
Abstract
The most critical issue in real world applications are class imbalance problems. Imbalanced data sets are common across different domain including banking, health care, finance and other. When such data sets are trained on typical classification algorithm they tends to be biased towards the majority class. The learning task becomes more challenging when there is also an overlap of instances from different classes. In this paper, we propose an undersampling framework for binary classification datasets by removing overlapped data points called Critical Instances Removal based Under-Sampling (CIRUS). Our method is designed to identify and eliminate majority class instances from the overlapping region. Accurate identification and elimination of these instances maximise the visibility of the minority class instances and at the same time minimises excessive elimination of data, which reduces loss of information. Extensive experiments using simulated and real-world datasets were carried out and the results show comparable performance with state-of-the-art methods across different common metrics with exceptional and statistically significant improvements in sensitivity.
Introduction
In machine learning, the classification algorithms learn from previously known information for predicting the unknown events. However, most of the datasets from real world domain contains noisy instances [24]. Typical examples include finance, fraud detection, medical diagnosis, customer churn prediction and many more [10]. Training on these samples degrades the classification performance dramatically. It shows bias towards the over-represented class samples called majority class and ignores under-represented class samples called minority class. Moreover, imbalance occurs in binary classification problem and most of the time the minority samples are of great importance. This problem has been addressed by the machine learning research community over the past decades. The proposed solutions are broadly classified into data-level and algorithm-level techniques [21, 38, 2, 15].
Data level techniques consist of sampling methods to adjust the class distribution while algorithm-level techniques involve modification of existing or creation of new algorithm. Algorithm-level techniques need deep understanding of algorithms and are complicated to implement where as data-level techniques are simple and concentrate on resampling process which in turn can be applied to any classification algorithms. The most popular and commonly used resampling methods include random under-sampling, random oversampling and Synthetic Minority Oversampling TEchnique (SMOTE) [7]. Recently proposed resampling techniques include k-means clustering [12], density-based clustering [4, 6], and ensemble [40]. These techniques are meant to balance the data distribution before classification. However, a number of authors in the past argued that the performance of the classifier was not affected only by unequal class distribution but due to many other reasons such as class overlapping, small disjunct and small sample size.
Overlapping data regions.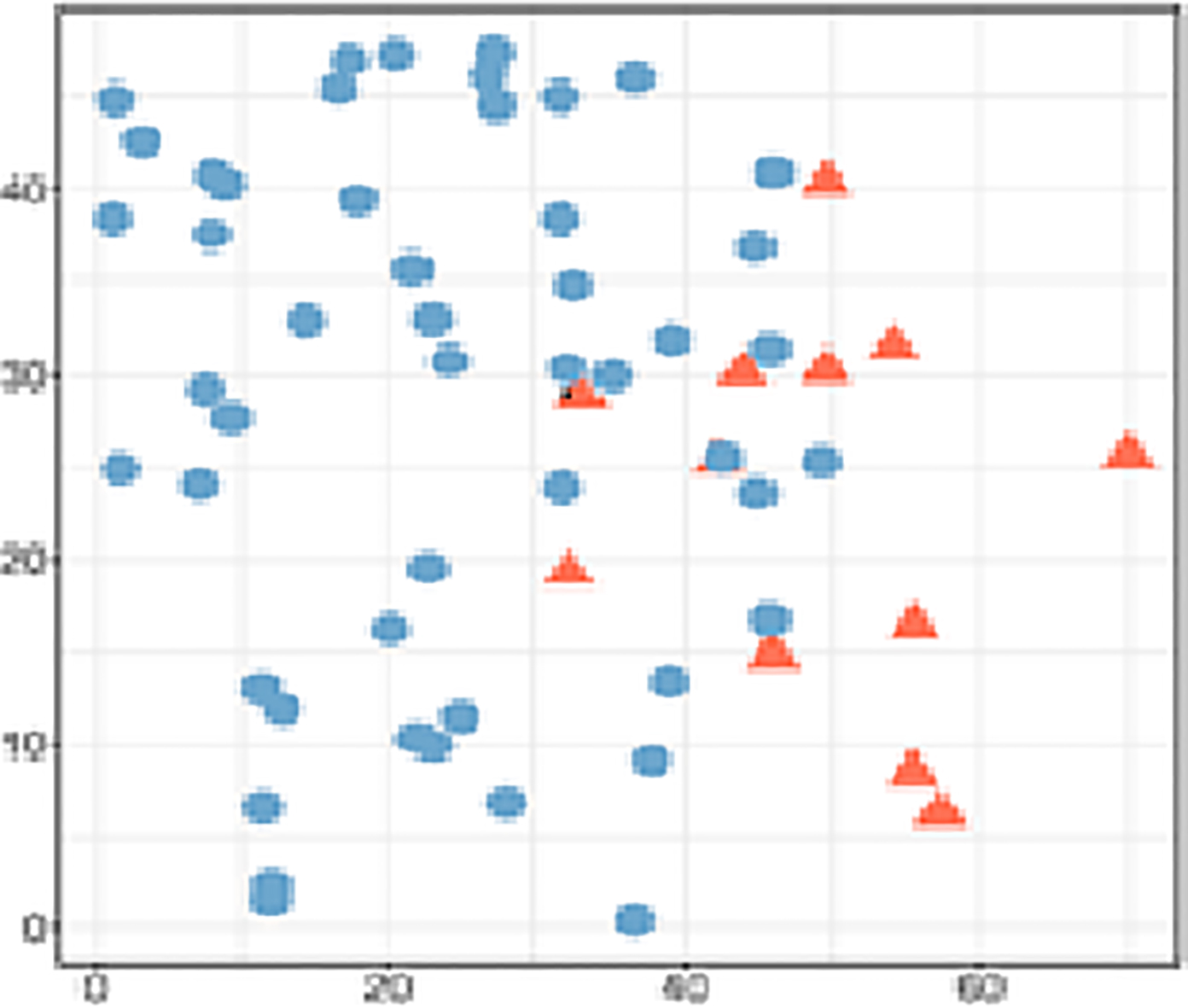
After removal of overlapping data.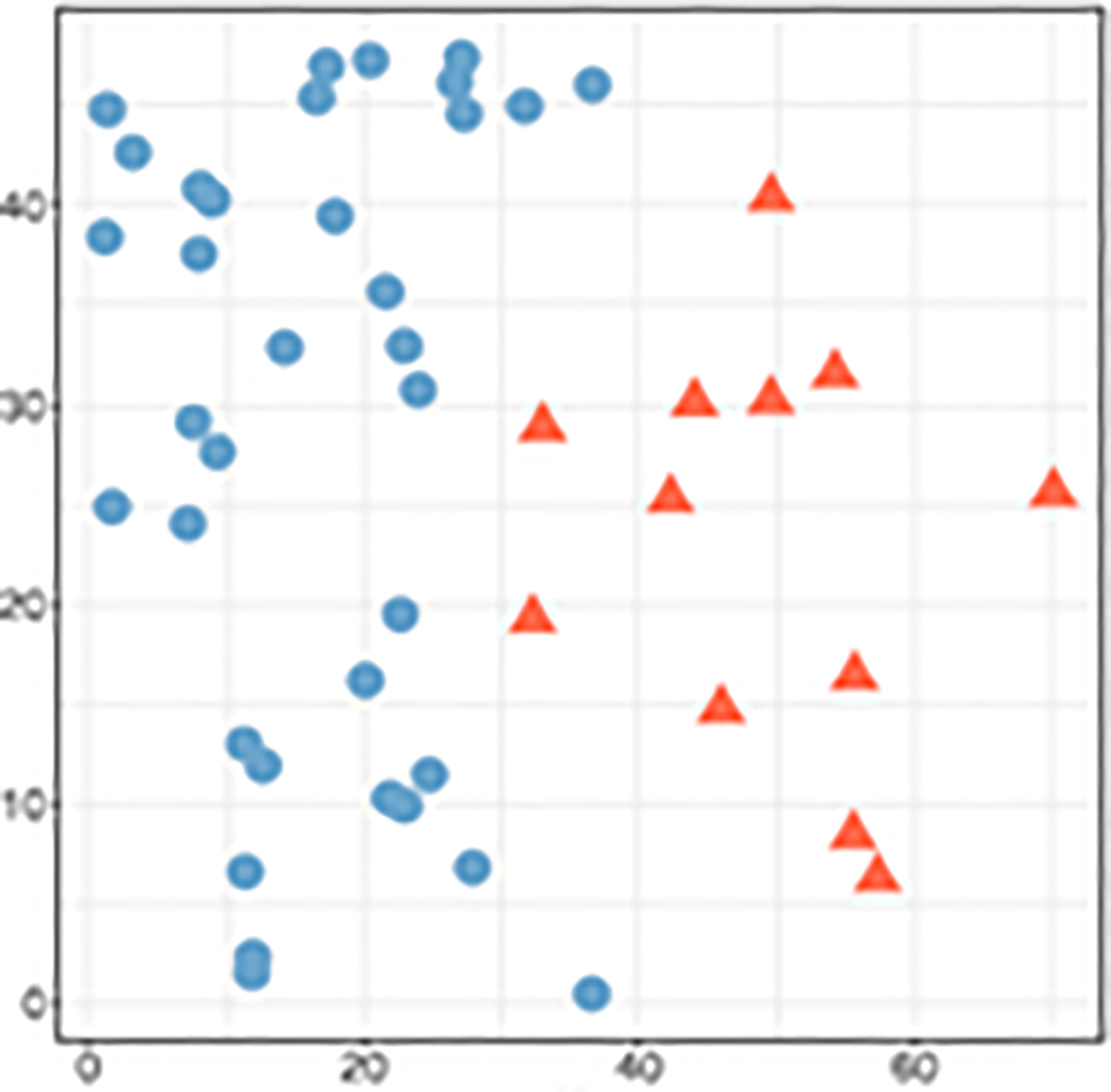
Consider Fig. 1, shows the class distribution of two datasets, the data is overlapped between the classes and may be difficult for the classification algorithm to train on such data. In real-world application, datasets usually not only found imbalance but also overlapped. Therefore removal of majority samples from the overlapped region as shown in Fig. 2 is a rational approach to improve the classification performance. In this work, we propose a nearest neighbor based undersampling approach for finding and eliminating the negative/majority samples from overlapped region. By using this approach, we assume that most of the majority samples from the overlapped region are eliminated from the dataset. The two fold advantages of our approach is firstly the visibility of positive/minority samples increases in the complete dataset and next, more specific overlapped majority instances are identified using k-nearest neighbor which avoid unnecessary information loss. The main contribution of this paper is to propose a framework for handling overlapping data in the decision boundary of a skewed data distribution. An extensive experiments were carried out on highly imbalanced and overlapped datasets.
A dataset is said to skewed distributed when the number of samples of one class are larger in number than the ones from other classes. Moreover, the class with smaller number of samples is usually the class of interest from the learning point of view [8]. In many real world applications, this problem is of great interest, such as telecommunication customers churn [13], oil spills detection in satellite radar images [26], fraudulent telephone call detection [14], and specifically in medical diagnosis [30, 16].
Traditional classifiers when trained on such datasets have a bias towards the classes with larger number of instances (i.e, majority class). In turn, the minority class are usually ignored by considering them as noise. In this way, minority class samples are most often misclassified even though they are important in classification. The learning task does not hinder only by skewed data distribution but there are series of issue related to this problem like small size samples, overlapping between classes and small disjuncts. In Fig. 3, we illustrate examples of the three kinds of imbalance class distribution.
Example of class distribution for two-class imbalance problems [38].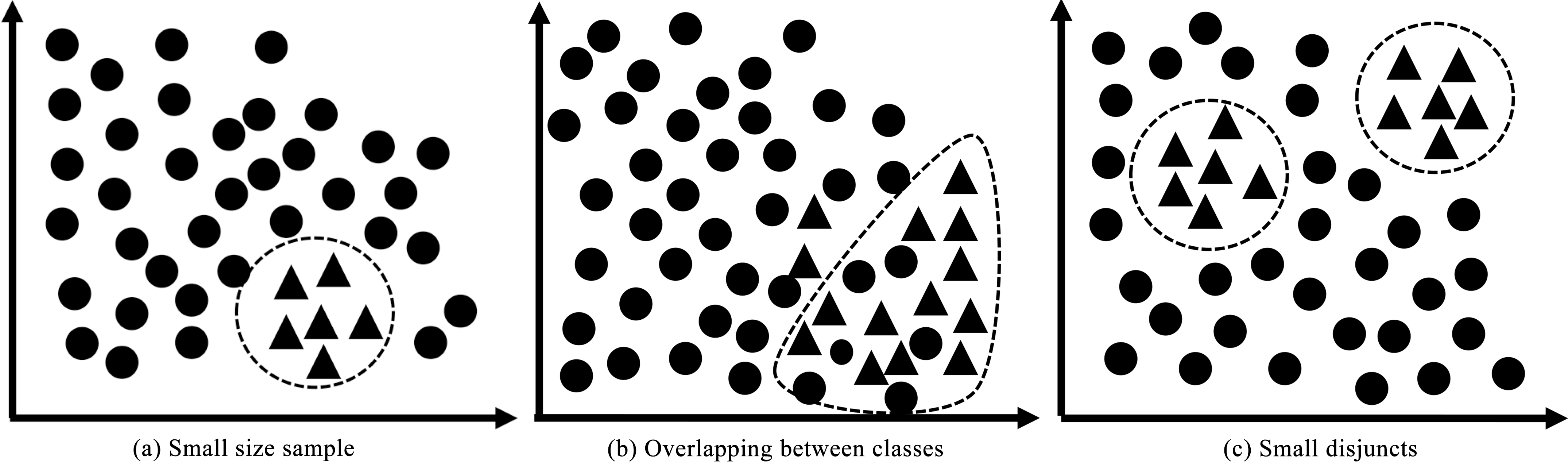
Small size sample: It refer to the problem where not all the classes for a given dataset are represented equally. The high imbalanced ratio may lead to poor classification, resulting in complete uncountable for the said class [10]. Class overlapping: In the presence of overlap between the classes, the classifier tend to wrongly classify the minority instances [35]. Hence, combination of overlapping between the classes with high imbalance ratio generally results in high misclassification rate for the minority class samples. Small disjuncts: The presence of small disjuncts in a data-set occurs when the classes are constituted of smaller sub-concepts. The existence of small disjuncts also increases the complexity of the problem because of small fraction of the data instances, usually not balanced.
The rest of this paper is organized as follows: In Section 2 we review the related work. Section 3 discuss the various challenges in handling skewed data distribution Section 4 presents the different evaluation metric for class imbalance problem domain. The proposed method is discussed in detail in Section 5. Section 6 discusses the experimental setup and results. Finally Section 7 presents the conclusion and discusses future scope.
The most popular and common approach for balancing the skewed data is by using data level techniques. The data level solutions practice re-sampling method by either oversampling the minority class instances or under-sampling the majority class instances. At the algorithm level, a new algorithm or modification of existing algorithms are proposed to handle class imbalance problem. However, in data-level techniques, a learning algorithm cannot be changed once implemented. Ensemble based methods combines data-level techniques with algorithm level methods in solving the imbalanced datasets. As the scope of this paper focused on data-level techniques and for detail review on algorithm and ensemble technique, readers are suggested to refer the following papers [29, 34, 19, 20, 36, 18]. The class imbalance problem has attracted the research community and various data-level solutions have been proposed in literature. However, if the imbalance dataset is linearly separable or sufficiently high, does not affect the results in spite of degree of imbalance. Recently few research studies showed that class overlap had a higher impact on classifier performance than skewed data distribution.
Thus, we broadly discuss the existing solutions for balancing the class distribution and class overlapping methods. The most popular and widely used data level technique is random resampling approach. It is based on undersampling the majority class instances or oversampling the minority class instances. However the main drawback of this two methods are undersampling may lead to loss of important information while oversampling may lead to overfitting. To substitute radom sampling methods, a new technique called SMOTE was introduced. This technique synthesis the minority samples based on linear interpolation using nearest neighbor concept. Various well-known extensions have been proposed such as Borderline-SMOTE [22] and SMOTE-IPF [39, 37], Safe-level-SMOTE [5] and DBSMOTE [6]. Other recent methods based on clustering [41, 33] and deep neural networks [25] have also been proposed.
As this paper deals with data-level techniques, a brief introduction to various data-level techniques are described as follow. In data-level approach, the sample dataset is modified to balance the class distribution. The foremost aim is to maintain equality in the class distribution for the datasets using sampling methods such as over-sampling, under-sampling and combination of both. The oversampling and under-sampling techniques are the two popular techniques in sampling-based classification to address the imbalanced datasets. In the oversampling technique, some samples are added to the minority class to make it balanced when very less information is available for minority class samples. In the under-sampling technique, some samples of the majority class are eliminated to make the dataset balanced. Apart from above, the hybrid techniques usually come with a combination of both over and under-sampling methods. Figure 4 presents different approaches applied at data-level to address the class imbalance problem.
Different data-level techniques proposed for handling class imbalance problem [38].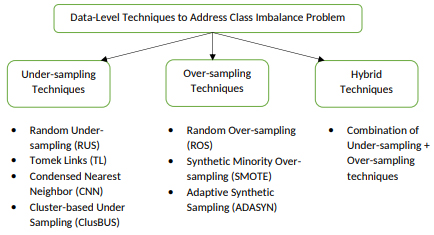
These methods balanced the class distribution based on the original data. But, a common drawback is it effects by degree of imbalance. If the class imbalance is high, a drastic loss of information may encounter and if imbalance is low, overfitting of samples may be generated. Since this paper concentrates on class overlapping regions, we reviewed literature work related to the same. Class overlapping deals with the samples near the borderlines and can be extend far from the class boundaries. Few existing literature shows the solution in addressing the class overlapping problem.
In [42], the author proposed oversampling based undersampling technique, based on negative instance removal from the overlapping region. They stated that the proposed method provide significant improvements over the state-of-the-art class distribution methods. In [4] the author proposed DBMUTE based on density-based clustering methods to identify and remove the majority instances from the overlapping boundaries. Another well established method ADAptive SYNthetic sampling approach (ADASYN) [23], generates more minority samples surrounded by majority instances as its neighbours. Results showed a better sensitivity compared with other state-of-the-methods. However, the visibility of minority class were not sure by this method because the majority instances may still be present in the overlapping areas. Another methods called Edited Nearest Neighbour (ENN) [9], proposed to focus on boundary instances. It adopts k nearest neighbor (k
In [22] the author proposed BorderLine-SMOTE (BLSMOTE), to over sample the minority samples near the borderline. The author stated that their method behave better in terms of F-Measure compared to existing methods. Redundancy-driven modified Tomek-link based undersampling [11] to detect outlier, redundant and noisy instances had least contribution in estimating accurate class labels. Evolutionary undersampling [17], Majority Weighted Minority Oversampling TEchnique (MWMOTE) [3] works by identifying the minority class instances at boundary regions and assign weights based on the distance from majority class samples. Then, forms a cluster of these minority samples for generating synthetic data. Adaptive Semi-Unsupervised Weighted Over-sampling (A-SUWO) [32] consider minority samples closer to the boundary region and mark them as hard-to-learn samples. Those samples are not involved in generating new samples. Hence in this section, we discuss different data level techniques proposed in literature for solving class imbalance problem. Now, next section will discuss about the different challenges in handling imbalance dataset/skewed data distribution.
Napierala and Stefanowski [31] proposed different method to analyze the minority samples by assigning it to predefined categories such as safe, borderline, rare and outliers. Such methods help in understanding the difficulties present in the data. Hence, some challenges are included here as:
As a future direction, it is important to propose new classification algorithms that incorporate the different difficulties in the data. Apart, while designing the classifier, attention should be needed towards individual minority samples. Another important issue is extreme class imbalance problems. The extreme imbalanced data sets exist in most of the real-world problems such as fraud detection with Imbalance Ratio (IR) approximately 1:3000. This poses a great challenge for classification algorithms to train on such extreme datasets. Third challenge is inefficient feature extraction for some problems such as protein data, online transaction data. It is very much important for the classifier to be trained on such high-dimensional and sparse feature set. Another way to solve class imbalance problem is by modifying the learning algorithm. However, a major drawback of such learning models gives much importance to minority samples, thus increasing the majority class misclassification. A technique needs to be proposed to select only uncertain samples and adjust the output accordingly. Recently, ensemble learning became the most popular techniques for handling class imbalance. Algorithms like Bagging, Boosting, Stacking, and Random Forests were robust in handling data difficulties. Ensemble learning along with sampling techniques provides better performance to handle the skewed distribution of data. The main drawback is diversity among majority and minority class. There is no proper indication of how large the ensemble should be constructed as their size is selected arbitrarily. Another problem is handling of multi-class imbalanced classification. The multi-class imbalance occurs when more than two classes with one majority class and multiple minority class exist. A deeper insight in handling multi-class imbalanced problems is needed. Data pre-processing technique is highly important in balancing the imbalance datasets as there are independent of classifiers. The possible difficulties appear in the data are class overlapping, noise and small disjunct. Therefore, efficient data cleaning and sampling techniques are needed to balance the data. For multi class imbalance problems, efficient sampling techniques need to be proposed. Multi class imbalance learning need special care while applying sampling techniques. Researchers should focus on developing algorithms which are robust in handling such skew distributions. In ensemble learning algorithms such as bagging and boosting, there may be different level of uncertainty while sampling the data into bags. There may be a high probability of consisting samples from the same class within a single bag. The need for proper probability distribution techniques such as normal, binomial distribution can be used to check the balance distribution in each bag. However, many difficulties may arise due to data distribution in each of the bags and also each bag may contain certain amount of noise which makes the classifier to perform poorly. So, efficient techniques need to be proposed in handling the size of the bags and the distribution of samples into each bags. Another important and yet popular challenge in class imbalance is learning from continuous data. The process of learning from the continuous data is called data streaming. The need for active learning algorithms to address data streaming issue is still at infant. The general open issue will be based on sampling the streaming data and classifying it. In last, extraction of efficient features and instance is also of major concern. Real time data such as bank data or genomic data are essentially have high-dimensional and sparse feature. The development of new approaches for high dimensional data is much needed, that will allow at the same time for an efficient processing and boosting discrimination of the minority class. Another interesting direction is to investigate the possibilities of using decomposition based solutions. Hence in this section, we briefly discussed about the different challenges in handling imbalance dataset/skewed data distribution. Next section presents the evaluation metric used in evaluation of classifier when trained on imbalanced dataset.
Most of the studies in skewed data distribution domain mainly concentrate on binary classification problem. By convention, positive class labels are considered as minority class and negative class labels as majority class. Table 1 illustrates a confusion matrix of a binary-class problem. TP and TN denote the number of positive and negative examples that are correctly classified, while FN and FP denote the number of misclassified positive and negative examples respectively.
Confusion matrix
Confusion matrix
Accuracy is a well-known performance metric used in classification. It is defined as the ratio between the correctly classified samples to the total number of samples Eq. (4). In the imbalanced datasets, accuracy shows bias towards majority class and lead to wrong decisions. Therefore, different performance metrics are need to assess the performance of the classifier when trained on imbalanced datasets. The suitable metrics used are precision, recall, Area Under Curve (AUC) to measure the performance of classifier when trained on imbalanced datasets.
Precision is the proportion of true positive to the total number of true positive and false positive as shown in Eq. (2). Recall/sensitivity/True Positive Rate (TPR) represents how well the model detects the true positive as shown in Eq. (3). The F-Score/F-measure combines both recall and precision and defined as Eq. (4). Therefore, F-measure is suitable in imbalanced scenarios than the accuracy metric.
In this paper, the various performance metrics used are AUC, F-Score and G-Mean.
This section describes the proposed method in detail. In Fig. 1 we showed how class overlap makes the classification algorithms difficult with skewed data distribution. It affects the performance of the classifier when trained on highly overlapped imbalanced datasets. So, to overcome that we propose a framework for removing majority samples from the boundary regions and provide maximum visibility for minority samples. By using the proposed approach, we assume that most of the majority samples from the overlapped region are removed from the dataset. The two fold advantages of our approach is firstly the visibility of positive/minority samples increases in the complete dataset and next, more specific overlapped majority instances are identified using k-nearest neighbor which avoid unnecessary information loss.
The main contribution of this paper is to propose a framework for handling overlapping data in the decision boundary of a skewed data distribution. This is implemented by removing the majority samples that are most nearer to that of the minority class samples. The nearest neighbors of minority samples are computed based on k-nearest neighbor algorithm. The value setting for K is vital in identifying the samples to be discarded. Here, we empirically set the value of k by considering the imbalance ratio with that of the size of the dataset. So Eq. (5) shows the computation for k.
Where, N is the number of samples in the dataset and ImbRatio is the imbalance ratio i.e., proportion of majority samples towards minority samples. Unlike existing methods, k values is defined based the real world datasets and its imbalance ratio rather manual assignment. In this paper, we proposed a boundary region based undersampling method as mentioned in Algorithm 1. The method vary with the existing algorithms in terms of identification and elimination of majority samples which are overlap with minority samples. As class imbalance problems is not a problem by itself but existence of overlap classes, sample disjunct and small sample size which in turn make the classifier complicated to perform better.
Datasets used
The AUC performance measure on different datasets using SVM
In this work, we concentrate on the boundary regions and identify the majority samples which are in the overlapping class region. This process eliminate the samples with out disturbing the data and may not lead to loss of information. This method showed a better accuracy for minority class samples as discussed in Section 5. The algorithm works by identifying and eliminating the majority class samples from the boundary regions. The undersampled data are used for training the classification algorithm.
Hence in this section, we discussed the solution to handle the class overlapping problem in imbalance dataset. Next section presents the experimental results of the proposed method trained on 15 real world datasets.
The F-Score performance measure on different datasets using SVM
The G-Mean performance measure on different datasets using SVM
The AUC performance measure on different datasets using J48
The F-Score performance measure on different datasets using J48
The G-Mean performance measure on different datasets using J48
The AUC performance measure on different datasets using RF
The F-Score performance measure on different datasets using RF
The G-Mean performance measure on different datasets using RF
Extensive experiments using 15 public real-world datasets were carried out for evaluation. Experimental results were compared with state-of-the-art namely, SMOTE [7], Clustering-based undersampling [28], BLSMOTE [22] and ENN [9]. Support Vector Machine (SVM), Decision Tree (J48) and Random Forest (RF) were chosen as the learning algorithms because of widely used algorithms for skewed data distribution.
Data set
We evaluate the proposed algorithm using 15 datasets from Keel repository with different imbalance ratio (IR) [1]. Table 2 shows the details of the imbalanced datasets with number of features and imbalance ratio.
Results
In this section, we compared the results using different state-of-the-art techniques namely, SMOTE, clustering-based undersampling, BLSMOTE and ENN on different classification algorithms such as SVM, J48 and RF. The metric used are AUC, F-Score and G-Mean. Tables 3–11 shows the results of different state-of-the-art techniques compared with our proposed method on different classification algorithms. The experiments are carried out using 3 classification algorithms.
Comparison of the proposed method with state-of-the-methods using J48 classifier (AUC metric).
Comparison of the proposed method with state-of-the-methods using SVM classifier (AUC metric).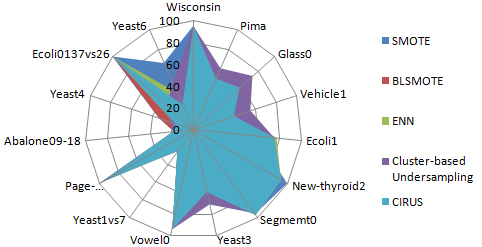
Comparison of the proposed method with state-of-the-methods using Random Forest classifier (AUC metric).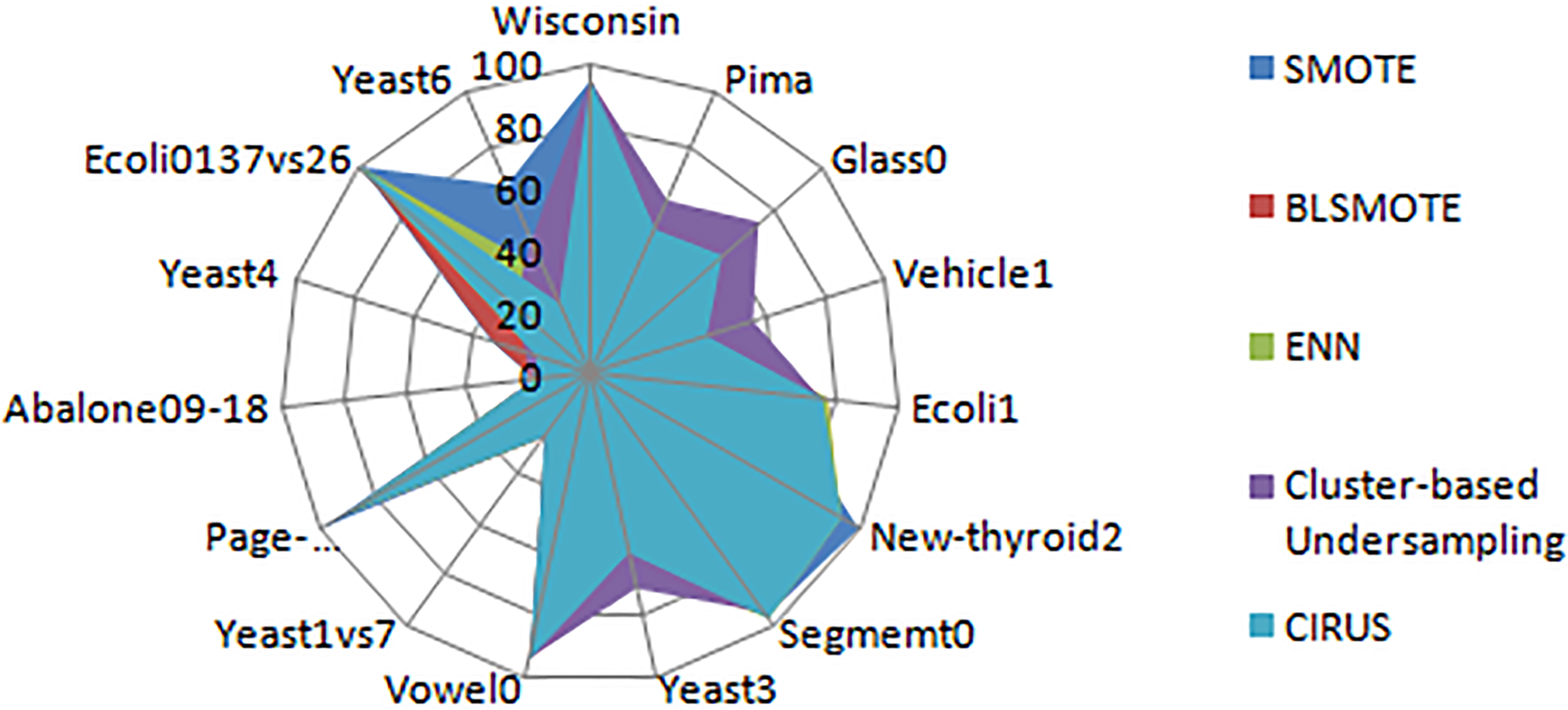
From the experimental results we observe that the performance of the proposed method is consistent across different algorithms and datasets. Figures 5–7 shows the comparison based on AUC on the proposed method with state-of-the-methods using three different classifiers.
It is clear from the experimental results that our proposed method is better than SMOTE, clustering-based undersampling, BLSMOTE and ENN for most of the datasets. CIRUS produces better performance in finding and eliminating the overlapping majority samples from the boundary region. The proposed model produces better performance using F-Score, AUC for majority datasets with SVM, Random Forest. From the experiments, we conclude that the proposed method is superior to state-of-the-methods on most of the datasets.
In this paper, we proposed a novel framework for undersampling the critical majority instances from the boundary regions. The proposed CIRUS method effectively identified and removed the majority instances in the boundary regions. Extensive experiments using real-world datasets were carried out. The proposed methods were compared against state-of-the-art methods with good performance. This method can be applied to imbalanced datasets with any classification algorithm in general.