
Abstract
K-means algorithm is an effective clustering algorithm based on partition, which has been widely used for clustering analysis. However, there are two main problems for K-means algorithm: how to provide appropriate number of clusters and how to determine initial cluster centers automatically. Plenty of methods have been proposed to address the above problems. In our previous work, we proposed the hierarchical initialization approach to determine initial cluster centers, but we cannot provide the number of clusters automatically. In this paper, in order to determine the number of clusters automatically, we propose the Davies Bouldin Index (DBI) based hierarchical K-means (DHIKM) algorithm on the basis of our previous work. The proposed algorithm can integrate DBI metric into our hierarchical K-means algorithm and can determine the number of clusters with low time cost. Experiments on UCI datasets and synthetic data demonstrate the effectiveness and feasibility of the proposed algorithm.
Keywords
Introduction
K-means algorithm has been widely used in clustering analysis. And lots of clustering algorithms are based on K-means, such as spectral clustering [1]. However, its disadvantage is also obvious; clustering result largely depends on the initialization. Firstly, the number of clusters,
In order to determine the initial cluster centers, we proposed a hierarchical K-means (HIKM) algorithm [2], which samples the data from low level to top level first, and then carries out clustering from top level to low level. Meanwhile, the cluster centers are also propagated from top level to low level. Finally, the better initial cluster centers can be obtained with less time cost. However, how to determine the number of cluster automatically is not addressed in this approach either. Existing clustering algorithms to determine the number of clusters automatically all require lots of control parameters in advance, such as Iterative Self-organizing Data Analysis Techniques Algorithm (ISODATA) and its extension method hybrid PSO-ISODATA [3] algorithm that combined POS and ISODATA. All of them need many control parameters, so they are hardly used on high-dimension dataset. Other clustering algorithms like method in [4] have specific requirements on datasets, and are easy to cause over-fitting.
In order to determine the number of clusters, we should find an appropriate evaluation metric to measure the performance of clustering. Most of clustering metrics are to maximize the similarity within class and minimize the similarity between classes. More precisely, the standard of clustering is proportional to the similarity within class and the difference between classes. Davies Bouldin index (DBI) [5] is a popular measure to evaluate clustering performance through the separation between the
Based on the evaluation ability of DBI, we propose DBI-based Hierarchical Initialization K-means algorithm (DHIKM), which can determine both the initial cluster centers and the number of clusters automatically. The proposed algorithm reduces the data by sampling level by level, and determines the number of clusters based on DBI criterion on the level where sampling ends. Then clustering is executed in the order of top-down, until reaching the original data level. If we directly apply DBI to the original data, the number of clusters can also be obtained, but its time cost may be unbearable, especially facing large volume data. But for our approach, the time cost to determine the number of clusters is very limited and may be ignored for some cases, which is the main contribution of this paper. Based on our previous work, the new proposed method can find not only the initial cluster centers but also the number of clusters. In other words, it can provide the better initialization for K-means algorithm.
The rest of this paper is organized as follows. The preliminary knowledge is presented in Section 2. In Section 3, we will provide the description and complexity analysis of proposed method. The experiments are conducted on UCI datasets and simulation datasets. The comparison and analysis are given in Section 4. Finally, conclusion is drawn in Section 5.
Preliminaries
This section will introduce the preliminary knowledge about the proposed method, namely, DBI and HIKM algorithm, which is very important for understanding of DHIKM.
Definition of DBI
Davies Bouldin Index (DBI) [5] is a measure to evaluate the clustering performance. Its basic idea is to evaluate the separation between the
The formula of Davies Bouldin Index is as follows:
Where
In this subsection, we will state why we choose DBI as the clustering metric. In general, clustering validations, which usually contain two main categories – external validation and internal validation, are used to judge the performance of clustering results. Rendon [6] presented a comparative study between four external indexes: F-measure, NMIMeasure [7], Entropy, purity [8] and five internal indexes: BIC, CH, DBI, SIL, DUNN [9]. They tested the K-means and Bissecting K-means algorithms on 12 synthetic data sets. Finally, for the Bissection K-means algorithm, correct rate is 86% with internal indexes, and 51.9% with external indexes. For K-means algorithm, the accuracy was 76.9% with internal indexes, and 61.5% with external indexes. On the other hand, DBI performs the best in both algorithms. In fact, not only the research results rule out external indexes, but also the requirement of external indexes implies that they are unsuitable for real data. The main difference between external indexes and internal indexes is whether the priori knowledge is needed. But for most real applications, prior knowledge is usually not available, thus, the external indexes are not suitable for determining the number of clusters.
In literatures, a large amount of internal validations have been proposed, for example, DBI. Liu et al. [10] studied 11 internal validations from 5 aspects: monotonicity, noise, density, subclusters and skewed distributions, including RMSSTD, RS,
In another paper [14], Arbelaitz et al. compares 30 cluster validity indices in many different environments with different characteristics. There are
The time complexity of DBI is in the linear order of clustered vectors, but if DBI is directly used to original data, the time cost will be very high, which may be intolerable. However, based on our Hierarchical approach, we can calculate the DBI at the top level, where the data amount is very limited, usually no more than 1000 instances. Therefore, time cost will be bearable. Based above analysis, we can see that DBI is a suitable index for determining the number of clusters, which can be easy to integrate into the Hierarchical Initialization K-means algorithm.
HIKM
HIKM [2] is our previous work, the main flowchart is as follows: First, all data are treated as the weighted data. We perform sampling on the preprocessed data level by level so as to reduce the amount of data and meanwhile maintain the original data information; Then, the clustering algorithm is carried out on the top level to get the initial clustering centers; Finally, these cluster centers are propagated from high level to low level so as to obtain the initial centers of original data. Here, we can take 2-dimension data as an example. First, we rasterize the original data, and average the weight of data in the grid when sampling from low level to high level. For non-weighted data, the weight is set to 1. The original data after rasterizing is called 1st level. The data after sampling is called 2nd level; and so on until the top level that sampling ends. Supposing that one instance
Where
Based on the above sampling method, the data amount will be reduced greatly after sampling and most of the noise will be filtered, but the information of the original data is well preserved. Finally, cluster centers at the
Algorithm description
This section will detail our algorithm, i.e. Davies Bouldin Index based hierarchical initialization K-means (DHIKM) algorithm.
Algorithm flowchart
DHIKM algorithm can determine the number of clusters and initial cluster centers automatically first. Then, it completes K-means clustering without any control parameters. Regarding the determination of initial cluster centers, it has been addressed in our previous work. Therefore, we’ll mainly focus on the determining of the number of clusters. The algorithm composes of 4 main steps: data transformation, sampling from bottom-up, determining the number of clusters and clustering from up-down, the detail is described in Algorithm 1.
[!t] Davies Bouldin Index based hierarchical initialization K-means (DHIKM)
then
Algorithm analysis
The linear transformation rule in Step 1 is
If every dimension of data does not meet integer powers of 2, we will expand the data to integer power of 2.
The strategy to determine the best number of cluster
If the average instances in each cluster is less than 20 after sampling, under this situation, we will use the data in second top level to recalculate DBI.
After that, the determination of the initial cluster center is as follows: The data points are sorted by weight, then we select the first
Complexity analysis
The main time cost of DHIKM lies on the computation of DBI in Step 3 and the top-to-down iterative clustering in Step 4, time cost for sampling is almost ignorable.
It is assumed that the dimension of dataset is
In summary, DHIKM algorithm only needs two control parameters. One is N, which represents the scale of instances after sampling, and the other is the T, which represents the size of test window for DBI. The parameter N relates to the size of final data
Experiments and results
In order to evaluate the performance of algorithm, we carry out two groups of experiments: First, we test the capability of determining the number of clusters automatically on 40 datasets which include 12 UCI data sets and 28 simulation data sets; then, we compare our DHIKM with 3 other clustering algorithms, ISODATA[15], ASC[4], NC-estimation[16].
Simulation data sets for performance experiment of DHIKM.
The main aim of our DHIKM is to determine the number of clusters
Test window size of automatically determining the number of clusters in DHIKM algorithm is set to 3. Since the cluster centers after hierarchical sampling are unique, and the projection rule of cluster centers from
Results of the number of clusters (k)
Results of the number of clusters (k)
As shown in the Table 1, among 40 datasets, our algorithm got the 32 correct results and 8 incorrect results. The performance of DHIKM is good in general, but it is found that the DHIKM is easy to be incorrect when the number of clusters is large and dimensions or instances are not large enough. On the other hand, DHIKM performs well on Gaussian distribution data sets, but badly on uniform distribution data sets. When the data sets are in uniform distribution, it is hardly to choose the initial centers for hierarchical initialization approach, because every point will have similar weight. On the other hand, the special simulation data sets (see in Fig. 2), which are difficult to find out the number of cluster even by human, the experiment results indicates that our DHIKM performance better for automatically determining the number of clusters.
To manifest the clustering capability of DHIKM, we choose 3 other algorithms for comparison, which all can automatically determine the number of clusters. They are ISODATA, ASC[4] and NC-estimation [16].
Comparison with ISODATA
First, we compare our DHIKM with Iterative Self-organizing Data Analysis Techniques Algorithm (ISODATA). ISODATA gets more reasonable number of clusters by splitting and merging clusters [3]. However, it requires the following control parameters:
k: Desired number of clusters L: Maximum number of clusters that can be merged at one time I: Maximum number of iterations ON: Minimum number of samples per clustering OC: Closeness criterion OS: Elongation criterion
We select Iris and Wine datasets to test, and the ISODATA control parameter setting is as follows [17]:
Iris: Wine:
Those sets of parameters can get the correct number of clusters. The results are shown in Table 2 to Table 3.
Performance comparison between the DHIKM and ISODATA algorithms on Iris dataset
Performance comparison between the DHIKM and ISODATA algorithms on Iris dataset
Two special simulation datasets.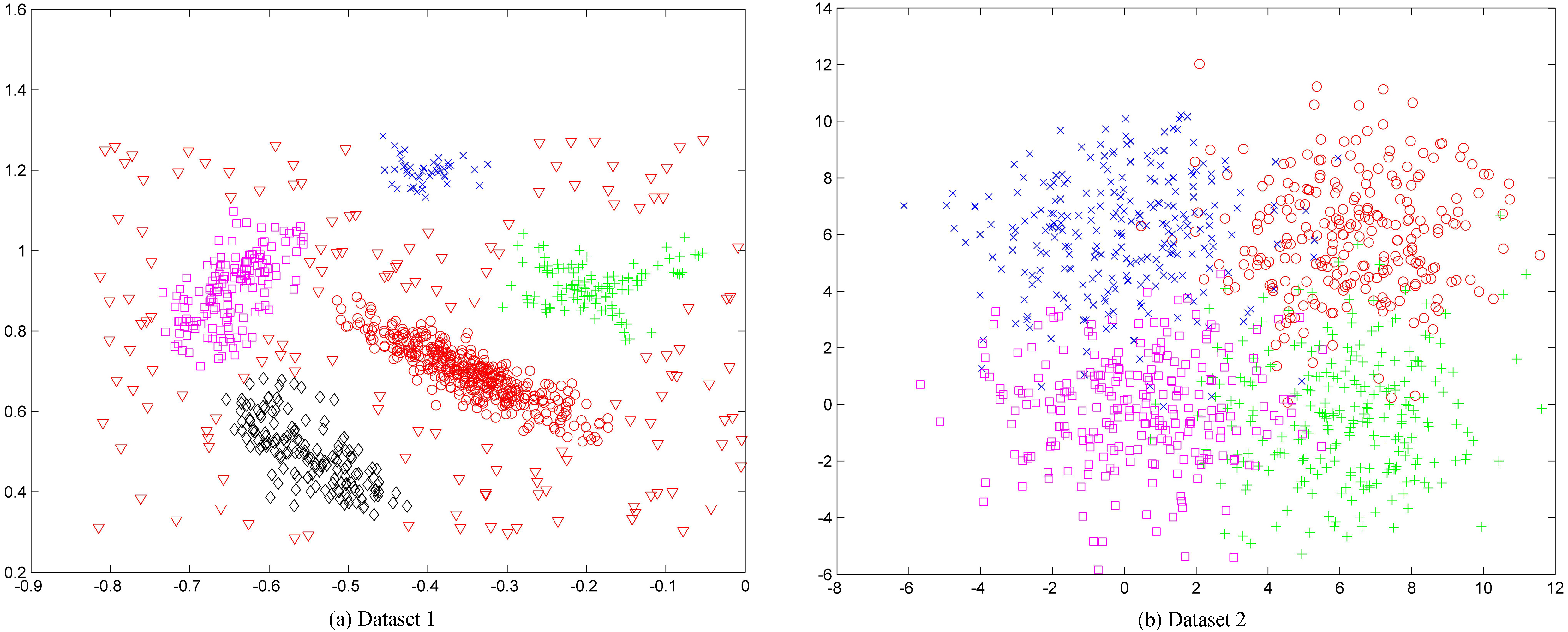
From Tables 2 and 3, we can get following conclusions: ISODATA converges faster, but it has poor performance of clustering and needs excessive control parameters; Although DHIKM runs slower than ISODATA, it has good performance of clustering, and few parameters is needed (see Section 3.3).
Performance comparison between the DHIKM and ISODATA algorithms on Wine dataset
This section will verify whether clustering performance will be affected after DBI measure is introduced into HIKM algorithm. The common evaluation metrics used to measure the clustering performance are sum of the squared errors (SSE) and purity.
We compared DHIKM algorithm with HIKM method and K-means combined with DBI directly. Since HIKM cannot automatically determine the number of clusters, we will use the real clusters number for it. For this part, we use 3 data sets, Iris, Glass and KRK which is a Chess Endgame Database contains 28056 instances, 6 attributes and 18 clusters. The average clustering results on three data sets after 100 times running are shown in Table 4 to Table 6. Besides, we also give the average iteration number and running time.
Performance comparison of the three algorithms on Iris dataset
Performance comparison of the three algorithms on Iris dataset
Performance comparison of the three algorithms on Glass dataset
As shown in Table 4 to Table 6, for DHIKM algorithm and HIKM algorithms, the number of iterations, sum of the squared errors and purity remain the same, which means the introduction of DBI has no influence on HIKM. Although the introduction of DBI makes the time cost of DHIKM higher than that of HIKM, running time of DHIKM in practice is still acceptable. However, running time of DHIKM is shorter than DBI combined with K-means clustering algorithm.
Performance comparison of the three algorithms on KRK dataset
Results of the number of clusters by compare with ASC and NC-estimation
Over-fitting result by ASC.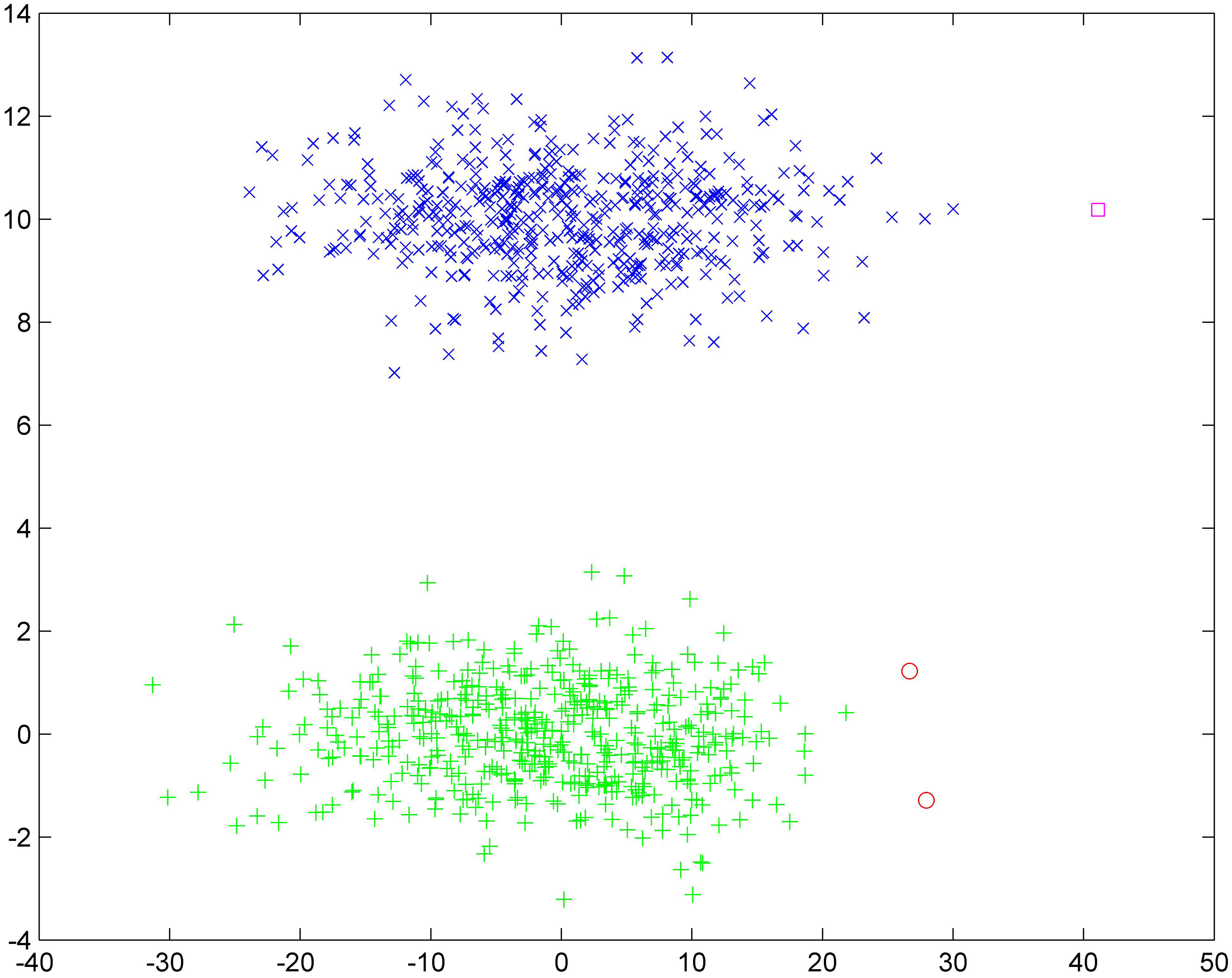
Sanguinetti et al.[4] introduced a spectral clustering algorithm that can automatically determine the number of clusters (ASC), and it is based on Mahalanobis distance [18]. The key of ASC is the elongated K-means that downweight distances along radial directions and penalizes distances along transversal directions. It keeps adding a center at the origin and computing another eigenvector, and this procedure is repeated until no points will be assigned to the centre at the origin, leaving the last cluster empty. NC-estimation [16] is to calculate 4 External validity indices and 8 internal validity indices, including Rand, Adjusted Rand, Mirkin, Hubert, Silhouette(Sil), DBI, Calinski-Harabasz(CH), Krzanowski-Lai, Hartigan, weighted inter-intra, Homogeneity-Separation, for each K beginning with 2, then find the number of clusters of those 12 indices. In our test, we only focus on the internal validity indices, and only show the most effective 3 indices, Sil, DBI and CH.
We choose 6 data sets including 2 UCI data sets and 4 simulation data sets to make the comparison between our DHIKM and the ASC. 2 UCI data sets are Iris and Wine and simulation data sets are the first 4 data sets in Fig. 1. The results are shown in Table 7.
Clearly, DHIKM has much better performance than ASC and NC-estimation. For ASC, it is easy to get an over-fitting result with outliers. Figure 3 shows the clustering result by ASC that 1 pink diamonds dot and 2 red round dots are grouped into another 2 clusters which obviously is a bad decision.
Meanwhile, it’s found that ASC heavily relies on the data distribution. It has two control parameters that should be set. One of them changes a lot with different datasets and has great influence on the cluster results. If the data distribution is regular, it will get the right number of cluster. If there are some outliers in data set, ASC is easy to lead to an over-fitting problem. Compared with ASC, our DHIKM has less control parameters and less dependence on the data distribution. For NC-estimation, the result based on DBI is better than the other two methods, but still lower than our DHIKM.
From the comparison with ISDATA, ASC and NC-estimation, obviously, DHIKM needs fewer control parameters and performs better. Moreover, it can handle the outliers well.
Conclusion
In this paper, we propose Davies Bouldin Index based hierarchical initialization K-means (DHIKM) algorithm which aimed to determine the number of clusters automatically. Our experiments on UCI datasets and Simulation datasets assess DHIKM from whether it can automatically determine number of clusters, clustering performance and practicality. DHIKM is easy to get the incorrect number of clusters for uniform distribution. In fact, in case of a uniform distribution, it is challenging to find the correct number of clusters even for human being. The algorithm performs well on Gaussian distribution that is very common in real applications. From the comparison with other clustering algorithms that can automatically determine the number of cluster, our DHIKM has much better result and less dependence on the data distribution. Besides, it needs fewer control parameters, which means it can be used easily. The main shortcoming lies in that time cost is a little bit higher.
Footnotes
Acknowledgments
This work was supported in part by Jiangsu Natural Science Foundation (No. BK20131351), by Jiangsu Provincial Science and Technology Support Program (No. BE2014714), by the National Natural Science Foundation of China (NSFC) (No. 91220301, 61233011), by the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions, by the 111 Project (No. B13022), and by Six talent peaks project in Jiangsu Province, by the project Funded by TCM Informatics Key Discipline of NJUCM (No. ZYYXXX-13).