
Abstract
We present a novel approach for the construction of ensemble classifiers based on dimensionality reduction. The ensemble members are trained based on dimension-reduced versions of the training set. In order to classify a test sample, it is first embedded into the dimension reduced space of each individual classifier by using an out-of-sample extension algorithm. Each classifier is then applied to the embedded sample and the classification is obtained via a voting scheme. We demonstrate the proposed approach using the Random Projections, the Diffusion Maps and the Random Subspaces dimensionality reduction algorithms. We also present a multi-strategy ensemble which combines AdaBoost and Diffusion Maps. A comparison is made with the Bagging, AdaBoost, Rotation Forest ensemble classifiers and also with the base classifier. Our experiments used seventeen benchmark datasets from the UCI repository. The results obtained by the proposed algorithms were superior in many cases to other algorithms.
Keywords
Introduction
Classifiers are predictive models which label data based on a training dataset
The need for dimensionality reduction techniques emerged in order to alleviate the so called curse of dimensionality [32]. In many cases, a high-dimensional dataset lies approximately on a low-dimensional manifold in the ambient space. Dimensionality reduction methods embed datasets into a low-dimensional space while preserving as much of the information conveyed by the dataset. The low-dimensional representation is referred to as the embedding of the dataset. Since the information is inherent in the geometrical structure of the dataset (e.g. clusters), a good embedding distorts the structure as little as possible while representing the dataset using a number of features that is substantially smaller than the dimension of the original ambient space. Furthermore, an effective dimensionality reduction algorithm also removes noisy features and inter-feature correlations. Due to its properties, dimensionality reduction is a common step in many machine learning applications in fields such as signal processing [53, 1, 2] and image processing [41].
Ensembles of classifiers
Ensembles of classifiers [36] mimic the human nature to seek advice from several people before making a decision where the underlying assumption is that combining the opinions will produce a decision that is better than each individual opinion. Several classifiers (ensemble members) are constructed and their outputs are combined – usually by voting or an averaged weighting scheme – to yield the final classification [46]. In order for this approach to be effective, two criteria must be met: accuracy and diversity [36]. Accuracy requires each individual classifier to be as accurate as possible i.e. individually minimize the generalization error. Diversity requires to minimize the correlation among the generalization errors of the classifiers. These criteria are contradictory since optimal accuracy achieves a minimum and unique error which contradicts the requirement of diversity. Complete diversity, on the other hand, corresponds to random classification which usually achieves the worst accuracy. Consequently, individual classifiers that produce results which are moderately better than random classification are suitable as ensemble members. In [42], “kappa-error” diagrams are introduced to show the effect of diversity at the expense of reduced individual accuracy.
In this paper we focus on ensemble classifiers that use a single induction algorithm, for example the nearest neighbor inducer. This ensemble construction approach achieves its diversity by manipulating the training set. A well known way to achieve diversity is by bootstrap aggregation (Bagging) [6]. Several training sets are constructed by applying bootstrap sampling (each sample may be drawn more than once) to the original training set. Each training set is used to construct a different classifier where the repetitions fortify different training instances. This method is simple yet effective and has been successfully applied to a variety of problems such as spam detection [67] and analysis of gene expressions [62].
The award winning Adaptive Boosting (AdaBoost) [22] algorithm provides a different approach for the construction of ensemble classifiers based on a single induction algorithm. This approach iteratively assigns weights to each training sample where the weights of the samples that are misclassified are increased according to a global error coefficient. The final classification combines the logarithm of the weights to yield the ensemble’s classification.
Rotation Forest [47] is one of the current state-of-the-art ensemble classifiers. This method constructs different versions of the training set by employing the following steps: First, the feature set is divided into disjoint sets on which the original training set is projected. Next, a random sample of classes is eliminated and a bootstrap sample is selected from every projection result. Principal Component Analysis [30] (see Section 1.2) is then used to rotate each obtained subsample. Finally, the principal components are rearranged to form the dataset that is used to train a single ensemble member. The first two steps provide the required diversity of the constructed ensemble.
Multi-strategy ensemble classifiers [49] aim at combining the advantages of several ensemble algorithms while alleviating their disadvantages. This is achieved by applying an ensemble algorithm to the results produced by another ensemble algorithm. Examples of this approach include multi-training SVM (MTSVM) [38], MultiBoosting [65] and its extension using stochastic attribute selection [66].
Successful applications of the ensemble methodology can be found in many fields, for example, recommender systems [55], fMRI decoding [8], manufacturing [48] and eye pupil localization [43].
Dimensionality reduction
The theoretical foundations for dimensionality reduction were established by Johnson and Lindenstrauss [33] who proved its feasibility. Specifically, they showed that
The dimensionality reduction problem can be formally described as follows. Let
be the original high-dimensional dataset given as a set of column vectors where
where
Dimensionality reduction techniques employ two approaches: feature selection and feature extraction. Feature selection methods reduce the dimensionality by choosing
Dimensionality techniques can also be divided into global and local methods. The former derive embeddings in which all points satisfy a given criterion. Examples for global methods include:
Principal Component Analysis (PCA) [30] which finds a low-dimensional embedding of the data points that best preserves their variance as measured in the ambient (high-dimensional) space; Kernel PCA (KPCA) [56] which is a generalization of PCA that is able to preserve non-linear structures. This ability relies on the kernel trick i.e. any algorithm whose description involves only dot products and does not require explicit usage of the variables can be extended to a non-linear version by using Mercer kernels [57]. When this principle is applied to dimensionality reduction it means that non-linear structures correspond to linear structures in some high-dimensional space. These structures can be detected by linear methods using kernels. Multidimensional scaling (MDS) [34, 14] algorithms which find an embedding that best preserves the inter-point distances among the vectors according to a given metric. This is achieved by minimizing a loss/cost stress function that measures the error between the pairwise distances of the embedding and their corresponding distances in the original dataset. ISOMAP [61] which applies MDS using the geodesic distance metric. The geodesic distance between a pair of points is defined as the length of the shortest path connecting these points that passes only through points in the dataset. Random projections [9, 17] in which every high-dimensional vector is projected onto a random matrix in order to obtain the embedding vector. This method is described in details in Section 4.
Contrary to global methods, local methods construct embeddings in which only local neighborhoods are required to meet a given criterion. The global description of the dataset is derived by the aggregation of the local neighborhoods. Common local methods include Local Linear Embedding (LLE) [51], Laplacian Eigenmaps [3], Hessian Eigenmaps [18], Local tangent space alignment [69], Discriminative Locality Alignment (DLA) [68] and Diffusion Maps [11, 52] which is used in this paper and is described in Section 3.
A key aspect of dimensionality reduction is how to efficiently embed a new point into a given dimension-reduced space. This is commonly referred to as out-of-sample extension where the sample stands for the original dataset whose dimensionality was reduced and does not include the new point. An accurate embedding of a new point requires the recalculation of the entire embedding. This is impractical in many cases, for example, when the time and space complexity that are required for the dimensionality reduction is quadratic (or higher) in the size of the dataset. An efficient out-of-sample extension algorithm embeds the new point without recalculating the entire embedding - usually at the expense of the embedding accuracy.
The Nyström extension [44] algorithm, which is used in this paper, embeds a new point in linear time using the quadrature rule when the dimensionality reduction involves eigen-decomposition of a kernel matrix. Algorithms such as Laplacian Eigenmaps, ISOMAP, LLE, and Diffusion Maps are examples that fall into this category and, thus, the embeddings that they produce can be extended using the Nyström extension [26, 4]. A formal description of the Nyström extension is given in Section 3.3.
The main contribution of this paper is a novel framework for the construction of ensemble classifiers based on dimensionality reduction and out-of-sample extension. This approach achieves both the diversity and accuracy which are required for the construction of an effective ensemble classifier and it is general in the sense that it can be used with any inducer and any dimensionality reduction algorithm as long as it can be coupled with an out-of-sample extension method that suits it.
The rest of this paper is organized as follows. In Section 2 we describe the proposed approach. In Sections 3–5 we introduce ensemble classifiers that are based on the Diffusion Maps, random projections and random subspaces dimensionality reduction algorithms, respectively. Experimental results are given in Section 6. We conclude and describe future work in Section 7.
The proposed approach achieves the diversity requirement of ensemble classifiers by applying a given dimensionality reduction algorithm to a given training set using different values for its input parameters. An input parameter that is common to all dimensionality reduction techniques is the dimension of the embedding space. In order to obtain sufficient diversity, the dimensionality reduction algorithm that is used should incorporate additional input parameters or, alternatively, incorporate a randomization step. For example, the Diffusion Maps [11] dimensionality algorithm uses an input parameter that defines the size of the local neighborhood of a point. Variations of this notion appear in other local dimensionality reduction methods such as LLE [51] and Laplacian Eigenmaps [3]. The Random Projections [17] (Section 4) and Random Subspaces [28, 50] (Section 5) methods, on the other hand, do not include input parameters other than the dimensionality of the embedding space. However, they incorporate a randomization step which diversifies the data (this approach already demonstrated good results using Random Projections in [54] and we extend them in this paper). In this sense, PCA is not suitable for the proposed framework since it does not include a randomization step and the only input parameter it has is the dimension of the embedding space (this parameter can also be set according to the total amount of variance of the original dataset that the embedding is required to maintain). Thus, PCA offers no way to diversify the data. On the other hand, dimensionality reduction algorithms that are suitable for the proposed method include ISOMAP [61], LLE [51], Hessian LLE [18], Local tangent space alignment [69] and Discriminative Locality Alignment (DLA) [68]. These methods are suitable since they require as input the number of nearest neighbors to determine the size of the local neighborhood of each data point. Laplacian Eigenmaps [3] and KPCA [56] are also suitable for the proposed framework as they include a continuous input variable to determine the radius of the local neighborhood of each point.
After the training sets are produced by the dimensionality reduction algorithms, each set is used to train a classifier to produce one of the ensemble members. The training process is illustrated in Fig. 1.
Ensemble training.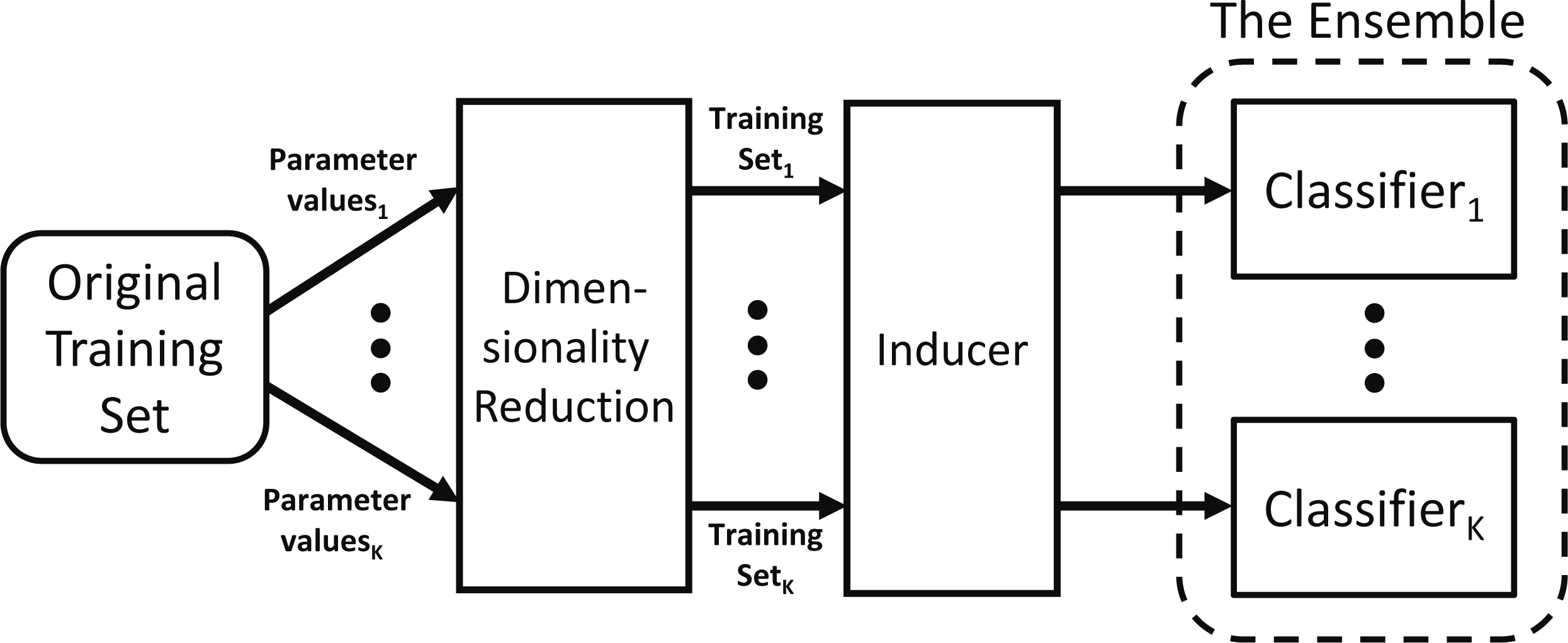
Classification process of a test sample.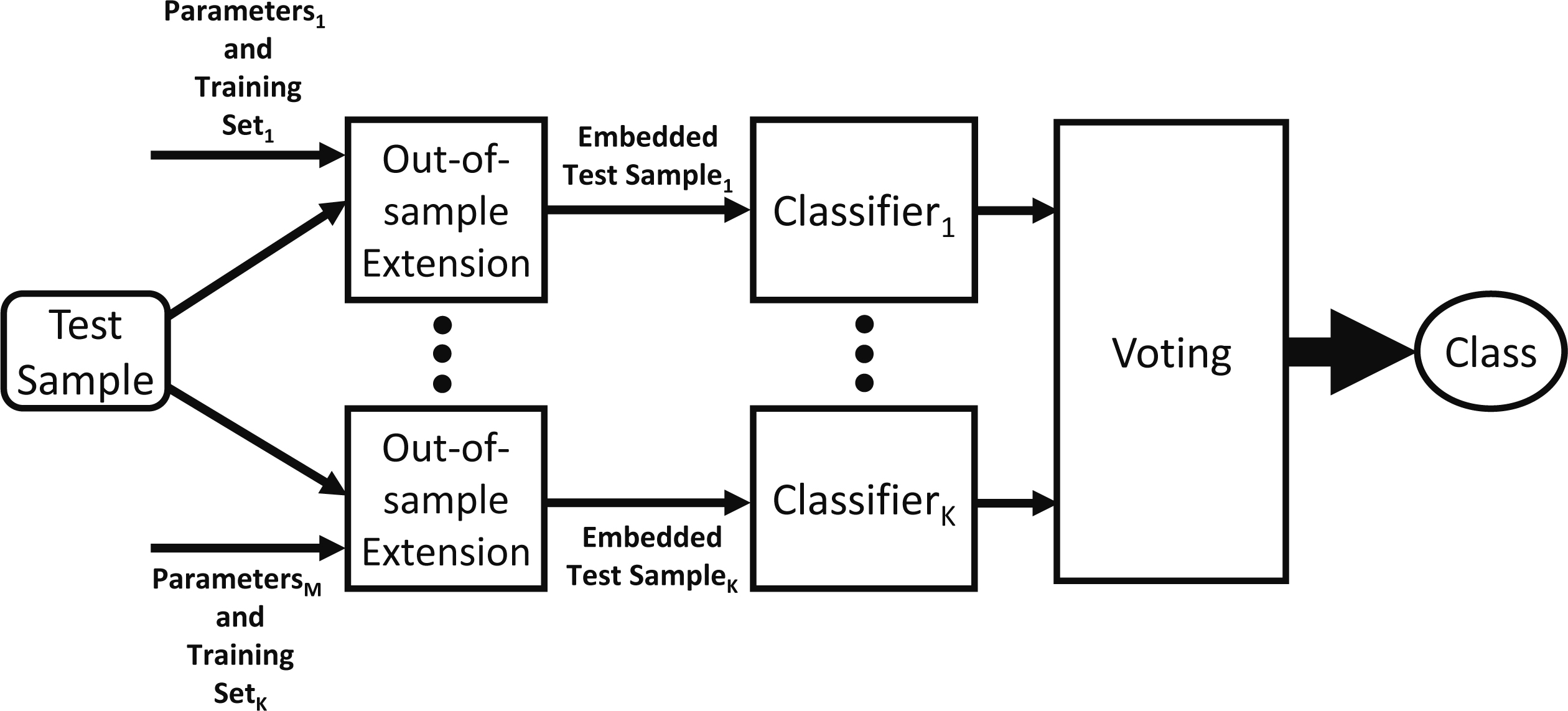
Employing dimensionality reduction to a training set has the following advantages:
It can decorrelate the data. For example, Principal Component Analysis transforms a set of data points whose variables may be correlated into a set of linearly uncorrelated variables. It can reduce noise. For example, the noise reduction capabilities of the DM algorithm are described and demonstrated in Section 3.2. It reduces the computational complexity of the classifier construction and consequently the complexity of the classification. It can alleviate over-fitting by constructing combinations of the variables [45].
These points meet the accuracy and diversity criteria which are required to construct an effective ensemble classifier and thus render dimensionality reduction a technique which is tailored for the construction of ensemble classifiers. Specifically, removing noise from the data contributes to the accuracy of the classifier while diversity is obtained by the various dimension-reduced versions of the data.
In order to classify test samples, they are first embedded into the low-dimensional space of each of the training sets using out-of-sample extension. Next, each ensemble member is applied to its corresponding embedded test sample and the produced results are processed by a voting scheme to derive the result of the ensemble classifier. Specifically, each classification is given as a vector containing the probabilities of each possible label. These vectors are aggregated and the ensemble classification is chosen as the label with the largest probability. Figure 2 depicts the classification process of a test sample.
Incorporating a-priori and domain knowledge is known to boost the classification performance in many cases. The proposed framework is general in the sense that it does not require neither a-priori knowledge of the datasets nor their domains. Nevertheless, it allows the incorporation of a-priori knowledge – for example by preprocessing the dataset – provided the resultant dataset is numeric.
The Diffusion Maps (DM) [11] algorithm embeds data into a low-dimensional space where the geometry of the dataset is defined in terms of the connectivity between every pair of points in the ambient space. Namely, the similarity between two points
Formally, let
For every real-valued bounded function
A common choice that meets these criteria is the Gaussian kernel:
A weight matrix
where
The transition matrix
Using matrix notation,
where
From the orthonormality of
When the spectrum decays rapidly (provided
where
We recall the diffusion distance between two data points
This distance reflects the geometry of the dataset and it depends on the number of paths connecting
Thus, the family of Diffusion Maps
embeds the dataset into a Euclidean space. In the new coordinates of Eq. (10), the Euclideandistance between two points in the embedding space is equal to the diffusion distance between their corresponding two high dimensional points as defined by the random walk. Moreover, this facilitates the embedding of the original points into a low-dimensional Euclidean space
which also endows coordinates on the set
The Gaussian kernel Eq. (3) produces a similarity value on the scale of
where
This means that all the points in the dataset will be included in the neighborhoods of the rest of the points. On the other hand, a small
In this case no points will be included in the neighborhood of the rest of the points in the dataset. The best choice, which is vital for the discovery of the dataset structure, lies between these two extremes. Finding the optimal value of
Noise reduction
The DM algorithm can reduce noise under some constraints. Suppose each point is perturbed by some additive noise function
Consequently, the noise effect on the Markov transition matrix
where
Let
Thus, the influence of the noise on the embedding is limited as long as the noise is smaller than
Noise reduction example of the DM algorithm.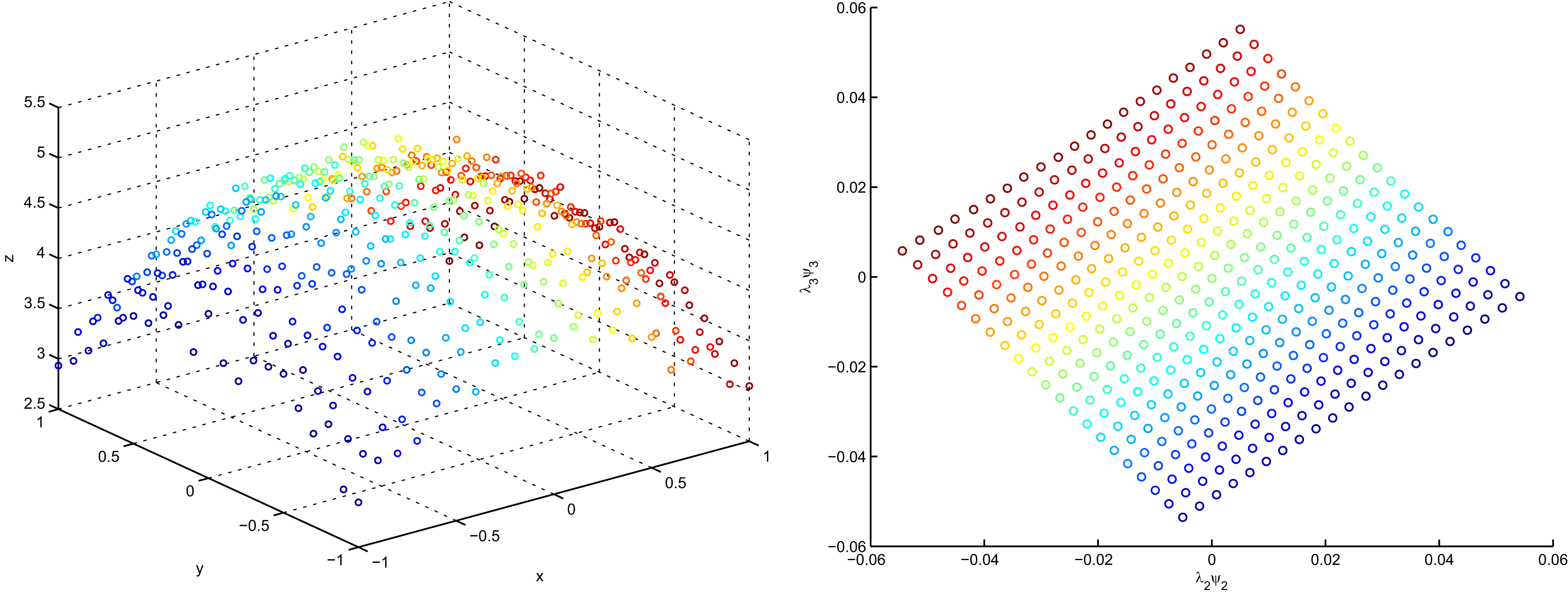
The Nyström extension [44] is an extrapolation method that facilitates the extension of any function
We describe the Nyström extension scheme for the Gaussian kernel that is used by the Diffusion Maps algorithm. Let
If
Let
The eigenfunctions
Using the Nyström extension, as given in Eq. (13),
The above extension facilitates the decomposition of every diffusion coordinate
Note that the scheme is ill conditioned since
The result is an extension scheme with a condition number
Let
Random projections
The Random projections algorithm implements the Johnson and Lindenstrauss lemma [33] (see Section 1.2). In order to reduce the dimensionality of a given training set
From a uniform (or normal) distribution over the From a Bernoulli
Next, the vectors in
The embedding
Random projections are well suited for the construction of ensembles of classifiers since the randomization meets the diversity criterion (Section 1.1) while the bounded distortion rate provides the accuracy.
Random projections have been successfully employed for dimensionality reduction in [21] as part of an ensemble algorithm for clustering. An Expectation Maximization (of Gaussian mixtures) clustering algorithm was applied to the dimension-reduced data. The ensemble algorithm achieved results that were superior to those obtained by: (a) a single run of random projection/clustering; and (b) a similar scheme which used PCA to reduce the dimensionality of the data.
In order to embed a new sample
Ensemble via random projections
In order to construct the dimension-reduced versions of the training set,
A new sample is classified by first embedding it into the dimension-reduced space
Random subspaces
The Random subspaces algorithm reduces the dimensionality of a given training set
This method is a special case of the random projections dimensionality reduction algorithm described in Section 4 where the rows (and column) of the matrix
Random subspaces have been used to construct decision forests [28] – an ensemble of tree classifiers – and also to construct ensemble regressors [50]. Ensemble regressors employ a multivariate function instead of a voting scheme to combine the individual results of the ensemble members. The training sets that are constructed by the Random subspaces method are dimension-reduced versions of the original dataset and therefore this method is investigated in our experiments. This method combined with support vector machines has been successfully applied to relevance feedback in image retrieval [60].
Out-of-sample extension
In order to embed a new sample
Ensemble via random subspaces
In order to construct the dimension-reduced versions of the training set,
A new sample is classified by first embedding it into the dimension-reduced space
Experimental results
In order to evaluate the proposed approach, we used the WEKA framework [25]. We tested our approach on 17 datasets from the UCI repository [39] which contains benchmark datasets that are commonly used to evaluate machine learning algorithms. None of the datasets contain missing values. No a-priori knowledge of the datasets and their domains was used in the experiments. The list of datasets and their properties are summarized in Table 1.
Properties of the benchmark datasets used for the evaluation
Properties of the benchmark datasets used for the evaluation
In order to reduce the dimensionality of a given training set, one of two schemes was employed depending on the dimensionality reduction algorithm at hand. The first scheme was used for the Random Projection and the Random Subspaces algorithms and it applied the dimensionality reduction algorithm to the dataset without any pre-processing of the dataset. However, due to the space and time complexity of the Diffusion Maps algorithm, which is quadratic in the size of the dataset, a different scheme was used. First, a random value
Steps for constructing the training set of a single ensemble member using the Diffusion Maps algorithm.
Steps for constructing the training set of a single ensemble member using the Diffusion Maps algorithm.
Select a random value Select a random sample Apply the Diffusion Maps algorithm to Extend
All ensemble algorithms were tested using the following inducers: (a) nearest-neighbor (WEKA’s B1 inducer); (b) decision tree (WEKA’s J48 inducer); and (c) Naïve Bayes. The ensembles were composed of ten classifiers (the information theoretic problem of choosing the optimal size of an ensemble is out of the scope of this paper. This problem is discussed, for example, in [35]). The dimension-reduced space was set to half of the original dimension of the data. Ten-fold cross validation was used to evaluate each ensemble’s performance on each of the datasets.
The constructed ensemble classifiers were compared with: a non-ensemble classifier which applied the induction algorithm to the dataset without dimensionality reduction (we refer to this classifier as the plain classifier). The constructed ensemble classifiers were also compared with the Bagging [6], AdaBoost [22] and Rotation Forest [47] ensemble algorithms. In order to see whether the Diffusion Maps ensemble classifier can be further improved as part of a multi-strategy ensemble (Section 1.1), we constructed an ensemble classifier whose members applied the AdaBoost algorithm to their Diffusion Maps dimension-reduced training sets.
We used the default values of the parameters of the WEKA built-in ensemble classifiers in all the experiments. For the sake of simplicity, in the following we refer to the ensemble classifiers which use the Diffusion Maps and Random Projections dimensionality algorithms as the DME and RPE classifiers, respectively. The ensemble classifier which is based on the random subspaces dimensionality reduction algorithm is referred to as the RSE classifier.
Tables 2–4 describe the results obtained by the decision tree, nearest-neighbor and Naïve Bayes inducers, respectively. In each of the tables, the first column specifies the name of the tested dataset and the second column contains the results of the plain classifier. The second to last row contains the average improvement percentage of each algorithm compared to the plain classifier. We calculate the average rank of each inducer across all datasets in the following manner: for each of the datasets, the algorithms are ranked according to the accuracy that they achieved. The average rank of a given inducer is obtained by averaging its obtained ranks over all the datasets. The average rank is given in the last row of each table.
The results of the experimental study indicate that dimensionality reduction is a promising approach for the construction of ensembles of classifiers. In 113 out of 204 cases the dimensionality reduction ensembles outperformed the plain algorithm with the following distribution: RPE (33 cases out of 113), DM
Ranking all the algorithms according to the average accuracy improvement percentage produces the following order: Rotation Forest (6.4%), Random projection (4%), DM
Results of the ensemble classifiers based on the nearest-neighbor inducer (WEKA’s IB1)
Results of the ensemble classifiers based on the nearest-neighbor inducer (WEKA’s IB1)
RPE is the Random Projection ensemble algorithm; RSE is the Random Subspaces ensemble algorithm; DME is the Diffusion Maps ensemble classifier; DME
Results of the Random Projection ensemble classifier based on the decision-tree inducer (WEKA’s J48)
RPE is the Random Projection ensemble algorithm; RSE is the Random Subspaces ensemble algorithm; DME is the Diffusion Maps ensemble classifier; DME
Results of the ensemble classifiers based on the Naïve Bayes inducer
RPE is the Random Projection ensemble algorithm; RSE is the Random Subspaces ensemble algorithm; DME is the Diffusion Maps ensemble classifier; DME
classifications with high probabilities damage accurate classifications obtained by other ensemble members. Figure 4 demonstrates how the accuracy decreases as the number of members increases when RSE is paired with the Naïve Bayes inducer. This phenomenon is contrasted in Fig. 5 where the behavior that is expected from the ensemble is observed. Namely, an increase in accuracy when the number of ensemble members is increased when an ensemble different from the RSE is used (e.g. the DME).
In order to compare the 8 algorithms across all inducers and datasets we applied the procedure presented in [15]. The null hypothesis that all methods have the same accuracy could not be rejected by the adjusted Friedman test with a confidence level of 90% (specifically F(7, 350)
Accuracy of the RSE algorithm using the Naïve Bayes inducer.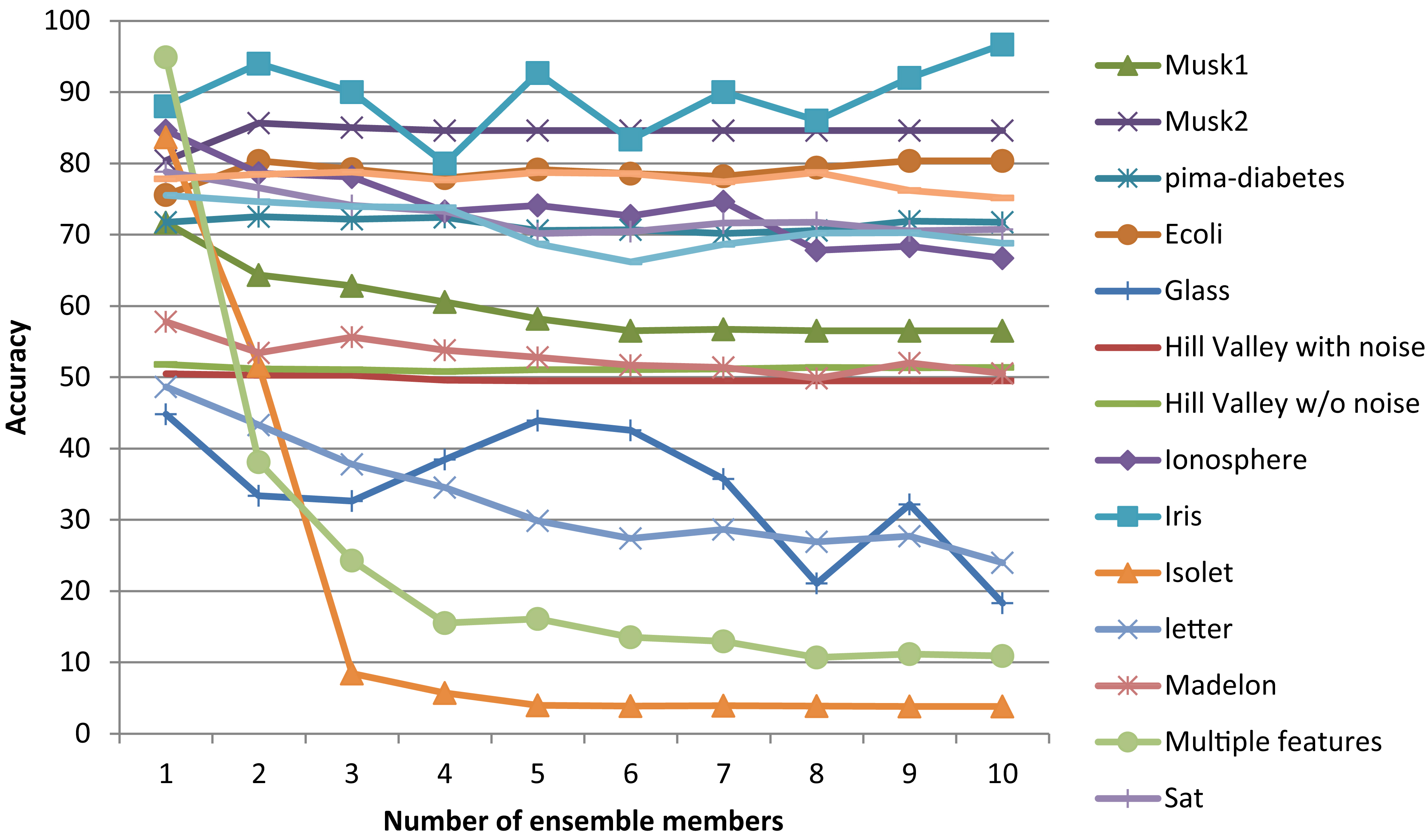
Accuracy of the DM ensemble using the Naïve Bayes inducer.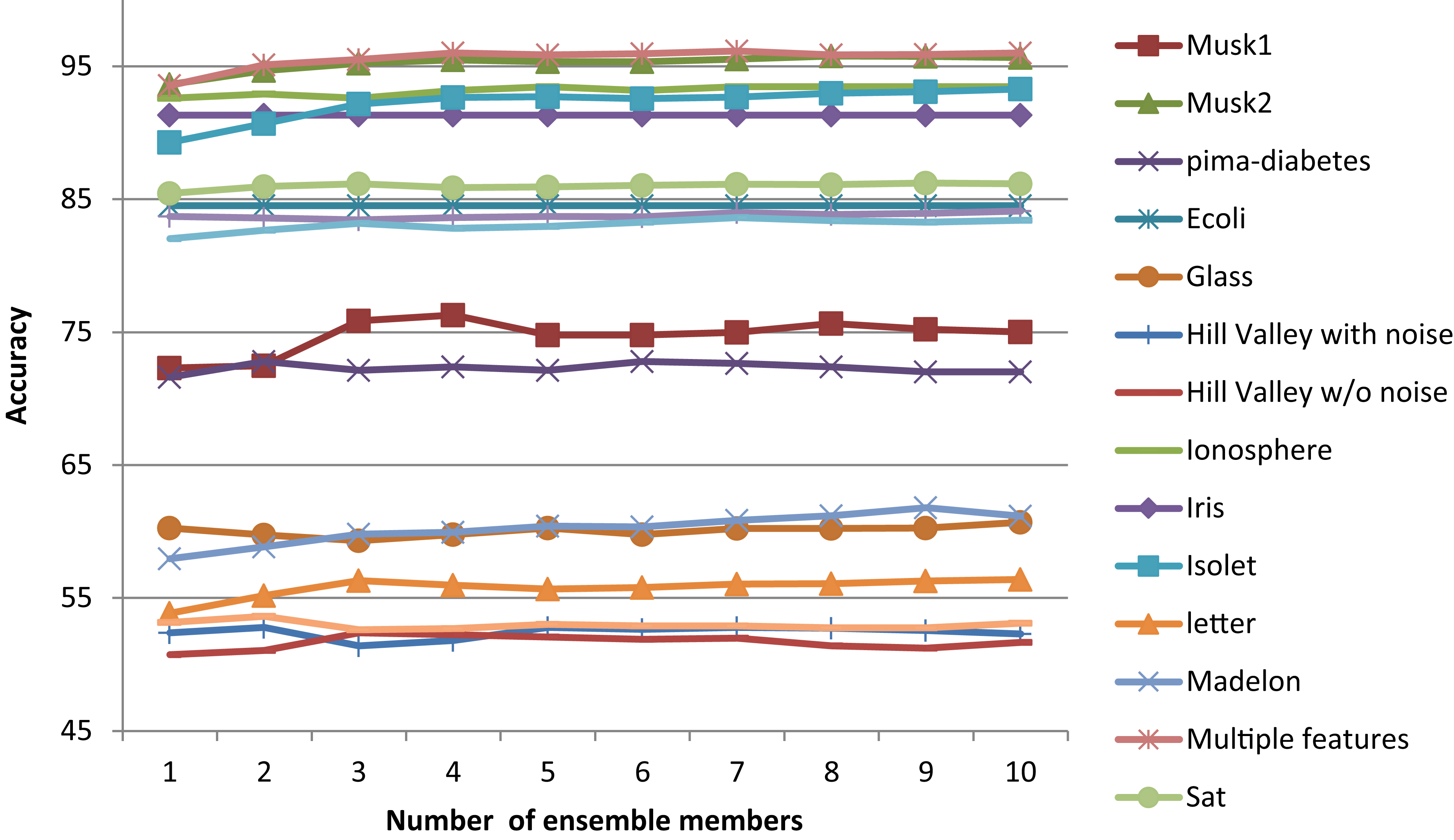
In terms of the average improvement, the RPE algorithm is ranked first with an average improvement percentage of 5.8%. We compared the various algorithms according to their average rank following the steps described in [15]. The RSE and RPE achieved the first and second average rank, respectively. They were followed by Bagging (
Using the adjusted Friedman test we rejected the null hypothesis that all methods achieve the same classification accuracy with a confidence level of 95% and (7, 112) degrees of freedom (specifically F(7, 112)
Results for the decision tree inducer (J48)
Inspecting the average improvement, the RPE and RSE algorithms are ranked second and third, respectively, after the Rotation Forest algorithm. Following the procedure presented by Demsar [15], we compared the various algorithms according to their average rank. The RSE and DM
The null hypothesis that all methods obtain the same classification accuracy was rejected by the adjusted Friedman test with a confidence level of 95% and (7, 112) degrees of freedom (specifically F(7, 112)
Results for the Naïve Bayes inducer
The DM
Employing the procedure presented in [15], we compared the algorithms according to their average ranks. The DM
When we compare the average accuracy improvement across all the inducers, the RPE and DM
Discussion
The results indicate that when a dimensionality reduction algorithm is coupled with an appropriate inducer, an effective ensemble can be constructed. For example, the RPE algorithm achieves the best average improvements when it is paired with the nearest-neighbor and the decision tree inducers. However, when it is used with the Naïve Bayes inducer, it fails to improve the plain algorithm. On the other hand, the DM
Furthermore, using dimensionality reduction as part of a multi-strategy ensemble classifier improved in most cases the results of the ensemble classifiers which employed only one of the strategies. Specifically, the DM
Conclusion and future work
In this paper we presented dimensionality reduction as a general framework for the construction of ensemble classifiers which use a single induction algorithm. The dimensionality reduction algorithm was applied to the training set where each combination of parameter values produced a different version of the training set. The ensemble members were constructed based on the produced training sets. In order to classify a new sample, it was first embedded into the dimension-reduced space of each training set using out-of-sample extension such as the Nyström extension. Then, each classifier was applied to the embedded sample and a voting scheme was used to derive the classification of the ensemble. This approach was demonstrated using three dimensionality reduction algorithms – Random Projections, Diffusion Maps and Random subspaces. A fourth ensemble algorithm employed a multi-strategy approach combining the Diffusion Maps dimensionality reduction algorithm with the AdaBoost ensemble algorithm. The performance of the obtained ensembles was compared with the Bagging, AdaBoost and Rotation Forest ensemble algorithms.
The results in this paper show that the proposed approach is effective in many cases. Each dimensionality reduction algorithm achieved results that were superior in many of the datasets compared to the plain algorithm and in many cases outperformed the reference algorithms. However, when the Naïve Bayes inducer was combined with the Random Subspaces dimensionality reduction algorithm, the obtained ensemble did not perform well in some of the datasets. Consequently, a question that needs further investigation is how to couple a given dimensionality reduction algorithm with an appropriate inducer to obtain the best performance. Ideally, rigorous criteria should be formulated. However, until such criteria are found, pairing dimensionality reduction algorithms with inducers in order to find the best performing pair can be done empirically using benchmark datasets. Furthermore, other dimensionality reduction techniques should be explored. For this purpose, the Nyström out-of-sample extension may be used with any dimensionality reduction method that can be formulated as a kernel method [26]. Additionally, other out-of-sample extension schemes should also be explored e.g. the Geometric Harmonics [12]. Lastly, a heterogeneous model which combines several dimensionality reduction techniques is currently being investigated by the authors.
Footnotes
Acknowledgments
The authors would like to thank Myron Warach for his insightful remarks.