
Abstract
Robust identification and tracking of the pupil provides key information that can be used in several applications such as controlling gaze-based HMIs (human machine interfaces), designing new diagnostic tools for brain diseases, improving driver safety, detecting drowsiness, performing cognitive research, among others. We propose a deep convolutional neural network for eye-tracking based on atrous convolutions and spatial pyramids. DeepEye is able to handle real world problems such as varying illumination, blurring and reflections. The proposed network was trained and evaluated on 94,000 images taken from 24 data sets recorded in real world scenarios. DeepEye outperforms previous eye-tracking methods tested with these data sets. It improves the results of the current state of the art in a 26%, achieving an accuracy of more than 70% in almost every data set in terms of percentage of pupils detected with a distance error lower than 5 pixels. DeepEye can be downloaded at:
Introduction
Eye-tracking is the process of measuring the gaze in order to quantify eye positions and movements. These data have been used for different purposes such as controlling gaze-based HMIs (human machine interfaces) [1, 2], designing new diagnostic tools for brain diseases [3, 4, 5], improving driver safety or detecting drowsiness [6, 7], analyzing the efficacy of advertisement [8, 9], among others. Some applications of eyetracking require real-time detection, e.g. driver safety or HMI, imposing the need of real time processing in order to have a reliable amount of eye positions per second. In other applications the data can be processed off-line with the aim of obtaining some kind of information from high frame rates, e.g. saccades for neurological diagnosis [10, 11]. In this kind of applications high quality quantification of the eye position and movements is essential. In the last decade, most eye tracking research was performed on data obtained under laboratory conditions [12, 13, 14, 15]. In the last years cameras have experimented large improvements in image quality and frame rate while making the size of the sensor smaller, which allows the development of new applications.
For all these reasons, a robust pupil detection that accounts for different illumination conditions, motion blur or pupil occlusion, is an essential part of any eye-tracking device. Rapidly changing illumination is a very common issue in videos recorded while driving or walking. For some diagnostic tools it is important to measure fast eye movements, such as saccades [10], that generate motion blur artifacts in the images. Other problems such as reflections produced by contact lenses, the eye not being centered in the image, or bad illumination that can produce dark regions surrounding the pupil [16]. All these problems have to be addressed by the eye-tracking algorithm executed in a real environment.
Pupil detection consist on analyzing the recorded data, in order to obtain an accurate identification of the center of the pupil. Classical methods were based on thresholding and contour detection to locate the center of the pupil, while more advanced proposals try to correct noise and reflections and use models to fit an ellipse to the pupil edges. The current state of the art in eye-tracking is ElSe [17], which has demonstrated a solid performance in different data sets. Summarizing, eye-tracking algorithms have been based on complex pipelines with different combinations of filtering, edge detection, thresholding, fitting ellipses, morphological operations, etc. This type of approaches, that make use of human intuition, have been widely used in general machine learning problems for the last three decades, whereas with the popularization of the Deep Convolutional Neural Network (DCNN) approaches, the detection performance in different fields has improved dramatically.
In this work we propose the use of a state of the art DCNN based on the proposal in [18] to obtain the coordinates of the pupil center. Instead of regressing the values of the pupil center, we draw a circle around the center coordinates in order to obtain a segmentation as output of the network. Finally, this segmentation is simply analyzed by a blob detector to detect its center, which is considered the center of the pupil. The proposed method is compared with ElSe [17], ExCuse [19] and Swirski [14] which are the current state of the art in the standard datasets of eye-tracking used. Our method improves the results of the current state of the art but it is only intended to be used in off-line applications such as obtaining biomarkers of eye movement for therapy or diagnosis of ocular or neurological disease because DCNN requires a GPU or a high-end CPU which is impossible to have in a on-line embedded system.
Related work
The problem of eye-tracking has been treated by many authors in the last two decades following different approaches. Proposals such as [12, 20] make use of histogram-based thresholding for pupil detection under laboratory conditions. Other proposals such as [15, 21] detect the pupil using the curvature of the thresholded edges of the image. Starburst, introduced by [22], is probably one the most representative algorithm based on this point of view. It makes use of a Gaussian filter to reduce image noise, followed by an adaptive thresholding to localize corneal reflection. The central step of Starburst consists of an estimate of the pupil center by detecting edges along a limited number of rays that come from different guesses of pupil centers. Other approaches such as SET [23] make use of a combination of manual and automatic steps to estimate the center of the pupil. SET uses a threshold to obtain a segmentation from the image, eliminates the segments that are greater than a certain size and finally looks for the pupil center using Convex Hull and ellipse fitting. ExCuSe [19] is an approach that is based on edge detection and morphologic operations. It makes use of a Canny edge detector to obtain the edges of the image and then applies several morphological operations that clean noise and erase straight lines. For all remaining curved lines it calculates their enclosed mean intensity, selecting the curve with the lowest value as the pupil. Finally, an Ellipse is fitted to this selected curve. ElSe [17] also operates over an edge image calculated using the Canny detector. It removes noise using morphological operations and then analyzes several features of the connected edges (straightness, inner intensity, elliptic values). If a valid ellipse is found, it is returned as the result. When a valid ellipse is not found, a second analysis is applied with further processing based on low pass filters and convolutions to avoid the noise and the blurring caused by the presence of the eyelashes.
Pupilnet [24] is a technique based on deep neural networks applied to eye-tracking. They divide the images in several subregions with a sliding window and use them as input. All subregions that are not centered in the pupil will be the negative class and the one centered will be the positive class. Therefore, Pupilnet classifies between patches belonging to the background and patches centered in the pupil. Pupilnet is composed of two networks. The first provides a coarse position of the pupil and the second network refines that position using smaller subregions as input. The main drawback of this approach is the need to process a lot of subregions within every frame, which imposes a compromise between the network complexity and the frames per second that can be processed. Another problem with this approach is that using only small regions reduces the context information and hence the accuracy is reduced.
In the field of Deep Learning there have been several improvements in the last years. One of the most important discoveries has been the Residual network [25] which added the residual technique to the Deep Learning toolbox. The residual technique provides a way to train deeper networks reducing the performance loss derived from stacking a high number of convolutions. On the other hand, the Inception GoogleNet [26] showed that the use of parallel convolutions in a sparse structure by dense building blocks is a viable method for improving neural networks for computer vision.
In the last two years a lot of techniques for segmentation using DCNN have been proposed. One of the most popular is the U-net architecture [27, 28, 29]. This architecture performs segmentation by encoding the image using convolutions and pooling, followed by a decoding step based on upsampling the feature maps generated by the encoding step. The upsampling, also called deconvolution, is usually performed using unpooling, which can be seen as the inverse operation of the max-pooling, or using transpose convolution which allows the learning of parameters. The proposals in [18, 30] have shown that atrous convolution allows to effectively enlarge the field of view of the filters to incorporate multi-scale context information while reducing the number of parameters. There are also some meta-algorithms [31, 32, 33] that analyze ROIs from the input image separately in order to perform a detailed localization, classification and segmentation for different objects in the image.
Apart from image recognition, DCNN have been applied successfully in different fields, such as civil engineering [34, 35], health [36] or economics [37].
In this work we decided to use a network similar to the DeepLab presented in [18] instead of something similar to a R-CNN network [32, 33] as both approaches give roughly the same results in the standard segmentation benchmark, while the DeepLab network analyzes the whole image at once instead of looking for different ROIs. This is more suitable to tackle our problem, because we expect to have just one pupil per image. Additionally, the R-CNN algorithms require a more sophisticated training than DeepLab because they need to join the ROIs selection step with the segmentation network, whereas DeepLab is trained with just an input-output images pair.
Materials and method
Data sets
In order to train and test our network, several data sets provided by [17, 19] have been employed. Figure 1 shows some examples of the data sets. Data sets I-XXII were recorded during an on-road driving experiment and during a supermarket search task [17, 38]. The challenge of these data sets come from the rapidly changing illumination and the reflections coming from eyeglasses and contact lenses. Data sets XXIII and XXIV [17] were recorded in-door from asian subjects where the challenges in this data sets are related to motion blur artifacts, reflections and low contrast between the pupil and dark regions around it. The data sets were recorded from different subjects and contain overall 94,161 images with an image resolution of 384
Examples of images from the data sets.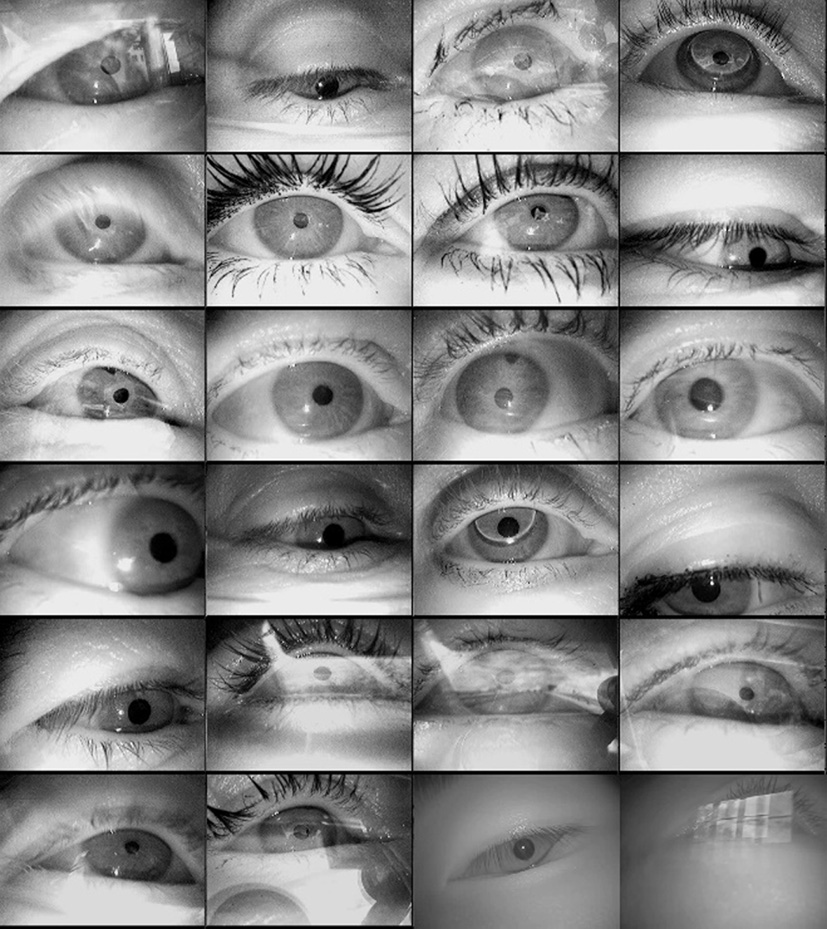
In order to obtain the coordinates of the pupil we are going to extract them as the center of a segmentation. A circular mask of size 20 pixels with value one was drawn in the position of the pupil’s center on a background of value zero, so that the DCNN generates a mask in which the pixels values represent the probability of being part of the circle centered in the pupil. Therefore, the network assigns high probability values to the pixels enclosed by the generated circle instead of providing the pupil’s coordinates directly. Figure 2 shows some examples of the ground truth masks for different input images.
Once the probability mask is obtained, we need to threshold it in order to obtain a binary image that classifies the pixels either as background or as belonging to the pupil circle. After this, further processing is needed to obtain the final coordinates of the pupil from this binary image. This is explained in detail in Section 3.5.
Ground truth masks for different input images in which a circle of 20 pixels with ones was drawn in images of zero value.
DCNN consist of several layers which contain neurons that perform local convolutions. The main variables of the model will be the weights of these convolutions. After a convolution, it is common to have an activation function such as a rectified linear unit (Relu), Sigmoid or hyperbolic tangent. The purpose of this activation function is to introduce non-linearity into the network, so that the network can learn a non-linear function.
After the initial convolutions and activation functions, a map of low-level features is obtained. In order to generate more informative features a common practice is to perform a pooling operation which consist in aggregating multiple low-level features over a small neighborhood. There are different ways to perform the pooling such as the max-pooling which simply reduces a neighborhood to its max value or the average-pooling which reduces it to the mean value. A pooling operation can be also performed using a convolution with stride. This adds more parameters to the model, but it allows learning a more complex feature combination. These are the basic components of a DCNN model. The model is finally trained using gradient descent optimization.
After this brief introduction to the DCNN, the following sections will describe the most important aspects of DeepEye architecture in more detail.
Batch Normalization and Batch Renormalization
Batch Normalization, [39] is a fundamental tool in Deep Learning that has been used over the last two years in several architectures. Batch Normalization helps to stabilize the distributions of internal activations during the training of the model, which makes the model less influenced by parameter initialization and enables the use of higher learning rates. These effects make the training more solid and faster. Batch normalization works on mini-batches in stochastic gradient training. It uses the mean and variance of the mini-batch to normalize it before the activation function, and also to estimate a moving average and variance that are used during inference. The drawback is that in order to obtain an accurate estimation for the mini-batch statistics, a sufficient number of examples in the mini-batch are needed, and these examples must be statistically independent. If the estimations in the mini-batches differ from the moving estimation, batch normalization will give poor results during inference.
The batch normalization was Tested in DeepEye. However, there were large differences between the performance of training and inference. This was probably due to the fact that the mini-batch used is small because of the size of our input images (384
In order to correct this problem, the creators of the Batch Normalization published an updated version called Batch Renormalization [40].
Batch Renormalization is an extension of batch normalization that solves the problem of having mini-batches with a small number of samples that are not independent. The aim of the batch renormalization is to reduce the dependence of model layer inputs on all the examples in the mini-batch and therefore the different activation between training and inference among the layers of the model. Batch renormalization ensures that the outputs computed by the model are dependent only on the individual examples and not on the entire mini-batch. At the same time, batch renormalization seems to retain the benefits of reducing the sensitivity to the initialization of the values in the kernels, while improving training speed compared to the traditional batch normalization. Based on all of these facts, batch renormalization was added to the model achieving lower differences between training and inference performance in comparison to the regular batch normalization.
Residual learning
The early works on modern deep learning showed that when you increase the number of layers of the network, i.e. the depth of the network, the error rate is reduced [26, 41, 42]. Nonetheless, when a certain point of depth is reached, the performance of the model starts to degrade rapidly [43, 44]; [25] shows that this degradation happens due to the difficulties of the solver to approximate identity maps by multiple non-linear layers. In order to address this problem, they propose residual learning, which consists on a shortcut that adds the input of a unit of several convolutions to its output. A schematic of the residual shortcut is shown in Fig. 3.
Consider a shallower architecture and its deeper counterpart that adds more layers onto it. If the shallower architecture is the optimal solution the following layers added in the deeper architecture should reproduce the identity and the error should be the same in both, whereas the degradation problem suggest that the solvers might have difficulties in approximating identity mappings by multiple non-linear layers. With the residual learning reformulation, if identity mappings are optimal, the solvers may simply drive the weights of the multiple non-linear layers towards zero in order to approach identity mappings. In real cases it is unlikely that identity mappings are optimal. However, the residual reformulation helps to precondition the problem if the optimal function is closer to an identity than to a zero mapping. In other words, the residual approach avoids the need of generating an identity function, which is hard to obtain, and instead just generate a nullity function which is easier to be generated by the convolution functions.
Residual shortcut in a convolutional block.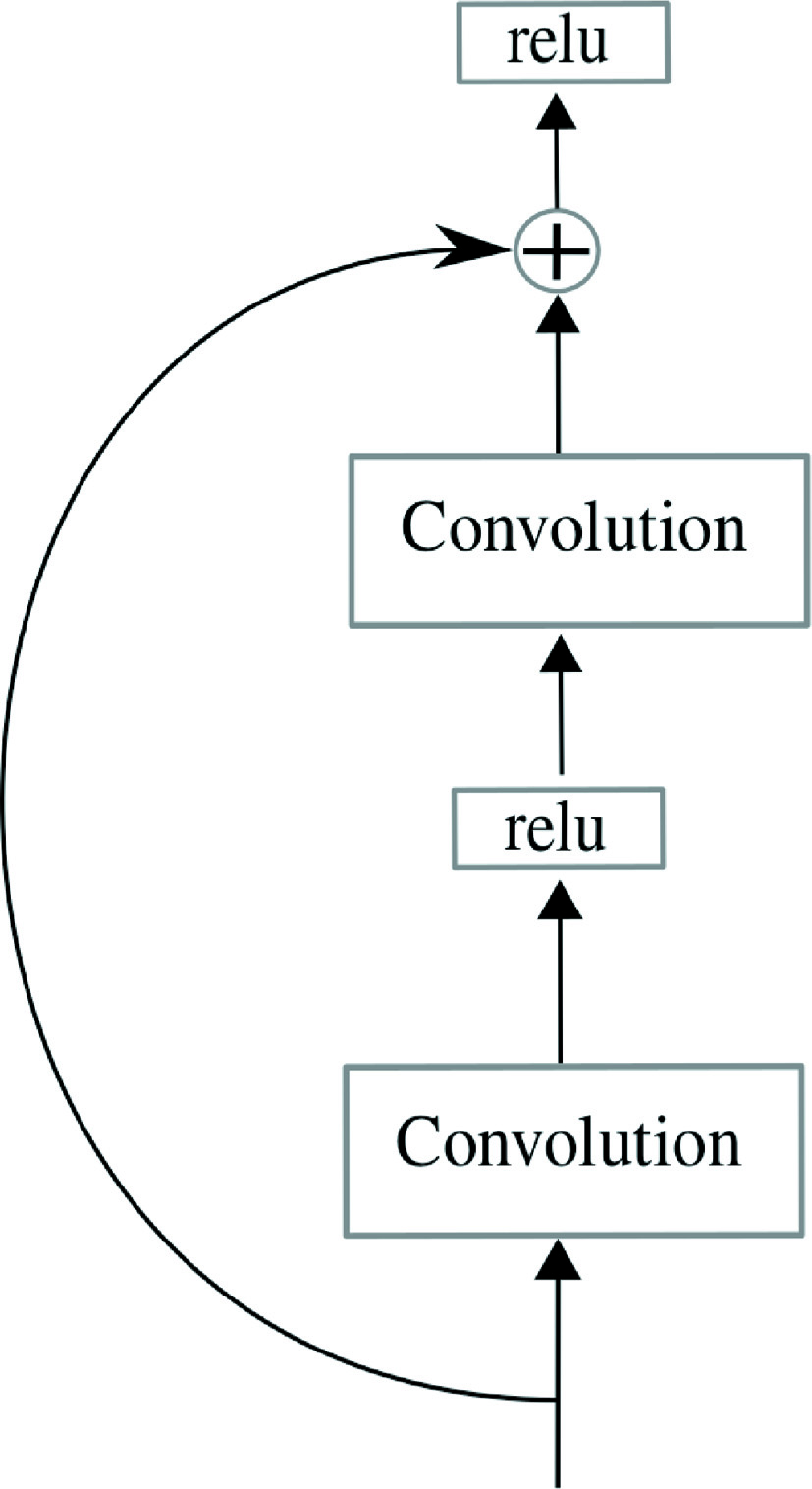
Atrous convolution was originally developed for the efficient computation of the undecimated wavelet transform in the “algorithme à trous” scheme [45]. This algorithm allows computing the responses of any layer at any desirable resolution. The atrous convolution for a two-dimensional signal can be defined as:
where
Residual shortcut in a strided block.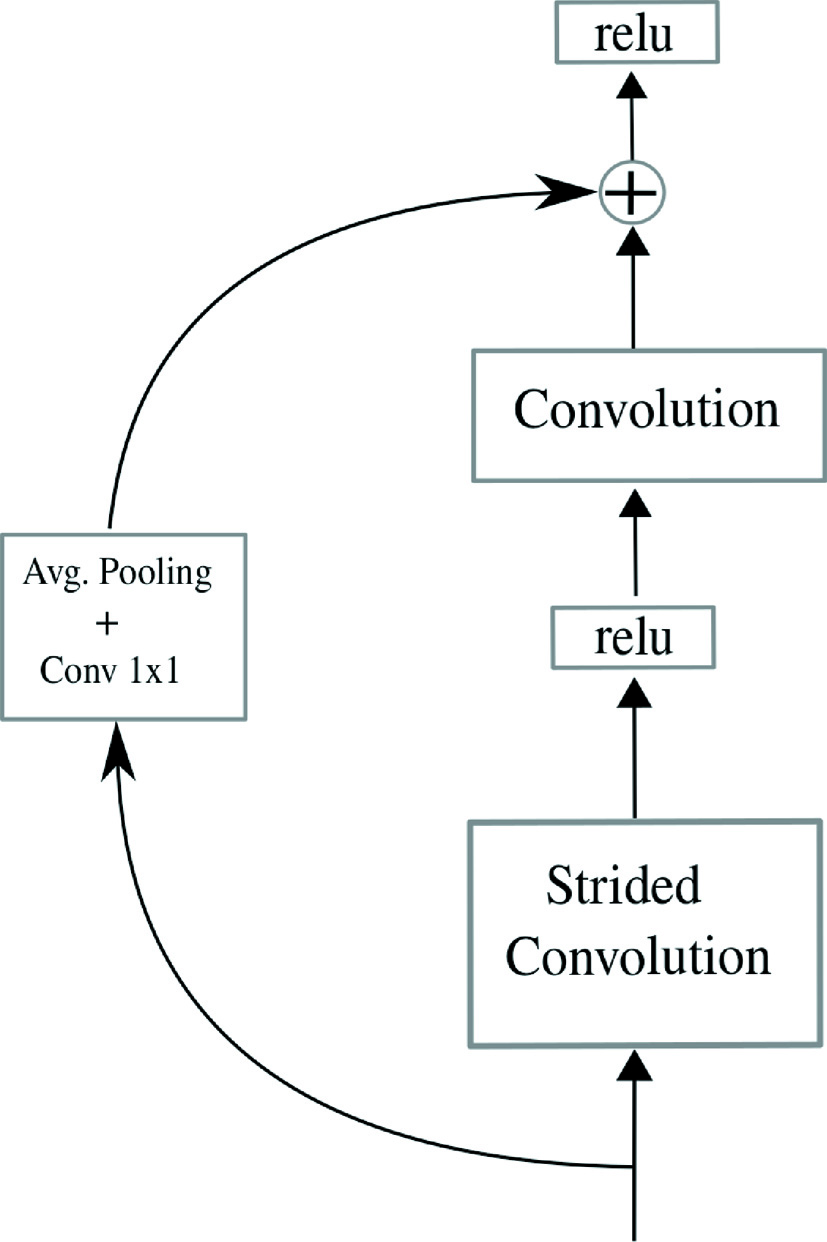
Atrous convolution allows enlarging the receptive field of the filters in the network. Therefore, it offers a good mechanism to control the field of view and finds the best combination of localization and context information. An example of this atrous kernels is shown in Fig. 5.
Atrous Spatial Pyramid Pooling (ASPP) is inspired by the success of spatial pyramid pooling, [46, 47], which showed that it is effective to sample features at different scales for accurately and efficiently classifying regions of an arbitrary scale. This strategy has been used with great success in [18, 30] for image segmentation. Following these proposals, a similar version of their ASPP has been implemented.
The implemented ASPP consist in three 3
Examples of atrous 3 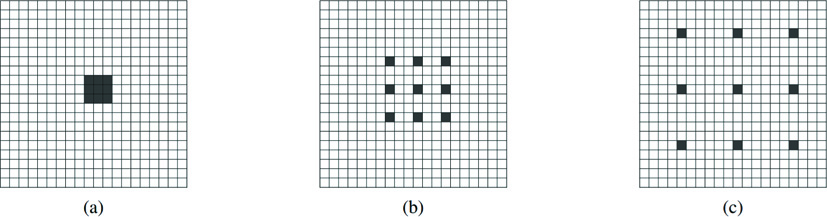
Atrous spatial pyramid pooling used in deepeye.
DeepEye schematic blocks.
Figure 7 shows a schematic of DeepEye. The representation is composed of blocks that represent various convolutions and operations. The convolution blocks represent two convolutions with the residual operation. For details, see Fig. 3. The strided blocks perform a convolution with stride to reduce the dimension of the image followed by a convolution. It is important to notice that the residual must be reduced in dimensions and increased in number of channels when a strided block is performed. The dimension of the residual dimension is reduced using an average-pooling and the number of channels is increased performing a 1
Training details
The training was performed using cross-entropy and soft-max. RMSprop with a learning rate of 10–3 and a decay of 0.9 was used as optimization method. One of the main difficulties with the data sets is the unbalance in the number of images across them, due to some data sets containing more than 10.000 images while others contain less than 1.000. Therefore, to avoid over fitting to the large data sets, every data set was repeated as many times as needed to have the same number of images in every data set. Data augmentation was also performed by randomly rotating between 0 and 360 degrees every image. This was done with the aim of making the network more robust to different camera-to-eye positions. The mini-batch size used in the following experiments is 4 and it contains random images coming from any data set in the training set. The minibatch size can be larger and the results are the same. We chose a size of 4 as it was the maximum mini-batch value for the biggest architecture tested. The models take around 60.000 iterations to converge.
Post-processing
As explained in Section 3.2 the network output is a probability image in which the pixel value represents the probability of being part of the circle centered in the pupil. The aim of this post-processing is to compute the coordinates of the pupil from this probability mask. First, the probability mask needs to be thresholded to obtain a binary image. Then, the biggest blob is extracted and the coordinates of its center will be considered the final pupil coordinates. An iterative thresholding has been implemented to account for images where the network has low confidence, which happens when the pupil is occluded or has low contrast.
The procedure consists of the following steps:
A threshold A blob detector is applied to locate the biggest blob. If the blob is not larger than If the blob is larger than
The parameters values selected were
In order to implement DeepEye, Tensorflow was used to build the deep learning network and OpenCV was used for the image processing. The algorithm has been tested in a PC with a Nvidia Tesla K40 and a Intel i7-6700K. The results have been reported in terms of the average pupil detection rate as a function of pixel distance between the coordinates obtained from DeepEye and the hand-labeled coordinates. For comparison with other methods, the percentage of frames with an error lower than 5 pixels have been reported, in a similar way to previous techniques [17, 19, 24].
Model selection
In this section the testing of several architectures with a different number of filters and ASPP blocks is reported. The first 50% of the frames of every data set were used as training set and the remaining 50% were used for testing. A combination of architectures using 2, 3 or 4 ASPP blocks and 8, 16, 32 or 64 filters was trained and tested. Figure 8 depicts the results as the percentage of frames in which the pupil is detected with a distance error lower than 5 pixels.
Detection rate with an error lower than 5 pixels for the architectures evaluated. The network architectures tested are encoded in DXLY, being X the number of ASPP used and Y the number of filters in the initial layer.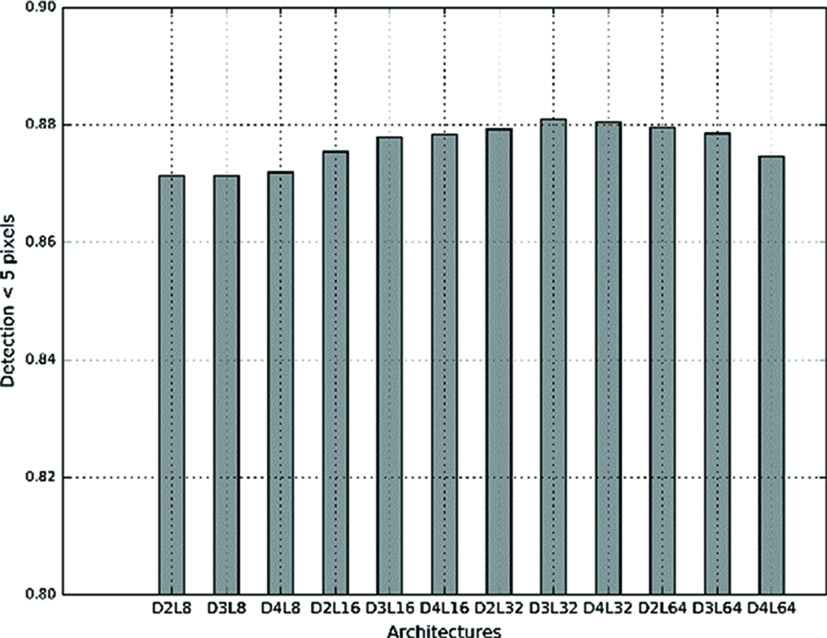
Frames per second and number of trainable parameters with every architecture evaluated. The network architectures tested are encoded in DXLY, being X the number of ASPP used and Y the number of filters in the initial layer.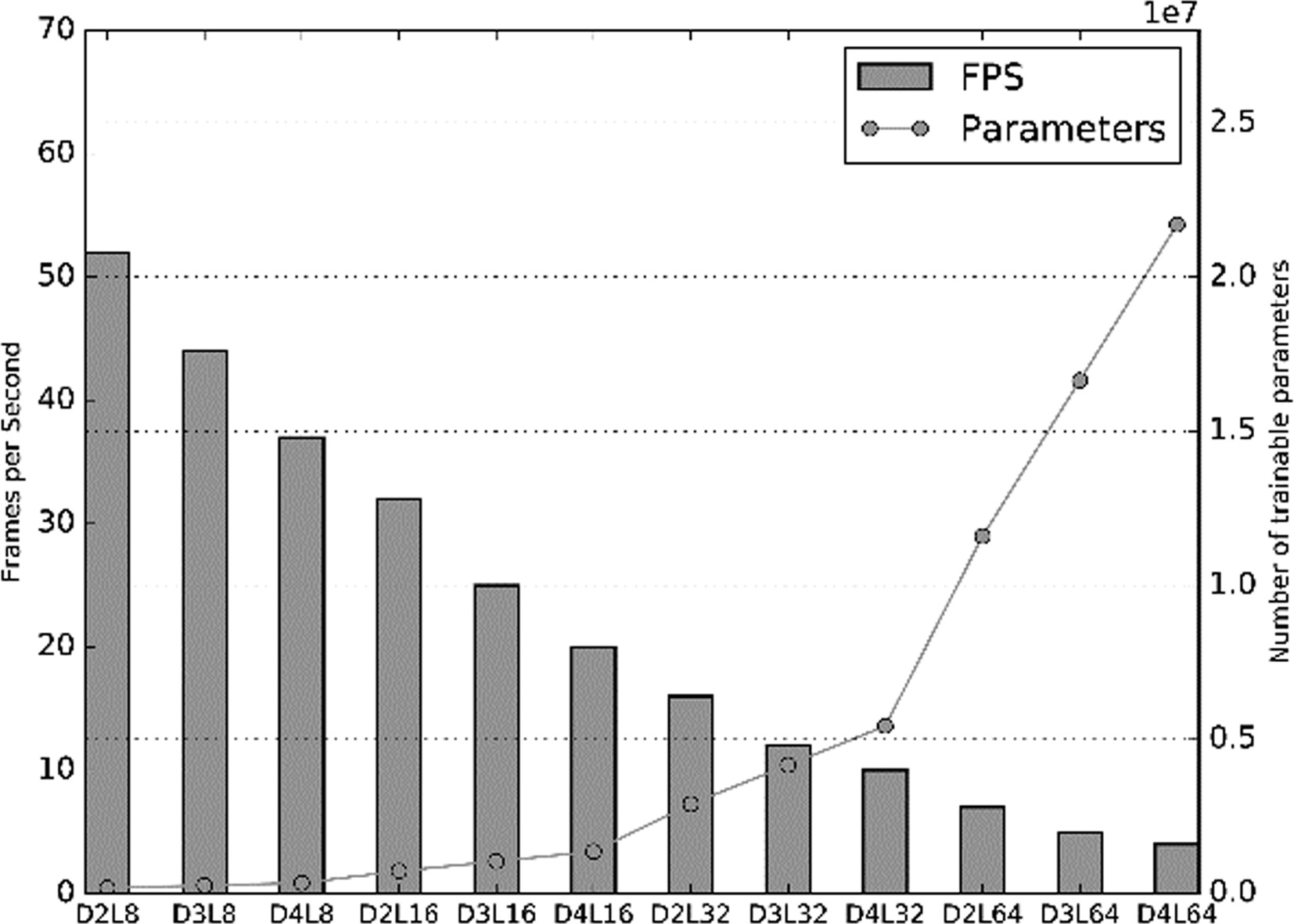
(a) Input images, (b) Probability masks, (c) Thresholded mask, (d) Masks with the center of the blob and (e) Final center of the pupil.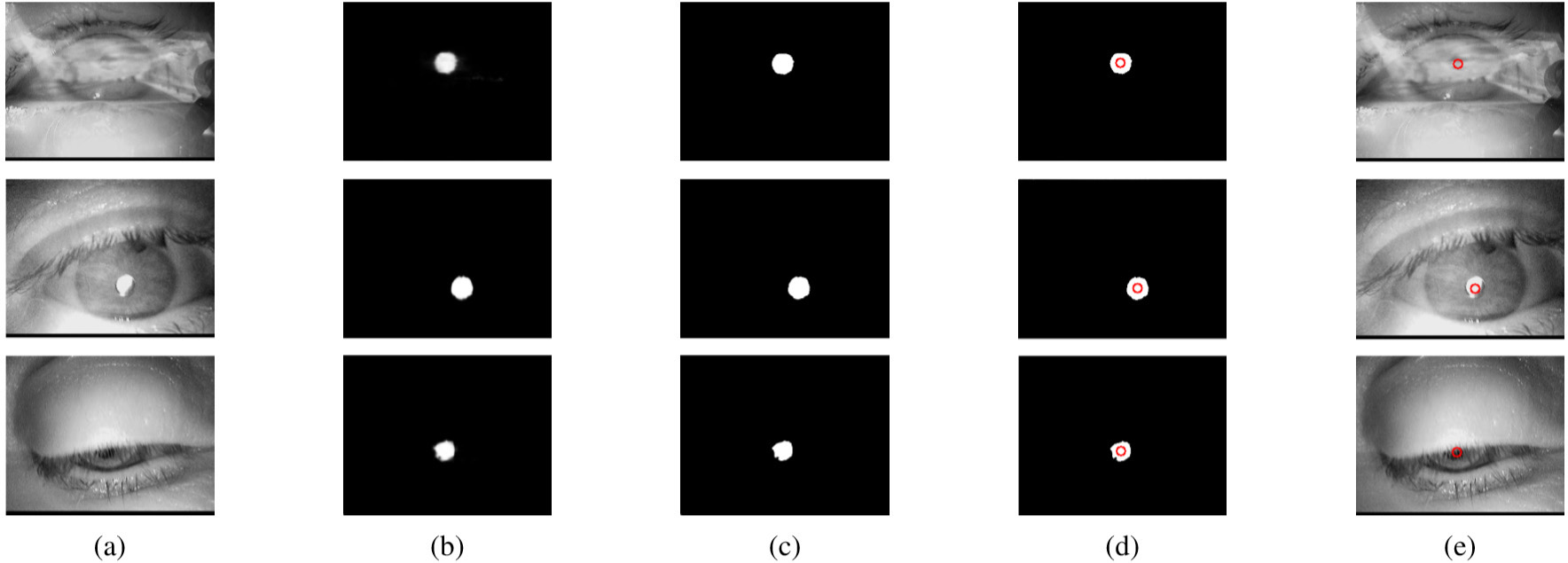
The architectures tested perform slightly different. Increasing the number of layers tends to improve the results until a certain number of layers is reached, a point at which figures decrease slightly. Something similar happens with the number of ASPP. The performance is increased until the 4th ASPP is added. The difference in performance can be due to over-fitting because the network is using too many trainable parameters to solve the problem. Nonetheless, the differences in performance are less than 3%. Figure 9 depicts the number of trainable parameters used in the tested architectures.
We have also evaluated the frames per second (fps) that the network can process in our set-up. These results are shown in Fig. 9. As the number of parameters is increased, the processing speed of the architectures decreases from 53 fps (19 ms per frame) to 4 fps (250 ms per frame). The post-processing steps take 2 ms in average, so the processing bottleneck is in the neural network.
Taking into account these results, the architecture with 2 ASPP blocks and 16 filters was selected as its performance is almost the same as that of a 3 block and 32 filter architectures, achieving speeds higher than 30 fps. In comparison with other algorithm of the state of art our network is very slow taking into account that ElSe and ExCuSe can process around 150 fps, depending on the hardware used, but our intention is mainly for off-line applications in which a high frame-rate processing and high precision is needed.
Quantitative results of the segmentation
Despite the fact that the segmentation is not the aim of this proposal, it is interesting in order to have an intuition of how our method is working. Figure 10 shows some examples of the probability maps provided by the network, the result after applying the threshold and finally the center founded by the blob analysis. Table 1 shows the Accuracy, Sensitivity, Specificity and Kappa factor of the segmentation compared to the generated ground truth. In all these figures the network composed by 2 ASPP and 16 initial filters was used.
Cross validation
The model with 2 ASPP blocks (depth
In order to do a fair comparison a cross validation between the data sets has been performed. This cross validation is performed using all the samples from a certain data set as testing set and using all the remaining data sets as training set. This provides information about the capability of generalization of DeepEye.
Detection error in function of the pixel distance in the cross validation compared with ElSe, ExCuSe and Swirski.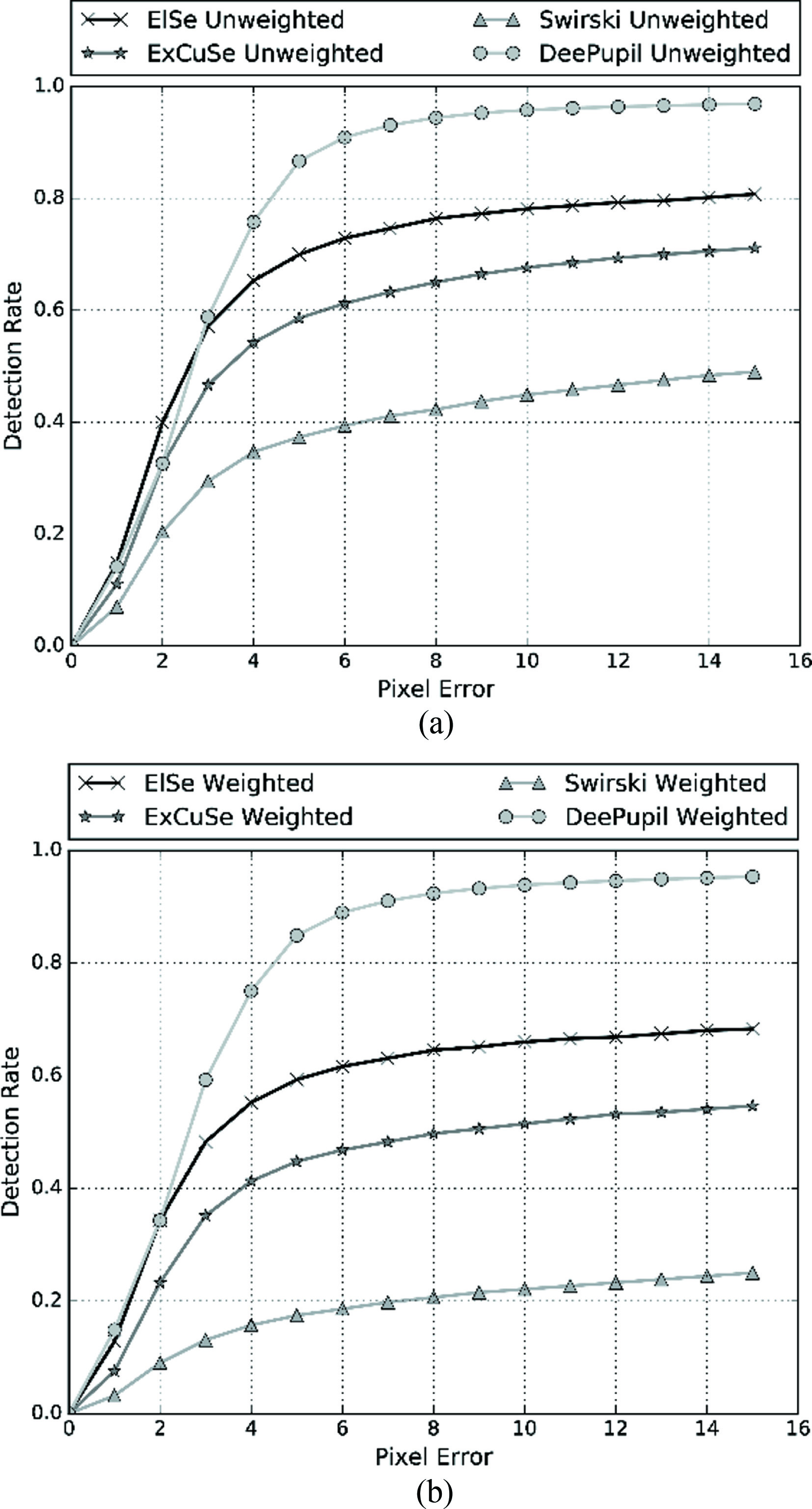
Performance comparison among data sets between Swirski, ExCuSe, ElSe and DeepEye in terms of detection rate up to an error of 5 pixels
Figure 11 depicts the performance in terms of the detection rate achieved with less than a certain pixel distance between the output and the hand labeled ground truth. Two results are displayed: the weighted result is the percentage of correctly detected pupil centers for all images in all data sets and the unweighted result is the mean of the results among all data sets not accounting for the differences in data set sizes.
Table 2 presents the performance of DeepEye for every data set compared with ElSe, ExCuSe and Swirski. The metric used is the percentage of frames in which the pupil is detected with a distance error lower than 5 pixels. DeepEye outperforms ElSe by 26% and it also shows much more consistency, as the detection rate is higher than 70% in most data sets. DeepEye achieves an 87% detection rate with less than 5 pixels of error in contrast to the rate of 69% achieved by ElSe. DeepEye also achieves a 96% detection rate with less than 10 pixels of error, this result indicates that the pupil is detected in most of the frames whereas in some cases the center cannot be localized precisely.
DCNN are usually trained with images with the same size in order to maintain a homogeneous scale for the features. This is due to the fact that training with different size is not always possible with the architecture used or makes the training harder. Some approaches are trying to solve these problems using different models for the different resolutions [48]. Nonetheless these approaches increase the complexity of the models. DeepEye was trained with images with a fixed size of 384
Conclusions
Eye tracking is a very useful technology for several applications, and there is a growing need for robust and efficient algorithms. We have presented DeepEye, an eye-tracking technique based on deep learning that outperforms the state of the art in eye-tracking algorithms, achieving high accuracy and consistency. The network is based on atrous convolutions in a ASPP scheme that generates a segmentation of the pupil. We compared DeepEye to the state of the art techniques for pupil tracking, obtaining an 87% of frames with less than 5 pixel error. DeepEye can process sequences at 32 fps with a Tesla K40 Graphical Processing Unit, and 25 fps with a Nvidia GTX 1060 which is suitable for a real time scenario. DeepEye was specially designed for outdoor scenarios and the authors highly encourage to use it in experiments in which a high accuracy of the pupil detection is needed, such as detection of saccades for neurological diseases.
As future work, we will optimize the architecture and reduce its complexity in order to work in lighter or embedded hardware. To achieve this aim, the use of binary networks [49] that reduce the complexity of the computation using just binary values for the kernels could be a solution. Also, reducing the image size and the number of parameters in the network, or the use of schemes such as R-CNN to make a full convolutional algorithm will be another asset to introduce in a future version of DeepEye.
Footnotes
Acknowledgments
This work was partially funded by project DPI2015-68664-C4-1-R of the Spanish Ministry of Economy and by Banco de Santander and Universidad Rey Juan Carlos Funding Program for Excellence Research Groups ref. “Computer Vision and Image Processing (CVIP)”. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Nvidia Tesla K40 GPU used for this research, and the anonymous reviewers that helped to improve the paper with their comments.