
Abstract
A novel supervised particle swarm optimization (S-PSO) classification algorithm is proposed for fault diagnosis. In order to improve the accuracy of fault diagnosis and obtain the global optimal solutions with a higher probability, two strategies, i.e. a hybrid particle position updating strategy and a fixed iteration interval intervention updating strategy, are designed to balance the effect of the local and the global search. These methods increase the diversity of particles, expand the particles ability of searching the entire solution space, and guide the particles adaptively jumping out of the local optimal area. Meanwhile, based on the shorter intra-class distance, longer inter-class distance and maximum classification accuracy of training samples, a fitness function is designed to constraint the output optimal class centers. Experimental results demonstrate that the proposed S-PSO classification algorithm can overcome the problems in the classical clustering algorithms, which only consider the similarity of data instead of their physical meanings. The comparison on GE90 engine borescope image texture feature classification is also conducted. The results show that the performance of S-PSO classification algorithm is robust. Its classification accuracy is higher than those of popular methods, including support vector machine (SVM), neural network, Bayesian classifier, and
Keywords
Introduction
Due to the continual improvement of the technical level, analysis and judgment on the fault mechanisms and fault modes of modern equipments become more difficult. Meanwhile, the influence on the production activities caused by faults is increasingly serious. For some key parts, such as engine and spindle bearing, their healthy statuses have a direct and critical relationship with the safety of the production activities. The failure of critical equipments is the largest contributor to machine downtime, even catastrophic accidents in the automotive manufacturing industry [1]. In industry, it is unacceptable to face unscheduled breakdowns and production losses. So it is greatly significant to carry out the research on fault diagnosis, which can improve the efficiency of trouble-shoot, shorten the maintenance period, reduce the maintenance costs, and ensure production safety.
In fact, it is difficult to use the equipment operation features based on traditional analytical models to accurately describe the operation process of complex equipment, and thus their development is limited. However, with the rapid development of the intelligence technology, research on the large state feature data promotes further development of fault diagnosis technology, and intelligence technology focuses on the analysis and discrimination of the monitoring data without considering the internal mechanism of the monitored object. Therefore, intelligence technology has been widely applied in fault classification. Some classic intelligence methods, such as artificial neural network, statistical pattern recognition, and kernel-based algorithms, and so on, have been paid much attention and get rapid development. A large number of researches were proposed to promote the development of fault diagnosis technology in a more practical direction [2, 3, 4, 5]. However, artificial neural network always has the drawback of poor convergence and generalization capability, and the network topology need to be determined artificially in advance [6]. Statistical pattern recognition is sensitive to the probability distribution of monitoring data [7]. Kernel-based algorithms are still confronted with the problems of optimizing the kernel parameters [8].
With the develop of bionic sciences, the swarm intelligent algorithms imitating natural phenomena have been widely used to solve various real-world problems including nonlinear process control, machine design, text mining, data clustering, features extraction, system optimization, grouping problems, path planning [9, 10, 11, 12], and so on. The particle swarm optimization (PSO) algorithm is one of classic swarm intelligent algorithms. In the field of data analysis, PSO is mainly used as data clustering or as an auxiliary tool to optimize other classification algorithms. Cagnina et al. [13] improved the accuracy and efficiency of short text clustering by using a novel discrete PSO. Lam et al. [14] proposed a PSO-based K-Means algorithm for unsupervised gene clustering, and experimental results show that this proposed algorithm is more effective in reducing clustering error and improving convergence rate. Avanija and Ramar [15] proposed an ontology-based clustering algorithm using semantic similarity measure and PSO, and the experimental result shows that the proposed method is feasible and performs better than other traditional methods. Zhang et al. [16] introduced dynamical crossover with variable lengths and positions to PSO and proposed an improved method to solve the problem of K-Means and obtain correct clustering results. Fathi and Montazer [17] proposed a new learning method based on a novel PSO for radial basis function (RBF) to optimize the optimum steepest decent (OSD) algorithm, which improves the classification ability of RBF. Guraksin et al. [18] used PSO to generate a new training instance for SVM and obtained higher classification accuracy. Pattern recognition as the main fault diagnosis tool has been widely used to solve many real-world fault diagnosis problems in the machinery industry [19], in which clustering and classification are main techniques for pattern recognition. Obviously, in most of classification applications, the research on PSO is few, so it is worth researching on the classification ability of PSO deeper for expanding the fault diagnosis technical methods.
It is known that the PSO is based on the collaborative swarm heuristic search algorithm, which can provide solutions closer to the global optimal area on different engineering problems due to its concise mathematical expressions and effective search strategy. However, similar to other swarm intelligent algorithms, an open problem of the PSO is that it may trap into local suboptimal areas due to the premature convergence, which is caused by the lack of diversity, especially for complex multi-mode problems. Therefore, many modifications were proposed to solve this problem, such as parameter adjustment [20, 21, 22], neighborhood topology [23, 24, 25], and human behaviors [26, 27, 28], and so on. In this paper, new updating strategies are designed to obtain better optimization performance, which aims to overcome defects mentioned above.
Virtually, the essence of pattern recognition is to find the mapping between features and labels. In this way, we can get the unknown data label by the existing mapping. In this process, if an algorithm is trained by the data possessing labels, it can be defined as supervised algorithm, the process is called classification. Conversely, it is an unsupervised algorithm, and the process is called clustering. Meanwhile, the previous studies have discussed the principles and defects of clustering in detail [29, 30, 31, 32]. It only relies on similar features among data and ignores the actual meaning of the data. Thus, there is often a big difference between the clustering results and true class in recognition, so clustering is not good at fault diagnosis. To solve this problem, a supervised PSO classification algorithm is proposed for classification of fault data collected from modern complex equipments. The proposed method is designed to overcome the shortcomings of normal clustering methods, and improve the accuracy of fault pattern recognition, so that faults can be located rapidly and accurately in the machinery industry.
The rest of the paper is organized as follows. In Section 2, the motivation and principle of the proposed S-PSO algorithm are introduced. Section 3 introduces the evolution process of PSO in detail. The application of engine is given in Section 4. Finally, in the last section conclusion is drawn.
Motivation and principle of S-PSO algorithm
Motivation of the prior class labels for classification
Because the operation characteristics, working environment, and load strength are not consistent, or there are different reasons and mechanisms for various faults, multi-dimensional monitoring data collected from monitored components exhibit the differences of equipment operations. It is necessary to use a signal processing method to analyze these monitoring data and then rapidly determine the state of the equipment operation, so that rational maintenance strategy can be made.
For discussing the classification method, the prior class labels are defined: the monitoring data, which reflect the same state or fault type of the equipment, can be classified into a category, and the prior label,
Although the data in the same class can reflect the same state of equipment, the distribution properties of data present certain distribution shape in the multi-dimensional space, such as reunion distribution and strip distribution, even irregular distribution, which proves the data in the same class also have differences; moreover, there is no obvious boundary between the data in different classes. In this case, the clustering always causes the recognition error for training data easily, and the prior class label can accurately identify these data in the same class, and prevent the error of classifying unknown data. Based on these analyses, Zheng and Gao [32] compared the recognition performance between clustering and classification, and the results show the classification is better. The recognition process of clustering needs to predefine class labels of training data, but the training data in classification are given labels in advance. Consequently, classification helps to classify unknown data rapidly.
If there is no prior class label, every training sample needs to be set a class label randomly, and then the classification will degenerate into the clustering process. The main problem of the clustering algorithm lying in the above assumptions may reduce the recognition accuracy. Therefore, the proper prior class labels have positive effect on the guidance of the classification.
The schematic diagram of the S-PSO classification algorithm is shown in Fig. 1.
S-PSO classification schematic diagram.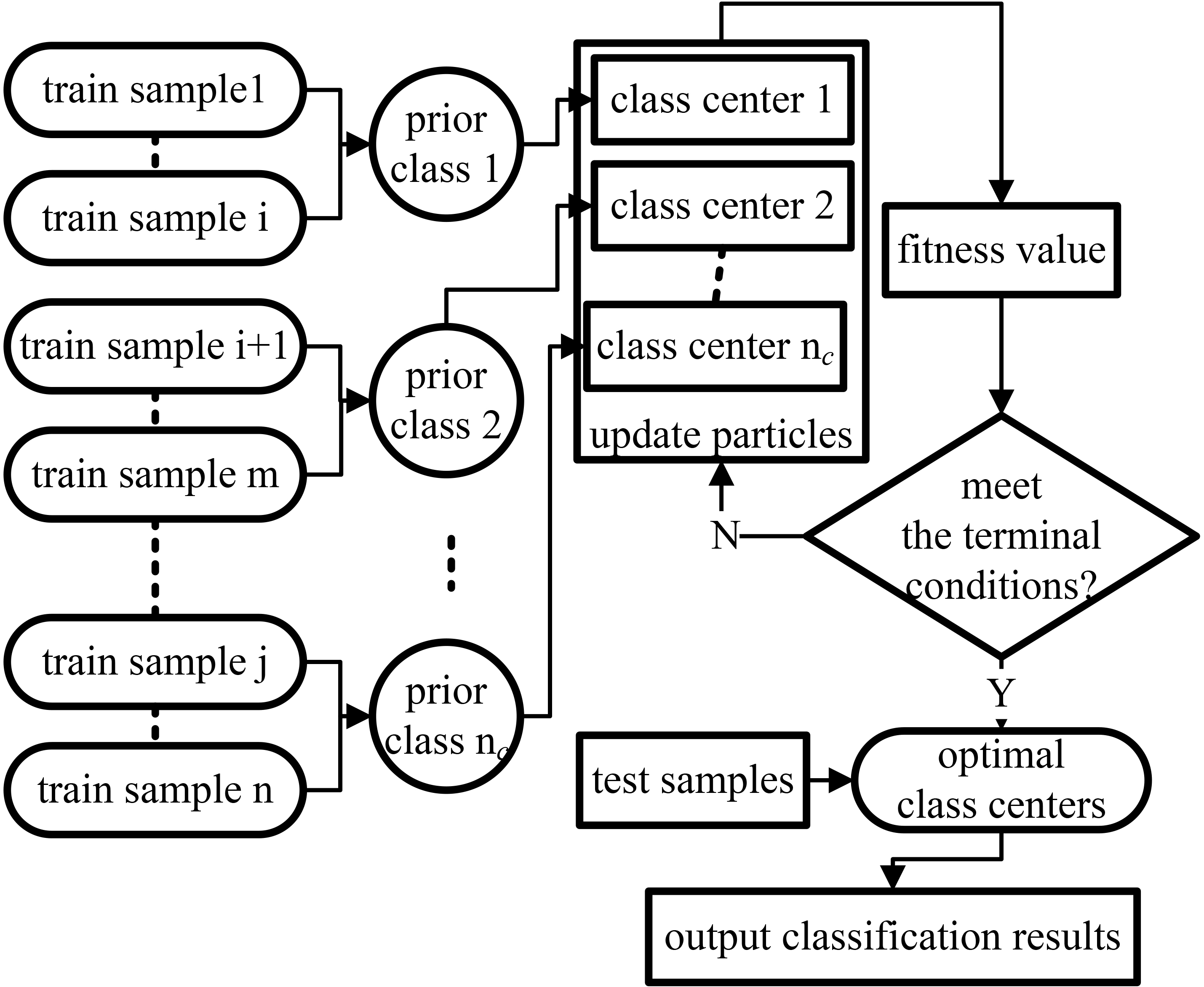
Actually, many definitions of distance have been used to measure the similar relationship of vectors, such as Minkowski distance, Mahalanobis distance, Manhattan distance, Chebyshev distance, Pearson correlation coefficient, and Cosine similarity [33, 34, 35, 36]. These definitions measure the similarity according to different theories. Generally, Euclidean distance has been widely used, and several popular algorithms are computed by Euclidean distance [29, 32, 37]. Euclidean distance is in the interval [0,
Let
The distance from a certain training sample to its class center should be shortest. Determining all class centers that satisfy the requirement of training sample classification is a process of searching for the optimal solution depending on some criterion in
In essence,
The class labels in clustering are set randomly. After updating the particles, all training samples need to be re-clustered according to a certain criterion. The class centers are calculated again, and fitness values are then calculated using fitness function. As for the problem of non-identifiability, Zheng et al. [29] analyzed the possible solution for recognizing unknown samples in clustering. Therefore, the S-PSO classification algorithm is proposed in this paper to overcome the problems existed in normal clustering algorithms and improve the accuracy of fault classification.
Fitness function
Fitness function, known as the important theoretical foundation of PSO algorithm, directly influences the optimization effect of class centers. The clustering algorithm in [38] used the shorter intra-class distance from training samples to their own clustering center as its fitness function. Based on the work in [38], Nanda and Panda [39] added the longer inter-class distance to the fitness function. In a supervised classification algorithm, a supervised signal should be fully used to design the fitness function. Therefore, the classification accuracy of training samples is introduced into the fitness function, which is beneficial to improve the accuracy. We assume that we confront a maximization problem in this paper. The fitness function based on the shorter intra-class distance is formulated as follows:
The fitness function based on the shorter intra-class distance and longer inter-class distance in this paper is defined as follows:
where
The supervised signal used to express the classification accuracy of training samples can be used to find the optimal class centers. The classification accuracy is calculated by Eq. (5):
where
The above fitness function, considering 3 factors of intra-class, inter-class distance, and classification accuracy on training samples, provides an accurate and clear guidance for S-PSO classification algorithm. The better value the
The traditional position updating principle of a traditional PSO algorithm can be found in [40]. The traditional algorithm is good at global search, which has the problem on obtaining the local optimum by tracing individual extremum and global extremum. To solve this, a differentiation random updating novel strategy enlightened by the intermediate value theorem is then proposed in this paper to enhance local search ability of particles.
A differentiation random positions updating strategy
According to intermediate value theorem, in a continuous search space, we can assume that the global optimal solution
The training and test samples should be normalized in the interval [0, 1]. It helps to eliminate influence of dimension, reduce the search area and improve the algorithm efficiency. Initialize particle position in the whole solution space. Assume that
where function Rank the particles in ascending order according to their fitness values. Generate the moving direction of particles in each dimension. Function Calculate the search speeds of particles. In theory, each dimension of the particle should search the solution on maximum interval [0, 1]. Assume that
where Update the particles using the following equation:
Meanwhile, update the particles by means of elitism approach. If the Stop the iteration until the terminal conditions are satisfied, or return to Step 3. The terminal conditions may include
As mentioned above, the proposed updating strategy without tracking individual extremum and global extremum has great improvement on local search, and it can obtain global optimal solutions easily. However, it is not beneficial to finding the general situation of the solutions distribution, which means this strategy is not good at the global search. If the initial positions of the particles are close to the optimal solutions, it is easy to obtain optimal solutions; otherwise, it may obtain poor solutions. Therefore, this strategy is sensitive to the initial positions of the particles, which will affect the convergence rate. A hybrid updating strategy is then proposed to combine the traditional updating strategy and makes a balance between the global search and local search.
Hybrid updating schematic diagram.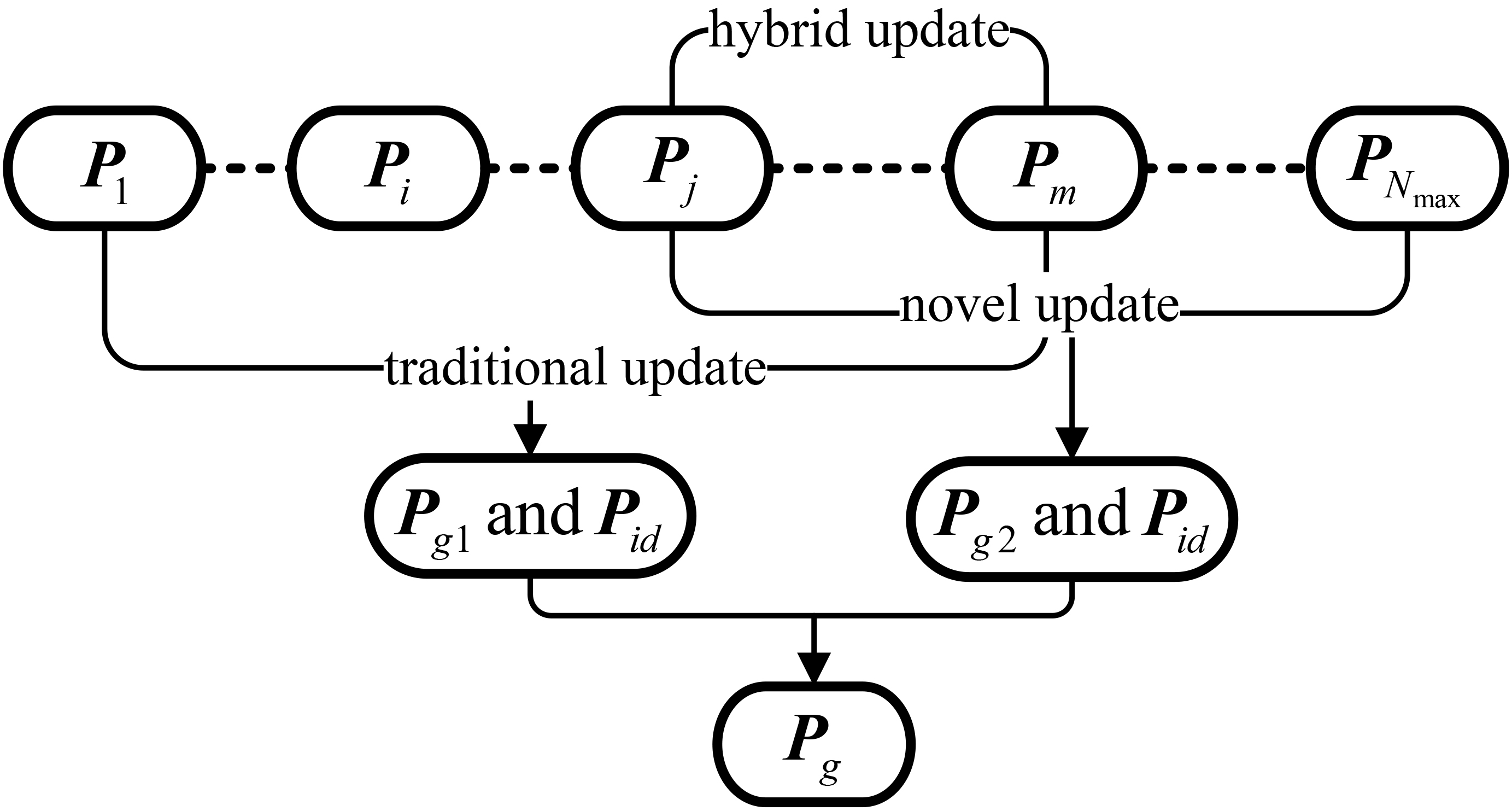
The schematic diagram of the proposed hybrid updating strategy is shown in Fig. 2. Before updating the particle positions, the particles need to be ranked in an ascending order according to their fitness values. The procedure of updating is described as follows:
From particles 1 to The novel updating strategy mentioned above is conducted on the particles from If
The element of
where
In essence, the advantage of the hybrid strategy lies in the mutual promotion of the traditional strategy and the novel strategy. Most of particles are updated by the traditional strategy and help to expand the solution space and increase the diversity, which can transport the excellent particles for the proposed hybrid strategy. Only a small part of excellent particles is updated by the hybrid strategy that has strong local search ability and provides more excellent particles than the traditional strategy. Furthermore, the hybrid strategy has more efficient updating, and accordingly it can obtain the optimal solution easily and rapidly.
Randomness, like a double-edge sword, has both positive and negative effects. On one hand, it can help to increase the diversity of the particles, and reduce the complicated mathematic calculation. On the other hand, it also increases the uncertainty in the optimal solutions. The influence of randomness may make final solutions fluctuating in the solution space, and may be non-uniqueness for each calculation, especially for complex problems. Therefore, the randomness may lead to the global optimal solution with a certain probability. One of solution is to use the intervention updating strategy, which can make some particles adaptively jump out of current search area under certain conditions and search the entire solution space as widely as possible. This strategy can ensure to obtain the global optimal solution with higher probability, reduce the influence of the randomness, overcome the defects of trapping into the local optimal area, and increase the diversity. In this paper, a fixed iteration interval intervention updating strategy based on dynamic neighborhood is thus proposed.
Flow chart of the particles intervention updating strategy.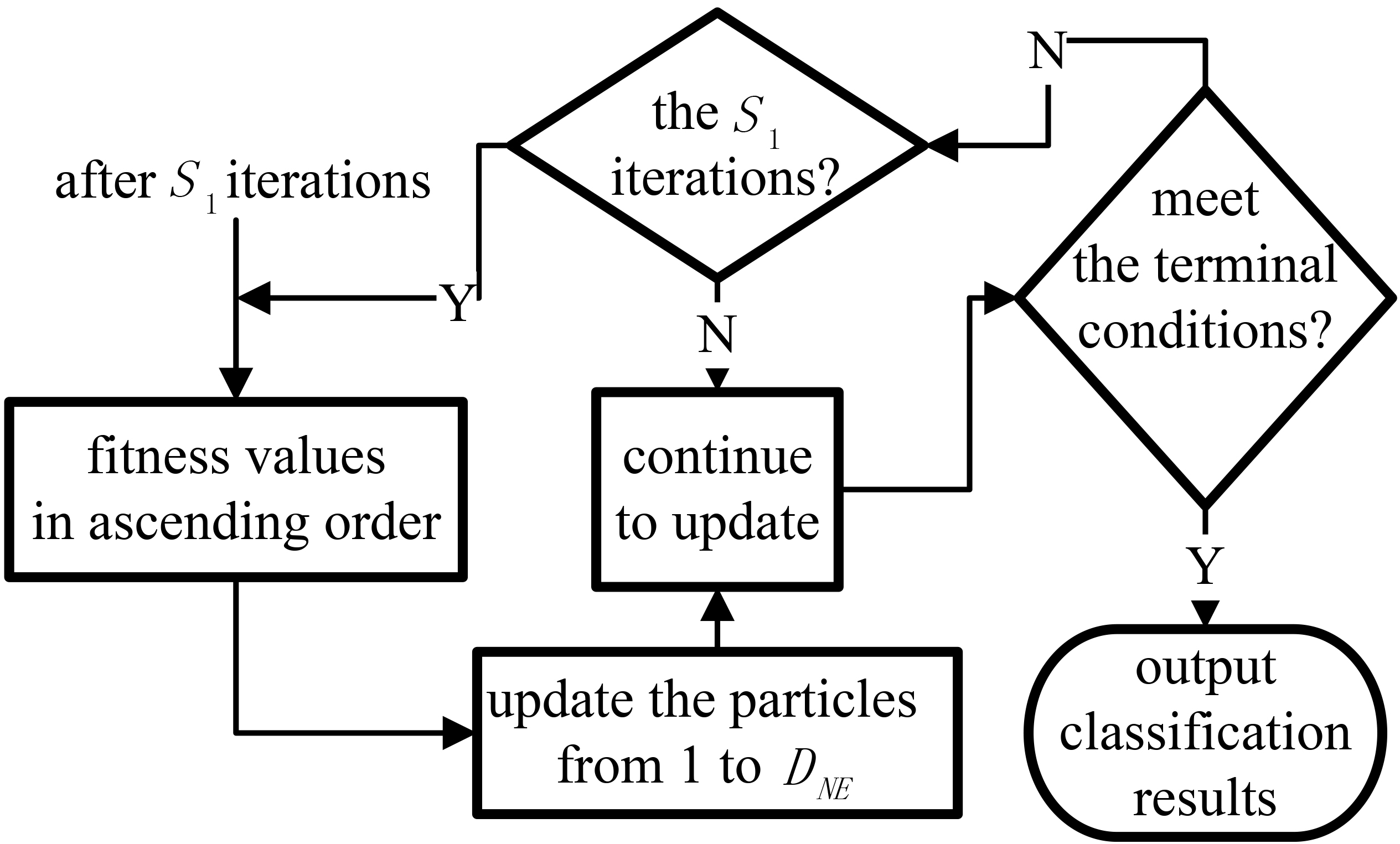
The schematic diagram of this strategy is shown in Fig. 3. Within the maximal iteration, a certain number of particles are firstly updated by Eq. (9) every
where
The ability of PSO global optimization enhanced by this intervention updating strategy can be proven as follows:
Let
Flowchart of the proposed PSO.
After using this strategy, at the early stage of iterations, updating a small proportion of particles with smaller fitness values not only increases the diversity of particles, but also keeps an acceptable convergence rate. At the later stage of iterations, updating a larger proportion of particles can help to increase the chance of jumping out of local optimal area. Therefore, this intervention updating strategy has a good balance between the efficiency of the algorithm and its optimization results. The flow chart of the proposed PSO is illustrated in Fig. 4.
Case 1: Data from UCI (University of California Irvine) database
This case is used to evaluate classification ability of algorithm using the commonly used data. Several typical data in the UCI database are used, and their relative information is shown in Table 1. Training and test samples are divided randomly. In this study, some widely used fault classifiers, such as SVM [41], Back Propagation (BP) network [42], Learning Vector Quantization (LVQ) network [43], the Bayes classifier based on expectation maximization (EM) and mixture normal distribution [44], and
The relative informations about data sets
The relative informations about data sets
The PSO is a heuristic swarm random search algorithm and randomness exists in many aspects, i.e., random initial positions and velocities of the particles. The position updating and the intervention updating strategy also involve the randomness. Therefore, the randomness is the main factor affecting the performance of the PSO algorithm, which may obtain a local extremum. Meanwhile, it is well known that the influence of random weight setting in BP and LVQ may lead to the uncertainty of results; in addition, kernel parameters of SVM optimized by the method in [41] and the estimator of parameters based EM are still keeping uncertainly. To obtain a statistical soundness on the results and verify the ability of classification, we did 50 experiments continuously under the same conditions to get the statistical parameters of classification accuracies including Min, Mean, Max, and STD (Standard Deviation).
Actually, although these algorithms are all used to classify data, each of them has its own principles. SVM relies on the nonlinear hyper-plane; BP network relies on the nonlinear mapping relation; LVQ network relies on the distance to the winner neurons; Bayes takes the mixture normal distribution of training samples as prior probability distribution; and
Classification accuracies comparison of S-PSO and other algorithms when using the 4 data sets
Aeroengine is a great achievement in the modern machinery industry. It is a complicated, huge and critical electronic and mechanical integrated system. Under the constantly working condition of high temperature, high pressure, and strong vibration, main mechanical components, such as blades, disk, spindle, have to suffer from corrosion, wear and fatigue. Serious faults, including performance degradation, abnormal vibration, and severe abrasion, are caused by these mechanical components. It has been proven that aeroengine’s malfunction contributes main threats to the flight safety [42]. The borescope image is a commonly used tool to detect mechanical component damages of the crackle, including tearing, corrosion, curling, burn, groove, and so on. These damages are usually caused by overheated internal environment, vibration, wear, erosion, and strike. Because the working environment of each mechanical component is different, these damages often occur on a specific mechanical component [47]. By using the Content-Based Image Retrieval (CBIR), the features, including color, texture, and shape from borescope images can be extracted, and then the database about the damage images can be constructed. Using this database, the diagnosis can be realized. In reality, the diagnosis results are valuable reference to the engineers and is also possible to improve the efficiency of fault diagnosis. Moreover, the automatic diagnostic results and the engineer’s judgments can confirm each others, which decreases the misjudgment rate and ensure the aeroengine operation reliability and safety.
Using the CBIR, Tang [48] firstly extracted mean and covariance of the surface texture parameters, including angular second moment, contrast, correlation, covariance, and inverse difference moment from the gray level co-occurrence matrixes calculated from the borescope images of GE90 aeroengine, and then constructed the database with 10 features of four borescope damage images, i.e. blade tip curling, corrosion, crackle, and tearing, which are shown in Fig. 5. Eighty samples were applied to the proposed method, in which 54 samples are used as training samples, and the rest are test samples. Part of samples are shown in Table 3, in which the meanings of headers are:
GE90 engine borescope image texture features
GE90 engine borescope image texture features
Four damage images of GE90 engine.
In Table 3, there are 54 samples for training. The first damage has 10 samples (Sample 1
To demonstrate the superiority of the proposed classification algorithm in fault diagnosis, common K-Means, fuzzy C-Means, the improved Shuffled Frog Leaping Algorithm (SFLA), and PSO clustering algorithm [9, 10] are also applied to diagnose the four damage types of GE90 engine for the purpose of comparing with the S-PSO classification algorithm. The specific discussion about SFLA can be found in Refs. [49, 50]. For this diagnosis problem, the population size of SFLA are 50 frogs that are divided into 5 memeplexes. The iteration number for each memeplex is 200 for the local search, and 200 iterations process of all memeplexes repeats 10 times. Thus, 5 memplexes, 200 iterations for each memplex, and 10 times for total iteration are parameters for the SFLA. Fifty particles are used in PSO algorithm, and the maximum iteration number
Comparison of clustering results in Case 2
Comparison of clustering results in Case 2
Comparison of 50 experiments.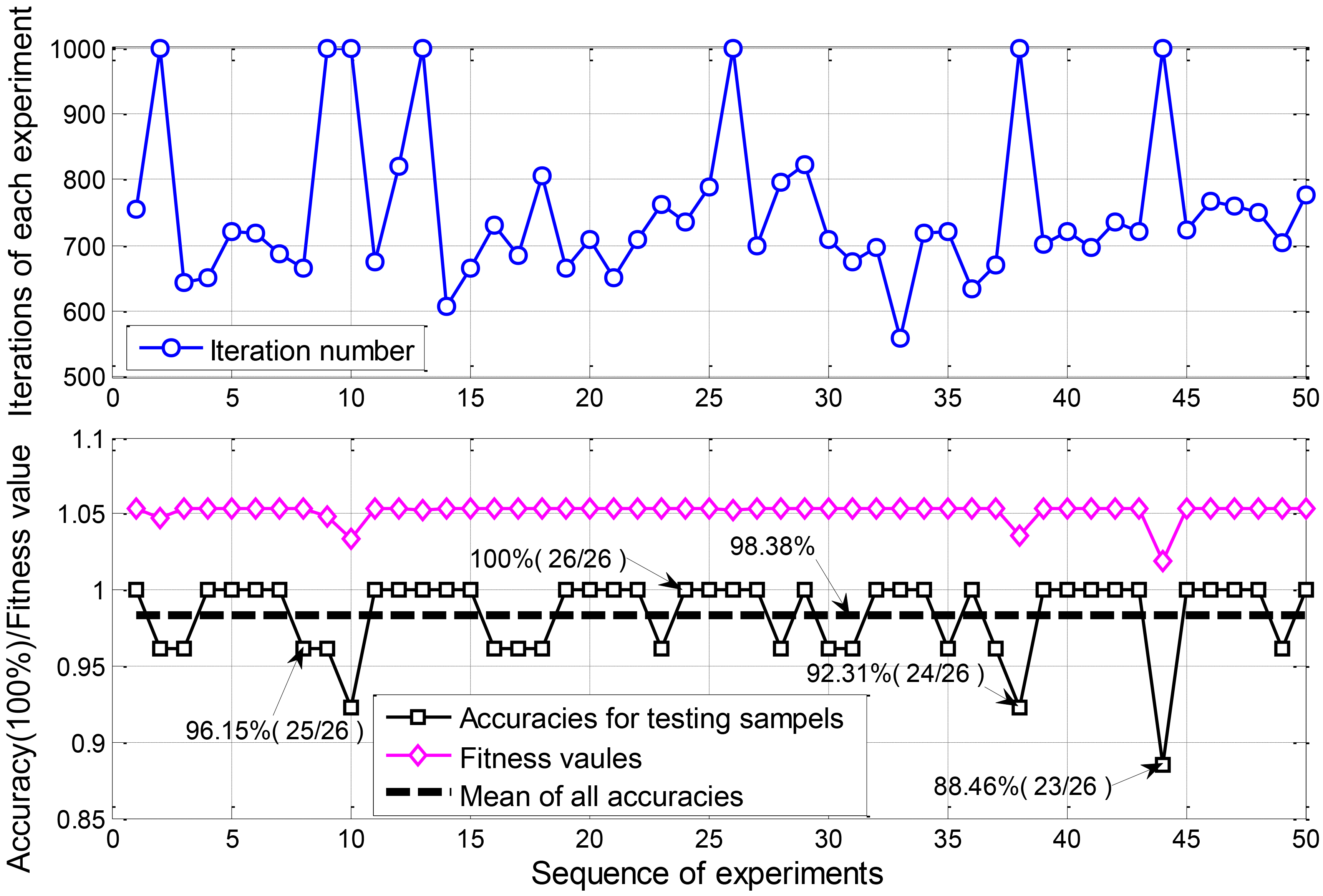
Fitness change curves of first 6 experiments.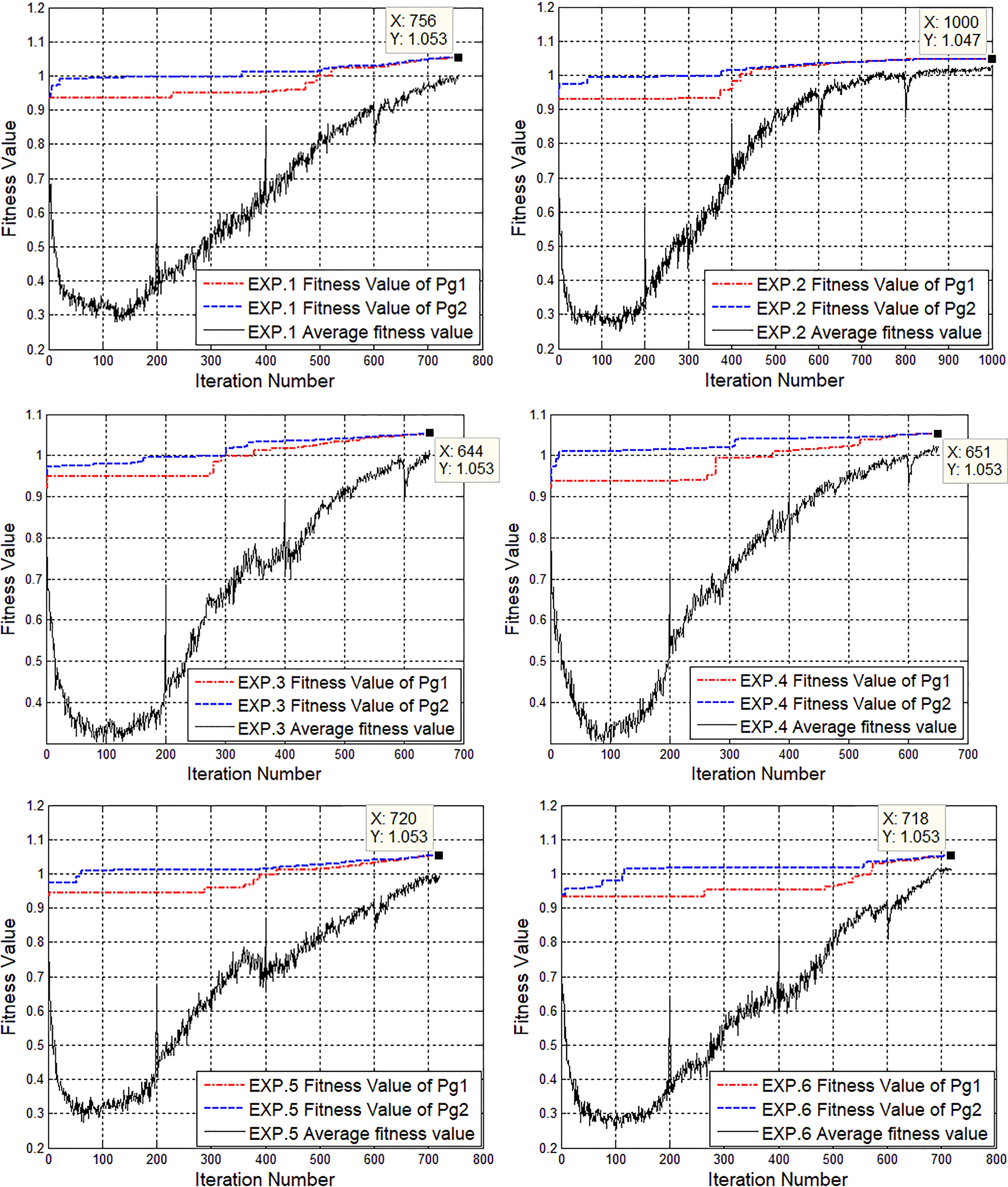
In this section, we also did 50 experiments repeatedly under the same condition to get the statistical parameters of classification accuracies and verify the influence of randomness. Let the total number of particles
Comparison of updating strategies
This section is to verify the classification ability of 6 models: (1) Model 1-1, S-PSO with hybrid positions updating strategy and intervention updating strategy, which has been calculated in Section 4.2.2; (2) Model 1-2, S-PSO with only hybrid positions updating strategy; (3) Model 2-1, PSO with traditional positions updating strategy and intervention updating strategy; (4) Model 2-2, PSO with traditional positions updating strategy; (5) Model 3-1, PSO with differentiation random positions updating strategy and intervention updating strategy; and (6) Model 3-2, PSO with only differentiation random positions updating strategy. The settings of these models are shown in Section 4.2.2 and these models are run under the same condition. Due to the influence of randomness on these models, we did 50 experiments for each model. The corresponding results are shown in Table 5. As shown in this table, the performance of Model 1-1 is optimal, the performance of Model 2-1 is suboptimal, and the performance of Model 3-2 is the worst. Table 5 also confirms the previous analysis about different updating strategies. The differentiation random positions updating strategy is not conducive to the global search and is very sensitive to the initial positions of the particles. Moreover, the intervention updating strategy can improve the performances of the classification models and increase the classification accuracy. These experiments further demonstrate the superiority of the S-PSO classification algorithm.
Comparison of classification accuracy using different updating strategies
Comparison of classification accuracy using different updating strategies
We also consider the influence of four fitness functions. Fitness function 1 only calculates the shorter distance of the intra-class, fitness function 2 only calculates the accuracy of training samples classification, fitness function 3 calculates both of the shorter distance of the intra-class and the longer distance of the inter-class, and fitness function 4 involves all of 3 factors. The fitness function 4 described in Section 4.2.2 are used. The setting of the algorithm is also shown in Section 4.2.2. The algorithms with different fitness functions are also ran under the same condition. We did 50 experiments for each model. The results are listed in Table 6. It is obvious that the fitness function considering three factors is much more conducive to classify test samples than others.
Comparison of classification accuracy using different fitness functions
Comparison of classification accuracy using different fitness functions
The proposed S-PSO classification algorithm is also compared with other popular classification algorithms mentioned in Section 4.1. The S-PSO has been calculated in Section 4.2.2, and the settings for all algorithms are also as same as in Section 4.1. We did 50 experiments to compare their classification performance. Specially, the vales of
Comparison of classification accuracy using different algorithms
Comparison of classification accuracy using different algorithms
From this table, in terms of 80 samples, the classification accuracy of S-PSO algorithm is the highest, the classification accuracy of LVQ network is the lowest, and the SVM algorithm and LVQ network are more stable than other methods. The main reason is that the non-linear situation of these 80 samples in space distribution is more obvious. There are some overlaps among different classes, but the overlaps can be distinguished by the non-linear hyperplane or non-linear mapping. Hence, SVM algorithm and BP network have a good performance. The LVQ network only uses Euclidean distance to measure the difference of samples, which easily cause wrong classification to the overlap areas, so LVQ network has the worst performance. Although the
Based on the above experimental results, the conclusions are drawn:
In this paper, the prior class labels are used as supervised signals to construct the PSO classification algorithm, which overcomes the problems of commonly used clustering algorithms. S-PSO classification algorithm improves the classification accuracy and can satisfy the requirement of accurate fault diagnosis. Aiming at the classification problem and taking the distance from sample to class centers as the basis of classification, a fitness function based on shorter distance of intra-class, longer distance of inter-class and maximum classification accuracy of train samples is defined to make these three factors constraint the output optimal class centers. It enhances the generality and fault-tolerant ability of the classification algorithm in fault diagnosis, and increases the classification accuracy. The hybrid particle position updating strategy, which consists of differentiation random positions updating strategy and traditional positions updating strategy, is proposed to increase the diversity and enhance the global search ability. Meanwhile, the fixed iteration interval intervention updating strategy is also designed to make some particles adaptively jump out of current search area under certain conditions and search the entire solution space as much as possible. Two strategies are designed to ensure that the global optimal solution can be obtained with higher probability.
In one word, the S-PSO can correctly classify unknown fault samples from different machinery, so that fault causes, fault locations and fault levels can be determined accurately, thereby improving the efficiency of trouble-shoot, shortening the maintenance period, reducing the maintenance costs and ensuring machinery operation safety reliable.
Footnotes
Acknowledgments
This work was supported by the Fundamental Research Funds for the Central Universities under Grant ZYGX2014Z010, SKLMT-KFKT-201601, and the General Program of Civil Aviation Flight University of China under contract number J2015-39.