
Abstract
In numerous real-world applications/domains, the class imbalance problem is prevalent/hot topic to focus. In various existing work, for solving class imbalance problem, almost data is labeled as one class called majority class, while fewer data is labeled as the other class, called minority class (more important class to focus). But, none of the work has performed efficiently (in terms of accuracy). This work presents a comparison of the performance of several boosting and bagging techniques from imbalanced datasets. The wide range of application of data mining and machine learning encounters class imbalance problem. An imbalanced datasets consists of samples with skewed distribution and traditional methods show biased towards the negative (majority) samples. Note that popular pre-processing technique for handling class imbalance problems is called over-sampling. It balances the datasets to achieve a high classification rate and also avoids the bias towards majority class samples. Over-sampling technique takes full minority samples in the training data into consideration while performing classification. But, the presence of some noise (in the minority samples and majority samples) may degrade the classification performance. Hence, the work presents a performance comparison using boosting and bagging (i.e., with both techniques) with and without using noise filtering. This work evaluates the performance with the state of-the-art methods based on ensemble learning like AdaBoost, RUSBoost, SMOTEBoost, Bagging, OverBagging, SMOTEBagging on 25 imbalance binary class datasets with various Imbalance Ratios (IR). The experimental results show that our approach works as promising and effective for dealing with imbalanced datasets using metrics like F-Measure and AUC.
Introduction
The skewed distribution in the datasets frequently appears in the field of financial systems, health science, information science, and mechanical engineering [20, 21, 2, 3]. The skew distribution occurs when the samples of one of the class (majority/negative) are severely outnumbered by those of other class (minority/positive). But traditional algorithms when trained on imbalanced (skewed) datasets tend to favour the majority/negative class, resulting in high overall classification accuracy. While the minority class will typically be the class of interest and often ignored by the traditional algorithm. For example, when a classifier is trained on a binary class data sets with 1% samples from the minority class and 99% with majority class, a 99% accuracy can be achieved by the classification models. But these models are practically not valuable. As the minority class are mostly the classes of interest. In the literature, several techniques for dealing class imbalance problem have been proposed. The common method for dealing with class imbalance problem is data sampling [18, 11]. Using data sampling, the data is balanced by adding samples to minority class called over sampling or removing the samples from the majority class called under-sampling. Two popular data sampling techniques are Random Under-Sampling (RUS) and Random Over-Sampling techniques (ROS). Apart, Synthetic Minority Oversampling TEchnique (SMOTE) [26] is most popular technique under oversampling technique. In the literature, Boosting and Bagging are effective techniques for training the imbalanced datasets [1, 38]. These techniques are commonly known as ensemble of classifiers, combining the individual classifiers for improving the accuracy of the classifiers. Boosting adaptively re-samples according to the weights attached to the samples to produces high accuracy. At each stage for the incorrect classified samples the weights are adjusted and trained on by the classifier. Whereas Bagging or Bootstrap Aggregating method trains multiple classifiers and combined into one predictor. Hence, the organization (remaining part) of this work/paper is followed as: Section 2 discusses the work related to class imbalance problem in brief. Further, the motivation behind working related to this problem is discussed in Section 3. Further ensemble technique is being discussed in Section 4. Further, our proposed method (with noise filtering and sampling technique) is discussed in Section 5 in detail. Later, experiments or simulation results have been discussed in Section 6 with several parameters like AUC, and F-Measure. Finally, Section 7 concludes this paper with some future enhancement (in brief).
Related work
Existing approaches (for dealing with class imbalanced problem) can be roughly categorized into algorithm level approaches and data level approaches. The former directly modifies the traditional algorithms to achieve cost sensitivity by taking different misclassification costs into consideration. The algorithms are designed such that the misclassification cost of positive examples is higher than that of negative ones. The goal of a classifier is to minimize the cost instead of classification error, and therefore the classification algorithms will bias towards the small class. At the data level, a data pre-processing step is added to rebalance the class distribution by undersampling the negative class, oversampling the positive class, or creating synthetic positive examples. Wang et al. [4] proposed an online cost-sensitive ensemble learning framework for their online version. They generalized a batch of widely used cost sensitive learning like bagging and boosting. The performance of online bagging and boosting cost-sensitive ensemble learning are determined largely by their batch mode consistency and also the batch ensemble algorithm performance. The results show an outstanding performance by bagging based algorithms both in terms of accuracy and consistency. The high comparable performance was achieved by AdaC2 and CSB2 on the other hand worse performance was achieved by RUSBoost and SMOTEBoost algorithms. To use the ensemble pruning methodology (in the context of imbalanced classification) or for improving the behavior, we used ensemble-based solutions in this work. The author developed a novel ordering-based pruning metrics to address the class imbalance problem [23]. The five most popular ordering-based pruning techniques are: Reduce-Error pruning with Geometric Mean (RE-GM), Kappa pruning (Kappa), Complementarity Measure (Comp), Margin Distance Minimization for imbalanced problems (MDM-Imb), Boosting-Based pruning for imbalanced problems (BB-Imb) have been adapted. The performance of Under-Bagging with RE-GM and Roughly-Based Bagging with BBImb pruning approaches are best among others. A novel ensemble method, called Bagging of Extrapolation Borderline-SMOTE SVM (BEBS), has been proposed in dealing with Imbalanced Data Learning (IDL) problems [30]. The BEBS framework employed an adaptive sampling method called Extrapolation Borderline-SMOTE and bootstrapping aggregation by taking the boundary information derived from the initial SVM and bagging mechanism. It contributes to the relief of overfitting and promotes the capability of models generalization. Learning from imbalanced data is still one of challenging tasks in machine learning and data mining.
The paper [30] discusses the different data difficulty factors which deteriorate classification performance for an imbalanced dataset. The general problems in class imbalance are decomposition of the minority class into rare sub-concepts, overlapping of classes and distinguishing different types of examples. Stefanowski [17] presented new experiment which shows the influence of these factors on classifiers. They also include critical discussions of methods for their identification in real world data. The author [32] proposed an effective Cost-Sensitive Classifier with GentleBoost Ensemble (Can-CSC-GBE) for the classification of breast cancer. The author [10] proposed Binary Particle Swarm Optimization (BPSO)-Adaptive BoostingK Nearest Neighbour (BPSO-Adaboost-KNN) ensemble learning algorithm for addressing the class imbalance problem for multi-class datasets. The BPSO are applied for selecting the important features and then Adaboost-KNN classifier is used to train the model. The performance is measure using AUC. The author [35] proposed an effective ensemble learning framework called adaptive Ensemble Under-Sampling (EUS). They applied Adaboost technique as individual classifier to train the EUS by changing the data distribution and acquiring balanced subsets. By using Real Adaboost they observed an improvement in the accuracy. The output by these classifiers is aggregated by a weighted voting system that is based on the error rate of each individual classifier. Finally, they proposed an adaptive threshold selection method based on OTSU [28] algorithm to find the optimal threshold for the final decision. The authors [5] mainly focused on four types of ensemble solutions such as bagging-based, boosting-based, random-forest-based and hybrid ensemble for customer relationship management churn prediction. They compared the solutions using AUC as general evaluation metric and Expected Maximum Profit (EMP) for domain specific from the perspective of costs and benefits. The original Bagging and random forest learning algorithms performed well with respect to the profit-based measure. Farid et al. [8] proposed multi class imbalance method based on clustering. They trained the classifiers on genomic data. The genomic data is considered noisy, high dimensional, and also with small sample size.
Initially, imbalanced data is divided into majority and minority clusters. The majority class in turn grouped into several clusters. Then, they find the most informative instances in each cluster by combining the instances of minority classes. Finally, multiple classifiers are used to train the different groups. C4.5 decision tree algorithm has been used as base classifier. Recently, some researchers have evidenced that not all the samples are valuable and donated to a classifiers learning [19]. Some samples may be redundant and tend to increase the computational cost. Some may even worsen a classifiers performance, which should be treated as noises and need to be removed/cleaned in both majority and minority classes. However, to the best of our knowledge, there is not much work available to verify the influence of noise (available in both, i.e., in the minority/majority class). Thus, we intend to propose a framework to deal with the noisy examples in both minority and majority classes via a noise filter combined with over-sampling. Note that in this work, we focus only on binary classification problems. This represents the first attempt to combine the noise filter with re-sampling methods. In order to verify the efficiency, we choose six popular sampling methods with ensemble classifiers, i.e., AdaBoost, RUSBoost, SMOTEBoost, Bagging, OverBagging and SMOTEBagging to implement the proposed framework with a K-Nearest Neighbor (KNN)-based noise filter. We design several experiments to test our proposed method with collected datasets (from KEEL Machine Learning Repository). In last, the propose framework is compared with the two metrics, i.e., Area Under the Curve (AUC) and F-measure. Hence, this section discusses about related work for handling class imbalance problem at data level. Now, next section will deal with different ensemble techniques to handle class imbalance problem.
Motivation
In the past decade, machine learning techniques have been used for solving several problems with respect to big data or class imbalance problem. In machine learning, decision making process or an output matter a lot to people or human-beings. Based on such output, further decision is made/taken for next/further process. But, when this accuracy or results (of collected datasets) differs based on a size or features of dataset, then it may create a serious problem to validity and originality of data/decision. So, to provide validity a data, we need to trained more minority sample than majority samples. For example, if a patient received false information based on a false result/inaccurate result or less features/data-sets, then it is a serious problem in e-healthcare application. We need to provide exact or accurate information to patients using appropriate tools/or efficient methods (based on analyzing collected data (of patients)). Hence, with keeping accuracy in our mind, we try to solve this problem of class imbalance using boosting and bagging techniques; with and without noise filtering method.
Ensemble techniques to handle class imbalance problem
As discussed, the ensemble methods are used to handle class imbalance problems. In [16, 24], the author proven that ensembles of classifiers will yield better performance/accuracy and are robust at handling the datasets that are imbalanced in nature. However, ensemble techniques with combination of either pre-processing or cost-sensitive approaches lead to promising results. The pre-processing techniques are embedded in to an ensemble learning algorithm [36, 7, 33]. The cost sensitive ensemble techniques are similar with that of cost-sensitive approaches. These techniques apply different misclassification cost for different classes using boosting algorithms. Apart, the most popular techniques used in the literature is ensemble methods combined with pre-processing techniques. In [22], author classified ensemble methods into bagging, boosting and hybrid-based approaches. These approaches adopted data-level techniques, such as undersampling and oversampling approaches to balance the data before training it with the base classifiers. The combination of data level techniques with ensemble algorithms (Bagging and Boosting) resulted in better performance [22, 12, 13]. The some of the ensemble methods used in this paper are discussed below.
SMOTEBoost [27]: It is an oversampling method based on Synthetic Minority Oversampling Technique (SMOTE). SMOTE uses K-Nearest Neighbour (K-NN) to generate the synthetic samples of the minority class. SMOTEBoost adopts SMOTE with Boosting technique. At each iteration, the newly generated samples using SMOTE are used to train the boosting algorithm. The newly generated synthetic samples are assigned weights which are proportional to the total number of overall samples and the weights of the other samples (original samples) are normalized. During the entire process, the weights of the samples are updated according to the Adaboost.M2 algorithm. RUSBoost [7]: It is similar to SMOTEBoost, but it adopts a random undersampling technique to remove the samples from the majority class in each iteration. Thus, it will not generate new samples, but it is enough to normalizing the weights of the samples using Adaboost.M2 algorithm. Underbagging [31]: It uses undersampling method applied to majority class samples. In each iteration, the majority samples are reduced randomly to that of the minority class and the base classifier are trained on this balanced dataset. OverBagging [33]: It is similar to random oversampling method applied to minority class. In each iteration, the oversampling process is applied to increase the minority samples to that of the majority class and the base classifier are trained on this balanced dataset. SMOTEBagging [33]: It is a combination of SMOTE with bagging ensemble algorithm. At each iteration, the method generates samples that has the two times the number of majority samples, wherein half of the samples are randomly generated with replacement from majority class and the remaining half is generated through SMOTE and Random Over-Sampling (ROS) on the minority class.
Hence, this section discusses about different ensemble algorithms for handling class imbalance problem at data level. Now, next section will deal with proposed data level framework for class imbalance problem.
The two common problems in the data quality are existence of noise and class imbalance which degrade the performance of the classifiers. For overcoming the noise, a pre-processing technique called noise filtering is used. Noise filtering detect the noise existing in the data and removes it. Noise basically present in most the real world data [37] and can degrade the system performance in terms of classification accuracy, time in building a classifier and the size of the classifier. Sáez et al. [15] proposed Iterative-Partitioning Filter (IPF) using oversampling algorithm called, SMOTE-IPF. This technique is used to pre-process the data before training it on to the classifier. They divided the training dataset into n subsets and used a set of n base classifiers to train it independently. To the best of our knowledge, existing noise filters in the literature are always combined with under sampling, over-sampling techniques or only deal with the noisy examples in the majority class. No noise filtering attempt focuses on entire dataset using ensemble approach in the process of solving class imbalance problem. Can such challenge boost a classifiers performance? Answering this question, this work proposes a Noise-Filtered Over-Sampling technique with Boosting (NF-OS with Boosting) and Bagging (NF-OS with Bagging) techniques, as shown in Fig. 1. In this work, we consider both boosting and bagging ensemble techniques with and without applying NF-OS noise filtering. NF-OS with boosting and NF-OS with bagging are based on the combination of noise filtering with sampling and ensemble (Adaboost, Bagging) algorithm. It is similar to RUSBoost, SMOTEBoost, SMOTEBagging with the critical difference with removal of noise occurring in the datasets. SMOTEBoost uses SMOTE method to oversample the minority class examples, RUSBoost uses random under-sampling on the majority class while SMOTEBagging uses SMOTE method to oversample the minority class. In comparison, our proposed NF-OS uses noise filtering with sampling from the majority class. Considering a given dataset D, I. We define subsets Smaj
A Noise-filtered Over-Sampling Technique with Boosting (NF-OS with Boosting).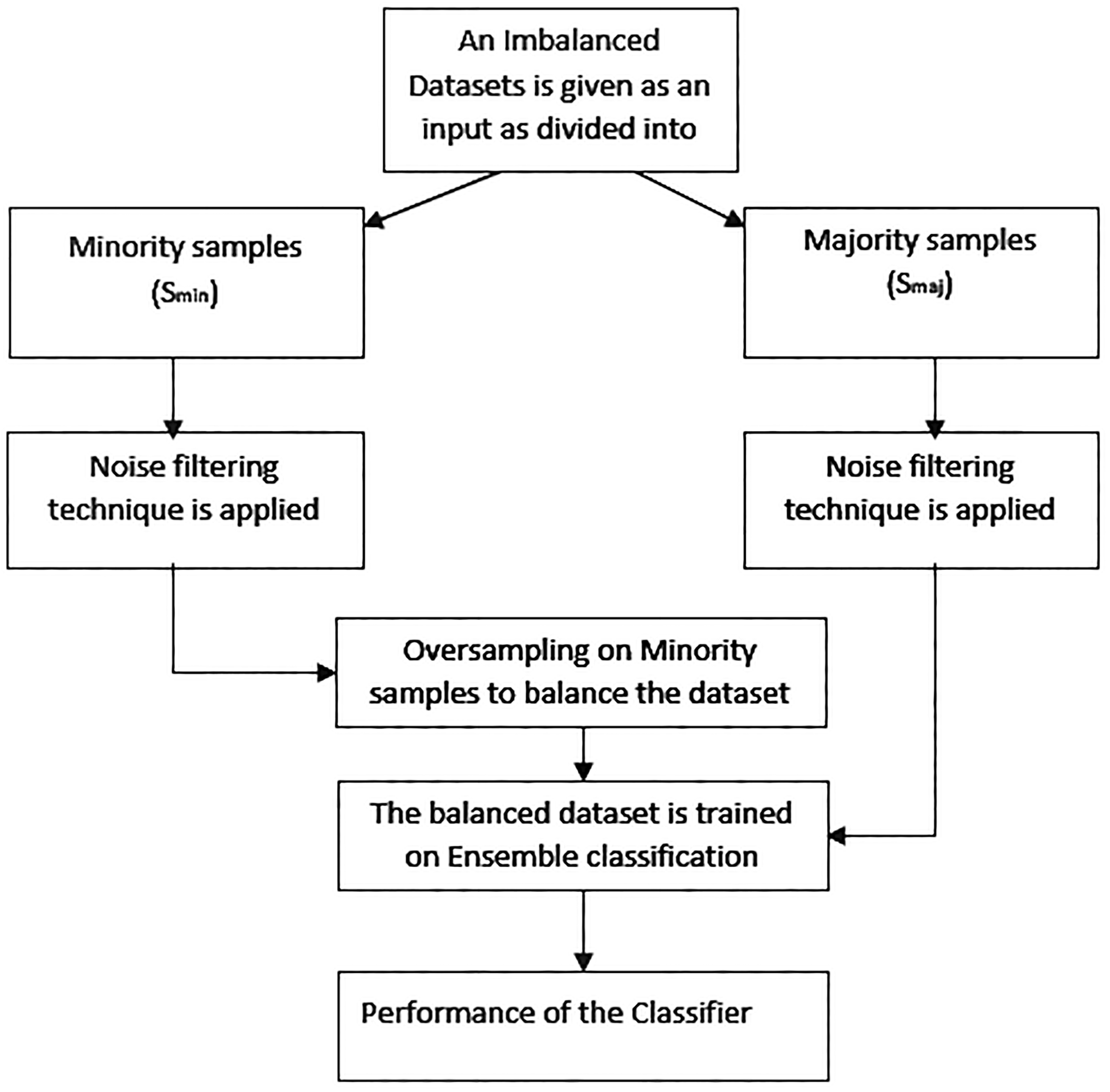
In this work, each sample falls into any of the six categories based on nearest neighbours.
Extremely useful majority sample: All the K-NN are majority class label (labelled as ‘A’ in the Fig. 2). Extremely useful minority sample: All the K-NN are minority class label (labelled as ‘a’ in the Fig. 2). Relatively useful majority sample: Most of the K-NN samples belong to majority class label (labelled as ‘B’ in the Fig. 2). Relatively useful minority sample: Most of the K-NN samples belong to minority class label (labelled as ‘b’ in the Fig. 2). Noisy sample: All the K-NN belongs to different class label (both for majority and minority samples) (labelled as ‘C’ and ‘c’ in the Fig. 2).
Six categories of samples. ‘*’ represents minority data. ‘o’ represents majority data.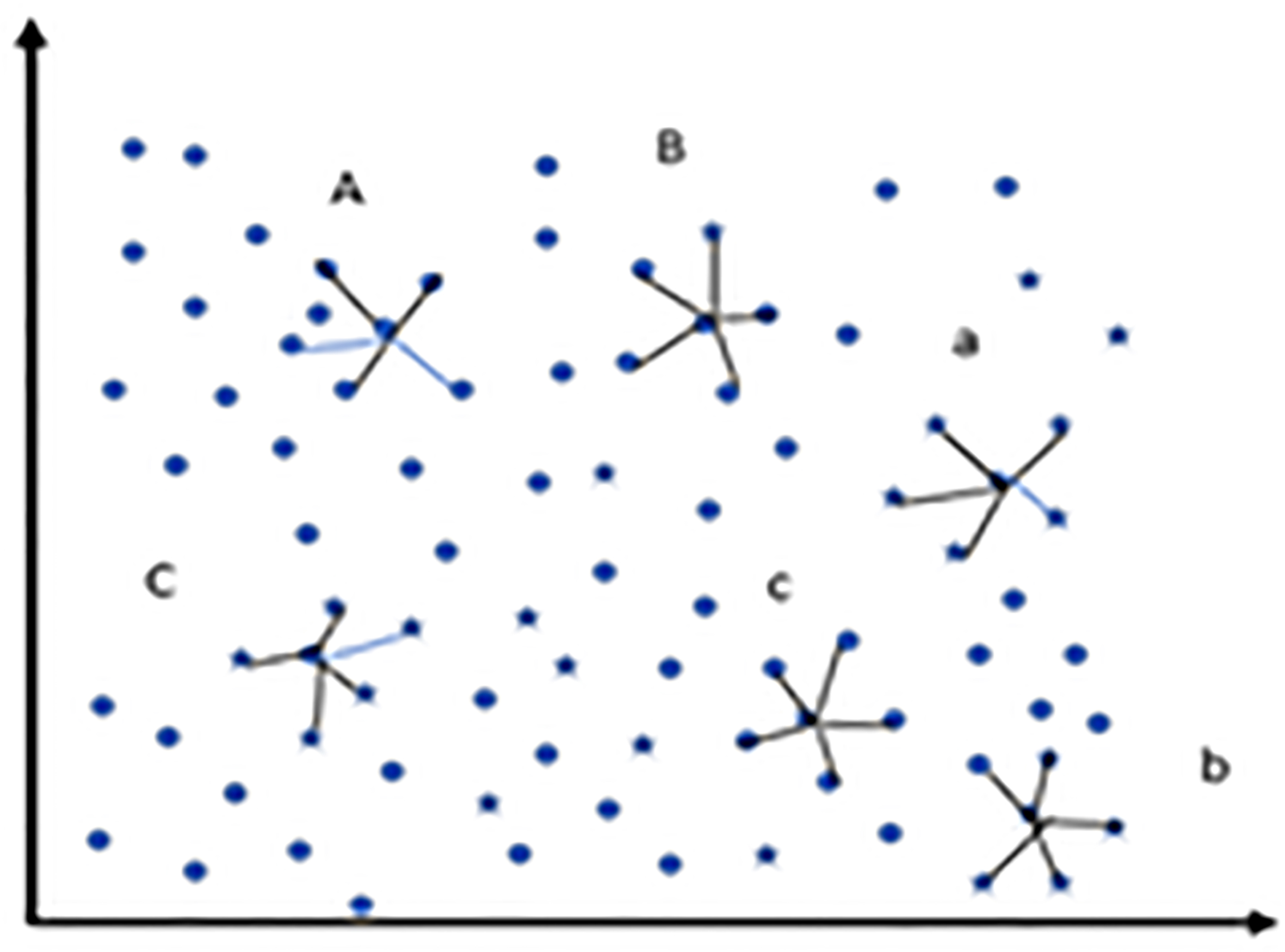
In this work, ‘noisy samples’ are identified using K-NN algorithm. Note that the choice of K will be highly influenced to find whether a sample is a noise or not. If K is too small then a sample can be classified as a noise and if K is too large then it is considered as a useful one. The best value of K is this work is considered as 5. The strength of our approach lies in the fact that it considers examples after removal of noise in the entire dataset. After, NF-OS applies SMOTE technique to oversampling the minority samples in order to balance the imbalanced dataset. Once the dataset is balanced, classification is done using Boosting and Bagging method. Note that, the Boosting algorithm considers a series of decision trees using C4.5 algorithm and combines the votes of each individual tree to classify new sample, whereas Bagging creates individual classifiers for its ensemble by training each classifier on a random redistribution of the training set. Each classifier’s training set is generated by randomly drawing, with replacement. Hence, this section discusses the proposed framework for handling class imbalance problem at data level. Now, next section will deal with the simulation and result for the proposed framework.
This section presents a series of experiments conducted to test the performance of our proposed method, pre-processing using noise filtering based ensemble learning for imbalanced datasets. We have selected 25 imbalanced binary datasets from the KEEL repository [14]. We analyse the performance of our proposed method with RUSBoost, AdaBoost, SMOTEBoost, Bagging, OverBagging and SMOTEBagging. Here first, we present the different evaluation metrics, benchmark datasets used and experimental settings for class imbalanced learning. Then, we show the results in form of two performance metrics for imbalanced learning, i.e., the AUC and F-measure.
Confusion matrix
Confusion matrix
Data-set used
In our experiment work, we tested the proposed scheme on 25 benchmark datasets shown in Table 2. For every dataset, we used C4.5 decision tree algorithms as a base learner in boosting and bagging. Here, each experiment is done with 20 independent runs with 10-fold cross validation and acquires the average results in terms of AUC and F-measure, respectively.
AUC-ROC curve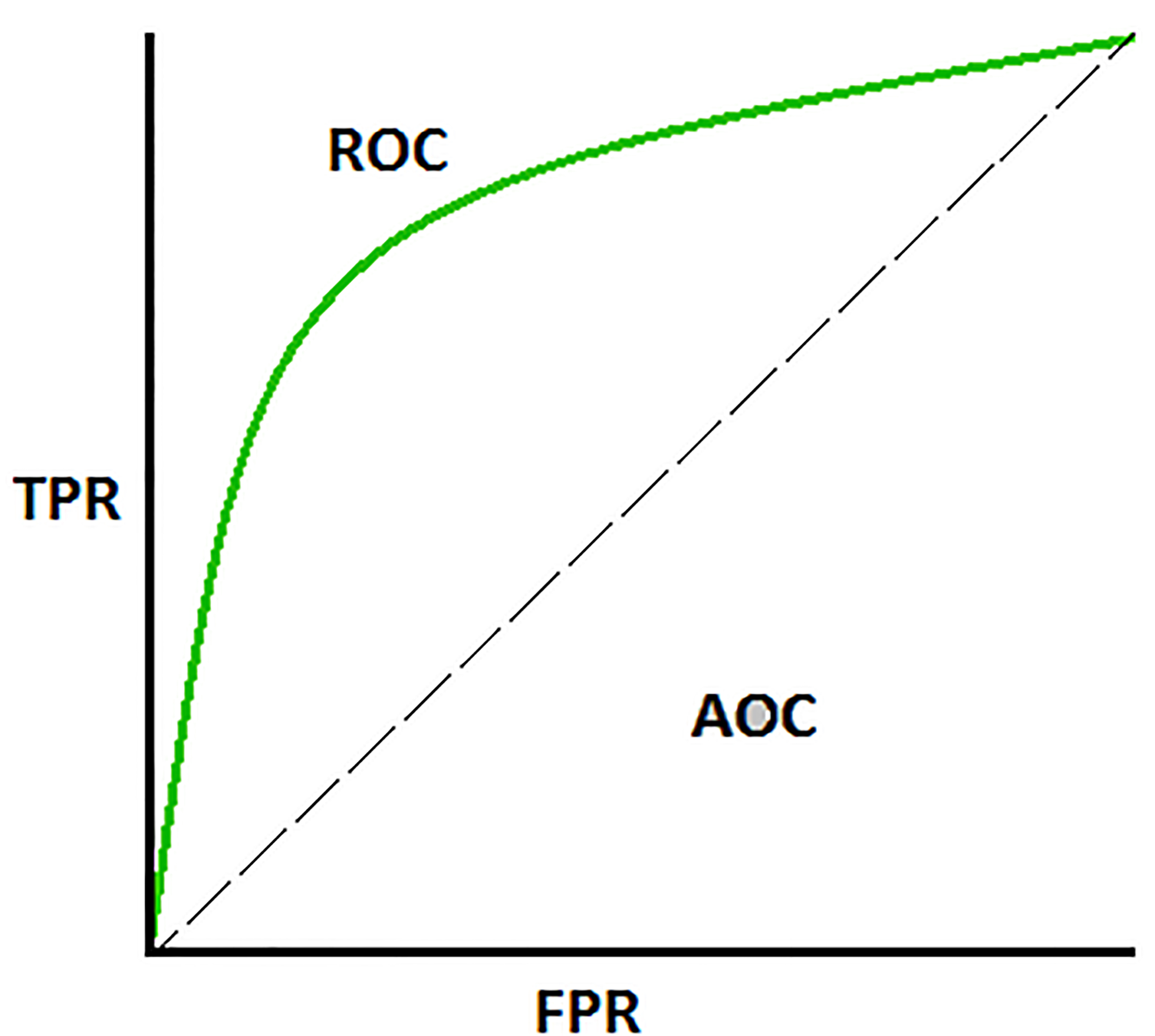
To evaluate the performance of the classifier, the way it has been evaluated play an important role. We have to use specific evaluation metrics based on the distribution of the data. Traditionally, the common metric used for evaluating the performance of balanced classification algorithms is the accuracy of the classifier. It is defined as ‘ratio of number of correctly classified samples to the total number of samples’.
However, it is not appropriate for imbalanced data sets. For example, there is a binary-class imbalanced problem with an imbalanced rate of 99:1, with 99 majority samples and only 1 minority one. The goal of traditional learning algorithm is to minimize the error rate and for imbalanced data set with 99:1 rate, which may simply group all the samples into the majority class and thus attains 99% accuracy. So, these learning algorithms are not a good approach to this problem. Since the only minority sample to which we should pay more attention is incorrectly classified. For this reason, different methods must be defined and used to validate the algorithms for handling class imbalance problems appropriately. In this paper, we study the two-class problems, in which the minority class is considered to be the positive class. Hence, the confusion matrix of a two-class problem shows the results of correctly and incorrectly classified samples of each class [6], as shown in Table 1.
In the literature, Receiver Operating Characteristics (ROC) curve evaluation metric has been proposed by many researchers for class imbalance problem. ROC makes use of the proportion of True Positive Rate (TPR) and False Positive Rate (FPR) (refer to Eqs (2) and (3)).
The ROC graph is formed by plotting TPR over FPR as shown in Fig. 3, and any point in ROC space corresponds to the performance of a single classifier on a given distribution. The ROC curve is useful because it provides a visual representation of the relative trade-offs between the benefits (represented by true positives) and costs (represented by false positives) of classification with respect to data distributions [29]. Here, AUC is defined as the area under the ROC curve, which has been proved to be a reliable evaluation criterion and used as a metric to measure the efficiency against imbalanced classification problems. Two other important evaluation metrics [6] for imbalanced classification problems are defined as follows:
Where precision is defined as TP by TP and FP and recall is defined as TP by TP and FN. Note that TPR and FPR has been discussed in detail in [9, 34].
Classification performance of Boosting algorithms using AUC metric
Classification performance of Boosting algorithm using F-measure metric
Classification performance of Bagging algorithm using AUC metric
In this work, we test the proposed method on 25 benchmark datasets from KEEL-dataset repository with different imbalance ratio shown in Table 2.
Classification performance of Bagging algorithm using F-measure metric
Classification performance of Bagging algorithm using F-measure metric
AUC graph for NF-OS with Boosting and Bagging.
F-measure graph for NF-OS with Boosting and Bagging.
This section discusses the results of the proposed metric in terms of AUC and F-measure.
AUC as a metric
Here, Table 3 shows the classification performance in terms of AUC obtained using different classification techniques using Boosting. As indicated by the results, the proposed NF-OS with boosting demonstrated the best performance on 17 out of 25 datasets in terms of AUC for almost many datasets. Similarly, Table 5 shows the classification performance with respect to Bagging. The AUC results show a better performance for 14 datasets out of 25. The Fig. 4 presents the AUC results of both Boosting and Bagging in the graph representation.
F-measure as a metric
Here, Table 4 shows the classification performance in terms of F-measure obtained using different classification techniques using Boosting. As indicated by the results, the proposed NF-OS with boosting demonstrated the best performance on 16 out of 25 datasets in terms of F-measure for almost many datasets. Similarly, Table 6 shows the classification performance with respect to Bagging. The F-measure results better for 12 datasets out of 25. The Fig. 5 presents the F-Measure results with Boosting and Bagging in the graph representation.
All these experiments were tested on the Weka [25]. These ensemble algorithms are combined with oversampling techniques. One group includes oversampling with bagging (Bagging, OverBag, SMOTEBag) and another group includes both undersampling and oversampling with boosting (AdaBoost, RUSBoost, SMOTEBoost). We compared the results with our proposed methods with NF-OS Bagging and NF-OS Boosting. The results reveal that application of noise filtering with ensemble learning to imbalanced data will improve the performance of the classifiers. We also observed that on noisy data bagging technique outperformed than boosting. Hence, this section discussed several simulation results with several parameters like AUC, F-Measure, etc., and provides efficient and scalable results for class imbalance problems. Now next section will conclude this work with some future enhancements in brief.
Conclusion and future work
Due to generating a lot of data virtually or online, balancing this huge data or analysing this data have raised several problems. In literature, we have discussed that no major work has been done with respect to/overcome this problem. Hence, this work presents a novel approach for removing noise from the datasets using Noise Filtering (NF) and also to deal with an imbalanced (classification) problem by performing SMOTE after NF. Hence in this work, before training a classifier, NF first filter the noisy samples from the original dataset using K-NN technique, and then use the new minority and majority dataset to train a classifier. The simulation results (using Weka tool) over 25 datasets shows outperform of NF-OS with Boosting and bagging on AUC and F-measure. Also, this work provides comparison among AdaBoost, RUSBoost, SMOTEBoost, Bagging, OverBagging, and SMOTEBagging techniques, which produces the best results. Further for future work, we can extend this/our work with several real world problems like balancing the Facebook data/twitter data, Google searched/communicated data, etc. So, all the researchers, who are working in/related to this problem/area are kindly invited to do their research in this area.
Footnotes
Acknowledgments
This research work is funded by the Koneru Lakshmaiah Education Foundation, Lingaya’s Vidyapeeth and Anumit Academy’s Research and Innovation Network (AARIN), India. The authors would like to thank Koneru Lakshmaiah Education Foundation, Lingaya’s Vidyapeeth and AARIN, India, an education foundation body and a research network for supporting the project through its financial assistance.
Conflict of interest
The authors have used reference number 9 and 34 as self-citation of their (his/her) work. No author has an objection of citing their work.