
Abstract
It seems clear that general adoption of electric vehicles is coming in the near future. But this adoption will bring new challenges as, for example, that of recharging the batteries of a large fleet of electric vehicles under power and other technological constraints of the charging infrastructure. Among others, these will require solving challenging scheduling problems as well. In this paper, we study one of such problems derived from a charging station designed to be installed in community parks, which consists in scheduling a set of jobs on a single machine with varying capacity over time and exhibits high computational complexity. We propose the use of meta-heuristics as a means to solving the problem efficiently. Concretely, we propose a memetic algorithm, that combines a genetic algorithm with a local search method specifically designed for the problem. The contributions are analyzed theoretically, with formal proofs of their properties, and evaluated empirically. Experimental results show that the proposed memetic algorithm is very effective at solving the problem, while keeping running times reasonably low.
Introduction
Scheduling problems have received a considerable attention over the last decades, due to their wide range of practical applications and their high computational complexity (these are often NP-hard [1]). As a result, numerous scheduling problems with different constraints and objective functions have been studied in the literature, and a considerable number of solving methods have been proposed as well. A large body of research in scheduling has focused on one machine scheduling problems, in which a set of jobs must be scheduled on a single machine. This family of scheduling problems stands out due to having simple formulations and for serving as building blocks in the resolution of other more general problems. Sometimes, one machine scheduling problems appear as natural relaxations of more complex problems and so they are useful to obtain lower bounds [2]; while in other situations the resolution of a scheduling problem may be reduced to solving a number of instances of some one machine scheduling problem [3]. The latter is the case of the problem considered in this paper, in which a number of jobs must be scheduled on a single machine with capacity to process more than one job at a time, but with this capacity varying over time, with the goal of minimizing total tardiness. It was introduced in [4] in the context of scheduling the charging times of a large fleet of Electric Vehicles (EVs).
This problem may be denoted as
Recently, in [6] a genetic algorithm (GA) was proposed for solving the
Genetic algorithms constitute a representative example of population-based evolutionary algorithms, and are at the core of several other successful metaheuristics, such as memetic algorithms [7], that hybridize genetic algorithms and local search, or cultural algorithms [8], that extend genetic algorithms with a belief space shared by all the individuals and updated along the search process.
In this paper, we build on the work in [6] and extend it substantially towards solving the
The main original contribution in the paper is the development of a memetic algorithm that combines the GA with a local improvement algorithm that is also proposed in the paper. The local search method exploits a neighborhood structure that is studied in detail, as well as an efficient condition for improvement that makes it very efficient in practice. The results from an experimental study report significant improvements of the memetic algorithm over the GA, and show that the local search method is very effective in practice. In addition, this paper extends [6] with a detailed theoretical study of the search space and the schedule builder, which leads to a better understanding of the problem.
The remainder of the paper is organized as follows. In Section 2 we review some of the EV charging models proposed in the literature, including the model proposed in [4], that gives rise to the problem addressed in the paper. In Section 3 we give a formal definition of the
Electric vehicle charging models
This section reviews recent literature on EVs charging models, and describes the setting that gives rise to the
The increasing adoption of EVs may have a significant impact on the environment. Although it could allow for a better use of alternative energy sources, it may also result in important issues on the distribution grid if no smart control strategy is used to distribute charging periods. According to the European Distribution System Operators’ Association [9], one of the challenges in EVs’ technology is the development of smart charging control systems to avoid increasing peak demand and satisfy user requirements. In this context, a number of charging control systems have been proposed (e.g. [10, 11, 12, 13, 14, 15]) that, in general, try to fill the overnight valley as a means to reduce daily cycling and operational costs of power plants. In many cases, these models pose challenging scheduling problems. For example, in [16] an EV charging problem is formalized as a scheduling problem with fixed duration and non-preemptive jobs with the objective of minimizing a weighted sum of the variance and peak of the aggregate load profile. The problem is solved by a real time greedy algorithm, which schedules EVs on arrival using dispatching rules.
The recent literature on EV charging systems and models is extensive, with different features and objectives to be satisfied. For instance, the model in [17] takes into consideration the price and source of energy used. Alternatively, other charging models consider that the charging periods may be interrupted [18] or that the charging power may be variable over time [19], while others require non interruption [16] or constant charging rate [20]. In addition, some models make estimations on the energy required for the day ahead [21], or consider charging/discharging schemes [22] or the use of storage units [23] as ancillary resources. Due to the above, there are many variants of EV charging scheduling problems, and in spite of the number of published models, to our knowledge there are yet neither standard problems nor benchmarks.
The EV charging scheduling problem (EVCSP) considered in [4] is motivated by a charging station, whose design is outlined in [24], to be installed in a community park where each user has their own space. Figure 1 shows the general structure and the main components of this charging station. Each space has a charging point which is connected to one of the three lines of a three phase feeder. The system is controlled by a central server and a number of masters and slaves. Each slave takes control of two charging points and each master controls up to eight slaves in the same line. The control system registers events as EVs arrivals and sends activation/deactivation signals to the charging points in accordance with a schedule.
General structure of the charging station. (1) Three-phase electric power 400v AC, (2) lines, (3) charging points Type 2/AC IEC 62196-2 with V2G communication interface ISO 15118, (4) masters, (5) server, (6) communication Rs 485, (7) communication TCP/IP, (8) slaves, (9) active vehicles, (10) inactive vehicles.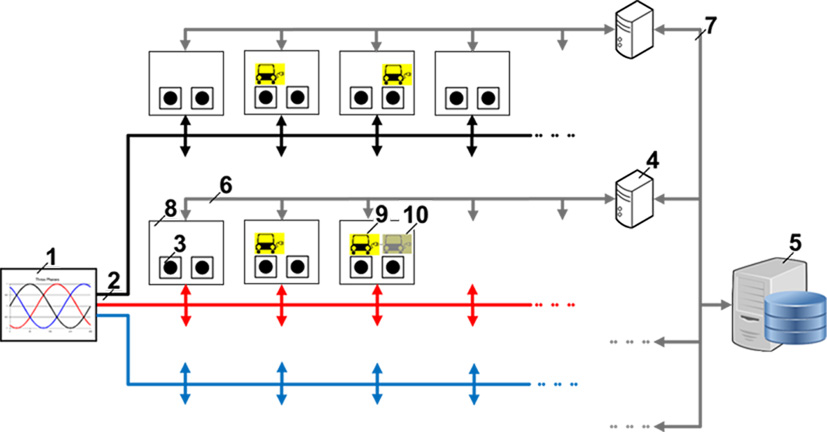
Due to the EVs arrivals being not known in advance, the EVCSP is dynamic, and so schedules must be computed at different points over time. Furthermore, the physical characteristics and the operating mode of the charging station impose some restrictions to the EVCSP which make it hard to solve. In particular, the contracted power is limited and so it restricts the maximum in each line. Besides, the load in the three lines must be similar to avoid an excessive imbalance among the three phases. The EVCSP assumes two simplifications of the model: (1) the contracted power is constant over time, and (2) the EVs charge at constant rate in the so-called Mode 1 in accordance with the regulation UNE-EN 61851-1 [25]. Therefore, there is a maximum number
Figure 2 shows a feasible schedule for a possible situation that may arise in the charging station represented in Fig. 1; dark bars represent the EVs that are charging at time
A feasible schedule for a problem instance that may arise in the charging station in Fig. 1. Each Gantt chart corresponds to one line in the charging station. Tasks 1–10 are the active EVs in lines 1, 2 and 3 at time 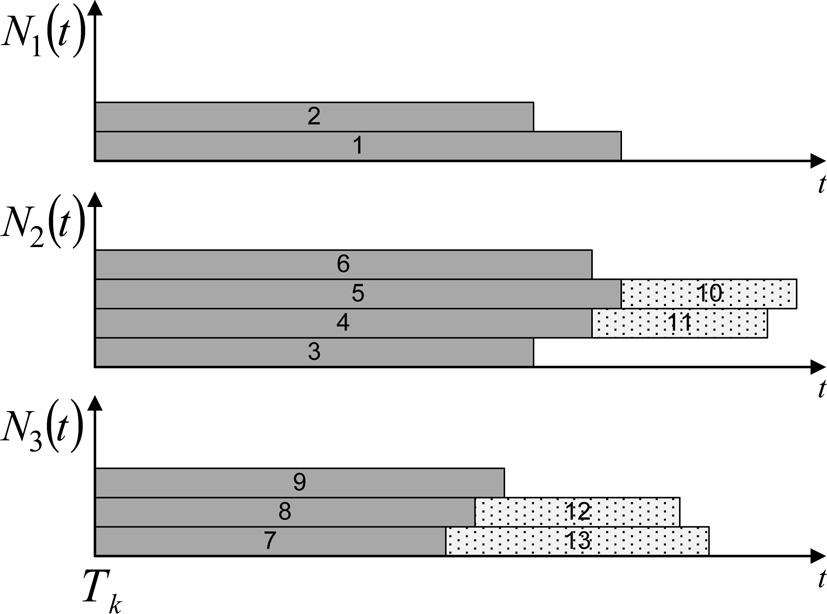
To solve the EVCSP, in [4] the authors proposed an algorithm which considers at each scheduling time the active EVs in each line (which cannot be rescheduled), the demanding EVs (which have not yet started to charge), the maximum number of active EVs in a line,
This paper focuses on the problem of scheduling the EVs on each line, subject to the maximum load and taking into account the active EVs, which may be viewed as the problem of scheduling a set of tasks on a machine with variable capacity over time. The calculation of the capacity of the machine from the active EVs and the maximum load profile is illustrated in Fig. 3. Note that this example does not follow the one depicted in Fig. 2. It is worth remarking that the capacity of the machine is always a unimodal function. It is increasing at the beginning as long as the active EVs complete charging, and decreasing towards the end due to the way the maximum profiles are updated. Furthermore, it finally gets stabilized at a value greater than 0, what guarantees that the scheduling problem is solvable. This problem was introduced in [4] and referred to as the
Definition of the capacity of the machine 
This section formulates the
Scheduling a job
[Capacity constraints] The consumption
[Non-preemption constraints] Jobs cannot be preempted during their processing; i.e.,
where
For a given problem instance,
This measure represents a penalization whenever the job is completed after its due date, with no reward otherwise (in contrast with the related notion of lateness).
Leaning on the definitions above, the
is minimized. Therefore,
The capacity of the machine over time,
Two feasible schedules for an instance of the 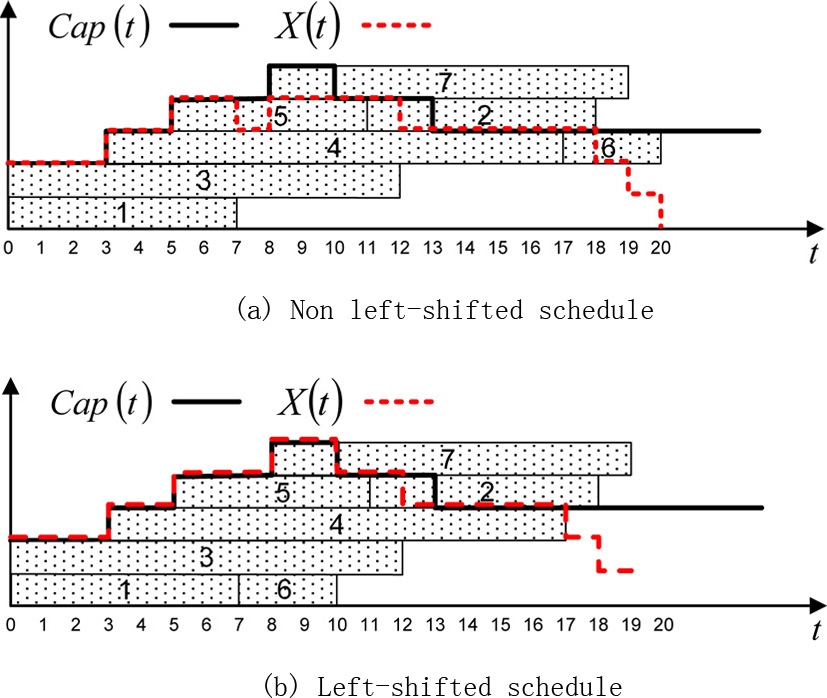
Without loss of generality, we consider that
The
Machine availability constraints have been extensively considered in the literature as a means to represent disruptions or maintenance operations [27]. In this context, most single machine formulations consider a machine with unary capacity that may be unavailable for some time periods. This model acts as a building block in formulations with parallel machines or in flow shop and job shop environments, which have been mostly studied for objective functions different than total tardiness minimization. To this respect, it is worth mentioning the
Scheduling problems, as the one studied herein, often exhibit a high computational complexity [28]. Although tractable classes and relaxations exist which can be solved by ad-hoc polynomial time procedures [1], in general solving a scheduling problem requires searching for solutions in a (potentially large) search space.
The nature of the search space, its size and properties, has an impact in both the performance and the effectiveness of the underlying solving algorithm. Therefore, procedures for defining suitable search spaces often constitute a key element in the development of successful algorithms.
To this respect, in scheduling a wide range of solving algorithms rely on the so-called schedule builders, also referred to as schedule generation schemes in the literature (e.g. [29, 30, 31]). These are constructive methods that implicitly define a subset of the feasible schedules that will be considered in the lookout for optimal solutions, thus conforming a search space.
Left-shifted schedules
In this section, we define a search space for the
(Left-shift movement).
Let
So, the application of a left-shift movement in a feasible schedule results in a different feasible schedule where a given job is moved earlier without any side effects on the starting times of any other jobs. Based on this operation, left-shifted schedules are defined:
(Left-shifted schedule).
Let
The following example illustrates the two definitions above.
Compared to the set of all possible feasible schedules
.
Let
Proof..
Let
Applying a left-shift movement never results in a schedule with total tardiness greater than the original one. As a consequence, we can conclude that the search space consisting of the left-shifted schedules is dominant for the
.
Let
Proof..
Let
Schedule builder
Algorithm 1 depicts the schedule builder proposed in this paper for computing left-shifted schedules. It operates in an iterative fashion, scheduling one job at a time at the earliest possible starting time so that all the constraints in the problem are satisfied. The algorithm maintains a set
[!h] Schedule BuilderA
Assign
Update
The selection of the job to be scheduled at each iteration is non-deterministic, so the resulting schedule depends on the sequence of choices made. For example, the sequence of choices
.
Algorithm 1 always results in a left-shifted schedule.
Proof..
At each iteration, a job
The non-deterministic nature of Algorithm
.
Let
Proof..
It suffices to define
The two propositions above prove that the schedule builder defines exactly the subset of the left-shifted schedules for any given problem instance. The schedule builder could also be instantiated by using any priority rule or heuristic. Besides, it can be used to transform a given permutation of the set of jobs (representing a sequence of choices) into a schedule. This enables using the schedule builder as a decoder in a genetic algorithm, as we will see in the next section.
Genetic algorithm
Genetic algorithms (GAs) have been used to solve hard combinatorial optimization problems with notable success (e.g. [33, 34, 35, 36, 37, 38], including scheduling problems [31, 39, 40]).
In this section, we review the main components of the GA used in this work for the
[!h] Genetic AlgorithmA
Recombination: mate each pair of chromosomes and mutate the two offsprings in accordance with
Evaluation: evaluate the resulting chromosomes;
Replacement: make a tournament selection among every two parents and their offsprings to complete
Coding schema
Individuals are defined each by a permutation of the jobs without repetition, i.e. a chromosome
Crossover and mutation
The GA uses the well-known Order Crossover operator (OX) [41]. Given two parents, an offspring inherits a sub-sequence (selected at random) in the same positions from the first parent and its other positions are filled in accordance with their relative order in the second parent. The second offspring is computed in the same way, but swapping the role of the parents. The mutation operator simply swaps two random elements in the chromosome.
Decoding algorithm
The GA searches for an optimal solution in the search space defined by the schedule builder presented in Section 4.2. Given a chromosome, the decoder builds a schedule using Algorithm 1, scheduling jobs in the order they appear in the chromosome, i.e. at the
Local search algorithm
Local search stands out as one of the most effective approaches for solving combinatorial optimization problems in a wide range of application domains, including scheduling (e.g. [42, 43, 44]). Although several variants of local search algorithms have been proposed in the literature (e.g. hill climbing, simulated annealing, tabu search, etc.), all of them exploit the same underlying principle: starting from a feasible solution, iteratively apply local perturbations to it, moving to a close solution in the search space, with the expectation of improving its quality.
In this section, we present the local search algorithm proposed for the
The local improvement algorithm is based on the notion of consecutive jobs in a feasible schedule:
That is, two jobs are consecutive in a schedule if one of them starts exactly after the other one is completed. Noticeably, two consecutive jobs in a schedule can be swapped, resulting in a new schedule with no side-effects on the starting times (and so on the tardiness) of any other jobs.
.
Let
Proof..
W.l.o.g. lets assume that
This result enables the definition of a neighborhood structure for the problem. Given a feasible schedule
where
Equations (5) and (6) allow for establishing a necessary and sufficient condition for improvement, which we state without proof.
.
Let
Assuming that
It is possible to design a local search algorithm fully exploiting the neighborhood structure above, i.e., at each iteration, consider all pairs of consecutive jobs in the schedule, and move to a neighboring schedule when the improvement condition is fulfilled.
However, we observe that, in a feasible schedule, jobs with earlier (later) starting times can be expected to contribute to the total tardiness to a lesser (greater) extent. This observation allows us to integrate the neighborhood structure inside an efficient procedure that aims at delaying jobs with low tardiness and scheduling earlier jobs with high tardiness. This procedure relies on the concept of C-path in a feasible schedule:
Note that several C-paths can exist in a feasible schedule, not necessarily disjoint or the longest ones, that is, we refer to set-wise maximality. We prove that the jobs in a C-path can be reorganized without altering the starting times of any other jobs outside it.
.
Let
Proof..
Any permutation of the jobs in
The result above can be exploited in different ways. Note that the jobs in a C-path
At the same time, we can establish an upper bound of the improvement that can be achieved by reorganizing the jobs in
Finally, Proposition 7 serves to prove the soundness of the local improvement procedure proposed herein, whose pseudo-code is shown in Algorithm 3.
[!t] A feasible schedule
The local search algorithm works on a feasible schedule
It is easy to see that Algorithm 3 performs at most
Main structure of the memetic algorithm.
Memetic algorithms are hybrid metaheuristics that combine genetic algorithms and local search (see [7] for a general description). This combination is often well suited for hard optimization problems with large search spaces, since it favors an appropriate intensification/diversification balance. The genetic algorithm conducts a global search, sampling diverse regions of the search space, while the local search method intensifies the search locally, allowing the overall method to converge to better solutions.
The memetic algorithm (MA) we propose for the
The MA instruments a Lamarckian evolution model, i.e., after issuing LS, the resulting schedule is coded back into the chromosome. This way, the characteristics that led to an improvement are translated from parents to offsprings along the search. To this respect, note that the local search method works on a C-path
Experimental results
We present the results from an experimental study carried out to evaluate the algorithms proposed in this work, namely, the genetic algorithm (GA) described in Section 5, the local improvement method (LS) introduced in Section 6 and the memetic algorithm (MA) proposed in Section 7.
Summary of results. Error (in percentage) of the solutions returned by each method w.r.t. the best solutions computed by all the methods in the table, averaged for groups of instances with the same number of jobs. Running times of GA are given in seconds
Summary of results. Error (in percentage) of the solutions returned by each method w.r.t. the best solutions computed by all the methods in the table, averaged for groups of instances with the same number of jobs. Running times of GA are given in seconds
For this purpose, we defined a testbed with instances of different sizes and characteristics. These instances are inspired in the expected structure of the instances generated when solving the real EV charging scheduling problem, but at the same time, we avoid generating trivial instances that appear in situations of low demand. Each instance is characterized by the number of jobs (
Each job Once all jobs have a processing time, these are assigned a random due date The capacity of the machine,
This procedure aims at avoiding the generation of under-constrained instances, which can be easily solved. The benchmark set includes instances of different sizes, with
All the algorithms have been implemented in a prototype coded in Python 2.7, and the experiments were run on a Linux cluster (Intel Xeon 2.26 GHz. 24 GB RAM).
The experimental study is structured in three parts. We first evaluate the GA and compare it to some well-known priority rules previously used for solving the problem [4]. Then, we assess the effectiveness and running time of LS over random solutions. Finally, we analyze the performance of MA, comparing it to GA.
The first series of experiments were run over the 120 instances with sizes up to 60 jobs, with the purpose of assessing the performance of the GA and the quality of the solutions it returns.
To this aim, it is compared with some well-known priority rules, which serve to select the job to be scheduled at each iteration of Algorithm 1. We integrated the following priority rules into our prototype: earliest due date (EDD), which selects the job with the smallest due date, shortest processing time (SPT), which picks the job with the smallest processing time and apparent tardiness cost (ATC), which schedules the job
where
ATC takes into account both processing times and due dates of the unscheduled jobs, and uses the parameter
In the experiments, ATC was run in four configurations on each instance, with
The results of the comparison are shown in Table 1, averaged for groups of instances with the same number of jobs. For each approach, it reports the relative errors (in percentage) of the cost of the solution obtained w.r.t. the best solution computed by all the methods in the table.2 For GA, it shows the best and average errors over the 10 runs of the algorithm and the average running time of one run (in seconds).
As we can observe, the best solution obtained overall by any methods in the table corresponds to the best solution found by GA over the 10 runs in all cases. The priority rules clearly lay behind GA, with (much) larger errors, and so worse solutions. ATC is the best performing priority rule when using
Summary of results. evaluation of LS
Comparison of ATC and GA. Distribution of error in percentage terms w.r.t. the best solutions found. 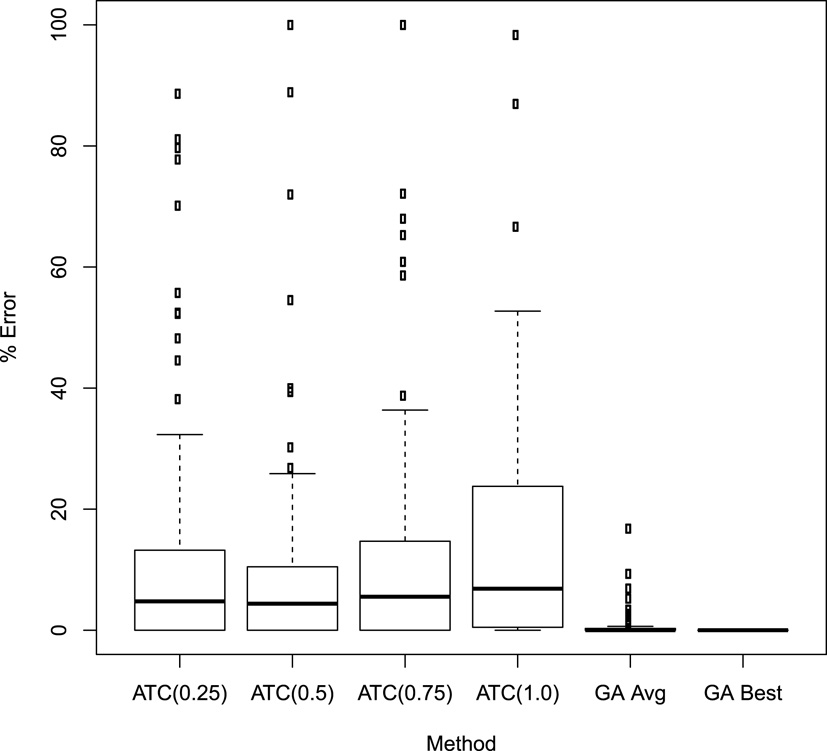
Figure 6 shows the errors of the solutions computed by ATC in its four configurations, and by GA, both the average and best solutions over the 10 runs. To make it clearer, the y-axis was limited to 100, although all the configurations of ATC included some values above this limit. This plot confirms that GA reaches higher-quality solutions than ATC.
In order to evaluate the performance of the local improvement algorithm (LS) we ran a series of experiments over the whole set of 180 instances. For each instance, we generated 1000 random solutions by making random choices in each iteration of the schedule builder (Algorithm 1) and applied LS to them, recording their total tardiness, as well as the time taken.
Average total tardiness of random schedules before (Random) and after (Random 
Table 2 summarizes the results averaged for groups of instances with same number of jobs. It shows the number of times (out of 1000) LS resulted in an improved solution (
Figure 7 shows a scatter plot comparing, for each of the 180 instances, the average total tardiness of the 1000 solutions before and after applying LS. As can be seen, in many cases the average improvement due to LS is remarkable.
The last series of experiments is aimed at evaluating the memetic algorithm (MA), comparing it to GA.
For the sake of fairness, both GA and MA have been configured with the same parameters as the ones used in the evaluation of GA, i.e.
Summary of results. Error (in percentage) of the solutions returned by GA and MA (both the best and average values over 10 runs) w.r.t. the best known solutions, averaged for groups of instances with the same number of jobs. Running times are the same for GA and MA, setting a timeout as
seconds
Summary of results. Error (in percentage) of the solutions returned by GA and MA (both the best and average values over 10 runs) w.r.t. the best known solutions, averaged for groups of instances with the same number of jobs. Running times are the same for GA and MA, setting a timeout as
Comparison of GA and MA. Distribution of error in percentage terms w.r.t. the best solutions found.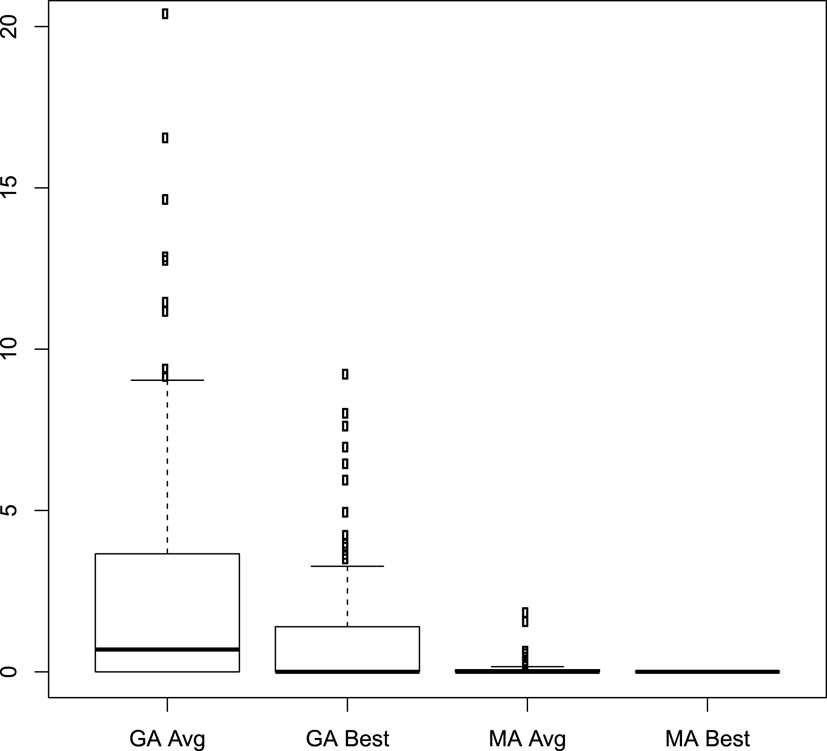
Table 3 compares GA and MA regarding the quality of the solutions computed by the timeout. The results are averaged for groups instances with the same number of jobs, and it shows the error in percentage terms of the best and average solutions computed by GA and MA w.r.t. the best solution known. As we can observe, in all cases, the best solution known for each problem instance is given by the best solution found by MA over the 10 runs. We can also observe that MA is quite stable, obtaining high-quality average solutions with total tardiness close to the best one. This provides evidence that the obtained solutions may be very close to the optimal ones. For the smallest instances, GA and MA perform similarly, being GA able to reach high quality solutions as well. However, as the size of the instances grows, the improvement of MA over GA becomes more significant, especially for the largest instances, where MA obtains (much) better average solutions than the best solutions obtained by GA.
Figure 8 compares GA and MA regarding the errors of the best and average solutions over the whole set of instances. The y-axis was limited to 20, although GA incurred in greater values for a few instances. As we can observe, MA clearly outperforms GA.
This paper addresses the
Due to the computational intractability of the
Future work will investigate alternatives to the algorithms proposed herein. A promising research line would be to develop methods based on the shifting bottleneck heuristic [45], as well as approaches based on constraint programming [47], such as large neighborhood search [48]. Another idea worth developing would be the use of hyper-heuristics [49] for solving the problem, with the aim of obtaining high-quality initial approximations in short running times. In addition, the good results obtained by the memetic algorithm proposed in this paper motivate future work on alternative evolutionary approaches, such as cultural algorithms [8]. On the other hand, a promising line of future research will be to extend the
Footnotes
In the results reported in this subsection, errors are computed w.r.t. the best solution obtained by GA and the priority rules (and not w.r.t. the best solution known) to make it consistent with the results presented in [6]. For many instances, the best solution known was found by the memetic algorithm in the experiments of Section ![]() .
.
Acknowledgments
This research has been supported by the Spanish Government under project TIN2016-79190-R.