
Abstract
Deep learning has demonstrated remarkable advantages in the field of human pose estimation. However, traditional methods often rely on widening and deepening networks to enhance the performance of human pose estimation, consequently increasing the parameter count and complexity of the networks. To address this issue, this paper introduces Ghost Attentional Down network, a lightweight human pose estimation network based on HRNet. This network leverages the fusion of features from high-resolution and low-resolution branches to boost performance. Additionally, GADNet utilizes GaBlock and GdBlock, which incorporate lightweight convolutions and attention mechanisms, for feature extraction, thereby reducing the parameter count and computational complexity of the network. The fusion of relationships between different channels ensures the optimal utilization of informative feature channels and resolves the issue of feature redundancy. Experimental results conducted on the COCO dataset, with consistent image resolution and environmental settings, demonstrate that employing GADNet leads to a reduction of 60.7% in parameter count and 61.2% in computational complexity compared to the HRNet network model, while achieving comparable accuracy levels. Moreover, when compared to commonly used human pose estimation networks such as Cascaded Pyramid Network (CPN), Stacked Hourglass Network, and HRNet, GADNet achieves high-precision detection of human keypoints even with fewer parameters and lower computational complexity, our network has higher accuracy compared to MobileNet and ShuffleNet.
Introduction
Human pose estimation [1, 2] is a computer vision task that involves locating joints on humans in images or videos. It has achieved significant advancements in applications such as human-computer interaction, motion capture, and posture correction in sports and fitness. Currently, the mainstream approach utilizes convolutional neural networks [3–5] to extract features.
The high-resolution feature network possesses strong feature extraction capabilities, but it suffers from significant feature redundancy, resulting in complex network models that are challenging to deploy on resource-constrained devices such as embedded systems and smartphones. Therefore, the pressing challenge in human pose estimation is how to effectively utilize informative features while reducing parameter count and computational complexity to the greatest extent possible, all while maintaining a high level of accuracy.
The mainstream methods for human pose estimation can be categorized into two types: Top-down and Bottom-up approaches.
Top-down methods [6–8] first use a human detection network to detect the bounding box of the human body, then crop the predicted human body information, and finally use the human pose estimation network to predict key points of the information. The success of keypoint prediction for this prediction method depends heavily on the accuracy of the human detection network.
On the other hand, the Bottom-up approach [9–14] directly predicts the positions of individual keypoints on the human body in the image. The final human pose estimation is obtained by assembling the predicted keypoints. This end-to-end approach allows for faster prediction, but it is prone to connection errors when the keypoints are close to each other, resulting in lower accuracy compared to the Top-down approach.
In 2015, Jaderberg et al. [15] proposed the Spatial Transformer Network (STN), which extracts useful spatial information from feature maps to reduce background interference. In 2017, Hu et al. introduced Squeeze and Excite Network (SENET) [16], which increases the weight of effective channels and suppresses irrelevant feature channels to better utilize effective feature information to improve the performance of the network.
In 2018, Woo et al. [17] introduced CBAM, which combines both spatial attention and channel attention mechanisms, establishing an information enhancement scheme that enhances effective channels and feature maps.
In 2020, Li et al. [18]. proposed SKNet, which enhances network robustness by integrating channel information extracted from different-sized convolutional kernels.
In 2022, Yang et al. proposed an instance-aware method to supervise attention and achieve key point detection and clustering in DGIA [19]. In 2022, Ullah et al. proposed a new multi-scale residual attention MRA-UNet [20] to make full use of the area of interest to improve model performance. In 2023, Ullah et al. used dense layers to extract spatial features in DAMNet [21], and the channel attention method adaptively established the weight of the main feature channels and suppressed redundant features.
While the above methods have made significant progress, they have also increased computational complexity and sometimes fail to fully utilize certain valuable features.
Lightweight networks have been a focal point of research, aiming to reduce the number of parameters by adjusting the depth and width of convolutional neural networks.
In 2012, in order to achieve multi-GPU training, AlexNet [22] introduced grouped convolution. In 2017, Howard et al. proposed depthwise separable convolution in MobileNets [23], which divides convolution into depthwise convolution (Dwise) and point-wise convolution (Pwise). Compared with traditional convolution, this method greatly reduces parameters. quantity. In 2018, MA et al. proposed shuffle operations on features in ShuffleNet [24] to obtain more feature information.
In 2021, YU et al. introduced lightweight units in Lite-HRNet [25] to implement a lightweight human pose estimation network by learning weights in multiple resolutions in all channel branches. In 2020, Han et al. introduced GhostModule in GhostNet [26] to improve ordinary convolutions by performing linear operations on the intrinsic feature maps, reducing feature redundancy, parameters, and computational complexity while enhancing network performance. Figure 1 illustrates the issue of feature redundancy when using GhostNet.

Feature redundancy.
The above lightweight model is small, and some effective features will be lost during the feature extraction process, making it difficult to accurately detect key point locations under complex working conditions.
In the field of human pose estimation, achieving high accuracy requires addressing the challenge that keypoints occupy a small proportion of the data, necessitating the use of different scale objectives.
DenseNet [27] proposed by Huang et al. in 2017 proposed a multi-feature fusion dense connection scheme. In 2019, Wang [28] and others used the parallel method of high-resolution and low-resolution branches in HRNet to enhance the extraction of feature information.
However, these networks are highly complex and require more computing resources and time.The models mentioned above exhibit a trade-off between high accuracy and high model complexity, with lower model complexity resulting in lower accuracy. Our goal is to find a balance between model complexity and accuracy, aiming to make the model as lightweight as possible while maintaining a certain level of accuracy. Building upon the aforementioned research, this paper proposes a human pose estimation network called Ghost Attentional Down-sampling Network (GADNet) based on the high-resolution network HRNet.
In GADNet, we have shortened both the high-resolution and low-resolution branches while integrating crucial information from high-resolution data into the low-resolution data, thereby boosting the weight of this valuable information. Furthermore, to drastically reduce the number of parameters and computational complexity, we took inspiration from the Ghost module and SE (Squeeze-and-Excitation) module designs and introduced GaBlock and GdBlock as replacements for the BasicBlock and Down sampling components used in HRNet. Through this approach, GADNet achieves both high prediction accuracy and minimizes the number of parameters and computational complexity of the network.
Drawing inspiration from the experience of HRNet with high-resolution parallel multi-branch fusion, we propose an efficient high-resolution network called GADNet. GADNet consists of an initial feature extraction stage and a feature fusion extraction stage. First, we perform initial information extraction using two regular convolutions and a bottleneck module. Then, the obtained features are subjected to feature extraction through the ADModule, which comprises four branches for feature fusion, effectively integrating information from high-resolution and low-resolution feature maps.
During our experimental process, we observed that while the network model exhibited lightweight features, its performance in extracting valuable features was not strong. Subsequently, we enhanced the effective features using GaBlock and GdBlock. With the introduction of these two modules, the network’s performance significantly improved with only a slight increase in channel weights. The overall structure of GADNet is illustrated in Fig. 2.
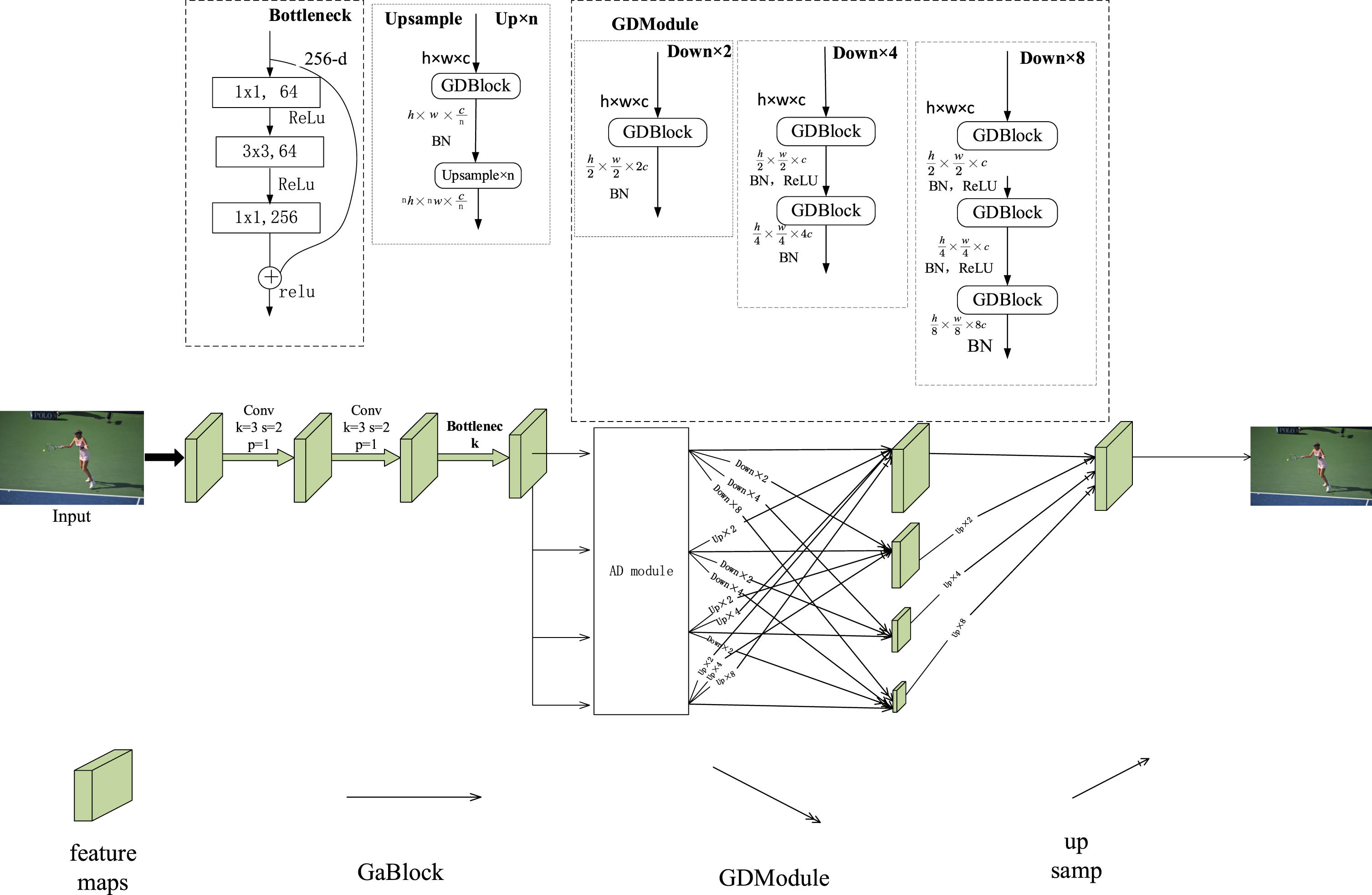
The overall structure of GADNet proposed in this paper.
To enhance feature perception and mitigate feature loss, we designed the ADModule, as depicted in Fig. 3. After the initial feature extraction network, it branches into four independent sub-branches. Within each sub-branch, we employ GaBlock as the fundamental block for extracting information from the images while utilizing the feature information from each branch and extending the receptivefield.
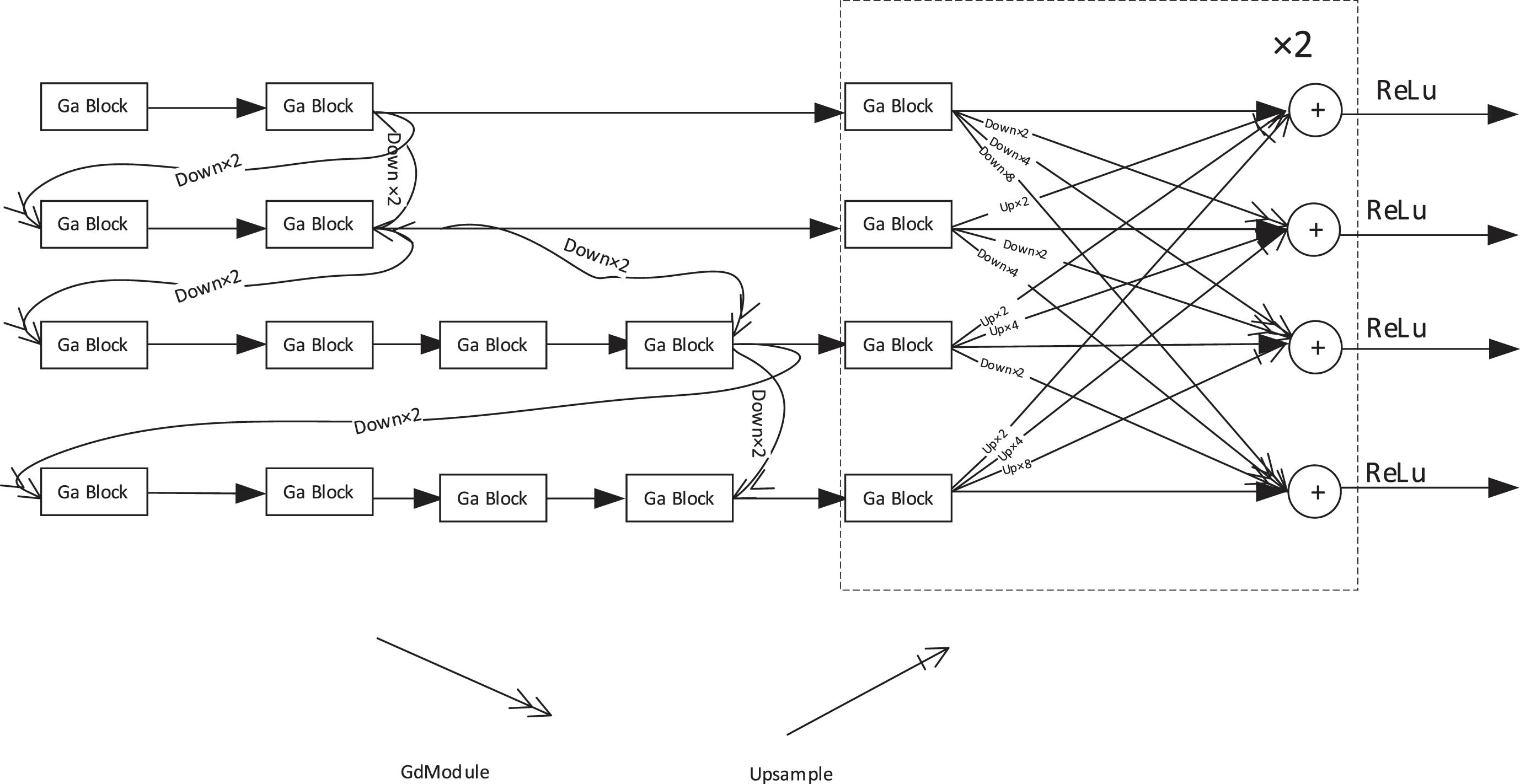
The structure of ADModule.
Certainly, in the ADModule, the number of GaBlocks in the second branch is identical to the number in the first branch. In contrast, the third branch contains twice as many GaBlocks as the second branch. Both the third and fourth branches have an equal number of GaBlocks. Additionally, at the conclusion of each layer, the results undergo down sampling and are integrated into the initial features of the subsequent layer. The channel count in the second layer is twice that of the first layer, the third layer has double the channels of the second layer, and the fourth layer doubles the channels of the third layer. To accomplish the down sampling process, we utilize a GDModule comprising GdBlocks.
In the first high-resolution branch of the ADModel, the emphasis lies on capturing richer details. However, to maintain computational efficiency and minimize memory usage, we utilize a relatively lower number of channels (primarily 32 and 48 as the base channels in this paper). GaBlock leverages feature mapping and channel-weight analysis to fully exploit effective features, thereby generating a more powerful model and faster convergence speed. In the subsequent low-resolution branch, global and semantic information becomes crucial. To better capture these details, we employ a higher number of channels. In the ADModel, the number of channels in the lower-resolution branch below is twice that of the higher-resolution branch above. We use GDModule to increase the channel count, striking a balance between image details and global semantics, which enhances the network’s performance.To enrich features with more details and reduce feature loss, we extract features from the upper-level network and fuse them into the lower-resolution branch. The entire network achieves an almost fully connected effect across all convolutional layers, significantly enhancing the receptive field and perception of details. The overall structure of ADModule is illustrated in Fig. 3. We use Table 1 to show the number of channels of the down-sampling map in ADModule. The key aspect of the feature fusion module is the presence of parallel multi-branch networks, allowing the transfer of valuable information extracted from the high-resolution branch to be reused in the low-resolution branch, thereby reducing feature loss.
The number of channels of branch
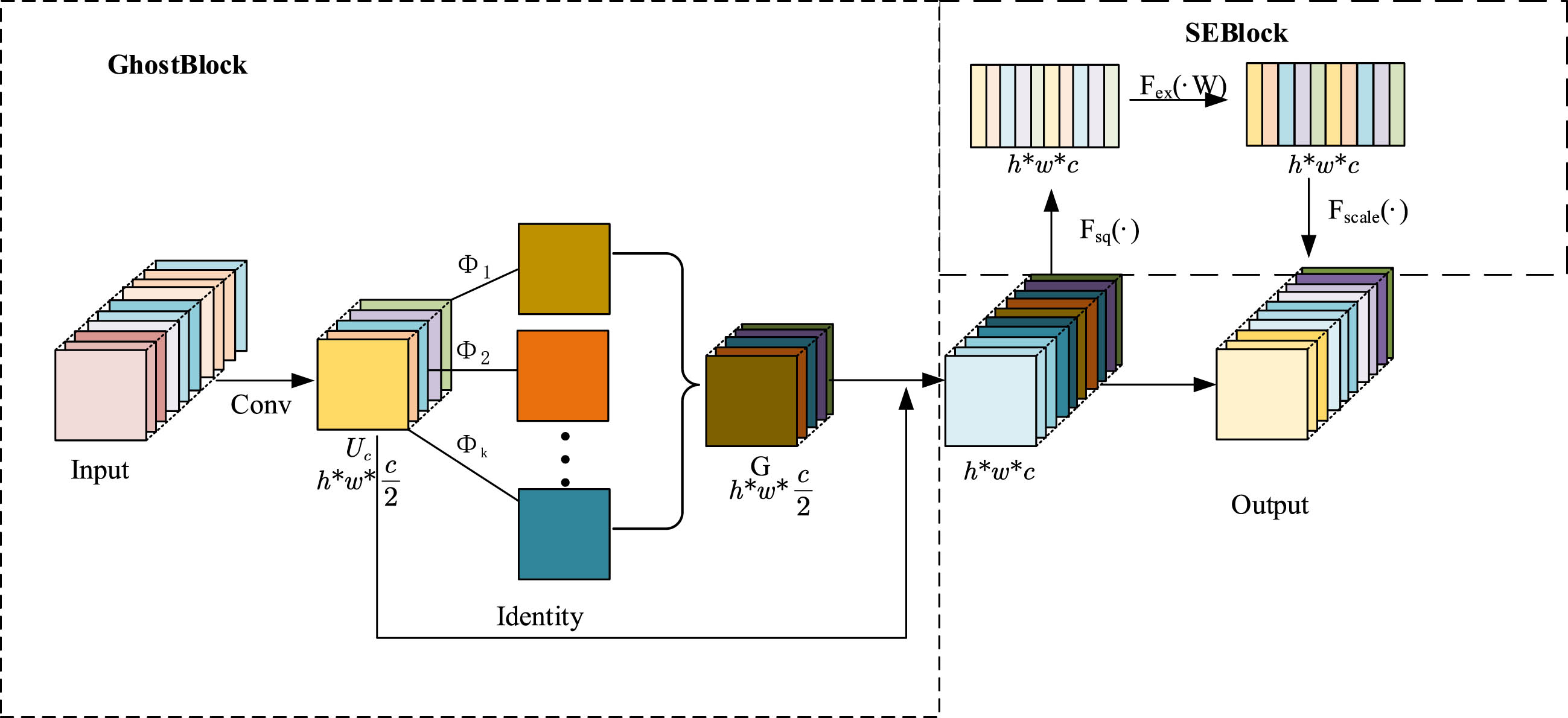
To enhance the precision of high-resolution image processing and concurrently reduce network parameters and computational complexity, this study introduces two fundamental modules, namely GaBlock and GdBlock, for network construction. These modules improve the Ghost module by generating more effective feature maps, thereby elevating model accuracy and minimizing feature redundancy. Additionally, the receptive field was explored to enhance module performance. The overall structure of GhostModel is illustrated in Fig. 4.

The structure of Ghost Block.
The limited receptive field of the Ghost module hinders the capture of global image features. To address this limitation, we have extended the receptive field and introduced attention mechanisms to enhance the model’s generalization ability and performance. The workflow of the GaBlock involves the following steps:At the outset, a standard convolution operation is applied to generate intrinsic feature maps that possess a greater abundance of original feature information. This allows for comprehensive utilization of the available data, while preserving intricate details. Subsequently, an attention mechanism is employed to optimize the feature information in the intrinsic feature maps, incorporating compression and excitation techniques to obtain attention feature maps. Through a cost-effective operation, these attention feature maps are then transformed into Ghost feature maps, effectively reducing feature redundancy and enhancing computational efficiency and memory usage. Finally, to mitigate feature loss, the initial intrinsic feature maps and the final Ghost feature maps are fused together through a stacking process, resulting in the creation of Ga feature maps. This fusion operation facilitates the combination of features from different levels, ultimately bolstering the model’s performance and enriching its representation capabilities.
The GABlock preserves the size and spatial position information of feature maps without altering the size and number of input and output features. This allows for a more precise capture of local information in images, thus enhancing the model’s performance. In comparison to the GhostBlock, the GABlock effectively leverages inter-channel information, thereby reducing feature redundancy and information loss during feature extraction. Figure 5 depicts the structure of the GaBlock, while Fig. 6 provides a detailed view of the GaBlock.
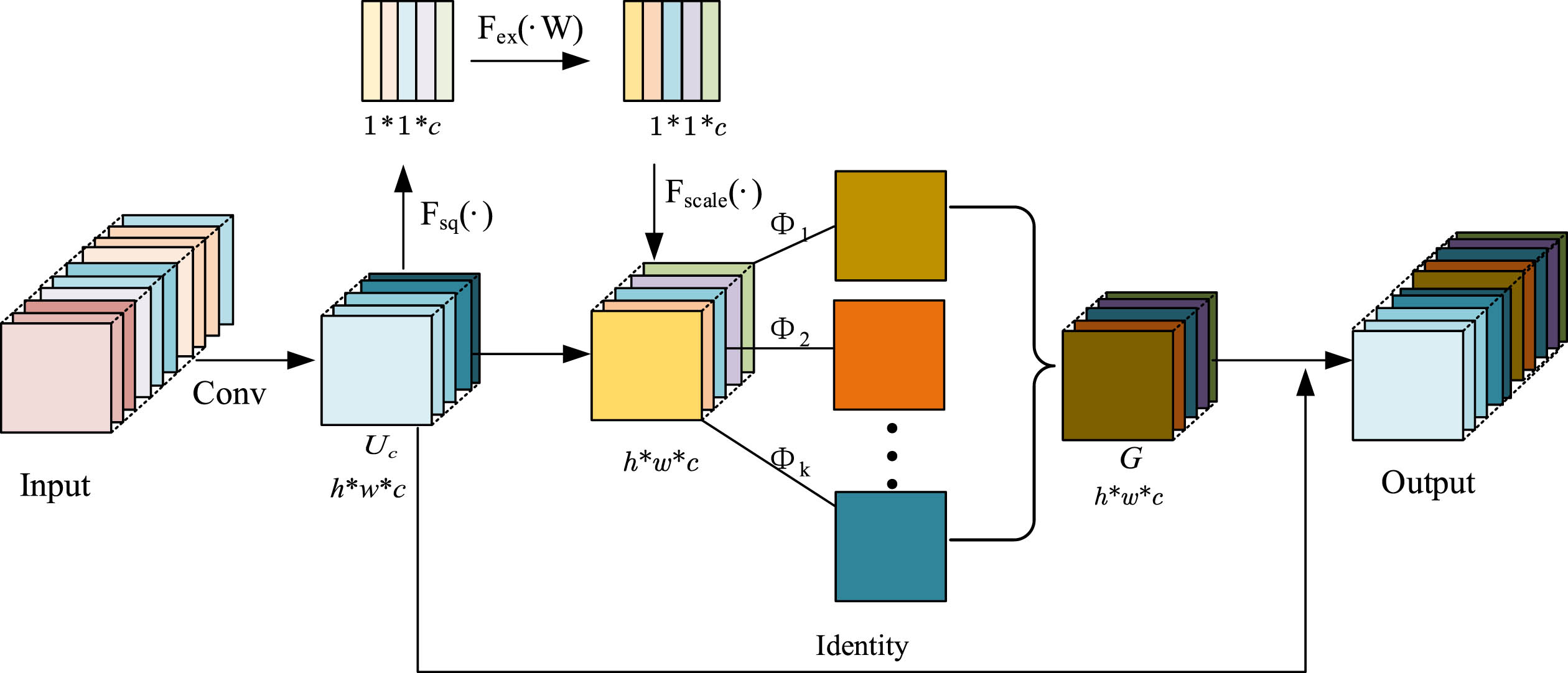
The structure of GaBlock.
Details of GaBlock.
GABlock reduces the number of parameters and feature redundancy, while also minimizing computational cost. The joint attention mechanism enhances the feature extraction performance. Here, “input” refers to the input feature map, “Conv” denotes regular convolution, and “Output” represents the output feature map. “U c ” refers to the intrinsic feature map generated by regular convolution, “Φi “ represents linear operations, “G” is the ghost feature map generated, and “Identity” is the identity mapping. “Fsq” denotes the squeeze operation, “Fex” denotes the excitation operation, and “Fscale” distributes weights channel-wise and generates inexpensive phantom channels through linear operations on the weighted channels. Finally, the regular convolution and the features generated by attention and phantom operations are concatenated to obtain the Ga feature map. The parameter quantity of the ghost operation is given in Equation 1:
Where “Cin” and “Cout” are the number of input and output channels of the feature maps, “k” is the kernel size of the regular convolution, “d” is the kernel size of the inexpensive operation, and “S” is the number of channels in the inexpensive convolution. “Fsq(ɵ)”represents the Squeeze operation, which performs dimensionality reduction with a reduction factor of 16, The dimensionality reduction operation is given in Equation 2
H and W are the height and width of the convolutional output feature. Fex(·W) is the excitation operation which performs dimensionality expansion with a factor of 16. The up-dimension operation is given in Equation 3
In which z represents the result after the Squeeze operation, W1 and W2 are the weights of the fully connected layers, δ denotes the ReLu activation function, and σ denotes the sigmoid activation function.
Fscale(·) is channel-wise multiplication. The channel-wise multiplication operation is given in Equation 4
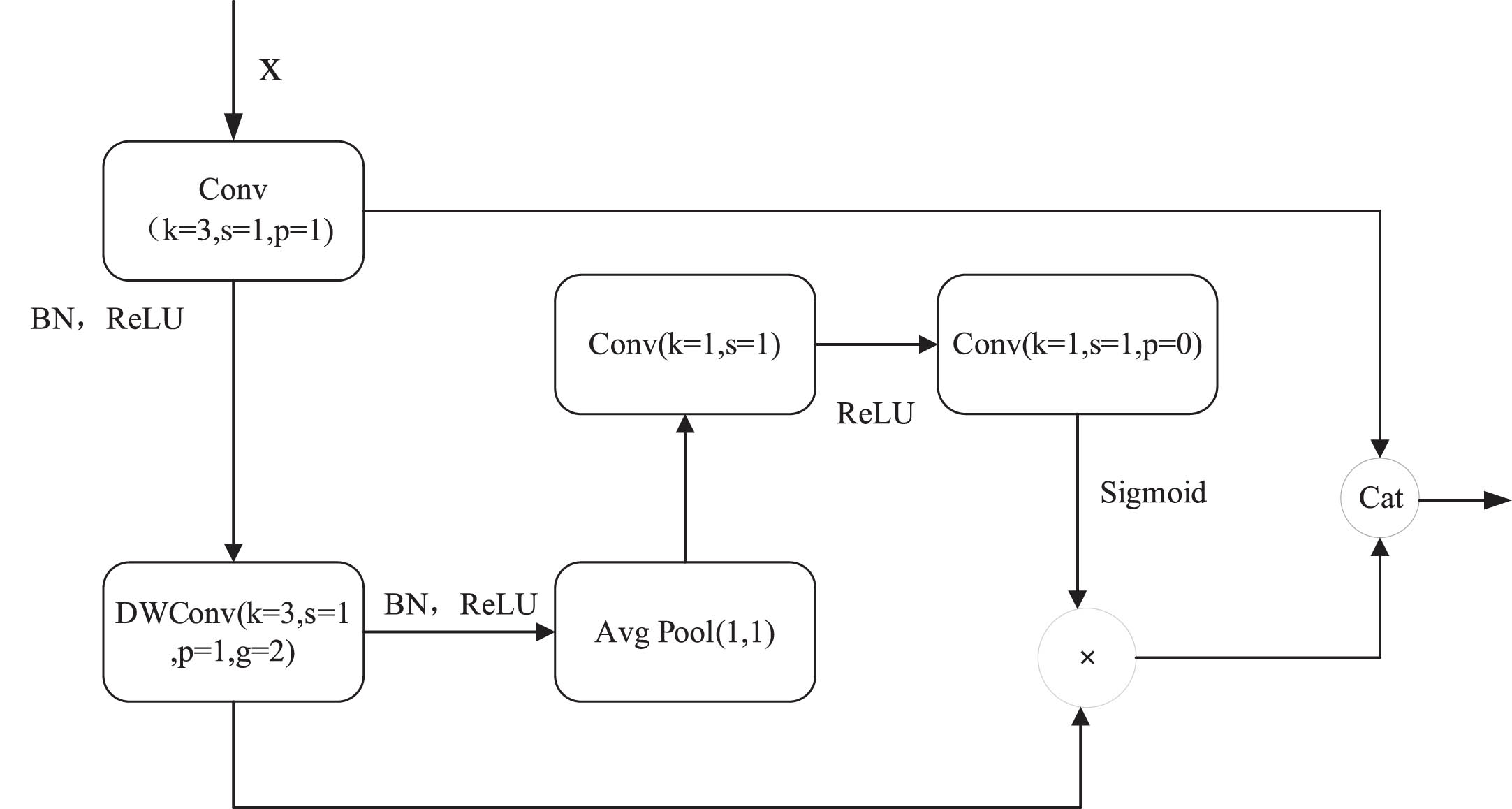
Due to the extensive down sampling in HRNet, which accounts for a significant portion of the parameter count, there is a risk of feature loss. To address this issue while maintaining accuracy, the GdBlock is proposed to reduce parameters in down sampling without compromising performance. The GdBlock efficiently captures channel relationships and preserves the original feature information with minimal parameters, thereby minimizing feature loss during down sampling. The workflow of the GdBlock is as follows:
To mitigate feature loss, the input feature map undergoes parallel operations: the first operation is a standard convolution to generate intrinsic feature maps, while the second operation applies inexpensive techniques to create Ghost feature maps. The Ghost feature maps are then subjected to compression and excitation operations to obtain attention feature maps. Finally, the attention feature maps and intrinsic feature maps are stacked to produce the Gd feature maps.
The intrinsic feature maps contain rich feature information, while the Ghost feature maps reduce feature redundancy, parameters, and computational complexity, thus achieving the goal of a lightweight network. The structure of the GdBlock is illustrated in Fig. 7.

The structure of GdBlock.
The purpose of down sampling is to reduce the resolution of feature maps, thereby decreasing parameter size, improving computational efficiency, and concurrently increasing the receptive field to enhance the model’s understanding of global information. However, this approach may result in the loss of fine-grained details, potentially leading to overfitting.
To tackle this issue, we employ hierarchical down sampling to extract valuable features comprehensively. Additionally, we have constructed a GDModule using GDBlock, which gradually performs down sampling. During this process, we only increase the channels of the last GDBlock output to minimize information loss, while the GDBlocks above it solely alter the size of feature maps without changing the channel count. Figure 8 provides a detailed depiction of the workflow of GDBlock and GDModel.
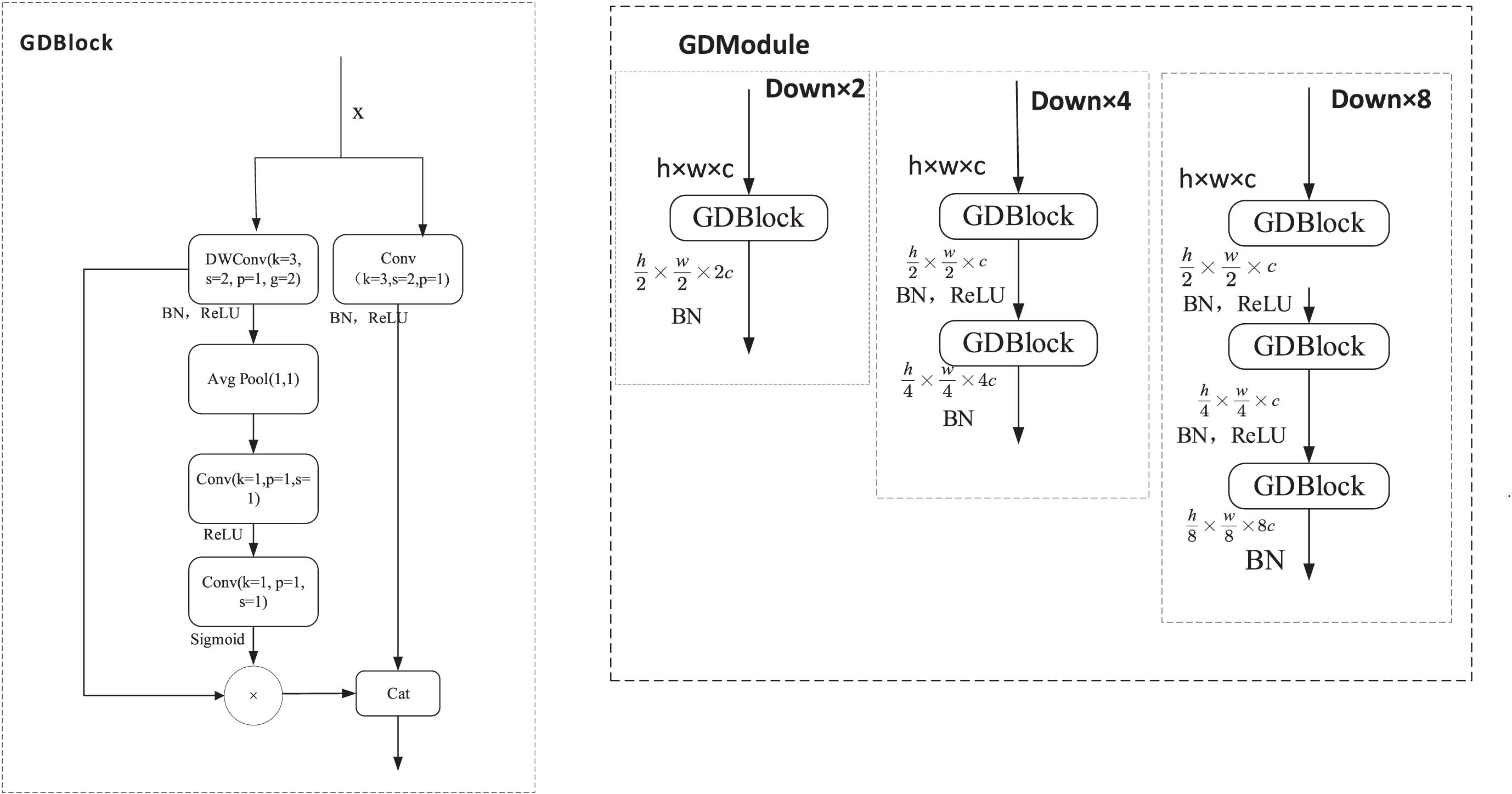
Details of GdBlcok and GdModule.
GDBlock utilizes the feature maps from upper layers as its internal feature maps. Since downsampling can easily lead to feature loss, using feature maps from upper layers helps to reduce feature loss and improve network performance. After applying the Fscale operation to assign weights to channels, linear operations are performed on the weighted channels to generate low-cost virtual channels. Finally, the normal convolution is connected to the features generated by attention and phantom operations to obtain the final Gd feature maps.
Using HRNet as the Backbone can provide higher resolution feature representations, allowing the model to better capture local details. The fusion of multi-scale features can improve the robustness of the model, while keeping computational costs low. By using both upsampling and downsampling, the model can fully extract and utilize information, enabling it to better capture the shape and details of human pose, as well as important features such as small objects and object boundaries.
The backbone network of GADNet first preprocesses the image using two standard 3 × 3 convolutions to reduce the resolution of the image to 1/4 of the original, which serves as the first stage of feature extraction. Then, feature extraction is performed using GABlock and down-sampling is done using GDBlock. The network uses parallel connections, greatly reducing the risk of feature loss. GABlock and GDBlock use lightweight and attention mechanisms to reduce computation while increasing accuracy. Stage 1 of the model includes StemNet and three Bottlenecks to extract features and increase channels. Stage 2, Stage 3, and Stage 4 use GABlock to extract features, and GDBlock is used for downsampling between the different stages to reduce parameters and enhance model performance. The parameter, computational complexity, and compression ratio of GABlock and GDBlock are denoted by GP, GG, and Rs, respectively, as shown in Equations 5, 6, and Equation 7
Among these, Cin represents the number of channels in the input feature map, Cout represents the number of channels in the output feature map, H and W denote the height and width of the feature map, s represents the number of squeeze channels, k is the size of the conventional convolution kernel, d is the size of the depth-wise convolution kernel, and r is the channel compression ratio, which is typically set to 16. The parameter increment and computational complexity in the attention mechanism are negligible relative to the overall network.
Dataset introduction
The COCO dataset is primarily used in computer vision research. The COCO training set contains 118,287 images, the validation set contains 5,000 images, and the test set contains 2,000 images. The dataset includes annotations for 17 keypoints, as shown in Table 2, which are used for tasks such as human pose estimation.
Annotation information for COCO keypoints
Annotation information for COCO keypoints
In this study, experiments were conducted on the COCO dataset and validated on the COCO validation set. The evaluation metric used is Object Keypoint Similarity (OKS), where AP50 represents the accuracy of detecting keypoints with OKS = 0.5, AP75 represents the accuracy with OKS = 0.75, mAP represents the average accuracy of predicting keypoints at ten threshold values of OKS between 0.50 and 0.95 with a step size of 0.05, APM represents the detection accuracy of keypoints for medium-sized objects, APL represents the detection accuracy of keypoints for large-sized objects, and AR represents the average recall of predicting keypoints at ten threshold values of OKS between 0.50 and 0.95 with a step size of 0.05. The specific implementation method is shown in Equation 8.
In the above formula, p represents a person in GroundTruth, pi represents the keypoints of the person with id p, dpi represents the Euclidean distance between the detected keypoints of the person with current id p and the annotated keypoints in the dataset, Sp represents the scale factor of person with id p, which is the square root of the area of the pedestrian detection box, σi represents the keypoint normalization factor of the keypoint with id i, which is the standard deviation between the predicted keypoint and the annotated keypoint in the dataset, and Vpi is the visibility information of the keypoint. OKS ranges between 0 and 1, where OKS = 0 means the predicted value does not match the ground truth keypoint, and OKS = 1 means a perfect prediction of the ground truth keypoint. The closer the OKS is to 1, the higher the matching degree.
The experimental environment in this study was configured as follows: a Windows 10 64-bit system with a single GeForce RTX 3080 12G graphics card, and the Pytorch 1.13.0 deep learning framework was utilized. During the training process on the COCO dataset, the images were scaled and cropped to a fixed size of 256×192. The AdamW optimizer was employed for network training with an initial learning rate of 1e-3, which was decayed to 1e-4 at the 170th epoch. The entire network was trained for 260 epochs with a batch size of 48. To prevent overfitting, we applied random flipping and rotation to the dataset, along with normalization and scaling. Table 3 lists the sizes and dimensions of all feature maps in the network.
The sizes and dimensions of all feature maps in the network
The sizes and dimensions of all feature maps in the network
The experimental results on the COCO dataset were analyzed and validated in this paper. Table 4 presents the performance comparison of GADNet with other pose estimation models on the COCO dataset. From the table, it can be observed that GADNet, as proposed in this paper, demonstrates a certain advantage compared to other pose estimation models. When using GADNet with an initial channel size of 32, although there is a slight decrease in accuracy, the parameter count is reduced by 154%, and floating-point operations are reduced by 158% compared to HRNet32. Additionally, AP50 increases by 2%. Compared to CNP and Simple Baseline, GADNet improves accuracy while significantly reducing the parameter count and computationalcomplexity.
Performance comparison of COCO validation set
Performance comparison of COCO validation set
In comparison to lightweight models such as MobileNetV2 and ShuffleNetV2, although GADNet may not have an advantage in model size, it significantly outperforms MobileNetV2 and ShuffleNetV2 in terms of model performance.
In order to evaluate the effectiveness of GaBlock and GdBlock in the model, a series of ablation experiments were conducted in this section.
The input image had a resolution of 256×192 pixels. AdamW was used as the optimizer for network training, with an initial learning rate of 1e-3. The learning rate was decayed to 1e-4 at the 170th epoch, and the total number of training epochs was 260. The batch size was set to 48. To prevent overfitting, we applied random flipping and rotation to the dataset, along with normalization and scaling.
The SEBlock was inserted after the GhostBlock to replace the BasicBlock in HRNet, reducing network parameters while improving performance. The module model can be seen in Fig. 9.
GhostBlock integrates SE attention mechanism.
Our study conducted ablation experiments on the COCO dataset using HRNet32 as the base network and replaced the BasicBlock in HRNet with GhostBlock, GhostBlock+SEBlock, GDModule+GABlock to validate the effectiveness of GABlock and GDBlock in the network model. The experimental results are presented in Table 5. After using the lightweight GhostBlock, although the network parameter count decreased, the model’s performance also slightly declined. The introduction of attention mechanisms led to a slight improvement in model performance. When GDModule+GABlock was used, the model’s performance further improved, demonstrating the effectiveness of GABlock and GDModule.
Results of ablation experiments with different models
Comparing GADNet with HRNet using GhostBlock, GADNet reduced the parameter count by 136% and lowered computational complexity by 84%. Additionally, it increased mAP by 7.3% compared to the HRNet with GhostBlock.
We also conducted feature map visualization and compared the feature maps at the same position in the GADNet and HRNet networks. For visualizations and feature map comparisons at the same position in GADNet and HRNet, please refer to Fig. 10.
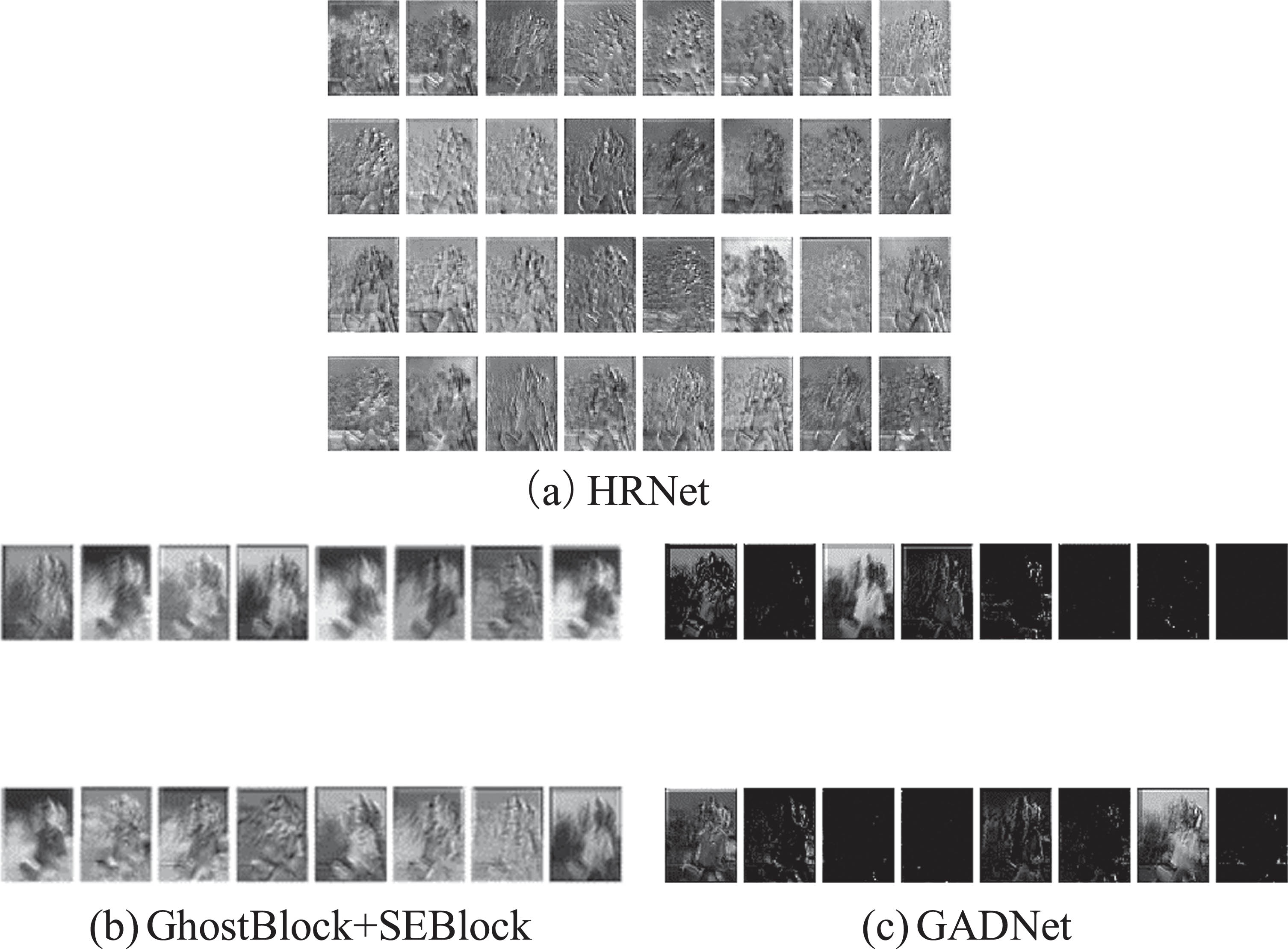
Feature map visualization.
In the figure above, there is a substantial amount of feature redundancy both in the HRNet feature maps and in the GhostBlocks with SE attention mechanism, particularly between adjacent feature maps. However, with the use of GADNet, feature redundancy is significantly reduced because the attention mechanism in GADNet assigns channel weights to each feature map, resulting in visually noticeable darkening of feature maps with higher weights. Furthermore, this study conducted experiments on the COCO 2017 validation dataset, including open-person and multi-person detection, as well as closed-person (occluded) single and multi-person detection, as shown in Fig. 11.

Prediction of key points of human body.
We have compared the processing of fine-grained information between HRNet and GADNet. Compared to HRNet, GADNet is able to extract more information, as shown in Fig. 12.

Visual comparison between HRNet and GADNet.
Human pose estimation is a fundamental task in the field of artificial intelligence because it forms the basis for future AI applications aimed at serving and understanding humans. Lightweight network models represent the most cost-effective solutions for deploying algorithms on low-performance hardware while reducing power consumption.
Our study introduces a lightweight human pose estimation network, GADNet, based on HRNet, with the goal of reducing network parameterization and computational complexity. Applied in situations that require high accuracy and low complexity.
GADNet achieves high predictive accuracy with lower parameterization and computational complexity, striking a balance between model prediction accuracy and model parameters. Experiments conducted on the COCO dataset demonstrate that GADNet outperforms HRNet networks based on GhostBlock and GhostBlock+SEBlock. While GADNet’s lightweight aspect may not surpass MobileNet and ShuffleNet, its accuracy shows a significant improvement compared to them. Furthermore, GADNet’s performance is very close to HRNet, and in some metrics, it even surpasses HRNet. In scenarios where high accuracy is required, GADNet exhibits a noticeable performance advantage.
The hypothesis and limitations of the develop method
Given the prevalence of mobile devices, future research will focus on migrating the model to mobile platforms, with the aim of achieving real-time monitoring while enhancing model performance, considering the convenience of mobile devices.
Declaration of competing interest
We declare that we have no financial and personal relationships with other people or organizations that can inappropriately influence our work, there is no professional or other personal interest of any nature or kind in any product, service and /or company that could be construed as influencing the position presented in, or the review of,the manuscript entitled.
Footnotes
Acknowledgments
This work was supported in part by the following projects: NaturalScience Foundation of Zhejiang Province (LO22E050012).