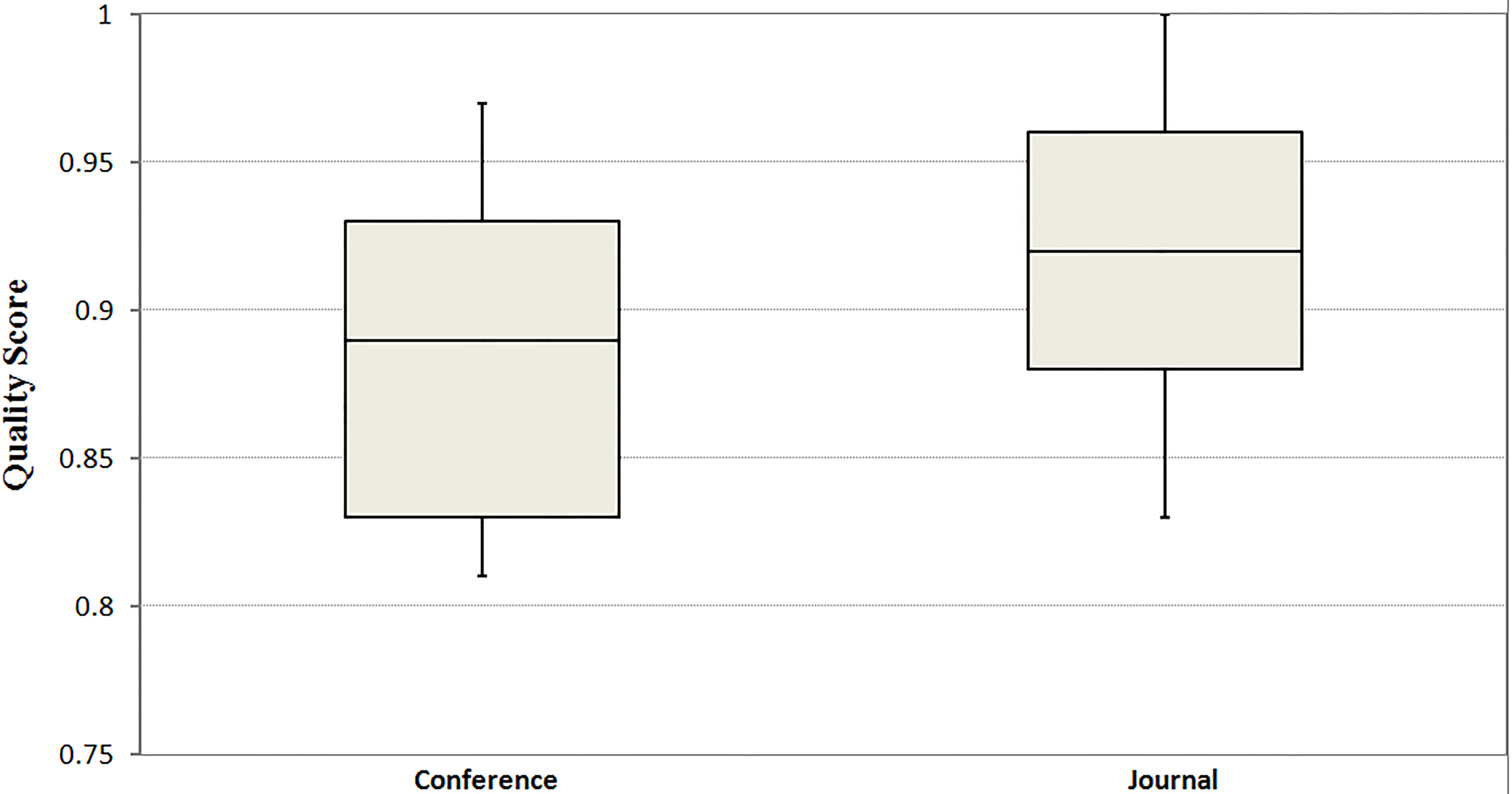
Average score of each quality question.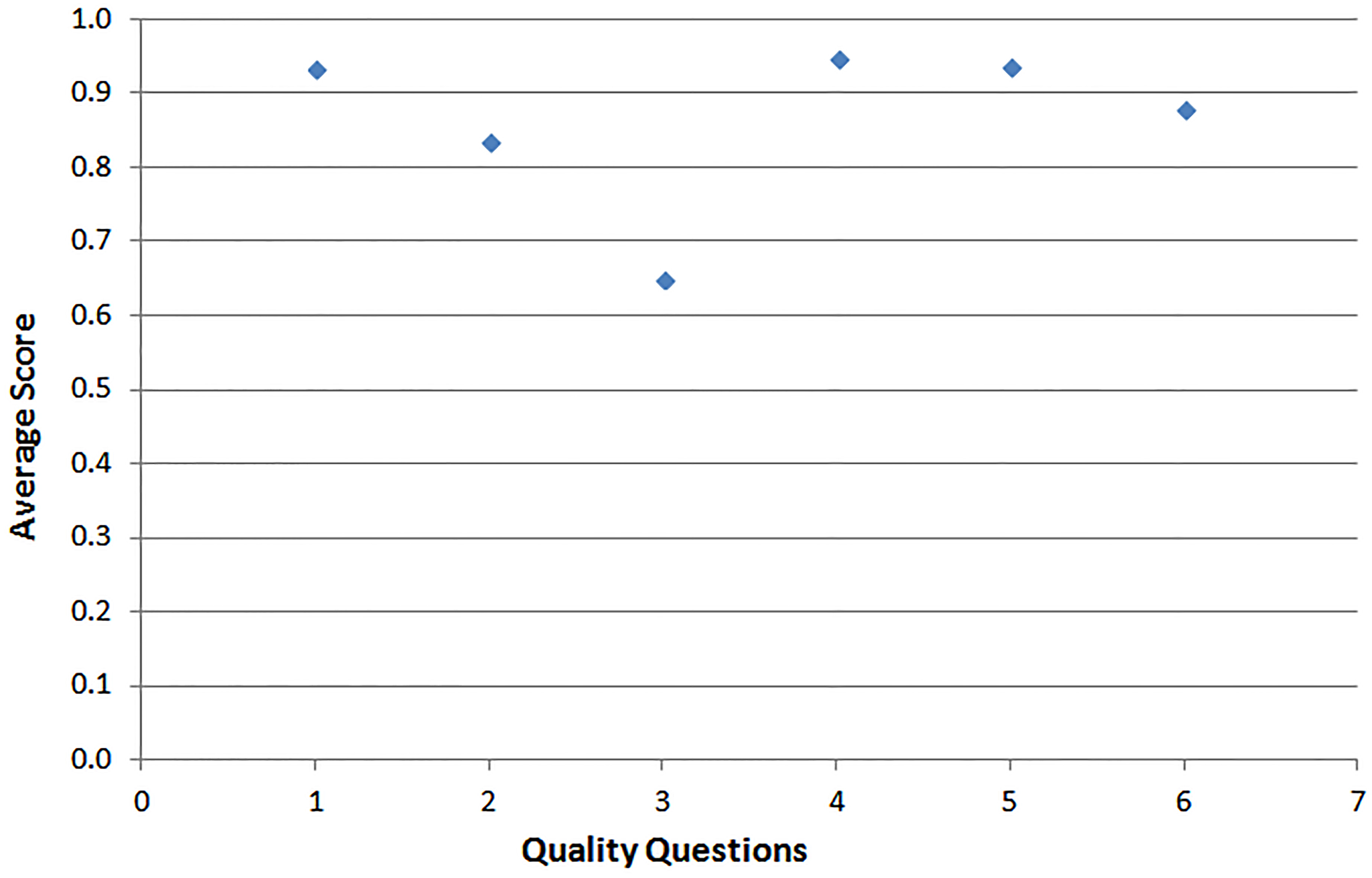
Addressed problems.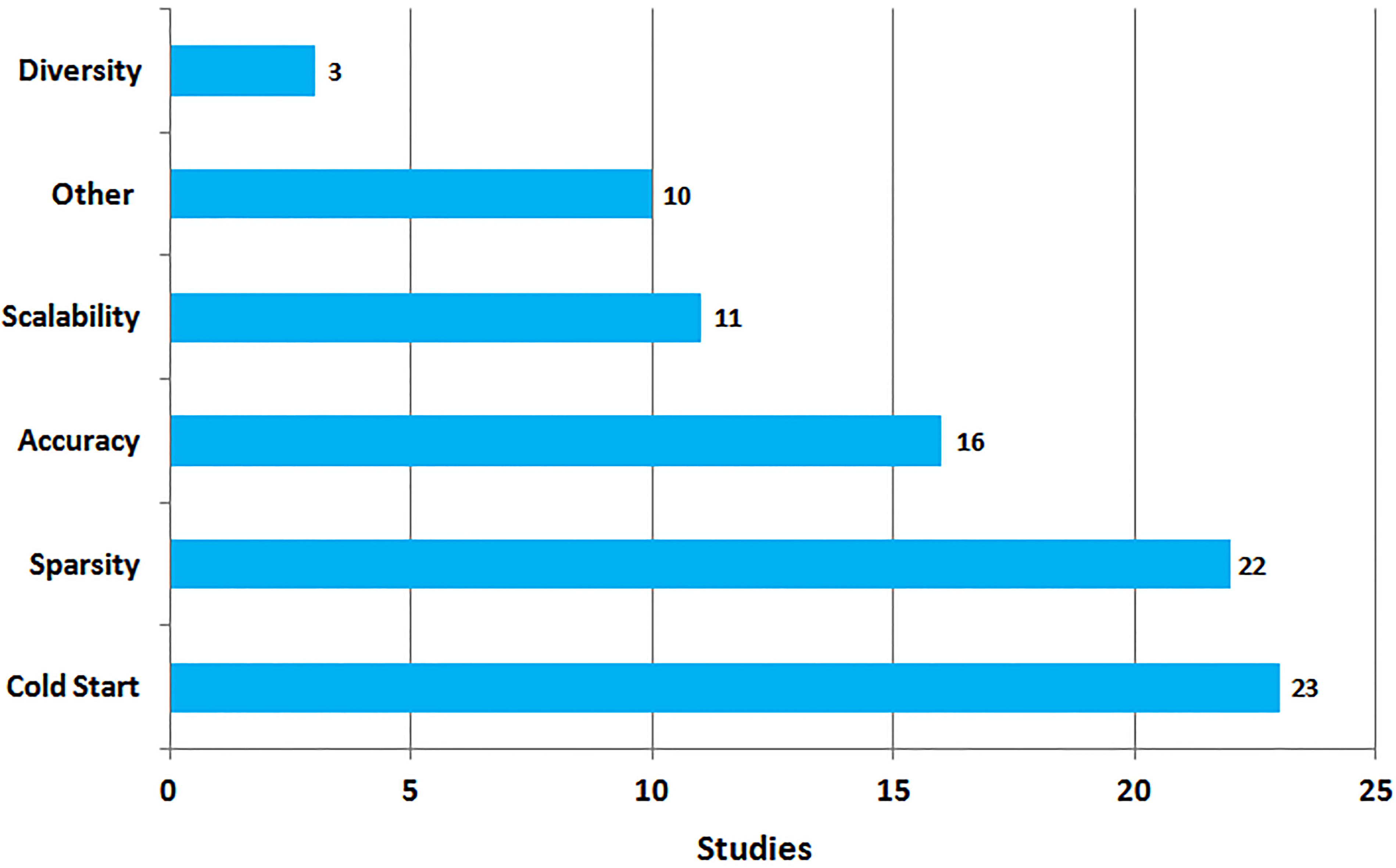
To answer RQ2 we summarize the most important RS problems the studies try to solve. A total of 12 problems were found. The most frequent are presented in Fig. 5 with the corresponding number of studies where they appear. Studies may (and often do) address more than one problem. Same thing applies for other results (data mining techniques, domains, evaluation metrics, etc.) reported in this section. Below we describe each of the problems:
Distribution of studies by DM/ML techniques
Distribution of studies by DM/ML techniques
In this section we address the distribution of the studies according to the basic Data Mining (DM) and Machine Learning (ML) techniques they use to build their hybrid RSs. The variety of DM and ML techniques or algorithms used is high. Authors typically use different techniques to build the diverse components of their solutions or prototypes. In Table 7 we present the most frequent that were found in the included studies. Below we describe some of them. More details about the characteristics of DM/ML techniques and how they are utilized to build RSs can be found at [24].
RQ3b: Recommendation technique combinations
In this section we present a list of the most common technique combinations that form hybrid RSs. We also present the problems each of this combinations is most frequently associated with. In the following subsections the construct and technical details of some of the prototypes implementing each combination is described. Table 8 presents the summarized results.
Hybrid recommendation approaches distributed per problem
Hybrid recommendation approaches distributed per problem
Here we report studies that combine CF with one other technique which is not CBF (those are counted as CF-CBF). An example of this combination is where the authors go hybrid to improve the performance of a multi-criteria recommender. They base their solution on the assumption that usually only a few selection criteria are the ones which impact user preferences about items and their corresponding ratings. Clustering is used first to group users based on the items’ criteria they prefer. CF is then used within each cluster of similar users to predict the ratings. They illustrate their method by recommending hotels from TripAdvisor4 and report performance improvements over traditional CF. Other attempt to improve the predictive accuracy of traditional CF is . Here the authors integrate in CF discrete demographic data about the users such as gender, age, occupation, etc. Fuzzy logic is used to compute similarities between users utilizing this extra demographic data and integrate the extra similarities with the user-based similarities calculated from ratings history. After calculating the final user similarities their algorithm predicts the rating values. The extra performance which is gained from the better user similarities that are obtained, comes at the cost of a slightly larger computational time which is however acceptable. In total CF-X combination was found in 6 studies with X being KBF, DF or a DM/ML technique from those listed in Table 6.
CF-CBF
This is a very popular hybrid RS utilizing the two most successful recommendation strategies. In many cases the recommendations of both systems are weighted to produce the final list of predictions. In other cases the hybrid RS switches from CF to CBF or is made up of a more complex type of combination (see Section 3.5). An example is where the authors develop a hybrid RS suitable for working with high volumes of data and solve scalability problems in e-commerce systems. Their solution first involves CF (Pearson’s product moment coefficients) to reduce the dataset by finding the nearest neighbors of each user, discarding the rest and reducing the dataset. Afterwards distance-to-boundary CBF is used to define the decision boundary of items purchased by the target user. The final step combines the CF score (correlation coeficient between two customers) with the distance-to-boundary score (distance between the decision boundary and each item) in a weighted linear form. The authors report an improved accuracy of their hybrid RS working in the reduced dataset, compared to other existing algorithms that use full datasets.
In the authors propose a CF-CBF hybrid recommender which is based on Bayesian networks. This model they build uses probabilistic reasoning to compute the probability distribution over the expected rating. The weight of each recommending strategy (CF and CBF) is automatically selected, adapting the model to the specific conditions of the problem (it can be applied to various domains). The authors demonstrate that their combination of CF and CBF improves the recommendation accuracy. Other studies involve similar mathematical models or constructs (e.g., fuzzy logic) to put together CF and CBF and gain performance or other benefits. In total CF-CBF contributions were found in 15 studies.
CF-CBF-X
Those are cases in which CF and CBF are combined together with a third approach. One example is where CF and CBF are combined with DF to generate recommendations for groups of similar profiles (users). These kind of recommendations are particularly useful in online social networks (e.g., for advertising). The goal of the authors is to provide good recommendations in data sparsity situations. First CBF is used to analyse ratings and items’ attributes. CF is then invoked as the second stage of the cascade to generate the group recommendations. DF is used to reinforce CF in the cases of sparse profiles (users with few ratings). In total CF-CBF-X was found in 8 studies. X is mostly a clustering technique or DF.
IICF-UUCF
Item-Item CF and User-User CF are two forms of CF recommenders, differing on the way the neighborhoods are formed. Some studies combine both of them to improve overall CF performance. An example is where the authors present a hybrid recommendation framework they call Collaborative Filtering Topic Model (CFTM) which considers both user’s reviews and ratings about items of a certain topic (or domain) in e-commerce. The first stage which is offline performs sentiment analysis in the reviews to calculate the User or Item similarity. The second stage of the cascade uses IICF or UUCF (switching) to predict the ratings. The authors evaluate using 6 datasets of different domains from Amazon and report that their hybrid approach performs better than traditional CF, especially in sparsity situations. IICF-UUCF combinations were found in 7 studies.
CBF-X
There were also 10 studies in which CBF is combined with another technique X which is not CF (counted as CF-CBF). X represents different approaches like KBF and DF or DM/ML techniques like clustering etc. One example is where the authors describe and use the interesting notion of user lifestyle. They select demographic information, consumer credit data and TV program preferences as lifestyle indicators, and confirm their significance by performing statistical analysis on 502 users. The most significant lifestyle attributes are binary encoded and used to form the neighborhoods and ratings of each user by means of Pearson correlation. The authors call the resulting complete (in terms of ratings) matrix pseudoUser-item matrix. It is then used for a Pearson based (classical CF) prediction of the original user-item ratings. Considerable performance improvements are reported.
Other
Other implementations include combinations of the same recommendation strategy (e.g., CF1-CF2 with different similarity measures or tuning parameters each), trust-aware recommenders that are being used in social communities, prototypes using association rules mining, neural networks, genetic algorithms, dimensionality reduction, social tagging, semantic ontologies, pattern mining or different machine learning classifiers.
RQ4: Classes of hybridization
To answer RQ4 we classified the examined hybrid RSs according to the taxonomy proposed by Burke [12]. This taxonomy categorizes hybrid RSs in 7 classes based on the way the different recommendations techniques are aggregated with each other. Each class is explained in the subsections below where we discuss in more details few examples from the included papers. The results are summarized in Fig. 6.
Distribution of studies per hybridization class.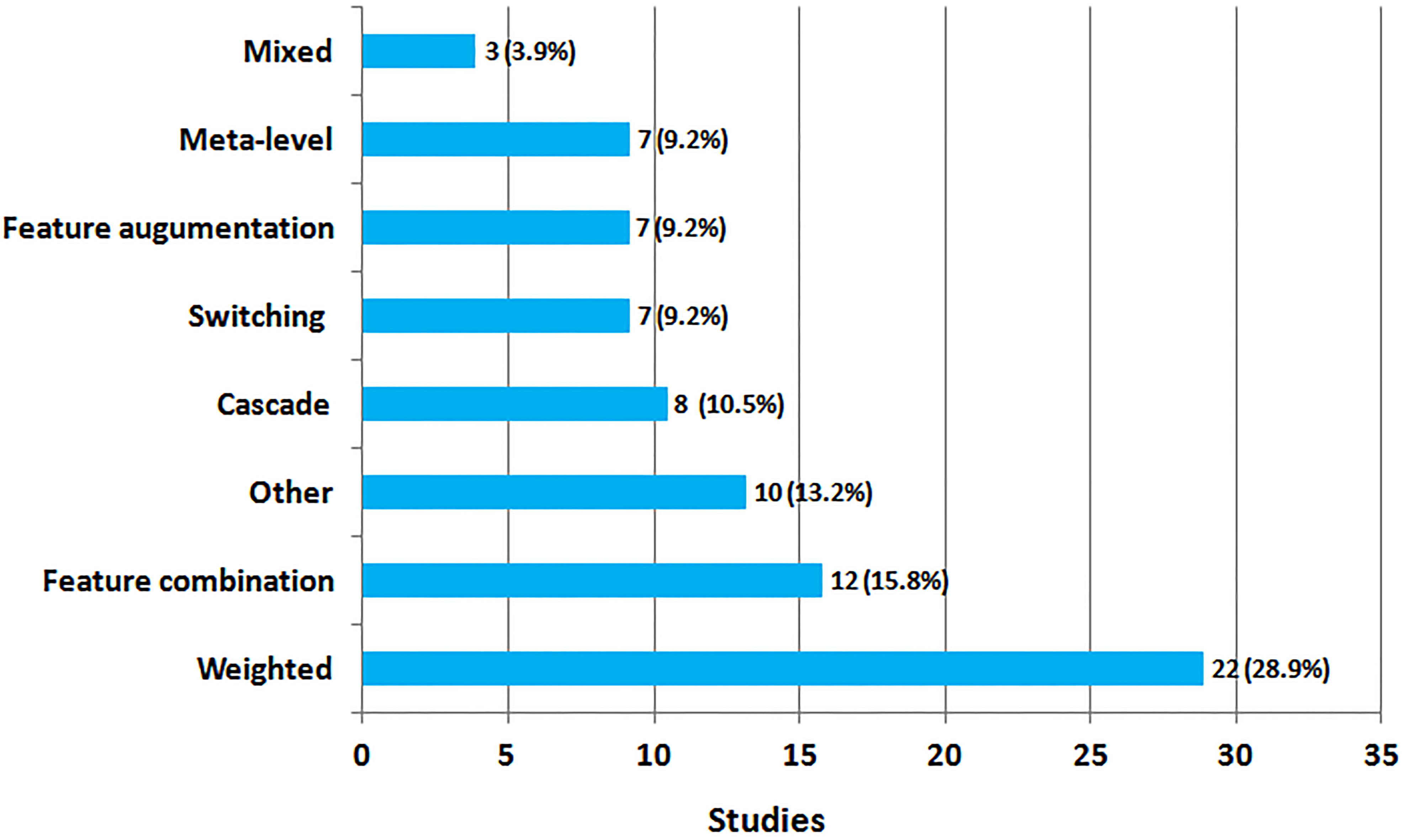
Weighted hybrids were the most frequent. They compute the scores of the items they recommend by aggregating the output scores of each recommendation technique using weighted linear functions. One of the first weighted recommenders was P-Tango [26] which combined CF and CBF rating scores in a linear weighted way to recommend online newspapers. In P-Tango, aggregation was made giving equal initial weights to each score and then possibly adapting by the feedback of users. The weights of CF and CBF are set on a per-user basis enabling the system to determine the optimal mix for each user and alleviating the “gray sheep” problem. In the authors propose a weighting method for combining user-user, user-tag and user-item CF relations in social media. The method they propose computes the final rating score of an item for a user as the linear combination of the above three CF relations. Unlike the traditional CF, this weighted hybrid CF recommender is completely based on tags and does not require that users provide explicit rating scores for the items that are recommended (e.g., photos). An other example is where the authors combine a content-based model with a rule-based model to recommend e-learning materials. They build their CBF using an education domain ontology and compute the scores of each learning material using Vector Space Model and TF-IDF. The rule-based recommender utilizes the ontology and the user’s previously visited concepts to realize a semantic mapping between user’s query and his/her semantic profile, resulting in adequate term recommendations about learning materials. The two RS modules set different weights to each recommended item based on user’s preferences and higher accuracy is achieved. Apparently the benefit of a weighted hybrid is the fact that it uses a straightforward way to combine the results of each involved technique. It is also easy to adjust priority assignment for each involved strategy by changing the weights. This class of hybrid RS was used in 22 (28.9%) of the included studies.
Feature combination
This type of hybrid RSs treats one recommender’s output as additional feature data, and uses the other recommender (usually content-based which makes extensive use of item features) over the new extended data. In case of a CF-CBF hybrid, the system does not exclusively rely on the collaborative data output of CF. That output is considered as additional data for the CBF which generates the final list. This reduces the sensitivity to possible sparsity of the initial data. For example, in the authors present a CF-CBF book recommender which implements an extended feature combination strategy. In the first phase new features (prefered books) are generated by applying CF among the readers. In the second phase they utilize fuzzy c-means clustering and type-2 fuzzy logic to obtained data for creating book categories of each user type (teacher, researcher, student). In the third and final phase CBF is involved to recommend the most relevant books to each user. The authors report performance improvements both in MAE and F1 accuracy scores. Also in the authors build an information system about courses and study materials for scholars. The system invokes a web crawler to collect related web pages and classifies the obtained results in different item categories (websites, courses, academic activities) using a web page classifier supported by a school ontology. An information extractor is later invoked to get significant web page features. Finally the system operates on the extra features of each item category to produce integrated recommendations based on the order of the keyword weight of each item. System verification reports higher recommendation quality and reliability. Feature combination hybrids were found in 12 (15.8%) studies.
Cascade
Cascade hybrids are examples of a staged recommendation process. First one technique is employed to generate a coarse ranking of candidate items and than a second technique refines the list from the preliminary candidate set. Cascades are order-sensitive; a CF-CBF would certainly produce different results from a CBF-CF. An example is which presents a mobile music cascade recommender combining SVM genre classification with collaborative user personality diagnosis. The first level of the recommendation process consists of a multi-class SVM classifier of songs based on their genre. The second level is a personality diagnosis which assumes that user preferences for songs constitute a characterization of their underlying personality. The personality type of each user is assumed to be the vector of ratings in the items the user has seen. The personality diagnosis approach estimates the probability that each active user is of the same personality type as other users. As a result the probability that a active user will like new songs is computed in a more personalized way.
In the authors combine two CF systems with different properties. The first module is responsible for retrieving the data and generating the list of neighbors for each user. This module uses two distance measures, Pearson’s coefficient and Euclidean distance in a switching way, depending on the user’s deviation from his/her average rating. The authors report that Euclidean distance performs better than Pearson’s coefficient in most of the cases. In the second module of the cascade, they experiment switching between three predictors to generate the final recommendations: Bayesian estimator, Pearson’s weighted sum and adjusted weighted sum. They also report that the Bayesian prediction gives best results. An other example of a cascade hybrid is . It implements a cascade of item-based CF and Sequential Pattern Mining (SPM) to recommend items in an e-learning environment. To adopt the CF to the e-learning domain they introduce a damping function which decreases the importance of “old” ratings. The SPM module takes in a list of k most similar items for each item and determines it support. At the end it prunes the items with support less than the threshold and generates the recommended items. The authors also apply this recommender in P2P learning environments for resource pre-fetching. Cascade hybrids were found in 8 (10.5%) studies.
Switching
In a switching hybrid the system switches between different recommendation techniques according to some criteria. For example, a CF-CBF approach can switch to the content-based recommender only when the collaborative strategy doesn’t provide enough credible recommendations. Even different versions of the same basic strategy (e.g., CBF1-CBF2 or CF1-CF2) can be integrated in a switching form. An example is DailyLearner, an online news recommender presented in [27]. It first employs a short-term CBF recommender which considers the recently rated news stories utilizing Nearest Neighbor text classification and Vector Space Model with TF-IDF weights. If a new story has no near neighbors the system switches to the long-term model which is based on data collected over a longer time period, presenting user’s general preferences. It uses a Naive Bayes classifier to estimate the probability of news being important or not.
In the authors build a switching hybrid RS that is based on a Naive Bayes classifier and Item-Item CF. The classifier is trained in offline phase and used to generate the recommendations. If this recommendations have poor confidence the Item-Item CF recommendations are used instead. First, they compute the posterior probability of each class generated by the Naive Bayes classifier. Then they assume that the classifier’s confidence is high if the posterior probability of the predicted class is sufficiently higher than the ones of the other classes. Movielens and Filmtrust are employed to evaluate the approach and performance improvements are reported, both in accuracy and in coverage. An other example of a switching hybrid is where the authors describe the design and implementation of a mobile locaton-aware CF-KBF recommender of touristic sites (e.g., restaurants). Their system involves both CF and KBF modules in generating recommendations. Then 3D-GIS location data are used to compute the physical distance of the mobile user from the recommended sites. The system switches from one recommendation strategy to the other and performs a distance-based re-ranking of the recommendations, choosing the sites that are physically closer to the user with higher accuracy. In most of the cases we see that complexity of switching RSs lies in the switching criteria which are mostly based on distance or similarity measures. However, this systems are sensitive to the strengths and weaknesses of the composing techniques. This hybrid RS category was found in 7 (9.2%) studies.
Feature augmentation
In this class of hybrids, one of the combined techniques is used to produce an item prediction or classification which is then comprised in the operation of the other recommendation technique. Feature augmentation hybrids are order-sensitive as the second technique is based on the output of the first. For example an association rules engine can generate for any item, similar items which can be used as augmented item attributes inside a second recommender to improve its recommendations. Libra presented in [28] is a content-based book recommender. It augments the textual features of the books with “related authors” and “related titles” data obtained from Amazon CF recommender to obtain a better recommendation quality. Libra uses an inductive learner to create user profiles. This inductive learner is based on vectorized bag-of-words naive Bayes text classifier. The authors report that the integrated collaborative content has a significant positive effect on recommendation performance.
presents a hybrid method which combines multidimensional clustering and CF to increase recommendation diversity. They first invoke multidimensional clustering to collect and cluster user and item data. Clusters with similar features are deleted and the remaining feature clusters are fed into the CF module. Item-Item similarity is computed using an adjusted cosine similarity which works for
Meta level
Meta levels are also an example of order-sensitive hybrid RSs that use an entire model produced by the first technique as input for the second technique. It is typical to use content-based recommenders to build item representation models, and then employ this models in collaborative recommenders to match the items with user profiles. A meta level recommendation strategy was implemented by Fab [10], one of the first website recommenders. Fab uses a selection agent which based on term vector model accumulate user-specific feedback about areas of interest for each user. There are also two collection agents: search agents which perform a search for websites, and index agents which construct queries for already found websites to avoid duplicate work. Collection agents utilize the models of the users (collaborative component) to collect the most relevant websites which are then recommended to the users.
Also presents a meta level recommender used in the domain of music which integrates CF with CBF. Here each user is stochastically matched with a music genre based on the collaborative output. Then the system generates a musical piece for the user based on the acoustic features. For the integration they adopt a probabilistic generative model called three-way aspect model. As this model is only used for textual analysis and indexing (bag-of-words representation) they propose the bag-of-timbres model, an interesting approach to content-based music recommendations which represents each musical piece as a set of polyphonic timbres. The advantage this hybridization class presents is that the learned model of the first technique is compressed and thus better used from the second. However, the integration effort is considerable and use of advanced constructs is often required. This hybrid RS class was found in 7 (9.2%) studies.
Mixed
Mixed hybrids represent the simplest form of hybridization and are reasonable when it is possible to put together a high number of different recommenders simultaneously. Here the generated item lists of each technique are added to produce a final list of recommended items. One of the first examples of mixed hybrids was PTV system [29] which used CBF to relate similar programs to the user profile and CF to relate similar user profiles together. The CBF module converts each user profile in a feature-based representation they call profile schema which is basically a TV program content summary represented in features. The CF module computes the similarity of two users utilizing a graded difference metric of the ranked TV programs in each user’s profile. At the end, a selection of programs recommended by the two modules is suggested.
Yet another example of recommending TV programs is a CF-CBF mixed hybrid named queveo.tv described in . Here the authors use demographic information such as age, gender and profession together with user’s history to build his/her profile which is used by the CBF module. This module makes use of Vector Space Model and cosine correlation to provide the recommended TV programs. The CF module uses both user-based CF to generate the top neighbors of the active user, and item-based CF to predict the level of interest of the user for a certain item. At the end the system takes recommendations from the two modules to generates the final list of TV programs. Those TV programs that were part of both listings (CBF and CF) are highlighted as Star Recommendations, as they are probably the most interesting for the user. Mixed hybrid RSs are simple and can eliminate acute problems like cold-start (new user or new item). They were found in 3 (3.9%) studies only.
RQ5: Application domains
A rich collection of 18 application domains was identified. Figure 7 presents the percentage of studies for each application domain. We see that most of the studies (21 or 27.6%) are domain independent. They haven’t been applied to a particular domain. Movie domain was considered by 17 (22.3%) studies. Next comes education or e-learning considered by 9 (11.8%) studies. Six (7.8%) studies were applied in the domain of music. There were also web service RSs implemented in 5 (6.5%) studies. Other domains are images, touristic sites, TV programs, web pages and microposts which appeared in 2 (2.6%) studies each. Domains like business, food, news, bibliography, etc. categorized as “Other” count for less than 10.5% of the total number of studies.
RQ6: Evaluation
Another important aspect of hybrid RSs that we examined is the evaluation process. In this section we present results about the evaluation methodologies and the corresponding involved metrics (answering RQ6a), evaluated RS characteristics and the utilized metrics for each (answering RQ6b) and finally the public datasets used to train and test the algorithms (answering RQ6c).
RQ6a: Evaluation methodologies
Evaluation methodology
Evaluation methodology
Distribution of studies according to the application domains.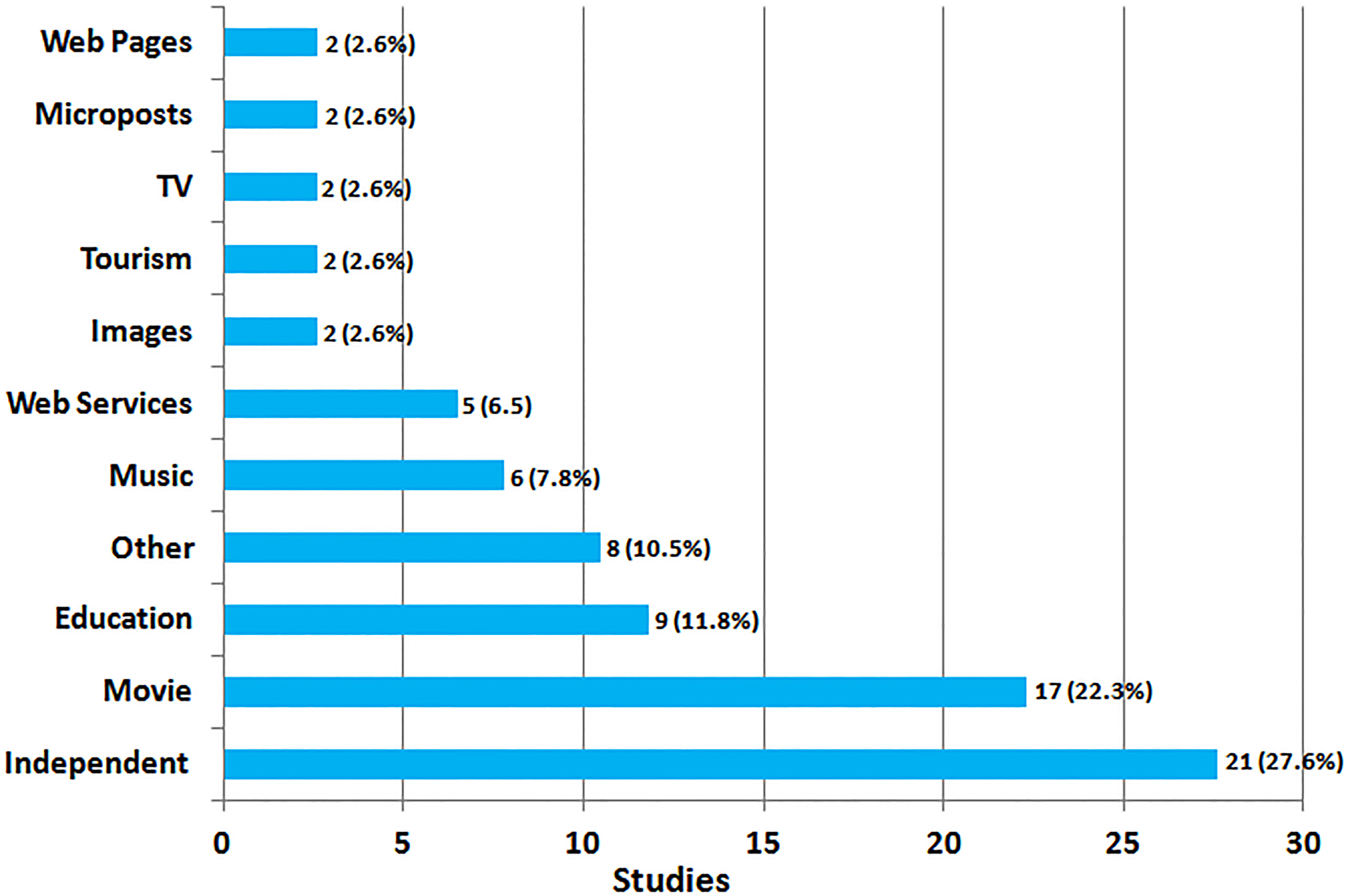
Here we try to explain how (with what methodologies) the evaluation process is performed and what metrics are involved in each methodology. Table 9 lists the distribution of studies according to the methodology they use to perform the evaluation. There are 58 (more than three-quarters) studies comparing the proposed system (or solution) with a similar well known method or technique. Usually CF-X or CF-CBF hybrid RSs are compared with pure CF or CBF. In some cases the proposed system is compared with different parameter configurations of itself. Accuracy or error measures like MAE (Mean Average Error) or RMSE (Root Mean Square Error) are very common. They estimate the divergence of the RS predictions from the actual ratings. Decision support metrics like Precision, Recall and F1 are also very frequent. Precision is the percentage of selected items that are relevant. Recall is the percentage of relevant items that are recommended. F1 is the harmonic mean of the two. User surveys are the other evaluation methodology utilized in 14 studies. They mainly perform subjective quality assessment of the RS and require the involvement of users who provide feedback for their perception about the system. Surveys are usually question based and reflect the opinion of users about different aspects of the hybrid recommender. An example of user surveys is where the participants were 30 high school students. In the users of the survey are customers of a web retail store who rated products they purchased. In a mix of real and simulated users are used to rate movies, books, etc. In total user surveys were conducted in 14 studies.
Both comparisons and surveys are used in 3 studies: where the participants were 17 males along with 15 females and different versions of the system were compared with each-other, where the system was compared with CF using Movielens and the survey involved 132 participants, and where online user profiles were utilized for the survey, and the proposed fuzzy hybrid book RS was compared with traditional CF. The only study with no evaluation at all was . Here the authors present a personalized hybrid recommendation framework which integrates trust-based filtering with multi-criteria CF. This framework is specifically designed for various Government-to-Business e-service recommendations. The authors leave the evaluation of their framework as a future work.
Evaluated characteristics
In order to address RQ6b we analyzed the recommendation characteristics the authors evaluate, and what metrics they utilize. Five characteristics were identified, listed in Table 10. The top characteristic is accuracy measured in 62 studies. It is followed by user satisfaction, a subjective characteristic assessed in 10 studies. Diversity is about having different list of recommended items each time the user interacts with the system. In total it was measured in 7 studies. Computational complexity of the RS is measured in 6 studies. Novelty and serendipity express the capability of the hybrid RS to recommend new or even unexpected but still relevant items to the user. They were measured in 4 studies. We also observed the metrics that authors use for each evaluated characteristic, summarized in Table 11. Accuracy is mostly measured by means of precision (31 studies), recall (23) and F1 (14). MAE and RMSE were found in 27 and 6 studies correspondingly. Other less frequent metrics used to evaluate accuracy include MSE (Mean Squared Error), nDCG (normalized Discounted Cumulative Gain), AUC, etc. They were found in 15 studies. As previously mentioned user satisfaction is measured by means of user surveys which were found in 10 studies. They usually consist of polls which aim to get the opinion of the users about different recommendation aspects of the system. Diversity is measured mostly by coverage which was found in 4 studies. In the other cases it is measured using ranking distances (3 studies). Execution time is the time it takes for the system to provide the recommendations and is a measure of the computational complexity. It was found in 6 studies. Novelty and Serendipity are measured by less known metrics such as Surprisal, Coverage in Long-Tail or Expected Popularity Complement.
Evaluated characteristics and involved metrics
Evaluated characteristics and involved metrics
We also kept track of the public datasets used by the authors to evaluate their hybrid RSs. These datasets are used by the scientific community to replicate experiments and validate or improve their techniques. There are 55 studies that use at least one public dataset. Sometimes a study uses more than one dataset. On the other hand 21 studies do not use any dataset. Sometimes they use synthetic data or rely on user surveys or other techniques. In Fig. 8 we present the datasets that were used and the number of studies in which they appear.
Distribution of studies according to the datasets they use for evaluation.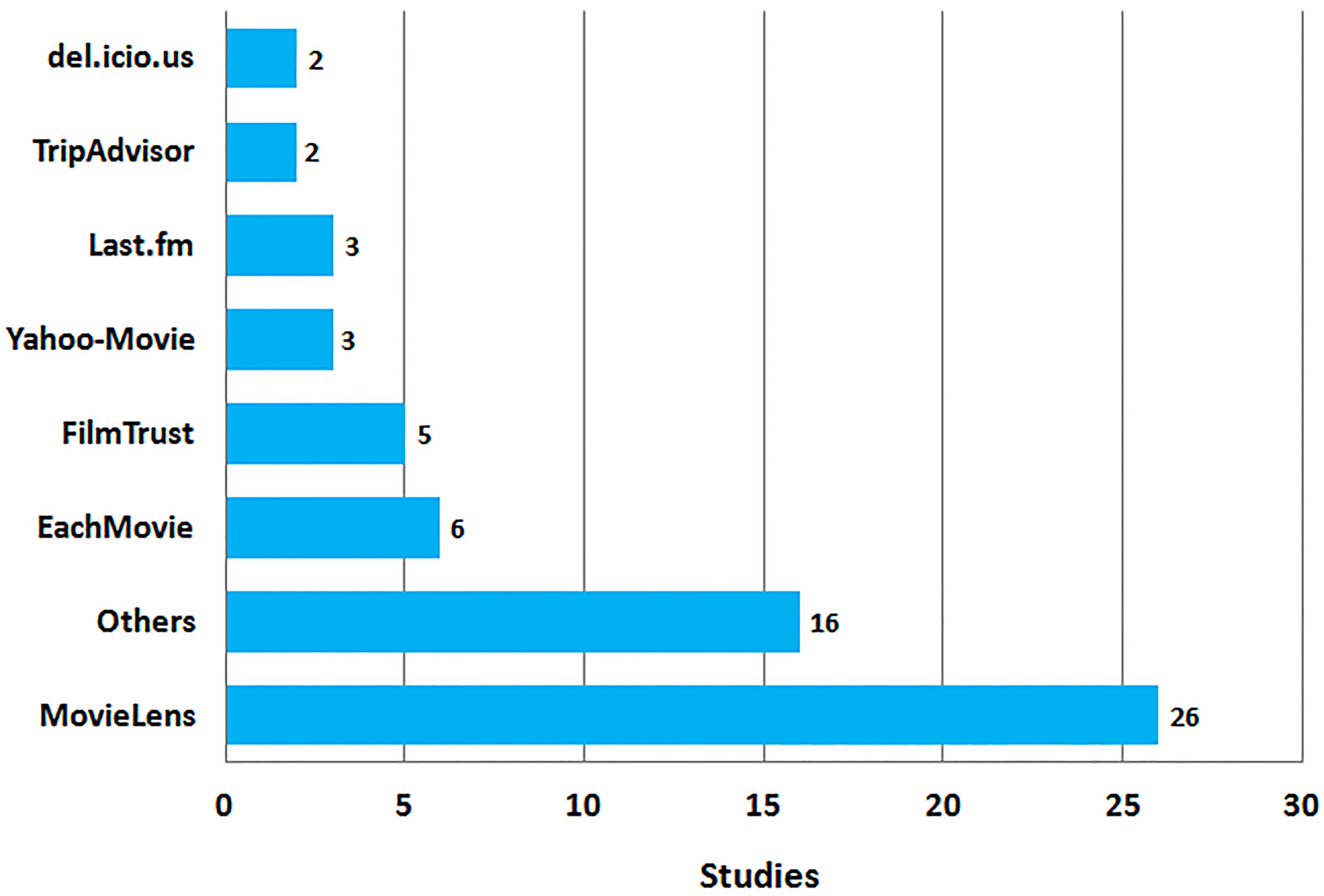
Future work suggestions
The last research question has to do with future work opportunities and directions. Our findings are summarized in Table 12 and shortly explained below:
Discussion
The main issues covered in this work are presented in the schematic model of Fig. 9. The issues are associated with the research question they belong to. In this section we discuss the obtained results for each research question.
RQs and higher-order themes.
The quality evaluation results of the selected studies are presented in Figs 3 and 4. These results indicate that journal studies have lower spread and slightly higher quality score than conference studies. The authors in [30], a systematic review work about linked data-based recommender systems, report similar results. Regarding the publication year of the selected studies, we see in Fig. 2 a steady increase in hybrid RS publications. More than 76% of the included papers were published in the second half (from 2010 later on) of the 10 years time period. This high number of recent publications suggest that hybrid RSs are still a hot topic. As mentioned in introduction, similar increased academic interest in RSs is also reported by other surveys like [14] or [15]. Some factors that have boosted the publications and development of RSs are probably the Netflix Prize9 (2006–2009) and the boom of social networks.
Problems and challanges
Cold-start was the most acute problem that was found. CF RSs are the most affected by cold-start as they generate recommendations relying on ratings only. Hybrid RSs try to overcome the lack of ratings by combining CF or other recommendation techniques with association rule mining or other mathematical constructs which extract and use features from items. Data sparsity is also a very frequent problem in the field of RSs. It represents a recommendation quality degradation due to the insufficient number of ratings. Hybrid approaches try to solve it by combining several matrix manipulation techniques with the basic recommendation strategies. They also try to make more use of item features, item reviews, user demographic data or other known user characteristics.
Accuracy has been the top desired characteristic of RSs since their dawn, as it directly influences user satisfaction. Improving recommendation accuracy is a problem that is mostly addressed by using parallel (i.e. in a weighted or switching hybrid classes) recommendation techniques. Scalability is also an important problem which is frequently found in association with data sparsity (appear together in 9 studies). Lack of diversity is a problem that has been addressed in few studies. As explained in [31] diversity is frequently in contradiction with accuracy. Authors usually attain higher diversity by tolerable relaxations in accuracy. In general we see that hybrid RSs try to solve the most acute problems that RSs face. In Table 13 we summarize some typical solutions about each problem with examples from papers discussed in Sections 3.2–3.5.
Problems and possible solutions
Problems and possible solutions
As shown in Table 7, K-NN is the most popular DM technique among hybrid RSs. This result highlights the fact that K-NN CF is one of the most successful and widespread RSs. Clustering techniques are also commonly used. There are different types of clustering algorithms with K-means being the most popular. Clustering as a process is mostly involved in preliminary phases to identify similar users, similar items, similar item features, etc. Association rules are also used to identify frequent relations between users and items. Fuzzy logic and matrix manipulation methods are also incorporated in hybrid RSs. In most of the cases authors combine 2 recommendation strategies. In few cases event 3 are involved. CF-CBF is the most popular combination, commonly associated with recurrent problems like data sparsity, cold-start and accuracy. CF-CBF-X is also common. Here CF and CBF are combined together and reinforced by a third technique.
In CF-X combinations, X is usually integrated in CF to improve its performance and usually represents fuzzy logic (reclusive methods are complementary to collaborative methods) or clustering. IICF-UUCF is also popular as it represents the combination of two basic version of CF. In conclusion, as can be inferred from Table 8, the most common recommendation techniques (with CF been the most popular) are combined to solve the typical problems which are cold-start, data sparsity and accuracy. Actually it is not a surprise that CF combines with almost any other recommendation technique. Other surveys report similar results. In [32] the authors present a broad survey about CF techniques. They also conclude that most of hybrid CF recommenders use CF methods in combination with content-based methods (CF-CBF is also the most frequent combination we found) or other methods to fix problems of either recommendation technique and to improve recommendation performance. CBF-X addresses problems like data sparsity, accuracy and scalability.
Other combinations put together techniques like Bayesian methods, demographic filtering, neural networks, regression, association rules mining or genetic algorithms. It is important to note that in some cases hybrid RSs are not built by combining different recommendation techniques. In those cases they represent combinations of different data sources, item or user representations, etc. embedded in a single RS. For this reason the number of the reported combinations is smaller than the number of total primary studies we analyzed.
Hybridization classes
Regarding the hybrid classes, weighted hybrid is the most popular. It often combines CF and CBF recommendations in a dynamic way (weights change over time). Feature combination is the second, putting together data from two or more sources. Cascade, switching, feature augmentation and meta-level have almost equal frequency of appearance whereas mixed hybrid is the least common class. There is also a last category we denoted as “Other” which includes 13.2% of the studies. It was not possible for us to identify a hybridization class of this recommenders based on Burke’s taxonomy (which might also need to be extended). In some studies hybrid RSs are not combinations of two or more recommendation strategies in a certain way. They put together different data sources and item or user representations in a single strategy. In this sense, the “Other” category means “we don’t know”.
Various mathematical constructs are used as “gluing” methods between the different components of the systems based on the hybridization class. Weighted, Mixed, Switching and Feature Combination are order-insensitive; there is no difference between a switching CF-CBF and a switching CBF-CF. In this sense these 4 classes are easier to concatenate compared to Cascade, Feature Augmentation and meta-level which are inherently ordered. The few mixed systems do not need the “glue” at all as their components generate recommendations independently from each other. Our results indicate that Weighted hybrids usually rely on weighted linear functions with static or dynamic weights which are updated based on the user feedback. Switching hybrids usually rely on distance/similarity measures such as Euclidean distance, Pearson correlation, Cosine similarity, etc. to decide which of the components to activate in a certain time. Feature combinations usually involve fuzzy logic to match the features obtained by one module with those of the other module. Feature augmentation, Cascade and Meta-level hybrids rely on even more complex and advanced mathematical frameworks such as probabilistic modeling, Bayesian networks, etc.
Application domains
A rich set of application domains was found as shown in Fig. 7. Many of the studies are domain independent (more than a quarter). They are not limited to any particular domain and the methods or algorithms they present can be applied in different domains with minor or no changes at all. Movies are obviously the most recommended items. It is somehow because of the large amount of public and freely accessible user feedback about movie preferences (i.e. many public movie datasets on the web10) which are highly helpful. There is also a rich set of algorithms and solutions (Netflix $1M challenge was a big motivation to improve movie recommenders). This allows researchers to train and test their recommendation algorithms easily. Education or e-learning is another domain in which hybrid RSs are gaining popularity. The amount of educational material on the web has been increasing dramatically in the last years and MOOCs (Massive Open Online Course) are becoming very popular. Other somehow popular domains are music and web services. More detailed information about the application domains of recommender systems can be found at [33] where the authors illustrate each application domain category with real RS applications found in the web.
Evaluation
Evaluation of Recommender Systems is an essential phase which helps in choosing the right algorithm in a certain context and for a certain problem. However, as explained in [34], evaluating recommender systems is not an easy task. Certain algorithms may perform better or worse in different datasets and it is not easy to decide what metrics to combine when performing comparative evaluations. With the three research questions about evaluation, we addressed different aspects of this delicate process. Based on our results most of the studies evaluate hybrid RSs by comparing them with similar methods. The experiments which are usually offline utilize accuracy or error metrics like MAE or RMSE and information retrieval metrics like precision, recall and F1. Similar results are reported in [35] where offline evaluations that typically measure accuracy are dominant. User surveys are less popular, using subjective quality assessments and occasionally precision or recall. These kind of experiments are mostly online (i.e. users interacting with the system and answering questions) and offer more direct and credible evaluation conclusions. From the results, we see that researchers find it easier to compare their system with other systems using public data rather than to perform massive user surveys for a more subjective and qualitative evaluation.
Regarding RS characteristics, accuracy results to be the most commonly evaluated characteristic of the hybrid RSs. This is partly because it is easy to represent and compute it by means of various measures that exist. The most frequent metrics used to evaluate accuracy are Precision, Recall and MAE. User satisfaction (subjective recommendation quality) comes second. It is evaluated by means of user surveys. There is a lot of discussion in the literature about recommendation diversity. In [36] the authors conclude that the user’s overall liking of recommendations goes beyond accuracy and involves other factors like diversity. On the other hand, in [31] the authors agree that increasing diversity in recommendations comes with a cost in accuracy. Our results show that diversity is still less frequently evaluated. Actually most of the studies that try to provide diversity do it by conceding accuracy. In [23] the authors explore the use of serendipity and coverage as both characteristics and quality measures of RSs. They suggest that serendipity and coverage are designed to account for the quality and usefulness of the recommendations better than accuracy does. In our results serendipity is rarely evaluated.
It is important to note that the difference between recommendation characteristics and evaluation metrics is sometimes subtle. This is the case for coverage. Is coverage a recommendation characteristic, a recommendation metric or both? In some works like [34, 23] coverage is considered as both a characteristic and metric. As a characteristic it reflects the usefulness of the system. The higher the coverage (more items predicted and recommended) the more useful the recommender system for the users. In other works like [37] it is only considered as a metric with which the authors evaluate diversity, another recommendation characteristic. In the studies we considered for this review coverage is both considered as a metric for estimating the diversity and as a recommendation characteristic of the systems. Few studies we analyzed evaluate the computational complexity of the systems they propose by measuring the execution time. Besides the new trends, the results indicate that accuracy is still the most frequently evaluated characteristic.
We also considered the public datasets used to perform the evaluation. With the exponential growth of the web content there are more and more public data and datasets which can be used to train and test new algorithms. These datasets usually come from highly visited web portals or services and represent user preferences about things like movies, music, news, books, etc. In [38] we present the characteristics of some of the most popular public datasets and the types of RSs they can be used for. It is convenient to exploit them for evaluating novel algorithms or recommendation techniques in offline experiments. The evaluation process steps are clearly explained in [39]. The result of this review indicate that movie datasets led by Movielens are very popular being used in more than 72% of the studies. This is somehow related with the fact that movie domain is also highly preferred. Many authors chose to experiment in the domain of movies to easily evaluate their prototypes. Music, web services, tourism, images datasets, etc. make up the rest of the datasets the studies use.
Future work
With RQ7 we tried to uncover the most important future work directions in hybrid recommender systems. Extending or improving the proposed solution is the most common future work the authors intend to undertake. Extension of the proposed solutions comes in diverse forms like (i) extend by applying more algorithms, (ii) extend the personalization level by adapting more to the user context and profile, (iii) extend by using more datasets or item features, etc. Performing a comprehensive evaluation is something in which many studies fail. This is why some authors present it as a future work. It usually happens in the cases when the authors implement their algorithm or method in a prototype. In these cases comparison with similar methods using accuracy metrics does not provide clear insights about recommendation or system quality. Reinforcing with subjective user feedback may be the best way to optimize evaluation of the system, making it more user oriented.
A highly desired characteristic from RSs is adapting to the user interest shifting or evolving over time, especially as a results of rapid context changes. As a result, different authors suggest to add context to their systems or to analyze different criteria of items or users as ways to improve the recommendation quality. Context-Aware Recommender Systems (CARS) and Multi-Criteria Recommender Systems (MCRS) are relatively new approaches which are gaining popularity in the field of RSs [40]. They are promoted by the increased use of mobile devices which reveal user details (i.e. the location) that can be used as important contextual inputs. Combining context and multiple criteria with other hybrid recommendation techniques could be a good direction in which to experiment.
Considering other application domains in which hybrid RSs could be applied is also stated by some authors. Many of the works were domain independent and can be easily adapted to different recommendation domains. One step further could be to have hybrid RSs recommend items from different (changing) domains and implement the so called cross domain recommender systems. Having found the best movie for the weekend, the user may also want to find the corresponding soundtrack or the book in which the movie may be based on. Cross-domain RSs are an emerging research topic [41, 42]. Different recommendation strategies like CF and CBF could be specialized in different domains of interest and then joined together in a weighted, switching, mixed or other hybrid cross-domain RS which would recommend different items to its users.
Combining more data from different sources or with various item features was a way to create hybrid RSs. Using more data is a common trend not only in recommender systems but in similar disciplines as well. However, having and using big volumes of data requires scaling in computations. One way to achieve this high scalability is by parallelizing the algorithms following MapReduce model which could be a future direction as suggested in [43]. Experimenting with other hybrid recommendation classes is also possible in many cases. The results indicate that some hybrid classes are rarely explored (i.e. mixed hybrid appears in 3 studies only). It could be a good idea to experiment building CF-CBF, CF-CBF, CF-KBF or other types of mixed hybrids and observe what characteristics this systems could provide. Other future work suggestions include increasing personalization and reducing the computational cost of the system.
Conclusions
In this review work we analyzed 76 primary studies from journals and conference proceedings which address hybrid RSs. We tried to identify the most acute problems they solve to provide better recommendations. We also analyzed the data mining and machine learning techniques they use, the recommendation strategies they combine, hybridization classes they belong to, application domains and dataset, evaluation process, and possible future work directions.
With regard to the research problems cold-start, data sparsity and accuracy are the most recurrent problems for which hybrid approaches are explored. The authors typically use association rules mining in combination with traditional recommendation strategies to find user-item relations and compensate the lack of ratings in cold-start situations. We also found that matrix factorization techniques help to compress the existing sparse ratings and attain acceptable accuracy. It was also typical to find studies in which collaborative filtering was combined with other techniques such as fuzzy logic attempting to alleviate cold-start or data sparsity and at the same time provide good recommendation accuracy.
We also presented a classification of the included studies based on the different DM/ML techniques they utilize to build the systems and their recommendation technique combinations. K-NN classifier which is commonly used to construct the neighborhood in collaborative RSs, was the most popular among the data mining technique. On the other hand, CF was the most commonly used recommendation strategy, frequently combined with each of the other strategies attempting to solve any kind of problem.
We identified and classified the different hybridization approaches relying in the taxonomy proposed by Burke and found that the weighted hybrid is the most recurrent, obviously because of the simplicity and dynamicity it offers. Other hybridization classes such as meta level or feature augmentation are rare as they need complicated mathematical constructs to aggregate the results of the different recommenders they combine.
Concerning evaluation, accuracy is still considered the most important characteristic. The authors predominantly use comparisons with similar methods and involve error or prediction metrics in the evaluation process. This evaluation methodology is “hermetic” and often not credible. User satisfaction is commonly evaluated with subjective data feedback from surveys which are user oriented, more credible and thus highly suggested. Additionally, computational complexity was found in few cases. We also investigated what public datasets are typically used to perform evaluation of the hybrid systems. Based on our findings movie datasets led by Movielens are the most popular, facilitating the evaluation process. Moreover movie domain was the most preferred for prototyping, among the numerous that were identified.
More than three-quarters of our included studies were published in the last five years. This high and growing number of recent publications in the field lets us believe that hybrid RSs are a hot and interesting topic. Our findings indicate that future works could be focused in context awareness of recommendations and models with which to formalize and aggregate severals contextual factors inside a hybrid recommender. Such RSs could be able to respond to quick shifts of user interest with high accuracy.
We also found that there are many combinations of recommendation techniques or hybridization classes which are not explored. Thus they represent a good basis for future experimentations in the field. Using more data was another possible work direction we found. In the epoch of big data, processing more or larger dataset (as even more become available) with hybrid parallel algorithms could be a good way to alleviate the problem of scalability and also provide better recommendation quality. Other future work direction could be using hybrid RSs to build cross domain recommenders or improve the computation complexity of the existing techniques.
Footnotes
Acknowledgments
This work was supported by a fellowship from TIM.