
Abstract
Classifying domain entities into their respective top-level ontology concepts is a complex problem that typically demands manual analysis and deep expertise in the domain of interest and ontology engineering. Using an efficient approach to classify domain entities enhances data integration, interoperability, and the semantic clarity of ontologies, which are crucial for structured knowledge representation and modeling. Based on this, our main motivation is to help an ontology engineer with an automated approach to classify domain entities into top-level ontology concepts using informal definitions of these domain entities during the ontology development process. In this context, we hypothesize that the informal definitions encapsulate semantic information crucial for associating domain entities with specific top-level ontology concepts. Our approach leverages state-of-the-art language models to explore our hypothesis across multiple languages and informal definitions from different knowledge resources. In order to evaluate our proposal, we extracted multi-label datasets from the alignment of the OntoWordNet ontology and the BabelNet semantic network, covering the entire structure of the Dolce-Lite-Plus top-level ontology from most generic to most specific concepts. These datasets contain several different textual representation approaches of domain entities, including terms, example sentences, and informal definitions. Our experiments conducted 3 study cases, investigating the effectiveness of our proposal across different textual representation approaches, languages, and knowledge resources. We demonstrate that the best results are achieved using a classification pipeline with a K-Nearest Neighbor (KNN) method to classify the embedding representation of informal definitions from the Mistral large language model. The findings underscore the potential of informal definitions in reflecting top-level ontology concepts and point towards developing automated tools that could significantly aid ontology engineers during the ontology development process.
Introduction
In recent years, two significant areas in Artificial Intelligence (AI) have collided again. On the one hand, we have ontologies, defined as a formal and explicit specification of a shared conceptualization (Studer et al., 1998). On the other hand, we have the advances in natural language processing (NLP) for text representation and classification with Large Language Models (LLMs) (Devlin et al., 2018; Radford et al., 2018; Touvron et al., 2023b; Jiang et al., 2024). This convergence has ushered in a new renaissance in ontology learning from text, in which the goal is to generate ontologies in an automatic or semi-automatic way, using text as input and state-of-the-art NLP techniques. While there are several approaches to tackle this challenge (He et al., 2022,2023; Babaei Giglou et al., 2023), the field is still rife with open questions and opportunities for exploration.
Among various uses of ontologies, knowledge representation and data management are two usages that stand out because ontologies provide a structured and standardized way to represent and organize complex information, allowing for improved data integration and interoperability and enabling information retrieval and knowledge sharing across different systems or resources (Cicconeto et al., 2022; Kulvatunyou et al., 2022; Qu et al., 2024). Also, ontologies enhance semantic clarity by precisely defining domain entities and their relationships, reducing ambiguity, and ensuring a common understanding of complex knowledge domains. In this context, state-of-the-art ontology engineering methodologies, such as NeOn (Suárez-Figueroa et al., 2011), recommend using a top-level ontology to ensure these benefits when using domain ontology.
A top-level ontology defines a foundational and high-level structure for categorizing and organizing knowledge across various domains (Borgo et al., 2022; Guizzardi et al., 2022; Otte et al., 2022). It serves as a broad and abstract framework for representing fundamental concepts and relationships that are universally applicable and not tied to any specific field. Thus, top-level ontologies are the starting point for organizing and categorizing domain-specific knowledge represented in domain ontologies and act as a common framework for the semantic integration of domain ontologies or data assets from distinct sources. However, identifying which top-level ontology concept a domain entity specializes in is laborious and time-consuming. This task is usually performed manually and requires expertise in the target domain and ontology engineering. Although ontology learning approaches often focus on tasks like entity recognition, extraction, and relationship extraction, which are crucial for building ontologies from text sources (He et al., 2022,2023; Babaei Giglou et al., 2023), classifying domain entities into top-level ontology concepts is particularly challenging, involving not only entity identification and extraction but also understanding the theoretical foundation and implications of choosing one top-level concept over another.
In this work, we addressed the problem of classifying domain entities into top-level ontology concepts using informal definitions to represent domain entities textually. From that, our central hypothesis is that the informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. In this context, we leveraged two crucial ideas. Firstly, since top-level ontologies also contain a taxonomy of concepts, i.e., concepts related through hierarchical relationships (e.g., “is-a” and “subclass-of”), we used the notion of similarity in taxonomies, which more specific entities grouped in the same more general entity share common features or attributes making them more similar to each other. Secondly, since our hypothesis uses a textual representation for domain entities, we leverage the Distributional Hypothesis (Harris, 1954), which suggests that words that occur in similar contexts are likely to have related meanings, i.e., they are closer in the distributional space. Therefore, since informal definitions provide the intended meaning of a domain entity in a particular domain (Seppälä et al., 2016) and possibly similar domain entities have similar informal definitions, we can use these definitions to find the top-level ontology concepts of domain entities.
In order to validate our hypothesis, we proposed the extraction of multi-label, multi-language, and multi-resource datasets from the alignment between OntoWordNet ontology (Gangemi et al., 2003) and the BabelNet semantic network (Navigli and Velardi, 2004; Navigli et al., 2021). From this alignment, we extract datasets in 291 languages and with various informal definitions resources, such as WordNet (Miller, 1995), and Wikipedia, and their variations. Also, we proposed two supervised classification pipelines for classifying domain entities into top-level concepts using text as input. The first pipeline utilizes a pre-trained language model that we fine-tuned to our target task. The second involves using a pre-trained language model to generate the embedding representation of the input text. From the embedding, we used classical machine learning classifiers (e.g., K-Nearest Neighbors, Decision Tree, and Support Vector Machine) to classify the embedding into top-level ontology concepts.
In our experiments, we conducted three study cases. Firstly, we examined the performance of the proposed pipelines using different textual representation approaches of domain entities, including terms, example sentences, and informal definitions. Secondly, we investigated the performance of our proposal for datasets in multiple languages. Thirdly, we evaluated the performance of our proposal by training and testing the proposed pipelines using informal definitions from different knowledge resources. The results suggest using informal definitions is the best way to represent domain entities textually and classify them into top-level ontology concepts. Also, our results show that our hypothesis is valid for different languages and resources. Furthermore, although fine-tuning a classification model for a specific task has promising results in many fields, our work shows that employing a K-Nearest Neighbor (KNN) approach using the embedding representation of informal definitions as input has better results and avoids the computation costs of fine-tuning. We achieved our best result using the Mistral7B language model in the second pipeline with a KNN classifier.
The paper is organized as follows. In Section 2, we present the evolution of ontologies from philosophical concepts to tools for knowledge representation. We also describe the importance of precise informal definitions for domain entities and the Distributional Hypothesis in computational linguistics. In Section 3, we review the advancements in language models, from embedding to transformer-based architectures, and their impact on ontology learning tasks. In Section 4, we introduce our proposed approach of using informal definitions for classifying domain entities into top-level ontology concepts, detailing dataset extraction, classification pipelines, and training methodologies. In Section 5, we discuss the practical results and effectiveness of the proposed classification pipelines over three study cases. Finally, in Section 6, we offer concluding remarks on our work.1
Background
In this section, we discuss the use of ontologies in computer science, contrasting their philosophical origins and highlighting their role in knowledge modeling. We focus mainly on top-level ontologies because they are general frameworks for knowledge representation across various domains. After that, we review informal definitions, highlighting the importance of clear and precise definitions for domain entities to disambiguate terms in a specific domain. Additionally, we review the Distributional Hypothesis, illustrating its importance in linguistics and computational linguistics, which influenced the development of word embedding and state-of-the-art language models.
Ontologies and Top-Level Ontologies
Ontologies are tools to support knowledge modeling. It is a term from Philosophy that has different meanings and uses in various communities. According to Guarino et al. (2009), the most divergent senses of ontology come between Philosophy and Computer Science, wherein the term Ontology (with capital ‘O’) refers to the study of the nature and structure of things per se, independently of any further considerations, and even independently of their actual existence. On the other hand, in Computer Science, an ontology (with a lower ‘o’) is a special kind of information object or computational artifact used to formally structure a body of knowledge. In Computer Science, ontology developers commonly use structured languages such as the Web Ontology Language (OWL) to implement ontologies. This approach allows computers to interpret and manage organized data effectively. From that, ontologies bridge human conceptual understanding and machine readability, thus facilitating more efficient and accurate data processing, analysis, and decision-making in complex systems and enabling semantic interoperability between different resources. Also, there are several ways to classify ontologies regarding the domain covered, the formal language used, or the level of generality of the entities defined in the ontology (Guarino, 1998; Prestes et al., 2013). A popular way to classify kinds of ontologies is in four levels of generality of their entities: (1) top-level ontologies, (2) core ontologies, (3) domain and task ontologies, and (4) application ontologies. Based on that, in this work, we use the term “domain entity,” referring to any entity described in Levels 2, 3, and 4 of these ontology types.
A top-level ontology (a.k.a, upper-level, foundational, or general ontologies) is an ontology that facilitates the interoperability of knowledge across different domains, critical for knowledge modeling and ontology engineering (Suárez-Figueroa et al., 2015). This type of ontology encapsulates fundamental concepts and principles that are universally applicable, regardless of the domain, including general concepts like time, space, events, objects, relationships, and qualities. From that, the primary purpose of top-level ontologies is to establish a shared understanding and a universal vocabulary from which the entities in the other types of ontologies can subsume and ensure consistency and interoperability between them. In this context, several top-level ontologies are proposed, for example, BFO (Arp et al., 2015; Otte et al., 2022), DOLCE (Gangemi et al., 2002; Borgo et al., 2022), SUMO (Niles and Pease, 2001), UFO (Guizzardi et al., 2022), among others.
In this work, we focused only on DOLCE’s top-level ontology structure, particularly on the DOLCE-Lite-Plus (DLP).2 The DLP top-level ontology represents the DOLCE (Gangemi et al., 2002) foundations using an OWL representation approach, extending the original DOLCE structure with other top-level concepts for representing descriptions, situations, temporal relations, information objects, actions, agents, social units, collections, and collectives. The whole taxonomic structure of DLP contains a total of 244 top-level concepts.
Informal Definitions
According to Robinson (1950), a definition is a statement that clarifies the meaning of a term or concept. In this context, Robinson posits that definitions are intended to elucidate the essence of what is being defined, thereby distinguishing it from other entities. He emphasizes that a good definition must be clear, precise, and concise, avoiding ambiguity or circular reasoning. From that, definitions are linguistic tools fundamental to logical analysis and philosophical inquiry. Also, definitions advance understanding, facilitate communication, and provide a foundation for further exploration across various fields of knowledge. From this perspective, definitions are more than mere explanations of words. They are crucial elements in the knowledge structure, aiding in articulating and differentiating concepts essential to intellectual discourse.
Other works, such as Seppälä et al. (2016), extend the contributions on definitions in ontologies. According to their work, the term “definition” can vary, depending on the context of use and target audience. However, definitions are essential tools for communication and understanding, specifically designed to align the intended context with their cognitive and linguistic requirements. From a linguistic perspective, definitions aim to align with a specific pre-existing lexical use, conveying the semantic value of a term by delimiting its intension and extension. In this context, definitions adjust the overall lexical competence of users by enhancing their inferential competence, particularly semantic inferential competence. From a cognitive perspective, definitions in ontologies bring about a reconfiguration of the receiver’s existing body of knowledge regarding the intended referent of the defined term. In this context, definitions augment and reconfigure the knowledge and beliefs of the user to align them more closely with those of relevant expert communities. Overall, definitions help disambiguate terms and ensure consistency in their use by providing precise and unambiguous intended meaning (often using Aristotelian principles) to distinguish a term from neighboring terms.
In this work, we use the term “informal definition,” referring to the Aristotelian form of the definition (“X is a Y that Z”), in which “X” is the Definiendum, “Y that Z” is the Definiens, and “is a” is the Copula. For example, “Rock is a naturally occurring solid mass or aggregate of minerals or mineraloid matter”. Definiendum is the defined term, the subject of the informal definition, i.e., what the informal definition is about (e.g., “Rock”). Definiens is the part that expresses the content of the informal definition, i.e., the explanatory part of the informal definition that specifies what the Definiendum is (e.g., “naturally occurring solid mass or aggregate of minerals or mineraloid matter”). Copula is the linking part that expresses an equivalence or subsumption between the Definiendum and the Definiens (e.g., “is a”). In this work, we used the terms Definiendum and Definiens to refer to a specific part of an informal definition.
Distributional Hypothesis
The Distributional Hypothesis (Harris, 1954) presents a foundational idea in linguistics, suggesting that words that occur in similar contexts are likely to have related meanings. This hypothesis proposes a method for inferring the semantics of words by analyzing their distributional patterns across texts. The approach proposed by Harris (1954) to structural linguistics emphasized the importance of context in understanding linguistic meaning, suggesting that the semantic attributes of words could be uncovered through a systematic examination of their usage in various linguistic environments. By focusing on empirical language analysis, Harris established a semantic analysis framework that relies on observable, quantitative data, shifting away from more introspective or purely theoretical methods. This framework has profoundly influenced how linguists and computational linguists approach language study by suggesting that words’ meanings can be deduced from their use patterns.
This hypothesis also had a significant impact on the development of computational linguistics, particularly in creating technologies like word embedding (Mikolov et al., 2013a,b; Pennington et al., 2014), and language models (Radford et al., 2018; Devlin et al., 2018; Touvron et al., 2023b; Jiang et al., 2024). These models represent words as vectors in a high-dimensional space, where the proximity between vectors indicates semantic similarity based on their distributional properties. This approach has enabled natural language processing (NLP) advances, allowing for a more nuanced and effective machine understanding of human language. The practical applications of the Distributional Hypothesis are evident in various NLP tasks, including machine translation, information retrieval, and sentiment analysis, demonstrating its vital role in bridging linguistic theory and computational applications.
Related Work
In this section, we investigate the current trend in Natural Language Processing (NLP), focusing on the advancements in language models. These models advance toward contextually rich word embedding generation. Also, we present ontology learning approaches, focusing on automating or semi-automating methods that leverage language models for tasks such as entity extraction and classification, ontology alignment, etc.
Language Models
The evolution of the Natural Language Processing (NLP) field from word embedding (Mikolov et al., 2013a,b) to context embedding and language models (Devlin et al., 2018; Radford et al., 2018; Touvron et al., 2023b; Jiang et al., 2024) marks a significant advancement in understanding and processing human language. The relation between language models and the distributional hypothesis (Harris, 1954) lies in how the models learn by predicting words based on their contexts (for example, a word before and after given words in a sentence). This predictive process inherently relies on the assumption that words with similar contexts have similar meanings as the models adjust their internal parameters to reduce prediction errors based on the contexts they observe. Consequently, state-of-the-art language models not only learn to predict words accurately but also implicitly learn rich, context-sensitive embedding for words and phrases that reflect their meanings and relationships, embodying the principles of the distributional hypothesis.
A significant advancement came with the development of transformer-based models, such as BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2018) and GPT (Generative Pre-trained Transformer) (Radford et al., 2018). These models revolutionized NLP by using attention mechanisms Vaswani et al. (2017) to understand the full context of a word in relation to all other words in a sentence or even across multiple sentences. The BERT model, in particular, marked a paradigm shift by pre-training on a large corpus of text and then fine-tuning for specific tasks, achieving unprecedented performance across a range of NLP benchmarks. Its bidirectional nature meant it could effectively understand the context from both the left and the right of each word in a sentence, providing a more thorough understanding of language. In the same line of transformer-based language models, GPT and its successors, GPT-2, GPT-3, and GPT-4, propose a generative language model that predicts the next word in a sequence given all the previous words, i.e., using only a left-to-right interpretation from a given sentence.
DistilBERT (Sanh et al., 2020), RoBERTa (Liu et al., 2019), and ALBERT (Lan et al., 2019) are advancements over BERT focusing on efficiency and performance. DistilBERT reduces the model size by 40% while retaining 97% of BERT’s capabilities through knowledge distillation, making it faster and lighter. RoBERTa optimizes BERT’s pretraining by removing the Next Sentence Prediction objective, extending training, and dynamically changing the masking pattern, significantly outperforming BERT on major benchmarks. ALBERT introduces parameter-reduction techniques and a Sentence Order Prediction loss, achieving better results with fewer parameters and focusing on inter-sentence coherence.
T5 (Text-to-Text Transfer Transformer) (Raffel et al., 2023) and BART (Bidirectional and Auto-Regressive Transformers) (Lewis et al., 2019) are two language model architecture advances. T5 operates on a unified text-to-text framework, which treats all NLP tasks as text-generation problems by converting inputs into a standardized text format. BART combines the bidirectional approach of BERT to encode and the autoregressive method of GPT to decode the input sentences. Also, both models are trained by inserting noise in the input sentences, such as sentence shuffling and token replacement, in order to enhance their text-generation capabilities.
LLaMA (Touvron et al., 2023b,a), Mistral (Jiang et al., 2023), and Gemma (Team et al., 2024) represent the current state-of-the-art language models. LLaMa incorporates several enhancements for improved training performance and efficiency, such as using pre-normalization, where transformer sub-layers are normalized using the RMSNorm function to improve training stability, using the SwiGLU activation function rather than the traditional ReLU, and using Rotary Positional Embedding (RoPE) to maintain the relative positional information across the input sequence. Mistral introduces novel attention mechanisms such as Grouped-Query Attention (GQA), which allows Mistral to process multiple queries in groups, significantly speeding up inference times and reducing the computational load during model deployment, and Sliding Window Attention (SWA), which optimizes the computational efficiency and enable effective handling of long sequences, making Mistral suitable for real-time applications. Gemma also employs RoPE and Multi-Query Attention, which allows Gemma to handle multiple queries within a single pass efficiently.
The field of language models continues to evolve rapidly, with ongoing research exploring even more sophisticated models and techniques for capturing the nuances of human language with an optimized training performance. Consequently, language models not only learn to predict words accurately but also implicitly learn rich, context-sensitive embedding for words and phrases that reflect their meanings and relationships, embodying the principles of the distributional hypothesis.
Ontology Learning
The field of ontology learning primarily focuses on developing ontologies through automatic or semi-automatic processes (Khadir et al., 2021). This area encompasses a variety of systems, methodologies, and algorithms aimed at either fully automating the ontology creation process or facilitating certain stages of it (Wong et al., 2012; Khadir et al., 2021). Typical tasks in ontology learning from text input include: entity extraction, where relevant terms are identified and classified as potential entities within a domain; relationship extraction, which involves identifying and categorizing the relationships between the extracted entities; and taxonomy discovery, which aims to organize the entities into a structured format, typically in a hierarchical manner reflecting the general-to-specific nature among the entities.
With the advancements in word embedding and language models, He et al. (2022) introduced BERTMap, an innovative system utilizing the BERT language model for ontology alignment tasks. This system performs mapping predictions and refinements, showing significant improvements over existing methods in handling large-scale ontologies. Extensive evaluations demonstrate BERTMap’s better performance, especially in biomedical ontology tasks, highlighting its practicality and effectiveness in ontology alignment and knowledge integration. Although ontology alignment and learning are not the same tasks, they are related areas.
In Chen et al. (2023), the authors proposed a method for taxonomy discovery within and between ontologies. The technique leverages BERT to compute contextual embedding of ontology entities. In this work, the authors employed custom templates to integrate entity context and logical existential restrictions, enabling predictions of various subsumers within the same or different ontologies. Extensive evaluations with real-world ontologies show that the proposed approach significantly outperforms baseline methods, highlighting the effectiveness of the templates in handling both named class and existential restriction subsumptions. The study underscores the importance of contextual embedding and tailored approaches for enhancing machine learning tasks in knowledge engineering.
In Babaei Giglou et al. (2023), the authors explored the application of Large Language Models in ontology learning. The study conducts comprehensive evaluations using the zero-shot prompting method across nine different LLM model families, focusing on three main ontology learning tasks: entity extraction, taxonomy discovery, and relationship extraction. The research spans various knowledge domains, including lexico semantic with WordNet Miller (1995), geographical, and medical knowledge. The findings suggest that while foundational LLMs have limitations in ontology learning, they could be effective assistants when fine-tuned, potentially alleviating the knowledge acquisition bottleneck in ontology development.
So far, only a few works have explored top-level ontologies for ontology learning tasks using state-of-the-art approaches in NLP. In this context, in Lopes et al. (2022), we started the discussion about using word embedding of Definiens concatenated with the word embedding of Definiendum as input of a machine learning pipeline, which classifies the input into a restricted number of DLP concepts from OntoWordNet project (Gangemi et al., 2003). After that, in Lopes et al. (2023), we explored the performance of multiple language models of the BERT’s family using as input the whole informal definition and classifying them into all leaf concepts of DLP used in the OntoWordNet project. As another work in this line, in Rodrigues et al. (2023), we explored the effectiveness of few-shot learning using manually generated prompts in ChatGPT for classifying domain entities from IOF (Industrial Ontology Foundry) ontology3 into concepts of DOLCE and BFO top-level ontologies. However, ChatGPT did not correctly deal with finer ontological distinctions and suffered from hallucinations on several generated responses.
In state-of-the-art ontology learning approaches, it is notable that there needs to be more focus on classifying domain entities into top-level ontology concepts. While existing methodologies have made significant progress in various aspects of ontology development, like entity extraction, relation extraction, and taxonomy discovery, there is a clear gap in developing approaches to classifying domain-specific entities into top-level ontology concepts. This research gap highlights the need for further exploration and innovative methods to address this deficiency, essential to enhancing the comprehensive and coherent development of well-founded domain ontologies.
Proposed Approach
This section details an approach for classifying domain entities into top-level ontology concepts using informal definitions as input. In this context, we introduced the vocabulary used throughout this section. After that, we present a methodology to extract multi-label, multi-language, and multi-resource datasets from the alignment between OntoWordNet and BabelNet. Then, we advocate for using informal definitions as the optimal textual representation for domain entities, proposing two classification pipelines leveraging language models to predict top-level ontology concepts. Finally, we present training methodologies for the data augmentation technique called the “explode” approach.
Technical Vocabulary
In the next sections, we used the following vocabulary:
Dataset Extraction
This section describes the methodology used to extract the multi-label, multi-language, and multi-resource datasets used in this work. Firstly, we present how we matched the domain entities from OntoWordNet and BabelNet resources. After that, we show how we transform the multi-class dataset from this matching into a multi-label dataset, covering a more comprehensive range of top-level concepts from Dolce-Lite-Plus and encompassing its hierarchical structure. Finally, we present the challenges in extracting this kind of dataset, such as partial coverage, special character discrepancies, and the unbalanced nature of top-level ontologies.
OntoWordNet Ontology and BabelNet Semantic Network
The starting point for extracting the datasets used in this work began with the ontology from the OntoWordNet project. This ontology project established a comprehensive alignment between WordNet—a structured collection of English words grouped into sets of synonyms (synsets)—and Dolce-Lite-Plus (DLP) top-level ontology concepts. The alignment process undertaken by OntoWordNet introduced a systematic categorization among the WordNet synsets. This categorization was pivotal to transforming WordNet from merely a lexical database into an ontology by clearly separating concept-synsets, relation-synsets, meta-property-synsets, and individual-synsets. The output of this alignment comprises a total of 65,973 domain entities. Also, OntoWordNet aligns its domain entities with 120 top-level concepts from the 244 of the whole structure of Dolce-Lite-Plus.
Figure 1 provides a detailed visualization of the number of WordNet synsets under the Dolce-Lite-Plus (DLP) top-level concepts in the OntoWordNet ontology. This figure strategically emphasizes only the direct top-level ontology concepts from DLP that WordNet synsets subsume in OntoWordNet. From that, the figure highlights the unbalanced nature of the OntoWordNet ontology, illustrating how certain top-level DLP concepts are associated with many WordNet synsets, while others have far fewer. This disparity is crucial for understanding the distribution and representation of concepts within the top-level ontology, offering insights into potential areas of richness or sparsity of domain entities, which we will address later in this work.
WordNet also divided the informal definitions of its synsets into two parts for technical purposes: definiendum and definiens. The definiendum part refers to each term within a synset, indicating the subject of the definiens. Conversely, the definiens provides the explanation or the descriptive content of the synset’s meaning, encapsulating the synset’s essence. In WordNet, each synset contains only one definiens to maintain the synset clarity and precision. Therefore, the domain entities in the OntoWordNet ontology also have their informal definitions divided into definiendum and definiens parts. This organization facilitates mapping the OntoWordNet domain entities to a more expansive and interconnected semantic network. One such network is BabelNet, which also integrates the comprehensive lexical coverage of WordNet extended with the extensive encyclopedic knowledge from Wikipedia in multiple languages. From that, it is possible to align the OntoWordNet domain entities with the domain entities in BabelNet because both use English WordNet definienda and definientia.
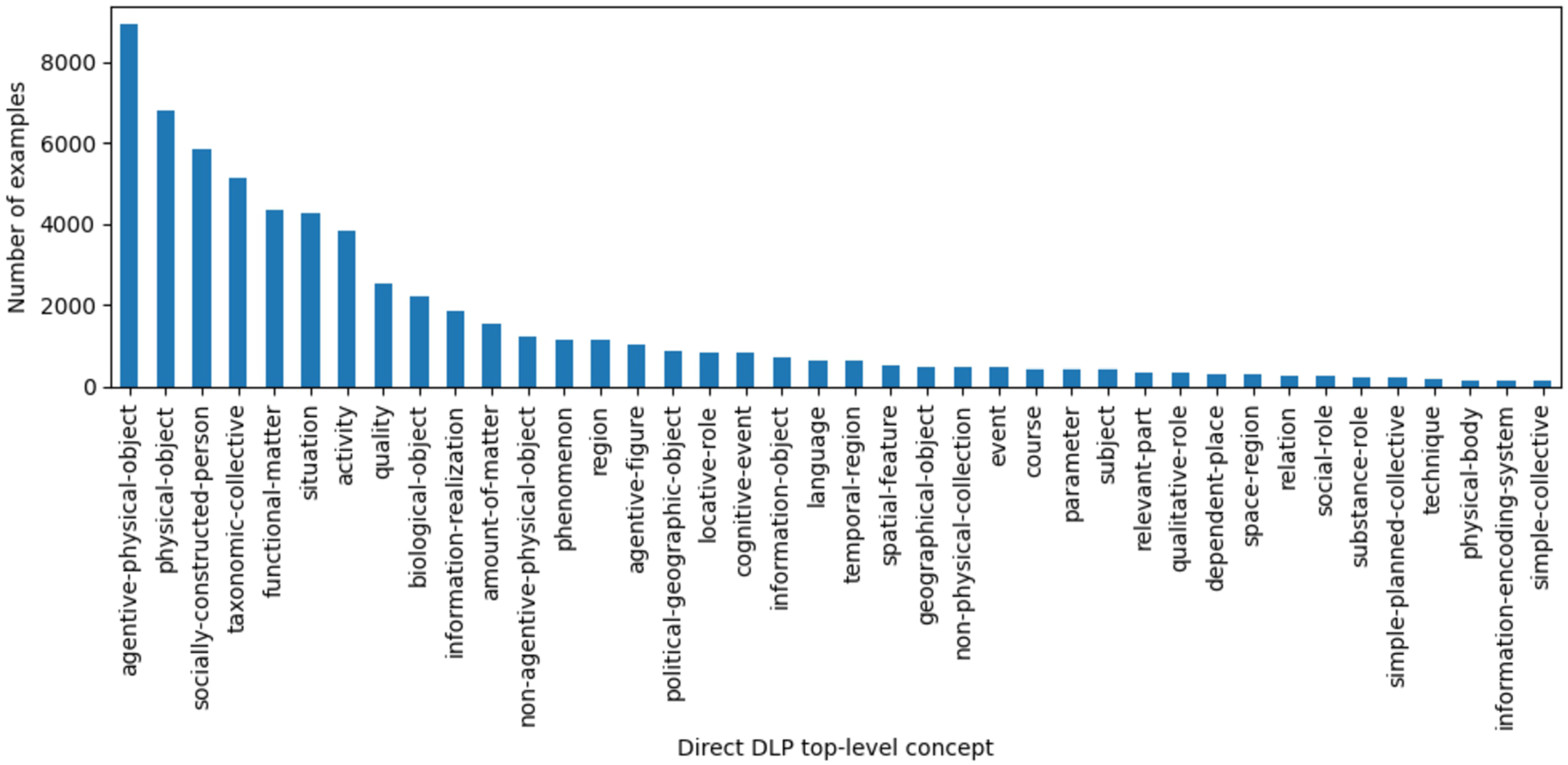
Top 40 most populated direct DLP top-level concepts of WordNet synsets in the OntoWordNet.
This work also introduces an approach to align the domain entities identified within the OntoWordNet ontology with those cataloged in the BabelNet semantic network. BabelNet encompasses more synsets than WordNet, from adding Wikipedia and synsets for more recent linguistic concepts not present in WordNet, such as streamer and influencer. This broadness of BabelNet provides an opportunity for the enhancement and expansion of OntoWordNet domain entities to multi-language and multi-resource datasets. In this context, we take the advantage that both the structure of WordNet inside OntoWordNet and BabelNet share almost the same definienda and definientia to propose the Algorithm 1 to match the domain entities between them.
Algorithm 1 inputs the OntoWordNet ontology
In addition, Algorithm 1 has an asymptotic complexity of

The resulting alignment contains a total of 65,018 domain entities if we consider the main dataset that comprises domain entities represented by informal WordNet definitions in English. Following the application of Algorithm 1, we transitioned from a single-language resource, relying solely on the definitions from WordNet, to multi-language and multi-resource datasets. This advancement enabled the extraction of datasets for predicting the top-level concept of a domain entity across 291 languages and from many kinds of resources, such as WordNet, Wikipedia, Wiktionary, Open Multilingual WordNet, WordNet 2020, OmegaWiki, etc. Also, this alignment made it possible to access other types of representation approaches for domain entities beyond just informal definitions, as well as example sentences, Wikipedia source pages, images, etc. Integrating these diverse elements significantly enhances the breadth and depth of linguistic and semantic information within our datasets, thereby enriching the scope and utility of the datasets that can be extracted.
From a Multi-Class to a Multi-Label Dataset
Currently, all approaches for classifying domain entities into top-level ontology concepts consider the task in a multi-class classification scenario, i.e., each domain entity belongs to one and only one label (or class). However, this scenario has several drawbacks for solving the task effectively. For example, as presented in Fig. 1, the classes tend to be imbalanced due to the nature of the concepts in top-level ontologies, which can negatively affect the classification accuracy for less populated classes. Also, this scenario can not represent the multiple inheritance that domain entities can have. In this context, we aimed to transform the multi-class dataset resulting from the alignment between OntoWordNet and BabelNet into a multi-label dataset, where we assigned the entire branch of the top-level ontology in which a domain entity subsumes, from the most generic concept to the most specific, as its labels.
The first step in this transformation involves processing the top-level ontology taxonomy (or hierarchy) in order to extract all the top-level concepts that are more general than a given top-level concept. After that, we obtained the top-level concept of each domain entity in the dataset, and from it, we retrieved all its more general top-level concepts. For example, consider the domain entity “rock.” In a multi-class dataset, “rock” might be classified under “Amount of Matter.” This classification refers to the entity’s characteristics that match the “Amount of Matter” concept. If “Amount of Matter” is categorized as “Endurant” in the Dolce-Lite-Plus top-level ontology, i.e., “Endurant” is more general than “Amount of Matter,” then “rock” also qualifies as “Endurant” in our multi-label dataset. With this transformation, more general top-level concepts contain all the domain entities of their more specific top-level concepts. This can be beneficial for classification purposes since more general concepts have more instances than more specific ones, reducing the impact of the imbalance characteristic of the datasets. Also, we can analyze the performance of a classifier for all granularity levels in the top-level ontology.
In our view, using the multi-label categories for domain entities enables the representation of the multiple inheritance characteristic of the domain entities, which is beneficial for evaluating classification pipelines in classifying domain entities into top-level ontology concepts. This multiple inheritance occurs when a domain entity inherently belongs to more than one parent concept within the top-level ontology hierarchy. For example, suppose a domain entity like “river” fits into both “Physical Object” and “Geographical Feature” top-level concepts due to its dual characteristics. In this case, the domain entity “river” showcases the need for a multi-label dataset over a restrictive multi-class dataset since, in the multi-class dataset, we have two examples with the same features but different labels, which downgrade the accuracy of a classification model. From that, in the multi-label dataset, we merged the classes of both examples into a single example. Thus, from the 65,018 examples in the original dataset, we reduced to 61,483 after considering this multiple inheritance processing.
When we merge the labels of domain entities with multiple inheritances, a new problem arises: disjoint labels. This issue occurs when a domain entity has two or more labels that should not co-occur due to their inherent conceptual or logical separation. This problem also poses a significant challenge in classifying domain entities into top-level ontology concepts, where we need to preserve the hierarchical and logical structure of the ontology. For instance, suppose a domain entity “justice” is erroneously assigned to both “Abstract” and “Physical Object” labels. From that, we created a contradiction, as these top-level concepts are fundamentally disjoint within the Dolce-Lite-Plus. This misclassification disrupts the integrity of the dataset and the top-level ontology, leading to inaccuracies in a classification model. In this context, we removed from the multi-label dataset all examples in which any of their labels are disjoint to each other. Thus, we reduced the number of examples from 61,483 after the multiple inheritance processing to 59,666 after applying the filter to remove disjoint labels, and this is the final number of dataset instances from the English WordNet employed in our experiments.
Coverage and Limitations
The OntoWordNet project mapped WordNet synsets to 120 from the 244 top-level concepts of Dolce-Lite-Plus (DLP), which means that OntoWordNet covers less than half of the DLP top-level concepts. Figure 2 compares level by level the number of top-level concepts in the DLP and the number of top-level concepts in the OntoWordNet. As presented, after level 2 of the DLP hierarchy, there is a discrepancy between the number of top-level concepts between DLP and OntoWordNet, which mostly follows the same growth pattern as DLP until level 12. Based on this, we can say that although OntoWordNet does not include some of the top-level concepts of DLP, OntoWordNet still represents all the most generic concepts in DLP.
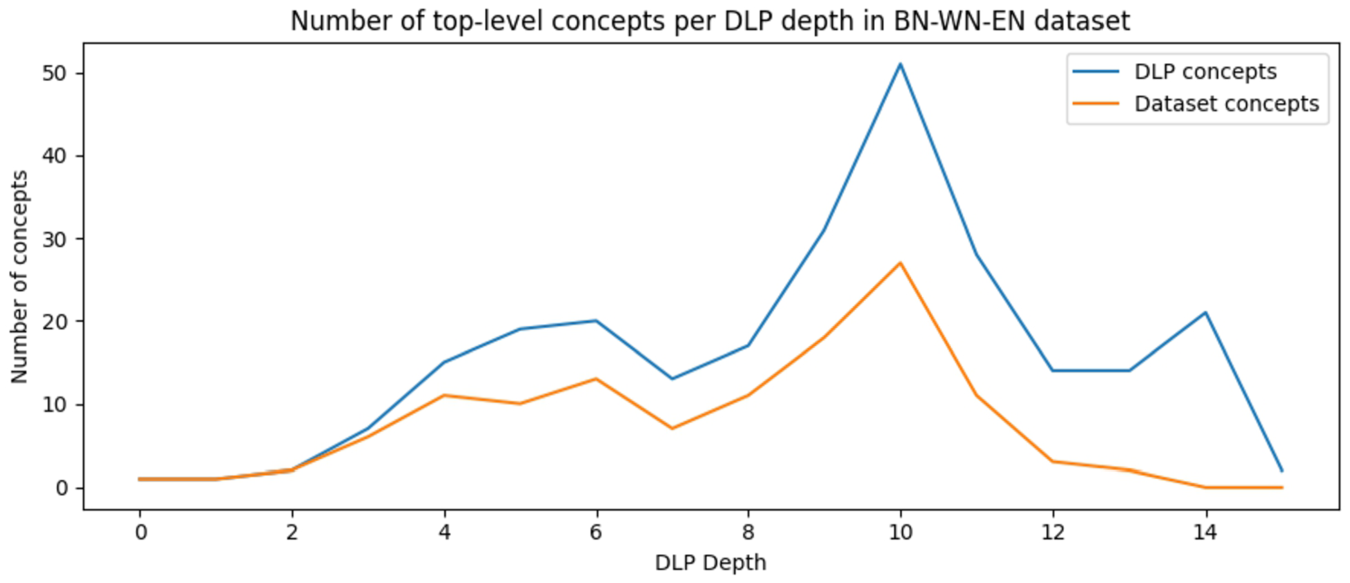
The number of top-level concepts per level in Dolce-Lite-Plus and from the alignment between OntoWordNet and Babel.
As another limitation, OntoWordNet does not handle special characters in the definiendum of WordNet synsets, i.e., OntoWordNet removed the special characters before the alignment with DLP. On the other hand, BabelNet indexes its synsets with special characters such as underscores, percent signs, or non-ASCII characters. Based on that, these discrepancies can cause searches to fail or return incorrect data if not adequately handled. Considering that we have a BabelNet synset that was erroneously retrieved, the ranking strategy adopted in Algorithm 1 can handle this problem by assigning a lower similarity score between the two compared definiens because they are different. Also, the ranking approach further reduces the value of the erroneous retrieved synset because the compared synsets share fewer definiendum than the right synset. In the other case, if there are no results in the BabelNet search for all definienda of an OntoWordNet domain entity, we do not include this domain entity in the alignment between OntoWordNet and BabelNet. This resulted in a decrease in the number of domain entities from 65,973 examples of original OntoWordNet to 65,018 of the alignment.
As a final limitation, top-level ontologies often exhibit an unbalanced nature due to the inherent complexity and diversity of the concepts they aim to represent. The unbalanced nature can be perceived as the difference in the number and the depth of different branches in the top-level ontology hierarchy. Also, some top-level concepts can represent only a limited number of domain entities due to their restrictions, and others can represent a broader number of domain entities because they are not so restrictive. Also, this imbalance can be attributed to the differential emphasis placed on certain areas or categories over others, reflecting the subjective priorities of the ontology designers or the specific needs of the intended application domain. Consequently, datasets derived from these top-level ontologies tend to inherit this imbalance, manifesting in skewed distributions of instances across different categories. Based on that, the performance of classification models that use such datasets can be negatively affected, and approaches to handle data augmentation in this scenario tend to be complex.
In this work, we propose an approach to classify domain entities into top-level ontology concepts using the textual representation of these domain entities. In this context, we hypothesize that informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. This hypothesis comes from two crucial ideas: similarity in taxonomies and distributional hypothesis.
A taxonomy is a classification system that organizes concepts, entities, or information into categories hierarchically based on common characteristics or criteria. Also, taxonomies are the base structure for ontologies and top-level ontologies, facilitating knowledge organization. Based on that, domain entities grouped in the same top-level ontology concept mean that they share common features or attributes, i.e., they are more similar to each other than those of other domain entities under another top-level concept. For example, all domain entities grouped under the “Amount of Matter” top-level concept, such as “gold,” “iron,” and “silver,” have a greater similarity score because they share common characteristics about physical substances or materials. These entities are inherently more similar to one another when contrasted with entities classified under a completely different concept, such as “evening,” “night,” and “day” under the “Temporal Region” top-level concept. In this context, since informal definitions provide the intended meaning of a domain entity in a particular context, they also contain attributes and features of a given definiendum described textually in their definiens.
Usually, informal definitions are written using the Aristotelian format (“X is a Y that Z”), containing the definiendum “X,” the copula “is a” and the definiens “Y that Z.” As discussed before, the definiendum is the defined term, the copula is the relationship between the definiendum and the definiens, and the definiens is the explanatory part of the informal definition. In this context, we expected that the definiens include the information necessary to guarantee the intended meaning of the definiendum in a particular context to guarantee a clear and precise interpretation of the defined domain entity. Table 1 describes examples of informal definitions from the dataset described in Section 4.2 for the domain entities “gold,” “iron,” “silver,” “evening,” “night,” and “day.” As we can see, these informal definitions contain unique characteristics that guarantee the meaning of each domain entity in an unambiguous way. However, even without explicit intention, we can informally categorize these domain entities into two groups, i.e., we can create a group with “gold,” “iron,” and “silver,” and another group with “evening,” “night,” and “day.” This classification can be justified because the first group contains informal definitions with terms related to matter and its composition, reactions, and practical usages. On the other hand, the second group contains informal definitions with terms related to time, period of the day, and certain aspects of the temporal order in which they occur.
Examples of domain entities and their informal definitions extracted from BabelNet

Examples of domain entities and their informal definitions extracted from BabelNet
Since the informal definitions of similar domain entities contain related definientia, we can take advantage of the distributional hypothesis, which says that words that occur in similar contexts are likely to have related meanings. The assumption is that in distributional space, the domain entities “gold,” “iron,” “silver,” “evening,” “night,” and “day” are closer to each other in their respective group based on their informal definitions. Based on that, we can use state-of-the-art language models founded in the distributional hypothesis to encode the informal definitions in an embedded form. Figure 3 describes an example of the distribution of the domain entities using the embedding of their informal definition with the BERT-Base language model. In this figure, we employed Principal Component Analysis (PCA) to reduce the length of the output embedding from BERT to a 2D vector for better visualization. As presented, our assumption is valid for this example, i.e., based on the embedding from BERT, we obtained the same groups as the ones we supposed based on our interpretation of the characteristics of the informal definitions of each domain entity of Table 1.
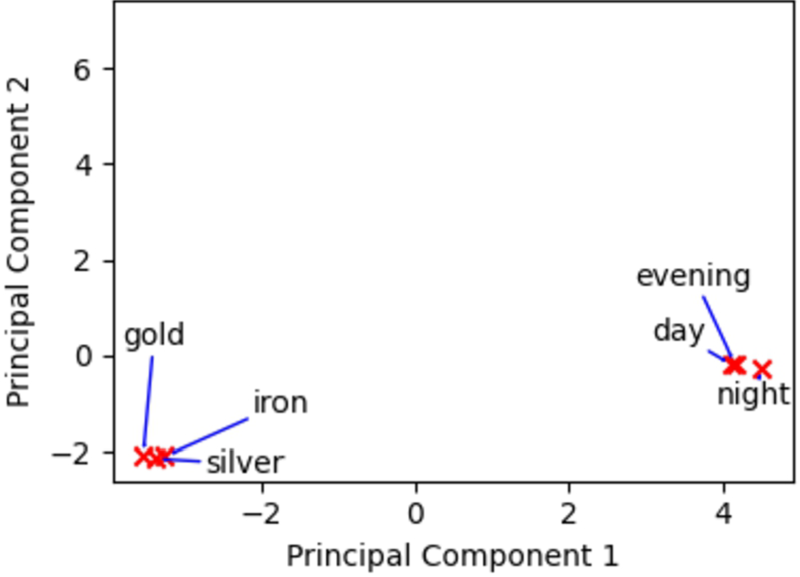
Distribution of domain entities based on the embedding of their informal definitions using BERT-base language model.
Following the line of reasoning line that top-level ontologies group domain entities that have common attributes or properties, the informal definitions are textual representations of domain entities that encapsulate some attributes or properties that express the intended meaning of the domain entities in a particular context and, based on the distributional hypothesis, we can group similar domain entities based on the embedding representation of their informal definitions, we support our original hypothesis, which says that informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts.
The datasets extracted through the alignment of OntoWordNet and BabelNet (as given in Section 4.2) present other ways of textually representing domain entities, such as using only the definiendum, only definiens, or an example sentence. As we discussed, the definiendum and the definiens are the parts of the informal definitions. Definiendum (or term) is the shortest way to represent a domain entity since the definiendum names a domain entity through a combination of a few words. Although definienda with similar meanings are closer because of the distributional hypothesis, they can be polysemous, i.e., a single definiendum can have multiple meanings. Using the examples in Table 1, the definienda “gold” and “silver” could also represent domain entities about color. However, colors are generally considered qualities in top-level ontologies rather than the amount of matter, like in the examples. From that, polysemy is certainly a problem that would cause unwanted effects on an approach to classifying domain entities into top-level ontology concepts. On the other hand, although the definiens is the explanatory part of an informal definition and it is expected that the definiens does not have problems with polysemy, a knowledge resource (e.g., WordNet) has only one definiens per domain entity to ensure its precision, which implies few instances in a dataset that contains only the definitions of the domain entities. Therefore, since a domain entity contains many definienda and only one definiens, the informal definitions discussed in this work combine each definienda with its respective definiens. From this, we can generate more dataset instances without the polysemy problem. The consequences of the combination between the definienda and the definiens are discussed in Section 4.5.
The example sentences are a good candidate against informal definitions for representing domain entities textually. These example sentences are pieces of text where the definiendum of the domain entity occurs in plain text. For example, an example sentence for the “gold” domain entity should be “The necklace, made of pure gold, gleamed brilliantly under the soft light of the chandelier.” However, this kind of representation for domain entities faces some challenges. The first challenge regards the polysemy problem of the target definiendum in the example sentence. In this situation, if the example sentence is not previously curated, its extraction requires using a word sense disambiguation technique to ensure the right sense of the target definiendum. Another challenge regards the length of an example sentence since longer sentences can provide more context. However, longer example sentences require language models with larger sequence lengths, which increases the time needed to convert the text into an embedding vector. In contrast, shorter example sentences often need more detail to convey the complete example of using a domain entity. As a last challenge, an example sentence always has the exact embedding representation for all the definienda. For example, we can use the example sentence for the “gold” domain entity to represent other domain entities like “light,” “necklace,” or “chandelier,” even though they are different domain entities with different top-level ontology concepts. We can mitigate this latter challenge by combining the target definiendum with the example sentence, like in informal definitions, where we combine the definiendum with the definiens. However, in the embedding space, the example sentences are still very close due to the distributional hypothesis since they have only the definiendum as the difference between them.
Based on the approaches for textually representing domain entities that we described throughout this section, we assume that the informal definition is the best option for several reasons: a domain expert curates informal definitions before or during the ontology development process; we can extract the informal definitions from existing knowledge resources, like WordNet or Wikipedia; informal definitions are provided early in the ontology development process; the length of informal definitions is relatively small, with an average of a few dozen words, which requires a smaller sequence length for language models, reducing the computational costs; informal definitions are free of polysemy problems since they aim to clearly and precisely explain a domain entity’s meaning in a specific context. In contrast, the most significant disadvantage of informal definitions is that we depend on their clarity and precision, i.e., the informal definition needs to express sufficient characteristics to ensure the meaning of a domain entity.
In this work, our task is to classify domain entities into top-level concepts using the informal definitions of these domain entities. So, we took advantage of the similarity in taxonomies and distributional hypothesis to support our hypothesis that informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. In this context, we employed Language Models (LMs), since they are state-of-the-art models based on distributional hypothesis, as classifiers or embedding providers in two distinct classification pipelines (Fig. 4). In Pipeline 1 of Fig. 4, we aimed to fine-tune a pre-trained LM for the desired task. On the other hand, in Pipeline 2 of Fig. 4, our goal is to use the LM to generate the embedding representation of the input text and then use classical machine learning approaches (e.g., K-Nearest Neighbor, Decision Tree, Support Vector Machine) to classify them into the top-level ontology concepts.
We draw inspiration from state-of-the-art models for text classification for pipelines 1 and 2. In Pipeline 1, fine-tuning a pre-trained language model for a specific task means updating the model’s internal weights to reduce the classification error during the training stage and have a better-adjusted model for predicting novel inputs. However, the training cost of Pipeline 1 tends to be higher than that of Pipeline 2, depending on the number of training epochs used, i.e., the number of times the entire training samples pass through the model. Also, observing the decision process made by Pipeline 1 when classifying a new input tends to be complex due to the characteristics of the language models. Based on that, Pipeline 2 employed traditional machine-learning approaches over the output embedding from a language model. In this case, we pass the training samples only once through the model to generate the embedding representation. However, we have the additional computational cost of the machine-learning classifier. Also, the main benefit of Pipeline 2 is the explainability of the output results. For example, we can see the closest training samples of a new input using a K-Nearest Neighbor as the machine-learning classifier.
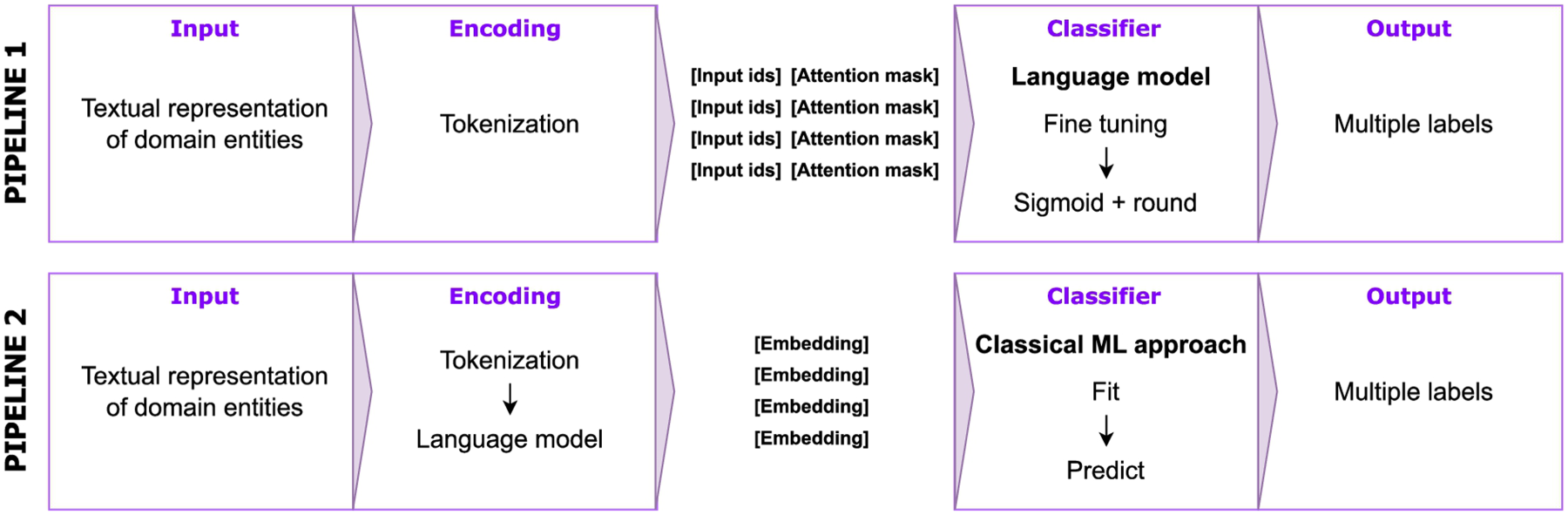
Proposed pipelines for classifying domain entities into top-level ontology concepts using the textual representation of these domain entities.
Pipelines 1 and 2 in Fig. 4 use the textual representation of the domain entities as input. As discussed in Section 4.3, we can access several textual representations of the domain entities from our alignment between OntoWordNet and BabelNet. Based on that, we can consider the informal definition, definiendum, definiens, example sentence, and the combination of definiendum and example sentence as possible candidates in the Input step. Also, in both pipelines, we choose not to apply text preprocessing techniques, such as lowercasing, stop word removal, and lemmatization, in the input text. In our view, these techniques remove the structural integrity of the text, which plays a crucial role in understanding the nuanced meanings and contextual cues inherent in language.
In the Encoding step, we used a pre-trained tokenizer to break the input text into smaller units (tokens). This process is fundamental to both pipelines, transforming unstructured text into a structured form that an LM can interpret. Also, the outputs of the tokenizer are the Input IDs and the Attention Mask values. In Pipeline 1, we fed and fine-tuned the LM with these values. On the other hand, in Pipeline 2, we directly transform the Input IDs and the Attention Mask values into embedding arrays. These embedding arrays comprehend dense and high-dimensional vectors encapsulating word meanings and their relationships in a vector space (which is particularly advantageous for classical machine learning models that use numerical input to find underlying patterns in the data).
The desired output of both classification pipelines is multiple top-level ontology concepts in which a given input subsumes. In this context, we represent all the possible top-level concepts in a one-hot encoded vector, i.e., each concept is represented by a binary value, with 1 indicating the presence of the concept and 0 indicating its absence. This vector serves as the target for the Classification step of both pipelines. In this context, for Pipeline 1, we used a sigmoid activation to transform the average pooled output from the language model into probability values. After that, we rounded these probability values to handle the one-hot encoding representation of the top-level concepts. On the other hand, for Pipeline 2, we do not need any transformation from a mathematical function since traditional machine learning approaches, such as K-Nearest Neighbor and Decision Tree, can handle binary decisions directly.
This section discussed dataset extraction and the relation between informal definition, distributional hypothesis, and top-level ontology concepts. From the dataset perspective, we represented each domain entity by a row containing three columns: the definienda, the definiens, and the labels. Since each knowledge resource, such as WordNet or Wikipedia, only includes one definiens per domain entity and a domain entity can have more than one definiendum, we can use an approach to augment the dataset (increase the dataset size) by creating rows for each domain entity definiendum. For each new row of a domain entity, we kept the same definiens and labels. This technique is also called the “explode” approach. For example, the “gold” domain entity in Table 1 has three different definienda in BabelNet: gold, Au, and atomic number 79. From that, we create a new row in the dataset for these three definienda and keep the same definiens and labels.
Figure 5 presents the number of definienda of the domain entities in the dataset from the alignment between OntoWordNet and BabelNet. Considering that most dataset domain entities have more than one definiendum, the “explode” approach helps increase the number of examples without artificially generating data. For instance, we can expand the dataset from 59,666 to 387,814 examples. However, this process has implications for the performance of a classification model. Considering the example of the “gold” domain entity (from Table 1) and that we followed this sequence of decisions, used Pipeline 2 (described in the previous section) with a KNN machine-learning model with

The number of definienda of the domain entities in the dataset.
In this work, we explored three training methodologies to deal with the consequences of the “explode” approach. Considering that the training and test samples are from the same dataset, the first method ignores this consequence, i.e., we apply the “explode” approach before dividing the dataset into training and test samples. However, suppose that we aim to evaluate the performance of a classification model with completely novel domain entities. In this case, as our second method, we must apply the “explode” approach after dividing the dataset into training and test samples, ensuring that no test domain entity is present in the training samples. As a third method, we considered that the training and test samples are from different knowledge resources, such as the training samples from WordNet and the test samples from Wikipedia, or vice-versa. In this case, although we can have the same domain entity in multiple resources, they usually do not have the same definiens. For example, in Wikipedia, “gold” is defined as “a chemical element; it has symbol Au and atomic number 79,” an almost entirely different definiens from the one described in Table 1. So, the embedding representation of the informal definitions of these domain entities is more discrepant than changing just the definiendum. Thus, the “explode” approach does not generate such perceptible consequences in this training methodology.
In this section, we present three study cases performed to validate our hypothesis that the informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. Each study case addresses the same task: classifying domain entities into top-level ontology concepts. However, each one has different objectives. In the first study case, we explored the different text representation approaches of domain entities obtained from our alignment between WordNet and BabelNet (discussed in Section 4.3). Also, we evaluated the performance of the proposed pipelines (presented in Section 4.4) using different configurations of the “explode” approach (described in Section 4.5). In the second study case, we performed experiments to validate our hypothesis across informal definitions from other languages rather than only English. In the third and final study case, we conducted experiments with several different Language Models (LMs) and Large Language Models (LLMs) in the proposed pipelines to validate our hypothesis using training and test samples from different knowledge resources.
In addressing the task of classifying domain entities into top-level ontology concepts with unbalanced labels, we used a stratified k-fold cross-validation approach with
In order to evaluate the results, we used the macro F1-score (Equation (1)) to ensure a better classification analysis in the unbalanced scenario. We also conducted the study cases and experiments on a machine equipped with an Intel i7-10700 CPU (4.8 GHz), 32 GB of RAM, and a GeForce RTX 3060 GPU with 12 GB of VRAM.

In this study case, we performed experiments regarding the effectiveness of several textual representations for domain entities to classify domain entities into top-level ontology concepts. In these experiments, we compared the two pipelines proposed in Section 4.4. For Pipeline 1, we employed fine-tuning the BERT-Base language model for our specific task trained over 4 epochs. On the other hand, for Pipeline 2, we also used the BERT-Base language model to generate the embedding representation of the input text and fed a K-Nearest Neighbors (KNN) classifier to predict the output labels. Also, we compared the performance of the “explode” approach for training and test samples from the same knowledge resource. In this case, we evaluate the textual representations provided by the WordNet knowledge resource since only WordNet contains both informal definitions and example sentences.
Table 2 presents a comparative view of dataset sizes of each textual representation approach across our preprocessing states of the dataset, considering the original dataset size from the alignment between OntoWordNet and BabelNet, the size after merging the labels of the domain entities with multiple inheritances and removing the ones that have disjoint labels, and after the application of the “explode” approach to increase the dataset size. For the informal definition and definiendum datasets, the original size is 65,018, which was reduced to 59,666 after merging domain entities with multi-inheritance and removing each one that presents disjoint labels (as discussed in Section 4.2.3). After using the “explode” approach for data augmentation, the size expands dramatically to 387,814. In contrast, the definiens dataset remains unchanged at 59,666 examples because each domain entity has only one definiens in WordNet. The example sentence dataset starts at a much smaller original size of 8,417 and decreases to 7,329 after preprocessing, with no increase after the “explode” step. Combining each definiendum of a domain entity with its respective example sentence, we increased the dataset size to 43,101 examples after the “explode” process.
The number of examples in each text representation dataset

The number of examples in each text representation dataset
Figure 6 presents the macro F1-score results achieved using the informal definitions as input of Pipelines 1 and 2. This figure also presents the specific results of using the “explode” approach before and after the k-fold split. Notably, when we used “explode” before the k-fold split, the results were more expressive than when we used “explode” after, with more than 90% across different levels of the Dolce-Lite-Plus (DLP) top-level ontology, i.e., informal definitions showed robust results from more general top-level concepts to more specific ones. In this experiment, Pipeline 1 showed better overall results regarding Pipeline 2, specifically in the experiment using “explode” after the k-fold split.
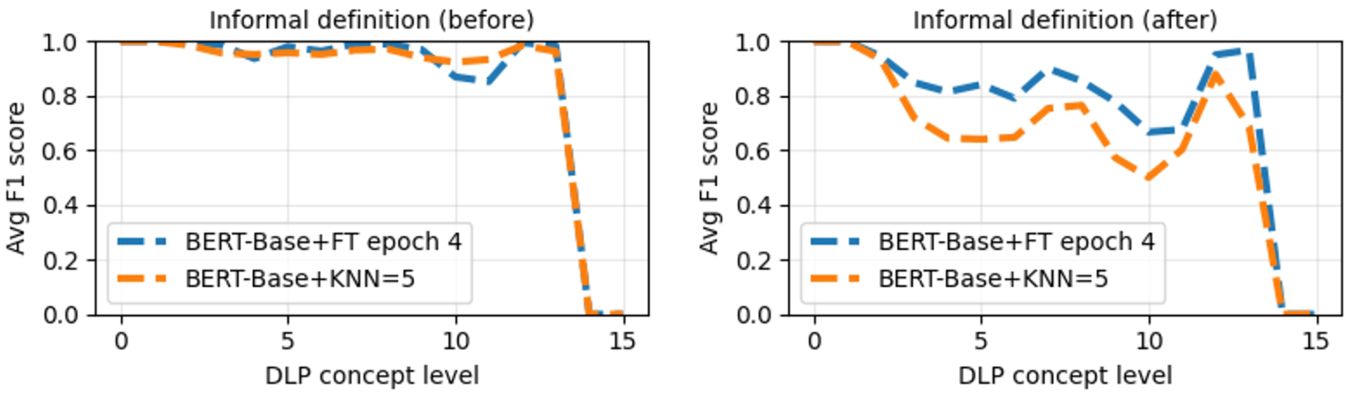
The average macro F1-score, for each DLP level, obtained by employing informal definitions as input for the pipelines. The figures depict the pipeline results utilizing the “explode” approach before (on the left) and after (on the right) the k-fold split.
Figure 7 describes the macro F1-score result achieved by combining the definienda and their respective example sentences as input for the evaluated classification pipelines. This figure shows that Pipeline 2 has better results than Pipeline 1 across most DLP levels, using the “explode” approach before the k-fold split. Also, Pipeline 1 has a more significant performance degradation after the 3rd level of DLP. In the same line, using the “explode” approach after the k-fold split, both pipelines showed poor performances over most DLP levels. Despite the performance degradation of Pipeline 1 in both “explode” scenarios, Pipeline 2, with embeddings from the BERT-Base language model and a KNN classifier, presented a close performance compared to Pipeline 2 of the experiment presented in Fig. 6.
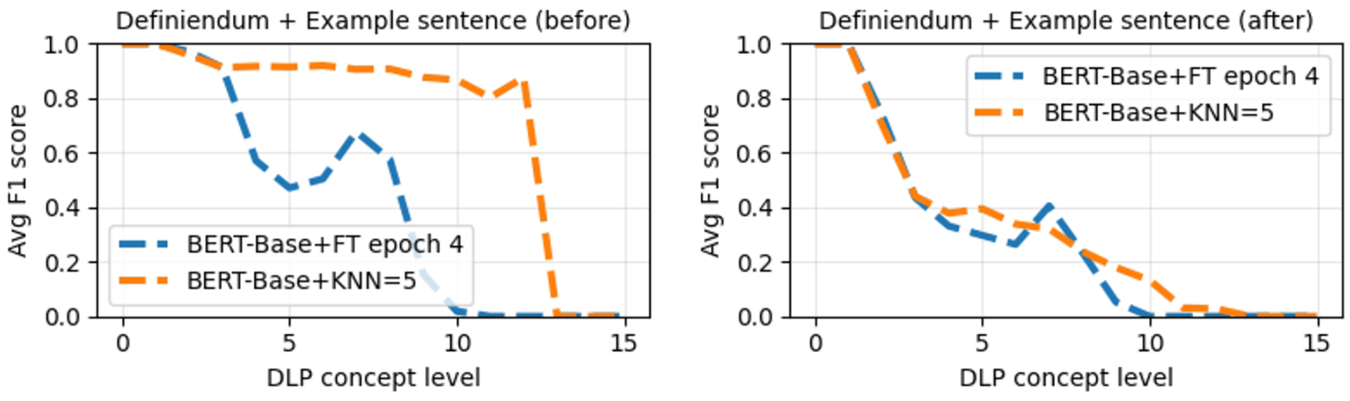
The average macro F1-score, for each DLP level, obtained by employing a combination of definienda and example sentences as input for the pipelines. The figures depict the pipeline results utilizing the “explode” approach before (on the left) and after (on the right) the k-fold split.
Figure 8 shows the experiments using only the definiens (on the left) and only the example sentences (on the right) of the domain entities as input of the evaluated pipelines. In these experiments, we do not need to apply the “explode” approach since WordNet has exactly one definiens and zero or one example sentence for each domain entity. For using only the example sentences, the results present a performance that decreases progressively as the DLP levels increase for both evaluated pipelines. These results indicate a potential challenge in capturing the full semantic scope of a domain entity, which is required for its classification into top-level ontology concepts, using only the example sentences as input. On the other hand, there is a notable variation in the average macro F1 when using only the definiens as input for the pipelines. In this case, the average macro F1 scores are substantially higher than those in the other experiment, achieving more than 80% across several DLP levels. In this context, the results suggest that using WordNet as the knowledge resource, the definiens are a better text representation approach for domain entities than example sentences. However, both approaches are still worse than using their systematic combination with their respective definienda, like in the experiments presented in Fig. 6 and Fig. 7.
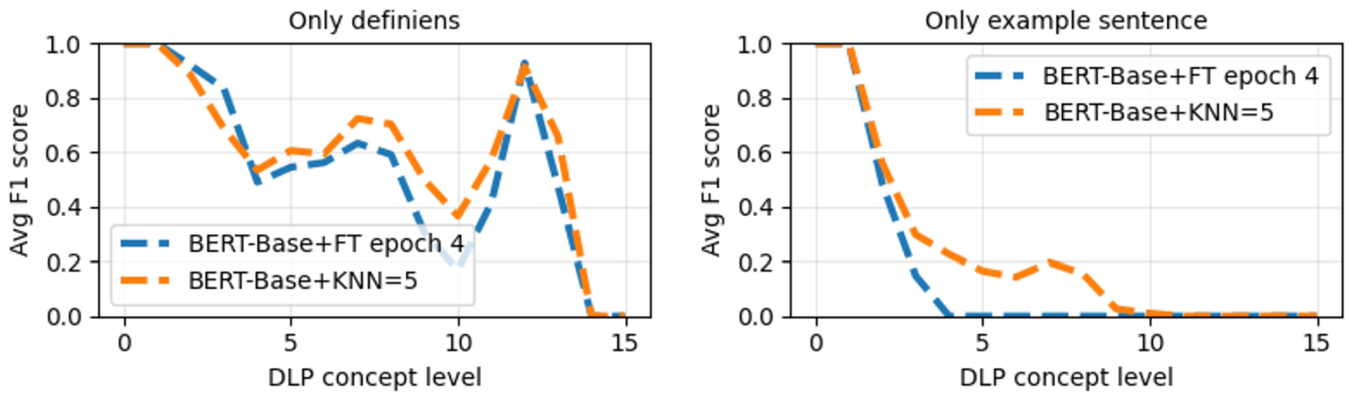
The average macro F1-score, for each DLP level, obtained by employing only the definiens (on the left) and only the example sentences (on the right) as input for the pipelines.
Figure 9 presents the experiments using only the definienda as input of the evaluated pipelines. In these experiments, although several definienda are polysemic, i.e., use the same terms but have different meanings, we do not conduct any duplicate removal to analyze the impact of the polysemy in classifying domain entities into top-level ontology concepts. In this context, the results showed similar behavior to those presented using other text representation approaches for domain entities, with performance decreasing as the DLP concept level increases. Also, in both “explode” approaches, the evaluated pipelines showed almost close average macro F1 scores, suggesting this kind of text representation tends to be less affected by the nuances of having the definienda that represent the same domain entity in the training and test samples that we used to evaluate the pipelines. However, even though using only the definienda to represent domain entities presented interesting results, they are unreliable due to the polysemy problem discussed in Section 4.3.
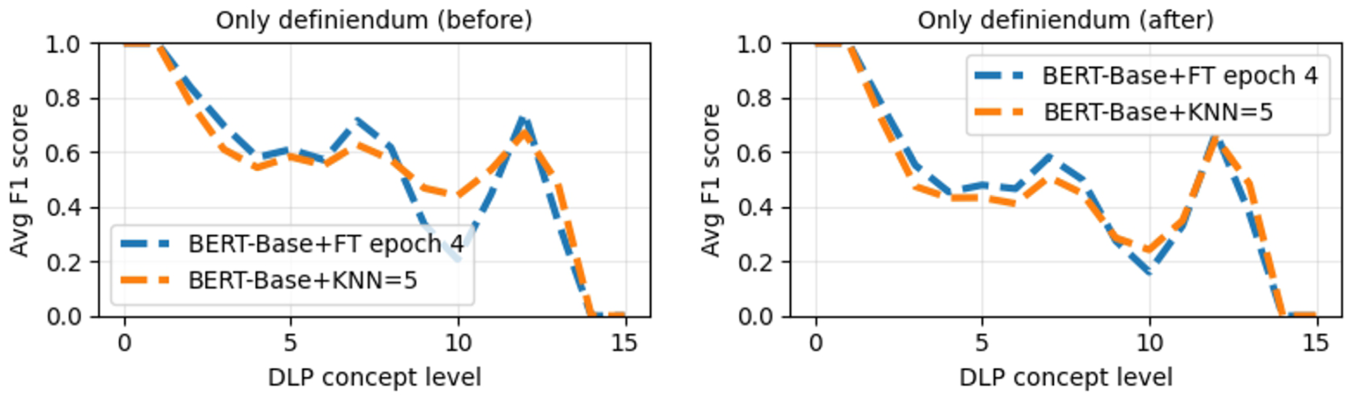
The average macro F1-score, for each DLP level, obtained by using only the definiendum as input for the pipelines. The figures depict the pipeline results utilizing the “explode” approach before (on the left) and after (on the right) the k-fold split.
In this study case, we evaluated the performance of several textual representations of domain entities to classify domain entities into top-level ontology concepts. Although several approaches achieved promising results, such as using only the definiens or the definiendum or the combination of definiendum and example sentences, the informal definitions proved to be the best way to represent domain entities in this task. Among the advantages is the possibility of extracting larger datasets, not suffering from the problem of polysemy, and presenting a better average macro F1-score for both “explode” approaches for data augmentation. In addition, Pipeline 2, which adopted the contextual embedding from the BERT-Base language model and used a KNN classifier to classify them into top-level ontology concepts, achieved the average better stability and performance across all the experiments conducted in this study case. Thus, the results suggest that using informal definitions as textual representation for domain entities and Pipeline 2 are the better options for classifying domain entities into top-level ontology concepts. From this, we will employ this combination for the other study cases conducted in this work.
We follow our investigation after the results of the previous study case that suggest that informal definitions are the best way to represent domain entities and that Pipeline 2 achieved better stability and performance of the macro F1-score in classifying domain entities into top-level ontology concepts. From that, in this case, we evaluate our hypothesis across informal definitions from different languages obtained from Wikipedia knowledge resources. Table 3 presents the number of examples in each language dataset across the same preprocessing and data augmentation approaches carried out in the previous study case for informal definitions. In detail, the English dataset presents 2 or 3 times more examples than most other language datasets, which can affect classification performance. Also, we evaluated Pipeline 2 using the “explode” approach before and after the k-fold split. In addition, the training and test samples are in the same language for every experiment.
The number of examples in each different language dataset
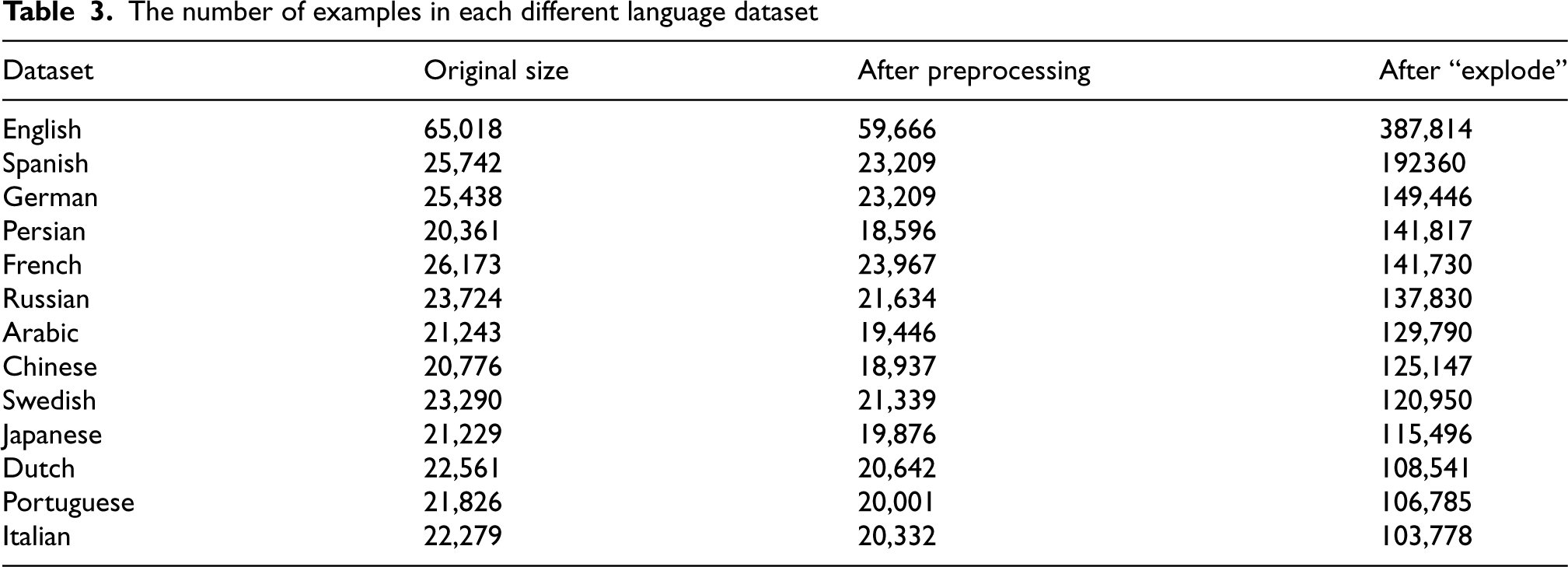
The number of examples in each different language dataset
Figure 10 presents the average macro F1-score results across all DLP levels for the experiment using datasets from different languages. Based on the results, we achieved a higher macro F1-score across all evaluated languages using the “exploding” approach before the k-fold split, with more than 90% of the average macro F1-score. Spanish and English lead with better scores, followed closely by Persian, and while Japanese and Russian trail at the lower end, the scores are still high. However, using “explode” after the k-fold split, all the macro F1-scores decreased, with most languages achieving less than 40% of the average macro F-core. In this case, the English dataset stands out as the highest scorer, followed by French, Spanish, and Portuguese. This result suggests there are challenges in embedding quality, issues related to the language’s complexity, or the dataset’s size matters for this task using the “explode” approach after the k-fold split. Overall, the scores for other languages besides English are relatively close, reflecting the consistent performance of Pipeline 2.

Macro F1-score results for each language dataset using Pipeline 2 and the “explode” approach before (left) and after (right) the k-fold split, respectively.
The previous two study cases have demonstrated that informal definitions are the best way to represent domain entities for classifying them into top-level ontology concepts and show that our hypothesis, which says “informal definitions represent semantic information that allows domain entities to be related to their top-level ontology concepts,” is also valid for languages other than English (with some considerations in using the “explode” approach after the k-fold split). However, we used only the BERT-Base language model in the pipelines explored in these study cases. Also, we presented that the results are drastically affected by the “explode” approach. In this context, if we use two datasets with informal definitions from different resources, one as the training sample and the other as the test sample, we can avoid the consequences regarding the “explode” approach, as discussed in Section 4.5. Additionally, we can also evaluate the performance of the pipelines presented in Section 4.4 in a cross-resource scenario.
In this study case, we evaluated several language models for both pipelines described in Section 4.4. For Pipeline 1, we employed the BERT-Base and GPT2, fine-tuned using 10 epochs. In Pipeline 2, we utilized the BERT-Base, BERT-Large, ROBERTA-Base, ALBERT-Base, GPT2, T5, BART, Gemma2B, Mistral7B, and Lamma7B, where 2B and 7B means the number of parameters of the respective language model. Also, for Pipeline 2, we only used the KNN classifier because it is the one that best fits our hypothesis, as presented in the previous study cases. In addition, Table 4 presents the number of examples of each evaluated dataset after performing preprocessing and “explode” steps. From that, we used the informal definitions from WordNet to train the pipelines and the informal definitions from Wikipedia to evaluate the pipelines.
The number of examples in each resource dataset

The number of examples in each resource dataset
Figure 11 presents the average macro F1-score of each evaluated pipeline across all DLP depths. Our best pipeline combined the Mistral7B large language model with a KNN classifier, achieving 86.6% of the macro F1-score. Following this kind of pipeline with a KNN classifier, other large language models, such as Llama7B and Gemma2B, also achieved results close to 80% of the average macro F1-score. Interestingly, although BERT-Large has more parameters than BERT-Base, they presented similar results. The pipelines with fine-tuned versions of BERT-Based and GPT2 achieved around 75% of the average macro F1-score, showing distinct results compared with their same version with a KNN classifier. In this case, the pipeline with GPT2 and KNN achieved the worst results in our experiments. Other pipelines with KNN and language models, such as ROBERTA, ALBERT, BART, and T5, showed results ranging from 60% to 75% of the average macro F1 scores.
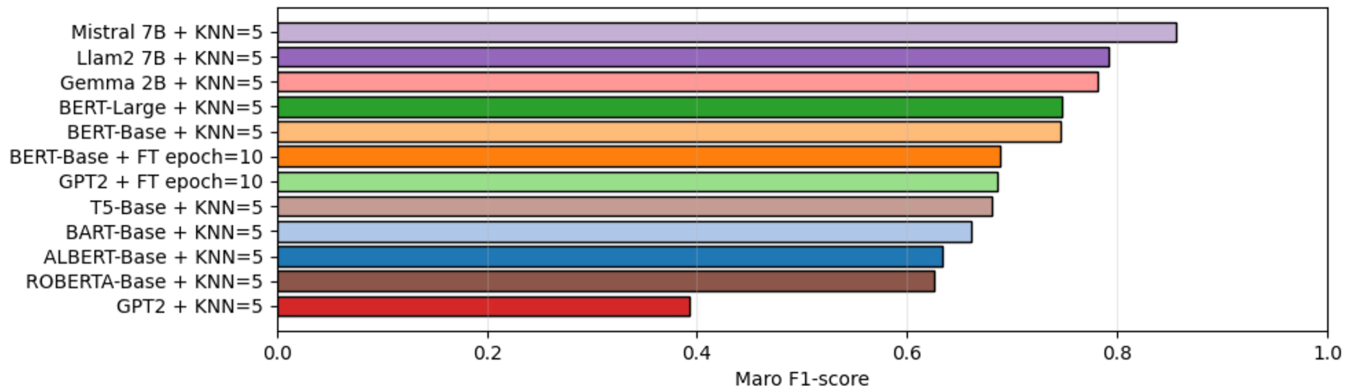
The macro F1-score results for each evaluated pipeline across all DLP levels.
Figure 12 presents in detail the average macro F1-score of each evaluated pipeline for each DLP depth. As in the other study cases, the scores appear to decrease as the level of DLP increases. Also, all pipelines generally maintain their performances until level 10, which can be associated with the 10th level having the more significant number of top-level concepts regarding all DLP levels. Also, we can justify the better performance of the pipeline with the Mistral7B large language model and the KNN classifier with their stability regarding a better classification performance from the more generic to the more specific top-level ontology concepts.

The macro F1-score results for each evaluated pipeline across each DLP level.
This case study presented a rich evaluation of our hypothesis that the informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. From that, we employed various language models and state-of-the-art large language models in the proposed classification pipelines. Also, the results suggest that we can avoid the computational cost of fine-tuning by employing the embedding from a pre-trained language model and using classical machine learning approaches, like KNN. In this context, we showed that using a KNN classifier with contextual embedding derived from informal definitions yields better results than fine-tuning methods. This outcome supports the notion that the distributional properties of informal definitions encapsulate the top-level ontology concepts associated with domain entities. Furthermore, the enhancement of this process by state-of-the-art models such as Mistral, Llama, and Gemma indicates that the classification of domain entities into top-level ontology concepts via informal definitions and contextual embedding benefits from advancements in language model improvements.
This study explains a novel approach leveraging the similarity in taxonomies and the distributional hypothesis to classify domain entities into top-level ontology concepts using the informal definitions of these domain entities. Firstly, we proposed a method to align the OntoWordNet ontology and Babel semantic network. From this alignment, we extracted multi-label datasets to encompass all the top-level ontology structures. Also, this alignment allows us to extract multi-language and multi-resource datasets, from which we extracted several text representation approaches for domain entities. Also, by harnessing state-of-the-art language models, we developed two distinct pipelines: one focusing on fine-tuning a pre-trained language model for our classification task and another utilizing a classical machine learning algorithm to classify the embedding generated from these models. We used these two pipelines to validate our hypothesis that the informal definitions represent semantic information that allows domain entities to be related to top-level ontology concepts. In addition, our findings underscore the significant impact of using informal definitions to represent domain entities concerning other representation approaches, demonstrating their intrinsic value in capturing the nuances necessary for accurately representing domain entities through contextual embedding from language models. Also, we proposed an approach for augmenting the extracted datasets without the necessity of generating artificial examples, underscoring its consequences during training and validation. In our experiments, we conducted 3 study cases to compare the performance of our hypothesis and pipelines for different textual representation approaches of domain entities, with informal definitions from different languages and informal definitions from different knowledge resources. In these study cases, we achieved our best results using a classification pipeline with the K-Nearest Neighbor approach and the Mistral7B large language model, highlighting the effectiveness of this classical machine-learning method over the expensive computational cost of fine-tuning. From the results analysis, we supported our hypothesis, demonstrated the versatility and robustness of our approach across different languages and resources, and emphasized the potential for automated approaches to assist ontology engineers during ontology development. In future works, we aim to expand the datasets for other top-level concepts not covered by OntoWordNet. Also, we will perform new experiments by translating the informal definitions in English to different languages to use the same data across all multi-language experiments.
Footnotes
Acknowledgements
Research supported by Higher Education Personnel Improvement Coordination (CAPES), code 0001, Brazilian National Council for Scientific and Technological Development (CNPq), and Petrobras.