
Abstract
Pose transfer, which synthesizes a new image of a target person in a novel pose, is valuable in several applications. Generative adversarial networks (GAN) based pose transfer is a new way for person re-identification (re-ID). Typical perceptual metrics, like Detection Score (DS) and Inception Score (IS), were employed to assess the visual quality after generation in pose transfer task. Thus, the existing GAN-based methods do not directly benefit from these metrics which are highly associated with human ratings. In this paper, a perceptual metrics guided GAN (PIGGAN) framework is proposed to intrinsically optimize generation processing for pose transfer task. Specifically, a novel and general model-Evaluator that matches well the GAN is designed. Accordingly, a new Sort Loss (SL) is constructed to optimize the perceptual quality. Morevover, PIGGAN is highly flexible and extensible and can incorporate both differentiable and indifferentiable indexes to optimize the attitude migration process. Extensive experiments show that PIGGAN can generate photo-realistic results and quantitatively outperforms state-of-the-art (SOTA) methods.
Introduction
Human pose transfer is an instantiation task that synthesizes a new image of a target person in a novel pose given a single image of the person [1, 2]. A few generated samples can be seen in Fig. 1. This topic is valuable in several applications, like video generation, movie making, and person re-identification [3, 4, 5, 6, 7, 8].
Generated samples by PIGGAN based on Market-1501.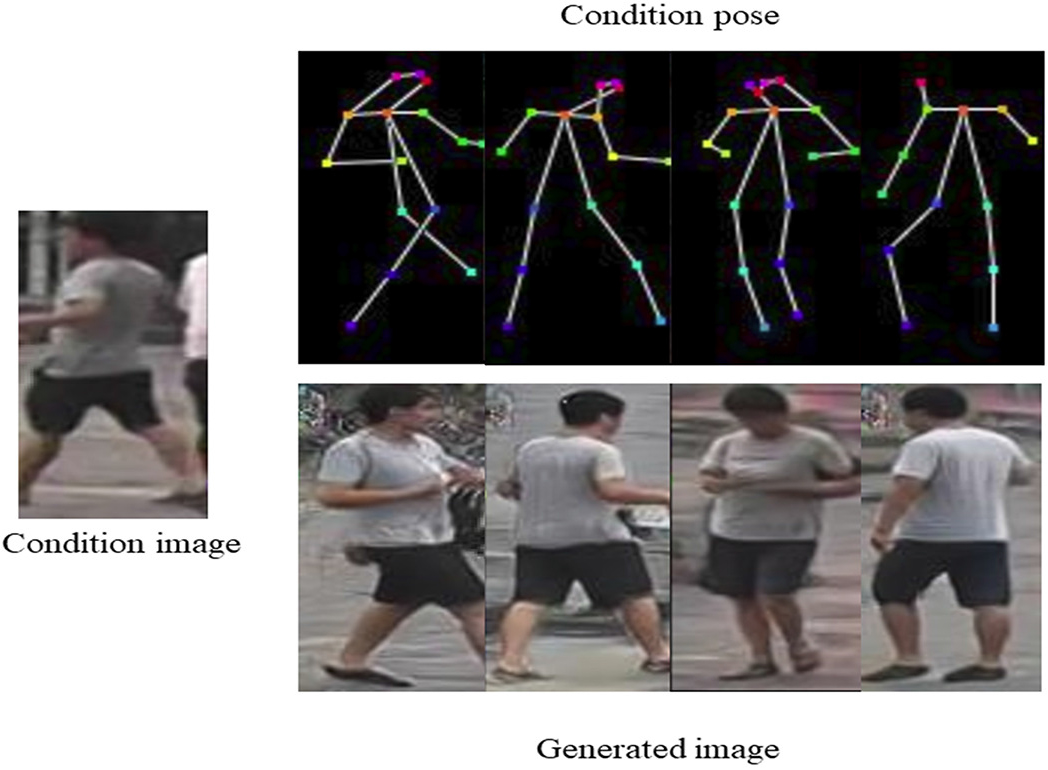
A lot of promising frameworks have been proposed for pose transfer task [9, 10, 11]. In order to generate realistic images, three main ideas have been used in previous work. The first kind of methods [12, 13] split the generation process into a coarse-to fine manner. The work in [9] generated the target images in two different stages. They further proposed a two-stage framework that can manipulate three different parts of the source image [16]. However, their methods require complicated training procedure and high computational cost. The second kind of methods [14, 15, 16, 17] propose to generate human images conditioned on an end-to-end approach. Tang et al. [17] proposed the Xing generator to learns a deformable translation mapping between the source image and the target image. The Xing generator consists of two different generation branches and can effectively update the personhape and appearance. However, that the goal of the generation phase and the evaluation phase are not completely consistent [18, 13]. Specifically, In the evaluation phase, these models employ Structural Similarity (SSIM) and other perceptual indexes to evaluate the gap between the generated human image and the target human image [19, 20]. In the generation phase, the mean square error loss (MSELoss, which calculates the mean square error of the difference between output and target) and the L1 norm loss (L1Loss, which calculates the absolute value of the difference between output and target) are currently used as the loss functions [9, 21, 22, 23, 24].
The aforementioned existing methods fail to synthesize images with fine-grained feature due to that the goal of the generation phase and the evaluation phase are not completely consistent in their methods [3, 25, 26, 27]. To address the above drawbacks, this paper introduces a general model-Evaluator. Evaluator can simulate any evaluation indicators and give the optimizer an explicit goal (as a loss function) for optimizing the model. Specifically, according to the protocol of [28]. Evaluator employs a Siamese CNN network for the Siamese CNN structure exhibit extremely good performance in learning a general similarity function between image patches [25, 29, 9, 14]. It can simulate the perceptual index through learning the sorting approach [3, 30, 31, 32]. It is worth noting that Evaluator does not directly give a specific absolute value, but rather gives a sorting value for the generated image. Just like in the real world, people donive a specific value when evaluating pictures, but they sort and compare them to give a relative value [3, 33, 34, 35]. Compared with previous works, the framework uses a trained director to make the framework have a SL, which can directly measure the quality of the generated picture [36, 37].
To train the proposed Evaluator, the results of different pose transfer algorithms (they have different perceptual index values) were marked to build a new data set. The Evaluator is trained on this dataset, after which it has the ability to sort the generated pictures according to the perceptual index value. Note that it does not mean the upper bound of Evaluator is the best one of chosen human generation methods. Then, the performance of the Evaluator is largely determined by the chosen attitude migration network. To achieve the best performance, this work has selected three SOTA models that have appeared in the past three years:
Yet, there are still several great challenges needed to be addressed during the PIGGAN training process. Human pose transfer has attracted enormous attention recently, which is to transform one personosture into another while keeping the appearance details [1, 2]. Most previous works utilize multiple perceptual indexes to evaluate generated images for using a single perceptual index cannot explicitly quantify generated images. However, setting too many targets for the generator makes PIGGAN difficult to train [38, 21, 22]. What is more, different generated images may have opposite ranking order on different evalution metrics in some cases. For these reasons, this paper employs SSIM, Inception Score (IS), and Detection Score (DS) in this study to give the optimizer a clear goal for optimizing perceptual quality. These perceptual Indexes are widely used in most recent works [39, 40, 41, 42]. This paper also uses the recent introduced Percentage of Correct Keypoints (PCKh) which measures the shape consistency of generated images [17].
The proposed method achieves qualitative and quantitative excellent results on challenging baselines. Moreover, the method in this paper can be used to improve pedestrian re-identification tasks. Specifically, the main contributions are:
This study introduce a novel model-Evaluator that can simulate any perceptual metrics in pose transfer task, and thus integrates the evaluation indicators into the generative model. a novel SL that can encourage the model is proposed to optimize the generator with multiple perceptual metrics and achieve the most advanced performance. This paper also introduces a texture attention module (TAM) to guide the module by hinting “where to add more texture”. The proposed PIGGAN is highly flexible and can simulate any perception metric to optimize the attitude migration process. Experiments show that PIGGAN outperforms SOTA methods. We demonstrate the advantage of our method over the state-of-the-arts by quantitative and qualitative evaluation, and show the capability to alleviate data insufficiency for person re-identification.
Human image generation
Recently, human image generation is a crucial sub-area of computer vision [9, 43, 44, 45]. Lassner et al. [37] exploited to combine GAN and VAE to generate full-body images by a differentiable two-stage model. In [46], Zanfir et al. proposed a similar 3D model to explicitly capture the body deformations. To better model appearance, Zhao et al. [47] adopted a more general approach for synthesizing human images from a single-view. Similarly, the work in [48] presented a modular GAN network that generates unseen poses using training pairs of images and poses.
Pose transfer
GAN is widely used in multimedia areas including works on pose transfer modeling [41, 49, 40]. These works can be decomposed into two categories. The first group of works split the generation process into a coarse-to fine manner. The work in [12] generated the target images in two different stages. They further proposed a two-stage framework that can manipulate three different parts of the source image [13]. However, their methods require complicated training procedure and high computational cost. In contrast, this study introduces an end-to-end generation method which obtains higher qualitative results.
The second line of works generates human images conditioned on an end-to-end approach. Zhu et al. [1] presented a pose-attentional transfer blocks (PATB) to optimize their model using the attention mechanism. However, PATB cannot capture long-range dependency to transfer the precise regions of the target image features. Likewise, Siarohin et al. [2] adopt a GAN-based approach with deformable skip connections. Tang et al. [17] proposed the Xing generator to learn a deformable translation mapping between the source image and the target image. The Xing generator consists of two different generation branches and can effectively update the personhape and appearance. However, most previous works [1, 2, 17] use the mean square error loss and the L1 norm loss used as the loss functions. In the generation phase, perceptual indexes such as SSIM are used in their works to evaluate the generated images. This may lead the goal of the generation phase and the evaluation phase are not completely consistent. In contrast, this paper designs a data-derived Evaluator that matches well the GAN. In this way, The PIGGAN is able to utilize the perceptual metrics to directly integrated them into the loss function of GAN.
This paper is organized as follows. In Section 3, we present the proposed PIGGAN network. In Section 4, we present the experimental results and application to person re-identification. Finally, Section 5 presents our conclusions.
The proposed method
Given a person image, the pose transfer model aims at generating an image for the person in another pose [39, 50, 51]. Private works gained considerable success on image synthesis [52, 53, 54]. The proposed framework consists of one generator and six discriminators. To guide the pose transfer process, this paper adopts the Human Pose Estimator (HPE) [1] to obtain the 2D human body poses. Specifically, this paper adopts 18 joints of a human body that are extracted using OpenPose [1] for fair comparison.
Overview of PIGGAN
where
where
The structure of the Evaluator.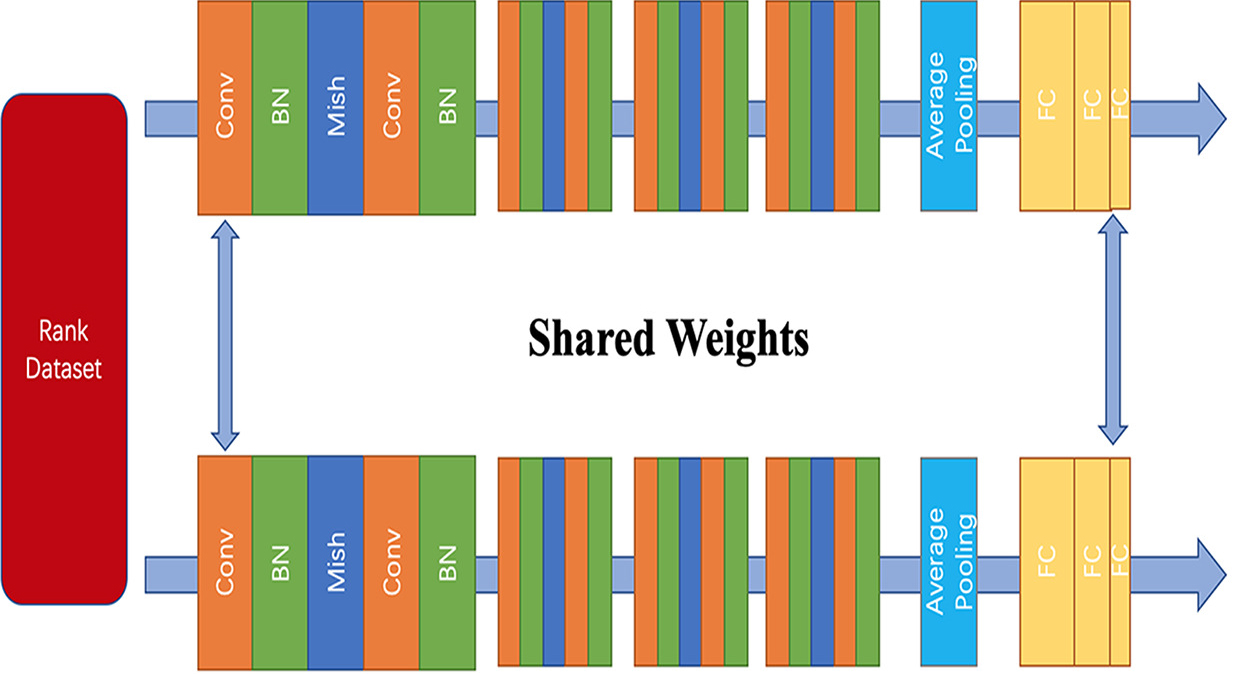
The structure of PIGGAN.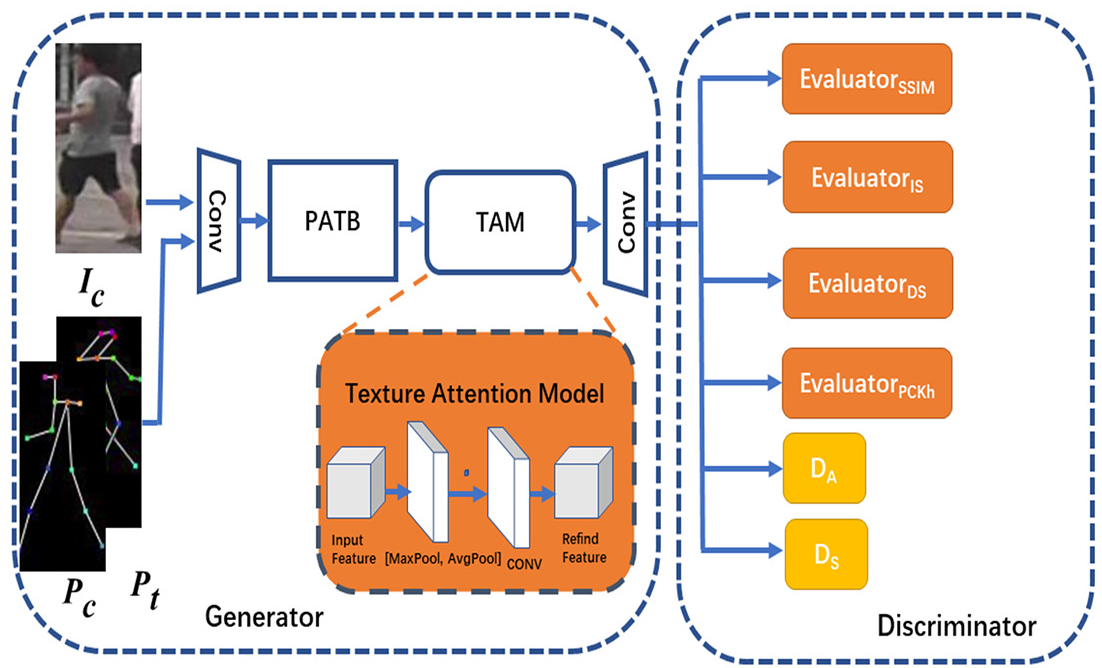
where
As shown in Fig. 3, the generator takes three inputs, the condition image
Discriminators
The discriminators in this work are composed of
As in [1], this paper adopts two discriminators, pose discriminator
Training
The full loss function for the pose transfer network is denoted as:
where
Where
The
where
where
The
where
Datasets
This study evaluates PIGGAN on the person re-ID dataset Market-1501, which contains images of 1501 persons [1]. All images are resized to 128
For the quantitative study, previous works [12, 9, 3, 2] employed IS, SSIM, mask-IS, mask-SSIM, and DS as their metrics. These metrics evaluate the differences between the generated image and the target image from different aspects. In [1], PCKh was introduced to further evaluate the the shape consistency of similarity between generated images and real ones. This paper employs all the above metrics for fair comparisons.
Comparison with the SOTA
Comparison with the SOTA
Generated samples by PIGGAN based on Market-1501 dataset. Zoom in for better details.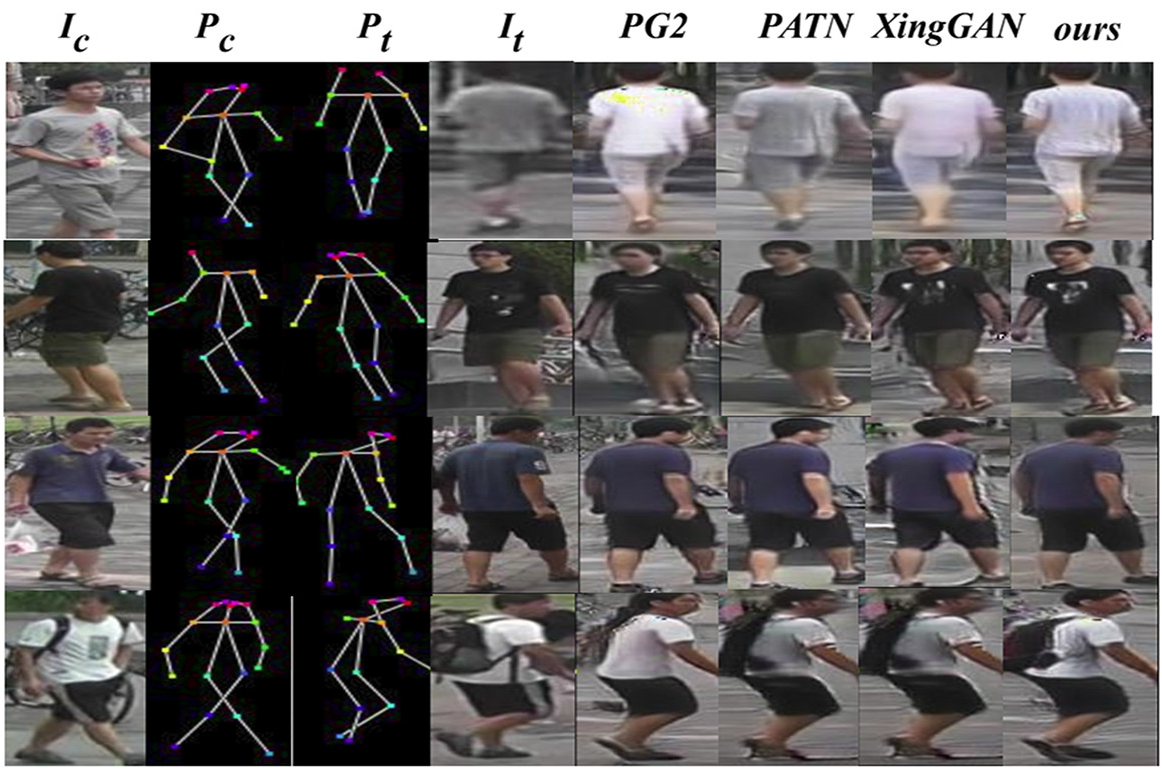
Generated samples by PIGGAN based on DeepFashion dataset. Zoom in for better details.
Comparison of computation complexity
Comparison of computation complexity
User study (%)
The results of the ablation study
The re-ID results using images generated by different methods
This study performs the ablation study to further analyze the impact of each component in PIGGAN. “Baseline” means only using PATN branch. “Evaluator” means adopting the proposed Evaluator in the baseline branch. “Full” is our PIGGAN model.
As shown in Table 4, there are significant improvements from the baseline methods to the Evaluator. “Full” is slightly better than “Evaluator” in both datasets. Specifically, “Evaluator” has better results in terms of DS on the Market-1501 dataset.
Application to re-ID
Many person-related vision tasks, like re-ID, are confronted with insufficient training data problems [65, 66, 67, 68, 69, 70, 71, 72, 73]. A good person pose transfer method can augment the datasets of person-related vision tasks by generating realistic person images [74, 75, 76, 77, 78]. Person re-identification has been drawing lots of attention from both academia and industry for its important applications in security and surveillance [79, 80, 81, 82]. This paper also evaluates PIGGAN on the mainstream re-ID dataset Market-1501. Following the protocol in [1, 12], a portion p of the real data was randomly selected as the reduced training set. Meanwhile, this paper employs the same data augmentation. The results in Table 5 show that PIGGAN achieves consistent improvements over baseline models, suggesting that the proposed method can generate more realistic human images and be more effective for the re-ID task. the numeric improvements are steady for different portion p.
Conclusions
For the pose transfer task, this study proposes a novel perceptual index guided GAN framework. Specifically, a general model-Evaluator that matches well the GAN is designed. This study trains the proposed Evaluator to simulate perceptual metrics and construct the SL to optimize the perceptual quality. The discriminators of this work are composed of
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China (Grant No. 62072348), the National Key R&D Program of China under (Grant No. 2019YFC1509604), the Science and TechnologyMajor Project of Hubei Province (Next-Generation AI Technologies) (Grant No. 2019AEA170), and the National Natural Science Foundation of China under Grant 62102268.