
Abstract
As a fundamental task in cluster analysis, community detection is crucial for the understanding of complex network systems in many disciplines such as biology and sociology. Recently, due to the increase in the richness and variety of attribute information associated with individual nodes, detecting communities in attributed graphs becomes a more challenging problem. Most existing works focus on the similarity between pairwise nodes in terms of both structural and attribute information while ignoring the higher-order patterns involving more than two nodes. In this paper, we explore the possibility of making use of higher-order information in attributed graphs to detect communities. To do so, we first compose tensors to specifically model the higher-order patterns of interest from the aspects of network structures and node attributes, and then propose a novel algorithm to capture these patterns for community detection. Extensive experiments on several real-world datasets with varying sizes and different characteristics of attribute information demonstrated the promising performance of our algorithm.
An social example of attributed graph.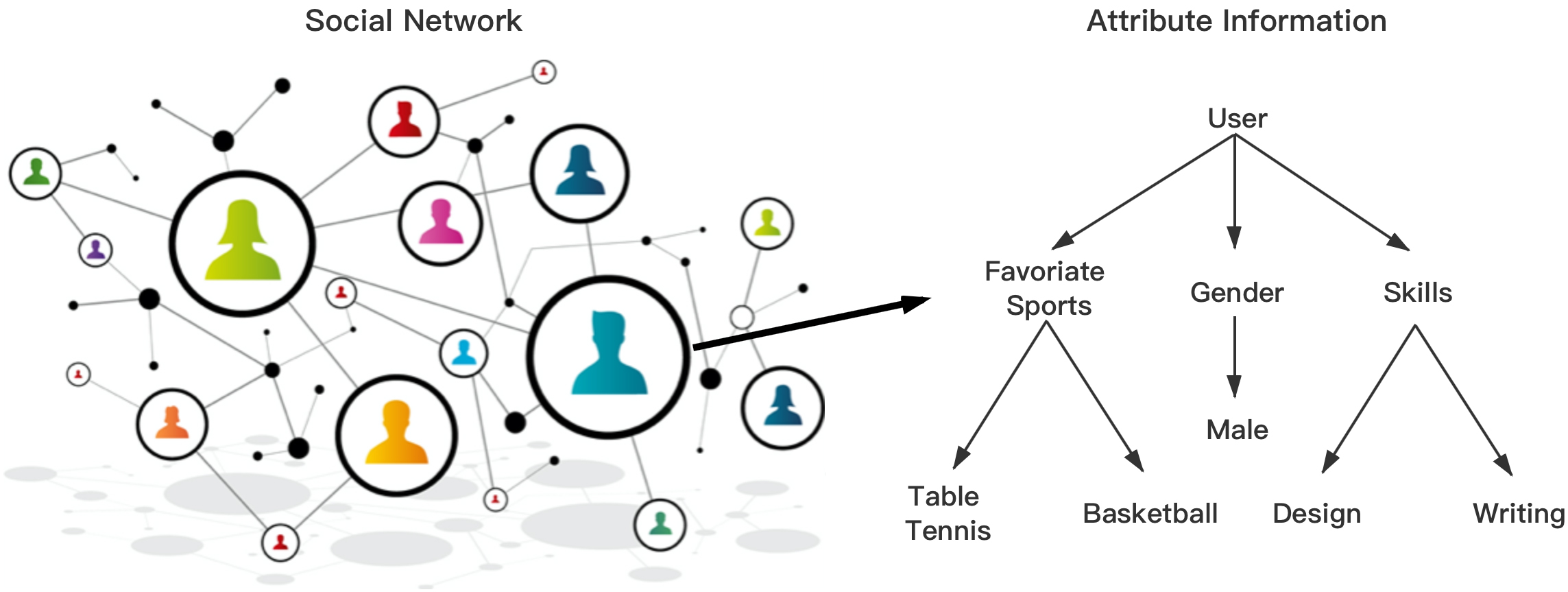
A graph consists of nodes that represent individual objects and edges that connect nodes to describe the relationship between them [6, 26]. In many practical applications, graphs are normally used to represent complex network systems and have been widely applied to many practical applications, such as membrane computing [9, 31], disease diagnosis [17, 18], and industrial system solutions [19, 20]. With the rapid development of information technology, the network sizes increase very quickly, and there is also a concomitant increase in the richness and variety of attribute information of nodes. Taking social networks as an example, the user-generated content provides us an alternative way to characterize users, thus facilitating the analysis of social communities [7, 25]. Another example can be found in protein-protein interaction networks, where the functional attributes of proteins are useful to the understanding of biological mechanisms [12, 15]. A formal representation to describe such networks is attributed graph.
Two sources of information are available in an attributed graph. One is the structural, or topological, information of graph and the other is the attribute information of nodes in that graph. In particular, the structural information of graph is represented by the set of links between nodes while the attribute information of nodes is the rich content associated with nodes, such as the user-generated content in social networks and the functional attributes of proteins in protein-protein interaction networks. An example of attributed graph is presented in Fig. 1, where the social network on the left side denotes the structural information describing the topology of that attributed graph while the user profiles on the right side denotes the attribute information associated with each of users. As has been pointed out by [21, 32], community analysis has been increasingly used for social, ecological, and other networks. However, regarding the problem of community detection in attributed graphs (CDAG), new challenges have thus been raised, as there is a necessity for us to take into account of these two sources of information simultaneously. Motivated by the intuition that nodes in the same community should be similar in terms of both structure and attribute information [27], certain attempts have thus been made to solve the CDAG problem and most of them are either distance-based or model-based.
Distance-based algorithms generally compose an augmented graph by introducing virtual links to connect nodes and their attribute values, and then design different distance metrics so that conventional clustering algorithms, such as Markov and K-Medoids clustering, can be explicitly applied to detect communities in that augmented graph. Based on both structural and attribute similarities through a unified distance measure, SA-Cluster [36] partitions a given attributed large into a set of clusters each of which is a densely connected subgraph where attribute values are homogeneous. In [1], the correlation between attribute sets and dense subgraphs is measured by the proposed statistical significance measures. CODICIL [37] introduces a measure of signal strength between two nodes in the network by fusing their link strength with content similarity and then prunes edges that are locally irrelevant for each node so that standard community discovery algorithms can be applied. Combining the content relevance and network structures, FCAN [14] allows the detection of overlapping communities. As a recent attempt in this direction, SToC [2] composes a new heterogeneous distance measure from an alternative view and performs the clustering task for attributes graphs based on bottom-k sketches and traditional graph-theoretic concepts.
Compared to distance-based algorithms, model-based ones consider the detection problem from an alternative view such that the design of specific distance measures can be avoided. In particular, a variety of Bayesian models are proposed to simulate the generative process of an attributed graph and the set of communities that most likely generate the given attributed graph is considered as the final solution for the task of community detection. In [29], a discriminative model is developed to alleviate the impact of irrelevant content attributes such that the link and related content analysis can be combined for community detection. As an accurate and scalable algorithm to solve the CDAG problem, CESNA [10] constructs a statistic model to simulate the interaction between the network structure and the node attributes, thus improving robustness in the presence of noise. To seamlessly handle different types of edges and node attributes, GBAGC [38] provides a general and principled framework and develops an efficient variational method for community detection under this framework. In [34], two models, namely the node-information involved mixed-membership model and the node-information involved latent-feature model, are developed to systematically incorporate additional node information and the efficiency of these two models is improved by using conjugate priors. Recently, motivated by the fact that node attributes have different contributions to the formation of communities, a three-layer node-attribute-value hierarchical structure is introduced by [13] to describe the attribute information in a flexible and interpretable manner and then TARA is proposed to solve the optimization problems for community detection.
However, existing algorithms are constrained only for the clustering consistency between pairwise nodes. More specifically, distance-based algorithms introduce a variety of measures to compute the similarity of two nodes in the augmented networks, while model-based algorithms rely on the difference in the probability of belonging to the same community between pairwise nodes when sampling their links and respective attribute values. Yet one should note that emphasizing the close similarity between pairwise nodes cannot guarantee the highly desirable consistency in both structure and attribute information to the other nodes in the same community, especially for many real-world applications, whose attributed graphs often suffer from the shortcomings of sparse structures and dispersed distributions of attribute values [3, 35]. Obviously, there is a necessity for us to consider the higher-order tensor patterns involving more than two nodes from the aspects of network structures and node attributes for improving the performance of detecting communities on the CDAG problem.
Recently, due to the ability of representing higher dimensional structure of data, tensor models are preferred to capturing the higher-order connectivity patterns in network data at the level of small subgraphs, or network motifs [4]. For a particular network motif, the clustering framework proposed by [5] is able to detect communities each of which is composed of many instances of that motif. Generalizing from spectral clustering based on random walks, GTSC [30] designs a new stochastic process that models higher-order Markov chains, namely superspacey random walk, to simultaneously clusters the rows, columns, and slices of a non-negative three-mode tensor. By viewing tensors with hypergraphs, the co-clustering algorithm proposed by [8] partitions the corresponding hypergraph based on the random sampling technique.
However, few of them can be applied to address the CDAG problem, as the incorporation of attribute information into the higher-order patterns largely remains an open issue. In this paper, we extend previous works [4, 5] to attributed graphs and propose a novel Tensor-based cOmmunity Detection Algorithm (TODA) for efficiently detecting communities based on higher-order patterns available in the structure and attribute information of attributed graphs. Our contributions can be summarized as follows.
We specifically design the higher-order patterns from the aspects of network structures and node attributes, and formulate the CDAG problem as tensor spectral clustering for attributed graphs by modeling these patterns as tensors. We then present our TODA algorithm to solve the CDAG problem by adopting the theory of spacey random walk, and also introduce a few heuristics to achieve a more efficient performance when applying TODA to large attributed graphs.
Preliminaries
Here, an attributed graph is represented with a 3-element tuple as:
where
Given an arbitrary attribute
For simplicity, we use upper-case underlined boldface letters to denote tensors and the same non-bold lower-case underlined italic letters stand for their entries. For instance, a three-mode tensor can be denoted as
The CDAG problem to be addressed in this paper is to partition
In our TODA algorithm, the CDAG problem is formulated as a
Tensor representation of higher-order patterns
Regarding the higher-order patterns about
where
A triangle motif can be observed among the nodes
Unlike most of existing algorithms that require a conversion from multi-valued attributes to binary attributes in advance, the use of tensor allows us to preserve the similarity information for each of attributes in
In Eq. (3.1), the case of
Since all entries in
where
where
With respect to Eq. (7),
However, in many practical applications, the instances of
Hence, regarding
where
and
Since
Two different stochastic processes. (a) regular second-order Markov chain; (b) spacey random walk process.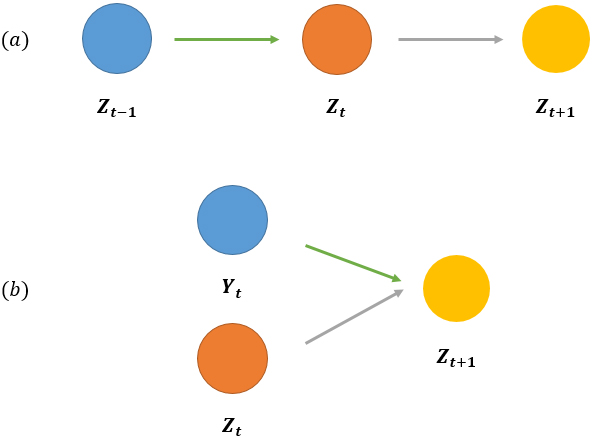
We now describe the stochastic process by following the theory of spacey random walk proposed by [30, 5]. Generally speaking, in the spacey random walk process, once the process visits
where
where
One should note that the state
To approximate the second-order Markov chain defined by Eq. (6), an equivalent first-order Markov chain can be derived from the stationary distribution of the spacey random walk by following a procedure in [30]. Assuming that M and x are the transition matrix of the first-order Markov chain and the corresponding stationary distribution respectively, the equations of M and x are then given by
where
Hence, we can use the iterative fixed-point algorithm to yield
Since
Given that
When we evaluate the partition
In particular, the value of
Regarding the quality of
According to Eq. (22), the value of
Concerning the attribute preferences in forming communities, the overall attribute conductance, denoted as
Heuristically, if we only consider the attribute information,
Once we obtain
One should note that the definitions of
For each node
A Complete Description of TODA[1]
When computing the conductance with Eq. (26), we find that it takes
For two continuous partitions
One should note that since attributed graphs are undirected, then we have
In this regard, there is no need for us to compute
Similarly, we can also update
For each iteration that partitions
Experiment results
To evaluate the performance of TODA, we have performed a series of extensive experiments on two practical applications, including document classification and social community detection. TODA was compared with several state-of-the-art algorithms specifically developed for solving the CDAG problem and they were CODICIL [37], CESNA [10], GBAGC [38], niMM [34] and Fuzzy c-means (FCM). Among them, CODICIL is a distance-based algorithm while CESNA, GBAGC and niMM are model-based. Moreover, we also selected a classical clustering algorithm, i.e., FCM, for comparison, as it can be used to define a baseline performance level. Regarding the implementation of FCM, we adopted the Euclidean distance measure to calculate the distance between pairwise nodes in the domain of
Evaluation metrics
To determine to what extent the communities detected by the different algorithms matched with the ground truth, we adopted two evaluation metrics, NMI and Accuracy. The reason why these two metrics were chosen is that they are both very widely used to evaluate performance of clustering algorithms [10, 14].
NMI is an acronym for
where
As for the Accuracy measure, we need to find the mapping function
According to the definitions of NMI and Accuracy, their values are larger if the communities detected from
To ensure that algorithms were compared at their best performances, parameters that had to be determined for them to work properly were set to the values recommended by the authors. For algorithms without such recommendation, their performances were tuned to respond best for the tasks. Regarding the parameter setting of TODA, we set the teleportation probability vector u with uniform distribution. Regarding the value of
All algorithms were run in exactly the same computation environment on the same machine equipped with Intel Dual-Core Processors at 2.20GHz and 16 GB of RAM.
The purpose of document classification is to classify documents into different topics. Given a collection of unlabeled documents with available link and attribute information, we attempt to apply clustering algorithms to identify clusters that are highly correlated with the true groups of the documents.
Experiment setup
Two classical datasets were used to compare the performance of TODA with state-of-the-art algorithms, one was the Cora dataset and the other was the Citeseer dataset. These two datasets were obtained from LINQS1 and they represented two different citation networks where nodes were scientific publications and links were added between nodes if one was cited by the other one [24]. The properties of these two real networks are described in Table 1.
Statistics of Cora and Citeseer datasets
Statistics of Cora and Citeseer datasets
*
For the Cora dataset, each document was classified into one of the seven categories including Case-based Reasoning, Genetic Algorithms, Neural Networks, Probabilistic Methods, Reinforcement Learning, Theory and Rule Learning. The keywords of each publication were obtained from a dictionary of 1433 unique words and they were considered as the values of the single attribute for the corresponding node.
For the Citeseer dataset, all the documents were classified into six categories including Agents, Artificial Intelligence, Database, Information Retrieval, Machine Learning and Human-Computer Interaction. When compared with the Cora dataset, the number of keywords involved in the Citeseer dataset was much larger, as the keywords were obtained from a dictionary of 3703 unique words.
After applying all the algorithms to the Cora and Citeseer datasets, the experiment results are reported in Table 2.
Community detection performances on document classification
Community detection performances on document classification
* Best scores are highlighted by bold face.
For the Cora dataset, in terms of NMI, TODA yielded the best score, as it performed better by 10.8% than CODICIL, which was the second best algorithm. Although the Accuracy score of TODA was not as good as NMI, TODA was still among the top three algorithms. We also noted that GBAGC and niMM yielded small NMI scores. That is to say, these two algorithms had only limited ability to distinguish the documents in different categories. Regarding the performances of algorithms on the Citeseer dataset, TODA was the best algorithm in terms of both NMI and Accuracy.
Another point worth to noting is that CESNA performed better than TODA in terms of Accuray on Cora dataset. After investigation into clustering results, we found that CESNA did not classify all documents, as the average rate of rejection was as high as 37% for Cora and Citeseer datasets. That is to say, CESNA only considered the documents that were easy to classify to perform its clustering task. It is for this reason that CESNA performed better than TODA in terms of Accuracy on Cora dataset. We also noted that TODA obtained a better performance than CENSA on Citeseer dataset. That is to say, even CESNA disregarded many documents during the clustering, its performance was not as good as that of CESNA. Since the Citeseer dataset was sparser than Cora dataset, we may reason that CESNA is more sensitive to the sparsity of attributed graph.
The purpose of social community detection is to identify meaningful communities from social networks. In this experiment, we applied TODA to two different social networks extracted from Facebook and Twitter respectively and discussed its performance as follows.
Experiment setup
The social networks of Facebook and Twitter are available for download from the Stanford Large Network Dataset Collection.2 The characteristics of these social datasets are presented in Table 3, where we could observe that the networks composed from social datasets were much larger and sparser than those obtained from the datasets of document classification. For the Facebook dataset, a set of total 27 profile attributes were extracted and the amount of possible values that could be taken by these attributes were 1406. In the Twitter dataset, a total of 33569 hashtags annotated by users in their tweets were considered as the possible attribute values for the single attribute associated with nodes.
Statistics of Facebook and Twitter Datasets
Statistics of Facebook and Twitter Datasets
Compared with the ground truth of these three social datasets, McAuley and Leskovec [11] extracted clusters from the ego-networks of different users in the respective social networking sites. The ego-network of a single user was defined as a personal social network. Given such an ego-network, several social circles could be identified as a subset of friends and the ego-network, and they were then processed further to obtain hand-labeled ground truth clusters.
For the Facebook dataset, TODA and CESNA, respectively, obtained the best Accuracy and NMI scores as indicated by Table 4. We noted that the Accuracy score of TODA was better by 17.4% than that of CESNA, but the difference in NMI between TODA and CESNA was rather small. Hence, the overall performance of TODA was believed to be better than that of CESNA.
Community detection performances on social networks
Community detection performances on social networks
* Best scores are highlighted by bold face.
When comparing the performances of all algorithms in Twitter dataset, we observed from Table 4 that the strong performance of TODA in terms of both NMI and Accuracy. In particular, the Accuracy score of TODA was better by 21.1%, 6.2%, 9.5%, 32.7% and 19% than CODICIL, CESNA, GBAGC, niMM and FCM respectively. For the NMI measure, TODA presented a significantly bigger margin against the other algorithms, as it outperformed them by 51% on mean. Moreover, CESNA rejected to detect the communities for around 18% of nodes in the Facebook dataset. It is for this reason that CESNA performed better than TODA in terms of NMI on Facebook dataset.
Lastly, we also performed the Wilcoxon test to verify the significance in the difference of NMI and Accuracy scores. The results indicated that the differences between TODA and all the other algorithms except CESNA were significant at 95% confidence interval.
In sum, we have reason to believe that the strong performance of TODA was an indication to the rationality behind the use of higher-order patterns in the structure and attribute information of attributed graph.
Comparison of running time between TODA and the other algorithms was conducted for all the datasets used in the experiments and the results were provided in Fig. 3.
The comparison of running time for all algorithms.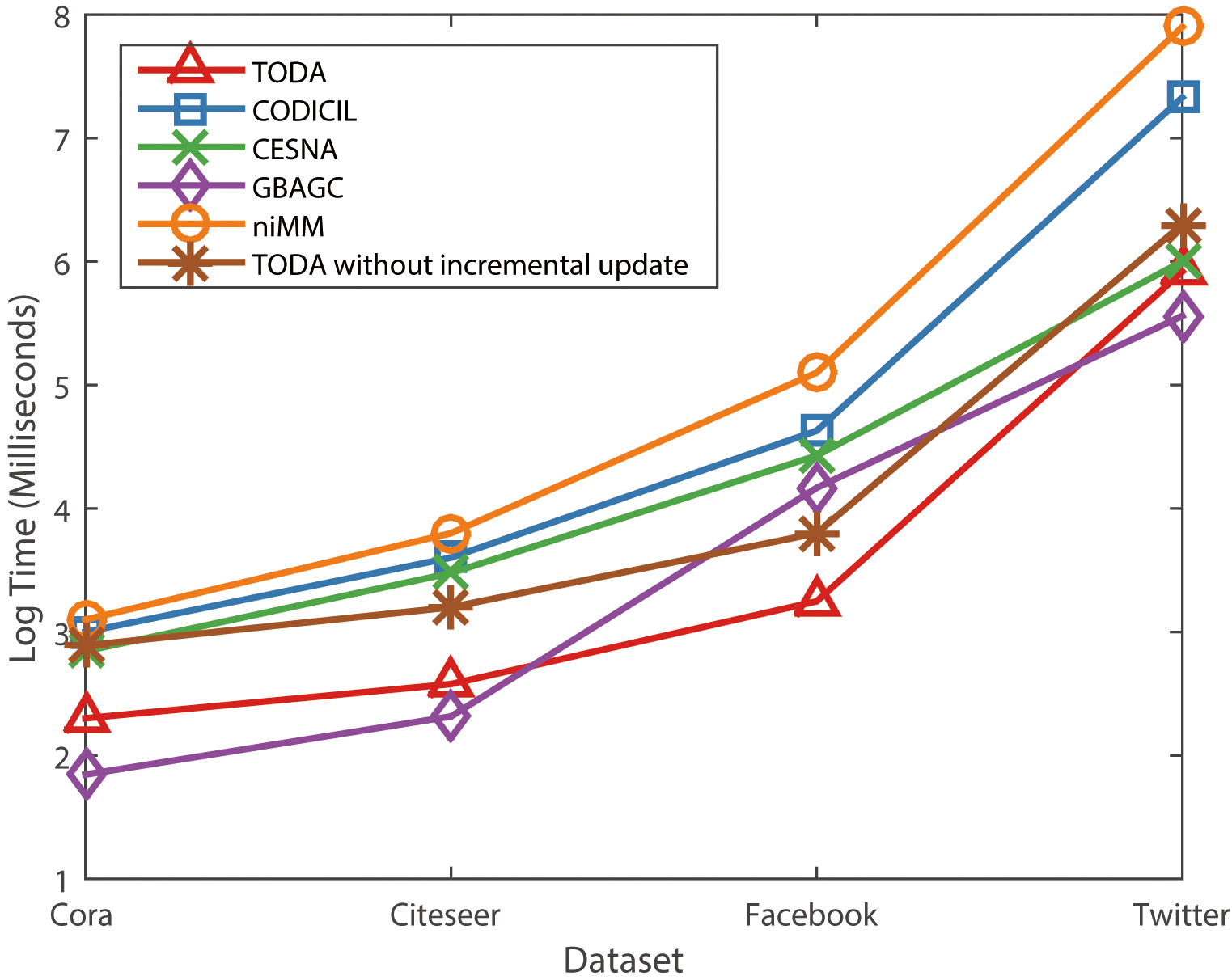
For the datasets with small sizes (i.e., Cora and Citeseer), we noted that although the performance of GBAGC was not as accurate as the other algorithms, GBAGC was the fastest. However for the Facebook dataset, even the number of nodes was comparable to that of the Citeseer dataset, we found that the increase in the running time between these two datasets was much larger. The reason for that was that the number of edges in the Facebook dataset was considerably more than that of Citeseer. That is to say, GBAGC took much more time to simulate the generative process of edges, thus increasing the overall running time.
Regarding the running time used by niMM, it was more sensitive to the increase in the network size, as it spent much longer time than the other algorithm when applied to networks with large sizes.
For TODA, it was seen that TODA was always among the fastest two algorithms. Especially for the Facebook dataset, TODA yielded the best performance. From the curve of TODA in Fig. 3, we noted that the impact resulted from the increase in
To better demonstrate the advantages of TODA, we selected a community detected by TODA from the Twitter dataset and gave an in-depth explanation.
A community detected by TODA from the Twitter Dataset.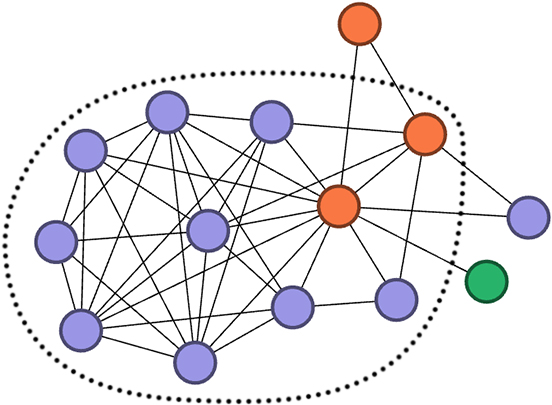
In Fig. 4, we show the topological structure of a ground truth community in the circle with ID 189875309 from the Twitter dataset. After investigating the corresponding community detected by each of the algorithms, we found that only TODA exactly detected this community whereas most of the other algorithms was only able to detect the part in the dashed circle. identified the part inside the dotted red circle. Nodes in the dashed circle were connected much more densely when compared to those outside the dashed circle. It is for this reason that all algorithms except TODA only detected the part in the dashed circle. However, since TODA considered the higher-order patterns involving three nodes, we noted that the three red nodes actually formed a triangle motif that could be captured by TODA according to the definition of
We also noted that the green node was not able to compose a triangle motif, as it only had one neighboring node. That is to say, solely resting on the structure information was insufficient for us to detect the community of the green node. However, if we took into account of the attribute information, we found that the green node shared three attribute values with the other two nodes. This value was relatively higher than the entries in the attribute tensor that involved the other nodes in Fig. 4. Hence, we have reasons to believe that the green node was more likely in the community of Fig. 4 and accordingly TODA successfully detected this ground truth community. This case, again, demonstrated the importance of considering higher-order patterns from the structural and attribute perspectives when detecting communities from attributed graph.
In this work, we proposed a novel community detection algorithm, i.e., TODA, for attributed graphs by considering higher-order patterns, which are able to enhance the internal consistence in terms of both structural and attribute information for more than two nodes (i.e., three nodes in our work). In doing so, the accuracy performance of community detection can be improved as indicated by the experiment results of TODA. Moreover, the existence of higher-order patterns in the structure and attribute information allows TODA to correctly detect the communities for peripheral nodes that are not connected as dense as those in the core parts of communities. Last but not least, in order to address the CDAG problem, TODA explores the possibility of elaborating the intrinsic correlation between communities and higher-order patterns, and also is able to extract semantically meaningful communities by incorporating the attribute information of nodes.
As there are so many different structures, such as rectangle and pentagon motifs, we would like to extend our TODA algorithm to the connectivity patterns beyond three-order as one of our future works. We are also interested to verify whether the performance of TODA can be further improved if different kinds of connectivity patterns, or their combinations, are taken into account. Lastly, considering the simplicity and efficiency of probabilistic neural network [20, 22], we would like to integrate higher-order patterns into a neural dynamic classification model [23] for an improved performance of community detection.
Footnotes
Acknowledgments
This research is supported in part by the National Natural Science Foundation of China under grants 61602352 and 61802317, and in part by the Pioneer Hundred Talents Program of Chinese Academy of Sciences.