
Abstract
We provide an automata-theoretic approach to analyzing an abstract channel modeled by a transducer and to characterizing its lossy rates. In particular, we look at related decision problems and show the boundaries between the decidable and undecidable cases. We conduct experiments on several channels and use Lempel–Ziv algorithms to estimate lossy rates of these channels.
Introduction
Modern digital communications are realized through channels. A communication system is modeled as a sender, a channel, and a receiver. The channel input is generated by the sender as an encoding of source input information. This process is referred to as channel encoding. The channel output is delivered to a receiver for decoding. Traditional analysis of such a system uses probability and random processes to model channel behavior. In the view of automata theory, the channel is a transducer, which is a finite state machine, possibly extended by counters, having both input instructions and output instructions. In automata theory, textbook results [14] focus on formal language aspects of the input–output relationship exhibited in a transducer, without formulation of any probabilistic description of a transducer’s behavior. It would be interesting to see if automata theory can be used to investigate certain key characteristics in a communication channel. In this paper, we use an automata-theoretic approach in studying the lossy rate of a channel modeled by a transducer.
A communication channel can be noisy. That is, the input symbols during transmission can be dropped or altered, or unwanted symbols added. As a result, the output of the channel may not be uniquely decoded back to the input. We abstract the problem as an automata theory problem: Given a transducer T and an input word language L, determine whether T is L-lossy. (That is, are there distinct words in L that are translated into the same word with T?) In the paper, the problem is shown decidable for nondeterministic finite state transducers (NFTs) as well as some NFTs augmented with reversal-bounded counters and their variations, while L is a regular language or in a certain class of nonregular languages. On the other hand, the problem is undecidable in general. Indeed, as shown in the paper, the undecidability remains even under a very restricted case: the T is a deterministic finite state transducer (DFT) augmented with the capability of making one turn on its input and the L is the universe. Hence, the decidability/undecidability boundary of the problem is subtle.
We also study the lossy rate of a channel modeled by a transducer. In the paper, we define the lossy rate based on a notion introduced by Shannon [22], which we call information rate. Using this definition, the input lossy rate (the output lossy, defined accordingly in the paper, as well) of the transducer T can be computed through computing the information rates of the input language, the output language, as well the language of input–output pairs, of T, without, as in traditional communication engineering analysis, explicitly introducing a probabilistic or stochastic model. Later in the paper, among other results, we show that the lossy rates are computable for NFT. We also conduct experiments on several channels and use Lempel–Ziv algorithms to estimate lossy rates of these channels.
Decision problems: Decidable and undecidable cases
We first recall the definition of reversal-bounded nondeterministic counter machines [15] used subsequently in this paper. A counter is a nonnegative integer variable that can be incremented by 1, decremented by 1, or stay unchanged. In addition, a counter can be tested against 0. Let k be a nonnegative integer. A nondeterministic k-counter machine (NCM) is a one-way nondeterministic finite automaton, with input alphabet Σ, augmented with k counters. For a nonnegative integer r, we use
Reversal-bounded NCMs and NPCMs have been extensively studied since their introduction in 1978 [15], and many generalizations have been identified, e.g., ones equipped with multiple tapes, with two-way tapes, etc. In particular, reversal-bounded NCMs and NPCMs have found applications in areas like Alur and Dill’s [2] timed automata [9,10], Paun’s [20] membrane computing systems [16], and Diophantine equations [27].
Two fundamental results in the theory of reversal-bounded NCMs and NPCMs are the following [15].
It is decidable to determine
A two-way reversal-bounded NCM M is finite-turn if, for a given nonnegative integer c, M makes at most c turns on its two-way input tape.
It is decidable to determine
We now formalize the problem under study. A transducer T is a nondeterministic automaton that accepts pairs of words; i.e., the set of pairs accepted by T is
Given: A transducer T and an input word language L.
Question: Is T L-lossy?
Clearly, like most decision problems in automata theory, the decidability relies on the exact classes of languages and automata to which L and T, respectively, belong.
Consider a nondeterministic finite transducer (NFT) [14] T, which is an NFA with outputs. An instruction of T is of the form
In the results below, “augmented with reversal-bounded counters” will mean “augmented with a finite number of reversal-bounded counters”.
It is decidable to determine
We construct a finite-turn two-way (with end markers on the input) reversal-bounded NCM
When M and T accept,
Note that the case when u (resp., v) is a proper prefix of v (resp., u) and hence different is taken care of in the above process. Clearly,
We can further generalize Theorem 2.3. A two-way reversal-bounded NCM M is finite-crossing if there exists a nonnegative integer c such that M crosses the boundary between any adjacent cells of the input at most c times.
It is decidable to determine
It is known that such an M can effectively be converted to an equivalent reversal-bounded NCM (i.e., one-way) [12]. The result follows from Theorem 2.3. □
A question arises whether Theorem 2.4 still holds when T has a two-way input. We will show that the answer is no, even when T is deterministic and makes only one turn on its input tape: a left-to-right sweep and then a right-to-left sweep (the output is one-way). In the proof, we use the undecidability of the Post Correspondence Problem (PCP).
An instance
It is undecidable to determine
We first show the undecidability when T is nondeterministic, i.e., a 1-turn NFT.
Let
We construct a 1-turn NFT M which accepts a set of transductions If the input is On the left-to-right sweep of x, M outputs If the input is On the left-to-right sweep of x, M outputs
Clearly, if x is a solution to PCP instance I, then two different inputs
We now modify the construction above to make M a 1-turn DFT The first track contains a string The second track contains a string The third track contains a string
Now,
A transducer T is single-valued on a language L if for every u in L, there is at most one w such that
A transducer T is k-lossy if for any word w, there are at most k words that are mapped by T into w. T is finitely-lossy if it is k-lossy for some k. A related notion that has been extensively studied in automata theory is the notion of k-valuedness of transducers (see, e.g., [21], for an early reference). We say that a transducer T is k-valued if, for every input word u, there are at most k output words w such that
The case when T is finitely-lossy (resp., k-lossy for a given k) is interesting. It implies that for some k (resp., for the given k), every output word w received has at most k possible choices of decoded input words (no matter how long w is). Hence, this number k can also be used as an indicator on how lossy the transducer is.
It is decidable to determine, given an NFT T, whether it is finite-valued (i.e., it is k-valued for some k) [25]. It is also decidable to determine whether it is k-valued for a given k [13]. Hence, we have:
It is decidable to determine
Currently, we do not know if the first part of Theorem 2.6 holds when M is an NFT augmented with an infinite memory (e.g., a reversal-bounded counter). However, we can prove the following.
It is decidable to determine
First consider an NFT T with no reversal-bounded counters and L accepted by an NFA M. Suppose we are given k. Using the idea in the proof of Theorem 2.3, we construct a
As in Theorems 2.3 and 2.4, the construction above generalizes to when T is augmented with reversal-bounded counters and L is accepted by a two-way finite-crossing reversal-bounded NCM. □
For deterministic pushdown transducers (DPDTs), the following result can be shown:
It is undecidable to determine
In [26], it was shown that there is a class of linear context-free grammars (which are equivalent to 1-reversal NPDAs) for which every grammar G in the class is either unambiguous or unboundedly ambiguous (i.e., not finitely ambiguous), but determining which of the two G belongs to is undecidable. It follows from Theorem 2.10 that it is undecidable, given a 1-turn DPDT T, whether it is lossless (resp., k-lossy for a given k, finitely-lossy). □
A bounded language is a subset of words in the form of
It is decidable to determine
The proof is similar to that of Theorem 2.3. The finite-turn two-way reversal-bounded NCM
Again, the theorem above generalizes to the case when L is accepted by a finite-crossing two-way reversal-bounded NCM.
Next, we investigate the subtle relationship between ambiguity in automata and lossiness in transducers. Let M be a (one-way) acceptor, e.g., DFA, NFA, DPDA, NPDA, etc. We say that a transducer T is of the same type as M, if when T’s output is suppressed, it reduces to an acceptor in the class where M belongs. So a DFT (resp., NFT, DPDT, NPDT, etc.) is of the same type as DFA (resp., NFA, DPDA, NPDA, etc.) We assume that in an acceptor or transducer, an accepting state is a halting state (i.e., the device has no move when it enters an accepting state).
The following statements are equivalent
It is undecidable
It is undecidable
The conditions remain equivalent if in
First we prove that if (1) is undecidable, then (2) is also undecidable. Let Σ be the set of rules of M (i.e., each rule is represented by a symbol). We construct a deterministic transducer of the same type as M whose input alphabet is Σ. Given a string w in
Now we show that if (2) is undecidable, then (1) is also undecidable. Suppose T is a deterministic transducer with input and output alphabets Σ and Δ, respectively. We construct a nondeterministic acceptor M with input alphabet Δ. M on input w in
The above result is interesting because it relates the ambiguity question of a nondeterministic acceptor to the lossiness question of a deterministic transducer of the same type as the acceptor. For example, it is undecidable, given a 1-reversal NPDA (which is equivalent to a linear context free grammar), whether it is unambiguous (resp., k-ambiguous for a given k, unboundedly ambiguous) [26]. Hence, it is also undecidable, given a 1-reversal DPDT (deterministic 1-reversal pushdown transducer), whether it is lossless (resp., k-lossy for a given k, finitely-lossy).
Clearly, Theorem 2.10 is not valid if M is deterministic. This is because such an acceptor is always unambiguous. Hence the unambiguity question is trivially decidable (since the acceptor is always unambiguous). However, from Theorem 2.8, the losslessness question for 1-reversal DPDT is undecidable.
Similarly, Theorem 2.10 is not valid if T is nondeterministic. Consider the following example: Let
The next result shows that undecidability of losslessness implies undecidability of k-lossiness for any k.
Let
The “only if” part is obvious. To show the “if” part, let T be a deterministic transducer in the class
We now define a form of transducers that are Shannon channels mentioned in the Introduction. Let T be a transducer of any given type. Suppose that
Formally, define the input distance (resp., output distance) of T on
The following are decidable
Given
Is T finite-input Shannon Let T be a reversal-bounded NPCMT with input and output alphabets Σ and Δ. Given To show that it is decidable if T is finite-input Shannon, we construct an NPCM M which accepts the language Decidability of k-output Shannon and finite-output Shannon can be shown by similar constructions as above. □
The previous section focuses on the problem of deciding whether a channel modeled as a transducer T is L-lossy for a given input language L. Suppose that T is L-lossy. Without introducing probabilities into T, can we still define a notion that characterizes how lossy T is? Before we proceed further, we first illustrate the intuition behind the definitions.
Consider a pair
The input lossy rate measures the “number” of inputs to which an average output can be decoded. Intuitively, the input lossy rate, using the classic Venn diagram of Shannon information theory, should be the information contained in the input u, given the output w. Notice that the lengths of the input and the output are in general unbounded and hence, a more scientific measurement would be information rate (in bits per symbol) instead of information (in bits). However, there is a problem. In computing the aforementioned information/mutual information, one usually needs a probability distribution which, unfortunately, the transducer T does not have and which, in practice, would be very hard to obtain.
Without an explicit probabilistic model, can we still define an information rate? There has already been a fundamental notion shown below, proposed by Shannon [22] and later Chomsky and Miller [4], that we have evaluated through experiments over C programs [6,7,11,19,28], fitting our need for the aforementioned complexity. For a number n, we use
The following result is fundamental.
The information rate of a regular language L is computable [4]
The case when L is nonregular (e.g., L is the external behavior set of a software system containing (unbounded) integer variables like counters and clocks) is more interesting, considering the fact that a complex software system nowadays is almost always with infinite/unbounded states (e.g., when an integer variable is interpreted in an unbounded range, instead of 32 bits), yet the notion of information rate has been applied to software testing [6,24]. However, in such a case, computing the information rate is difficult (sometimes even not computable [17]) in general. Existing results (such as unambiguous context-free languages [18], Lukasiewicz-languages [23], and regular timed languages [3]) are limited and mostly rely on Mandelbrot generating functions and the theory of complex/real functions, which are also difficult to generalize. A recent important result, using a complex loop analysis technique, is as follows.
The information rate of the language accepted by a reversal-bounded DCM is computable [8]
Note that the case for a reversal-bounded NCM is open.
We now return to our definitions. Assume that T is length-preserving. That is, for all
We first consider the case when T is a length-preserving NFT (i.e., without ε-instructions).
The input and output lossy rates are computable when T is an NFT without ε-instructions and L is a regular language
Notice that L,
We now consider a DFT T augmented with reversal-bounded counters. In every instruction of T, if the instruction reads a nonnull inout symbol, it will also output a nonnull symbol and vice versa. We call such a T nonnull and obviously it is length-preserving. The following result uses Theorem 3.2.
The output lossy rate is computable when T is a nonnull DFT T augmented with reversal-bounded counters and L is the language accepted by a reversal-bounded DCM
It is an exercise to show that the shuffle encoding of
We currently do not know if Theorem 3.4 can be generalized to the input lossy rate. This is because in computing the input lossy rate, one needs
Currently, we are not clear on how to generalize the definitions of input and output lossy rates to the case when T is not necessarily length-preserving. The difficulty is that, in this case, T can map a low (resp., high) bit rate input to a high (resp., low) one, even when T is one-to-one. Hence, it is not obvious how information rates used in the definitions can faithfully catch the intuitive meaning of lossy rates. We leave this generalization for future work.
Automata are a fundamental model for all modern programs. Therefore, using the results presented so far, we would be able to compute the input and output lossy rates for a channel modeled by a transducer, which, in practice, is implemented by a program. However, there are difficulties since, as was shown earlier, there are only limited cases when the lossy rates are computable. In general, when the channel is complex enough, it is treated as a black-box (i.e., its internal implementation is unknown). In the rest of the section, we provide a practical approach that uses a Lempel–Ziv compression algorithm to estimate the lossy rate of a black-box channel. In the following, our experiments consist of two parts. In the first part, we will do experiments and estimate the lossy rates of several simple black-box channels. In the second part, experiments will be conducted on complex black-box channels and the corresponding lossy rates also will be estimated. We will explain the meaning of simple and complex in the corresponding subsection.
Simple black-box channels
Herein, we say a black-box channel is simple if the internal structure of the channel is a k-lossy and
Information theory analysis of the simple black-box channels
In this subsection, we use a 2-lossy and 2-valued channel as an example to explain the information theory analysis of a simple black-box channel. It is not difficult to generalize this analysis method to other k-lossy and
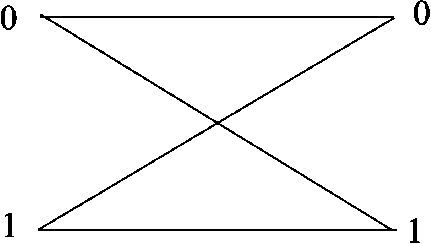
A 2-lossy and 2-valued channel with uniform distribution.
The channel in Fig. 1 is a 2-lossy and 2-valued channel. From the perspective of information theory, it is a binary symmetric channel with bit error probability 0.5, and uniform input and output bit probabilities. Let X be the channel input, Y be the channel output, and
From the definitions of output and input lossy rates given previously, and using the relation between mutual information and entropy above, it follows that the output lossy rate, (i.e.,
In the previous subsection, we have shown information theory analysis of simple black-box channels. In this subsection, we will conduct an array of experiments on these channels. We will also compare our experimental results to ideal results from theoretical analysis in order to demonstrate our experimental results as reasonable approximations of ideal values. The channels considered are diagrammed in Fig. 2, and in every case the channel input distribution is uniform, and the channel transition probabilities are uniform over the indicated links. For example, the binary symmetric channel in Fig. 2(d) has bit error probability 0.5.

Structures of all transducers used in our experiments: (a) is a lossless and single-valued transducer; (b) is a 2-lossy and single-valued transducer; (c) is a lossless and 2-valued transducer; (d) is a 2-lossy and 2-valued transducer; (e) is 3-lossy and single-valued transducer; (f) is a lossless and 3-valued transducer; and (g) is a 3-lossy and 3-valued transducer.
The procedure of our experiments has four steps.
First, for a given (black-box) transducer, a sequence of symbols with length 100,000 is generated using a pseudo-random number generator as an input to the transducer. Then, we apply a “packing” method to encode as many input symbols as possible into one byte, subject to the input symbols being uniquely decoded from the packed bytes. (This is done for coding efficiency, since the commonly available LZ algorithm implementations, such as gzip [1], are byte-based.) As a result, the input sequence is converted into a packed input sequence. We use a Lempel–Ziv compression algorithm to compress the packed input sequence and obtain its compression ratio.
Second, the input sequence is fed to the transducer, symbol by symbol, to generate the output sequence. A nondeterministic choice in the transducer is simulated by a uniform probabilistic choice. Similarly to the previous step, we also apply the “packing” method to convert the output sequence into the packed output sequence. A Lempel–Ziv compression algorithm is used to compute the compression ratio of the packed output sequence.
Third, while the input sequence is fed to the transducer, we record every input symbol and the corresponding output symbol to obtain an input–output pair. As a result, a sequence of input–output pairs is generated. However, this process may not be length-preserving. Thus, to solve this problem, we use aforementioned shuffle coding to translate every input–output pair into a single symbol so that a new sequence, called a transducer sequence, is formed. Applying the packing approach in previous steps, the packed transducer sequence is generated. Again, a Lempel–Ziv algorithm is used and the compression ratio of the packed transducer sequence determined.
Fourth, we use the inverse of the compression ratios of the packed input sequence, the packed output sequence, and the packed transducer sequence to estimate, respectively, the information rates. Directly from their definitions, the input lossy rate and output lossy rate of the transducer are then calculated.
The experimental results are shown in Table 1. The transducers are implemented in Python. All of the experiments are performed on the Ubuntu 12.04 operating system.
The estimated and ideal information rates for the input/output/transducer sequence of various transducers
In Table 1, under the term “Input” (resp., “Output” and “Transducer”) is listed the estimated information rate (i.e., the inverse proportion of the compression ratio) of the input (resp., output and transducer) sequence. The columns immediately after each estimated information rate contain the ideal rate (the respective entropy).
In Table 2, under the term “Input lossy rate” (resp., “Output lossy rate”), two columns are listed: one includes the estimated input (resp., output) lossy rate of the corresponding transducer and the other one contains the ideal input (resp., output) lossy rate (respective conditional entropy) of the corresponding transducer. From the previous definitions, it is known that the input (resp., output) lossy rate of a transducer equals the information rate of its transducer sequence minus the information rate of its input (resp., output) sequence.
The estimated input/output lossy rates of various transducers (bits/symbol)
We summarize our findings from the experimental results as follows.
In Table 1, the estimated information rates in our simulation results are very close to their ideal values for every transducer. The largest difference between the experimental results and their ideal values are for the estimated information rates of the transducer sequence in case (g). The estimated information rate is only 1.6% larger than the ideal value. This case also corresponds to the least effective packing of symbols into bytes prior to LZ algorithm encoding. The results demonstrate that our approach provides reasonable estimates of information rates.
When the output lossy rate of a transducer is 0 (resp., positive), the transducer is likely single-valued (resp., k-valued (
When the input lossy rate of a transducer is 0 (resp., positive), the transducer is likely lossless (resp., k-lossy (
In a k-lossy (
In the previous subsection, we have shown how to use a Lempel–Ziv algorithm to estimate the input and output lossy rates of simple black-box channels. These channels were characterized by transducers that mapped a single input symbol to a single output symbol. The size of the input and output alphabets could be different, but the respective transducer mappings considered were fixed-length (single symbol) input to fixed-length (single symbol) output. It is rare to find such simple channels in computer programs, and so generally we are interested in transducers that are variable-length input to variable-length output mappings. We refer to these as nonfixed length channels, or simply as variable-length channels. So, before proceeding we need to outline how lossy information rates are estimated for the more general transducer channel model.
In this subsection, we will do our experiments on a compiler channel that is a compiler program treated as a variable-length input to variable-length output channel. Thus, in the following, we use a compiler channel as an example to explain the approximation approach for variable-length channels. In practice, it is known that for a compiler channel, the length of its input is always less than or equal to the length of its corresponding output. Obviously, it is not length preserving.

A small part of a transducer sequence in a compiler channel.
To illustrate the concepts, consider the input to the compiler channel to be a C program, and the output the compiled assembly program. The input to the compiler channel consists of a sequence of input symbols. Every input symbol represents exactly one character (i.e. an ASCII character in the original input). A sequence of symbols is used to construct a statement, and a computer program is a sequence of statements. The compiler accepts a statement as input and generates one or more output statements. For example, Fig. 3 lists two input (C-code) statements and the resulting compiler output (assembly language). The first input statement (line 1) results in three lines of compiler output (lines 2–4), and the second input statement (line 5) results in one line of output (line 6). In this example, the input of the compiler channel only includes line 1 and line 5; the output of the compiler channel only contains lines 2–4 and line 6; the transducer sequence of the compiler channel includes all statements in this example and in the same format (i.e., every input statement is followed by its corresponding output statements). In every input statement (i.e., line 1 or line 5), every input symbol is a (ASCII) character. In every output statement (i.e., line 2–4 and line 6), every output symbol represents around 1.5 (ASCII) characters. Using this ratio, the number of input symbols equals the number of output symbols. It does not suggest that, for every input statement, the length of the corresponding output statement is 1.5 times of its length. It means, throughout the compiling process, every output symbol, at average, corresponds to around 1.5 (ASCII) characters in compiler output. (Note that, Fig. 3 only shows a small part of the complete transducer sequence. The ratio 1.5 is only determined by the length of the complete output file to the length of the complete input file. More details regarding the ratio will be defined and explained later.)
Through the channel, at the output side, every input symbol corresponds to exactly one output symbol. However, an output symbol may correspond to one or more output characters. Now, we may raise a question, how many characters can an output symbol represent? The answer depends on the program. We assume that, for a program, every output symbol represents the same number of characters in its output side. (Notice that the output symbol has a larger size of alphabet. For example, if a output symbol can represent two characters, then, the size of output symbols’ alphabet is the square of the size of the characters’ alphabet.) Hence, the number of characters represented by a output symbol is simply decided by the ratio of the length of the compiler’s output and the length of the compiler’s input. We call this value compiler ratio. The compiler ratio means the average number of characters represented by a output symbol, or says the average number of characters in output side generated by one character in the input side. Following these settings and assumptions, the compiler channel is length-preserving in input/output symbols format.
Now, we have a length-preserving channel and a compiler ratio for the channel. How can we compute the lossy rates? The key is determining how to compute the information rate of the output and the transducer (i.e., input–output pair) since the information rate of the input is computed as in previous experiments. We use the output side as an example to explain this. In the previous subsection, we have shown that the Lempel–Ziv algorithm can be used to approximate the information rate of the input/output on a length-preserving channel. Now, we use the same technique to compute the information rate of the output of the compiler channel in character format, rather than in output symbol format. But, under the length-preserving channel assumption, the output consists of output-symbols, not characters. Thus, we need to find a relation between the information rate of the output in character format and the information of the output in output symbol format. Then, we notice that every character-format sequence can be transformed into an output-symbol sequence by a one-to-one mapping. When an output-symbol represents m characters, the number of words in the output in characters format with length
Experiment subjects and setting.
The GNU coreutils is a collection of basic tools in Unix-like operating systems. It is also appropriate to use them as the inputs of the compiler. However, this toolset contains more than 100 programs, so that we do not have enough space to show results for all programs. Instead, we randomly chose 10 commonly used unix shell commands to present our results.
Experiment procedure. First, before compilation, each program is compressed using a Lempel–Ziv compression algorithm. Using its original length and compressed length, the compression ratio is obtained. Similarly to the previous experiments, the information rate of the input is approximated as proportional to the inverse of the compression ratio.
Second, we use
Third, after compilation for each program, we can compress its combined output (i.e., the output in the transducer side) and its pure assembly output to get corresponding compression ratios. Then, the information rates of the transducer and the output are computed. Because a compiler is non-length-preserving, we then compute compilation ratios for each type of output. Using Eq. (1), the information rates of the transducer and the output are obtained.
Fourth, using the definitions above, the lossy rates are also computed for each program.
Experimental results and findings. The experimental results are presented in Tables 3–6.
In each table, the term “Name” represents the program being compiled and the program is treated as a black-box channel. The term “Input lossy” (resp., “Output lossy”) indicates the input (resp., output) lossy rate of the corresponding channel. Each table’s name represents the architecture on which programs are compiled.
ARM
MIPS
PowerPC
x86
We summarize our findings from the experimental results as follows.
On each architecture, both input lossy rate and output lossy rate of each program are positive. It indicates that the compiling process is equivalent to a k-lossy (
As shown in Tables 3–6, for every architecture, and for every program, the output lossy rate is larger than the input lossy rate. This observation is interpreted as follows. For a compiler, the input is just a
Comparing Tables 3 and 4, we find that, for the same program, the values of the input lossy rates for the ARM architecture and for the MIPS architecture are very similar. In Tables 5 and 6, the input lossy rates for the PowerPC architecture and the x86 architecture are also similar in value. Reviewing all data generated in our experiments, we seek an explanation for this observation. For a channel, the input lossy rate is determined by two terms: the information rate of its transducer side and the information rate of its output. Both the transducer side and the output contain information from the output. Then, the amount of information in the output may be a key factor in the input lossy rate. We also know that the output depends on the architecture and hence the input lossy rate. This really says the input lossy rate of a channel reflects its architecture characteristics. Both ARM and MIPS use a RISC instruction set and are mainly used in mobile devices and embedded systems. Thus, their platform characteristics are similar, and we observe similar lossy input rates over a broad collection of
Through the above experiments, we demonstrate that the lossy rate in a channel is a useful analysis tool in practice. Note that in the previous experiments, the implementation of a compiler is unknown, and its structure is simply modeled as a black-box channel. Even with a black-box model, we still can use its external behaviors to compute the lossy rates of the channel and gain some knowledge regarding the channel’s properties.
Footnotes
Acknowledgements
We would like to thank Klaus Wich for pointing out to us that the finite-ambiguity problem for linear context-free grammars was shown undecidable in his PhD thesis, Eric Wang for comments that improved the presentation of our results, and the referees for their suggestions.
Supported in part by NSF Grants CCF-1143892 and CCF-1117708.