
Abstract
In recent years, forums offering community Question Answering (cQA) services gained popularity on the web, as they offer a new opportunity for users to search and share knowledge. In fact, forums allow users to freely ask questions and expect answers from the community. Although the idea of receiving a direct, targeted response from other users is very attractive, it is not rare to see long threads of comments, where only a small portion of them are actually valid answers. In many cases users start conversations, ask for other information, and discuss about things, which are not central to the original topic. Therefore, finding the desired information in a long list of answers might be very time-consuming.
Designing automatic systems to select good answers is not an easy task. In many cases the question and the answer do not share a large textual content, and approaches based on measuring the question-answer similarity will often fail. A more intriguing and promising approach would be trying to define valid question-answer templates and use a system to understand whether any of these templates is satisfied for a given question-answer pair. Unfortunately, the manual definition of these templates is extremely complex and requires a domain-expert.
In this paper, we propose a supervised kernel-based framework that automatically learns from training question-answer pairs the syntactic/semantic patterns useful to recognize good answers. We carry out a detailed experimental evaluation, where we demonstrate that the proposed framework achieves state-of-the-art results on the Qatar Living datasets released in three different editions of the Community Question Answering Challenge of SemEval.
Introduction
The huge amount of data that is stored and constantly produced in the Web represents an endless source of information. Unfortunately, only a small percentage of this data has a structured form, such as a Database schema, that can be easily accessed and queried. Most data is constituted by documents written in a natural language, whose treatment requires sophisticated Information Retrieval (IR) and Natural Language Processing (NLP) Techniques in order to extract meaningful information and transform it into usable knowledge.
Several applications of these technologies are already part of our everyday life. On a daily basis, millions of users retrieve documents using search engines, or employ automatic machine translation systems to translate texts from one language to another. Spell checkers are implemented in most of the text editors, and spam filtering is automatically performed by email services.
Prior attempts to tackle language-processing tasks were based on the direct hand coding of large sets of rules, whose manual definition is an extremely tedious and labor-intensive process that requires a deep knowledge of the linguistic phenomena characterizing a specific task. For example, early automatic machine translation models were based on thousands of rules, leading to overly complicated systems that were consequently hard to maintain and adapt to new languages or domains [49].
The usage of large corpora became more and more common for tackling several Computational Linguistics problems [15], including Machine Translation [13], and parsing [16].
A paradigmatic shift has characterized modern NLP techniques: the rule-based engineering was successfully replaced by the application of Statistical Machine Learning (ML) methods, able to automatically extract and learn such rules through the analysis of large collections of texts.
Nowadays, the most common approaches to tackle NLP tasks are based on supervised learning techniques, which learn to extract knowledge from labeled training data. The training material is a set of pairs, consisting of an input textual object, such as a document or a sentence, and a desired output value, e.g., a document category or a predicate label. The goal of the learning algorithm is to analyze the data and to estimate a decision function that will be used to provide predictions on future unseen instances, i.e., input documents and sentences.
In this framework, a key problem is the definition of expressive representations for the input objects that should allow the learning algorithm to automatically extract meaningful information from the data. The problem of modeling input data is even more acute when the instances are not individual objects but pairs of objects, such as text and hypothesis in Recognizing Textual Entailment, or question and answer in Question Answering.
In this work, we will describe a kernel-based framework in which sentence pairs are modeled using a structured representation derived from their parse trees. The framework automatically induces from training question-answer pairs the syntactic-semantic patterns to be used for future pairs, in order to establish whether a sentence answers a given question. In [25], we initially proposed this framework to solve other tasks involving sentence pairs, namely Paraphrase Identification, which is the problem of understanding whether two text snippets covey the same information, and Recognizing Textual Entailment, which concerns determining if a text implies a hypothesis. Instead, in this work we tackle the task of Answer Selection in community Question Answer (cQA), demonstrating the extreme flexibility of the proposed solution. We will extensively describe and motivate the system we adopted to win the 2016 and 2017 editions of the cQA challenge of SemEval [45, 46]. To better understand the effectiveness of the proposed solution, we will study the impact of different individual kernels and their combinations. Furthermore, we will perform additional experiments on the dataset from the 2015 edition of the cQA challenge [44] reaching the new state-of-the-art results on that dataset.
The rest of the paper is organized as follows. Section 2 discusses the task of answer selection in cQA. Section 3 describes different approaches to model the lexical, syntactic and semantic information of individual texts. It aims at providing all the background material for understanding the following sections. Section 4 describes the task of community Question Answer and the proposed solution. Section 5 reports the experimental results on three editions of the community Question Answering challenge of SemEval. Finally Section 7 draws the conclusion and describes the future work.
Answer Selection in Community Question Answering
Community Question Answering (cQA) is a variant of a typical QA setting put in a Web forum context, where users can freely post questions and expect answers from other users, i.e., the community. This kind of interaction allows users to share opinions, experiences and ideas. Online forums such as Quora 1 , Yahoo! Answers 2 , or Stackoverflow 3 are an endless source of information that is largely accessible.
Most forums are moderated only indirectly via the community, and usually there are no restrictions on who can post and answer a question, or on what questions can be asked. This means that users can freely ask any question and can expect a variety of answers. However, it is often the case that many answers are only poorly related to the actual question, and some even change the topic. This is especially common for long threads where, as the thread progresses, users start talking to each other, instead of trying to answer the initial question. Therefore, a user has to go through all possible answers and to make sense of those. This is a real problem, as a question can have hundreds of answers, the vast majority of which would not satisfy the users’ information needs. Thus, finding the desired information in a long list of answers might be very time-consuming. Automatic systems for answer selection can largely improve the user experience.
Recently, three consecutive editions of SemEval focused on the task of selecting the
relevant answers is cQA [44–46]. In particular, given a
question and several community answers, the task was to classify each comment as relevant
(good), potentially
useful (potential); and bad or irrelevant (bad). This includes also dialogues and
non-English comments.
The corpus used in the competition is extracted from the Qatar Living forum 4 . A simplified example is shown in Fig. 1, where answers 2 and 3 are good, Answer 1 is potentially useful, and Answer 4 is bad 5 .

Example from SemEval-2016 Task 3.
Examples are organized in threads, and both questions and comments have a subject (a brief description) and a body, as well as some meta-information, such as the question category (according to the Qatar Living taxonomy), and the user identifier. This kind of information is usually available in every forum; so, even if the models described in the following sections have been developed specifically for the Qatar Living case, they can be effectively applied to different cQA domains and to different corpora.
Table 1 reports some statistics of the Qatar Living datasets of the 2015, 2016 and 2017 editions of the SemEval cQA Challenge [44–46]. In the 2017 only a test set was released, and the datasets from the previous year were intended to be used as training material. The potential class, which is an intermediate class between good and bad , is the least frequent, while the good and bad classes are pretty balanced.
Class distribution in the Qatar Living datasets.
The performance of machine learning algorithms heavily depends on the representation of the data they are provided with. The traditional ML approach consists in modeling instances as feature vectors. In NLP and IR [4, 54], the most common representation based on feature vectors is the Bag-of-Words (BoW) model [30], where each feature corresponds to a specific word in the dictionary. Each document is then mapped into a vector whose feature values express the occurrence of specific terms in the document. This kind of representation is very simple and neglects some important linguistic information: the words are considered mere symbols whose semantics is completely ignored. Furthermore, the BoW model is unable to capture syntactic information, which instead is central in the approach we will propose. The following sections will describe some alternative representations that we will use in this work. The aim is to provide all the background material to the reader in order to properly understand the model we propose in Section 4 for solving the answer selection task in community Question Answering.
Generalizing lexical information: Distributional models of lexical semantics
The BoW model does not generalize lexical information and cannot match semantically related words, such as synonyms. For instance, a pure direct matching between words cannot capture any similarity between “buy a car” and “purchase an automobile”, and a lexical generalization is needed to capture the quasi-synonymic usage of car vs. automobile and buy vs. purchase. This kind of information can be extracted from large scale lexicons, e.g., WordNet [21, 40], but their coverage is usually not satisfactory. Moreover, some tasks require a domain-specific notion of similarity that lexicons, which are usually general-purpose, cannot provide. These limitations can be overcome by defining word representations, i.e., vectors embodying the semantics of words. These methods have a significant impact in a variety of applications, such as document classification [55], question answering [66], information retrieval [37], named entity recognition [68], and parsing [61].
Usually words are represented as vectors in a low dimensional space, such that similar, or semantically related concepts are close. In these semantic spaces, the notion of word similarity is captured through cosine similarity, inner product, or other vectorial operations.
In Computational Linguistic there is a wide literature regarding techniques for automatically generating word vectors. These methods rely on the Distributional Hypothesis, which has been synthesized by Firth (see [26]):
a word is characterized by the company it keeps
The underlying intuition behind Distributional Semantic Models is that the meaning of a word can be described by the set of textual contexts in which it appears. In fact, words appearing in similar contexts are semantically related by some type of semantic relation, either paradigmatic (e.g., synonymy, hyperonymy, antinomy) or syntagmatic (e.g., meronymy, conceptual and phrasal association), as observed in [53].
The two main approaches for generating word vectors differ in how the distributional hypothesis is exploited. In the classic count-vector-based models 6 , the word-context co-occurrences are globally counted from a large scale corpus; in the context-predicting models (more commonly known as neural language models), the vector estimation problem is treated as a learning task, in which the values of the word vectors have to be set in order to optimize a cost function defined on the available corpus. Obviously, in both approaches, a good approximation of the word distributional information can be achieved only if a sufficient amount of observations is gathered. Several large-scale corpora are available for English, e.g., the British National Corpus (BNC) [3] made of 100 million words, or the ukWaC corpus [6], made of 2 billions word.
A deep comparison of the effectiveness of different word embedding strategies on downstream tasks can be found in [7].
In this work, we will adopt Word2Vec [39], which is one of the most popular context-predicting models, thanks to its simplicity (the model is a neural network with a single hidden layer) and to the quality of the produced word embeddings.
Exploiting the syntactic information
Syntactic information is necessary for a complete understanding of the semantics of texts. For instance, two sentence having the same words can have opposite meaning, such as in Vettel passed Hamilton and Hamilton passed Vettel. In this case, a BoW model will result in two identical vectors, and only a syntactic analysis can clarify who is ahead.
A possible approach for capturing syntax can be the manual definition of an artificial feature set that should emphasize the syntactic and semantic aspects useful to solve a target problem. Referring to the previous examples, some informative features can be extracted from their syntactic parse trees in Fig. 2.
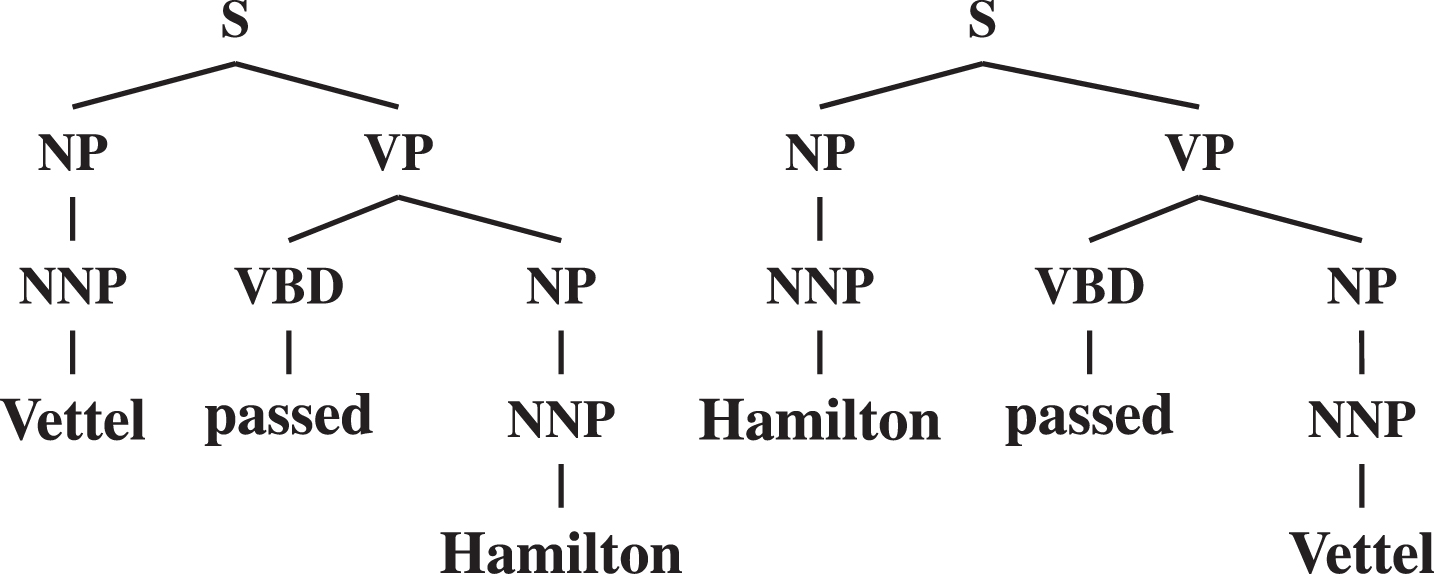
Constituency trees of the sentences Vettel passed Hamilton and Hamilton passed Vettel.
For instance, an artificial feature can be the syntactic path between a given word and the predicate (i.e., the word evoking the underlying situation, in this case passed). The two sentences have different paths from the argument Vettel to the predicate passed, reflecting the different semantic roles of Vettel: he is ahead in Vettel passed Hamilton, and behind in Hamilton passed Vettel.
These kinds of features are basically the building blocks of the underlying rules characterizing an NLP problem, and the task of determining how to exploit these features to generate robust predictive models is left to the learning algorithm. Therefore, the feature engineering approach can be somehow considered a simplification of the development of the rule-based systems mentioned in Section 1. However, the definition of meaningful features is still a rather expensive and complicated process that requires a domain expert; moreover, every task has specific patterns that must be considered, making a manual feature engineering an extremely complex and not portable process.
Kernel methods [18, 52] are an elegant and efficient alternative to the manual definition of features, thanks to their capability to operate directly on structured data, such as sequences, trees or graphs. In NLP, sentences can be naturally represented through their syntactic parse trees. Then, instead of trying to design a synthetic feature space, tree kernels [17] can be employed to directly operate on the parse tree of sentences, evaluating the tree fragments shared by the input trees. This operation equals to a dot product in the implicit feature space of all possible tree fragments (which, of course, include most of the artificial features that can be engineered, such as the predicate-argument path, see for instance [28]). The dimensionality of such space is extremely large and an explicit representation is not viable due to computational and memory usage issues: the number of different sub-fragments in a tree is combinatorial in the number of tree nodes, therefore, even a small tree can generate up to thousands of billions of features. Tree kernels lead to state-of-the-art performance in several NLP tasks, where syntactic information is crucial, including Question Classification [19], Semantic Role Labeling [43], Paraphrase Identification and Recognizing Textual Entailment [25].
Tree Kernels (TKs) allow to estimate the similarity among texts, by directly comparing their parse trees.
The underlying idea is that the similarity between two trees
T1 and T2 can be derived from
the number of shared tree fragments. Let the set
Different tree kernels can be defined according to the types of tree fragments
considered in the evaluation of the matching structures. In the Subtree
Kernel [71], valid fragments are
subtrees, i.e., any node of a tree along with all its descendants. Subset trees are
exploited by the Subset Tree Kernel [17], which is usually referred to as Syntactic Tree Kernel (STK); they are
more general structures since their leaves can be non-terminal symbols. The subset trees
satisfy the constraint that grammatical rules cannot be broken. For example, the
constituency tree in Fig. 3a has
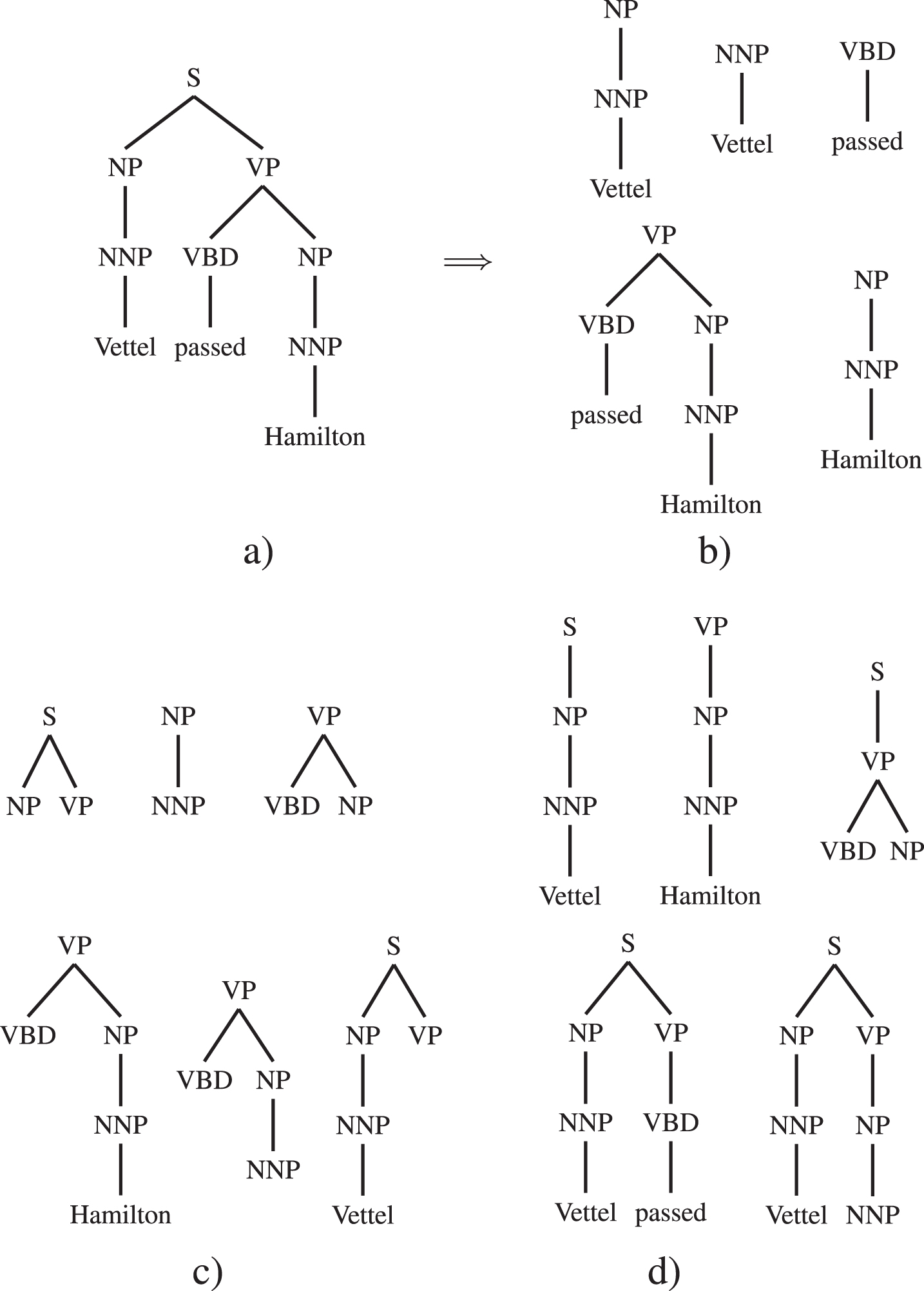
a) Constituency parse tree for the sentence Vettel passed Hamilton, b) some subtrees, c) some subset trees, d) some partial trees.
Given a sentence s with |s| words,
We define
where c n (k) is the k-th child of the node n, and λ and μ are decay factors in (0, 1] that penalize large child subsequences (that can include gaps) and deep partial trees, respectively.
The computational complexity of a PTK computation is
In the previous section, we introduced different approaches for modeling individual texts. However, in NLP several tasks are defined over pairs of texts. For instance, Paraphrase Identification (PI) consists of determining whether two sentences are paraphrases or not (see [20]); Recognizing Textual Entailment (RTE) (see [27] for a detailed description) is defined as a directional relation extraction between two text fragments, text and hypothesis. The relation holds whenever the truth of the hypothesis follows from the text. In this section we will propose a framework for modeling these kinds of tasks. In particular, we will focus on the task of Answer Selection in community Question Answering. Our model consists of a multi-kernel SVM operating on different features and data representations that we will describe in the following sections.
A shallow intra-pair similarity approach
A very simple approach to Answer Selection consists of evaluating the similarity between the question and the answer. For instance, answer A2 in Fig. 1 contains some relevant keywords appearing in the question, such as gold and sell.
The similarity between two sentences can be captured in different ways and at different levels (lexical, syntactic and semantic). Various similarity measures have been proposed in literature and many of them have been originally developed for the Semantic Textual Similarity task [1].
In the experiments reported in Section 5, we will adopt the following similarity
measures:
Each similarity generates a feature, so that each question-answer pair can be converted into a feature vector. Then supervised learning algorithm, such as SVM, can learn how to combine these features for solving the classification problem. We define LK sim as a linear kernel operating on the above described intra-pair similarities. A system based on the direct comparison between question and answer provides a strong and efficient baseline. However, it has some inherent weaknesses that are evident if we consider the answer A3 from Fig. 1: this comment is definitely good , although it does not contains words similar to the ones in the question.
Learning from sentence pairs
In question answering, many good question-answer pairs, can be generalized to some latent answering template. For instance, a very high-level generalization of the question in Fig. 1 could be Can I do something?; while valid answers can be Yes you can …, or No you cannot …, which match A2 and A3, respectively 8 .
In a general-purpose forum, such as Qatar Living, a large variety of these question-answering templates can be considered. Their manual definition through hand-coded rules is extremely complex and time-consuming, and probably it will lead to a poor and low-coverage solution.
With the assumption that the targeted question-answer templates characterize multiple examples in the dataset, we propose a kernel-based approach to automatically learn syntactic-semantic patterns from training data. These patterns can somehow correspond to the question-answering templates we aim at capturing. The intuition we follow is quite simple: an answer is probably valid for a given question if similar question-answer pairs are labeled as good in the training set. For instance, the following question-answer pairs from the Qatar Living dataset have a very similar structure, although they treat completely different topics:
Q2: Which is the best beach here in Qatar?
A Q 2 : Sealine Resort is the best option
Q3: Which is the best bank around?
A Q 3 : CQB is the best option
This is a paradigmatic shift with respect to the similarity approach described in the previous section: sentences are not only compared with the other element of their pair, but inter-pair analysis is also performed.
Kernels on question-answer pairs
Pairs which can be associated with a common question-answering template share a similar syntactic structure, as illustrated in Fig. 4 (for the moment ignore the red REL prefixes). Therefore, high syntactic similarity between the two questions and between the two answers can be assumed to be a good indicator that the two pairs respect the same underlying template. We opted for a shallow parse tree representation, i.e., a tree where words have their POS tags as fathers, which are then grouped into chunks. In fact, the quality of more complex tree representation, such as full constituency trees, is largely affected by the noisy nature of the text in community Question Answering. Furthermore, sentences can be very long thus a full syntactic parse tree may result too large for a tree kernel computation. Finally, shallow parsing is significantly more efficient.
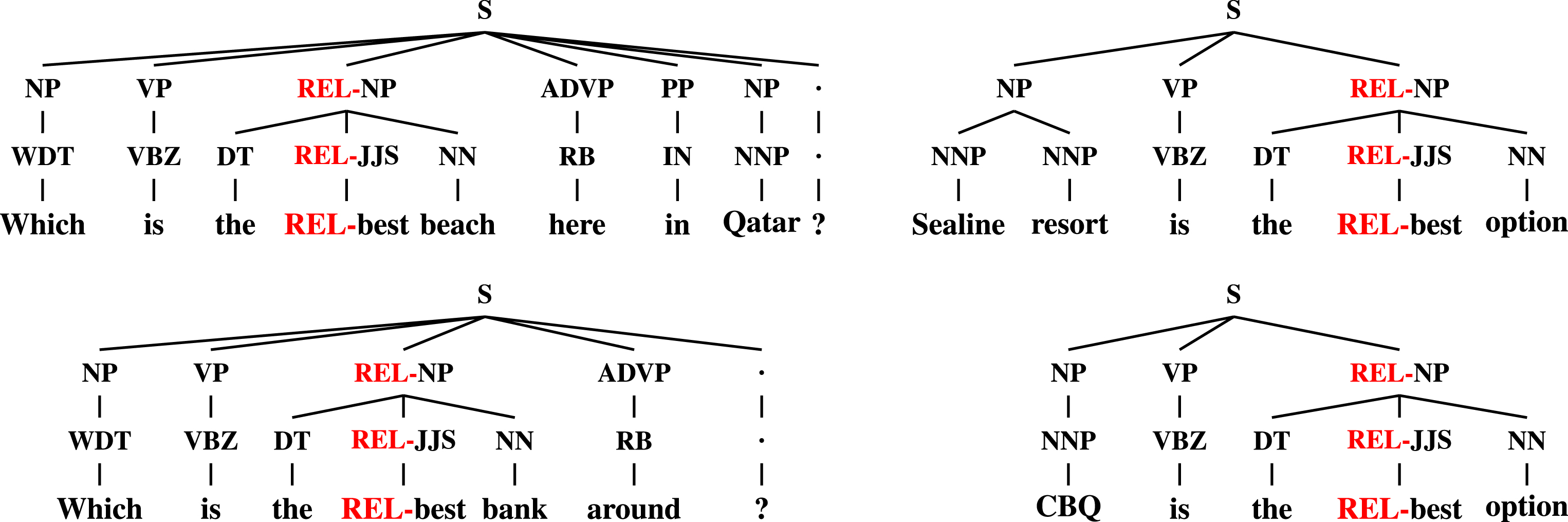
Shallow trees of two question-answer pairs exhibiting the same answering structure.
The tree kernel methods described in Section 3.2 can effectively establish the syntactic
similarity between two sentences. We can extend this evaluation to question-answer pairs
using a simple tree kernel combination. In particular, given two pairs
p
i
= 〈q
i
,
a
i
〉 and
p
j
= 〈q
j
,
a
j
〉, and a tree kernel TK, such as the PTK,
the following kernel on pairs can be defined
9
:
which simply sums the tree kernel similarities between the two questions and between the two answers. It is worth noting that the core difference between the approach discussed in Section 4.1 and the proposed TK+ is that the former evaluates intra-pair similarities, i.e., questions are compared with their answers, while the latter performs an inter-pair analysis, i.e., questions are compared with questions and answers with answers.
As suggested in [25] the text pairs representations are enriched by using a special tag, i.e., the red REL prefix in Fig. 4, to mark the words appearing in both the texts of a pair. In order to involve the syntactic part of the trees, the REL tag is propagated to the father and grandfather of the matching words, i.e., the POS tag and chunk nodes. This is a simple yet effective strategy to establish intra-pair relations and to allow the learning algorithm to distinguish the words having a counterpart in the other element of its pair.
The proposed tree kernel combination implicitly generates a huge feature space that
includes relational features, such as
An interesting aspect of kernel methods is that kernel can be easily combined to create more sophisticated models. In particular, we can combine TK+ with a kernel operating on the intra-pair similarity feature vectors described in Section 4.1, for instance a Linear Kernel (LK). This will result in a stronger kernel that can leverage both the intra-pair and inter-pair approaches.
The explicit similarity features proposed in Section 4.1, as well as the implicit tree kernel features described in Section 4.2 have a large applicability in other tasks such as Paraphrase Identification or Textual Entailment Recognition. Instead, in this section we will present some features, proposed in [8], which have been developed specifically for the cQA scenario.
In particular, forty-four Boolean features express whether a comment: includes URLs or emails
(2 feats.). In fact, exploring the training data, it is possible to notice that many
good comments suggest visiting a Web site or contacting an email
address; contains the words “yes”,
“sure”, “no”, “can”, “neither”, “okay”, and “sorry”, as well as symbols ‘?’ and ‘@’
(9 feats.); starts with “yes” (1
feat.); This features, as well as some features from the previous group, indicates
the presence of a direct answer in a yes/no
question; includes a sequence of three
or more repeated characters, or a word longer than fifteen characters (2 feats.).
These features signal the presence of non-proper English words that are usually
associated with a very informal text, which is typical of conversations, i.e.,
bad comments; belongs to one of the categories of the forum (Socializing,
Life in Qatar, etc.) (26 binary feats.). Some categories are less
“serious” than others, in the sense that often contain “silly” questions or jokes,
which obviously attract bad comments
10
. Therefore, the category represents a sort of a
priori information of the comment quality; has been posted by the same user who posted the question, such a
comment can include a question (i.e., it contains a question mark), and
acknowledgement (e.g., it contains thank*,
acknowl*), or none of them (4 feats.). Usually users do not
answer to themselves: their comments are typically requests for further information
or acknowledgments to the users who provided helpful answers.
A particular aspect that characterizes Community Question Answering is that the comments in a thread typically reflect an underlying concrete discussion, which is more than a sequence of independent answers 11 . For instance, users replicate to each other, add additional information to someone else’s answers, ask for further details, or tease other users.
We modeled thread-level dependencies by designing specific features that are able to capture the dependencies between the answers in the same thread.
The following notation will be adopted: q is the question posted by user
u
q
, c is a comment from
user u
c
, in the comment thread. Four features indicate
whether c appears in the proximity of a comment by
u
q
. The assumption is that an
acknowledgment or further questions by
u
q
in the thread could signal a
good answer. More specifically, they test if among the comments
following c there is one by
u
q
(i) containing
an acknowledgment, (ii) not containing an acknowledgment,
(iii) containing a question, and, (iv) if
among the comments preceding c there is one by
u
q
containing a question. The
value of these four features —a propagation of the information captured by the
feature group 6 — depends on the distance k, in terms of the number
of comments, between c and the closest comment by
u
q
:
Other six
features try to model potential dialogues, which at the end represent
bad comments, by identifying interlacing comments between two
users. These dialogue features are identifying conversation chains: Another interesting
aspect is whether a user u
i
has been
particularly active in a question thread. One boolean feature captures whether
u
i
wrote more than one comment in the
current thread. Three more features identify the first, the middle and the last
comments by u
i
. One extra feature
counts the total number of comments written by
u
i
. It can be empirically observed that the likelihood of a comment
being good decreases with its position in the thread. Therefore,
another real-valued feature was included: max(20, i)/20, where
i represents the position of the comment in the
thread.
We define LK qa as a linear kernel operating on the features specific to the task described above.
Evaluation measures
In the 2015 edition [44], the cQA challenge was a classification task where the official measure was the macro F1 measure of the three classes, namely good, bad and potential . Instead, in the 2016 and 2017 editions [45, 46], the organizers defined the task as a re-ranking problem where the participants had to provide a ranking of the comments in each QA thread. In this case, the official evaluation measure was the Mean Average Precision (MAP) and there was no distinction between the potential and bad classes. This change was partially motivated by the generally low performance observed in detecting the potential comments. In fact, as discussed in [10], the boundaries of this intermediate class are not well defined. We performed experiments with the two class setting also on the 2015 edition. In addition to the MAP, we will also report the Mean Reciprocal Rank (MRR), and the Average Recall (AvgRec). In solving the task, we will use a point-wise approach, where the scores of a binary classifier are used to rank the comments. Thus, we will also provide the standard classification metrics, namely accuracy, precision, recall and F1 w.r.t. the good class.
Finally, to have a comparison with the 2015 challenge results, we will also run a 3-class setting experiment on the 2015 data. In this case we will report the accuracy and macro-F1.
Text preprocessing
As we can observe in Fig. 1, the text is very informal and inherently noisy. It contains spelling errors, special characters, non-standard word forms, grammatical mistakes, usage of multilingual words, and so on. Standard NLP methods are usually affected by noise in text and there is a broad literature discussing text cleaning [62, 63] and the development of NLP algorithms robust to noise [5, 11].
In addition to general text normalization techniques, such as spelling correction and HTML tag removal, the forum setting requires some specific treatment.
Both questions and answers have a subject and a body. The subject can have three
different forms: it is a synthetic sentence summarizing the content of the post, as in Fig. 1 for
it is a copy of the
first part of the body; it has the
form “RE:question-subject” (only for comments). This happens for
all the comments in Fig. 1, where the subject was omitted for
simplicity.
Therefore, in the first case the subject is highly informative; in case (ii) it is only a useless redundancy; in case (iii) the subject introduces fake question-comment similarities, that can significantly impact the system accuracy. We used simple rules to detect cases (ii) and (iii) and remove the uninformative subjects.
Furthermore, several users put a signature at the final part of their posts. For instance, many comments from user U947 end with the following sentence:
dEV,∥eVeRyTHinG dEsIRAblE, Is eITHEr eXPEnSIVe, bAnnED, ilLOgiCal oR SeEING(maRRiED to) sOMEonE ElsE......;-)
User signatures are completely uncorrelated with the thread topic, and introduce a significant amount of noise in the data. In fact, they produce irrelevant lexical overlaps between different comments of a given author, and drastically reduce the similarity between related comments 13 . To detect and remove user signatures we applied a simple procedure. We grouped posts by user, and compared the post in each group to verify the presence of common final parts. Those parts can be considered signatures to be removed. Using this algorithm we discovered and removed a signature from about 10% of the comments.
A manual analysis on the retrieved user signatures showed that the proposed approach is extremely precise in detecting user signatures, i.e., no core part was erroneously considered a signature. When a signature is present in a single comment of the dataset, it cannot be detected with such a procedure. This problem can be partially mitigated removing the text appearing after some “signature separator” 14 in a comment.
Models and Parameterization
We train our models using the C-SVM algorithm [14] within KeLP
15
, a
Kernel-based Machine Learning platform [24] that
implements the tree kernels described in Section 3.2. In the 3-class setting we used a
one-vs-all schema. With this setting, the data is rather imbalanced, as the
potential class occurs far less than the other classes. We took this
into account by emphasizing the regularization parameter for the positive class, i.e.,
In the 2-class setting, we used a binary SVM trained to recognize good answers.
PTK was used with the default parameters, i.e., λ = μ = 0.4, while we selected the hyper-parameter C = 1 of SVM using a tuning stage on the 2015 dev. set.
We generated shallow trees from the question-answer pairs by using the OpenNLP 16 chunker.
To study the impact of the various features proposed in Section 4, we tested different
kernels: LK
sim
is a Linear Kernel operating on the
intra-pair features defined in Section 4.1; LK
qa
is a Linear Kernel operating on
the task specific features defined in Section 4.4; TK+ is the tree kernel combination performing the
inter-pair analysis described in 4.3
Finally, we linearly combined these kernels to create a more robust approach.
When testing on the 2015 and 2016 test sets, we trained the models by using the training and development sets of the corresponding year. Instead, for the 2017 test set, we used all the 2016 datasets as training material.
Results
Table 2 shows the results on the 2015 test set in the 3 class setting. In the bottom part of the table we reported the results of the three best systems at SemEval-2015. The JAIST team [67] won the 2015 competition using an SVM operating on several features that include, intra-pair similarities, alignment-based features, topic-based features and some heuristics. HITSZ-ICRC [32] adopted a hierarchical classifier trained to firstly identify bad comments and then to distinguish the good answers from the potential ones. They employed intra-pair similarities and several linguistic features, such as the counts of name entities, punctuation marks or specific POS in the comments. Finally, the QCRI system [48] used a preliminary version of the features described in sections 4.1 and 4.4.
Results on the 2015 test set with the original 3-class setting.
Results on the 2015 test set with the original 3-class setting.
All the proposed kernels are significantly above the Majority Baseline (i.e., always good).
The LK sim model is the weakest model, it confirms the issue we highlighted at the end of Section 4.1, which justifies our inter-pair approach: many good comments directly answer without repeating the words (and more in general the concepts) expressed in the question.
The LK qa model, instead, is rather accurate; this is not surprisingly, as it is based on a set of manually defined features that have been specifically developed to capture some frequent phenomena appearing in general-purpose fora.
The TK+ model reaches similar results: this is very impressive considering it does not exploit task or domain specific features, but implements a general approach that can be used in every task defined on text pairs. Furthermore, this result is even more remarkable if we consider that the intra-pair reasoning, which represents the more straightforward approach to solve this problem, is basically neglected, as the TK+ model applies an intra-pair similarity only in establishing the REL tags on the parse trees of the question-answer pairs.
Finally, we defined kernels of increasing complexity, by linearly combining the individual kernels. The results are outstanding, demonstrating that the information provided by the different kernels is largely independent. Therefore, a joint learning model (i.e., an SVM equipping a kernel combination) can take the best by the these three different sources of information. The LK sim +LK qa is competitive with the best systems, while the LK sim +LK qa +TK+ achieves the new state-of-the-art on this dataset.
Similar results are obtained in the 2-class setting, reported in Table 3. According to MAP, the best individual kernel is TK+. Again, linearly combining the three kernels leads to state-of-the-art results, which largely outperform the best systems at SemEval-2015 17 Furthermore, our best model achieves higher accuracy and F1 than MaxEnt+GraphCut [36] and FCCRF [35], which are two systems developed after the SemEval-2015 challenge. They both approach the answer selection in cQA as a graph task, where all the comments in a question thread should be globally classified.
Results on the 2015 test set with the 2-class setting.
Finally, Tables 4 and 5 report the official results of the 2016 and 2017 semEval challenges, respectively. We participated with the LK sim +LK qa +TK+ model under the pseudonym KeLP. In both occasions, we won the competition. In the 2016 edition 12 systems participated to the challenge and apart KeLP, the best two were ConvKN [9], which jointly used convolutional neural networks and kernel methods, and SemanticZ [38], which relied on several semantic similarity features based on fine-tuned word embeddings and topic similarities.
Results on the 2016 test set with the 2-class setting.
Results on the 2017 test set with the 2-class setting.
In the 2017 edition, there were 14 systems participating to the challenge, and the best systems apart KeLP were Beihang-MSRA and IIT-UHH. Beihang-MSRA [23] is based on a gradient boosted regression tree model that using several features including various NLP features, neural network based matching and task specific features. IIT-UHH [47] is an SVM based system that makes use of textual, domain-specific, word embedding and topic-modeling features.
The results obtained on the 2017 data are significantly higher than those derived on the other two years in terms of ranking metrics. This depends on the fact that there are many threads with mostly good comments, or mostly bad comments. Consequently, their re-ordering impact less on the initial MAP. This is also confirmed by the high results achieved by the chronological baseline. Instead, the accuracy is in line with the one observed in the previous years, demonstrating the consistency of the proposed model.
In order to get an intuition about the effect of the proposed inter-pair approach, we show a comparison between LK sim and TK+ in Fig. 5. All the comments are classified correctly by the TK+ model, and incorrectly by the LK sim . This confirms that the TK+ model effectively learned valid question-answer patterns, such as Q:“Is there any …?” A:“Try …”. In contrast, the intra-pair similarities cannot capture any useful information from these question-answer pairs, which are consequently all classified as bad .

A real question–comments threads from the 2016 test set (ID Q386_R4). The class label before the arrow corresponds to the prediction provided by LK sim , while the right-hand label is the prediction provided by TK+, which always provides the correct class.
The problem of selecting the relevant text passages (i.e., those containing good answers) has been tackled in QA research, either for non-factoid QA or for passage reranking. Usually, automatic classifiers are applied to the answer passages retrieved by a search engine to derive a relative order [31, 77].
One research direction has been to try to match the syntactic structure of the question to that of the candidate answer. For example, [75] proposed a probabilistic quasi-synchronous grammar to learn syntactic transformations from the question to the candidate answers. [31] used an algorithm based on Tree Edit Distance (TED) to learn tree transformations in pairs. [74] developed a probabilistic model to learn tree-edit operations on dependency parse trees. [77] applied linear chain conditional random fields (CRFs) with features derived from TED to learn associations between questions and candidate answers. Although, these approaches are accurate and inject some structure in the models, they cannot express the same richness of relational features we introduce thanks to our inter-pair kernels.
Regarding the use of syntactic structure, e.g., [73] proposed a retrieval model for finding similar questions based on the similarity of syntactic trees. In contrast, we proposed a tagging solution similar to the one for passage reranking used in [56, 59], which was further improved in [69, 70], exploiting relational tags and linked open data.
Another important research direction has been on using neural network models for question-answer similarity [22, 72]. For instance, [65] used neural attention over a bidirectional long short-term memory (LSTM) neural network in order to generate better answer representations given the questions.
Regarding the community scenario of QA, one early work is that of [50], who tried to determine whether a question is “solved” or not, given its associated thread of comments. As a first step in the process, they performed a comment-level classification, considering four classes: problem, solution, good feedback, and bad feedback.
Conclusion
This paper describes a kernel-based method for tackling the answer selection task in community question answering. The novel aspect of the proposed approach is its capability to automatically learn pairwise question-answer patterns from training question-answer pairs. For instance, the model can recognize valid question answer templates such as answers to Yes or No questions, e.g., Q:“Can I...?” A:“Sure …, Yes …, You can …, No …”, or answers to a request of indication, e.g., Q:“Which is the best...?” A:“Try …, Go to …”. This allows the model to properly solve those cases in which the question and the answer do not share similar words. We represent question-answer instances as pairs of linked parse trees, and apply a combination of tree kernels to perform an inter-pair reasoning, which leads to state-of-the-art results on three different editions of the community question answering challenge of SemEval.
This is a paradigmatic shift with respect to most other approaches in literature relying on an intra-pair comparison between the question and the answer.
In the future, we plan to apply this approach to other question-answer datasets and to investigate universal dependencies in order to define cross-language solutions.
Footnotes
In the task of answer selection in community question answering, the problem is establishing whether a comment directly answers a question, without verifying the correctness of the provided information. This means that the sentence A2 is to be considered good , although the user who is replying is ignoring the fact that a gold certificate is required.
The tree kernels TK are usually normalized applying the formula
For instance in the Qatar Living Lounge category the following question has been posted: “Google: does anyone know how to find Google? I tried to Google it but found myself stuck in a paradox loop.”. Obviously many ironic comments answered this question.
The task organizers report that some comments in the threads were discarded due to disagreement in the annotation process. The extent of discarded comments is unknown.
The constants in equation 5 are so that the information is propagated to 10 comments, with a linear decay factor that depends on their distance k from the comment by u q .
For instance, after the kernel normalization process, the possible similarity in the core part of two comments is hidden by the presence of different user signatures.
For instance, an horizontal line such as “——–”.