
Abstract
Many contemporary data sources in a variety of domains can naturally be represented as fully-dynamic streaming graphs. How to design an efficient online streaming clustering algorithm on such graphs is of great concern. However, existing clustering approaches are inappropriate for this specific task because: (1) static clustering approaches require expensive computational cost to cluster the graph for each update and (2) the existing streaming clustering neither could fully support insertion/deletion of edges nor take temporal information into account. To tackle these issues, in this work, firstly we propose an appropriate streaming clustering model and design two new core components: streaming reservoir and cluster manager. Then we present an evolution-aware bounded-size clustering algorithm to handle the edge additions/deletions. It requires the clusters to satisfy the maximum cluster-size constraint, and maintains the recency of edges in the temporal sequence and gives high priority to the recent edges in each cluster. The experimental results show that the proposed BSC algorithm outperforms current online algorithms and is capable to keep track of the evolution of graphs. Furthermore, it obtains almost one order of magnitude higher throughput than the state-of-the-art algorithms.
Introduction
With the rapid development of information technology, the amount of network-structured data sets in various applications are growing explosively, and the relationships between various entities are becoming increasingly large and complex. Graph, as a generic data structure, can be a good representation of the complex relationships among entities of networks [10]. In practice, many real-world graphs are fully-dynamic where the relationships among entities change along with time rapidly such as social and web networks. In such dynamic scenario, they can be represented as streaming graphs in which edges/vertices insertions and deletions occurring in an arbitrary (even adversarial) order [19, 3]. To understand the structures of graph and capture the rapid change in real-time, effective and efficient online graph clustering methods are of great demand.
Graph clustering [5, 6, 17] is one of the most important issues in graph mining. Its aim is to group the vertices into clusters with dense intra-cluster link and sparse inter-cluster connectivity. There are numerous studies on graph clustering in the literature but two challenges exist in previous studies. The first challenge of this work is that most networks in practice are large-scale and in a streaming fashion. These real graphs might contain millions or even billions of vertices/edges and fully-dynamic, but most of existing algorithms mainly focus on clustering in an offline setting on the premise that the entire graph is given beforehand [13, 14]. Several types of static clustering algorithms, e.g., overlapping [6], non-overlapping [7], hierarchical [20], multi-level [17] clustering have been studied widely. However, current offline methods are not suitable for the fully-dynamic streaming graphs which involve the additions and deletions of vertices/edges, because they require to re-cluster the entire graph for each update which leads to the expensive computational cost. Furthermore, the newly obtained clusters may significantly differ from the preceding ones, but they are supposed to be smooth with the previous clusters, as offline methods can not react in a continuous way to the smooth changes in the graph. Another challenge is that existing streaming clustering algorithms do not fully support insertion/deletion of edges while taking temporal priority into account. Incorporating the ability to delete edges is important in a fully-dynamic streaming setting, for example when clustering is performed over a sliding window (i.e., edges are deleted from the tail end of the sliding window). As graphs encountered in real applications are often fully-dynamic, temporal priority is of crucial importance to capture the formation of clustering structures and track the cluster changes in real time. If the method does not consider the importance of the arrival sequence, it is not capable to be sensitive to evolving events. The challenge is how to incrementally capture the clustering evolution as it happens. The intuition is to use edge recency as a measure of weight to study the process of graph clusters’ evolution.
Addressing the above issues, the streaming version of clustering model is preferred for such kind of graphs, and it should process a stream of edge insertions/deletions in an incremental manner, where each edge can be processed only once, and extremely fast under the limited memory [4, 11, 23]. To satisfy the memory limit, the common practice is to use the specific time-window to control the size of streams and fix it into a manageable size and give approximate results. Meanwhile, the model should support both static large-scale graphs (stored as a list of edges streaming from storage) and streaming graphs. Thus, the clustering algorithm designed to process fully-dynamic streams is also applicable for static large-scale graphs.
In this paper, we propose a streaming clustering model and devise an incremental clustering algorithm which is suitable for fully-dynamic streaming setting where both edge additions and deletions are allowed. It is capable of maintaining a high quality clustering and also can capture the evolving events (namely, evolution-aware) while updates are performed on the fly. Specifically, our contributions can be summarized as follows:
We propose an appropriate streaming clustering model and design two new core components: streaming reservoir and cluster manager. Streaming reservoir is designed to keep the sampled graph (i.e., a set of finite non-empty clusters) up-to-date in real time and make it satisfy two properties: conformity and maximality. Meanwhile, cluster manager creates a new augmented union-find data structure to store, find, merge and remove clusters efficiently. We present an evolution-aware bounded-size clustering algorithm for fully-dynamic streaming graphs in which edge insertions and deletions are allowed under specific time-window settings (i.e., to satisfy the memory limitation). It treats individual connected components as clusters subject to a constraint on the maximum cluster-size. Furthermore, it keeps the recency of edges in the temporal sequence and gives high priority to the recent edges in each cluster of the sampled graph such that it is capable to capture the clustering evolution on the fly. We conduct quality and throughput experiments on synthetic and real-world networks. The results show the proposed BSC algorithm outperforms current online clustering algorithms in terms of the clustering quality. In addition, our algorithm performs almost one order of magnitude higher throughput than the state-of-the-art algorithms.
The remainder of the paper is organized as follows. We give the problem definition in Section 2, and then the existing work of streaming graph clustering are provided in Section 3. In Section 4 we outline the proposed streaming clustering model, and provide a detailed description of the associated update operation. Experimental evaluation on both synthetic and real-world networks is given in Section 5. The paper is concluded and future work is presented in Section 6.
We focus on the problem of bounded-size clustering in a fully-dynamic streaming graph where edge insertions and deletions are allowed. Khandekar et al. [15] have proved that the BSC (bounded-size clustering) problem is NP-hard. Thus it motivate us to develop a heuristic approximation method for this problem. Firstly, we give the definition of fully-dynamic streaming graph. Formally, for any discrete time-stamp
For simplicity, we do not allow the same edge to appear multiple times in the streams and do not execute deletion if the edge does not exist in the model.
Secondly, the bounded-size clustering problem we address is to partition the vertices into clusters of size at most a given budget and minimize the total edge weights across the clusters on the fully-dynamic streaming graphs. There exists a constraint on the maximum number of vertices in each cluster denoted by
the size of each cluster is bounded: the total edge-weight across the clusters is minimized and the sum weight of the intra-clusters is maximized under the maximum cluster-size constraint:
each cluster contains at most one individual connected component, i.e., there is a path from
Concretely, we can see that these three restrictions make a clustering satisfy: (i) the first constraint (i.e., conformity), which means each cluster should satisfy the maximum cluster-size constraint; (ii) the second constraint (i.e., maximality), which means the sum weight of the intra-cluster of each cluster is maximized and no more edges can be added to each cluster without violating the constraint; and (iii) each cluster contains at most one connected component.
Graph clustering is a fundamental optimization problem with applications to a variety of areas like recommendation systems, image segmentation, online marketing analysis, discovering communities in social networks, etc. Most of contemporary algorithms are suitable for an offline setting in which the entire graph is given beforehand. The most well-known offline clustering/partitioning algorithm is METIS [14]. It is based on the multilevel graph partitioning paradigm and is shown to produce high-quality (balanced) partitions. However, when used in streaming graph, it is generally inefficient since offline algorithms need to re-cluster all the edges for each new update. For the streaming setting, there exist two research baselines to handle streaming graph which are denominated as balanced k partitioning [22, 21, 25, 18] and bounded-size clustering [9, 15] problems, respectively. They look similar but turn out to have different emphasis. The balanced k partitioning assumes that the number of clusters is an input parameter, and seeks to minimize the number of edge cut such that the partitions have nearly equal size. Its aim is not network analysis but the preprocessing of graphs for parallel computing tasks. It is not our focus of this work and the reader can refer to [22] for more detail.
Unlike balanced k partitioning problem which needs prior knowledge of cluster number and balances each cluster evenly, the bounded-size clustering problem uses a different cluster constraint, i.e., a maximum cluster-size as an input and the balance constraint is removed. [29] solved the graph clustering problem in an online fashion using an Erdős–Rényi mixture model, but it does not allow deletion or modification of the graph. Also it does not scale well with the number of clusters. Aggarwal et al. [1] designed the hash-compressed micro-clusters and found structurally similar graphs in a stream of large number of small graphs. However, their algorithm does not deal with edge deletions, making it not applicable to cluster streaming graphs in the face of sliding windows. [2] utilized constraint reservoir sampling and proposed an outlier-detection GOutlier algorithm for detecting temporal outliers in graph streams. Their scheme is based on finding multiple vertex clusterings in a streaming graph and only supports edge additions. Besides, this algorithm is likely to yield a clustering with many small clusters. In [26] the algorithm was used for dynamic clustering in weighted graph streams. A local weighted-edge-based structure is devised to describe a local homogeneous region and is computed efficiently by maintaining top-
The structural-sampler algorithm proposed in [9] samples over the edges in the random order and discards the edges exceeding a sample threshold
To the best of our knowledge, there are no recent methods that could track the changes of clusters in real time and make it always satisfy maximality and conformity criterions [9] to handle fully-dynamic streaming graph (i.e., a sequence of edges additions and deletions in arbitrary order). Therefore, we design an appropriate streaming clustering model and propose two core components: streaming reservoir and cluster manager, and present a new bounded-size clustering algorithm to solve those problems. This approach allows for both edge additions and deletions, and is capable to capture the clustering evolution on the fly.
The evolution-aware bounded-size clustering
In this section, first we generalize the streaming clustering model and describe the details of core components. Then, we will describe the new evolution-aware bounded-size clustering (BSC) algorithm.
Main components of the streaming clustering model.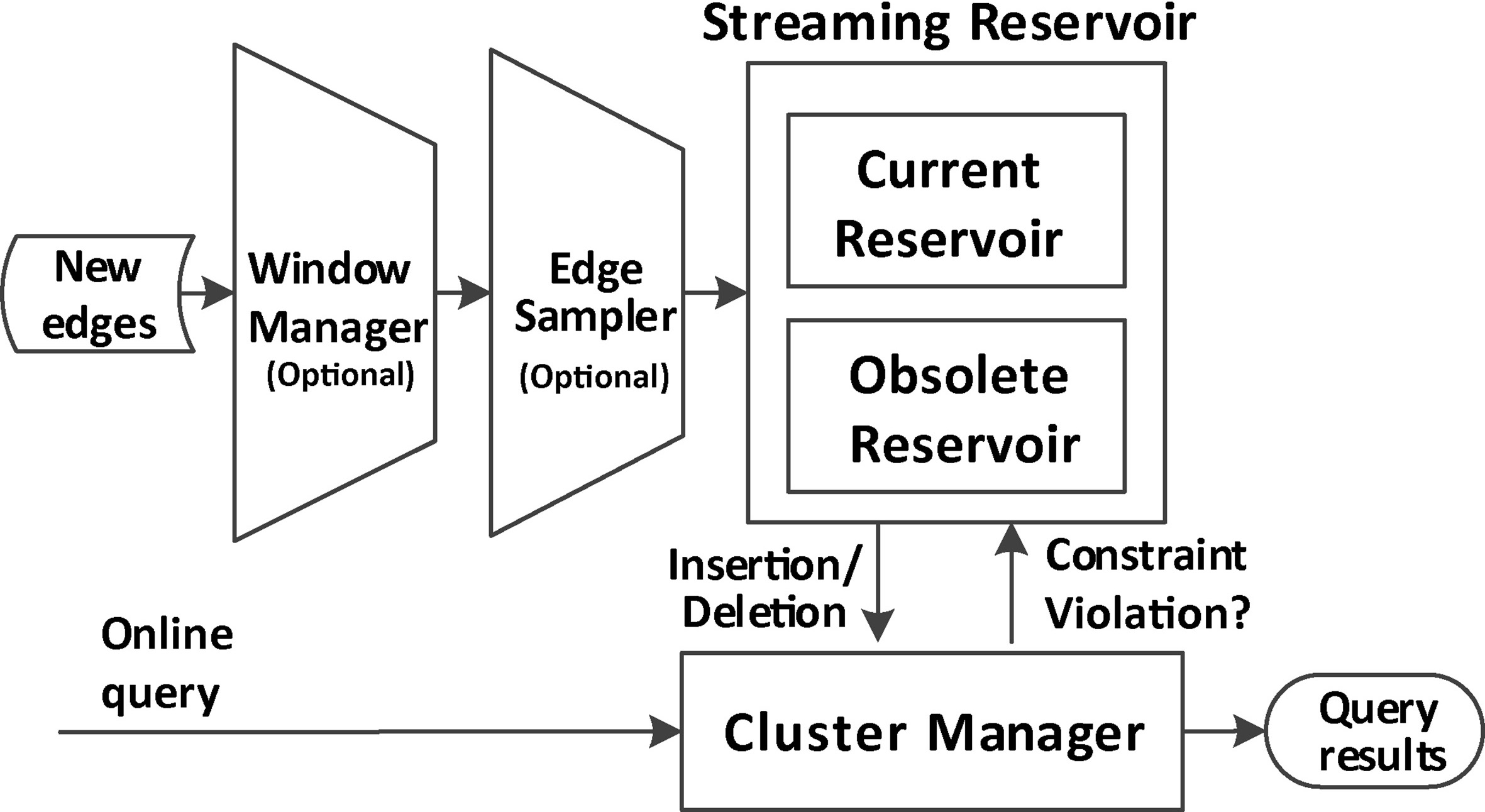
As shown in Fig. 1, the streaming clustering model consists of four components including: window manager, edge sampler, streaming reservoir and cluster manager.
Window manager is a vital component when one needs to maintain a graph over a certain time window and to satisfy the restriction of the limited memory. There exist two classic time-windows, sliding window and tumbling window, to process the streaming data [8]. They usually require a single parameter to limit the amount of edges which only need a fixed amount of memory space. Tumbling window processes the edges in batch modes. Once the window is full, it empty the accumulated edges in the window and start a new window. Sliding window keep the most recent edges of a graph. As new edges continue to stream in, old edges are removed from the time-window. In our model, we mainly focus on sliding window because it does not accumulate edges and process the edge streams in near real-time.
Edge sampler is optional to speed up the clustering process and it requires the user to specify a sampling threshold
In our model, in order to maintain a decent clustering in real time and keep track of the evolution of graphs, we mainly design the new streaming reservoir and cluster manager and we will discuss them in the next section in more details.
New component description
In brief, streaming reservoir is designed to maintain a set of sampled edges and keep the clusters formed by the sampled edges up-to-date, and store the outdated edges so far which need to be recycled at an appropriate time. Meanwhile, cluster manager is devised to create a new augmented union-find data structure to store, find, merge and remove clusters efficiently.
The evolution-aware streaming reservoir.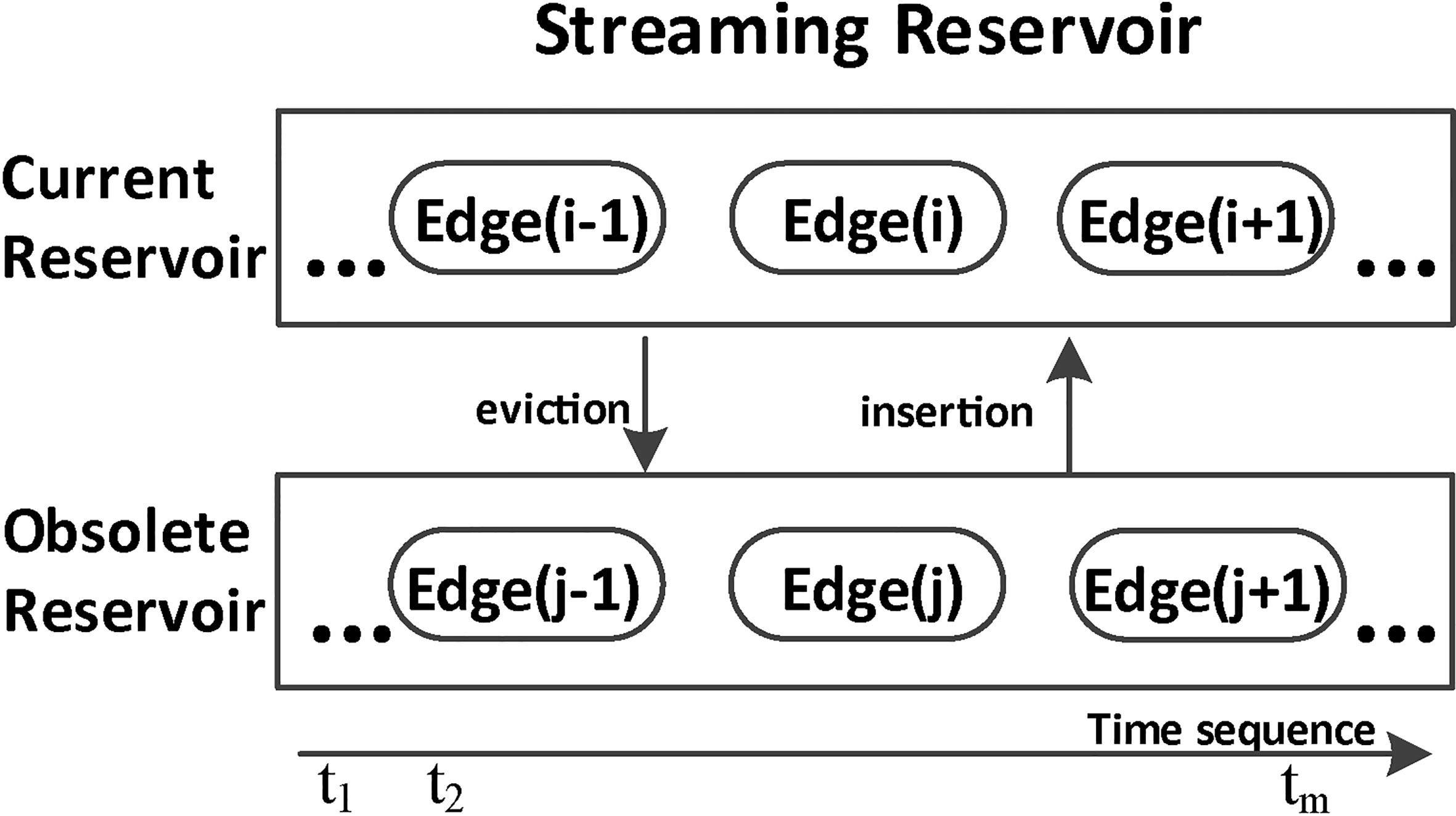
As shown in Fig. 2, streaming reservoir maintains two sub-reservoirs: current reservoir and obsolete reservoir, and we treat connected components formed by the currently sampled edges in current reservoir as the sampled graph. Streaming reservoir is configured in this way in order to make the sampled graph up-to-date and satisfy two properties: conformity and maximality. Conformity means that each cluster of the sampled graph satisfies the maximum cluster-size constraint. Maximality means that no more edges can be added to the sampled graph without violating the constraint and it makes sure that as many edges as possible are sampled into each cluster of sampled graph. The edge-recycling mechanism can guarantee that the sum weight of the intra-cluster of each cluster is maximized. Without edge-recycling, the maximality will not be satisfied. Now we give the formal definitions as follows:
Cluster manager
The union-find data structure is quite simple yet efficient to model a collection of disjoint sets (i.e., connected components). Hence, we utilize it in cluster manager to store, find, merge and remove clusters efficiently. Note that some dynamic connectivity data structures were proposed [24] for fully-dynamic graph connectivity. However, the connectivity query (i.e., whether two vertices are connected) is not the main task of the cluster manager.
Cluster manager is configured to receive edges from the streaming reservoir to guarantee that the maximum cluster-size constraint is satisfied and it creates the new union-find data structure to store, find, merge and remove clusters efficiently. Furthermore, cluster manager needs to keep track of changes in the union-find structure in order to check whether the edge update violates the maximum cluster-size constraint or not. Compared with [9], we create the up-tree union-find structure which maintains linked lists of vertices belonging to different clusters, and each element of linked lists points to the corresponding vertex in the up-tree structure. Meanwhile, we augment the union-find data structure to store the the actual cluster-size of each vertex in the linked lists.
The up-tree union-find data structure in cluster manager. (a) The initial up-tree structure formed by the edges received so far. (b) The up-tree structure and the number of vertices belonging to the same cluster for each vertex are updated when the new edge stream in.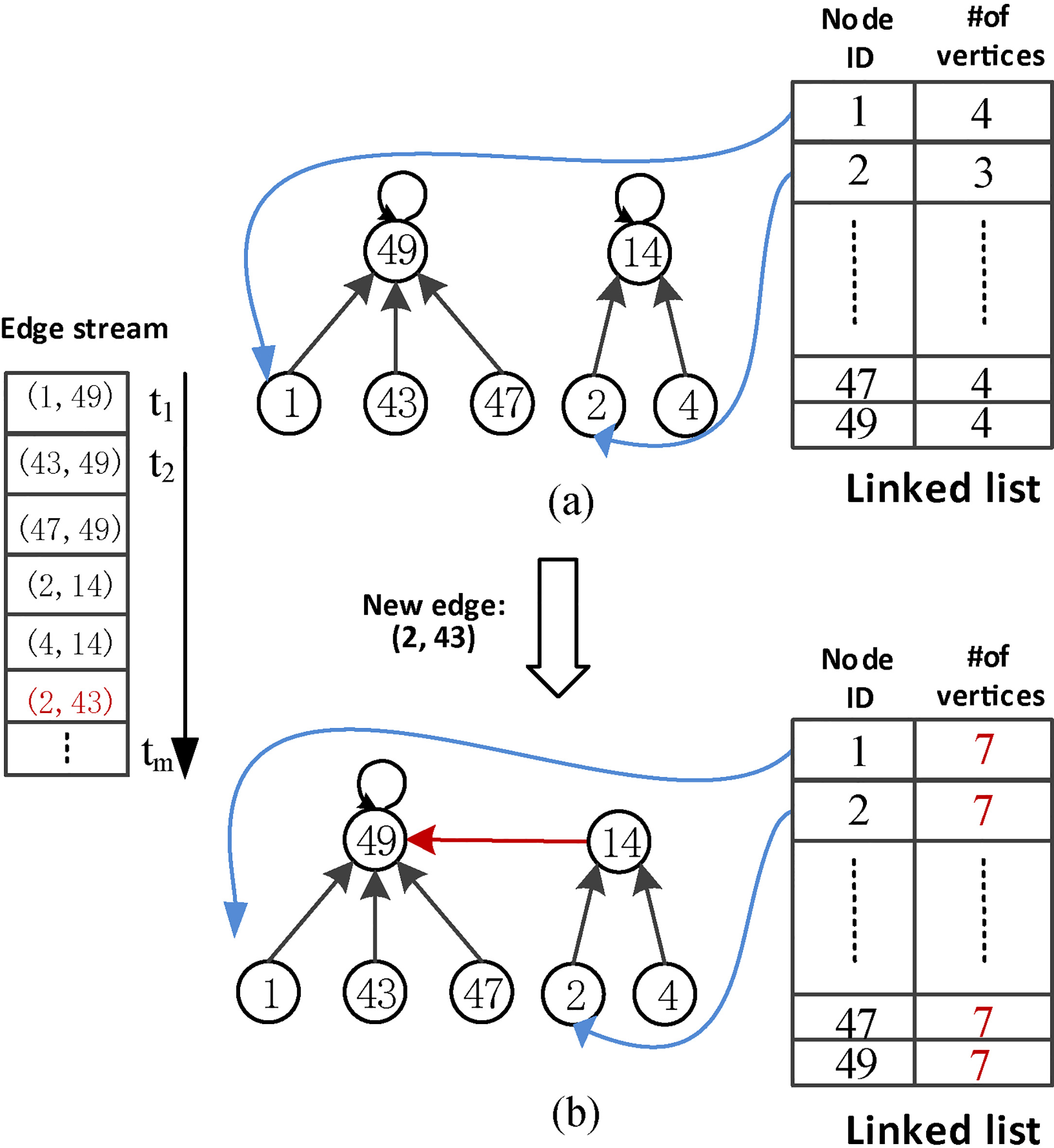
Once the new edge is transmitted to cluster manager, we construct the up-tree union-find structure and the vertices in the same up-tree should belong to the same cluster. The basic operations of cluster manager can be described as follows:
For the query operation, we need to find which cluster a given vertex belongs to, and it is efficient to access to the vertex in the up-tree structure and climb up the up-tree until we reach the root. The index of root is the cluster ID of the vertices in the linked-list. For the edge removal operation, we design a new re-cluster method. First it breaks the cluster apart into individual vertices by disconnecting them in the up-trees, and then rebuilds the up-trees using all edges existing among the affected vertices. This method can efficiently re-construct the corresponding edges chronologically by using the up-tree structure of the linked list. For the merge operation, if two clusters are merged by the new edge, we make the root of one up-tree as a child of the root of the other cluster. Meanwhile, we calculate the actual cluster-size of each cluster and check whether it exceeds the maximum cluster-size. If it occurs, we need to remove the oldest edges successively until it satisfies the cluster-size constraint.
A concrete example illustrates the construction of linked list and up-tree structure in Fig. 3. Initially, we construct the up-tree union-find structure by the edge streams {(1,49), (43,49), (47,49), (2,14), (4,14)}. When the new edge (2,43) arrives, two clusters are merged by the edge and we make the root (node id: 14) of one up-tree as a child of the root (node id: 49) of the other cluster. Meanwhile, we calculate and update the actual cluster-size of each cluster and check whether it exceeds the threshold. If so, it is finished, otherwise, we need to delete the edges from old to new and invoke the edge removal operation iteratively until satisfying the cluster-size constraint.
Besides, the clustering queries are sent directly to cluster manager which responsively produces query results. The queries can be divided into three types: 1) Given a vertex
Based on the streaming clustering model, we propose the evolution-aware bounded-size clustering (BSC) algorithm. The algorithm executes an edge update process each time a new edge update is received. The edge update includes the edge insertion and deletion. The following parts will describe the insertion process and deletion process, respectively.
Insertion process
As shown in Algorithm 4.3.1, the BSC algorithm executes the insertion process each time a new edge
The reason for the maximality restoration is that by eliminating edges from the sampled graph during the conformity restoration, the maximality property of the sampled graph may no longer be satisfied. Accordingly, the maximality restoration ensures the maximality of the sampled graph by adding the eligible edges from obsolete reservoir to current reservoir. After the two restoration steps, we can guarantee that the sampled graph meets the conformity and maximality criterions, and then the process updates the corresponding structure in current reservoir, obsolete reservoir and cluster manager.
[!h] Insertion process of the BSC algorithm.[1] New edge:
[!h] Deletion process of the BSC algorithm.[1] Edge to be deleted:
Algorithm 4.3.1 shows the deletion process of the BSC algorithm. It executes a deletion process each time an edge is to be deleted. The edge to be deleted might be either in current or obsolete reservoir. Firstly, the method determines whether the edge is in obsolete reservoir. If so, the edge can be deleted directly. Otherwise, the edge should be removed from current reservoir and it also needs to be deleted from the augmented union-find structure in cluster manager. Notice that deleting an edge from current reservoir might cause it no longer maximal, so it will invoke the maximality restoration process which is different from insertion process.
As a result, the method adds those eligible edges to current reservoir and cluster manager. Thereby the maximality of the sampled graph is restored.
Table 1 shows the analysis of the time complexity. For the sake of brevity, we assume that the size of sliding window is
Inseration: In the best case of insertion, the BSC algorithm only needs to insert the edge into current reservoir and cluster manager, adding it into current reservoir only needs constant time while inserting it into union-find structure (implement with path compression and union by rank) of cluster manager costs only
Deletion: For the best case of edge deletions, the BSC will delete edges directly from obsolete reservoir and cost
Note that the time complexity of the algorithm heavily relies on the structure of real-world graph streams and the cluster-size constrain B. On one hand, in some graph streams, if the nodes in each cluster are tightly connected but few connections to other clusters, we set the cluster-size constraint B is bigger than any of clusters, then the whole edge streams will be processed in the best case. On the other hand, if the graph streams are highly evolved (e.g., new clusters always appear in a short time while old clusters do not update), it will invoke the conformity and maximality restoration frequently, then the graph streams are processed under the worst case in most instances.
Experimental setup
The experiments are performed on a single machine, with
Datesets
Synthetic graphs
We adapt the dynamic network benchmark [12] to generate a set of step graphs with embedded clustering structures. The changes between step graphs are controlled through the injection of a user-specified number of evolving events of a specific type, e.g., merging/splitting, birth/death. These step graphs share similar characteristics and have the ground-truth embedded in them. In order to produce the streaming edges, we record the generated and extinct orders of edges as their temporal weights, and in this way we can give the quantitative evaluation along with edge updates.
The complexity analysis of BSC algorithm. Note that
is the inverse Ackermann function, where
for any practical value of
The complexity analysis of BSC algorithm. Note that
In our implementation we generate four synthetic networks for four different event types, including merging/splitting, birth/death, expansion/contraction and switching node types, over five time steps. Meanwhile, at each subsequent time step, a number of instances of corresponding events occur. The edge updates are streamed in the system according to chronological order and all the metrics are calculated at specific five snapshots in which ground-truth is known. The step graphs share a number of parameters according to [12] to simulate real-world graphs: the number of vertices:
Merging/splitting (MS) benchmark: we consider the case where merging and splitting events are embedded in the streams. Based on the initial set of clusters, at each subsequent time step, 2 instances of clusters splitting occur, together with 2 instances of existing clusters are merged. Birth/death (BD) benchmark: for this case, we create 2 additional clusters by removing nodes from other existing clusters, and randomly remove 2 existing clusters for each step graph. Expansion/contraction (EC) benchmark: we create rapid cluster expansion and contraction in each step graph where Switching node (SN) benchmark: we generate it to simulate the natural movement of vertices between clusters over time and a low level of overlap and
The real-world graphs are chosen from different domains (e.g., scholar citations, social media, web-crawling graphs). To normalize the timescales in different networks, we use a sequence of integers as associated temporal weights sorted by the arrival timestamps of edges. The descriptions of networks are listed as follows:
Summary of real-world graphs used in the experiments. Abbreviations are described as follows: # of vertices: number of vertices of the end stream; # of edges: number of edges of the end stream; Clustering-coefficient: the average clustering-coefficient for all vertices in the end stream; Diameter: the greatest distance between any pair of vertices
Summary of real-world graphs used in the experiments. Abbreviations are described as follows: # of vertices: number of vertices of the end stream; # of edges: number of edges of the end stream; Clustering-coefficient: the average clustering-coefficient for all vertices in the end stream; Diameter: the greatest distance between any pair of vertices
The enron-employee network: It covers email communication within 151 Enron employees between 1999 and 2003. Vertices in the network are individual employees and edges are individual emails. It is possible to send an email to oneself, thus this network contains self-loops. The citations dataset of High Energy Physics: It collects the related papers from the e-print arXiv in the range of 124 months and covers 27,770 papers with 352,807 citation relations. Note that the number of vertices in this dataset increases gradually with time changes because old papers still appear as they are cited by newer ones. The higgs-reply network: It is a Twitter reply network within five days and this dataset is the most sparse among the four datasets. There are 38,918 vertices and 32,523 edges in total. The web-Notre-Dame network: It is a directed network of hyperlinks between the web pages of the University of Notre Dame in 1999. There are 325,729 vertices and 1497,134 edges in it. Note that the dataset has no timestamps, so we assign a random sequence to the edges in the graph.
For the synthetic graphs in which the ground-truth is already known, we utilize supervised quality metrics (i.e.,
For the large real graphs, we need to choose the sliding window which eliminates the outdated edges outside the time window and adds new edges, and we fix the sampling threshold
Synthetic graph results
In the experiment we calculate the values of metrics over the five-step graphs and the experimental results are shown in Fig. 4. We can draw conclusions as follows:
Quality comparison of different clustering algorithms on synthetic benchmarks containing different types of embedded evolving events.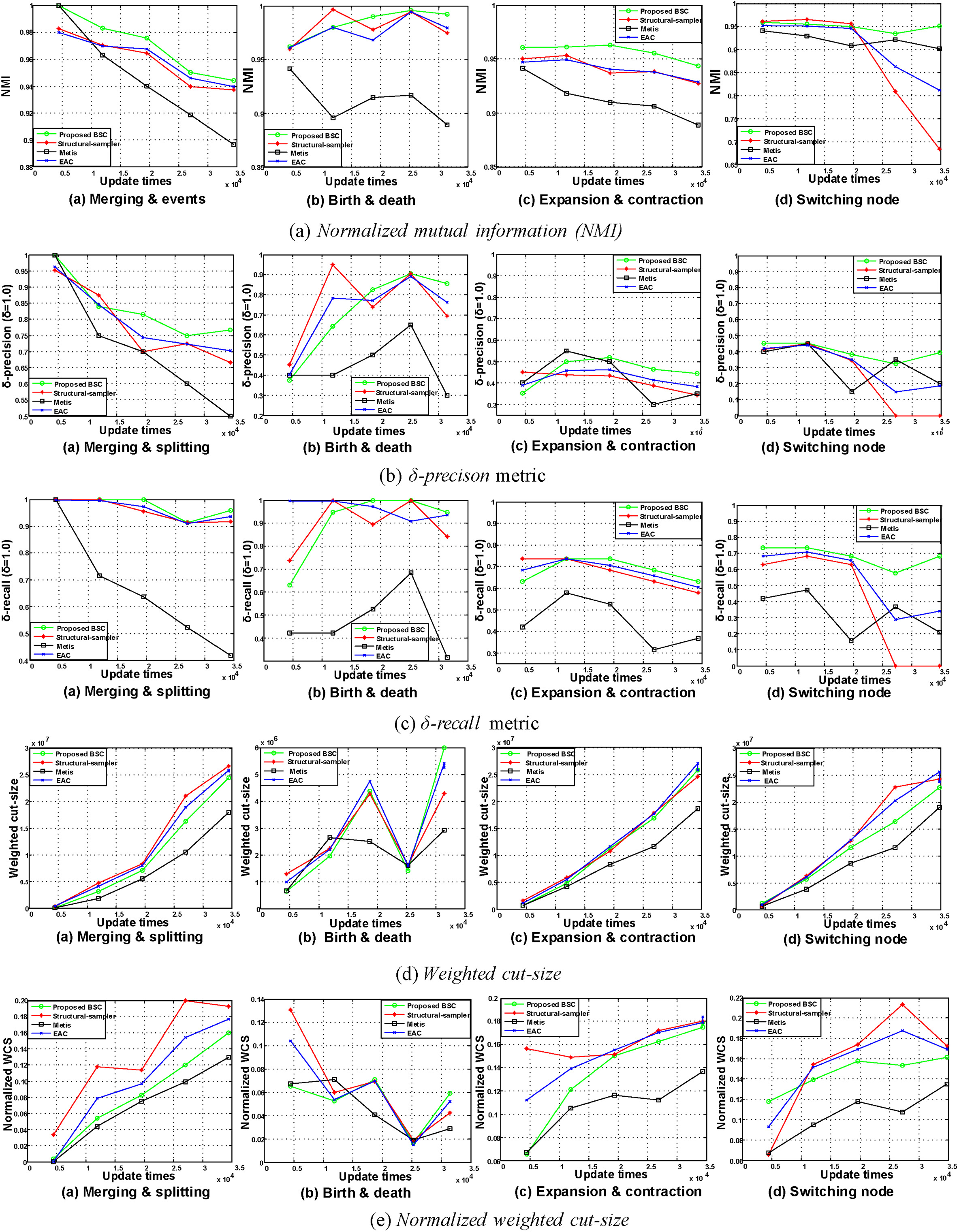
The total charts of these results are conclusive. These four benchmarks exhibit considerable volatility in the clustering structure and associated internal/external edges between time steps. As expected, we observe that in most cases METIS outperform other algorithms in terms of normalized weighted cut-size and weighted cut-size metrics. The reason is that its objective function is to minimize the cut-size and it works in an offline mode. For NMI, For normalized weighted cut-size and weighted cut-size metrics, we can observe that the clustering results produced by the proposed BSC algorithm is second only to METIS. Meanwhile, BSC algorithm outperforms other algorithms in
In order to evaluate the clustering quality in a streaming setting, we take a snapshot every 2000 edge updates and compute the values of quality metrics for each snapshot, then we calculate the “average” value of normalized weighted cut-size over all the snapshots to assess the overall clustering quality. We conduct the experiments on the entire real-world networks with varying the maximum cluster-size using the sampling threshold
Average quality results for the four real-world networks by varying maximum cluster-size with a fixed window size of 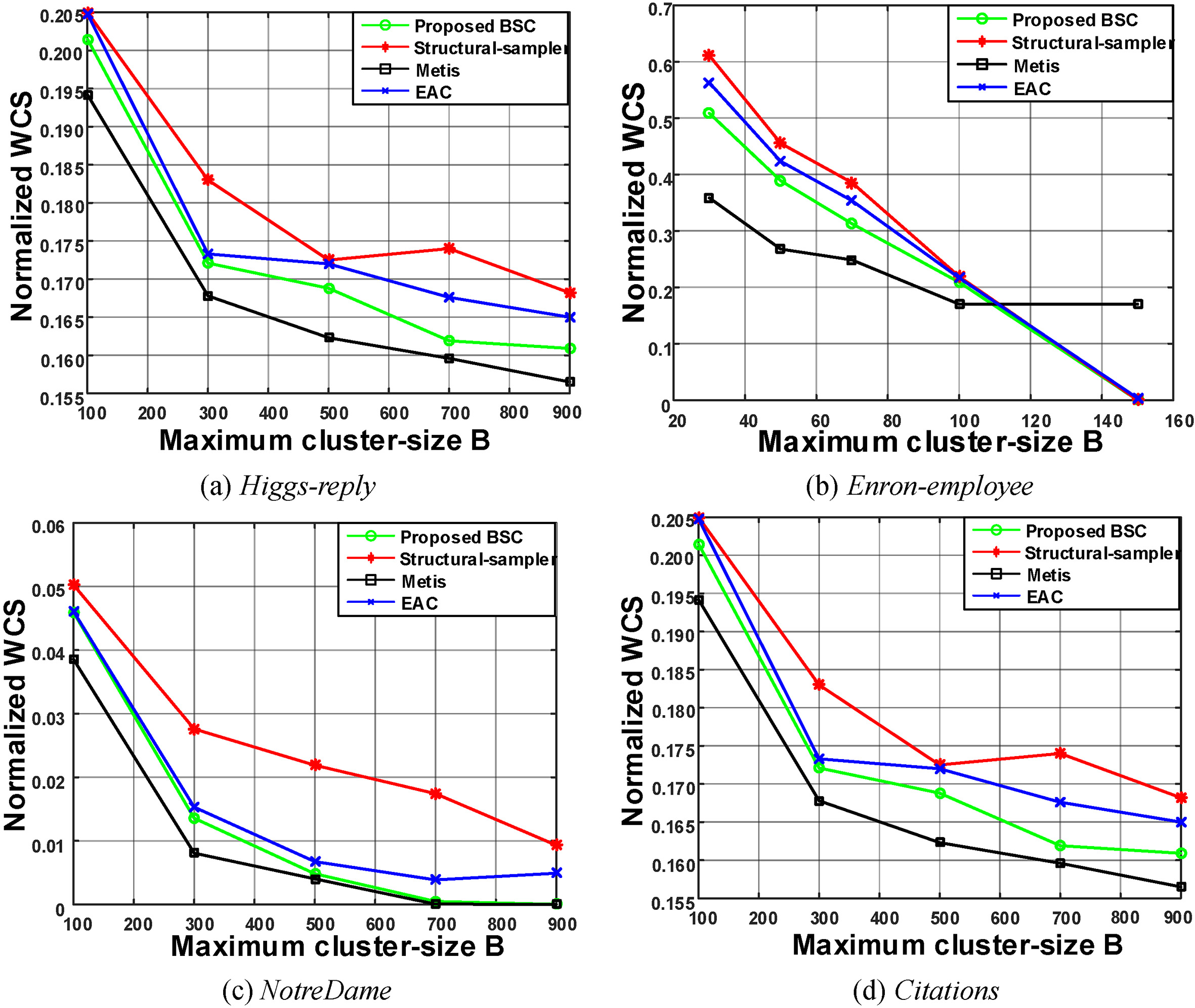
The figure does follow the same trend as the effect on most of the real-world networks. The normalized weighted cut-size decreases steadily with the increase of maximum cluster-size As expected, the clustering results produced by METIS algorithm are the best among all the algorithms in term of normalized weighted cut-size and the proposed BSC algorithm performs better than evolution-aware EAC algorithm. The EAC algorithm gives better clustering quality than structural-sampler algorithm, but still worse than BSC algorithm.
In order to back up why the temporal priority is important in real-world streaming graphs, firstly we analysis the stableness (i.e., the dynamic property of the streaming graph) of the four real-world networks in same way as [9]. The stream is stable if the cluster structure of the graph does not change so much along with edge updates. Conversely, when the new edge often leads to the evolving events (e.g., merge and birth), the stream is unstable. Through the stableness analysis, it shows that higgs-reply network is the most unstable while enron-employee network is the most stable network. Secondly, we randomly shuffle the arrival sequence of each edge in these networks, and then we calculate the quality metrics for the given snapshots. Figure 6 shows the clustering results on enron-employee and higgs-reply networks with a fixed window size of 5000. We compare the results with structural-sampler and then we can draw the conclusions as follows:
The results show that when the stream is very stable and dense such as the enron-employee network, the difference is not significant. The interpretation is that the enron-employee network has obvious clustering structure and most of edges exist within the clusters. In the initial phase, the clusters have already formed and do not change much, and new edges only come into existing clusters so that only the density of the clusters changes, but no much evolving events occur. Conversely, when the stream is less stable, e.g., the higgs-reply network, the clustering results with shuffle sequence are very different from those with natural temporal sequence. We can observe that the values of normalized weighted cut-size have two peak regions along with the natural temporal sequence. Without the temporal information, the shuffle sequence ruins the formation of clustering structures and cannot track the cluster changes accurately. Even though the values of metrics with shuffle sequence are better than the ones with natural temporal sequence, it does not reflect the actual situation.
Thus the observations imply that the proposed BSC algorithm is more powerful when the networks is unstable and continuously evolving (e.g., the online social network).
Throughput is the time usage it takes for an algorithm to calculate the specified clustering queries, and the clustering queries can be randomly generated as we mentioned in Section 4.2. Because the query/update ratio indicates the average ratio of number of queries to number of updates in a time window, we use different query/update ratios to measure the throughputs of the algorithms. We conduct the throughput experiments as follows: firstly, a given number of edge updates are executed, and then the clustering queries are executed. This is done until there are no more edges from the input. Notice that METIS is an offline algorithm and is not applicable to incrementally cluster graphs, because it needs to re-cluster the entire graphs for each query which would decrease the throughput severely. Meanwhile, EAC algorithm does not support the re-insertion operation which would give unfair throughput comparison. Thus, here we compare the system throughput with structural-sampler algorithm which has proved to have a better throughput than METIS and supports the deletion and re-insertion operation. The throughputs of BSC and structural-sampler algorithms are tested on higgs-reply and citations networks and the results are shown in Table 3. Conclusions can be drawn as follows:
Performance experiments for different query/update ratios with a fixed window size of 5000 and the maximum cluster-size of 50
Performance experiments for different query/update ratios with a fixed window size of 5000 and the maximum cluster-size of 50
Evaluation on the selected clustering algorithms on enron-employee and higgs-reply networks with a fixed window size of 5000 and the maximum cluster-size of 50.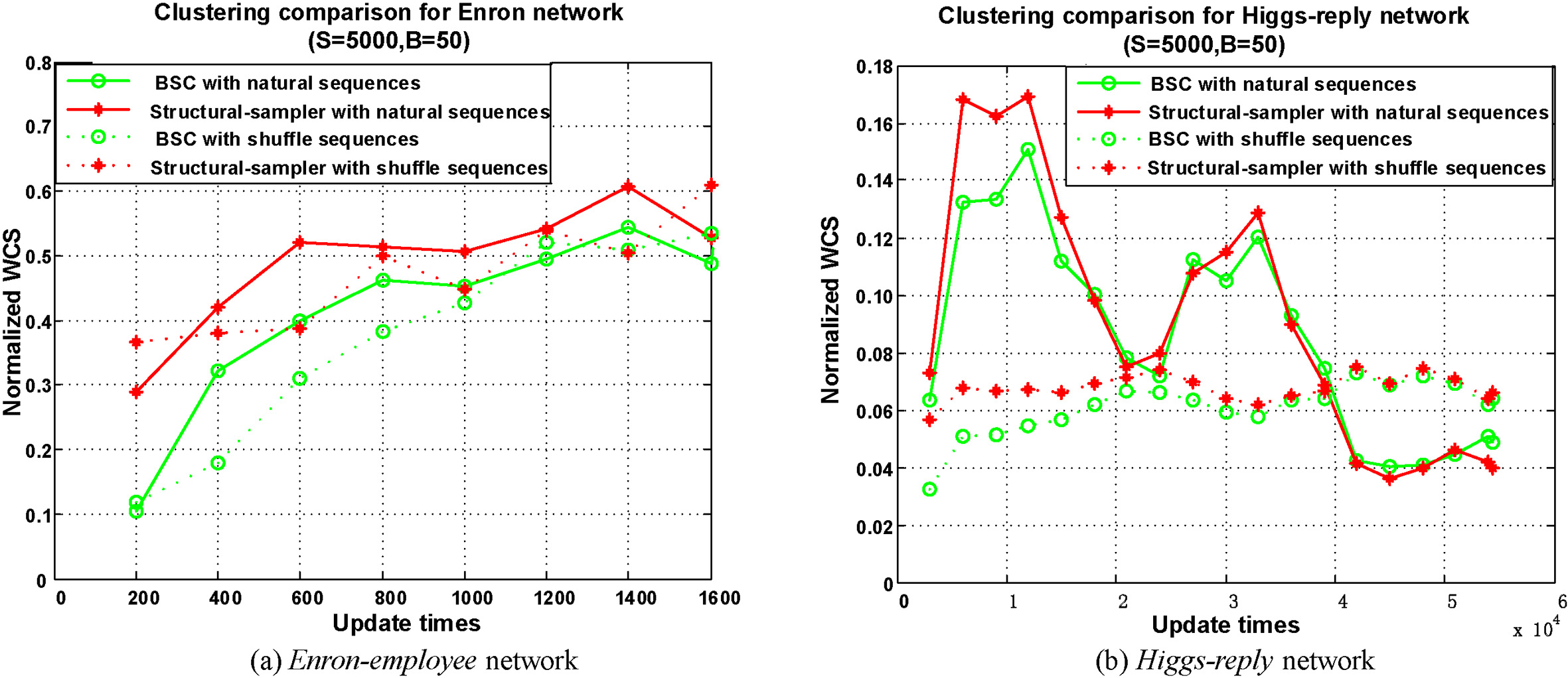
We can observe that given the same number of queries, more edge updates will gain more system throughputs for both algorithms. For low query/update ratios, both algorithms can process more edge updates continually and do not execute any query operation until the queries are required. It makes both algorithms achieve high throughputs.
BSC algorithm obtains almost one order of magnitude higher throughput than structural-sampler algorithm for different query/update ratios. That is because that: (1) the edge addition and deletion mechanisms of BSC algorithm are more efficient than structural-sampler algorithm in which unnecessary deletions/re-insertions always occur to the clusters which do not violate the constraint; (2) the augmented union-find structure is capable to merge, remove and re-cluster the clusters efficiently.
Evaluation on the selected clustering algorithms on Enron-employee and Higgs-reply networks with a fixed window size of 5000 and the maximum cluster-size of 50.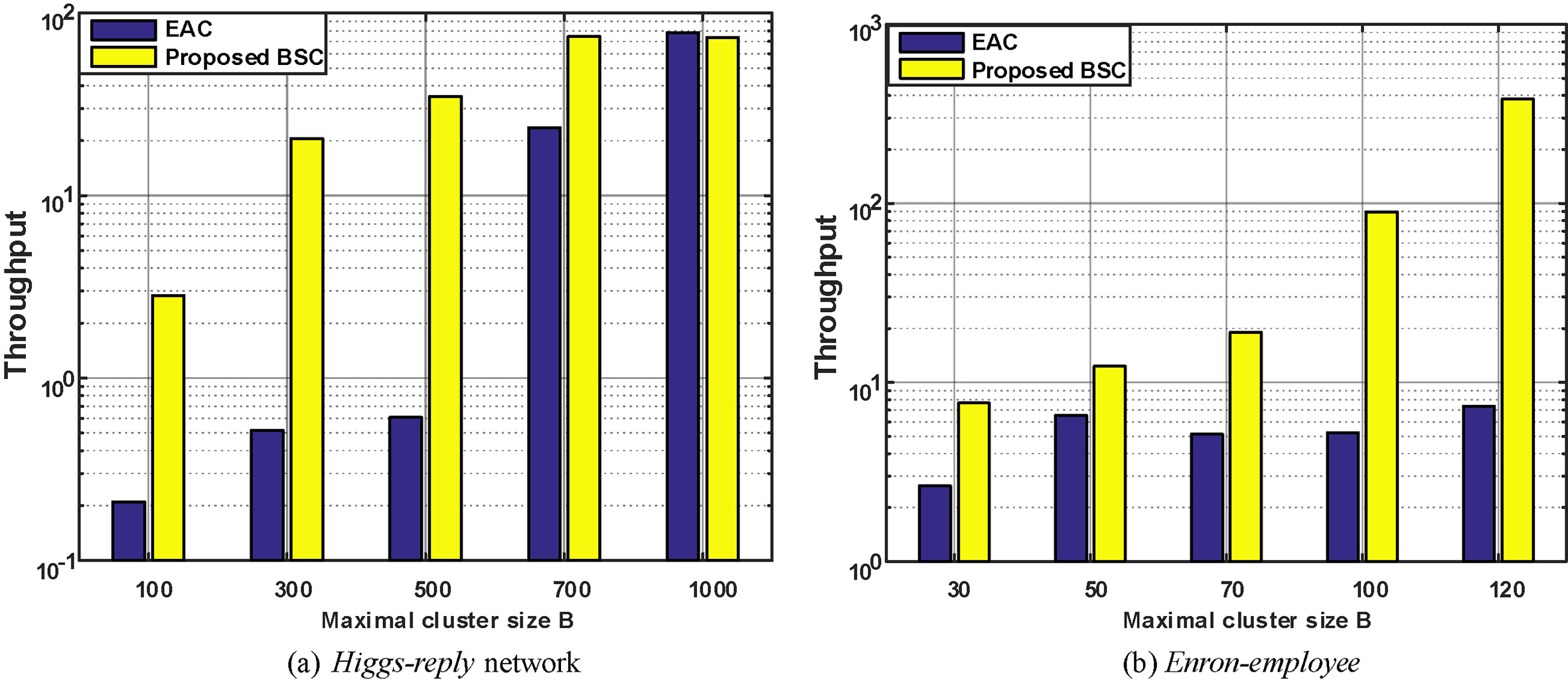
Figure 7 shows the throughputs with different maximal cluster-size
We can observe from Fig. 7a, the throughput is stable when In Fig. 7b, We can see that proposed BSC is superior to structural-sampler in all cases. This is because the enron-employee network is very dense (the average number of edge connections per vertex) and the number of edges to be removed/reinserted is abundant. Both algorithms need to execute more tedious deletion operation. This observation further validates the superiorities of the BSC algorithm.
In this paper, we proposed a streaming clustering model which is applicable to manipulate fully-dynamic graphs which are induced by edge streams and evolve constantly. We designed two new core components: streaming reservoir and cluster manager to make the sampled graph up-to-date. Meanwhile, the sampled graph always needs to meet the conformity and maximality criterions. Based on the model, we presented an evolution-aware BSC algorithm to handle the edge additions/deletions under specific time-windows. It keeps the recency of edges and gives high priority to the recent edges in each cluster based on the temporal weights. In addition, it is capable to keep track of the changes of the evolving networks. We conducted extensive experiments on synthetic and real-world networks. Our results show that the proposed BSC algorithm outperforms current online algorithms in terms of the clustering quality. It also performs higher system throughput than structural-sampler algorithm.
In future work we will explore an estimation method to determine the maximum cluster-size
Footnotes
Acknowledgments
This research of Zhang is supported by the Foundation for Innovative Research Groups of the National Natural Science Foundation of China (Grant No. 61521003), and National Natural Science Foundation of China (Grant No. 61309020). The research of Pei is supported by the Netherlands Organisation for Scientific Research (NWO).