
Abstract
A wireless sensor network consists of a large number of sensor nodes. The key parameters of the wireless sensor network are limited energy, network lifetime, limited ability, secure communication, quality of service, data aggregation, and synchronization. In wireless sensor network when the single base station multi-hop communication model is used, the adjacent nodes to the base station transmitted all the data to the base station. Thus the adjacent nodes deplete their energy earlier than other nodes and create the energy holes near the base station. These energy holes minimize the lifetime of the network. The primary objective in large-scale wireless sensor networks is to increase the lifetime with limited energy resources. This can be achieved by placing the multiple base stations using an intelligent clustering technique in a wireless sensor network. In this paper, an intelligent clustering technique has been proposed to choose the optimal position of multiple base stations with the help of k-means++ clustering technique in conjunction with the local+ scheme. The simulation result shows that the proposed method provides minimum energy consumption with an extended lifetime in comparison to the two individual clustering techniques.
Keywords
Introduction
Sensor nodes are one of main components of a wireless sensor network(WSN), which acts as a transducer to collect the real data. This data is analyzed using an inbuilt micro-controller and sent to nearby sensor node or base station for final compilation of results. To make the longer lifetime of a WSN energy consumption is a primary concern because sensor nodes use energy-constrained batteries as an energy source. Transmission of data exhibits the highest percentage in the consumption of total energy [1, 2]. In a WSN, position of the base station, which are used to gather all the information, is also a prime factor in the consumption of total energy. In literature, many algorithms have been proposed for the positioning of base stations in the WSNs [3–7]. Use of multiple base stations (MBS) is also an important technique to conserve the energy in a WSN. This technique also provide following advantages: Total energy consumption reduces drastically in MBS technique because it requires very less number of hops for data transmission from nodes to the base stations as compared to single base station technique [8]. MBS technique maximizes the lifetime of a WSN by distributing the entire load on all sensor nodes uniformly [9]. MBS technique helps to overcome the routing hole problem which occurs location based routing protocols. For example, neighboring nodes of the sink become bottlenecks and drain their energy rapidly than other nodes [10]. The base station positioning in WSNs influence the tolerance against faults, congestion from communication and coverage of sensor nodes. Thus MBS arrangement is helpful to increase coverage, decrease the congestion and make wireless sensor networks robust against the faults [11]. MBS method conquers the problem of scalability which arises due to the deployment of thousands of nodes in a large scale WSN [12]. In some applications, each cluster head (CH) needs to communicate with a base station directly which requires high transmitting power if only the single base station is deployed. This leads to high energy consumption and interference problem which can be avoided by the use of MBS arrangement [13].
Taking aforementioned advantages of MBS technique into the consideration, this paper presents an energy efficient clustering scheme for optimal positioning of multiple base stations along with the local advantage of the extended lifetime in a WSN.
MBS positioning techniques are basically utilized in large scale sensor networks in which several thousands of sensor nodes are deployed over a monitored region. Such networks are applied in agricultural scenarios, environmental monitoring and other such fields. To achieve maximum coverage, energy efficiency and lifetime multiple base stations are necessary over single base station in these WSNs. To address this issue a MBS positioning algorithm has been proposed in this work. Now days different types of smart sensors such as Crossbow/Berkeley mica motes (sensor) are utilized in the various applications of large scale WSNs. The remaining part of the paper has been organized as follows. In Section 2, the related work is presented. The system model is discussed in Section 3. Section 4 describes different clustering algorithms. In section 5, Local+ technique concept is mentioned. The Proposed algorithm is presented in Section 6, and the simulation results and discussion have been demonstrated in Section 7. Finally, the conclusions have been made in Section 8.
Related work
In this part of the paper, some of the earlier reported work has been reviewed regarding the energy efficient routing protocols based on reliable data forwarding, clustering and other parameters in WSNs.
Oyman et al. [9] introduced a multiple sink network design, by utilizing this design optimal position of the base stations are calculated based on various design parameters. They have given time constraint that states the minimum required operational time to the sensor network for locating sink nodes.
Alsalish et al. [10] address the problem of unbalanced energy consumption in a WSN wireless sensor network. To minimize the effect of this issue, the author proposed the multiple mobile base station scheme. In this scheme, optimal positions of the base stations are found with the routing pattern to send the data to the base stations.
Kim et al. [11] proposed a Multiple-Objective Metric (MOM) that reproduce four distinct metrics, to place the MBS at the optimal location in WSNs. The deployment of MBS using these metrics can increase coverage, fault tolerance with reduced energy consumption and average delay in a network.
Guvensan et al. [12] suggested a heuristic algorithm, K-means Local+ for the MBS deployment in the WSN. In this algorithm, optimal location of the base station is obtained on the basis of data traffic load. This provides better network lifetime as compare to the k-means algorithm.
Cao et al. [13] developed a method to deploy multiple mobile sink to prolong the lifetime of the WSN where the lifetime is divided into distinct time durations called as round, and after each round the position of the sink is changed. To find a new position for the sink and best possible use of energy, two techniques, known as integer linear program and flow-based routing protocol during each round, has been developed in this work.
Lin et al. [14] provided different methods of deploying the multiple base stations to extend the lifetime under one-hop and multihop communication models. A heuristic approach is given to deploy the base stations for the one-hop communication method in which the base stations are placed at the geometric center of each cluster. An iterative algorithm has been proposed for routing the data in the multihop communication model. This algorithm is based on the mathematical derivations and linear programming.
Dandekar et al. [15] considered the problem of optimal placement of k base stations in a WSN and proposed particle swam optimization based algorithm for the best possible position of the base stations. The objectives of this algorithm is to reduce the average hop distance between sensor nodes and nearest base station, and to maximize connectivity of one hop sensor nodes with each base station.
Latha et al. [16] proposed an optimal sink algorithm for finding the optimal number of base stations and a K - Partitioned Minimum Depth Tree method for placing the multiple base stations and to route the network.
Jain et al. [17] proposed an algorithm to optimized the lifetime of the multiple sinks, single hope wireless sensor network using the energy balancing. In this work, the energy balancing is achieved through the restructuring the network by modifying the neighbor nodes of the base station. This algorithm minimizes the energy consumption of a sink and hence increases the lifetime of the network.
Chatterjee et al. [18] proposed the MBS placement methods with an objective of reducing the cost of placement of a sink node and to enhance the lifetime of the WSN. For cluster-formation, a distributed greedy algorithm has been suggested that optimize the number of clusters and the diameter of the cluster based on the classical random graph decomposition theorems.
Yasotha et al. [19] proposed a new method for placing the MBS at optimal location and relocation the static base station that improves the lifetime of the WSNs. In this approach, static sink is placed towards the large traffic region for energy reduction. This shifting is done in the routing phase for avoiding the packet loss. These new locations increase the energy efficiency of the sensor nodes and improve the lifetime of the network.
In this paper, a mathematical relationship has been established for computing the optimal locations of multiple base stations in a WSN to increase the lifetime of the network. In this work, multihop communication model has been exploited for data transmission in which nodes closer to the base station deplete their energy much faster than other nodes they relay data packets for all other nodes. To mitigate the issue of extending the lifetime, the excessive load on closer nodes should be shared by placing the base stations in the region of dense nodes. Basically hop is a part of communication path through which data transfers from source to destination. In a WSN having multihop communication, hop defines the intermediate nodes which transfer the data from one node to another or base station. In this work, one hop away node means that a node can send his data directly to the base station. A clustering algorithm can be used to find these dense places. K-means++ is one of the promising clustering algorithms that gives the best locations for placing the k base stations by calculating the Euclidean distance between the sensor nodes within a cluster. In this work, K-means++ and Local+ algorithms have been clubbed together to get K-means++Local+ algorithm for maximizing the network lifetime. The simulation results show that the proposed algorithms reduce the energy consumption and enhance the lifetime of the network as compared to k-means and other existing algorithms.
System Model
Radio Model
A radio model is used to analyze the parametric effect during the designing and working of a protocol. In a WSN, this type of model is required to measure the power expenditure in the process of communication by making many postulates about the radio model components. In this work, same first order radio model, shown in Figure-1, has been used as by Heizelman et al. [20] in which energy consumption takes by both the sections of transmitter as well as receiver. The transmitter section consumes energy in radio electronics and amplifier electronics while The receiver section depletes the energy in the receiver electronics. The distance (d) between transmitter and receiver decides the use of free space (fs) or multi-path (mp) loss model.
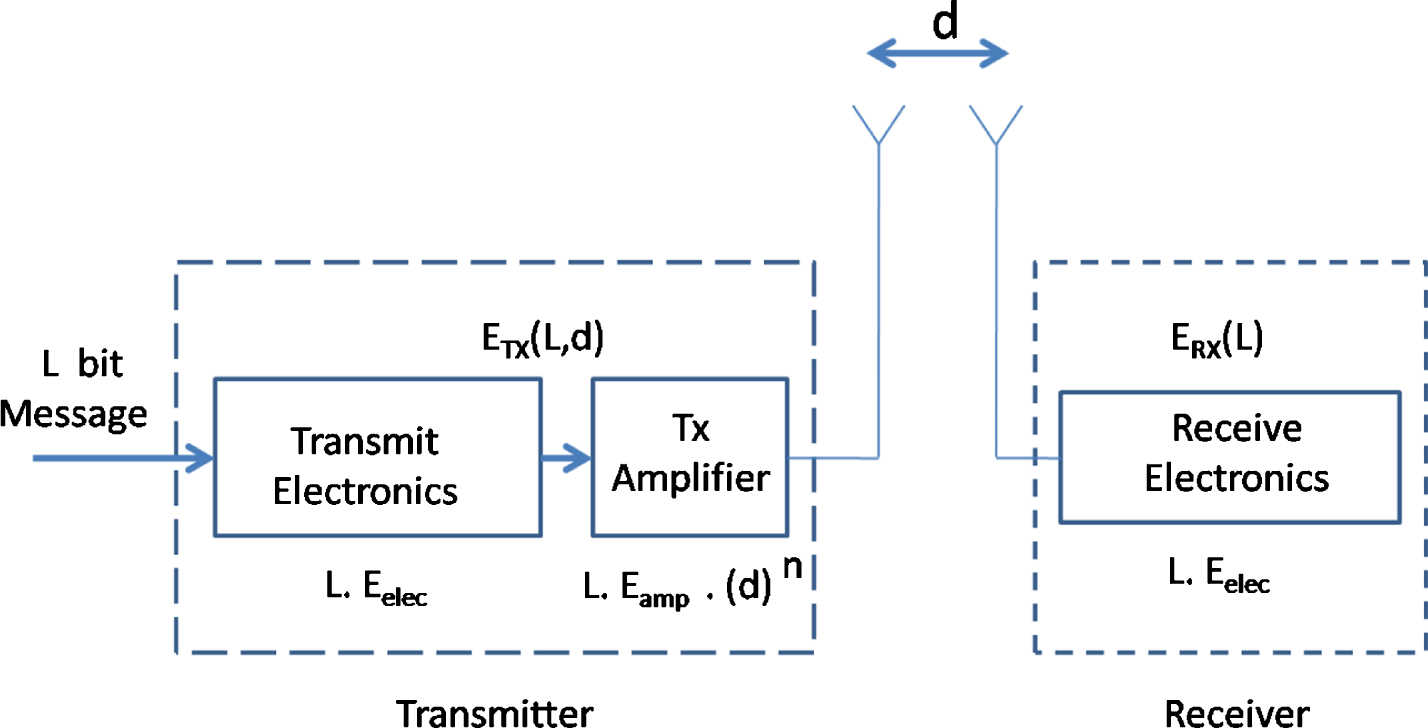
Radio Model.
The transmitter amplifier uses multipath or free space model depending upon the value of path exponent n = 2 or 4, respectively. The consumption of amplification energy E amp by a sensor node depends on these two radio models and distance ’d’ as following:
where, E fs and E mp are the free space energy loss constant measured in J/bit/m2 and multi-path energy loss constant measured in J/bit/m4 respectively while d0 is the threshold distance calculated as:
Total energy required to transmit L number of bits by a node is given as:
Total energy spent for receiving L bits at the receiver can be written as:
In this work, energy consumption clustering model, low-energy adaptive clustering hierarchy(LEACH) used by Heinzelman et al. [20] has been taken into consideration. In this clustering routing protocol, sensor nodes form a clustered network in the field which consists of various clusters along with their individual cluster head (CH) node. Only these CH nodes transmit the information to the base station while all other nodes send data to CH node. Let us consider M × M area with n number of uniformly distributed sensor nodes forming k number of clusters which makes
Total energy (E CH ) consumed by a particular CH is the sum three different energies. It includes energy consumption in information reception by non CH nodes, aggregation (E DA ) and transmission to the base station. Thus, the expression for E CH can be written as:
Now, the total energy (E total ) consumption by all the nodes can be given as:
where, the node i and j are belong to the different sets, and p and q represents the number of nodes that are closer (if d i <d0) and farther (if d j ≥ d0) from the base station respectively. E1 is the total energy consumption other than amplification energy by all nodes.
In the WSN, sensor nodes are bound to energy by them. All these nodes spend their energy in sending information to the sink. However, closer nodes to the sink spend their energy quickly than the other farther nodes. Several approaches are used to reduce this energy consumption by placing base station at an optimal location in the region of congested nodes. Clustering technique is one of them, i.e., used for reduced the energy consumption and increases the lifetime of the sensor network. The network lifetime can be increased by placing the base stations at the place where sensor node density is high so that they share the excessive load. K-means is one of the most popular and simplest algorithms to find the optimal locations for k base stations taking short iteration time. In the succeeding sub sections some these types algorithms are explained.
The K-means Algorithm
K-means is one of the most popular and simplest algorithms to find the optimal locations for k base stations taking short iteration time. This algorithm is based on Euclidean distance and makes an effort to improve arbitrary k-means clustering locally [21]. Randomly select the initial k number of centers from all the nodes as: C ={ c1, . . . , c
k
}. For all i ∈ (1, . . . , k), placed the cluster C
i
so belongs to the set of points in χ that are adjacent to C
i
than they are to c
j
for all j ≠ i. For every i ∈ (1, . . . , k), set C
i
to be the center of mass of all points in C
i
: Repeat the Step 2 to get the fixed the initial clusters or no change in C.
In this algorithm, initial centers are selected randomly, therefore, it offers lesser accuracy. Shortcoming of traditional k-means algorithm has been minimized in K-means++ [22] algorithm by employing better initialization technique. Thus, the K-means++ algorithm provides fast convergent and better accuracy.
The K-means++ algorithm
The k-means algorithm suffers from the local optimum problem due to initial cluster center randomly selected. The k-means++ provides a probability function for the k-means algorithm to select the initial cluster center.
Consider a set D(x), having data point x. The distance between, this data point and already selected closest center should be minimum. The steps of k-means++ algorithm are as follows [22]. Choose the first initial center c1, orderly at random from χ. Select the next center c
i
, selecting c
i
= x′ ∈ χ with probability Repeat previous step to achieve k number of centers. Now perform the basic k-means algorithm steps.
The Local+ technique
In WSN, the most of the energy of nodes consume in the data transfer from nodes to the base station and base station to then central gateway. These energy expenditures can be minimized and the lifetime of the network can increase. The consume energy depends on how far the base station from the nodes and how much data the sensor nodes wants to transfer. By reducing the distance between the sensor node and the base station the energy consumption is reduced. Based on this concept, the local+ technique shifts the base station towards their one hop nearest neighbor which has the largest data to be transferred. The idea of the local+ technique shown in Fig.2. With the help, this method the distance between the base station and its nearest neighbor is reduced and the network lifetime increases [12].

Shifting of BS by Local+ Technique.
In this work, an energy efficient algorithm, termed as k-means++local+, is suggested which combines k-means++ and local+ algorithms for taking the merits of both the algorithms altogether. In this algorithm, base stations are moved closer to their one hop neighbor nodes with more sub nodes using weighted centroid method. The steps of the proposed algorithm are as follows. Select the first (initial) center c1 from randomly ordered χ. Select the next center c
i
= x′ ∈ χ with probability Repeat previous step to achieve k number of centers. Pick out k centers, that are called initial centers C ={ c1, . . . , c
k
}. Place all the Points of χ in the cluster c
i
that are closer to c
i
. Set C
i
i ∈ (1, . . . , k) to be the center of mass of all points as: Repeat fifth and sixth steps until initial clusters are fixed at a point or no change in C. Find the nearest neighbor of the cluster center node or base station node. Find the one hope away nodes (A nearest node to base station that can send his data directly to the base station) in the nearest neighbor nodes from the base station node. Get the one hop away nearest neighbor node having maximum sub nodes. Obtain the final positions of base stations (X
k
, Y
k
) which are moved closer to their one hop neighbor nodes with more sub nodes using weighted centroid method.
where, (x i , y i ) is the position of i th one hop neighbor node, d i represents the relayed packet data size from i th one hop neighbor to k th base station and m k denotes the number of one hop neighbors for k th base station.
The Fig. 3 describes the flowchart of the proposed algorithm. The n number of sensor nodes are randomly distributed in the WSN, out of which first cluster center is selected randomly. Now the k number of centers are obtained by the probability function given in step 2. Initially, the cluster centers are as possible as far away from each other. After getting the initial centers, the clustering process begins. The clustering process based on Euclidean distance. The distance between the cluster center and nodes is calculated. The closer nodes of the cluster center or which are at the minimum distance from the cluster center make a cluster. Now the position of the cluster center is to be verified whether it is fixed or variable. If it varies then, the whole process is repeated till the position of the cluster center become fixed. At this stage, the clustering process is completed, and all the base stations are placed at the cluster centers locations. Now the one hope away nearest neighbors of the base station in a cluster are calculated, then the base stations are moved closer to their one-hop neighbor nodes with more sub-nodes. The new location for the base station is calculated using weighted centroid method. The final locations of base stations are with less energy consumption and higher lifetime.
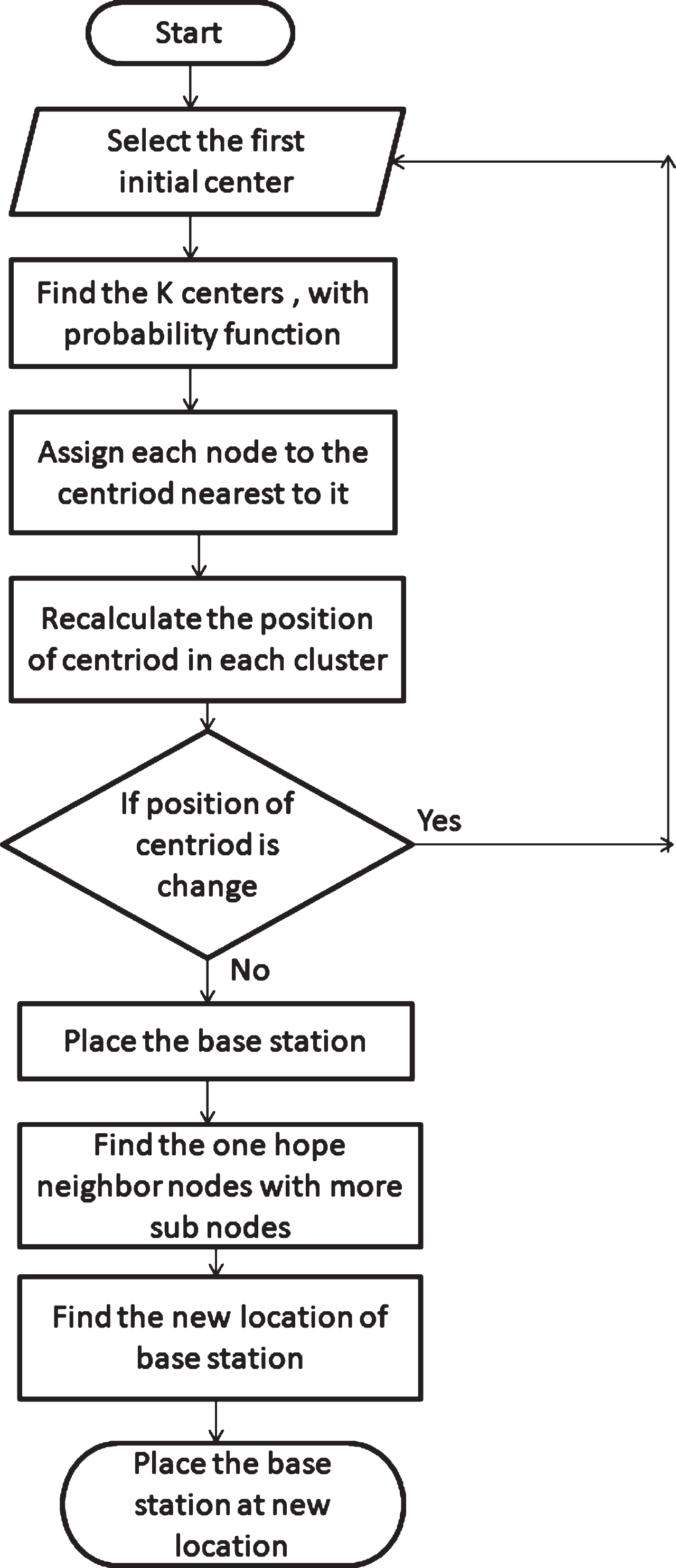
Flow Chart for Proposed Algorithm.
Simulations have been carried out using 100 randomly distributed nodes in 400 × 400 m2 area with initial energy of 22100 J. Packet size of 64B with data rate rate 250 Kbps is taken in simulation process. Sensor nodes are fixed in the communication range of 60m and the number of clusters (k) is varied from 2 to 22 in the steps of 2 to place k base stations in the sensor field using existing and proposed algorithms. In this section tables and figures are shown that gives the energy consumption and lifetime of the network for different clustering techniques for the different number of clusters. The number of clusters also affects the energy consumption in wireless sensor network. When the number of clusters varies the energy consumption and lifetime of the network also varies for the same topology. So in this paper, energy consumption and lifetime calculated at different values of k.
For K=2 k-means++ and proposed algorithms are not performing well compare to k-means and k-means local+ algorithms as the number of neighbor nodes to first neighbors of cluster centers is nearly same as shown in Table I, Fig.4 and Fig.5. This can be verified from Fig. 8 in which standard deviation of neighbor nodes is minimum at k=2. The k-means and k-means local+ performs all most same and better than others for k=2.
Comparison of different algorithms for k=2
Comparison of different algorithms for k=2

K-means vs K-means Local+.
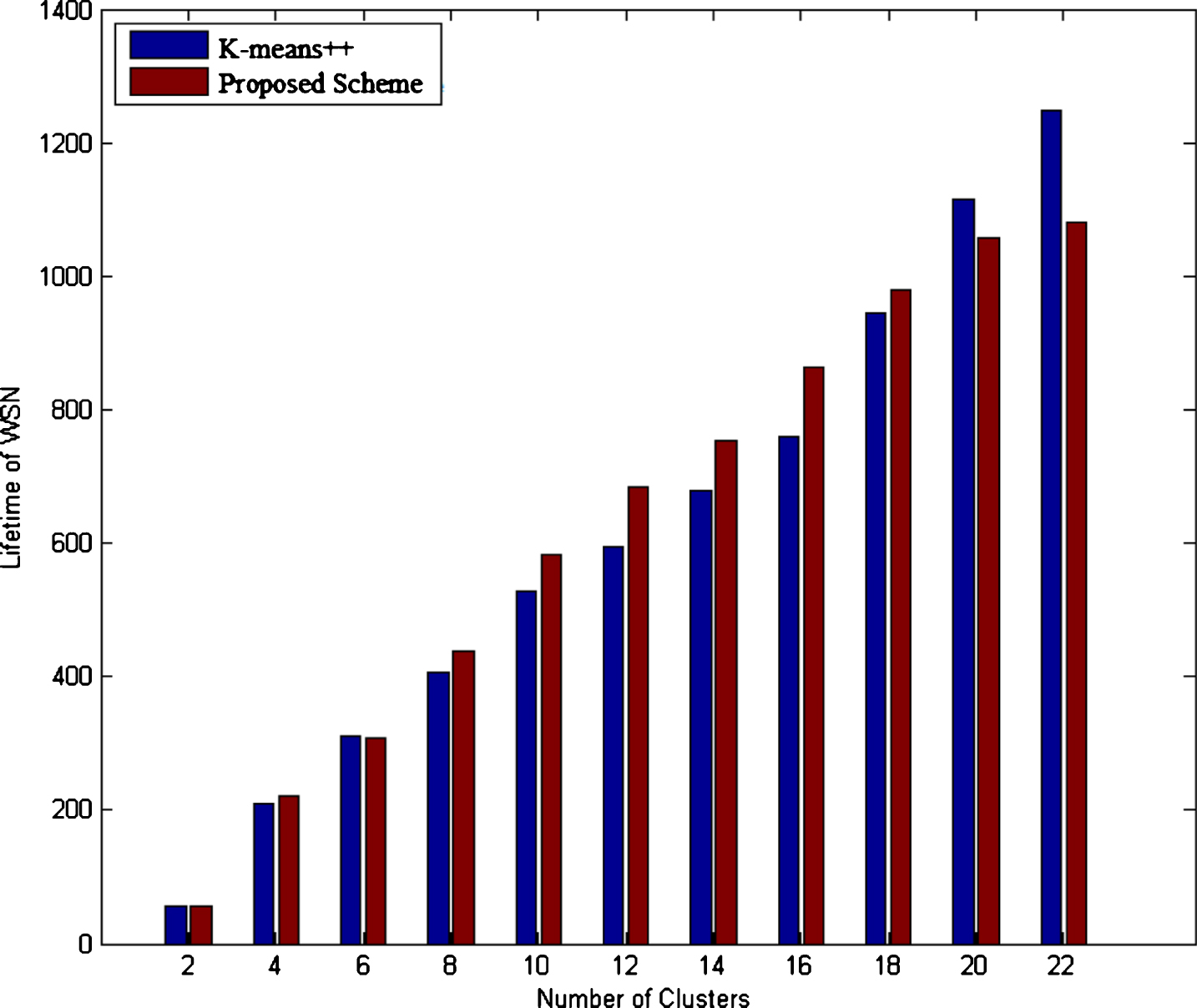
K-means ++ vs Proposed Scheme.
In table-II the comparison is done for the k=12. Here as the number of cluster increases, k-means++ and proposed clustering schemes perform better than other clustering algorithms. The life time gain in k-means local+ and proposed algorithms are 6.69% and 12.37% compared to k-means and k-means++ algorithms as illustrated in Table-II. However, huge lifetime gain of 134.57% in k-means++ and of 147.19% have been achieved in proposed algorithm as compared to k-means algorithm.
Comparison of different algorithms for k=12
Further, Table-III shows that as the number of clusters k increases, both k-means++ and proposed clustering algorithms achieve better performance. For k=22, lifetime gain of k-means local+ algorithm is 6.95% as compared to k-means algorithm. However, proposed scheme has 14.75% lesser lifetime gain in comparison to k-means++ algorithm as shown in Table-III. The lifetime gains of k-means++ and proposed algorithm are 337.61% and 256.57% compared to k-means++ and k-means local+ algorithms respectively as shown in Fig. 6. The performance of the proposed algorithm degrades for number of clusters due to reduced average number of first neighbor per cluster. It can be verified from Fig. 9 that the average number of neighbors decreases as k increases. For optimal clustering the average number of neighbors nodes should be near to 0.5.
Comparison of different algorithms for k=22
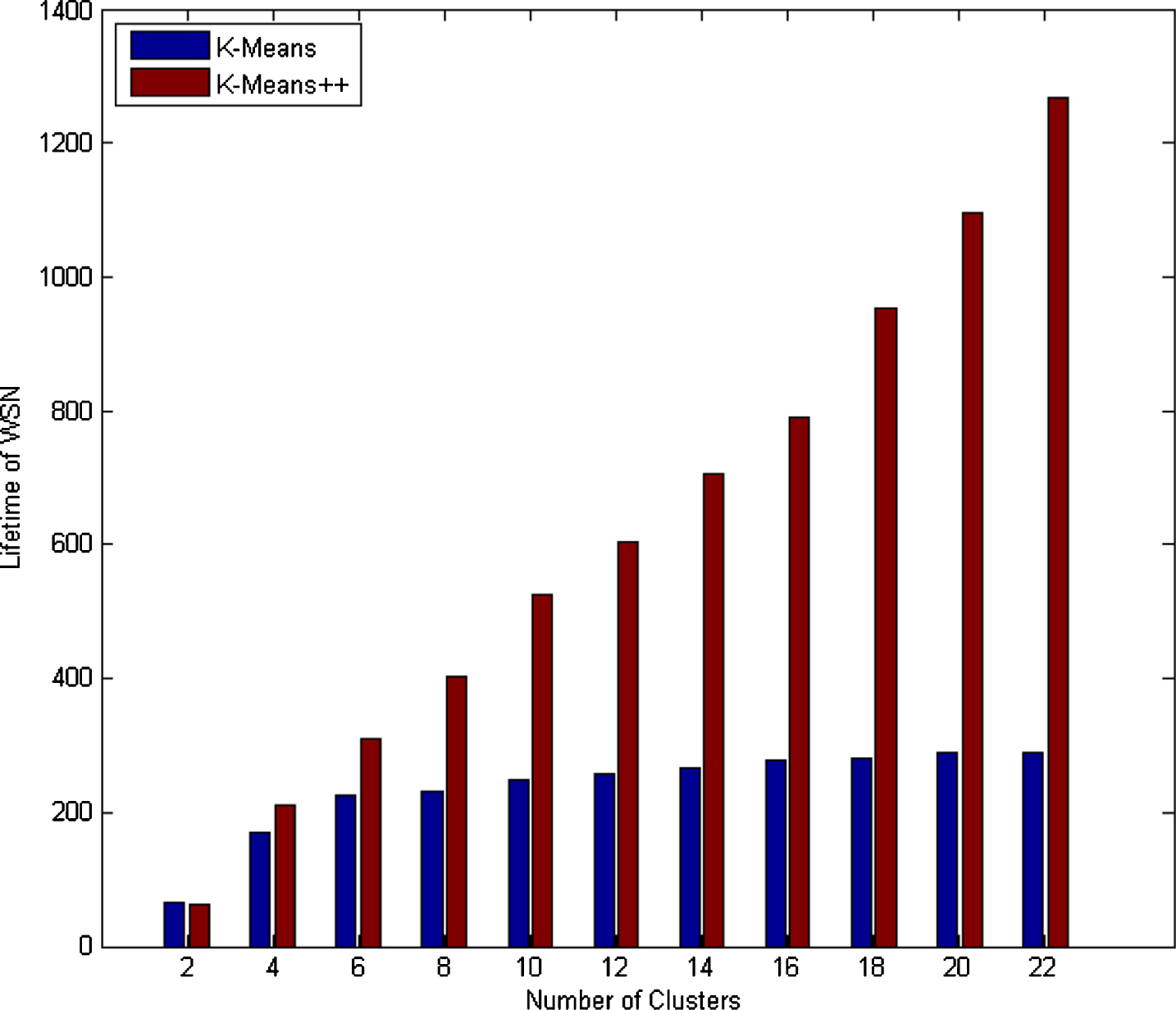
K-means vs K-means ++.
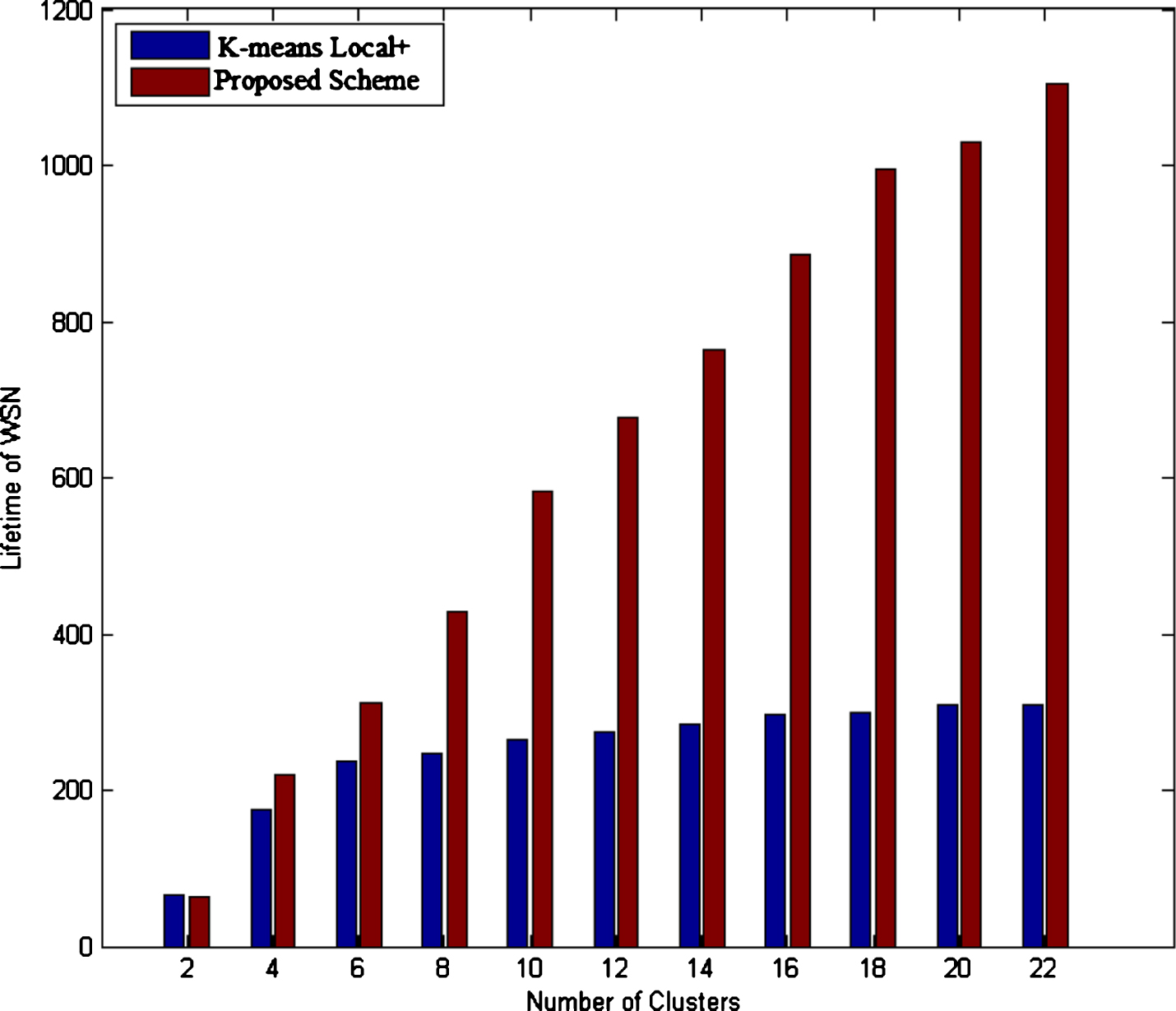
K-means Local + vs Proposed Scheme.

Standard deviation of available nodes in different cluster.
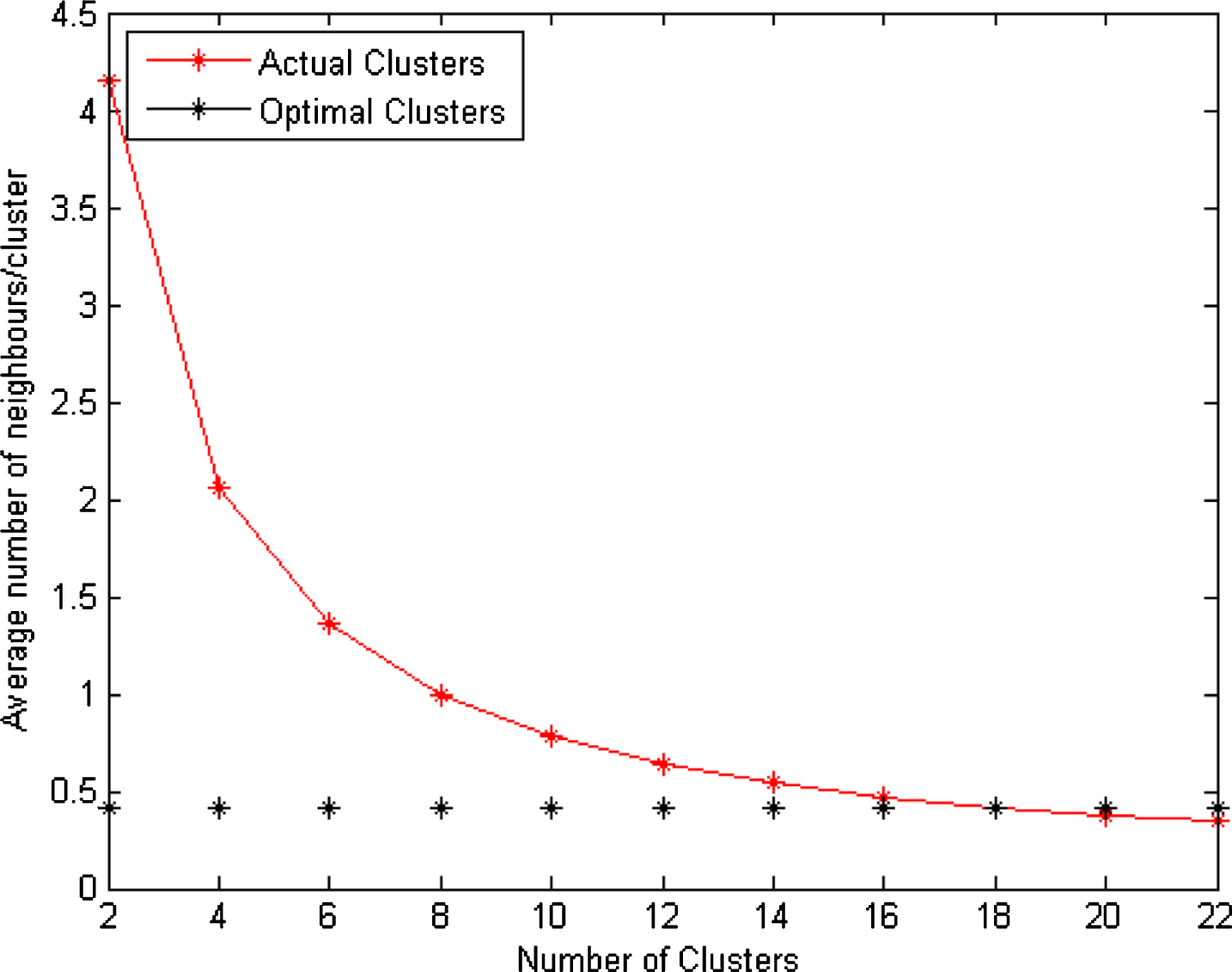
Average number of neighbors per cluster.
In this paper, optimal positioning of multiple base stations in WSN with maximum lifetime has been proposed. In this work a clustering scheme has been proposed which is based on k-means++ and Local+ algorithms. The proposed algorithm performs better than the two individuals clustering algorithms for the moderate number of clusters, or we can say the optimal number of clusters. However, the proposed algorithm do not perform well for the less number of clusters as well as the higher numbers of clusters because the nodes have the least variation in the number of neighbors. In this work, we consider that the base stations are static in nature. In the future work, proposed method can be applied to the mobile base stations to get further improvement in the performance.