
Abstract
This paper studies the computation of ensembles of priority rules for the One Machine Scheduling Problem with variable capacity and total tardiness minimization. Concretely, we address the problem of building optimal ensembles of priority rules, starting from a pool of rules evolved by a Genetic Programming approach. Building on earlier work, we propose a number of new algorithms. These include an iterated greedy search method, a local search algorithm and a memetic algorithm. Experimental results show the potential of the proposed approaches.
Keywords
Introduction
This paper tackles the one machine scheduling problem with variable capacity denoted
Given the tight time requirements of online scheduling, priority rules are of common use in that setting. A priority rule is an expression that assign a priority to each candidate job to be scheduled at a given time, and so it can be exploited by efficient greedy algorithms. Such algorithms will indeed provide high quality schedules only if the guiding priority rules capture relevant problem knowledge. As an example, in [2] the
In this respect, several authors have adopted the classic GP paradigm proposed by Koza in [7] for learning rules for scheduling problems. These include job shop [8, 9, 10], single machine [11, 12], unrelated parallel machines [13] or resource constrained project scheduling problems [14, 15], among others. Other approaches have emerged such as cartesian genetic programming [16, 17], single node genetic programming island model [18] or hybrid genetic programming [19]. Burke et al. taxonomy [20] classifies these approaches as heuristic generation approaches; more specifically these algorithms are named genetic programming based hyper-heuristics. Besides, data mining alternatives as those proposed in [21, 22, 23] could be exploited to evolve priority rules as well.
In any case, the general idea is to use a set of training instances of the specific problem from which the GP approach conducts a learning process. As in any other machine learning context, these rules must then be evaluated on a number of unseen instances, i.e., a test set. The use of approaches as GP presents two main drawbacks: it is time consuming and, at the same time, it is highly stochastic, so the obtained rules from two independent runs are usually rather different.
As it may be expected, a single rule, even being very effective on average at solving a large set of instances, may not be good for a number of them. For this reason, a number of research works have been focused on calculating sets of rules (ensembles) that collaboratively solve the problem.
The use of ensembles has been considered in some domains, as for example financial risk prediction [24]. Furthermore, in scheduling domains ensembles have been explored in different ways. For example, in [9] Hart and Sim propose a GP approach to obtain a set of rules that are applied in turn to schedule a single operation. This approach was adopted by Park et al. in [25] to analyze four popular combination schemes to solve dynamic job shop scheduling problems. The combination schemes included majority voting, linear combination, weighted majority voting and weighted linear combination. A survey, including these and other schemes, was presented in [26]. Generally, the results showed that the linear combination scheme performs better compared to the other approaches. Durasevic and Jakobovic [27] studied several ensemble learning algorithms for the dynamic scheduling problem with unrelated machines. These methods are simple ensemble combination, BagGP [28], BoostGP [29] and cooperative coevolution. The authors concluded that the best approach was simple ensemble combination. So, in [30] they extended the work presented in [27], focusing on simple ensemble combination. One common feature of these ensemble methods is that all of them exploit the ensemble to produce a single rule following two main approaches: sum and vote. As stated in [27], in the first one the priority values of all rules are summed up to get a priority value, while the second one determines the job receiving the largest number of votes.
In this paper, we follow an alternative approach. Given the short time required to compute a solution to the instances of the
The approach proposed herein starts from a large set of rules produced by GP [12] from a given training set in a number of runs. Due to the stochastic nature of GP, one may expect that this set will include quite different rules. So, the objective is to come up with an ensemble covering all the instances in the training set, i.e., such that for each training instance at least one rule in the ensemble produces a good solution. This problem is termed Optimal Ensemble of Priority Rules Problem (OEPRP) herein. As we will see, the Maximum Coverage Problem (MCP) can be reduced to OEPRP, so this problem is NP-hard and some algorithms for MCP may be adapted to OEPRP.
Earlier work [31] proposed a genetic algorithm for solving the OEPRP. In this paper we extend this work and propose a number of solving methods, namely an iterated greedy algorithm adapted from a classical approach for MCP, a local search algorithm specifically designed for the OEPRP and hybrid algorithms that combine local search with the greedy algorithm and with the genetic algorithm, resulting in a memetic algorithm.
We conducted an experimental study, comparing the evolved ensembles to the best online and offline methods in the literature to solve the
The remainder of the paper is organized as follows. In the next section we give the formal definition and the solving method used for the
The One Machine Scheduling problem with Variable Capacity
In this section we formally introduce the One Machine Scheduling problem with Variable Capacity and Total Tardiness minimization,
Problem definition
The
At any time
The processing of jobs on the machine cannot be preempted, i.e.,
where
The objective function is the total tardiness, defined as:
which must be minimized.
Figure 1 shows a schedule for a problem with 7 jobs; the capacity of the machine is 2 at
A feasible schedule for an instance of the 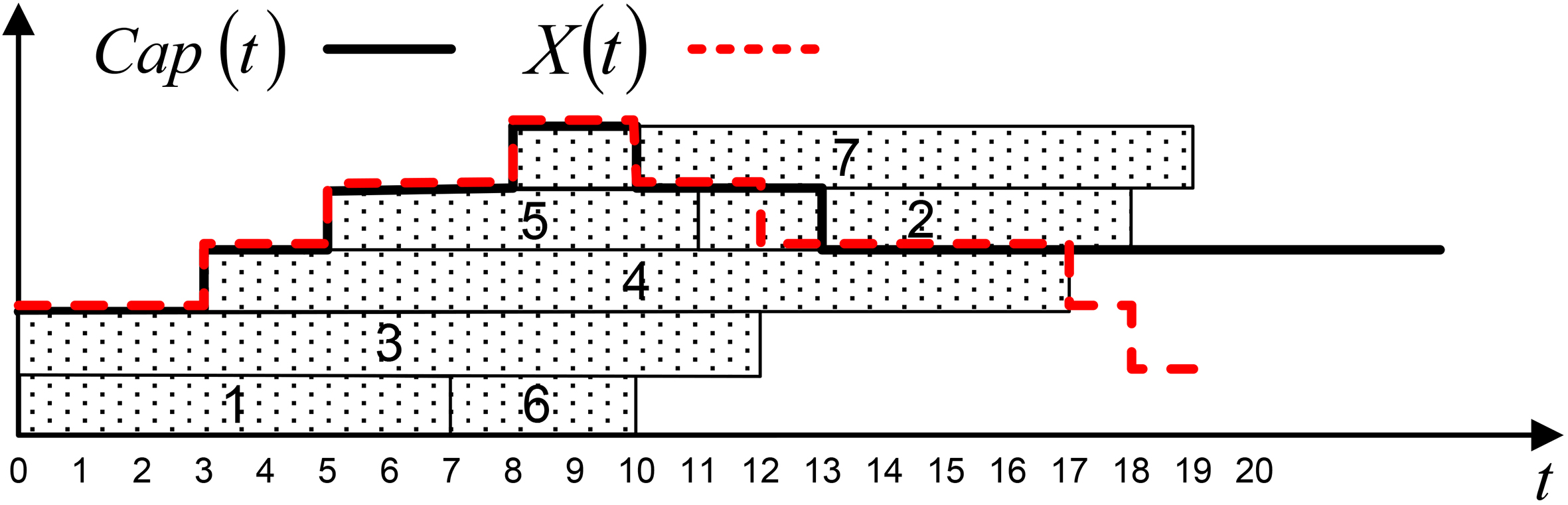
One particular case of this problem is the parallel identical machines problem [3], denoted
To solve the
Schedule builders are non-deterministic methods that allow for computing and enumerating a subset of the feasible schedules, thus defining a search space. Algorithm 2.2 shows the schedule builder considered herein, based on the one proposed in [32]. The schedule builder operates iteratively, scheduling one job at a time. In this algorithm
[t] A
In Algorithm 2.2, priority rules may be used to select a job
where
The above rules were designed manually by experts and so they have a clear interpretation. They capture some single features of the problem that may be exploited to devise heuristics; however there may be other complex features that are not evident to the human eye, which can only be captured by some automatic learning mechanism. Under this hypothesis, in [12], a Genetic Program (GP) was proposed to evolve new priority rules, which were shown to outperform the aforementioned EDD, SPT and ATC rules.
We propose a new benchmark set that consists of instances more realistic than those considered in [12]. More concretely, we have observed that in the instances considered in [12] the capacity intervals are in general very long compared to the processing times of the operations. As a result, most operations can be scheduled before the capacity of the machine begins to decrease, which is not realistic. In order to overcome this drawback, we generated a new set of instances by means of a new procedure. Below, MC denotes the maximum capacity of the machine,
The generation procedure works as follows:
For each operation The initial capacity of the machine is set as The duration of each capacity interval is set as Finally, for each operation
With this procedure, we generated a total of 2,000 instances, 1,000 for the purpose of training and the other 1,000 for testing. These instances are such that both the EDD rule and the ATC rule with
Results from previous methods and working hypotheses
The instances proposed above were solved by the memetic algorithm (MA) proposed in [32] and by the schedule builder given in Algorithm 2.2. In the last case, considering different priority rules, namely EDD and ATC with 10 values of parameter
From these results, our hypotheses are that the use of ensembles is promising and that it may be possible to improve the solutions from the ensemble of ATC rules if we could select the same number of rules from a large set of rules with different characteristics. To prove that, we propose to establish a large pool of rules and evaluate them over a large benchmark of instances of the
Summary of results obtained by the rules ATC (with different values of the parameter
), EDD and MA. For MA, results from 30 independent runs are reported. The ensemble is formed by ATC rules with the 10 different values of
Summary of results obtained by the rules ATC (with different values of the parameter
In this section we formalize the Optimal Ensemble of Priority Rules Problem, denoted by OEPRP, and analyze its complexity. Besides, we propose a number of solving methods: an iterated greedy algorithm (IGA) inspired in a similar algorithm for the Maximum Coverage Problem (MCP), a genetic algorithm (GA) that is an extension of that proposed in [31], and a new local search algorithm (LSA), which can be combined with both IGA and GA to improve their solutions.
Problem definition
Given a set of priority rules
The set
Remark. The maximum size of the ensemble
Complexity of the problem. The maximum coverage problem (MCP) is a well-know NP-hard problem defined as follows. Given a number
is maximized.
MCP can be polynomially reduced to OEPRP, showing that the latter is NP-hard as well. To do that we can simply define
and, for all
Informally, an instance of the MCP may be viewed as an instance of the OEPRP where each priority rule produces a solution to any instance of the
In [34], an iterated greedy algorithm (IGA) is proposed for the MCP that achieves an approximation ratio of
Algorithm 3.2 shows how IGA can be naturally extended to solve the OEPRP. For this problem, in each iteration the priority rule chosen to be included in the set
Remark. If
A set
Genetic algorithm
Genetic algorithms (GAs) have been used efficiently in combinatorial and optimization problems [35, 36, 37, 38, 39]. They display high performances when tailored to the problem at hand [40] and through fine-tuning of their parameters to avoid undesired algorithmic behaviors [41]. In [31], a GA was proposed to solve the OEPRP, whose main components were chosen as follows.
Coding scheme
Individuals are given by variations with repetition of the
Initial population
Initial chromosomes are random variations of the
Crossover
In this problem, the order of rules in the chromosome is not relevant, so it may be enough to guarantee that each offspring inherits some rules from each parent. Therefore, a simple scheme as the following may be appropriate. Given two parents, two offsprings are obtained. First, a binary string of length
Mutation
Mutation plays an important role as it is in charge of including in the population new rules from the set
[t] A set
Evaluation. For each of the
Local search algorithm
In this section we describe the local search algorithm (LSA) proposed to improve ensembles. The general structure is shown in Algorithm 3.4. The neighbourhood structure has size
In each iteration, at most
[!t] A set
Hybrid algorithms
As remarked in [42], it is usual combining search algorithms to obtain a synergistic effect so that the obtained hybrid approach is better than each individual algorithm separately. One of the most common hybridizations is the combination of genetic algorithms with local search, which is called memetic algorithm (MA) [43, 44, 45]. For this reason, a multitude of surveys have emerged, such as [46, 47, 48, 49, 50] and some advanced activation rules were proposed [51, 52] for the continuous domain.
We propose here combining GA with LSA so that LSA is exploited to improve some of the chromosomes evolved by GA. Specifically, LSA is applied to an individual after it is evaluated, and the resulting improved chromosome replaces the original one in the population. In order to achieve a proper balance between exploration and exploitation, LSA is only applied to a fraction of the individuals in each generation (i.e. with a given probability introduced as a parameter). Besides, the size of the neighbourhood and even the number of iterations of LSA should be limited to get reasonable balance on the time taken by GA and LSA.
In addition to MA, we propose combining LSA with IGA in two different ways: (1) In the first one, LSA is applied to the solution generated by IGA, in the same way as the GRASP metaheuristic combines randomized greedy algorithms with local search. The difference is that IGA is deterministic and so only one solution is produced by this method. (2) The second method consists in applying LSA to each partial solution obtained by IGA, which is a new way of combining greedy and local search algorithms.
Results
We have conducted an experimental study aimed at analyzing and evaluating the proposed methods for the OEPRP, namely GA, HC-LSA, GD-LSA, IGA and the combined approaches MA (GA-LSA) and IGA-LSA. To do that, we implemented the above algorithms in Java and ran a series of experiments on a Linux cluster (Intel Xeon 2.26 GHz, 128 GB RAM).
Test bed
The test bed includes a new set of instances of the
The instances of the
To build a pool of priority rules, we executed GP for each one of the 20 training sets using the parameters shown in Table 2. In order to include rules of high quality in the pool, GP was executed for each training set a number of times until it reached a priority rule being better than ATC considering any of the 10 values of the parameter
Values of the GP parameters proposed in [12]
Values of the GP parameters proposed in [12]
The above rules are called general as they are evolved to be good on average for a number of 50 instances of the
From the pool of 2,000 rules (1,000 general and 1,000 specialized on the training instances) and the 1,000 training instances of the
Set of rules (
Table 3 shows the main characteristics of these instances: the number of rules after removing equivalent ones, the tardiness cost produced by an optimal ensemble with no limited size and by the best rule in the ensemble, and finally an upper bound on the size of the optimal ensemble. It is remarkable the difference in the upper bound values on the size of the optimal ensemble: it is the lowest for general rules, showing that on average a single rule may cover many instances, while specialized rules can only cover a small number of them on average. Noticeably, with only 493 of the 939 specialized rules the 1,000 instances of the
From all the above, one may expect that the joint set could be the best option as it contains more diverse rules; however when the size of the ensemble is limited to small values, as for example 10 rules, it could be the case that only with general rules could a training set be properly covered to obtain low values of tardiness cost. This issue have to be studied empirically.
We start analyzing the performance of IGA. To this aim, we ran this algorithm considering the maximum size
Average tardiness obtained by IGA with 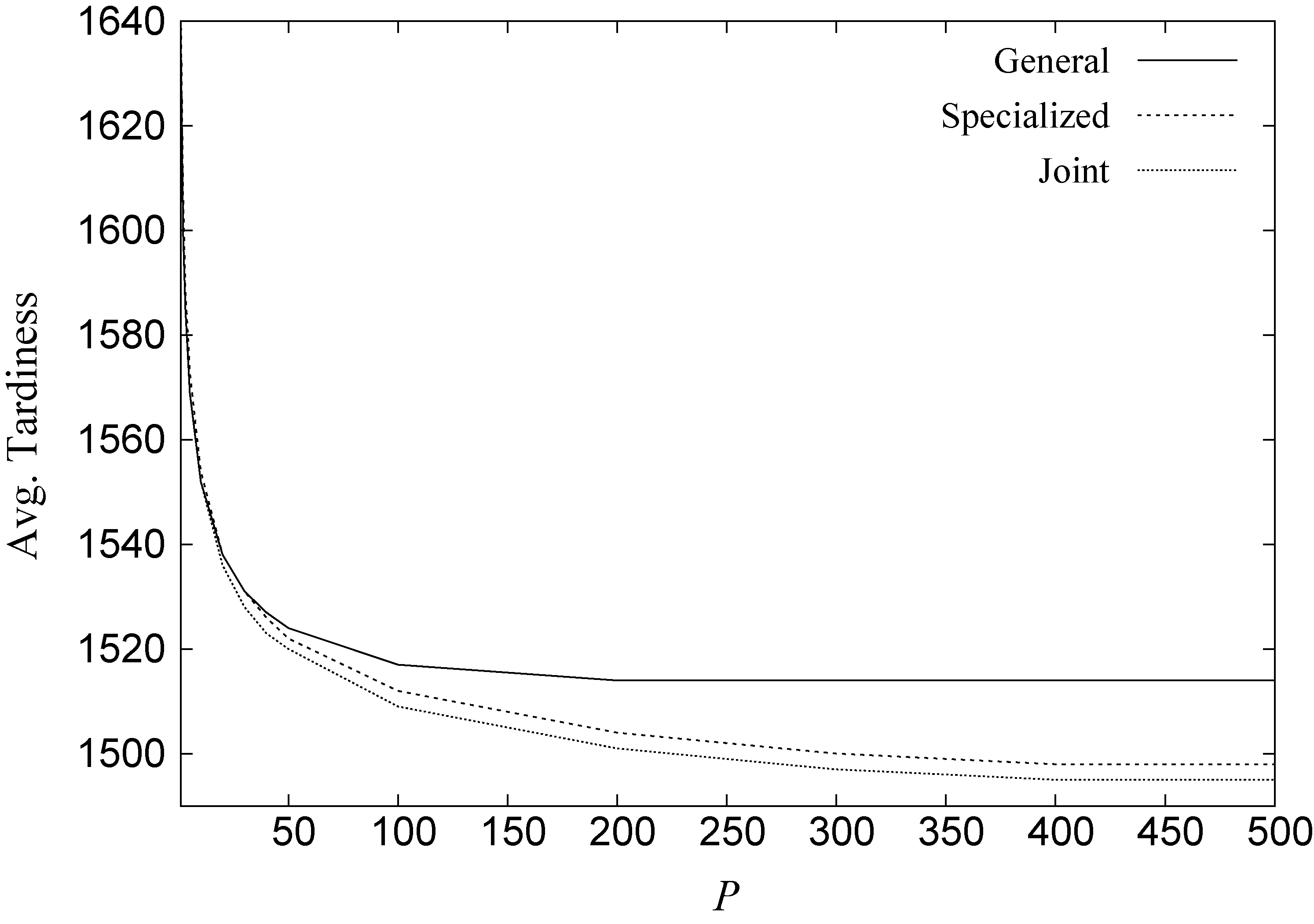
Figure 2 shows the tardiness cost for all the generated ensembles. As we can observe, the best ensembles are obtained from the Joint set of rules, as it could be expected. At the same time, we can observe that the capability of the general rules is actually limited since after about
Table 4 shows the solutions produced by the ensembles calculated by IGA from the Joint pool of rules. We can observe that they perform much better than ensembles of the same size obtained from the best rules in the pool. Besides, the quality of the ensembles improves with their size and, as expected, the time taken by IGA to obtain the ensembles grows with size.
Summary of results obtained by IGA and the ensemble composed by the best
The GA was run with the parameters given in Table 5; these values were fixed in the preliminary results presented in [31].
Values fixed for some of the GA parameters
Values fixed for some of the GA parameters
GA evolution in one run. The figure shows the average and best solution evolution over generations 0 to 500.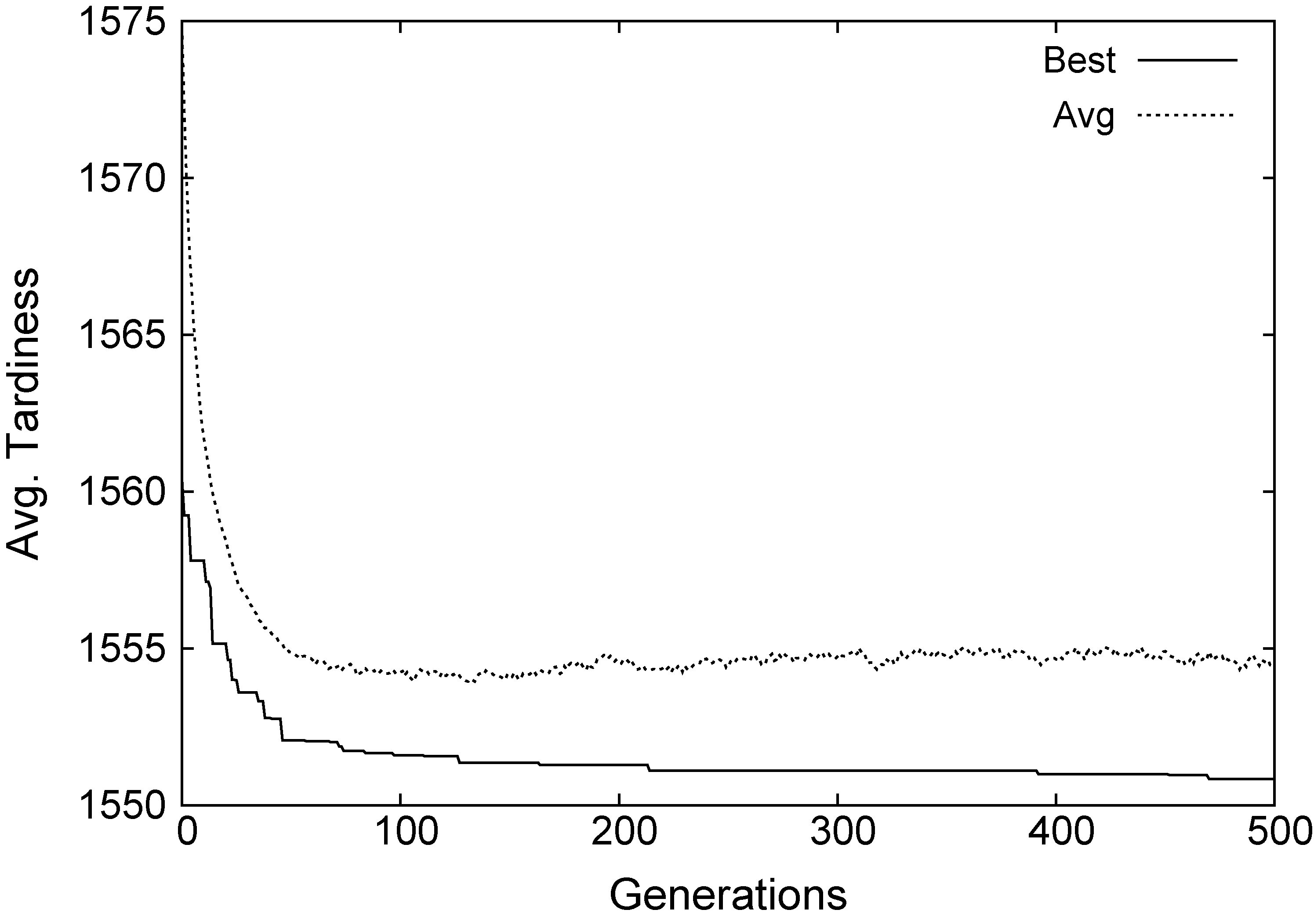
Summary of results obtained by GA from the Joint pool of rules with
Results from the ensembles obtained in 30 independent runs of GA on the test set from the Joint pool of rules with
Figure 3 shows the evolution of GA for the Joint pool of rules and
Table 6 summarizes the solutions obtained in 30 executions of the GA for a number of ensemble sizes. The GA produces better ensembles for
In order to assess the performance of LSA, we performed a series of experiments. In each one, LSA is issued from 1000 random ensembles under different limits on the number of iterations and the size of the neighbourhood. The ensembles are generated in the same way as the initial chromosomes of the GA (see Section 3.3), the average tardiness cost being 1574,82. We considered 1, 3, 5, 10, 20 and unlimited number of iterations, and the neighbourhood size varying in 10, 50, 100, 500 and all rules in the Joint pool of rules (1930). Besides, we considered two variants of LSA, hill-climbing (HC-LSA) and gradient-descent (GD-LSA). In both cases, we registered the average tardiness obtained and the time taken. The results are reported in Figs 4 and 5 respectively.
Average tardiness values obtained by LSA starting from 1000 random ensembles considering different number of iterations (1, 3, 5, 2, 10, 20, unlimited “–”) and neighborhood sizes (10, 50, 100, 500, and all rules (1930)).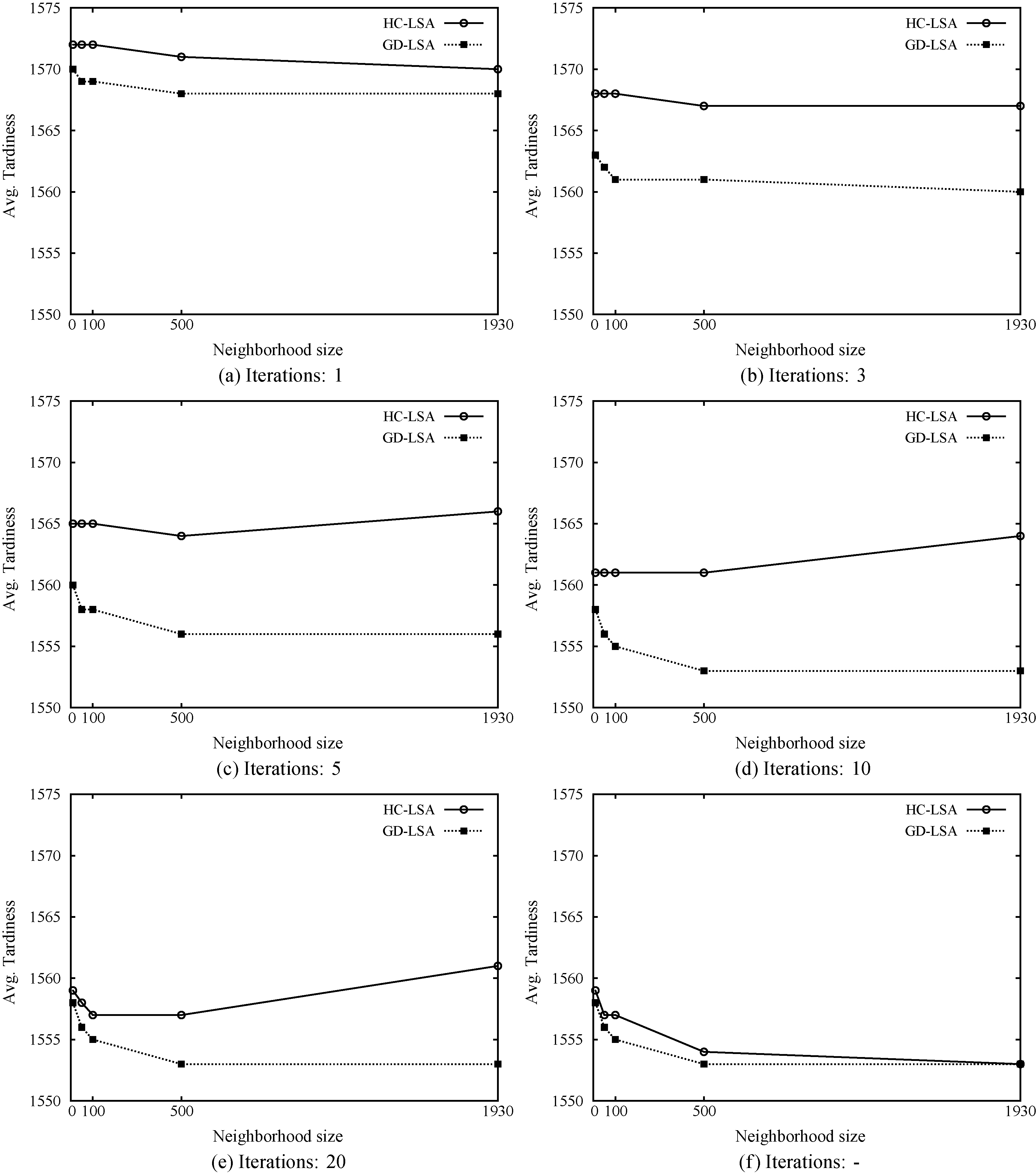
Time taken by LSA in the experiments reported in Fig. 4.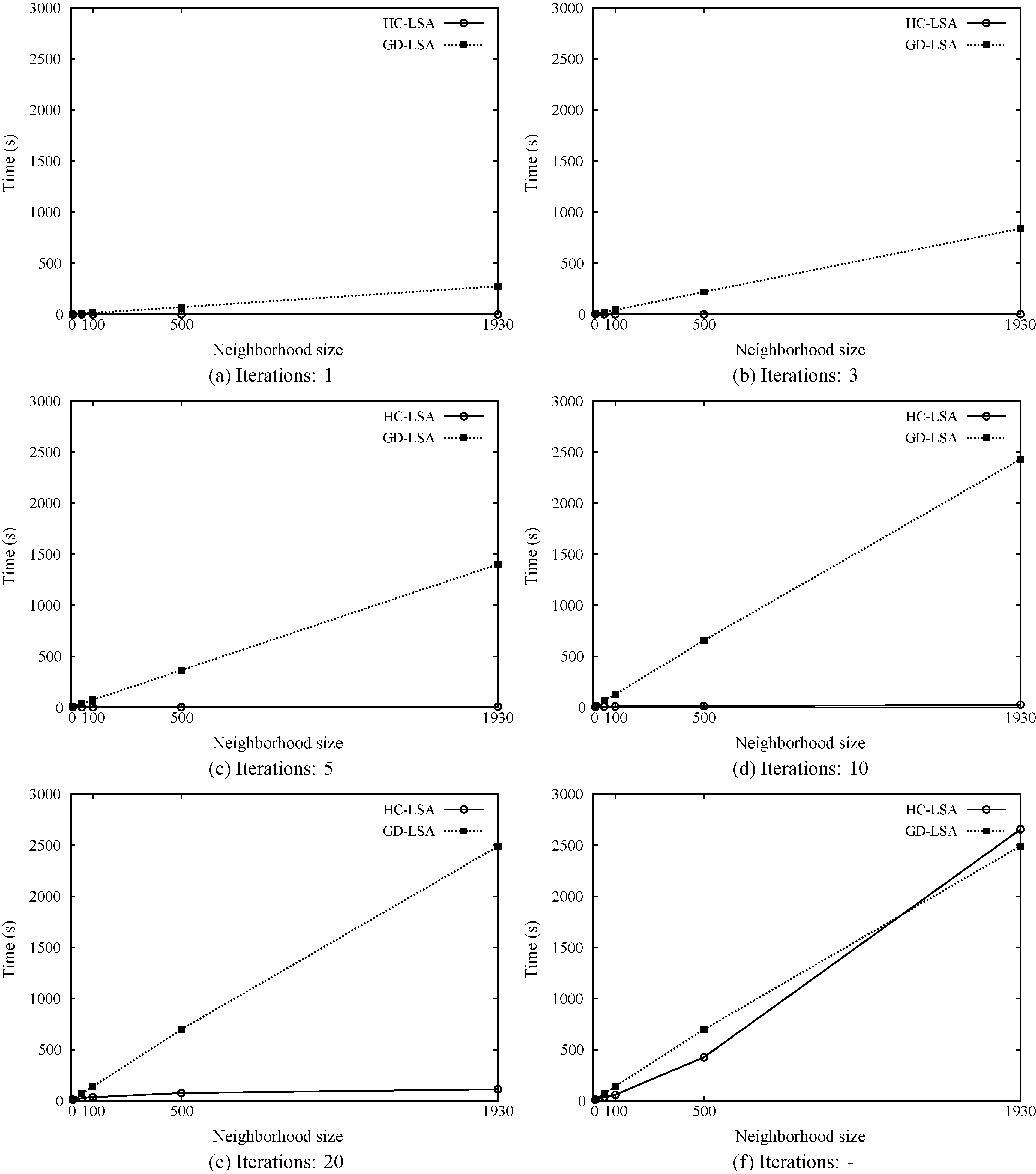
Summary of results from MA evolving ensembles of size 10, with HC-LSA and GD-LSA local searchers and different neighbourhood sizes. The best, average and standard deviation from 30 independent executions, as well as the number of runs that MA reached the best solution found by GA, are reported
Summary of the results obtained by the OEPRP resolution methods and the best 10 rules
Overall, we can observe that in all cases LSA is able to improve the starting solutions, and the improvement is generally in direct ratio with the limit of iterations and the neighbourhood size; being GD-LSA better than HC-LSA in all cases. However, there are three cases where the quality of ensembles produced by HC-LSA gets worse when the neighbourhood size grows from 500 to 1930. Besides, the time taken by HC-LSA is very low in comparison to the time taken by GD-LSA, with the only exception in the case of unlimited iterations, in which case both algorithms reach quite similar solutions. In this last case, HC-LSA performs 30,209 iterations, while GD-LSA needs only 4,385. GD-LSA reaches average tardiness of 1552.69 and the tardiness of the best ensemble is 1550.89. This solution is better than the best one produced by IGA (1551.50) and very similar to the best ensemble produced by GA (1550.82), although GD-LSA takes much more time.
We considered a number of combinations of LSA with IGA and GA. In the first one, HC-LSA and GD-LSA were applied to the ensembles of 10 rules reached by IGA without limit in the number of iterations and neighbours. In all cases, the reached ensembles were the same and only a small improvement was produced w.r.t. the initial solution (1551.30 versus 1551.50), while the time taken grew from 3.17 s to 6.8–11.3 s depending on HC or GD. So, it seems that LSA can hardly improve the results obtained by IGA.
Then we combined LSA with GA so that LSA is applied to 20% of the ensembles in each generation of GA. This combination is called memetic algorithm (MA). In this case, we considered two limits for the neighbourhood size, 10 and 100, in order to control the execution time, in the first case with unlimited iterations and in the second one with 10 and 5 iterations for HC-LSA and GD-LSA respectively, to get similar running times in both cases. The results are summarized in Table 8. We can see that in all cases the best solution reached is the same as the solution given by GA (1550.82 in the training set and 1557.61 in the test set), maybe this is due to these solutions being optimal. However, GA reached this solution only once for the training set, while MA was able to reach this solution much more times, from 14 to 26 times depending on the parameters. For this reason, MA is much more stable than GA, and could be expected to reach better solutions than GA if harder instances of the OEPRP were considered.
Summary of the most relevant characteristics of the rules that form the best calculated ensemble of size 10, and the degree of coverage that they have on the instances of the training and test sets
Summary of the most relevant characteristics of the rules that form the best calculated ensemble of size 10, and the degree of coverage that they have on the instances of the training and test sets
Summary of the results obtained by the
Table 9 summarizes the results obtained by the proposed algorithms for ensembles of size 10. MA produces the best results of all methods, but taking long time. On the contrary, IGA takes very short time and reaches good solutions as well, which are only slightly worse than the solutions from the other methods. So all algorithms are worth to be considered to be applied in different situations.
It is also worth considering the characteristics of rules taking part in the best ensembles. Table 10 shows the features of the rules of the best ensemble of size 10 calculated in our experiments. First of all, we can see that all the rules contribute to the ensemble in a similar proportion; each one covers in average 101.80 instances of the training set and 101.40 of the test set. Besides, the rules are uniformly distributed between the general (6 rules) and specialized (4 rules) pools; the best of all rules in the joint pool not being included in the ensemble. The average depth of the rules is almost 6 (the maximum depth allowed in GP) and the average size is 28; these are different values of those in ATC rule, depth 8 and size 17. This fact suggests that a larger maximum depth could allow GP to obtain better rules to generate ensembles.
Comparison to existing approaches
Table 11 summarizes the results obtained in our experiments, across the training and test sets of instances of the
At the same time, the results from the ensembles are still far from the results obtained by the memetic algorithm proposed in [32], which as far as we know is the best method proposed in the literature to solve the
Conclusions and future work
We have seen that the performance of online schedulers can be improved by exploiting small ensembles of rules. We considered a single scheme in which all the rules of the ensemble are exploited in parallel. The proposed methodology gives rise to the OEPRP (Optimal Ensemble of Priority Rules Problem), which is NP-hard. In the OEPRP, we start from a large set of rules and the goal is to reach the best subset of a given size. As a case study, we consider the
Future research will investigate the inclusion within the proposed framework of new classes of rules. In addition, the use of exact any-time algorithms, e.g. branch-and-bound [53], seems an interesting research avenue. Finally, the same methodology could be applied to devise online methods for other scheduling problems, which would allow for a comparison with other methods proposed in the literature [54, 19].
Footnotes
Acknowledgments
This research has been supported by the Spanish Government under research project TIN2016-79190-R and by the Principality of Asturias under grant IDI/2018/000176. Francisco Gil-Gala is supported by the scholarship FPI17/BES-2017-08203.