
Abstract
The recent breakthroughs in the field of deep learning led to state-of-the-art results in several NLP tasks, such as Question Answering (QA). Unfortunately, the requirements of such neural QA systems are very strict due to the size of the involved training datasets. In cross-linguistic settings these requirements are not satisfied as training datasets for QA over non-English texts are often not available. This represents the major barrier for a wide-spread adoption of neural QA methods in NLP applications. In this paper, the acquisition of a large scale dataset for an open-domain factoid question answering system in Italian is discussed. It is obtained by automatic translation and linguistic elicitation of an existing English dataset, i.e. the SQuAD question-answer pair corpus. Even though the quality of the resulting corpus for Italian might not be completely satisfying, our work allowed to generate more than 60 thousand question-answer pairs. In the paper the impact of this resource on the QA process over the Italian Wikipedia is studied, according to different training conditions and architectural constraints. A comparative evaluation against the English version, in line with standards in the SQuAD literature, is carried out. The outcomes show that the results achievable for Italian are below the state-of-the-art for English, but the ability of learning not to respond (i.e. the adoption of techniques for detecting question whose answers are simply not available, i.e. EMPTY set of answers) allows the system to pursue reasonable levels of precision. This make it already usable within realistic application scenarios. Finally, an error analysis is presented that suggests possible future research directions on still critical but highly beneficial enhancements, in view of concrete QA applications in Italian.
Introduction
Question Answering (QA) ([8]) tackles the problem of returning one or more answers to a question posed by a user in natural language, using as source a large knowledge base or, even more often, a large scale text collection: in this setting, the answers correspond to sentences (or their fragments) stored in the text collection. A typical QA process consists of three main steps: the question processing that aims at extracting requirements and objectives of the user’s query, the retrieval phase where documents and sentences that include the answers are retrieved from the text collection and the answer extraction phase that locates the answer within the candidate sentences [7, 11]. Various QA architectures have been proposed so far. Some of these rely on structured resources, such as Freebase, while others use unstructured information from sources such as Wikipedia (an example of such a system is the Microsoft’s AskMSR [3]), or generic Web pages, e.g. the QuASE system [16]. Hybrid models exist as well, that make use of both the structured and the unstructured information. These include IBM’s DeepQA [6] and YodaQA [1].
In order to initialize such systems, a manually constructed and annotated dataset is crucial, from which the mapping between questions and answers can be learned. Datasets designed for structured-knowledge based systems, such as WebQuestions [2], usually contain the questions, their logical forms and the answers. On the other side, datasets over unstructured information are usually composed of question-answer pairs: WikiMovies [13] is an example of this class of systems and it is made of a collection of texts from the movie domain. Finally, some datasets contain the entire triplets made of the questions, the paragraphs and the answers, that are expressed as specific spans of the paragraph and thus located in the paragraph. This is the case of the recently proposed SQuAD dataset [15].
The systems proposed in literature are often strongly language specific that adds a further level of complexity. Even if the proposed approaches might be portable across different languages, the limited availability of training data for languages different from English still remains an important problem. Even though multilingual data collections, such as Wikipedia, do exist for many languages, the portability of the corresponding annotated resources for supervised learning algorithms remains low: large-scale annotated data mostly exist only for the English language. Small datasets for QA in Italian exist, such as the dataset consisting of about one thousand examples presented in [4], but their size is still quite limited. Manual acquisition of large datasets for a new language requires a significant effort and as a consequence, training a supervised model for a language different from English, such as Italian, is a challenging problem.
In this paper, we propose a weakly supervised method for the training of a QA system in the Italian language, where the annotated resource is obtained by automatically translating an existing QA dataset for English. Even though the method is less expensive, it is more difficult to apply due to the lower quality of the resulting training material. Specifically, the SQuAD dataset (one of the largest QA datasets in English consisting of more than 100, 000 question/answer pairs) was automatically translated into Italian and the first large scale QA resource for this language was produced 1 . The basic research question follows: how can we leverage an accurate QA system from annotated data of a quality far below the human annotation standards? How can we make our QA system resilient to the inevitable noise introduced by the machine translation process applied to the English annotations? For this study, we adopted a recent state-of-the-art neural-based QA architecture, presented in [5] that allowed us to release the first neural-based QA system over Italian texts. The experimental outcomes are encouraging when compared to the English QA system. Finally, since the adoption of a noisy dataset may affect the precision of the system, an extension of the investigated model was created to support the training of a system able not to respond if the answer is probably incorrect. The paper will discuss the process, the neural architecture and the dataset to finally outline interesting extensions for future investigation.
The adopted neural QA approach is discussed in Section 2. Section 3 describes the SQuAD dataset. The acquired novel Italian dataset, called SQuAD-IT, is presented in Section 4. The experimental evaluation of the model over the SQuAD-IT dataset is presented in Section 5 and 6 while Section 7 draws the conclusions.
Neural networks for question answering
Among the existing approaches to question answering, we investigated the model presented in [5], namely DrQA. The approach was chosen mostly due to its reduced dependence on the language of the input dataset and for its significant performance, that makes it a crucial reference paradigm in the current research on QA. The DrQA question answering system was designed in order to use Wikipedia as the only source of information. Wikipedia is here adopted just as a plain collection of articles, without making use of its graph structure: this makes the approach highly reusable in any other context. Given a question and a (possibly huge) set of texts that contain the answer to the question, the system first finds a few among the relevant documents (as in a classic Information Retrieval task) and then identifies the answer span within these. An example is reported in Fig. 2.
The DrQA component responsible for finding the most relevant documents to the query is referred to as the Retriever while the Reader Component is a component that retrieves the correct answer span from the documents, [5]. In order to obtain a better understanding of the processes triggered by a new input query, the overall information flow is displayed in Fig. 1.
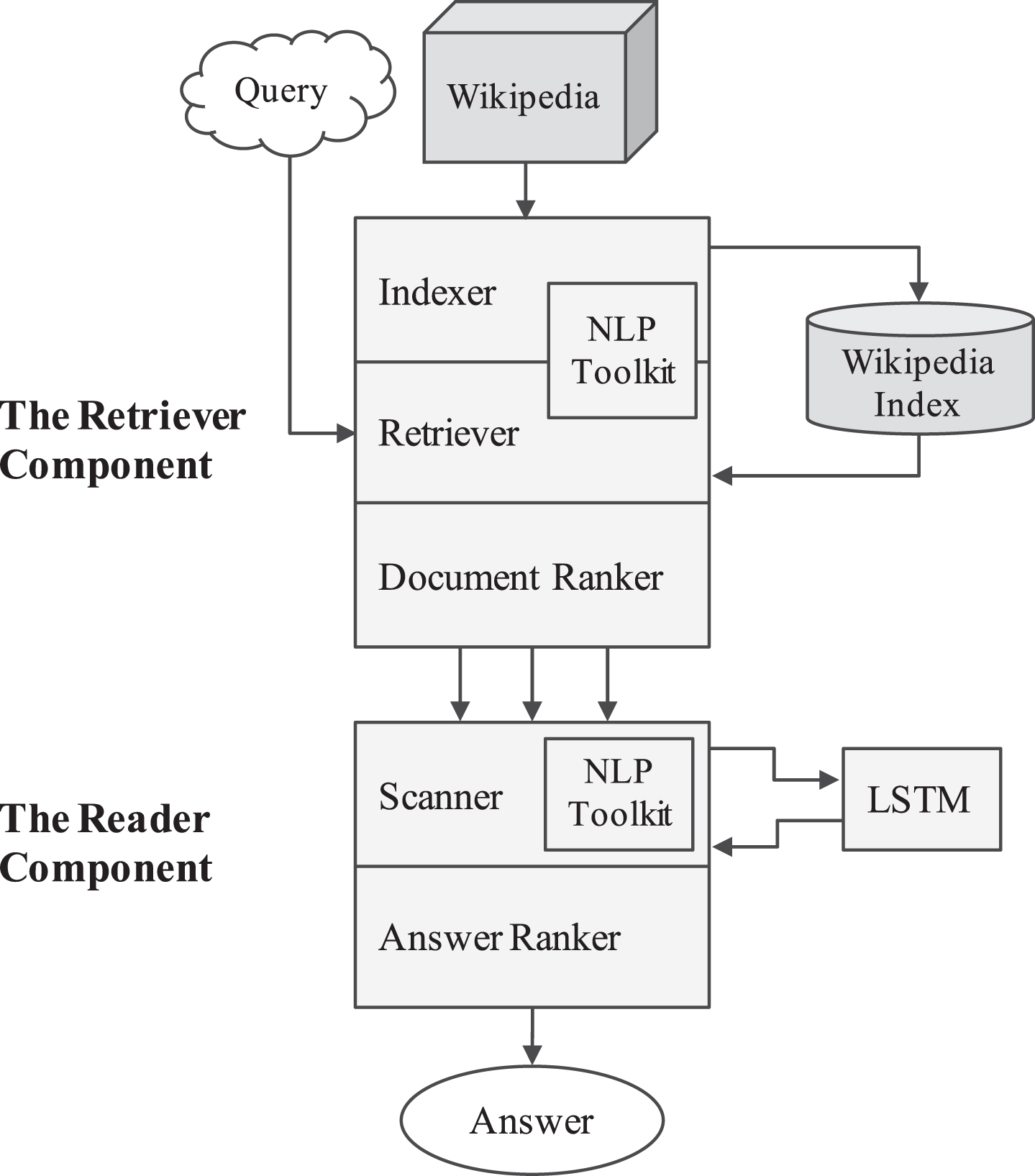
The architecture of the DrQA system.

An example of the SQuAD dataset [15].
When a user makes a query, the Retriever Component exploits its Indexer. This takes in input all available Wikipedia articles in English and creates the corresponding Wikipedia Index. The stored data consist of tf-idf vectors and relevant metadata necessary for the retrieval process triggered by an input query. The Retriever uses unigram and bigram counts of the documents in order to compile the tf-idf vectors. It makes use of a hashing function to support efficient vector retrieval. When a query is issued, the documents are retrieved from the Index: their tf-idf representation is compared with the query through the cosine similarity between the query-document vector pairs. Given the similarity ranking, the Document Ranker returns the top documents to the Reader Component.
The Reader Component triggers first the Scanner that seeks possible answer spans. The Ranker is then applied to compile the ranking of the candidate answers. The ranking is performed by making use of an LSTM neural network [9]. Such a network is trained to detect particular passages of the documents retrieved in the previous step. The answers obtained from each paragraph are then aggregated in order to make the final prediction and the best one is returned to the user. Consistently with [5], the training of the network is based on the features created from both the paragraph and the query. First, the sequence of tokens {p1, …, p
m
} in a target paragraph P
i
is represented as feature vectors
Specifically, a multi-layer bidirectional long short-term memory (LSTM) network is applied and the resulting word embeddings: exact match between the paragraph tokens and the question tokens token features, it is a dense one hot encoding of the part-of-speech tags, named entity categories and (normalized) term frequency represented as the following concatenation: ftoken (p
i
) = (POS (p
i
) , NER (p
i
) , TF (p
i
)) aligned question embedding which corresponds to the linear combination of the word embeddings from the question q where higher weights are associated to words highly correlated to p
i
: falign (p
i
) = Σ
j
ai,j
The question q is encoded by using another recurrent neural network on top of the word embeddings {q1, …, q
l
} of q and combining the resulting hidden units into one single vector {
The overall model is thus a 3-layer bidirectional LSTM neural network. In [5], both the paragraph and the question encodings use d = 128 hidden units. The best performing system reported in [5] uses GloVe embeddings [14] (trained on the Common Crawl corpus) of dimension n = 300 with more than 2 million tokens. The data was processed in mini-batches of length of 32. Adamax was used for the optimization as well as a dropout of 0.3 in the RNN encoding. On top of the question and paragraph encoder, two classifiers are used to predict the start and the end of the answer span in the input paragraph. The probabilities of a token being a start or an end token are than modeled as
where
The best span is chosen such that its length is not superior to 15 tokens, and Pstart × Pend is maximized over all the spans chosen in the given paragraph. The exponential in Eq. 1 is not normalized in order to obtain results compatible among various paragraphs. The creation of all the features needed by the system requires a significant preprocessing of the text. The original DrQA system uses the Stanford CoreNLP tool-kit [12]. It is worth noticing that almost all the features used to represent the input questions and the texts can be adapted to any other language with a rather limited effort: the word embeddings can be acquired in an unsupervised fashion over any document collection. The linguistic features (e.g. the recognition of the Named Entities) can be made available through a language-specific processing chain.
The resources for the training and the functioning of the original DrQA system include a document collection necessary for questioning the system and a dataset used for the training of the answer ranking LSTM component. The information source used in DrQA is derived from an English Wikipedia dump. The data was filtered in order to get rid of link pages, disambiguation pages and similar, and 5, 075, 182 pages were obtained in total.
In order to create the data for the training of the question answering system, articles from a wide range of topics from Wikipedia were selected. This led to the creation of the SQuAD dataset [15] made of more than 100, 000 question-answer pairs about passages from the articles. The question-answer pairs were created by crowd-workers. These answered up to 5 questions about the content of a chosen paragraph, where each question’s answer was a span from the corresponding paragraph. Other crowd-workers were also asked to provide answers to the questions created previously, in order to obtain human performance and mark the questions that might be unanswerable. This increased the quality of the data, since the unanswerable questions were deleted from the dataset. An example from the SQuAD dataset, showing the Wikipedia answer to the question “What was Marie Curie the first female recipient of?” is reported in Fig. 2. The dataset presents a few challenges. First of all, since the crowd-workers were asked to write the questions in their own words, some of them may not use the Wikipedia style and are not fully clear and understandable. The system must deal with complex phenomena such as syntactic variability (due to the difference in writing style and lexical choices) as well as semantic vagueness that often make Wikipedia texts and the queries very different. Another challenge is the high lexical variation, that makes lexical generalizations often depending on external knowledge and implicit (i.e. missing in the passage characterizing an answer). This includes differences in the vocabulary used by different users in making reference to the same target concept in the text. Sometimes, the syntactic variability exhibited by a question-answer pair is high, as the structure of their syntactic parse trees differs significantly: this makes the detection of the correct answer passage more difficult. Finally, correct answers might span through multiple sentences, which introduces additional complexity. The number of questions, paragraphs and answers in the dataset are summarized in Table 1. Notice that only the training and development sets are made available.
The quantities of the SQuAD dataset elements
The quantities of the SQuAD dataset elements
In order to create an equivalent DrQA system for Italian, new training data are needed: a collection of examples, i.e. (question, paragraph, answer span) triplets, is needed to suitably induce the correct answer selection function. For this purpose, a database was created from a dump of the Italian Wikipedia and the documents were processed by the tf-idf creator. The quantity of the stored documents is lower than the original, also due to the smaller size of the Italian Wikipedia counterpart. In order to store only meaningful articles, these were filtered and only those that contain more than one phrase in the document text were chosen, with a resulting dataset of 772, 342 documents.
In order to create an equivalent DrQA dataset for Italian (although a smaller one), automatic translation was applied to the English texts. Despite its lower quality with respect to the original one due to the precision in the currently available automatic translation systems, such a collection would definitely represent a reasonably large scale resource. Each of the answer paragraphs was translated automatically
2
together with all its corresponding questions and respective answers. In order to preserve lexical consistency in the management of contextual information, a batch translation of an entire pseudo document is carried. This includes the questions and the paragraphs together with all its answers: by cumulating a context with all the golden information available during the translation, we aimed to maximize the disambiguation capability. On some fragments of the original dataset the translation system could not derive any acceptable target translation, due to non standard characters or particular words in the text. The size of the translated data derived from the training and the development set is reported in Table 2. One of the most important requirements we imposed on the resulting data was that the answer for each question about a candidate paragraph was required to be contained also in the translation. This allows to express an answer numerically through the start and end token, i.e.
Number of elements for the English and the Italian datasets, with their percentage w.r.t the original English dataset. The Italian test set was obtained from the English development set, being the English test set not available publicly
Number of elements for the English and the Italian datasets, with their percentage w.r.t the original English dataset. The Italian test set was obtained from the English development set, being the English test set not available publicly
It was observed that often the translated answer was not part of the translated paragraph any more (mostly because of morphological differences, errors in the translation, etc.). These answers were not suitable for the training of the model: to obtain the highest possible percentage of the original data, a similar answer was looked for in the paragraph in this case. The morphologically different but equivalent answers that were searched for are the following ones: The lower-cased answer was looked up in the lower-cased paragraph; if it was found, the translation was substituted by the lower-cased translation. Answer with diverse punctuation was searched for in the original paragraph. This was mainly the case for numerical answers, where “.” was substituted by “,” and vice versa during the translation. In case such string was found in the paragraph, the punctuation was exchanged. For example, if the original answer was “90.000” but the translated paragraph contained “90,000”, these two versions of writing the same number were exchanged. The original English answer was looked up in the Italian paragraph and substituted in case of a match. This was the case for mostly scientific expressions deriving from Latin, such as “Streptococcus” and “Streptococco”. The answer in this case was translated as “Streptococcus”, whilst the paragraph translation included the Italian version of the word. Lemmatized answer was looked for in the lemmatized paragraph, in case the lemmatized tokens appeared in the paragraph lemmas, the original form of the answer was substituted by the original form of the matching lemmatized tokens. This happened since in the Italian language nouns, adjectives and verbs change form based on the gender and person, and the same English word might be translated in different way based on the context. An example is the answer “democratic” that was translated as “democratico”, whilst in the paragraph the same word assumed the version of the noun it followed, and thus “democratici”. In case of answers expressed through multiword expressions, a phrase with exchanged word order was searched in the paragraph as well, since in English most of the adjectives precede a noun, whilst the opposite is mostly true in Italian.
In case no such string was found in the paragraph, the question-answer pair was discarded from the translated dataset. It was observed that most of the discarded answers were phrases that were incorrect in the Italian language, some others were synonyms not compatible with the meaning of the paragraph and other errors were found as well. Having revised the dataset, the quantity of training and development data shown in Table 3 was obtained.
The quantities of the elements of the final dataset obtained by translating the SQuAD dataset, with the percentage of material w.r.t the original dataset. The Italian test set was obtained from the English development set, being the English test set not available publicly
This dataset preserves almost all the paragraphs from Wikipedia, while discarding almost 40% of question/answer pairs. However, at the best of our knowledge, the size of the obtained dataset is far greater than any other existing QA dataset in Italian. We will refer to such a dataset as
The aim of the experiments was to measure the quality of the QA process for Italian given the indirect supervision obtained from the translated SQuAD dataset. The direct evaluation of the acquired translations would be too vague and costly. We measured instead its impact through the indirect evaluation corresponding to the application of the DrQA architecture to the new Italian corpus. In this way, we verify the differences in the performance with respect to the original counterpart, trained over the well-formed English dataset 3 .
First, the adaptation of the original DrQA architecture with the aim of analyzing the Italian version of the SQuAD dataset will be described. Then, the results of the application of the Reader Component, i.e. the core answer matching algorithm, in English and Italian will be presented and some evidences about their performances will be provided. Although the DrQA system is a pipeline of the Retriever and the Reader components, we concentrate our analysis on the evaluation of the neural network used by the answer matching stage, consistently with [5].
Experimental setup
In our work, most of the original DrQA architecture was preserved, and just minor changes have been applied to the existing workflow. First, the data storage needed for further elaboration was changed. It is to be noticed that the distribution of the lengths of individual documents was not uniform: the system often produced errors just when dealing with the selection of the target documents. The ranking scores of the chosen documents (produced by the Retriever) were slightly biased (i.e. higher) towards longer documents against the shorter ones. Some documents have an excessive length, only 12 documents contain more than 300 paragraphs. In order to improve the document ranking, we implemented a new ranking model for the retrieved documents as follows:
This makes longer documents stay lower in the final ranking, which is what we want. The SpaCy NLP tool-kit, [10], was used, for both the English and the Italian setting, since the original CoreNLP tool-kit is not available in Italian. The differences between the two languages are reflected also in the variety of the features created by the tool-kit. Whilst the English SpaCy offers 74 features, most of which are various POS-tags and named entity classes, the Italian SpaCy identified 267 features. Most of these include POS-tags and NEs as well, but it also differentiates various subclasses of these, such as Number, Person, Gender, Type (for pronouns), Tenses (for verbs), etc. Notice that 267 features correspond to a much larger and a sparser feature space.
A first evaluation was carried out as a consistency check aiming at reproducing the experiments reported in [15] by repeating those measures in our setting (e.g., by adopting a different language processor). The comparative results w.r.t. the official evaluation are reported in Table 4. The parameters of the neural network were set equal to those of the original work, including the word embeddings resource. Two evaluation metrics are used: exact string match (EM) and the F1 score, which measures the weighted average of precision and recall at the token level. EM is a stricter measure evaluated as the percentage of answers perfectly retrieved by the systems, i.e. the text extracted by the span produced by the system is exactly the same as the gold-standard. The adopted token-based F1 score smooths this constraint by measuring the overlap (the number of shared tokens) between the provided answers and the gold standard. Although the DrQA architecture is the same, the results of our setting are slightly lower due to differences in the NLP tool-kit used.
In a second experiment the DrQA was evaluated after being trained over the Italian SQuAD-IT proposed in this work. Given the high cost of the fine-tuning of the network parameters, these were kept equal to those of the original model. An embedding set of more than 300,000 words with dimension 250 was used, applying the GloVe architecture to a dump of the Italian Wikipedia. Results in Table 5 were obtained through the official evaluation script for the SQuAD dataset 4 . Both EM and F1 scores of the Italian Architecture (DrQA-IT) are lower when compared with the English ones (DrQA-EN full), however they are encouraging given the complexity of the task and the simplicity of our methodology. We also investigated if the gap is due to the differences in terms of the training set size: the Italian training set covers only 60% of the questions of the English one. We thus sampled 60% of the examples from the English training material and then used them to train the DrQA English version: this setting corresponds to the row “DrQA-EN reduced”. As expected, the results lowered (e.g., 64.0 of EM) although they are still higher with respect to the Italian performance (i.e. 56.1 of EM). We speculate that the difference of such performances is due to the lower quality of the Italian data set and the problems introduced during its translation. Moreover, different lexicons are used: the embedding files include 300,000 words in Italian with respect to the English lexicon made of more than 2 million tokens.
The performance evaluation of the Italian system
In order to have a deeper insight about the generalization capability of the adopted neural architecture, we evaluated the DrQA-IT trained on different training data sizes. The performance was thus measured for various percentages of the training set. Two smaller subsets from the training material (acquired by sampling the 50% and 75% of the total amount of Italian questions respectively) were used to train the DrQA-IT, which is then evaluated over the entire Development set. The learning progress of the Italian version of the DrQA system is shown in Table 6, evaluated the on Exact Match and F1 measures. Considering the size of the training material (more than 50,000 questions) even adopting the half of the dataset (first row in Table 6) allows the DrQA-IT to achieve reasonable results: the measures increase when increasing the dataset size, starting from 52.3% of EM for 50% of the training set to 56.1% for the case when the whole training data was used.
The learning progress of the Italian DrQA system with different percentages of the training set size
The original system does not include the case in which no answer is available for a given question. On the contrary, it always produces a selected, i.e. most likely, span. However, in a real scenario, it is often the case that the Retriever is even unable to locate a candidate paragraph, as no answer is available in the targeted corpus. In this case, one can expect the system to behave in a robust manner: even if some paragraph is incorrectly supposed to contain the answer to some questions, the probability of the best solution (i.e., the best matching fragment) should become very low. In this perspective, a new setting was designed. We trained a system also able to provide the
The extended system is based on an Open World assumption and it is correspondingly trained in order to return a “no answer” reply in case the answer is probably incorrect. The SQuAD-IT training dataset was thus extended with a non empty set of labeled cases with a
The extended part of the dataset should inform the system about cases where “no answer” is the correct outcome. The discussion in Section 4 showed that, after the translation, many of the question-answer pairs in the original English corpus were removed from the training set, as the answer was no longer contained in their corresponding translated paragraph. On the contrary, these cases are of interest for training the Open World system. We adopted here a distant supervision algorithm in order to retrieve interesting training paragraphs. In particular, selected paragraphs contain the answers to some questions but they show a low similarity with those questions. In this way, we simulate cases close enough to the correct answers, useful to locate the answer-start feature in all the paragraphs of the dataset, but still unsupportive of the correct answer. This was true for several paragraphs removed from the previous tests, that were analyzed and added as new positive training examples of the
The dataset created for the training of the Open World Italian system. The first row consists of the whole SQuAD Italian dataset, whilst the second line refers to the data generated by distant supervision. The Italian test set was obtained from the English development set, being the English test set not available publicly
The dataset created for the training of the Open World Italian system. The first row consists of the whole SQuAD Italian dataset, whilst the second line refers to the data generated by distant supervision. The Italian test set was obtained from the English development set, being the English test set not available publicly
The performance was measured on the original DrQA data with the added random token. The evaluation is performed on Exact Match, Precision and Recall at token level. The results are shown in Table 8, where the new setting is referred to as DrQA-IT with no answer. The most significant increase of nearly 1 percentage point is observed in the Exact Match measurement. Moreover, a slight improvement in terms of Precision is observed, which was the main motivation of such a simple extension of the DrQA model.
The performance evaluation of the Open World Italian system
The above model gives rise to a working application dealing with the Italian version of Wikipedia. Some examples are reported below. The question “Qual è la capitale della Slovacchia?” (“What is the capital of Slovakia?”) receives the correct answer Bratislava matched in the retrieved page concerning the Danube river, from the Italian Wikipedia 5 .
The question “Dove si trovano le isole Marshall?” (“Where are the Marshall Islands?”) triggers the retrieval of three answers. The first answer is Pacifico (i.e., the Pacific ocean) from the Italian Wikipedia entry about the Marshall Islands 6 , specifically at the paragraph: “Facente parte della Micronesia, le Isole Marshall sono un gruppo di atolli e isole situate nel [Pacifico], poco a nord dell’Equatore. La capitale, la cittá di Majuro ... ” 7 .
The second ranked answer is Likiep and it is much less precise. However, the matching in the paragraph “... L’isola piú grande della Repubblica delle Isole Marshall è Kwajalein, un atollo con la laguna piú grande del mondo. Il punto piú alto del paese, che raggiunge soli i 10 metri di altitudine, si trova nell’atollo di [Likiep]. ... ” 8 suggests a surprisingly good ability of the system to deal with information spread across multiple sentences. Finally, the third answer “Stati Federati di Micronesia a ovest e Kiribati a est” (i.e. “Federated States of Micronesia on the West border and Kiribati on the East one”) extracted from the paragraph “La nazione (una repubblica presidenziale) è composta dagli arcipelaghi Ratak e Ralik situati fra gli [Stati Federati di Micronesia a ovest e Kiribati a est].” 9 and again it is a very good response: it is semantically consistent with the question and, mainly, adds further details to the previous answer.
In order to have a deeper insight about the generalization capability of the adopted neural method (applied to the SQUAD-IT dataset), further analysis are performed and described in this section. First, a qualitative analysis of the errors will be made by considering various question types, then different answer mismatches will be commented as well and the results on various paragraph and question lengths will be discussed.
Grouping results by “Question words”
First, the DrQA-IT was analyzed separately for various subsets of the answers, based on question types, which typically characterize the focus of the question and its inherent complexity. The question-answer pairs were divided into various categories by different question words. These were chosen to be the same for both English and Italian in order to obtain comparable results. All the question words of the English dataset can be assigned to one of the following categories: “What”, “How many/much”, “When”, “Which”, “Who”, “Why“, “Where” and “How”. Notice that some questions from both the English and Italian corpora do not belong to any category. An example of such a phrase is “Denominare un tipo di camion compatti Toyota.” (“Denote a kind of compact Toyota truck.”) that is a command in Italian, i.e. does not correspond to a grammatically well-formed question.
The distributions of questions and the quantities of question-answer pairs across categories are shown in Figs.3 and 4 for the English and the Italian language, respectively: each column represents a question type and it contains the number of questions assigned to that type. An example of a question assigned to the class “When” is “Quando è stata scoperta l’America?” (“When was America discovered?”), whilst “A quanto ammontavano gli aiuti d’ urgenza a Israele?” (“How much emergency aid did Israel receive?”) belongs to the class “How many/much”. One can notice that both the models perform quite poorly on the class “Why”. This might indicate a difficulty and particular complexity of these questions.

Percentage of correct and incorrect answers for various question types of the English SQuAD dataset.

Percentage of correct and incorrect answers for various question types of the Italian SQuAD-IT dataset.
The results suggest that the number of the incorrect answers is slightly higher for the Italian QA system across all classes, which confirms the better performance of the English system. However, it is interesting to notice that both languages exhibit a similar distribution of the accuracy scores across all classes. Although some categories do demonstrate a slightly different percentage of correct answers, when compared across the two languages, particularly complex classes (e.g. class for which the same question might belong to a different category once translated) are problematic in both cases. However, these results seem suggesting that the overall information from the SQuAD dataset has been preserved during the translation process across the different question classes.
A second analysis aimed at providing a more comprehensive insight on the quality of the neural method in detecting a correct answer while searching for its span in a sentence. Even though the gap between the system capability in the perfect retrieval of an answer and the number of tokens correctly identified within a span is measured by the Exact Match and F1 score (as adopted in the previous section) the following analysis aims at providing the type of mismatch performed by the neural system. Various types of possible mismatches were defined. These include the cases when, first, the prediction is a partial match of the correct answer, such as when it is a part of the correct answer but not completely, and vice-versa, when the correct answer is a part of the prediction. Second, when a correct sentence was detected but not the correct span and lastly, when the prediction is completely incorrect.
Given a sentence S where the gold answer is matched, also called gold sentence, let us define
For example, when the correct answer O is “la dinastia Ming” (“the Ming dinasty”) and the model answer R is “dinastia Song e la dinastia Ming” (“Song dinasty and the Ming dinasty”), we classify the error as a Superset Mismatch. On the other hand, if R =“400” but O = “oltre 400” (“beyond 400”), the error is a Subset Mismatch. It is thus important to understand the nature and causes of these types of errors, since they are crucially different from the errors due to the focus on wrong (i.e. non gold) sentences. The distribution of question-answer pairs across the different error categories is shown in Fig. 5.
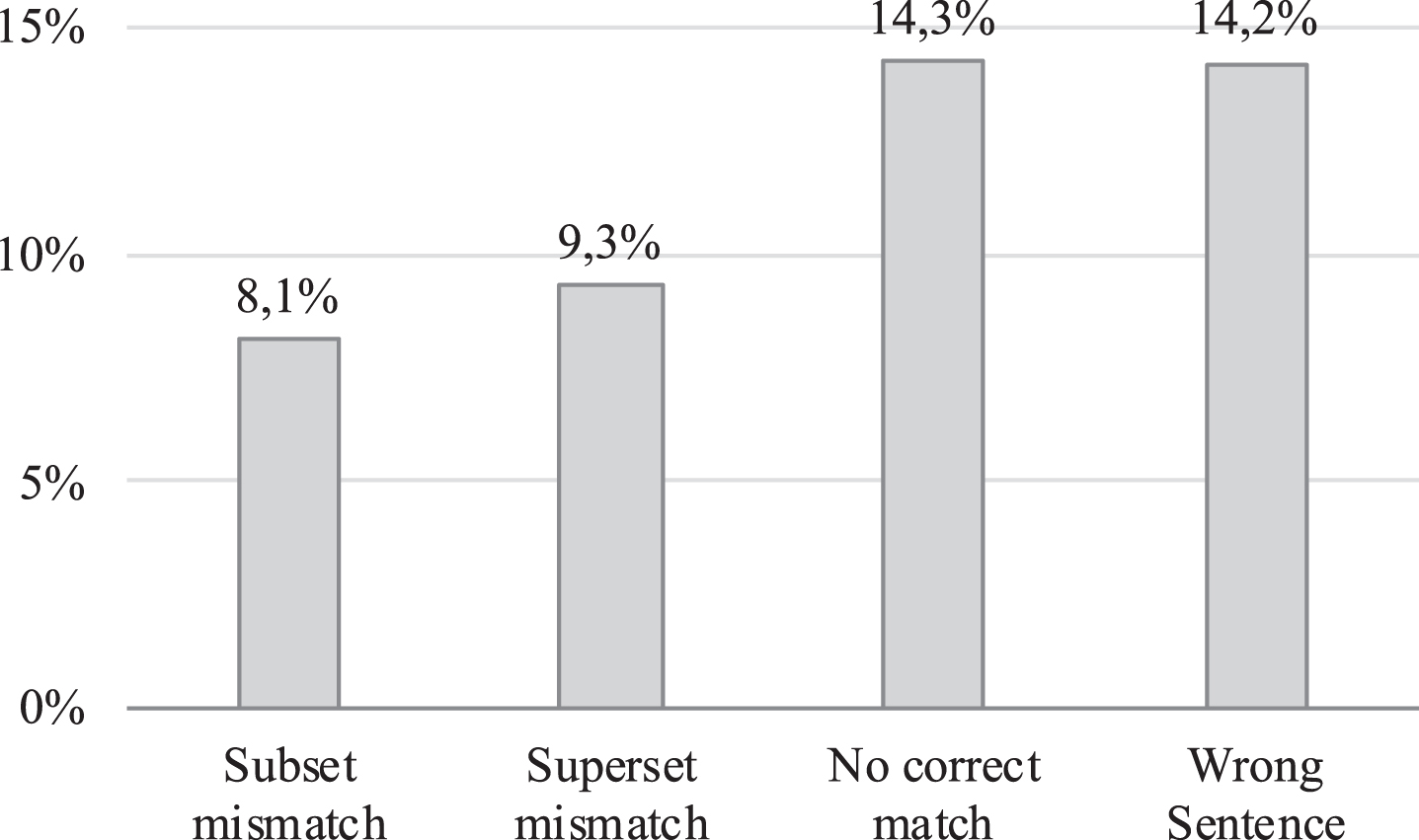
The percentage of error types over the answers returned by the Italian Reader Component on the SQuAD-IT test set.
One can observe that the Subset and Superset mismatches affect the 8.1% and 9.3% of the questions, respectively. It is worth noticing that the 9.3% (i.e. the Superset mismatches) are able to produce the entire gold answer and thus provide useful information to the user. On the contrary, the percentages of the No Correct Match or Wrong Sentence correspond to the 14.3% and 14.2% of the cases, respectively. These are the problematic failures, since no useful information is returned.
In a question answering system, it might be more difficult to determine the answer if the question or the paragraph are too long. In fact, it is more difficult to localize the correct span when the paragraph has an excessive length and also “understanding” the question is a more complex task for longer (and more complex) questions.
Thus, the questions and the paragraphs were sorted based on their length and an analysis was performed on single subsets of these. The results follow in Tables 9 and 10 for questions and paragraphs respectively. One can observe that the achieved results are better for shorter questions, adding more than 1 percentage point to the Exact Match measure, whilst the best results for the paragraph lengths are obtained for those ranging between 150 and 200 tokens. When the paragraph length increases over 200 tokens, the results get worse due to the increasing complexity.
Italian Reader Component evaluation on subsets based on question length
Italian Reader Component evaluation on subsets based on question length
Italian Reader Component evaluation on subsets based on paragraph length
Notice that, in a real scenario, a QA system may provide more than one answer (with the corresponding snippets containing them) and the user may get the possibility of assessing their correctness. In fact, it was noticed that, when the answer returned by the system was not correct, the correct one was often in a few top ranked answers even though the Exact Match on the top 1 answer is equal to 0. This might be caused by the limited ability of the Ranker Component to properly reassign the weights to the candidates, as discussed in Section 5. Given that the DrQA architecture is able to return a list of answers (all ranked according to Equation 1) we can evaluate the quality of a variant of the system DrQA-IT by considering all the top five answers, i.e. the ones receiving the first five highest scores. In this setting, among the top five provided answers, we selected only the one that maximizes the overlap with the gold-standard answer and this only one is then used for evaluating EM and F1. Results are shown in Table 11.
EM and F1 measures for the variant of the DrQA-IT system relying on the top 5 returned answers as obtained over various training set sizes
EM and F1 measures for the variant of the DrQA-IT system relying on the top 5 returned answers as obtained over various training set sizes
As expected, the performances increases and EM of 75.0% and F1 score of 82.2% is reached significantly higher if compared to the EM of 56.0% and F1 score of 65.9% reported in Table 5: even these are not characterized by the highest scores, this measure shows that the system is anyhow able to target the correct answers. More work on the optimization of the ranking criteria is thus required: in the current version, it seems that probabilities output by the Reader are not effective to rank and partition correct to wrong answers. Further work will concentrate on these aspects aiming to improve and better reward correct vs. wrong answers.
Since the experimental results obtained so far are derived from a test dataset produced by an automatic translator, a further evaluation was performed on manually validated data. This additional measure aims at confirming the robustness of the DrQA-IT, which may be biased by systematic errors of the automatic machine translator. A smaller dataset, made of about 50 paragraphs, was thus chosen randomly from the Italian test set and manually checked and corrected. More than 200 questions (depending on the paragraphs) were then selected and validated. Only the answers from the test set were considered, no further data was added. The size of the dataset manually created is summarized in Table 12.
The size of the manually validated dataset
The size of the manually validated dataset
Obviously, such data represents the most natural-like example available for the evaluation. The results of such predictions are reported in Table 13. Overall, the performance is comparable to that obtained on the whole test set, and both the EM and the F1 measures are slightly improved, up to 62% of the Exact Match (against a 56.1% reported in the last row of Table 5) and 70% of the F1 measure (against a 65.9% reported in Table 5).
The results for the Italian Reader Component measured on a manually validated dataset
Although these results are not directly comparable, they suggest that the performances measured on the automatically translated data used in this work can be effectively adopted to evaluate Question Answering system in Italian. Additional effort will be devoted to improving the manual validation of the translations.
This paper introduced a new dataset for the task of Question Answering for the Italian language. The data were created by making use of the automatic translation and a large-scale dataset for the Italian question answering task on factoid questions was created, that might be reused and extended in the future.
We argue that the results obtained by the Italian DrQA system are satisfying, even though there is certainly space for future improvement of both the network architecture and the dataset. Nevertheless, the overall training method and the resource obtained by a simple methodology lead to the creation of, possibly, the first neural network based QA system for the Italian language. An extension of the Italian QA system was set up, that includes the possibility of the system not to answer, which increased slightly the precision with respect to the original system and represents an interesting extension of the capabilities of the original model. An extensive error analysis was performed then, that might give insights on future developments of the newly created system.
As a future improvement, the quality of the document retrieval and the indexes creation in the Italian language can be improved by a major computational power. This might also enable the evaluation of the whole system pipeline. Further steps might include the structural or parameter optimization of the neural network for the Italian system and an improvement of the quality of the text processing for the Italian language.
Footnotes
One of the currently best performing and freely available system, i.e. deepl.com, was used.
Obviously, this measure is indicative, since the dataset will be different and the quality of the subset used as a test set was not manually validated.
“As part of Micronesia, the Marshall Islands are a group of atolls and islands located in the [Pacific], just north of the Equator. The capital, the city of Majuro ... ”
“... The largest isle of the Marshall Island Republic is Kwajalein, an atoll with the largest lagoon in the world. The highest point of the country, which reaches only 10 meters above sea level, is located in the atoll of [Likiep] ... ”
“The country (a presidential republic) includes the Ratak and Ralik arcipelagos located between [Federated States of Micronesia on the West border and Kiribati on the East one].”