
Abstract
Frequent itemset mining (FIM) is one of the most common data mining techniques, which is based on the analysis of the occurrence frequencies of items in transactions. However, it is inapplicable in real-life situations since customers may purchase several units of the same item and all items may not have the same unit profits. High-utility itemset mining (HUIM) was designed to consider both the quantities and unit profits of items in databases, and has become an emerging and critical research topic in recent decades. The SKYMINE approach was proposed to mine the skyline frequent-utility patterns (SFUPs), by considering both the utility and the occurrence frequencies of items. A SFUP is a non-dominated itemset, where the dominance relationship between itemsets is based on the utility and frequency measures. Mining SFUPs using the SKYMINE algorithm and its (UP)-tree structure requires, however, long execution times. In this paper, we propose a more efficient algorithm named skyline frequency-utility (SFU)-Miner to mine the SFUPs, utilizing the utility-list structure. This latter structure is used to efficiently calculate the actual utilities of itemsets without generating candidates, contrarily to the SKYMINE algorithm and its UP-tree structure. Besides, an array called utility-max (umax) is further developed to keep information about the maximal utility for each occurrence frequency, which can be used to greatly reduce the amount of itemsets considered for directly mining the SFUPs. This property can be used to efficiently find the non-dominated itemsets based on the utility and frequency measures. Substantial experiments have been carried out to evaluate the proposed algorithm’s performance. Results have shown that SFU-Miner outperforms the state-of-the-art SKYMINE algorithm for SFUP mining in terms of runtime, memory consumption, number of candidates, and scalability.
Introduction
Knowledge discovery in databases (KDD) has became an important research topic in recent decades since its techniques can be used to find potential and implicit information in very large databases. Frequent itemset mining (FIM) is a fundamental KDD task, used to identify the set of frequent itemsets (FIs). An itemset is considered as a FI if its occurrence frequency is no less than a minimum support threshold. Many methods have been proposed to discover FIs. They generally belong to one of two categories: level-wise [3, 25, 28] and pattern-growth [12, 13, 17] approaches. The most famous level-wise algorithm is called Apriori [3]. It utilizes a generate-and-test mechanism to produce candidate itemsets of different sizes (levels). Apriori scans the database for each level to retrieve the FIs from the generated candidates. These FIs are then combined to generate the candidate itemsets of the next level. This recursive process is repeated and guarantees finding all FIs respecting the minimum support threshold constraint. Then, the discovered FIs can be combined to obtain association rules (ARs) respecting a minimum confidence threshold. The most representative pattern-growth algorithm is called FP-growth [13]. It discovers FIs by recursively exploring a designed FP-tree structure. The FP-tree structure maintains information about the occurrence frequencies of all frequent items. The FP-growth algorithm recursively explores that structure and performs projections to count the support of itemsets. Both level-wise and pattern-growth algorithms treat all items in a database as binary variables. That is, they consider that items may appear or not in transactions, but they do not consider their quantities. Besides, another drawback of FIM and association-rule mining (ARM) algorithms is that they only consider the support of items, but not other measures that are important in real-life such as the prices, unit profits, interestingness, and weights of items. In real-life situations, the occurrence frequencies of itemsets are generally not representative of their importance to the user. For instance, consider the use of FIM to analyze customer transactions for the purpose of refining marketing strategies in terms of sales and discounts. Albeit it may be found that the purchase of bread is very common, the sale of diamonds may be much less frequent but may still be globally more profitable than the sale of bread. The reason is that the profit yield by the sale of one diamond is much higher than the profit obtained by the sale of one bread. For this reason, only considering the occurrence frequencies of items is inadequate to find highly profitable itemsets.
To solve the aforementioned limitations of FIM, several algorithms have been designed for high-utility itemset mining (HUIM) [5, 31, 32, 33, 35, 36]. Their purpose is to discover “useful” and “profitable” itemsets in quantitative databases. An itemset is considered as a high-utility itemset (HUI) if its utility is no less than a predefined minimum utility threshold. The utility mining problem was introduced by Chan et al. [7] as a generalization of FIM. Yao et al. [31] then defined the concept of internal and external utilities, which represent the purchase quantities of items in transactions and their unit profits, respectively.
Albeit FIM and HUIM have numerous real-world applications, they both uses only one criterion to assess the interestingness of patterns (either their occurrence frequencies or utilities). But in some cases, both the frequency and utility measures are relevant to users. As a solution, Goyal et al. [11] defined the skyline frequent-utility pattern (SFUP) mining problem and the SKYMINE algorithm to mine these itemsets. The algorithm can be used to find itemsets that are both highly frequent and profitable. An itemset
An efficient utility-list structure is adopted in this paper to efficiently mine the set of SFUPs. The utility-list structure allows finding An umax array is further developed to keep information about the maximal utility for each occurrence frequency. This array guarantees that the algorithm is correct and complete to discover all non-dominated itemsets. Hence, the algorithm is highly efficient in terms of runtime and memory usage. Using the designed SFU-Miner algorithm, the user can discover the set of SFUPs without having to set a minimum utility threshold or minimum support threshold, while considering both the occurrence frequencies and utility constraints.
Related work
In this section, work related to HUIM and the concept of skyline patterns are briefly reviewed.
High-utility itemset mining
High-utility itemset mining (HUIM) is an extension of FIM, which considers both the quantities and the unit profits of itemsets in databases. Yao et al. [32] proposed the UMining algorithm which utilizes an estimation method to prune the search space. It cannot, however, discover the complete set of HUIs since some itemsets may be incorrectly pruned by its proposed estimation method. To obtain a downward closure (DC) property for mining all HUIs, Liu et al. [21] then developed a two-phase (TWU) algorithm. It mines HUIs by first identifying a set of itemsets called the high transaction-weighted-utilization itemsets (HTWUIs), to maintain a transaction-weighted downward closure (TWDC) property. Based on the TWDC property, unpromising itemsets can be pruned early while still ensuring that all HUIs can be discovered. Although the TWU model mines the complete set of HUIs, numerous candidate HTWUIs are still generated, and multiple database scans are required to mine HUIs in a level-wise way. To solve the above limitations, pattern-growth approaches such as the IHUP-tree [5], HUP-tree [18] and UP-Growth+ [30] algorithms have been designed. The IHUP-tree algorithm maintains a tree structure to interactively mine HUIs. Transactions are sorted in three different orders for evaluation. The HUP-tree algorithm keeps quantity information about items in its tree structure and the HUP-growth algorithm is applied to directly mine HUIs in the compressed HUP-tree structure. The UP-Growth+ algorithm [30] adopts several pruning strategies to speed up the mining process based on the developed utility-pattern (UP)-tree.
Besides pattern-growth approaches, a novel list-based algorithm called HUI-Miner [22] was developed to mine HUIs without candidate generation. It consumes less memory than previous algorithms but can still efficiently retrieve all HUIs. Each tuple of the designed utility-list structure keeps three elements, which respectively are the transaction ids (tid), the utility value of an item in a transaction (iutil) and the remaining utility value of an item in a transaction (rutil). The FHM algorithm [10] was then developed. It relies on the utility-list structure and a triangular matrix to maintain information about the utility of 2-itemsets (pairs of items), and speed up the discovery of HUIs. Many other studies on HUIM have also been recently carried out [10, 19, 36].
Although algorithms for FIM and HUIM can mine interesting and meaningful information, they only consider one measure for selecting patterns, that is either the occurrence frequency or the utility. Yeh et al. [34] first proposed the two-phase algorithm for mining high utility itemsets with high frequencies. Podpecan et al. [27] then proposed a fast algorithm to mine the frequent-utility itemsets. However, it remains difficult to define an appropriate minimum utility threshold and minimum support threshold to retrieve information that is relevant to users. Thus, Goyal et al. proposed an efficient skyline itemset mining (SKYMINE) algorithm [11] to discover the skyline frequent-utility patterns (SFUPs). Using SKYMINE, the user does not need to define thresholds to find the complete set of non-dominated itemsets, by considering both the occurrence frequency and utility factors. The SKYMINE algorithm relies on the UP-tree structure [30] to store the required information for mining SFUPs using a pattern-growth approach. However, the SKYMINE algorithm fails to handle very large databases since its level-wise approach for mining SFUPs often produces a large number of candidates.
Skyline concept
The concept of skyline has become an important topic in recent years since it can return a set of interesting points or information from a huge data space. It is based on the notion of dominance between tuples when multiple dimensions of a dataset are considered. Given a set of
The skyline of a 2-dimensional dataset.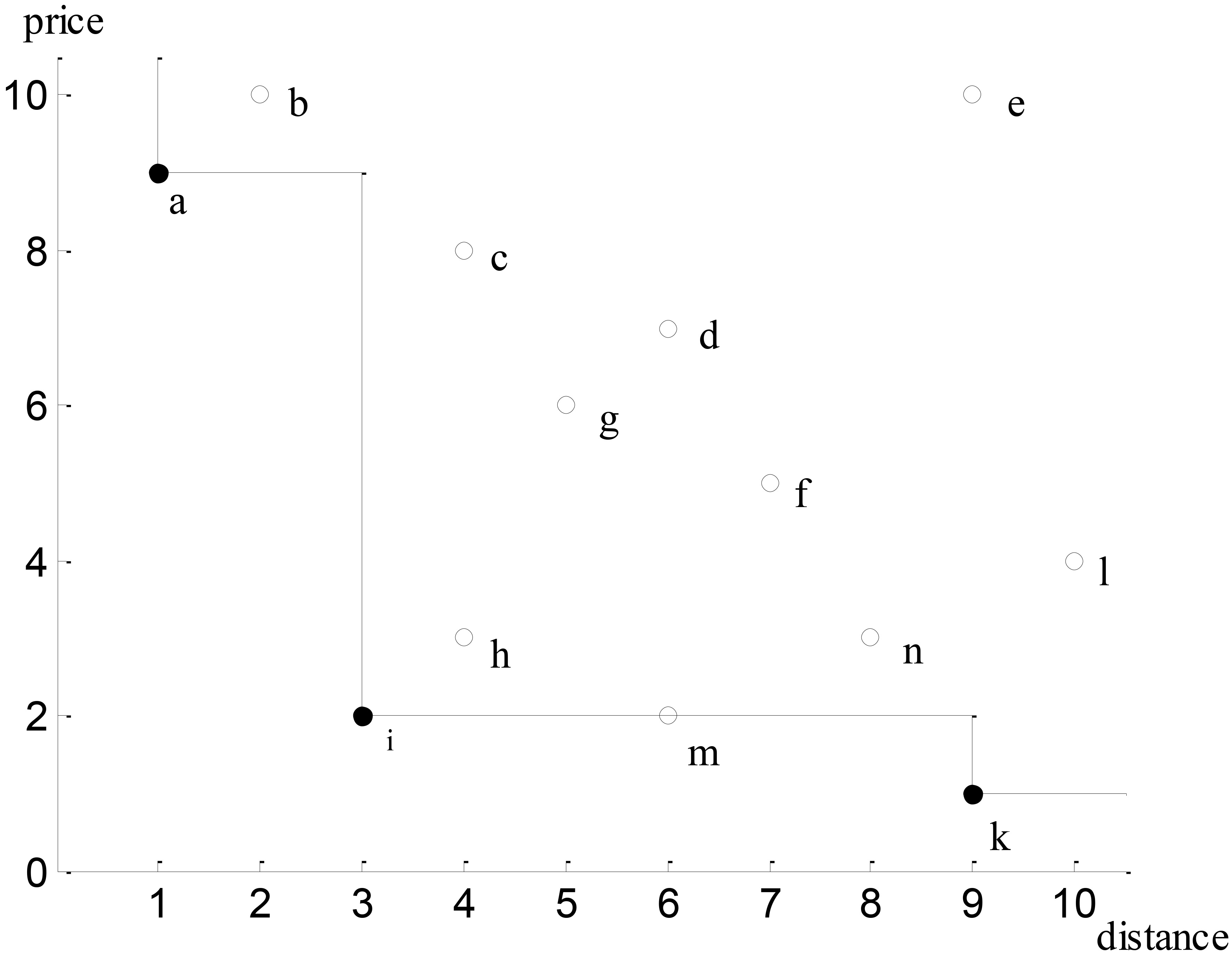
Borzsonyi et al. [6] first considered the concept of skylines in database systems and developed several algorithms based on the use of block nested loops, a divide-and-conquer approach, and an index scanning mechanism. An improved version of block nested loops was presented by Chomicki et al. [9], which employs an ordering of tuples in a window to increase performance. Tan et al. [29] proposed progressive (or on-line) algorithms that can progressively output skyline points without scanning the entire dataset. Kossmann et al. [14] presented a NN algorithm to apply a divide-and-conquer approach based on a nearest-neighbor search optimized using R-trees. The experimental evaluation has shown that NN outperforms previous algorithms in terms of overall performance for datasets having varied characteristics. Another benefit of this approach is the support for online processing. However, NN has also some serious shortcomings such as the needs for duplicate elimination, multiple node visits, and large space requirements. Motivated by this fact, Papadias et al. [24] proposed a progressive algorithm called branch-and-bound skyline (BBS), which utilizes a nearest-neighbor search considering I/O costs, to achieve better result. The discovery of skylines in databases is an active research area [2, 8, 15, 16].
In traditional HUIM or FIM, only one measure is considered to extract patterns from databases. But in real-life, it is beneficial to consider more than one measure. It is thus an interesting topic to apply the skyline concept in high utility mining to consider both the occurrence frequency and utility measures. In this paper, an efficient algorithm called SFU-Miner is proposed based on the utility-list structure to first generate the potential SFUs. This utility-list structure can be used to reduce the combinatorial cost by using a simple join operation to calculate the utilities of itemsets and upper-bounds to reduce the search space. Besides, an utility-max (umax) array is designed to efficiently identify SFUPs from the set of potential SFUs. The developed pruning strategy can greatly reduce the search space for mining SFUPs. The preliminaries and the problem statement of skyline frequent-utility pattern mining (SFUPM) are presented next.
Preliminaries
Let
A quantitative database
A quantitative database
A profit table
.
The occurrence frequency of an itemset
For example, the frequency of (
.
The utility of an item
For example, the utility of the items (
.
The utility of an itemset
For example, the utilities of the itemsets
.
The utility of an itemset
For example, the utilities of the itemsets
.
The transaction utility of a transaction
For example,
.
The transaction-weighted utility of an itemset
For example,
The above definitions have been used in previous work to determine if an itemset is a FI or HUI. The state-of-the-art algorithms for FIM and HUIM consider either the frequency or the utility measure to select itemsets. The concept of skyline frequent-utility patterns (SFUPs) is based on the following definitions.
.
An itemset
For example,
.
An itemset
For instance, in the running example, the utilities and frequencies of the itemsets
In this section, an efficient algorithm called SFU-Miner is designed for mining the set of skyline frequent-utility patterns (SFUPs). It is based on the well-known utility-list structure. This structure allows quickly combining itemsets using a simple join operation. Details related to this structure are given next.
Utility-list structure
Let
For example, the utility-lists of items
The constructed utility-lists for the running example.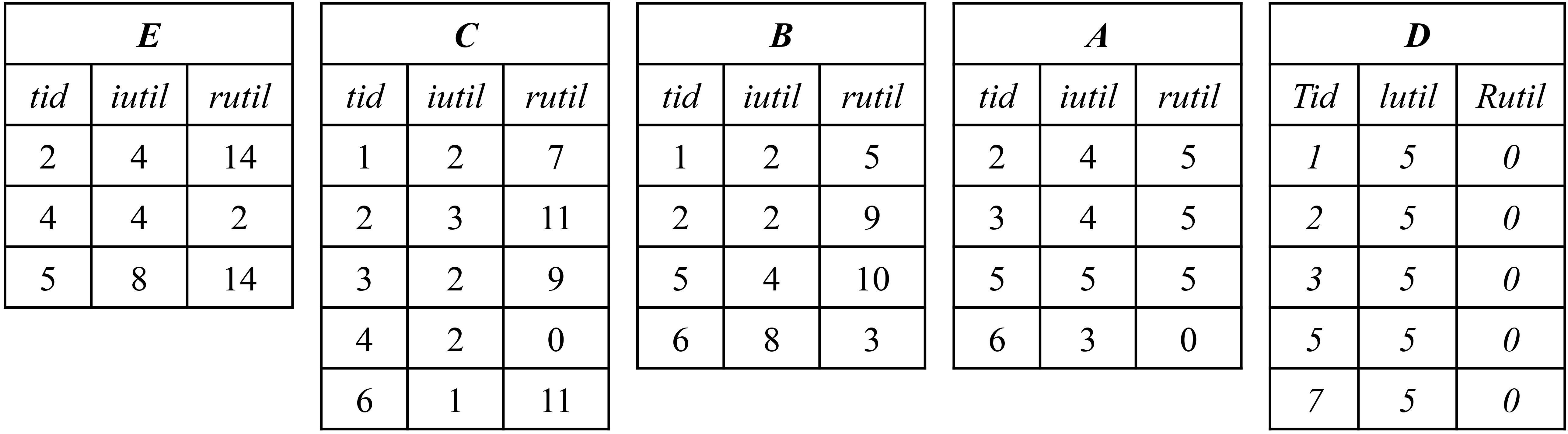
Using the utility-lists of 1-itemsets (single items), the utility-lists of any
.
An umax array stores the maximal utility for each frequency value
.
An itemset
For example, the frequency of
To mine SFUPs, the SKYMINE algorithm utilizes the UP-tree structure. A drawback of SKYMINE is that it often generates a large number of candidates. The reason is that it utilizes the two-phase model to overestimate the utilities of itemsets. To avoid this problem and speed up the discovery of SFUPs, we define two strategies.
(SFUPs
PSFUPs).
If an itemset is not a PSFUP, it is also not a SFUP. Thus, all SFUPs are not PSFUPs.
Proof..
∎
For instance, the set of PSFUPs for the running example is (ECBAD), (EBAD), (AD),
Proof..
For each itemset
Proposed algorithm
The designed SFU-Miner algorithm performs the following steps (listed in Algorithm 4.3). It first build the utility-list structure. The transaction-weighted utilities (twu) of all 1-itemsets are discovered by scanning the database. The 1-itemsets in the database are sorted by twu-ascending order. The sorted database is then used to construct the initial utility-lists of 1-itemsets.
SFU-MinerD, a transactional database; ptable, a profit table; The set of skyline frequent-utility patterns (SFUPs).
In the designed SFU-Miner algorithm, the transaction-weighted utility of each item is first calculated and the database is then reorganized according to the ascending order of transaction-weighted utilities of 1-itemsets. The database is then scanned again to construct the utility-lists (ULs) of all 1-itemsets. The array umax is then used to prune unpromising itemsets during the mining process. Besides, the sets of SFUPs and PSFUPs are initalized as the empty set. They are used by the algorithm to store the current SFUPs and PSFUPs found by the algorithm, respectively. The procedure called
P-Miner
Algorithm 4.3 shows the pseudo-code for mining potential SFUPs. For each utility-list
S-MinerPSFUPs, the set of potential SFUPs. SFUPs, the set of skyline frequent-utility patterns. each
The utility-lists of 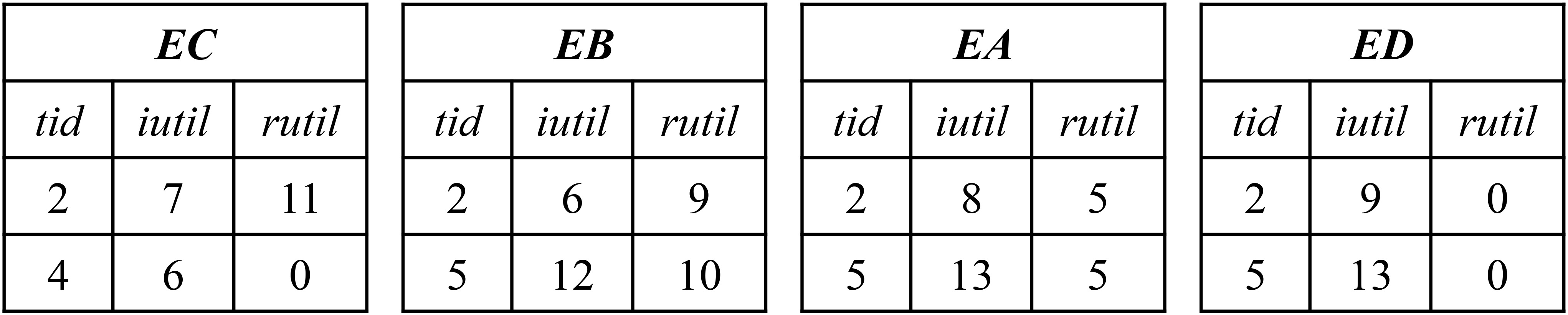
This section provides a detailed example of how the proposed algorithm is applied on the database of Table 1 and the profit table shown in Table 2. The quantitative database of Table 1 is first scanned to find the transaction-weighted utilities of items. Those are shown in Table 3. After that, the items in Table 3 are sorted in
The sorted database of Table 4 is then used to build the utility-lists of all 1-itemsets. The result is shown in Fig. 2. Consider the itemset
The pruning strategy is then applied to determine if extensions of each 1-itemset should be considered by the depth-first search. In this example, since the sum of the iutil and rutil values of
It is found that the frequency of (EC) is 2 and that the utility of (EC) is 13, which is greater than the current value umax(2) (
Transaction-weighted utilities of items
Transaction-weighted utilities of items
The database after sorting transactions by twu-ascending order
The updated umax array
Besides, the umax values are updated to umax(1) (
The SFUPs
This section presents the result of substantial experiments to evaluate the proposed SFU-Miner algorithm for mining SFUPs in several datasets. The performance is evaluated in terms of runtime, memory usage, number of candidates, and scalability. Notice that only one algorithm called SKYMINE [11] was previously proposed to mine SFUPs by considering both the frequency and the utility of itemsets. All the algorithms were implemented in Java and experiments were carried out on a personal computer equipped with an Intel Core2 i3-4160 CPU and 4GB of RAM, running the 64-bit Microsoft Windows 7 operating system. Four real-world datasets called chess [1], mushroom [1], foodmart [23] and retail [1], as well as five synthetic datasets, denoted as T10I4N4KDXK (where
Parameters to describe the datasets
Parameters to describe the datasets
Characteristics of the datasets
The extensions of the itemset 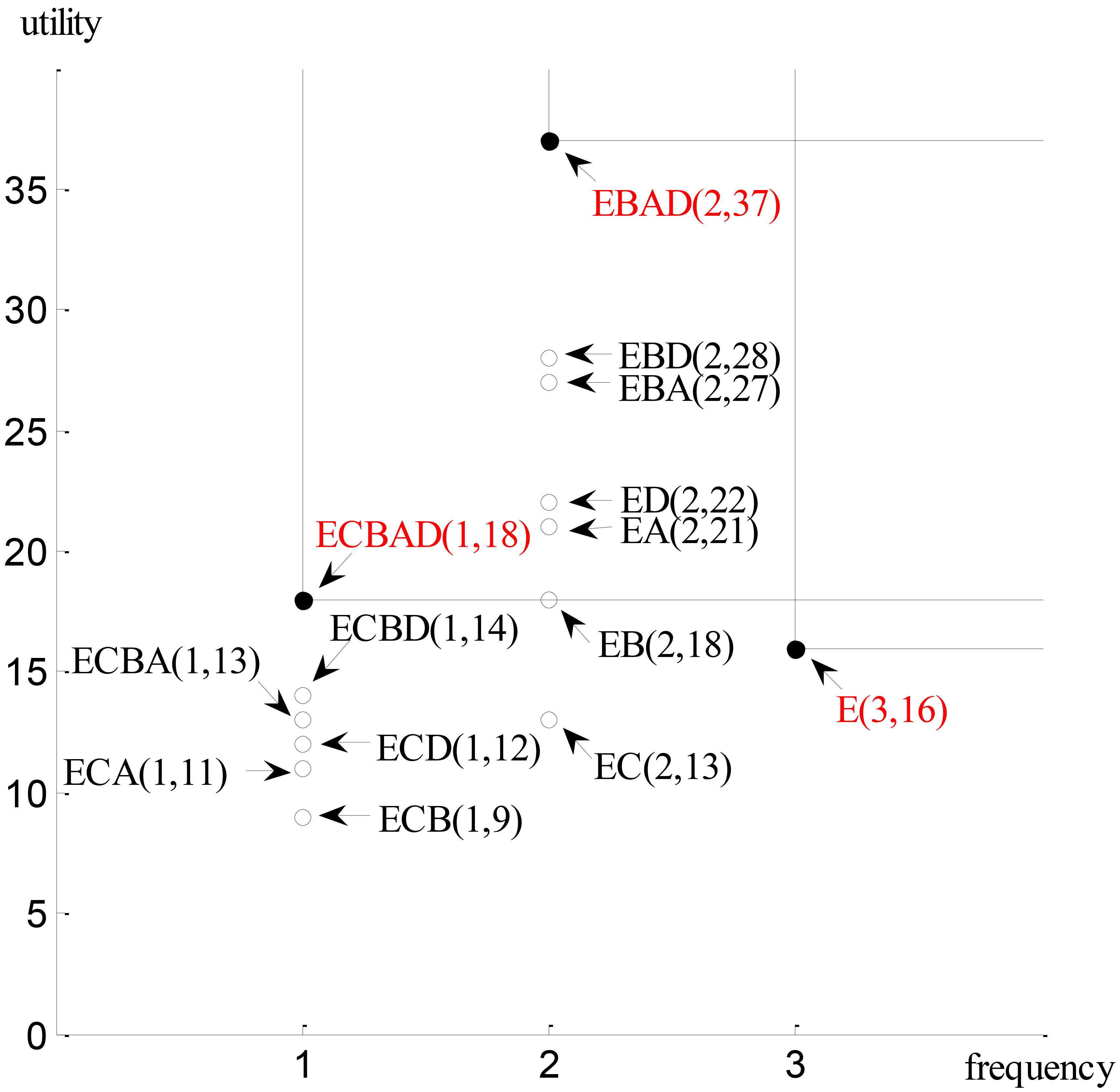
This subsection compares the runtimes of the proposed algorithm and the SKYMINE algorithm [11] on five datasets. Results are given in Table 9.
Runtimes of the compared algorithms
Runtimes of the compared algorithms
In Table 9, it can be observed that there are no results for the SKYMINE algorithm on the chess and retail datasets. The reason is that SKYMINE ran out of memory for those two datasets. We also observed that the proposed SFU-Miner algorithm outperforms the SKYMINE algorithm and is generally about one to two orders of magnitude faster than the SKYMINE algorithm. For example, for the mushroom dataset shown in Table 9, the runtimes of the SFU-Miner and SKYMINE algorithms are 10.57 and 202.82 seconds, respectively. This is reasonable since the proposed algorithm utilizes the utility-list structure and uses the umax array to keep the maximal utility of each frequency, to mine SFUPs efficiently. The SFU-Miner algorithm always outperforms the SKYMINE algorithm since the SFU-Miner algorithm can directly calculate the actual utility of itemsets by scanning the database only twice. The SKYMINE algorithm generates, however, many redundant candidates because it overestimates the utility of itemsets using the two-phase model. As a consequence, the SKYMINE algorithm requires more time for generating the candidates and determining the actual SFUPs.
This subsection compares the memory usage of the proposed algorithm and the SKYMINE algorithm. Memory measurements were done using the Java API. The results for all datasets are given in Table 10.
Memory usage of the compared algorithms
Memory usage of the compared algorithms
In Table 10, no results are reported in terms of memory usage for the SKYMINE algorithm on the chess and retail datasets since it ran out of memory. It can be clearly seen that the proposed SFU-Miner algorithm requires less memory than the SKYMINE algorithm on all datasets. For example, the proposed SFU-Miner algorithm consumes 18.87 MB on the mushroom dataset while the SKYMINE algorithm utilizes 423.80 MB. This result is reasonable since the proposed SFU-Miner algorithm relies on the utility-list structure to directly mine SFUPs, and unpromising candidates can be easily pruned using the developed pruning strategy. The SKYMINE algorithm mines, however, the SFUPs based on the UP-Growth algorithm, which requires to generate numerous candidates. For this reason, it is not an efficient algorithm for mining the SFPUs.
In this subsection, the number of candidates produced by the proposed algorithm and the SKYMINE algorithm to discover SFUPs is compared on all datasets. The detailed results in terms of number of SFUPs and number of candidates are given in Table 11.
Numbers of SFUs and PSFUs
Numbers of SFUs and PSFUs
It can be seen in Table 11 that the number of candidates produced by the SFU-Miner algorithm is generally about three to four orders of magnitude smaller than that of the SKYMINE algorithm. For example, the number of candidates produced by the designed SFU-Miner algorithm and the SKYMINE algorithms on the foodmart dataset are 61 and 1,214,466, respectively. This is reasonable since the SFU-Miner algorithm can prune unpromising candidates early using its developed pruning strategy, while the SKYMINE algorithm generates numerous candidates for mining SFUPs. For example, on the foodmart dataset, the designed algorithm finds 6 SFUPs from a set of 61 candidates, while SKYMINE finds 1,214,466 candidates to then derive 6 SFUP (as it can be seen in Table 11). Thus, it can also be observed that the SKYMINE algorithm requires more time and memory than the developed SFU-Miner algorithm since SKYMINE produces more candidates for mining the actual SFUPs.
The scalability of the proposed algorithm and the SKYMINE algorithm was compared on the synthetic dataset T10I4N4KD
Scalability of the compared algorithms.
In Fig. 5, it can be observed that the designed SFU-Miner algorithm has better scalability than the SKYMINE algorithm in terms of runtime, memory usage, and number of candidates, when the dataset size is varied. The proposed SFU-Miner algorithm always outperforms the SKYMINE algorithm in terms of runtime and memory usage. For example, the developed SFU-Miner algorithm is about one to two orders of magnitude faster than the SKYMINE algorithm when the dataset size is increased from 100 K to 500 K transactions, as shown in Fig. 5a. An interesting observation is that the runtime and memory consumption of the proposed SFU-Miner algorithm steadily increases as the number of transactions increases, while the runtime and memory usage of SKYMINE sharply increases as the dataset size increases. Moreover, the SKYMINE algorithm produces three to four orders of magnitude more candidates for mining the SFUPs compared to the designed SFU-Miner algorithm, as shown in Fig. 5c. From the results of this scalability experiment, it can be concluded that the proposed algorithm has good scalability in terms of runtime, memory usage and number of candidates, for mining SFUPs.
In the past, many approaches have been proposed to mine frequent itemsets or high utility itemsets in transaction databases. However, to the best of our knowledge, few studies have jointly considered the measures of frequency and utility to select a set of patterns that is both useful and frequent. This paper has proposed a novel algorithm called SFU-Miner to mine the set of skyline frequent-utility itemsets by considering both the frequency and utility measures. The designed SFU-Miner algorithm relies on the utility-list structure and the umax array for mining SFUPs. A pruning strategy has further been designed to prune unpromising candidates early for deriving the SFUPs efficiently. Using the designed algorithm, a user does not need to set a minimum support threshold or a minimum utility threshold to discover the set of all dominant patterns in the utility and frequency dimensions. Substantial experiments were conducted on both real-life and synthetic datasets to assess the performance of the proposed algorithm in terms of runtime, memory usage, number of candidates, and scalability. Results have shown that the proposed algorithm largely outperforms SKYMINE, the previous state-of-the-art algorithm for SFUP mining.
Since few studies have considered the issue of skyline frequent-utility pattern mining, there are numerous opportunities to extend the techniques presented in this paper to other problems, such as stream mining, top-k pattern mining or dynamic data mining. Besides, more efficient and condensed structures for mining SFUPs in various real-life applications can be further discussed and studied.
Footnotes
Acknowledgments
This research was partially supported by the National Natural Science Foundation of China (NSFC) under grant No. 61503092, by the Shenzhen Technical Project under JCYJ20170307151733005, by the Science Research Project of Guangdong Province under grant No. 2017A020220011, and by the National Science Funding of Guangdong Province under Grant No. 2016A030313659.