
Abstract
Graph clustering is a crucial technique for partitioning graph data. Recent research has concentrated on integrating topology and attribute information from attribute graphs to generate node embeddings, which are subsequently clustered using classical algorithms. However, these methods have some limitations, such as insufficient information inheritance in shallow networks or inadequate quality of reconstructed nodes, leading to suboptimal clustering performance. To tackle these challenges, we introduce two normalization techniques within the graph attention autoencoder framework, coupled with an MSE loss, to facilitate node embedding learning. Furthermore, we integrate Transformers into the self-optimization module to refine node embeddings and clustering outcomes. Our model can induce appropriate node embeddings for graph clustering in a shallow network. Our experimental results demonstrate that our proposed approach outperforms the state-of-the-art in graph clustering over multiple benchmark datasets. In particular, we achieved 76.3% accuracy on the Pubmed dataset, an improvement of at least 7% compared to other methods.
Introduction
Deep neural networks such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have demonstrated remarkable performance in dealing with traditional Euclidean-structured data, such as images, text, and video. However, in practical applications, the relationships between objects are intricate and complex. They are naturally represented as graphs, with each node containing a wealth of attribute information. Graph clustering is a fundamental technique for identifying dense subgraphs within a given graph. The objective of this technique is to classify graph data into distinct clusters, wherein nodes within the same cluster are structurally closely connected and exhibit as many similarities in node attributes as possible, while nodes in different clusters are distant from each other and exhibit as little similarity in attribute features as possible. Graph clustering has been extensively applied in various domains, including personalized recommendations, disease analysis, link prediction, community detection, face clustering, target detection, information retrieval, image segmentation, and contrast learning. Therefore, the development and implementation of graph clustering algorithms have gained considerable attention among researchers.
Traditional clustering algorithms such as subspace clustering networks [1], fuzzy number data clustering [2], evidential clustering [3], density-based clustering [4], and extended clustering [5] are unsuitable for graph structures. To overcome this limitation, Graph Neural Networks (GNNs) have been developed as an effective solution.
There has been a proliferation of graph clustering algorithms based on GNNs over the years, covering a wide range of techniques such as sparse autoencoder-based graph clustering algorithms [6], random walk-based graph clustering algorithms [7], and non-negative matrix decomposition-based graph clustering algorithms [8]. These algorithms prioritize the graph topology, which is essential for identifying dense subgraphs within a given graph. However, in practical applications, relationships between objects are intricate and complex, with each graph node containing a wealth of attribute information. The presence of attribute information necessitates considering both graph topology and node attributes, leading to a significant challenge in the implementation of attribute graph clustering.
In response to this challenge, Wang et al. [9] proposed the deep attention embedded graph clustering approach DAEGC, which is a goal-directed learning method that enables graph embedding and self-training processes to be learned together within the unified framework. Weng et al. [10] use lightweight attention mechanisms to capture the relationships between nodes and their neighbors. More recently, Peng et al. [11] integrated a deep autoencoder (DAE) and a graph convolutional network (GCN) [12] to extract node attribute information and topology information simultaneously. Also, they proposed a deep attention-guided graph clustering method with dual self-supervision to improve the clustering performance [13]. These methods demonstrate the potential of combining topology and attribute information to improve the accuracy and efficiency of graph clustering.
Although the aforementioned methods successfully integrate both structure and attribute information, their effectiveness is still limited by certain factors. As the utilization of these two types of information may not be comprehensive enough, those methods show suboptimal clustering results, which become more apparent with large graphs. Therefore, there is a need to explore more advanced and efficient methods that can address these limitations and improve the overall performance of attribute graph clustering.
To overcome the limitations of existing attribute graph clustering algorithms, we proposes a novel approach that combines the transformer and graph attention self-encoder. Building on the work of DAEGC, our algorithm employs the graph attention autoencoder to generate robust node embeddings by leveraging both the graph topology and node attribute information. Specifically, the graph attention autoencoder is employed to encode graph structure and node attributes into a latent space. Subsequently, the obtained node embeddings are further refined by a Transformer. The clustering effect is optimized via clustering loss and reconstruction loss. Notably, compared to DAEGC, this paper has been improved in the following ways.
We introduce Mean Squared Error (MSE) loss into the model to improve the quality of the reconstructed graphs, and incorporate L2-Norm Normalization and layer normalization techniques to ensure smoother attention coefficients and stable feature distributions across the data. We employ the Transformer to refine the node embedding feature information obtaind from the encoder to improve clustering performance. By conducting comparative experiments, the results demonstrate that our proposed method is highly competitive for attribute graph clustering.
Attribute graph clustering
The significance of research in attribute graph clustering is highlighted by its wide range of real-world applications. Yang et al. [14] proposed the CESNA (Communities from Edge Structure and Node Attributes) algorithm, which integrates the network structure with node attributes to detect overlapping communities in attribute graphs. While Kuang et al. [15] developed a graph clustering algorithm based on symmetric non-negative matrix decomposition. their approach only considers graph topology. To overcome this, Huang et al. [16] and Li et al. [17] applied non-negative matrix decomposition to merge topological structure and node attribute information.
In recent years, the advancement of GNNs has significantly improved the performance of attribute graph clustering. Many of these methods employ deep neural networks to learn node embeddings and then use traditional clustering techniques to perform clustering. Kipf et al. [18] proposed a graph autoencoder (GAE) and a variational graph autoencoder (VGAE), which use a GCN encoder and an inner-product decoder to learn latent representation of undirected graphs. To enhance clustering performance, Zhu et al. [19] introduced supervised information into VGAE and proposed a collaborative decision-reinforced self-supervision method for learning graph node representation. Wang et al. [20] proposed that the multi-scale graph attention subspace clustering network MSGA improves the clustering performance. Zhang et al. [21] proposed a method for attribute graph clustering using multi-task embedding learning. This method constructs two prediction tasks based on structure and features, ensuring that node embeddings retain both types of information after backpropagation. Li et al. [22] improved the information extraction capability of non-negative matrix decomposition and learned the graph structure and node attribute information uniformly in a comparative learning framework. However, the smoothing of the attention coefficients and the stability of the node feature distribution is not always taken into account, which may lead to poor-quality node features.
Transformer
The Transformer model [23] was introduced by the Google Brain team in 2017 primarily for natural language processing (NLP). It aimed to address the issue of recurrent network models, such as the long short-term memory [24] and the gated recurrent unit [25], which could not be efficiently trained in parallel. Building on the Transformer’s fundamental architecture, researchers have developed numerous related models that demonstrate the Transformer’s potent language learning capabilities.
The application of Transformer-based models to graph-related tasks is becoming increasingly important. For instance, Dwivedi et al. [26] developed a graph Transformer model that handles arbitrary graphs using Laplacian feature vectors as node position encoding. Similarly, Kreuzer et al. [27] proposed an attention-based spectral network (SAN) that employs learnable location encoding to improve the performance of downstream tasks. Furthermore, Mialon et al. [28] introduced the GraphiT model, which leverages the Transformer structure to better incorporate both graph structure and node position information, thereby outperforming classical graph neural networks. These studies have demonstrated the effectiveness of Transformer-based models in graph-related applications beyond natural language processing.
In summary, the Transformer architecture is widely used in natural language processing and computer vision tasks [29, 30]. However, its application in graph clustering is still limited, making it a challenging task to explore the correlation between Transformer-based models and graph clustering.
Method
Formal definition
In this paper, we use
Summary of key symbols
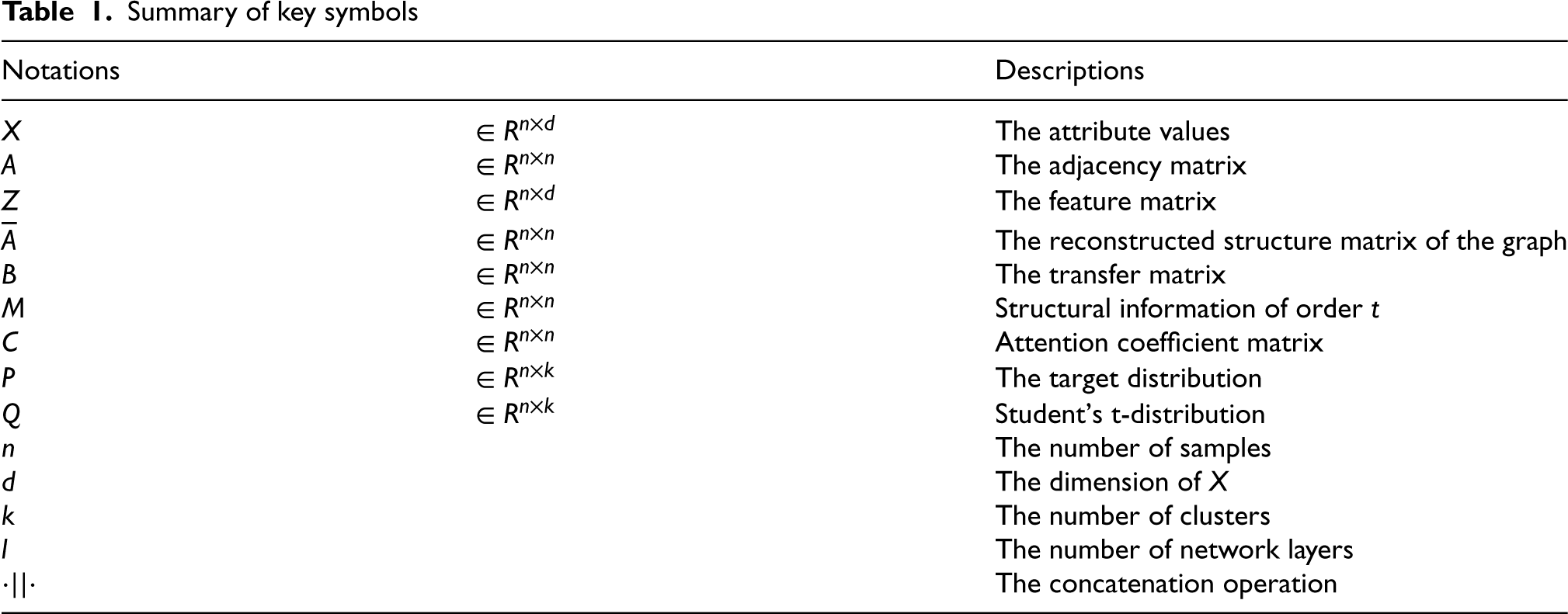
Summary of key symbols
Figure 1 illustrates the proposed attribute graph clustering algorithm that combines Transformer and graph attention autoencoder. The algorithm is divided into two main modules: graph embedding and self-optimization. The first module consists of two stages. In the first stage, the graph adjacency matrix and node attribute information are fed into a graph attention autoencoder to obtain transformed features, which are then normalized to obtain the node embedding. In the second stage, a simple inner-product decoder is used to reconstruct the graph structure. The reconstruction loss is calculated using MSE and binary cross-entropy. In the second module, it takes the node embedding as input and uses a Transformer to obtain new node embeddings, and then optimizes the node embedding and clustering results by Kullback-Leibler(KL) divergence clustering loss along with reconstruction loss.
Graph attentional autoencoder
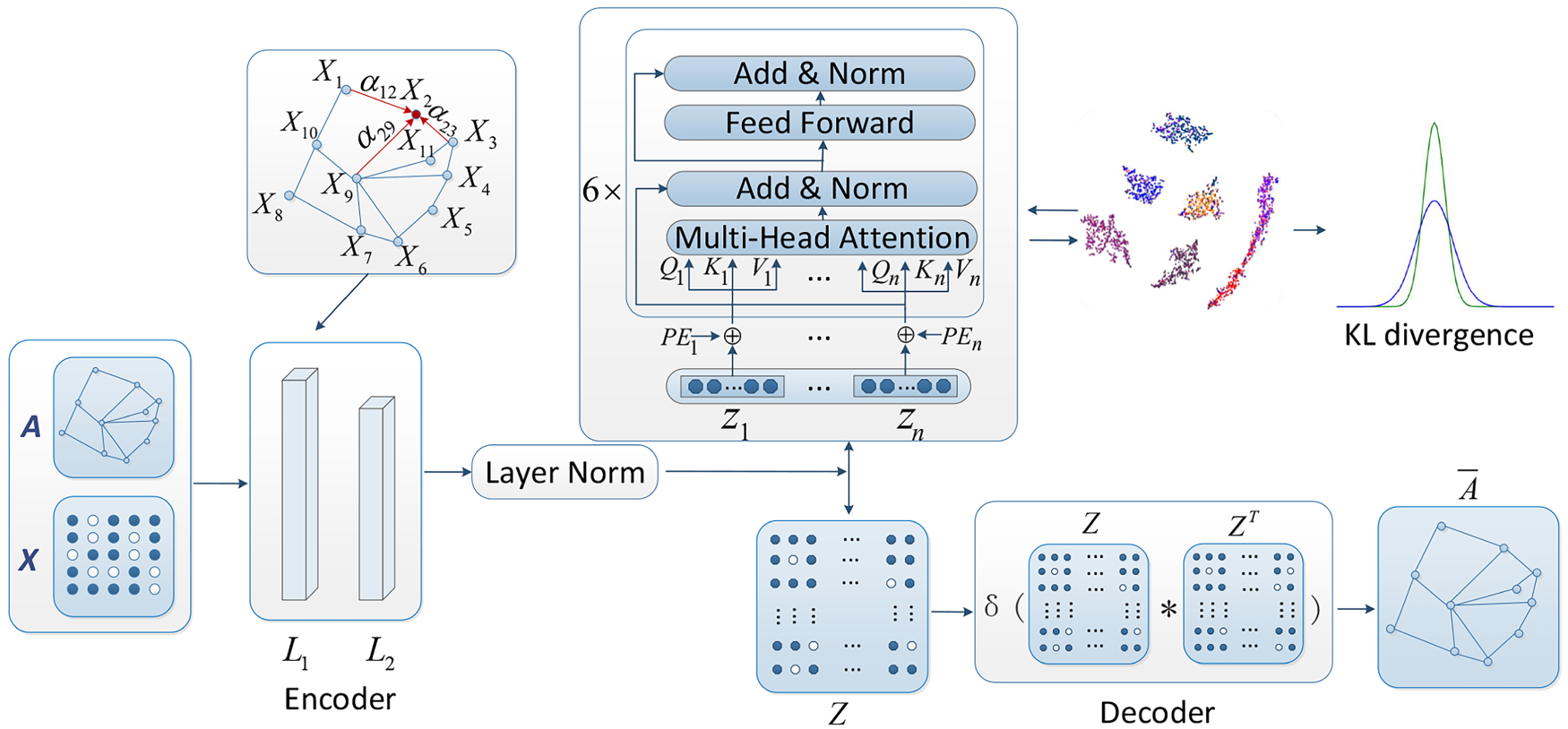
The workflow of the proposed attribute graph clustering algorithm, which includes Transformer and graph attention self-encoder.
We modified the encoder used in DAEGC [9]. Specifically, to achieve smoother attention coefficients and increase the generalization ability of the model, the attention coefficients are processed by L2-Norm normalization. The effectiveness of this approach is verified through ablation experiments in Section 4.5. The attention coefficient matrix is denoted as 

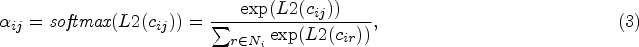
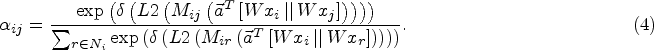
We leverages the node neighbor information and node attributes to learn the embedding representation of each node. Unlike most existing methods that treat node neighbors equally, the proposed method assigns different weights to node neighbors using the attention coefficients. Additionally, layer normalization [31] is applied in the final layer of the network. This helps to stabilize the data distribution of the same node features, mitigate the model overfitting problem, and provide a smoother training process. The formula for layer normalization is expressed as follows:

In the formula of (5), 

Thus the final node embedding can be obtained by the following equation:


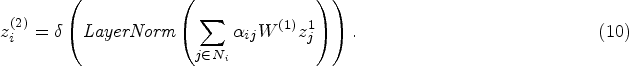
The node embedding obtained by the graph encoder above can be used for subsequent decoding work.
After obtaining the node embeddings, decoding is performed to predict the relationships between nodes. Various types of decoders can be employed for this purpose. In this study, a straightforward inner product decoder is used. The formula for the inner product decoder is as follows:

In order to better reconstruct the graph, we add the MSE loss. Thus, our reconstruction loss is composed of both binary cross-entropy loss and MSE loss. The two loss functions are formulated as follows:
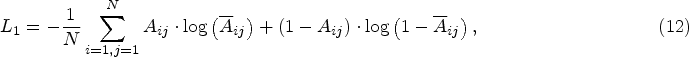

To improve the training results, we employ two different loss functions with different weight coefficients during training. The overall reconstruction loss is thus defined as follows:

As the graph clustering task is unsupervised, it is not feasible to directly assess the quality of the model’s output features during the training process. To address this issue, a self-optimizing embedding algorithm is introduced. Here, we minimize the following objectives:
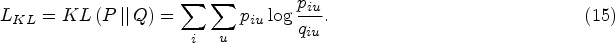
Graph Transformers allow nodes to interact with all other nodes in the graph, making it easier to access global information and mitigating the problem of over-smoothing caused by sparse graphs [32]. Therefore, we consider using the Transformer to refine the node embedding 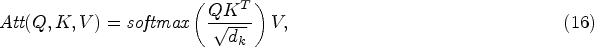

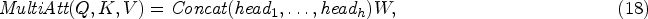

Then 
The 
To increase the credibility of the target distribution
In this model, the loss function is used as follows:


To achieve improved clustering performance, this study employs a two-phase model training approach. The first training phase focuses on generating node embeddings
Experiments and results
To thoroughly evaluate the performance of our proposed algorithm, this section conducts extensive experimental investigations.
Datasets
The performance of the proposed algorithm was evaluated on three widely accepted benchmark datasets for attribute graph clustering. The data set are briefly summarized in Table 2.
Benchmark graph datasets

Benchmark graph datasets
The Cora dataset consists of 2708 machine learning papers, each represented by a word vector of dimension 1433. In other words, the graph in this dataset consists of 2708 nodes, each with a feature dimension of 1433. There are 5429 edges between the nodes. The dataset is categorized into seven research areas: case based, genetic algorithms, neural networks, probabilistic methods, reinforcement learning, rule learning and theory.
The Citeseer dataset is another citation network graph dataset, comprising 3327 research papers, each with a feature dimension of 3703. The nodes of this graph are connected by 4732 edges. The papers in this dataset are categorized into six research areas: Agents, Artificial Intelligence (AI), Databases (DB), Information Retrieval (IR), Machine Learning (ML), and Human-Computer Interaction (HCI).
The Pubmed dataset comprises 19717 research papers related to diabetes, which can be categorized into three groups: Diabetes Mellitus Experimental, Diabetes Mellitus Type 1, and Diabetes Mellitus Type 2. There are 44,338 links between papers, with each paper represented by a 500-dimensional word vector.
This paper compares the proposed algorithm with several classical algorithms, which can be categorized into three groups: those focusing exclusively on the structural information of the graph, such as Deepwalk [7]; those concentrating exclusively on the attribute information of graph nodes, such as K-means [33]; and those considering both structure and attribute information of the graph nodes, including TADW [34], AANE [35], ASNE [36], ARGA & ARVGA [37], DAEGC [9], Similarity-based Attention Embedding Approach for Attributed Graph Clustering (SAEAGC) [10], CDNMF [22].
K-means: K-means is a renowned clustering algorithm mainly used for unsupervised learning.
Deepwalk: Deepwalk is a classic graph embedding algorithm that learns the vector representation of nodes based on the structural relationships between graph nodes. In other words, the algorithm only takes into account the structural information of the graph.
TADW: TADW integrates textual information with structural information, taking into account both structural and node attribute information of the graph.
AANE: AANE used a distributed approach to achieve fusion learning of graph structure and node attribute information.
ASNE: ASNE combines structural proximity with attribute proximity to represent the final embedding of a node.
ARGA & ARVGA: ARGA & ARVGA proposes two novel adversarial methods, namely adversarial regularized graph autoencoder (ARGA) and adversarial regularized variational graph autoencoder (ARVGA), for learning graph embeddings and joint optimizing graph encoder and adversarial regularization in a unified framework.
DAEGC: DAEGC employs an attention mechanism to learn node embeddings and incorporates graph structure information to achieve goal-oriented attribute graph clustering. The method jointly optimizes embedding learning and graph clustering to achieve its objectives.
SAEAGC: SAEAGG applies a lightweight attention scheme to capture the relationship between a node and its neighbors, improving the aggregation of the graph structure and node attribute information.
CDNMF: CDNMF uses a comparative learning framework to integrate graph topology and node attributes.
Evaluation indicators and parameter settings
Evaluation metrics
This paper employs four commonly used evaluation metrics in clustering tasks [38]: Accuracy (ACC), F-score, Normalized Mutual Information (NMI), and Adjusted Rand Index (ARI). The higher the value of each metric, the better the clustering performance.
Parameter settings
In this study, the model architecture is specified to have 256 hidden layer neurons and 16 embedded layer neurons, as suggested in previous research [9]. The Layer Normalization module is applied with a “normalized_shape” parameter of 16, and the L2-Norm normalization dimensionality reduction parameter is configured at 0. The number of layers in the Transformer is set according to the dataset. The Adam optimizer is utilized for optimization with a learning rate of 0.0001.
The comparison methods employed in this study are initialized according to the description of the original paper. For Deepwalk, the dimension of node embeddings is set to 128, and the number of random walks generated for each node is set to 80. In TADW, the regularization term
Analysis of results
Table 3 displays the experimental results for the Citeseer, Cora, and Pubmed datasets. In the table’s input section, “F” means that only node attribute information is taken into account, “S” means to focus exclusively on graph structure information, and “B” indicates the incorporation of both node attribute and graph structure information. The most outstanding experimental outcomes are highlighted in bold.
Experimental results of each method on different datasets
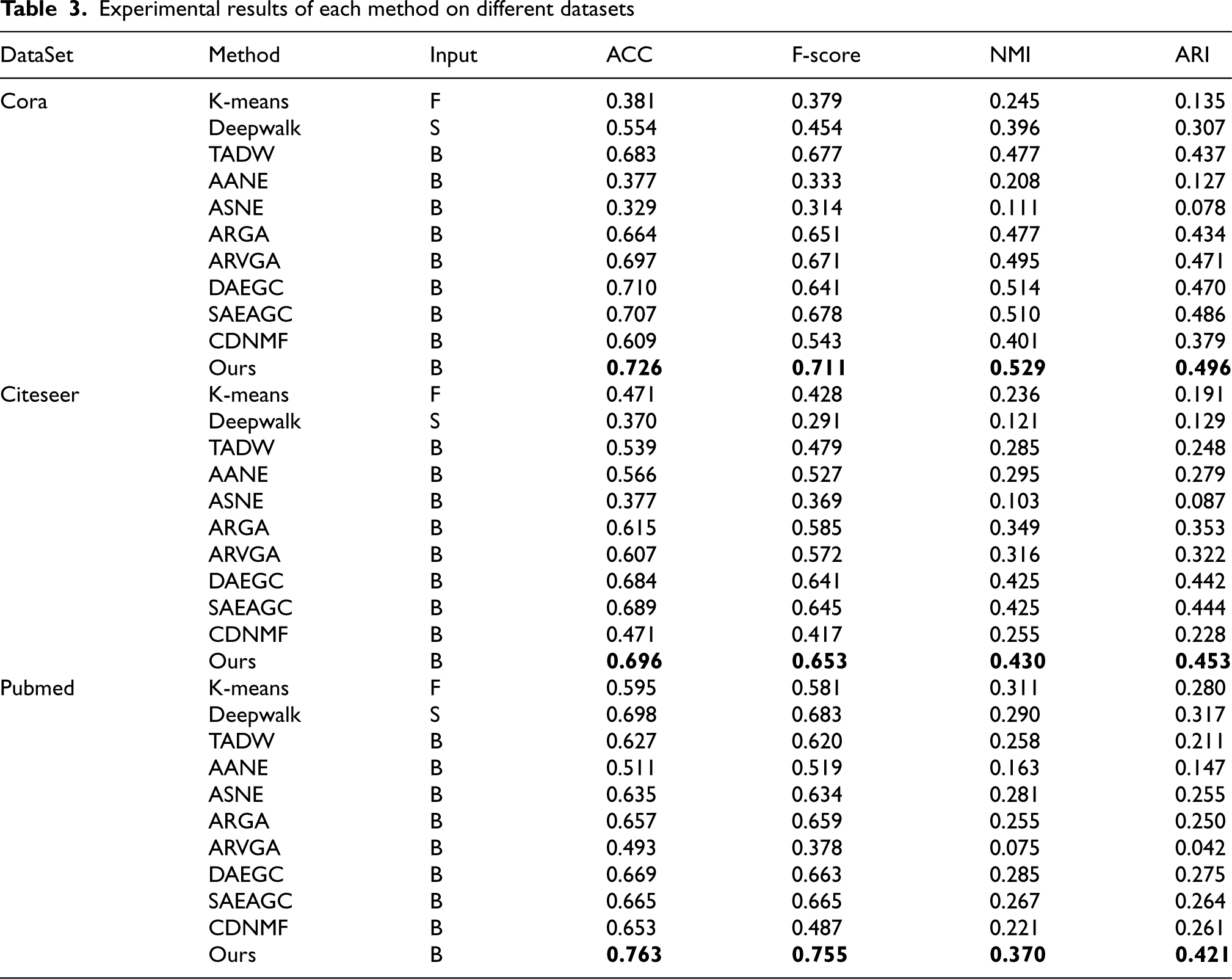
Experimental results of each method on different datasets
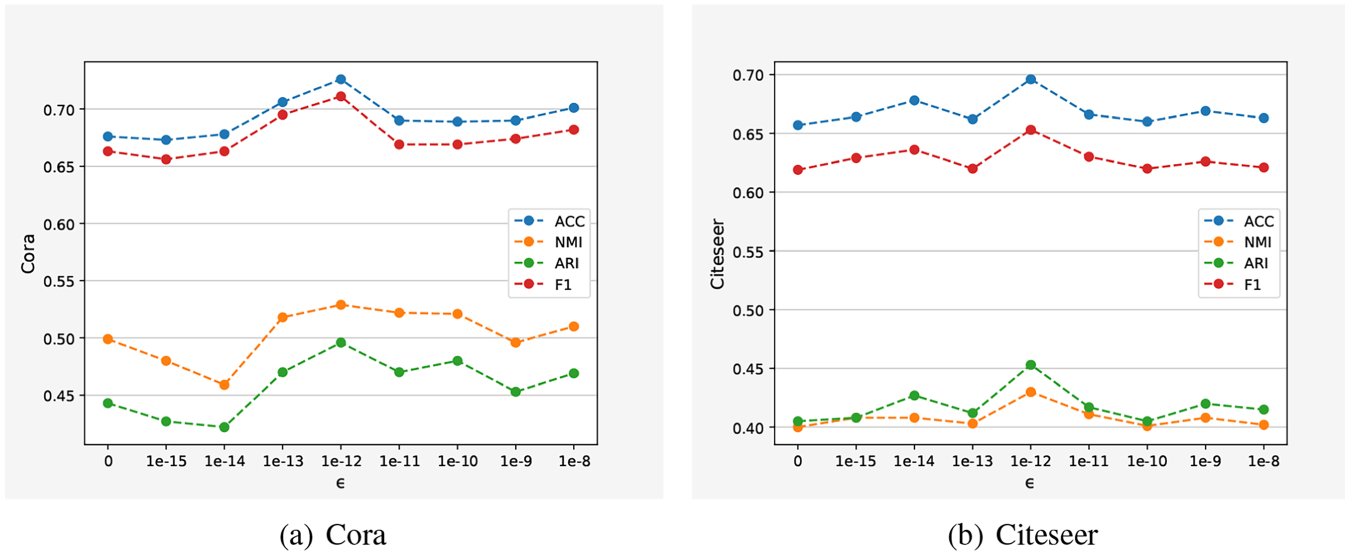
The experimental results indicate that the proposed method significantly outperforms other methods. This suggests that both types of information contain crucial information for node embedding, and that considering both can enhance the quality of node embedding representation. Furthermore, it can be seen more intuitively from Fig. 2 that the proposed method achieves optimal results for each metric in each dataset, indicating that it is effective in learning node embeddings and improving clustering performance. The proposed method has made significant progress on the Pubmed dataset, indicating that it is suitable for learning large datasets. Furthermore, this paper analyzes the impact of L2-Norm normalization and finds that its use results in an ACC of 0.717, while its non-use results in an ACC of 0.669. This demonstrates the effectiveness of L2-Norm normalization.

A comparative analysis of the performance of each method on various datasets.
(1) Analysis of the parameter
(2) Parametric analysis of the loss function: We investigate the effect of hyperparameters in the reconstruction loss and clustering loss on the clustering effect. We performed a corresponding comparison experiment using the Citeseer dataset as an example. Figure 4 shows the resulting clustering effect when different values are chosen for these two parameters:
Since the MSE loss is a summation of the squares of the differences between the predicted and actual values, it is more sensitive to outliers. To mitigate this, we give a smaller parameter to the MSE loss. We can see that the performance is the worst when the weight of In this paper, we combine the reconstruction loss with the clustering loss to optimize the clustering results. As can be seen from Fig. 4, the clustering effect is the best when
We performed a complexity analysis of the models. As shown in Tables 4 and 5, we recorded the model parameters and running times for each dataset as an indication of the complexity of the model. It can be seen that due to the addition of the Transformer in the second stage, our algorithm requires more parameters and runtime, but we can obtain better clustering results. For example, the accuracy of the Pubmed dataset is improved by 10% without significantly increasing the number of model parameters and running time, so the approach in this paper achieves a good balance between parameter sizes, running time and performance.
Evaluate model parametric quantities across multiple datasets

Evaluate model parametric quantities across multiple datasets
The effect of the value of
Model run time (s/100 epoch)

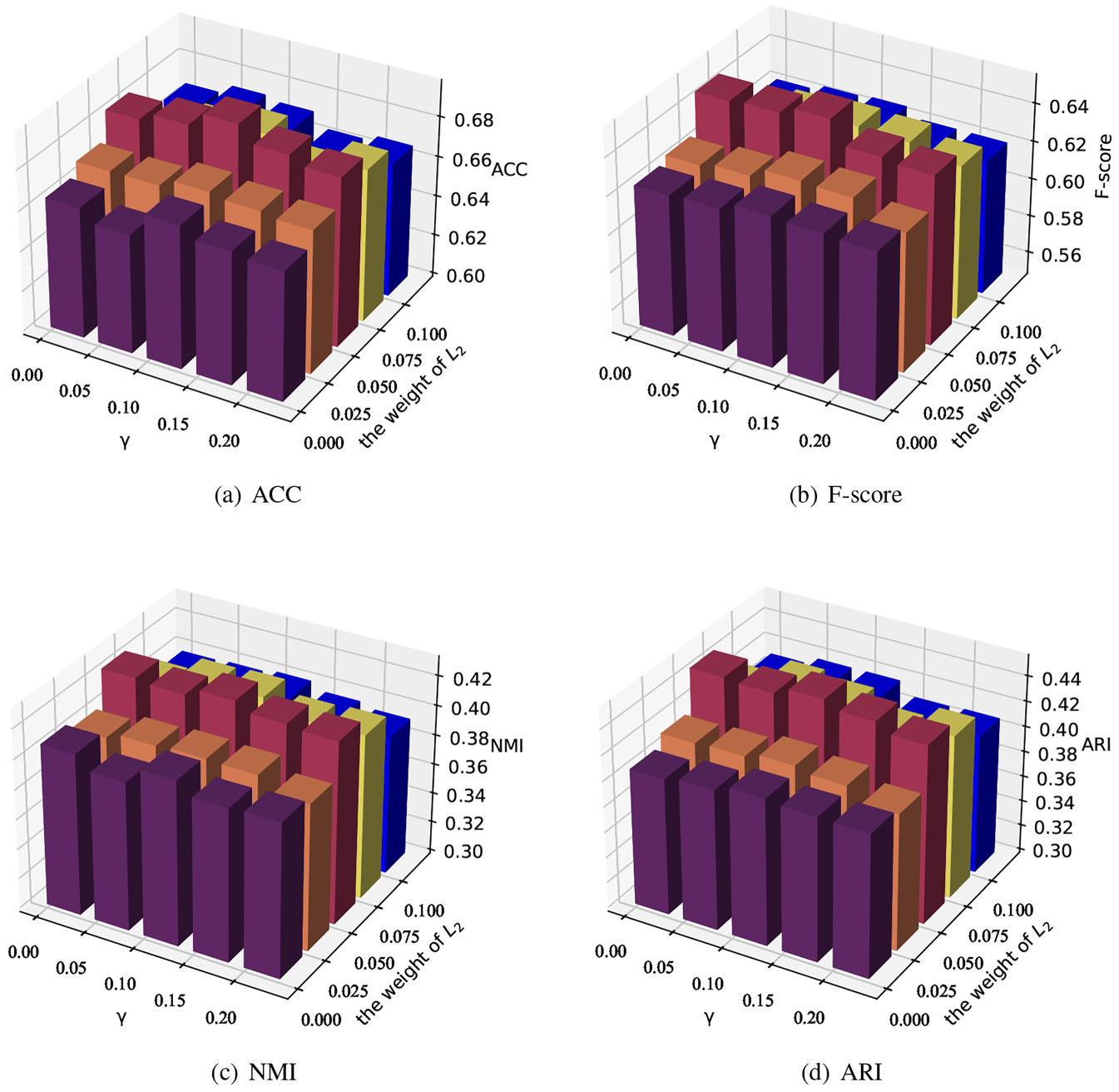
The effect of hyperparameters

A comparative visualization of the clustering effects from four distinct methods.
In this paper, we leverage the t-distributed Stochastic Neighbor Embedding (t-SNE) algorithm [39] to visualize the clustering effects of the Citeseer dataset under different methods in a two-dimensional space, as depicted in Fig. 5. Each color denotes a distinct category. it can be seen from the figure that the clustering results of Deepwalk, which only considers the graph structure, are scattered and disordered. The results of ARVGA, which considers both graph structure and attribute information, are relatively partitioned into several categories, but the boundaries between different categories are still unclear. The results of DAEGC have clearer boundaries, but the categories are not clear enough, and there is some overlapping between different categories. In contrast, the proposed clustering method achieves relatively well-distinguished boundaries between categories.
Summary and prospect
In this paper, we propose several improvements to the DAEGC method. We optimized graph embedding and clustering by incorporating a normalization step into the node embedding learning process and jointly leveraging MSE loss, binary cross-entropy loss, and clustering loss. Furthermore, we strenghened the clustering effect by incorporating the Transformer architecture to deepen the learning of node embeddings while making full use of the topology and attribute information of the attribute graph. In addition, we optimized the attention mechanism to strenghthen the generalization ability of the model. In the future, we will focus on improving the quality of node embeddings by optimizing the position encoding in the Transformer architecture.
Footnotes
Acknowledgments
This work is partially supported by the Natural Science Foundation of Fujian Province of China (Nos.2021J011187 and 2021J011182). The authors extend their gratitude to the reviewers for their constructive comments and suggestions that have significantly enhanced the quality of the presentation. Wei Weng and Fengxia Hou collaboratively conceived the model framework; where Wei Weng took responsibility for revising the manuscript, while Fengxia Hou was responsible for devising the algorithm, conducting pertinent experimental investigations, and preparing the initial draft of the paper. Shengchao Gong, Fen Chen, and Dongsheng Lin jointly contributed to discussions on the model design.