
Abstract
Tagging recommender systems allow Internet users to annotate resources with personalized tags. The connection among users, resources and these annotations, often called a folksonomy, permits users the freedom to explore tags, and to obtain recommendations. Releasing these tagging datasets accelerates both commercial and research work on recommender systems. However, tagging recommender systems has been confronted with serious privacy concerns because adversaries may re-identify a user and her/his sensitive information from the tagging dataset using a little background information. Recently, several private techniques have been proposed to address the problem, but most of them lack a strict privacy notion, and can hardly resist the number of possible attacks. This paper proposes an private releasing algorithm to perturb users’ profile in a strict privacy notion, differential privacy, with the goal of preserving a user’s identity in a tagging dataset. The algorithm includes three privacy-preserving operations: Private Tag Clustering is used to shrink the randomized domain and Private Tag Selection is then applied to find the most suitable replacement tags for the original tags. To hide the numbers of tags, the third operation, Weight Perturbation, finally adds Laplace noise to the weight of tags.
We present extensive experimental results on two real world datasets, De.licio.us and Bibsonomy. While the personalization algorithm is successful in both cases, our results further suggest the private releasing algorithm can successfully retain the utility of the datasets while preserving users’ identity.
Introduction
The widespread success of social network web sites, such as Del.icio.us and Bibsonomy, introduces a new concept called the tagging recommender system. These web sites enable Internet users to annotate resources using customized tags, which in turn facilitates the recommendation of resources. Over the last few years, these social network web sites have generated a large collection of data, but the privacy issue in utilizing the data for tagging recommendation has generally been overlooked [19]. Release or sharing these kinds of tagging dataset in their raw form may raise a serious privacy violation. An adversary with background information may re-identify a particular user in these tagging datasets and obtain the user’s historical tagging records [11]. Moreover, in comparison with traditional recommender systems, tagging recommender systems involves more semantic information that directly discloses the preference of a user. Hence, the privacy violation involved is more serious than traditional ones [19]. Consequently, how to preserve privacy in tagging recommender systems is an emerging issue that needs to be solved.
Over the last decade, a variety of privacy preserving approaches have been proposed for traditional recommender systems [20]. For example, cryptography is used in the rating data for multiple parties computation [5,28]. Perturbation adds noise to the users’ ratings before rating prediction [21,22], and obfuscation replaces a certain percentage of ratings by random values [1]. However, these approaches can hardly be applied in tagging recommender systems due to the semantic property of tags. Specifically, cryptography completely erases the semantic means of tags, while perturbation and obfuscation can only be applied to numerical values rather than words. These deficiencies render those approaches impractical in tagging recommendation. To overcome these deficiencies, the tag suppression method has recently been proposed to protect a user’s privacy in a tagging recommender system by modeling a user profile and eliminating selected sensitive tags [19]. However, this method only releases an incomplete dataset that significantly affects the recommendation utility. Moreover, most existing approaches suffer from one common weakness: the privacy notions are weak and hard to prove theoretically, thus impairing the credibility of the final results. Accordingly, a more rigid privacy notion with a more sophisticated privacy preserving approach is needed in tagging recommender systems.
As privacy research advances, especially with the recent development of differential privacy, it is now possible to overcome the previous weakness. As a strong and provable privacy definition that quantifies the risk of individuals [7,8], differential privacy provides a strict privacy guarantee for tagging recommendation. It applies a randomized mechanism suitable for both numeric and non-numeric values and has been proven effective in recommender systems. This paper introduces differential privacy into tagging recommender systems, with the aim to prevent re-identification of users and to prevent the association of sensitive tags (e.g., healthcare tags) with a particular user.
However, although these characteristics make differential privacy a promising method for tagging recommendation, there remains some research barriers:
The naive differential privacy mechanism only focuses on releasing statistical information that can barely retain the structure of the tagging dataset. For example, the naive mechanism lists all the tags, counts the number and adds noise to the statistical output, but ignores the relationship among tags, resources and users. This simple statistic information may not be adequate for recommender systems to reasonable perform.
Differential privacy utilizes the randomized mechanism to preserve privacy, usually inducing a large noise due to the sparsity of the tagging dataset. For a tagging system with millions of tags, the randomized mechanism will result in a large magnitude of noise.
Both barriers indicate that the naive differential privacy mechanism can not be directly used in a tagging recommender system, and a novel differentially private mechanism is needed. To overcome the first barrier, rather than releasing simple statistical information, we generate a synthetic dataset that retains the relationship among tags, resources and users. The second barrier can be addressed by shrinking the randomized domain, because the noise can decrease when the randomized range is limited. Based on these observations, we propose a tailored differential privacy mechanism that retains the acceptable performance of recommendation within the constrains of differential privacy.
The contributions of this paper can be summarized as follows:
The main contribution is to design a practical Private Tagging Releasing algorithm with a rigid privacy guarantee. To the best of our knowledge, this is the first work that adopts differential privacy for the tagging recommender system. It maintains an acceptable utility of the tagging dataset by preserving the relationship among users, resources and tags.
A private clustering operation is proposed to shrink the randomized domain. The effectiveness of the proposed operation is verified by extensive experiments on a real-world dataset.
Considering the advantage of the differential privacy composition properties, a theoretical analysis confirms an improved trade-off between privacy and utility.
The rest of this paper is organized as follows. We present the preliminaries in Section 2, and propose the Private Tagging Releasing algorithm in Section 3, together with the theoretical utility and privacy analysis of the algorithm. Section 4 presents results from the experiments, followed by the conclusion in Section 5.
Preliminaries
Notations
Let G be a dataset to be protected, two datasets G and
In a tagging recommender system, G is a tagging dataset consisting of users, resources and tags. Let
Foundational concepts
Differential privacy
Differential privacy acquires the intuition that releasing an aggregated report should not reveal too much information about any individual even if his/her record is included in the dataset [7]. A formal definition of Differential Privacy is as follows [9]:
(ϵ-differential privacy).
A randomized mechanism
The mechanism
(Sensitivity).
For
To satisfy this definition, two mechanisms are utilized: the Laplace mechanism and the Exponential mechanism. Among them, the Laplace mechanism is suitable for numeric output and relies on the strategy of adding controlled noise to the outcome of a query. It is formally defined as [10]:
(Laplace mechanism).
Given a function
On the other side, the Exponential mechanism focuses on non-numeric queries [15]. It is paired with an application dependent score function An Exponential mechanism (Exponential mechanism).
Tagging recommender systems
The tagging recommender system recommends a set of tags
A considerable amount of literature has explored various techniques for tagging recommendation, which offers users the possibility to annotate resources with personalized tags and to ease the process of finding good tags for a resource [24]. Sigurbjornsson et al. provided a typical recommender strategy [25]. Given a resource with user-defined tags, an ordered list of candidate tags is derived for each user-defined tag based on tag co-occurrence. After tag aggregating and ranking in the candidate list, the system provides top-N ranked tags. Another well-known study is FolkRank [13], which adapts the well-known PageRank into a tagging recommender system. There are other methods for tagging recommender systems, such as clustering based methods [24], tensor decompositions [26], and topic-models [14].
Related work
Privacy violations and attacks in recommender systems have been well studied [6,27]. The first study concerned with this issue was undertaken by Ramakrishnan et al. [23]. They claimed that users’ rated items across disjointed domains could face a privacy risk through statistical database queries. This hypothesis was proven by Narayanan and Shmatikov [16,17] because they re-identified part of the users in the Netflix Prize dataset by associating it with the International Movie DataBase (IMDB) dataset. Calandrino et al. [4] presented a more serious privacy violation. By observing temporal changes in the public outputs of a recommender system, they inferred a particular user’s historical rating and behavior with background information. At present, the privacy issue in recommender systems is gaining the attention of both academics and industry.
Several traditional privacy preserving methods have been employed in recommender systems, including cryptographic [5,28], perturbation [21] and obfuscation [1,18]. Canny [5] proposed a multi-party computation method that allows users to publicly aggregate data without disclosing their true data, and each user applies local computation to obtain personalized recommendations. Zhan et al. [28] solved a similar problem by applying homomorphic encryption and scalar product approaches. The cryptographic method retains high performance because it does not disturb the original record. But extra computational cost and complicated security protocols makes it harder to apply widely and it appears to be used for recommender systems rather than normal users. Perturbation and obfuscation are similar. Specifically, perturbation systematically changes a user’s rating by adding noise before submission. For example, Polat and Du [21,22] deployed a centralized server to store the perturbed ratings, and uniform noise was added to each rating before making a recommendation. Obfuscation replaces a certain percentage of a user’s rating by random values. Berkovsky et al. [1] decentralized rating profiles among multiple repositories and replaced some ratings with the mean. Both perturbation and obfuscation offer a high level of privacy because all or part of a user’s ratings are not true. But the magnitude of noise or the percentage of replaced ratings are subjective and difficult to control. Therefore, how to obtain a trade-off between privacy and utility is still a challenge to both techniques.
Although privacy preserving in traditional recommender systems has been well studied, less attention has been given to the issue of privacy in tagging recommender systems. Compared to traditional recommender systems, the privacy problem in tagging systems is more complicated due to its unique structure and semantic content. The most relevant paper was from Parra-Arnau et al. [19], who made the first contribution towards the development of a privacy preserving tagging system by proposing the tag suppression approach. They first modeled the user’s profile using a tagging histogram and eliminated sensitive tags from this profile. To retain utility, they applied a clustering approach to structure all the tags and suppress those less represented. Finally, they analyzed the effectiveness of their approach by discussing the semantic loss of users. However, there are several limitations on tag suppression. It only releases an incomplete dataset, with parts of the sensitive tags deleted. The sensitive tags are subjective without any quantity measurement. Furthermore, if the dataset is publicly shared, users can be identified because the remaining tags still have the potential to reveal a user’s identity. The privacy issue in tagging recommender systems is still largely unexplored, and we will attempt to fill this void in this paper.
Hence, in this paper, we propose a Private Tagging Releasing algorithm, with the aim of preserving comprehensive privacy for individuals and maximizing the utility of the released dataset. Specifically, we attempt to address the following issues:
How to retain the unique structure of a tagging dataset? As mentioned earlier, the tagging dataset has a unique structure, and the relationship among users, resources and tags should be preserved within the private mechanism, otherwise, the utility will significantly decrease. Unfortunately, a naive differentially private mechanism will lose its structure. An effective way to solve this problem is to provide a synthetic dataset instead of simple statistical information.
How to decrease the large magnitude of noise when using differential privacy? In the tagging dataset, the key method to decreasing the noise is to shrink the scale of the randomization mechanism. Previous work focuses on methods that eliminate the number of tags, but this results in high utility loss.
In this paper, we retain the structure by using an improved differential privacy mechanism and shrink the randomized domain to limit the size of the noise. Both issues will be investigated in the following sections.
Private Tagging Releasing
In a tagging recommender system, a user
However, even the tagging dataset replaces the user’s name by random number before releasing, and profile
Users with Tags
Users with Tags
Differential privacy considers the worst-case of background information, which makes it a promising choice for preserving privacy when releasing the profile of users. Unlike traditional methods, the differential privacy mechanism assumes
One way to reduce the noise is to shrink the randomized domain, which refers to the diminished number of bins in the histogram. To achieve this objective, tags can be partitioned and merged within groups. A user profile is represented by a group-based histogram, in which the frequency of each group is computed according to the fraction of tags. Calibrated noise is then added to each group and the noise size will significantly diminish in the meantime. It should be noted that a group need to be chosen carefully because information about the original dataset may be disclosed.
In this section, we propose a Private Tagging Releasing (PriTag) algorithm to address the privacy issues in tagging recommender systems. Specifically, we first present an overview of the algorithm, then provide details for each operation. A theoretical analysis is further provided to answer why this algorithm achieves the ϵ-differential privacy while retaining the utility for recommendation purposes.
The PriTag algorithm aims to publish all users’ profiles by masking the exact tags and weights under the notion of differential privacy. Three private operations are introduced to ensure that each individual in the releasing dataset cannot be re-identified by an adversary.
Private Tag Clustering: This creates tag clusters but masks the exact number of tags and the centers of each cluster. From the clustering output, the adversary cannot infer which group a tag belongs to.
Private Tag Selection: This aims to mask a user’s profile that an adversary cannot infer the tags flagged by this user.
Tag Weight Perturbation: This masks the true weight of the tags in a user’s profile to prevent an adversary from inferring how many times a user tagged certain resources.
On the basis of these private operations, the proposed PriTag algorithm outputs a new tagging dataset for tagging recommendations. As shown in Algorithm 1, step 1 divides the privacy budget into three parts. One part is used in private clustering and the other two are applied in each user’s profile to hide the tag’s information and weights, respectively. Step 2 clusters all the tags into k groups. Then in step 3, each user’s tag is replaced by privately selecting tags within related clusters. After perturbing the weight of each tag using the Laplace mechanism in step 4, the sanitized dataset

Private Tagging Releasing (PriTag) algorithm
The three private operations guarantee the differential privacy and retain the acceptable recommendation performance simultaneously. Details for the Private Tag Clustering operation is presented in Section 3.1.1, and the Private Tag Selection and Weight Perturbation are provided in Section 3.1.2.
In this subsection, we describe the Private Tag Clustering operation that privately groups tags into several clusters in the differential privacy budget. Private Tag clustering categorizes unstructured tags into groups to eliminate the randomization scope for privacy purposes. According to the notion of differential privacy, this operation ensures that deleting a tag will not significantly affect the clustering results. This means an adversary cannot infer which group a tag is located in from the clustering output. This objective can be achieved by adding Laplace noise in the distance measurement during the clustering process.
We apply K-means as the baseline clustering algorithm and apply the Laplace mechanism into it. Blum’s initial work of SuLQ claims that a private clustering method should mask the cluster center and the number of records in each cluster [2]. Following this work, we roughly conceptualize the Private Tag Clustering in three steps:
Modeling each tag by annotated resources.
Defining a quantitative measure of distance between tags.
Adding noise in each iteration to privately clustering all tags into groups.
We first model each tag using a numeric vector that contains the counts of the tag marked on each resource. For example, tag
On the basis of the tag vector model, the second step aims to evaluate the tag’s distance, which is measured by Cosine distance:
The third step introduces differential privacy into K-means, which is a popular iterated algorithm for grouping data observations into k clusters. Let
When combined with differential privacy, Laplace noise is added in the objective function D. According to Definition 2, Laplace noise is calibrated by the sensitivity of the objective function D and the privacy budget. The sensitivity of D is the maximal distance between a tag to a cluster center:

Private Tag Clustering operation
After shrinking randomized scope via clustering, suitable tags should be selected to replace the original tags of an active user. The challenge in Private Tag Selection is that for a tag in an active user’s profile, uniform tag selection within a cluster is unacceptable due to significant utility detriment. However, on the other hand, it is also dangerous to replace the original tag with one the most similar because the adversary can easily figure out the most similar tag by simple statistical analysis. Consequently, the Private Tag Selection needs to: 1) retain the utility of tags, and 2) mask the similarity between tags.
To achieve these, Private Tag Selection adopts the Exponential mechanism to privately select tags from a list of candidates. To be precise, the operation for a particular tag
We apply the similarity between tags as the score function. For example, the score function q for a target tag
The sensitivity for score function q,
On the basis of score function and sensitivity, the probability arranged to each tags

Private Tag Selection
The weight of a tag is defined as the fraction of the tag in a user’s profile, and the objective of Tag Weight Perturbation is to preserve the weight of each tag for individuals.
Laplace noise is added to each weight to preserve privacy. According to Definition 2, the sensitivity of weights is measured by the tag’s fraction, which is denoted as
In this section, we provide a theoretical analysis for the proposed PriTag algorithm from the utility perspective.
The dataset
Because tag system contains three element in one tuple
After this, we apply a widely used utility definition in differential privacy by Blum et al. [3]:
((α, δ)-usefulness).
A dataset mechanism
This definition can be applied to evaluate
For any users
Given a user
According to Marlkov’s inequality, for user
Let
When we use Cosine distance, which has a maximum value of 1, the maximal
The proof shows the semantic loss for each user mainly depends on the privacy budget and the normalization factor
Therefore, the size of
Privacy Budget Allocation in PriTag Algorithm
Privacy Budget Allocation in PriTag Algorithm
To analyze the privacy guarantee, two composite properties of the privacy budget are normally used in differential privacy: the sequential composition and the parallel composition [15]. The sequential composition accumulates privacy budget ϵ of each step when a series of private analyze is performed sequentially on a dataset. The parallel composition corresponds to the case that the each private step is applied on disjointed subsets of the dataset. The ultimate privacy guarantee then depends only on the mechanism with the maximal ϵ. Both properties are shown in Lemmas 1 and 2.
Sequential Composition [
15
]:
Parallel Composition [
15
]:
Based on the above lemmas and privacy budget allocation in Table 2, we measure the privacy level of our algorithm as follow:
The Private Tag Clustering consists of p iterations, which are sequentially performed on the whole dataset. The privacy budget of each iteration is
The Private Tag Selection processes the Exponential mechanism successively. For one user u, each tag in the profile is replaced by a privately selected tag until all tags are replaced. From the definition of the Exponential mechanism, each selection preserves
The Tag Weight Perturbation applies the Laplace mechanism to the weights of tags. The noise is calibrated by the
Consequently, the proposed PriTag algorithm preserves ϵ-differential privacy.
In this section, we evaluate the performance of the proposed PriTag algorithm by answering the following questions:
How does the private clustering operation affect cluster quality? As mentioned in Section 3.2, the quality of clustering result has a significant impact on the performance of recommendations. We answer this question by comparing the proposed private clustering operation with the traditional one in terms of the internal index, a cluster validation metric [12]. How does the PriTag algorithm affect the semantic loss of the datasets? Private operations revise a user’s profile to preserve privacy. We quantify the profile change by using the semantic loss. Moreover, to illustrate its effectiveness, we compare the PriTag algorithm with tag suppression [19] in terms of semantic loss. How does the PriTag algorithm perform in a real tagging recommender system? Private operations decrease the utility of recommendations. In this part, we investigate the performance of PriTag in a real tagging recommender system. How does the privacy budget affect the performance of the algorithm? In the context of privacy preserving, the privacy budget is a key parameter that controls the privacy level of the algorithms. To show the impact of the privacy budget, we examine the trade-off between the utility and the privacy of PriTag by varying over a wide range.
Datasets
To obtain a thorough comparison, we conduct the experiment on four datasets: Del.icio.us, Bibsonomy, MovieLens and Last.fm, all of which are structured in the form of triples (user,resource, tag).
The Del.icio.us dataset is retrieved from the Del.icio.us web site by the Distributed Artificial Intelligence Laboratory (DAI-Labor).1
The Bibsonomy dataset is provided by Discovery Challenge 2009 ECML/PKDD2009.2
The MovieLens and Last.fm datasets were obtained from HetRec 2011,3
Characteristics of the datasets
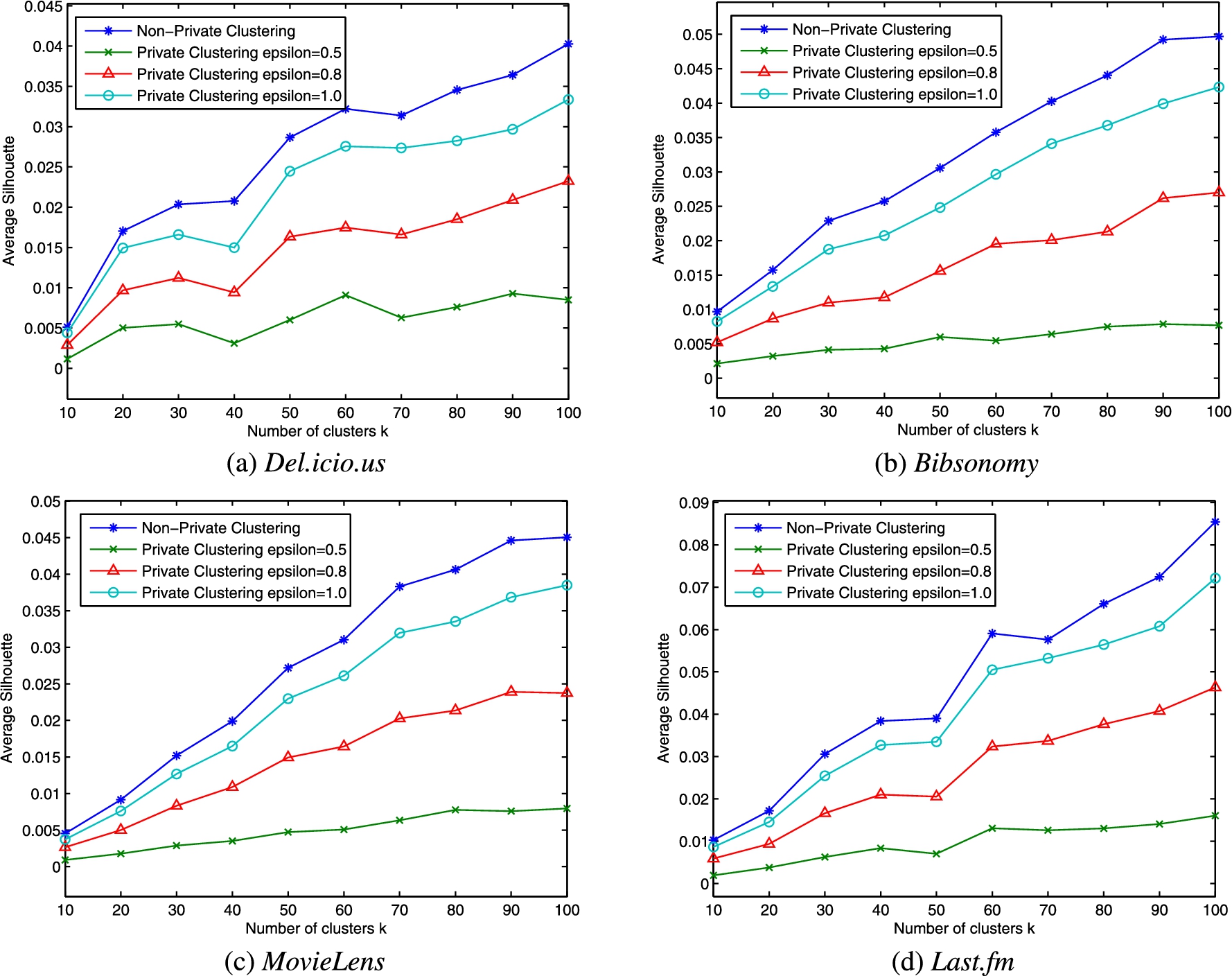
Comparison between Private Clustering and Non-private Clustering.
The performance of the private clustering operation is assessed by Silhouette Coefficient metric, which is a popular internal index that measures the quality of clusters by combining both cohesion and separation [12]. For each tag
An overall quality of a clustering operation can be obtained by computing the average Silhouette Coefficient of all tags. It varies between
We compare the private clustering with the non-private clustering in terms of Silhouette Coefficient. The number of clusters is specified from
As shown in Fig. 1, for all clustering results,
On the other hand, for private clustering, where the privacy budget ϵ is fixed to 1, the average Silhouette Coefficients are very close to the non-private ones. This indicates the quality of clusters can be properly retained when the noise size is limited. For example, in Fig. 1(a), when
Similar trends can also be observed on other datasets. Figures 1(c) and 1(d) also show an increase in average Silhouette Coefficient when k becomes larger. For private clustering, when
Please note that even we can obtain a higher Silhouette Coefficient with a larger number of d, but the noise in the perturbation operation will be increased. So we need to determine a suitable d rather than choosing the high number of clusters. The impacts of parameter d will be further analyzed in Section 4.3.
Semantic loss analysis
To maintain consistency with previous research, we follow the strategy of [19] and utilize the semantic loss as the measurement metric, which refers to the percentage of eliminated tags for each user or resource. A smaller semantic loss means better performance. Eq. (13) in Section 3.2 defines the average semantic loss of users. In this section, we also test the semantic loss of each resource, which is formulated as follows.
To achieve a thorough investigation, we conducted experiments to compare PriTag with tag suppression [19] on two datasets. The average semantic loss exhibits a linear relationship with the tag suppression rate σ in tag suppression [19]. We choose the most represented parameters with

The Semantic Loss of Users and Resources on Del.icio.us and Bibsonomy.
Figures 2(a) and 2(b) shows the results of the average semantic loss of users and resources on the Del.i.cio.us dataset, respectively. It can be observed that PriTag outperforms tag suppression on both datasets. For tag suppression, when the elimination parameter
Similar trends can also be observed in Figs 2(c) and 2(d). Both figures show that PriTag obtains a stable semantic loss at a low level. All these indicate that PriTag retains more utility than tag suppression. This is because PriTag retains the relationship between tags and resources. Consequently, the semantic information can be consequently well preserved and the tags still make resources meaningful. The only exception occurs in 2(d), in which the semantic loss of resources is slightly exceeds the tag suppression when
A further analysis is conducted to investigate the impact on the number of cluster k on the semantic loss. Specifically, for the user semantic loss, it decreases as k increases at the very beginning. When the parameter k achieves a larger value, semantic loss does not significantly decrease. For example, in Fig. 2(c), user semantic loss achieves its lowest when
In this section, we investigate the effectiveness of PriTag in the context of tagging recommendations. Specifically, we apply a state-of-the-art tagging recommender system, FolkRank [13], to measure the degradation of tag recommendations in terms of accuracy that is caused by privacy preserving.
The key idea of FolkRank is that a resource which is flagged with important tags by important users becomes important itself. The importance is measured by weight

FolkRank Private Recall Result.

FolkRank Private Precision Result.
In the current investigation, we set
For the measurement protocol, we apply the Leave-One-Out strategy, which is a popular configuration when evaluating tag recommendations. To begin with, we randomly select one resource of each user, and predict the tags using all the remain tags in the dataset. Two measurements are applied to quantify the performance, precision and recall. For a test user that receives a list of N recommended tags (top-N list), precision and recall are defined as follows:
Figure 3 shows the recall performance on four datasets, Del.icio.us, Bibsonomy, MovieLens and Last.fm. It presents the recommendation performance achieved by PriTag when the privacy budget ϵ varies from
These results on a real tagging recommendation system confirms the practical effectiveness of the proposed PriTag algorithm on tag recommendations, as we analyzed in Section 3.2.

Clustering Private Result.

Impact of ϵ on User Semantic Loss.
In the context of differential privacy, privacy budget ϵ serves as a key to determining the privacy level. According to literature [8], the lower ϵ represents a higher privacy level. The budget
Figure 5 reveals the impact of privacy budget ϵ on the clustering result when k is fixed. It was observed that as ϵ increases, the private clustering operation achieves a better performance. For example, in Fig. 5(a), when
Figure 6 presents the impact of ϵ on user semantic loss on Del.icio.us and Bibsonomy datasets when k is equal to
Conclusions
Privacy preserving is one of the most important aspects of recommender systems as it protects the sensitive information of users. A tagging recommender system will be confronted with more serious privacy violations due to its semantic property [19]. Even differential privacy is considered as a promising solution to provide a rigid and provable privacy guarantee for recommender systems. However, the solution still suffers from two important deficiencies: 1) it fails to retain the relationship among users, resources and tags; 2) it introduces a large volume of noise, which significantly affects the performance.
This paper proposes an effective privacy tagging releasing algorithm for recommendation purposes and makes the following contributions:
We propose a private tagging releasing algorithm to protect users from being re-identified in a tagging dataset by adversaries. A private clustering operation is designed to reduce the magnitude of noise by shrinking the randomization domain. In addition, two successive private operations, private selection and perturbation, are applied to achieve the privacy purpose. A better trade-off between privacy and utility is obtained by taking the advantage of the differentially private composition properties. We provide theoretical analysis and experimental results to demonstrate the effectiveness.
These contributions provide a practical way to apply a rigid privacy notion to a tagging recommender system without high utility costs. The experimental results also show the robustness and effectiveness of the proposed PriTag algorithm.
Most notably, and to the best of our knowledge, this is the first study to investigate differential privacy in tagging recommender systems. It has been proven that our algorithm can retain a better utility than the previous method, tag suppression [19]. However, the current evaluation only concentrates on one recommender algorithm, FolkRank, with other recommendation techniques, such as topic model, and the tensor decompositions method, still requiring a further investigation.