
Abstract
An important method of spatial-temporal data mining, trajectory clustering can mine valuable information in trajectories. However, cluster results without special sanitization pose serious threats to individual location privacy. Existing privacy preserving mechanisms for trajectory clustering still contend with the problems of narrow applicability, low-level utility, and difficulty in being applied to real scenarios. In this paper, we therefore propose a differential privacy preserving mechanism, Cluster-Indistinguishability, to support trajectory clustering. Firstly, a general model of typical trajectory clustering algorithms is given, and the definition of differential privacy is introduced according to the model. Then, we derive the probability density function of two-dimensional Laplace noise, which satisfies the above definition. Finally, we transform the noise from a Cartesian coordinate system to a Polar coordinate system to efficiently apply it in real scenarios. Experimental results show that Cluster-Indistinguishability has general applicability and better performance compared to existing methods.
Introduction
Nowadays, with the popularity of mobile devices and equipment supporting GPS positioning, trajectory clustering, which aggregates similar locations, has become prevalent in many applications, such as population density analysis, advertisement recommendation, and travel route planning [1]. Trajectory clustering provides results as a quasi-circular area, which includes the total number of points in the cluster and its center. It has thus attracted considerable attention.
While trajectory clustering provides significant benefit, it poses serious threats to individual privacy [2]. The cluster results, the total number of points, and the center of the cluster, may reveal a person’s precise position. A diagram of the location privacy disclosure model is shown in Fig. 1.
Diagram of a location privacy disclosure model.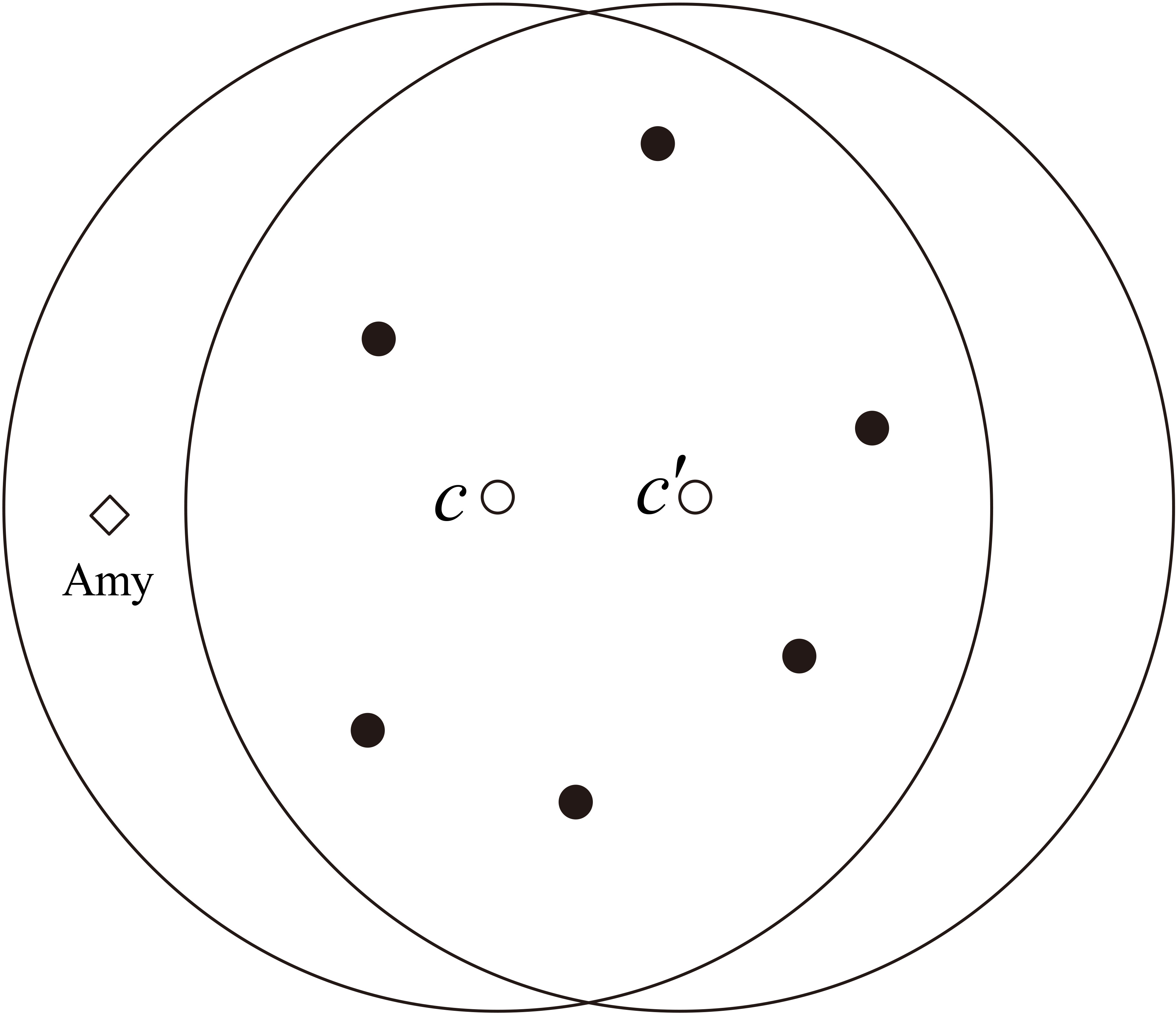
As illustrated in Fig. 1, let us consider a malicious attacker who does not know the precise location data of Amy. This attacker can additionally obtain one’s position only through several queries and from cluster results. The first query reveals the total number of points and the center of the cluster; the other queries contain those of the adjacent area. However, if two adjacent areas satisfy the condition that the total number of points in them only differs by one, and if Amy is located in the cluster, then Amy’s precise position can be inferred by Eq. (1).
The above attack model illustrates that the total number of points in a cluster and its center can disclose an individual’s location privacy. To address this problem, several methods have been proposed. Most early solutions [3, 4, 5] rely on an anonymity/generalization model (e.g.
In order to solve the problems with which the anonymity/generalization model contends, differential privacy [7] was recently introduced to preserve the privacy of statistical databases. This privacy model makes no assumptions on adversaries’ background knowledge; moreover, it can guarantee that the released data will not breach an individual’s privacy. On the study of differential privacy for clustering, existing approaches mainly focus on the schemes for a certain clustering algorithm (e.g.
Compared with the anonymity/generalization model, the above methods achieve better balance on security and utility; nevertheless, they are affected with the following problems.
They are designed for only a certain clustering algorithm. Furthermore, they lack robustness to different clustering algorithms and are not practical for trajectory clustering. They can guarantee the complete security of a single position; however, when applied to privacy preserving of trajectory clustering, they ignore the restrictive conditions of the cluster boundary, which will cause the problem of security reduction. In general, different dimensions of multidimensional data are correlated, and independently adding noise in existing methods will lead to a decrease of data utility.
In this paper, we aim to solve these challenges and propose a practical differential privacy preserving mechanism for trajectory clustering. We refer to our approach as Cluster-Indistinguishability. Firstly, we define differential privacy for trajectory clustering under the constraint condition of the cluster boundary to support most typical clustering algorithms. Then, we derive the joint probability density function (JPDF) of noise distribution according to the definition. Finally, we transform the noise from a Cartesian coordinate system to a Polar coordinate system to efficiently apply it in real scenarios. Our contributions are threefold:
We provide the general model of typical clustering algorithms and differential privacy definition under the constraint condition of the cluster boundary to provide complete security for trajectory clustering. Instead of independent distribution noise, we derive the JPDF of noise to achieve better utility. In addition, to improve the practicality of Cluster-Indistinguishability, we perform it in a Polar coordinate system. Experiments demonstrate that our approach maintains a higher utility and is scalable to most typical trajectory clustering algorithms.
The remainder of this paper is organized as follows. In Section 2, we summarize related work on privacy preserving trajectory clustering. We then describe the limitations of existing methods in Section 3 and briefly introduce the notations adopted in this work. Our approaches and experiments are described in Sections 4 and 5, respectively, followed by our conclusions and discussion of future work in Section 6.
Existing privacy preserving mechanisms for clustering can be classified into two types. One type is anonymity/generalization-based. It generalizes trajectories to achieve privacy preservation. A typical anonymity-based algorithm is
Trajectory anonymity
The first type takes advantage of anonymity-based privacy preserving models, such as
Despite the above work [15, 16, 17] demonstrated that anonymity-based privacy models are vulnerable to numerous types of attacks. As a result, they are deemed unable to provide sufficient privacy protection in trajectory clustering. Because they classify the data that have a property similar to a category, the utility of published data is weak.
Differential privacy
Owing to the drawbacks of anonymity-based privacy models, differential privacy – a type of randomization-based privacy model – has been recently employed for privacy preservation. Blum et al. [8] proposed a differential privacy mechanism, P
Problem statement
In this section, we first present the model of typical trajectory clustering algorithms. Then, we review the theory of differential privacy and state the privacy-preserving problem in trajectory clustering from the perspective of the probability distribution model. Finally, we present an overview of our framework.
Model of trajectory clustering
Taking common clustering algorithms as an example (such as
where Clu and Cor represent clustering and centering algorithms, respectively.
Equation (2) depicts the mathematical representations of the trajectory clustering model.
Summary of notations
Differential privacy is a currently recognized preservation model that can guarantee stricter security. It is essentially a kind of noise-perturbed mechanism. By adding noise to the raw data or statistical results, differential privacy can guarantee that the value changing of a single record has a minimal effect on the statistical output results. Thus, differential privacy can not only preserve privacy of sensitive data, but also support data mining on statistical results. Its formal definition is as follows:
where
A smaller
Output probability distribution of random algorithm 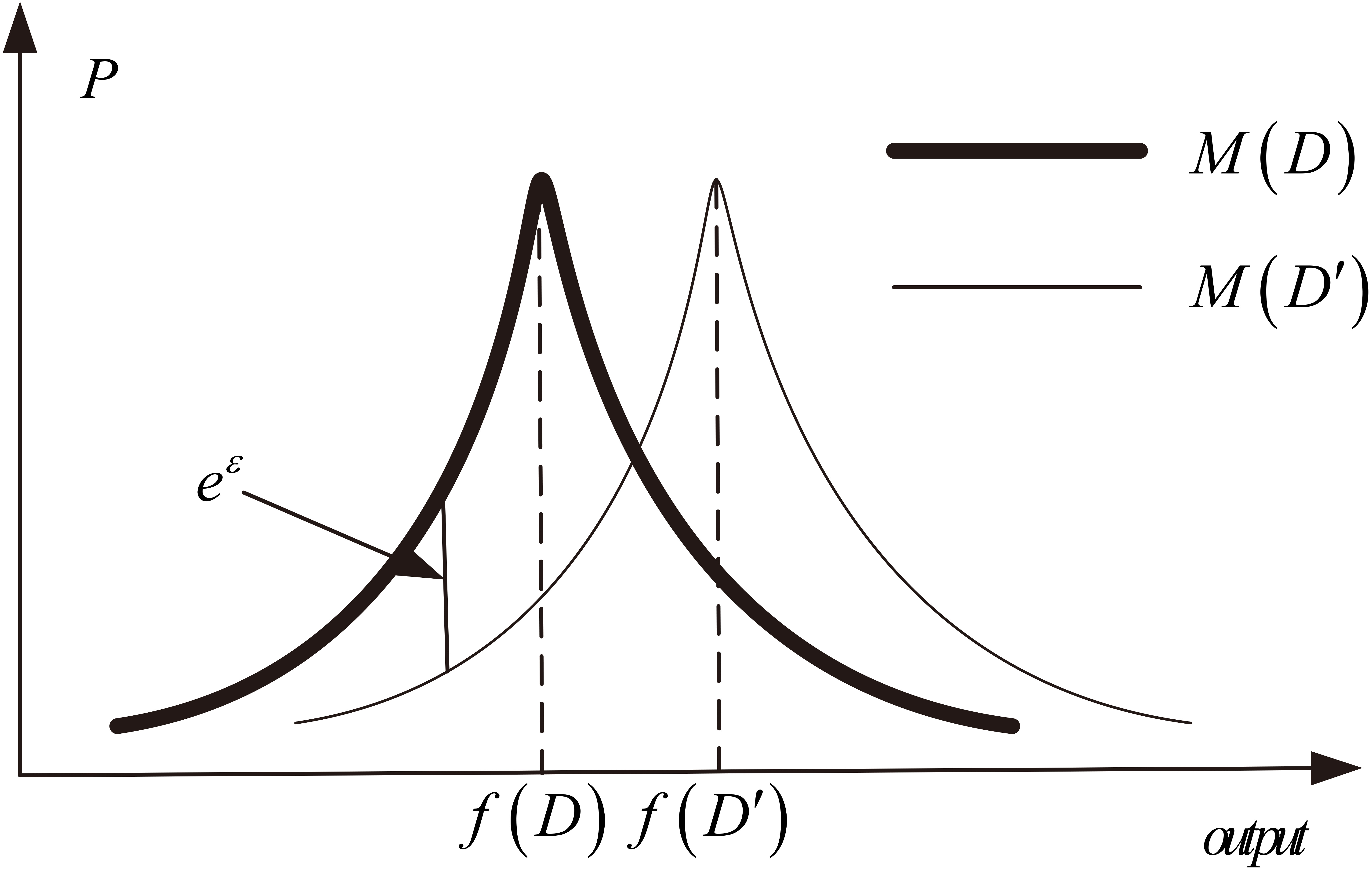
Preserving intensity
Scale parameter
where
As an example, consider a dataset whose sensitivity of a query is 1. According to differential privacy, adding to the true answer noise distributed according to
As the closest method in differential privacy preservation for location data, Geo-Indistinguishability performs well in privacy preservation for a single point. However, in trajectory clustering applications, Geo-indistinguishability is subject to the constraint of the cluster radius. To intuitively explain the limitations of anonymity-based algorithms and Geo-indistinguishability, we elaborate these two mechanisms from the aspect of a probability statistics model and then state the problem.
Anonymity
We take the classic
a.
Probability distribution of 
On account of the generalization of
Unlike the defects and deficiencies of
As shown in Fig. 4, compared with
Probability distribution of Geo-Indistinguishability.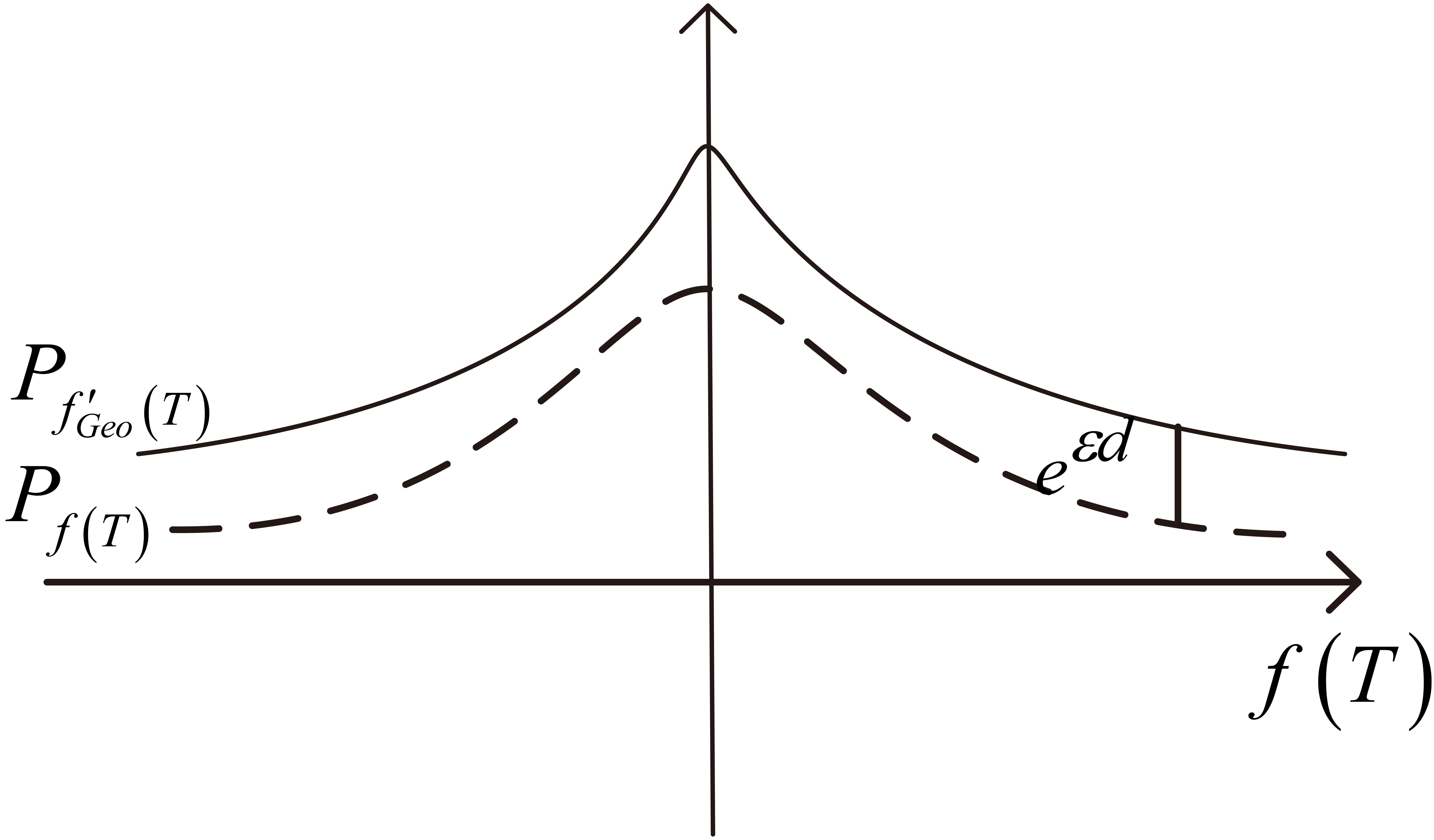
The probability distribution model of Cluster-Indistinguishability is shown in Fig. 5. Let us observe the probability distribution between original output
Probability distribution of Cluster-Indistinguishability.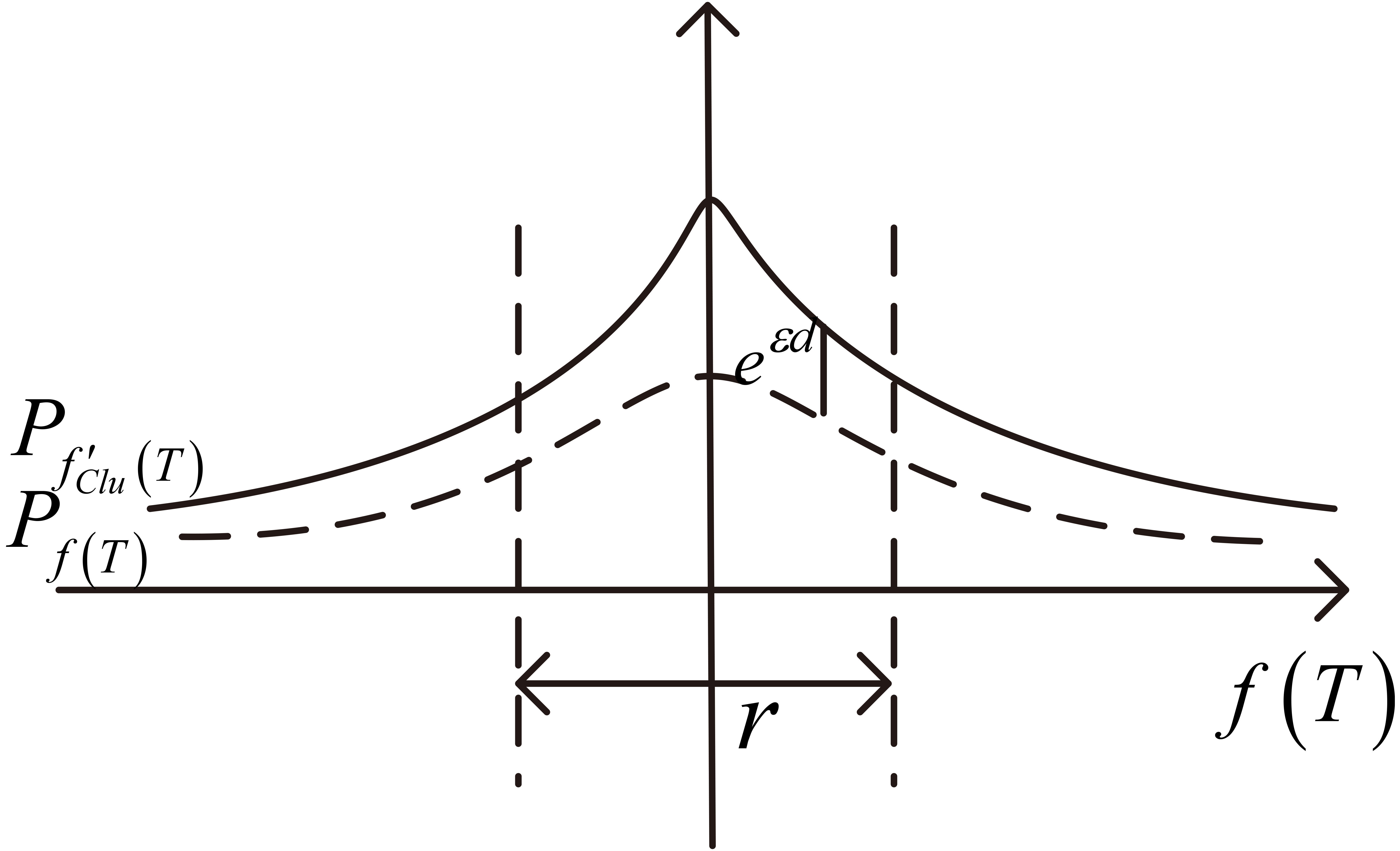
Noise added in the original dataset
We elaborate the framework of this study in two aspects: a privacy preserving framework, and a cluster indistinguishability procedure. Figure 6 illustrates the framework for trajectory clustering privacy preservation. It is composed of three participants: Data Owner, LBSP, and Data Analyzer. They play different roles in trajectory mining and are defined below.
Framework of privacy preservation.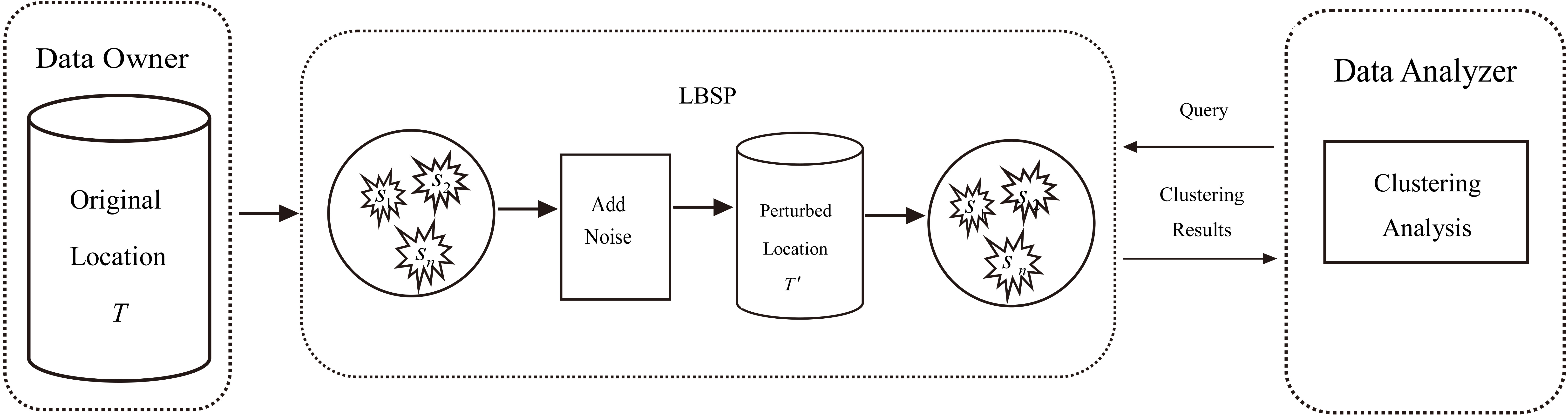
Data Owner: A user, whose mobile device supports positioning, sends his/her location dataset T to LBSP to acquire LBS.
LBSP: It clusters
Data Analyzer: The third party requesting statistical results and conducting clustering analysis.
Data Owner uploads its location data to LBSP to obtain better location-based services. LBSP collects trajectories from various Data Owners and sends trajectory clustering results to Data Analyzer. After obtaining the clustering results, Data Analyzer can mine useful information, such as commercial hot spots, and returns the mining results to LBSP. Based on the mining results, LBSP can improve some business decisions (e.g., advertisement recommending).
Nonetheless, if LBSP directly sends Data Owner’s original trajectories to Data Analyzer, a malicious Data Analyzer may violate Data Owner’s location privacy. Thus, before sending trajectories to Data Analyzer, LBSP should randomize the real trajectories and provide the processed location data to Data Analyzer.
In the process, the domain expert plays the role of designing a randomized algorithm to preserve Data Owner’s location privacy. The procedure of Cluster-Indistinguishability is shown in Fig. 7.
Procedure of Cluster-Indistinguishability.
Firstly, we describe the model of typical clustering algorithms. Secondly, we define differential privacy for trajectory clustering. Then, we derive the PDF of noise in the Cartesian coordinate system. Finally, we transform the form of noise from a Cartesian coordinate system to a Polar coordinate system to practically apply noise.
In this section, we present the design of our methodology. We first give the definition of Cluster- Indistinguishability, which can guarantee differential privacy for trajectory clustering. We then conduct a noise design according to the definition and apply it in a Polar coordinate system.
Clustering-Indistinguishability
We demonstrate in the attack model (Fig. 1) that the privacy of
Assumption 1.
a.
Condition (a) indicates that processed positions
However, owing to the existence of a large amount of auxiliary information, Dwork [18] proved that a complete privacy preserving mechanism does not exist. Geo-Indistinguishability achieves a good balance in security and utility of a single point and is suitable for applications of location-based query services. Intuitively, however, it cannot be applied in privacy preserving for trajectory clustering because of the cluster radius constraint. The number of points and the cluster center are two core elements for obtaining the cluster results; nevertheless, they tend to leak privacy. Thus, we discuss the effect that
In order to solve the privacy issue of trajectory clustering, differential privacy adds noise to the original positions. Therefore, the value of the number of points
where
We limit the maximum effect that a single position has on cluster results to
The definition of Cluster-Indistinguishability is given in Section 4.1. In this section, we illustrate the noise design procedure. Noise in differential privacy is a Laplace distribution, and the scale
Because the third party obtains the number and centroid of cluster
Then, sensitivity function is:
The total number of T and
where
Proof. We denote
We can obtain the PDF of one-dimensional noise through the above analysis. However, location data is two-dimensional; thus, we should consider the PDF of the Laplace distribution in two-dimensional space.
where
The two-dimensional form of the Laplace distribution in a Cartesian coordinate system is given in Eq. (13). However, it is not practical to apply it in real scenarios. Therefore, we transform the noise from a Cartesian to a Polar coordinate system. The JPDF
Then, the PDF of r and
PDF of
Procedure of algorithm
In this section, we report our empirical evaluation conducted to assess the performance of our methods. In terms of privacy evaluation, we theoretically analyze the security of our algorithm and verify its validity by experiments. For a utility evaluation, we conducted qualitative and quantitative analyses to evaluate the effect of our algorithm on a single point and cluster results.
Experiment setup
We conduct our experiments on three real-world trajectory datasets. The experiments were performed on an Intel Core 2 Quad 3.06-Hz Windows 7 machine equipped with 8 GB of main memory. Each experiment was run 1,000 times.
Geolife trajectory dataset: Owing to the Geolife project [20, 21], we obtained the published real trajectories of volunteers. This global positioning system (GPS) trajectory dataset was collected in the (Microsoft Research Asia) Geolife project by 182 users over five years (from April 2007 to August 2012). A GPS trajectory of this dataset is represented by a sequence of time-stamped points, each of which contains the latitude, longitude, and altitude coordinates. This dataset contains 17,621 trajectories with a total distance of 1,292,951 km and a total duration of 50,176 h.
T-Drive taxi trajectories: A set of GPS trajectories was recorded by 8,602 taxi cabs in Beijing, China, in May 2009. The trajectories covered the region of Beijing within the bounding box (39.788N, 116.148W) and (40.093N, 116.612W), approximately 34 km
Check-in dataset: The dataset consisted of the check-in data generated by over 49,000 users in New York City and 31,000 users in Los Angeles as well as the social structure of the users. Each check-in included a venue ID, the category of the venue, a time stamp, and a user ID.
Privacy evaluation
We firstly theoretically analyzed the privacy preserving degree of Cluster-Indistinguishability.
then
Proof. If
Probability distribution of different methods.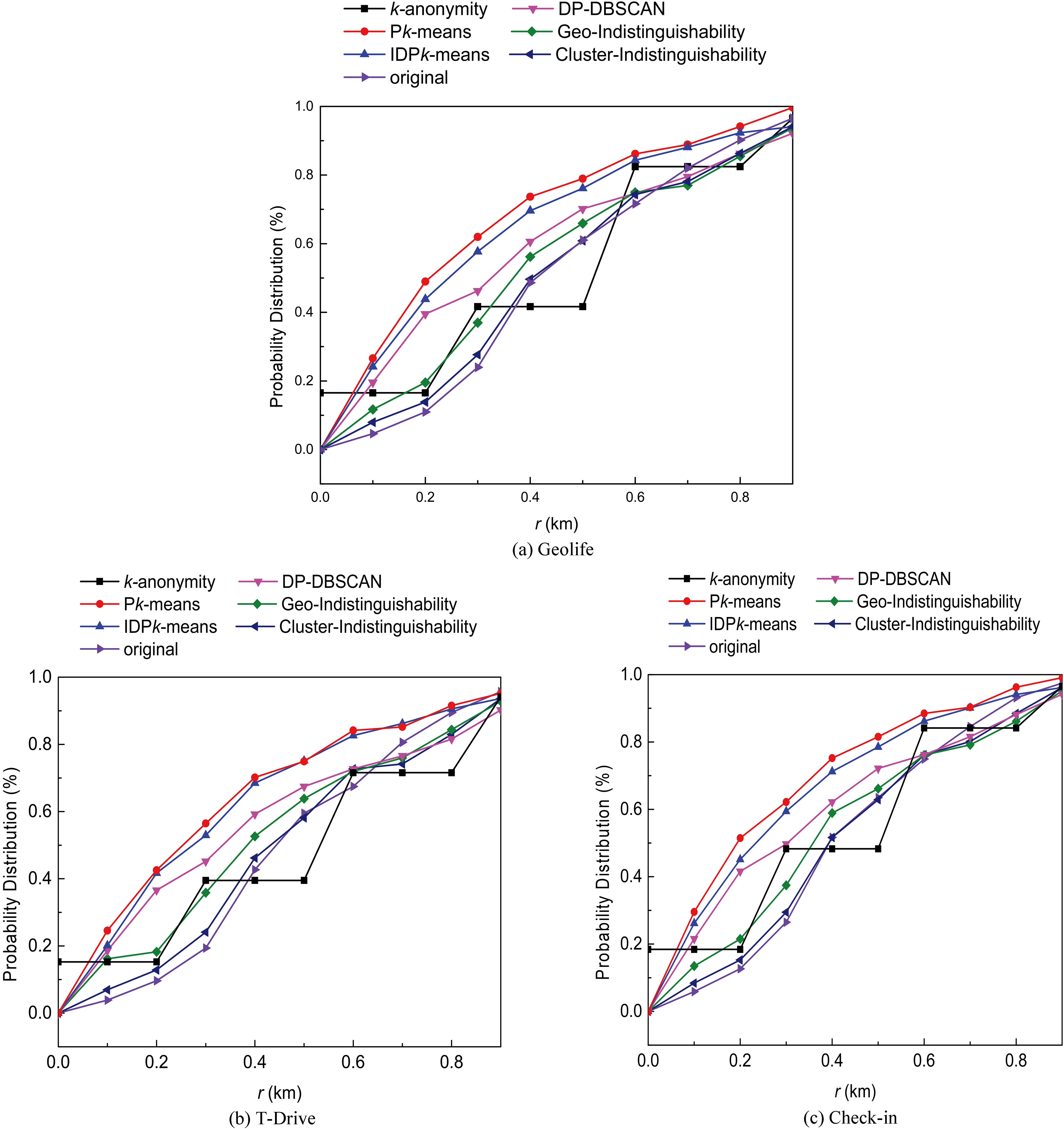
where
To achieve
To verify the privacy-preserving performance of Cluster-Indistinguishability, we analyzed the statistics probability distribution of cluster results
Figure 8 shows the probability distribution of different algorithms. A distribution that is close to the original data distribution means a high degree of privacy preservation. Since
Cluster results.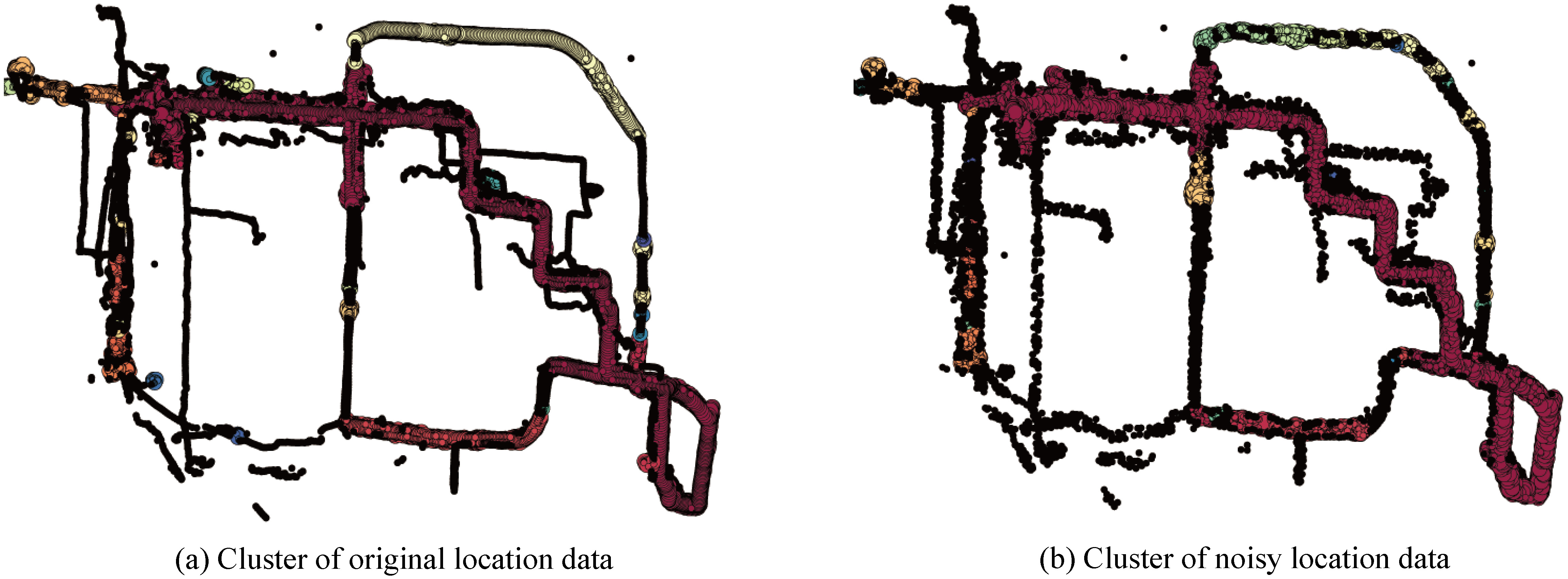
Total number of clusters.
Average relative error of noisy position.
Homogeneity of clusters.
Completeness of cluster.

From the results in Table 2, we conclude that Cluster-Indistinguishability has the smallest
To evaluate the effect of Cluster-Indistinguishability on the cluster results, we respectively qualitatively and quantitatively demonstrate and analyze the cluster results.
Qualitative analysis
We chose the trajectories of 60 users in Geolife as test objects. The cluster result of the original location data is shown in Fig. 9a. Then, we set
The cluster result of the noisy position is shown in Fig. 9b. Comparing these two figures, we can conclude that our algorithm has a minimal effect on the cluster results.
Quantitative analysis
In terms of quantification, we illustrate the performance of Cluster-Indistinguishability on the number of clusters and the error of the individual position. We also comprehensively evaluate the cluster results.
Total number of clusters
To evaluate the effect of cluster indistinguishability on the number of clusters, we collect statistics of the total number of clusters under different
Figure 10 reflects the change of the total number of clusters with the reduction of the privacy preserving degree. Cluster-Indistinguishability achieves the best results with the numbers nearest to the original clusters. Owing to the spatial generalization,
Error of the individual’s position
We proofed the security of Cluster-Indistinguishability in Section 5. In this section, we discuss the effect of Cluster-Indistinguishability on an individual’s real position. We utilize the norm of the average relative error to evaluate the error of the individual position. The average relative error of the user’s position in a cluster is defined as follows:
The above definition reflects the maximum offset distance caused by noise added in the original position.
To verify the effectiveness of Cluster-Indistinguishability, we compare Cluster-Indistinguishability with existing privacy preserving methods for clustering. The results are shown in Fig. 11.
From Fig. 11, we conclude that the privacy preserving degree is gradually weakened with the increase of
Performance of clusters
Compared with evaluation index
Assume that a trajectory dataset can be clustered by two means: a set of classes,
where
Figure 12 shows the homogeneity of clusters under different algorithms. Based on the figure, we conclude that the homogeneity of Cluster-Indistinguishability is better than that of the other algorithms and stabilizes at approximately 90%.
Figure 13 shows the completeness of the clusters. It is evident that P
The
Quantitative and qualitative experimental analyses show that the average relative error of Cluster-Indistinguishability is approximately 15%, and the performance of the cluster results improves 40% compared to those of existing privacy preserving methods for clustering. Thus, Cluster-Indistinguishability can better support LBS and trajectory clustering applications.
To address problems of narrow applicability, low-level utility, and difficulty in real-world applications in existing privacy preserving schemes, we herein proposed a practical differential privacy mechanism for trajectory clustering: Cluster-Indistinguishability. Firstly, we provided the general model of typical trajectory clustering algorithms and the definition of differential privacy for trajectory clustering. Then, we presented our noise design according to the definition, and derived the two-dimensional JPDF of noise. Finally, noise was transformed from a Cartesian coordinate system to a Polar coordinate system to efficiently apply it.
An experimental evaluation using a real-world dataset showed that Cluster-Indistinguishability can adapt to most typical trajectory privacy preserving clustering algorithms. The average error of a single point was approximately 15%, and the performance of cluster results improved by approximately 40% compared with existing methods. Therefore, Cluster-Indistinguishability can better support LBS and trajectory clustering applications. Our future work will primarily focus on differential privacy preserving mechanisms to support continuous location releasing and multiple trajectory mining tasks.
Footnotes
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (41671443, 41371402) and the Applied Basic Research Program of Wuhan (2016010101010024). The authors are grateful for the anonymous reviewers who made constructive comments and improvements.