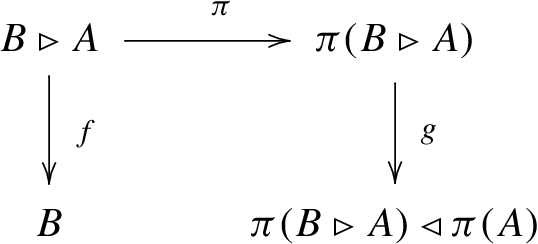Given any 1-random set X and any r in , we construct a set of intrinsic density r which is computable from both r and X. For almost all r, this set will be the first known example of an intrinsic density r set which cannot compute any r-Bernoulli random set. To achieve this, we shall formalize the into and within noncomputable coding methods which work well with intrinsic density.
We shall study the sets whose intrinsic density is in the open unit interval. By a result of Astor [2], intrinsic density r is equivalent to injection stochasticity r, which is the uniform variant of Kolmogorov-Loveland stochasticity. Our goal is to separate intrinsic density from randomness: for almost all r in the open unit interval, we shall construct sets which have intrinsic density r, or injection stochasticity r, which cannot compute any set random with respect to the r-Bernoulli measure.
We briefly recall the notion of (asymptotic) density in the natural numbers:
Let .
The density of A at n is , where .
The upper density of A is .
The lower density of A is .
If , we call α the density of A and denote it by .
Astor [2] introduced intrinsic density, which requires that the asymptotic density remain fixed under any computable permutation.
The absolute upper density of A is
The absolute lower density of A is
If , we call α the intrinsic density of A and denote it by . In particular, if and only if for every computable permutation π.
A natural question to ask is what reals in the unit interval can be achieved as the intrinsic density of some set. Sets of intrinsic density 0 and 1 are well-known. In the open unit interval, Bienvenu (personal communication) gave a straightforward probabilistic argument that shows the sets of intrinsic density r have measure 1 under the r-Bernoulli measure. In fact, something stronger is true.
Let be a real number. The Bernoulli measure with parameter r, , is the measure on Cantor space such that for any ,
If X is ML-random with respect to , we say it is r-random.
If we say 1-random, we are specifically referring to -ML-randomness. For a review of randomness with respect to noncomputable measures, see Reimann and Slaman [6].
Let. If X is r-random, then X has intrinsic density r.
Standard arguments for can be generalized to r to prove this. It is true for r-Schnorr randomness. See, for example, Nies [5, Theorem 3.5.21] for the proof in the case .
Thus every real in the unit interval is achieved as the intrinsic density of some set. Furthermore, we will not be able to find an ML-random set which does not have intrinsic density as was done for computable randomness and MWC stochasticity by Ambos-Spies [1] and was done for Schnorr randomness and Church stochasticity by Wang [8]. However, it is still possible to find sets which have intrinsic density r but are not r-random. We shall not only do this, but in fact provide examples which cannot even compute an r-random set. To achieve this, we shall next develop some tools which work well with both asymptotic and intrinsic density and allow us to change densities. Computable operations like the join can only preserve intrinsic density, and set operations such as the intersection and union behave unpredictably with respect to asymptotic density.
We shall follow the convention, unless otherwise stated, that capital English letters represent sets of natural numbers and the lowercase variant, indexed by a subscript of natural numbers, represents the elements of the set. As an example, if E is the set of even numbers, then . Recall that the principal function for a set A, , is defined via .
Using this representation, it is not hard to see the following characterization of upper and lower density:
Letbe. Then
Note that if has a 0 in the final bit, then
Therefore, to compute the upper density it suffices to check only those numbers n for which has a 1 as its last bit. Those numbers are exactly by the definition of , and . Therefore is a subsequence of which dominates the original sequence, so . Finally, .
Similarly, to compute the lower density it suffices to check only the numbers n such that the final digit of is a 0, but the final digit of is a 1. (That is, if there is a consecutive block of zeroes in the characteristic function of A, we only need to check the density at the end of the block when computing lower density, as each intermediate point of the zero block has a higher density than the end.) These numbers are exactly by definition, and . Therefore is a subsequence of which is dominated by the original sequence, so . □
A critical proof technique will involve proving that two sets A and B cannot have different intrinsic densities by creating a computable permutation which sends A to B modulo a set of density zero. The following lemma shows that if we can do this, then the density of the image of A is the same as the density of B, and therefore that they cannot have different intrinsic densities.
If, thenand.
Notice that
By definition. Therefore
By subadditivity of the limit superior,
As and ,
However, because , so as desired.
The argument for the union and the argument for lower density are functionally identical. (For the union we use , X, and in place of X, , and respectively.) □
Our strategy is to find some process which takes a set A of intrinsic density α and a set B of intrinsic density β and codes B and A in such a way that we are left with a set which has new intrinsic density obtained as some function of α and β. The following lemma will be useful for computing intrinsic densities.
Letbe a finite collection of injective computable functions and let C be an infinite computable set. Then there is an infinite computable setsuch thatfor all i.
Let . Then given , define to be the least element c of C with for all i. Set . Then for all i because . □
We shall see in Section 2 that we cannot hope for such a process to be computable in a way that allows us to recover the original sets. Instead we shall use the following noncomputable coding methods. They are natural and have been used informally by others such as Jockusch and Astor.
Let A and B be sets of natural numbers.
, or B into A, is
That is, is the subset of A obtained by taking the “B-th elements of A.”
, or B within A, is
That is, is the set X such that .
With , we are thinking of A as a copy of ω as a well-order and is the subset corresponding to B under the order preserving isomorphism between A and ω. We make a few elementary observations to illustrate how these operations behave:
For all A, .
For all A and B and any i, is either in B or . Therefore i is either in or respectively, so .
If , then . Furthermore, .
⊳ is associative, i.e. : By definition, and thus
Similarly, , and therefore by definition
⊲ is not associative: Consider the set of evens E, the set of odds O, and the set N of evens which are not multiples of 4. Then
However,
⊳ and ⊲ do not associate with each other in general:
but
Similarly, , but is a subset of B.
In Section 2, we shall construct examples of sets which have intrinsic density r but are not r-random. However, all of these examples will trivially compute r-random sets, so we shall then turn our attention to constructing examples which cannot. In Section 3 we shall prove our main technical theorems which allow us to complete the construction in Section 4.
Nonrandom sets of intrinsic density r
The following theorem allows us to easily generate sets of intrinsic density r which are not r-random from Proposition 1.4.
if and only if.
We shall first argue the forward direction via contrapositive. We proceed by showing that, for any given computable permutation π, there are computable permutations which send to modulo a set of density 0, and similarly for . Then the upper (and lower) density of under these permutations will match that of and respectively. Therefore if , the density of is not invariant under computable permutation.
Let and . For any fixed computable permutation π, there is another computable permutation defined via enumerating the odds onto the factorials in order and enumerating the evens onto the nonfactorials according to the ordering induced by π. That is, and .
Then as F has density 0, Lemma 1.6 shows
As the image of the odds under is a subset of F,
and
Notice that is just with each element n increased by . Thus
As F is the factorials, the final expression tends to in the limit, so we see that
and
by a nearly identical argument.
In particular, and because we are taking the limit superior and inferior over all computable permutations, of which is but one. Reversing the use of the evens and the odds in the definition of , we get that the same is true for B in place of A, so and . Therefore if , as desired.
We now prove the reverse direction using a technical lemma.
Let π be a computable permutation and let. Then
Let send the n-th element of to n (the inverse of the principal function), and let be defined via . Then notice that . Furthermore, observe that for any , by the definition of h and the within operation. Therefore
As ,
Thus . We shall now massage h and d into permutations which preserve the relevant densities.
By Lemma 1.7, there is a computable set with . Now define the computable permutation via for , and have enumerate onto in order. Similarly, define the computable permutation via for , and have enumerate onto .
As agrees with d on , we now see that
Furthermore, applying π shows that
As agrees with h on and , we have
Therefore and .
By choice of H, , so Lemma 1.6 shows that
and
Therefore, as and is a computable permutation,
A nearly identical argument with O in place of E and B in place of A shows similarly that
□
We shall now show that this implies that . Consider . By definition,
As ,
The latter expression can be rewritten as
Let m be the largest number such that the m-th element of is less than n, and let k be the analogous number for . Now notice that
and
by the definition of the within operation. Therefore, we can rewrite as
Using the fact that ,
Rearranging, this is equal to
Taking the limit as n goes to infinity, m and k both go to infinity. Thus
goes to 0 by Lemma 2.1.1. As is bounded between 0 and 1 by definition, the second term vanishes. Therefore
as desired. □
Using Theorem 2.1, we may take any set X which is r-random and then has intrinsic density r but is not random as desired. However, this is merely a structural difference between the notion of randomness and the notion of intrinsic density as opposed to a computational difference.
Core theorems
We would now like to build examples of sets with intrinsic density r which cannot compute an r-random set. To do so, we shall prove two main theorems which allow us to apply the into and within operations to study asymptotic and intrinsic density.
Let C be computable and. Then.
Under the map which takes to n, is mapped to . However unless C is ω, this is not a permutation. Using Lemma 1.7, we are able to massage this map into a permutation which takes to n modulo a set of density 0. Then under this permutation, (and A) goes to modulo a set of density 0. Therefore if did not have intrinsic density r, A could not either by Lemma 1.6.
Formally, assume . Suppose π is a computable permutation with . Let be defined via . Then :
By Lemma 1.7, there is computable with . Define via for , and for define to be the least element of not equal to for some . As f agrees with on ,
Therefore by applying π,
Using the above equality,
As , we can apply Lemma 1.6 and see
As ,
However, we assumed that , so . As is a computable permutation, this implies .
This proves that if π is a computable permutation with , then . If there is no such permutation, there must be a computable permutation π with because we assumed that . Then because
we have for all n. Therefore by the subtraction properties of the limit superior,
As we assumed ,
Thus . We now apply the previous case to get that , which automatically implies . □
If we are successful in building a set of intrinsic density r which cannot compute an r-random set, then we will be able to use this theorem to automatically get many more such examples.
We now turn our attention into, which is more useful. We first make a crucial observation about the asymptotic density of , which will be critical for investigating the intrinsic density of sets obtained via use of the into operation.
.
.
By Lemma 1.5,
By the submultiplicativity of the limit superior,
Now is a subsequence of , so
Therefore as desired.
The case for the limit inferior is nearly identical, reversing ⩽ to ⩾ and using supermultiplicativity along with the corresponding identity from Lemma 1.5. □
Ifand, then.
Therefore, if has intrinsic density, its intrinsic density must be the product of the densities of A and B. This will occur in certain instances, which is our second main theorem. Recall that a set X has Y-intrinsic density, or intrinsic density relative to Y, if its density is invariant under all Y-computable permutations as opposed to just the computable ones. We use to denote the Y-intrinsic density of X if it exists.
Ifand, then.
The proof is similar to the proof of Theorem 3.1, however we shall present it fully here without referring to techniques from that proof, as it is quite technical. The idea is that for any fixed computable permutation π, there is an A-computable permutation which sends B to modulo a set of density 0. Therefore if π witnesses that does not have intrinsic density , i.e. does not have density , and then as A has intrinsic density α by assumption, Lemma 3.2 will show that does not have density β. Thus B does not have A-intrinsic density β.
Formally, assume . Assume that . We shall show that . First suppose that there is some computable permutation π such that . We shall let . Let be defined via and via , f maps A to its indices and g maps to its indices. Then and :
Note by Lemma 3.2 that : From the definition,
and by assumption. because , so would contradict Lemma 3.2.
From this point forward we shall let
for the sake of readability.
By Lemma 1.7 relativized to A and applied to , there is an A-computable set such that:
We shall now define permutations which preserve the properties of f and g outside of H. Define via for , and for , let be the least element of not equal to for some . Define similarly using , , and in place of A, H, and respectively. Then and are A-computable because H, f, and g are, and it is a permutation because f and g are bijections (from A and to ω respectively) which have been modified to be total without violating injectivity or surjectivity.
Now we shall compute . As and f agrees with on ,
Furthermore
As and agrees with g on ,
Thus . As , Lemma 1.6 shows
By the definition of X,
which is greater than β by the above. As ,
and thus
Therefore
As is an A-computable permutation, .
Therefore we have proved that if there is some computable permutation π such that , then . If there is no such permutation, then there must be a computable permutation π such that because we assumed . As , . Therefore
The fact that combined with the properties of the limit superior with regards to subtraction implies
We know that because . As we assumed that ,
Bringing this together,
Thus we can apply the first case of the proof to show that , which automatically implies , so we are done. □
Ifand, then.
By definition,
As , Theorem 3.1 relativized to A shows that . Therefore we can apply Theorem 3.4 to A and to get that
□
Astor [2] proved the special case of Corollary 3.5 when A has intrinsic density α and B is 1-random relative to A.
It is natural to ask if any of the intrinsic density requirements in Theorem 3.4 can be dropped. It is immediate that we cannot drop the requirement that A has intrinsic density: for any A, so ω always satisfies the requirements on B, but , so A must have intrinsic density. Similarly, for any B, so B must have intrinsic density. Therefore the only possible weakening of Theorem 3.4 would be to require as opposed to . However, this fails.
Let. Thenbutdoes not have intrinsic density.
Note that has intrinsic density by Theorem 2.1 as implies .
Let E represent the set of even numbers. Notice that contains exactly one of or for all . Therefore the n-th element of is if and if . Thus
by definition. By the properties of the within operation,
By Proposition 2.1, however, does not have intrinsic density. □
Intrinsic density r sets which cannot compute an r-random set
We are now ready to construct sets of intrinsic density r which cannot compute an r-random set. To do this, we would like to have a countable collection of sets which all have intrinsic density relative to each other so that we may apply Theorem 3.4 repeatedly.
Any 1-random set X uniformly computes a countable, disjoint sequence of setssuch thathas intrinsic density, i.e., for each i. Furthermore, the’s form a partition of ω.
Recall that given a set X, denotes the i-th column of X, i.e. . Let be 1-random. Then for all i, is 1-random relative to . (Essentially Van Lambalgen [7], Downey-Hirschfeldt [4, Corollary 6.9.6]) Proposition 1.4 relativizes to the fact that Z-1-randoms have Z-intrinsic density . In particular, taking a single 1-random automatically gives us infinitely many mutually 1-random sets, and thus infinitely many sets with intrinsic density relative to each other. Using these together with Theorem 3.4, we can construct the desired sequence, where the mutual randomness ensures that the conditions of Theorem 3.4 are met.
Let . Given , let
and
Note that for all i, and , as and . Then for , because . Thus is disjoint. Furthermore, the ’s and ’s are in fact uniformly computable in X, as X can uniformly compute all of its columns and is uniformly computable in . We now verify that and by induction.
, and is computable. Suppose that is -computable and that . Then and are both -computable, and therefore -computable. By the above, both and are 1-random relative to and thus have intrinsic density relative to . Therefore by the relativization of Proposition 1.4. Thus by Theorem 3.4 and the induction hypothesis,
A nearly identical argument for verifies , which completes the induction.
Finally, suppose for the sake of contradiction that the ’s do not form a partition of ω. Since we have already shown that the sequence is disjoint, there must exist a least m with for any i. Therefore, there must be some k such that m is the least element of for all . This is because every m is in and is a subset of missing only elements of . It follows that for all , as would imply that since and m is the least, i.e. 0-th, element of . However, this means that is an infinite computable subset of X, which contradicts the assumption that X is 1-random since it is a basic fact that 1-random sets cannot have infinite computable subsets. Therefore, every m must be in some as desired. □
Jockusch and Schupp [3] proved that asymptotic density enjoys a restricted form of countable additivity: if there is a countable sequence of disjoint sets such that exists for all i and
then
The intrinsic density analog of this results follows immediately from the fact that permutations preserve disjoint unions. That is, if there is a countable sequence of disjoint sets such that exists for all i and
then
Note that must be true for any sequence satisfying Lemma 4.1, as . This together with the previous lemma allows us to construct our desired set.
For everyand any 1-random set X,computes a set with intrinsic density r.
Let . Let be the set whose characteristic function is identified with the binary expansion that gives r, the set of all n such that the n-th bit in the binary expansion for r is 1. Let be as in Lemma 4.1 applied to X, i.e. a uniformly X-computable partition of ω with having intrinsic density for each i. Let . We now describe the process by which is computable from . For a given m, for some n since the ’s form a partition of ω. X can uniformly compute the ’s and thus compute n where . Then if and only if , which r can compute.
Now, note that
because and . By the fact that countable unions sum intrinsic densities and the definition of ,
By the definition of the binary expansion,
□
Reimann and Slaman [6, Proposition 2.3] says that if is a representation of some measure μ on , then Y computes a function such that for all and all ,
Take μ to be , the r-Bernoulli measure. Fix to be 1, the binary string of length one with first bit 1. Then we have . Thus the Y-computable function has the property that for all ,
In other words, g can be used to compute r. As Y was arbitrary, every representation of computes r.
By definition ([6, Definition 3.2]), a set X is r-random if and only if it is random with respect to some representation Y of . Therefore Y cannot compute X. However, by the above argument, Y computes r. Thus r cannot compute X. □
For almost all r, r computes a set A which has intrinsic density r but cannot compute an r-random set.
Let r be 1-random. Then we may apply Theorem 4.2 with r playing the role of both r and X to obtain an r-computable set A which has intrinsic density r. Every A-computable set is r-computable because A is r-computable, but by Proposition 4.3, no r-random set can be r-computable. Therefore, A cannot compute an r-random set.
As almost all reals are 1-random, this completes the proof. □
From each such set, we may use Theorem 3.1 to generate more examples.
Closing remarks and future work
We showed a computational separation between the notions of intrinsic density and randomness by constructing examples of sets with intrinsic density r which cannot compute r-random sets. There is room for future work in investigating whether this can be done for all r, or at least for all noncomputable r.
Additionally, there is room for applying these techniques to compare other notions of stochasticity with randomness. Many of the results proved for intrinsic density have analogs for MWC stochasticity, however it is currently open whether infinite unions work in that setting as they do for intrinsic density. Thus the analog of Theorem 4.2 for MWC stochasticity remains open.
Footnotes
Acknowledgements
The author would like to thank his advisor, Dr. Peter Cholak, for the advice, discussion, and support that made this project possible. The author would also like to thank Dr. Laurent Bienvenu, Dr. Denis Hirschfeldt, and an anonymous referee for helpful advice and resources provided in critique of earlier versions of this paper.
This work was partially supported by NSF-DMS-1854136.
References
1.
K.Ambos-Spies, Algorithmic randomness revisited, in: Language, Logic and Formalization of Knowledge, Coimbra Lecture and Proceedings of a Symposium Held in Siena, 1997.
C.G.Jockusch, Jr. and P.E.Schupp, Generic computability, Turing degrees, and asymptotic density, Journal of the London Mathematical Society85(2) (2012), 472–490, ISSN 0024-6107. doi:10.1112/jlms/jdr051.
4.
R.G.Downey and D.R.Hirschfeldt, Algorithmic Randomness and Complexity, Theory and Applications of Computability, Springer, 2010.
5.
A.Nies, Computability and Randomness, Oxford Logic Guides, Oxford University Press, 2009.
6.
J.Reimann and T.A.Slaman, Measures and their random reals, ArXiv (2013), arXiv:0802.2705v2.
7.
M.van Lambalgen, The axiomatization of randomness, The Journal of Symbolic Logic55(3) (1990), 1143–1167, ISSN 0022-4812. doi:10.2307/2274480.
8.
Y.Wang, Randomness and complexity, PhD dissertation, Ruprecht-Karls-Universität Heidelberg, 1996, https://webpages.uncc.edu/yonwang/papers/thesis.pdf.