
Abstract
AIM:
Unilateral sensorineural hearing loss is a brain disease, which causes slight morphology changes within brain structure. Traditional manual method may ignore this change.
METHOD:
In this work, we developed a novel method, based on the double-density dual-tree complex (DDDTCWT), and radial basis function kernel principal component analysis (RKPCA) and multinomial logistic regression (MLR) for the magnetic resonance imaging scanning. We first used DDDTCWT to extract features. Afterwards, we used RKPCA to reduce feature dimensionalities. Finally, MLR was employed to be the classifier.
RESULT:
The 10 times of 10-fold stratified cross validation showed our method achieved an overall accuracy of 96.44
CONCLUSION:
Our method performed better than both raw and improved AlexNet, and eight state-of-the-art methods via a stringent statistical 10
Keywords
Introduction
Hearing loss is a partial or dead inability to hear. It may be caused by a massive of different problems, such as birth complication [1], infection [2], medications [3], ageing [4], genetics, noise [5], trauma [6], toxins [7], etc. The hearing loss is defined when the subject cannot hear 25 decibels and above for more than one year. Disabling hearing loss is defined as hearing loss greater than 40 decibels (dB) in the better hearing ear in adults and a hearing loss greater than 30 dB in the better hearing ear in children. Until 2017, it is reported by word health organization (WHO) that there are about 466 million people suffering from disabling hearing loss, and 34 million of these are kids. According to the estimation made by WHO, there will be over 900 million people have disabling hearing loss by 2050. 60% of childhood hearing loss is caused by preventable causes. The unaddressed hearing loss caused an annual global cost of 750 billion dollars every year. Interventions to prevent, identity and address hearing loss are cost effective and can bring great benefits to individuals. Therefore, in this paper, we proposed using machine learning method for the early detection of one specific type of hearing loss, which can be effectively visually inspected from Magnetic resonance imaging (MRI).
Sensorineural hearing loss is a type of hearing loss. Its cause may lie in either sensory tissues or neural tissues [8]. It may occur in one or both ears. In this study, we aim to detect unilateral sensorineural hearing loss (USHL) into two types: left-sided and right-sided.
MRI is an efficient tool to help diagnose USHL, because the USHL patients have distinct difference with healthy controls from the view of brain structures [9]. Nevertheless, these differences are slight and subtle especially in the prodromal stage in USHL disease. Therefore, computer vision techniques are essential to help neuro-radiologist to find those minor alterations.
In the last decade, Li [10] used fractional Fourier transform (FRFT) to detect left-sided and right-sided hearing loss. Chen [11] used wavelet packet decomposition (WPD) technique and least-square support vector machine (LSSVM). Gorriz and Ramírez [12] combined wavelet entropy (WE) and directed acyclic graph support vector machine (DAG-SVM). Chen Y. and Chen X.-Q. [13] employed three successful techniques: discrete wavelet transform (DWT), principal component analysis (PCA), and generalized eigenvalue proximal support vector machine (GEPSVM). Sun [14] employed wavelet energy, and proposed a quantum-behaved particle swarm optimization method. Wu [15] used contrast-limited adaptive histogram equ- alization approach. Lu [16] used radial basis function neural network. Chen [17] used fractal dimension based on Minkowski-Bouligand method to detect pathological brains. Lu [18] used wavelet packet entropy and back propagation (BP) algorithm. Pereira [19] used a Hu moment invariant (HMI) approach. Jia [20] used a deep autoencoder method.
After studying above literatures, we found they share three common problems: (i) Their datasets are imbalanced. This is because healthy controls are easily enrolled, while hearing loss patients are usually with other brain diseases, and hence those patients are not obedient for MRI scanning. (ii) They used wavelet or its variant as the feature, but wavelet decomposition can only detect textures along horizontal, vertical and diagonal directions. (iii) The performance of these detector systems are not satisfying and can be improved.
To solve these issues, Wang et al. [21], our previous work in IWINAC 2017, enrolled more USHL patients to balance the dataset. Besides, they proposed to combine dual-tree complex wavelet transform (DTCWT) and kernel principal component analysis to reduce the features. They chose the multinomial logistic regression as the classifier.
This paper is an extension of Wang et al. [21]. The new extensions include following eleven points: (i) We increase the 60-subject dataset to 90-subject. (ii) We replace dual-tree complex wavelet transform (DTCWT) with double-density DTCWT (DTCWT). (iii) We add contents describing discrete wavelet transform, double-density DTCWT, principal component analysis. (iv) We add three simulation experiments. (v) We add an experiment to illustrate the decomposition result by double-density DTCWT. (vi) We add an experiment to show the statistical analysis of our method. (vii) We design an experiment to select the optimal feature extraction method and find the optimal decomposition level. (viii) We design an experiment to select the optimal feature reduction method and corresponding optimal thresholding. (ix) We compare proposed MLR to traditional classifier (decision tree, support vector machine, and back-propagation neural network). (x) We compare our proposed method to a pretrained deep learning method (AlexNet). (xi) We use GPU to accelerate our method and compared GPU with CPU in terms of computation time.
The structure of this paper is organized as follows: Section 2 contains the demographics of 90 subjects. Section 3 shows the image preprocessing method. Section 4 describes three feature extraction methods: discrete wavelet transform (WT), dual-tree complex wavelet transform (DTCWT), and double-density DTCWT. Section 5 relates three dimensionality reduction methods: principal component analysis (PCA), and two kernel PCA methods. Section 6 presents the fundamental of multinomial logistic regression, and the implementation of our whole method. Section 7 offers the results of three simulation experiments. Section 8 gives the results over realistic data. Finally, Section 9 provides the conclusion of this paper.
Subjects
This study followed to use the 60 subjects in our previous work [21], and we enrolled 30 new subjects. Finally, we have a 90-subject dataset, including 30 healthy controls (HC), 30 left-sided sensorineural hearing loss (LSHL) patients, and 30 right-sided sensorineural hearing loss (RSHL) patients. The demographic data of the balanced new dataset is listed in Table 1, which clearly shows that all three classes are well matched with regards to gender, age, and education level.
The inclusion and exclusion criteria, the pure tone audiometry implementation, the imaging parameters are all the same as in Reference [13]. Ethics Committee of Southeast University approved this research. The audiograms of two patients are shown in Fig. 1.
Demographics of the 90-subject dataset
Demographics of the 90-subject dataset
Data are mean
PTA scores of two subjects.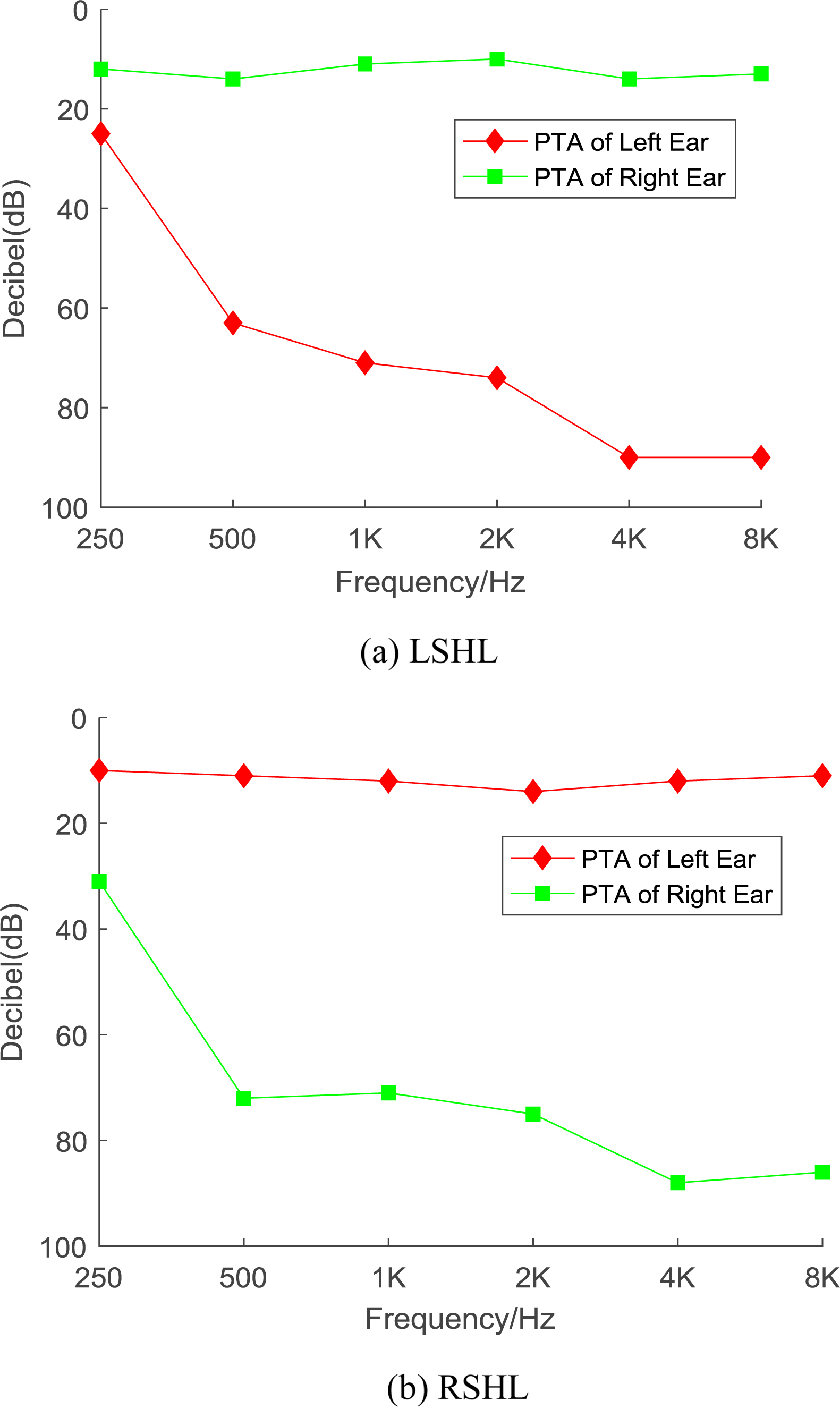
Illustration of detected case of left hearing loss, right hearing loss and healthy case.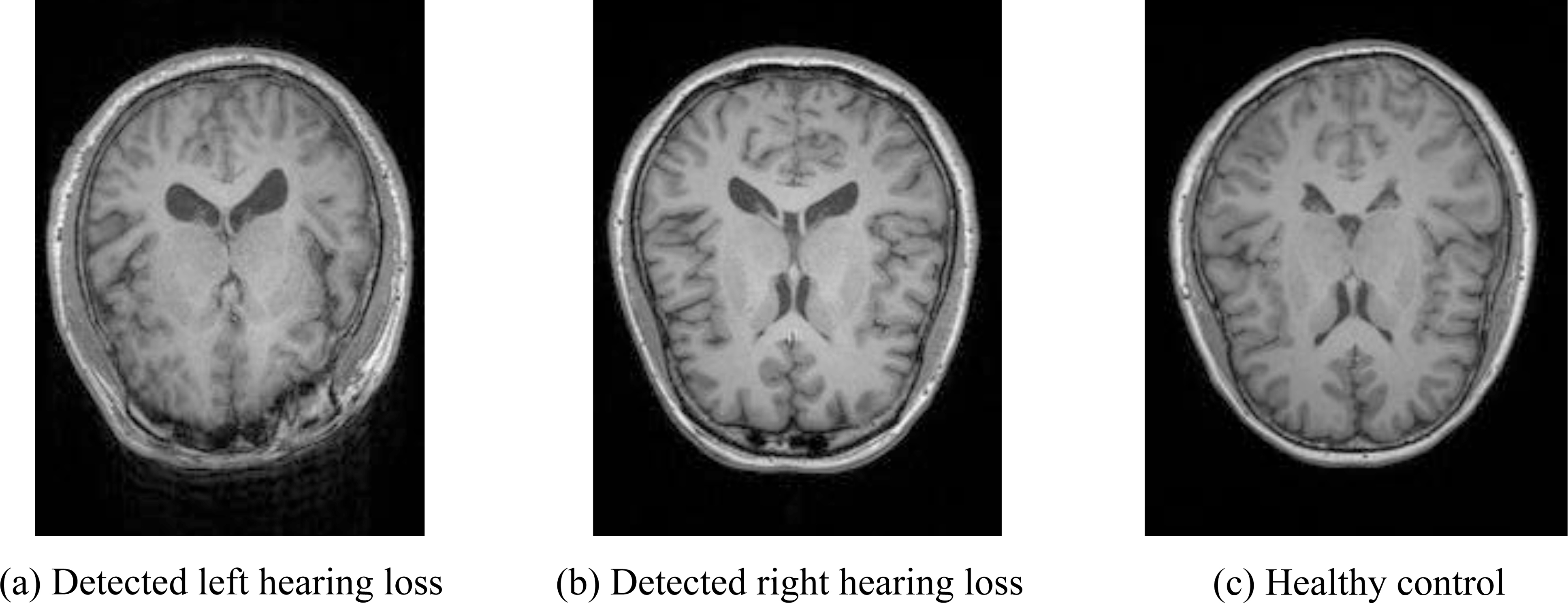
The images were obtained via a Siemens Verio Tim 3.0 T MR scanner (Siemens Medical Solutions, Erlangen, Germany). The parameters for imaging were set as Time of Echo (TE)
Image preprocessing follows the standard steps. First, the brain extraction tool (BET) v2.1 software [22] was employed to extract brain tissues. Figure 3a shows an original head image. Figure 3b gives the BET result, where the yellow line marks the brain area. Figure 3c shows the final extracted brain image.
Second, all the brain images of 90 subjects were normalized to the Montreal neurologic institute (abbreviated as MNI) template by FMRIB’s Linear Image Registration Tool (FLIRT) [23, 24] and FMRIB’s Nonlinear Image Registration Tool (FNIRT) [25]. Third, we resampled them to 2 mm isotropic voxels, and smoothed them by Gaussian kernel. Finally, three experienced otologists were instructed to select the optimal slice for each subject that covers his/her majority tissues related to hearing. The selected slice was at
Brain extraction result (the yellow line marks the brain region).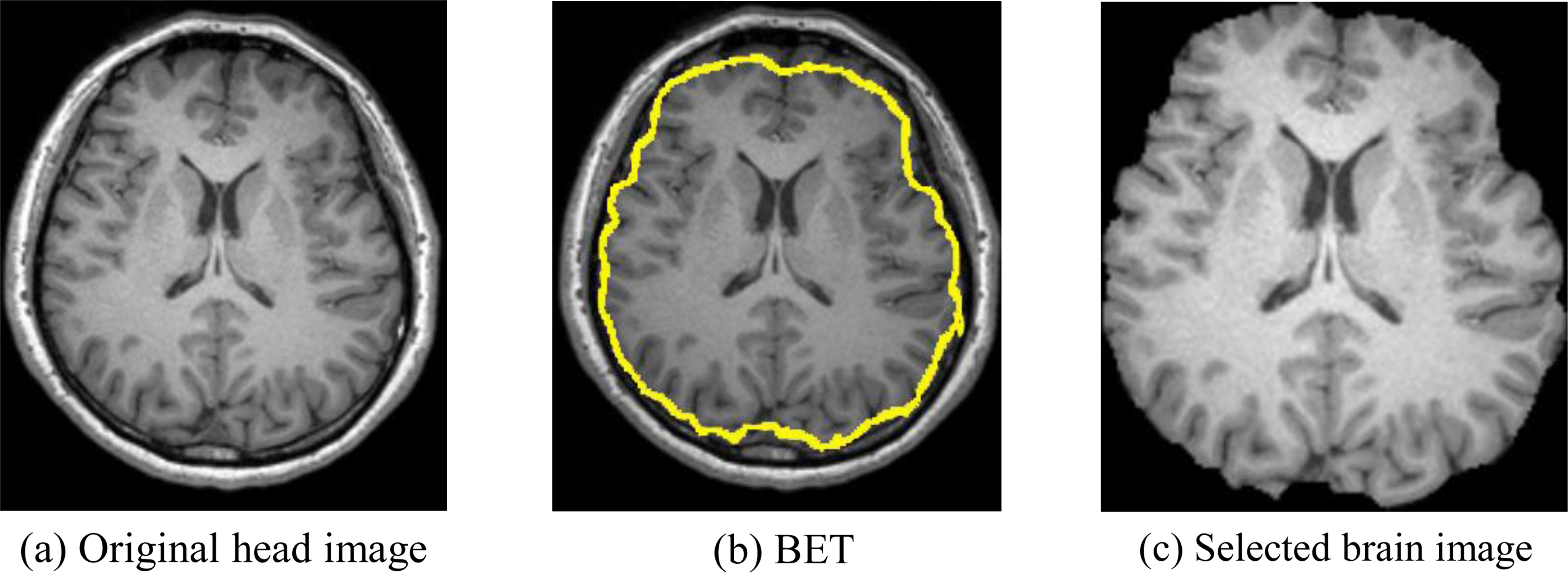
Here we select the slice at
Illustration of potential selected slices.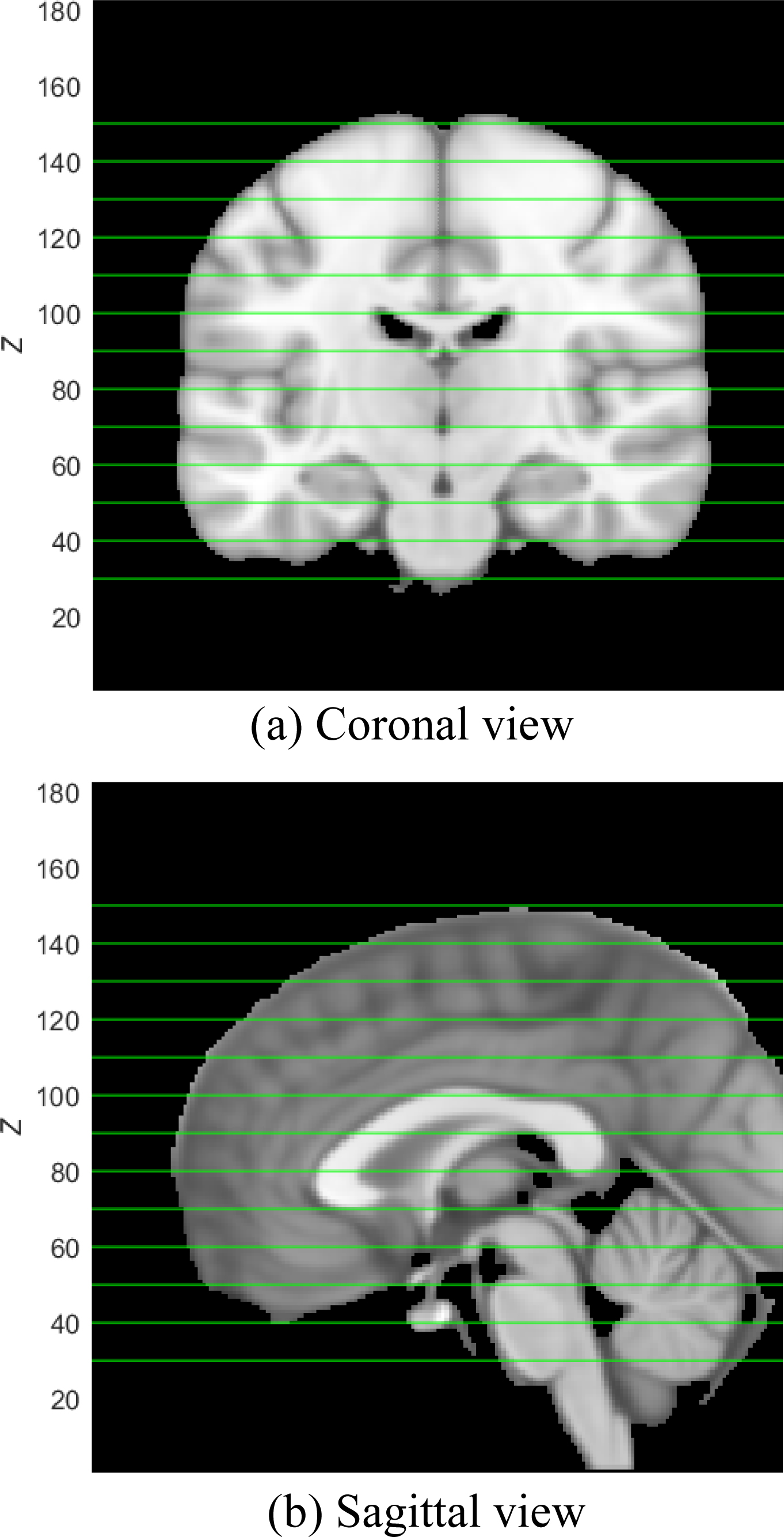
The physical structures of the brain are similar to fingerprints as they both have gyrus, which can be analyzed by wavelet successfully. Hence, in this paper, we proposed to use wavelet for the brain structure analysis. In this Section, we briefly introduced three wavelet transforms: discrete wavelet transforms, dual-tree complex wavelet transforms, and double-density dual-tree complex wavelet transform.
Discrete wavelet transform
The discrete wavelet transform is a mathematical implementation of wavelet transform [26, 27] using discrete sets of various scales and translations. Assume
where
When
Among the four sub-bands, the
The dual-tree complex wavelet transforms (DTCWT) used two separate two-channel filter banks to improve the directional selectivity. In the implementation, we need to design two separate DWT decompositions (tree
Diagram of a 2-level DTCWT.
For a 2D DTCWT, it produces at each decomposition level 6 directionally selective sub-bands with six different rotation angles [35] for both real (
The double-density dual-tree complex wavelet transform (DDDTCWT) used one scaling and two wavelets for each tree. The two wavelets serve for real and imaginary parts of a complex wavelet. Suppose we have two filter banks
The one scaling function
The scaling and wavelet functions in the synthesis side of
To guarantee primary bank
where
Patil et al. [37] summarized three important advantages of DDDTCWT: (i) double-density wavelets; (ii) directional-selectivity; (iii) shift-invariance. Those advantages guarantee that DDDTCWT will provide better performances than either DWT or DTCWT. Wavelet basis of traditional wavelet decomposition include Harr wavelet, db wavelet, bior wavelet, etc. Nevertheless, those wavelet bases are not suitable for DDDTCWT. The only wavelet basis can be used in this research is dddtf1.
Principal component analysis
The principal component analysis (PCA) is a standard procedure that is commonly used for dimensionality reduction [38]. The first PC has the largest variance [40], the second PC should be orthogonal to 1st PC and have the largest variance [41], and so on. The two lines in here denote for the 1st and 2nd PC, respectively. They are shifted to compensate the expected mean of (1, 2).
Kernel PCA
The shortcoming of PCA is that it only deals well with dataset with linear structure. The kernel principal component analysis extends standard PCA, and it implements the same procedure but transforms the dataset into a higher dimensional space [42]. Two important kernel PCAs are introduced below: One is polynomial kernel PCA (shorted as PKPCA):
The other is radial basis function kernel PCA (shorted as RKPCA):
Note
Logistic regression model
Logistic regression (LR) extends traditional regression analysis to the binary situation. Assume we have
and assume there is one dependent variable
where the values of the parameter vector
To create the LR model, we create a latent variable
Obviously
We can finally define the binary LR model as
where
Traditional LR can only handles binary class problem. The multinomial logistic regression (MLR) generalizes traditional LR to multiclass problem [48], and it is widely used in academic and industrial fields. The idea of MLR is simple. Suppose we have
then we can generate (
To simplify this expression, we let
and
Afterwards, we can transform Eq. (6.2) as
Using simple mathematical knowledge [49], we can solve Eq. (22) and deduce following result:
Finally, we can obtain the probability of the pivot class via basing on the fact that all of
and
In this study, since we need to handle a 3-class problem (LSHL, RSHL, and HC), the multinomial logistic regression was employed. Some other classifiers can also handle the multi-class problem; nevertheless, the MLR has several advantages: (i) It is one of the simplest classifiers, and (ii) it is fast to implement. Therefore, we chose MLR in this work.
Figure 6 presented the pipeline of proposed method. In the first step, we compared three different wavelet extraction methods: DWT, DTCWT, and DDDTCWT. Next, we compared three feature reduction methods: PCA, PKPCA, and RKPCA. Third, we employed multinomial logistic regression as the classifier. Finally, the stratified cross validation was utilized to output the generalization error.
Pipeline of proposed method.
In the 10-fold stratified cross validation, we segment the entire dataset into ten folds randomly with equal distribution of each fold. Remember we have 90 subjects: 30 LSHLs, 30 RSHLs, and 30 HCs. Then each fold will contain 3 LSHLs, 3 RSHLs, and 3 HCs.
The platform was configured as 8 GB RAM, Windows 10 64-bit Operating System. One Intel Core i5-3470 CPU and one GeForce GTX 1050 GPU were used separately to perform this task, because GPU has already been applied to discrete wavelet transform [50], implement kernel PCA [51] and multinomial logistic regression [52].
Directional selectivity comparison
Standard DWT only has three directional selections (horizontal, vertical, and diagonal) shown in Fig. 7. DTCWT has in total 12 directional selections shown in Fig. 8. The proposed DDDTCWT has in total 32 directional selections as shown in Fig. 9. This comparison result gives an experimental that why DDDTCWT gives superior performance than both DWT and DTCWT.
Directional selectivity of DWT (
Directional selectivity of DTCWT.
Directional selectivity of DDDTCWT.
We performed a comparison between standard DWT, DTCWT, and DDDTCWT over a decagon simulation image shown in Fig. 10a. Next, the decagon image was decomposed at a 4-level decomposition. Their reconstruction was performed based on the 4-th level detail subband. Figure 10b–d gives the DWT reconstruction, DTCWT reconstruction, and DDDTCWT reconstruction, respectively.
We can observe easily from Fig. 10 that the DTCWT yields better edge reconstruction than DWT. The DWT reconstruction has a discontinued edge, and yet the DTCWT reconstruction has a clear and solid contour line. In addition, the DTCWT has some aliases along the borders and suffers from slight checkerboard effect. While DDDTCWT solved above problems well. This result suggests us the superiority of DDDTCWT.
The reconstruction comparison between DWT and DTCWT.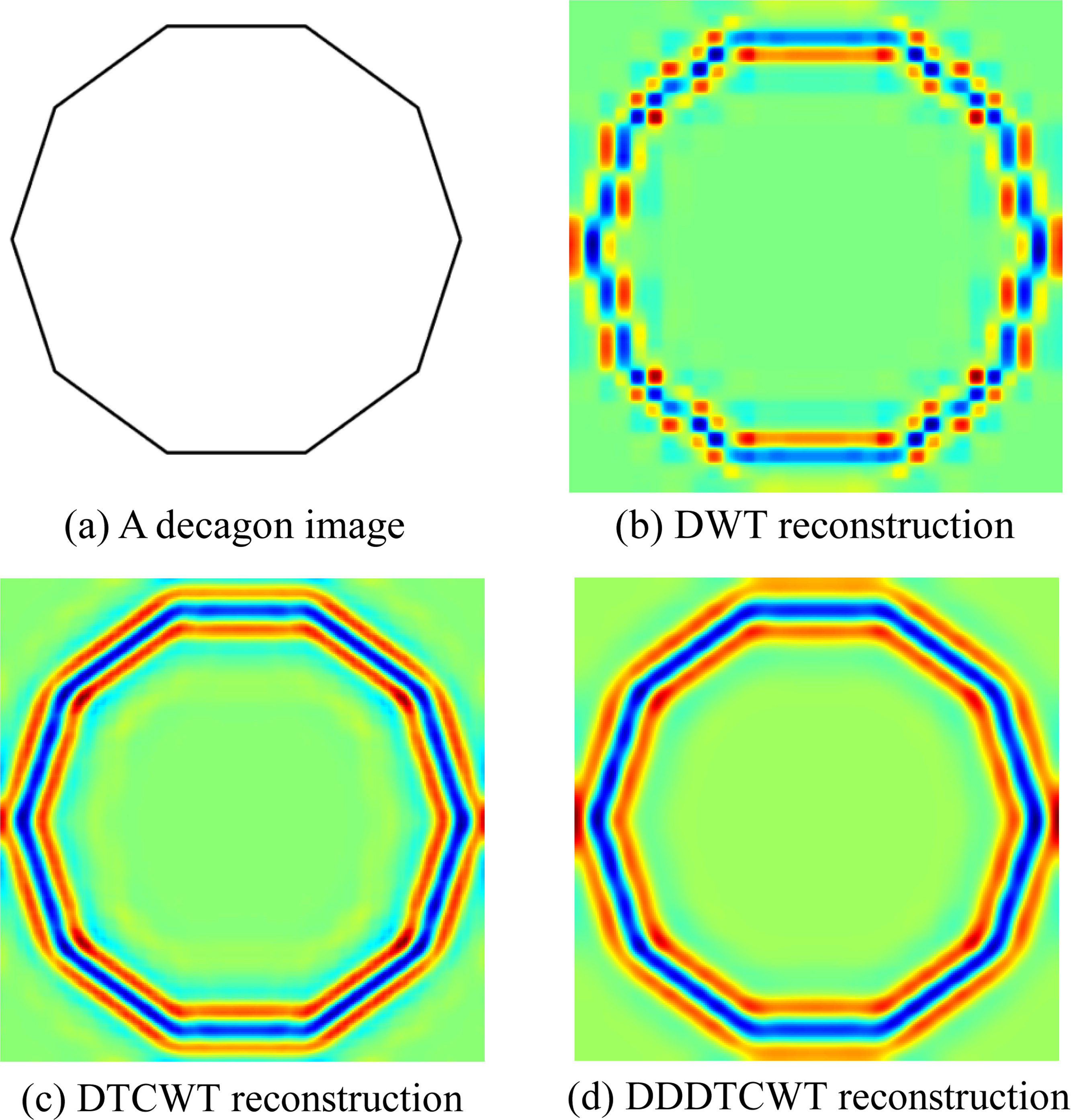
In the second experiment, we carried out a comparison among PCA, PKPCA, and RKPCA. Figure 11a shows the simulation data. Suppose we have three categories, and the number of each category is 361. The points in Class 1 lie in a sphere with radius of 1. The points in Class 2 lie in a sphere with radius of 2. The points of Class 3 lie in a sphere with a radius of 3.5. The original matrix size is 3249.
Figure 11b shows the PCA result, and Fig. 11c shows the PKPCA results. The results suggest 2PCs selected by either PCA or PKPCA cannot segment different classes. Figure 11d and e shows the RKPCA result, which indicates that even 1 PC selected by RKPCA can segment the three classes. Table 3 shows whether it is separable via difference PCA.
KPCA versus PCA (here C1, C2, C3 represents the first class, second class, and third class, respectively).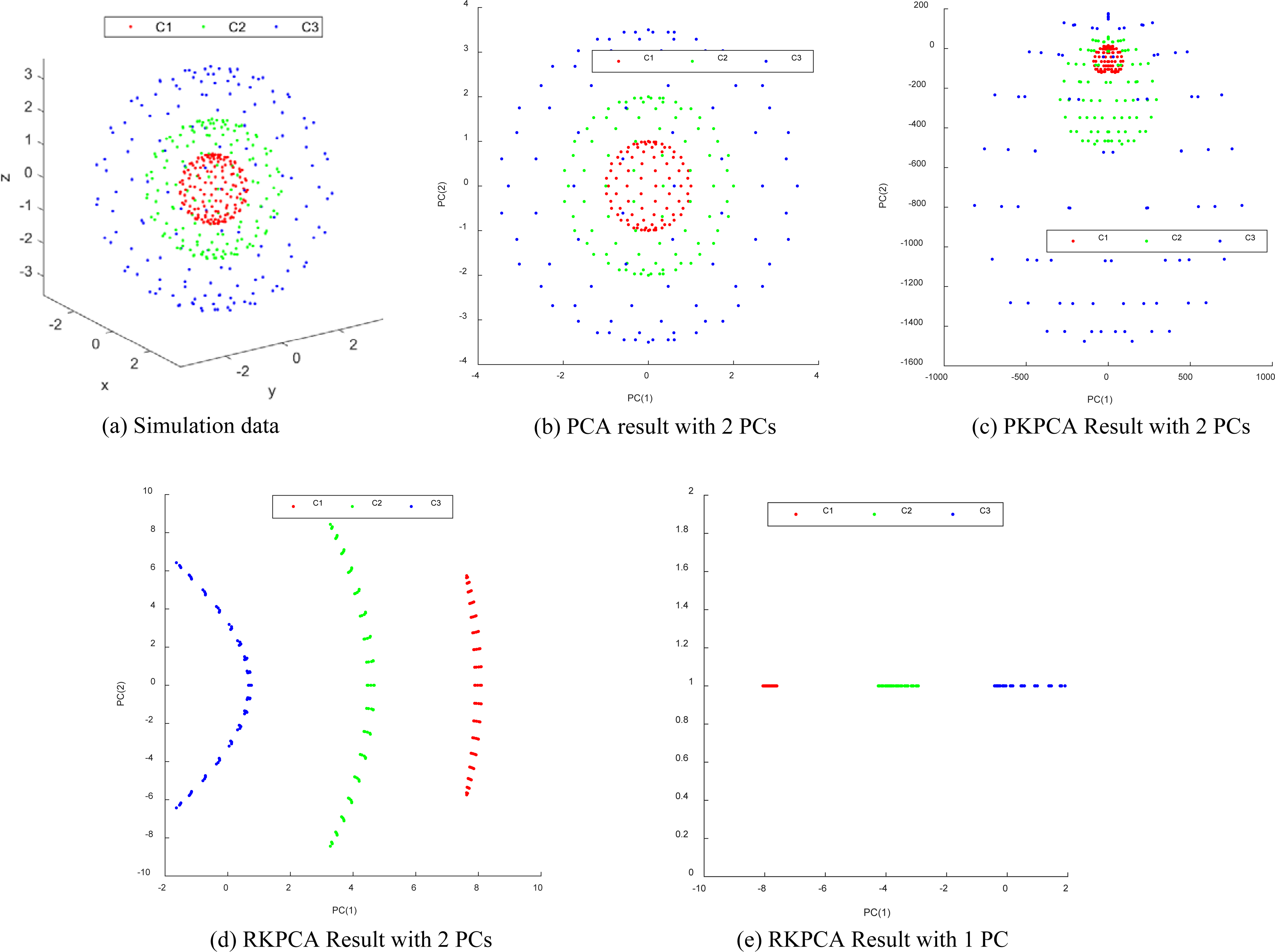
The matrix size of the application of PCA
Table 2 shows the original size of the simulation data as 1083*3, after different types of PCA, the data can be reduced to either 1083*2 and 1083*1.
Linear separability (X means inseparable,
In the experiment, our method used the following setting by the grid searching method. We used three-level DDDTCWT and used RKPCA with threshold of 99% of total variance. Our results were compared to eight state-of-the-art approaches. The 10 repetitions of 10-fold cross validation were used. The overall accuracy was used as the measure.
Decomposition of DDDTCWT
Take the photo in Fig. 3c as an example, we show its 1-level and 2-level DDDTCWT results in Figs 12 and 13, respectively. In each figure, the first column shows the real part of tree 1, the second column shows the imaginary part of tree 2, the third and last column shows the real and imaginary part of tree 2, respectively. Obviously, each level decomposition will generate 32 sub-bands (eight orientations multiplied by two trees multiplied by two parts).
One-level DDDTCWT decomposition.
Two-level DDDTCWT decomposition.
Considering the dataset sample is small, the cross validation was employed to validate the proposed method. The 10
10 runs of 10-fold stratified cross validation
10 runs of 10-fold stratified cross validation
The sensitivities of each class based on 10 runs are offered in Table 5. Here we see the LSHL has a sensitivity of 96.67
Table 6 gives the overall accuracy based on 10 runs. It shows that our method achieves an average accuracy with value of 96.44
Sensitivities of each class (unit: %)
The overall accuracy (unit: %)
We tested the performance of DWT, DTCWT, and DDDTCWT, and let their corresponding decomposition level (
Overall accuracy of different decomposition levels and different feature extraction methods (Unit: %)
Overall accuracy of different decomposition levels and different feature extraction methods (Unit: %)
Select the best feature extraction method and the optimal decomposition level.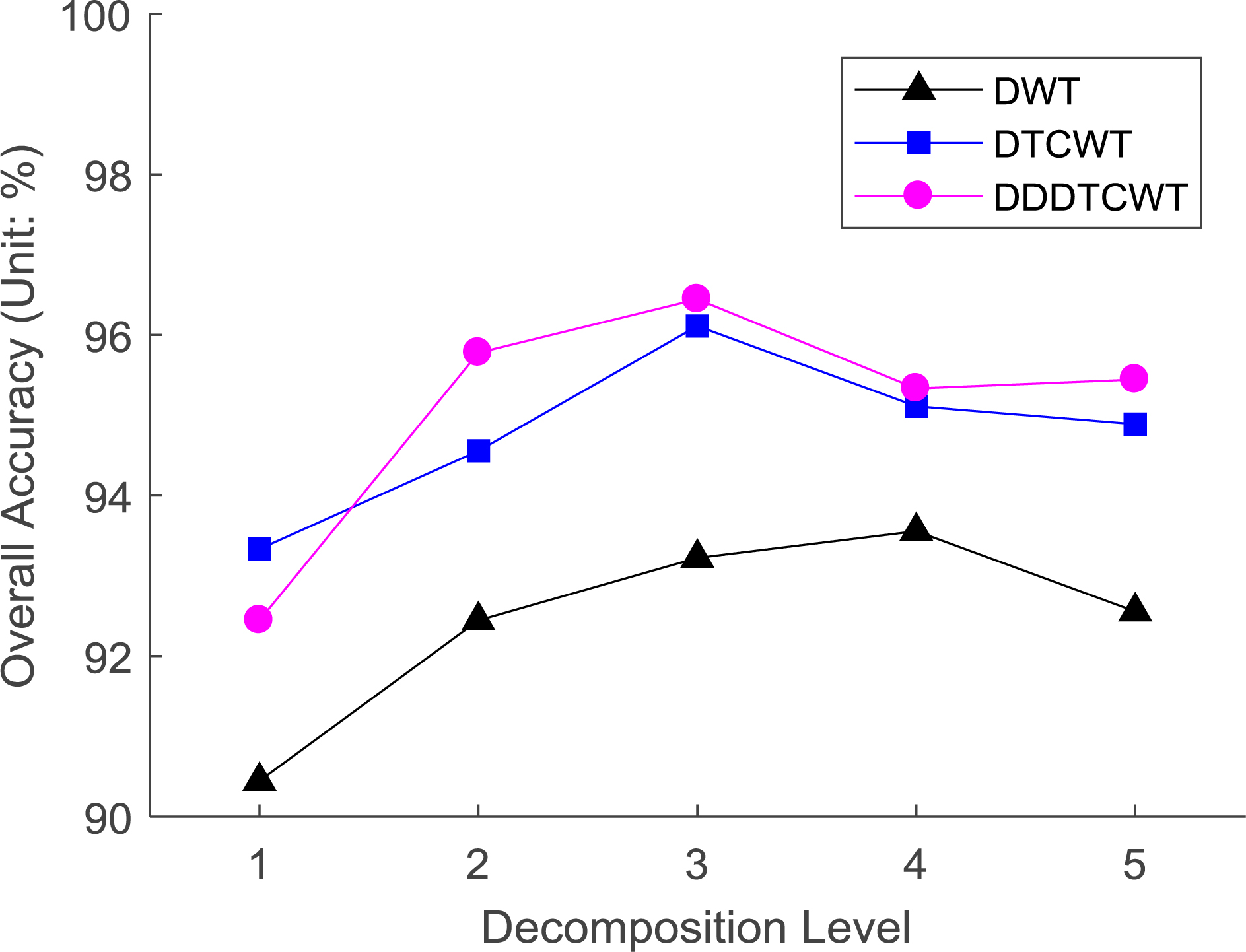
Figure 14 shows the overall accuracy under different decomposition levels and different feature extraction methods. As is seen, the best decomposition level for DWT is 4, and the best decomposition level for DTCWT and DDDTCWT are three. The reason may be two folds: On one hand, more decomposition level will give better analysis of the brain image. On the other hand, too large decomposition level will introduce calculation error, thus decreasing the performance. In all, we found from Fig. 14 that 3-level DDDTCWT achieves the highest overall accuracy than other settings.
In this experiment, we compared PCA, PKPCA and RKPCA at different thresholds (
Overall accuracy of different feature reduction methods with different threshold setting
Overall accuracy of different feature reduction methods with different threshold setting
Figure 15 shows that the optimal feature reduction method is to use RKPCA with threshold as 0.99. The superiority of RKPCA to PCA and PKPCA is in line with the simulation result in Section 7.3. The RKPCA has a better capability of mapping data from linear space to nonlinear space, so as to unwrap the interwoven data.
In this experiment, we compared the MLR with other commonly used classifiers, including C5.0 decision tree (DT), support vector machine (SVM) [53], and back propagation neural network (BPNN) [54]. The features were obtained by (i) three-level DDDT CWT, and (ii) RKPCA with threshold of 99% of total variance. The overall accuracy of 10
Classifier comparison
Classifier comparison
Select the best feature reduction method with optimal threshold.
The overall accuracy results of different classifiers in Table 9 show that our MRL method got the best overall accuracy, and the least standard deviation (only 0.88), although it is a rather old technique. In addition, the SVM obtained an overall accuracy of 94.11
Currently, MLR is also widely applied in the last layer of the convolutional neural network, which is the most successful tool in the field of deep learning. Therefore, we cannot refer SVM is better or MLR is better without considering the exact problems. In this paper, we applied the algorithm to a multi classification problem. According to the test based on our dataset, the MLR outperforms the SVM.
Statistical analysis (Unit: %)
Statistical analysis (Unit: %)
Table 10 shows the accuracy performed by AlexNet (raw), AlexNet (improved) and our proposed method. In order to validate our proposed method, we test the statistical significance for our method. The
In this experiment, we compared our method with AlexNet [58], which is a well-pretrained 25-layer neural network in the field of deep learning. The AlexNet model in Matlab is trained on a subset of ImageNet database, and it can classify 1000 object categories (for instance, pencil, mouse, keyboard, etc.). We invoked the model by Matlab command of “alexnet” and compared with our method. The parameter settings were the same as previous sections. The raw AlexNet [58] and improved AlexNet [59] are both tested in this experiment. The improved AlexNet retrains the last three layers.
Comparison to AlexNet
Algorithm comparison based on 10-fold cross validation over our 90-image dataset
Here we see that raw AlexNet [58] gives an overall accuracy of only 93.11%, and the improved Alex-Net [59] yields an overall accuracy of 95.22%. Both methods perform less than our MLR method of 96.44%. The reason is three folds. First, the raw AlexNet [58] is pretrained to identify natural images, and our MLR method is trained particularly to accomplish the hearing loss identification task. Second, raw AlexNet [58] can identify 1000 types of objects, but none of them are brain magnetic resonance images. Third, retraining AlexNet [59] usually needs a median-size dataset, but our 90-image dataset is too small in terms of size, due to the difficulty of collecting more medical data. Therefore, our method can give better performance than both raw and fine-trained pretrained CNN. This suggests that hand engineering is still quite important in classification on small-size dataset.
Table 12 offers our proposed method with eight methods: FRFT
The comparison results in Table 12 show that our proposed DDDTCWT
As three main advantages of DDDTCWT are summarized in Patil et al. [37]: (i) double-density wavelets; (ii) directional-selectivity; (iii) shift-invariance. Those advantages guarantee that DDDTCWT will provide better performances than either DWT or DTCWT.
Time analysis
We used our trained classifier on 1000 new brain images and calculated the average time. The computation time on CPU and GPU at each stage is listed in Table 13.
Time analysis for predicting a new brain image
Time analysis for predicting a new brain image
This experiment aimed to seek the optimal slice from
Overall accuracy changes with selected slice.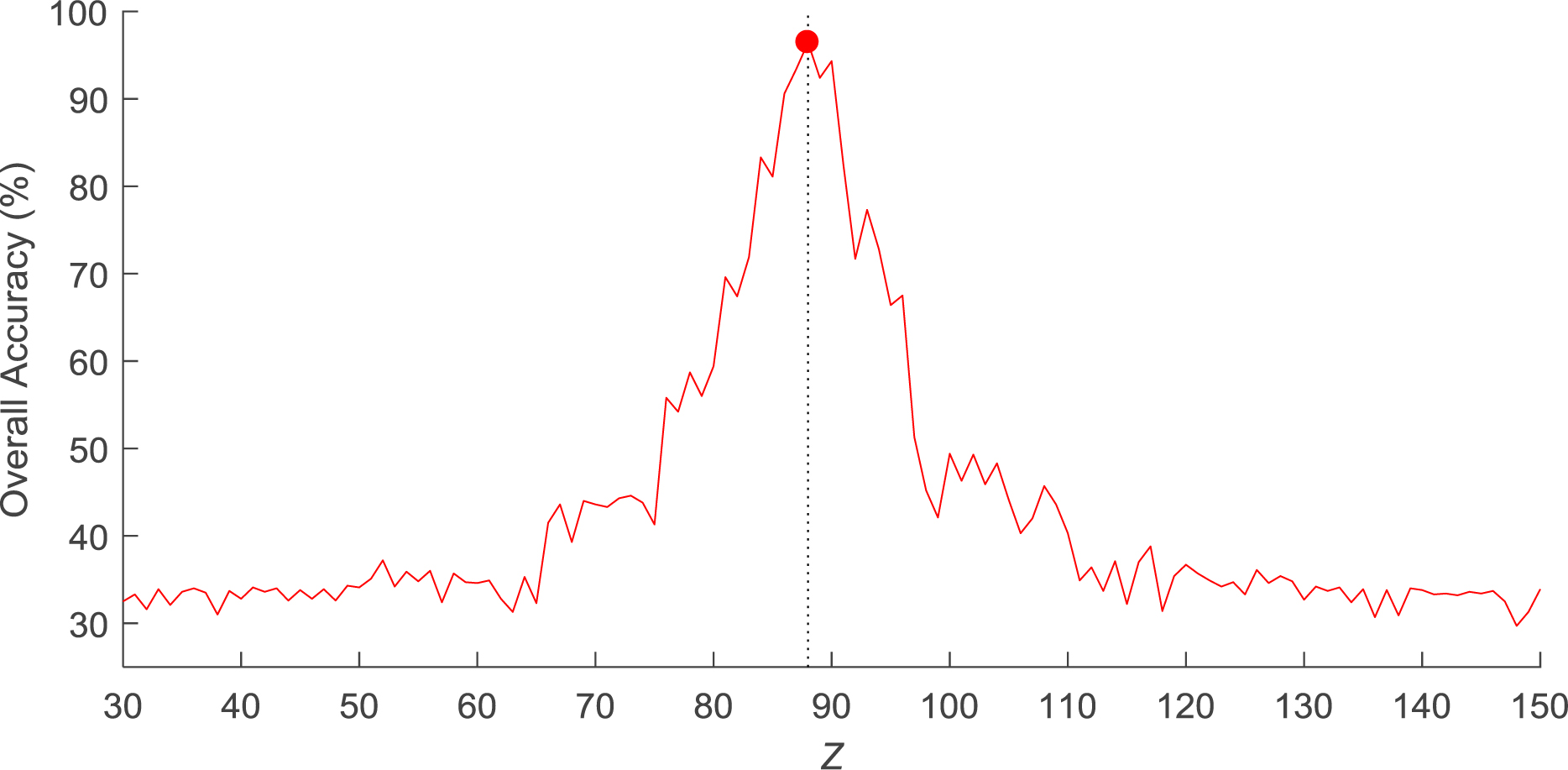
Here we can see from Fig. 16 that, 88-th slice achieves the highest overall accuracy. This is in line with the result suggested by experienced radiologists. It indicates that 88-th slice contains the most distinguishing brain tissues between left hearing loss, right hearing loss, and healthy control. The lobe containing 88-th slice shows that the neighboring slices of 88-th slice also contribute to the identification but are not as efficient as 88-th slice. For those slices far away from 88-th slice, the overall accuracy decreased to 33.3%, which is the overall accuracy for a random-guess classifier for a three-class task.
Nevertheless, the optimal slice may be chosen vertical to
In this study, we proposed a novel unilateral sensorineural hearing-loss detection method, which can identify left-sided hearing loss and right-sided hearing loss from healthy controls. Our method is based on three successful techniques: double-density dual-tree complex wavelet transform, kernel principal component analysis, and multinomial logistic regression. The results showed our method is superior to both raw and improved AlexNet, and eight state-of-the-art approaches.
In the future, we may apply our method to other brain disease detection, such as Alzheimer’s disease and Parkinson’s disease, etc. Other research directions contain multi-slice processing and surface analysis.
Footnotes
Acknowledgments
This paper was supported by Natural Science Foundation of China (61602250), Natural Science Foundation of Jiangsu Province (BK20150983, BK20150982), Program of Natural Science Research of Jiangsu Higher Education Institutions (16KJB520025), and the MIN ECO under the TEC2015-64718-R project, the Salvador de Madariaga Mobility Grants 2017 and the Consejería de Economía, Innovación, Ciencia y Empleo (Junta de Andalucía, Spain) under the Excellence Project P11-TIC-7103.