
Abstract
The cortical learning algorithm (CLA) is a time series prediction algorithm. Memory elements called columns and cells discretely represent data with their state combinations, whereas linking elements called synapses change their state combinations. For tasks requiring to take actions, the action-prediction CLA (ACLA) has an advantage to complement missing state values with their predictions. However, an increase in the number of missing state values (i) generates excess synapses negatively affect the action predictions and (ii) decreases the stability of data representation and makes the output of action values difficult. This paper proposes an adaptive ACLA using (i) adaptive synapse adjustment and (ii) adaptive action-separated decoding in an uncertain environment, missing multiple input state values probabilistically. (i) The proposed adaptive synapse adjustment suppresses unnecessary synapses. (ii) The proposed adaptive action-separated decoding adaptively outputs an action prediction separately for each action value. Experimental results using uncertain two- and three-dimensional mountain car tasks show that the proposed adaptive ACLA achieves a more robust action prediction performance than the conventional ACLA, DDPG, and the three LSTM-assisted reinforcement learning algorithms of DDPG, TD3, and SAC, even though the number of missing state values and their frequencies increase. These results implicate that the proposed adaptive ACLA is a way to making decisions for the future, even in cases where information surrounding the situation partially lacked.
Keywords
Introduction
The time-series data prediction is one of the important information technologies attracting much attention, especially in the computational intelligence domain, to make valuable decision makings for the future. The cortical learning algorithm (CLA) [1, 2, 3] is a time-series prediction algorithm based on hierarchical temporal memory (HTM) [4, 5], which is inspired by the structure and behavior of the human neocortex. The CLA predictor is composed of two memory elements, column and cell, and one linking element, synapse. The algorithm uses discrete data representations inside the predictor. The input value at each time step is represented by a column combination. In a time-series context, this input value is represented by a cell combination; a predictive input value at the next time step is represented by another cell combination. CLA has been reported to achieve higher prediction accuracy than long short-term memory (LSTM) [6], a variant of the recurrent neural network, on a taxi-demand prediction task [7] and an electricity load prediction task [8].
The action-prediction CLA (ACLA) [9] is an extension of CLA for action prediction tasks. ACLA has two CLA predictors: the state predictor and action predictor. The state predictor receives the state values from the environment at each time step, and predicts the state values at the next time step. The action predictor receives (self-recognizes) the action values made at each time step and predicts the action values to be made at the next time step. The state and action predictors are connected by synapses, and the action values to be obtained at the next time step are determined by both the state and action predictors. Even in an uncertain environment where the state values are missing probabilistically, ACLA predicts the action values because the missing state values can be complemented by their predictions in the state predictor. ACLA has been reported to achieve better performance than deep deterministic policy gradient (DDPG) [10] on a two-dimensional mountain car task with probabilistically uncertain missing state values [9]. Real-world tasks often require action, even in uncertain environments with missing state values. For these situations, action decision methodology including not only ACLA but also reinforcement learning algorithms including DDPG, TD3 (twin delayed DDPG), and SAC (soft actor-critic) combined with LSTM that deals with uncertainty due to missing state values with their predictions have been proposed so far [11, 12, 13, 14, 15].
This study focused on two issues in conventional ACLA. (i) Synaptic adjustment: Conventional ACLA repeats the addition of synapses to establish successful predictions of predictors. However, in an uncertain environment, missing state values generate excess synapses that negatively affect the appropriate action predictions. (ii) Action output: Conventional ACLA uses a fixed threshold to extract action prediction values from the action predictor. However, the uncertainty of missing state values decreases the stability of data representation in the action predictor, and the fixed threshold is not always appropriate for extracting action prediction values. In addition, conventional ACLA cannot effectively treat multiple action values. Because the conventional ACLA processes multiple actions simultaneously, a case in which actions cannot be extracted partially arises when the data representation in the action predictor is biased owing to uncertainty.
To address the above two issues and improve the action prediction accuracy of ACLA in an uncertain environment with missing multiple state values, in this work, we propose an adaptive ACLA introducing an adaptive synapse adjustment (ASA) [17] and an adaptive action-separated decoder (AAD). To suppress excess synapses that negatively affect action prediction in uncertain environments, ASA assesses the partial prediction accuracy of each synapse set and adjusts the number of synapses based on the partial prediction accuracy. To output appropriate action values even in uncertain environments, AAD determines each action value separately and adaptively in the action predictor. For the experiments, we used uncertain two-dimensional mountain car tasks providing two state values probabilistically and requiring one action value, and uncertain three-dimensional mountain car tasks providing four state values probabilistically and requiring two action values. We compared the proposed adaptive ACLA using ASA and AAD with conventional ACLA [9], DDPG [10], LSTM-DDPG [14], LSTM-TD3, and LSTM-SAC [15] including an LSTM assist that deals with uncertainty due to missing state values.
This paper is an extended version of our previous work [18] presented at the NaBIC 2022 conference for a special issue. The differences between this study and the previous one are as follows. (1) The previous study used uncertain two-dimensional mountain car tasks with two state values and one action value. This study used three-dimensional mountain car tasks with four state values and two action values. (2) For tasks requiring multiple action values, this work generalizes the action decoder to treat multiple action values, whereas the previous paper treated a single action value. (3) For performance comparison, the previous study employed conventional DDPG [10] and LSTM-DDPG [14]. In addition, this study employs conventional LSTM-TD3 [15] and LSTM-SAC [15].
Cortical learning algorithm
Predictor
CLA predictor.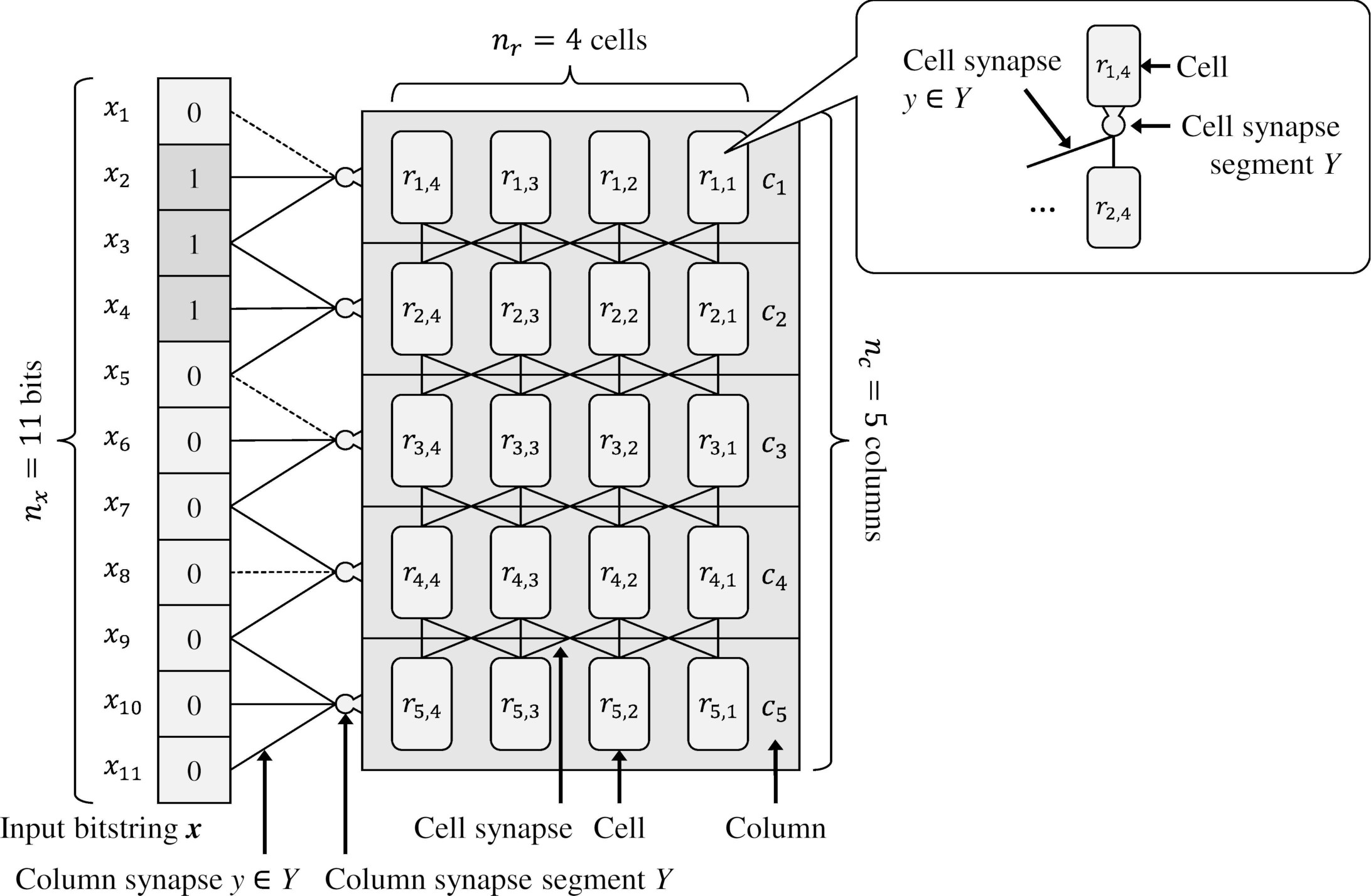
Figure 1 shows the CLA predictor [3]. At each time step
Figure 2 shows an example of the CLA procedure. At each time step
CLA Procedure.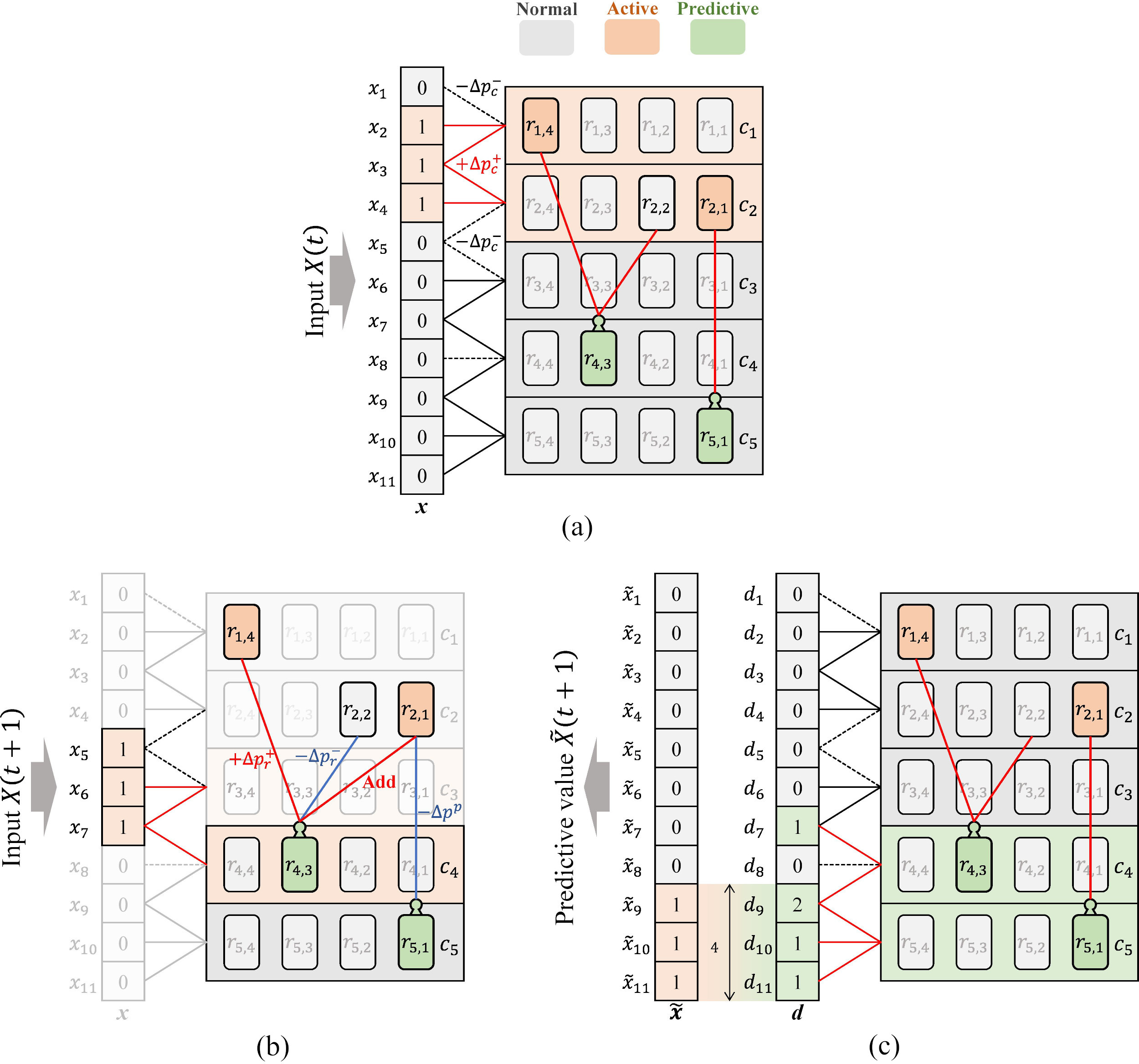
where
First, we create a set of columns in the active state. For each column
Next, we attempted to establish an active column combination by adjusting column synapses. For each column synapse of the active column, we increase its permanence value
First, we create a set of cells in the active state. Each active column formed at least one cell in the active state. Each of the active columns, including the predictive cells, makes one of them active. Each active column, not including predictive cells, places all the cells in the active state. In Fig. 2a, two cells
Next, we created a set of cells in a predictive state. For each cell synapse segment
For each predictive cell at time step
To further establish the successful predictive cell combination in the predictor, we added cell synapses between a segment
For each data bit
ACLA is a CLA extension for action prediction tasks. The time series prediction in CLA is utilized to predict the action to be made at the next time step and to complement missing state values owing to the uncertainty of their prediction values.
ACLA Procedure.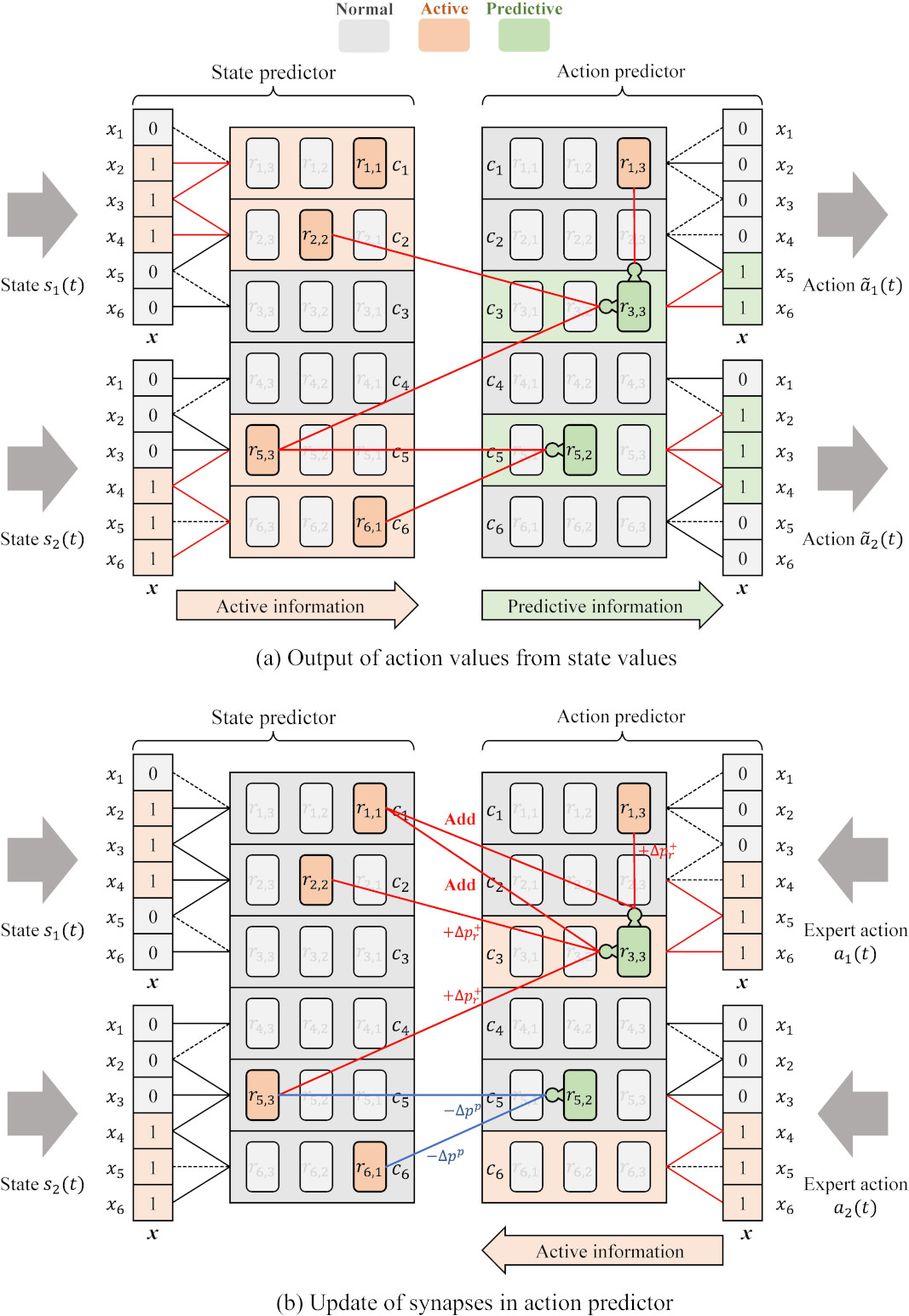
The ACLA predictor is composed of the state predictor and action predictor. ACLA receives
Algorithm
For each time step
For action decoding, the conventional ACLA uses predictive cells in the action predictor. Note that the action predictor treats multiple action values simultaneously. The conventional ACLA uses predictive cells distributed in the entire action predictor for action decoding without considering multiple actions separately. To obtain the
ACLA needs training based on imitation learning, which requires expert action. The learning process updates the permanence values of the cell synapses such that each action prediction value
When the state values
Issue focus
This study focused on two issues in conventional ACLA.
The cell synapse adjustment is the first issue. Excess cell synapses owing to the uncertainty of the missing state values make appropriate action prediction difficult. The conventional ACLA repeats the addition of cell synapses up to the maximum number The second issue is action decoding. Conventional ACLA uses a fixed threshold
To address the above two issues in the conventional ACLA particularly when multiple state values are missing due to uncertainty, in this work, we propose an adaptive ACLA using (i) an adaptive synapse arrangement (ASA) based on partial prediction accuracy to suppress excess cell synapses and (ii) an adaptive action-separated decoder (AAD) that robustly outputs each prediction action value separately.
Adaptive synapse adjustment (ASA) in the proposed adaptive ACLA.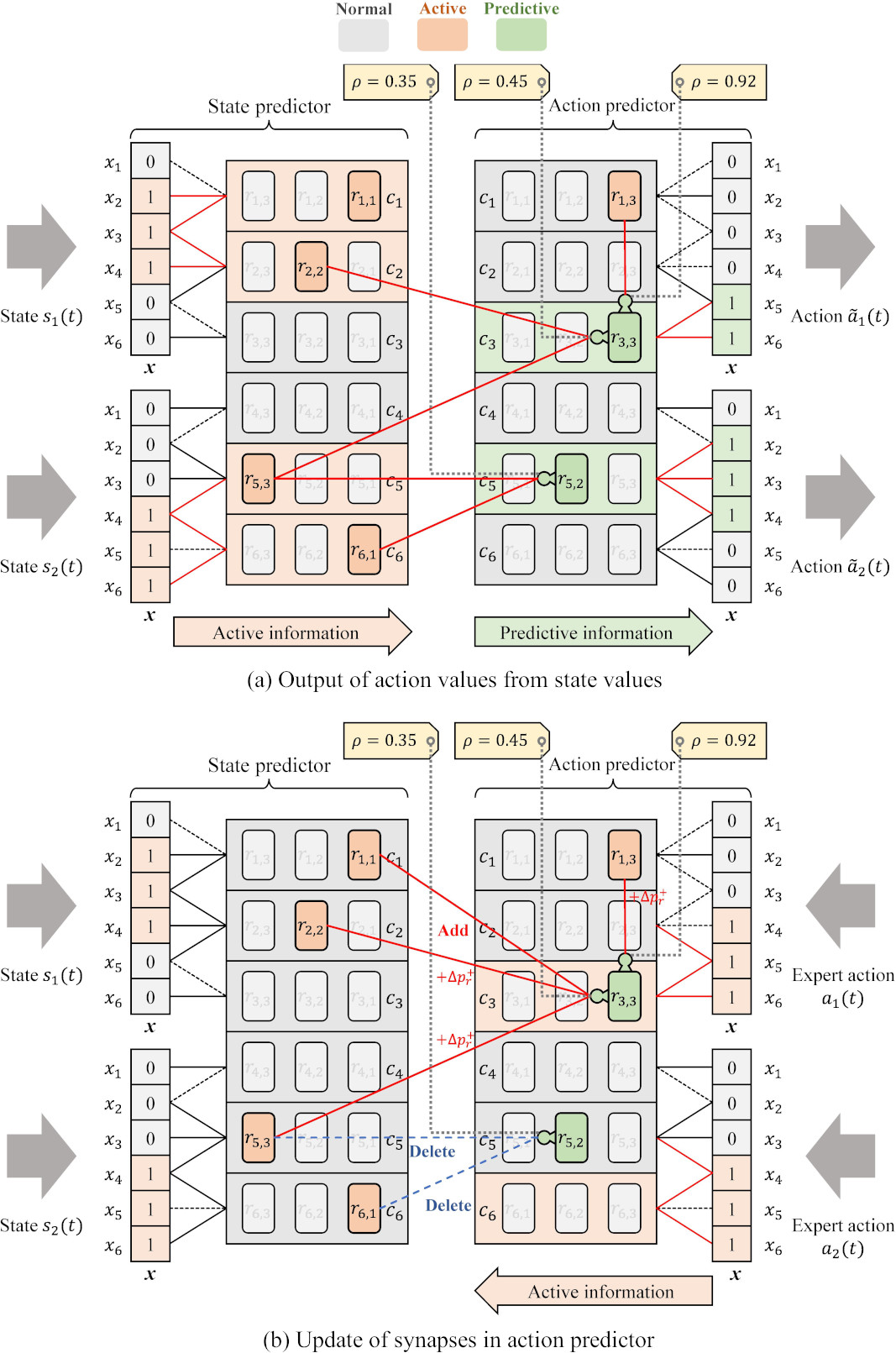
ASA assesses the partial prediction accuracy
Each cell synapse segment
where
ASA adjusts the number of synapses to be added
The synapse is added to each segment
where
Synapse deletion is performed on each segment
The lower the partial prediction accuracy
Adaptive action-separated decoding (AAD) in the proposed adaptive ACLA.
The proposed adaptive action-separated decoding (AAD) uses adaptive segment selection using relative segment ranking instead of segment selection using the fixed threshold
For action decoding, AAD does not simply use the predictive cells in the action predictor, because columns treating each action value may not have predictive cells. Figure 5 shows a conceptual figure of AAD. To obtain
Figure 5 considers
Benchmark tasks
Mountain car task setting
Mountain car task setting
2D mountain car task.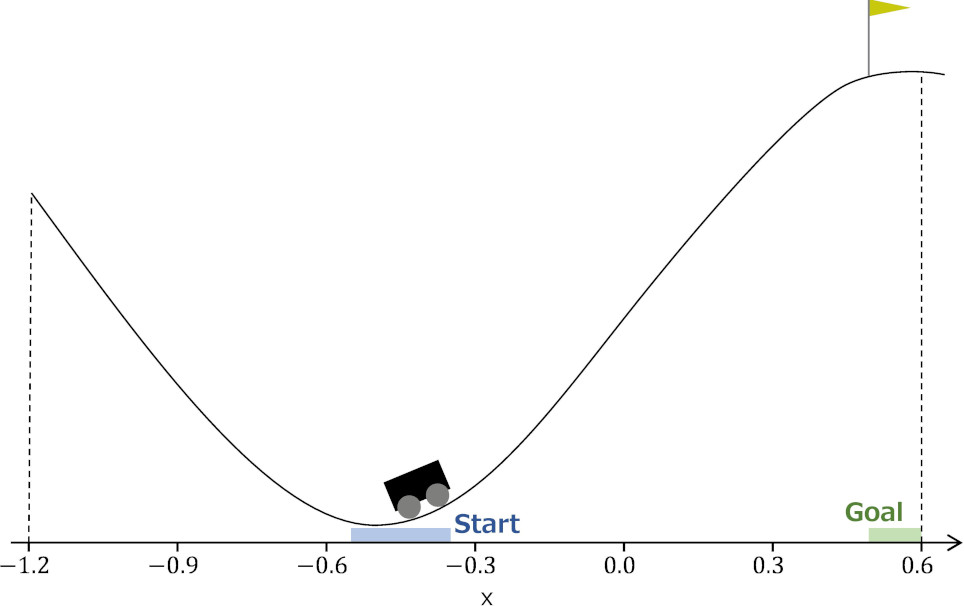
3D mountain car task.
We used two- and three-dimensional mountain car tasks under uncertainty with missing state values as benchmarks. Figure 6 illustrates these mountain car tasks. Table 1 shows specifications used in this work. We used the implementation of OpenAI Gym [20]. The task is for the car to reach the top of the mountain from the bottom of the valley by recognizing the position and velocity as a state and pushing the car as an action. The 2D mountain car task provides
Eight algorithms
Eight algorithms
Parameter values for ACLA-based algorithms
Table 2 shows eight algorithms compared in this work. DDPG, TD3, and SAC are reinforcement learning algorithms that are combined with LSTM to address uncertainty due to missing state values.
To verify each contribution and the combined contribution of ASA and AAD, we used three adaptive ACLAs with only ASA, with only AAD, and with both ASA and AAD. These are denoted as the proposed adaptive ACLA (ASA), adaptive ACLA (AAD), and adaptive ACLA (ASA
Table 3 shows parameter specifications for the conventional ACLAs. Table 4 shows parameter specifications for the proposed adaptive ACLA. As the expert actions for the training, we sampled 1,000 epochs from the results of a trained DDPG in the environment without missing state values, while excluding poor epochs taking 80 steps or more to reach the goal.
Parameter values for the proposed adaptive ACLA
Parameter values for the proposed adaptive ACLA
Each algorithm was executed 31 times on each of the 50 task instances with different initial positions in a single-task setting with a missing-state probability combination of
Experimental results and discussion
2D mountain car problem
Step numbers to reach the goal when exponential weight 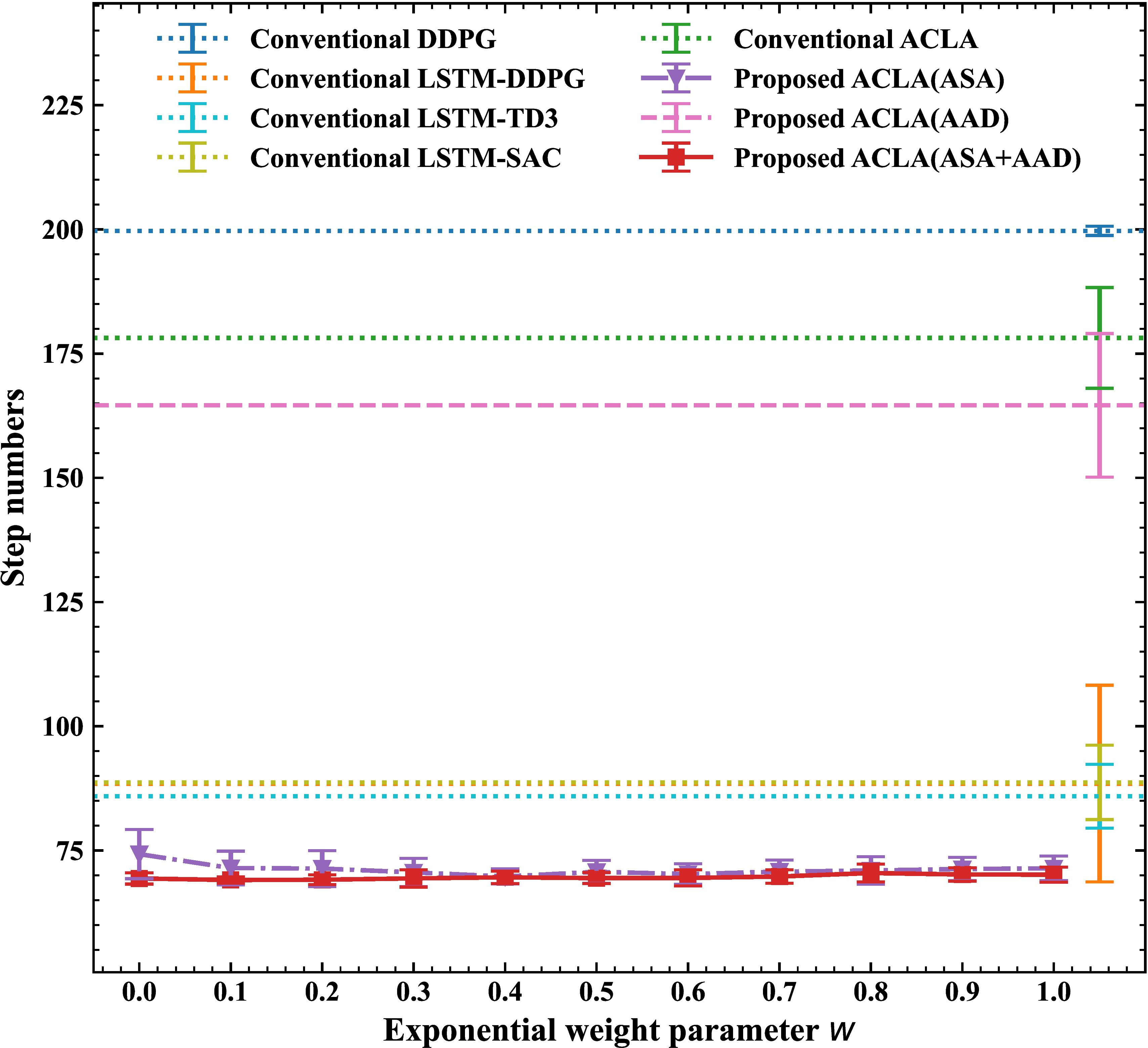
Figure 8 shows the mean step numbers to reach the goal in the 2D mountain car task with missing probabilities
Mean step numbers to reach the goal in the 2D mountain car tasks with different position missing probability 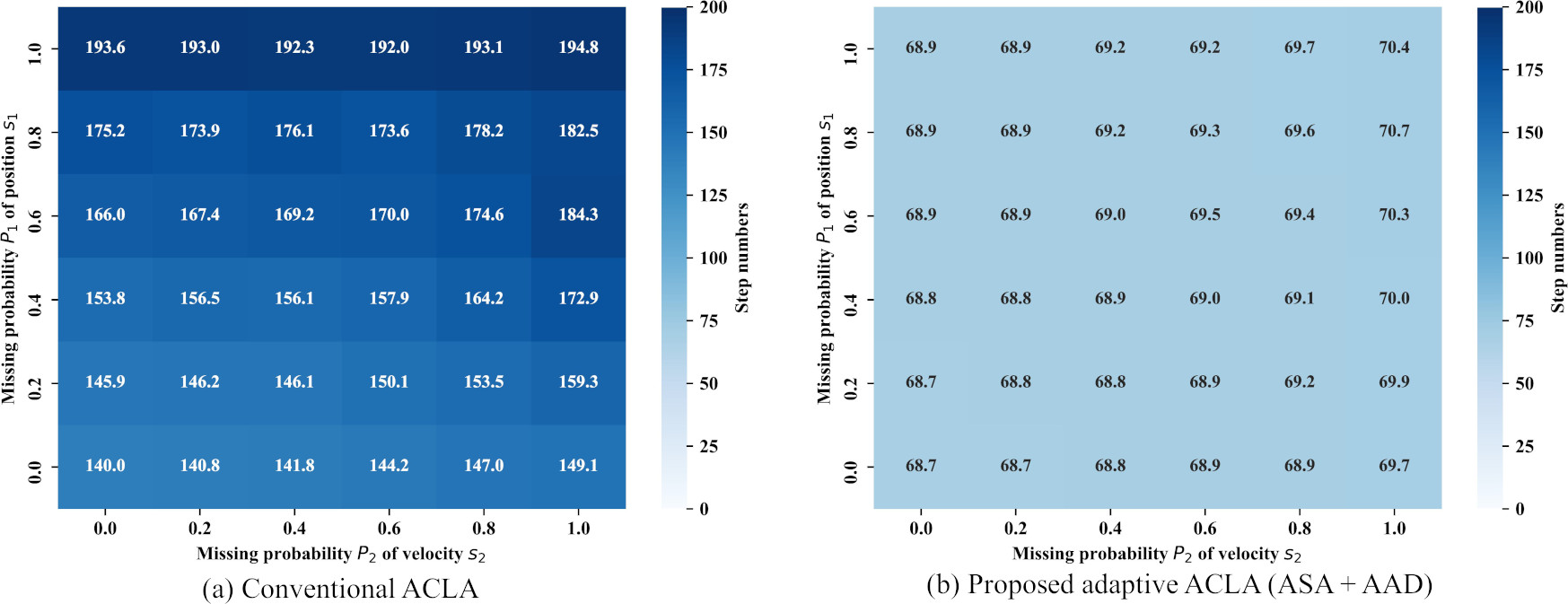
Mean step numbers to reach the goal in the 2D mountain car tasks with different missing probabilities of state values.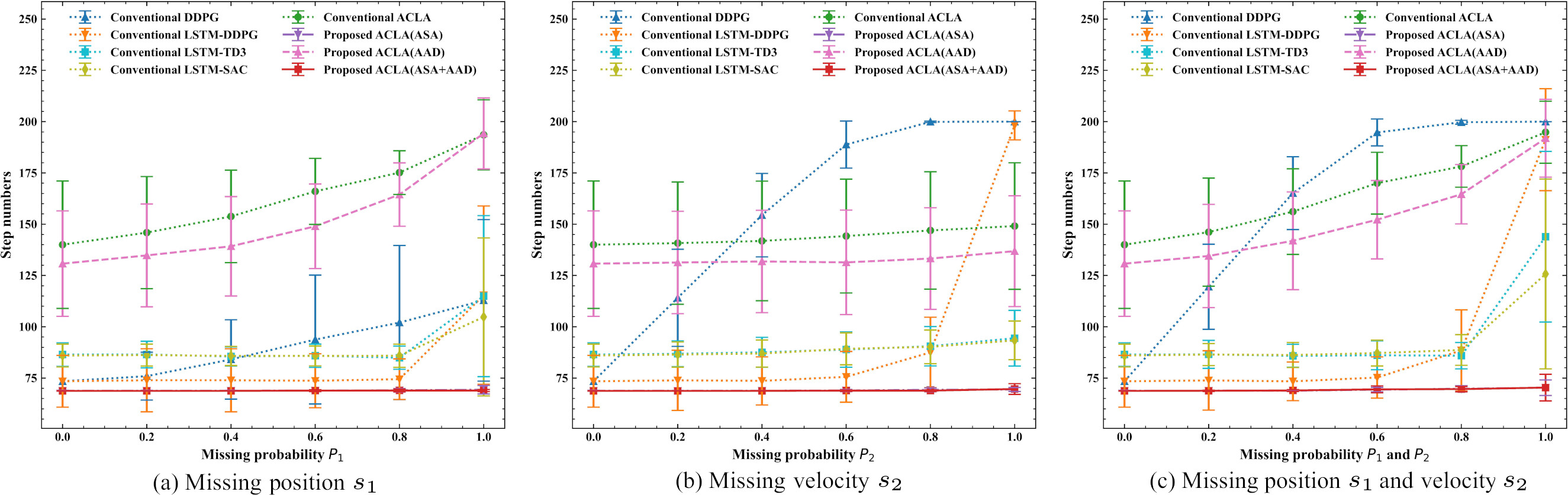
Figure 9 shows heatmaps of the mean step numbers achieved by the conventional ACLA and the proposed adaptive ACLA (ASA
Figure 10a–c show the mean step numbers when missing only the position, only the velocity, and both the position and the velocity, respectively. Error bars indicate the standard deviation. From Fig. 10a, we can see that all algorithms tend to deteriorate the step numbers to reach the goal as the missing probability
State trajectories in the 2D mountain car task with the position missing probability 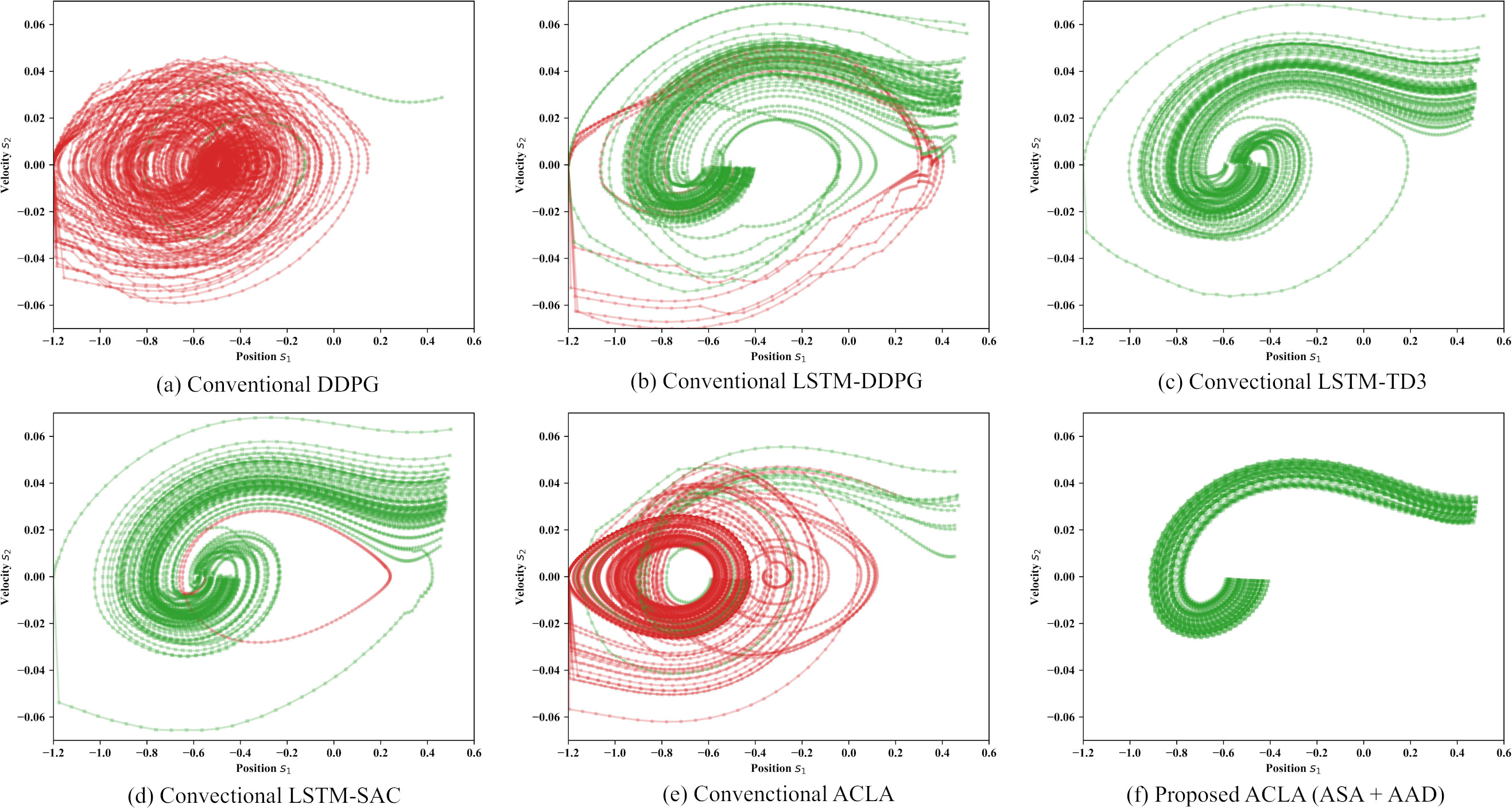
Figure 11 shows the state trajectories in the 2D mountain car problem with the position missing probabilities
These results revealed that the proposed ACLA (ASA
Step numbers to reach the goal when exponential weight 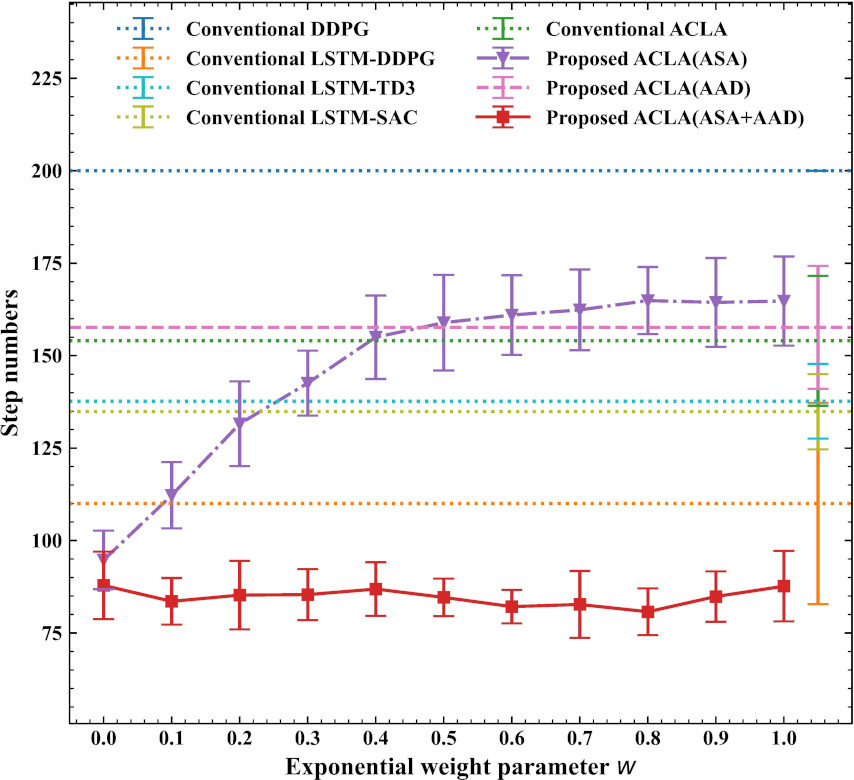
Mean step numbers to reach the goal in the 3D mountain car tasks with missing single state value.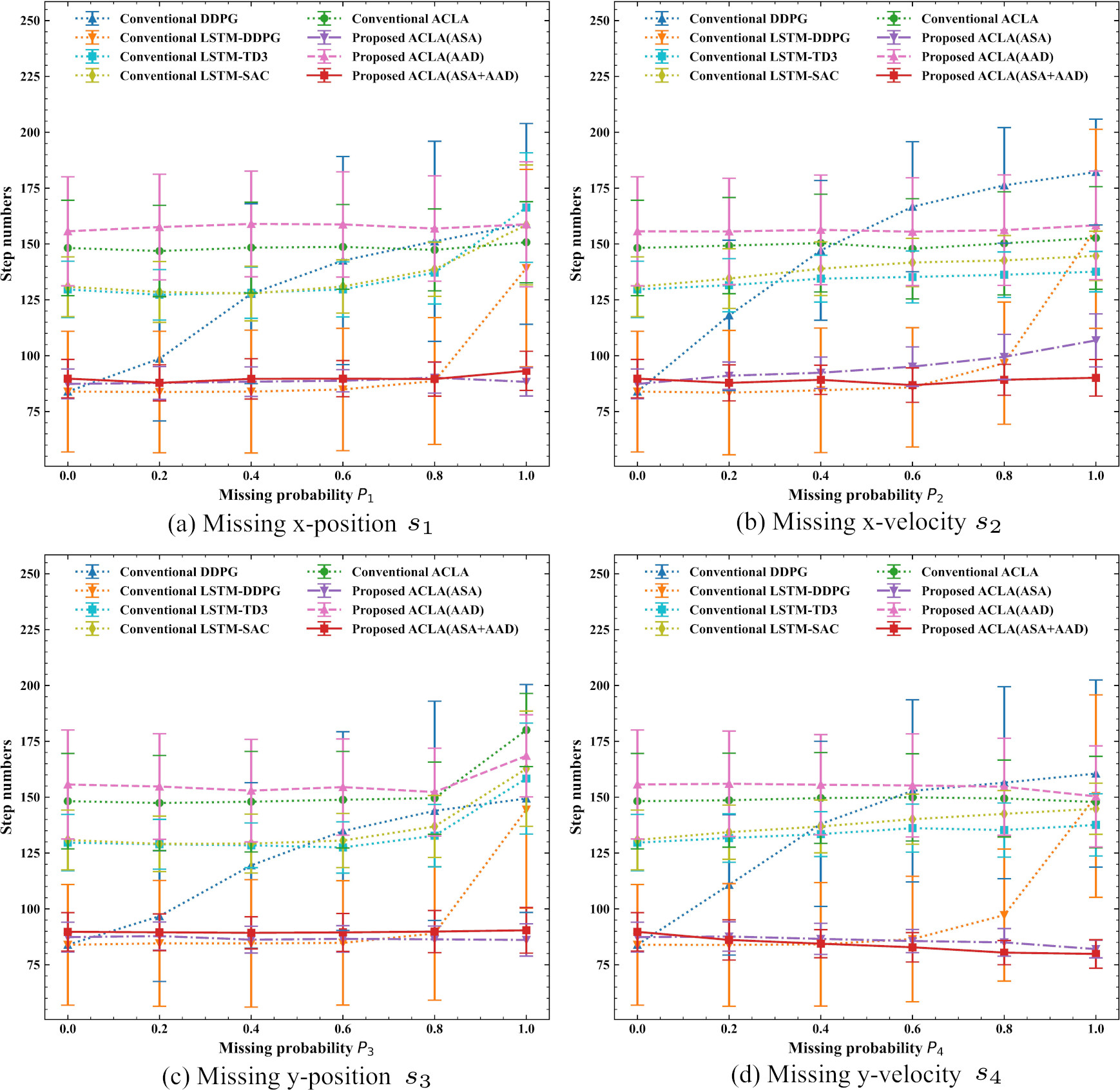
Figure 12 shows the mean step numbers to reach the goal in the 3D mountain car task with missing probabilities
Mean step numbers to reach the goal in the 3D mountain car tasks with missing two state values.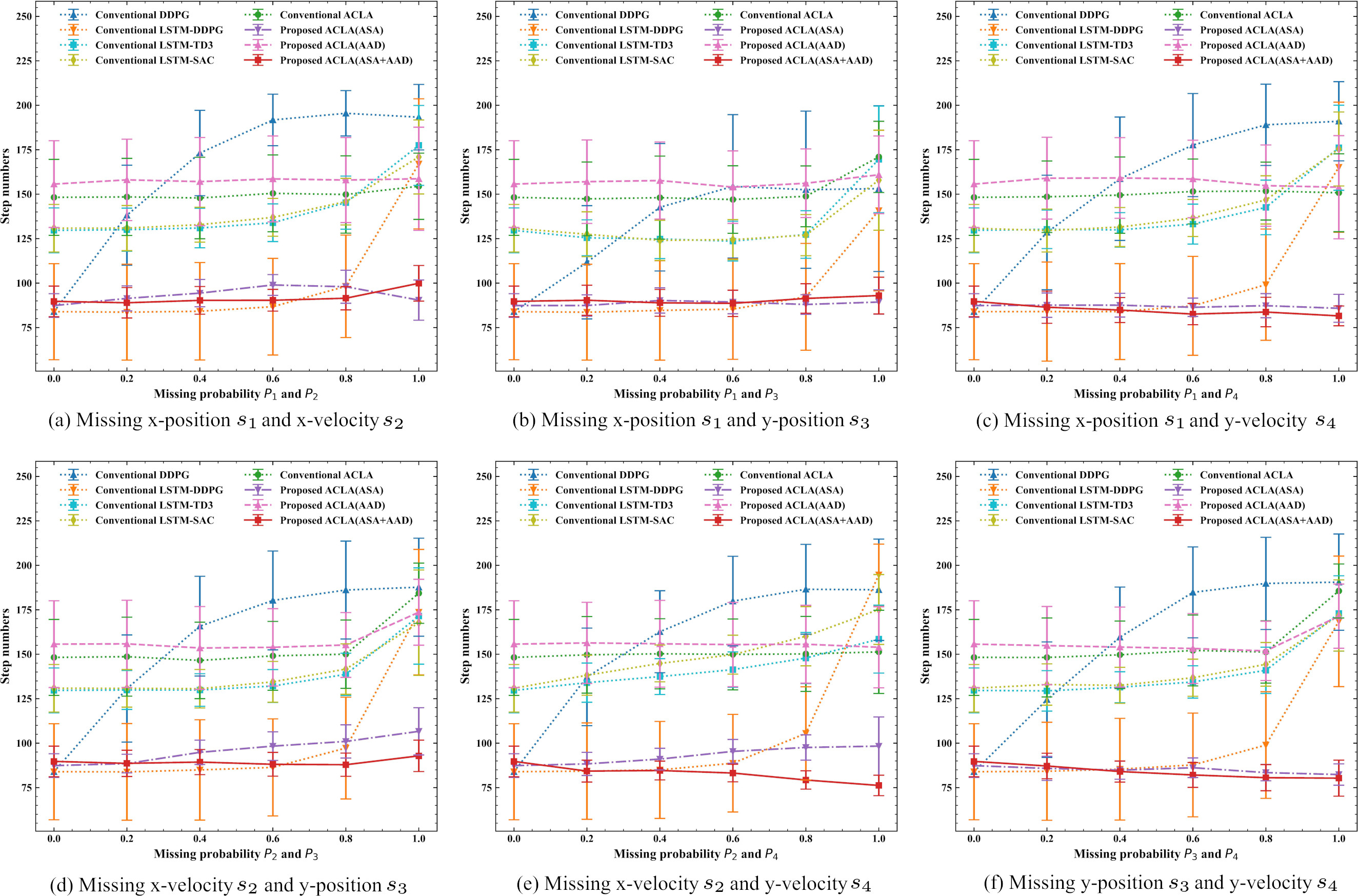
Mean step numbers to reach the goal in the 3D mountain car tasks with missing three state values.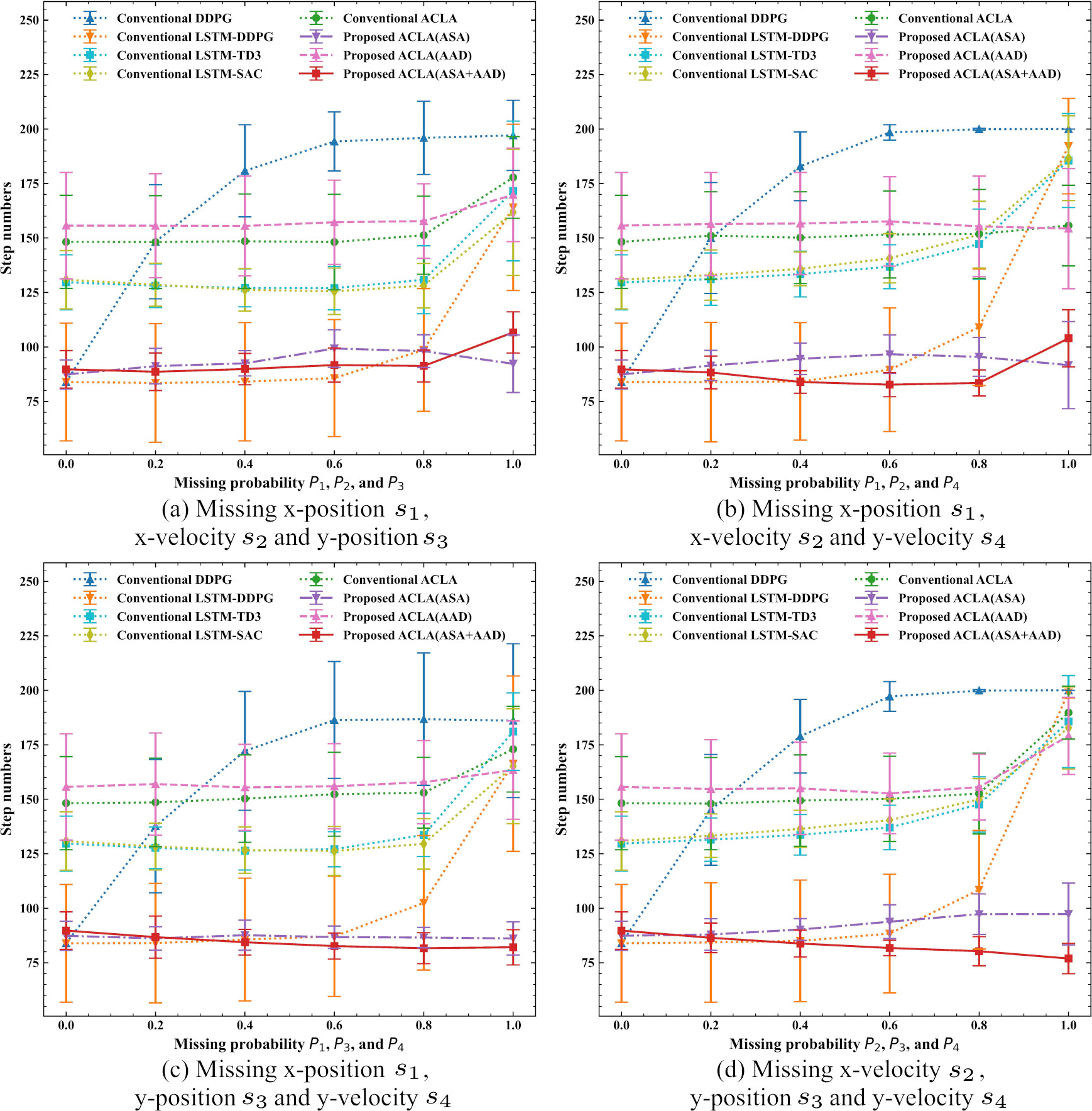
Mean step numbers to reach the goal in the 3D mountain car tasks with missing four state values.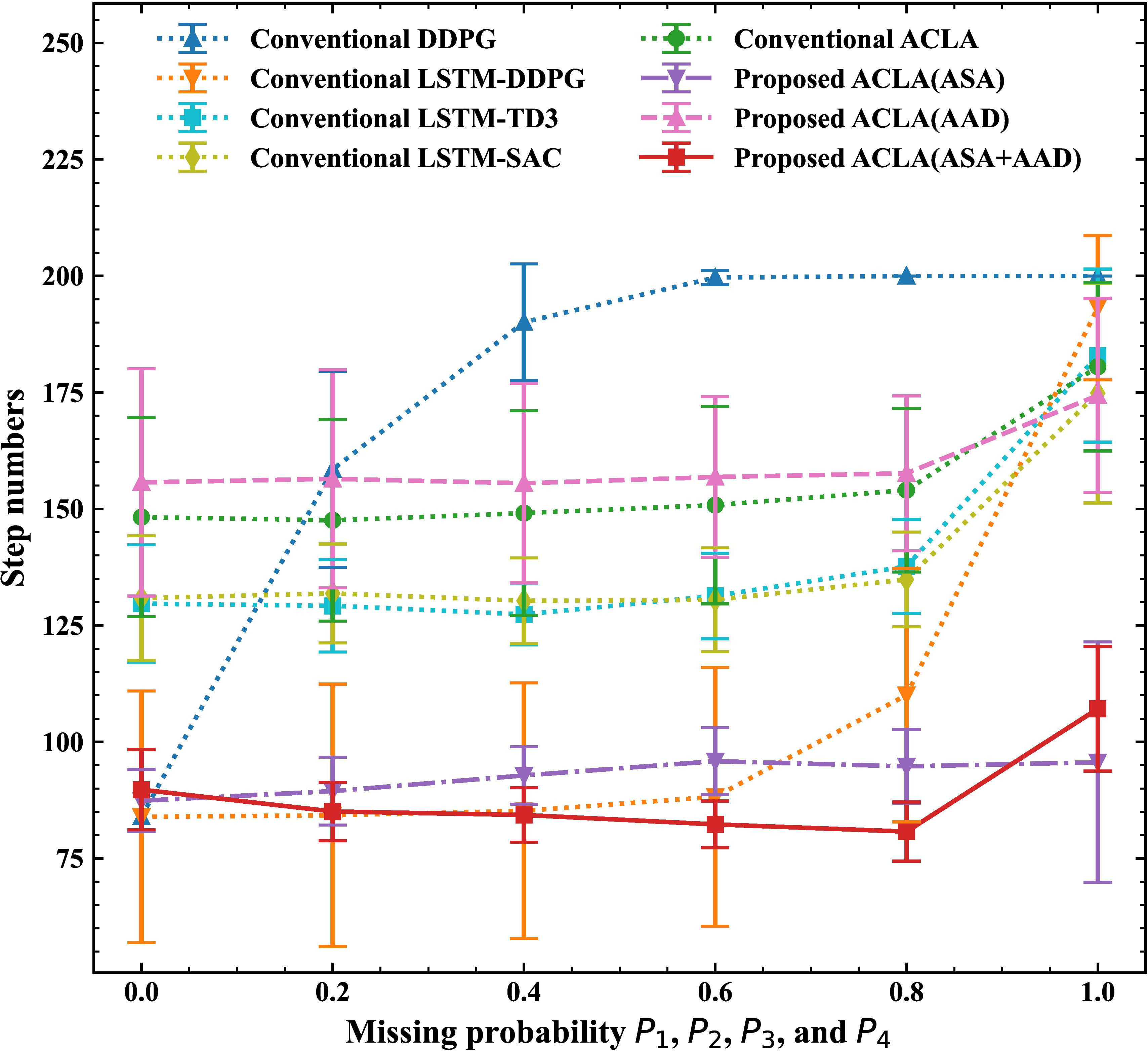
Figure 13a–d respectively show mean step numbers to reach the goal when a single state value is missed. Error bars indicate the standard deviation. The results show that the step numbers of both conventional DDPG and LSTM-DDPG deteriorate as each of the missing probabilities
Figure 14a–f respectively show mean step numbers to reach the goal when two state values are missed. These results show that the step numbers of conventional DDPG, LSTM-DDPG, LSTM-TD3, and LSTM-SAC deteriorate as the two missing probabilities increase. In contrast, the conventional ACLA and the three proposed adaptive ACLAs tend to maintain the step numbers even when two missing probabilities increase. From Fig. 14e, we can see that the proposed ACLA (ASA
Trajectories in the 3D mountain car task with missing probabilities 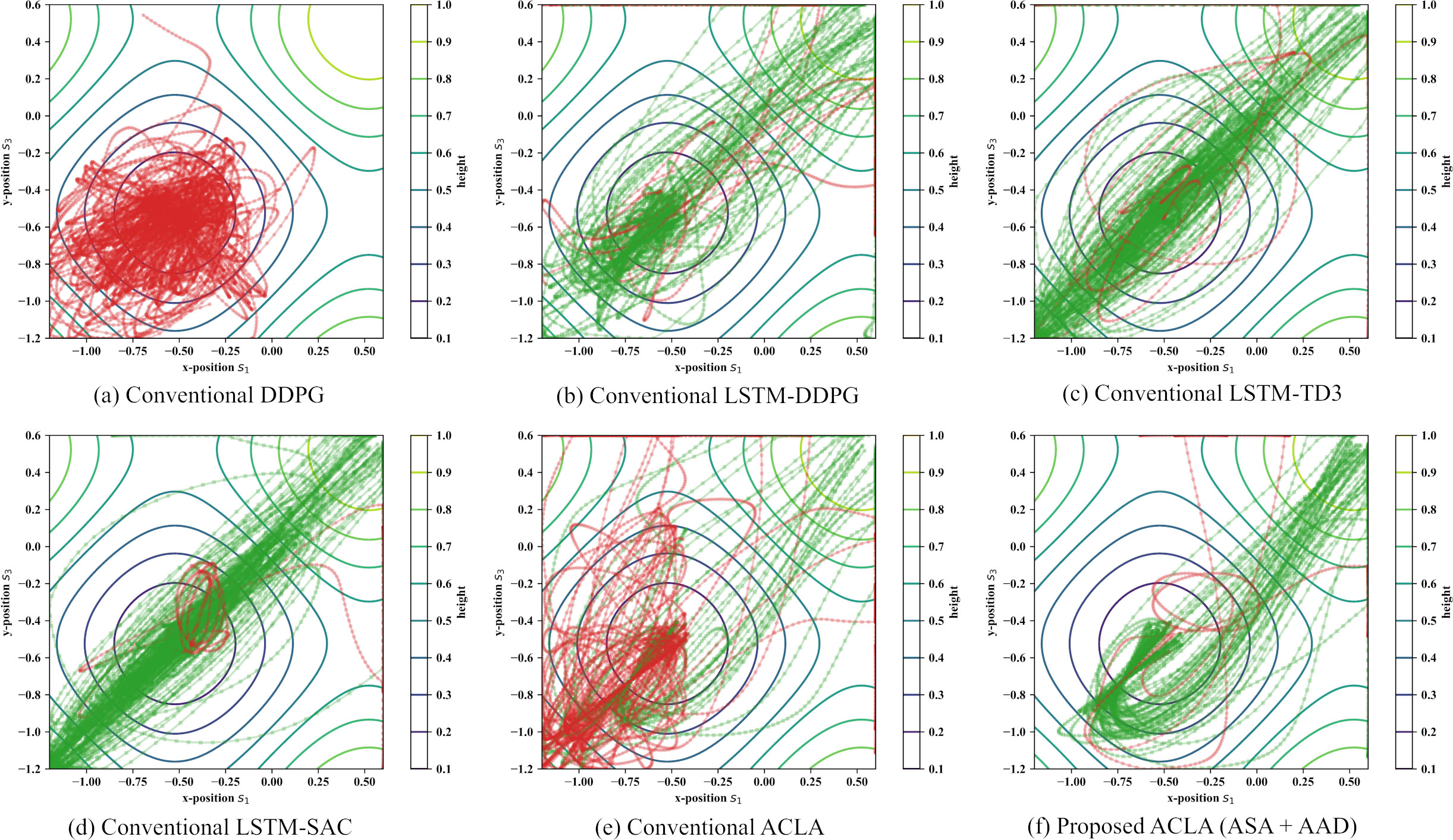
Figure 15a–d respectively show mean step numbers to reach the goal when three state variables are missed. From these results, we can see that the conventional ACLA and the three proposed adaptive ACLAs suppress the increase in the number of steps required to reach the goal when the three missing probabilities increase. However, the adaptive ACLA (ASA
Finally, Fig. 16 shows the mean number of steps required to reach the goal when four state variables are missed. We see that the proposed ACLA (ASA
Figure 17 shows the trajectories in the 3D mountain car task with all missing probabilities
These results reveal that the proposed ACLA (ASA
To improve the action prediction accuracy of the action-prediction cortical learning algorithm (ACLA) in an uncertain environment, missing multiple state variables simultaneously and probabilistically, we propose an adaptive ACLA that introduces the adaptive synapse adjustment (ASA) and the adaptive action-separated decoding (AAD). Experimental results showed that the combination of ASA and AAD worked well in the 2D and 3D mountain car tasks, and the proposed adaptive ACLA with both achieved lower step numbers to reach the goal, particularly with a high missing probability of state variables. These results implicate that the proposed adaptive ACLA contributes to making decisions for the future, even in cases where information surrounding the situation partially lacked. However, this work supposed that input state values were probabilistically missing, but non-missing state values are true (without any noises).
In future work, we will verify the proposed adaptive ACLA in another uncertain environment with noise state values.