
Abstract
Co-citation analysis can be exploited as a bibliometric technique used for mining information on the relationships between scientific papers. Proposed methods rely, however, on co-citation counting techniques that slightly take the semantic aspect into consideration. The present study proposes a semantic driven bibliometric techniques for co-citation analysis through measuring the semantic similarity (SS) between the titles of co-cited papers. Several computational measures rely on knowledge resources to quantify the semantic similarity, such as the WordNet “is a” taxonomy. Our proposal analyzes the SS between the titles of co-cited papers using word-based SS measures. Two major analytical experiments are performed: the first includes the benchmarks designed for testing word-based SS measures through the correlation coefficients for expressing the measures efficiency; the second exploits the dataset DBLP
Introduction
This paper is an extended version of the previous work highlighting the co-citation concept in scientometric field [49, 58]. A citation usually reflects that an author is influenced by the work of another but does not provide an explicit indication on the degree or direction of that influence [17]. By contrast, co-citation quantifies the relationship between co-cited documents with the assumption that more frequently co-cited documents express greater co-citation strength [31]. Many works such as [6, 16, 32, 38, 42, 59, 60] proved paper co-citation analysis as useful to define the structure and evolution of research about a scientific domain. That is why scientists have been interested so far to develop methods for the analysis of co-citation behaviors using a variety of techniques [17, 48] ranging from Natural Language Processing to Network Science as shown in Fig. 1.
Keyword cooccurrence network for the research papers indexed in Web of Science Core Collection between 2017 and 2019 and dealing with co-citation (Software: VOSViewer 1.6.13 [41]).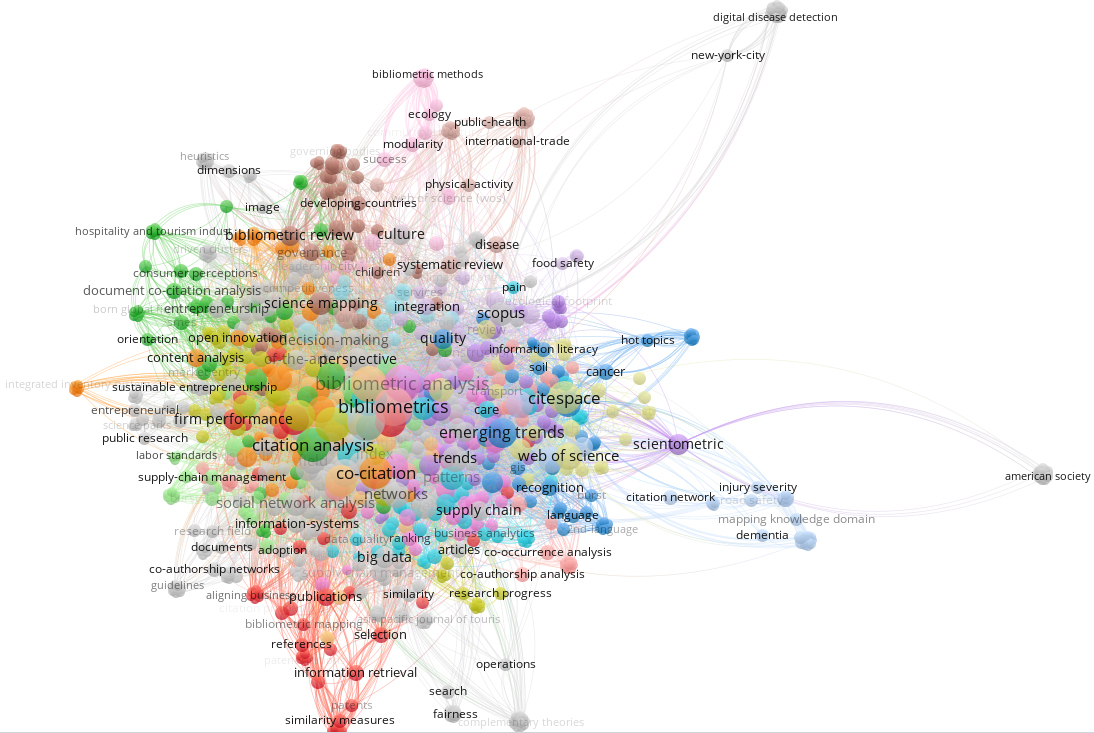
In another context, some works such those of [14, 18] showed that the title plays an important role as the first point of contact between writer and potential reader. Therefore, they can be exploited for studying the semantic perspective for the relation between co-cited papers.
That is why the present paper focuses on the semantic level assigned to the highly repeated co-citations through the analysis of the DBLP citation network. It computes the SS between the co-cited papers based on the nouns existing in their titles. In fact, the conventional approaches do not, however, take the semantic aspect of co-citations into account to identify the intellectual structure of a target domain based on the title of the cited paper. The choice of paper title is essentially driven by the fact that authors usually pay substantial care to include appropriate words that best reflect the important content of their paper in the title [26].
The computation of the semantic similarity between words is an important application in a wide range of research fields, including the knowledge management, information retrieval, artificial intelligence, natural language processing, and biomedical domains. A measure of SS takes two concepts as input and returns a numeric score that quantifies how much they are alike. The semantic similarity is different from another concept which is the semantic relation which does not focus only on the similarity, but it includes any semantic relation that can be interpreted for the semantic computation models. Among the semantic relatedness approaches, the distributional models are the famous. In fact, they are based on statistical computational models such as tfxidf [2, 10] and BM25 [28] which are used to express the semantic relatedness and not the semantic similarity. Moreover, word embeddings is an evolution of the distributional semantic approach proposed by [50]. They represent a latent representation of the word based on its contexts learned from corpora. The family of word embedding model scan be divided into two categories including text-based models and recent hybrid embedding models combining text-based models with the use of ontologies [51]. These latent representations can be used for providing semantic similarities scores using the cosine similarity measure.
Here, we focus on the ontological-based SS measures because they realize a rich sense representation due to the semantic relations expressed explicitly. They are, also, based on two dimensions which the first is the sense representation exploiting the semantic resources such as the ontologies providing machine readable representation of concepts. As for the second dimension, it is the computing model used for quantifying the shared features between two concepts using as examples the topological parameters of the ontologies (WordNet for general domain and, MesH and SNOMED CT for the biomedical field).
Several measures judged as structural approaches exploited the taxonomic parameters extracted from the “is a” taxonomy. Among these approaches we can cite:
Taxonomic measures estimate the similarity based on the topological parameters [11, 13, 15, 19, 21, 46]: number of taxonomic links, the depth, the hyponyms and the lowest common ancestor (LCA). Information content-based approach quantifies the similarity between concepts as a function of the Information Content (IC) that both concepts have in common in a given ontology. The basic idea is that general and abstract entities found in a discourse present less IC than more concrete and specialized ones [12, 20, 25, 29]. Hybrid measures combine between measures in order to merge their advantages [47].
The rest of the paper is organized as follows. Section 2 presents an overview about the related work. Section 3 provides the proposed methodology for computing semantic similarity between paper titles to estimate the semantic similarity between the referenced papers of a co-citation. Section 4 presents some semantic similarity measures based on the topological parameters extracted from the WordNet “is a” taxonomy. Section 5 describes the datasets used for performance evaluation such the semantic similarity datasets and the DBLP citations network exploited for the determination of co-cited papers and in the study of their semantic perspective. Section 6 reports on the evaluation of benchmarks and the study of semantic similarity between highly repeated co-citations. The final section is devoted to presenting our conclusions and recommendations for future research.
The role, value and usage of research paper titles
Several works focused on the importance of the titles in the scientific papers as they are the most freely and easily available data about scientific papers [22].
The title is considered as the more attractive component composing a scientific paper. [14] studied the readers behaviors in front of the titles of research papers related to several disciplines such science and literature and how they motivate them to deep reading of the papers.
The analysis study made by [18] shows that research papers having shorter titles are best cited than others. In fact, the short title is more attractive through the best selection of the words playing the marketing role. This study was based on the data collected from Scopus and bibliometric platforms such DBLP.
Therefore, the importance of the titles as short, freely available and precise description of the paper makes them a useful component that can be exploited for the quick semantic comparison between the contents of the papers.
That is why several scientists began since the 1980s to assess the efficiency of the use of titles for the similarity verification of research papers using co-word analysis technique [37]. These scientists concluded that co-word analysis of titles fails to precisely prove paper similarity due to a lack of recognition of synonyms and abbreviations (e.g.: NO
In this research paper, we propose semantic similarity measures as a more effective method to assess the similarity of papers and particularly co-cited ones as these SS measures depend on high-scale linguistic resources and are consequently able to detect all synonyms and abbreviations within paper titles.
Coupling co-citation analysis and semantic measures
Paper co-citations have been studied by several authors using clustering techniques, co-citation proximity analysis and quantitative methods [6, 8, 32, 38] as they are useful to extract the relationships between covered topics in scientific literature, to find the relations between researches, and to study the structure and the evolution of the research efforts about a specific domain [30, 33, 35, 36, 44].
However, although the importance of co-citation analysis, it gives limited information about the context of why papers are co-cited as it is mainly based on statistical approaches [17]. That is why several scientists decided to work on using semantic methods to give another dimension to co-citation analysis [40].
Braam et al. [3, 4] proposed to define the thematic contexts of paper co-citations by retrieving the main keywords for each paper co-citation cluster. They proved the accuracy of their method to easily verify the results of co-citation analysis, mainly concerning aspects related to the cognitive content of publications. They also confirmed that co-word analysis can be used to enrich co-citation analysis results, particularly when the number of co-citations is limited due to the lack of focused internal references within the analyzed set of research papers.
The semantic similarity computation process between 
Chen [5] used Latent Semantic Indexing and Pathfinder Network Scaling to recognize the common field of research interest for each author co-citation cluster. In fact, he analyzed the titles, abstracts and keywords of the set of papers of each two co-cited authors to generate a document-document lexical similarity matrix. All built matrices are successfully used later to define the main research topics of each author co-citation cluster.
Elkiss et al. [7] proposed to justify paper co-citation through the analysis of the lexical similarity of the abstracts and full texts of co-cited papers. They proved that lexical similarity between co-cited papers is significantly better when there is a higher proximity of co-citing sentences within the full texts of citing papers (
The works [17, 34] interested in finding the reasons behind co-citations through the analysis of the sentences introducing them within the full text of citing papers. Effectively, Small [34] proposed to find the relationship between co-cited papers through the retrieval and analysis of the structures that link the sentences citing the co-cited papers within the full texts in analyzed papers. He postulates that the relationship between co-cited papers can be symmetric (similarity [Similar to] and opposition [In Contrast]) or asymmetric (explanation [explains], characterization [Property of] and connective transition [And Also]). As for Jeong et al. [17], they computed the lexical cosine similarity of the sentences defining the co-citations received by each two authors within the full text of each analyzed paper after stemming and removing stop words to let author co-citation network take into consideration the semantic contexts of author co-citations and succeeded to prove that their adjusted co-citation network gives a better overview of authors’ topics of interest than traditional co-citation networks.
In this work, we will apply semantic similarity measures on the titles of co-cited papers to determinate if co-cited papers deal about similar topics. Detailed explanation about the methods we used can be found in Sections 3 and 4.
In order to evaluate the semantic similarity between the referred papers in a co-citation (
Pre-treatment step
The stop words in each paper title are removed according to a list composed of 673 stop words. The POS tagger tool of the Stanford CoreNLP2[23] is then used to select the nouns represented by the tags (NN: Noun, singular; NNS: Noun, plural; NNP: Proper noun, singular; NNPS: Proper noun, plural).3 After that, each noun is lemmatized to obtain its singular form. Finally, the sets of nouns of each title
Computing semantic similarity
The estimation of the semantic similarity degree between the titles
WordNet “is a” taxonomy fragment [12].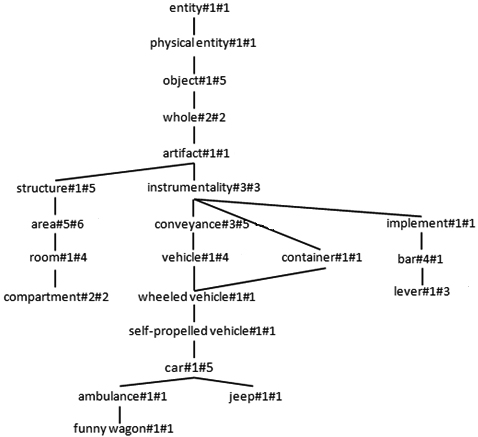
WordNet4 is a semantic resource focusing on English language [9]. As it is illustrated in Fig. 3, it exploits the synset concept for representing the words senses pertaining to different part of speech. Synset represents a specific sense of a word and it includes similar words sharing the same meaning. These sysnets are related through various semantic relations. Then, a polysemous word
Computational model
The Semantic Similarity (SS) between two titles is based on the calculation of the SS between their constituent nouns using the SS measures. The computing process is expressed as follows:
where
In WordNet, each noun
where
In literature, the quantification of semantic similarity between words is based mainly on the taxonomies “is a” like the one present in WordNet because they represent the share of common characteristics.
This section presents some WordNet-based SS measures that exploit topological parameters of concepts, including the depth, hyponyms, hypernyms and Lowest Common Subsumer (LCS). These measures are based on the hierarchical structure of the taxonomies independently from the language of the semantic resource as will be explained in next paragraphs.
Path and depth-based measures
Wu and Palmer [46] proposed a new measure (WP) defined as follows:
where
Li et al. [19] have proposed a similarity measure (Li) to overcome the limitations associated with the edge counting methods.
Hao et al. [15] proposed a measure (Hao) using the semantic distance between two concepts (the shortest path length:
The interval of
Liu et al. [21] presented a different measure to estimate the SS between concepts in WordNet using edge-counting techniques. The fundamental idea of this measure is based on the assumption that the human judgment process for semantic similarity can be simulated by the ratio of common features to the total features between words using two formulae (Liu1) and (Liu2):
Where
Gao et al. [11] presented an approach for measuring the SS (Gao) based on edge-counting and information content theory. In the second strategy, instead of weighting each edge along the path from
Hadj Taieb et al. [13] proposed an ontology-based method (Hadj1) exploiting the depth and the hyponyms for estimating the semantic similarity between two words as follows:
with:
Where
The IC-based measures consist of a pair including the computing IC method and the similarity measure. Hadj Taieb et al. [12] proposed an IC computing method (Hadj2) based on the quantification of the subgraph formed by the ancestors of a target concept
The similarity measure proposed by Lin exploits the IC of the lowest common subsumer (LCS) because it represents the commonality between the two concepts
Sánchez et al. [29] proposed another strategy for computing Information Content (IC) (Sanchez) by using the hyponyms through the leaves of the hyponym subgraph of a concept and integrated a novel parameter, ancestors(c). The IC formula is expressed as follows:
This IC computation method is then used with the similarity measure of Meng and Gu [24] which is based on Lin’s measure. It is expressed by the following equation:
Zhou et al. [47] proposed a measure (Zhou) that takes information content measures and path based measures as parameters by using a tuning factor
In the next section, we detail the dataset DBLP citation network exploited in the determination of co-cited papers for studying their semantic perspective based on their titles.
The performance evaluation of the method proposed in the present work for measuring the Semantic Similarity (SS) between co-cited papers is based on two analytical experiments. The first is based on word-based benchmarks and aims to study the performance of the word-based semantic similarity measures outlined in the previous section; the second analyzes the semantic similarity between the highly co-cited papers using the dataset DBLP citation Network.5
Semantic similarity benchmarks
In this study, we have experimentally evaluated machine generated values of semantic similarity between words and compared them against human ratings [57]. Rubenstein and Goodenough [53] (RG65) obtained “synonymy judgments” on 65 pairs of words. The participants were asked to rate them on the scale of 0.0 to 4.0 according to their similarity of meaning. Miller and Charles [27] (MC30) extracted 30 pairs from the original 65 and then obtained similarity judgments from 38 participants. Likewise, Agirre et al. [1] created a semantic similarity dataset (AG203) that contained 203 pairs of terms from Fin353.
Halawi et al. [54] created a new dataset (MTurk771) wherein the similarity value of each word pair was taken as the mean score given by the workers in Amazon Mechanical Turk (AMT). Bruni et al. [56] created dataset (MEN3000)6 benchmark that consisted of 3000 word pairs, randomly selected from words that occurred at least 700 times in the freely available ukWaC and Wackypedia7 corpora. Hill et al. [55] presented SimLex-999 which contains a range of concrete and abstract adjective, noun and verb pairs. In this paper, we exploit only the noun subset (SimLex666).8
Evaluation metrics
The comparison between values provided by a measure and human judgments is particularly based on correlation coefficients.
The formatted entry of each paper in the dataset DBLP citation network.
Paper number distribution according to year of publication.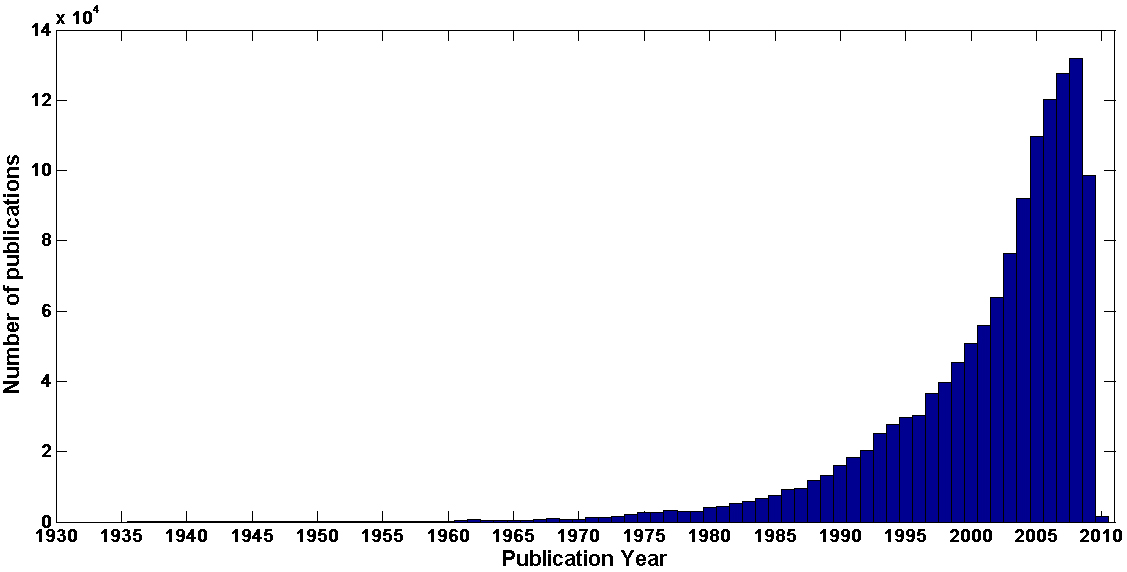
Co-citation frequency distribution in logarithmic scale (a) and frequency distribution of highly repeated (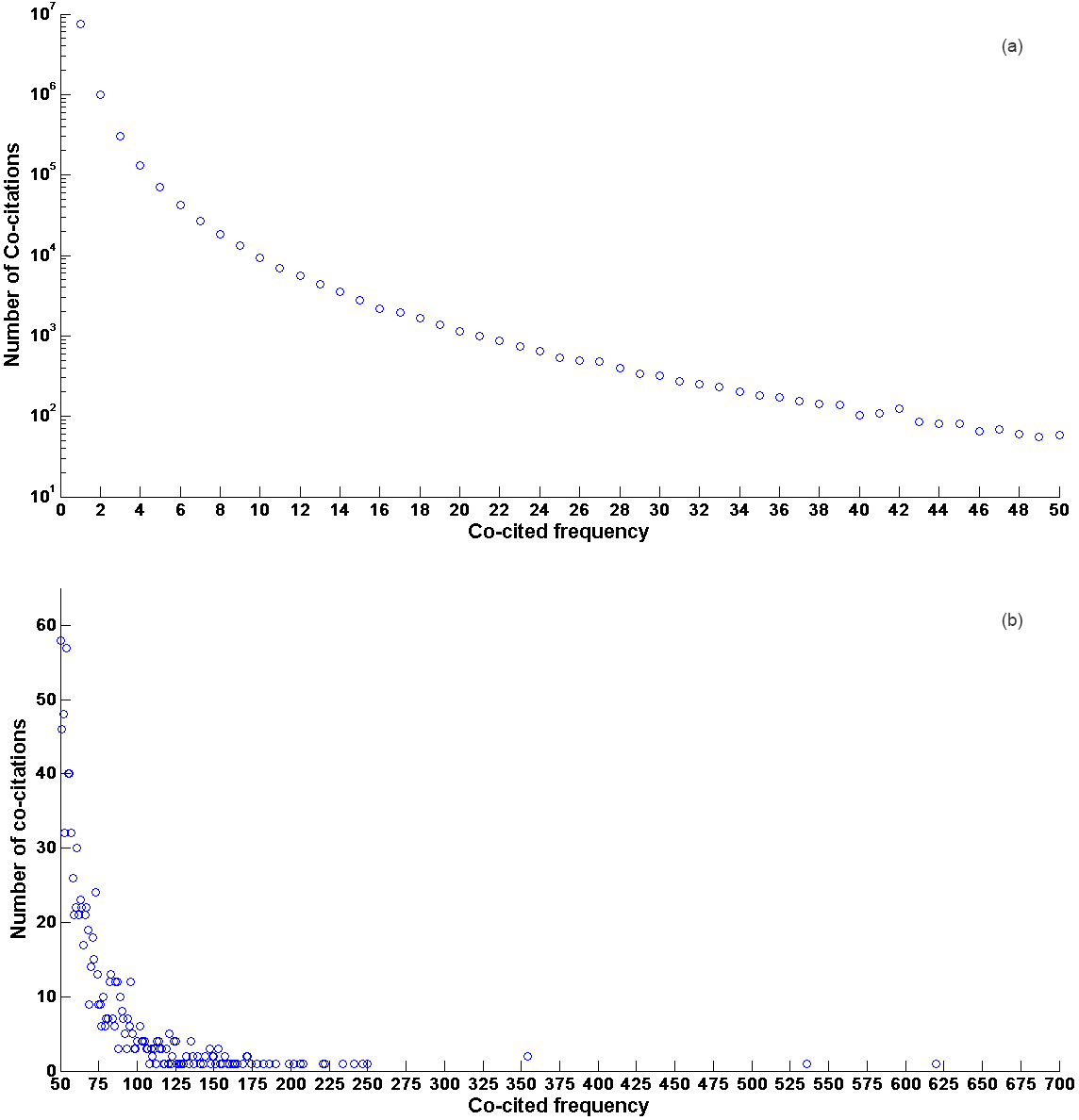
Curves representing Pearson correlation values (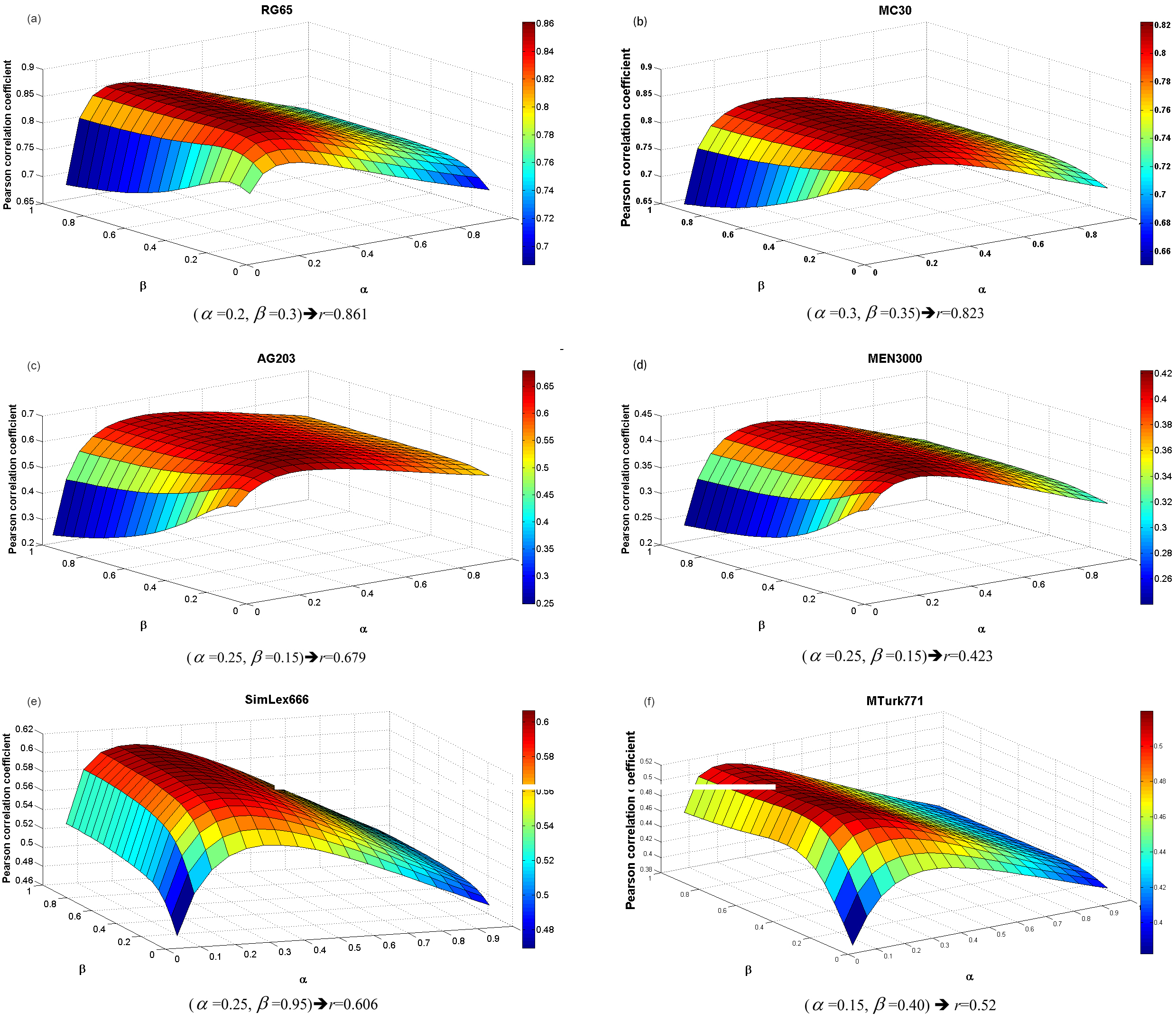
The Pearson product-moment correlation coefficient
where
This is used to correlate word pair rankings. The quality of such ranking is quantified by the Spearman rank order correlation coefficient
Results of semantic similarity measures applied on a set of word-based benchmarks using the Pearson correlation (
The DBLP [39] citation network consists of all papers dated before September 29, 2013. Each entry represents a paper and includes the title, authors, year, publication venue, index id, pid in AmentMiner database, and ids of references of the paper and the abstract. The dataset contains 2,084,055 papers and 2,244,018 citation relationships. Figure 4 describes the formatting way of each paper. The dataset contains 2,084,055 papers and 2,244,018 citation relationships.
Figure 5 shows the number of papers according to the publication year. It is clear that majority of the papers pertaining to the dataset dated back to the period between 2000 and 2010.
This dataset is exploited to study the semantic similarity between the highly pairwise co-cited papers based on their titles.
The inset Fig. 6a shows the co-citation frequency distribution in a logarithmic scale and the inset Fig. 6b is a zoom in on the co-citations repeated more than 50 times. Figure 6 also shows that most of the co-citations occur only once (1904758
Experiments’ results
The results from the analytical experiments are detailed in three parts: the first concerns the determination of the optimal values for the parameterized SS measures, the second part treats the results according to the word-based benchmarks, and the third part analyzes the semantic similarity between the highly repeated co-citations in the DBLP citation network dataset.
Determination of optimal tuning values
The semantic similarity measures exploit some of the tuning parameters described by Li et al. [19] in (Eq. (4)). So, the first step is to determine the optimal tuning values through the cited benchmarks. We just compute the Pearson correlation values (
Results of word-based benchmarks
Tables 1 and 2 show the correlation values obtained using the Pearson (
Results of semantic similarity measures applied on a set of word-based benchmarks using the Spearman correlation (
)
Results of semantic similarity measures applied on a set of word-based benchmarks using the Spearman correlation (
Curves representing the distribution of similar co-citations using different semantic similarity measures with a variation of the threshold 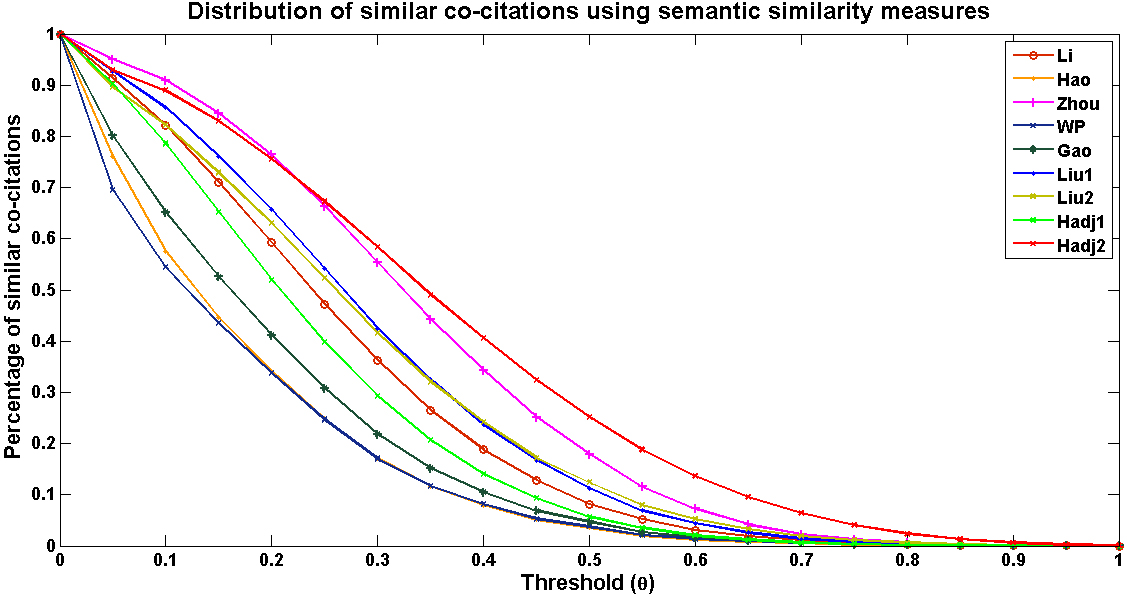
Tables 1 and 2 show that the results with the datasets RG65 and MC30 are very close to the human judgments, for example the correlation value
The performance evaluation of the method proposed in the present work for measuring the Semantic Similarity (SS) between co-cited papers is based on two analytical experiments. The first is based on word-based benchmarks and aims to study the performance of the word-based semantic similarity measures outlined in the previous section; the second analyzes the semantic similarity between the highly co-cited papers using the dataset DBLP citation Network.9
We extract from the DBLP dataset 2305156 distinct co-citations. From this dataset, we select a subset (
Despite the difference at the used computational models, Fig. 8 shows that several semantic similarity measures have similar behaviors, such as (Liu1 and Liu2) and (Hao and WP). Moreover, we note that the Zhou measure provides the most high similarity values when compared to other measures. We also note the marked congestion visualized by the curves for the
Each point pertaining to a curve refers to the percentage of co-citations having a similarity degree higher than or equal to the threshold
Conclusion and future work
In this paper, we propose a new method for analyzing the semantic similarity between the referenced papers in a co-citation. This method can be considered as a continuation of [7, 17]. Our approach is based on the semantic similarity measures applied on paper titles. Each title is submitted to a pre-treatment analytical step, including principally the POS tagger tool of Stanford, to extract the nouns and transform them into their lemma. The analysis proceeds by a semantic similarity computation procedure that principally integrates the word-based semantic similarity measures, which are based on the topological parameters extracted from the WordNet “is a” taxonomy. The exploited parameters are the depth, the hyponyms, the hypernyms and the LCS. Among the used SS measures, we exploit the intrinsic IC-based SS measures combining between IC-computing methods and IC-based measure. The evaluation includes two parts: the exploitation of recent and old word-based benchmarks and the use of the dataset DBLP citations network.
The results from the experiments performed on benchmarks show that the SS measures can simulate the human thinking process due to the good correlations using Pearson (r) and Spearman (
Therefore, these SS measures are exploited to calculate the SS between the titles of referenced papers related to highly repeated co-citations. In fact, a couple of paper titles is considered similar if the soft value provided by a SS measure is higher than a threshold
Considering the promising results generated by the method proposed in the present study, further research, some of which is currently underway in our laboratory, is needed to apply it in a process of co-citation clustering and investigate the topical relatedness between co-cited papers and to investigate if SS measures of the titles of co-cited papers significantly correlate with co-citation proximity, with co-citation frequency, and with human judgment of the similarity of co-cited papers.
Footnotes
Stanford CoreNLP provides a set of natural language tools for treating the text and gives the base forms of words, their parts of speech.
Appendix A
Appendix B: Top pairs of co-cited papers
Rank
Co-cited papers
Frequency
1
J. Ross Quinlan. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.
354
J.R. Quinlan. 1986. Induction of Decision Trees. Mach. Learn. 1, 1 (March 1986), 81–106.
2
J. Ross Quinlan. 1993. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA.
202
Leo Breiman. 1996. Bagging predictors. Mach. Learn. 24, 2 (August 1996), 123–140.
3
V. Jacobson. 1988. Congestion avoidance and control. In Symposium proceedings on Communications architectures and protocols (SIGCOMM ’88), Vinton Cerf (Ed.). ACM, New York, NY, USA, 314–329.
151
Sally Floyd and Van Jacobson. 1993. Random early detection gateways for congestion avoidance. IEEE/ACM Trans. Netw. 1, 4 (August 1993), 397–413.
4
C.A.R. Hoare. 1978. Communicating sequential processes. Commun. ACM. 21, 8 (August 1978), 666–677.
139
R. Milner. 1982. A Calculus of Communicating Systems. Springer-Verlag New York, Inc., Secaucus, NJ, USA.
5
Ricardo A. Baeza-Yates and Berthier Ribeiro-Neto. 1999. Modern Information Retrieval. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA.
137
Sergey Brin and Lawrence Page. 1998. The anatomy of a large-scale hypertextual Web search engine. In Proceedings of the seventh international conference on World Wide Web 7 (WWW7), Philip H. Enslow, Jr. and Allen Ellis (Eds.). Elsevier Science Publishers B. V., Amsterdam, The Netherlands, The Netherlands, 107–117.