
Abstract
The interoperability of devices from distinct brands on the Internet of Things (IoT) domain is still an open issue. The main reason is that pioneer companies always deliberately neglected to deploy devices able to interoperate with competitors products. The key factors that may invert such a trend derive, on one hand, from the abstraction of communication protocols that facilitates the migration from vertical to horizontal paradigms and, on the other hand, from the introduction of common and shared ontologies encoding devices specifications. The Semantic Web, with all its layers, can be considered the main framework for delivering ontologies, and by virtue of its features, it is surely the ideal means for providing shared knowledge. In this paper we present a framework that instantiates cognitive agents operating in IoT context, endowed with meta-reasoning in the Semantic Web. The framework, called
Keywords
Introduction
The historical trend of the first Internet of Things (IoT) companies, which were leaders of such a domain, deliberately conceived IoT as a black-box where interoperability with external devices is not allowed. Indeed, if you are an industry leader, you are discouraged to interoperate with competitors and you indirectly gain the chance to create the basis for a monopoly in that slice of market as well. Such a resistance against standards, which had its expression in realizing vertical solutions, shaped a scenario where other stakeholders (down to end-users) struggle at the moment of making work together devices from different brands. In such a scenario, on one hand, a weak level of interoperability can be achieved by exploiting additional cloud services such as IFTTT. 1 On the other hand, although such services seem an effective solution to the issue of different protocols in usage by clouds and devices, they end up being a mere patch that increases global overhead and odds of malfunctions.
Another issue to consider is that the two major enterprises in the market of IoT, namely Amazon and Google, aim more at increasing their product’s pervasiveness rather than at improving native reasoning capabilities, by leveraging their massive dataset for training models in the task of vocal commands recognition. Each vocal command can be related to a pair of requests/operation triggered by specific words, but with no enhanced reasoning capabilities. With “enhanced reasoning capabilities”, here we intend the ability not only to infer the proper association command→plan from utterances, but also to combine facts with rules to infer new knowledge and assist the user in decision-making tasks. In order to help users in their cognitive processes by using a form of logic reasoning, we must provide the assistant with a combination of facts and rules or, more simply, we must give assistants the capabilities of freely and implicitly extracting what they require from texts in a natural language.
In a previous work [2, 3], some of this paper’s authors designed a cognitive architecture called
In this paper, we propose a framework called
Ontologies are formal, explicit specifications of a shared conceptualization [4], and the Semantic Web is currently the main framework for building ontologies and ontology-oriented applications.
The closed-world assumption applies when a system has complete information, like many database applications. On the contrary, the open-world assumption applies when a system has incomplete information. For example, considering the clinical database of a hospital, if the patient’s history does not include a particular allergy, it would be incorrect to state that he/she does not suffer from that allergy; such information is considered unknown, unless more knowledge is retrieved to disprove it.
A Python prototype implementation of
The paper is structured as follows: Section 2 illustrates the issues of ontology learning from natural languages; Section 3 describes the state-of-the-art of the related literature. Section 4 shows in detail all the architecture’s components and underlying modules of the
The issue of Natural Language Ontology
The task of automatic creation of ontologies derived from the description in natural language of a specific domain implies several biases that must be considered. In general, ontology learning can be accomplished in three ways: manual learning, i.e., by leveraging the effort of experts of the domain; cooperative learning, where most or all the tasks are supervised by experts; semi-automatic learning, where the ontology construction process is performed automatically with limited intervention by users or experts. It is worth mentioning that full automatic learning by a system is still a significant challenge and it is not likely to be feasible [5]. When sentences are not specifically well-formed, the task of ontology learning from natural languages can be quite hard, because of all possible semantic ambiguities of idioms and the arbitrary descriptive nature of the world, which can induce morphologically distinct sequences of words to express the same concept.
In [6], it is reported that
Natural Language Ontology is a branch of both methaphysics and linguistic semantic. It aims to uncover the ontological categories, notions and structures which are implicit in the use of natural language, that is, the ontology that a speaker accepts when using a language.
But such an acceptance implies several issues to be addressed by an ontology learning system designer. For instance, for a speaker it would be quite natural and simple to express that a certain object does not exist. In a closed-world assumption, we can limit ourselves to not assert such a concept, or at least to retract its representation from the knowledge base. But how to operate in an open-world assumption, in order to let such information participate in a reasoning process in a human-like fashion? How to keep consistency when a piece of information and its complement are possibly both present in an ontology, as it could happen in texts given by a speaker? In linguistic science, intentional objects as nonexistent are considered particularly problematic [7]; for instance, having an ontology A representing a domain of existing entities and another ontology B representing a description in natural language of the same domain, we cannot definitively say that A and B are equivalent, due to a possible introduction in B of entities that do not exist but are functional to the arbitrarily descriptive use of words present in the sourcetext of B.
Let us consider the following two sentences: “Roy walked down the street” and “Roy had a walk down the street”. How can one infer that they express the same concept in a decision process? In the second sentence we are in presence of the so-called deverbal nominalization of the verb walk versus a noun expressing the action of walking. So we are forced to create somehow a bridge between the two sentences, in order to achieve the same result when either the one or the other are participating in a reasoning process. Similarly, let us consider also the simple verbal phrase “the friends are happy” and the snippet “happy friends”. In this case, we are in presence of a deadjectival nominalization, because the adjective happy becomes the object of a copular 4 verb (be), thus the subject (friends) has the property denoted by the adjective. Hence, how to express, by means of an ontology, that the two pieces of information yield the same concept?
Pinker describes in [8] a hypothetical language of the mind, the so-called mentalese, which should stand above all ambiguities, universally homogeneous across languages. He affirms also that whatever language people speak is hopelessly unsuited to serve as our internal medium of computation, because of five different type of issues: ambiguity, lack of logic precision, coreferencing, deixis, and synonymy. As for ambiguity, it generally happens when the same word may have different meaning depending on context. For instance, the word bass can represent either a musical instrument or a fish, depending on the context. In [3], it is shown how
An inference-making device would deduce: Ralph lives in Africa and Ralph has tusks. The issue is that Africa is the common place where all elephants live in, but Ralph’s tusks are his own and the agent doesn’t know that, because the distinction is nowhere to be found in any of the statements. The third issue, called “co-reference” (or, alternatively, anaphora resolution), concerns the resolution of pronouns referencing nouns in the scope of the same discourse. The state-of-the-art comprises several tools acting as co-referencers: one of these that we have been testing is Neuralcoref, 5 which can work also on different level of greediness. Greediness is one of the parameter of the model that makes it stricter about resolving coreferences. Neuralcoref works with a default greediness of.5, but, depending on the domain, it could be necessary to change it to make coreferences resolved correctly. The fourth issue comes from those aspects of language that can only be interpreted in the context of a conversation or text, i.e., what linguistics refers to as “deixis”. Considering articles like a and the, what is the difference between killed a policeman and killed the policeman? Only that in the second sentence it is assumed that some specific policeman was mentioned earlier or is salient in the context. Thus in isolation the two phrases are synonymous, but in the following context (the first from an actual newspaper article) their meaning are completelydifferent:
Outside of a particular conversation or text, then, the words a and the are quite meaningless. The fifth issue, namely synonymy, is when different sentences refer to the same event and therefore licence many of the same inferences, similarly to deverbal and deajectival nominalization. For instance, consider the following sentences:
In all four cases, one can conclude that the wall has paint on it. But despite the four distinct arrangements of words mean the same thing, no simple processor would infer implicitly such a conclusion.
The above questions and many other issues related to the natural language ontology are described in [6], which can be a good starting point for filling the gap between a domain and an arbitrary description of it given by a speaker.
In [2, 3] there is a detailed overview of
Related works
This section is focused on the state-of-the-art of ontology learning from natural language, which is one additional contribution of
The disruptive growing of textual data on the web, coupled with an increasing trend to promote the Semantic Web, has made the automatic ontology construction from texts a very promising research area, since manual construction of ontologies is a time consuming, extremely laborious and costly process. For this reason, several approaches have been designed to automatize ontology learning from text, each with different levels of human interaction. Such approaches can be divided into two broad categories: linguistic-based and machine learning approaches.
Among linguistic-based approaches, the authors of [9] use semantic templates and lexico-syntactic patterns such as “NP is type NP” to extract hypernym 6 and meronym 7 relations. It is well known that these approaches have reasonable precision but a very low recall [5], i.e., a high number of undetected relations.
In order to achieve terms extraction, [10] leverages Parts-Of-Speech (POS) tagging to assign POS tags to each word and a rule-based sentence parser. However, many words are ambiguous and so this approach will lead to low accuracy, without a valid disambiguation strategy. Although similar, our approach adopts also a performative disambiguation module, described in details in [3], and extracts also conditional-word based axioms.
The authors of [11] make use of a dependency parser to map syntactic dependencies into semantic relations. Such approaches are useful for terms and concepts extraction and also for relations discovery, even though they need to cooperate with other algorithms and/or rules for better performance.
As for machine learning approaches, the system ASIUM [12] adopts agglomerative clustering, which is the most common type of hierarchical clustering used to group objects in clusters based on their similarity. Also known as AGNES (Agglomerative Nesting), the algorithm starts by treating each object as a singleton cluster. Afterwards, pairs of clusters are successively merged until all clusters have been merged into one big cluster containing all objects. The result is a tree-based representation of the objects, named dendrogram, which will be used for taxonomy relation discovery. But the inferred axioms only express subsumption relationship (IS-A) between unary predicates and concepts, which is a remarkable limitation.
The system OntoLearn [13] extracts only taxonomic relations, taking into account hypernyms from WordNet [14].
The system HASTI [15] builds automatically ontologies from scratch, using logic-based, linguistic-based, and statistical-based approaches. It is one of the few systems that attempts to learn axioms using inductive logic programming, even though they are very general. Furthermore, such a system has the limitation that each intermediate node in the conceptual hierarchy has at most two children, affecting the overall expressiveness level of the system. Section 5 explains the importance of avoiding constraints in building relation taxonomies, where any instance should have hierarchical kinship equivalent to the related natural language utterances.
Worth mentioning, there is also Text-to-Onto [16], which builds taxonomic and non-taxonomic relations that make use of data mining and natural language processing, although it is not designed to achieve a human-fashioned reasoning without manual intervention on the built ontologies. Other approaches [17–19] are also interesting, although either they have limitations on the composition of learned concepts or they generate too many hypotheses, making the involved calculation unmanageable.
Besides a large analysis of state-of-the-art, the authors of [20] discuss on reasons and techniques about the usage of deep neural networks in the Ontology Learning. In these cases, neural networks are often hard to train, although in many cases they give better results by using large, domain-related datasets.
The Architecture
As outlined in the introduction, the proposed architecture, namely
The architecture’s components are illustrated in Fig. 1, each one highlighted with a distinct colour. Specifically, the Translation Service (in yellow) is the module responsible for translating a natural language sentence into a logical form. The Reactive Reasoner (in green) is a module encompassing the Belief-Desire-Intention (BDI) engine [21] Phidias [22] and providing routing functions between beliefs from/to other components. By using Phidias, programs have the ability to perform logical-based reasoning (in Prolog style) and therefore developers are allowed to write reactive procedures, i.e., pieces of programs that can promptly respond to environment events. The Smart Enviroment Interface (in red) provides bidirectional interaction between the Reactive Reasoner and the outer world’s sensors and devices. The last module is the Cognitive Reasoner (in grey) which enables the architecture with meta-reasoning capabilities.

The Software Architecture of SW-CASPAR.
One of
The architecture’s knowledge base (KB) is divided into two distinct parts operating separately, which we identify as the Beliefs KB and the Ontology. The former KB contains information about physical entities that affect and are affected by the agent, whereas the latter contains conceptual information not directly perceived by the agent’s sensors, but on which the agent can make inferences. Each production rule can be triggered on the basis of the Beliefs KB content. When a rule is triggered, a specific plan is executed, whose details can encompass the assertion of further beliefs or can be coded in a high-level language aimed to interact with external devices. The Ontology, implemented in OWL 2, provides support for the conceptual meta-reasoning in the Semantic Web, in order to subordinate fast-dynamic real-world perceptions and actions with high-level cognition. Such level of reasoning is not directly linked with the agent’s domain, but related enough to achieve the desired behavior in correspondence of specific plans executions, thus providing the agent with the decision-maker role on the execution of plans.
We believe that the two KBs represent, somehow, two different kinds of human being memory: the so-called procedural or implicit memory [23], made of thoughts directly linked to concrete and physical entities, and the conceptual memory, based on cognitive processes of comparative evaluation. In the same line as human beings, in this architecture the two KBs interact with each other through the meta-reasoning, in a very reactive decision-making process.
Fig. 2 shows a simple data flow schema of

The Data Flow Schema of
Next, we provide a detailed overview of all the components of this architecture.
The Translation Service component (left box in Fig. 1) consists of a pipeline of five modules conceived to translate a text in natural language in a neo-Davidsonian FOL expression that inherits the shape from the event-based formal representation of Davidson [25], with every term
with
Such representation also takes into account the analysis introduced in [26] concerning the so-called slot allocation, which indicates specific policies about entity’s location inside each predicate, depending on verbal cases. Each verb and its relation with subjects and object is represented by a ternary predicate: the first argument, defined as davidsonian variable, identifies uniquely the related action linked to the verb semantically described by the label, whereas the other two arguments represent the subject and the object. The order of subject and object is inverted in the presence of passive verbs, morphologically described by specific dependencies as nsubjpass and agent that implicitly summarize the agent-driven Parsons [27] approach (usually called also “neo-Davidsonian”); in case of intransitive or imperative verbal phrases, subject or object slots are left empty, respectively. Moreover, terms with only one argument are used for both noun representation and quality modificators (adjectives and adverbs), which share one argument that links themtogether.
Adverbs are represented by one-arity terms, whose arguments will be equal to the davidsonian variable of the verb which are referred to.
Finally, prepositions are represented by binary predicates; the first argument is either a davidsonian or common variable, wheares the second argument is a variable shared with the object of the preposition.
For instance, let us consider the following sentence:
Roy slowly drinks good wine.
One of the possible outcomes of the Translation Service is the following expression:
where each predicate’s label is constituted by a lemmatized word concatenated with a Part-Of-Speech (POS). 8 The form of each label can be changed by modifying a parameter in a configuration file, thus allowing one to omit the POS, introduce or exclude lemmatized words, and even enabling or disabling the use of WordNet synsets 9 as labels (selected with a disambiguation process that considers the context).
The presence of a copular verb within a sentence, which, as already described in Section 2, is an intransitive verb that identifies a subject with an object, allows one to enrich the Ontology with the so-defined assignment rules, that participate actively in the logical reasoning. For instance, let us consider the following sentence:
Roy is a man,
whose corresponding logical form is:
Thanks to the analysis of be, we find this lemma within the synset encoded by
where
In light of the meaning of
By admitting such rule in a KB, we can implicitly admit additional clauses with
Furthermore, the above expression can also be rewritten as a composite fact such as: 11
where
As for another type of implicative axioms, this component is capable to find out whether a group of predicates in a FOL expression subordinate the remaining ones in the same expression by means of a dependency analysis. For instance, let us consider the following sentence:
When the sun shines strongly, Roy is happy.
In this case, the final outcome of the Translation Service is:
We now give a brief overview of all pipeline’s modules.
The first module of the Translation Service, which plays the role of Automatic Speech Recognition (ASR), receives from the Reactive Reasoner utterances in natural language coming from the Smart Environment Interface. The information transferring is performed by the module inside the Reactive Reasoner called Sensor Instance.
The next pipeline module, namely Dependency Parser (which is provided by spaCy 12 in the current version of the framework), extracts all semantic relationships between words in a utterance coming from the Sensor Instance. The extracted relationships, also called dependencies, play a key role in the building of FOL expressions presented in this work, since their analysis permit to fill the gap between utterances in natural language and the representation of information.
The module Uniquezer provides a distinct entity encoding for each dependency coming from the Dependency Parser, a mandatory step for identifying the correct semantic when the same word is present in multiple occurrences within a sentence. This process, which is achieved thanks to words offset extraction provided by spaCy, is aimed to guarantee the correctness of the next module outcomes in the pipeline.
The module MST Builder is constituted by a system of production rules with the task of building a novel semantic structure called Macro Semantic Table (MST) that summarizes in a canonical shape all the semantic features of a sentence. MSTs can only represent verbal phrases and are built by matching each dependency with a production rule, taking into account languages diversity and dependency tag-set. Two or more distinct sets of dependencies can give rise to the same MST. Furthermore, by exploiting a good knowledge of any idiom’s grammar, the MST Builder can be adapted to language in order to create MSTs in a flexible and scalable expressiveness level. Since the MST Builder is constituted by production rules that consider relations (dependencies) among words, as long as such relations are treated properly by ad-hoc rules, the accuracy of the conversion from natural language to logical form can be clearly considered equal to the accuracy of the dependency parser. We recall that the dependency parser adopted in this work is spaCy, which has an accuracy of 90% for all trained models available for the English idioms, as reported by the authors. 13
Finally, the module FOL Builder has the task of building FOL expressions starting from the MST structures. Since (virtually) all approaches to formal semantics assume the principle of compositionality, 14 formally formulated by Partee [28], every semantic representation can be incrementally built up when constituents are put together during parsing. In light of such a principle, it is possible to build FOL expressions straightforwardly starting from a MST, which summarize all semantic features in a sentence.
The Reactive Reasoner (central box in Fig. 1) has the task of enabling other modules to communicate with each other; it also includes additional modules such as the Speech-To-Text (STT) Front-End, Sensor Instances, IoT Parsers (Direct Command Parser and Routine Parser) and Ontology Builder.
The SST Front-End has the task of managing whatever information comes either from the Translation Service or from the Smart Environment Interface, which is transformed in beliefs that interact with the production rules system.
The Sensor Instances have the task of getting physical information coming from the outside world and of inserting it into the Belief KB. They are instances of the superclass Sensor provided by Phidias. Each instance works asynchronously from the main agent’s engine.
The Direct Command Parser has the task of classifying the beliefs coming from the STT Front-End, whose semantic can be considered close to the one of IoT commands. After the classification, the module also extracts from any logical forms (coming from the Translation Service) all the useful features required by the Smart Environment Interface.
The Routine Parser’s function is similar to the Direct Command Parser’s one, with the difference that only logical forms containing implication symbols are considered, which are then classified as routines. Such routines reside into the Beliefs KB until related beliefs coming from some Sensor Instance are asserted. After that, such routines are transformed in commands to be executed and sent to the Smart Environment Interface.
The Ontology Builder is one of the two modules that distinguish
The Smart Environment Interface
The Smart Environment Interface component (the box in the upper right part of Fig. 1) provides a bidirectional interaction between the architecture and the external world. In [29], we showed the effectiveness of this approach by leveraging the Phidias’s predecessor, namely Profeta [30], even with a shallower analysis of the semantic dependencies, as well as a label encoding process that uses WordNet synsets to make the operating agent multi-language and multi-synonymous.
The Cognitive Reasoner
The Cognitive Reasoner component (the box in the bottom right of Fig. 1) allows an agent to implicitly invoke a Semantic Web reasoner (in our case Pellet [31]) at runtime, in order to achieve a meta-reasoning step whose outcome subordinates IoT commands. To better express the concept, the reader has to consider a first level of reasoning, the one where utterances are parsed from natural language and transformed into beliefs, matching or not production rules in the Smart Environment Interface. The meta-reasoning is achieved by a proper encapsulation of the so-called active beliefs 15 into one or more production rule. The latter can be triggered or not, depending of the values of the active beliefs.
Any type of code can be executed inside an active belief, in this case an invocation of the reasoner Pellet before enquiring the ontology with specific SPARQL 16 queries (meta-reasoning), whose result subordinates the above first level of reasoning.
The Cognitive Reasoner also encompasses the OWL 2 ontology, which is populated by the Ontology Builder within the Reactive Reasoner.
The usage of the cognitive reasoner component is analogous to the one in [2, 3], but it involves a knowledge base constituted by OWL 2 classes, instances, and Semantic Web Rule Language (SWRL) [32] rules instead of first-order logic expressions.
The Ontology Learning
Differently from most approaches to ontology learning, we believe that, regardless of the technique adopted, a general ontology for natural language is always biased. With this in mind, our approach provides firstly an ontological representation directly related with the linguistic features of the sentences considered, starting from first-order logic clauses coming from the Translation Service; secondly, a set of domain-specific rules, suitably constructed with the SWRL language, an extension of the OWL language with Horn-like axioms that provide the ontologies with additional reasoning in a human-like fashion.
Each ontology built by the Ontology Builder belongs to a specific family, which for its direct derivation from the Davidson notation, we define as
The general schema of Entity. Instances of this class represent entities referenced by either the object-property hasSubject or hasObject. Compound nouns are concatenated in order to form a single individual. Verb. Instances of this OWL class represent what is derived from the Translation Service as verbal phrase in the Davidsonian notation. They exploit the following object-properties: hasId, whose value is a unique identification code; hasSubj, representing the verb subject in the domain of Entity; hasObj, representing the verb object in the domain of either Entity or Verb (in the case of embedded verbal actions); isPassive, indicating whether a verbal action is passive or not. A typical instance Verb involves the following entities and triples, with Subj and Obj instances of the class Entity, as follows: Verb(x1), hasSubj(x1, x2), Subj(x2), hasObj(x1, x3), Obj(x3). Id. Instances of this OWL class represent unique identification codes (e.g. a timestamp) related with verbal actions. These individuals are the ones involved as value of the object property hasId, which is used with instances of the class Verb. Instances of the class Id can be useful to deal with inconsistency cases: the higher is the Id, the more valid is the related instance of Verb, even when the latter has the property hasAdverb expressing the value Not;
17
Furthermore, the object property hasTime can be used to express the tenses of the verbal actions (Present, Past Tense, Past Participle, Gerund) that agree with the identification code by taking into account the POS. A typical instance is used as follows: Verb(x1), hasId(x1, x2), Id(x2). Adjective. Instances of this class take the values of the object-property hasAdj with instances of the class Entity (Subj) as follows: Subj(x1), hasAdj(x1, x2), Adj(x2). Preposition. Instances of this class represent prepositions and are referenced by the object-property hasPrep with instances of either the class Verb or the class Entity. Moreover, instances of Preposition (Prep) are involved in the object property hasObject referencing instances of the class Entity (Subj and Obj). For example, instances of Preposition are used as follows: Subj(x1), hasPrep(x1, x2), Prep(x2), hasObj(x2, x3), Obj(x3), or Verb(x1), hasPrep(x1, x2), Prep(x2), hasObj(x2, x3), Obj(x3). Adverb. Instances of this class represent adverbs and have the values of the object property hasAdv with instances of the class Verb: Verb(x1), hasAdv(x1, x2), Adv(x2).
In addition to the classes described above, Assignment Rules. These rules are implicitly asserted in the presence of a FOL expression representing a copular verb (possibly identified also by its synset) and its satellite predicates. Formally, in the presence of the following Davidsonian FOL expression coming from the Translation Service (see Fig. 1): The rationale of such a rule is that, by the virtue of the copular verb (such as be), the class membership of the verb’s object will be inherited by the subject. Legacy Rules. Legacy rules are implicitly asserted together with the Assignment Rules, to allow a copular verb’s subject to inherit both adjectives and preposition properties of the verb’s object. The following legacy rule
19
is built together with (2): Subject(?x2), Object(?x1), hasAdj(?x1, ?x3), Adjective(?x3) ->hasAdj(?x2, ?x3). Deadjectival Rules. In presence of an instance of Adjective, deadjectival rules assert new deadjectivated instances of the class Adjective as new memberships of the adjective related noun, in order to improve reasoning as explained in Section 2. A deadjectival rule has the following form: Entity(?x1), hasAdj(?x1, ?x2), Adjective(?x2) ->Entity(?x2). Deverbal Rules. In the presence of an instance of Verb, such rules assert new deverbalized instances of the class Verb in order to improve reasoning, as explained in Section 2. Our work currently does not include deverbal rules, which will be part of our future works. Implicative Copular Rules. These rules are built starting from implicative axioms coming from the Translation Service and containing a single copular verb in the implication’s head. Such rules are useful to infer new memberships of the initial sentence subject (which is required to be present also in the body). The beliefs pattern
20
required to build implicative copular rules must have the following shape:
where the label Subject(?x
obj
),... ->Object(?x
obj
). Any other implicative FOL expression with a non-copular verb in the head will be discarded, due to the non-monotonic featuresof SWRL. Value Giver Statements. These optional rules contribute to assign values to the data property hasValue related with the specified individuals, which are parsed by the Ontology Builder by matching the following patternof beliefs: The first argument ( Values Comparison Conditionals. These optional rules are parsed from sentences in an analogous way as to the Value Giver Statement, but they will take place within the body of Implicative Copular Rules.
For example, given the following sentence:
the Translation Service builds the following FOL expression:
Then, considering the POS and arguments cardinality, the STT Front-End produces the following set of beliefs:
Since implicative copular rules can be applied to sentences only once, the label
Fig. 3 depicts an example of an ontology built by SW-Caspar from the sentence (3). OWL classes are presented with a circle, individuals with diamond shaped boxes, subclasses relationships with dotted arrows, whereas object-properties with full arrows. On the top of the figure are illustrated the main classes, namely Verb, Entity, Preposition, and Adverb, together with their corresponding subclasses; all individuals names encompass also a reference of the verb identifier Id
21
. In Fig. 3 the reader can straightforwardly find what explained in detail at the beginning of this section about the composition of verbal phrases, adverbs, adjective and prepositions in a
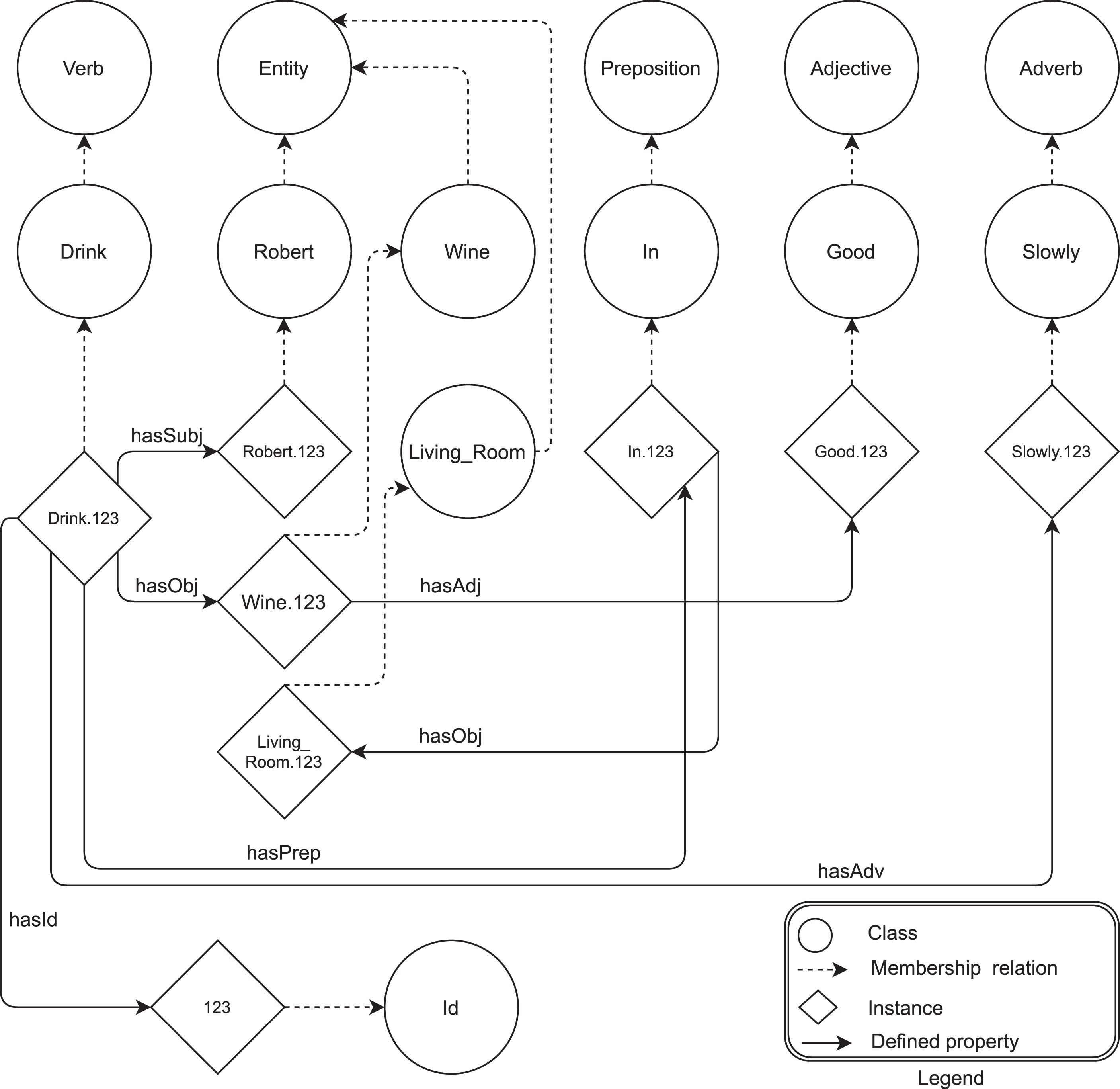
A simple instance of
Due to the presence of the adjective good (individual Good.123) associated with the wine (individual Wine.123), one might optionally activate the
Wine(x1), hasAdj(x1, x2), Good(x2),
we are able to assert that:
Wine(x2),
as desired.
The rationale of above is that, in the case of sentences like the wine is good, their composition has clearly a distinct reasoning contribution than respect the snippet good wine in sentence (3).
As already shown in the previous sections, the usage of variables shared between entities and their adjective is inherited from the Neo-Davidsonian first-order logic representation.
This section discusses about agent interoperability, which is implemented in SW-C
Among the other advantages mentioned in the previous section, the Semantic Web is also exploited by SW-C
Protocol layer
The protocol layer implemented in SW-C
In any case, Phidias intra-agents communication can be achieved through the HTTP protocol, which allows one to move intelligence from cloud to edges, encouraging Fog Computing designers to adopt new paradigms leveraging MAS approaches. In order to deal with distinct communication protocols, Phidias provides a service called Message Gateway (see Fig. 4), which allows devices to communicate even in presence of different protocols such as Bluetooth Low Energy, ZigBee, etc.
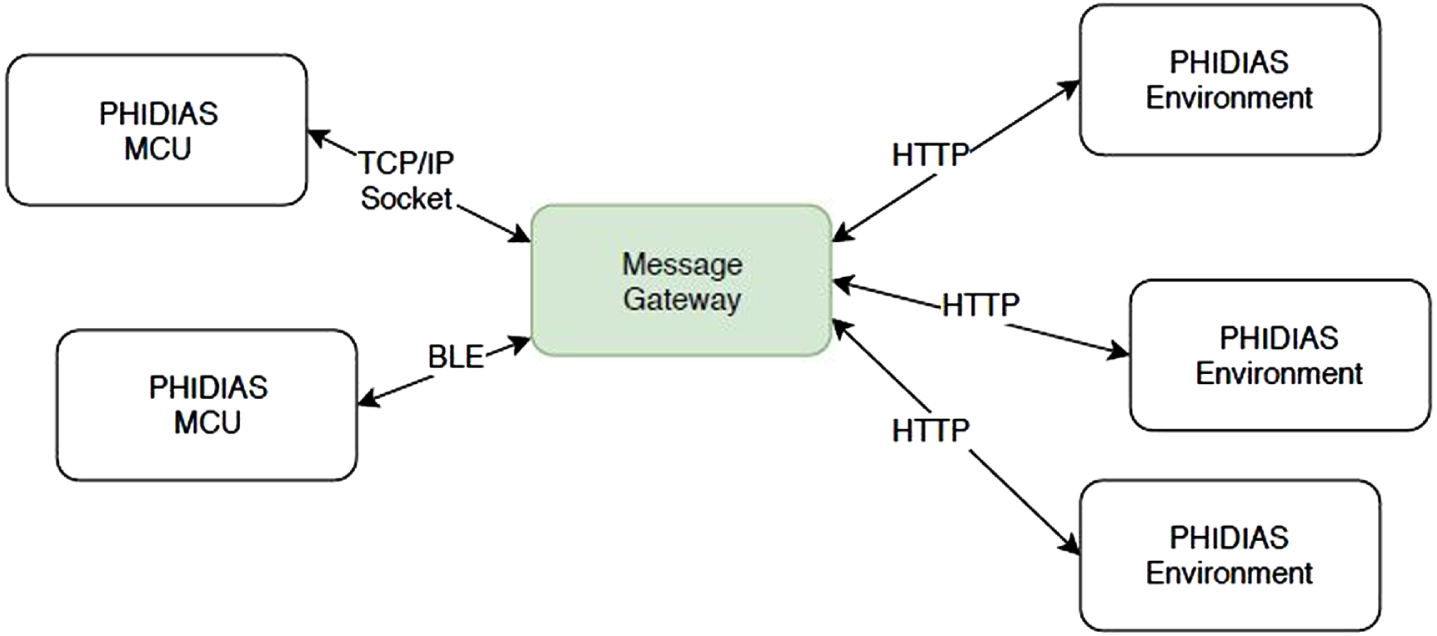
Phidias Message Gateway.
Fig. 5 depicts Phidias’ messaging protocol among the IoT widespread ones. At the bottom level (depicted in blue), there is the physical layer which is made of antennas and hi-profile appliances; above this layer, there is the link level (in green), which permits to transfer packets of types IPv4, IPv6, 6LowPan, etc. Above the link layer, there is another one (in orange) constituted by either TCP or UPD packets. The upper level (in gray) is a session-like one, which in IoT context is usually made of protocols like CoAP [37], RESTful [38], and MQTT [39]. In Fig. 5, it appears clear that, since they have a common underling HTTP layer, Phidias-derived agents can easily share information with devices using RESTful protocol by embedding properly XML code inside specific beliefs. Future versions of Phidias will permit translation towards other protocols too.
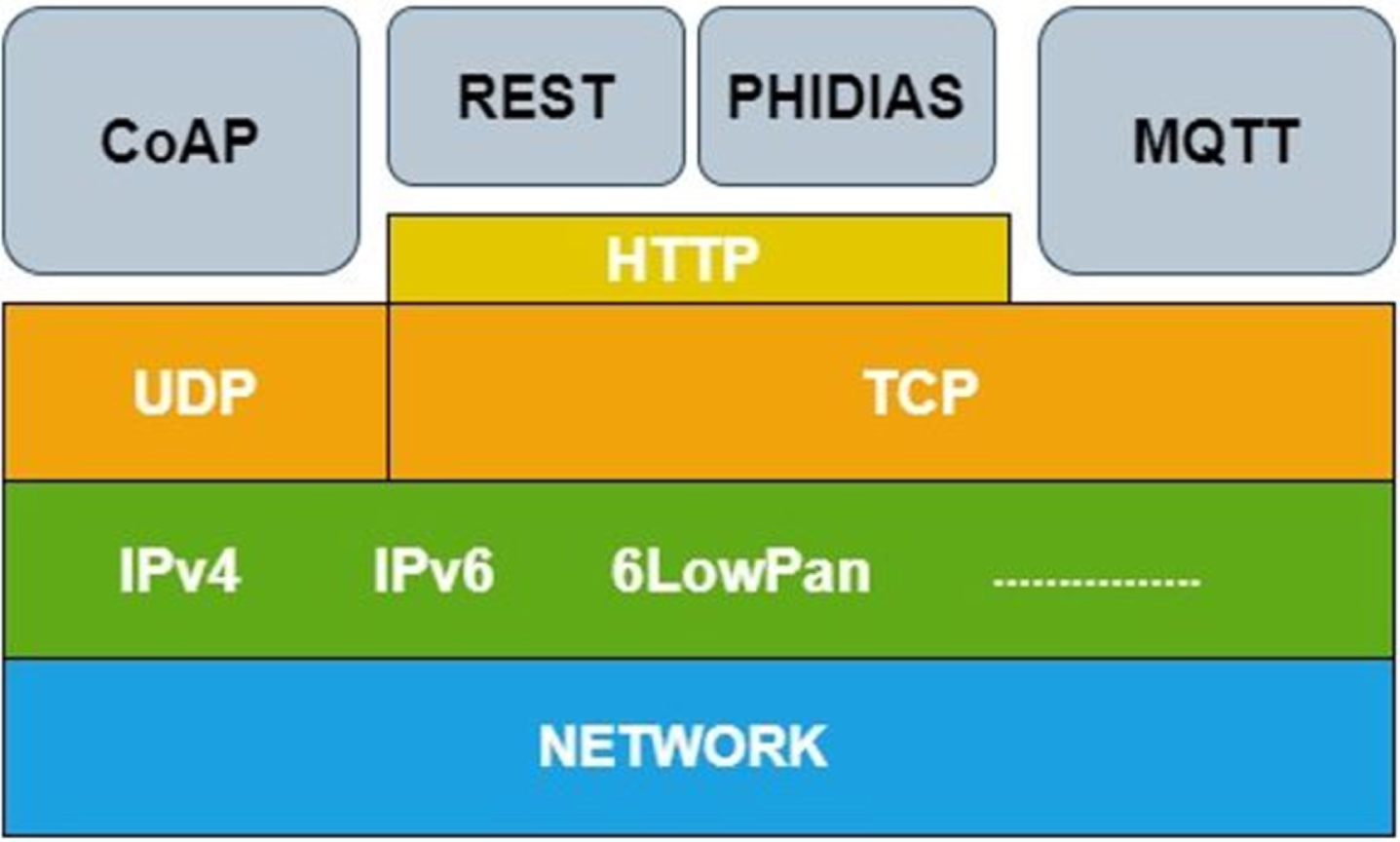
Phidias messaging system among widespread IoT protocols.
In order to achieve conceptual reasoning/meta-reasoning, The SWRL language, which is part of the OWL 2 semantics, is a suitable means to express automation routines in the form of Horn-like rules involving devices and triggering their changes of state. For future developments, a repository containing such rules should keep trace of all current states of either one or more set of devices, by a proper bidirectional inter-device beliefs exchange. The ideal node containing such a repository would have a Broker-like role, and should have enough resources to run a reasoner and work as Message Getaway as well (which is embedded in each of Phidias-based architecture). This can surely give hints for MAS Fog Computing solutions, aimed at decentralizing intelligence from clouds to edges. In this context, the authors of [40] introduced the Ontology for Agents, Systems, and Integration of Services
26
(in short, OASIS), a foundational OWL 2 ontology that defines a request-execute communication protocol for agents, and in particular for Internet of Agents (IoA), based on a mutual exchange of ontology fragments that allow a full transparent and high-level interoperability of agents.
Case-Study
In this section it is shown how
The Owlready [41] library, which, as reported in [42], gives also the chance of reasoning in the local closed world,
27
has been of fundamental use in the development of
We begin with a well-known Knowledge Base (KB) adopted in [43], namely the Colonel West KB,
28
which has been slightly modified for the purposes of our work as it follows (the rationale of that change is explained next):
Colonel West is American
Cuba is a hostile nation
Missiles are weapons
Colonel West sells missiles to Cuba
When an American sells weapons to a hostile nation, that American is a criminal
whose fifth beginning sentence from [43] was:
It is a crime for an American to sell weapons to hostile nations,
encoded in [43] as:
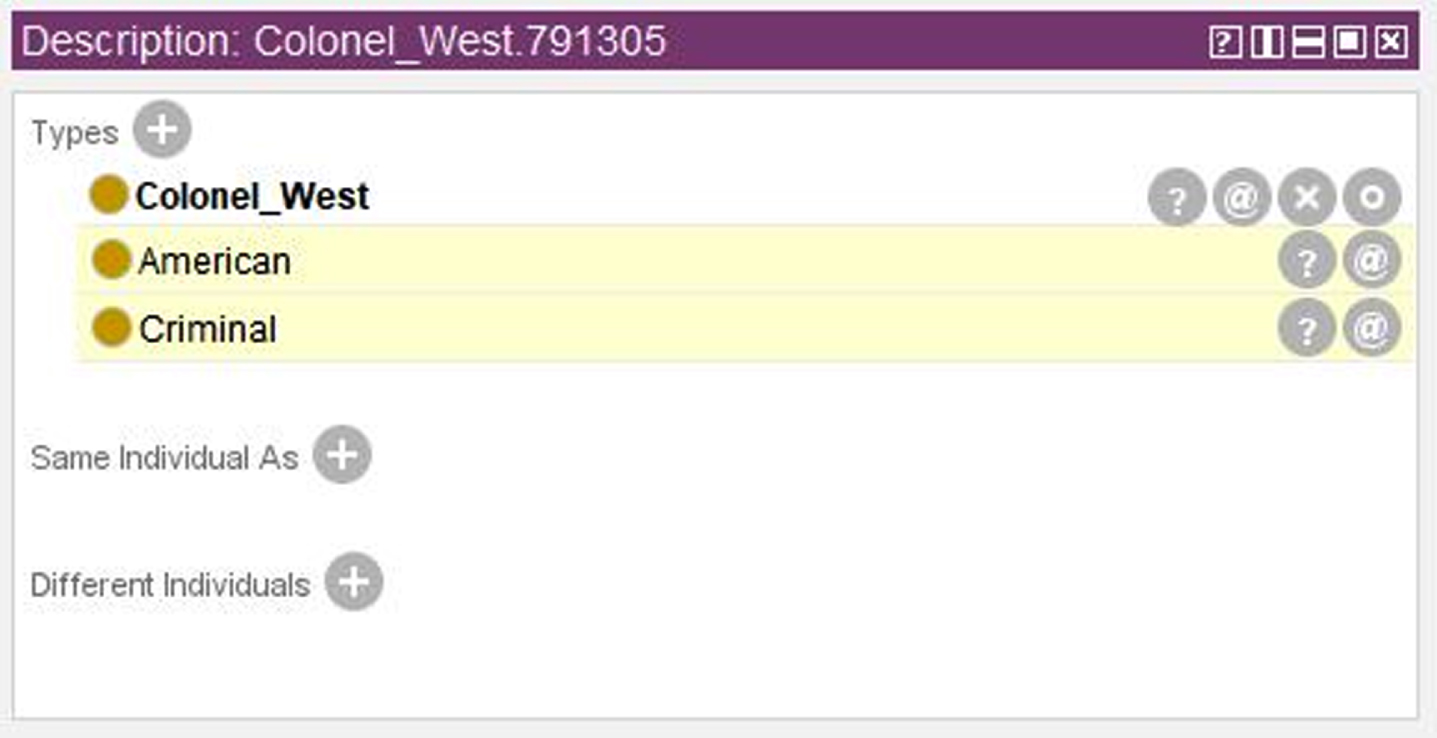
We consider also the following query: Colonel West is a criminal?
which still in [43] was encoded as the following ground literal:
We recall that since the encoding is not unique, the knowledge base suffers from the so-called tailorability problem, and hence there are many distinct logical forms entailed from the same sentence.
Now, if we asserted a SW-C
Fig. 6, which is generated by means of the tool Protégé, shows all classes and instances introduced for the considered example. For instance, Fig. 7 shows all the triples involving the object-properties related with the individual

Classes and individuals for the Colonel West case-study.
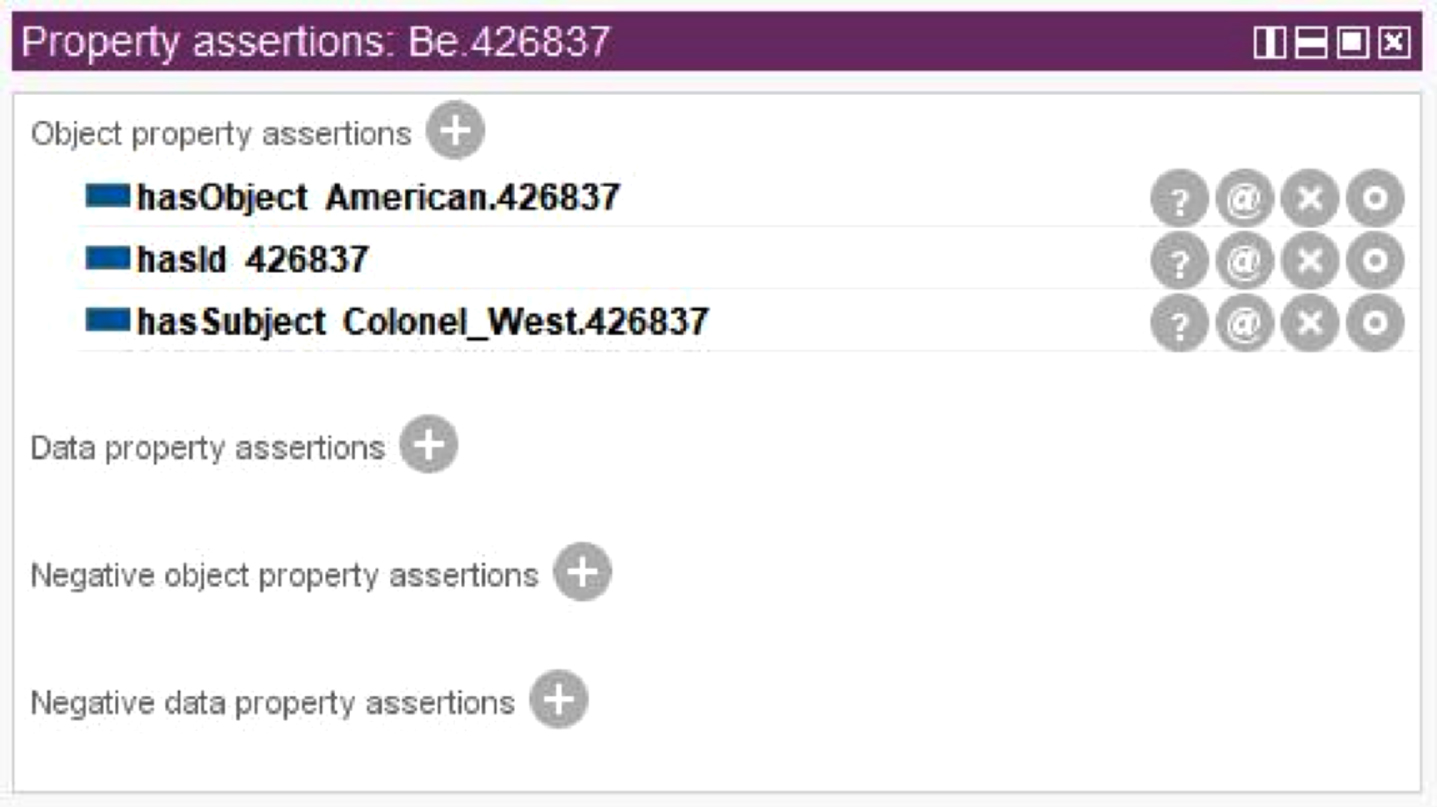
Assertion concerning the individual

The SWRL rules for Colonel West case-study.
Inferences about the Colonel West case-study.
Next, we present a simple case study of ontology building and meta-reasoning that explains how IoT agents based on SW-C
Let us assume to provide a hospital with a (semi-) automatized drug distribution system based on natural language recognition. In this scenario, we also suppose to define one or more agents assisting physicians in the decision-making task related with the administration of drugs, on the basis of known drug’s issues and clinical picture of patients. We extend the Smart Environment Interface of SW-C
Each production rule that starts with
Next, we show how the domain-legacy ontology exploiting LODO is built, together with all the required information about the patient Robinson Crusoe and his health disorders. The natural language sentences from which the ontology is built are the following ones: Robinson Crusoe is a patient. Robinson Crusoe has diastolic blood pressure equal to 150.
32
When a patient has diastolic blood pressure greater than 140, the patient is hypertensive.
The first sentence is parsed as both regular verbal phrase and assignment rule (considering the criteria seen in Section 5), whose resulting classes and individuals are shown in Fig. 10. Classes and instances have similar names (except for the identification code) by virtue of punning patterns [44], whereas a unique identification code is adopted for all the elements of the same verbal phrase.
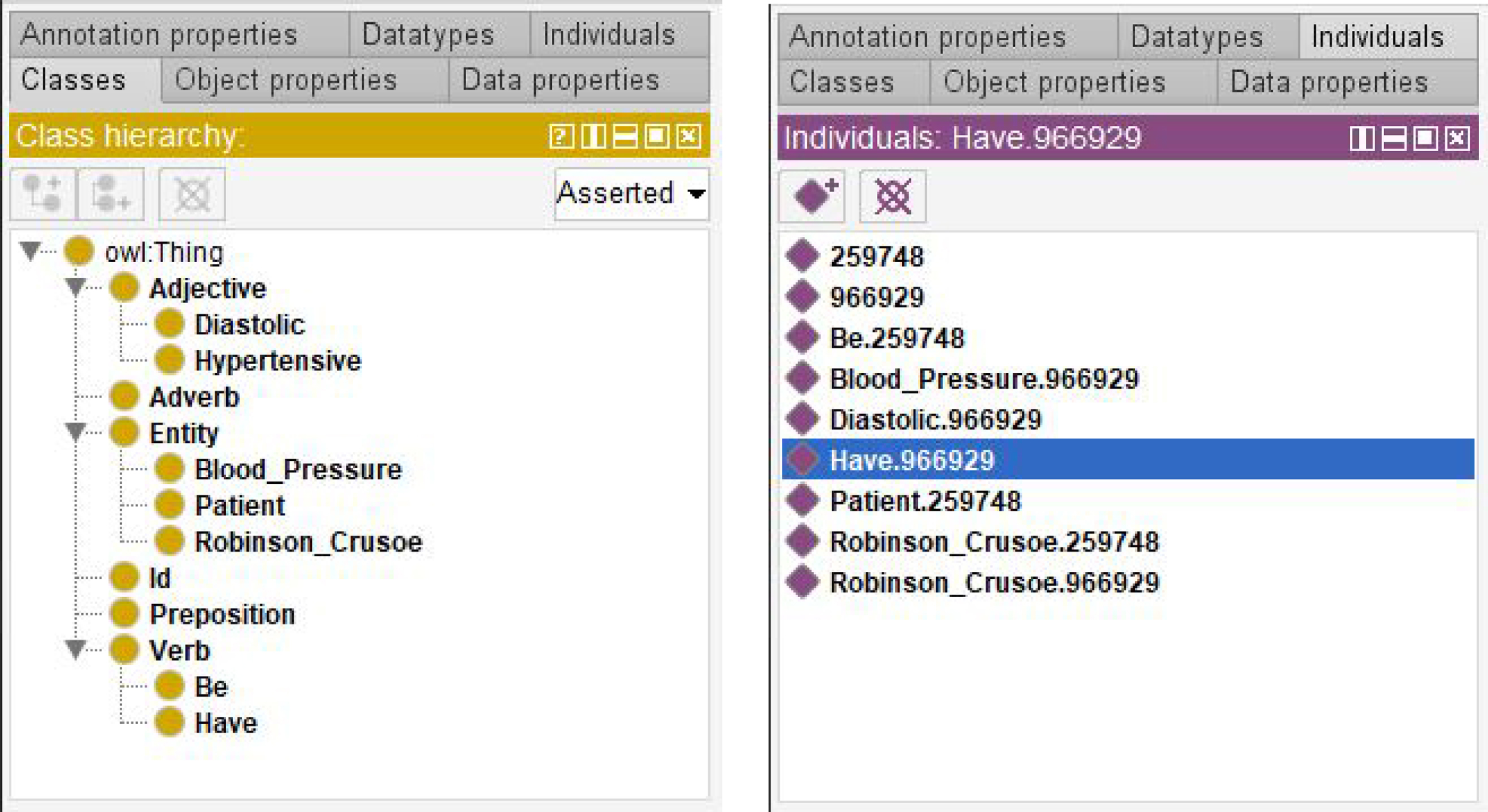
Classes and individuals for the Robinson Crusoe case-study.
In addition to classes and individuals, legacy rules are also asserted (first and third rule of Fig. 12) to allow the individual representing Robinson Crusoe to inherit all the features related with patient. The developer might also provide customized Internationalized Resource Identifier (IRI), either manually or automatically, by means of a pre-compiled association table.
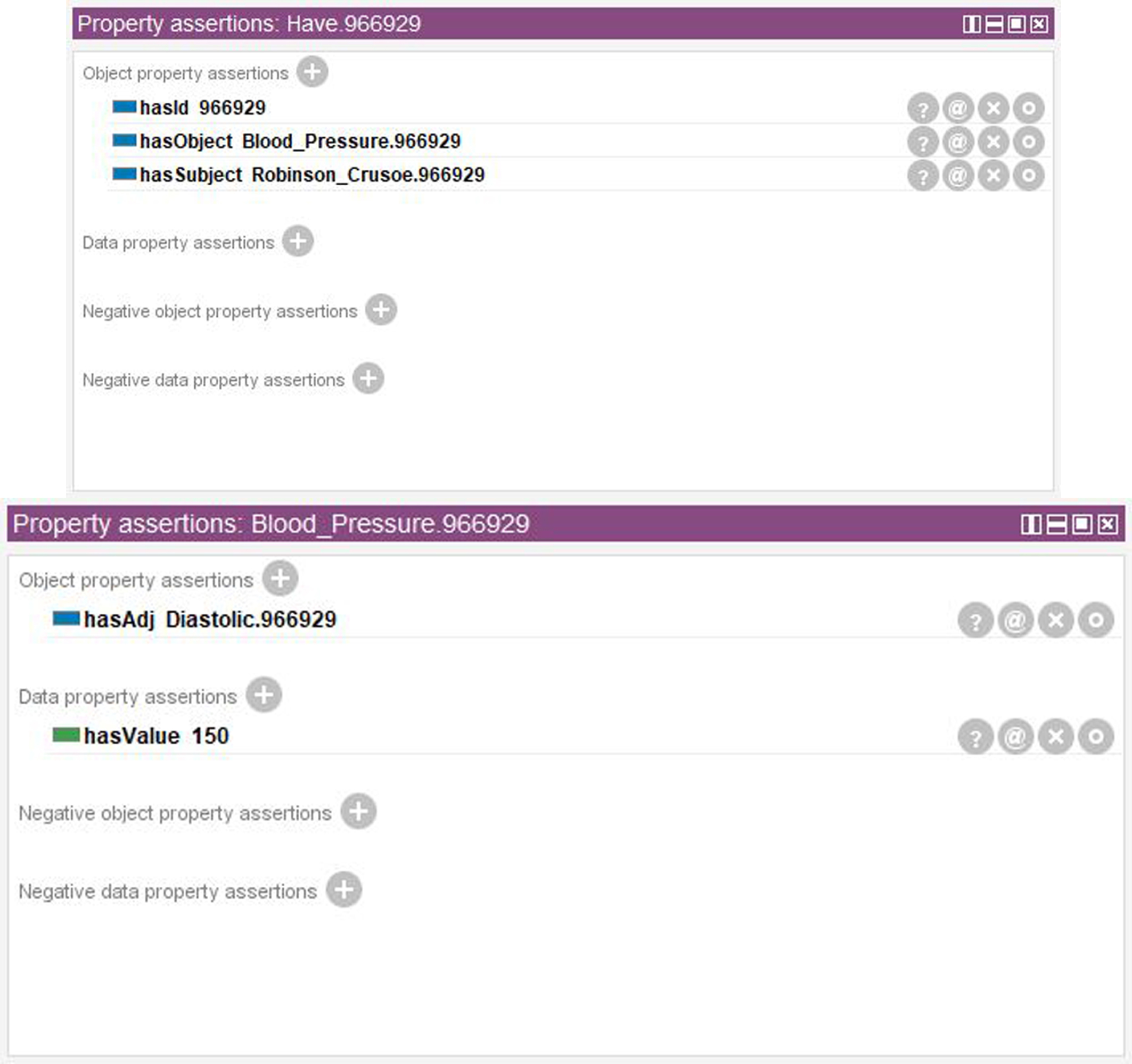
Fragment of the ABox for the Robinson Crusoe case-study.

The SWRL rules for the Robinson Crusoe case-study.
As shown in Fig. 12, the second sentence is parsed as a regular verbal phrase containing also a value giver statement (reported in Fig. 11).
The third sentence is parsed by the Translation Service as a FOL expression containing an implication of the form:
Then, on the basis of above, the Ontology Builder asserts an implicative copular rule containing a value comparison conditional (the second entry in Fig. 12).
At the end of the ontology building process, the agent is ready to parse a command such as:
Give Rinazina to Robinson Crusoe.
Then, the agent invokes one of the selected reasoner and checks for the membership of Robinson Crusoe to the class Hypertensive (as shown in Fig. 13). After the step of meta-reasoning involving the active belief

Inferences about the Robinson Crusoe case-study.
In this paper, we presented the design of a cognitive architecture called
The specific design of
As future work, we intend to address in more depth other issues and ambiguities of natural language ontologies, in order to include additional rules in
At this point the reader can straightforwardly understand that such an approach aims to include additional semantic expressions to the ontology, in order to improve reasoning, but with the drawback of possibly making it noisy, i.e., risking an overpopulation with instances whose utility we are not sure about. Such an issue can be surely addressed in a future work with a pre-analysis of the domain and queries (when possible), in order to detect the most recurrent expressions that might have a future reasoning contribution; then, the Ontology builder can be shaped for adapting it to such analysis and avoid instantiating possible useless instances.
Finally, an integration of
Footnotes
Acknowledgments
We are thankful to the anonymous reviewers for their precious comments and suggestions that helped to improve and clarify this manuscript.
Where SW stands for
A copular verb is a special kind of verb used to join an adjective or noun complement to a subject. Common examples are: be (is, am, are, was, were), appear, seem, look, sound, smell, taste, feel, become, and get. A copular verb expresses either that the subject and its complement denote the same thing or that the subject has the property denoted by its complement.
In linguistics and lexicography, a hypernym is a word whose meaning includes the meanings of other words. For instance, flower is a hypernym of daisy and rose.
A term that denotes part of something but is used to refer to the whole of it, e.g., the term ‘faces’ when used to mean people in I see several familiar faces present.
We recall that
A synset is set of one or more synonyms.
Notice that in the new conceptual domain, the semicolon between lemmas and POS is replaced by the underscore.
We assume to be in a conceptual domain, where possible.
The principle of compositionality asserts that “the meaning of a whole is a function of the meanings of the parts and of the way they are syntactically combined”.
Active belief is a Phidias native type of changing belief that assumes either the value True or False.
Negations are treated as whatever adverbs.
By omitting the POS for the sake of shorteness.
An analogous rule is generated for preposition, where hasAdj is replaced with hasPrep.
In a specific production rule of the Ontology Builder.
In this example we used 123 as identifier but it is more convenient to adopt timestamp in the real world
MicroPython is a fully featured Python environment running on a wide range of MCUs, also providing a small memory footprint and good performances.
Owlready reasoning capability in the local closed world is limited to a set of individuals and classes.
Any reference to places or people is totally random.
We recall that we used the reasoner Hermit and Pellet to obtain the inferences illustrated in this work.
For the sake of the case-study we consider a simplified form of rules. The reader is referred to the Github repository for more details.
The
An analogous case concerns the systolic pressure.