
Abstract
In data mining, finding frequent itemsets is a critical step to discovering association rules. The number of frequent itemsets may, however, be huge if the threshold of minimum support is set at a low value or the number of items in the transaction database to be mined is large. In the past, some approaches were thus proposed to keep frequent itemsets with compact representation. For example, the approach of maximal itemsets keeps a borderline composed of the maximal itemsets, which separate frequent itemsets from non-frequent ones. It can recover all the frequent itemsets, but cannot get their actual frequencies back. On the contrary, the approach of closed itemsets can correctly recover each frequent itemset and its frequency. Besides, another approach called reference itemsets can recover each frequent itemset and approximately estimate its frequency. In this paper, we propose an efficient algorithm to recover each frequent itemset and its approximate frequency based on the kept maximal itemsets, frequent 1-itemsets, their supports, and some key information. The maximal frequent itemsets are used to recover all frequent itemsets, which are then organized into a simple flow network with levels. Next, the kept key information is used to derive approximate supports of the frequent itemsets in the flow network through the flow process. Finally, a series of experiments are conducted to show the compression effects of the proposed algorithm.
Introduction
Mining frequent itemsets and association rules plays a basic but important role in knowledge discovery. There were many approaches proposed for it, and among them the Apriori algorithm was the most easily understood [1]. The algorithm first checks itemsets with single items by scanning a database. If the frequency of an itemset is larger than or equal to a threshold called minimum support, then the itemset is said frequent. Then the itemsets with 2 items are then generated from the frequent 1-itemsets based on the anti-monotone property. The same procedure is then repeated to find frequent itemsets with more items. After all the frequent itemsets are found, the association rules could then be derived based on another parameter called minimum confidence by comparing their conditional probabilities. Since the Apriori algorithm needs to scan the database several times, several other methods have been proposed to improve the efficiency of mining frequent itemsets. For example, Hipp et al. have made a survey and comparison about association rules in [9]. Besides, Han et al. used a tree structure called FP-Tree to mine frequent itemsets. They could avoid rescanning a database multiple times and thus the execution performance could be improved. Liu et al. then further adopted the concept of the DB projection [13] to avoid not enough memory space to put the entire tree.
Different criteria were proposed to judge an itemset interesting. For example, Webb et al. stated an interesting itemset should satisfy the following properties, such as positive association, productivity property, redundancy property and independent productivity property [23, 24]. Gallo et al. defined several types of rule dependences and proposed a mining algorithm to mine them [7]. Some scholars built models to predict frequencies of itemsets and judged interestingness using the difference between real and predicted frequencies [14, 15]. Leeuwen et al. considered an interesting itemset should involve two properties, namely quality and diversity [11].
Some mechanisms were also proposed to decrease the storage space of databases and the frequent itemsets mined. On compact representation of a database, Wang et al. summarized a database with a summary set [22]. Chandola et al. used two objective functions, namely compaction gain and information loss [5], to solve it. Yang et al. represented a database as pairs of TID and items, and adopted a minimal cost cover set [25] to get fewer pairs.
On the concise representation of frequent itemsets, closed itemsets [18] and maximal itemsets [2] are two main approaches. Maximal itemsets are the frequent itemsets with none of their immediate supersets being frequent. Closed itemsets are different from maximal itemsets in that none of the immediate supersets of a closed itemset has the same frequency as the itemset. Maximal itemsets can recover all frequent itemsets, but cannot derive their actual frequencies back. On the contrary, closed itemsets correctly recover the frequency of each frequent itemset and its frequency.
Recently, Huang et al. proposed a new compact representation of frequent itemsets, called reference itemsets, which lay between maximal itemsets and closed itemsets [10]. In this paper, we propose another approximate representation of frequent itemsets. Different from the reference itemsets, the given frequent itemsets are organized into a structure of a flow network rather than a prefix tree. Instead of all frequent itemsets and their supports, only the maximal itemsets, frequent 1-itemsets, their supports and some key information are kept. The maximal frequent itemsets are used to recover all frequent itemsets, which are then organized into a simple flow network with levels. Nodes at different levels represent frequent itemsets with different length. Initially, the frequent 1-itemsets are put at the first level and the support value of a frequent 1-itemset is put on the edge from the start node to the node corresponding to the frequent 1-itemset. These flow values are then propagated to the next levels according to a specific rule and derive one or more intervals at each level of the flow network. Each interval contains a pair of correction values for some itemsets at that level. These intervals are thought of the key information, which will be kept, for approximating the supports of the frequent itemsets. The supports of the frequent itemsets at the latter of any two adjacent levels can then be estimated by the itemsets at the former plus the additional key information. The approach brings an advantage in time efficiency because frequent itemsets to be compacted can be handled separately. Finally, a series of experiments are implemented, and the results show the proposed method is effectiveness for approximate representation of frequent itemsets and is efficient when low representation rates are requested.
The rest of the paper is organized as follows. In Section 2, some previous works related to the research are reviewed. In Sections 3 and 4, some terms are defined and the purposes are introduced in details, respectively. In Section 5, the proposed method is stated. In Section 6, the experimental results are described to show the performances of the method. Conclusion and future work are given in Section 7.
Related works
In this section, some related concepts and approaches about compact representation of frequent itemsets are briefly reviewed, including maximal itemsets [2], closed itemsets [18] and some others.
For a frequent itemset, if no other frequent itemsets are its supersets, then it is called a maximal itemset. Maximal itemsets can be thought of as a boundary between frequent and infrequent itemsets. All the itemsets above the boundary (included) are frequent and all the ones below it are infrequent [2]. For a given transaction database and a minimum support, Bayardo proposed a method called enumeration of a complete set-enumeration tree to identify frequent maximal itemsets [2]. The complete set-enumeration tree stores all frequent itemsets. The enumeration starts from the special node, namely {}, which is the root of the tree. Itemsets enumerated below the special node are frequent itemsets with only an item. Itemsets enumerated below 1-itemsets are frequent with two items and one of two items is its parent. The operation is repeated until there is no frequent itemset below previously enumerated ones. The itemsets that belong to the leaves of a complete set-enumeration tree, are considered maximal itemsets. In addition to mining maximal itemsets from traditional transaction databases, mining maximal itemsets from other different data types was also discussed. For example, Unil et al. discussed how to efficiently identify weighted maximal frequent itemsets from data streams [21]. Chiranjeevi and Hari proposed an algorithm called modified MGUIDE(LM) for mining high utility itemsets on data streams [6].
Closed itemsets have a stricter constraint than maximal itemsets. A frequent itemset is said as a closed itemset if none of its frequent supersets has the same frequency as it has. Thus, the derived closed itemsets from a database are more than the derived maximal itemsets. Closed itemsets can be used to recover the frequencies of all frequent itemsets, but they need more storage space than maximal itemsets. Pasquier et al. proposed a method to find closed itemsets [18]. Their method is executed iteratively, with each iteration including two main steps [18]. The first step generates candidate frequent generators (itemsets) from existing frequent itemsets, and the processed transaction database is scanned to check which candidates are frequent. The second step checks the immediate parents of new generated frequent itemsets to re-identify members of closed itemsets. Over these years, several researches focused on improvement of efficiency of mining closed itemsets. Prabha et al. have conducted a survey of them [20]. In addition, mining closed itemsets from other different data types was also discussed. For example, Nori et al. proposed a closed itemset mining approach for data streams [16].
According to the description above, both closed and maximal itemsets can reduce the number of frequent itemsets. Closed itemsets can derive all frequent itemsets and their frequencies back, but maximal itemsets can get only frequent itemsets back. In addition to the purpose of compression, the two concepts can be used to improve the performance of existing algorithms. For example, Lin et al. proposed the number of potential itemsets in the process of mining high utility patterns can be reduced through the concept of maximal itemsets [12]. Since the number of potential itemsets is related to the mining time, the spent execution time can then be reduced in their approach. Besides, in rule-based classification, it is time-consuming to mine rules from a large database because it is a combinatorial search problem in the worst case. Okada et al. used the concept from closed itemsets to reduce the exhaustive extraction of non-redundant and condensed patterns [17].
In addition to closed itemsets and maximal itemsets, some other compact representations were also proposed. For example, Calders et al. proposed the concept of derivable itemsets. They proposed some methods to predict lower and upper bounds of an itemset [4]. When the values of the two bounds were the same, the support of the itemset was exactly determined and the itemset was called a derivable itemset. Boulicaut et al. proposed the concept of free sets [3]. They proposed that for an association rule
Besides, when the size of a database is large, the mining time is usually very time-consuming. Riondato and Upfal then used a sampling approach to select a subset of transaction records for mining [19]. Their approach requested the number of selected transaction records needed to be enough to keep the distance of the frequencies of the two kinds of frequent itemsets, one generated from the original database and the another from the subset, was small. The sampling number could be calculated based on the number of the transaction records in an original database and the user-specified tolerant degree of the distance.
Term definitions
The approach proposed in this paper is described as follows. Let
Flow network
A flow network contains three parts, namely two special nodes
An example of a flow network. An example of a lattice.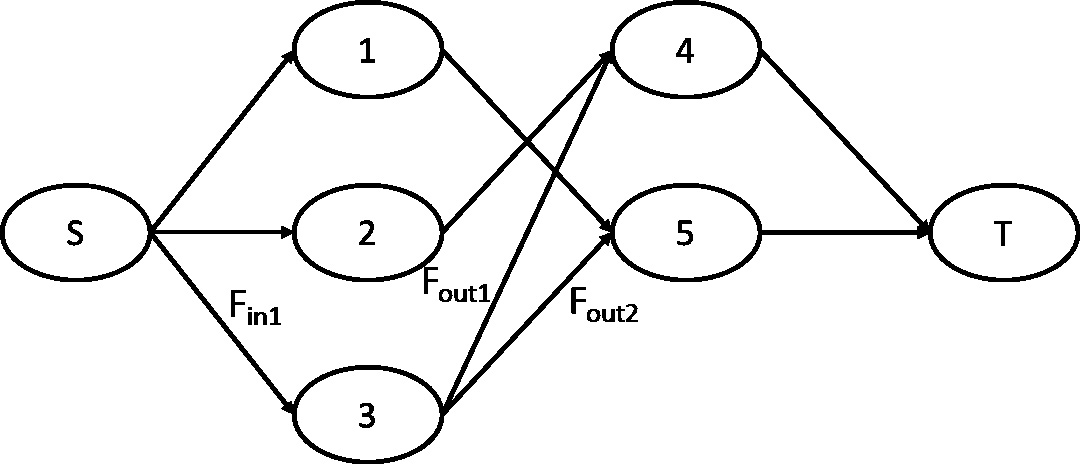
Two terms relating to the network are defined below, namely
For example in Fig. 1, the flow in edge S-3 is the only
For a given flow network, there are three properties described below.
The flow in an edge must be equal to or smaller than the capacity. For a given intermediate node The summation of values of all
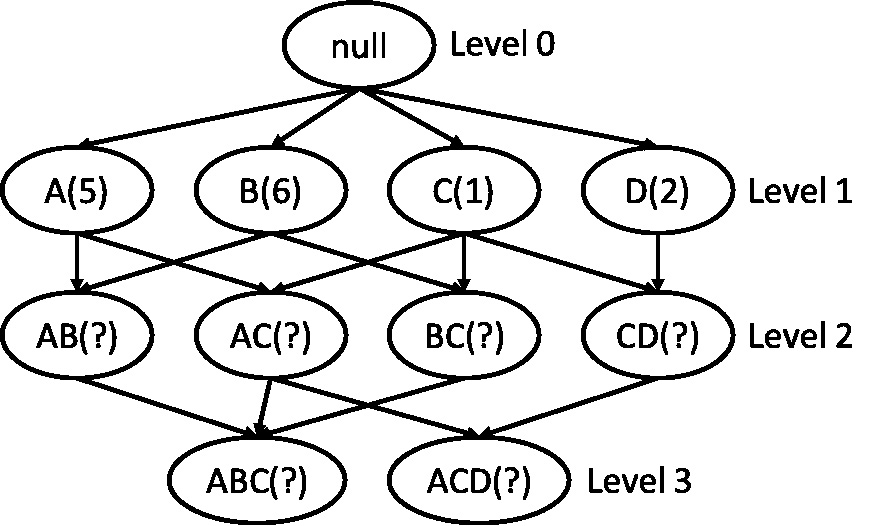
In a lattice of frequent itemsets, only the itemsets with their frequencies equal to or larger than the given minimum support threshold are kept. A special value null is put at the only node at level 0, and there is a directed edge between the null node and each node with a frequent itemset containing only one item at level 1. The content of a node at each level contains a frequent itemset with their item number the same as the level number, and the itemsets are arranged according to the alphabetical order. There is a directed edge between two nodes at neighboring levels, if one itemset can fully contain the other. Figure 2 shows an example of a lattice. For example, there is a directed edge between
A term relating to the lattice is defined below, namely relating itemsets of an itemset in a lattice, which will be mentioned again in other sections.
For example in Fig. 2, the relating itemsets of AB are
Simple flow network of frequent itemsets
A simple flow network is transformed from a lattice of frequent itemsets, with the content and the order of each level fully corresponding to those in the lattice, and two nodes
A simple flow network of frequent itemsets.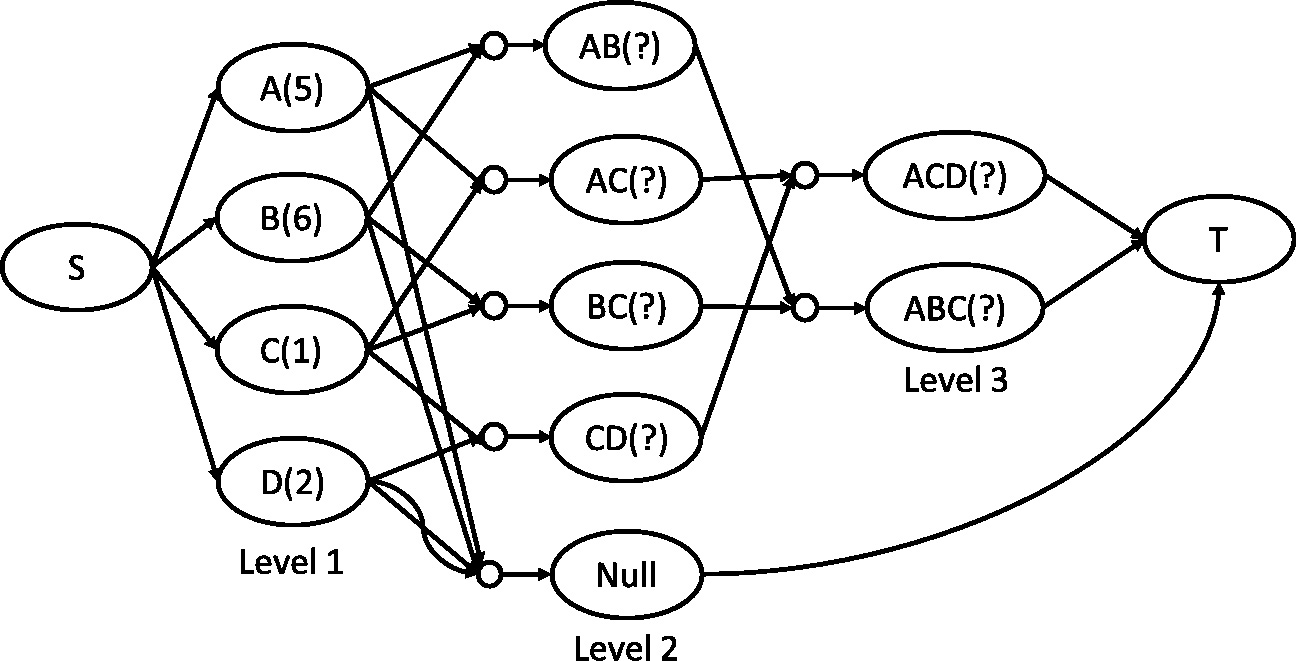
The paragraph describes the edges relating to the two special nodes (
In the simple network, except the two special nodes (
For example in Fig. 3,
For a level in the simple network, a special node Null is added to the next (right) level of the level, and each itemset at the left level links to the node with
For example at level 1 of Fig. 3, the max_deg of the level is 3 if we ignore the edges linking to the node Null at level 2, and the itemset that has the out-degree is
The complex network is extension of the simple network. Two additional factors are added to the complex network, namely interval and correcting edge pair, and they are described in Definitions 4 and 5, separately. Figure 4 shows an example of the complex network. Note that, the two factors are represented by dotted lines.
For example in Fig. 4, level 2 contains two intervals, namely [AB, AC] and [BC, CD]. The number of AB is 1, of AC is 2, and the difference of the numbers of the two near itemsets is 1. Situation of [BC, CD] is similar to [AB, AC].
Figure 4 shows an example of a complex flow network. Note that, the correcting edge pairs at level 3 are not shown for simplicity. The itemsets AB and AC at level 2 of the figure are at same interval; hence, correcting edge pairs of the two itemsets have same value pair, namely (
A complex flow network of frequent itemsets.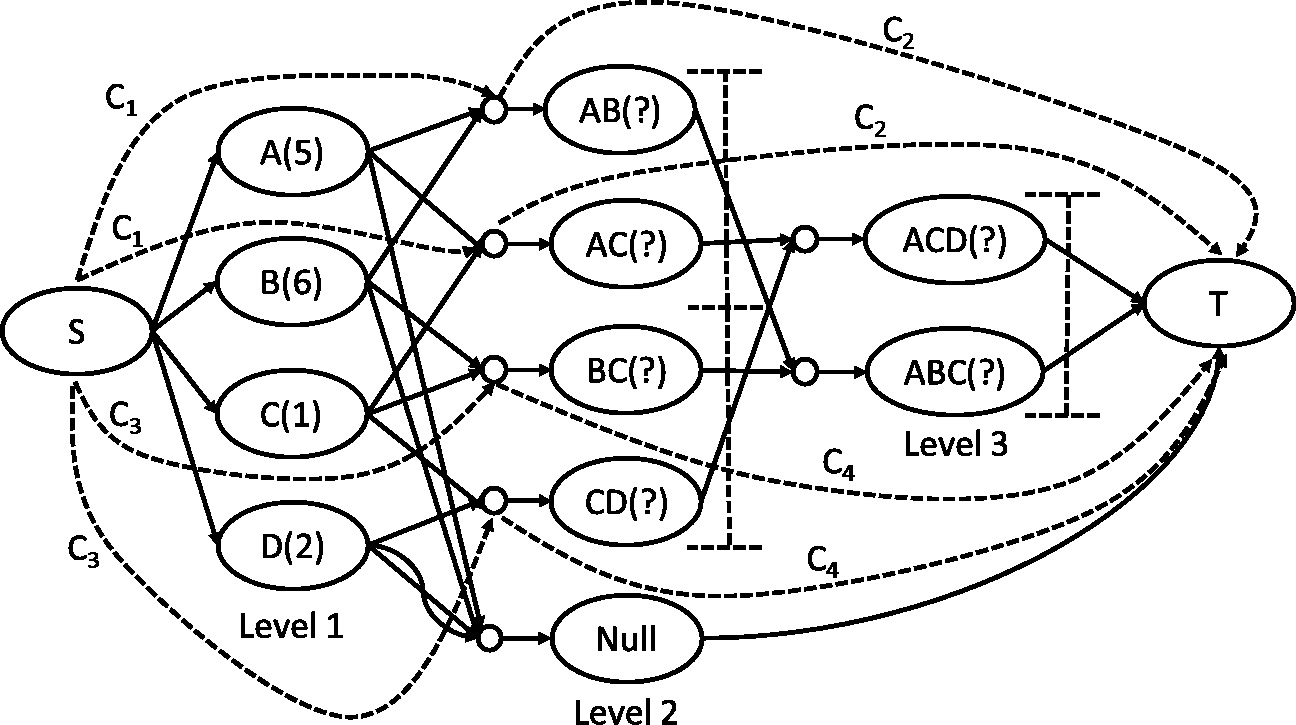
For a given lattice of frequent itemsets, assume supports of the itemsets at level 1 are known and supports of the itemsets at the other levels are unknown. A simple heuristic can be applied to predict the unknown supports from the known supports. The heuristic is based on the observation among the itemsets at any two near levels of the lattice, which is described in Observation 1. In the paper, this concept is implemented through a flow network.
For example in Fig. 2, the relating itemsets of AB are
Observation 1 has shown the phenomenon, and it is also known that the content and structure of the simple network fully correspond to the lattice. At any two near levels of the simple network, except the levels between
For example, in Fig. 3, the
Take level 1 and level 2 in Fig. 3 as an example. The relating itemsets of the itemset AB are
A simple flow network can only distinguish the frequent itemsets, but it does not exactly predict the support of each itemset. In order to reach the purpose, we expand the simple flow network to the complex flow network. Before discussing why the complex network can closely predict supports of the itemsets in detail, some terms must be defined.
Definition 9 discusses the predicted flows of the itemsets in a complex network, and the method which adjusts the predicted flow of each itemset in the network is also discussed. A question is, whether a complex flow network can be used to get close predicted flow of each itemset? The answer is sure if the intervals in a complex network are put to suitable locations, and the details are shown in Observation 3. How to set the capacities of the edge pairs and to find the best intervals are described in Sections 5.1 and 5.2, respectively.
Adjusting capacities on the collecting edge pairs to make 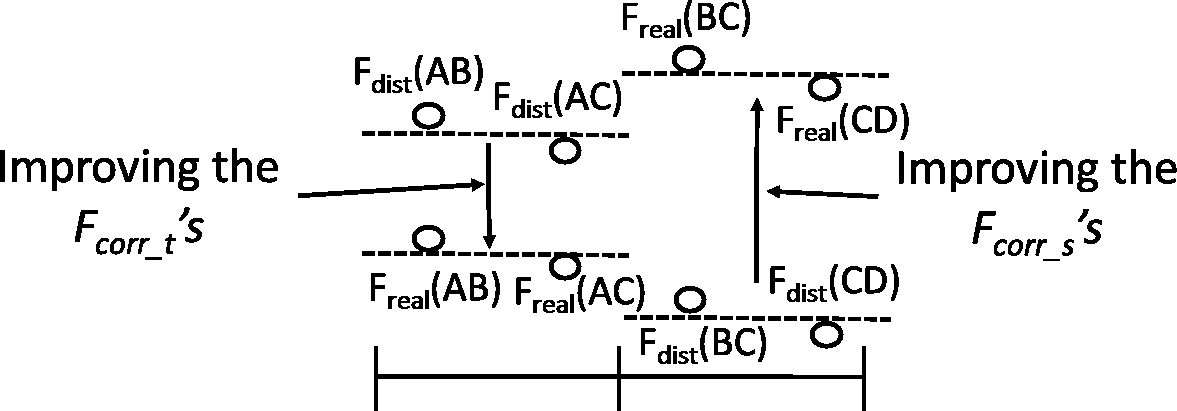
In summary, the purpose of the paper is to reduce the information for storing frequent itemsets and their frequencies. For a set of given frequent itemsets, only the maximal itemsets, all frequent 1-itemsets and the intervals, are saved, instead of all the frequent itemsets. The itemsets and their approximate supports can be recovered through the following steps: 1. recovering the lattice of frequent itemsets using the maximal itemsets, 2. rebuilding the complex flow network using the 1-itemsets and intervals, and 3. obtaining the close support of each itemset according to the properties of the complex network. Note that the maximal itemsets know their real supports; hence, they are not put into the complex network.
In the section, we describe our methods in details. Section 5.1 describes how to set capacities of the correcting edge pairs in the complex network, and Section 5.2 describes how to identify the best intervals at a level of the complex network.
Setting capacities of correcting edge pairs
According to the description of Observation 3, the predicted support of the itemsets in an interval can be close to their real supports, if the values of the
where
Before discussing how to assign the capacities in details, Eq. 2 and some theorems relating to the formula are introduced, which is useful to understand the problem.
where
In Theorem 1, when the condition is a positive number, most values of the
In Theorem 2, when the condition value is a positive number, most values of
The optimizing 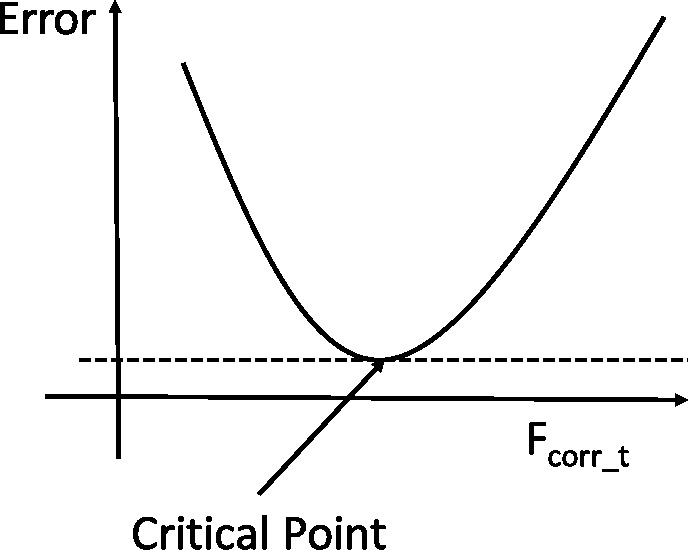
Based on the above discussions, if the condition is a positive number, optimizing value of the
The opposite situation can be calculated with Eq. 4:
where
Proof
Proof
For a level of the complex network, Section 5.1 has shown how to set capacities of the correcting pairs to make the predicted flows close to their real supports. The section then introduces how to efficiently put the intervals to suitable locations. Before introducing how to find the best intervals, some definitions about the representation of an interval are first given below.
For example in Fig. 4, the default cuttings of level 2 are put into top of [AB] and bottom of [CD], respectively, and the two cutting are represented as [AB] and [AC], separately. The level 2 can be represented as [AB, CD].
Definition 4 shows the definition of the interval. It is clear that an interval can be represented by a pair of the itemsets, which consists of top-boundary-cutting and bottom-boundary-cutting of it. Definition 12 shows that the cuttings can be represented as the numbers. Based on the two reasons, an interval can thus be represented as a pair of the numbers of the top-boundary-cutting and bottom-boundary-cutting. Note that, the number of the itemsets contained in an interval or at a level can be calculated by the difference of the numbers of the two cuttings, namely Number(bottom-boundary-cutting)
Our methods relate to the Eqs 5–10, which are described below in detail. The number of the cuttings at a level can be specified by Eq. 5 as follows:
where
Given the number of the cuttings, it is important to put the cuttings to correct the locations (described in Definition 11) to make the predicted flows as close to the corresponding real supports as possible. The problem can be viewed as a series of decision of optimization-binary-division. First, a cutting is put to a location of a level to allow the itemsets divided into two disjoint parts. The cutting is expected as an optimization partition, which means it can make the summation of the minimum errors of the top part and the bottom part of the cutting minimum. How to calculate the minimum errors of the two parts, which can apply similar operation to the two parts, separately. The concept above can be summarized as shown in Eq. 6:
where the term Error
Equation 7 represents the top boundary must be above the bottom boundary, and the number of the itemsets contained by an interval must be more than or equal to 1; otherwise, the interval is illegal.Equation 8 represents the error of the interval can be calculated if the number of the cuttings assigned to the interval is 0, and it is related to Section 5.1.Equation 9 represents the error must be 0 if the number of the itemsets contained in the interval is 1. The reason is shown in Theorem 3 below.Equation 10 represents that the error must be 0 if the number of the cutting assigned to the interval is enough to let each sub-interval only contain an itemset. The reason is shown in Theorem 4 below.
According to Eq. 1, the error of the interval can be written as
In the situation of Theorem 4, an interval at a level can be divided into a set of the sub-intervals that only contain an itemset. According to Theorem 3, the errors of all the sub-intervals are 0, and the error of the interval is the summation of the errors of the sub-intervals; hence, the theorem is valid.
In the paper, the concept of dynamic programming is applied to solve the problem. A 3-dimensional array is used to save results of the sub-problems, and each element of the array represents result of a triple Error
Observing the top part (Error
Figure 7 shows the details of the algorithm. It numerates the
The algorithm for mining best intervals at a level of the complex network.
The section contains the two sub-sections, namely Experimental Datasets and Criteria (Section 6.1) and, Experimental Results (Section 6.2). Section 6.1 explains the sources and generation of datasets used in the paper and uses three criteria of performance. Section 6.2 demonstrates the performance of our method on different datasets and parameter values. Besides, the performance of the approaches of closed and maximal itemsets is also included to make a comparison with the proposed method.
Experimental datasets and criteria
Three criteria are used to evaluate approximate representation of frequent itemsets. They are representation rate (Eq. 11), error (Eq. 12), and running time.
The representation rate is defined as follows:
where Intervals represents the number of all intervals in the complex network, Items represents the number of all frequent 1-itemsets, MIs represent maximal itemsets and
The error is defined as follows:
where CIs represents the itemsets in any interval,
Representation rate shows how much data is needed for representing the list of given frequent itemsets and their approximate supports. A smaller representation rate represents the information which needs to be stored is less than a larger one. Error represents the summation of distances among real supports and predicted supports of given frequent itemsets. A smaller error is more desired than a larger one. Let
| Datasets | Minimum | Frequent | Maximal | Closed |
|---|---|---|---|---|
| supports | itemsets | itemsets | itemsets | |
| Accidents | 1950 | 1385 | 3.177% | 49.675% |
| Accidents | 1750 | 3025 | 3.008% | 49.455% |
| Accidents | 1600 | 5487 | 2.479% | 48.916% |
| Pumsb | 2650 | 1342 | 6.483% | 42.176% |
| Pumsb | 2580 | 3207 | 4.365% | 33.801% |
| Pumsb | 2540 | 5026 | 3.144% | 29.686% |
| Pumsb_star | 1300 | 1626 | 2.399% | 28.598% |
| Pumsb_star | 1260 | 3488 | 1.147% | 17.747% |
| Pumsb_star | 1230 | 5786 | 0.847% | 12.876% |
| Chess | 2650 | 1758 | 3.527% | 65.131% |
| Chess | 2570 | 3495 | 3.405% | 60.315% |
| Chess | 2500 | 5682 | 2.499% | 56.441% |
| Mushroom | 1800 | 1199 | 1.001% | 3.003% |
| Mushroom | 1400 | 3471 | 0.576% | 2.218% |
| Mushroom | 1200 | 5407 | 0.721% | 2.423% |
| Connect | 2999 | 1279 | 0.313% | 0.391% |
| Connect | 2998 | 3071 | 0.228% | 0.391% |
| Connect | 2997 | 5119 | 0.156% | 0.391% |
The multipliers of error and running time in the six datasets
Subsets of the six datasets were involved in the experiments, namely Accidents, Pumsb, Pumsb Star, Chess, Mushroom and Connect. The six datasets could be found in the website
The testing program was written in Java. The environment for software development is as follows. The OS is Microsoft Windows 8.1
The errors for datasets accidents and pumsb.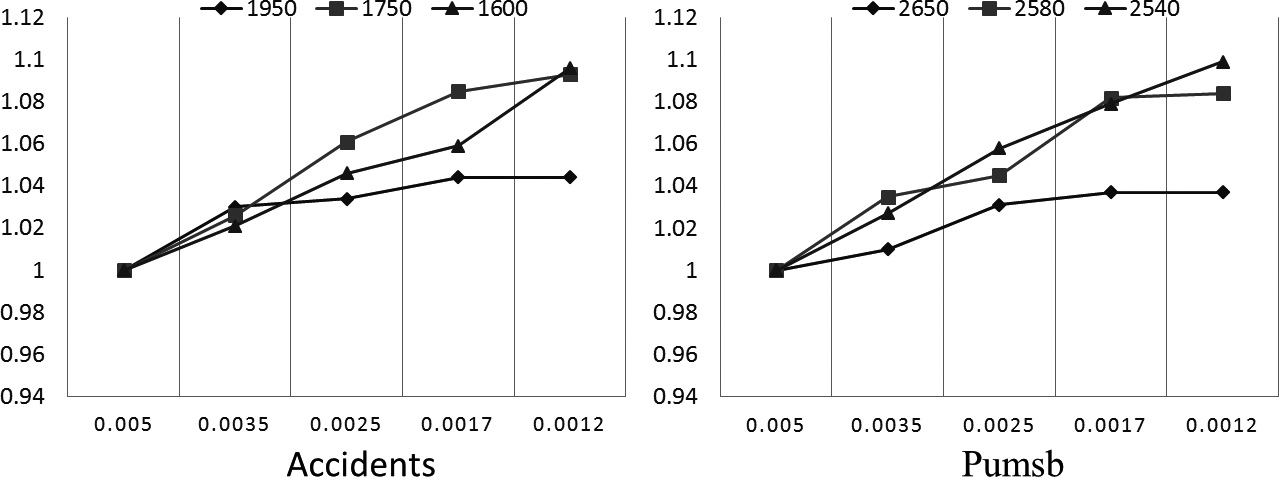
The errors for datasets pumsb_star and chess.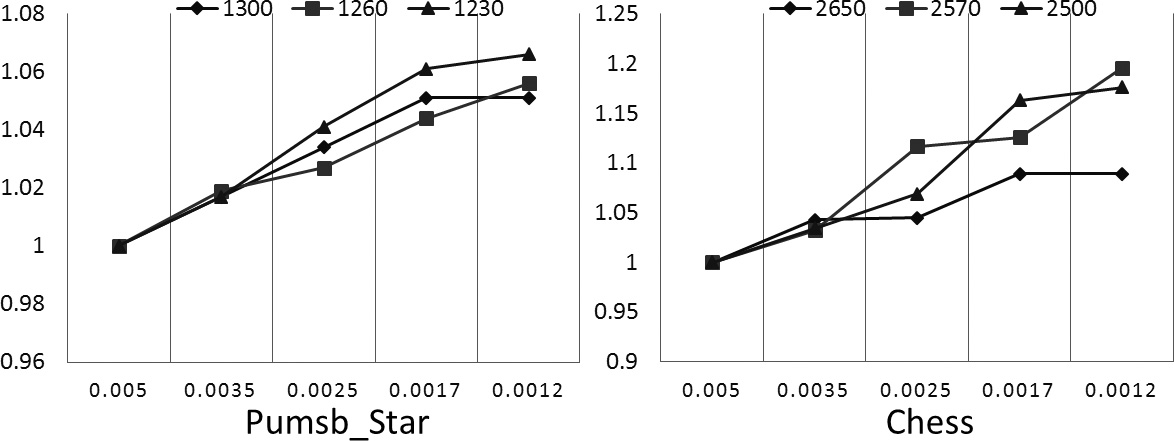
The errors for datasets mushroom and connect.
Table 1 shows numbers of frequent itemsets, and the ratios of closed itemsets and maximal itemsets in all frequent itemsets for different minimum support thresholds and datasets. It is notable that setting the minimum support values to the above values maintains consistency of numbers of the frequent itemsets.
The running times for datasets accidents and pumsb.
The running times for datasets pumsb_star and chess.
The running times for datasets mushroom and connect.
Figures 8–10 show the errors of the six datasets for the different factors, namely datasets, minimum supports and the
Figures 11–13 then show the running times of proposed approach for the six datasets. The x-axles represent various
According to the above results, a trend is clear, namely the running time decreases when the
In this paper, we propose a new compact representation that lies between closed itemsets and maximal itemsets. It reserves all the frequent itemsets and identifies their approximate supports. A list of all frequent itemsets is first recovered through the maximal itemsets, and they are organized as the complex network. Next, the itemsets at each level of the network are partitioned into intervals except level 1. Through the information of the 1-itemsets and the intervals, the approximate supports of the itemsets in the intervals can be obtained. Experiments show the proposed method is suitable when low represent rate is requested. The proposed approach may be not efficient if we need very close approximate supports. It represents a trade-off between efficiency and accuracy. In the future, we will continue discovery on efficient division of a level to ensure the concept can fit in all kinds of situations. We will also make more experiments on more datasets and on other approaches such as non-derivable itemsets.