
Abstract
Diabetes has become a global health problem, where a proper diagnosis is vital for the life quality of patients. In this article, a genetic algorithm is put forward for designing type-2 fuzzy inference systems to perform Diabetes Classification. We aim at finding parameter values of Type-2 Trapezoidal membership functions and the type of model (Mamdani or Sugeno) with this optimization. To verify the effectiveness of the proposed approach, the PIMA Indian Diabetes dataset is used, and results are compared with type-1 fuzzy systems. Five attributes are used considered as the inputs of the fuzzy inference systems to obtain a Diabetes diagnosis. The instances are divided into design and testing sets, where the design set allows the genetic algorithm to minimize the error of classification, and finally, the real behavior of the fuzzy inference system is validated with the testing set.
Keywords
Introduction
Diabetes is a disease that occurs when glucose level, also called blood sugar, is too high and the body does not metabolize it. If this disease is not properly treated can trigger other health problems in the heart, liver, and lungs [38]. Diabetes has become a serious worldwide health problem [10]. Its diagnosis is crucial, because its correct diagnosis can allow the patients to make the right decisions for their health [27, 32, 36]. Many intelligence techniques have been considered for assigning a correct diagnosis to this and other chronic diseases, mainly artificial neural networks and fuzzy logic [11, 31]. In [30], the authors classify the status of a liver by proposing an interesting deep classifier using off-line trained deep convolutional neural networks (CNNs) trained with liver images to perform the classification of liver status: normal, cirrhosis, or hepatitis. In [2], a review of fuzzy logic techniques applied to infectious diseases is shown. In addition, methods such as, rule-based fuzzy logic, adaptive neuro-fuzzy inference system (ANFIS), and fuzzy cognitive maps, have been successfully applied to dengue fever, hepatitis, and tuberculosis. In [14], fuzzy approaches are proposed to cyclist injury-severity classification in bicycle-vehicle accidents. Information such as pavement type, accident type, and vehicle-movement are used to perform the classification. The results obtained showed the advantages of using fuzzy decisions. A fuzzy neural network (FNN) for pattern classification is proposed in [16], where a Radial Basis Function Neural Networks (RBFNN) is modified with a supervised fuzzy clustering to determine the number of clusters with their centroid applied to pattern recognition. In [29], type-2 fuzzy inference systems have also been successfully applied to medical diagnosis, mainly for breast cancer, fertility, and diabetes. In works related to the diagnosis of diabetes we can find: an adaptive neuro-fuzzy inference model for diabetes diagnosis and a recommender of diets for personalized management of diabetes is proposed in [28]. In [38], the authors perform a recompilation of fuzzy logic techniques used in data mining and applied to diabetes prognosis and the advantages of each technique applied to this disease are shown. In general, the literature demonstrates the different areas where Type-2 fuzzy inference systems have been successfully applied to classification, pattern recognition, and fuzzy logic controllers, to mention a few [17, 21]. Also, optimization techniques have allowed designing fuzzy systems. For example, in [7], a bat optimization algorithm is proposed to design classification systems where Radial Basis Function Neural Networks are applied to perform this task. In [4], type-2 fuzzy inference systems have also been considered in classification and their parameters optimized with an Ant Lion Optimizer. In [25], the authors proposed a hybrid method, where a fuzzy rule-based approach and a harmony search (HS) algorithm are combined to classify medical datasets. They applied the harmony search algorithm to select the best fuzzy if-then rules using 9 datasets to prove the effectiveness of the proposed hybrid method. The genetics algorithms have been applied to various areas, such as forecasting, classification, segmentation of images, and routes for robots [1, 33]. In [6], the authors highlight the benefits of this optimization technique and how its hybridization with other techniques improves the results for the price predictions of energy commodities, metals, and agricultural products. In [31], an ensemble model is proposed, where techniques such as artificial neural networks, fuzzy inference systems, adaptive neuro-fuzzy inference systems, extreme machine learning, and support vector regression are optimized using a genetic algorithm to predict the energy demand, the results showed the improvement of the accuracy in the prediction. The genetic algorithms have also proved to be a great tool to optimize fuzzy inference system parameters [19, 20]. For this reason, in previous work [22], Type-1 fuzzy inference systems were designed for diabetes classification. The optimal parameters of three triangular membership functions considered each variable were obtained using a genetic algorithm, which has proved to be a useful tool as a search algorithm [24, 39]. The inputs of the fuzzy inference systems were: Glucose, Blood Pressure, Body Mass Index, Diabetes Pedigree Function, and Age. The best result was achieved using 13 if-then fuzzy rules. In this work, we propose an optimization of parameters of Type-2 Trapezoidal membership functions and the type of fuzzy model (Mamdani or Sugeno). The achieved results are compared with type-1 fuzzy systems that also were optimized using the same type of membership function to achieve a fair comparison.
This paper is organized in the following form: In Section 2, the basic concepts are described. Section 3 contains details about the proposed method. In Section 4 the experimental results are presented and in Section 5, the conclusions are outlined.
Basic concepts
The basic concepts required for understanding the approach presented in this article are summarized in this section.
Fuzzy logic
Fuzzy logic is one of the main areas of computational intelligence and allows imprecise information to be processed [34]. In traditional logic, an element can belong absolutely to a set or not, which means 1 or 0, respectively. In 1965, L. A. Zadeh [40] introduced the definition of a fuzzy set, where an element can partially belong to a set with a membership degree having crisp values in
Type-1 trapezoidal membership function.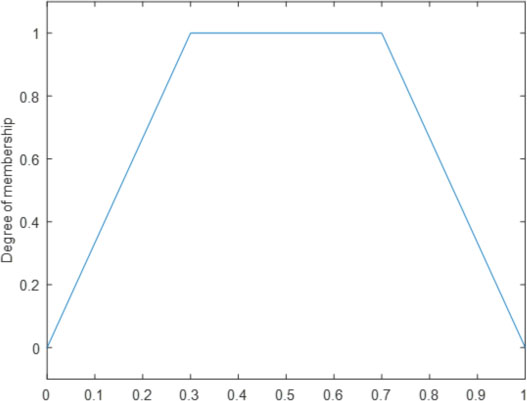
Zadeh also proposed in 1975 [41] the concept of type-2 fuzzy set, where the membership degree of an element is defined with a fuzzy set in
Type-2 trapezoidal membership function.
Genetic algorithms (GAs) are search procedure based on the mechanics of evolution natural selection and developed by John Holland [9]. In this kind of optimization technique, the strongest individual survives to the next generations. An individual (solution) is represented by a chromosome (real or binary), where a chromosome contains genes, and one or more genes can determine a characteristic or property to be optimized. In Fig. 3, a representation of the flowchart of a genetic algorithm is shown. When the algorithm begins its execution, a population is initialized with random values. The following steps will repeat until the stopping criteria are satisfied. Usually, as stopping criteria, a maximum number of generations is established. As the first step, the population is evaluated to assign it a fitness. The population is ranked, and the best individual (with the best fitness) is saved, in this way preventing that it suffers modifications. In the selection step, depending on the selection rate, a part of the population is modified by using the genetic operators (crossover and mutation). In crossover, two individuals have the role of parents, and they are combined to generate new offspring [15]. In the mutation, one or more genes are modified (its values). The individual previously saved (in the elitism) is reinserted to the new population as the next step. These steps are repeated until the stopping criteria are satisfied [1, 8, 18].
Flowchart of a genetic algorithm.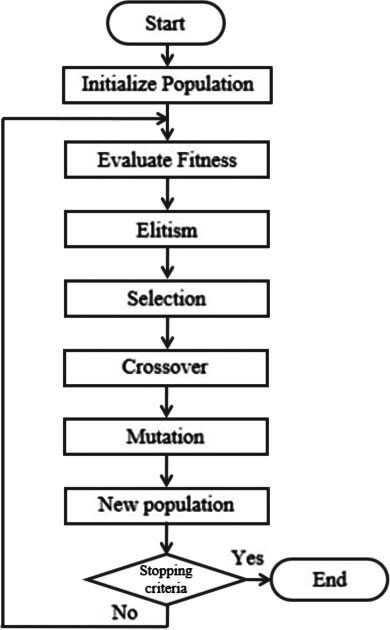
The proposed method performs classification of Diabetes using 5 attributes: Glucose, Blood Pressure (BP), Body mass index (BMI), Diabetes Pedigree Function (DPF), and Age (years) using type-2 fuzzy inference systems. These attributes were previously used in [22], where optimization of a type-1 fuzzy inference system using Mamdani Models with Triangular membership function was proposed. In this work, the Trapezoidal membership function is used due to its ability to take the appearance of a triangular membership function. The genetic algorithm seeks the Type-2 Trapezoidal membership function parameters and the type of model (Mamdani or Sugeno). In Fig. 4, the proposed method is represented.
Proposed method.
An illustration of the variable type-2 fuzzy inference can be observed in Fig. 5. The fuzzy if-then rules used in this work are shown in Fig. 6. In [22], the experiments were performed with six and thirteen fuzzy if-then rules. In this previous work, the best result was achieved using 13 fuzzy if-then rules. For this reason, now in this work, the experiments are performed using these 13 fuzzy if-then rules.
Example of Type-2 Trapezoidal membership functions.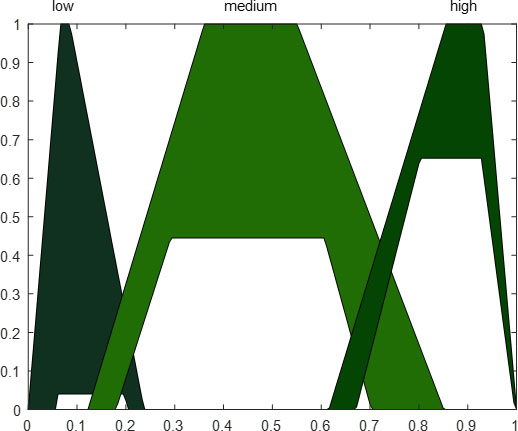
Fuzzy if-then rules.
Chromosome of the genetic algorithm.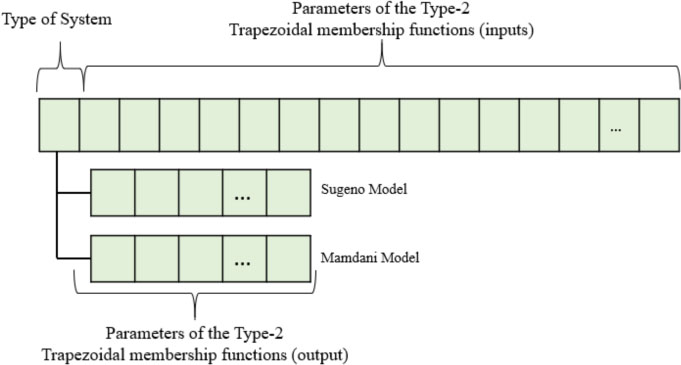
Diagram of the proposed method.
In this work, the PIMA Indians Diabetes Database (PID) from the National Institute of Diabetes and Digestive and Kidney Diseases [26] is used to design the fuzzy inference systems. This database has 768 instances with 8 attributes (risk factors) with 2 classes (0–1), where 0 represents “negative” and 1 represents as “positive”. Only 336 instances contain all the information in each of the attributes. In this work, these 336 instances are used to design the fuzzy inference systems. Originally, the database has 8 attributes: Pregnancies, Glucose, Blood Pressure (BP), Skin Thickness, Insulin level, Body mass index (BMI), Diabetes, Pedigree Function (DPF), and Age (years). In this work, only 5 of the 8 original attributes are used to design the fuzzy inference system applied to Diabetes classification. These attributes are Glucose, Blood Pressure, Body Mass Index, Diabetes Pedigree Function, and Age. These attributes will be the inputs of the fuzzy inference systems, and the classification will be the output (Classification). These attributes were also used in [22], where type-1 fuzzy systems containing triangular functions were designed. The range of values of these attributes is shown in Table 1. These ranges are used to design the minimum and maximum values of each fuzzy variable.
The PID dataset attributes
The PID dataset attributes
Type-1 FIS of evolution #2.
The 336 instances are divided into design and testing sets. The design set is used during the execution of the genetic algorithm to minimize the classification error. The best fuzzy inference system of each evolution is proved with the testing set to evaluate its real accuracy. For the design phase, 70% of the instances are used (235), and for the testing phase, 30% of the instances (101).
This genetic algorithm was aimed at minimizing the classification error. The accuracy equation used in this work is given by:
where
The parameters used in the GA for designing the type-2 fuzzy systems are presented in Table 2.
Parameters of the GA
Convergence of evolution #2.
The chromosome of the implemented genetic algorithm for the type-2 fuzzy systems is illustrated in Fig. 7. In Fig. 8, the diagram of the proposed method is illustrated, where the genetic algorithm designs the type-2 fuzzy inference systems for Diabetes classification.
Type-1 FIS of evolution #4.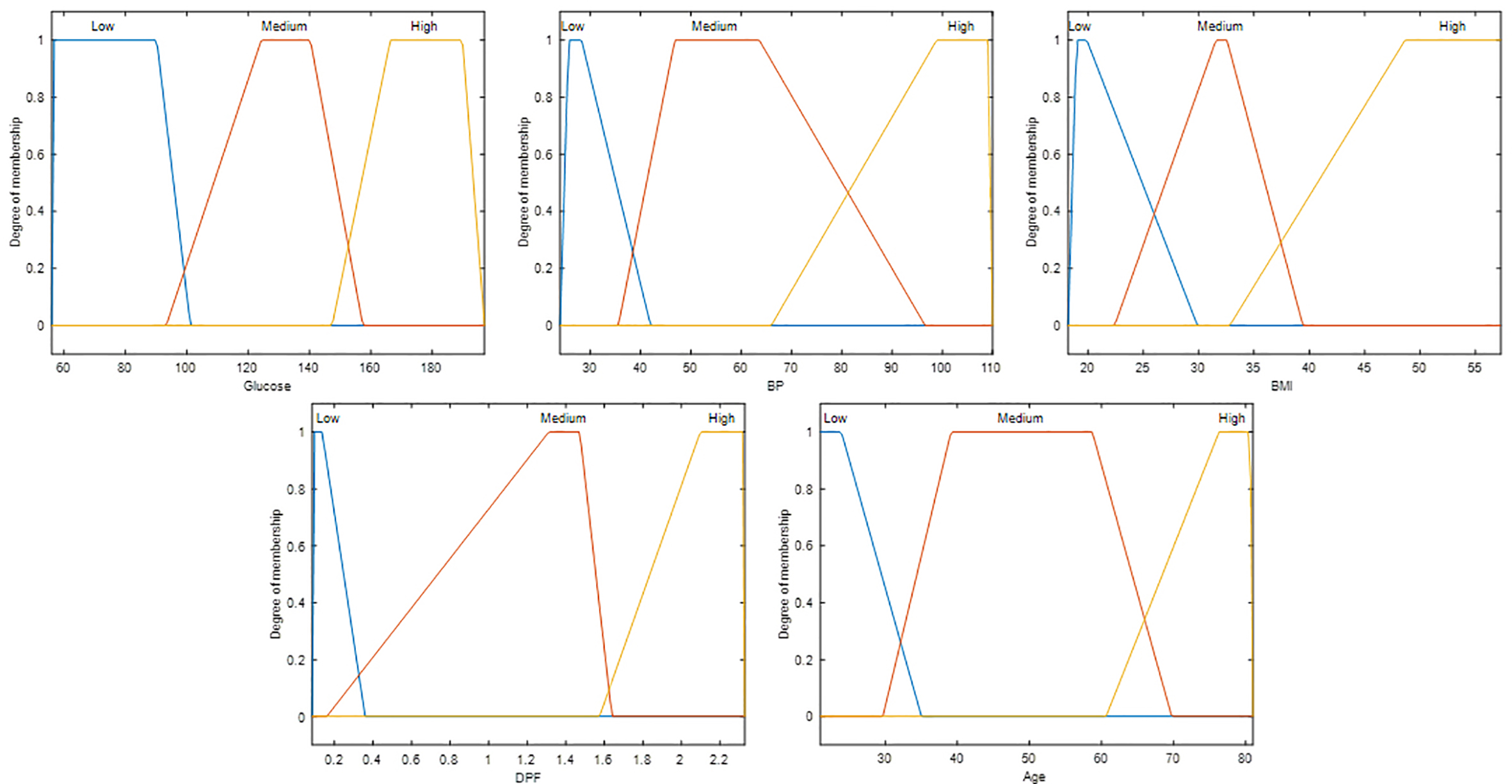
The results achieved with the proposed method are presented in this section. For the particular case of this work, 30 evolutions were performed with the 13 fuzzy if-then rules above mentioned. To compare the proposed method, the results of type-1 fuzzy inference systems are also shown.
Results with type-1 fuzzy logic
The next 5 evolutions obtained the best results when the genetic algorithm is ap-plied to designing Type-1 fuzzy inference systems. The Type-1 FIS achieved with evolution #2 is shown in Fig. 9. It is a Sugeno model, and its convergence is illustrated in Fig. 10. This type-1 fuzzy system achieved in the design phase an accuracy of 81.70%, but for the testing phase, the accuracy decreases to 79.21%.
The Type-1 FIS achieved with evolution #4 is shown in Fig. 11. It is a Sugeno fuzzy model, and its convergence is shown in Fig. 12. This Type-1 FIS achieved in the design phase an accuracy of 80.00%, but for the testing phase, the accuracy has a little decrease to 79.21%.
The Type-1 FIS achieved with evolution #13 is shown in Fig. 13. It is a Sugeno fuzzy model, and its convergence is shown in Fig. 14. This Type-1 FIS achieved, in the design phase, an accuracy of 81.70%, but for the testing phase, the accuracy has a decrease to 79.21%
Best 5 evolutions (type-1 fuzzy logic)
Best 5 evolutions (type-1 fuzzy logic)
Convergence of evolution #4.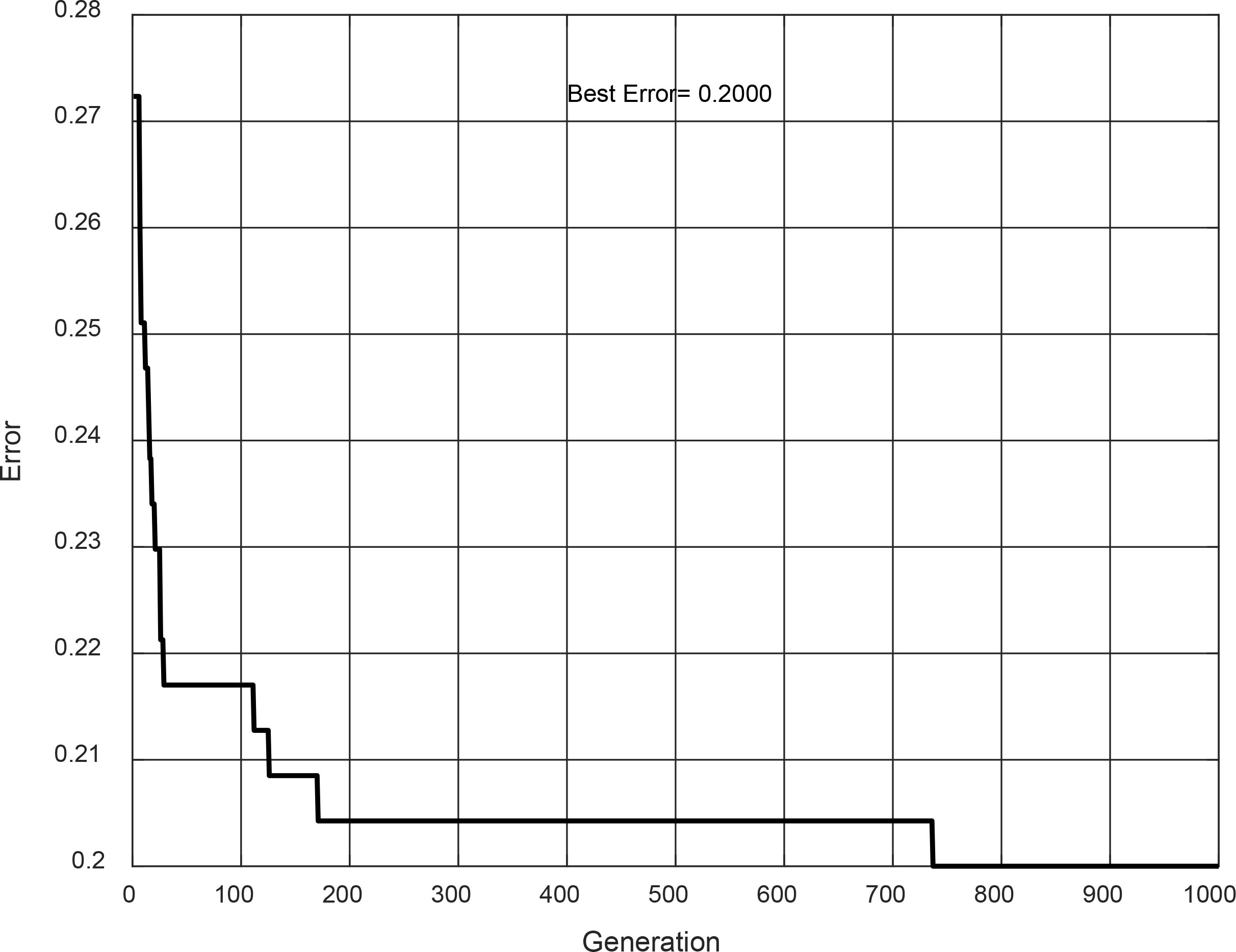
Type-1 FIS of evolution #13.
Best 5 evolutions (type-2 fuzzy logic)
Convergence of evolution #13.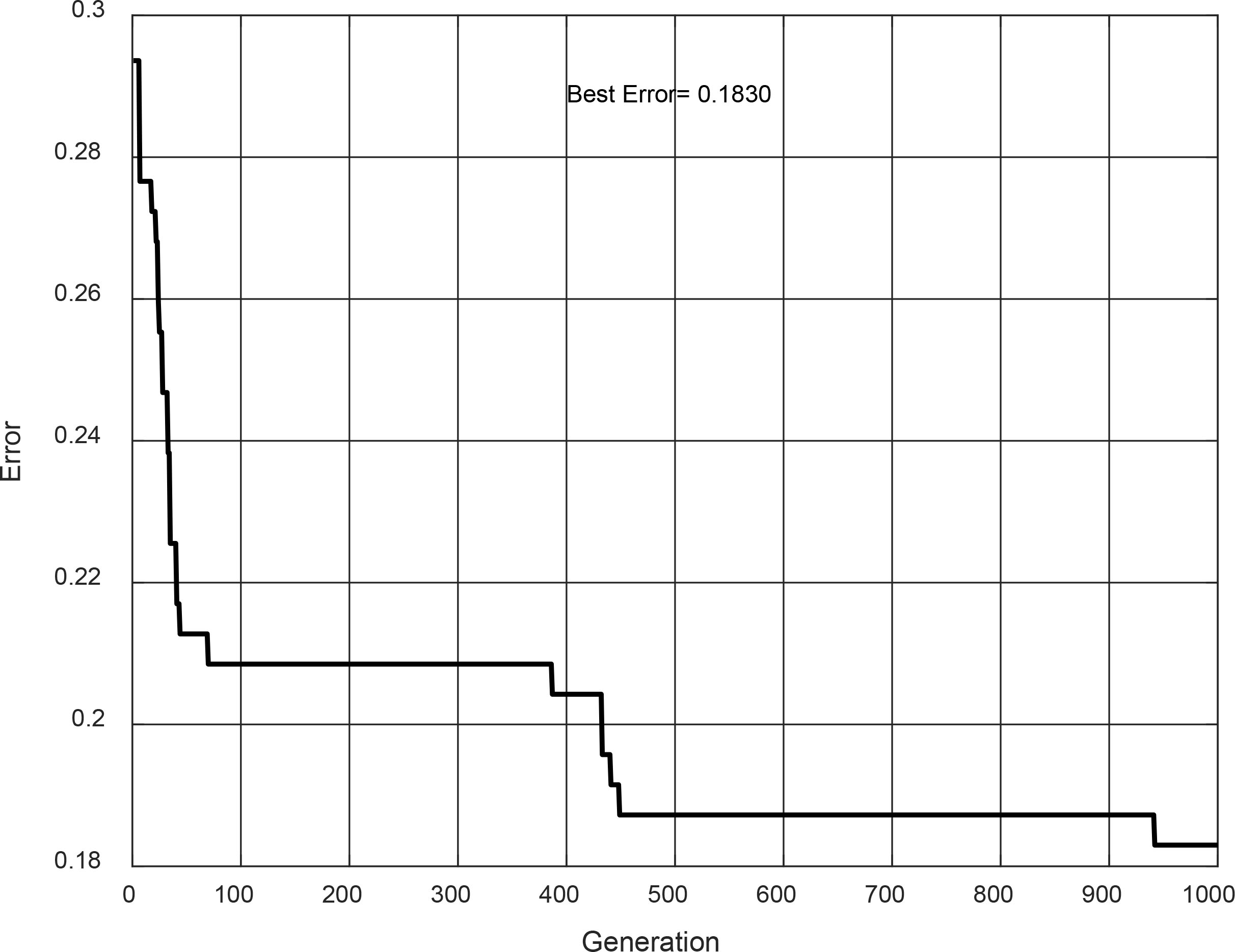
Type-1 FIS of evolution #19.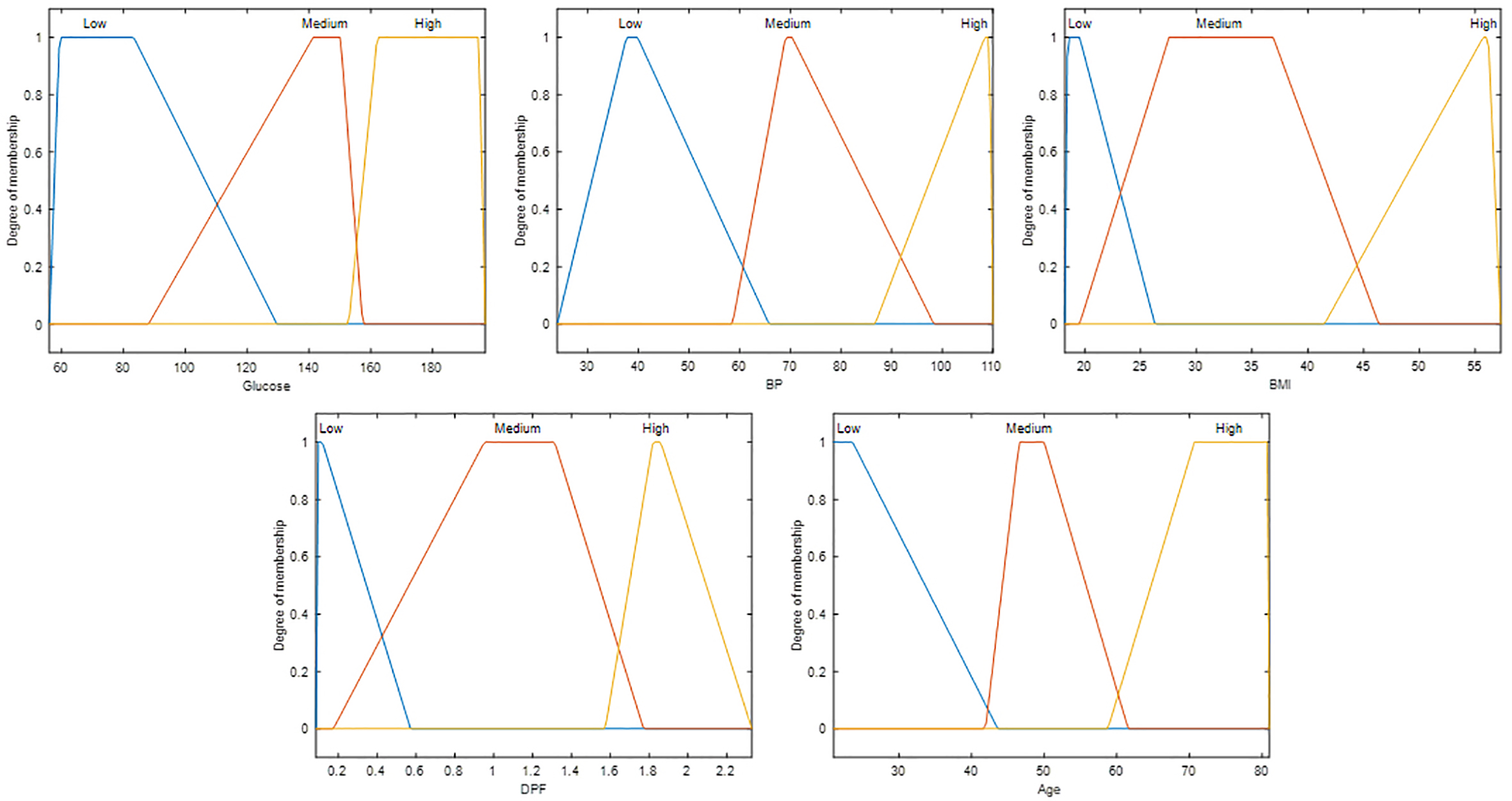
The Type-1 FIS achieved with evolution #19 is shown in Fig. 15. It is a Sugeno model, and its convergence is shown in Fig. 16. This Type-1 FIS achieved in the design phase an accuracy of 82.55%, but for the testing phase, the accuracy has a decrease to 80.20%.
Summary of results
Convergence of evolution #19.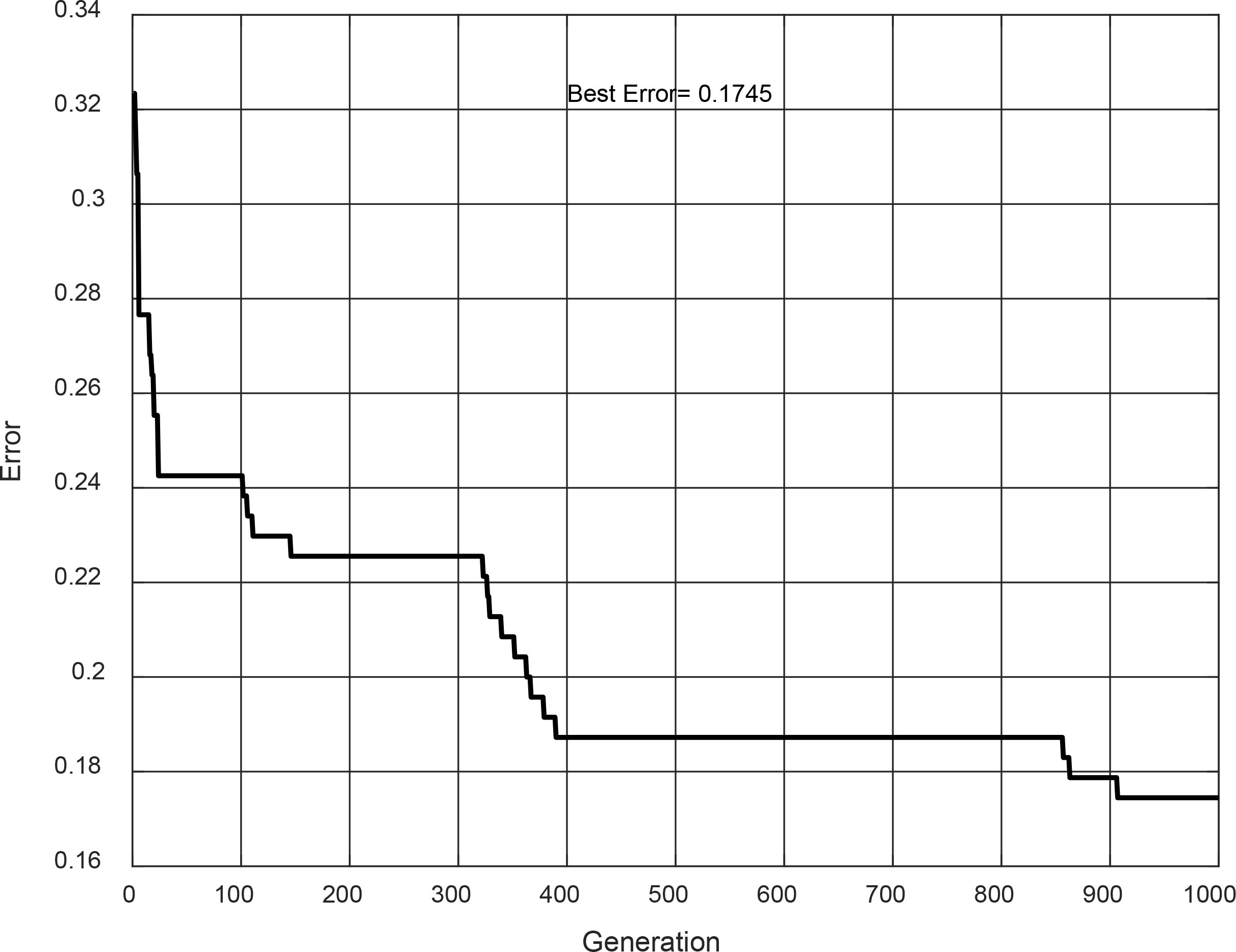
Type-1 FIS of evolution #12.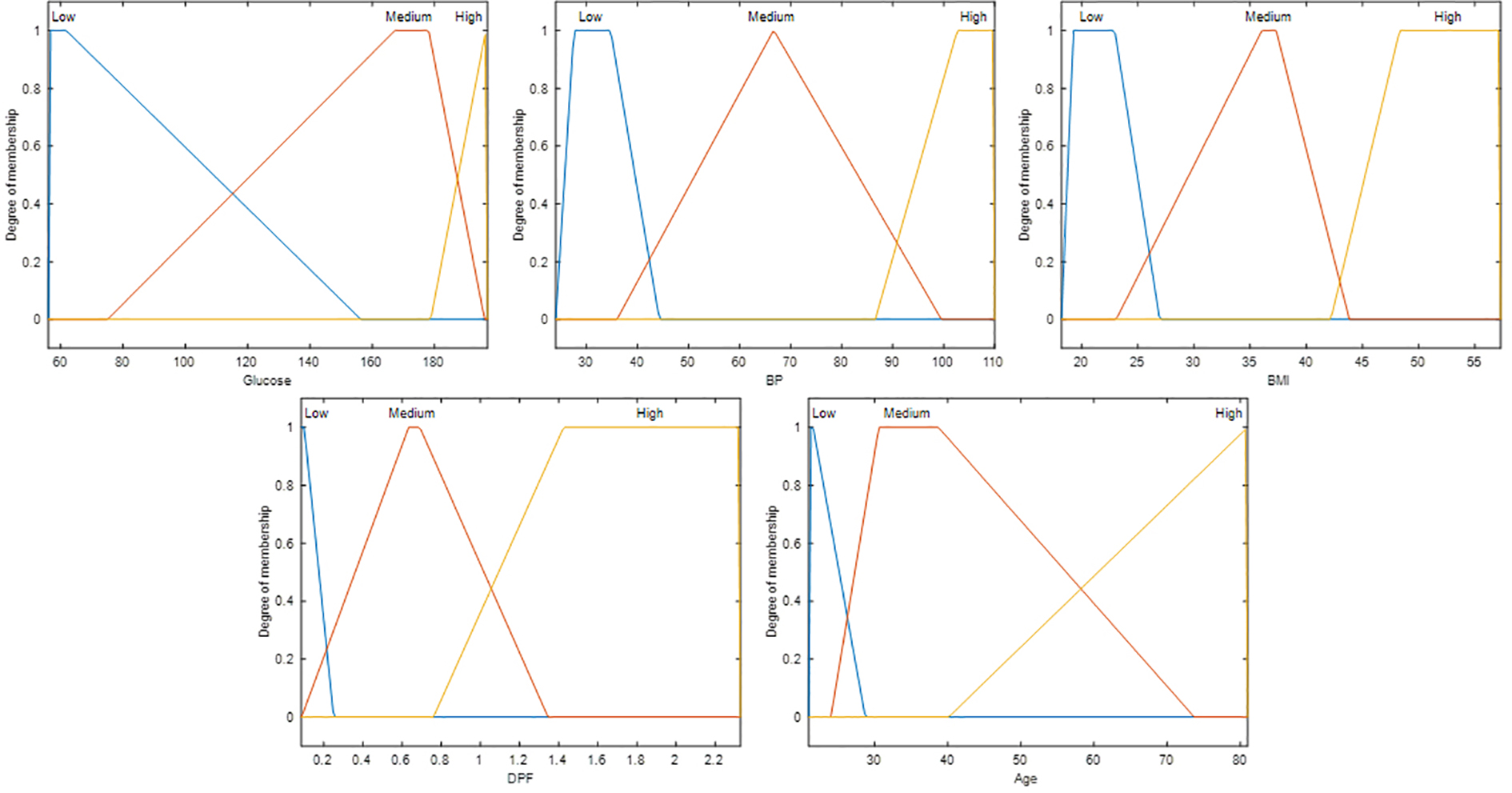
Convergence of evolution #12.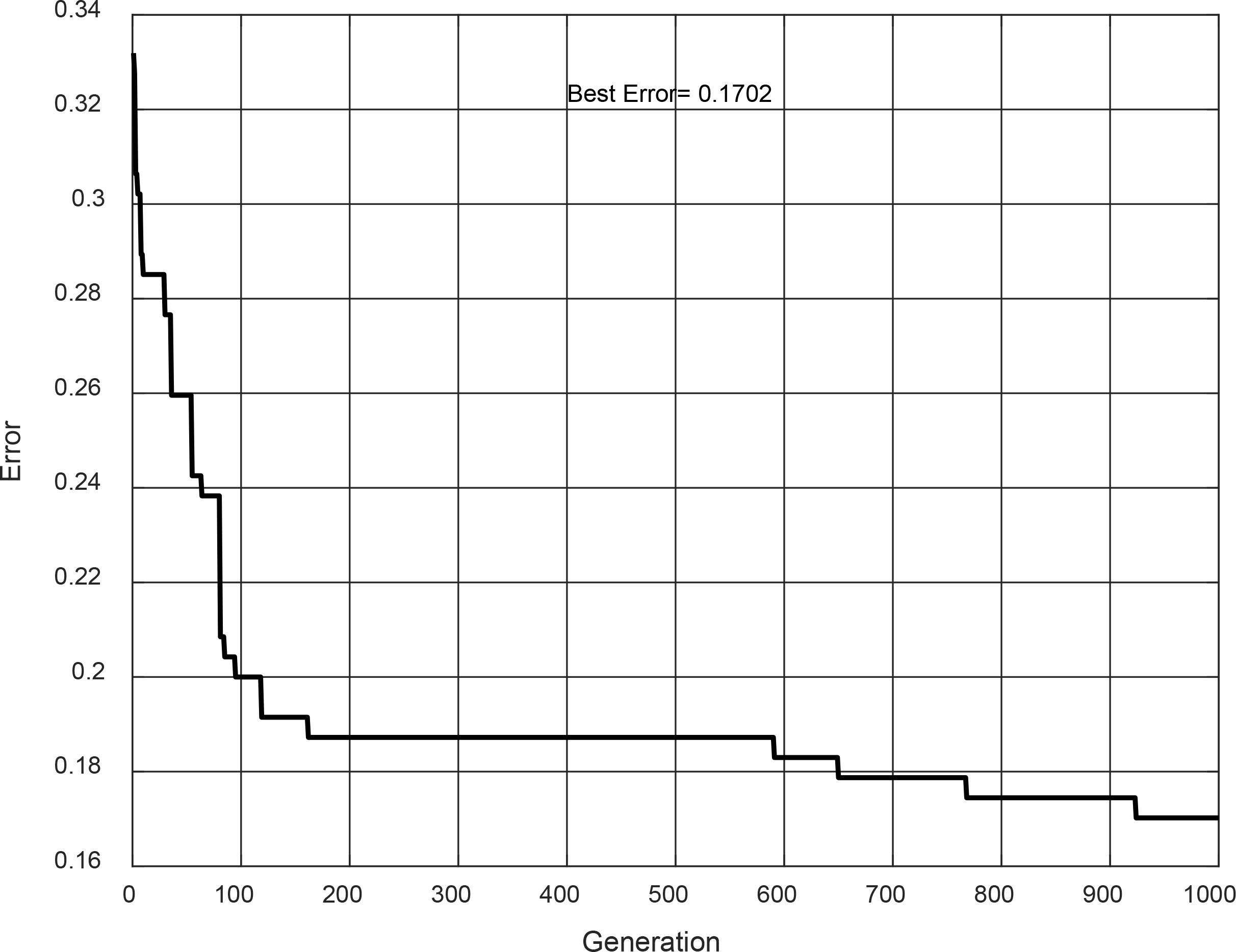
Type-2 FIS of evolution #2.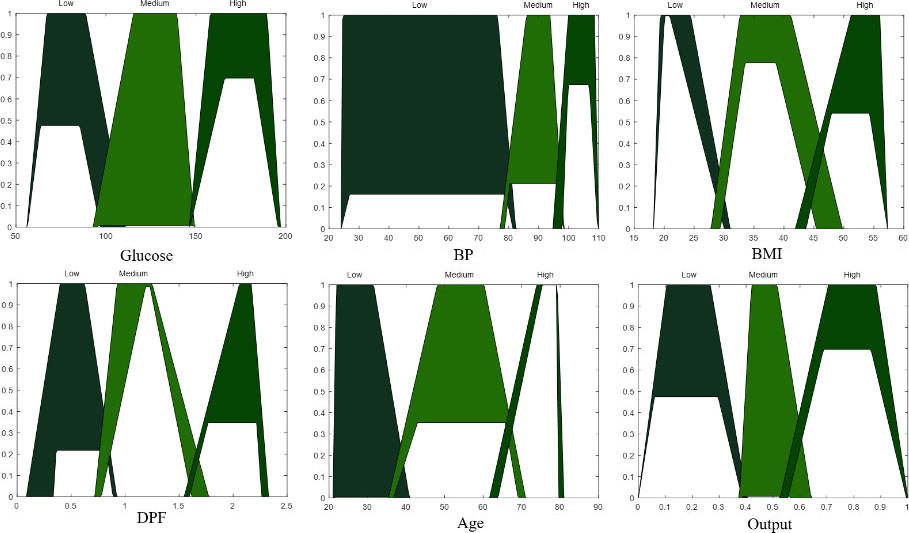
The best results (design and testing phase) are achieved in evolution #12. The Type-1 FIS is shown in Fig. 17. It is a Sugeno model, and its convergence is shown in Fig. 18. This Type-1 achieved in the design phase an accuracy of 82.99%, but for the testing phase, the accuracy has a decrease to 80.20%.
In Table 3, a summary of the results mentioned above is shown, where the error and percentage of accuracy for the design and testing phases using Type-1 fuzzy logic are shown. For the design phase, the best percentage of accuracy is obtained by evolution # 12 with 82.99%, and for the testing phase, evolution #12 and #19 achieved 80.20% of accuracy.
Comparison (best)
Convergence of evolution #2.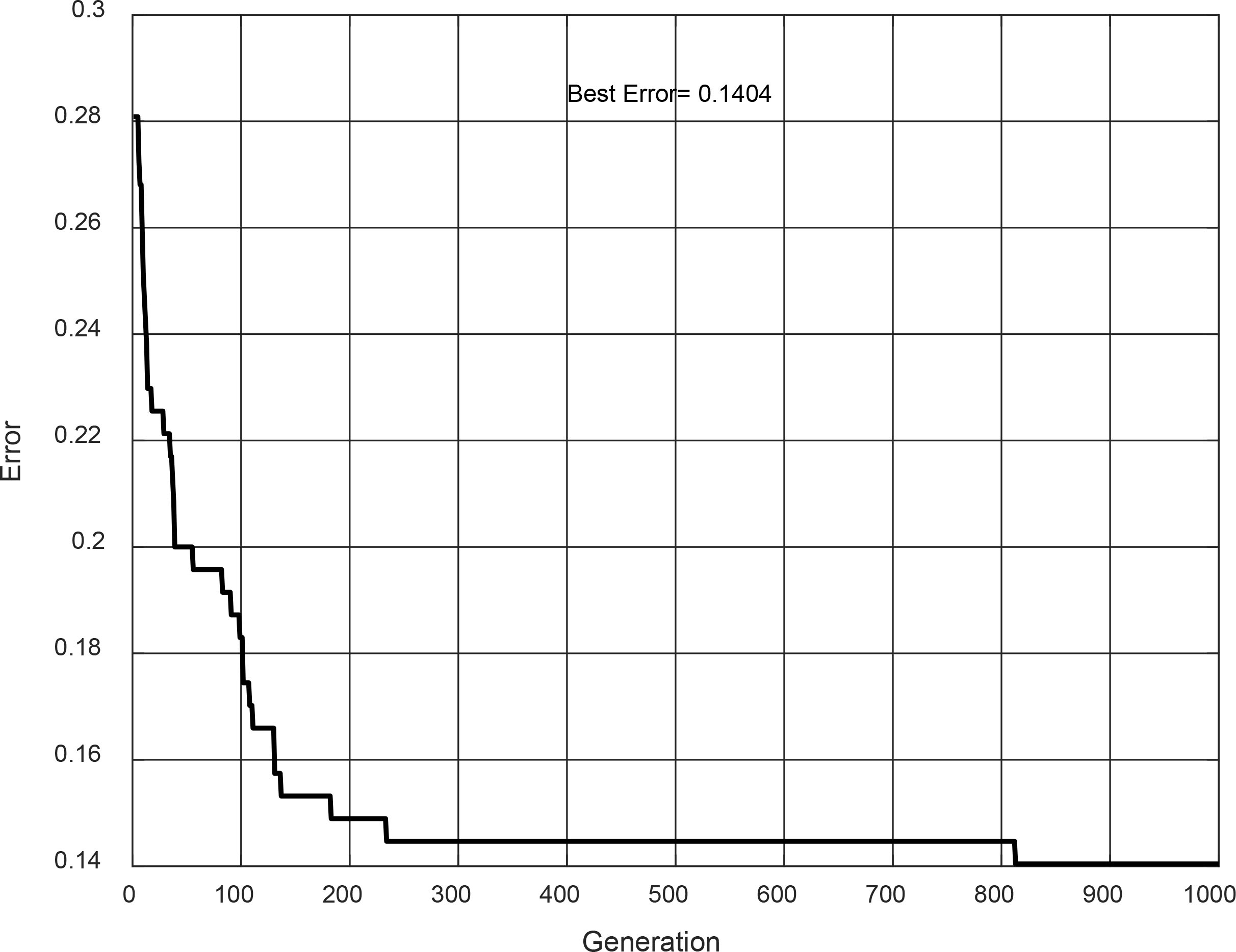
The best 5 evolutions obtained by the proposed method are shown. The achieved Type-2 FIS with evolution #2 is shown in Fig. 19. It is a Mamdani model, and its convergence is shown in Fig. 20. This Type-2 FIS achieved in the design phase has an accuracy of 85.96%, but for the testing phase, the accuracy decreases to 80.20%.
The Type-2 FIS achieved with evolution #10 is shown in Fig. 21. It is a Mamdani model, and its convergence is shown in Fig. 22. This Type-2 FIS achieved in the design phase an accuracy of 80.43%, for the testing phase, the accuracy increased to 81.19%.
The Type-2 FIS achieved with evolution #20 is shown in Fig. 23. It is a Mamdani model, and its convergence is shown in Fig. 24. This Type-2 FIS achieved in the design phase an accuracy of 81.28%, for the testing phase, the accuracy increased to 83.17%.
The Type-2 FIS achieved with evolution #30 is shown in Fig. 25. It is a Sugeno model, and its convergence is shown in Fig. 26. This Type-2 FIS achieved in the design phase an accuracy of 84.68%, but for the testing phase, the accuracy decreased to 80.20%.
The best results (design and testing phase) are achieved in evolution #26. In Fig. 27, the Type-2 FIS is illustrated. It is a Mamdani model, and its convergence is shown in Fig. 28. This Type-2 achieved in the design phase an accuracy of 86.68%, but for the testing phase, the accuracy has a decrease to 83.17%.
Table 4 summarizes the above-mentioned results, where error and percentage of accuracy for the design and testing phases using Type-2 fuzzy logic are shown. For the design phase, the best percentage of accuracy is obtained by evolution #12 with 86.38%, and for the testing phase the evolutions #20 and #26 achieved a 83.17% of accuracy.
Values of
-test (design phase)
Values of
Type-2 FIS of evolution #10.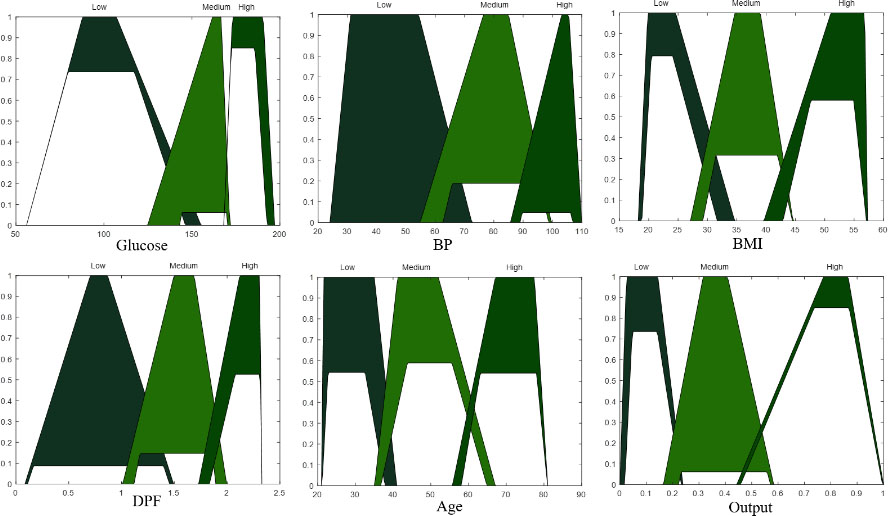
Convergence of evolution #10.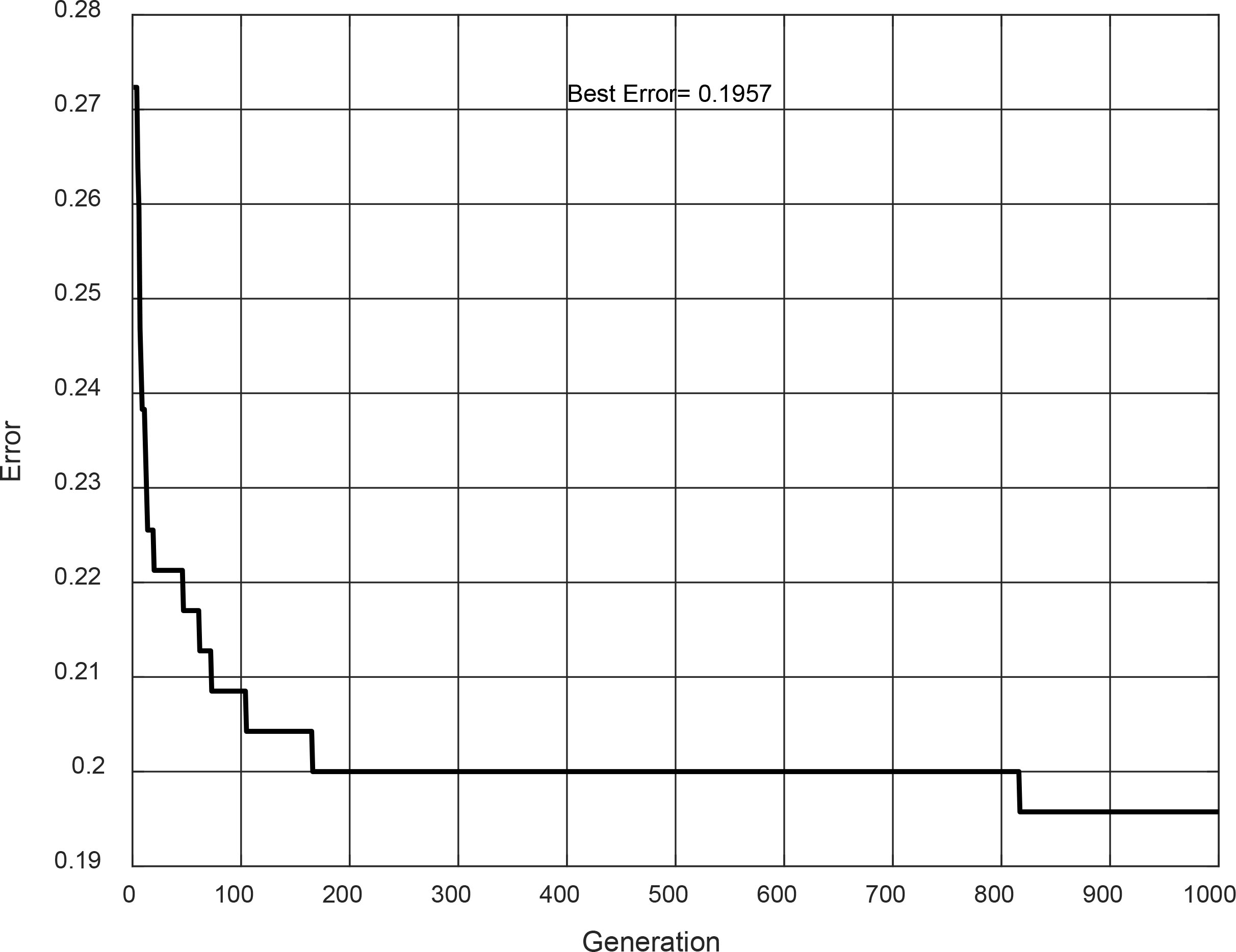
Type-2 FIS of evolution #20.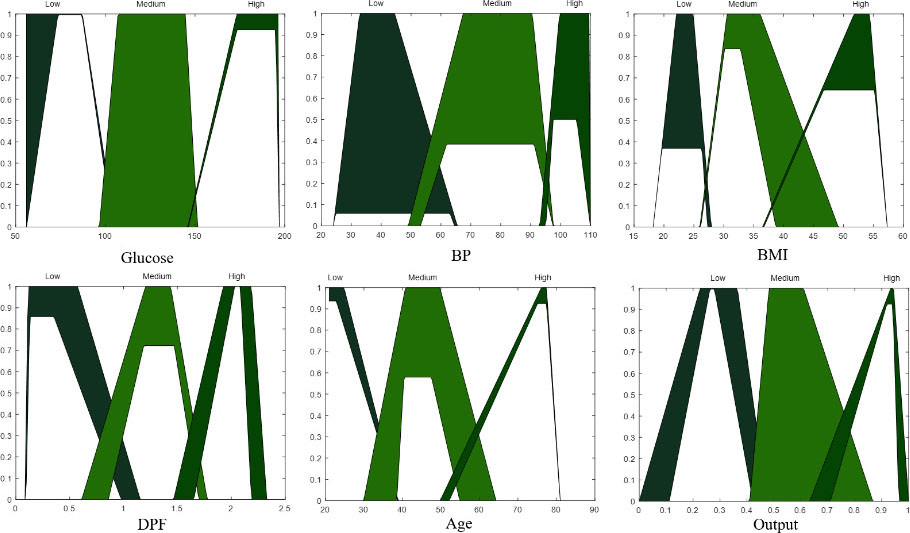
Convergence of evolution #20.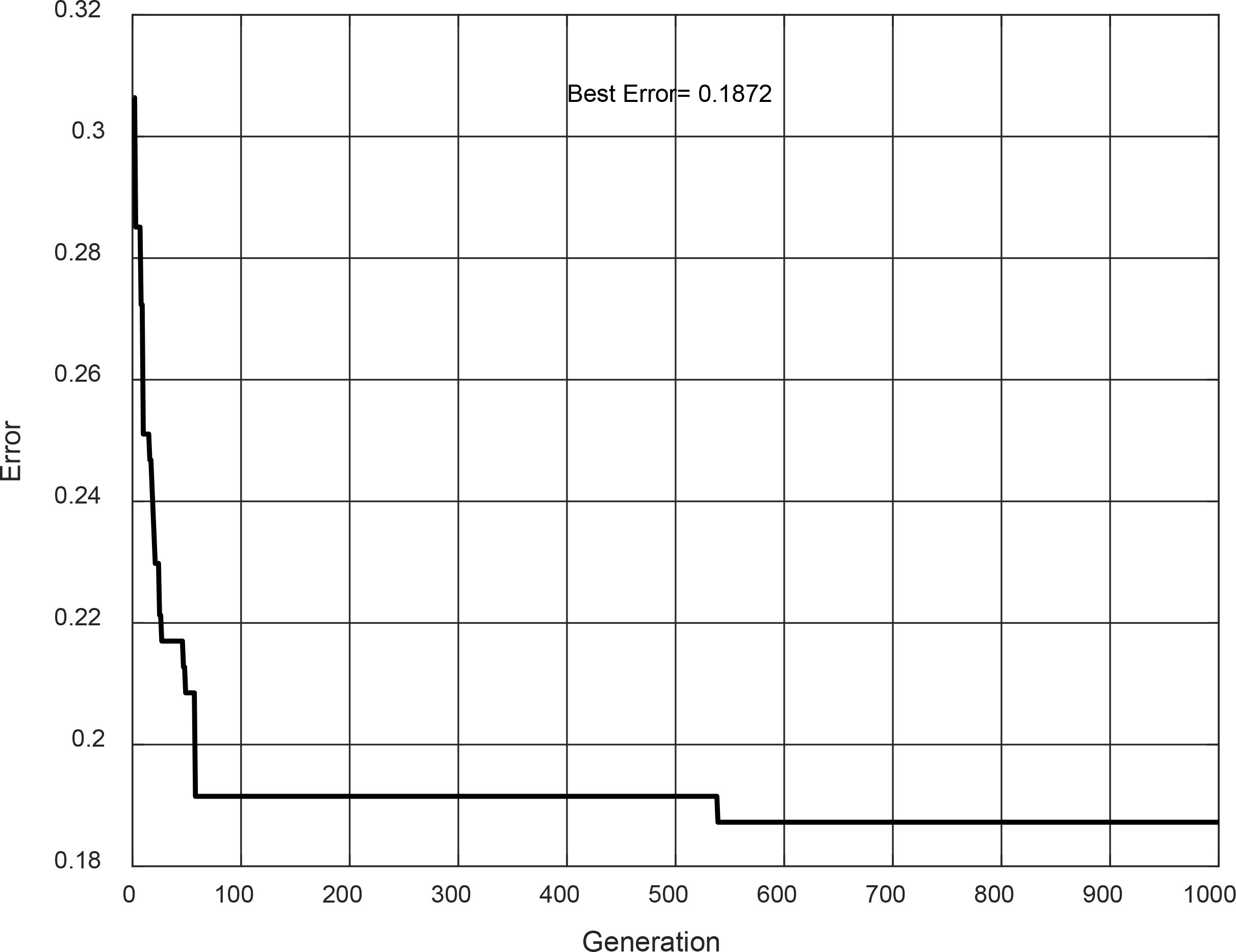
Type-2 FIS of evolution #30.
Convergence of evolution #30.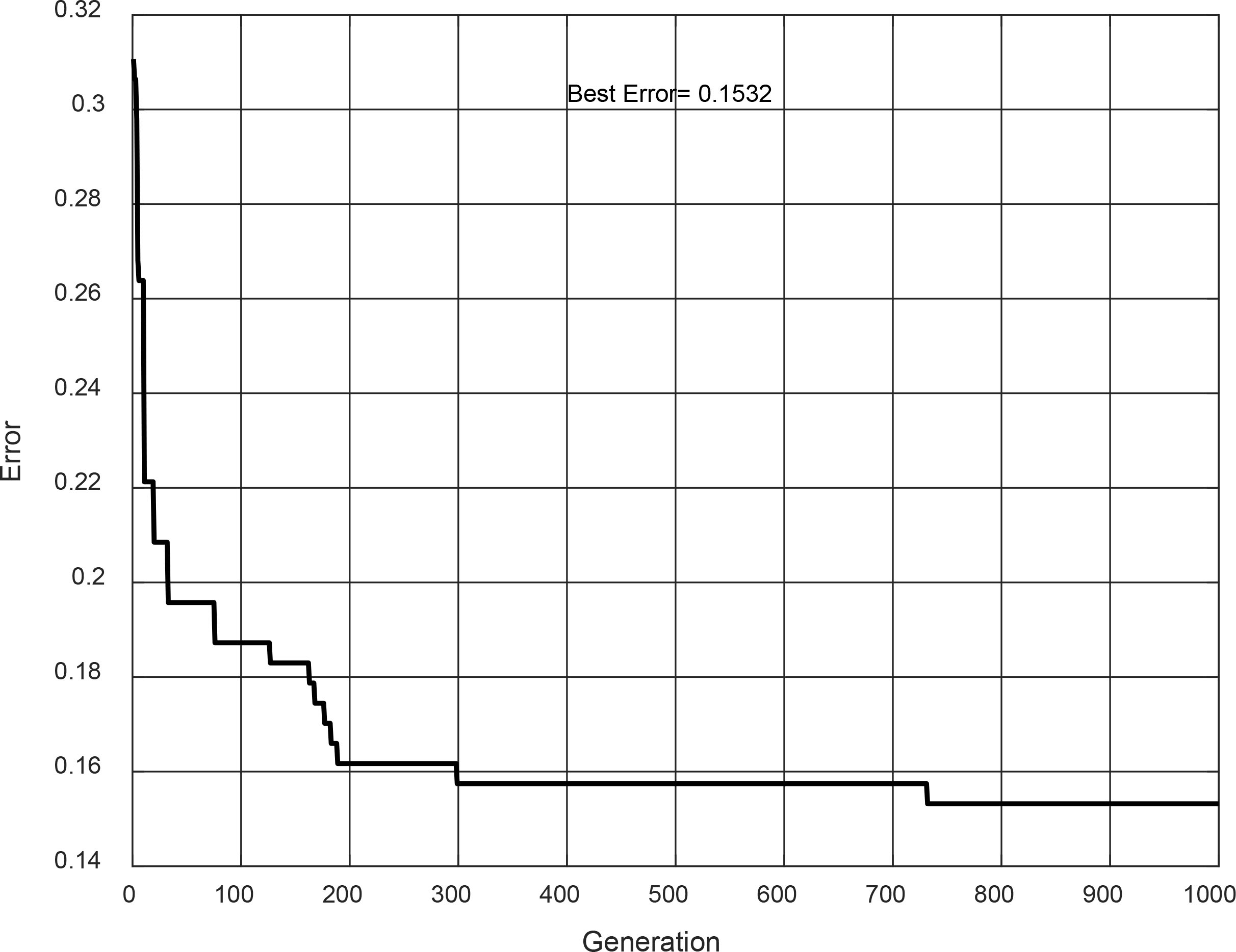
A summary of results obtained using 336 instances of the PIMA database, 70% for the design phase (when the genetic algorithm seeks to minimize the error) and 30% for the testing phase is presented in this Section. Table 5 is presenting the results achieved with the same 5 attributes (Glucose, Blood Pressure, Body Mass Index, Diabetes Pedigree Function, and Age). The best results are achieved with Type-2 Fuzzy inference systems for both phases: design and testing. This means that Type 2 fuzzy inference systems allow better results with instances that did not participate in its design, allowing for better behavior in a real environment.
Comparing the best result achieved in the testing phase, the type-2 fuzzy system achieved the best result over the previous work [22], where Triangular membership functions are optimized, and the results shown in this work are with Type-1 Trapezoidal membership functions. These results are illustrated in Table 6.
Statistical comparison of results
The statistical
Values of
-test (testing phase)
Values of
Type-2 FIS of evolution #26.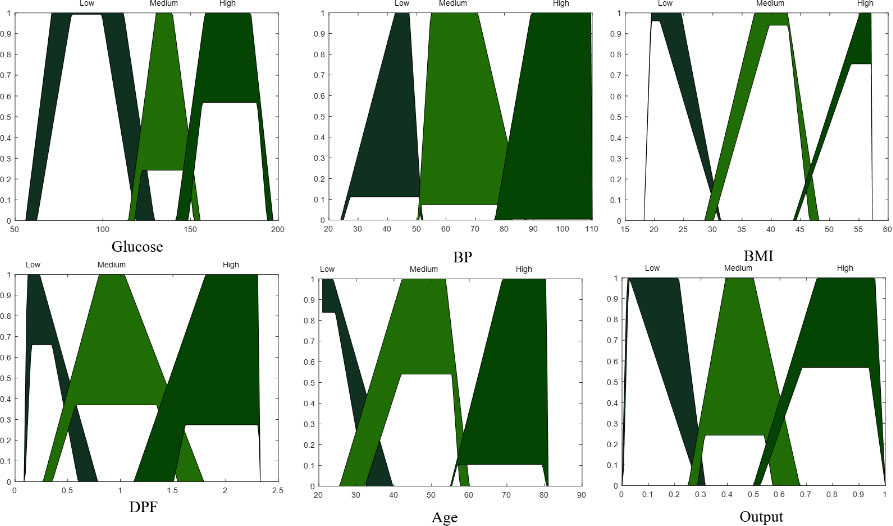
Convergence of evolution #26.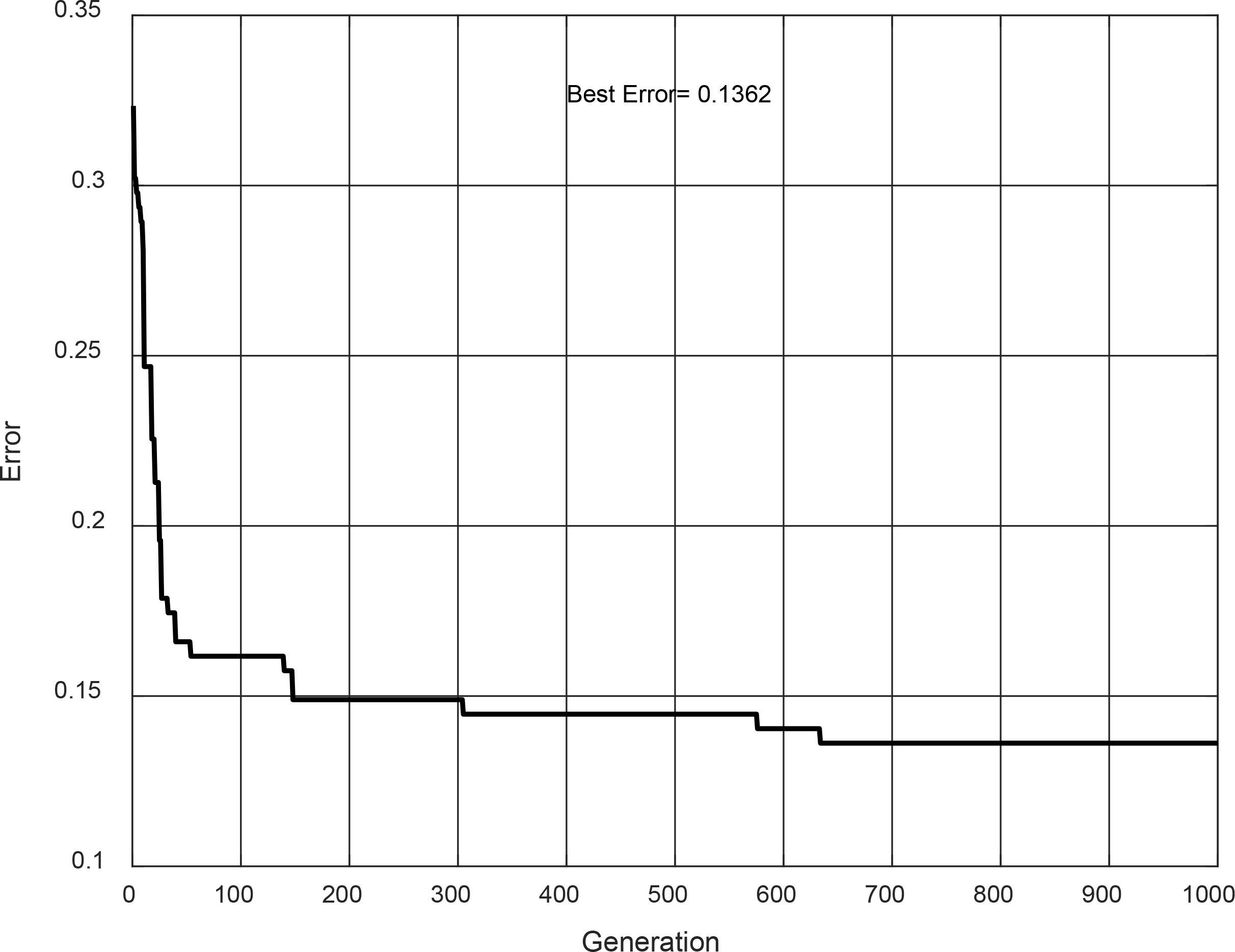
In Table 8, the values obtained in the
In this paper, the design of Type-2 fuzzy inference systems is performed for the Diabetes classification application. The optimization of parameters is performed using a genetic algorithm. This optimization consists of searching parameters for Trapezoidal membership functions in each fuzzy variable and its type of model (Mamdani or Sugeno). The fuzzy rules used in each fuzzy inference system were designed in a previous work. As inputs of the fuzzy inference systems 5 attributes of the PIMA database are used: Glucose, Blood Pressure, Body Mass Index, Diabetes Pedigree Function, and Age. To test the effectiveness of each fuzzy inference system, 336 instances of this database are divided into design and testing sets, using 70% and 30%, respectively. In the design phase, each individual of the genetic algorithms designs the fuzzy inference system, and with the design set, the FIS is evaluated to assign it a fitness value. The best fuzzy inference system obtained for each evolution is evaluated using the testing set to obtain real accuracy, using instances not used in the evolution (design phase). Results with type-1 fuzzy inference systems are shown to perform a fair comparison. This comparison proves the effectiveness of the type-2 fuzzy systems, which allows for better performance with the testing set of instances. As future works, the optimization of the fuzzy if-then rules is considered, and another optimization technique will be implemented to improve the results achieved in this work.