
Abstract
Class imbalance problem (CIP) exists when the class distribution is not uniform. Many real-world scenarios face CIP which attracted the researcher’s attention to this problem. Training machine learning (ML) models with class imbalanced datasets is a challenging problem. Ensemble methods in ML involve training multiple classifiers, combining or averaging their predictions to come to a final prediction. Specifically designed ensemble-based methods can overcome the difficulty faced by traditional classifiers and can handle the CIP. The performance of 19 ensemble methods for 44 unbalanced datasets is assessed in this paper in order to observe the effects of the class imbalance ratio (CIR). For performance evaluation, we divide these datasets into three categories, i.e., Slightly Imbalance (SI), Moderately Imbalance (MI) and Highly Imbalance (HI) based on CIR. With the proposed perspective, we observe that different ensemble methods perform well in different categories suggesting that the percentage of minority or majority class could be a criterion for the selection of ensemble methods for class imbalance datasets. Moreover, visual representations and different non-parametric statistical tests are also used to have more reliable results.
Introduction
Machine learning (ML) uses various algorithms to extract information from a huge amount of raw data. These ML algorithms have been applied in different domains. Most learning algorithms usually assume that training datasets are balanced [1]. However, many real-world applications frequently experience imbalance dataset, which shows up when one class’s proportion is higher than that of the other class. The class having a larger number of samples is called the majority class and the one having a smaller number of samples is called the minority class [2]. However, most ML algorithm learning procedure is guided by evaluation criteria that can result in relegating the minority class and becoming biased towards the majority class. This problem is popularly referred to as the Class Imbalance Problem (CIP). It makes classifier learning from imbalanced datasets a challenging task [3]. This situation is significant since it can be seen in many real-world domains like fault diagnosis [4], anomaly detection [5] etc.
Several approaches have been reported in the literature to address the issue of CIP. These approaches are grouped into 3 categories: Data level (DL), Algorithm level (AL) and Hybrid level (HL) [2, 6]. The DL approaches are considered to be external approaches. In this, either instances of the over-represented class are under-sampled or the instances of the under-represented class are over-sampled to balance the dataset. This prevents ML classifiers from getting biased towards the majority class. However, data level approaches may lead to overfitting due to random over-sampling or may cause loss of information in under-sampling. Then there are AL approaches that are considered to be internal approaches. Classification algorithms are either modified or new algorithms are developed under this category. However, AL approaches require in-depth knowledge and understanding of the algorithm. Lastly comes the HL approaches that take advantage of both the DL and AL approaches. Cost-sensitive approaches and ensemble methods come under this category [3, 6]. Cost-sensitive approaches assign weights to each instance in the dataset, and these weights are updated based on the classifier’s performance. Weights represent the probability of an instance getting selected for the classifier’s training in the next iteration. Ensemble approach involves training different classifiers (base classifiers) and combining their predictions to come to a final hypothesis as shown in Fig. 1. Ensemble methods improve the overall performance by handling the overfitting issue and reducing the variance of the model. Each classifier utilizes different training data set to minimize bias.
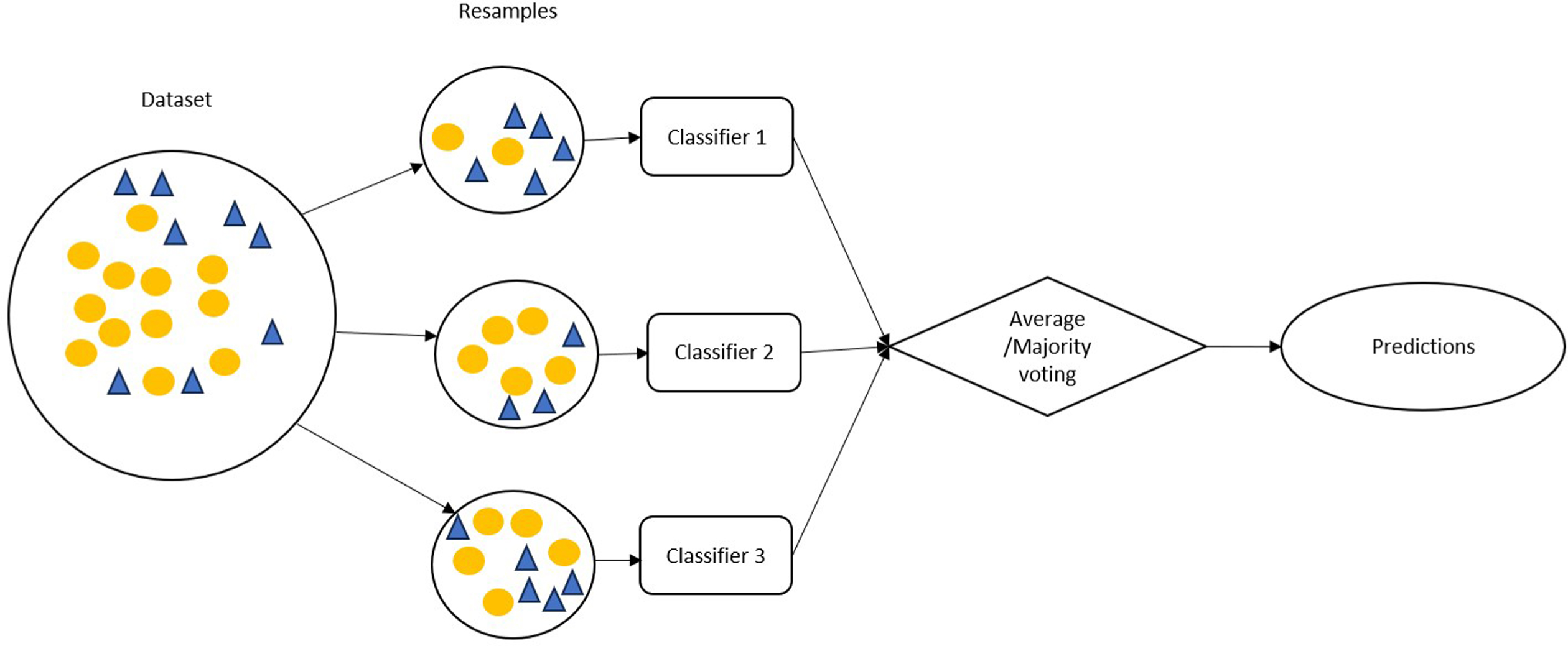
An ensemble approach.
In the recent years, many researchers have provided the comparative studies using state-of-the-art techniques with Imbalanced datasets.
Wongvorachan et al. in 2023 [7] compared a variety of sampling methods in a dataset to address the different ratios of the CIP. The authors used Random Forest for evaluating the performance of each sampling method. The findings indicated that hybrid resampling for Highly imbalanced data and random oversampling for moderately imbalanced data appeared to work well. Jiang et al. in 2023 [8] proposed a new taxonomy for imbalanced data learning approaches and performed comparison of traditional approaches and Generative adversarial networks. But as reported by the researchers, the study has few limitations such as more datasets were not explored and upcoming techniques such as transfer learning etc., were not taken into consideration. Singh et al. in 2022 [9] have contrasted the effectiveness of class balancing techniques and classification algorithms on a single dataset. The authors observed that ensemble classification models like AdaBoost, XGBoost, and Random Forest performed well when oversampling was followed by under-sampling.
In the literature, there are multiple studies which provide the comparison of the ensemble-based methods which have been used for the CIP [3, 6]. Here, the researchers have put these methods into 3 categories: Boosting-based, Bagging-based and Hybrid methods.
The performance of these methods was compared on different datasets according to the category of the ensemble methods.
Contrary to previous studies, our study aims to analyze the impact of CIR on the performance of the ensemble methods using new perspective of dataset categorization (discussed in Section 4) as Slightly, Moderately and Highly Imbalance datasets. CIR measures the degree of imbalance in a dataset [6]. It is the ratio of the majority class size to the minority class size. Methods may perform well with low CIR datasets and may fail for the datasets with high CIR.
To address this research gap, we design the experimental framework with 19 ensemble methods using 44 imbalanced datasets. Out of these 19 ensemble methods, 10 are Boosting based, 7 are Bagging based, whereas the remaining 2 are Hybrid methods.
The key contributions of this study are as follows: We propose a new perspective for the performance evaluation of ensemble methods using dataset categorization. The 44 imbalanced datasets used in this study have been categorized as Slightly Imbalance, Moderately Imbalance and Highly Imbalance datasets depending on the CIR. Figure 2. shows the visual representation of these categories, including balanced dataset. Methods are evaluated using Area Under the curve (AUC) to analyze their performance category-wise. Finally, different non-parametric statistical tests as employed in the literature [3, 6] are employed for the comparison of ensemble methods. For Slightly and Moderately imbalance datasets, Over-sampling and under-sampling approaches perform considerably well, although Under-sampling performed better for Highly imbalanced datasets. For Slightly imbalance datasets, UnderBagging performs better, whereas SmoteBagging outperforms the other methods for Moderately imbalance datasets. RUSBoost had the best performance for Highly imbalance datasets. It is observed that EUSBoost method takes more model learning time in comparison with other methods whereas there are no significant differences noticed in the model learning time for others.
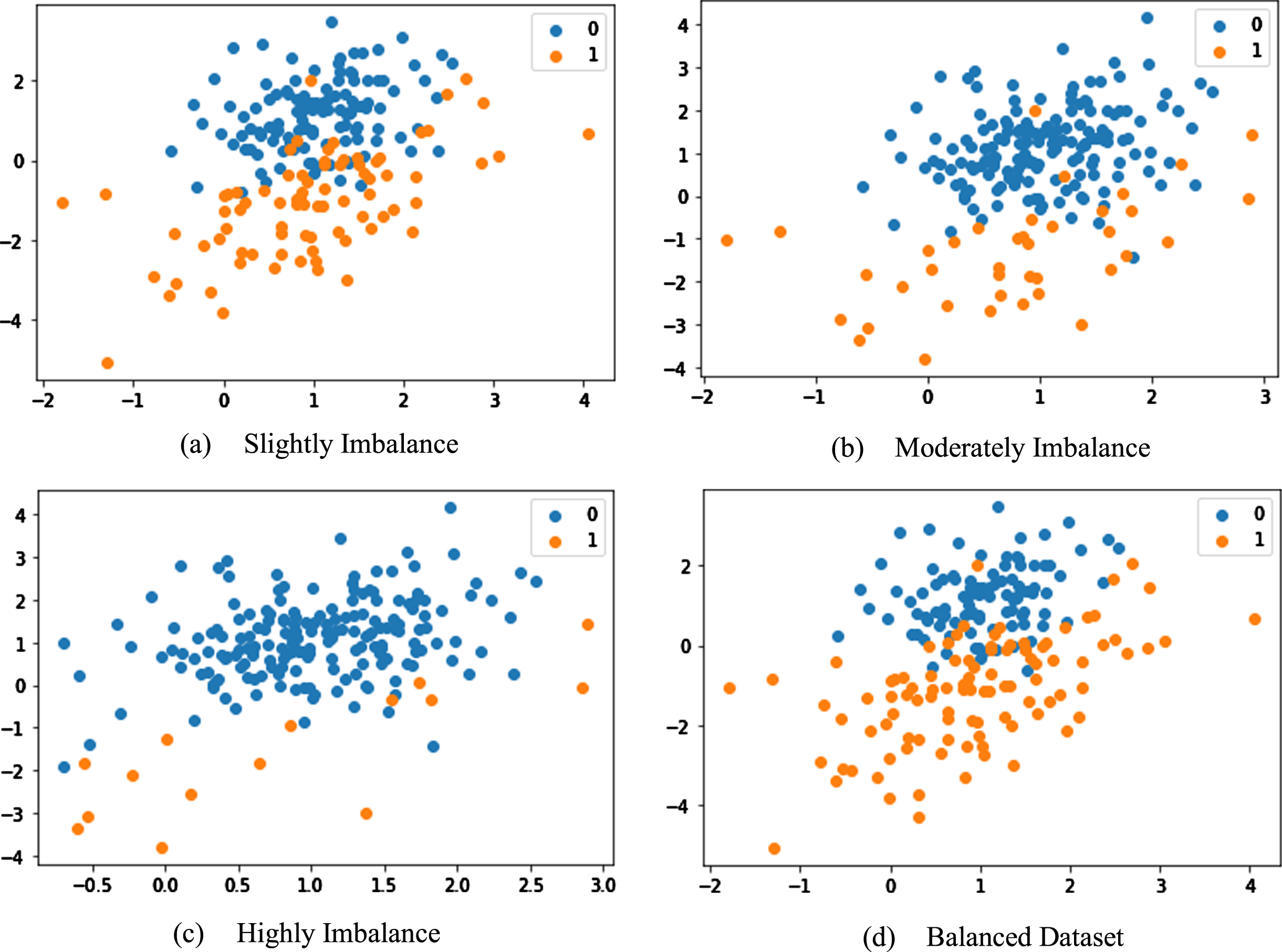
Datasets with different degrees of imbalance data.
In several application fields such as sentimental analysis, medical diagnosis, credit card fault detection, etc., imbalance data is a serious issue that impairs the model’s performance. Overall, this study provides a novel viewpoint to researchers and practitioners to consider the CIR for the best imbalance classification model.
The organization of the paper is as follows: Section 2 describes the state of the art of different ensemble methods used. Section 3 discusses the performance metric used for performance evaluation measures and Section 4 presents the dataset properties. Section 5 depicts the Experimental setup and results and Section 6 concludes the paper.
This section discusses the ensemble-based methods to handle the CIP. An ensemble approach [10–15] tries to increase the performance of single classifiers by inducing and combining numerous classifiers to create a new classifier that outperforms them all. As a result, the primary concept is to build numerous classifiers and combine their predictions when unknown cases are provided. Figure 3 shows the ensemble methods reviewed in the paper.
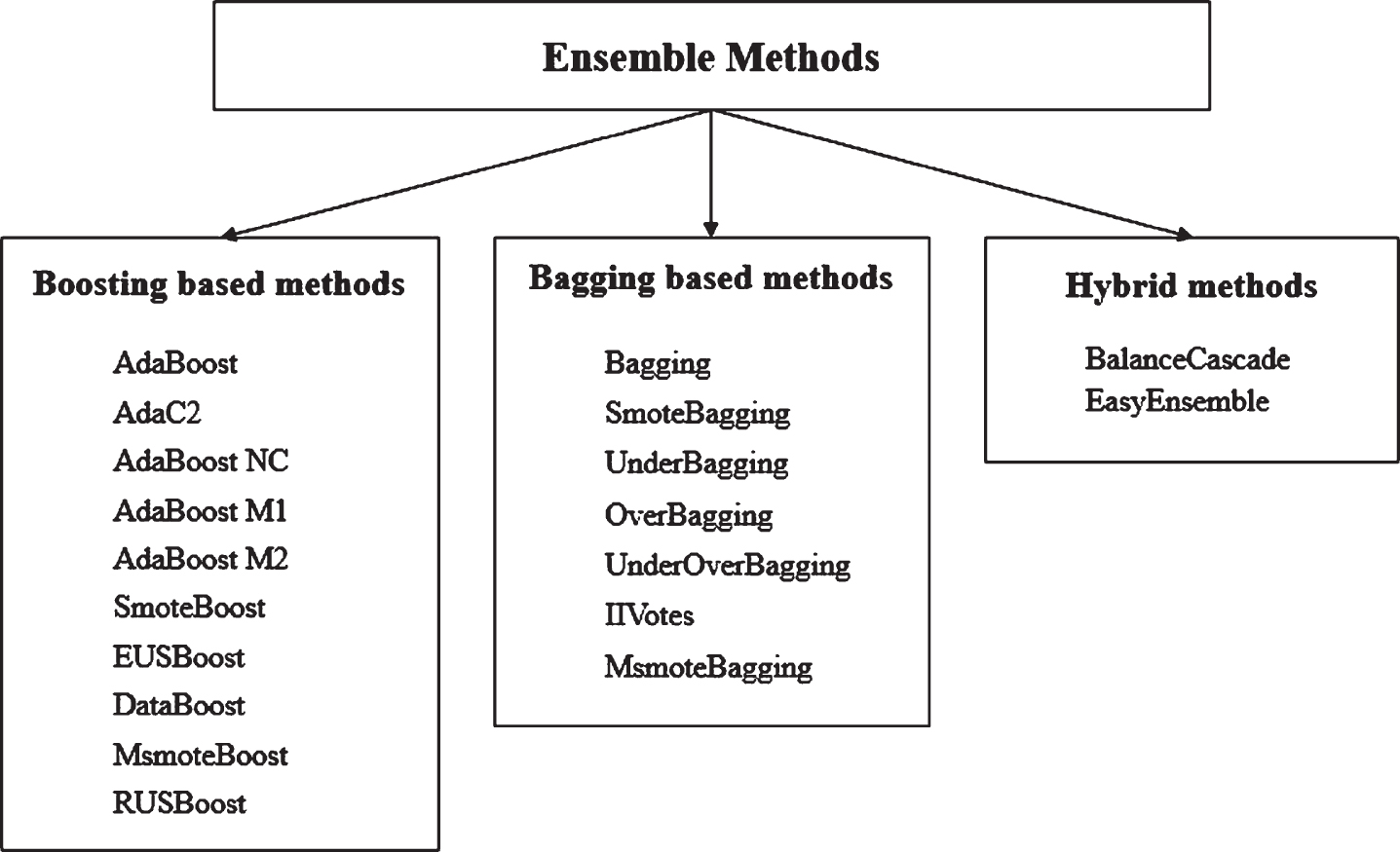
Ensemble methods used to handle CIP.
Boosting aims to model the weak learner into a strong learner by increasing the accuracy of their prediction. Boosting involves training numerous weak classifiers successively, with the misclassified cases being selected by the next classifier after each iteration and so on. The process continues until the required accuracy is obtained or a certain number of classifiers are employed.
Several approaches have been proposed in the literature and as discussed below.
AdaBoost (1997)
Freund and Schapire [16] proposed Adaptive boosting algorithm.
All the instances are assigned with equal weights and the entire dataset is used to train the classifiers sequentially. After every iteration, the next classifier is more focused on the instances that are hard to classify. The AdaBoost algorithm selects the class label for the unseen instance on a majority basis. Eventually, each weak classifier learns and the overall accuracy is improved [17–19].
AdaBoost NC (2010)
AdaBoost NC, a variation of AdaBoost proposed by S. Wang et al. [20] is a negative correlation learning algorithm for classification ensembles. Unlike AdaBoost, AdaBoost NC uses the penalty term to improve diversity. AdaBoost NC attempts to handle the overfitting issue reported in AdaBoost and thus has better generalization ability. Moreover, in AdaBoost NC, the information exchange is better than in AdaBoost which results in lower computation time.
AdaC2 (2007)
AdaC2 was proposed by Sun et al. [21] as a variation of AdaBoost which represents the different identification importance by introducing cost items. AdaC2 is able to differentiate between different types of samples and ensures that the learning is biased towards the minority class.
AdaBoost M1 and AdaBoost M2
These two algorithms are the extension of the AdaBoost algorithm. Unlike AdaBoost, these two are for multiclass problems [16, 22] and are different in terms of weight update calculation.
SmoteBoost (2003)
SmoteBoost [23] was proposed by Chawla and Hall which combines the smote preprocessing technique with the boosting method to handle the class imbalance problem. However, SmoteBoost takes more model learning time for preprocessing and may create synthetic data points around the noise instances.
Databoost-IM (2004)
Databoost-IM was proposed by Hongyu Guo and Herna L Viktor [24] which combines boosting with data generation to increase classifier prediction capability and address the problem of class imbalance. However, DataBoost-IM takes significantly more model learning time as compared to AdaBoost.
MsmoteBoost (2009)
MsmoteBoost was proposed by Hu et al. [25] as an improvement to Smote algorithm. MsmoteBoost combines Msmote and Adaboost to handle the class imbalance problem. Unlike Smote algorithm, Msmote also considers the latent noises and recognizes the minority class better than Smote algorithm. However, the Msmote algorithm does not consider the differences in important features.
RUSBoost (2009)
The random under-sampling boosting method [26] was proposed by Seiffert et al. is a variation of the SmoteBoost algorithm. RUSBoost combines random under-sampling with boosting. Unlike SmoteBoost, RUSBoost is faster and simpler. However, RUSBoost does not employ an intelligent method for under-sampling and thus, it may lead to the loss of potential information.
EUSBoost (2013)
Evolutionary under-sampling boosting [27] was proposed by Galer as a variation of the RUSBoost algorithm. Unlike RUSBoost, EUSBoost performs evolutionary under-sampling and obtains the best subset which cannot be further improved for each boosting iteration. Thus, EUSBoost improves the predictive accuracy. However, EUSBoost takes more model learning time than other ensembles.
Ensemble using Bagging
Bagging (1996)
The algorithm proposed by Breiman [28] is also known as Bootstrap aggregating. In this algorithm, several classifiers work parallelly with diverse subsets of the original dataset [29, 30]. It helps to overcome the issues of overfitting and improves the accuracy of the classifier [20–22].
Underbagging
The UnderBagging algorithm combines the under-sampling technique with bagging [31]. In UnderBagging, the number of instances drawn will depend on the re-sampling rate, i.e., a. Its value ranges from 10 to 100. In each subset, the majority class instances are undersampled.
Overbagging
The OverBagging algorithm combines the over-sampling technique with bagging [31]. In OverBagging, a = 100, which leads to drawing all the instances from the majority class, and oversampling will be done to the minority class instances.
UnderOverbagging (UOB)
The UnderOverBagging algorithm uses the hybrid of oversampling and under-sampling with bagging [31]. UnderOverBagging considers different resampling rates in every iteration and creates more diverse subsets. As the value of a gets close to 100, the ensemble changes from UnderBagging to Over Bagging, thus modelling a hybrid.
IIVotes (2010)
The Imbalanced Ivotes method was proposed by J. Blaszczynski et al. [32] to address the CIP and to have a better balance between sensitivity and specificity. IIVotes combines the selective pre-processing method, i.e., SPIDER, and the adaptive ensemble, Ivotes proposed by Breiman [33]. IIVotes is more focused on the minority class and can achieve acceptable overall accuracy.
Smotebagging and Msmotebagging (MSB)
Here, we are using the smote and msmote with the bagging method respectively [3, 31]. Both techniques involve the creation of synthetic samples during the subset generation. The instances of the under-represented class are oversampled to address the CIP.
Ensemble using hybrid bagging and boosting
Hybrid ensembles combine the benefits of both bagging and boosting. Xu-Ying Liu et al. [34] proposed two strategies in the literature, which are discussed below.
Easy ensemble
It is an unsupervised approach and appears as an ensemble of ensembles. The output is a single ensemble. It employs bagging as the main ensemble learning approach. It explores the majority class set N by creating subsets N1, N2,., NT and then combines Ni and P (minority class instance set) to train Adaboost. In the end, all the predictions are collected and voting is done to classify the final output [34].
BalanceCascade
It works in a supervised manner. Unlike EasyEnsemble, BalanceCascade removes the correctly classified majority class instances from N after every iteration and thus reducing the size of the subset to be learned by the next Adaboost ensemble. The learning process terminates after the last iteration T, when the size of N becomes less than P. BalanceCascade reduces the model learning time and works better than under-sampling [34].
Performance evaluation metric
To evaluate the performance of the classifiers, different performance metrics such as Precision, Recall, F1 Score, AUC etc., have been used in the literature. In this paper, we use AUC to compare the performance of the ensemble methods as it is a better measure having advantages such as the measurement of quality using the AUC metric is unaffected in imbalanced datasets [35]. AUC is a curve in which the percentage of correctly classified positive instances, i.e., true positive rate TPrate and the percentage of correctly classified negative instances, i.e., True negative rate TNrate are plotted against the x-axis and y-axis The more the area under the ROC (Receiver Operator Characteristics), the better the classifier is performing [6]. AUC is evaluated using equation (1):
We have used 44 imbalanced datasets obtained from the KEEL dataset repository. These datasets have no missing values and the class attribute represents two values which are ‘positive’ and ‘negative’. Table 1 lists the attributes of the datasets.
Properties of datasets
Properties of datasets
Based on the CIR, we have divided these datasets into three categories: 11 belonging to Slightly imbalance, 11 for Moderately imbalance and 22 for Highly imbalance datasets. Table 2 shows the criteria used for the division of these categories. Here, the minority class instances are represented by ’m’ and majority class instances are represented by ‘M’.
Criteria used for datasets categorization
The datasets fall under the Slightly imbalance category if the percentage of the majority class is more than 50% but less than equal to 75% or the percentage of the minority class is less than 50% but greater than equal to 25%.
In the Moderately imbalance category, the percentage of the majority class is more than 75% but less than 90% or the percentage of the minority class is greater than 10% but less than 25%.
For the Highly imbalance category, the percentage of the majority class is greater than or equal to 90% or the percentage of the minority class is less than equal to 10%.
Table 3 shows the division of datasets category-wise.
Category-wise division of datasets
In this paper, we perform the comparative analysis of 19 ensemble methods with Slightly, Moderately and Highly imbalance datasets to address the CIP. We have used C4.5, i.e., the Decision tree as the base classifier in the KEEL tool. Different statistical tests are conducted using the AUC metric to evaluate the performance of the ensemble methods. Initial parameter settings in the tool are shown in Table 4.
Initial parameter settings
Initial parameter settings
The average performance of the classifiers in terms of AUC values category-wise is shown in Table 5.
Category-wise average AUC values comparison of the classifiers
Figures 4–6 shows the category-wise average performance of all the ensemble methods.
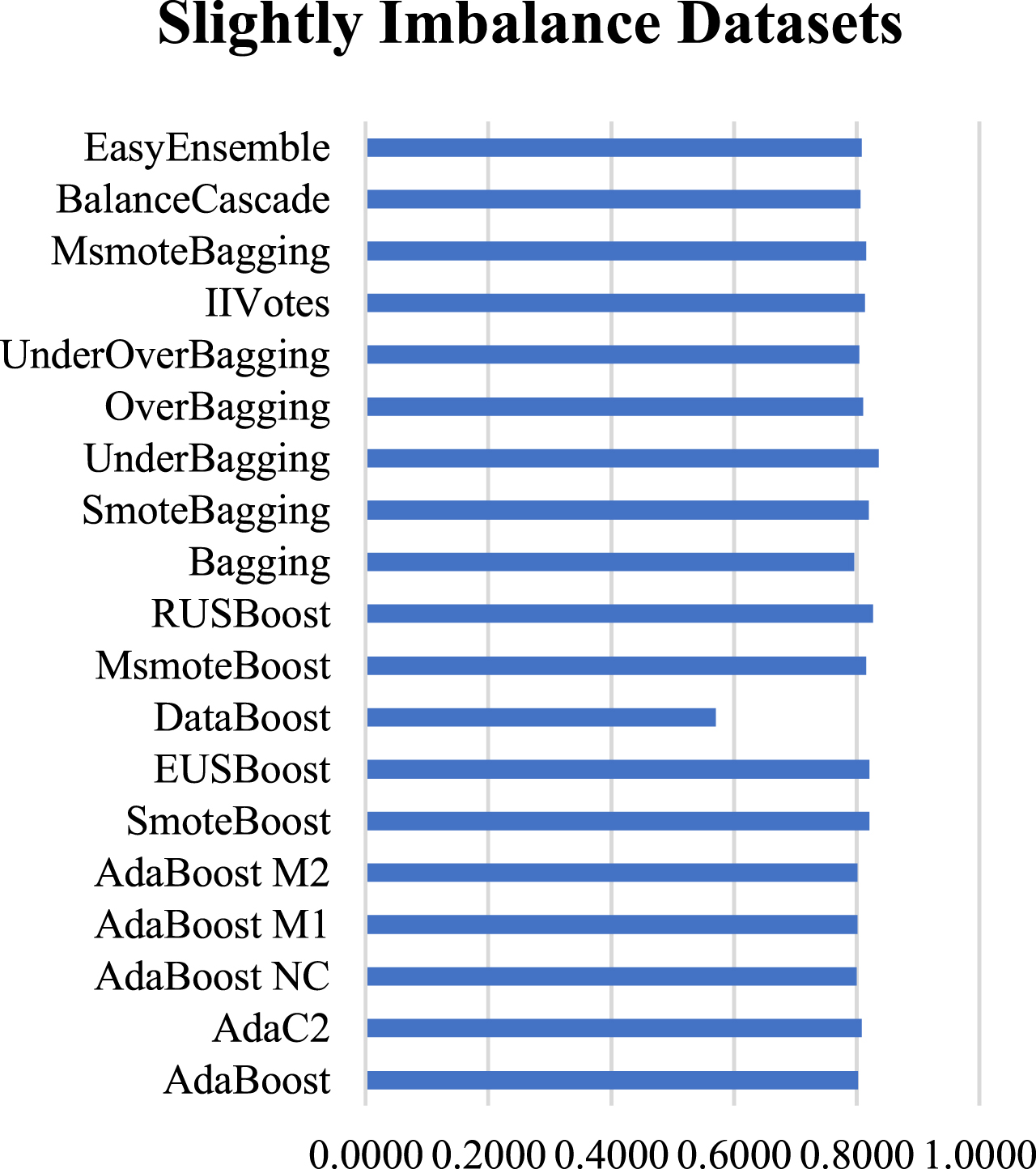
Average performance for SI datasets using AUC.
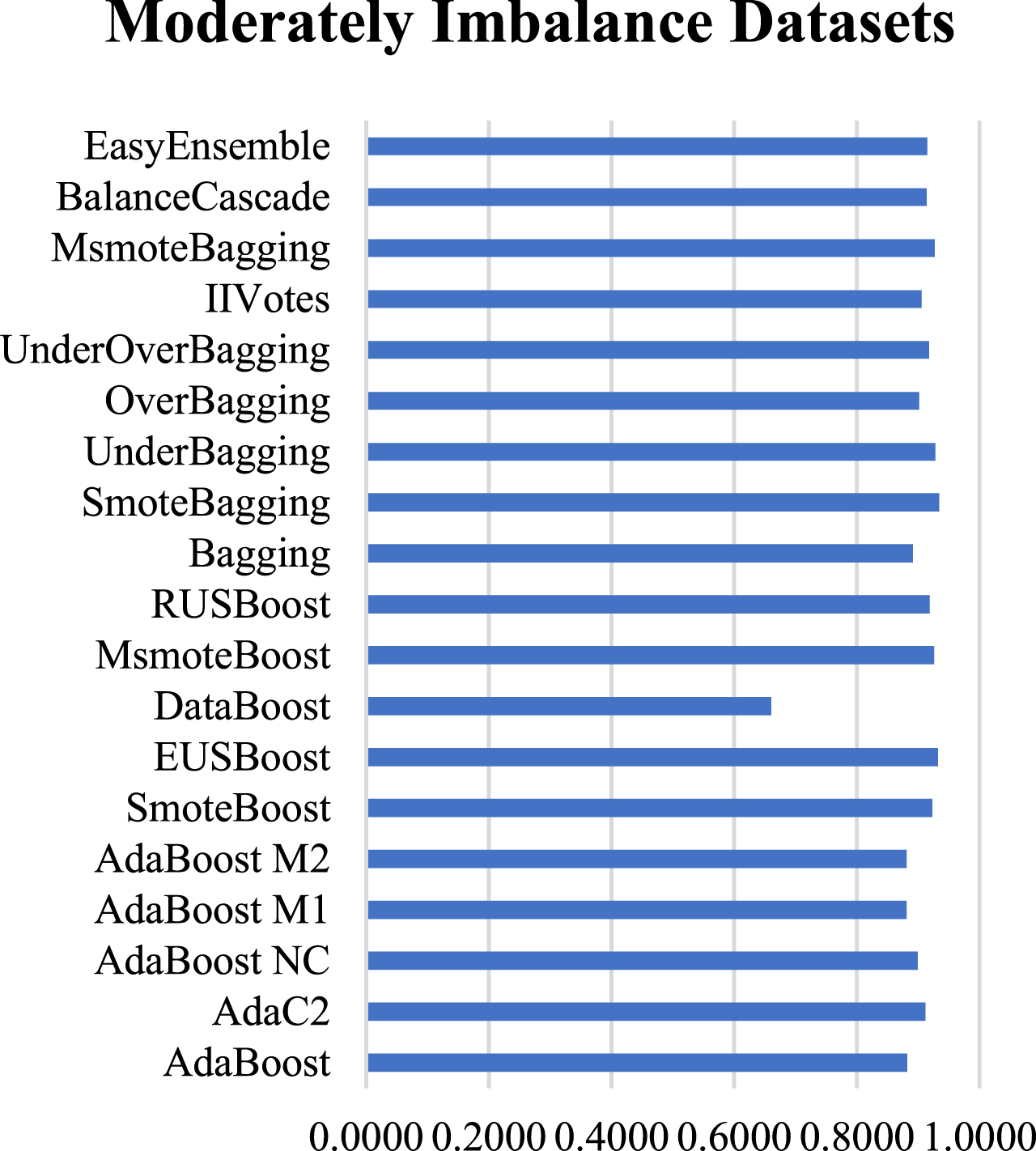
Average performance for MI datasets using AUC.
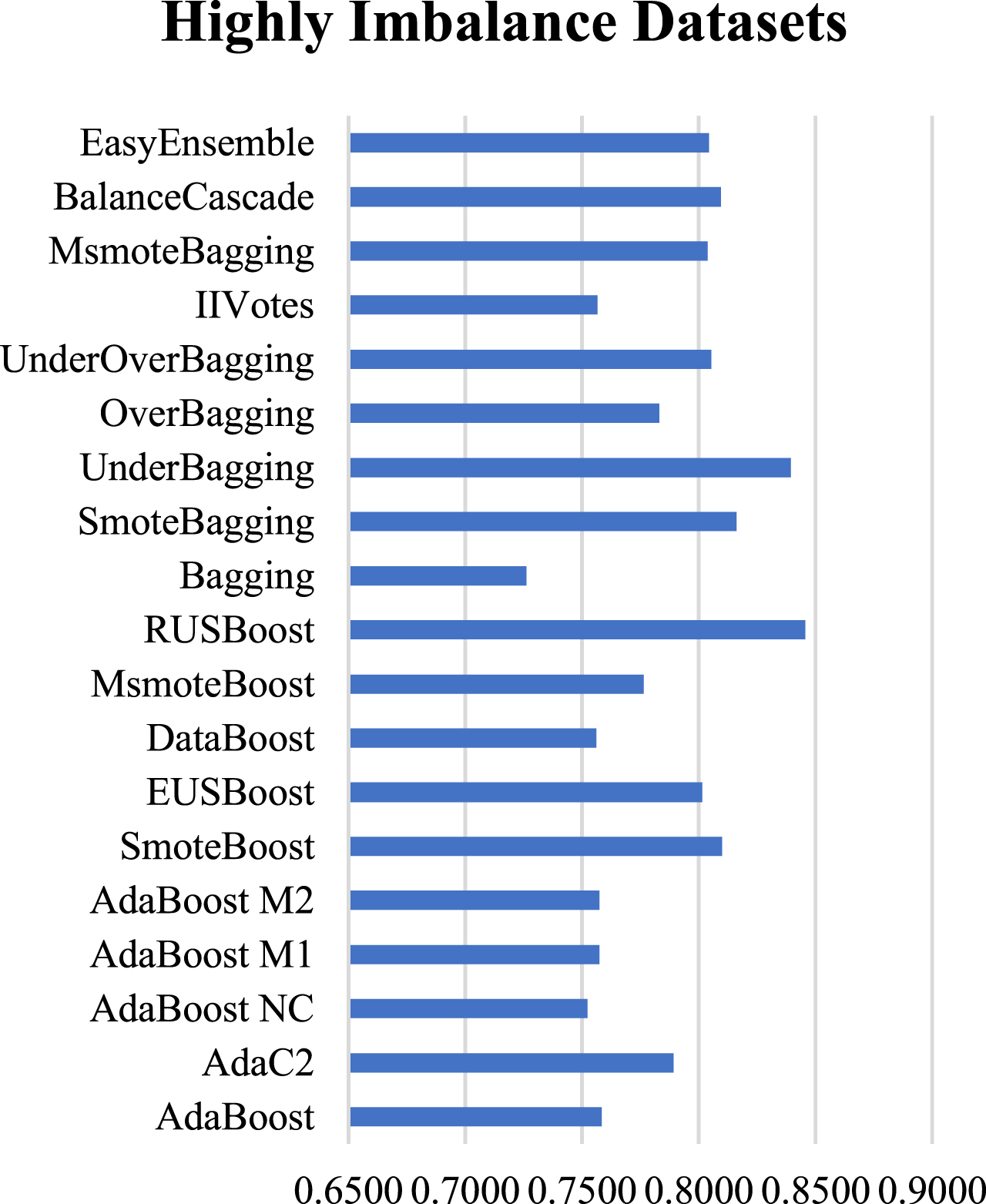
Average performance for HI datasets using AUC.
From the visual representations, it is observed that for Slightly imbalance datasets, the variation in AUC values ranges from 0.5709 to 0.8358 and the best performing classifier is UnderBagging. For Moderately imbalance datasets, the average performance of the classifiers is best with AUC values ranging from 0.6608 to 0.9343 and SmoteBagging outperformed other classifiers. In the case of Highly imbalance datasets, the AUC values range from 0.7263 to 0.8456 and RUSBoost attained the best results under this category.
The results depict that the overall performance of the classifiers in Highly imbalance datasets is least which can be attributed to fewer minority class instances for the classifier’s learning. Moreover, the performance variation of the classifiers in Highly imbalanced datasets is more because of the difficulty in the learning process.
We are using three statistical tests namely the Friedman Test (F Test), Holm post-hoc (HP) and Wilcoxon Matched Pair signed-rank test (WMPSR Test) to perform the empirical assessment of ensemble methods for different categories of datasets. For the average ranking of the ensemble methods, F Test is used where the performance of the ensemble method is inversely proportional to their average ranking and then HP analysis is performed to find the significant difference between the ensemble methods. Thereafter, we are applying the WMPSR Test to find the best performer out of all the ensemble methods in each category.
Slightly imbalance datasets
For Slightly imbalance datasets, we run the F Test as shown in Fig. 7. As per the F Test, UnderBagging achieves the lowest rank and turns out to be the top performer.
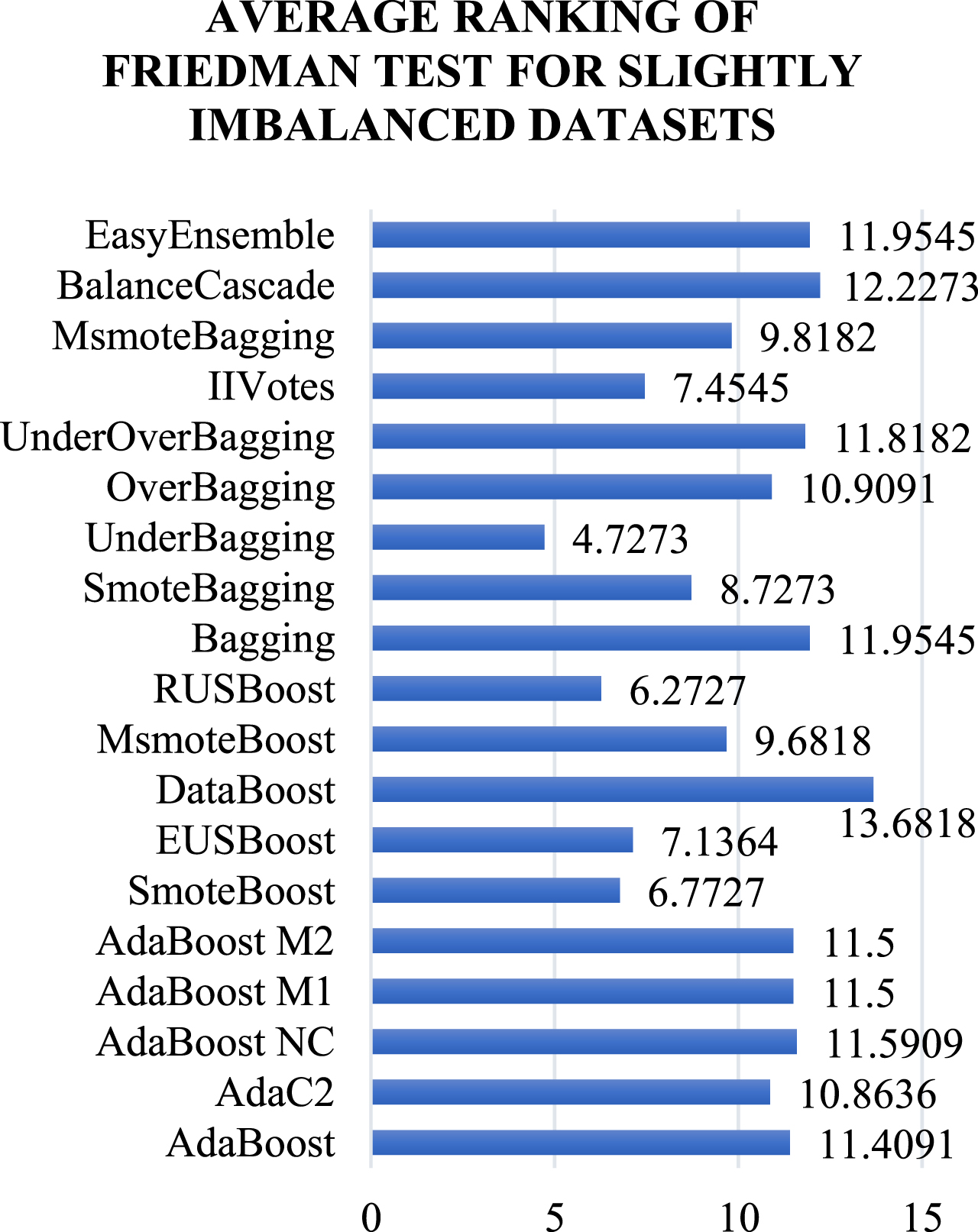
Average rankings obtained by Friedman Test for Slightly imbalance category.
Table 6 shows the F test statistics for the Slightly imbalance category. Here, N represents the number of datasets used and the degree of freedom is one less than the methods used. The test computed the p-value as 0.004214, which means significant differences exist between the ensemble methods. Hence, we used the HT by taking UnderBagging as the control method. The result of the HP comparison is shown in Table 7. The hypothesis for all the ensemble methods except RUSBoost is rejected as the p-value is less than 0.05. For RUSBoost, the p-value is 0.05, which means that no significant differences exist between UnderBagging and RUSBoost. The null hypothesis is not rejected. We run the WMPSR Test to compare UnderBagging and RUSBoost.
Friedman test statistics
Holm Post-hoc comparison for SI category
Table 8 shows the WMPSR Test statistics comparison for UnderBagging vs RUSBoost.
Wilcoxon test statistics for UnderBagging vs RUSBoost
R+ represents the sum of ranks for the dataset where the number of times the first method (UnderBagging) performed better than the second method (RUSBoost). R– rank tells us the sum of ranks for the dataset where the number of times the second method performed better than the first method. The p-value recorded is 0.13086, i.e., greater than 0.05; therefore, the null hypothesis is not rejected and no significant differences exist between the methods. As R+ is greater than R–, UnderBagging is selected as the best performer in Slightly imbalanced datasets.
For Moderately imbalanced datasets, F Test average rankings are shown in Fig. 8. As per the F Test, SmoteBagging achieves the lowest rank and turns out to be the top performer.
F Test statistics for Moderately imbalanced datasets are shown in Table 9.
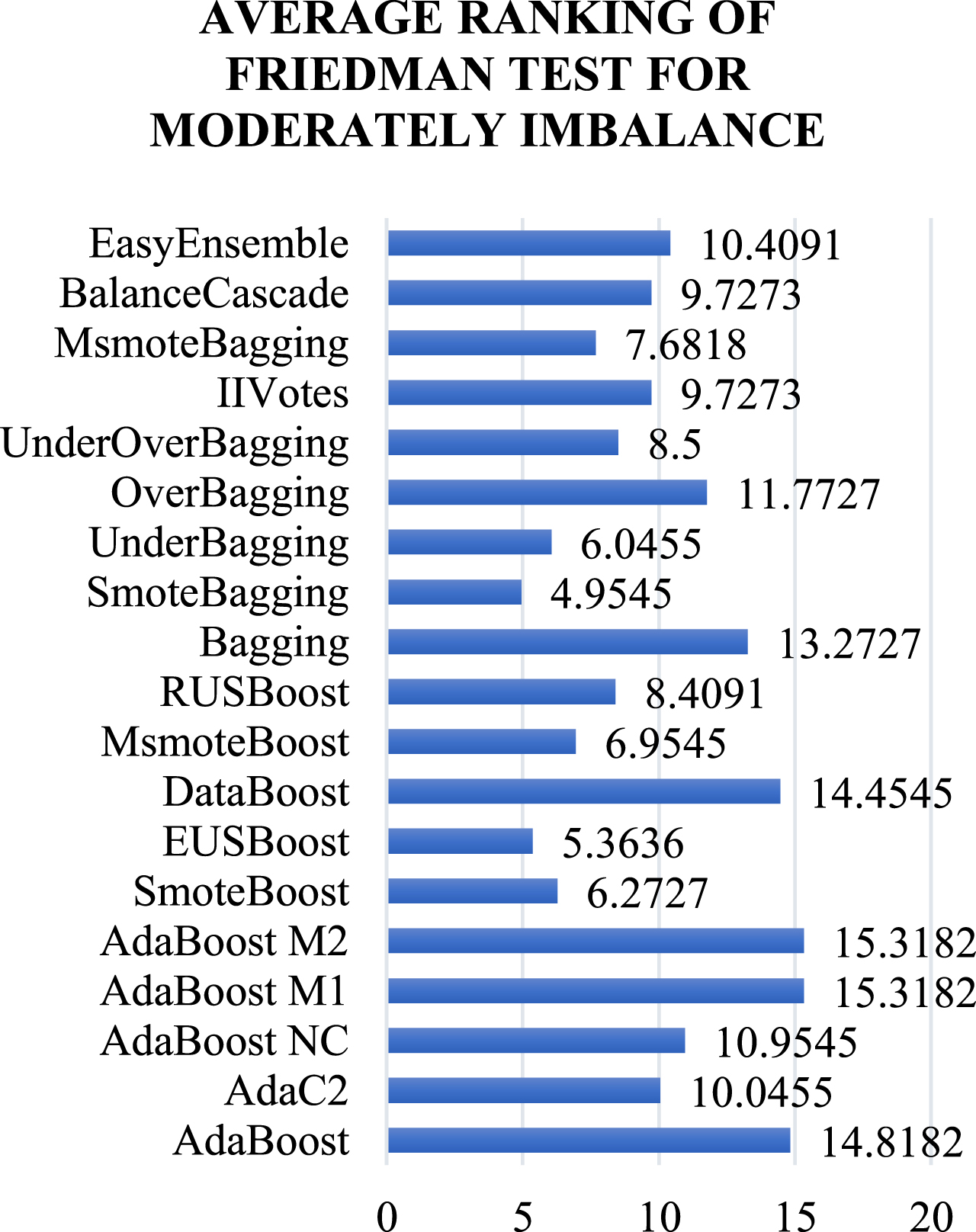
Average rankings obtained by Friedman Test for Moderately imbalanced datasets.
Friedman test statistics
The p-value computed is 0.0000, which means significant differences exist. Hence, we used the HP test by taking SmoteBagging as the control method. The result of the HP comparison is shown in Table 10. The hypothesis for all the ensemble methods except EUSBoost is rejected. For all the ensemble methods, the p-value is less than 0.05. The p-value of EUSBoost is 0.05, which means no significant differences exist between SmoteBagging and EUSBoost. The null hypothesis is not rejected.
Holm Post-hoc comparison for MI category
We run the WMPSR Test to compare SmoteBagging and EUSBoost. Table 11 shows the WMPSR Test statistics comparison for SmoteBagging vs EUSBoost. The p-value recorded is≥0.2, which is greater than 0.05. The null hypothesis is not rejected. As R+ is greater than R–, SmoteBagging turns out to be the best performer in Moderately imbalance datasets.
Wilcoxon test statistics for SmoteBagging vs EUSBoost
The F test rankings for Highly imbalance datasets are shown in Fig. 9. As per the F Test, RUSBoost achieves the lowest rank and turns out to be the top performer.
Table 12 shows the F test statistics for Highly imbalance.
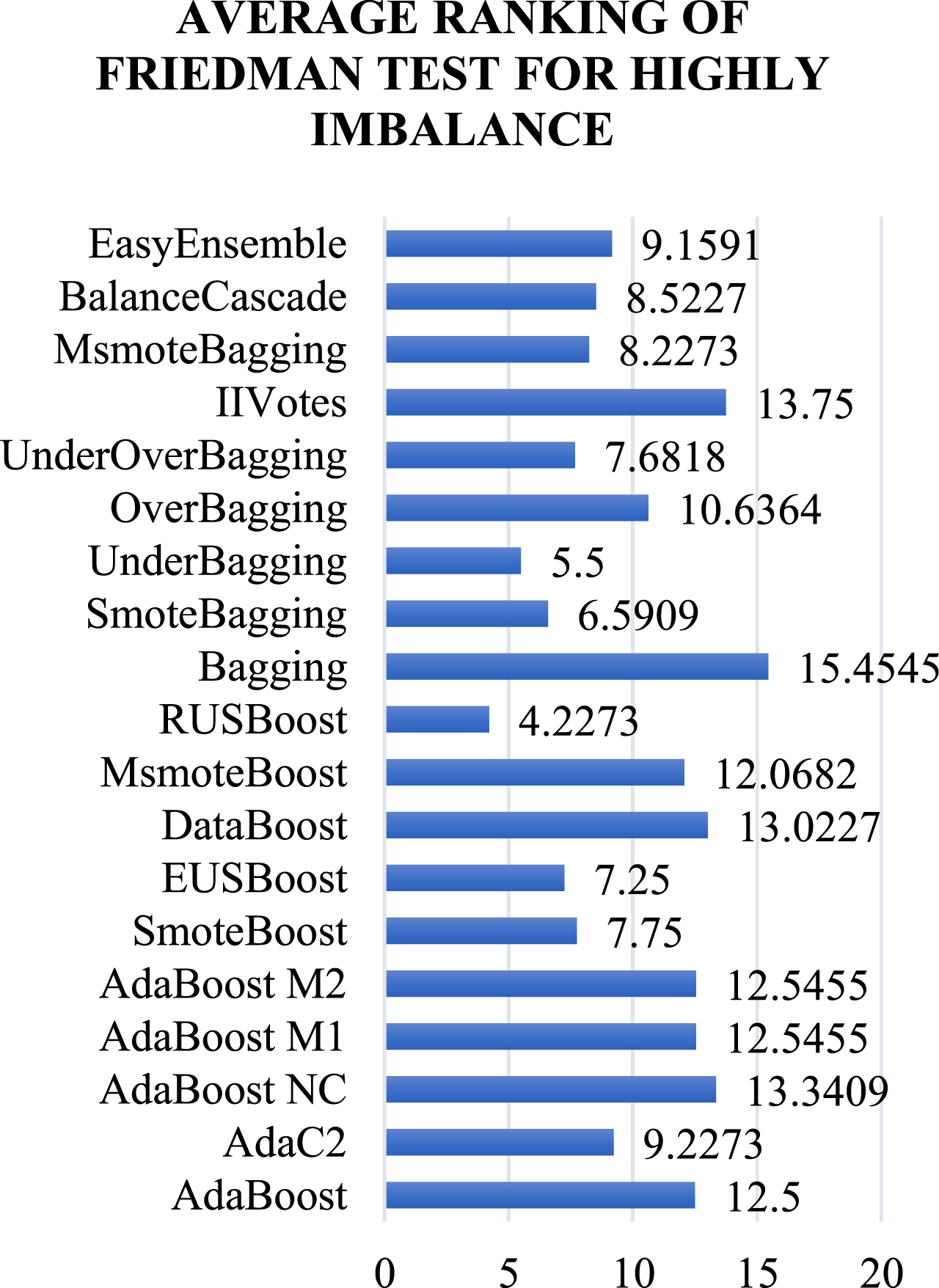
Average rankings obtained by Friedman Test for Highly imbalanced category.
The p-value computed is 0.0000, which means significant differences exist. Hence, we use the HP test by taking RUSBoost as the control method. The result of the HP comparison is shown in Table 13. The hypothesis for all ensemble methods except for UnderBagging is rejected. For all the ensemble methods, the p-value is less than 0.05. The p-value of UnderBagging is 0.05, which means no significant differences exist between RUSBoost and UnderBagging. We run the WMPSR Test to compare RUSBoost and UnderBagging. Table 14 shows the WMPSR Test statistics comparison for RUSBoost vs UnderBagging. The p-value recorded is≥0.2, which is greater than 0.05; therefore, the null hypothesis is not rejected. As R+ is greater than R–, RUSBoost turns out to be the best performer in Highly imbalanced datasets.
Friedman test statistics for boosting based ensembles
Holm Post-hoc comparison for HI category
Wilcoxon test statistics for RUSBoost vs UnderBagging
In this paper, we observe the impact of the CIR by evaluating the performance of 19 ensemble methods using 44 imbalanced datasets with different values of CIR. For performance evaluation, we have categorized the datasets as Slightly Imbalance, Moderately Imbalance and Highly Imbalance datasets. It is observed that the best-performing methods vary as the degree of imbalance increases. The experimental results show that UnderBagging, SmoteBagging and RUSBoost are the top performing models in Slightly, Moderately and Highly imbalanced datasets respectively. We also observe that the learning of the ensemble methods is significantly affected in Highly imbalanced datasets. We use visual representations and non-parametric statistical tests namely F Test, HP and WMPSR Test. The study has few limitations such as issues like class-overlapping and noise disturbance are not considered under this work. For future work, we will observe the joint impact of CIR and noise disturbance on the performance of ensemble methods for CIP.
Footnotes
Acknowledgments
The authors express the gratitude towards USICT, GGSIPU, New Delhi, India for the opportunity to do this research.