
Abstract
IoT devices dealing with complex tasks usually require powerful hardware capabilities or, as a possible alternative, to get on the Cloud those resources they need. When an IoT device is “virtualized” on the Cloud, it can take benefit from relying on one or more software agents and their social skills to mutually interact and cooperate. In particular, in a Cloud of Things scenario, where agents cooperate to perform complex tasks, the choice of a partner is a sensitive question. In such a context, when an agent is not capable to perform a reliable choice then, like real social communities, it can ask information to other agents it considers as trustworthy. In order to support agents in their partner choices, we conceived a local trust model, based on reliability and reputation measures coming from its ego-network, adopted to partition the agents in groups by exploiting trust relationships to allow agents to be associated with the most reliable partners. To this aim, we designed an algorithm to form agent groups by exploiting available local trust measures and the results obtained in a simulated scenario confirmed the potential advantages of this approach.
Introduction
Today, the “Internet of Things” (IoT) world performs complex tasks requiring increasing hardware and power capabilities to IoT devices. These device requirements become particularly crucial in presence of small and low-cost devices. In the meantime, Cloud Computing (CC) was introduced as a main Internet information technology addressed to share services, processes and data stored to form knowledge accessible in distributed environments. In this scenario, both IoT and CC converged into the so called Cloud-of-Things (CoT) [2, 3]. This integration is motivated from the necessity of supporting the computational and storing requirements [4] coming from a wide number of heterogeneous, small and low-cost IoT devices [5], to create new services also available in nomadic scenarios [6]. Furthermore, cooperation among IoT devices, for instance to realize complex tasks, can be encouraged by giving them the opportunity to be associated with software agents to exploit their social attitudes [7–10]. In this scenario, agents have the problem of selecting the most reliable partners for cooperation. Unfortunately, in some cases, it could happen that agents do not have enough information about other peers. Indeed, the choice of a reliable partner needs of suitable information that could be also required as recommendations to trustworthy agents.
We propose of supporting this process by encouraging agents to form groups of reliable recommenders agents. Even though a common viewpoint considers that groups should be formed on the basis of some criterion representing commonalities of relations, interests and/or preferences [11], it is known that a high level of mutual trustworthiness existing among the group members is an important social property within a community [12–14].
Consequently, to maximize the benefits that an agent can receive in joining a group (and vice versa), the adoption of trust measures, usually derived by combining reliability and reputation measures, could improve both individual and global satisfaction [15–18]. Therefore, we regard the trust-based processes to form agent groups of reliable recommenders over a CoT context. This approach significantly improves the activities also of those IoT devices poorly equipped. The synergy deriving by integrating CoT and software agents allows to boost social activities (i.e., interacting, forming groups, federating groups or CCs and so on) having place therein e.g. it could be meaningless with respect to devices only providing a measure on request.
However, as it happens in real user communities, in place of the global reputation, it is possible to adopt a local reputation [19] approach where the reputation value is derived by the opinions coming from the friends (or friends of friends and so on) of an agent, i.e. its ego-network (see Fig. 1). It is usual when a user can not reach a reliable decision so that commonly he/she will adopt a local approach requesting an opinion to his/her friends. This local approach gives important benefits, among which i) avoiding heavy computational tasks, communication overloads in collecting opinions as well as in evaluating the sources trustworthiness and ii) significantly increasing the system reactivity.

The construction of ego-networks of the agent a: (A) the network of a; (B) the ego-networks of the agent a including all the nodes of the virtual community (nodes from a to f) for which a direct link to a there exists and (C) some other agents indirectly connected to a by a path of length 2 (e.g., all the agents connected to a by continue and dash links).
To further improve the effectiveness of such a process we suggest to drive the formation of agent groups by exploiting a measure obtained by combining the local trust (formed by reliability and local reputation) and helpfulness. In order to verify the performance of this process, we considered a competitive CoT environment where heterogeneous devices consume/produce services and/or extract/exchange knowledge assisted by personal software agents working over the CC. Each associated agent will be able to support the group changes of its device in the CoT environment performed based on the temporary device convenience. Note that in the following each IoT device and its associated agent will be considered as the same entity.
The basic idea is that the generic consumer agent when chooses a data service (s) supplied by a provider agent, should consider its past experiences. If the agent is unable to make a reliable choice, then it could exploit the recommendation (i.e., a value belonging to the interval [0, 1]) provided by the community [20]. Moreover, we suppose that among agents belonging to the same group recommendations/opinions will be provided for free, otherwise a fee has to be paid for the recommendation/opinion. Therefore, groups/agents will be interested in accepting/belonging to those agents/groups having a high reliability and helpfulness by leading this approach to realize the desired competitive scenario. To evaluate the helpfulness of an agent we consider the relevance of its recommendations, while for a group we assume that it is the average of the helpfulness of its members. Like human societies [21], we adopt a voting mechanism to carry out the group affiliation process. To this purpose, we designed a distributed algorithm for group formation (see Section 5) that we verified, in terms of efficiency and effectiveness, by means of some experiments on a simulated agent CoT scenario, which confirmed our expectations. The rest of the paper is organized as follows. Section 2 refers to the related literature, Section 4 describes the adopted local trust model and voting mechanism, while Section 5 presents an algorithm to form groups. The experimental results are dealt in Section 6 and, finally, in Section 7 some conclusions and future development are drawn.
Trust systems can be profitably exploited in open, competitive and distributed scenario to limit the risks to be engaged with unreliable partners [22–25].
In particular, in social communities, the aggregation rules [26], informative sources [27] and the modalities for inferring trust [28] are the factors that must be considered in computing trust measures.
In this respect, to solve the problem of suggesting to a group/member of a community if accepting/joining with a candidate/group, several trust-based approaches have been proposed. For instance, in [29] the authors verify that trust-based groups are more stable over time with respect to groups formed without taking into account the contribute given by trust. Indeed, the expectations of receiving benefits is higher among the members of trust-formed groups. But, they not consider the local trust to obtain the group formation. In large communities where each member usually interacts only with a narrowest share of the community members, the adoption of local trust mechanisms is predominant with respect to the global one. Indeed, some studies found that the accuracy of local trust is greater when a personal viewpoint is used [30, 31], while its narrower horizon depth contributes to reduce the computational costs [32].
In social contexts, it is conveniently to represent trust processes by means of a graph, named trust network, where nodes and oriented edges represent the members and their trust relationships, respectively. In such a way, the topological properties of the trust network help to study trust properties. In particular, Golbeck et al. [33] adopt a variant of the Breadth First Search to gather the reputation scores and, by using a voting mechanism, to compute an updated reputation rate for each user. To avoid overloading the system, in [34] updated trust scores are propagated only by using fixed length paths. Examples of local trust approaches are adopted by the TidalTrust [35] and MoleTrust [36] algorithms. The first one exploits the closer neighbors to compute its trust predictions, also by ignoring part of the neighbors if the trust network is too sparse. The second one performs a backward exploration by fixing a maximum depth in the search-tree of the trust network to calculate trust scores by using at depth x only the trust scores at depth x - 1. All these approaches, unlike our work, do not use the advantages introduced by the concept of ego-network.
Another characteristic of our proposal is that of adopting a voting to reach a decision within a group. The adoption of a voting mechanism [37] is able to optimize the social utility and limiting conflicts [38], although the risks of manipulations always exist and, particularly, in software agent communities where agents can easily realize different malicious manipulations [39]. However, in huge communities a local voting might represent the best solution with respect to the difficulties of a global voting [40]. Similarly to a voting process also trust-based decisions place a bet on the basis of the expectations to receive some benefits [41] by one or more future events or behaviors [42]. Therefore, local trust and local voting have some intrinsic characteristics in common that can be usefully exploited in real or virtual communities denoted by a great (sparse) population in presence of poor communication infrastructure or storage and power constraints (like some IoT devices).
To this aim, [43] presents a local trust-based voting system, working in a mobile wireless scenario, where a node is admitted in a transmission path on the basis of its trustworthiness as perceived by the other nodes. The actual trust of a node is propagated among neighbors placed at one hop of distance on an oriented trust network by combining their confidence values assumed as trust measures. A node will be trusted/distrusted by using a local voting scheme. SocialTrust [44] is a framework to realize users’ social trust groups by adopting a friends-of-friends relationship model, where by limiting the radius of this approach it is also possible to limit the impact of malicious users. In SocialTrust each user rates each other user he/she interacted with and converts such rates in a binary vote. In particular, a vote is a pair (user, vote), where user is a unique user identifier (the profile number) and vote is either “good” or “bad”. Three voting mechanisms characterized by increasing levels of security and resilience can be adopted: (i) open voting; (ii) restricted voting; and (iii) trust-aware restricted voting. In particular, open voting is subject to ballot stuffing. By restricting the total size of vote allocated to each user, this restricted voting scheme avoids the problem of vote stuffing by a single user. They have no assurances that a malicious user will choose to vote truthfully for other users it has actually interacted with, but we do know that the total amount of voter fraud is constrained. Unfortunately, such a voting scheme is subject to collusive vote stuffing, in which many malicious users collectively decide to boost or demote the feedback rating of a selected user. Finally, to handle the problem of collusive vote stuffing, the authors advocate a weighted voting scheme in which users are allocated voting points based on how trustworthy they are.
Unfortunately, any ideal global or local voting procedure exists because all of them can be affected by manipulation, like strategic vote. This aspect is very critical for software agent communities, indeed agents can efficiently and effectively examine manifold manipulation opportunities, but this problem is assumed as orthogonal with respect to the focus of our proposal where trust drives voting.
Finally, some trust systems have been conceived for IoT and CC contexts. In literature, the approaches consider only neighbors for the calculation of the trust and they does not allow to obtain a correct value of local trust, as demonstrated in our work.
For instance, in [45] a word of mouth approach is used to propagate IoT devices’ trust evaluations to the other nodes and in [46] each node evaluates the trustworthiness of its friend nodes and the opinions of the common friends (by adopting local trust measures). In the same social context, Chen et al. proposed in [47] a trust system to take into account the dynamic evolution of social relationships and self-adapting to trust fluctuations. In [48], for improving the performance of a grid of agent-based sensors, monitoring traffic flows on the roads by analyzing acoustical signals generated by vehicles in their motion, a distributed trust-system is built where each sensor-agent interacts only with its neighbor agents.
In a cooperative context, [48] gives attention to evaluate the skills of heterogeneous IoT devices in different cooperative tasks with a distributed approach. First and second-hand information and observations coming from the neighboring, are exploited to gather trustworthiness information, matching demand and offer for services, learning from past experiences and generating trust suggestion about other devices. BETaaS [50] is a system, also dealing with Big Data, which includes a trust model to esteem the reliability of monitored things and behaviors. Its trust model considers different aspects among which security, QoS, scalability, availability and gateways reputation. A Trust Management system for a CC marketplace in [51] evaluates a multidimensional trustworthiness of the CC providers by exploiting different sources and trust information. In [52], the authors designed a trust management architecture for CC marketplaces supporting customers in identifying trustworthy CC providers by verifying suspicious feedback arising by system and social threats. Unlike the previously mentioned approaches, a fully decentralized trust-based model for large-scale CC federations is described in [53] to allow any node to efficiently find the best collaborators in a set of candidate nodes without the need to explore the whole node space.
Scenario
We introduce a CoT environment where devices exchange services and/or extract/exchange knowledge supported by their associated software agents.
More formally, let A be the set of software agents living in the Cloud and let G = 〈N, L〉 be a directed graph that we, for convenience, adopt to represent the agents and their trust relationships, where N is the set of nodes (i.e., agents belonging to A), while L is the set of links (i.e., relationships occurring between two agents). For detail, see Section 4. Moreover, we suppose that a generic agent is trying to join with one or more groups based on its real or perceived potential advantages. Now, we define the role of the agent administrator. It manages a group and can contact/remove those other agents it considers as useful/ineffective for joining with/removing from its group. The main objective of an agent administrator is that of maximizing the effectiveness of its group. In other words, the adopted mechanism implies that groups are interested to accept those agents having a high reliability; at the same time, agents are interested in being affiliated with those groups formed by agents denoted by a high reliability.
From an operative viewpoint, an agent (i.e., requester) can require a service to another agent (i.e., provider). To perform this task the requester can take benefit from its past experiences, but if the experiences are not sufficient to perform a good choice it can also require the opinions of other agents. In other words, if a i (i.e., a generic i-th agent) has not an appropriate direct past experience about a provider agent a j , it can ask a recommendation ξr,j ∈ [0, 1] to another agent a r . The selection of a r is established by the algorithm described in the Section 5. Therefore, given that services are provided only for payment, while recommendations can also be provided for free only if a r is in the same group of a j , then the proposed scenario has a competitive nature. Each agent tries to introduce in each group other agents that are capable of delivering multiple services. At the same time, it requires to pay a fee for a service when an agent does not belong to its group.
The local trust model and the voting mechanism
The Local Trust Model
Let the oriented edges linking two nodes (i.e., agents) of the graph G be associated with the trust level ranging
on the basis of all the feedback
To this aim, let
where the value m can be chosen by the system administrator due to a proper sensitivity analysis or a real time tuning.
To give an appropriate relevance to the recommender agents that in E i are the closer to a i , a parameter ω is introduced, computed as:
where
Now, we define the local reputationσi,j that is an indirect measures by taking into account how much, on average, the agents of E i estimate the capability of a j of having good interactions. By assuming that a i , in its ego-network, is able to receive recommendations about a j by a number z of recommenders, then σi,j can be calculated as:
where the suggestion ξr,j is weighed by the path ωi,r and the helpfulness ɛi,r. In this way, suggestions from closer and more reliable users are enhanced.
The local trust measure τi,j that an agent a i has about an agent a j can be computed by combining reliability and local reputation (which also includes the helpfulness) as:
τi,j = α i · ρi,j + (1 - α i ) · β i · σi,j
where α
i
and β
i
are two parameters ranging in
Note that a newcomer agent will receive suitable “cold start” values of reliability, reputation and helpfulness (see Section 6).
In this context, the local trust of a g group perceived by a i denoted as Tg,i is the average of all local trust measures calculated by a i for all agents belonging to g. Similarly, the local trust of an agent a i perceived by a group g (i.e., Tg,i), is assumed to be the average of all the local trust measures about a i computed by all the agents belonging to g. Note that an agent can belong to many groups, and we denote by D the maximum number of groups that an agent can join with.
The voting mechanism
To take a decision about a new affiliation with a group g, we adopt a voting mechanism, which is based on the computation of a local trust defined in the previous Section. The voting process is carried out by all the agents belonging to g (i.e., each agent gives a vote v ∈ {0, 1} to accept or refuse this agent into g, where 0/1 to mean “refuse”/“accept”) [54].
In particular, the vote is influenced by the local trust measure that the voter computed about the potential new member, also exploiting the recommendations coming from its ego-network. Also, we introduce a suitable threshold varGammag ∈ [0, 1]. The vote is equal to 0 (i.e., 1) if τ < varGammag (i.e., τ ≥ varGammag). In the following, the voting criterion v referred to a group g for a potential new member y will be assumed as the output of a function V (g, v, y). In this respect, a reasonable strategy may be that of adopting a simple majority criterion to accept a requester into a group.
The distributed agent grouping algorithm
The proposed distributed agent grouping algorithm is described below, it consists of two procedures that are executed by: each CoT agent that desires to find the “best” groups to join with, on the basis of the value of Ti,g (where g identifies a generic group); each group administrator that must evaluate if affiliating a new member with its administrated group based on the mutual trust existing among the group members and the potential new member.
The list of the experimental parameters adopted in the description of the algorithm is shown Table 1.
Table of the main symbols
Table of the main symbols
Algorithm 1 The agent a
i
executes this algorithm for improving its group configuration with respect to the mutual trust with the related group members. To this aim, we define Gr that is a set of groups formed in a random way. Let H
i
⊂ Gr be the set of the groups which a
i
is affiliated to and for each group g ∈ H
i
⊂ Gr, contacted in the past, a
i
stores its local trust measure Ti,g and let
Algorithm 1. The procedure executed by an agent
Initially, the administrator a
g
requires to the members of its group to update their local trust measures about a
i
(lines 1 - 5), then if: ||X|| < Q (line 6), then all the agents in g provide their vote about a
i
. The function V (·), see Section 4, combines all the votes to determine if the agent a
i
is accepted or not in g. ||X|| = Q and the agent a
i
is accepted into the group but in place of another agent. To make comparable agents can be used the measure of the trust that the group has about them, which is computed as explained in Section 4 (line 16). In particular, Tg,n denotes the current value of trust between the group g and the agent k
n
∈ X ⋃ {a
i
}.
Algorithm 2. The procedure executed by a group administrator
In this section we present and discuss the results of a few experiments aimed at verifying the effectiveness of the approach. The experiment were performed by means of an ad hoc simulator written in the scientific programming language Octave [55].
More in detail, the ability of our algorithm to form groups denoted by a higher, in average, mutual trust among their members with respect to different compositions has been tested. The list of the parameters adopted in the experiments is reported in Table 2. For convenience, we will refer to each parameter with a parameter ID, reported in the first column of the same table.
Experiment setting
Experiment setting
We simulated a network of 1000 different CoT agents (each one associated with an IoT device), 1000 initial trust relationships and |Gr| groups formed in a random way (par. ID 9). Trust values were set by a normal distribution and two different profiles: “low performance” (par. ID 3) and “high performance” (par. ID 4). In this way we could model two different users profiles; in the first case user show, in average, low performances as the feedback for services assume values around the value 0.2 with a given standard deviation, while in the second case (“high performance”) the mean is 0.9. The values of feedback that have been generated based on the basis of the two normal distributions are depicted in see Fig. 2. Moreover the trusted/distrusted agents ratio (par ID 6) has been set to 0.5 – the same value was set for the cold start trust value – and the initial sparsity of the trust network decreased along the simulation thanks to the availability of new reliability information.

Generated feedback values.
The interactions among agents have been simulated by means of the Poisson distribution with expected value λ = 50 (par ID 2). The remaining simulation parameters are listed in the third part of Table 2, (par ID 7 – 12). In particular, as we discuss later in this section, we consider a variable parameter D (par ID 8), while the remaining parameters have been fixed on the basis of a preliminary sensitivity analysis aimed at obtaining a minimum benefit from the algorithm execution. For instance, the selected value of θ = 0.2 represents the minimum value for the algorithm to avoid a trivial selection of all the groups as candidates.
More in detail, for each simulation iteration: a number of agents mutual interactions is simulated; this number is not fixed, it is generated on the bases of the Poisson distribution, as indicated in Table 2 (par ID 2). An interaction is simulated by registering a feedback given by an agent. 100 execution of the algorithm have been simulated by triggering the Algorithm 1 on 100 different agents randomly chosen and each time an agent affiliation request to a group is simulated, the administrator-side of the Algorithm 2 is executed to decide whether or not admitting the requiring agent into its group; some statistics are computed.
To evaluate the results, we define the measure Average Mutual Trust among the components of a group g as:
Figure 3 shows the median value of MAMT measured after each single iteration of the simulation for the different values of D = [5 ÷ 10] for the first 30 iterations of the simulation. For D = 5 can be observed a slow convergence of the MAMT values, while for D ≥ 6 there exist a radical change. In fact, D is the number of new groups the can be analyzed by a i at each iteration of the Algorithm 1 execution, which are then mixed in the new set P with groups already into the set H i . Therefore, we deduce the higher D, the higher the number of new groups analyzed in the Algorithm 1, the higher the probability to join with a new group where are present distrusted agents and replacing those having the worst trust value (by increasing in this way the MAMT value because, sooner or later, distrusted agents must leave groups). Moreover, in Fig. 4 it is shown the presence into the all groups of distrusted agents at different simulation iterations per different values of D. Results confirmed that almost distrusted agents are replaced by trusted agents into the groups.
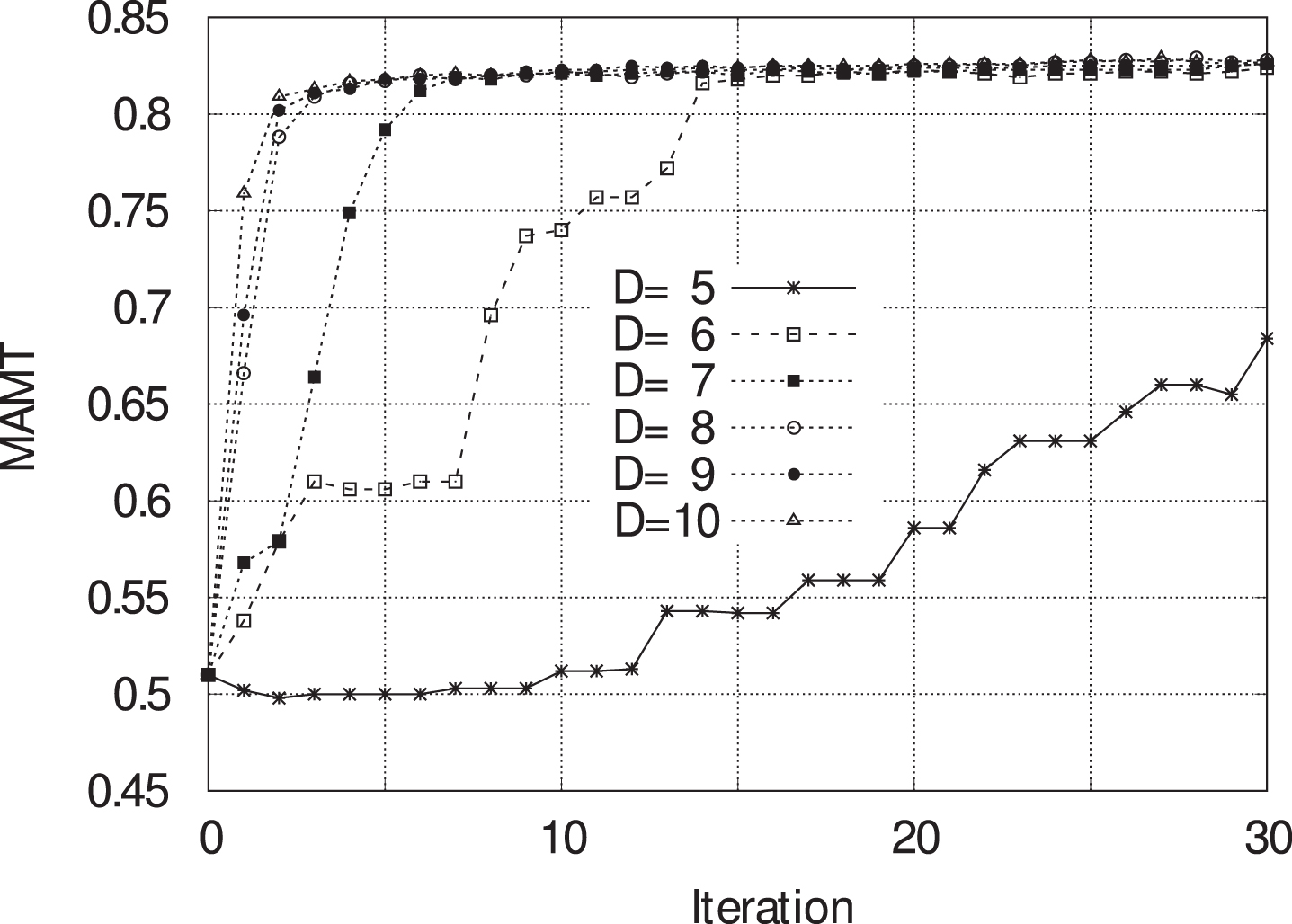
MAMT - results until 30 iterations.
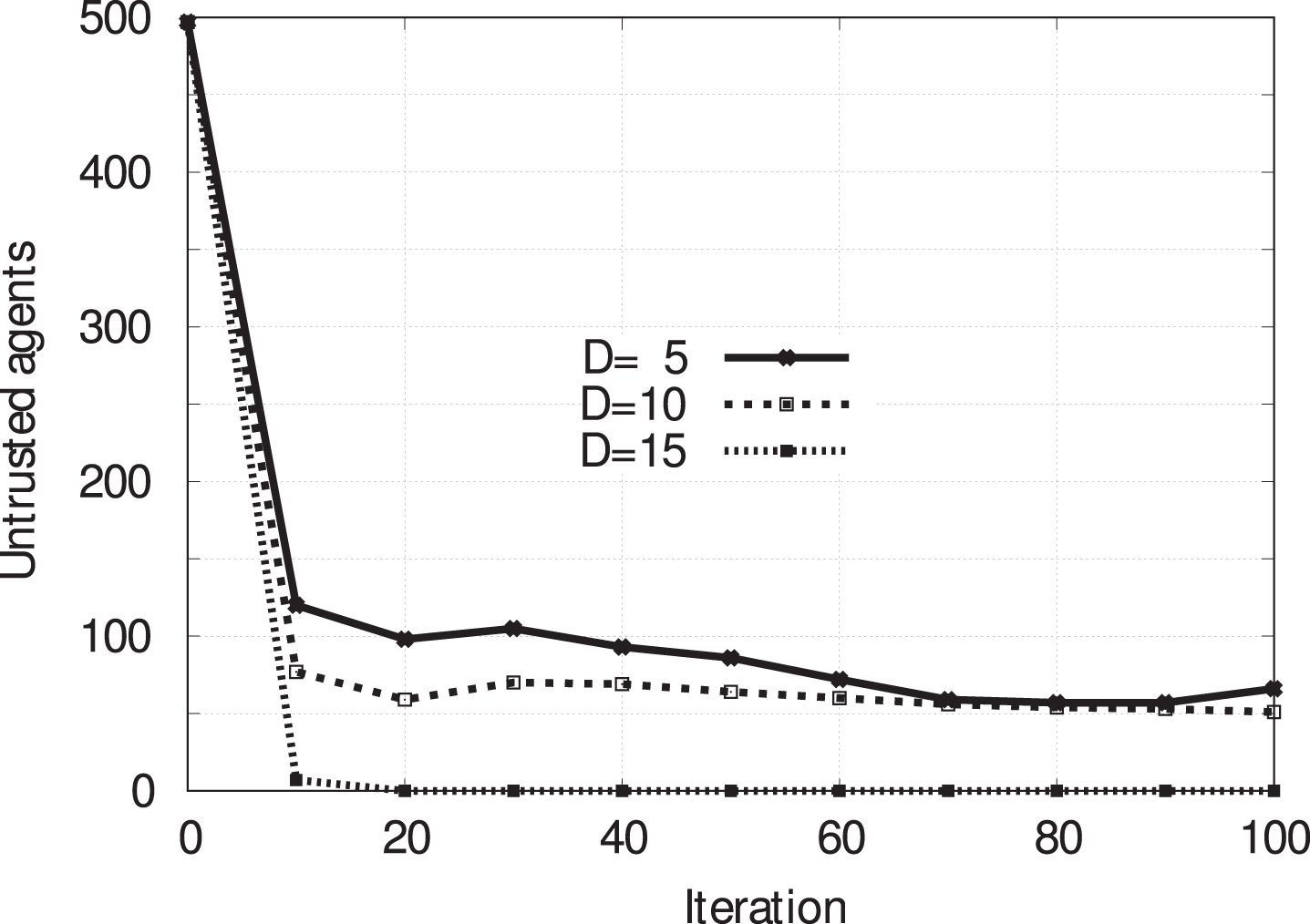
Sum of untrusted agents vs number of iterations of the simulation.
Therefore, the execution of the distributed algorithm allows a configuration of groups with a high level of (average) mutual trust among its members to be reached. More specifically, in a simulated environment, the convergence of the algorithm towards a group configuration with trusted agents is reached very rapidly (when the algorithm parameters are properly set) by improving the group composition very quickly. Conversely, a different choice, e.g. a lower D, will allow a few untrusted agents to be affiliated to some groups, so they can get benefit from the services of the trusted agents present within the group.
In this paper, a CoT scenario supporting the IoT devices virtualization over the Cloud Computing in a multi-agent context has been presented. The social attitude of software agents to cooperate has been exploited to form groups for promoting satisfactory agents interactions which tightly depends on the choice of the partner. However, in absence of suitable information to perform a good choice, some suggestions can be asked to those agents perceived as the mostly trustworthy in the community.
To promote the formation of agent groups of reliable recommenders we designed a distributed algorithm that, in a competitive and cooperative scenario, adopts a voting procedure based on the agent capability to provide useful recommendation exploiting local trust and helpfulness measures. In particular, the adoption of local trust measures avoids heavy computational tasks and communication overheads because only a little share of the agent community is involved in this process. Some experiments, in a simulated agent CoT scenario, confirmed the potential advantages given by our proposal to improve individual and group satisfaction in terms of mutual trust.
In our ongoing researches, we are studying to improve the effectiveness of the group formation process by adopting in the voting procedure a new measure (denoted ζ) combining the local trust measure with an utility measure of the devices (i.e., agent) for the group itself.
In particular, the utility measure should take into account all those cases where the presence of agents provided of some skills could give significant benefits to the groups. Therefore, a group might decide the affiliation of these agents regardless of their trust values. In other words, let S g = {k1, k2, ⋯ , k n } be the n skills needed to a group and let m be the skills present in a group, with m < n; if this group is interested to maximize its effectiveness, it could be interested in accepting those agents having one or more of the n - m skills for which the group is lacking.
More in detail, we are supposing that the contribution given by the utility term (i.e., υ) should increase with respect to the number of skills owned by the agent a i and absent in the group g. More formally, υg,i = f (S g , S i ), where υi,g is the utility of a i for g and f (·) is a function returning a value (ranging in [0, 1]) and receiving in input the skills owned by a i (i.e., S i ) and needed to the group g (i.e., S g ), respectively.
ζg,i = λ g · υg,i + (1 - λ g ) · τg,i is a new measure, where ζ g is a real value belonging to [0, 1] and λ is a parameter (a real value ranging in [0, 1]) to weight the relevance assigned by the administrator of g to the utility with respect to the local trust (taking into account reliability, local reputation and helpfulness) of a i . In particular, λ = 1 denotes that the administrator accepts to risk inserting in its group agents having a higher percentage of skills regardless of their values of trust; conversely, λ g = 0 indicates that the administrator of g only considers the local trust of the agents.
Footnotes
Acknowledgments
This work has been partially supported by the Networks and Complex Systems (NeCS) Laboratory - Department of Engineering Civil, Energy, Environment and Materials (DICEAM) - University Mediterranea of Reggio Calabria, by the Italian MIUR, PRIN 2017 Project “Fluidware” (CUP H24I17000070001), and by the University of Catania, Piano per la Ricerca 2016-2018 - Linea di intervento 1 (Chance), prot. 2019-UNCTCLE-0343614.
If no recommendation was provided by a r to a i , then the helpfulness of a r perceived by a i will be ɛi,r = 0.