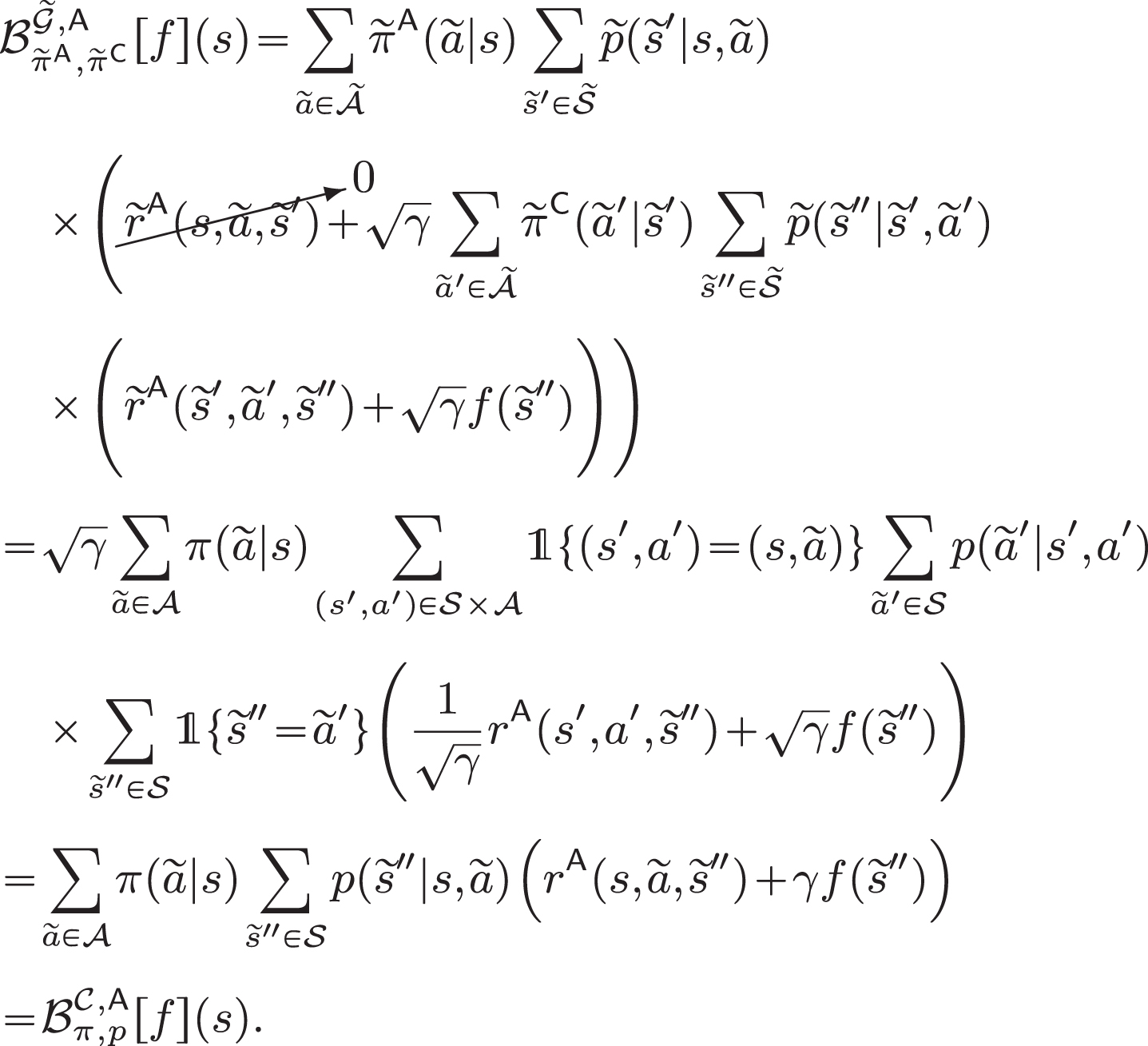In this paper, we provide a unified presentation of the Configurable Markov Decision Process (Conf-MDP) framework. A Conf-MDP is an extension of the traditional Markov Decision Process (MDP) that models the possibility to configure some environmental parameters. This configuration activity can be carried out by the learning agent itself or by an external configurator. We introduce a general definition of Conf-MDP, then we particularize it for the cooperative setting, where the configuration is fully functional to the agent’s goals, and non-cooperative setting, in which agent and configurator might have different interests. For both settings, we propose suitable solution concepts. Furthermore, we illustrate how to extend the traditional value functions for MDPs and Bellman operators to this new framework.
Reinforcement Learning [RL, 43] has attracted significant attention, in the last decade, as an effective approach to addressing complex control tasks when the knowledge of the underlying environment is not available. Remarkable successes have been achieved in industrial robot control [10], trading [7], playing videogames [30], and autonomous driving [14]. RL is rooted in the particular nature of the interaction between the artificial agent and the environment. The agent observes the state of the environment, performs an action, and the environment responds by evolving to the new state and providing the agent with a reward signal. The agent’s goal consists in maximizing the expected cumulative reward (possibly discounted) collected during its experience in the environment. This form of interaction is modeled with the Markov Decision Process [MDP, 37] formalism.
Although simple and intuitive, this kind of interaction rules out a number of real-world scenarios of interest. Indeed, in the traditional formalism, the environment is considered a fully passive entity, whose dynamics is fixed and cannot be altered. Although some approaches did account for a changing environment; the majority of the literature has focused on non-stationary evolution [12, 13] in which the dynamics naturally modifies, independently of the agent activity. Instead, there exist several realistic scenarios in which a limited interventional power over the environment is possible. Such intervention on some environmental parameters, usually possible to a confined extent and more expensive than policy learning, is called environment configuration.
The Configurable Markov Decision Process [Conf-MDP, 17, 18, 23] framework has emerged in the last three years as a useful approach to model and analyze the scenarios in which it is possible to configure some parameters of the environments, with an effect on the environment transition probabilities. The entity entitled to this modification can be either the agent itself or an external configurator. The literature [17] has considered a surge of settings that differ according to several dimensions. The main distinction is between cooperative and non-cooperative Conf-MDPs. In the former case, the agent and the entity entitled to carry out the configuration activity share the same goal, modeled by a unique reward function. Instead, in the latter case, agent and configurator, which are now clearly distinct entities, have different goals, inducing different levels of strategic behavior. Before proceeding further, let us consider the following two examples.
Example 1.1. (Car Driving). Consider the setting of a driver that wants to learn how to drive an F1 car. The car is a part of the environment, but some of its features can be configured, while other portions of the environment cannot (e.g., physical laws). For instance, we can change the kind of tires, the brake repartition between front and rear, and the wing orientation. The effect of these vehicle elements impact the transition probabilities of the environment. We observe that the configuration activity can be carried out by the agent itself or by some external configurator (e.g., a track engineer). Furthermore, the goal of the configuration can be multiple. The agent might be interested in finding the vehicle that best fits its driving abilities, or the track engineer might want to provide the agent with vehicles of increasing difficulty to guide the agent learning process. In both cases, however, the agent and the configurator (the agent itself or the track engineer) share the same objective, i.e., improving the agent learning experience. Thus, we are in a cooperative setting.
Example 1.2. (Supermarket). Suppose we are the owner of a supermarket and we have to decide how to place the goods on the shelves. The goods placement is a feature of the environment that can be subject to configuration by the supermarket owner, that plays the role of the configurator. Their goal consists in maximizing the supermarket profit by inducing, for instance, the customers to spend as much time as possible in the supermarket. The customers, instead, represent the agents in this problem and might have an objective that is different from that of the supermarket owner. For instance, the customers want to find the goods they are interested in, minimizing the time spent inside the supermarket. Thus, in this setting, differently from the previous case, the agents (customers) and the configurator (supermarket owner) have diverging interests, i.e., we are in a non-cooperative setting.
In this paper, we provide a unified presentation of methods and approaches to deal with Conf-MDPs. The goal of this paper is to provide a common notation and extend the traditional tools employed for MDPs (e.g., value functions and Bellman operators) to Conf-MDPs. Furthermore, we want to take stock of the advancements in this novel area. We start in Section 2 with a review of the literature about Conf-MDPs, focusing on modelization, algorithms, and theoretical results. In Section 3, we introduce the notation and the background needed in the subsequent sections. In Section 4, we introduce and discuss the general definition of Conf-MDP, while in Section 5, we extend the traditional value functions to the case of Conf-MDPs together with the corresponding Bellman operators. Moreover, we prove that those operators preserve the contraction property and, consequently, they can be employed to iteratively compute the value functions. Then, in Section 6, we introduce the notion of policy and configuration best responses, together with the corresponding value functions and operators. We show that finding the policy and configuration best responses can be reduced to the solution of a traditional MDP. Section 7 is devoted to the presentation of the cooperative setting, for which we introduce the solution concept, operators and value functions. Moreover, we illustrate that solving a cooperative Conf-MDP is equivalent to solving a suitably defined deterministic MDP. In Section 8, we move to the non-cooperative setting providing a first distinction between turn-based and leader-follower Conf-MDPs, based on the kind of interaction taking place between agent and configurator. In Section 9, we focus on the turn-based setting. We first reduce the turn-based Conf-MDP to a suitably defined turn-based Markov Game (MG). We highlight the existence of the Nash equilibrium, and we define the corresponding value functions. The particular case of zero-sum Conf-MDPs, in which agent and configurator display fully competitive interests, is addressed in Section 10. For this setting, we provide the value functions and the corresponding Bellman operators, studying their properties. We move to the leader-follower setting in Section 11, adapting the notion of Stackelberg equilibrium to the Conf-MDPs and providing value functions and operators. We conclude in Section 12 summarizing the results and suggesting future research directions. Part of the results reported in this paper was presented in the Ph.D. dissertation [17].
Literature review
In this section, we survey the literature in order to provide a complete presentation of the formalizations, methods, and algorithmic approaches to address environment configurability. Table 1 summarizes the reviewed papers.
Schematic comparison among the papers reviewed in Section 2
The notion of configurable environment has been introduced in [23], in its cooperative form. In the same work, a learning algorithm, Safe Policy Model Iteration (SPMI) was proposed. SPMI is applicable to finite state-action environments and under the assumption, the effect of the configurable parameters on the transition probabilities is known to the learner. The resulting algorithm, endowed with strong theoretical guarantees on the performance improvement, was tested on illustrative domains. In [19], the main limitations of SPMI were addressed by proposing a novel approach, Relative Entropy Model Policy Search (REMPS), belonging to the class of trust-region methods. REMPS is able to learn in presence of parametric policy and configuration models and does not require knowing in advance the effect of the configurable parameters, which, instead, are inferred by interacting with the environment. The algorithm was tested on a realistic car configuration task, based on the TORCS simulator, showing the advantages of employing environment configuration over fixed-configuration learning. Recently, it has been proved that, in the cooperative setting, when the configurator has access to a limited configuration space, finding the optimal configuration is an NP-hard problem [41].
The idea of intervening in the environment features with the goal of inducing a specific behavior of the agent was considered in previous works about environment design [48, 49]. In this framework, introduced by the planning community, there exists an interested party, compatible with the notion of configurator, that is allowed to alter dynamically the reward function and the transition dynamics in order to induce a specific behavior of the agent. In this setting, the agent is assumed to be unaware of the interested party presence and, consequently, it acts as a best responder. However, the interested party is assumed to know how the agent will react to any environment proposed, which does not need to be an MDP. Subsequent papers considered specific teaching purposes [50]. Among the environment design approaches, the equi-reward utility maximization design [11] considers the case in which the interested party displays the same goal as the agent. In this case, the formulation is restricted to the MDP case and the interested party task is to plan an optimal sequence of environment changes so as to maximize the agent’s performance.
To account for the possibility that configuring the environment can be an expensive task, in [42] an approach to environment configuration that embeds in the objective function a notion of cost is proposed. The goal is to find the environment that favors the agent learning, regularizing with the cost of implementing a specific configuration. The notion of environment configurability has been employed coped with policy gradient approaches, with the goal of reducing the variance of the gradient estimation, in combination with off-policy methods [25, 34], by increasing the probability of rare events [5]. Another application of Conf-MDPs is policy space identification [21]. In this setting, the task consists in identifying the capabilities of the agent in terms of perception and actuation. Altering the environment can induce the agent to reveal its capabilities in a more effective way. Furthermore, in [22], a specific environmental parameter, the control frequency, is configured with visible advantages on the learning performance in the context of batch RL algorithms.
Among the approaches that consider the presence of a configurator displaying a goal explicitly diverging from that of the agent we mention [39]. In this work, a regret minimization approach is proposed in the case in which the agent and configurator have arbitrary reward functions. The model resembles the leader-follower interaction, in which the configurator commits to a configuration and the agent is a best responder with a limited strategic power. From a certain perspective, policy poisoning [16] can be considered a form of environment configuration in which the goal of the configurator is to make the agent play a specific policy, by acting either on the reward function or on the transition dynamics.
Preliminaries
In this section, we introduce the necessary background that will be employed in the remainder of the paper.
Notation
Let be a finite set, we denote with the simplex over . Let another finite set, we denote with the set of functions . Let , we denote with the identity operator , with the max operator , and with the L∞-norm.
Markov Decision Processes
An infinite-horizon discounted finite Markov Decision Process [MDP, 37] is defined as a 5-tuple , where is a finite set of states, is a finite set of actions, is the transition model mapping every state-action pair to a probability distribution of the next state p (· |s, a), is the reward function mapping every state-action-next-state triple to the corresponding reward r (s, a, s′), and γ ∈ [0, 1) is the discount factor. The agent’s behavior is modeled by a policy mapping every state to a probability distribution over the actions π (· |s).
Interaction Protocol. At each step , the agent observes the environment state , plays an action sampled from its policy π (· |st), the environment evolves to the next state according to its transition model p (· |st, at), provides the agent with a reward r (st, at, st+1), and the process repeats.
Operators. Let , we denote with the policy operator induced by policy , defined as:
Let , we denote with the transition model operator induced by transition model , defined as:
In particular, we define the expected rewards for every state-action pair :
Furthermore, we introduce the following inverse operators via the Neumann series:
Value Functions. A policy in an MDP induces a value function [43] , defined as the expected discounted sum of the rewards obtained by executing policy π from a state :
where we denote with the expectation w.r.t the state-action visitation distribution induced by policy π. The optimal value function is defined for every state as:
A policy is optimal if it maximizes the value function starting from every state, i.e., if vπ* (s) = v* (s) for every . It is well-known that in an MDP a deterministic optimal policy exists [37]. The optimal policies can be derived as greedy policies w.r.t the optimal value function v*, i.e., for every state :
where is the set of the greedy actions.
Bellman Operators. The value functions vπ and v* can be computed by means of the iterative application of suitably defined Bellman operators [2]. Let be a policy, the Bellman expectation operator is defined for every and as:
is a linear operator and a γ-contractions in L∞-norm. Thus, it admits a unique fixed point represented by the value function vπ. The optimal Bellman operator is defined for every and as:
is no longer linear but it remains a γ-contractions in L∞-norm and its unique fixed point is the optimal value function v* [37].
Two-players turn-based Markov Games
An infinite-horizon discounted finite two-players turn-based Markov Game [MG, 15, 40] is defined as a 8-tuple , where and are finite set of states in which the first and the second player are entitled to play respectively with , and are finite set of actions for the first and second player respectively and , is the transition model mapping every pair
1
to the probability distribution of the next state p (· |s, a), are the reward functions of the first and second player respectively, and γ ∈ [0, 1) is the discount factor. The agents’ behaviors are defined in terms of policies and for the first and second player respectively.
Interaction Protocol. At each step , both players observe the state of the environment . If (resp. ) is the turn of the first (resp. second) player that takes an action (resp. ) according to its policy π1 (· |st) (resp. π2 (· |st)) that is observed by the other player too. The environment evolves to the next state according to the transition model p (· |st, at) and each player collects the reward r1 (st, at, st+1) and r2 (st, at, st+1) respectively and the process repeats.
Value Functions A pair of policies and in a MG induces the value functions for the two players, i.e., the expected discounted sum of the rewards obtained by executing policies π1 and π2 from a state :
where we denote with the expectation w.r.t the state-action visitation distribution induced by policies π1 and π2. The best response value functions are defined for every state as:
A pair of policies is a Nash equilibrium if no player has interest in unilaterally deviate from the equilibrium, i.e., for every state we have: and . We say that a turn-based MG is alternating if every turn of the first player is followed by a turn of the second player and vice versa, i.e., if the following conditions hold:
Bellman Operators. In the case of alternating turn-based MGs, we introduce the following Bellman operators [9] , defined for every and :
The rationale behind these operators is that of applying alternatively policies π1 and π2, based on whether the initial state s belongs to or . These operators are γ2-contractions in L∞-norm and their unique fixed points correspond to the value functions and respectively.
Model formulation
In this section, we introduce and discuss the definition of Configurable Markov Decision Process [Conf-MDP, 17, 18, 21–23, 39]. As we mentioned above, a Conf-MDP can be regarded as a traditional MDP with the additional possibility to configure some environmental parameters leading to a modification of the transition probabilities. Furthermore, the presence of the agent and configurator pursuing possibly different goals, requires considering two reward functions.
Definition
For the sake of this paper, we limit to the case of finite states and actions, although most of the results can be extended to the continuous setting.
Definition 4.1. (Configurable Markov Decision Process). A discrete-time infinite-horizon discounted finite Configurable Markov Decision Process (Conf-MDP) is defined as a 5-tuple where is a finite state space, is a finite action space, are the agent and configurator reward functions respectively, and γ ∈ [0, 1) is the discount factor.
The definition of Conf-MDP is obtained from that of the MDP by neglecting the transition model p, that we will also call configuration in the following, and considering two reward functions: one for the agent rA and one for the configurator rC. It is worth noting that in Definition 4.1, we considered reward functions depending on the next state too. While for traditional MDPs, focusing on reward functions depending on the current state-action pair is without loss of generality as the transition model is fixed, for the Conf-MDPs the dependence on the next state is essential as the transition model can be altered as an effect of environment configuration [17]. A graphical representation of the MDP and the Conf-MDP framework is reported in Fig. 1.
Graphical representation of the interaction between an agent and an environment in an MDP (left) and in a Conf-MDP (right).
Policies and configurations
In a Conf-MDP, the agent is entitled of choosing a policyπ, mapping states to actions (like in traditional MDPs), and the configurator is in charge of selecting a configuration, i.e., a transition model p mapping state-action pairs to next states. Concerning the policy, we limit to the case of Markovian stationary policies mapping states to probability distributions over actions π (· |s). Concerning the configuration, we define a Markovian stationary configuration (or transition model) as a function mapping state-action pairs to probability distributions over states p (s′|s, a) with .
2
Value functions
In this section, we introduce the notion of value function for Conf-MDPs. We extend the analogous concept defined for standard RL [43], representing the expected discounted sum of the rewards collected during an interaction between agent and environment. For this purpose, we introduce the operator to denote the expectation w.r.t the state-action visitation distribution induced by policy π and configuration p.
Definition 5.1. (Value Functions). Let be a policy, and be a configuration. The agent value function is defined for all states as:
The configurator value function is defined for all state-action pairs as:
It is worth noting that since the agent is entitled to perform actions, we define its value as a function of the state only, whereas, since the configurator decides the next state, having observed the agent’s action, its value is a function of the state-action pair .
Agent and configurator Bellman operators
In full analogy with traditional RL [37], we can express these value functions by means of suitable recursive relations which are formalized by Bellman equations [2]. To this purpose, we now introduce the Bellman expectation operators.
Definition 5.2. (Bellman Expectation Operators). Let be a policy and be a configuration. The agent Bellman expectation operator is defined for all functions for all states as:
The configurator Bellman expectation operator is defined for all functions for all state-action pairs as:
The operators and are in all regards the traditional Bellman expectation operators for the state-value function and state-action-value function. Therefore, they fulfill the following properties regarding contraction and fixed points [37].
Proposition 5.1.The Bellman expectation operators and are γ-contractions in L∞-norm, i.e., for all and :
Moreover, the agent value function and the configurator value function are their unique fixed points respectively:
Proof: We prove the statement for the configurator operator , as the proof for the agent case is analogous:
By taking the L∞-norm, we obtain:
where we observed that ∥PΠ ∥ ∞ = 1 being PΠ a stochastic matrix. Thus, is a γ-contraction. As γ < 1 and is a non-empty complete metric space where d∞ is the metric induced by the L∞-norm, thanks to the Banach fixed point theorem, we have that admits a unique fixed point. It is immediate to prove that is the fixed point. □
Value function computation
Algorithm 1 shows how to iteratively compute the fixed-point value functions. It repeatedly performs the application of the Bellman expectation operators until a convergence threshold is achieved. The following result derives the per-iteration time complexity of the algorithm and an upper bound on the number of iterations needed for convergence.
Theorem 5.2. (Algorithm 1). The per-iteration time complexity of Algorithm 1 is . If ∥rA ∥ ∞ ≤ R and ∥rC ∥ ∞ ≤ R, then Algorithm 1 terminates in at mostwith the guarantee:
Proof: The time complexity is dominated by the application of that requires for each state-action pair two nested summations over . Therefore, the per-iteration time complexity is .
Let be the value function approximated at the beginning of iteration i ≥ 1. By exploiting the γ-contraction of Proposition 5.1, we have:
having exploited that . By enforcing the last equation ≤ɛ, we have:
For the second statement, recalling that and and using Proposition 5.1, we have:
From which, we obtain:
The proof is fully analogous concerning the configurator value function. □
A Conf-MDP involves the interaction of two entities, the agent and the configurator each playing a policy π and a configuration p respectively. In full analogy with what is done in game theory [40], it is convenient to define the notion of best response policy and configuration. To this end, we start by introducing the concept of best response value function.
Definition 6.1. (Best Response Value Functions). Let be a configuration. The agent best response value function to confiuguration p is defined for every states as:
Let be a policy. The best response configurator value function to policy π is defined for every state-action pair as:
Furthermore, we say that a policy is a best response policy w.r.t the configuration if it holds for all that:
i.e., if it attains the agent best response value function. We denote with the set of all best response policies w.r.t configuration p. Similarly, we say that a configuration is a best response configuration w.r.t policy if it holds for all that:
that is, if it attains the configurator best response value function. We denote with the set of all best response configurations w.r.t policy π.
Existence of best response policies and configurations
In principle, we might wonder if best response policies and best response configuration do exist. This question is not trivial as, by Definition 6.1, the maximization is carried out for every state s and state-action pair (s, a) possibly leading to different best responses. Instead, we have defined a best response policy and configuration as a unique policy or configuration attaining the best response value function.
Concerning the existence of the best response policy , we observe that its determination consists, in all regards, to the solution of a traditional MDP with transition model p. Therefore, its existence is ensured and it can be any policy fulfilling the greedy condition for every :
Instead, for the existence of the configuration best response value function, we prove in Theorem 6.1 that we can reduce its determination to the solution of a suitably defined MDP. Therefore, its existence is guaranteed too, by means of the greedy configuration defined for every :
Specifically, the following result provides a reduction of the problems of computing the best response policy and configuration in a Conf-MDP to the problem of solving a traditional MDP.
Theorem 6.1.Let be a Conf-MDP. Let be a configuration and be an MDP. Then, for every and every state it holds that:Let be a policy and let be an MDP defined as follows:
, defined for every and as:
, defined for every as:
Then, for every , we define the policy for every state-action pair and as:Then, for every and for every state-action pair it holds that:
Proof: The first part of the theorem is straightforward. Concerning the second part, it suffices to prove that the Bellman operator associated to in the Conf-MDP , i.e., equals the Bellman operator associated to in the MDP , i.e., . Let and let :
□
Thus, we have shown that finding the best response policy in the Conf-MDP is equivalent to solve (i.e., finding the optimal policy) the MDP and, analogously, finding the best response configuration in the Conf-MDP is equivalent to solve the MDP .
Best response Bellman operators
We now introduce the best response Bellman operators and prove the corresponding contraction and fixed-point properties.
Definition 6.2. (Bellman Best Response Operators). Let be a configuration. The agent Bellman best response operator to configuration p is defined for all as for all states :
Let be a policy. The configurator Bellman best response operator to policy π is defined for all as for all state-action pairs :
We observe that the agent best response operator is equivalent to the optimal Bellman operator for traditional MDPs [37] and inherits all its properties. The following result generalizes the properties for the configurator best response operator .
Proposition 6.2.The Bellman best response operators and are γ-contractions in L∞-norm, i.e., for all and :Moreover, the agent best response value function and the configurator best response value function are their unique fixed points respectively:
Proof: The operator is the traditional optimal Bellman operator, whose properties are known from [37]. We prove the statement for the configurator operator :
where with the symbol (_ , _ , ·) we denoted the fact that the operators are applied to the third argument only. By taking the L∞-norm, we obtain:
where we observed that . Since γ < 1 and where d∞ is the metric induced by the L∞-norm, thanks to Banach fixed point theorem, the operator admits a unique fixed point. We now prove that if then . We first prove that if then . If it means that for every it holds that . Thus, we have for every :
where we exploited that for a function if h ≥ γPΠh then that, in turn, implies h ≥ 0 if γ < 1 [Lemma 4.2, 31]. As for all , we have that . With an analogous argument we can prove that if then . Combining the two results, we have proved that if then . □
Best response computation
Algorithms 2 and 3 provide the pseudocode of the iterative algorithms to compute the best response value functions for the agent and the configurator respectively. They perform a repeated application of the Bellman best response operators until a given convergence threshold is reached. It is worth noting that both algorithms terminate with a number of iterations that can be bounded analogously to what is done in Theorem 5.2 thanks to the similar properties of the best response Bellman operators. Moreover, the final guarantee of Theorem 5.2 is preserved for both Algorithms 2 and 3:
Finally, we point out that once the best response value function is available, the computation of the best response policy or configuration is straightforward via Equations (1) and (2).
Algorithm 2. Agent Best Response (A-BR)
procedureA-BR(configuration p, error ɛ)
Initialize vA (s) ←0 for all
do
while
returnvA
end procedure
Algorithm 3. Configurator Best Response (C-BR)
procedureC-BR(policy π, error ɛ)
Initialize qC (s, a) ←0 for all
do
while
returnqC
end procedure
Cooperative Conf-MDPs
In this section, we focus on the cooperative setting characterized by the fact that the agent and the configurator share the same objectives. In such a case, we can consider a unique reward function r and we speak of cooperative Conf-MDPs.
Definition 7.1. (Cooperative Conf-MDP). Let be a Conf-MDP. is a Cooperative Conf-MDP if for every state-action-next-state triple it holds that:
In this case, we abbreviate r : = rA = rC.
Moreover, we will remove the superscripts A and C from the value functions and from the operators. The goal in a cooperative Conf-MDP can be stated as determining a policy and a configuration such that they jointly optimize the expected discounted sum of the rewards. As there is no competition between agent and configurator, it is straightforward to define a solution concept for this setting. The following definition formalizes intuition.
Definition 7.2. (Optimal Value Functions). The agent optimal value function is defined for all states as:
The configurator optimal value function is defined for all state-action pairs as:
We observe, given the identity of the reward functions it holds that for all . Moreover, we say that a policy-configuration pair is optimal if it fulfills the following condition for all :
that is, if it attains the optimal value functions.
Existence of optimal policy-configuration Pairs
Similarly to the case of best responses, we wonder whether the optimal policy-configuration pairs actually exist. For this purpose, we provide the following reduction showing that determining the optimal pair (π*, p*) in a cooperative Conf-MDP is indeed equivalent to solving a suitably defined deterministic MDP.
Theorem 7.1.Let be a cooperative Conf-MDP and let be an MDP defined as follows:
, defined for every and as:
, defined for as:
Then, for every define the policy for the MDP for every as:Then, for every state-action pair it holds that:
Proof: It is sufficient to prove the Bellman operator associated to the policy-configuration pair in the cooperative Conf-MDP , i.e., equals the Bellman operator associated to in the MDP , i.e., . Let and let :
The proof for the operator of the configurator value function is analogous. □
Thus, thanks to the reduction, we can compute the optimal policy-configuration pair (π*, p*) as the greedy pair w.r.t the corresponding optimal value functions as done in Equations (1) and (2). Moreover, one deterministic optimal pair exists.
Optimal Bellman operator for cooperative Conf-MDPs
We now introduce the optimal Bellamn operator for cooperative Conf-MDPs and provide the analysis of its properties.
Definition 7.3. (Optimal Bellman Operator for Cooperative Conf-MDPs). The optimal Bellman operator for the state value function is defined for every function and every state as:
The optimal Bellman operator for the action value function is defined for every function and every state-action pair as:
It is immediate to prove that these operators are γ-contractions in L∞-norm and, consequently, they admit a unique fixed point, represented by the optimal value functions.
Proposition 7.2.The Bellman optimal operators are γ-contractions in L∞-norm, i.e., for all and :Moreover, the optimal value functions υ*,* and q*,* are their unique fixed points respectively:
Proof. We prove the result for the first operator, as the derivation for the second is equivalent:
where we denoted with (_ , ·) the fact that the operator is applied to the second argument only. By taking the L∞-norm, we have:
Thus, we can extend the last part of the proof of Proposition 6.2 to deduce that admits a unique fixed point that corresponds to υ*,*. □
Optimal value function computation
The computation of such optimal value functions can be derived by exploiting an iterative procedure, like the one in Algorithm 4. This algorithm inherits all the properties derived in Theorem 5.2. It is worth noting that in the cooperative setting the reward functions are the same for the agent and the configuration, it is sufficient to compute one of the value functions, say q*,*, and then derive the other v*,*.
Algorithm 4. Agent Configurator Cooperative
Optimization (A-C-CO)
procedureA-C-CO(error ɛ)
Initialize q (s, a) ←0 for all
do
while
returnv, q
end procedure
Non-cooperative Conf-MDPs
In this section, we introduce the setting of non-cooperative Conf-MDPs, i.e., the case in which agent and configurator might have diverging interests, modeled by possibly different reward functions rA ≠ rC. While the cooperative setting has been diffusely addressed, the non-cooperative one is less studied [39].
In order to properly address the setting, we distinguish two types of interactions between the agent and the configurator, leading to different suitable solution concepts:
Turn-based Conf-MDPs: the interaction is carried out in steps. At every step, the agent selects the action and the configurator, having observed the action, selects the next state .
Leader-Follower Conf-MDPs: the configurator commits to a configuration at the beginning of the interaction, while the agent then selects the policy to be played.
Other kinds of interactions might be inappropriate for the Conf-MDP setting. For instance, the simultaneous selection of the action by the agent and of the next state by the configurator, based on the current state only, is unrealistic as the configurator usually has access to the agent’s action. We will dive into the details of the non cooperative setting in the next sections.
Turn-based Conf-MDPs
In turn-based Conf-MDPs, at each step , the agent observes the state of the environment and selects the action to be played based on its policy π (· |st). Then, the configurator, observing the state and the action at, chooses the next state st+1 according to the transition model p (· |st, at). In this setting, it is reasonable to consider the Nash equilibrium [32] a suitable solution concept, that we adapt for Conf-MDPs.
Definition 9.1. (Nash Equilibrium in Conf-MDPs). A policy and a configuration are a Nash equilibrium for the Conf-MDP if the following two conditions hold for every state-action pair :
Thus, a pair is a Nash equilibrium of the Conf-MDP if the value functions υπ*,p* and qπ*,p* for the agent and the configurator are equal to the corresponding best response value functions υ*,p* and qπ*,*, respectively. This means that neither the agent nor the configurator has a unilateral interest in deviating from the equilibrium.
Existence of the Nash equilibrium for Conf-MDPs
A legit question is whether the Nash equilibrium as in Definition 9.1 does exist. In order to show the existence of a Nash equilibrium for the turn-based Conf-MDPs, we provide the following reduction to a turn-based Markov Game for which a Nash equilibrium is known to exist [4, 44].
Theorem 9.1.Let be a turn-based Conf-MDP and let = , × , , , , , , be an alternated turn-based MG, defined as follows, where and :
, defined for every and as:
where the symbol ⊥ denotes undefined;
, defined for as:
Then, for every define the policies for the turn-based MG for every as:Then, for every state-action pair it holds that:
Before moving to the proof, it is worth commenting the above construction. First of all, we observe that the game is deterministic. Moreover, the rationale is to construct a turn-based MG in which agent and configurator alternate in playing, with the agent selecting an action and the configurator the next state. In particular, the reward is given to the agent and to the configurator at the end of two steps, when the configurator has played. This is why the reward function is corrected by the factor .
Proof: We prove that the Bellman operators associated to in the Conf-MDP , i.e., and , equal the Bellman operators associated to policies and in the MG , i.e., and . We limit the derivation for the agent case, as for the configurator the steps are analogous. Let and :
□
Being the turn-based Conf-MDP isomorphic to the turn-based Markov Game, we can immediately conclude the existence of the Nash equilibrium in (possibly) mixed strategies (i.e., stochastic policies) [4, 44]. We now focus on a particular case of interest represented by the zero-sum Conf-MDPs.
Zero-sum Conf-MDPs
In this section, we consider the case in which agent and configurator demonstrate fully competitive interests. We refer to this setting to as zero-sum Conf-MDPs, that are formalized in the following definition.
Definition 10.1. (Zero-Sum Conf-MDP). Let be a Conf-MDP. is a Zero-Sum Conf-MDP if for every state-action-next-state triple it holds that:
In such a case, we denote with r : = rA = - rC.
Thus, looking at the problem as a zero-sum game, the agent seeks to maximize the reward r, while the configurator aims at minimizing it, i.e., we are in a fully competitive setting.
Minimax value functions
Similarly to what done in the previous scenarios, we introduce the minimax value functions, that can be defined based on the Von Neumann minimax theorem [45].
Definition 10.2. (Minimax Value Functions). The agent minimax value function is defined for all states as:
The configurator minimax value function is defined for all state-action pairs as:
It is worth noting that, thanks to the reduction of Theorem 9.1, we are in presence of an interaction that can be modeled as a turn-based MG. In particular, it is well-known that for zero-sum turn-based MG the Nash equilibrium exists in pure strategies (i.e., deterministic polices) [3, 35]. Thus, we can restrict our attention to the deterministic policies and configurations. Once we have to compute the minimax value functions, the equilibrium policy and configuration can be computed by the greedyfication operation as in Equations (1) and (2).
Bellman minimax operators
We now proceed at introducing the Bellman minimax operators for the case of zero-sum Conf-MDPs.
Definition 10.3. (Bellman Minimax Operators). The agent Bellman minimax operator is defined for all as for all states :
The configurator Bellman minimax operator to configuration p is defined for all agent value functions as for all states :
We now prove that such operators are a γ-contractions and admit the minimax value function as corresponding fixed points.
Proposition 10.1.The minimax Bellman operators and are γ-contractions in L∞-norm, i.e., for all and :Moreover, the agent minimax value function and the configurator minimax value function are their unique fixed points respectively:
Proof: We prove the contraction property for the first operator, as the proof for the second is fully analogous:
where we exploited the fact that for generic functions h and h′, we have:
By applying the L∞-norm, we have:
To prove that the minimax value function is the unique fixed point, we can apply an argument analogous to that of Theorem 6.1. □
Minimax value function computation
Before showing the algorithm able to compute the minimax value functions via an iterative procedure, it is worth noting that since the Nash equilibrium exists in pure strategies (i.e., deterministic policy and configuration), we can simplify the application of the Bellman minimax operators, by replacing the optimization of the space of stochastic policies and transition models with the optimization over the deterministic actions and deterministic next states . This observation leads to the following simplified operators defined for , and :
Algorithm 5 reports the pseudocode of the iterative procedure consisting in the repeated application of these operators until ɛ-convergence. This algorithm preserves the guarantees of Theorem 5.2 thanks to the properties of the minimax Bellman operators. Concerning the computational complexity, it is worth noting that the application of the operators, in the form reported right above, requires, in the worst case, enumerating all state-action pairs for the minimax, leading to the same complexity as in Theorem 5.2.
Algorithm 5. Agent Configurator Minimax
Optimization (A-C-MMO)
procedureA-C-MMO(error ɛ)
Initialize vA (s) ←0 for all
Initialize qC (s, a) ←0 for all
do
while or
returnvA, qC
end procedure
Leader-follower Conf-MDPs
In the leader-follower setting, instead, the configurator selects a transition model and commits to it. Subsequently, the configurator selects a policy to be used for the interaction [39]. This setting resembles the leader-follower game in which the leader is represented by the configurator and the follower by the agent. Under the assumption that the agent reacts to a configuration p with one of its best response policies, i.e., it acts as a best responder, the Stackelberg equilibrium is a suitable solution concept for this setting [6, 45].
Definition 11.1. (Stackelberg Equilibrium in Conf-MDPs). Let be a choice function in the set of agent best response policies, i.e., for every configuration it holds that βA (p) ∈ BRA (p). A policy and a configuration are a βA-Stackelberg equilibrium for the Conf-MDP if the following two conditions hold for every state-action pair :
Furthermore, we define the βA-Stackelberg value function for every state-action pair as:
Thus, the definition of Stackelberg equilibrium depends on the choice function βA, leading to different instances of the equilibrium. In particular, if ties are broken in favor of the leader (i.e., the configurator), we speak of strong Stackelberg equilibrium, whereas if ties are broken in favor of the follower (i.e., the agent), we refer to a weak Stackelberg equilibrium. Unfortunately, we are currently unable to show the existence of such a class of equilibria and whether they are actually attained, in Conf-MDPs, with Markovian policies or configurations [46]. Nevertheless, we can introduce suitable extensions of the Bellman operators.
βA-Stackelberg Bellman Operator
Similarly to the previous settings, we introduce a suitable operator for the computation of the βA-Stackelberg value function.
Definition 11.2. (βA-Stackelberg Bellman Operator). Let be a choice function in the set of agent best response policies, i.e., for every configuration it holds that βA (p) ∈ BRA (p). The βA-Stackelberg Bellman Operator is defined for all for all state-action pairs as:
where BA (p) is the operator induced by policy βA (p).
It is simple to prove that such an operator is contraction and its fixed point is represented by the βA-Stackelberg value function.
Proposition 11.1.The βA-Stackelberg Bellman operator is a γ-contractions in L∞-norm, i.e., for all :Moreover, the βA-Stackelberg value function qβA(*),* is its unique fixed point:
Proof: We limit to prove that the operator is a γ-contraction, the existence and the value of the fixed point can be proved analogously to Proposition 6.2:
By taking the L∞-norm, we obtain:
□
Computation of the βA-Stackelberg value function
We now provide an algorithm for the iterative computation of the βA-Stackelberg value function, under the assumption that we can computationally evaluate the choice function βA (Algorithm 6). The convergence guarantees of this algorithm are analogous to those provided in Theorem 5.2. Unfortunately, the computational complexity depends on the evaluation of the βA, in principle, for every candidate transition model p.
In this paper, we have provided a unified view of the configurable MDP framework. We have shown how the cooperative and non-cooperative settings can be modeled, how to extend the traditional value functions, and Bellman operators to these settings, and how to exploit them to compute iteratively those value functions. Relevant results have been provided regarding the reduction of the computation of the best response value function and the solution of the cooperative Conf-MDP to the solution of a traditional MDP. Furthermore, we have provided a reduction of the turn-based non-cooperative Conf-MDP to an alternated turn-based MG. This allowed us to exploit the available result regarding the existence of the Nash-equilibrium. Finally, the leader-follower formulation, although of interest for real-world application, requires additional attention and study to understand its properties in terms of equilibria existence and efficient computation of the value functions. Overall, the degree of development of the environment configuration research line displays a mature study of the cooperative setting, justified by its intrinsic simplicity and existence of intuitive solutions. Instead, the non-cooperative setting deserves further analysis.
Clearly, being a recent research line, Conf-MDPs offer numerous research opportunities, including the adaptation of model-based approaches [8, 47] and off-policy/off-distribution methods [29, 36]. A completely disregarded topic in the environment configuration area is the problem of effective exploration of the configuration space [1]. Previous approaches designed for standard RL could be adapted to the Conf-MDP setting [20, 24]. Furthermore, Conf-MDPs could be applied to inverse reinforcement learning [27, 51], i.e., the process of recovering a reward function by observing the demonstrations of an expert agent. Similarly to policy space identification, configuring the environment can induce the expert agent to reveal its intent, helping the reward reconstruction process.
Footnotes
Formally, it must be that .
The study of the effects of considering non-Markovian policies and configurations in the Conf-MDP setting is beyond the scope of the present work.
References
1.
Peter Auer, Nicolò Cesa-Bianchi and Paul Fischer,
Finite-time analysis of the multiarmed bandit problem, Mach. Learn.47(2-3) (2002), 235–256.
2.
Richard Bellman, The theory of dynamic programming, Bulletin of the American Mathematical Society60(6) (1954), 503–515.
3.
A. Bensoussan and J. Frehse, Stochastic games for n players, Journal of Optimization Theory and Applications105(3) (2000), 543–565.
4.
Krishnendu Chatterjee, Rupak Majumdar and Marcin Jurdzinski,
On Nash Equilibria in Stochastic Games. In Computer Science Logic, 18th International Workshop (CSL), pages 26–40, 2004.
5.
Kamil Andrzej Ciosek and Shimon Whiteson, OFFER: off-environment reinforcement learning, In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI), pages 1819–1825, AAAI Press, 2017.
6.
Vincent Conitzer and Tuomas Sandholm, Computing the optimal strategy to commit to, In Proceedings 7th ACM Conference on Electronic Commerce (EC), pages 82–90. ACM, 2006.
7.
Yue Deng, Feng Bao, Youyong Kong, Zhiquan Ren and Qionghai Dai, Deep direct reinforcement learning for financial signal representation and trading, IEEE Trans. Neural Networks Learn. Syst.28(3) (2017), 653–664.
8.
Pierluca D’Oro, Alberto Maria Metelli, Andrea Tirinzoni, Matteo Papini and Marcello Restelli,
Gradient-aware model-based policy search, In The Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), pages 3801–3808, AAAI Press, 2020.
9.
Zehao Dou, Zhuoran Yang, Zhaoran Wang and Simon S. Du,
Gap-dependent bounds for two-player markov games, CoRR, abs/2107.00685, 2021.
10.
Tuomas Haarnoja, Sehoon Ha, Aurick Zhou, Jie Tan, George Tucker and Sergey Levine, Learning to walk via deep reinforcement learning, In Robotics: Science and Systems XV, University of Freiburg, 2019.
11.
Sarah Keren, Luis Enrique Pineda, Avigdor Gal, Erez Karpas and Shlomo Zilberstein,
Equi-reward utility maximizing design in stochastic environments, In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), pages 4353–4360. ijcai.org, 2017.
12.
Erwan Lecarpentier and Emmanuel Rachelson,
Non-Stationary Markov Decision Processes, a Worst-Case Approach using Model-Based Reinforcement Learning. In Advances in Neural Information Processing Systems 32 (NeurIPS 2019)), pages 7214–7223, 2019.
13.
Boris Lesner and Bruno Scherrer,
Non-stationary approximate modified policy iteration, In Proceedings of the 32nd International Conference on Machine Learning (ICML)), volume 37, pages 1567–1575. JMLR.org, 2015..
14.
Amarildo Likmeta, Alberto Maria Metelli, Andrea Tirinzoni, Riccardo Giol, Marcello Restelli and Danilo Romano,
Combining reinforcement learning with rule-based controllers for transparent and general decision-making in autonomous driving, Robotics and Autonomous Systems131 (2020), 103568.
15.
Littman MichaelL., Markov games as a framework for multi-agent reinforcement learning, In Proceedings of the Eleventh International Conference (ICML)), pages 157–163. Morgan Kaufmann, 1994.
16.
Yuzhe Ma, Xuezhou Zhang, Wen Sun and Jerry Zhu,
Policy poisoning in batch reinforcement learning and control, In Advances in Neural Information Processing Systems 32 (NeurIPS)), pages 14543–14553, 2019.
17.
Alberto Maria Metelli, Exploiting environment configurability in reinforcement learning, PhD thesis, Politecnico di Milano, March 2021.
18.
Alberto Maria Metelli,
Configurable environments in reinforcement learning: An overview, In Luigi Piroddi, editor, Special Topics in Information Technology, pages 101–113, Cham, 2022. Springer International Publishing.
19.
Alberto Maria Metelli, Emanuele Ghelfi and Marcello Restelli,
Reinforcement learning in configurable continuous environments, In Proceedings of the 36th International Conference on Machine Learning, (ICML), volume 97, pages 4546–4555. PMLR, 2019.
20.
Alberto Maria Metelli, Amarildo Likmeta and Marcello Restelli,
Propagating uncertainty in reinforcement learning via wasserstein barycenters, In Advances in Neural Information Processing Systems 32 (NeurIPS)), pages 4335–4347, 2019.
21.
Alberto Maria Metelli, Guglielmo Manneschi and Marcello Restelli,
Policy space identification in configurable environments, Machine Learning111(6) (2022), 2093–2145.
22.
Alberto Maria Metelli, Flavio Mazzolini, Lorenzo Bisi, Luca Sabbioni and Marcello Restelli,
Control frequency adaptation via action persistence in batch reinforcement learning, In Proceedings of the 37th International Conference on Machine Learning (ICML)), volume 119, pages 6862–6873. PMLR, 2020.
23.
Alberto Maria Metelli, Mirco Mutti and Marcello Restelli,
Configurable Markov decision processes, In Proceedings of the 35th International Conference on Machine Learning (ICML)), volume 80, pages 3488–3497. PMLR, 2018.
24.
Alberto Maria Metelli, Matteo Papini, Pierluca D’Oro and Marcello Restelli,
Policy optimization as online learning with mediator feedback, In The Thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI), pages 8958–8966.
AAAI Press, 2021.
25.
Alberto Maria Metelli, Matteo Papini, Francesco Faccio and Marcello Restelli,
Policy optimization via importance sampling, In Advances in Neural Information Processing Systems 31 (NeurIPS)), pages 5447–5459, 2018.
26.
Alberto Maria Metelli, Matteo Papini, Nico Montali and Marcello Restelli,
Importance sampling techniques for policy optimization, Journal of Machine Learning Research21(141) (2020), 1–75.
27.
Alberto Maria Metelli, Matteo Pirotta and Marcello Restelli,
On the use of the policy gradient and hessian in inverse reinforcement learning, Intelligenza Artificiale14(1) (2020), 91–124.
28.
Alberto Maria Metelli, Giorgia Ramponi, Alessandro Concetti and Marcello Restelli,
Provably efficient learning of transferable rewards, In Proceedings of the 38th International Conference on Machine Learning (ICML) ), volume 139, pages 7665–7676. PMLR, 2021.
29.
Alberto Maria Metelli, Alessio Russo and Marcello Restelli,
Subgaussian and differentiable importance sampling for off-policy evaluation and learning, In Advances in Neural Information Processing Systems 34 (NeurIPS). 2021.
30.
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin A. Riedmiller, Andreas Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg and Demis Hassabis,
Human-level control through deep reinforcement learning, Nat.518(7540) (2015), 529–533.
31.
Rémi Munos,
Performance bounds in lp-norm for approximate value iteration, SIAM J. Control. Optim.46(2) (2007), 541–561.
32.
John Nash,
Non-cooperative games, Annals of Mathematics54(2) (1951), 286–295.
33.
Andrew Y. Ng and Stuart J. Russell, Algorithms for inverse reinforcement learning, In Proceedings of the Seventeenth International Conference on Machine Learning (ICML)), pages 663–670. Morgan Kaufmann, 2000.
34.
Matteo Papini, Alberto Maria Metelli, Lorenzo Lupo and Marcello Restelli,
Optimistic policy optimization via multiple importance sampling, In Proceedings of the 36th International Conference on Machine Learning (ICML), volume 97 of Proceedings of Machine Learning Research, pages 4989–4999. PMLR, 2019.
35.
T. Parthasarathy,
Discounted, positive and noncooperative stochastic games, International Journal of Game Theory2(1) (1973), 25–37.
36.
Doina Precup, Richard S. Sutton and Satinder P. Singh, Eligibility traces for off-policy policy evaluation, In Pat Langley, editor, Proceedings of the Seventeenth International Conference on Machine Learning (ICML), pages 759–766. Morgan Kaufmann, 2000.
37.
Martin L Puterman, Markov decision processes: discrete stochastic dynamic programming, John Wiley & Sons, 2014.
38.
Giorgia Ramponi, Amarildo Likmeta, Alberto Maria Metelli, Andrea Tirinzoni and Marcello Restelli,
Truly batch model-free inverse reinforcement learning about multiple intentions, In Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics (AISTATS), volume 108, pages 2359–2369. PMLR, 2020.
39.
Giorgia Ramponi, Alberto Maria Metelli, Alessandro Concetti and Marcello Restelli,
Learning in non-cooperative configurable markov decision processes, In Advances in Neural Information Processing Systems 34 (NeurIPS), 2021.
40.
Lloyd S. Shapley, Stochastic games, Proceedings of the National Academy of Sciences39(10) (1953), 1095–1100.
41.
Rui Silva, Gabriele Farina, Francisco S. Melo and Manuela Veloso,
A theoretical and algorithmic analysis of configurable mdps, In Proceedings of the Twenty-Ninth International Conference on Automated Planning and Scheduling (ICAPS)), pages 455–463. AAAI Press, 2019.
42.
Rui Silva, Francisco S. Melo and Manuela Veloso,
What if the world were different? gradient-based exploration for new optimal policies, In 4th Global Conference on Artificial Intelligence (GCAI)), volume 55 of EPiC Series in Computing, pages 229–242. EasyChair, 2018.
43.
Richard S. Sutton and Andrew G. Barto, Reinforcement Learning: An Introduction, MIT Press, 2018.
44.
Csaba Szepesvári and Michael L. Littman,
Generalized markov decision processes: Dynamic-programming and reinforcement-learning algorithms, In Proceedings of International Conference of Machine Learning (ICML), volume 96, 1996.
45.
Heinrich Von Stackelberg, Marktform und gleichgewicht, J. Springer, 1934.
46.
Yevgeniy Vorobeychik and Satinder P. Singh,
Computing Stackelberg equilibria in discounted stochastic games, In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence (AAAI), 2012.
47.
Tingwu Wang, Xuchan Bao, Ignasi Clavera, Jerrick Hoang, Yeming Wen, Eric Langlois, Shunshi Zhang, Guodong Zhang, Pieter Abbeel and Jimmy Ba,
Benchmarking model-based reinforcement learning, CoRR, abs/1907.02057, 2019.
48.
Haoqi Zhang, Yiling Chen and David C. Parkes,
A general approach to environment design with one agent, In Proceedings of the 21st International Joint Conference on Artificial Intelligence (IJCAI)), pages 2002–2014, 2009.
49.
Haoqi Zhang and David C. Parkes,
Value-based policy teaching with active indirect elicitation, In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (AAAI), pages 208–214. AAAI Press, 2008.
50.
Haoqi Zhang, David C. Parkes and Yiling Chen,
Policy teaching through reward function learning. In Proceedings 10th ACM Conference on Electronic Commerce (EC), pages 295–304. ACM, 2009.
51.
Brian D. Ziebart, Andrew L. Maas, J. Andrew Bagnell and Anind K. Dey, Maximum entropy inverse reinforcement learning, In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (AAAI), pages 1433–1438. AAAI Press, 2008.


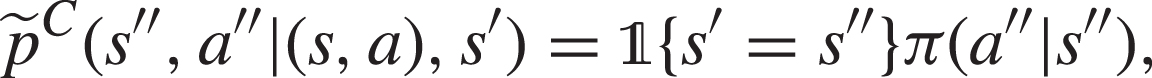
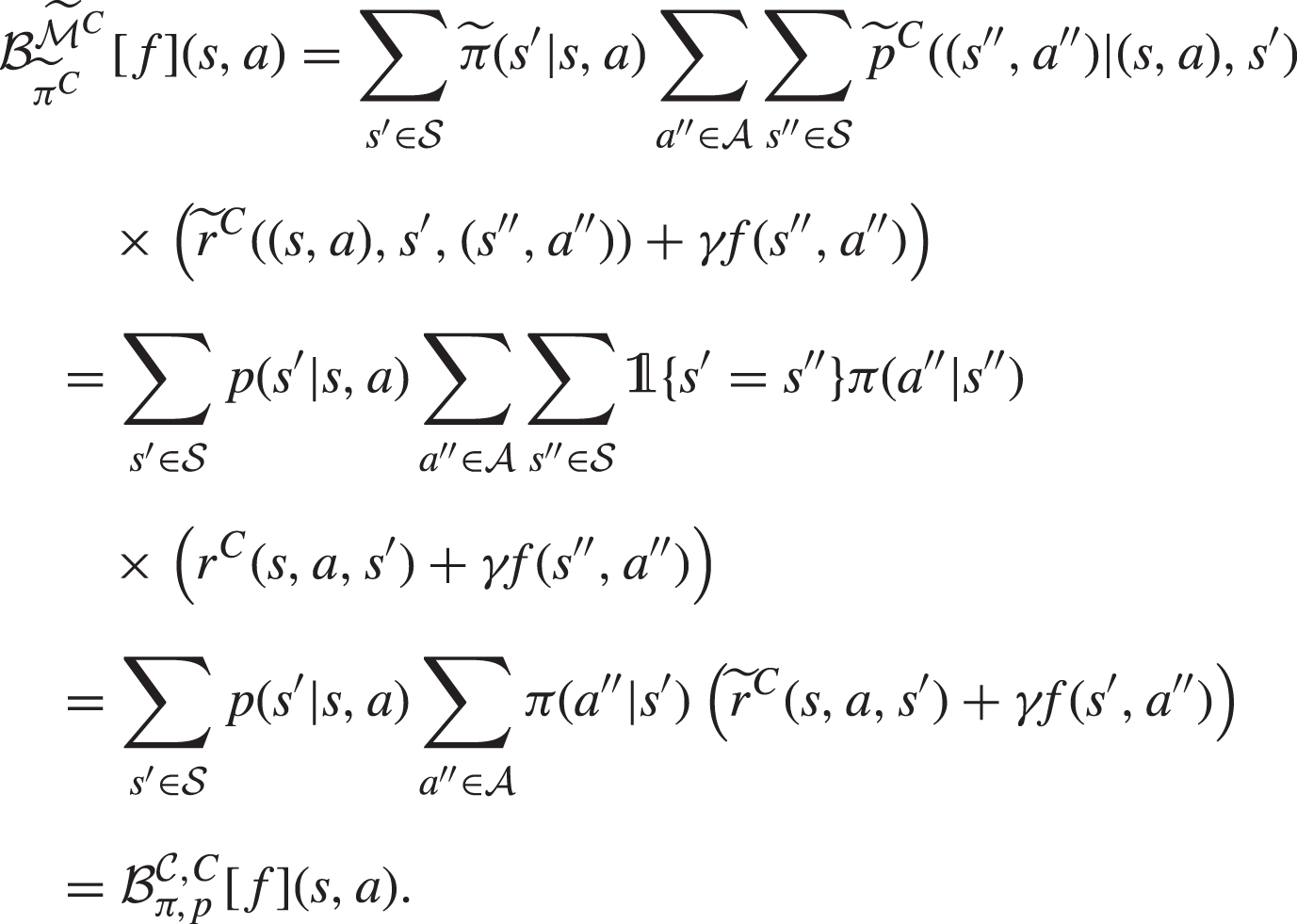 □
□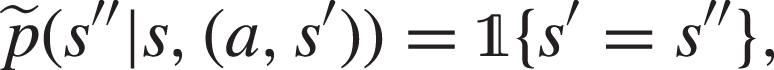
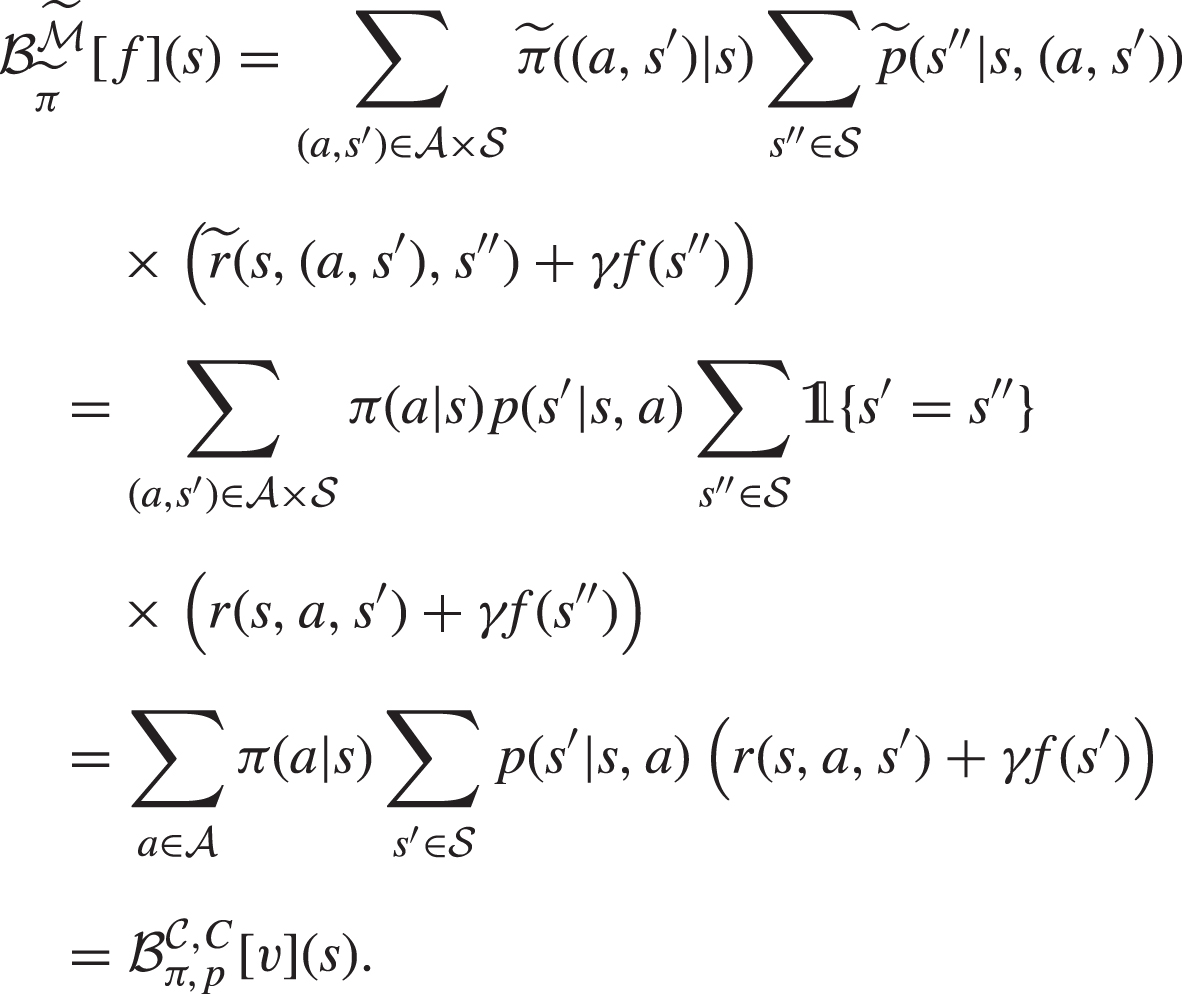
 where the symbol ⊥ denotes undefined;
where the symbol ⊥ denotes undefined;