
Abstract
. Word Sense Disambiguation, which is one of the most challenging problems in the process of machine translation, can be considered as a classification problem. In this paper, we use K-Nearest-Neighbor, as one of the most popular classification methods, as well as some knowledge based resources in order to design a WSD scheme. The success of K-Nearest-Neighbor is tightly dependent on two factors; the features used to represent the context in which an ambiguous word occurs and the distance/similarity measure used for comparison of text vectors. Hence, in the present study, we focus on these two matters. For the first purpose, we extract three sets of features; syntactic features, lexical features and semantic features. In order to produce enriched and useful corpora, we apply preprocessed steps. In this work, we carry out a feature selection process as well as a feature weighting policy in order to fine-tune the classifier. For the second purpose, we try several distance/similarity metrics (rather than one metric) in order to find the most proper one. We also assign and use feature weights and propose a weighted formula for every metric. Moreover, to show that the proposed schemes are not language-dependent, we apply the suggested schemes to two sets of data; English and Persian corpora. The evaluation results, with regards to the feature selection and feature weighting strategies, show that the semantic and syntactic features have a significant effect on the classification ability of the system. The results are also encouraging compared to state of the art.
Keywords
Introduction
We all have frequently referred to a dictionary to look up the translation of a word and found that it bears several definitions. Human language is abundant with such so called “Ambiguous words”. The right meaning of those words are determined by the context. The context of an ambiguous word is the word(s), phrase(s) and sentence(s) surrounding it. Here we encounter an attractive and difficult process called Word Sense Disambiguation (WSD) which would automatically recognize the meaning of the ambiguous word based on the context bearing it.
This hard and interesting process is an important technique in many NLP (Natural Language Processing) applications such as machine translation, information retrieval, text mining and so on.
WSD is important in many fields specially the subcategories of Computational Linguistics and we can say advancement in this regard would improve many fields including speech recognition and information extraction and the like.
One of the most important applications of WSD is in Machine Translation in which a text shall be automatically translated from one language into another. For instance, consider an English to Farsi Machine Translator which is going to translate the word “paper” while translating a sentence. The word “paper” could be translated as “رو؆امه” (newspaper), “مقاله” article or “کاذذ” letter. WSD can improve this process.
WSD is also required in Information Retrieval (IR) systems. In IR systems, ambiguity arises in some queries. For example, given the query “depression”, it may be unclear for the system whether to return documents about illness, weather systems, or economics.
WSD methods based on supervised approaches normally yield acceptable results. But the problem with these methods is lack of sense-annotated data which is big enough. In this article we used a supervised approach as the system’s main engine to resolve the ambiguity and we benefited from several knowledge resources to resolve the data shortage as well.
We used K-Nearest-Neighbor (KNN) Algorithm which is one of the well-known and credible supervised approaches to solve WSD matter.
We believe that two factors guarantee the success of KNN: the type and the quality of features used to represent the context in which an ambiguous word occurs and the type measure used for comparison of text vectors.
For this reason,at the first step, our approach extracts three sets of features: the lexical features, the syntactic features and the semantic features. In fact we tried to add most features that include lexical, syntactic, and semantic levels of language to our feature sets as influential factors. Another feature influencing the success of KNN is the method of comparing the input sentence with former input sentences to choose the meaning of ambiguous word.
In order to obtain the most suitable measure for comparison between the new sentence which houses the ambiguous word and existing sentences using KNN algorithm, we examine the various distance/similarity measures.
It should be noted that in order to improve the accuracy of the WSD method, a feature selection process for lexical and syntactic features and some weighting schemes will be proposed and discussed.
One of the other points considered in this article is using two different languages of English and Persian.
Persian language (also known as Farsi or Parsi) is spoken in Iran, Afghanistan, Tajikistan and Uzbekistan. This language has also had a significant effect on neighboring languages, especially Armenian, Turkic and Georgian languages. There are only few efforts to develop natural language processing resources, tools and researches despite of Persian language potential and high number of its speakers in the world. So we aim to do this language a little favor and also we intend to apply the suggested schemes to two sets of data; English and Persian corpora to show that the proposed schemes are not language-dependent.
WSD methods are usually tested in two different ways. When certain words in the text are being disambiguated, which is called Sample Word WSD, and when all the words in the text are disambiguated, which is referred to as All Words WSD. The first way is highly useful for systems using Supervised Approaches. As this article presents Supervised Approach, we used the first case for our experiments.
This paper is structured as follows. Section 2 is devoted to the introduction of related literature. Section 3 illustrates the feature extraction process. Section 4 presents feature selection process. Section 5 introduces the corpus and also illustrates the preprocessing steps for our goals. Section 6 describes the combination of the proposed system and also presents a variety of distance/similarity measures. Experimental settings and results are presented in Section 7. Finally, Section 8 concludes the paper.
Related work
Several methods have already been proposed to be applied in WSD problem. WSD methods can be divided into supervised, unsupervised and hybrid scheme sub categories. The first category includes methods which are based on supervised learning. These methods use classification systems to determine the correct translation of ambiguous words. The second category includes methods that use unsupervised learning. Text clustering is the main learning process used by the methods included in this category. Generally, supervised methods compared to unsupervised once produce better results. There is also another category of disambiguation methods which propose a combination of supervised and unsupervised learning.
From another perspective, WSD methods can be categorize into two main knowledge-based and corpora-based approaches [1, 2, 3]. Knowledge-based methods mainly rely on external knowledge base, such as machine readable dictionaries, large lexical semantic resources, ontologies, thesauri, etc., for disambiguation. However, the corpora-based approaches do not make use of any of these resources.
Supervised approach has been applied for WSD problem frequently. They use data mining and machine learning techniques to train a classifier sense-annotated data. Some of these approaches rely on Decision List [4, 5], Naïve Bayesian [6, 8], Nearest Neighbor [9], Boosting [10], Winnow [11], Transformation Based Learning [12], Naïve Bayesian Ensemble [13] and Support Vector Machine [14].
Pedersen, has presented a corpus-based approach to word sense disambiguation that builds an ensemble of Naive Bayesian classifiers. Each Bayesian classifier is based on lexical features that represent co-occurring words in varying sized windows of context [13].
The system presented by Ng and Lee in [9] is based on the Nearest Neighbor method. The prototypes are the instances of the ambiguous word in the training corpus, each containing the following features: singular/plural; POS tags of the current word; three words on either side; support for verbs, which have a different verbal morphological feature; a verb–object syntactic feature for nouns; and nine local collection features. Note that the local collection features are the words that are frequently adjacent to the ambiguous word. These features are calculated for each instance of w in the sense-tagged training data, where w is an ambiguous word. The results are stored as exemplars of their senses. By calculating the same feature vector for the current word and comparing by all the examples of that word, the given word is disambiguated choosing the closest matching instance. The accuracy of the system on test sets from the Brown corpus and the WSJ corpus was reported to be 58% and 75.2%, respectively. The results were calculated on a task including 121 nouns and 70 verbs, using fine-grained sense distinctions from WordNet.
Dandala et al. used parallel corpora that help map the sense transfer from the initial language to the final language. Word Sense Disambiguation uses Wikipedia as a source of sense annotations. Through experiments on four different languages, they showed that the Wikipedia-based sense annotations are reliable and can be used to construct accurate sense classifiers [15].
In addition to supervised approaches, unsupervised approaches and their combinations have also been proposed for word sense disambiguation. For example, an unsupervised learning method using the Expectation-Maximization (EM) algorithm for text classification problems was proposed by Nigam and McCallum in [16], which then was improved by Shinnou and Sasaki [17], in order to apply it to the ambiguity resolution problem. The approaches presented in [18, 19, 20, 21] are other examples of unsupervised learning methods. Navigli et al., built a sub-graph of the entire lexicon containing vertices useful for disambiguation and then used graph connectivity measures to determine the most appropriate senses [22]. Chaplot et al. [23] proposed a graph-based unsupervised to solve WSD. Using sense dependency and selective dependency, they concluded that the sense of a word depends on senses of few other words in the sentence. A combined supervised and unsupervised lexical knowledge methods for word sense disambiguation is proposed by Agirre et al. [24]. Yarowsky applied rule-learning and neural network approaches respectively to the task of WSD [25].
There are many other WSD methods which require a bilingual corpus. This problem is more challenging for some language pairs such as Persian, since a sufficiently large bilingual corpus can hardly be found [26, 27, 28]. Sarrafzadeh et al. try to overcome the lack of knowledge resources and NLP tools for the Persian language. They propose a cross lingual approach to tagging the word senses in Persian texts. The method makes use of English sense disambiguators, the Wikipedia articles in both English and Persian, and a newly developed lexical ontology named FarsNet which has a similar structure to WordNet [29].
There are some approaches that takes advantage from multiple languages simultaneously to solve WSD [30, 31, 32]. The method presented by Navigli and Ponzetto was based on a large multilingual encyclopedic dictionary, called BabelNet, that was built from WordNet and Wikipedia. Their approach used the graph structure of “BabelNet” to identify complementary sense evidence from translations in different languages.
The method proposed by Dagan and Itai [33] chooses the most probable sense of a word using frequencies of the related word combinations in a target language corpus. In this method, first of all, the system identifies syntactic relations between words using a source language parser and maps those relations to several possibilities in the target corpus using a bilingual lexicon. Two evaluations were carried out for this method, one using Hebrew sentences and the other using German sentences. The accuracy of the system was 91% and 78% for Hebrew and German sentences, respectively.
There are a lot of WSD methods which use heuristic algorithms. Schwab et al proposed the use of Ant Colony Optimization to solve WSD. This approach uses a variant of the original Lesk algorithm where glosses are expanded using the relations in WordNet. Each word is represented as a component in a vector. The algorithm starts with a graph. The graph is built based on the text structure where each word is linked to its predecessor sentence, and each sentence is linked to its predecessor paragraph [34]. Abualhaija et al introduced D-Bees as a knowledge-based unsupervised method for solving WSD problem. D-Bees has been inspired by bee colony optimization where artificial bee agents collaborate to solve the problem [35].
Feature extraction process
As described before, WSD refers to the process of automatically identifying the correct meaning of an ambiguous word based on the context in which it occurs. Therefore what is important here is the context of ambiguous word presented in the form of Feature in this study. We believe that in addition to the words that appear beside the ambiguous word, we’d better to extract the words that have a special syntactic relation with the ambiguous word as well as the words that are not in the context of ambiguous word but could be relied on semantically, as features to improve the disambiguation process.
So we extract three set of features; lexical features, syntactic features and semantic features. Then, we employ several sub features for each set.
The lexical features are the set of words which exist in the context of the ambiguous word, the syntactic features are part of speech, syntactic relation and head of phrases, and finally, the semantic features are synonym, antonym, same lemma, hyponymy and hypernymy of words which exist in the context.
Syntactic features
Part of speech
When we consider POS as a feature, this procedure can be useful in two cases and help us throughout the word sense disambiguation process. In the first case, a word belongs to different POS categories with different senses. For example, consider the following sentences:
He turned off the light. (noun/lamp) Chandeliers light the house. (verb/make brighter) Magnesium is a light metal. (adjective/not heavy)
The word light, has different syntactic roles in each sentence and as its POS changes, its sense also becomes different. Similarly in Persian language, the meaning of the word “مرد” as a noun is “man”, and its meaning as a verb is “died”. Undoubtedly, in this case, the POS of the ambiguous word determines the correct meaning of the target word.
The second case occurs when a word has more than one sense, while its different senses fall under the same POS category. For instance, the word paper, when falls into the noun role, has more than one sense such as newspaper, composition and scholarly article. Similarly, in Persian language the word “شیر”, which is a noun, has more than one sense, i.e., lion and milk. In this case, the POS of words around the ambiguous word can be a useful feature for the WSD model.
Hence, in this work, we considered the POS of the target word as well as the POS of two words before and two word after the ambiguous word.
In this study, syntactic relation is the important relation of an ambiguous word with other words in a sentence based on their POS and syntactic roles. We believe these relations if don’t clearly determine the correct meaning of target word, at least can help us reach this goal. For example when the target word is subject of a sentence its verb can guide the system to ambiguity resolution. In the following sentence this claim has been clearly shown.
Black bass can swim very fast in short distances.
Bass is the subject and also is the target word in this sentence and swim is its verb. As is obvious, swim can uniquely determine that the right sense of bass is a type of fish. Also consider the following Persian sentence:
Nozad shirr ra noushid. (نوØاد شیر را نوشید)
In this sentence the ambiguous word is shirand its role is object. On the other hand, the verb is noushid. Similarly, this verb is clearly related to the milk sense of shir. Hence, we extracted syntactic relations as shown in Table 1 and considered them as a set of features.
Syntactic relation of an ambiguous word with other words in a sentence
Syntactic relation of an ambiguous word with other words in a sentence
A phrase is a small sequence of words that forms a meaningful unit within a sentence. Most phrases contain a central word that identifies the type of the phrase known as the head. The Part of speech of the head is used to determine the category of the phrase, for example, a phrase whose head is a noun is called as noun phrase. “Black sea bass” is a noun phrase which bass as head is noun.
A high-level view of the proposed WSD system.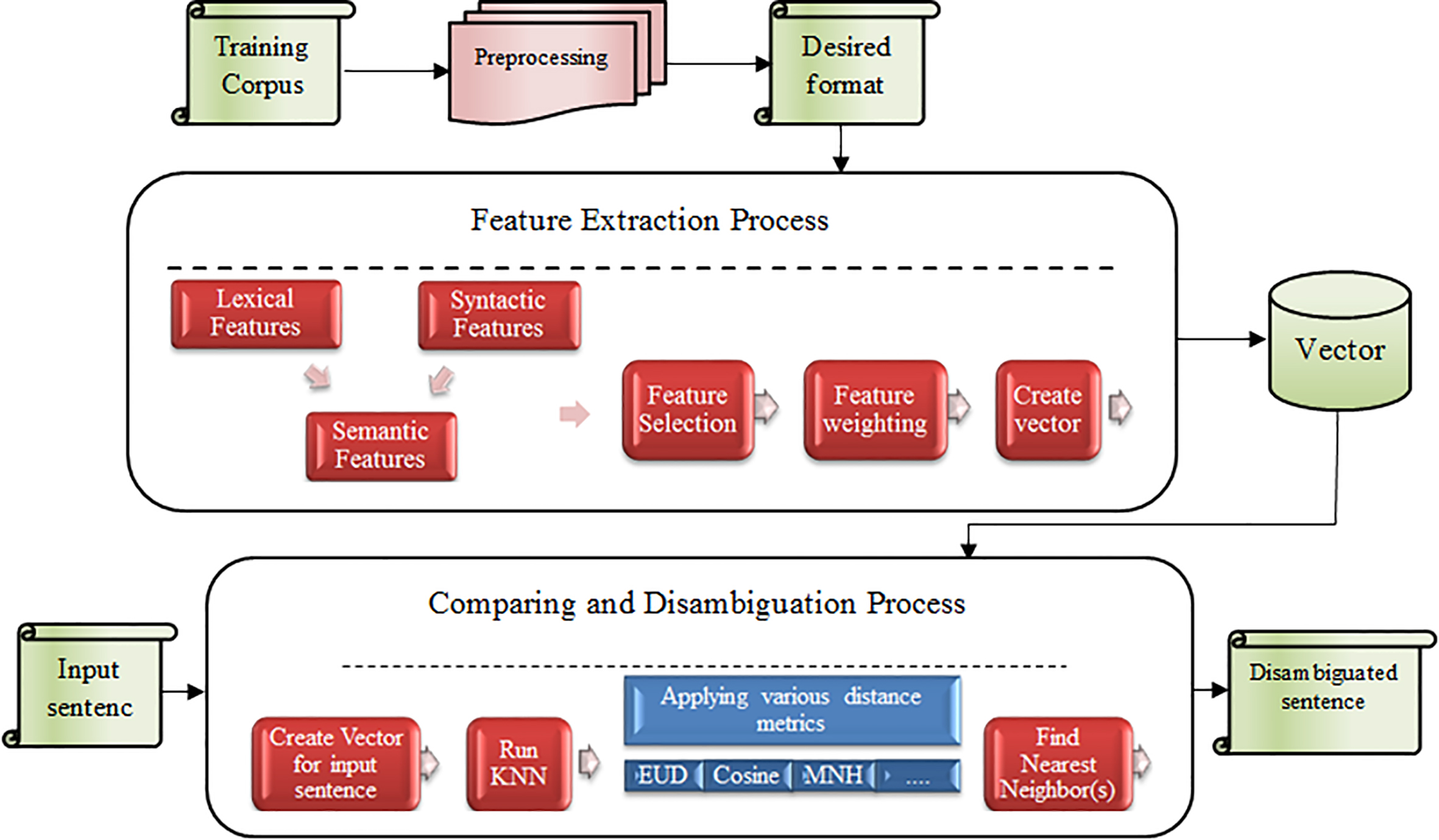
We believe the head word of a phrase that includes the ambiguous word, if does not directly determine the correct meaning of the ambiguous word, can be a helpful factor to this process. For instance, consider the following noun phrases:
a light metal. light colors.
The ambiguous word light has many senses, such as, little physical weight and small amount of color. As is obvious, the head words of these phrases, metal and colors, can clearly determine the correct meaning of the light. So we employ the head word of the phrase, which includes the ambiguous word, as a sub feature.
Similar to the head word of a phrase, the head word of its parent phrase that includes the ambiguous word can also help to identify the proper sense. For instance, consider the following sentence as well as some part of its parse tree shown in Fig. 2.
Part of parse tree structure.
Soldiers learn how to explode a tank
The ambiguous word in this sentence is tank which has many senses such as, container and vehicle. This ambiguous word is part of a noun phrase a tank. The parent phrase of this phrase is a verb phrase which its head is the verb explode. It is obvious that this verb conduces our system to war vehicle sense of tank. So we employ the head word of the parent phrase of the phrase, which includes the ambiguous word, as a sub feature.
In addition to the head word of a phrase and the head word of the parent phrase, the head word of the child phrase that includes the ambiguous word can help the WSD method to discriminate the correct meaning of the target word. For example, consider the following sentence as well as some part of its parse tree shown in Fig. 3.
Part of parse tree structure.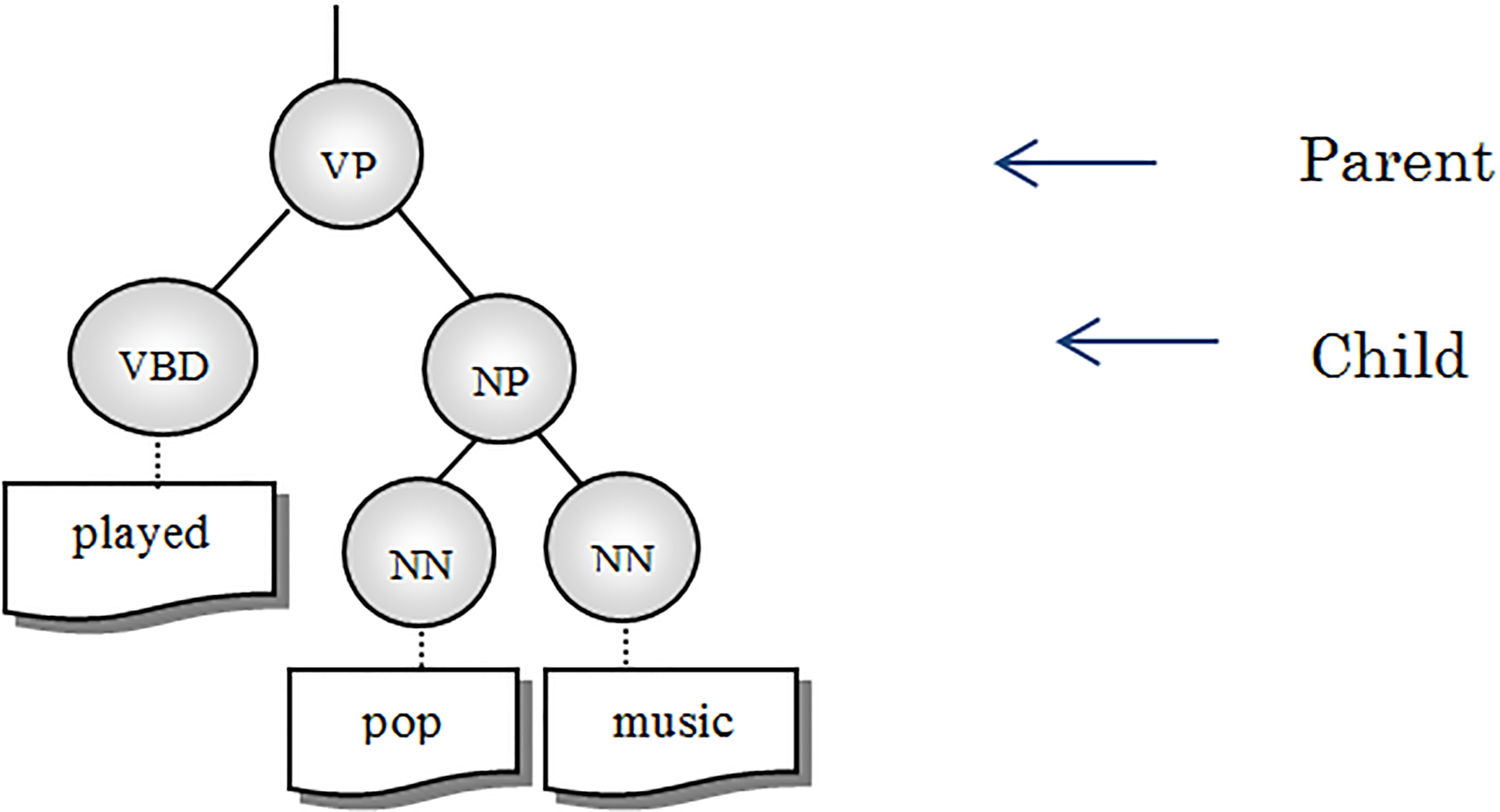
I played pop music with my guitar.
The target word in this sentence is play. The semantic concept of play is divided into entertainment and music. This ambiguous word is a part of a verb phrase which is made up of a noun phrase and a prepositional phrase. These phrases are the child phrases of the verb phrase. As shown in Fig. 3, The head word of the noun phrase is music that guides the algorithm towards the music sense of play. So, we employ the head word of all child phrases of the phrase, which include the ambiguous word, as sub features.
Similar to the head of phrase which was described before, the head word of sibling phrases of the phrase which include the ambiguous word is also considered as a sub feature in this study. These features as shown in the following sentences can help us to apply word sense disambiguation process. In the English sentence, the target word is crane. Bird and motion are the senses of this ambiguous word.
Part of parse tree structure.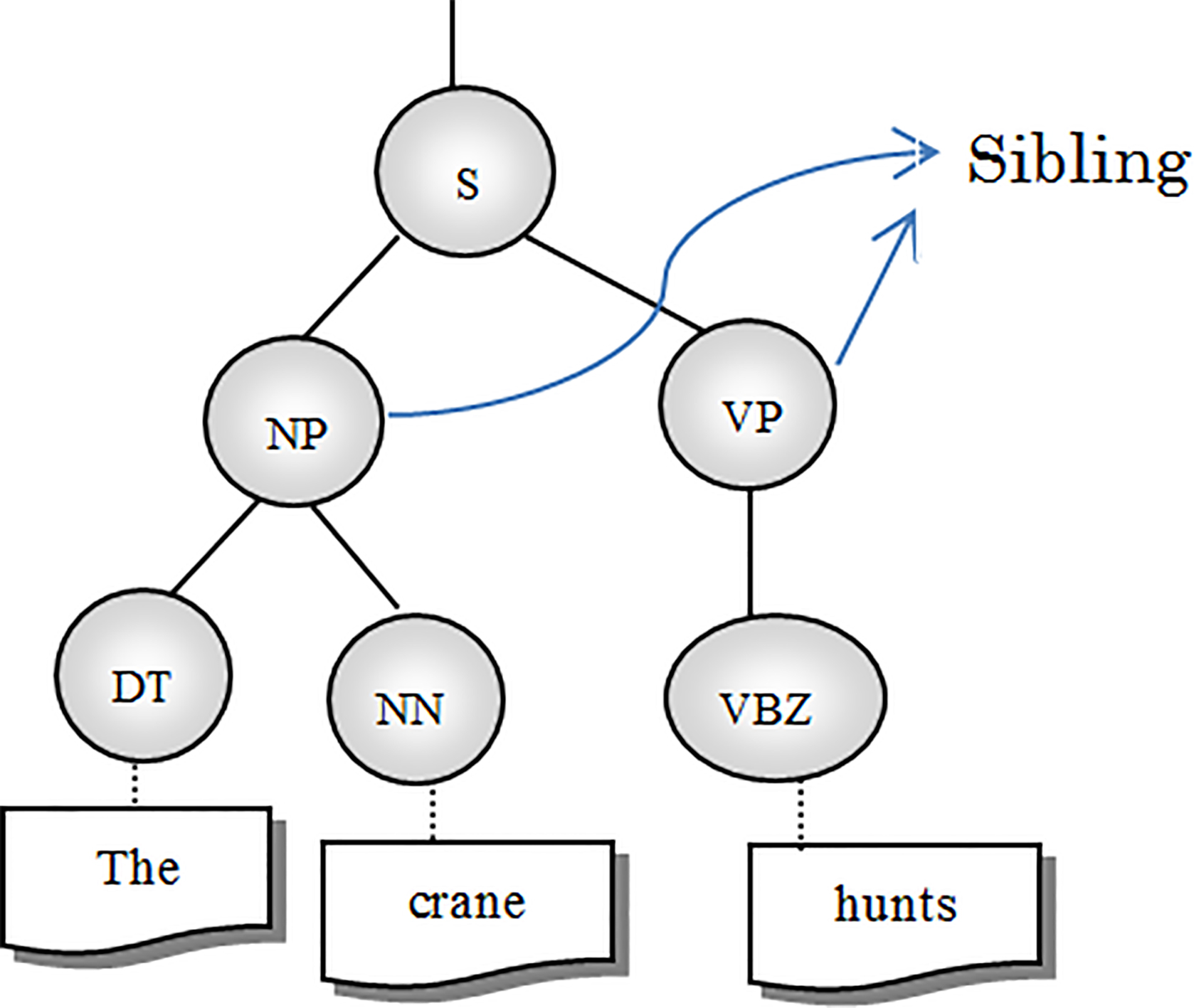
Part of parse tree structure.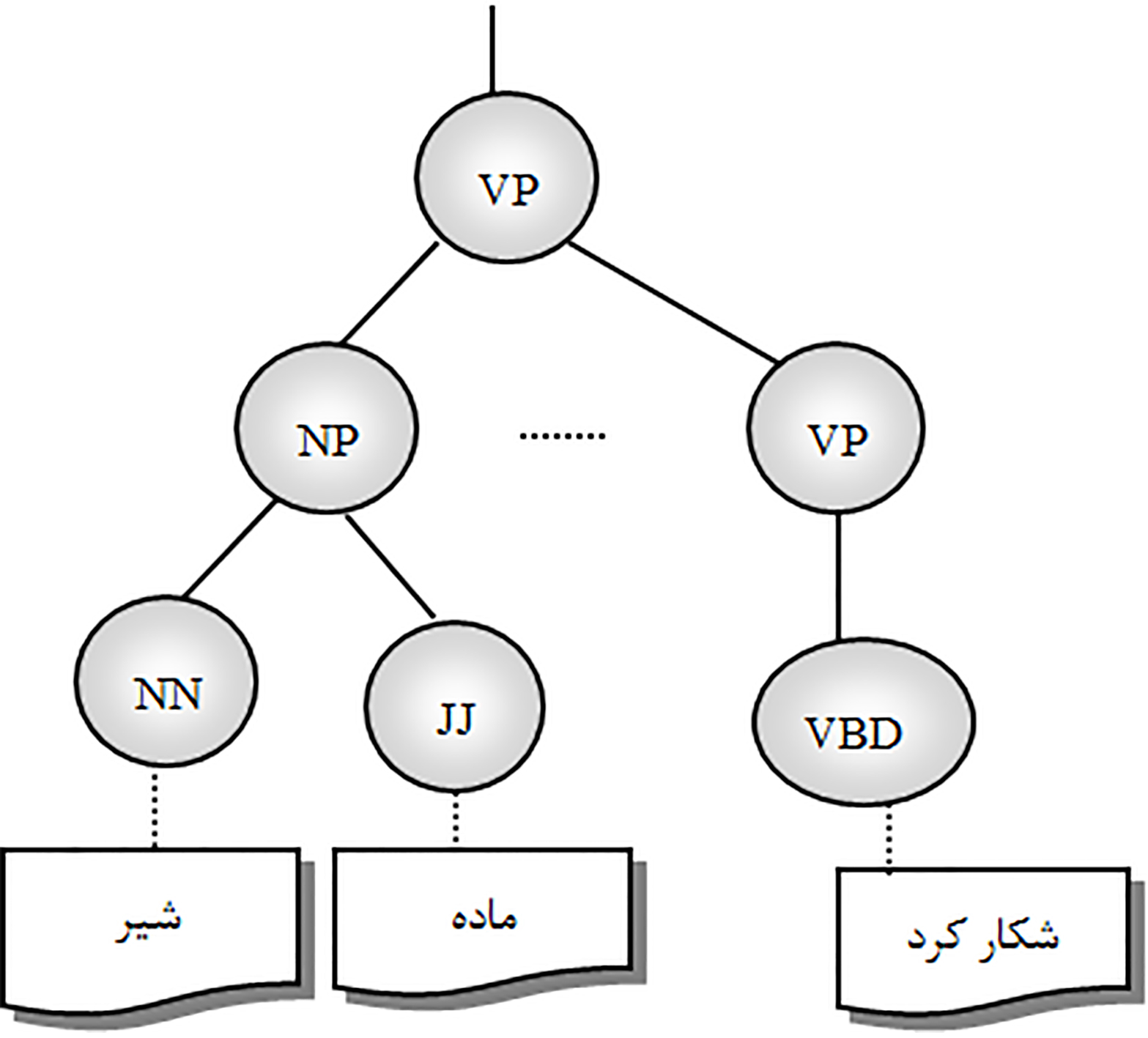
As presented in Fig. 4, Crane is a part of a noun phrase and this noun phrase is the left sibling of the verb phrase with head word of hunts. It is obvious that this head word can help the system to select the bird sense of crane. Also in the following Persian sentence the ambiguous word is ‘شیر’ (shir) and it is a part of a noun phrase. As shown in Fig. 5 this noun phrase is the left sibling of the verb phrase with head word of ‘شکار کرد’ (shekar kard) that guides the algorithm towards the lion sense of ‘شیر’ (shir).
shir madeh gavazn ra shekar kard (شیر ماده Ú¯ÙˆØÙ† را شکار کرد).
Set of frequent words
The first subset of the extracted lexical features includes frequent words. Every word that frequently occurs in the training corpus is represented as a feature in this set. The value of a typical feature is dependent on the number of times it has co-occurred with the ambiguous word (in the same paragraph), ignoring the position of its occurrence in the paragraph.
A word such as
Where
where
The second condition is checked for the words that satisfy the first condition. The first condition tries to prevent selecting the words based on spurious and rare occurrences. The second condition is used to reduce the probability of selecting words that are frequent, but co-occur with all senses of the ambiguous word.
After detecting a number of words that satisfy the above pair of conditions,
For example, consider the Persian word “شیر” (shir) which has two meanings (i.e., Lion and Milk). our system extracted the Persian words “ØÙ†Ú¯Ù„” (janagl), “شکار” (shekar), “یال” (yal), “Øانور” (janevar) and “ببر” (babr) as features for the first sense of “شیر” (i.e., Lion) and the Persian words “گاو” (gav), “لبنیاؔ (labaniat), “پاØØوریØÙ‡” (pastorize), “چربی” (charbi), “Ú©Ù„Øیم” (kalsium) were extracted as features for the second sense of “شیر” (i.e., Milk). These features have been extracted from the Persian corpus. Section 4.1 will describe this corpus in detail.
Every feature in this subset is assigned a weight value according to its positional distance to the ambiguous word. For this purpose, we select
This set of features does not get binary values (i.e., 1 and 0, showing whether the word exists or not), instead, the positional distance to the ambiguous word will affect the weight value assigned to a typical feature. As a heuristic, we assign the value of
Semantic features
Lexical features, which are extracted from a small tagged corpus, only in limited cases can guide the disambiguated system to correct meaning of a word. As it is impossible to find all co-occurrence words in a corpus, a knowledge based resource such as WorldNet can help us to solve this problem. We believe that when a word is considered as a lexical feature, it can be a root for a lot of other features. These features will be extracted from a knowledge based resource. Notice that these features can partly cover the shortage of co-occurrence words. We entitled these features as semantic features.
In fact using this set of features as well as other tools finding syntactical relations, we tried to employ a combination of supervise approach and knowledge based algorithm in ambiguity resolution.
Synonym
A synonym is a word that has exactly or closely the same meaning as another word. When a word is extracted as a lexical feature, its synonym can also consider as a helpful feature for disambiguated system. Because this lexical feature has frequently occurred with ambiguous word and its synonym may also happen in a new sentence that houses ambiguous word. In such cases, synonym can lead the system to the correct meaning.
For example, when bass as an ambiguous word is employed to the fish sense of itself, the word sea was extracted as one of its lexical features. Therefore we obtained its synonym. Based on WordNet the synonym of sea is ocean. Now consider the following sentence:
Oceans is only one of the places hosting bass
Between lexical features that we extracted from our corpus for fish sense of bass, there are none of them in this sentence. So based on lexical features the disambiguated system cannot detect the right meaning oftarget word. But ocean as a semantic feature can guide our system to the fish sense of bass.
Antonym
An antonym is a word that means the opposite of another word. Similar to the synonym, the antonym of a lexical feature which has been extracted from corpus, can sometimes guide the disambiguated system to the correct meaning of a target word. For example consider the following sentence:
After long inspections, the expert informed us that the palms were fruitless.
In this sentence the target word is palm (has two senses, hand and tree). We know the correct meaning of palm is tree here, but there is no lexical feature for this sense in the sentence. of course it is not the later sense because one of lexical features extracted for the second sense of palm (tree) is “fruitful”, and the antonym of it i.e., fruitless exists in this sentence and our system based on this semantic feature can determine the right meaning of the target word. So we consider antonym of lexical feature with adjective roles as semantic features.
Same lemma
A word can lay in different forms. For example, a verb can be in form of simple present tense, present participle, simple past, past participle and so on, or a noun can be singular and plural, while an adjective can be a normal adjective, comparative and superlative. When a word was extracted as a lexical feature based on its part of speech, all of its word forms are considered as same lemma features. For instance consider the following sentence:
Only two members voted against the new motion.
In this sentence the target word is motion, which has been used in legal sense. In addition, when motion is in legal sense, vote is one of its lexical features. But in this sentence, vote has been used in past simple form, and only with same lemma features of vote we can guide our system to the correct meaning of target word.
Hyponym and hypernym
Hyponym and hypernym refer to a hierarchical semantic relationship between words. Hypernym presents a general term and hyponym shows the more specific terms that fall under the category of the general term.
For example, the fork, knife and spoon are hyponyms. They fall under the general term of utensil, which is the hypernym. Also in Persian the “شیر”, “پلنگ”, and “ببر” are hyponyms of “گربه Øان” which is their hypernym.
Hyponyms and hypernyms can be described by using a taxonomy, as seen in the Fig. 6.
An example for Hypernym and Hyponym.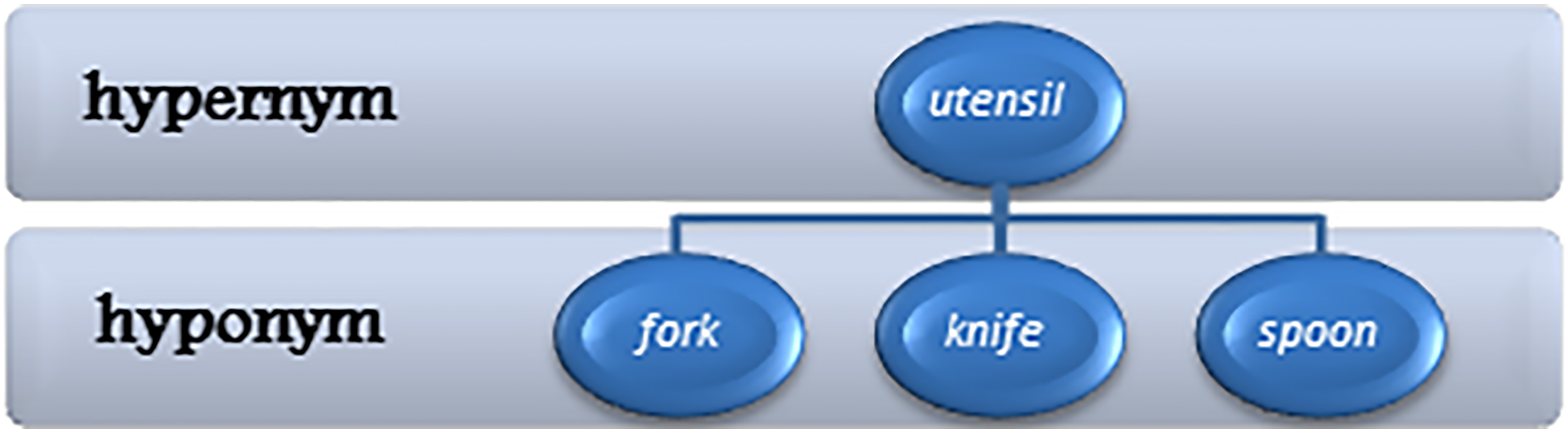
Similar to synonym a hypernym or all hyponyms of a lexical feature which have been extracted from the corpus can be a helpful item to our system, so we consider all of them as semantic features in the process of feature extraction.
Generally, Feature selection is the process of selecting a subset of input features by eliminating most irrelevant and redundant features. Undoubtedly, choosing a proper feature affects the final functionality significantly. As we are going to extract certain words as feature and such features are acquired from a limited context, some words might repeatedly be chosen as feature in each set. Emergence of repeated features might have negative effects on classifier. To solve this problem, a feature selection process has to be added to the system.
As discussed above, three sets of features are extracted in our system. We apply the feature selection process for the lexical features and the syntactic features. Because lexical features are the input of system to extract the semantic features, this process doesn’t need to be employed for semantic features.
Syntactic feature selection
Between three subsets of syntactic features that are extracted by our system, two of them are likely to have common features. These two subsets are the head of phrase and the syntactic relation. This case occurs when one of the head phrase that is important for us, has exactly a syntactic relation with the target word as shown on Table 1. So, the system extracts such features more than once. For example, consider the example given in Fig. 4. In this example the word “hunts” is the head word of sibling phrases of the phrase which includes the ambiguous word (i.e., the head of phrase feature). This word also has “subject
Lexical feature selection
As discussed above, two subsets of features are extracted for lexical features in our system. The features of the first subset are extracted from the paragraphs in which the ambiguous word occurs and the features of the second subset are extracted from a window of words that surrounds the ambiguous word. These two subsets of features are likely to have common features. In other words, one feature may exist in both sets of features. Undoubtedly, for each pair of common features, one is redundant and also has a negative impact on the KNN classifier. Thus, we should omit redundant features.
It should be noticed that the features which exist in both of the sets have two different values. Thus, it matters which of them is omitted. Regarding this fact, we do not omit one of the common features randomly. Instead, among a pair of identical features (with different values) we hold the feature which leads to a higher classification accuracy on training data and remove the other [36].
Corpora and preprocessing steps
Prior to performing feature extraction and feature selection processes, the existing datasets are required to be preprocessed in a way that the mentioned processes could be easily performed on them. Additionally, these preprocessing steps would yield a set of enriched corpora which could be used for other NLP works.
Datasets
A proper dataset significantly affects the final functionality when using a Supervised Approach. We used two English and Persian datasets to extract features and assess our proposed scheme and we implemented our preprocess steps on these two datasets.
In the English dataset, we focused on 6 nouns, 1 adjective and 1 verb, namely palm, bass, crane, plant, motion, tank, light and call all of which involve sense ambiguity. We used a corpus which includes a set of texts including the mentioned words frequently in their different senses. A great part of this corpus has been obtained from a corpus named TWA (developed at University of North Texas by [37]). These ambiguous words have higher frequencies compared to other words in the texts and appear in different situations in the training data. Further information about this corpus can be found in Table 2.
The details about the datasets that include six English ambiguous words
The details about the datasets that include six English ambiguous words
In the second dataset, we concentrate on two Persian ambiguous words, namely “شیر” and “شکر”. The corpus which includes a set of texts including these two Persian words in their different senses has been collected using Google search engine. Additional details about this corpus can be found in Table 3. The aim of this part of the experiments is to show that the proposed method is applicable for Persian as low-resource language and is not language-dependent.
The details about the datasets that include two Persian ambiguous words
For syntactic features, the treebank is created on top of the tagged corpus, also a dependency relation is added to each sentences. In English, this task is done using Stanford parser. In Persian, because there isn’t a good parser, this task is done manually. Finally we present the prepared corpus in Xml format. Figure 7 shows an English example sentence before syntactic preprocessing as well as some part of its XML representation after preprocessing.
An example sentence of the corpus (a)Before syntactic preprocessing (b)Part of Xml representation after syntactic preprocessing.
The sub-features of POS and also the head of phrase are extracted from Treebank (
For lexical features, we omit all stop-words (i.e., the words which are not quite valuable, such as articles, all types of pronouns, etc.) as well as the punctuations from the context. The processing we perform over the text is not case sensitive, i.e., it does not make a difference between upper case and lower case letters.We present the preprocessed corpus in XML format and enhance it by providing some other information such as the word frequencies in the corpus and part of speech of each word. Figure 8 shows an example sentence before preprocessing as well as some part of its XML representation after preprocessing.
An example sentence of the corpus (a)Before lexical preprocessing (b)Part of Xml representation after lexical preprocessing.
The preprocessing task for semantic features is carried out after extraction of lexical and syntactic features. These features are the input of the semantic features extraction step. For this purpose, an array list is created each row of which can be represented as al
An example of semantic features after lexical and syntactic features extraction.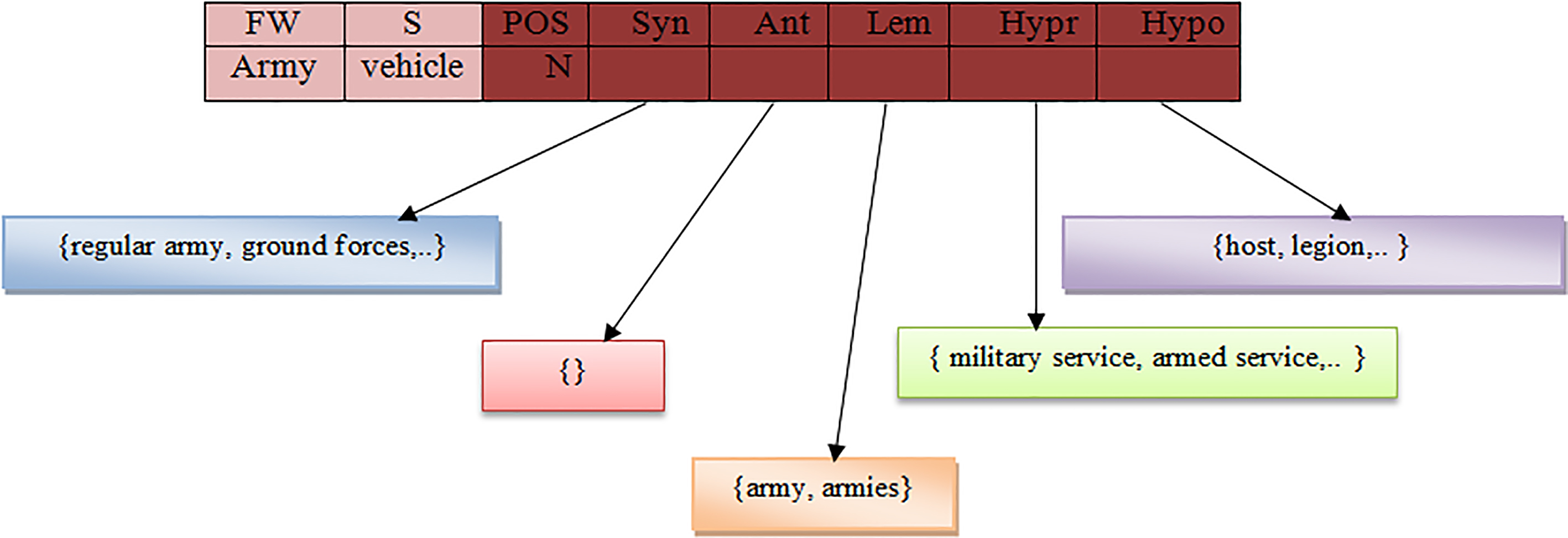
For instance, Fig. 9 shows a frequent word (for second sense of tank) and its semantic features in format of the array list.
The semantic feature extraction algorithm.
The algorithm of semantic features extraction is presented in Fig. 10. As it is illustrated in this algorithm, here we tried to compensate for the sense tagged corporashortage using some knowledge based resources.
In this section, we explain how the processes already mentioned are integrated and form a seamless disambiguation system. In general, as is demonstrated in Fig. 1, the preliminary input is the very English and Persian dataset receiving the preprocess operation and formed in the desired format.
Then the feature extraction process is performed and from the enriched and preprocessed corpus, three sets of features are extracted whereas every set consists of some sub features. Then, following a feature selection process, a pure subset of the extracted features is chosen to be used for classification. In order to improve the classification capacity, we propose a heuristic feature weighting method and assign different weights to the selected features. Finally, each paragraph included in the corpus is converted into a vector including values of the syntactic, lexical and semantic features.
Disambiguation process
After performing the mentioned processes, the system is ready to receive the sentence housing an ambiguous word. At this moment, the second part of the system that is responsible for disambiguation process starts working.
This part converts the input sentence to a vector based on the features extracted in previous processes and the features existing in this vector are compared with the vectors resulting from the previous part. It is a classifier that uses an improved version of K-NN and performs the WSD task on the set of constructed vectors.
Since the type of measure which is used for comparison between vectors is very important in KNN, we illustrate and employ various distance/similarity measures for this task as the following. We also assign and use feature weights and propose a weighted formula for every metric.
Distance/similarity measures
K-NN is a supervised learning algorithm in which the classification is accomplished based on learning by analogy, that is, by comparing a given test vector with training vector that are similar to it.
When an unknown vector is introduced, K-NN classifier finds
In K-NN, the number
As mentioned, the KNN algorithm is based on comparison. Thus, first of all, a proper metric for comparison should be determined. Since selection of a proper metric has a high effect on the accuracy of the WSD system, in this section, we aim to find the most proper similarity (or distance) measure among a set of standard metrics. In order to illustrate any of the distance (or similarity metrics), we use two typical vectors X1
The distance values must non-negative, i.e., dist(x The distance of two vectors equls zero, if and only if the vectors are identical, i.e.,
dist(x,y) is a symmetric function, i.e., dist(
Triangular Inequality Rule: dist(x
Table 4 presents some distance/similarity measures, namely Euclidean, Squared Euclidean, Manhattan, Chebyshev, Canberra, Bray Curtis, Hamming, Cosine and Pearson. In Table 4, the distance/similarity, for each metric, between two points (vectors) is reported as “formula” and once, the feature weights are used for computing the distance/similarty of a pair of vectors, denoted as “Weighted formula”.
Distance/similarity measures between two points with/without applying feature weights
Note that in all relations, xji is the value of the i-th feature of the vactor xj and in weighted relations,
The Chebyshev Distance is also known as Chessboard distance, since in the game of chess, the minimum number of moves needed by a king to go from one square on a chessboard to another equals the Chebyshev distance between the centers of the squares, if the squares have side length one, as represented in 2-D spatial coordinates with axes aligned to the edges of the board. For example, the Chebyshev distance between F6 and E2 equals 4.
In Canberra and Bray-Curtis distance, if both points are zeroes, they are omitted from the result (because in mathematics
Similarity metrics have a reverse meaning to distance metrics. Cosine similarity is a measure of similarity between two vectors in which, the cosine of the angle between the vectors is used to represent the similarity.The Cosine similarity measure of two vectors is given in relation (17). The cosine of the angle between two vectors varies from
The weighted Cosine similarity is also given in relation (18).
The Pearson’s correlation is another similarity metric that commonly denoted by
Setting classifier
We initially divide each corpus into 5 equal folds in a 5 fold cross-validation method. Of which four folds were used to extract the features and to train K-NN classifier, while the remaining folds were used as test data. This method is used for 5 times in a way that each fold is once chosen as data test. Training vectors are made after extracting features from 4 folds that are not related to the test. These vectors include syntactic features, lexical features, semantic features, as well as a class label (which is in fact the meaning of the ambiguous word) for each data instance.
Then using the K-NN algorithm, every test vector (which exists in fold test) is compared with all training vectors to find the
Note that Weighted Voting is a strategy each neighbor of the test vector s(found as one of the nearest neighbors) is assigned a weight according to its similarity(reverse ) to the vector. Since the similarity of two vectors (say sim(
where
Based on the goal of this study, the experiments are divided into two parts. The first part shows the effect of the various features and the second part compares distance/similarity measures. also the experiments is tried to do on three type of part of speech (Bass, Crane, Motion, Palm, Plant, Tank as noun, light as adjective and call as verb). Unfortunately, for Persian we suffer from lack of such resources. Hence, we did this experiment on two nouns.
Feature selection evaluation
In this section the effect of various features on classifier accuracy is presented.
Error rate of the KNN by considering the lexical features before and after lexical feature selection
Error rate of the KNN by considering the lexical features before and after lexical feature selection
Table 5, shows the average error rate of the proposed method across the 5 fold cross validation by considering the set of frequent words as well as the set of the surrounding words, simultaneously (before and after lexical feature selection).
It can be observed in Table 5, that applying feature selection reduces the error rate. For example, applying feature selection on palm has led to a 3.5% reduction in the error rate. Consequently, it is obvious that selection of the better feature from each couple of equal (common) features will have an outstanding effect on the error rate reduction. In the cases where selection of the better feature seems to be non-influent, surely there had been either no common feature or a few ones among the pair of feature sets. Note that the comparison of these two sets of lexical features (before and after feature selection and feature weighting) are shown by [36].
Error rate of the proposed scheme using syntactic features
The average error rate of the proposed method across the 5 fold cross validation is reported in Table 6. by considering the syntactic features. As described before, we utilized the part of speech, the syntactic relation and the various head of phrase as syntactic features. The results based on these features are presented under syntactic features in Table 6.
We created the semantic features based on lexical features, POS and some extra features such as synonym, antonym, same lemma, hyponym and hypernym of the frequent words. The effect of the semantic features to reduce the classification error rate is evaluated in Fig. 11. As it was predictable, the obtained results based on the semantic features are better than the results obtained based on lexical features for all datasets.
Note that in the above results, Euclidean was used as distance/similarity measures to compare records.
As described before, one of the important factors affecting success of KNN is selection of a good distance/similarity measure used for comparison of text vectors. In order to evaluate the distance/similarity effect on classification accuracy, this evaluation was repeatedly carried out using all distance measures presented before. Figure 12, shows the result, based on semantic features for Euclidean, Squared Euclidean, Manhattan, Chebyshev, Canberra, Bray Curtis, Hamming, Cosine and Pearson metrics in two cases. Note that Fig. 12a presents the results where we used Bass, Crane, Motion, Palm and Plant as dataset and Fig. 12b presents the results where we used Tank, Light, Call, شیر and شکر as dataset.
Classification Error rates (%) after performing feature weighting and feature selection compared to other classifiers
Classification Error rates (%) after performing feature weighting and feature selection compared to other classifiers
The effect of semantic features on reducing the error rates of the classifier.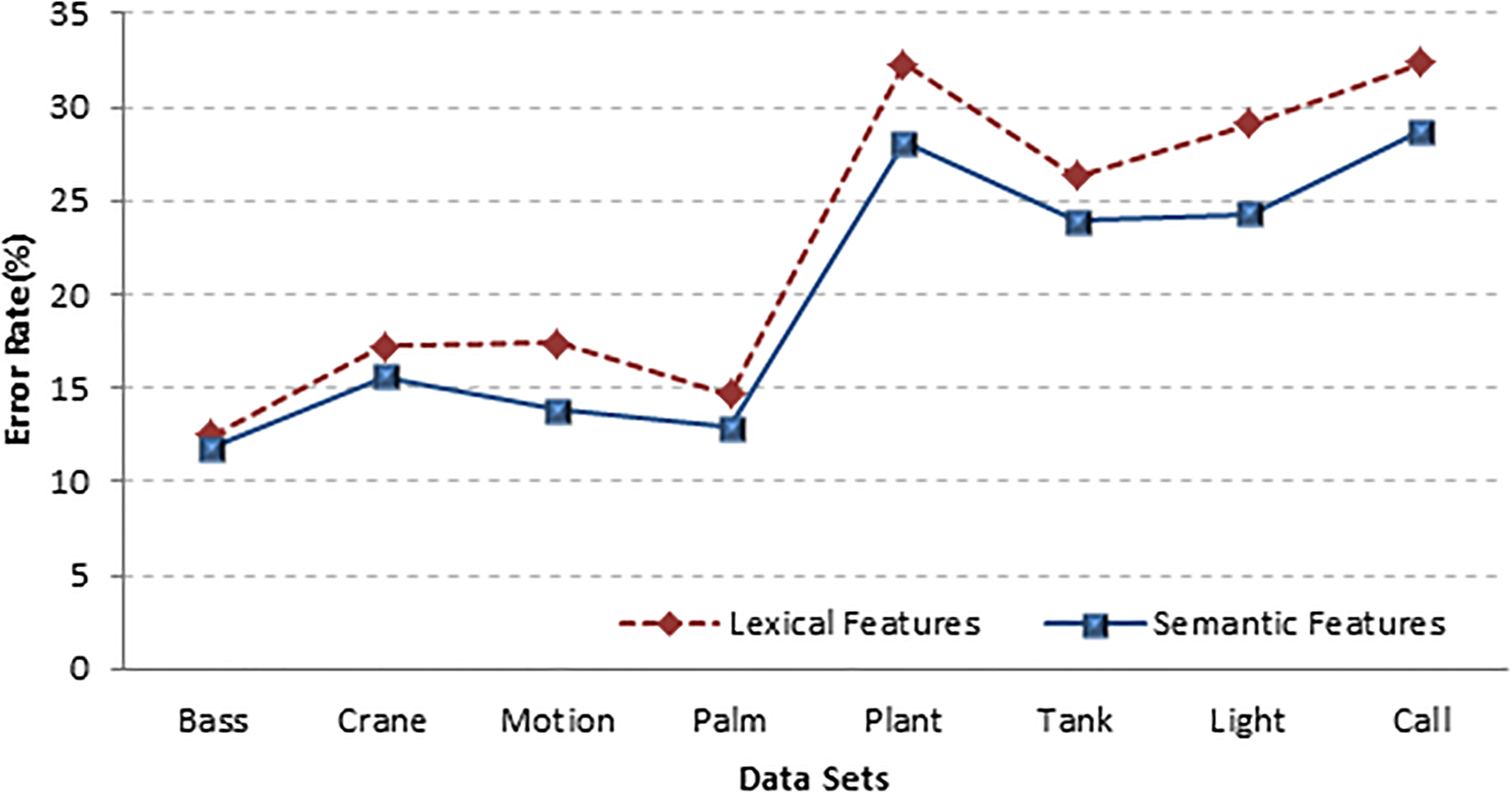
Comparison of various distance/similarity measures (a) using five first corpora (bass, crane, motion, palm and plant) (b) using five second corpora (tank, light, call, شیر and شکر). 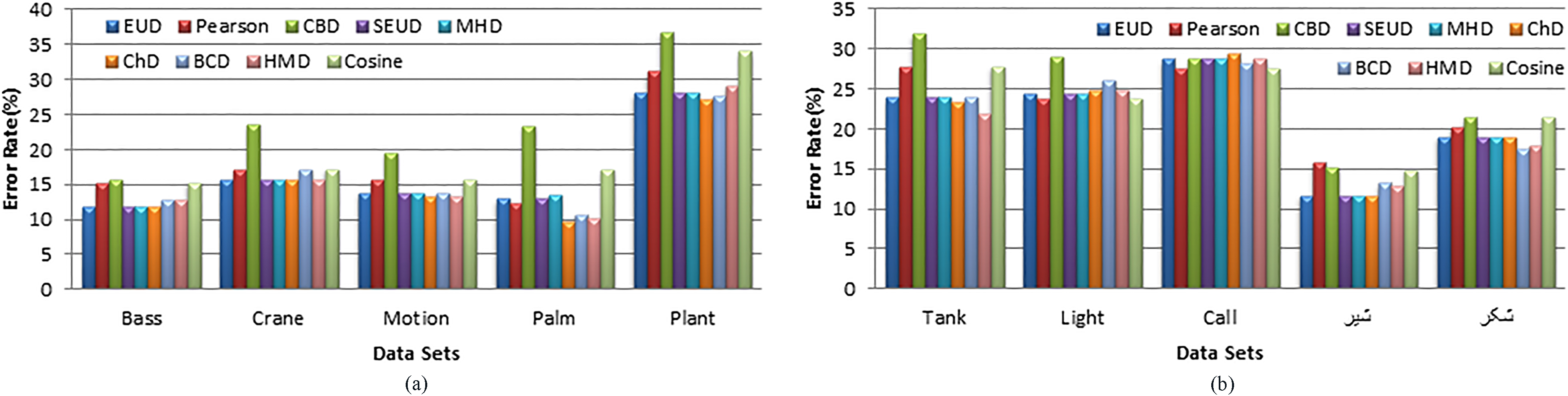
In order to compare the results with other disambiguation methods, we executed some of the existing corpora-based methods over the same data. The results are also shown in average in Table 7. As it can be observed, our results are better than most of the results obtained based on other methods. For example, the average error rate of the proposed method is significantly lower than the Dagan method [33] as a method that had outperformed others.
WSD is a crucial and useful matter in many subcategories of Computational Linguistic as well asnatural language processing .In this paper, we proposed an accurate word sense disambiguation system based on K-Nearest Neighbor algorithm. We first created enriched Persian and English corpora using preprocessing steps. Then we extracted three sets of features: the lexical features, the syntactic features and the semantic features. In order to improve the classification accuracy of K-NN, we proposed and evaluated a feature selection process as well a feature weighting strategy. We also examined and described various distance/similarity metrics in order to find the most proper metric for the KNN classifier. The proposed scheme was compared with some other classifiers already proposed for WSD. It demonstrated a uniform good behavior and achieved results which are comparable or better than other efficient classification systems, proposed in the past.