
Abstract
Active learning has proven to be quite effective in a vast array of machine learning tasks. Despite the lower labeling cost of active learning, it has been shown that active learning still can not reach state-of-the-art performance on several classification tasks and is sensitive to initial state. In this work, we propose a novel algorithm to improve the performance of active learning and it’s robustness to initial state. More specifically, we integrate low-rank transformation (LRT) with active learning. In each iteration, LRT is applied to project original high dimensional data to a feature space where data are easier to be classified and then support vector machines classifier is updated in this feature space. As iteration goes on, active learning’s propriety of labeling data improves the performance of LRT, which further promotes the accuracy of SVM classifier. Experiment on several benchmark binary classification datasets results showed the proposed algorithm outperforms other active learning methods in accuracy and robustness.
Introduction
Beyond highly publicized victories in computer vision [35, 14] as in image recognition [18], there have been many successful applications of active learning in text classification and speech recognition. Recent explorations and applications also include those in malware classification [20] and target tracking [29].
Although all of these applications suffer the problem of lacking class label, active learning still reaches remarkable performance on these tasks. The reason is that active learning is designed to achieve best classification performance with least labeled data. Active learning accomplishes this goal by automatically picking up most informatics data samples as labeled data during training process. The algorithm structure of active learning is shown in Fig. 1.
Active learning structure.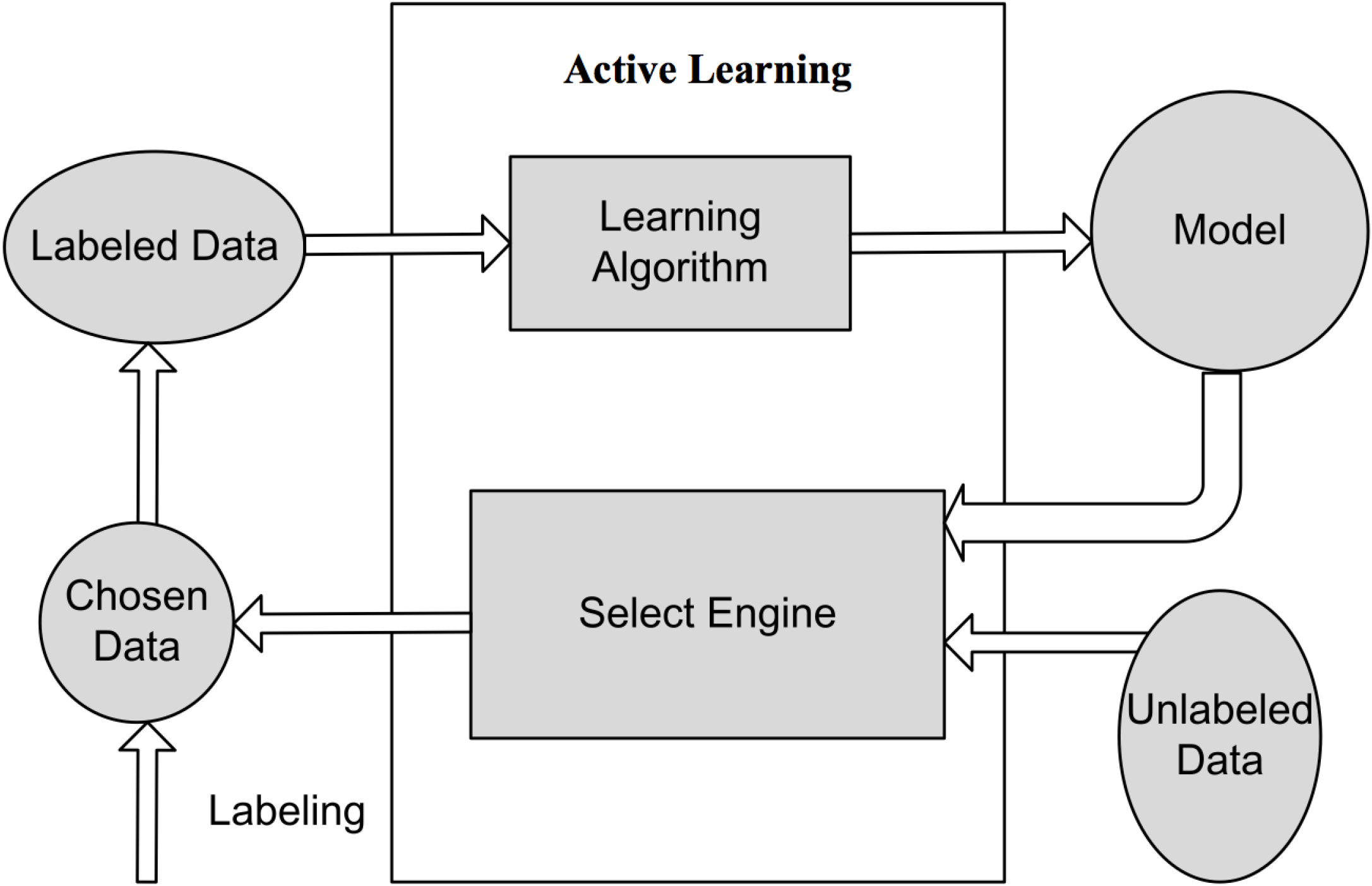
As shown in Fig. 1, active learning is mainly composed of learning algorithm and select machine, where learning algorithm is supervised learning method, such as support vector machines (SVM), and select machine is used to select data samples during each iteration according to uncertainty sampling [22]. During active learning process, learning algorithm first obtains an initial model from
However, the traditional active learning algorithms ignore the data distribution characteristics of training data, which in some cases may lead to local optimum [9]. As introduced before, active learning select labeled data according to current model, which means that active learning can not reach desirable results when current model is not well trained. In the first several iteration of active learning, the trained model usually does not perform well because the useful information is limited. Thus, the selected data samples is likely to contain redundant or even wrong information, which in turn influences the subsequent iteration even the final results.
Former research [3, 12, 13, 16] try to solve this problem by exploring distribution characteristics of unlabeled data. Although they improve the performance of active learning to some degree, effectiveness of these methods are constrained by some factors. More specifically, with the iteration goes on, the information containing in unlabeled data reduces, which means the explored information may not be enough for further utilizing. Another factor is the correctness of explored information. Due to lacking of labels, the information learned from unlabeled data maybe inaccurate. Applying these information will mislead the classification model and get even worse performance than traditional active learning.
In this paper, instead of exploring the distribution characteristics of original unlabeled data, we continuously utilize the information of labeled data mined by a manifold learning method. Manifold learning has been widely used to recover the intrinsic structure of high dimensional data and improve the resistance of machine learning methods [31, 32]. An advanced active learning algorithm based on low-rank transformation (LRT) for binary classification problems is proposed. During each iteration, after labeling the selected data samples, we first utilize the labeled data samples to obtain a subspace transformation. Then, the model is upgraded by the transformed data. The iteration goes on till the end of active learning.
The low-rank transformation is introduced to restore the low-dimensional subspaces of high-dimensional data and force a maximally separated structure for data from different subspaces. Therefore, the projected data are much easier to be classified. More importantly, active learning’s propriety of labeling data improves the performance of LRT. In particular, as more and more data samples are labeled, it is easier for LRT to achieve a better representation of whole dataset, which benefits the subsequent active learning process and promotes the accuracy of SVM classifier.
To evaluate the proposed algorithm, we compare it to other active learning methods with experiments on several standard datasets. The experimental results show that our method is superior to them in accuracy and convergence speed.
The rest of paper is structured as follows. Section 2 summaries related work. In Section 3, we introduce active learning SVM. Section 4 then presents the proposed algorithm and Section 5 evaluates our method on several benchmark datasets. We conclude in Section 6 with some discussion of the significance of our results and future work.
As is discussed in Section Introduction, prior endeavors in improving performance and efficiency of active learning mainly focus on exploring unlabeled data. Here, we summarize these works and discuss their limitations respectively.
[3, 16, 13] sought to improve the performance of active learning by different clustering algorithms. They applied selected clustering algorithm to original unlabeled dataset and divided data into different clusters. Based on the clustering results, the most uncertain data samples are selected as labeled data. Although these methods improved the classification accuracy of active learning, the performance of these methods highly depend on clustering algorithms. If the selected clustering algorithm cannot precisely explore the distribution of unlabeled data, performance of these methods will reduce to a large degree. [12] introduced a semi-supervised learning algorithm to active learning SVM. During each iteration, selected semi-supervised learning algorithm is used to extracted underlying manifolds of whole dataset and select most informative data samples for next iteration. However, most of semi-supervised learning algorithms also suffer the problem of being sensitive to initial state, combining active learning with these algorithms will weaken the robustness of active learning.
Active learning support vector machines
Support vector machines
Support Vector Machines [5] has been proven to be highly successful in binary classification problems both theoretically and empirically.
Given training data samples
where
However, when training data are not linearly separable, a punishment term
where
In practice, most classification tasks are nonlinear. To solve these problems, we need to introduce kernel trick [2]. One of the widely used kernel is RBF kernel.
where
Then
As discussed in Introduction, the difference between active learning and standard supervised learning mainly lies in select machine. Select machine decides which data sample will be chosen in training process. Existing selecting criteria mainly are query by committee [28], expected model change [27], expected error reduction [25] and uncertainty sampling [17, 22]. Among these methods, the most widely used one is uncertainty sampling.
In this paper, uncertainty sampling is selected as select machine. In each iteration, the most uncertain data samples in unlabeled data pool are chosen for labeling. Uncertain data stand for the data samples whose label are hard to be determined according to current classification model. For example, in probability model (such as logistic regression), the data sample whose posterior probability nearly to be 0.5 should be chosen:
As to discrimination model, the data sample with the largest uncertainty are those lies near the current hyper-plane. As to SVM, select engine choose data samples according to the following equation:
The algorithm procedure of active learning support vector machines with uncertainty sampling is shown in Table 1.
Active learning support vector machines with uncertain sampling
As presented in Introduction, improving the performance of active learning by taking advantage of data distribution characteristic has
Low-rank transformation
Labeled data samples are only used to derive classification model in traditional active learning. However, in this paper, we learn a low-rank transformation
Suppose the dimensionality of input space
Let
Suppose the projected data can be written as:
In order to find these subspaces,
Data samples in same subspace should be as close as possible, which means rank(PX) should be as large as possible, given that the distance between different subspaces should be so far as possible.
According to the aforementioned attributes, the optimization function of finding
where the constraint is to prevent the condition of
Given matrices
with equality if and only if
with equality if matrices are independent. When the matrices
Algorithm of computing sub-gradient of matrix nuclear norm
We use the nuclear norm of matrix to replace rank in Eq. (14), because nuclear norm is the best convex approximation of the rank function in the rank optimization [6, 24]. Then, the optimizatioin function can be described as follows:
As to matrix
Since this optimization problem is the subtraction of two convex term, it should be solved by concave-convex procedure [23].
The basic idea of concave-convex procedure is to obtain the optimal solution of non-convex problem by iteratively solving the sub-problem of original problem. Sub-problem is constructed by replacing the concave terms in original optimization function with their one-order Taylor series [30, 36].
Then sub-problem of Eq. (17) is:
Based on Algorithm 2, the sub-gradient of
Given the sub-gradient of
Algorithm of solving concave-convex sub-problem
According to the former analysis, we derive the algorithm of computing transformation matrix
Algorithm of computing transformation matrix
After introducing LRT, we present the proposed algorithm. This algorithm embeds LRT into each iteration of active learning SVM. More specifically, during each iteration, besides updating the classification model, the labeled data samples are used to calculate the transformation matrix
Active learning with low-rank transformation
Active learning with low-rank transformation
As shown in Table 5, labeled samples set
In practice, threshold value
The Time complexity of the proposed method depends on the computational cost of SVM in Algorithm 1 and LRT in Algorithm 4.
As to SVM, we introduce a relatively fast algorithm called LASVM [4]. It requires the number of operations proportional to the number of support vector
When it comes to LRT, the time complexity of Algorithm 2 is the same of asymptotic time of SVD, which is O(
Since the proposed algorithm requires finite times of iteration, and computes one time of
Evaluations
To evaluate the performance of the proposed method, we conduct experiments on several widely used benchmark datasets. All of these datasets come from LIBSVW [7].In order to show the effectiveness of this method, other popular algorithms are used for comparison. The main idea of these algorithms are introduced as follows:
Active learning SVM: standard active learning algorithms, the details of this algorithm is shown in Table 1; Passive learning: randomly selects certain number of data samples in each iteration, this method can be considered as traditional support vector machines; Active learning with principle component analysis (PCA): since the proposed method is based on the manifold assumption [37], we compare it with another manifold learning method. This method applies PCA to extract main features of unlabeled data before active learning process [8, 11, 26].
Statistic indexes of error rates on DNA 1 vs others over 100 runs
Statistic indexes of error rates on DNA 2 vs others over 100 runs
Average error rates on DNA 1 vs others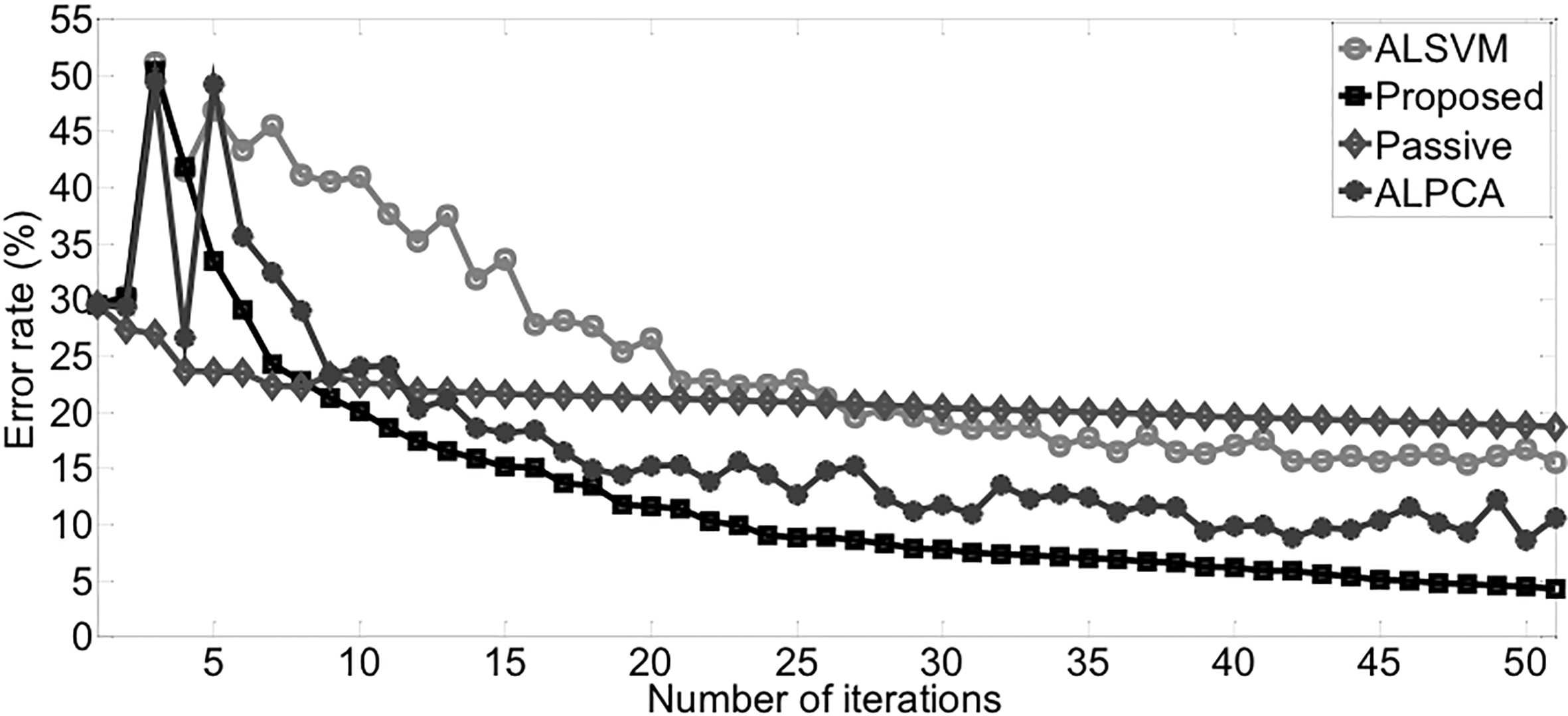
Firstly, we evaluate our method on DNA dataset [7]. DNA dataset contains 2000 data samples of 3 different classes. We conduct three experiments on this dataset, each experiment distinguishes one class of data samples. We reset the labels of data samples and convert the problem to binary classification. This strategy has been widely used when SVM is applied to multi-classes classification problems [19].
Statistic indexes of error rates on DNA 3 vs others over 100 runs
Statistic indexes of error rates on DNA 3 vs others over 100 runs
Average error rates on DNA 2 vs others.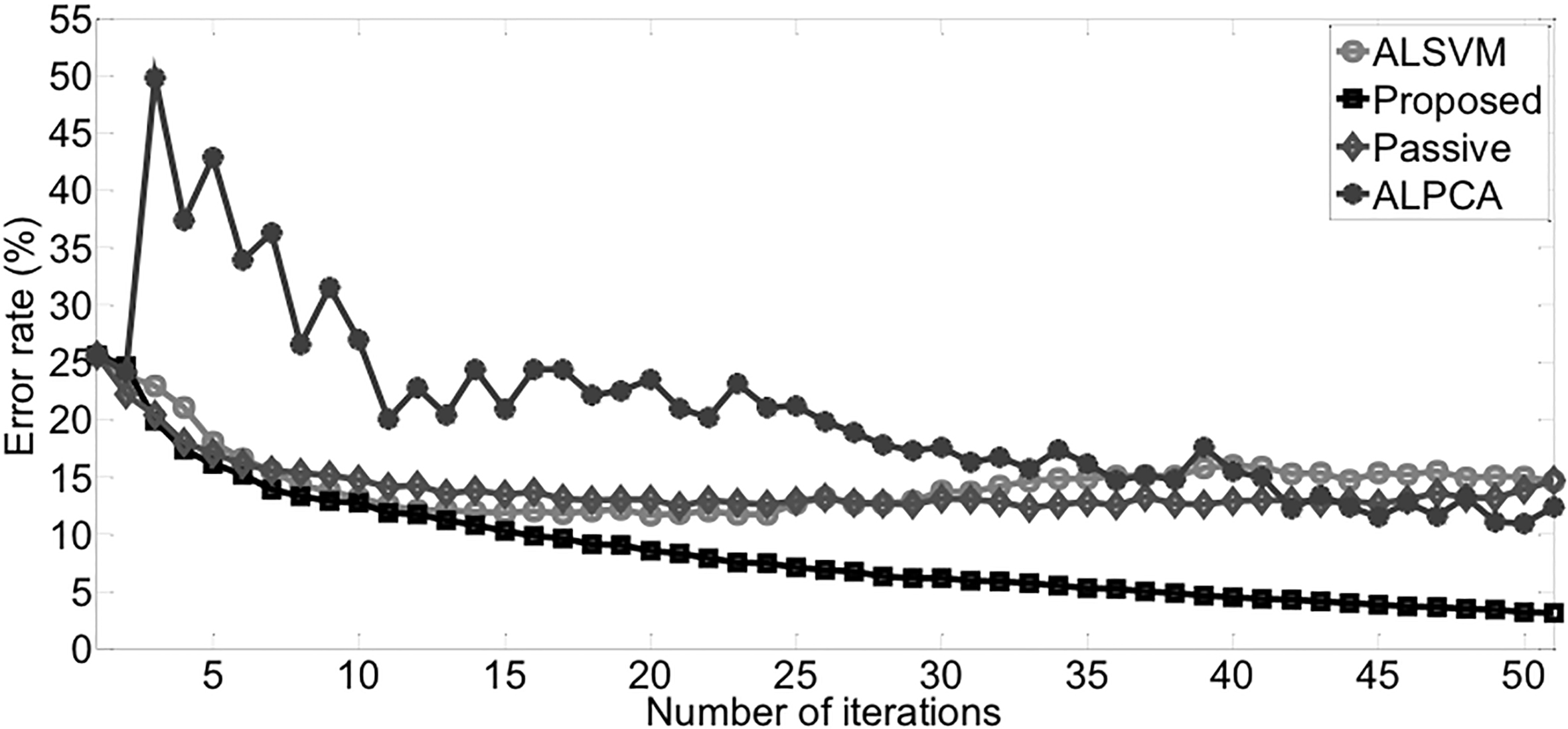
Average error rates on DNA 3 vs others.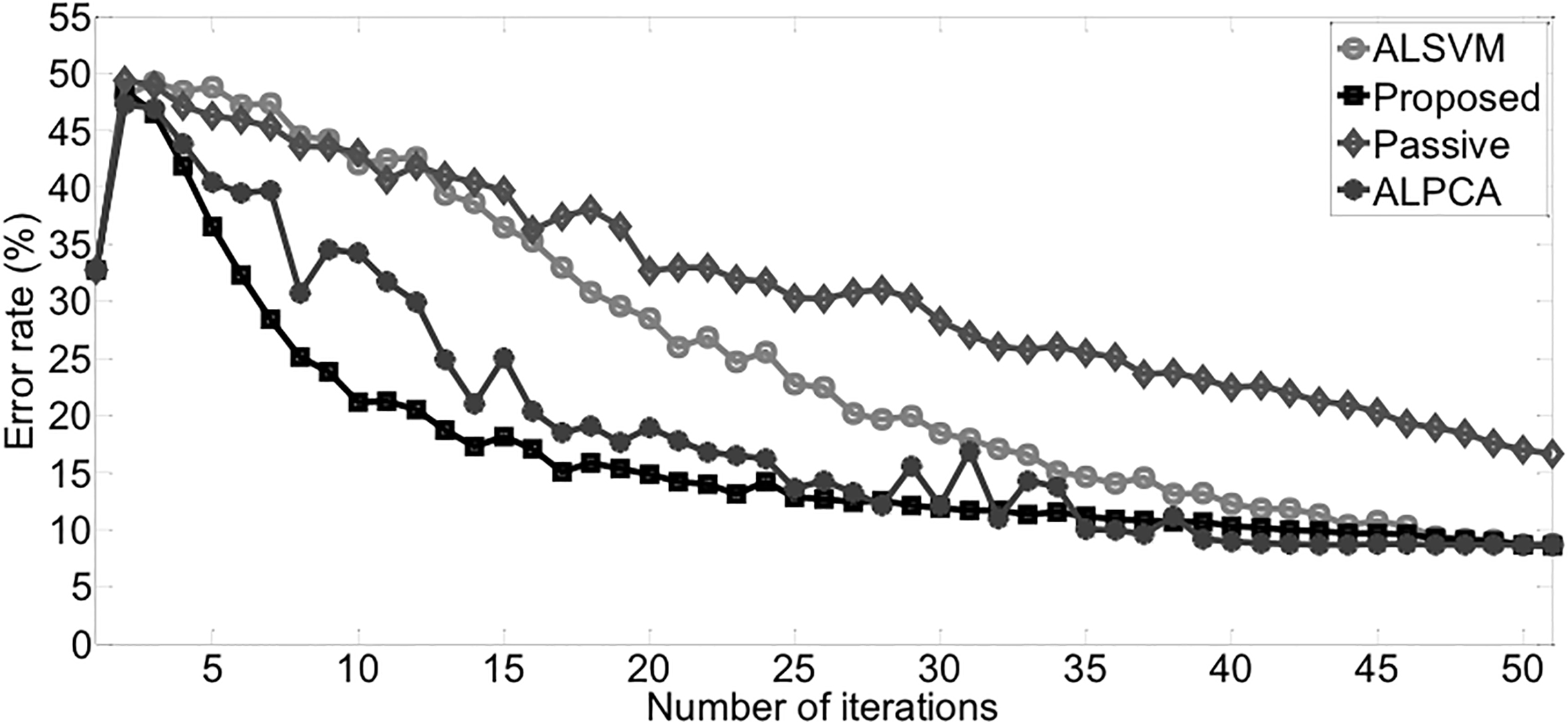
Original dataset is divided into training set and test set. The labels of original training set are hid and only the selected samples will be labeled during training process. Hyper-parameter
In each run, we choose 10 data samples as initial labeled set, and during each iteration, 5 data samples are selected from unlabeled data pool. We run these algorithm 100 times, and draw the average error rates according to number of iterations.
Figure 2 shows the results of recognizing class
Four statistics indexes of error rates after fiftieth iteration are shown in Table 6, these results are calculated from the final error rates over 100 runs. Bold face means the best performance. STDEV means the standard deviation of the final error rates.
Statistic indexes of error rates on w5a over 100 runs
Statistic indexes of error rates on w5a over 100 runs
Statistic indexes of error rates on letter D vs O over 100 runs
Statistic indexes of error rates on letter M vs N over 100 runs
Average error rates on w5a.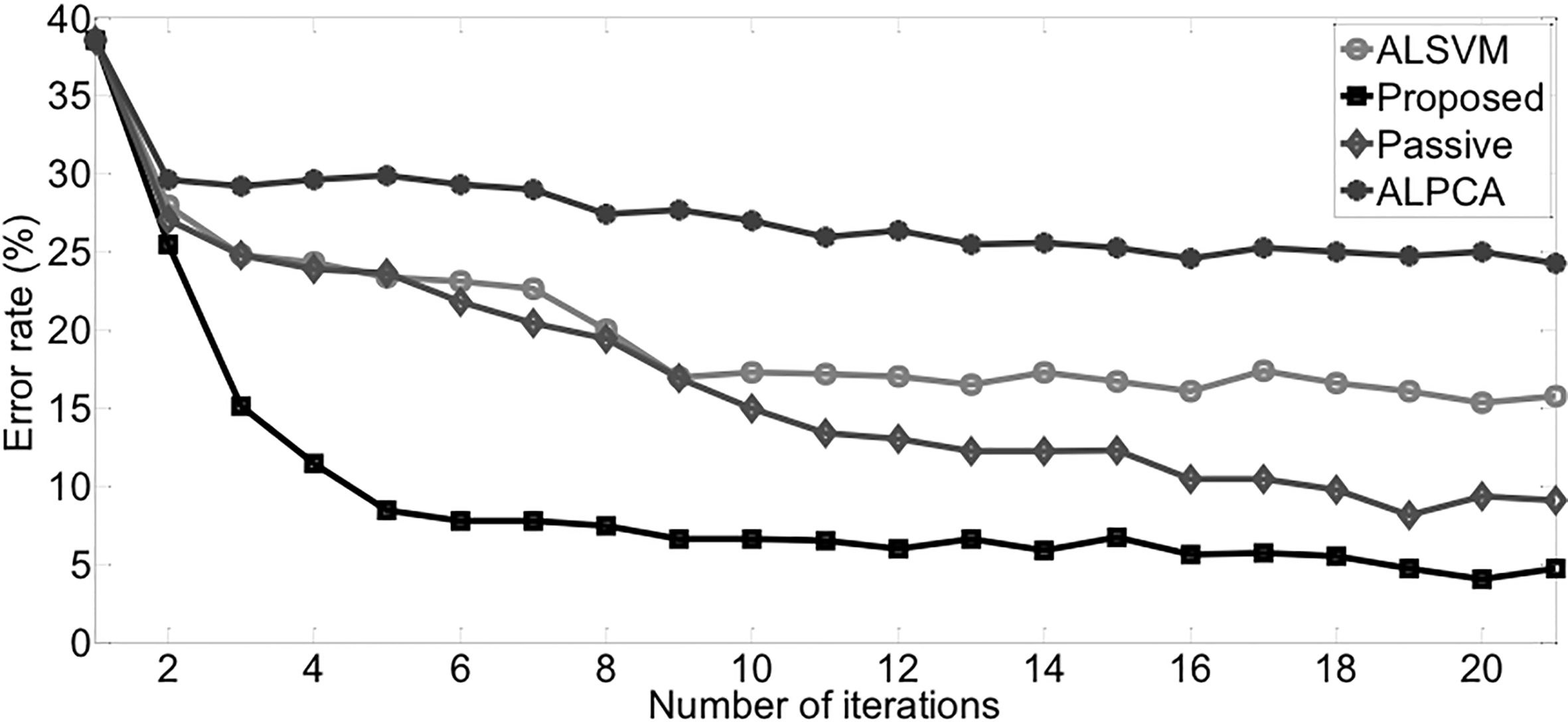
Table 6 shows that the proposed method is superior to other methods in three indexes, which indicates that besides achieving best classification performance, proposed method is more robust to initial state than other methods.
The average error rates of classifying class 2 are shown in Fig. 3. The proposed method obtains the fastest convergence speed and the lowest average error rate. Table 7 shows that proposed method stands out from other algorithms in all of four indexes.
DNA 3 vs others
Average error rates on letter D vs O.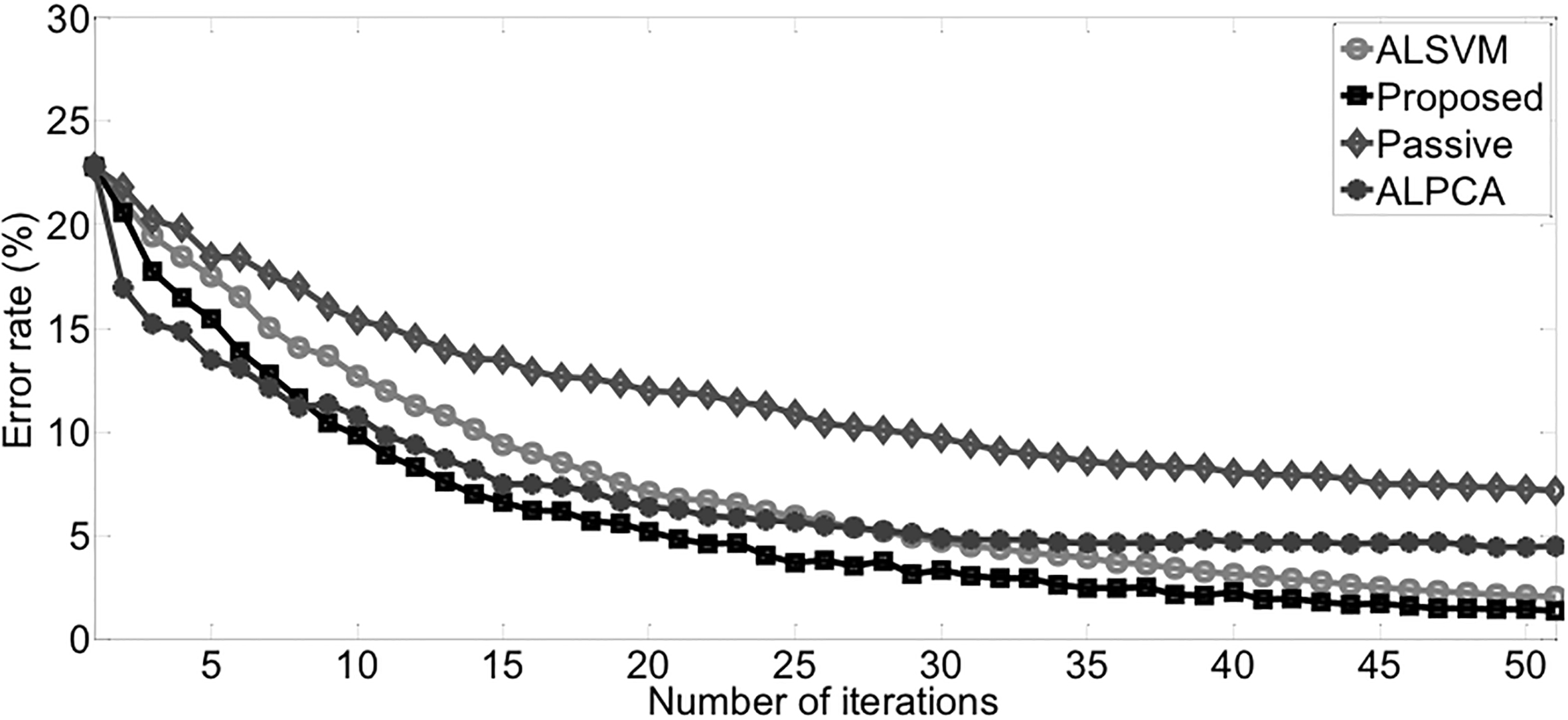
Average error rates on letter M vs N.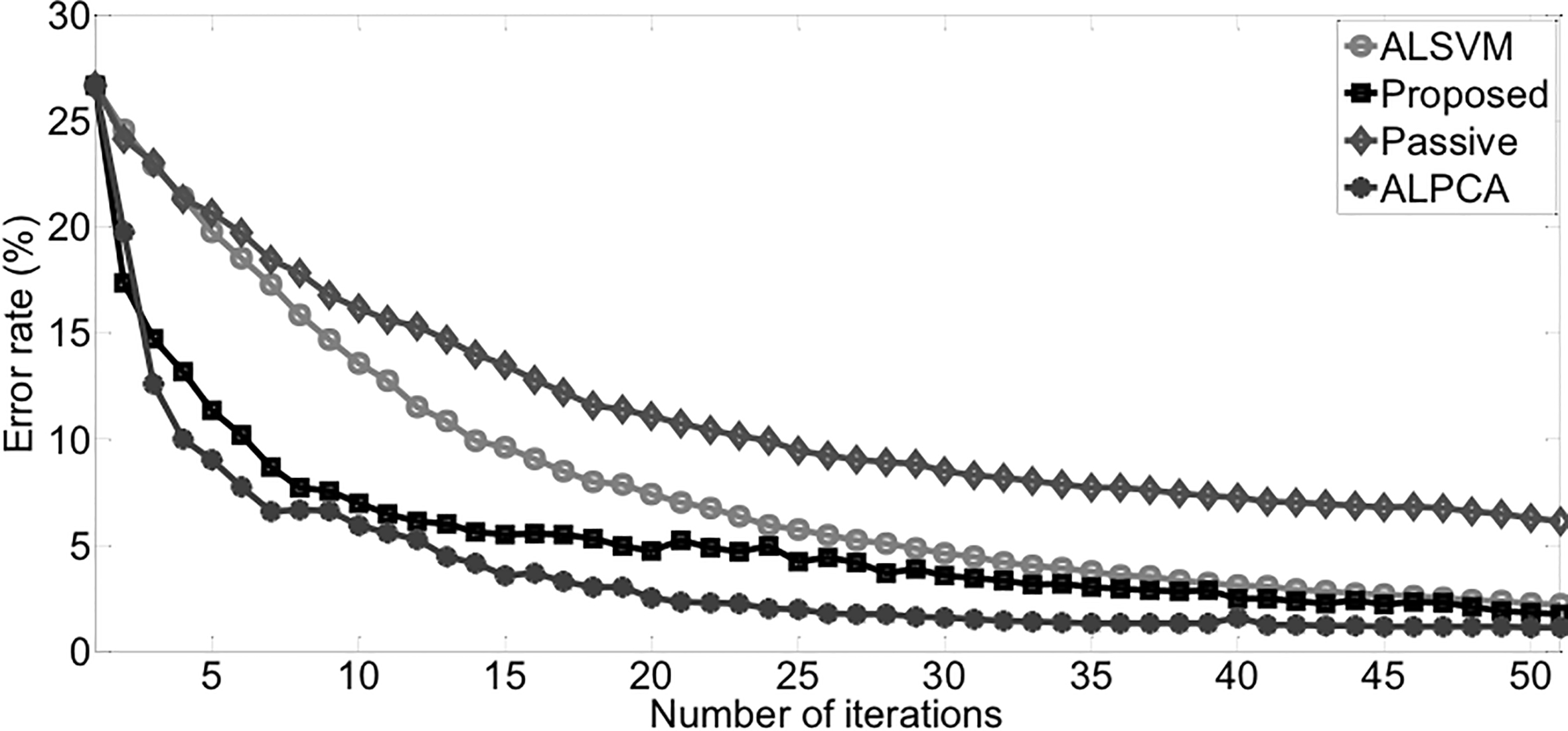
Figure 4 shows the results of DNA 3 vs others. In this experiment, the average error rate of proposed is slightly lower than ALPCA and ALSVM. This experiment demonstrates the advantage of active learning over passive learning methods. Based on the MEAS and STDEV in Table 8, proposed method achieves the best robustness over other methods.
Results of experiments on other datasets over 20 runs
W5a is a text classification dataset, where label means whether a web page belongs to a certain category or not. The dataset contains 9888 samples, and each sample has 300 features of 0 or 1 [21]. We choose 5 data samples of each class for initialization and during each iteration, 5 most uncertain instances are labeled. The parameters are set as:
The results of this experiment are shown in Fig. 5 and Table 9. Proposed method also beats other algorithms from second iteration and it achieves the lowest standard deviation. Once again, the proposed algorithm is more robust than other methods with respect to initial labled data.
Experiments on letter
This experiment is conducted on letter dataset. It is a handwritten characters recognition dataset with 20000 data samples of 26 different characters [7]. In this experiment, we choose two subsets of letter: ‘D’ vs ‘O’ and ‘M’ vs ‘N’.
We also run the experiments 100 times, each time with 50 iterations. The hyper-parameters are
Letter D vs O
The results of letter D vs O are shown in Fig. 6 and Table 10. The proposed method slightly surpass other methods in classification performance and robustness. Similar to the experiment on DNA 3 vs other, active learning methods achieve lower error rate and better robustness than passive learning.
Letter M vs N
Figure 7 and Table 11 present the results of experiment on letter M vs N. ALPCA achieve the best classification performance and robustness on this dataset. Proposed method is not far behind. This experiment indicates that taking advantage of the data distribution information can improve the performance of active learning.
Other datasets
Final error rates and statistics indexes of different methods on some other datasets [1, 7] are shown in Table 12. These experiments are all binary classification and the hyper-parameters are also listed.
In Table 12, each cell has two numbers, where the upper one is the average of final error rates and the other is the standard deviation of the final error rates. From the table, we can find out the proposed method achieves lowest error rate on 13 out of 18 datasets, and lowest standard deviation on 12 out of 18 datasets. The results indicate that proposed algorithm obtains better generalization ability and are more robust than other methods. From the table, we can also draw the conclusion that active learning beats passive learning in most of scenarios.
Conclusion
We propose a novel active learning algorithm to improving the performance and robustness of active learning. The algorithm is designed based on an analysis of the limitations of current methods. In particular, LRT can project data to a feature space where data samples belonging to different classes are easier to be separate. Training the classifier on projected data will improve the performance of final SVM model.
Empirically, we have demonstrated that three widely used algorithms are insufficient when compared with proposed method. Applying our new algorithm to more than 20 standard datasets, we have shown that our algorithm effectively improves the classification accuracy. In addition, statistic indexes show our algorithm also improves the robustness of final classifier to initial state.
Future work will entail investigating other data transformation methods, e.g. adaptive manifold learning [37], to lower the computational complexity of our algorithm, and further explore how to utilize the information of labeled data and unlabeled data at the same time.