
Abstract
Deviating behavior within an organization can lead to unexpected results. The effects of deviations are often negative, but sometimes also positive. Therefore, it is useful to detect deviations from event logs which record all the behavior of the organization. However, existing model-based and cluster-based approaches are inaccurate or slow when dealing with complex event logs, i.e. logs of less structured processes having many activities and many possible paths. This paper proposes a novel approach that is faster than cluster-based approaches because it creates a so-called profile which is less time-consuming than creating clusters. Furthermore, the approach is also more accurate than model-based approaches because we use an iterative approach to improve the result. Our experiments show that approach outperforms existing techniques in a variety of circumstances.
Introduction
Process mining is a family of techniques to extract knowledge about business processes from event logs which record process executions consisting of different business activities [1]. Process mining techniques are widely used, not only in situations where processes are structured and well-defined (e.g., procurement, finance, and e-government), but also in environments such as healthcare, customer relationship management (CRM) and product development where things are less structured [2]. Such environments often allow for a higher degree of freedom and this may lead to unexpected deviations, e.g., a patient can directly visit a doctor without an appointment in an emergency. Since deviations impact business processes, it is of the utmost importance to detect them from event logs.
Deviation detection is a significant problem which has been explored within diverse research areas and application domains [3], such as detecting failure behavior (e.g., bugs) in software systems [4], detecting fraudulent claims in insurance companies [5] and detecting intrusions in a network [6]. The lion’s share of deviation detection done in context of process mining focusses on conformance checking. This requires a normative model and therefore knowledge of what constitutes a deviation. In this paper we focus on deviation detection without a normative process model and just used the event data to detect deviations.
Deviation detection techniques can be divided into two categories, i.e., model-based approaches and cluster-based approaches. Techniques in the first category basically employ conformance checking method on a discovered process model to detect deviations [7, 8]. These techniques first mine an appropriate model as a reference model and then classify cases which do not fit the model as deviations. This works well on structured processes, but has problems when dealing with less structured processes. It is difficult to specify an appropriate model in this setting due to the high variety of behavior. Within the second category, techniques use clustering [9, 10, 11] to detect deviations based on the idea of perceiving cases in small clusters as deviations. In this case there is no conformance checking on a discovered reference model: by grouping similar cases the outliers become visible. Clustering techniques are more suitable for complex processes (i.e., no need to learn a reference model), but they are more time-consuming compared to techniques in the first category. In summary, although there already exist techniques such as the ones mentioned above, deviation detection in less structured environments remains a challenge. As an example, consider a log, recording the behavior for a loan process, extracted from the BPI Challenge 2012.1
http://www.win.tue.nl/bpi/2012/challenge.
A model discovered from BPI Challenge 2012.
In order to deal with these challenges, we propose a novel approach, whose basic principle is that a case from a log is a deviation if it is not similar to the collection of mainstream cases in the log.
More precisely, as shown in Fig. 2, (1) we sample the cases (
The framework of detecting deviations.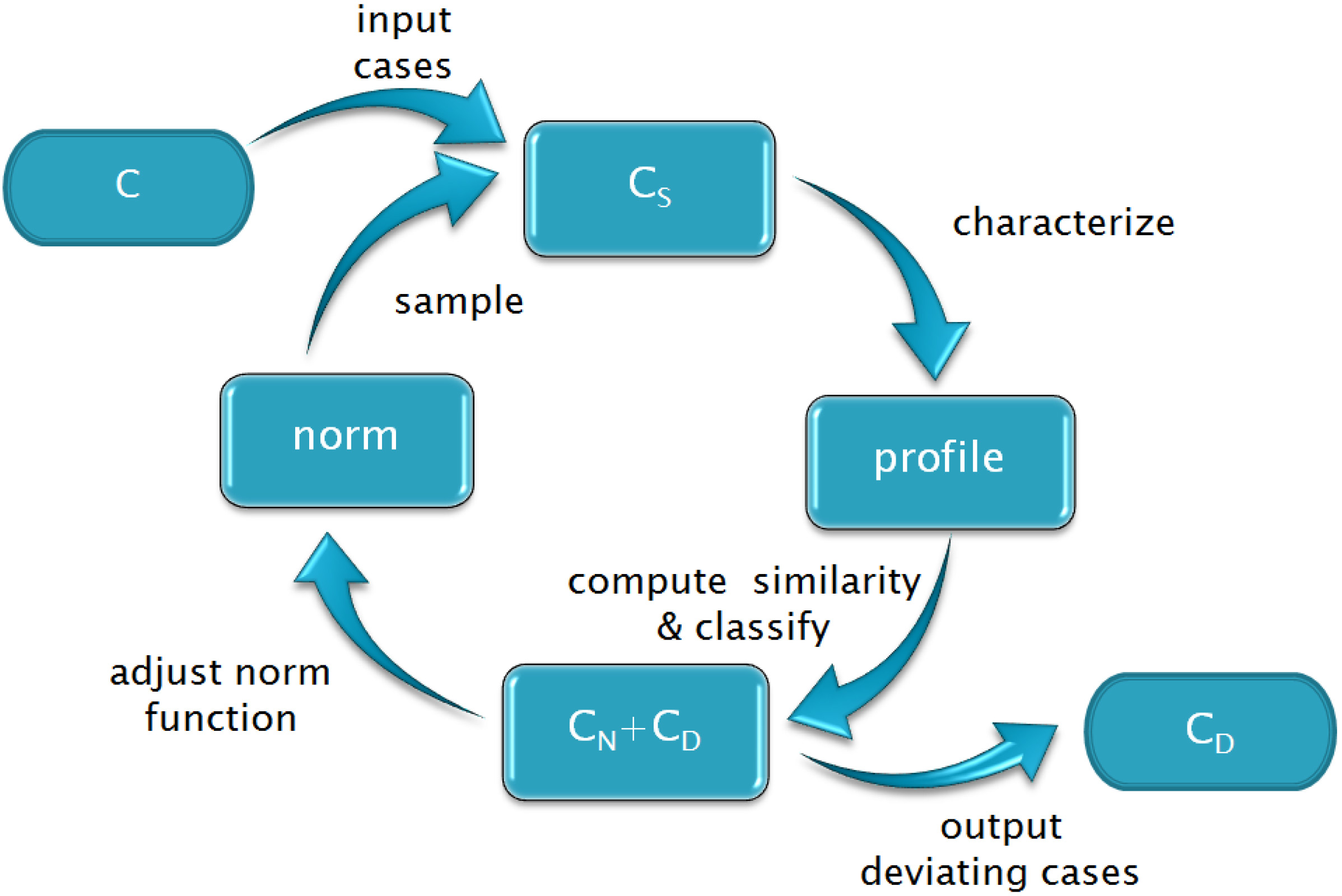
In summary, our contribution is based on creating a profile, rather than models or clusters, to detect deviations and improving the performance iteratively. Our approach is more accurate than model-based approaches and faster than cluster-based approaches when dealing with complex and less structured logs.
The remainder of the paper is organized as follows. The next section summarizes existing approaches for deviation detection. In Section 3, we introduce preliminaries and provide a definition for the profile notion. Section 4 proposes a framework for detecting deviations and we apply it to the control-flow perspective in Section 5. The approach has been implemented in ProM and in Section 6 we evaluate the approach. Finally, Section 7 concludes the paper.
The idea of detecting deviations from event logs is not new and many approaches have been proposed. In this section, we provide an overview of existing approaches and compare them with our approach.
Model-based Approaches. Bezerra and Wainer [12] propose three similar methods to detect deviating cases, i.e., threshold ([13] extends it to dynamic thresholds), iterative and sampling algorithms. Among these methods, the last one gives the best result. It first creates a sample log through sampling a given log and then considers the cases, which do not perfectly fit the model discovered from the sample log, as deviations. In [14], authors propose an approach which consists of five steps: (i) scoping, (ii) process discovery, (iii) filtering of fitting models, (iv) model selection, and (v) splitting of log. The key step in the approach is to select the most appropriate model which is structurally simple and behavioraly specific among fitting models. Similarly [15], employs the genetic algorithm [16] to discover an appropriate model from a preprocessed log and then classifies the cases which are not instances of the model as deviations.
The model-based approaches typically discover an appropriate model as a reference model, and then use the conformance checking technique to classify cases which do not fit the model as deviations. However, it is a challenging (and often impossible) task to discover and select the appropriate model from a complex log. In any case this requires domain-specific knowledge. In our approach, a profile is created to replace the appropriate model to detect deviations, which is much easier and more accurate.
Cluster-based Approaches. Ghionna et al. [17] cluster cases based on frequent patterns extracted from a log, and then treat cases in clusters whose sizes are below a threshold as deviationss [18] performs a hierarchical clustering of a log, in which each case is seen as a point of a properly identified space of features. The method was originally devoted to discovering an expressive process model from each cluster, but we can also use it to detect deviations by classifying cases in small clusters as deviations. Song et al. [19] create a profile (which is different from the notion used in this paper) to contain specific attributes of a case and then map a case to a vector based on the profile. In this way, the whole log is mapped into a vector space. According to the distances between every two vectors, clusters are generated and cases in small clusters are considered as deviations.
Cluster-based approaches are more suitable for unstructured processes than model-based approaches. However, cluster-based approaches are optimized to find clusters rather than deviations. As a consequence, they are time-consuming due to the time it takes to cluster cases. In contrast, our approach is more efficient since it detects deviations based on the similarity between each case and a sample log.
Preliminaries
This paper proposes a novel method based a so-called profile which characterizes “normal cases” from specific perspectives. In this section, we first define event logs because the definition of a log used in this paper is quite different from the standard notation [1] and then provide a definition for the profile notion.
(Universes).
In the remainder we assume the following universes:
Cases (process instances) are represented by a unique identifier. This allows us to refer to a specific case even if two cases have the same trace.
(Event logs).
Let
(Profile).
Let
If a profile is based on some feature
(Combining profiles).
Let
The above definitions do not give concrete functions to quantity the similarity. The profile functions used vary when detecting deviations from different perspectives. In Section 6, we concrete profiles focusing on the control-flow perspective. In the remainder, we will drop the subscripts and simply assume a given profile function
In Section 3, we create a profile to quantify the similarity between a case and
Sampling
Basically, we create
(Norm Function).
Let
The norm function needs to be initialized by users and we will give more details in Section 4.3. Based on norm values and a given sample size, we employ a function named sampling to derive
(Sampling).
Let
Note that the same case cannot be included twice in
Classifying
After deriving
(Classifying).
Let
for any
where
Note that
The classification step detects deviating cases and updates norm based on
(Cycling).
Let
The above definition presents the input, output and steps of the cyclicSC algorithm, which is also shown in Fig. 3. Initially, we set
The flowchart of the algorithm cyclicSC.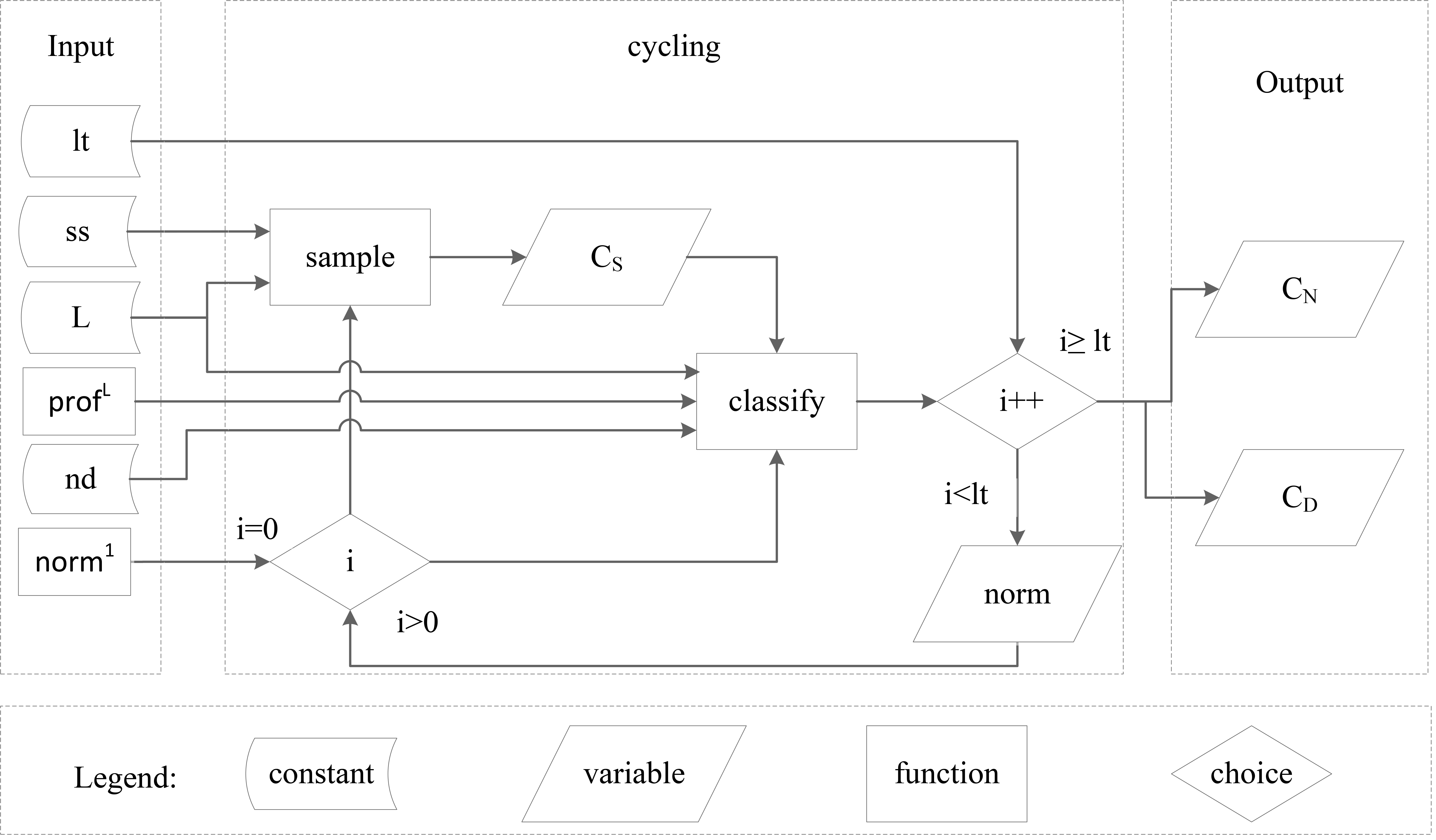
At the beginning of the algorithm, we need to configure some input constants and functions. In our experiments in Section 6, we let
If there is no a-priori or domain knowledge, function norm is initialized as
Using the framework proposed in Section 4, we can detect deviations from different perspectives through creating different profiles. In this section, we present an application of the framework to detect deviations from the control-flow perspective. Specifically, we create a combined profile
Creating a profile based on the directly follows relation
The directly follows relation is a key relation in process mining used in many model discovery methods, such as the
The definition of the directly follows relation in this paper is different from the one in [1], where the relation is in the context of a log and the frequency is not taken into consideration. Here the directly follows relation is in the context of a case (rather than a log) and the frequency is used to quantify the directly follows relation. Specifically, given a set of cases
(Profile Based On Directly Follows Relation).
Let
In order to better understand the above definition, we use a small example. Consider the set of cases is
Creating a profile based on the dependency relation
The profile based on the directly follow relation only abstracts characteristics between two successive events. Therefore, it is not enough to adequately represent the control-flow perspective. In order to derive more features, we create another profile based on a so-called dependency relation to abstract features between two disconnected events.
(Co-Occurrence Relation).
Let
The co-occurrence relation is commutative. For instance,
Based on the co-occurrence relation, we define the dependency relation to reflect the non-local dependency between events.
(Dependency Relation).
Let
For a dependency relation
Next, we create a profile based on the dependency relation to compute the similarity between a case
(Profile Based On Dependency Relation).
Let
In order to better understand the above definition, we use the same set of cases
Experiments and evaluation
The cyclicSC algorithm has been implemented as a plugin in the ProM.2
https://svn.win.tue.nl/repos/prom/Packages/LiGuangming/Trunk/.
First we use synthetic data in order to do a controlled experiments where the ground-truth is known. The basic process of evaluation on synthetic logs is: (i) creating normal logs, (ii) adding artificial deviations into the logs, (iii) detecting deviations, and (iv) checking whether the detected deviations are real deviations, i.e., artificial deviations.
In order to get convincing evaluation, it is necessary to test the algorithm on a wide variety of logs. In this paper, we employ the method in [20] for the random generation of business processes and their execution logs.
Log Generation. The method has four key parameters AND (A), XOR (X), loop (L) and deep (D) to control the collection of randomly generated processes as shown in Fig. 4 (e.g.,
Once we have synthetic logs, as shown in Table 1, we inject artificial deviations using the following three deviation types (dt) :
add an event at a random place in a case;
remove an event at a random place from a case;
replace an event at a random place in a case.
Created deviating cases using different deviation types
Processes with different parameters.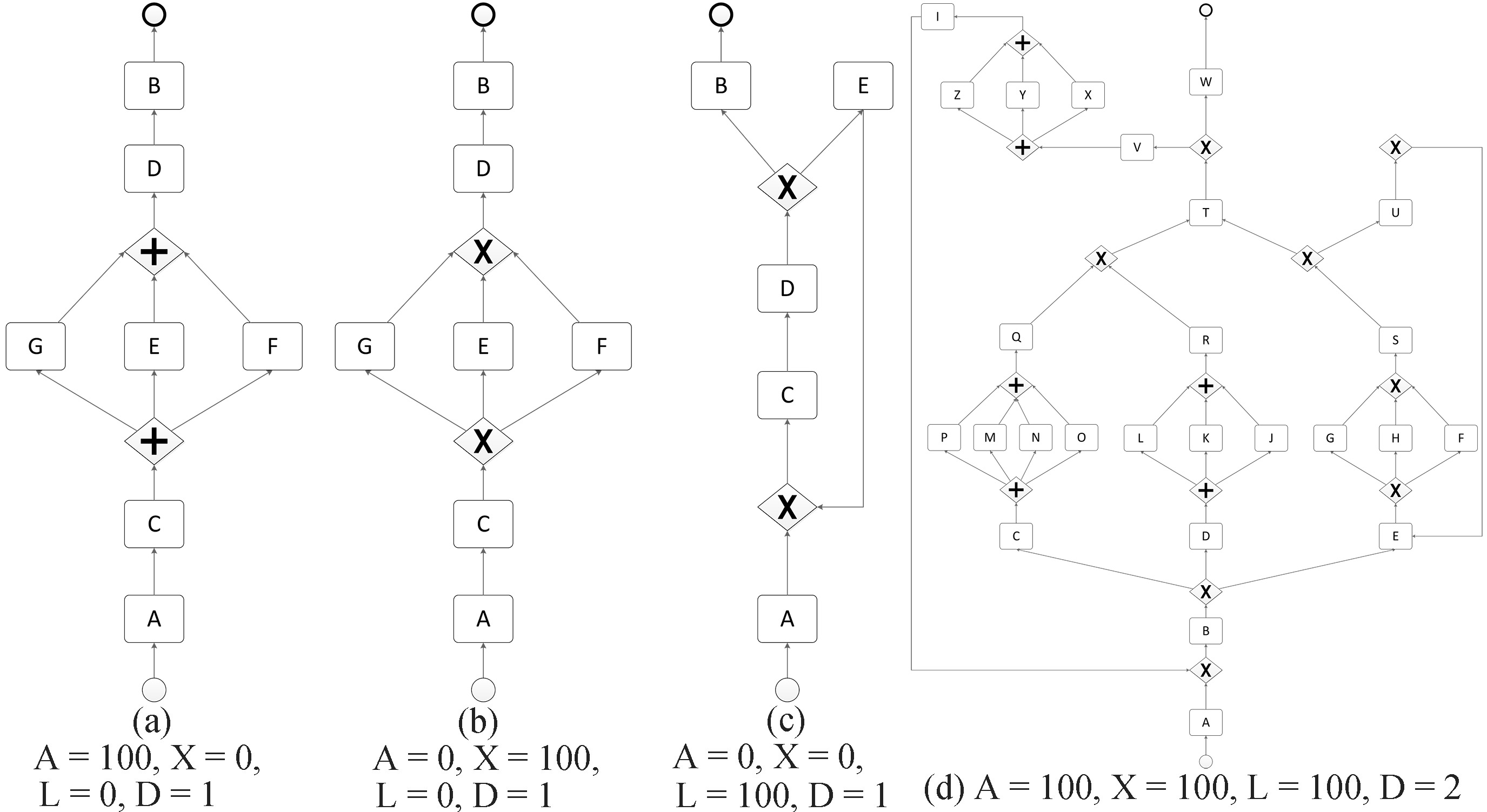
In order to control how many normal cases are transformed into deviation, we introduce a parameter deviation percentage (dp) which describes what fraction of the cases in the log are deviating after we import deviations. With different deviation types (add, remove and replace) and percentages (0.1, 0.2 and 0.3), we create 9 deviating logs for each normal log, i.e., there are
Evaluation Metrics. In a sense, the deviation detection problem can be regarded as a classification problem with two classes of objects: deviating cases and normal cases. Therefore we can create a confusion matrix [1] to compute accuracy, precision and recall to show the performance of an algorithm to detect deviations. Since the experiments are on a broad collection of logs (
In experiments, the cyclicSC algorithm will always detect the same number of deviations as we create, which is the reason that the precision and recall are always the same. However, for the naive and clustering algorithms (cf. Section 6.3), these numbers may be different. Sometimes the deviating clusters or variants may not only contain the right number of cases as we hope. In this case, we find out the closest number of deviations, i.e., closest to the number of real deviations.
Among the parameters of the cyclicSC algorithm, the profiling function
Experiments with psrofiling functions
In Section 5, we create
First we test profiling functions on logs with different patterns (e.g.,
Next we test the algorithm on logs with different deviations, i.e., different deviation types (
The performance of the cyclicSC algorithm configured with different profiling functions for logs with different patterns.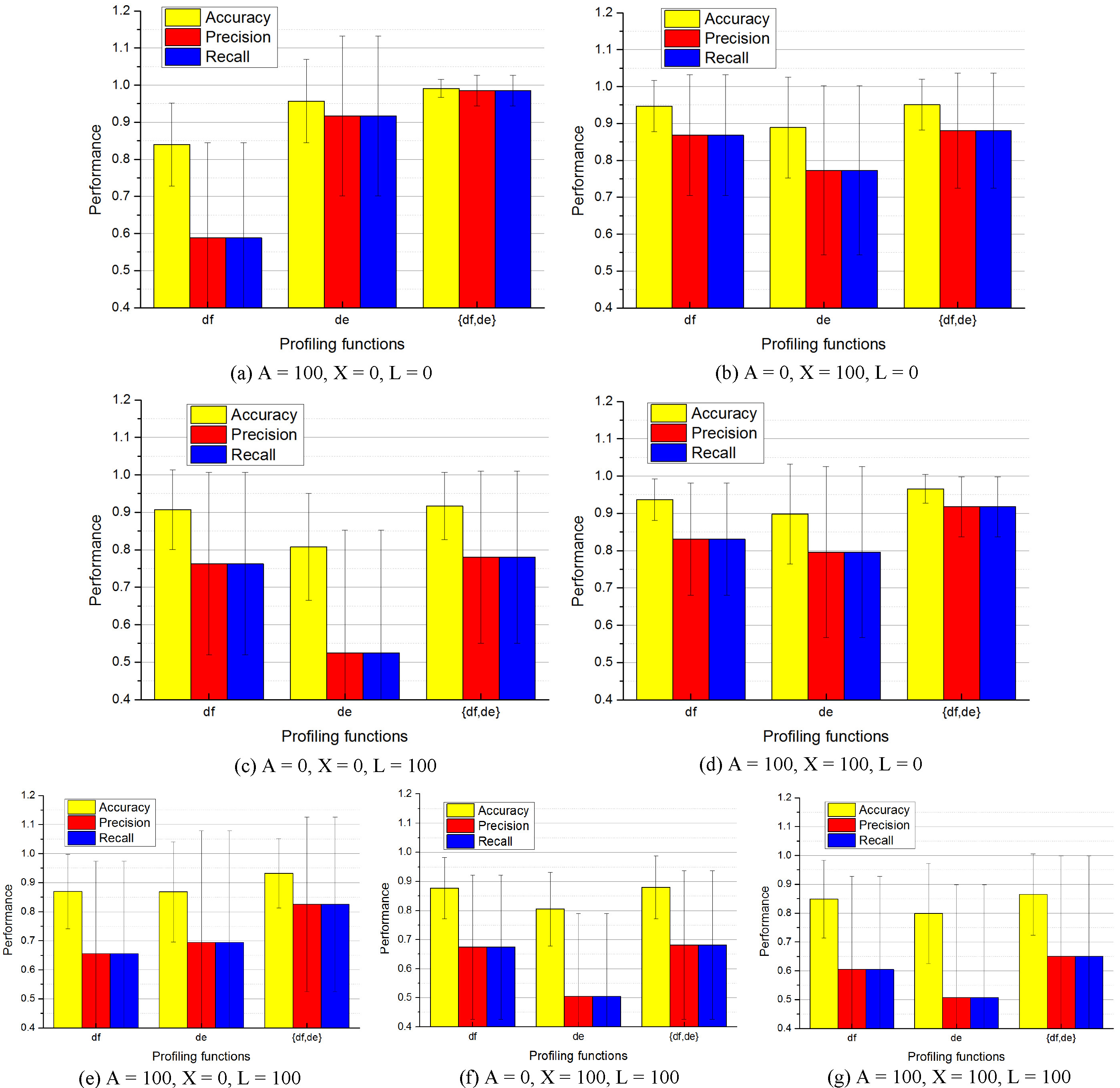
As we can see in the last three charts, along with the increase of the deviation percentage, the performance of
In summary: the above experiments show that,
The performance of the 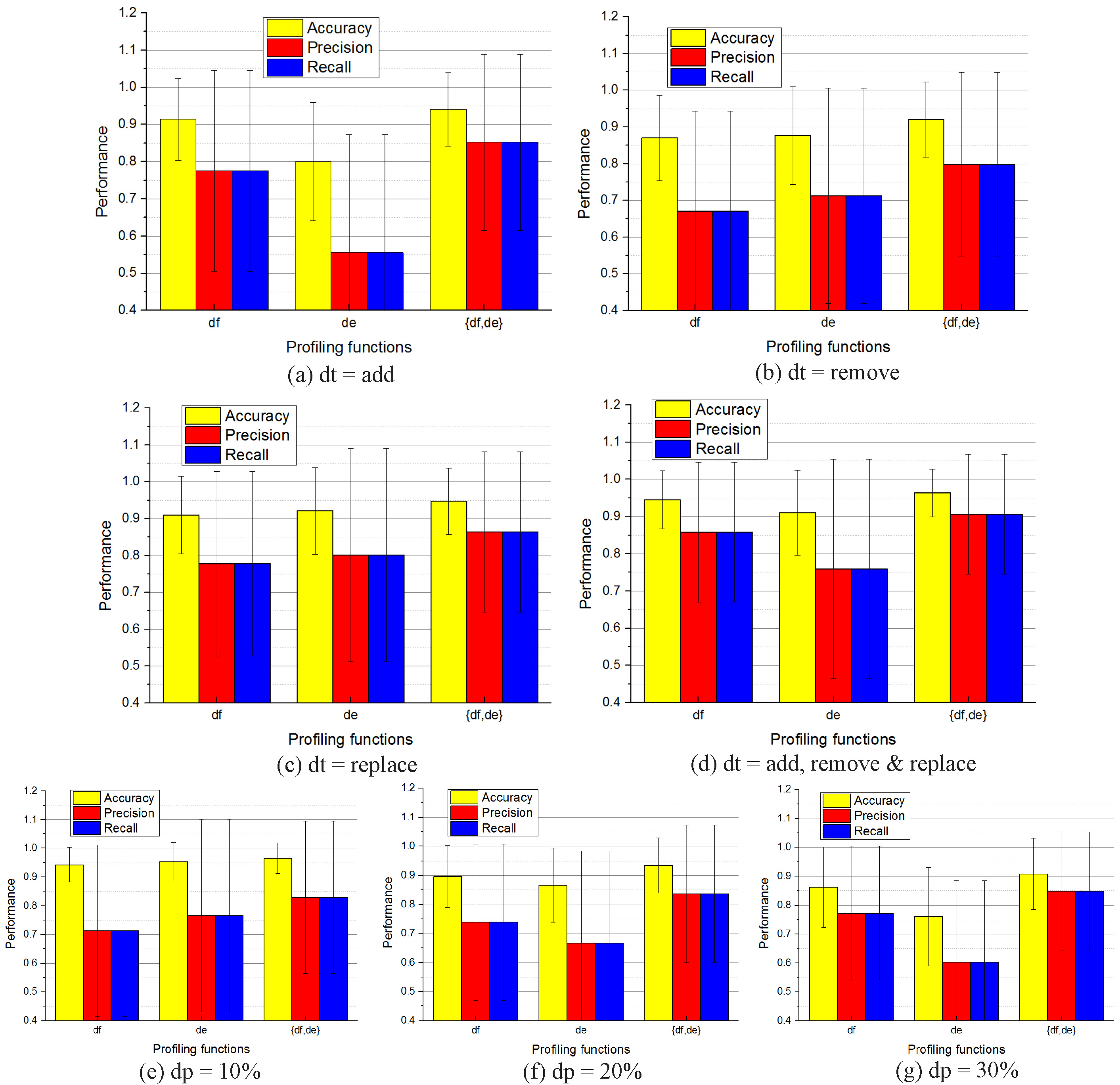
In the algorithm, we try to get a log containing “more normal” cases by integrating the sampling and classifying steps. However, the actual identification from “normal” cases may fail. Therefore, we test the algorithm on various logs to reveal this limitation in particular situations.
Since we know which cases are real deviating ones, we filter them to create a normal log. Then, we replace the sample log with the normal log to detect deviations. In this case, the performance should be the best and we call it “perfect performance”. In the experiments
Performance of the 
Among all the logs, we choose four typical logs, Log1 (
In the following, we compare the cyclicSC algorithm with two other algorithms, i.e., the sampling algorithm [12] which is a representative model-based method and the clustering algorithm [21] which is a leading cluster-based method. Besides, we import a baseline method, the naive method which considers the low frequent variants created by Disco as deviations (Disco3
http://www.fluxicon.com/products/.
Except for the naive method, the other three algorithms have parameters to set for good performance. We have discussed the parameters of the cyclicSC algorithm in previous experiments. For the sampling algorithm, one needs to choose the mining algorithm (HM, IM or ILP) and the sampling size (0
The best performance of four algorithms with their parameter settings.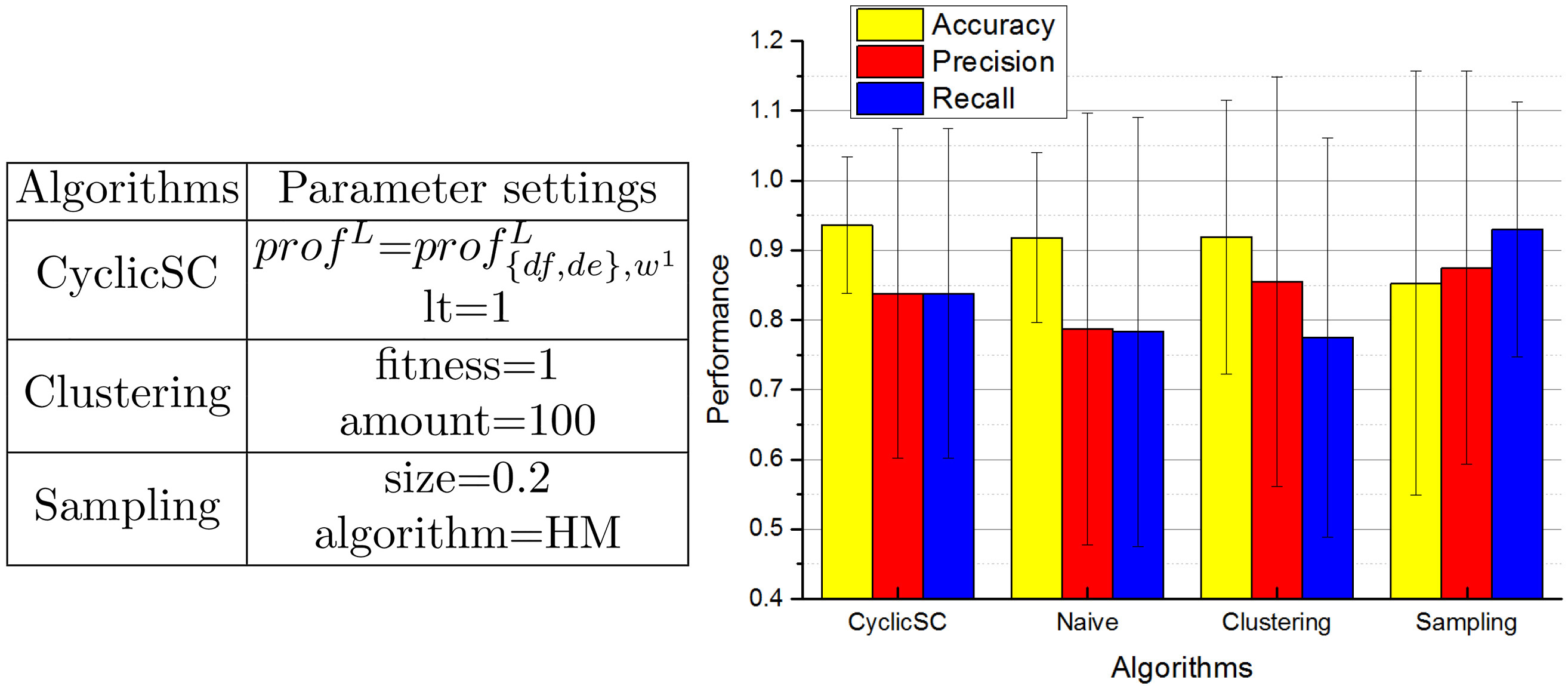
Overall, as shown in Fig. 8, the naive algorithm performs worst while the other three have their own advantages. The cyclicSC algorithm provides results with better accuracy than others, while the clustering algorithm has high accuracy and precision, but low recall. The sampling algorithm has the best recall but the accuracy is not good.
The performance of four algorithms on logs with different structure.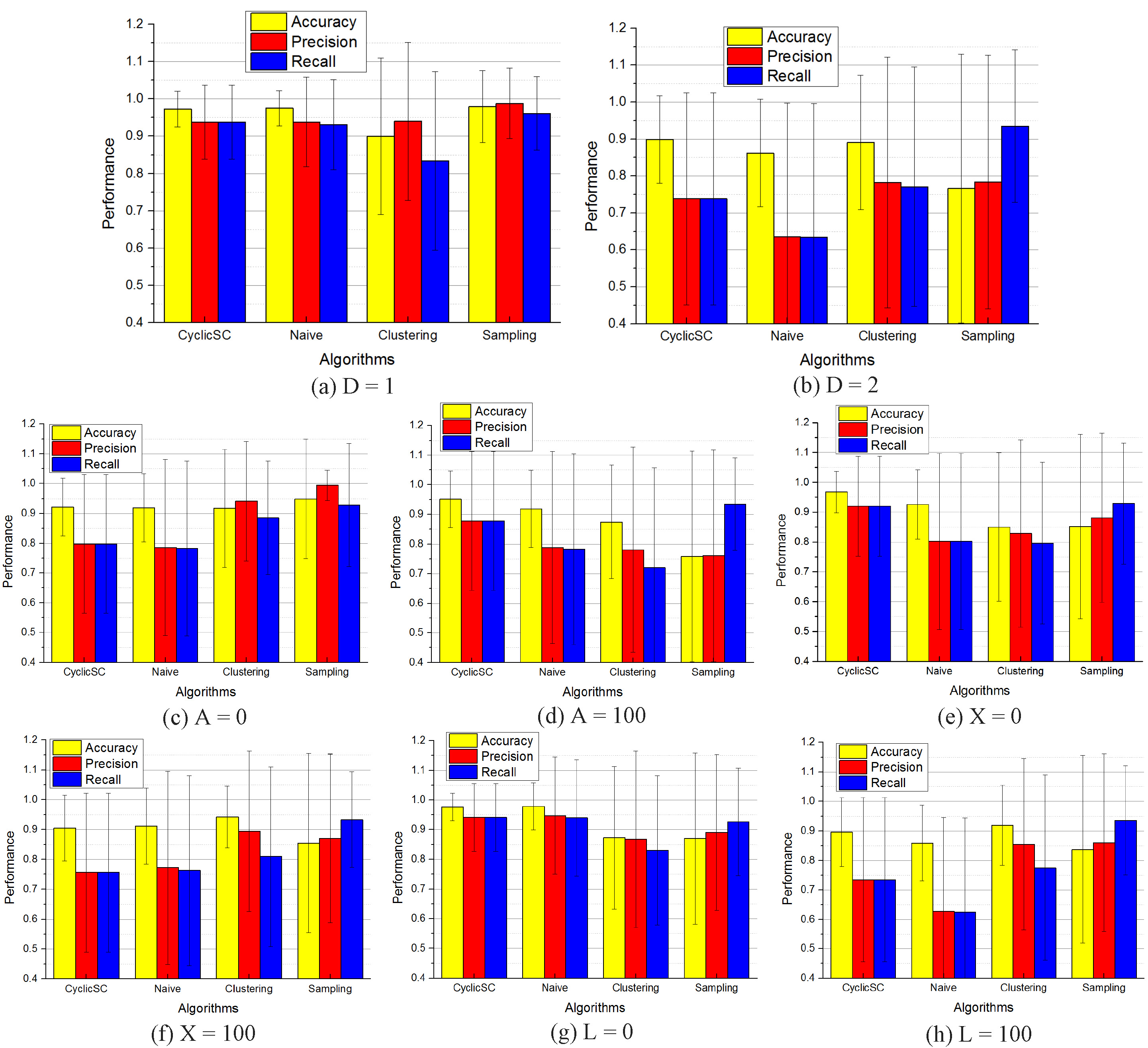
Besides the overall performance, we also look into how each algorithm performs in different situations. First we see how each algorithm works on logs of different complexity. More precisely, we classify the logs into two categories in terms of the parameter deep (deep indicates the complexity of the models which generate the synthetic logs), and the performance is shown separately in Figs 9(a) and (b).
As shown in Fig. 9(a), when the underlying model (i.e., the model to generate logs) is easy, the sampling algorithm performs best since it can discover a model which is almost the same as the underlying model. The cyclicSC and naive algorithms also work well, while the clustering algorithm achieves bad performance since it often classifies normal and deviating cases into one cluster. When the underlying model is complex, the sampling algorithm tends to obtain an easy model and considers normal cases as deviating ones by mistake, which leads to high recall and low accuracy as shown in Fig. 9(b). The naive algorithm achieves bad performance since in this case, there exist many normal unique traces such that cases having these traces may be classified as deviating cases. In contrast, the clustering algorithm performs best while the cyclicSC algorithm achieves a medium performance.
Next, we compare the performance of four algorithms on logs based on processes employing different patterns. Similarly, we split logs into two categories in terms of parameter
In comparison, the cyclicSC algorithm performs better than others on logs with AND patterns and logs without XOR or loop patterns, while the clustering algorithm has very different characteristics, i.e., logs with XOR and loop patterns are handled well, but does not perform well on logs with AND patterns. The naive approach works well when
Figure 9 shows the comparison among four algorithms for logs with different structures. We also tested how sensitive the four algorithms are with respect to different deviation percentages and deviation types. As shown in the top three charts in Fig. 10, along with the increase of deviation percentage, the performance of clustering and sampling algorithms degrades while the performance of the cyclicSC algorithm remains stable. The naive algorithm has bad precision and recall when the deviation percentage is low. In comparison, the cyclicSC algorithm is more suitable for high deviation percentage. For different deviation types as shown in the bottom three charts, the clustering and sampling algorithms perform poorly for the remove deviation type while the other two algorithms are hardly influenced by the different deviation types. When we mix the three different deviation types together, the cyclicSC algorithm and the clustering algorithm outperform the other ones. Overall, the cyclicSC algorithm has better performance and stability than the others considering a range of different situations. This does not imply that our approach always works best, however, it is more robust for the 9
The performance of four algorithms for different deviations.
Next, we compare the running time of four algorithms over various logs as shown in Table 2. More specifically, we classify all logs into two or three categories based on each parameter and then compute the average time on logs of each category for each algorithm. For instance, we separate all logs into two parts based on parameter
The running time of four algorithms over various logs
The final part of the experimental evaluation comprises the application of four algorithms to a real life-log which we mentioned in Section 1. The log is derived from BPI Challenge 2012 and it contains 262,200 events in 13,087 cases which record the loans in a bank for a period of five months. For the deviation detection based on such a real-life log, it is impossible to verify the accuracy, precision and recall, since we do not know which cases are real deviations. Therefore, we find out one deviating case from the log with each algorithm and compare the four cases on the activity frequency and running time perspectives.
Detected deviations from a real-life log.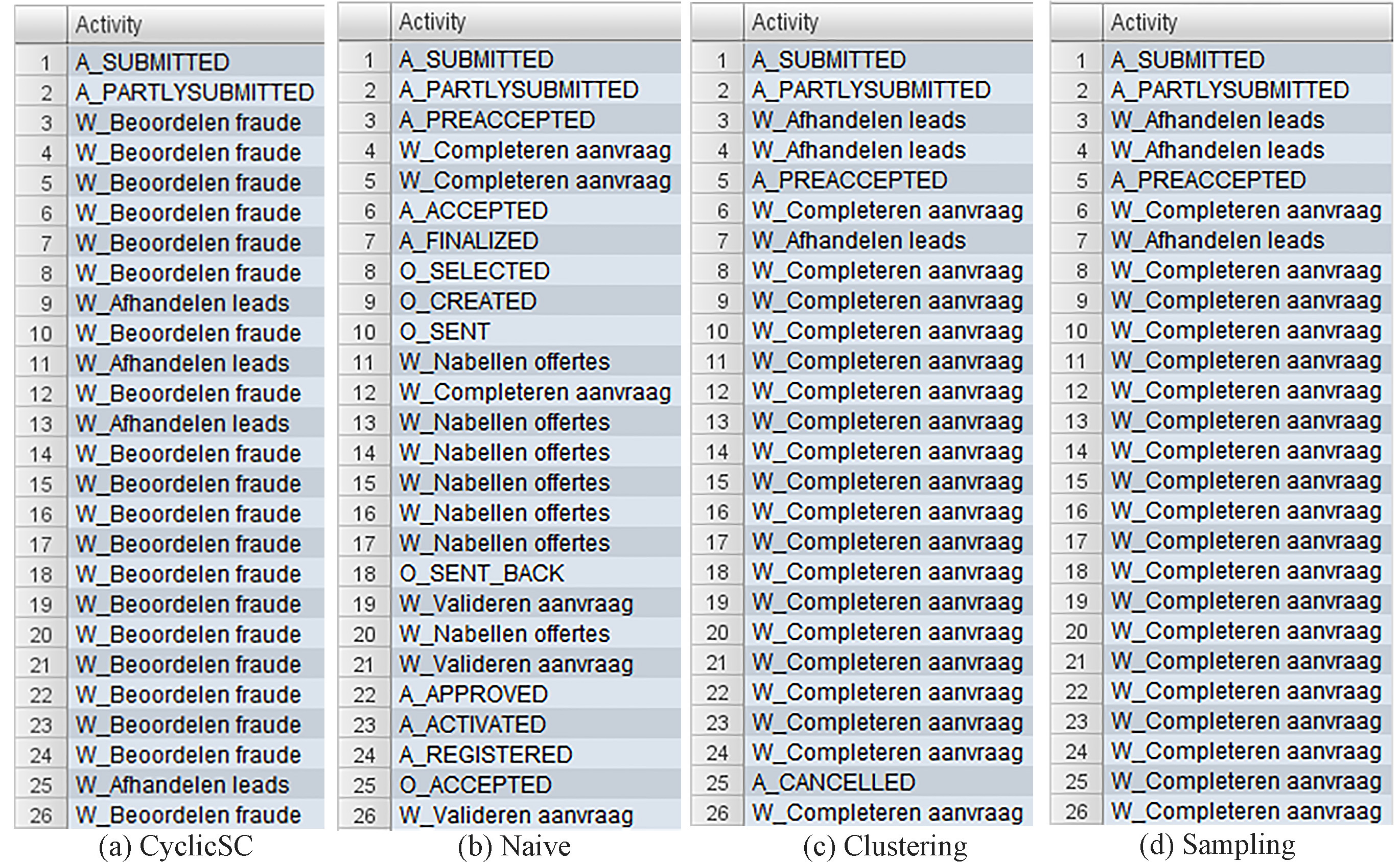
As shown in Fig. 11, the cyclicSC algorithm achieves a deviating case (case ID: 197216) which mainly contains an infrequent activitiy, “W_Beoordelen fraude” which means a fraudulent activity and occurs very little (there are just 0.25% of all events in the log having this activity). The naive algorithm finds an approved loan (case ID: 173736) as a deviation. However, the detected deviating case is not a real deviation, but a unique trace which has some frequent activities, e.g., “W_Nabellen incomplete dossiers” (8.7%). The sampling algorithm detects an unfinished loan (case ID: 211182) while the clustering algorithm takes quite a long time to get a cancelled loan (case ID: 176894). The deviations detected by the above two approaches contain a frequent activity “W_Completeren aanvraag” (18%).
On the running time perspective, the naive algorithm spends the least time (44 seconds) among the four algorithms. The sampling algorithm uses 65 seconds to finish the detecting process (i.e., conformance checking). However, if we take the process to create and find an appropriate model into consideration, the practical time is much more than 65 seconds. The clustering algorithm takes much longer time (40 minutes) than the others. In comparison, our approach uncovers deviations in a fraction of the time used by clustering (140 seconds) while avoiding the creation of a reference model.
Through analyzing the activity frequency and running time perspectives, we figure out the cyclicSC algorithm can achieve a meaningful result and take limited time when applied to a real-life log.
Traditional deviation detection approaches have problems in situations where event logs contain a variety of process behavior. In this paper, we propose a novel algorithm named cyclicSC which is faster than cluster-based approaches and more accurate than model-based approaches. Besides, experiments based on 80 models and 9
The cyclicSC algorithm also has some limitations (cf. Section 6.2.2). For instance, in some situations, the loops are not handled properly, yet overall the approach is more robust than others. In future work we would like to address these limitations and apply the approach to more real-life event logs for which we engage with end-users to establish the ground truth (as we did for the synthetic data). We would also like to test the approach in a streaming setting with concept drift. In this setting the process may gradually change and including what constitute its mainstream behavior. The iterative nature of the approach seems particulary suitable to handle this scenario.
Footnotes
Appendix: The algorithm cyclicSC
In the paper, we describe the
In the paper, we describe the