
Abstract
Community Question Answering (CQA) websites has become an important channel for people to acquire knowledge. In CQA, one key issue is to recommend users with high expertise and willingness to answer the given questions, i.e., expert recommendation. However, a lot of existing methods consider the expert recommendation problem in a static context, ignoring that the real-world CQA websites are dynamic, with users’ interest and expertise changing over time. Although some methods that utilize time information have been proposed, their performance improvement can be limited due to fact that they fail they fail to consider the dynamic change of both user interests and expertise. To solve these problems, we propose a deep learning based framework for expert recommendation to exploit user interest and expertise in a dynamic environment. For user interest, we leverage Long Short-Term Memory (LSTM) to model user’s short-term interest so as to capture the dynamic change of users’ interests. For user expertise, we design user expertise network, which leverages feedback on users’ historical behavior to estimate their expertise on new question. We propose two methods in user expertise network according to whether the dynamic property of expertise is considered. The experimental results on a large-scale dataset from a real-world CQA site demonstrate the superior performance of our method.
Introduction
In the past years, many Community Question Answering (CQA) [20] websites, such as Stack Exchange 1 and Zhihu 2 , have gained popularity among users. On CQA websites, users can raise their questions, and answer the questions posted by others. However, a CQA website may have tens of thousands of questions every day, which are difficult to be solved in a short time. Under this situation, expert recommendation [22], which aims to provide an answerer who are most likely to post satisfying answers for the questions, has become a promising technique to tackle the challenge.
Existing research methods on expert recommendation include feature based methods [13, 18] and matrix factorization(MF) based methods [7, 12]. The former methods focus on estimating user expertise level relying on crafted features. The latter methods rely on feedback information(e.g., votes in Stack Exchange). Recently, some related works [6, 24] proposed to use network embedding to solve the expert recommendation and question retrieval problem due to its capability to handle sparsity data. However, the vast majority of these methods consider the expert recommendation problem in a static context. In particular, the expert recommendation is based on a snapshot of users’ previously asked or answered questions, ignoring the temporal information. However, the context of expert recommendation is dynamic due to the following two reasons. First, similar to general recommendation systems, users’ interests change over time. A user who answered a question related a certain topic may no longer to answer the questions in this topic anymore. Moreover, a lot of previous works [1] have proved that when buying goods or reading news, users’ next behavior is closely related to his recent behavior instead of remote historical behavior. This phenomenon also exists in CQA. For example, if a user just answered a question about English grammar, there’s a good chance that he will answer the questions in this field again. Second, users’ expertise may not be consistent as well, as users’ skills may improve or decline over time. Especially in some question fields where the updating of knowledge is very quickly, such as programming and artificial intelligence, this phenomenon is more obvious. The knowledge level of experts should be continuously evolving, otherwise they may lose their expertise. Thus, it is necessary to consider the dynamic change in CQA to to provide precise recommendation. There are some previous works attempting to make the expert recommendation methods adaptive in a dynamic context. Some of them used a decaying factor to suppress questions answered in remote history and focused on users’ recent behavior. Some methods designed time related features and fed them into classifier. However, these methods are relatively simple and most of them only consider one aspect of dynamic interest and dynamic expertise.
In order to overcome the above limitations, we propose Dynamic User Modeling method (DUM) for expert recommendation. Similar to previous works [15, 24], we cast the expert recommendation problem as a pair-wise ranking problem and we aim to learn accurate user embedding to make recommendation. But different from those methods which learn one embedding for each user that preserve both interest information and expertise information, we propose to learn user interest embedding and user expertise embedding separately. Because when assuming that the environment is static, the users’ interest is consistent with users’ expertise as users are interested in a question domain if they are specialized in it. But in the dynamic reality, a user may not answer the question because his current interest is not in this question domain even if he once has high expertise on it. Under the circumstances, user interest and user expertise are inconsistent, making it hard to capture both of them by one embedding.
Specifically, for user interest, we model users’ recent answering behavior by LSTM to capture users’ dynamic short-term interest and incorporate it with long-term interest to get users’ interest representation. For user expertise, we leverage the designed user expertise network, which exploits users’ historical answering behavior and feedback information to capture user expertise on different question domains. It has two network structures. The first one is treating historical answers disorderly, which applies to the scene with little expertise change. The second one is using LSTM to model the historical answering sequence so that the dynamic change of users’ expertise can be captured. We use the similar ranking strategy with the work [15] in which answerers who get more votes should get higher score. As illustrated in the previous works [19, 22], the experts should have both high interest and high expertise. Thus, the score predicted by our model is a combination of interest score and expertise score.
The main contributions of this paper are as follows: We propose a novel framework DUM to predict the best answerers for new questions in CQA sites. Based on our knowledge, our approach is the first work that consider the dynamic change of both user interest and user expertise in expert recommendation problem. We design a user expertise network, which can estimate users’ expertise on new questions based on their historical answer performance. By appling attention-based LSTM in the user expertise network, the dynamic change of user expertise can be captured precisely. We demonstrate the effectiveness of the proposed framework on the real-world Stack Exchange datasets.
Related work
Expert recommendation, also known as expert finding [3, 26], aims at recommending the best answerer to a new question. The majority of previous works fall into feature based methods, matrix factorization based methods and network embedding based methods. According to whether temporal information is used, these methods can be divided into static methods and dynamic methods. The former uses a snapshot of users’ previously asked or answered questions and they consider that user interest and expertise are static. Pal et al. [18] use three classes of features to train a binary classifier, including question features, user features and user feedback on answers. However, heavily relying on well-designed feature and feature selection limits its robustness. Cho et al. [7] combine generative probabilistic model and matrix factorization to solve the problem. Huang et al. [10] utilize a tree to guide the decomposition of 4th rank tensor data consisting of questions, topics, voting and expertise information. However, they model question content by simple language model or topic model, which are unable to capture the complex semantics of question content. Fu et al. [8] propose a recurrent memory reasoning network to explore the implicit relevance between a requester’s question and a candidate expert’s historical records. It performs much better than the above methods because it applies deep understanding and reasoning of semantic information. Recently, network embedding received a lot of attention in expert recommendation. Since it can capture the implicit association between users and questions by analyzing the network structure. Zhao et al. [25] adopt a random-walk based learning method with recurrent neural networks to learn ranking metric embedding from the CQA network. Li et al. [15] treat question raisers and answerers as different entities to make the recommendation more personalized. They learn representations of entities by metapath based random walk and compute ranking scores for answerers by a designed CNN scoring function. Although these methods obtain good performance, they ignores the time information, which is the focus of this paper.
There are a few methods belonging to the dynamic methods. They tend to consider different dynamic aspect separately, such as user availability, user interest, and user expertise. Currently, user availability is the most commonly considered dynamic aspect for the expert recommendation problem. Several studies used temporal features to estimate the availability of users for a given day or for a specific time of the day. For example, Sung et al. [21] use all replies of users to train a sigmoid function and Chang et al. [4] build binary classifiers using all answers of users within a fixed time frame. For dynamic user interest and expertise, a straightforward solution is to use a decaying factor to suppress questions answered in remote history and focus on users’ recent interest. Yeniterzi et al. [23] incorporate temporal information to model dynamic user expertise and apply two models, namely exponential and hyperbolic discounting models, to discount the effect of older records in calculating z-scores. This method is still rather straightforward being equivalent to using a decaying factor. Neshati et al. [17] consider four feature groups: topic similarity, emerging topics, user behavior and topic transition features. They found that all of these feature groups can be beneficial to predict the probability of becoming an expert in the dynamic environment. However, most existing dynamic methods rely on feature engineering [22], which is time-consuming and problem specific [5]. Thus, we design the neural network to exploit the dynamicity in an automatic way in this paper.
Problem statement
Let U ={ u1, u2, . . . , u
l
} denote a set of users and Q ={ (q1, t
q
1
) , (q2, t
q
2
) , . . . , (q
c
, t
q
c
) } denote a set of questions, where (q1, t
q
1
) means the question q1 is raised at time t
q
1
. A user’s answering history is represented by an ordered list: B (u) =
Using above notations, we define the expert recommendation problem as follows: Given a set of questions Q<T raised before time T, accompanying with answerers and feedback information (e.g. votes), compute the ranking scores of all potential users u ∈ U for each new raised question q ∈ Q≥T so that the user with the highest score is the expert.
Framework
The architecture of the proposed framework is shown in Fig. 1. The first component of the framework is user interest modeling, shown in Fig. 1 (b). Considering that user’s interest is changing over time and user’s recent behavior can better reflect their current interest, we propose to learn the short-term interest representations from their recent behavior by LSTM. Then we combine it with the long-term interest, which is the average of users’ all history answered question embedding. The second component is user expertise modeling, shown in Fig. 1 (c). Feedback information from answers reflects users’ expertise. By using these feedback information, we design user expertise network to capture users’ expertise in specific question domain. In the ranking component shown in Fig. 1 (d), user interest embedding and user expertise embedding are fed into score function to compute the score of contributing the “accepted answers” for each user. The flow chart of the proposed framework is shown in Fig. 2.
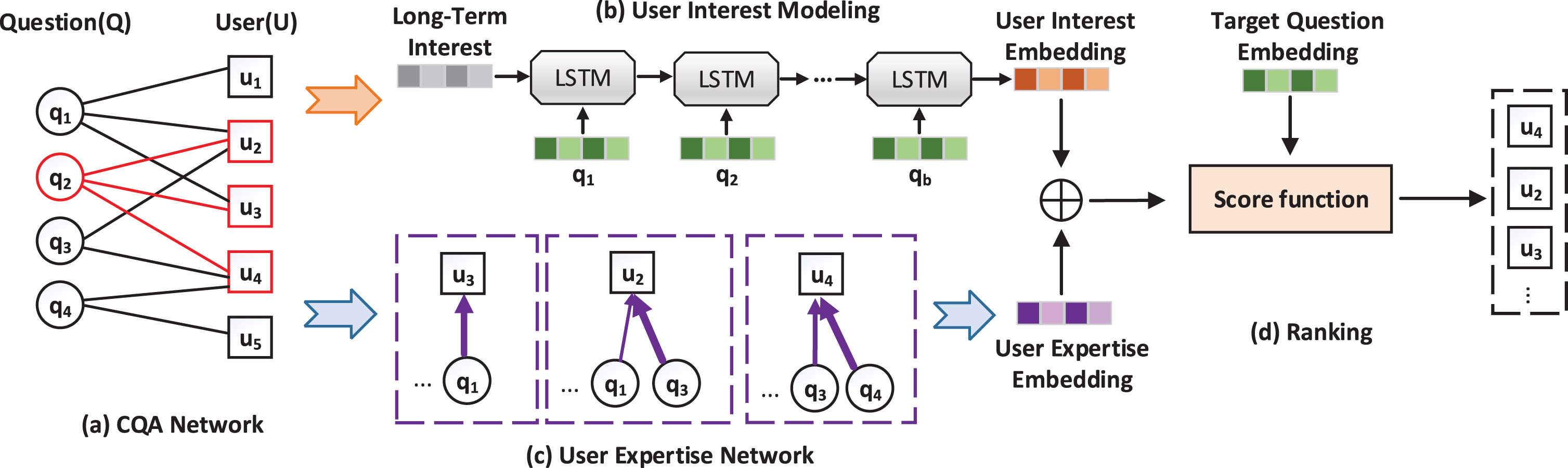
Overview of the proposed framework DUM. (a) An example of CQA network. The highlighted part in bold means the question q2 is answered by u2, u3, u4. (b) Using LSTM to model users’ short-term interest and combine long-term interest to get user interest embedding. (c) Designing user expertise network to generate user expertise embedding. The detailed network structure is shown in Fig. 3. (d) Rank the user given user interest embedding, user expertise embedding and target question embedding. The user with the highest score is the expert.
Flowchart of the framework.
In CQA websites, the question is described by the question title, content and tags. Generally, the question title and tags can clearly express the meaning of the question so we use them to represent questions. For question title, there are multiple ways to get its representation, such as TF-IDF and Doc2vec [14]. We choose to pretrain a LSTM [27] and extract the last hidden state as the title representation, denoted as
User interest modeling is to learn embedding of user interest, denoted as
Users may have dynamic short-term interests, which to a great extent determines whether they are willing to answer the given questions. Consequently, we use LSTM to capture the sequential patterns due to its remarkable ability in processing sequential data. Specificly, we define the questions answered in the last n days as users’ recent behavior, which can be denoted as
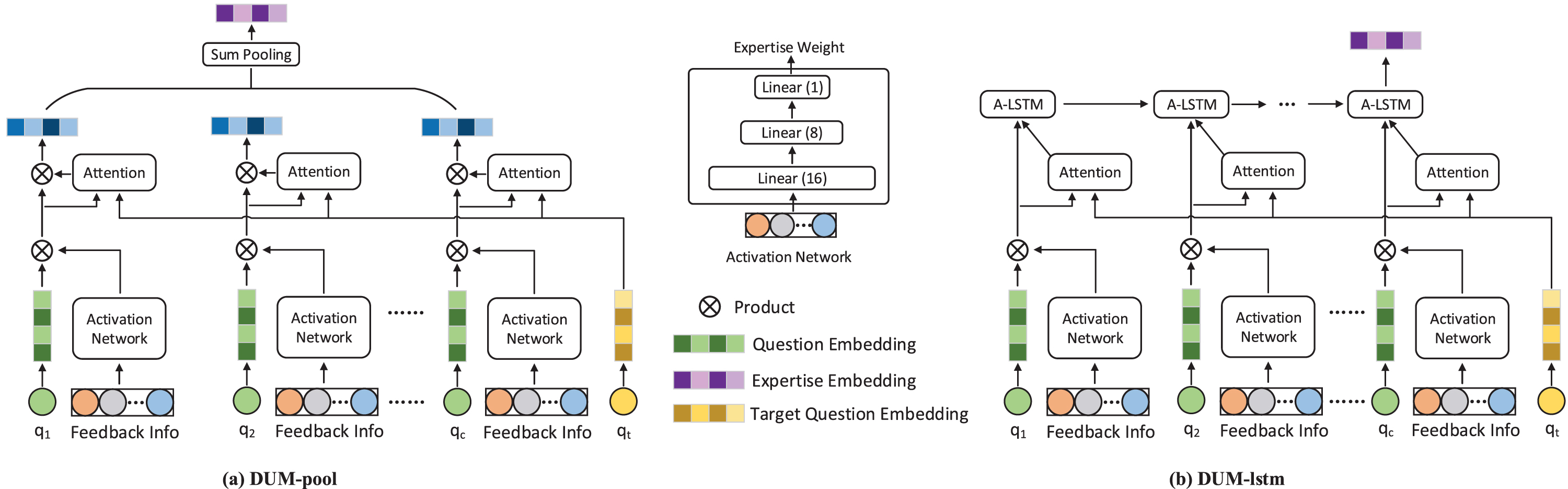
The architecture of the user expertise network.
User expertise modeling is to learn embedding of user expertise, denoted as
Considering that different users answer different numbers of questions, We introduce two methods to transform the list of embedding vectors to a fixed-length embedding. The first method is pooling, as shown in Fig. 3 (a). We denote this method as DUM-pool. A straightforward way is to use mean pooling to maintain the most information. Nevertheless, it is biased to treat all historical answers equally, because for different target question, the contribution of each historical answers is significant different. For example, when the target question is about English Grammar, we should pay more attention to historical answers on this topic. Thus, we use attention mechanisms [2] to compute the weight. Note that for target question q t raised at t q t , we use B (u) <t q t to generate expertise embedding. For each question in B (u) <t q t , its attention weight is computed as follows:
Feedback Statistics
where
The pooling method ignore the temporal information, treating the answering behavior in a disordered way. Typically, the user’s performance sequence can reflect his expertise’s evolution. For example, If a user’s answering performance is constantly improving, the more likely he is to become an expert, and vice versa. Thus, we propose to use LSTM to capture the the trend of the user’s expertise level changing with time. We denote this method as DUM-lstm, as shown in Fig. 3 (b). Specificly, the activated answering sequence, which contains the expertise information of the question, serve as the input of the LSTM. Similar with the DUM-pool, we also use attention mechanisms to focus on the questions which are similar to the target question and reduce the noise brought by unrelated questions. We denote it as A-LSTM. The attention weight is calculated in the same way with Equation 5. Then we utilize these scores to adjust the cell and hidden states of A-LSTM:
Obtaining the interest embedding
Following previous works [15, 25], we introduce the relative rank to model the score. Given the votes of the answers, we design the following rules: (1) Users with higher vote score higher than those with lower vote. (2) Users who answered q
t
score higher than those who did not. Let the tuple (i, j, q
t
) mean that “user i’s answer obtains more votes than user j’s answer on the question q
t
", (i, j, q
t
) ∈ D1. Let the tuple (y, z, q
t
) mean that “user y answered the question q
t
while user z didn’t”, (y, z, q
t
) ∈ D2. The inequality holds:
The parameters in our model include question tag embedding
Experimental settings
Datasets
We experimented our method based on Stack Exchange Dataset, which contains many sub-dataset with specific topics. Two of them are used to evaluate our method: English and StackOverflow (SO) 3 . Each dataset contains questions posted over eight years (from July 2011 to March 2019) and covers a lot of tags of questions. The datasets differ in sizes and they have different propertiet so that DUM can be comprehensively tested. Considering that the StackOverflow dataset is extremely large, we random sample a set of questions of several important tags (e.g. Java, Python, C#, PHP). The statistics of the dataset can be seen in Table 2, where u, q, t, u/q, v/a represent users, questions, tags, average number of users per question and average number of votes per answer respectively.
Statistics of the datasets
Statistics of the datasets
Since the expert recommendation problem is regarded as a ranking problem and usually only top returned results are of interest, we adopt three commonly used ranking metrics: Mean Reciprocal Rank (MRR), Hit at 5 (Hit@5), and Precision at 1 (Prec@1). MRR takes into account of the rank of the correct answerer among recommended answerers for query question q:
Hit@k considers if the correct answerer appears in the top-k, defined as:
Prec@1 considers if the correct answerer appears in the first place, defined as:
The comparisons of MRR, Hit@5, and Prec@1 between DUM-pool, DUM-lstm and baseline models
We evaluate the performance of our approach by comparing it with several baseline methods, In these methods, Temporal-ZScore, GBDT and LSTUR are dynamic methods because they take time into consideration and others are static methods. Similarity. Find the closest question to the target question based on TF-IDF and recommend the answerer who has the highest votes. Temporal-ZScore [23]. ZScore is calculated for each time interval and then it is exponentially discounted with respect to its temporal distance from question’s interval. We refer it as T-ZScore in the following. Gradient boosting decision tree(GBDT). It’s a feature based method and we use LightGBM [11] as the implementation for its fast speed. Extracted features are reported in Table 4. ConvNCF [9]. It’s a multilayer neural network architecture based matrix factorization method. It uses an outer product to find out the pairwise correlations between the user and item embedding. RMNL [25]. A network embedding based methods which exploits both users’ relative quality rank to given questions and their social relations. Note that the Stack Exchange Dataset doesn’t contain social relations, so we replace it by user badges relation [16], which is defined as there is an edge between two users if there are more than 5 common badges between them. NeRank [15]. This model is the state-of-the-art method based on network embedding. It learns representations of entities by the HIN embedding method and compute ranking scores by an explicitly defined CNN scoring function. LSTUR [1]. This is a neural news recommendation approach which considers both long-term and short-term user representations. It uses LSTM to capture user’s short-term interest and it proposes two methods to combine long and short-term interest.
Selected features of GBDT
Selected features of GBDT
As illustrated in Section 3, questions raised before the timestamp T are treated as training data and questions raised in or after T are left for evaluation. We design two different train/test splits by setting T = “2019-01-01” and “2018-10-01”. To avoid cold start, we remove those users whose historical records are less than 5 in test set. In addition, we set n = 30 when capturing users’ short-term interest. We set d q 1 = 256 and d q 2 = 64 and the size of user embedding d is set as 256.
Performance comparison
The performances of all methods are reported in Table 3, where the best results are highlighted in bold. We have the following main findings:
First, dynamic methods (e.g. T-ZScore, GBDT and LSTUR) perform quite different. T-ZScore makes little improvement compared to Similarity because it is rule-based, which is too simple. GBDT performs better for using a lot of handcrafted features. But it falls behind other deep-learning based methods probably because features are usually not optimal. What’s more, limited by simple language model, it fails to exploit the semantic information of question. LSTUR performs well thanks to the powerful ability of LSTM to process time series, which helps to capture users’ short-term interest. In addition, network embedding based methods are superior to other baseline methods because they captures not only the interactions but also the questions’ content information. NeRank outperforms RMNL and LSTUR because it considers the question raiser’s information and the CNN score funtion captures more complex relationships compared with inner product.
Second, our model significantly outperforms all the baseline methods, including the network embedding based methods, such as RMNL and NeRank on both datasets and train/test settings. The reason is that compared with the baseline methods which only learn one single embedding for each user, our model considers the inconsistency between user interest and user expertise and learn the embedding for each of them. The result turns out that it can enhance the expression ability of the model. By considering both users’ long-term and short-term interest, users’ dynamic behaviors can be predicted more precisely. What’s more, compared with LSTUR which only captures users’ interest, the designed user expertise network in our model explicitly exploit the feedback information to capture user expertise on the specific question domain. In addition, attention mechanism helps learn more critical information, boosting the performance.
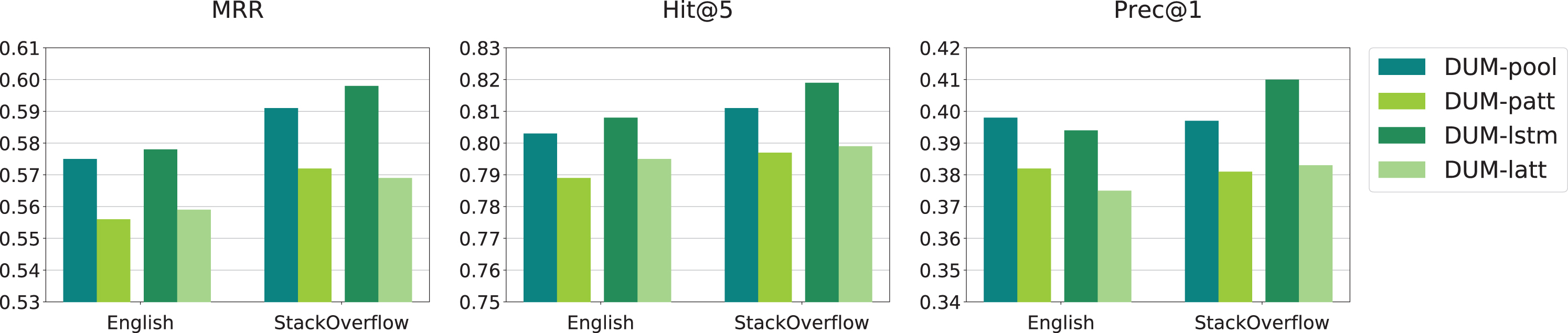
Third, our proposed two methods to learn user expertise, i.e., DUM-pool and DUM-lstm, can achieve comparable performance and both outperform baseline methods, which validate the effectiveness of these methods. By comparison, we can find that DUM-lstm performs much better in the StackOverflow dataset than in the English dataset. This is because the properties of the datasets are different. In English, the knowledge is relatively fixed and the update is slow. However, in StackOverflow, the programming languages and technologies continue to develop so that the experts have to keep improve their knowledge level over time. The time information plays a more important role in StackOverflow when estimating users’ expertise.
The effectiveness of capturing both long-term and short-term user interest.
The effectiveness of the activation network.
The effectiveness of the attention mechanism.
Effect of recent behavior n and the dimension of user embedding d on the performance of model.
The DUM provides model components to (1) capture users’ short-term interest by LSTM and combine it with long-term interest and (2) capture user expertise by user expertise network. In order to validate the effectiveness of each component, we will provide further investigations to better understand the contributions of model components to the proposed framework. The analytical experiments are based on T = “2019-01-01” due to page limit.
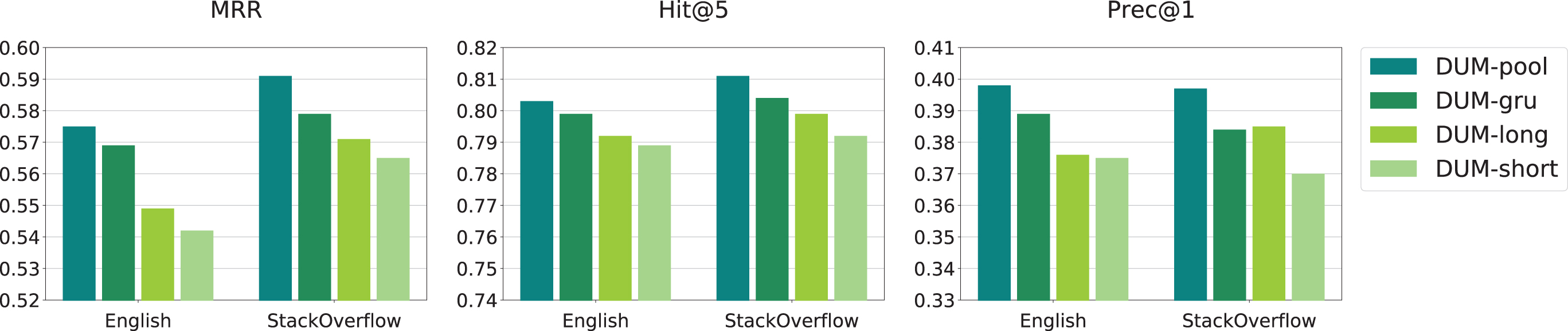
First, we conduct several experiments to explore the effectiveness of capturing both long-term and short-term user interest. The results are summarized in Fig. 4. We compare the performance of our method DUM-pool with the model variants DUM-long and DUM-short. The former removes the users’ long-term interest
Second, we design several experiments to validate the effectiveness of the user expertise network. The activation network and the attention mechanism are the essential elements of the user expertise network. So we will explore their effectiveness separately.
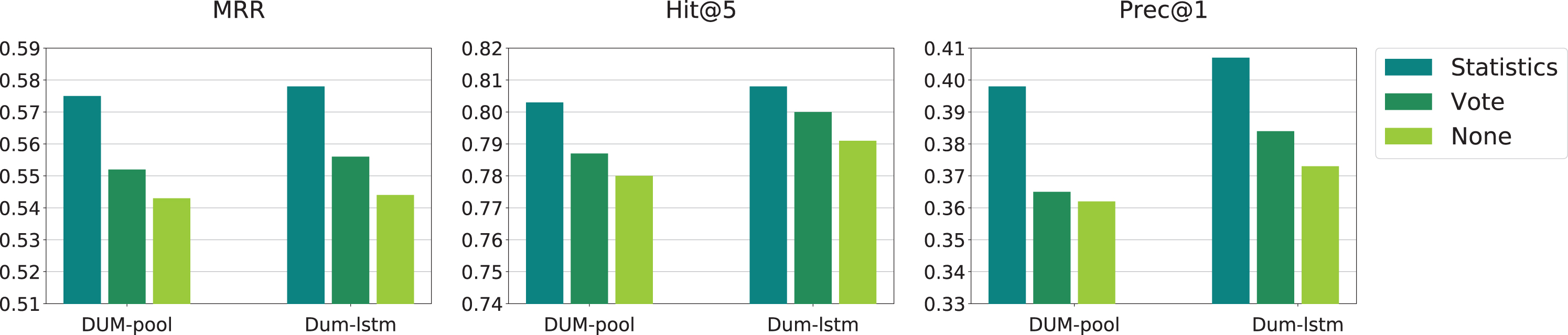
In our approach, the activation network takes the statistics of the feedback as input and output the expertise weight. We denote it as Statistics. We compare it with the designed variants, denoted as None and Vote. The former removes the activation network and the latter takes the vote as the expertise weight directly. The results on two datasets are similar so we just show the result on English dataset in Fig. 5. Both the performance of DUM-pool and DUM-lstm are severely decreased. Although Vote contains the vote information, it dose not make much improvement compared with None. The reason is that the absolute votes of answers are dependent on the question popularity, so using it directly will bring noise to the model. The result demonstrates that the vote information is critical for capturing users’ expertise. Moreover, the activation network can eliminate the bias, estimating the expertise precisely.
In order to evaluate the effectiveness of attention mechanism, we compare our model with several variants. In DUM-pool, we replace the attention mechanism with the average of all the question embedding in recent behavior, denoted as DUM-patt. In DUM-lstm, we remove the attention mechanism in LSTM, denoted as DUM-latt. The result is shown in Fig. 6. It can be seen that both variants have worse performance. It demonstrates that by concentrating on questions which are more related to the target question, the user expertise is captured more accurately.
To summarize, the user expertise network can precisely capture user expertise on specific question domain with the help of attention network, and modeling users’ short-term interest is useful to predicte users’ answering willingness.
Parameters sensitivity
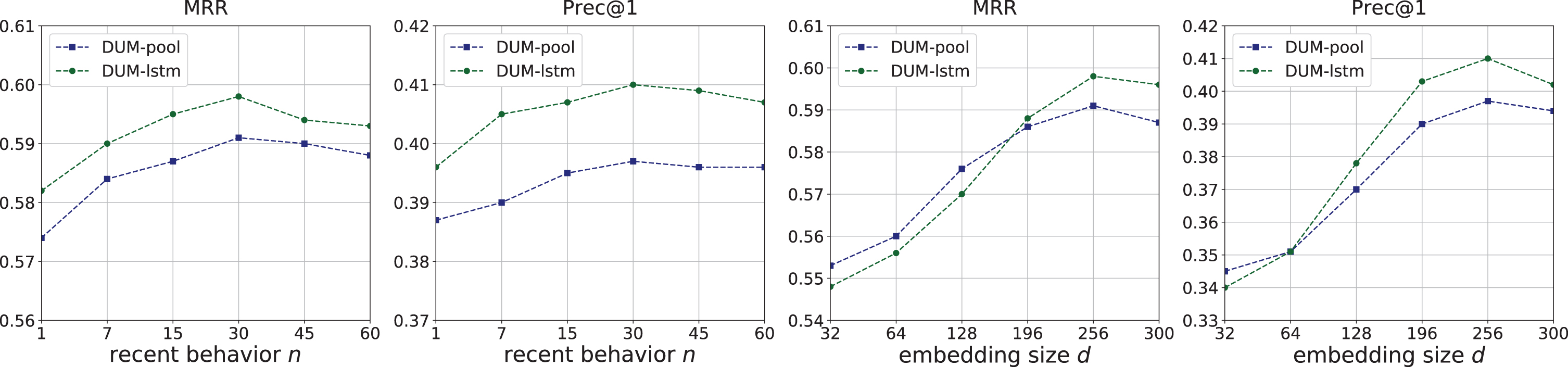
We conduct experiments to analyze the impacts of two key parameters, i.e., the parameter n which defines users’ recent behavior and the size of user embedding d. The performances (in terms of MRR and Prec@1) on various settings of n and d are shown in Fig. 7.
It is observed that with the increment of n, the performance increases before n = 30 since more recent behaviors are involved in, contributing to a better short-term interest embedding. Then it stops improving because remote behaviors bring noise to the short-term interest modeling. Similar to n, increasing the embedding size from 32 to 256 can improve the performance significantly. However, with the embedding size of 300, the performance degrades. It demonstrates that using a large number of the embedding size has powerful representation. But too large size will lead to over-fitting.
Question information
Question information
We conduct case study to reveal the inner structure of DUM on English dataset. Table 5 lists the information of the target question q16 and q55 and historical questions answered by user u11, where the feedback is as illustrated in Table 1. We first visually explore the effectiveness of user expertise network. Fig. 8 shows the expertise weight and attention weight of these questions with respect to the target question q55. We can find that questions which are answered well get higher expertise weight, e.g.,q89, q281, q91, q332. In addition, questions related to the target question such as q675, q281, q332 get higher attention weight.
Then we compare the ranked lists of our model DUM-pool, DUM-lstm and variant model DUM-short for target question q16 and q55, respectively. As shown in the upper half part in Table 6, there are 6 candidate users for q16 and the last two users u11 and u94 are sampled from answerers who didn’t answer q16. The ground truth is highlighted in red. we can find that DUM-short ranks u11 first probably because u11 has a good performance in answering questions on the java tag. But it neglects that he hasn’t answered questions of java tag for a long time. DUM-pool manages to avoid this problem by considering users’ short-term interest.
For another target question q55, it has 6 candidate users and u11 is the ground truth. We can find that DUM-lstm makes the right recommendation but DUM-pool fails. It’s probably because the answering performance of u11 on python tag is improving. However, DUM-pool can’t capture this trend because it ignores the time information when estimating user expertise. The DUM-lstm can make up this shortage by using the A-LSTM.
Ranked list of q16 and q55
Ranked list of q16 and q55
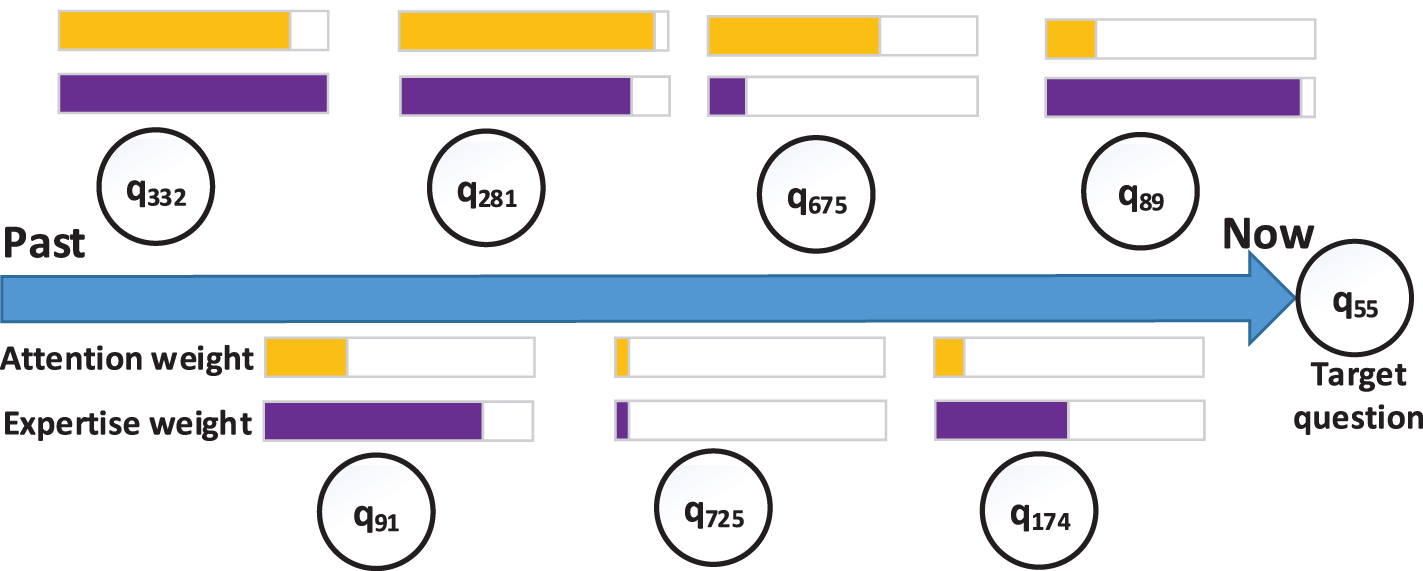
Illustration of the user expertise network.
In this paper, we propose a new framework to dynamically model user interest and user expertise for expert recommendation. For user interest, we learn both long-term and short-term interest to precisely predict the user’s next behavior. For user expertise, we propose to explicitly model the feedback information on history answers to estimate users’ expertise on new questions. In addition, in order to adapt to the characteristics of different question domains, we use two methods to learn user expertise, i.e., using mean pooling of history sequence to generate expertise embedding or using A-LSTM to capture the trends of users’ expertise. Experimental results on two real-world datasets show that the performance is boosted by capturing users’ short-term interest and accurate user expertise modeling. Some potential future work includes: (1) the questions representation can be improved by using attention mechanism; (2) the profile of user such as user personal description should be considered to solve the cold-start problem.