
Abstract
The ontology language OWL 2 EL, is designed for knowledge modeling and has been widely used in real applications. However, modeling knowledge as OWL ontologies is an error-prone process, where logical errors or contradictions would be imported. Further, it is almost impossible to manually find errors occurring in large-scale ontologies. Finding justification, an important service for error pinpointing, has then attracted much attention of researchers and developers. However, current methods of finding justifications suffer from an issue: high-coupling of reasoners, i.e., there is a tight relation between reasoners and the task of finding justifications. This makes the performance of finding justifications be highly influenced by the utilized reasoner, and, it is also restricted to optimize the algorithms effectively. In order to tackle this problem, we consider giving a method such that the task of finding justifications is independent from the utilized reasoner. Specifically, we propose a kind of graph called Explanation Dependency Graph (EDG) which guides to compute justifications from the reasoning results directly. We further give several optimizing strategies and prove the correctness of our method. We implement our method and evaluate it on real ontologies, including SNOMED CT. The experimental results show that our method is practical and performs better than current methods.
Introduction
The Web Ontology Language OWL has been designed as one of the major standards for formal knowledge representation and automated reasoning in the Semantic Web. The most recent version of OWL is OWL 2.2
As OWL has begun to be used in many real applications, a lot of developers and users have participated in ontology building and editing. However, the development and maintenance of large-scale ontologies are complicated and error-prone. Some “unwanted” reasoning results (or entailments) may be derived from an ontology containing logic errors or contradictions. Given an unwanted entailment for a large-scale ontology like SNOMED CT with nearly six hundred thousand axioms (statements for concepts and properties), it is almost impossible to find the erroneous axioms responsible for it manually. Thus, it is necessary to provide explanation services to automatically find the erroneous axioms. Finding justifications is a service of this kind, which helps users or developers to understand an entailment by presenting minimal subsets (called justifications) of the target ontology which are responsible for the entailment.
The existing methods of finding justifications can be classified into two categories: glass-box methods and black-box methods. The glass-box methods trace how an entailment is derived based on reasoning information from the internals of a reasoner. This can be done by modifying the implementations of the reasoning algorithms for tracing the derivation of entailments (see [4, 5, 6]). Since the utilized reasoners need to be modified for glass-box methods, some key optimizing strategies (e.g., pruning techniques, optimized encoding) cannot be further used [7]. The black-box methods treat a reasoner as an “oracle” and use it to check the satisfiability of an ontology or the derivability of an entailment (see [6, 8, 7]). In this way, justifications can also be computed. However, black-box algorithms typically require a bunch of calls of reasoners. This makes it difficult to find justifications in limited time for large ontologies even when some optimization strategies are utilized [8, 9, 10]. In summary, both of black-box methods and glass-box methods are highly-coupled with reasoners, i.e., there is a tight relation between reasoners and the task of finding justifications. This makes the performance of finding justifications be highly influenced by the utilized reasoner, and, it is also restricted to optimize the algorithms effectively.
Motivated by the above issue, we consider extending our previous work [1] and giving a method of finding justifications for OWL EL in the way the task of finding justifications is independent from the utilized reasoner. It is challenging to give such a method due to two requirements: 1) reasoners are disallowed to be modified to extract internal information of the reasoning procedure; 2) reasoners cannot be used during the task of finding justifications. Current methods cannot work under the above requirements. To satisfy the requirements, we propose a kind of graph called Explanation Dependency Graph (EDG) where each node in the graph is a set of ontology axioms and entailments that can derive the target entailment. Intuitively, EDG can replace reasoners to provide reasoning information that can further guide to find justifications. We show how to find justifications based on EDG without using a reasoner. In this way, the utilized reasoner needs a single run for the purpose of classification and does not need to be modified. We also give several optimizing strategies and prove the correctness of our method. We implement this method and evaluate it on real ontologies, including SNOMED CT. The experimental results show that our algorithm is practical and performs better than current implementations.
The rest of the paper is organized as follows. We first introduce basic notions of the description logic that underpins OWL EL in Section 2. We discuss related works in Section 3. We then introduce the method based on EDG in Sections 4 and 5. We further give optimization strategies in Section 6. After that, we present implementation and evaluation results in Section 7. Finally, we conclude this paper in Section 8.
In this section, we introduce the notions that are used in this paper.
The description logic:
We first introduce the syntax and semantics of
Syntax and semantics of
Syntax and semantics of
A justification is a minimal set of axioms in an ontology that is responsible for a target axiom. Finding all justifications is to compute all such minimal axiom sets with respect to a given axiom. We follow the definition of justification for highly expressive description logics [7], and give the formal definition in our case as follows:
.
(Justification) Given a DL ontology
.
Given an
The above axioms describe investment relationships between companies:
The classification task
The task of finding justifications is tightly related to the corresponding reasoning task. In this part, we introduce the task of classification which is an important reasoning task of
A state-of-the-art reasoning system (referred as CEL) [12] is given to perform classification of
The CEL Rules for
Classification
The CEL Rules for
.
We consider using the method of CEL to classify the ontology
The classification starts with some tautological conclusions for concept names (see Eqs (1) and (2)) and then repeatedly applies the CEL rules. The entailments Eqs (3)–(8) are added to the set of classification results
In this section, we introduce the related issues and notions of finding justifications, including what is the problem of finding justifications originated from, and the major approaches proposed for tackling it. Finally, we discuss the advantages and drawbacks of current approaches.
Issues
Constructing and maintaining ontologies is a difficult and error-prone process [13, 14, 15]. Logical errors or contradictions are quite common in real ontologies, specially, when the target ontologies are large in scale [14, 16]. At first, logical errors or contradictions denote the problems of incoherence for an ontology. Specifically, a TBox is incoherent[5] whenever there are unsatisfiable concepts: concepts which are interpreted as empty sets in all models of the TBox. The authors of [5] first give the formal definitions of unsatisfiability and propose the notions of MUPS (minimal unsatisfiability-preserving sub-TBoxes) and MIPS (minimal incoherence-preserving sub-TBoxes). A MUPS, with respect to a TBox
In the following, we organize the discussion of the major approaches by two lines based on highly-coupled reasoners: black-box and glass-box methods.
Black-box methods
In black-box methods, a reasoner is used as a black-box (or an oracle) for certain reasoning tasks, e.g., classification, testing satisfiability, and etc. A typical black-box method focus on detecting dependencies between unsatisfiable concepts, i.e., identifying the root concept that causes the incoherence and the concepts derived from it [19, 25, 4]. This method suffers from low performance when computing all justifications (or MUPS). Researchers then adapt the techniques used in the contexts of model-based diagnosis[26] to the case of ontology debugging. Specifically, a diagnose specifies the minimal set of axioms that have to be ignored in order to turn the terminology coherent. Diagnoses can be computed by constructing a tree that is called hitting set tree (HST). HST is first used to compute MUPS in [27]. In [7] and [28], this method is used in highly expressive OWL languages, and evaluated on small ontologies. There is also works that uses HST techniques to translate the problem of ontology debugging to SAT problem [29, 30]. Some other optimizing strategies are further applied to accelerate the computation based on black-box methods, such as module extraction [8, 9] and other heuristic approaches [31, 32, 33].
Glass-box methods
In glass-box methods, reasoning information from the internals of a reasoner is extracted and presented to the developers for tracing how a conclusion is derived. That is why these methods are called glass-box methods. The work of [5] takes the first attempt to compute MUPS in the description logic
Discussion
In following paragraphs, we discuss the advantages and drawbacks of black-box and glass-box methods. For black-box methods, they have one advantage over glass-box ones: no need for a specialized, explanation generating reasoner. However, to compute MUPS or justifications, a number of calls for reasoners is always necessary. Since reasoning tasks are inherently expensive in terms of running time, black-box methods can hardly work on large ontologies. This is also shown by current experimental results.
For glass-box methods, the biggest difference from black-box ones lies in that they just need single run of reasoners. However, glass-box methods still suffer from some problems: 1) A glass-box method requires to modify the implementation of reasoner. Some optimizations (like pruning techniques, optimized encoding) for reasoners have to be dropped in order to record special information for finding justifications. Furthermore, different modifications are needed when applying different reasoners. 2) Extra data structures should be maintained. This brings additional space and computation consumption. 3) It is hard to introduce some heuristic blocking techniques to speed up the computation of finding justifications. This is because, when backtracking attached tags, it is difficult for us to acquire global information that can guide us to avoid failed branches.
In summary, both of black-box and glass-box methods suffer from a common issue: they are highly-coupled with reasoners, i.e., the performance of finding justifications is highly influenced by that of the utilized reasoner. Thus, some optimizations cannot work as discussed above. In order to tackle this problem, we consider giving a method such that the task of finding justifications can be conducted independently from the utilized reasoner, and thus, cannot be influenced by the performance of the reasoner. In the following sections, we discuss this method in detail.
Explanation and EDG
Our target is to give a method of finding justifications in the way that the task of finding justifications is independent from the utilized reasoner. Thus, two requirements should be satisfied: first, reasoners are disallowed to be modified to extract internal information of the reasoning procedure; second, reasoners cannot be used during the task of finding justifications. In other words, we should give a method of finding justifications with the original ontology and the set of classification results as the only information that we can use.
Driven by the above requirements, we attempt to find a kind of data-structure that has two features: 1) it can be computed from the original ontology and the set of classification results; 2) it can be further processed to compute justifications. To this end, we first introduce a notion of explanation. An explanation for some entailment
.
(Explanation) Given a normalized
.
Let
It is obvious that for an entailment
Based on explanations, we can organize our method of finding justifications as two steps: for some entailment
We next discuss how to complete Step 1. That is, for some entailment, to compute its explanations. We conduct our work based on an observation: explanations can be computed by using the CEL rules. Recall Example 3. Given the explanation (
.
(Deductive dependency) Given two explanations
In Example 3, we can say that (
.
(Explanation dependency graph (EDG)) Given a normalized
An example of EDG.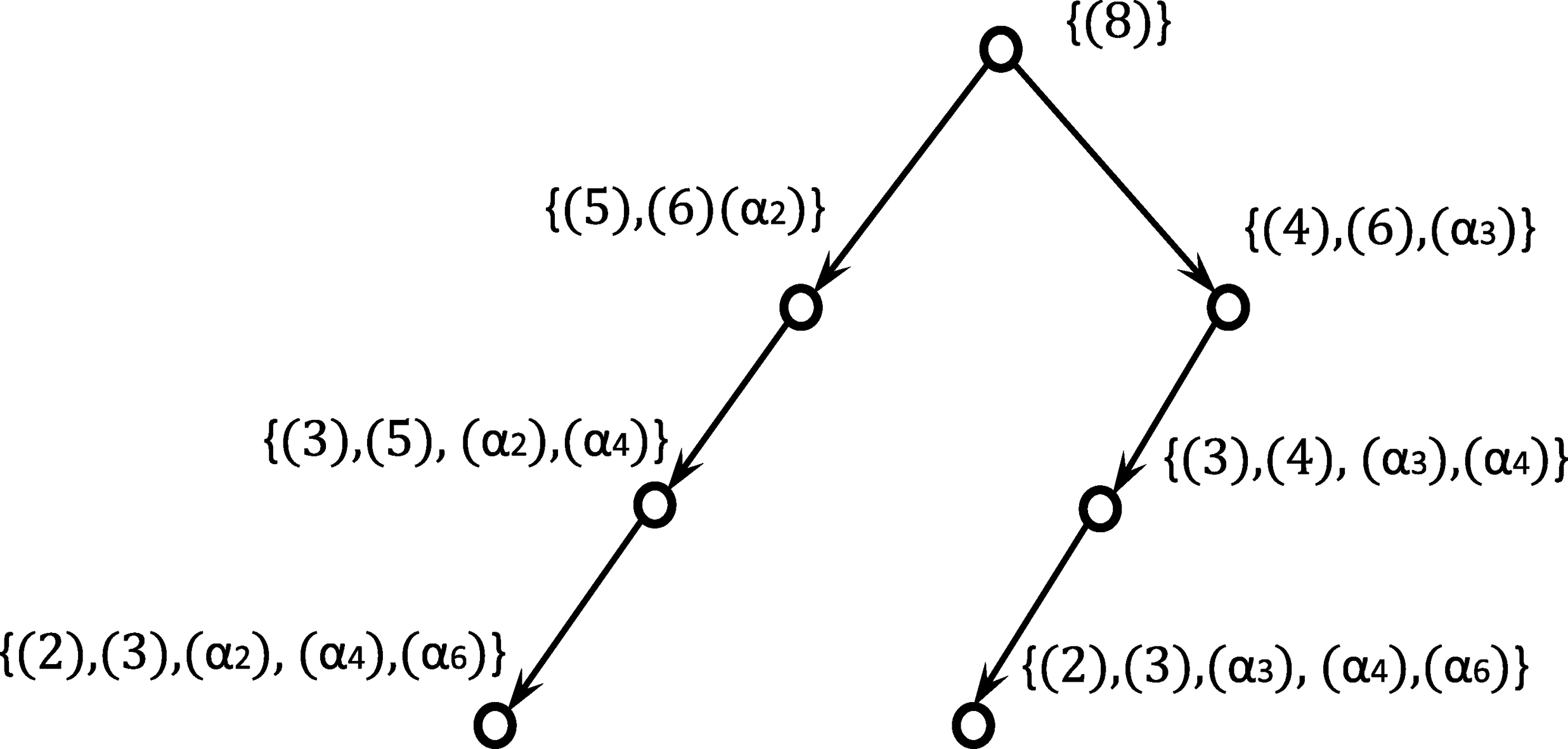
.
We give an EDG
Without special statements, we do not distinguish the nodes in an EDG and the explanations. We say that a complete EDG w.r.t
.
There exists an EDG
Proof. Suppose
Backing to Step 1, we have that, given an EDG
According to the discussion of the previous section, if a complete EDG can be constructed, then we can obtain all explanations (Step 1), where justifications can be further identified (Step 2). In this section, we specify Steps 1 and 2 based on EDG and give algorithms of finding justifications.
Traveling patterns
Recall that deductive dependencies are defined based on the rules in Table 2. This also means that deductive dependencies between explanations can be further distinguished by different rules in Table 2. Consider explanations
Suppose
If If If there exists a concept If there exists axioms If there exists axioms
In the above patterns, we say that
Suppose
If there exists a concept If there exists a role If there exists axioms
In the above patterns, we say that
Patterns
Based on the traveling patterns, we can construct a complete EDG and obtain all explanations for a given entailment
At the beginning of Algorithm 5.2, the algorithm checks whether the axiom
[H] Constructing a Complete EDG
.
Given a node
A case where the program will not terminate.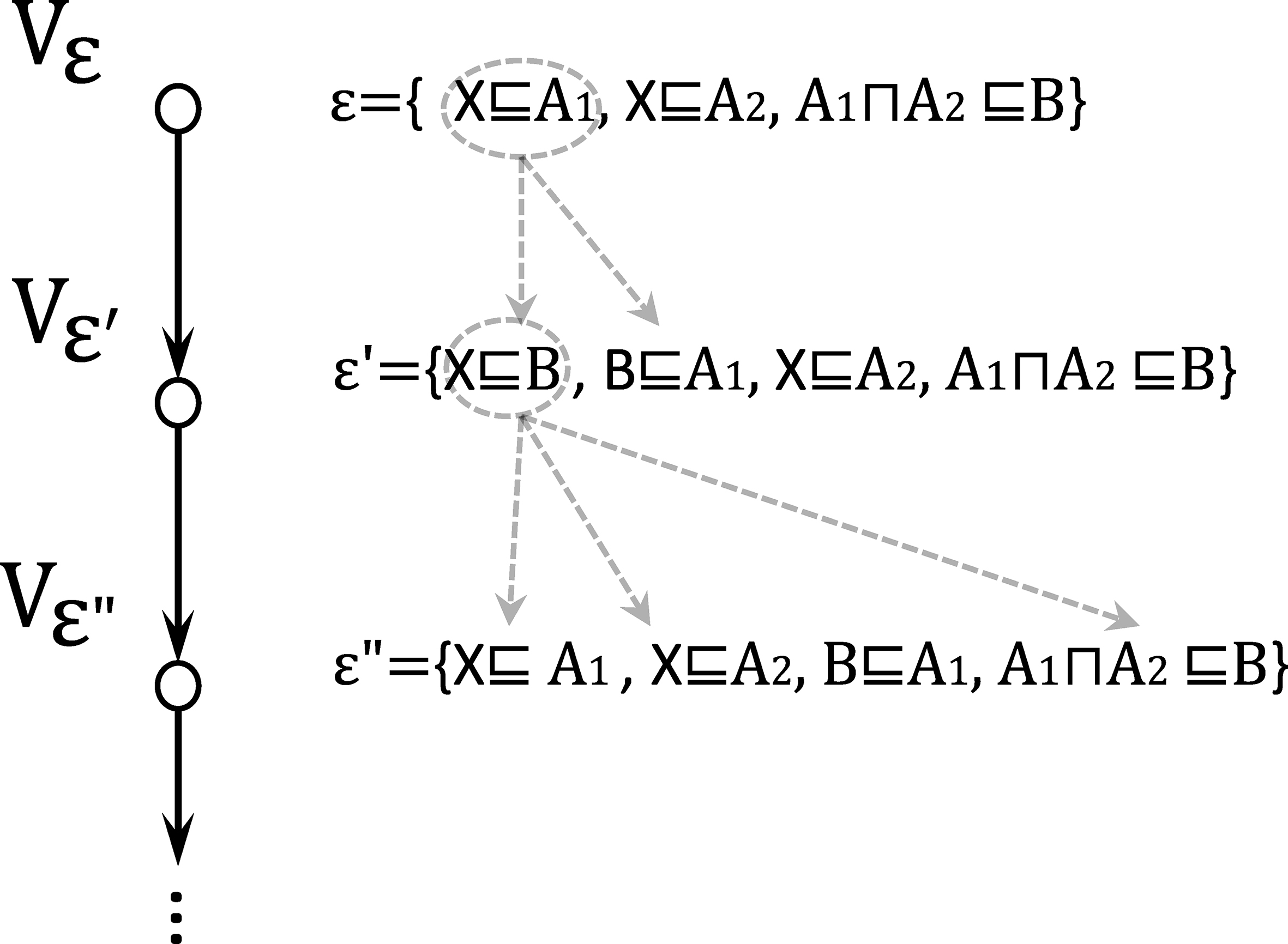
To avoid the non-termination problem, we follow an intuitive idea: if a node
Suppose a node
Intuitively, by applying BC1, in each path of an EDG constructed by Algorithm 5.2, all nodes have different buds. Since the number of entailments with respect to an ontology is fixed in the size of the given ontology, EDGs constructed by Algorithm 5.2 have to be finite in size.
At this point, Step 1 has been finished, i.e., we can use Algorithm 5.2 to obtain all explanations for an entailment. We give the following theorem to show the correctness of Algorithm 5.2,. That is: (1) BC1 guarantees the termination of Algorithm 5.2; (2) Algorithm 5.2 can always construct a complete EDG.
.
Given a normalized
The above theorem can be proved based on Lemmas 2 and 3.
.
Given a normalized
Proof. Since
.
Given two normalized
Proof. The above lemma can be proved based on the conclusion that
To finish this lemma, we first define the depths of nodes in an EDG
(Basic case) Suppose
(Inductive cases) We have an induction hypothesis that, for an depth
Suppose
(Case
(Case
(Case
(Case
(Case
(Case
(Case
(Case
The proof of Lemma 3 is finished. We now prove Theorem 1. For each justification
We now discuss the scale of a complete EDG. In the worst cases, a complete EDG may contain exponential number of nodes in the size of the target ontology. Specifically, in the while iteration, Algorithm 5.2 constructs the target EDG by starting from a node
[H] Computing All Justifications
Algorithm 3 computes all justifications for an entailment
In this section, we consider further optimizing Algorithm 5.2 in two ways. First, we propose other blocking conditions to prune a complete EDG constructed by Algorithm 5.2, such that not all nodes in this graph have to be checked. On the other hand, we apply parallel techniques to improve the efficiency of EDG construction. Based on these two optimizations, we give a new algorithm of constructing EDGs. Furthermore, we ensure that the optimized algorithm can always construct complete EDGs.
Blocking conditions
In the work of [7, 8], the authors propose a method of finding justifications based on a kind of tree structure (known as Hitting Set Tree). A simple blocking condition is studied in this work to avoid visiting all branches of a hitting set tree when generating justifications. The basic idea is to use the visited branches to filter out the useless branches. We follow this idea and study the blocking conditions in our case. That is, to give conditions to block the explanations that will not generate justifications during the construction of an EDG. Since an EDG is not a hitting set tree, the blocking condition given in [7, 8] cannot apply in our case. We give our own blocking conditions as follows.
Suppose a node
If there exists a node If there exists a candidate justification If there exists a child node
The condition BC2 is used to avoid repeated expansion of the same node. BC3 states that when a node
.
In Fig. 3,
A case of using BC4 to block nodes in an EDG.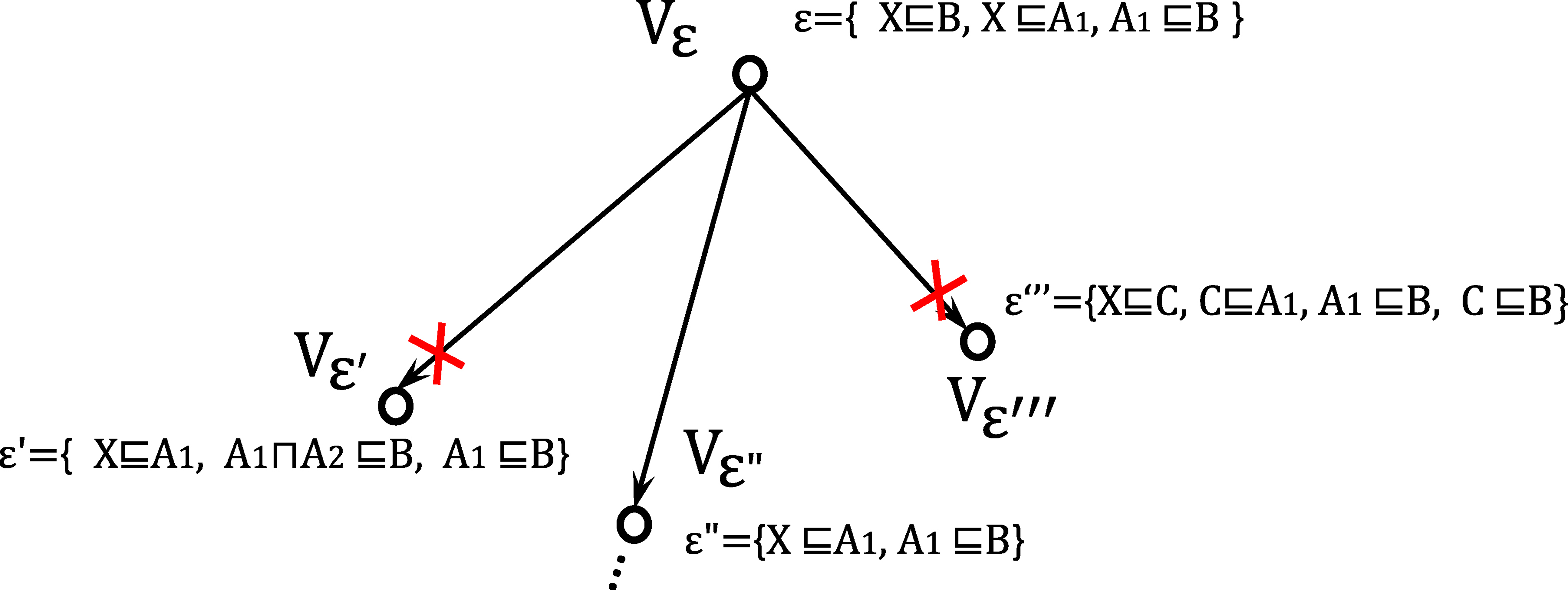
Parallelizing the task of finding justifications is rarely studied due to its inherent high complexity. One parallel method of ontology debugging is given in the work of [37]. This method focus on partitioning the target ontology into smaller pieces and conducting ontology debugging in parallel. Since this method aims at parallelizing the target ontology but not the algorithm, it cannot be used in our case. For parallelizing EDG construction, we give our method based on the observation that the paths in an EDG are independent from each other. This indicates that the generation of each path in an EDG can be performed in a parallel way. This is the basic motivation of our method. Specifically, we give Algorithm 6.2 which parallelizes EDG construction and utilizes the above blocking conditions as well.
[H] Computing justifications in parallel
.
Given a normalized
Proof. We first construct a new algorithm
We now prove the above theorem by checking that all nodes in the EDG
(Basic case) Suppose
(Inductive cases) We have an induction hypothesis that, for an depth
Evaluation and analysis
The classification and transformation time in seconds
The classification and transformation time in seconds
In this section, we evaluate our method by conducting experiments on real ontologies. We further compare our method to glass-box and black-box implementations. Finally, we give analysis for the experimental results.
We implemented our algorithms by using Java multithread techniques. Since the queue in Algorithm 1 would be visited concurrently, we implemented it based on a thread-safe datatype ConcurrentLinkedQueue. To classify an ontology, we used
We used five real ontologies to perform our experiments: Galen-core (a tailored version of Galen), Galen, NCI, GO and SNOMED CT.5
SNOMED CT can be obtained from
For Galen-core, NCI and GO, we sampled 20% of all the entailments based on the method of simple random sampling [38]. For Galen and SNMOED CT, we sampled 200 entailments. The above samples do not include the entailments of the form
The experimental results of our method
The experimental results of our method
We ran our system on the sampled entailments, and collected the experimental results in Table 4. The fourth (resp., seventh) column of Table 4 collected the averagely (resp., maximal) occupied space for storage of a constructed EDG (a kilobyte per unit). From Table 4, we can see that there is no time-out case for Galen-core, NCI and GO due to their small sizes. By comparing the results of different ontologies, we can find that, the average computing time is close. This is similar to the results of the average numbers of expanded nodes. This is because the main proportion of samples tends to be easily handled (we call them the easy samples), i.e., the EDGs of the easy samples contain a handful of nodes, and, can be constructed within a second. On the other hand, the results of the average cases are significantly better than that of the worst cases. This can also be explained by the large proportion for the easy samples.
In order to investigate the effect of the blocking conditions given in Section 6, we give Fig. 4 where five histograms are involved for the tested ontologies respectively. In each histogram, the abscissa axis records the numbers of nodes in an EDG, the vertical axis records the numbers of samples, and, the white bars (resp., the black bars) denote the numbers of samples for which the numbers of finally expanded nodes (resp., the numbers of blocked nodes) fall in the corresponding intervals of the abscissa axis. From Fig. 4 we can find that each histogram has relatively higher bars in its head and shorter bars in its tail. This indicates that the easy samples take a large proportion, i.e., the numbers of finally expanded nodes are small. On the other hand, the areas of black bars are close to that of white bars. This means that, the number of blocked nodes is close to the number of finally expanded nodes. According to Algorithm 1, visiting a node occupies a time unit. Thus, the computing time is actually reduced by nearly 50% compared to a naive algorithm without using the blocking conditions.
The experimental results of Sys-Glass-Box
The statistics of constructing EDGs.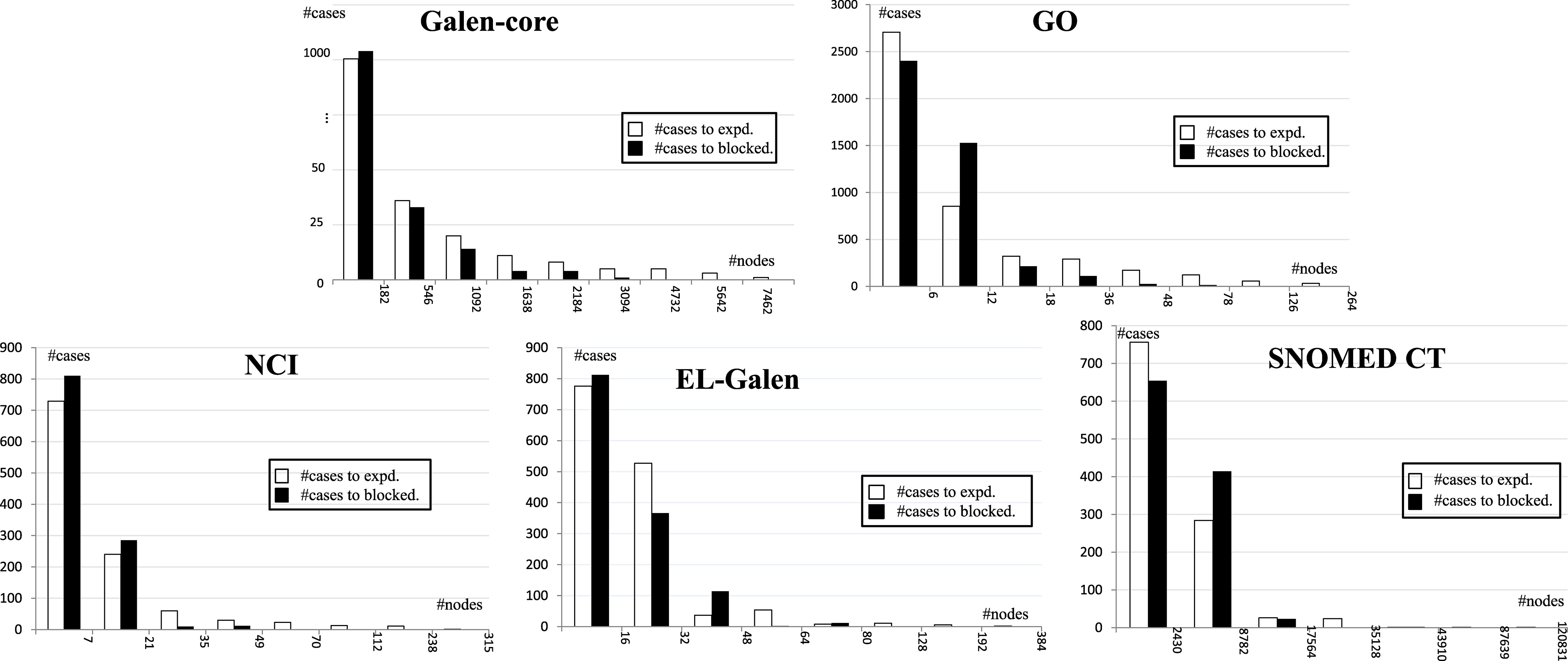
In this part, we compare our method to traditional glass-box and black-box methods by evaluating the same samples. Since there is no available implementation of traditional glass-box method for finding justification in OWL EL, we follow the idea given in [6] and implement a system (denoted by Sys-Glass-Box) using Java. For black-box implementation, we choose a well-developed Prot
We use the sampled entailments in the previous experiment to evaluate Sys-Glass-Box and the Explanation Workbench and collected the results in Tables 5 and 6 respectively. In Table 5, the third (resp., fifth) column collects the averagely (resp., maximal) occupied space for storage of tracing information (a kilobyte per unit). In Table 6, the third (resp., fifth) column collects the average (resp., maximal) number of reasoner calls.
The experimental results of the Explanation Workbench
The experimental results of the Explanation Workbench
By comparing the results in Tables 4 and 5, we can find that, the occupied space of our method is far less than that of Sys-Glass-Box. This is due to two reasons: 1) our method does not attach extra information to the classification results, while Sys-Glass-Box has to tag each entailment to trace reasoning procedure; 2) an EDG is only constructed for a target entailment. In other words, the unrelated axioms and entailments will not be considered during computing. On the other hand, some optimizing strategies, e.g., pruning techniques, cannot be used in Sys-Glass-Box. This is because that the tracing paths used in [6] are inter-dependent. This kind of inter-dependence makes it impossible to use block conditions and introduce parallelism techniques. The experimental results also show that our method performs better in terms of computing time. Further, the rate of time-out cases of our method stays lower.
From Tables 4 and 6, we can see that for all test ontologies, the proportion of time-out cases in our system is less than that of the Explanation Workbench. The average time of computing justifications of these two systems is close. We observed that the time-out cases occurring in our system and the Explanation Workbench are not always the same. For example, when handling SNOMED CT by the Explanation Workbench, a time-out case is to compute justifications of the subsumption between the concept “Entire inferior process of eleventh thoracic vertebra ” and the concept “Musculoskeletal structure of thoracic spine”, which has 7 justifications, and takes nearly 20 seconds to finish the computation. In contrast, our system gives the results within one second. On the other hand, a time-out case in our system is to compute justifications between the concept “Bisoprolol fumarate 10mg tablet” and the concept “Cardiovascular drug” which has only one justification. For this case, the Explanation Workbench finishes immediately. The difference lies in that the efficiency of the black-box method is decided by the sizes of the target ontologies and the number of reasoner calls, while the efficiency of our method depends on the number of nodes in the constructed EDGs.
In this paper, we proposed a method of finding justifications of OWL EL ontologies based on the notion of explanation and Explanation Dependency Graph (EDG), which allows us to compute justifications from classification results directly. Since constructing EDGs can work independently from the task of reasoning, we do not need to modify the inner implementation of a reasoner like glass-box methods, or call reasoner a number of times like black-box methods, for the purpose of finding justification. Further, in order to make our algorithm more efficient, we proposed several blocking conditions and parallelize the construction of EDGs. The experimental results show that our algorithm is practical and performs better than glass-box and black-box implementations. In the future work, we plan to apply our method for other OWL languages, e.g., OWL QL and OWL RL. The basic idea is to define specific EDGs for different languages. However, there are also challenges. For example, OWL RL has more than twenty rules. This inevitably makes searching space large. We have to find more techniques to improve the performance.
Footnotes
Acknowledgments
This work was partially supported by NSFC grant 61672153 and the 863 program under Grant 2015AA015406.