
Abstract
In 2012, inspired by developments in group theory and complexity, Jockusch and Schupp introduced generic computability, capturing the idea that an algorithm might work correctly except for a vanishing fraction of cases. However, we observe that their definition of a negligible set is not computably invariant (and thus not well-defined on the 1-degrees), resulting in some failures of intuition and a break with standard expectations in computability theory.
To strengthen their approach, we introduce a new notion of intrinsic asymptotic density, with rich relations to both randomness and classical computability theory. We then apply these ideas to propose alternative foundations for further development in (intrinsic) generic computability.
Toward these goals, we classify intrinsic density 0 as a new immunity property, specifying its position in the standard hierarchy from immune to cohesive for both general and
Introduction
For years, there has been strong interest in the distinction between the idealized world of computation and complexity and that of its real-world applications, particularly in problems or algorithms where we find a separation between the worst-case complexity (or, more broadly, difficulty) and the worst cases actually encountered in practice. The simplex algorithm for linear programming is the classic example; there is a family of examples on which the algorithm takes exponential time [13], yet in practice, every problem actually encountered is solved within polynomial time bounds. Even more extreme examples are known, including several problems in group theory (including some variants of the word problem) that are non-computable in general, but for which a low-complexity algorithm solves all examples encountered in practice [12]. In complexity theory, current methods for exploring such structure include the average-case complexity introduced by Gurevich [7] and Levin [14], though this is sensitive to one’s choice of probability measure, as well as the smoothed analysis of Spielman and Tang [22]; however, none of these methods have been adapted to computability theory, and it may well be that none are well-suited to such problems.
Taking a more direct approach, several researchers have begun work on the question of whether an algorithm’s problematic behavior might be restricted to a negligible set. This is clearly related to the analysts’ notion of “almost everywhere”, whereby one works modulo sets of measure 0 so as to disregard problematic variations with no practical effect. In a sense, this study is motivated by envy of their methods – in recent years, we have discovered problems that seem to be “computable almost everywhere”, and are working to find the right definition for the phrase. In this paper, we take the direct approach, studying a new definition of negligibility as applied to the non-negative integers; we will spend most of our time fitting this idea into its proper computability-theoretic context, and then lay the foundations for further investigation into our motivating problem.
The essential difficulty in defining “computable almost everywhere” is that there is no uniform probability measure on the integers, and thus no natural notion of a null set. Instead, if we want a uniform measurement of the size of a subset of ω, we are forced to abandon countable additivity and fall back to pseudo-measures. One of the most practical is asymptotic density.
Let
We define the nth partial density of S as
If the limit of the partial densities exists (i.e.,
Of course,
A set
In 2003, Kapovich, Myasnikov, Schupp and Shpilrain introduced generic-case complexity [12], considering problems modulo sets of density 0. They showed that this captured the phenomenon observed in several group-theoretic problems that are known to have non-computable instances while being simple to solve for every case encountered in practice; for instance, they demonstrated that for any G in an extremely large class of groups, the word problem for G has linear-time generic-case complexity. Myasnikov, in collaboration with Hamkins, went on to apply these ideas to Turing’s halting problem [8], and proved that (for reasons having to do with the prevalence of trivially halting or trivially non-halting programs in many models of computation) the halting problem is “generic-case decidable” in said models. This was later refined by Rybalov [20], who proved that the halting problem is not “strongly generic-case decidable” (that is, decidable modulo sets with partial density converging to 0 exponentially fast); this proof, by contrast, is valid for all Turing-machine models of computation.
Jockusch and Schupp [10] have since defined and begun the study of the computability theory corresponding to generic-case complexity, and more generally the relations between asymptotic density and computability. Their work has been further developed in collaboration with Downey [6] and McNicholl [5], and refined in specific cases by Igusa [9] and Bienvenu, Hölzl and Day. [1]
However, we return the focus to the notion of negligibility, since one would expect such a definition to have interesting ties to classical computability theory. For one, a negligible set might be said to be “small”, “sparse”, or even “thin”. Such “thinness” properties have historically been of great interest in computability; they were the focus of Post’s program [18], the first attempt to construct an incomplete c.e. set, and have since proven to be of interest for unrelated reasons.
Negligibility (in the sense of asymptotic density) is closed downwards under the subset relation; any subset of a negligible set is itself negligible. It seems natural that it should be in the same family as the classical immunity properties, which provide the unifying computability-theoretic model for “thinness”. However, negligibility does not lend itself to the same analysis that we apply to immunity. Choosing an alternate coding for the parameters of a membership problem is equivalent to applying a computable permutation to the underlying set, which can dramatically alter its asymptotic density. The most extreme example comes when we consider the class of infinite, co-infinite computable sets; the resulting consequences for c.e. and co-c.e. sets are essential to the remainder of this paper. We will need one standard definition of computability theory to incorporate a result of Downey, Jockusch and Schupp: we say that a real a is left-
Suppose A is an infinite
We note first that there is an infinite, co-infinite computable set B with lower density a and upper density b. In fact, this is nearly a theorem of Downey, Jockusch and Schupp [6], which states that for any a and b meeting our preconditions, there is a computable set B with lower density a and upper density b. Unless
Since the infinite, co-infinite computable sets form an orbit under computable permutations, there is a computable permutation
If A is infinite and c
Since A is infinite and c.e., A has an infinite (and co-infinite) computable subset B. By Proposition 1.3, there is a computable permutation
If A is co-infinite and co-c
Since any infinite c.e. set has density 1 under some computable permutation, any problem that is decidable on some infinite c.e. subset of ω is in fact generic-case decidable if we choose the “correct” coding of the input. The corresponding coding is usually highly artificial, having little to do with the problem at hand.
In short, due to the sensitivity of asymptotic density to computable permutation, generic-case computability is sensitive to the coding we choose for a given problem. As some of the great strengths of Turing computability come from its invariance under choice of coding, we might hope to strengthen generic-case computability in such a way as to recover this invariance. To do so, we need to develop a stronger concept of negligibility, considering not only the upper and lower densities of a set, but those of all its images under computable permutations of ω.
In Section 2, we follow this approach and obtain a new pseudo-measure, intrinsic density, which is invariant under computable permutations of ω. We discuss various classes of sets that have intrinsic density, including the 1-random sets, which provide the foundation for our investigations in the rest of this paper.
For the remainder of the paper, we turn our focus to the new properties of intrinsic density. In Section 3, we begin with intrinsic density 0, the natural notion of being intrinsically negligible, discussing it in the context of classical computability theory. In fact, intrinsic density 0 is an immunity property, fitting naturally into the hierarchy between immunity and cohesiveness, and we determine its place in the hierarchy for both unrestricted and
In Section 4, we reflect on the relation between intrinsic density and randomness, and the connection it provides between classical computability and randomness. In fact, intrinsic density provides a continuum from immunity to stochasticity, as any intrinsic density from the range
Lastly, in Section 5, we return to our motivating problem: the task of strengthening generic-case computability. After discussing some additional reasons for considering computably invariant notions of generic-case computability, we propose four such definitions, varying in degree of uniformity. All are strictly weaker than ordinary Turing computability, but even the weakest of our notions does not consider the halting problem (or, in fact, any nontrivial index set) to be computable.
In the remainder of the Introduction, we collect notation and definitions that will be used for the rest of this paper. We will denote the eth partial computable function by
We will routinely identify a set
Given two finite binary strings v and w, we say v is a prefix of w, denoted
The prefix-free Kolmogorov complexity of a binary string w is denoted as
A set
Let
If the absolute upper and lower densities are equal, then we say that S has intrinsic (asymptotic) density
If a set has intrinsic density 0, we say it is intrinsically negligible.
By Proposition 1.3, all infinite, co-infinite computable sets have absolute lower density 0 and absolute upper density 1. Thus, they are “as far as possible” from having an intrinsic density, at least in the sense that, under computable permutations, their densities range as widely as possible.
However, some might argue that 1-generic sets are further from having an intrinsic density than computable sets. It is simple to show that all 1-generic sets have lower density 0 and upper density 1. Since the class of 1-generic sets is closed under computable permutation, we can conclude that all 1-generic sets in fact have intrinsic lower density 0 and intrinsic upper density 1. This puts them “as far as possible” from having an intrinsic density, in the sense that no computable permutation can bring their upper and lower densities together.
For the rest of our work in this paper, we will focus primarily on sets that have an intrinsic density, rather than classes of sets that do not. With a few examples, we begin to establish the connections between intrinsic density and other computability-theoretic properties, and (particularly in discussing sets with intrinsic density strictly between 0 and 1) lay the groundwork for our later results.
We start with the r-cohesive and r-maximal sets. Recall that an infinite set C is r-cohesive if there is no computable set R such that
Every r-cohesive set has intrinsic density
We note that if a set C is r-cohesive, then its image under any computable permutation of ω is also r-cohesive; it thus suffices to prove that every r-cohesive set has density 0.
If we have a finite computable partition of ω (i.e.,
Every r-maximal set has intrinsic density
However, sets of intermediate intrinsic density (strictly between 0 and 1) provide a more versatile basis for further investigation; as such, the 1-random sets will be essential to certain constructions later in this paper.
Every
Any 1-random set obeys the Law of Large Numbers, in the sense that it has density
We can use 1-randoms to construct sets of other intermediate intrinsic densities as well, by means of the following lemma and its corollaries.
If A has density d
Interpreting B as a binary sequence, consider the A-computable subsequence
However, by the definition of
Since being 1-random is invariant under computable permutation, we obtain one more pair of corollaries:
If A has intrinsic density d
If
Having established a few tools to use in controlling the intrinsic density of sets (in this paper, largely useful for the construction of counterexamples), we can now proceed to consider intrinsic density in a broader context.
As discussed in the Introduction, asymptotic density was defined as a substitute for a probability measure on a countable space. Its use in generic-case computability (and other topics) is in defining a density-0 set to be negligible, in the sense that its elements are eventually scarce. This provides one of the more practical notions of a “small” or “thin” subset of the integers, in some senses more natural than asserting that a set has no infinite c.e. subset (i.e., is immune).
Unfortunately, having density 0 is not computably invariant. From the perspective of computability theory, set properties that vary under computable permutation have limited applications. By addressing this one issue, having intrinsic density 0 proves to be more powerful; for example, any infinite set having intrinsic density 0 (or, in fact, any intrinsic lower density other than 1) must be immune.
Any infinite non-immune set has density
This immediately follows from Corollary 1.4. If S is infinite and not immune, it contains an infinite c.e. subset A. By Corollary 1.4,
Any infinite set with intrinsic lower density
It is clear that the upper density of a set bounds the upper density of any of its subsets, so intrinsic density 0 is closed downwards under the subset relation. Since having intrinsic density 0 is a computably invariant property, closed under subsets, and implies immunity, intrinsic density 0 (here abbreviated id0) is a natural new immunity property, describing a strong notion of “thinness”.
We therefore seek to determine its relation to the classical immunity properties:
A c.e. list of pairwise disjoint finite sets
An infinite set A is hyperimmune (sometimes abbreviated h-immune) if for every strong array
It was quickly noted that a set A is hyperimmune iff no computable function dominates its principal function
An infinite set A is cohesive if, for all c.e. sets
These properties are organized in a natural hierarchy of implication, shown as Fig. 1. Chapter XI.1 of Soare [21] provides an excellent reference for this hierarchy (though focused on co-c.e. sets). We note that in the general case, the lack of implication between cohesiveness and dense immunity is witnessed by the existence of a non-high cohesive set, as constructed by Jockusch and Stephan [11]. Also, shh-immunity and hh-immunity are distinguishable in the general case, but by a remark of Cooper [2], are equivalent for
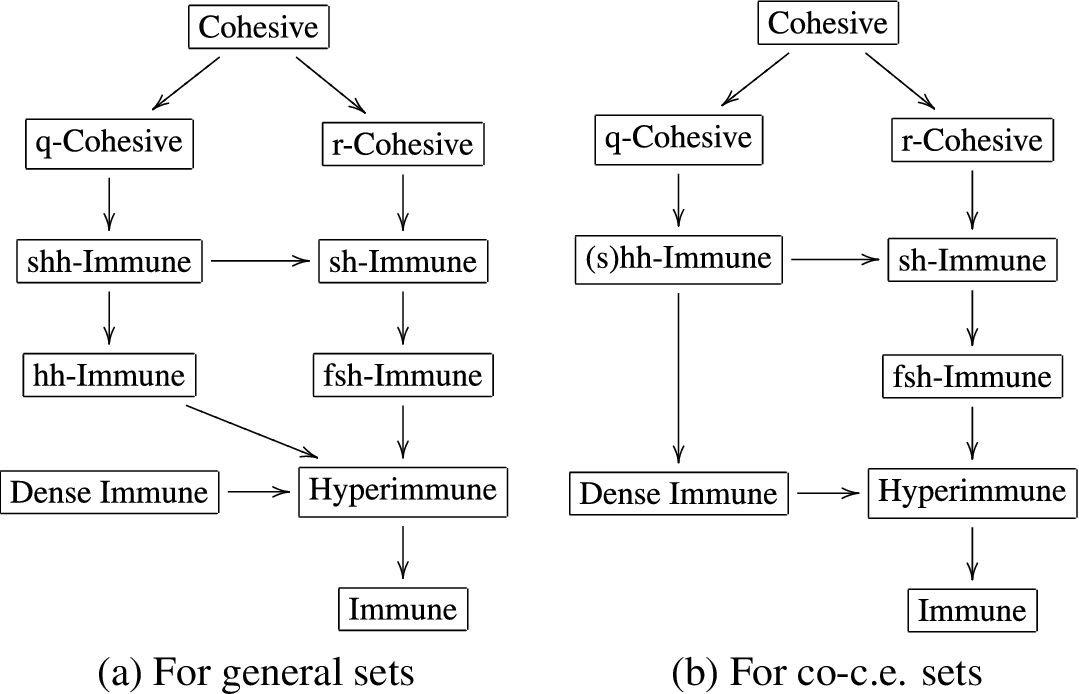
The graphs of the implications between the classical immunity properties; for
By Theorem 2.2, r-cohesiveness implies intrinsic density 0. This has a simple corollary, included here for completeness:
Every quasi-cohesive set has intrinsic density
As a finite union of cohesive (and thus r-cohesive) sets, any quasi-cohesive set Q is a finite union of sets of intrinsic density 0. Since density is finitely subadditive, Q must also have intrinsic density 0. □
It is slightly more interesting to note that dense immunity also implies intrinsic density 0. To show this, we note that dense immunity is computably invariant, and that a certain domination property is equivalent to having density 0.
For any infinite set
Consider the sequence
An infinite set
S has density 0 iff
If the set A is dense immune
Let π be a computable permutation, and consider a computable function f. We define
However, by construction of
If
By Proposition 3.7, dense immunity is a computably invariant property. It therefore suffices to show that dense immunity implies density 0. However, this is an immediate consequence of Proposition 3.6, as all linear functions are bounded by computable functions, and so are dominated by the principal function of any dense immune set. □
None of the remaining standard immunity properties imply intrinsic density 0. In fact, as demonstrated by Downey, Jockusch and Schupp [6], for every
For all
We assume that ε is rational; if not, we can replace it by any rational less than ε. We will construct A as a
We work to satisfy the requirements:
The negative requirements
Our negative requirements should, in principle, be simple to satisfy. We simply omit a set from each weak array of small lower density, thus leaving us with a set A with high upper density. There are slight complications in ensuring that taking all of these requirements still cannot force A’s upper density to fall below
The trouble comes in attempting to identify the
Towards this end, we will make heavy use of the following sentence, for varying values of e, n, and r:
Putting (*) in context, we understand it to say that there are n elements of our weak array
If we have a maximal tuple for our weak array, and
Organization:
As we combine multiple negative requirements, we allow finite injury of each negative requirement by higher-priority requirements, though never revoking any previous decisions as to whether
Each requirement
Module for
On activation at stage s: We first consult
If
At stage s: We assume that
If
If
We first determine
We then ask
Otherwise, the (*) does not hold with
Verification of the basic module:
Suppose that the module for
By the construction of
Given such an
We note that the sequence
Lastly, the module must force
Construction of A:
At stage 0, begin by activating
At stage s, check whether
Next, consult all active requirements in priority order. If any restrict s out of A, we declare that
Verification:
Nothing can deactivate
Suppose, towards a contradiction, that some requirement is never permanently activated. Let
At this stage,
However,
Finally, since every module is eventually activated, we must activate a new module infinitely often. This can only happen if
We have yet to consider implications in the other direction; what immunity properties are implied by intrinsic density 0? The first such result is simple; as established above in Corollary 3.2, intrinsic density 0 at least implies immunity for infinite sets.
On the other hand, we already know that hyperimmunity (even shh-immunity) does not imply intrinsic density 0. We can further prove that a set of intrinsic density 0 need not be hyperimmune; we can construct
For every
Suppose that
By van Lambalgen’s Theorem [23], given a 1-random set R, there exists a uniformly R-computable sequence of sets
Let
We then define
Repeating this process, we see that
Finally,
As a convenient side effect, this theorem immediately gives us some information on the Turing degrees of infinite sets with intrinsic density 0: such sets exist below every 1-random Turing degree, but cannot be computable. Among other things, this implies that there are infinite id0 sets in non-computable
It still eliminates any hopes we might have of further positive implications between the immunity properties and intrinsic density, as we will discuss in our summary below. By falling back to intrinsic lower density, we can recover one more positive implication, as shown by Jockusch in private correspondence.
Every hyperimmune set has intrinsic lower density
Since hyperimmunity is computably invariant, it suffices to show that every hyperimmune set has lower density 0.
Suppose A is hyperimmune. Consider the strong array
The above results, along with earlier work [10], [6], will suffice to disprove all other potential implications between intrinsic density 0, intrinsic lower density 0, and the standard immunity properties.
We first repeat, per Jockusch and Schupp [10], that any 1-generic set has lower density 0 and upper density 1; since 1-genericity is computably invariant, 1-generics in fact have intrinsic lower density 0 and intrinsic upper density 1. Therefore, intrinsic lower density 0 does not imply intrinsic density 0, even for
In addition, all 1-random sets are immune; otherwise, there would be a 1-random R with an infinite computable subset, which admits a trivial computable martingale that succeeds on R. Since 1-randoms have intrinsic density
Lastly, Theorem 3.9 above demonstrates that for every
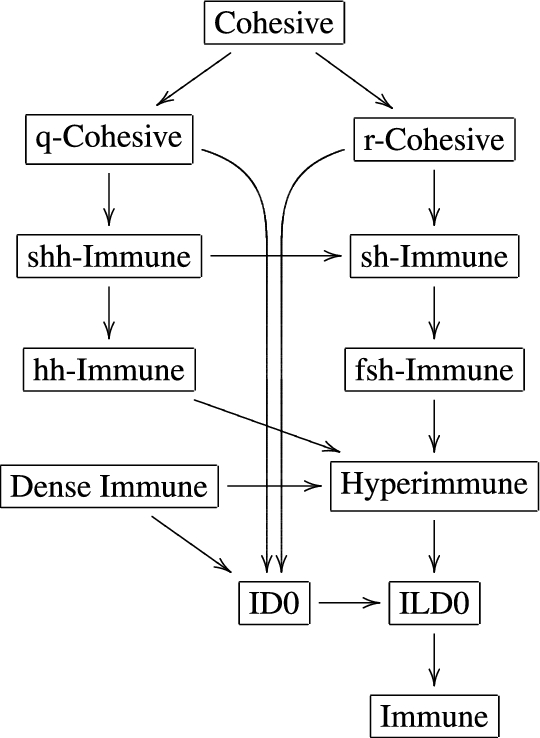
The graph of implications between the classical immunity properties and intrinsic density 0. Again, for
Combining these counterexamples with our results above, we exhaust all possible implications between intrinsic density 0, intrinsic lower density 0, and the standard immunity properties. The graph of the resulting implications for infinite sets is shown in Fig. 2; all implications depicted are strict, and counterexamples are discussed above for all arrows not present in the diagram.
Unfortunately, in the co-c.e. case (well-studied due to Post’s Program), the majority of our proofs of failures of implication collapse. Since hh-immunity does imply dense immunity for co-c.e. sets, it seems unlikely that our proof method from Theorem 3.9 will help separate the higher immunity properties from intrinsic density 0. In fact, most of our other failures of implication are exhibited by 1-generics or derived from 1-randoms, examples that are inherently not co-c.e. This leaves the co-c.e. diagram incomplete, with a few interesting open questions.
Is there an infinite c.e. set with intrinsic density 1 that is not hypersimple? (f)sh-simple?
Is there a hypersimple set with lower density less than 1? Equal to 0? For all
Let us move from the extremes of density (density 0 or 1) to the intermediate densities, as exemplified by density
The notion of “density
There are several standard notions of stochasticity that will be useful to keep in mind. Church-stochastic sequences are stochastic under computable monotonic selection rules, whereas von Mises–Wald–Church-stochastic sequences are stochastic under partial computable monotonic selection rules. By this definition, sets with density
Passing to intrinsic density
As mentioned above, stochasticity is generally taken to require selection of proper subsequences to preserve density
Given a total computable injection p and an infinite binary sequence
However, even though this new method of sampling generalizes our previous method of considering sets under computable permutations of ω, it has no additional power as far as density is concerned.
Given any total computable injection p
Given a total computable injection p, we define a computable permutation π by assigning values
The sizes of
From this minor lemma, we note that in fact, any set with intrinsic density has constant density not only under all computable permutations of ω, but also under all computable “samplings” of ω. To be more precise:
A set A has intrinsic density d iff
The reverse direction is obvious by definition, since computable permutations of ω are also total computable injections.
The forward direction is, at this point, also quite straightforward. Fix a total computable injection p. By Lemma 4.2, there is a computable permutation π such that
This corollary reveals that intrinsic density
Permutation stochasticity and injection stochasticity coincide
Considering this interpretation of intermediate intrinsic densities (strictly between 0 and 1) as a form of stochasticity, we find that intrinsic density provides an interesting link between the immunity properties and randomness-theoretic ideas. As discussed above, intrinsic density 0 is an immunity-type property, and so intrinsic density 1 is a form of co-immunity (or, as it is called for c.e. sets, simplicity). Thus, intrinsic density illustrates the relations between immunity, randomness and simplicity, and provides a continuum of intermediate concepts, all of which follow in the spirit of stochasticity as established by von Mises. This calls our attention to the fact that all of these properties are, in essence, descriptions of unpredictability: a set is immune if it is sufficiently difficult for a computable enumeration to stay within the set, co-immune if it is difficult to avoid the set, and stochastic if it is difficult to achieve any sort of persistent pattern of biased intersection with the set or its complement.
Of course, all of this relies fundamentally on our use of intrinsic density. Considering asymptotic density alone, we find no useful connection to computability or randomness. A set with density 0 need not be immune in any useful sense, as is made clear by considering the computable set of perfect squares. Taking the complement, we obtain a set with density 1 that is trivial to avoid. Moreover, density
Having begun by investigating the implications of adding computable invariance to asymptotic density, we end by returning to the motivating problem with which we began: strengthening Jockusch and Schupp’s generic-case computability to obtain similar invariance. They defined generic-case computability as follows:
A partial function
We say that
In practical terms, the weakness of generic-case computability was shown by Hamkins and Miasnikov [8], who demonstrated that, in several reasonable codings, the halting problem is in fact decidable on a set of asymptotic density 1, due to the density of trivially non-halting programs. This suggests that we should strengthen generic-case computability, to avoid rendering the halting problem “decidable” for trivial reasons.
Rybalov [20] has shown that if we insist on convergence on a set with density exponentially approaching 1 (also known as strong generic-case computability), then the halting problem is instead undecidable. Of course, his analysis makes use of asymptotic density on the set of Turing programs, considering the programs with at most n non-final states; strong generic-case computability is not directly applicable to arbitrary subsets of ω, so we must look for an alternative approach.
Furthermore, Corollary 1.4 has a somewhat unfortunate consequence for generic-case computability. For any problem, if there is an algorithm that converges on an infinite set of inputs, that algorithm becomes a generic-case solution for the problem under some alternate coding of the input. After all, the domain of the algorithm is necessarily c.e.; there is therefore some coding of the underlying problem (corresponding to a permutation of ω) under which the algorithm converges on a set of density 1. In other words, most natural problems have generic-case computable solutions (as defined by Jockusch and Schupp [10]) under some computable permutation. This gives us another reason to use a stricter notion of generic-case computability.
Returning to the original definition of generic-case complexity for group-theoretic problems, from Kapovich, Myasnikov, Schupp and Shpilrain [12], we note that the authors defined a problem in a finitely generated group to have generic-case complexity
We will call this new notion intrinsic generic-case computability, as it must be preserved under computable permutations of ω. Below, we propose four definitions, varying in degree of uniformity.
Our weakest candidate notion of intrinsic generic-case computability is the direct translation of the definition by Kapovich, Myasnikov, Schupp and Shpilrain:
A set A is (weakly) intrinsically generic-case computable iff
Note that we place no requirements on the relationships between the generic-case descriptions for each such image
Insisting on a bare minimum of uniformity, we obtain our next candidate definition:
A set A is (uniformly) intrinsically generic-case computable iff there is a uniformly computable family of functions
On the other hand, allowing our description to require an index may weaken our notion of uniformity; after all, this means that our description f cannot be given only a black-box oracle specifying the computable permutation, but actually requires knowledge of how the permutation can be computed – and in particular may depend on the specific program provided to compute the permutation.
Requiring the description to work with only an oracle might seem a trivial variation, but significant differences have been observed in analogous situations; specifically, in computable model theory, the index-based definition of uniform computable categoricity has been shown to be strictly weaker (and less natural) than the definition providing only an oracle. [4] (In general, any oracle-based definition must be at least as strong as the corresponding index-based definition, since it is well-established that there is a Turing-machine procedure allowing us to convert an index into an effective oracle.) We therefore include this option in our list of candidate notions. In this case, we would say that:
A set A is (oracle) intrinsically generic-case computable iff there is a Turing functional
Finally, we might insist on complete uniformity, and require that a single algorithm provide a description of A on a set that has density 1 under all computable permutations; in other words, that the algorithm converge on a set of intrinsic density 1.
A set A is (strongly) intrinsically generic-case computable iff it has a description
Since r-maximal sets are c.e. and have intrinsic density 1, any r-maximal set is in fact strongly intrinsically generic-case computable. This provides a convenient demonstration that even this strongest definition is weaker than ordinary computability.
More work will be required to distinguish these definitions of intrinsic generic-case computability, and some of them may prove to be equivalent. At this point, though, there are no reasons to presume any equivalences. The author personally expects that the uniform and strong definitions of intrinsic generic-case computability will be the most useful of these four.
On the other hand, even our weakest definition has a certain demonstrable strength. A set
Suppose
The reverse implication is obvious; we will only consider the forward implication.
By the Padding Lemma for Turing machines [21], for any e, we can enumerate a set
Suppose
The halting problem is not
The halting problem is 1-equivalent to a non-computable index set (e.g. ,
Footnotes
Acknowledgements
Significant thanks are owed to Denis Hirschfeldt and Robert Soare for innumerable helpful discussions on both the broad strokes and details of the work found herein; in particular, the proof of Theorem ![]() is based on an approach suggested by Hirschfeldt. The author is also grateful to Carl Jockusch, Paul Schupp and Rod Downey, for the work that inspired this research and for several conversations on the specifics of this investigation, and to an anonymous referee, whose suggestions have added substantial clarity to this paper.
is based on an approach suggested by Hirschfeldt. The author is also grateful to Carl Jockusch, Paul Schupp and Rod Downey, for the work that inspired this research and for several conversations on the specifics of this investigation, and to an anonymous referee, whose suggestions have added substantial clarity to this paper.