
Abstract
Data needs to be released to the relevant decision makers and researchers. Privacy protection should be carried out first because it contains personal sensitive information. The
Introduction
The large amounts of data generated everyday by different organizations for various purposes have catalyzed research opportunities related to data science [1]. The sharing of data between the organizations has also been found to be beneficial for business growth [2]. However, publishing raw data may raise security concerns among the users or actors who provide sensitive information in the raw data [1]. Privacy-preserving data mining is an active area in data mining [2], and topics relating to data security have therefore received much attention [3]. Moreover, privacy-preserving data publishing has received a considerable amount of attention in research communities, and the privacy-preserving publishing of microdata has been studied extensively in recent years [4]. The
Recently, data utility has become a significant performance measure for data anonymization. Moreover, efficiency is also very important for real-time processing. Therefore, the main purpose of this paper is to reduce the runtime of the algorithm to improve its efficiency. Another aim is to reduce the range of data generalization to improve data quality and maximize data availability after anonymization. The results of experiments presented in this paper also demonstrate the ability of the proposed algorithm to protect data privacy in large-scale high-dimensional data mining because of its high efficiency, sufficient security, and high data utility.
The main contributions of this paper are as follows. i) Considering global and local optimization, we propose a probabilistic search for finding the optimal dimensions from a probabilistic selection of some dimensions instead of all dimensions. Treating a locally optimal dimension as the globally optimal dimension and then looking for the optimal partition point in that dimension can greatly speed up the algorithm. ii) A dual-interval method is proposed for finding the optimal partition point. By increasing the scope of the search, it can determine a more reasonable division, improve the data quality, and hence compensate for the probability that a non-globally optimal dimension has been chosen, which increases the final data quality and availability. iii) A newly designed KD tree is used to store the partitioned data space. In contrast to traditional KD tree nodes, which are data points, all the nodes of the KD tree in this paper are sets, and non-leaf nodes correspond to anonymous sets that require division. A leaf node is a final
This paper is structured as follows. Section 2 introduces related work. Section 3 presents the basic issues related to the current research. Section 4 introduces the basic concepts used in this article. Section 5 presents the
Related work
Sweeney [10, 11, 12] first applied the
Gong et al. assumed that one individual has multiple records and proposed the 1:M-generalization algorithm, which addresses disclosure risks in 1:M data publishing, and is based on their proposed (k, l)-diversity model [17]. Ni et al. devised an (s,
Data privacy and data utility are quite naturally opposing concepts [24]. This is because the utility of data is essential for researchers and analysts during data publishing and data mining. Hence, discussions about privacy protection in these fields focus on strong guarantees to avoid information disclosure and protect individuals’ privacy.
Partitioning is a common method in
Wang et al. [27] proposed a
To address these problems, Wang et al. [28] adopted an approach that finds the optimal projection dimension before finding the division points, which gives a global perspective to the selection of the division dimensions and partition points. The algorithm studies the choice of dimensions, calculates the discrete value of all dimensions, finds the optimal dimension, and achieves the optimal division in the global domain. Moreover, the traditional k-dimensional (KD) tree structure [29, 30, 31] was redesigned for data storage, and an optimal projection partitioning method based on it was proposed. The quality of the data can be increased from 10% to 22% after anonymity. However, it is very time-consuming to search high-dimensional data, especially in large datasets, and the generalization process is slow. Therefore, it is still necessary to improve the efficiency of the algorithm while ensuring the quality and availability of data. Hence, in this paper, a probabilistic locally optimal dimension is used to replace the globally optimal dimension to improve time efficiency. To improve the quality of the data after anonymization, a dual-interval method is adopted to extend the search range of the optimal partition point.
Problem description
Data attributes
The data in a data table for publication has the following three main attributes.
Quasi identifier (QI) attributes: An attacker cannot directly identify a set of data through the QI attributes, but can indirectly determine a tuple in the data table by means of external links or related background knowledge. Privacy attributes (PAs): These are the data attributes that should be protected by Irrelevant attributes: These attributes are any attributes other than QI attributes and PAs in the data table (e.g., identifying attributes). They can be removed during anonymization.
Assume that the data table to be published is
Original data set
Original data set
Suppose there are 17 records in Table 1, and each record has seven attributes, where attribute A1 is a PA, and A2 to A7 are QI attributes. If the data in Table 1 are projected onto three selected dimensions, the projection points are distributed in three-dimensional space. In Fig. 1, these data are projected onto dimensions A2, A3, and A4 as well as onto A5, A6, and A7. It can be seen from Fig. 1 that the distribution density of projection points is different.
Partition results for Table 1 using different dimensions.
In Fig. 1, the aggregation and degree of dispersion of the blue and green dots differ. The choice of dimensions in the partition influences the quality of data after anonymity. The more reasonable the partition is, the higher the quality of data will be after anonymity. Therefore, how to choose the dimensions for the partitions is a question worth exploring.
Further analysis of Table 1 shows that if we want to choose the best division dimension AX, we need to consider all the attribute dimensions from A1 to A7. When there are more attributes, it is very complicated to determine the discrete situation for all attributes. In fact, if we only select the three dimensions of A2, A3, and A4, we can determine the optimal dimension AX. Local judgment can achieve the same result as global optimization. In the real world, when people analyze problems, they usually make judgments and decisions by examining a part of the problem. Therefore, in dimension selection, we can select some attributes, analyze the degree of dispersion, and treat the best dimension as the “globally optimum” dimension. This probabilistic search for optimal dimensions fits the way people think. Therefore, in this paper, we propose to select some attribute dimensions according to a certain probability to improve the data quality and efficiency of the algorithm.
In high-dimensional space partitioning, not only will the selection of projective dimensions affect the division results, but the selection of partition points will also affect the projection results. Based on previous work, this paper proposes a method for finding an optimal dimension by probabilistic selection and searches for the dividing point using a double interval to divide the high-dimensional space.
Partition results for Table 1 obtained using different methods.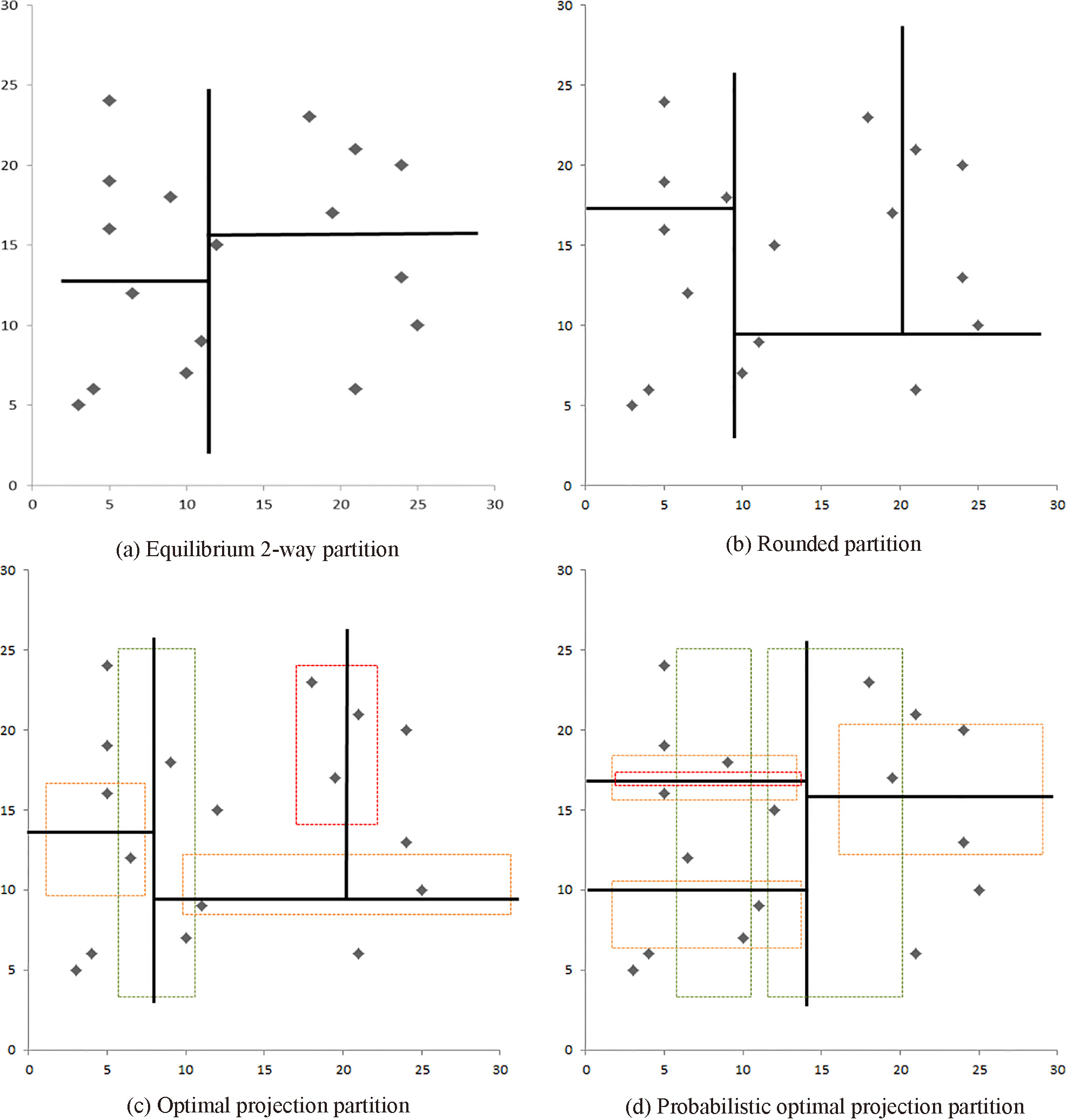
An example is used to illustrate the selection of the partition point in this paper. Suppose that T
Partition discrimination of Table 1 using different methods.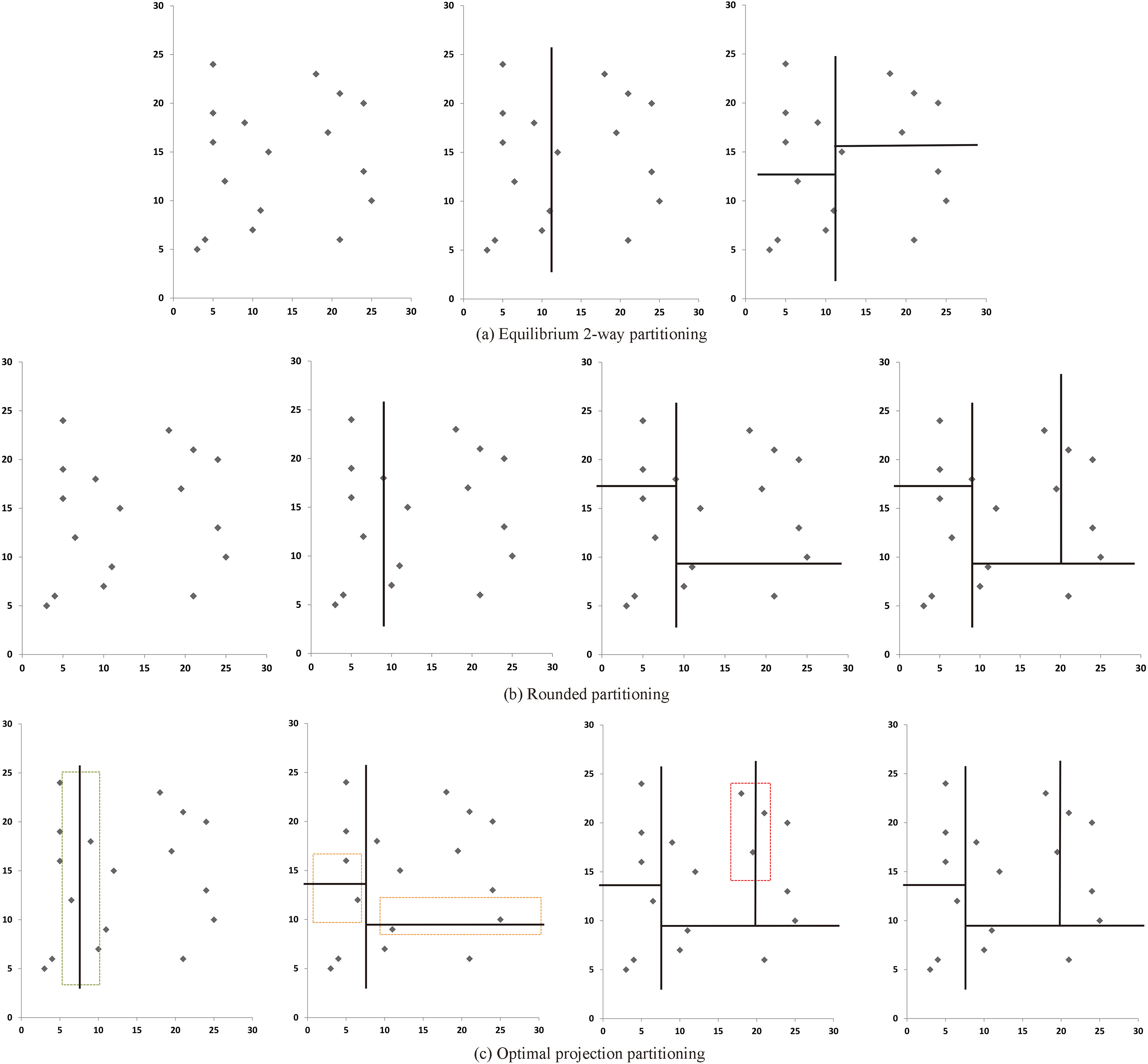
The rounded partition is the optimization of the traditional equilibrium 2-way partition. It obtains more reasonable divisions and the number of anonymous groups is lower. The rounded partition and equilibrium 2-way partition are both directly located at a partition point and have no search interval. Optimal projection partitioning searches for the optimal partition points from a single interval, and the proposed partitioning uses two intervals to find the optimal partition point.
Related definitions
The following definitions are used in this paper.
Temporary equivalent cluster Tec. The anonymous dataset can be considered as an equivalent cluster, and each division divides a large temporary equivalent cluster into two smaller temporary equivalence clusters. Equivalent cluster center Ecc. Suppose that an anonymous equivalent cluster contains
and we can calculate the mean of any attribute
Here, Equivalence set range Esr. Each item of data in the equivalent cluster contains
Smaller values of Esr indicate less data information loss. Average data range
Here, Esr is an anonymous equivalent cluster. Smaller values for Adr indicate less data information loss.
Discrete degree. The discrete degree of the projection of the data onto the
The formula for
Larger values for Partition metric, Pm. This metric measures the quality of a partition. A temporary anonymous equivalent cluster
Here, Data set range Dsr. Each record Suppose record
Average dataset range Adsr. Suppose there are
The KD tree is often used to search for key data in range and nearest neighbor searches. It is a data structure that divides data points in high-dimensional space.
In this study, the traditional KD tree is improved. In contrast to traditional KD tree nodes, which are points, each node of the proposed KD tree is composed of a dataset corresponding to the m-dimensional space data points that are to be divided. When we partition the high-dimensional space, we try to place similar points on the same subtree of the KD tree. By calculating the variance of all numerical data points in each dimension, we can choose a dimension such that the variance and data fluctuation of the dimension is greater. A higher degree of discrete data points increases the probability that the data points in that dimension do not belong to the same space, which means it is more suitable for the dimension division. All nonroot nodes can be regarded as a hyperplane. The left subtree of the node corresponds to the left side of the hyperplane, and the right subtree corresponds to the right side of the hyperplane.
Structure of the proposed KD tree.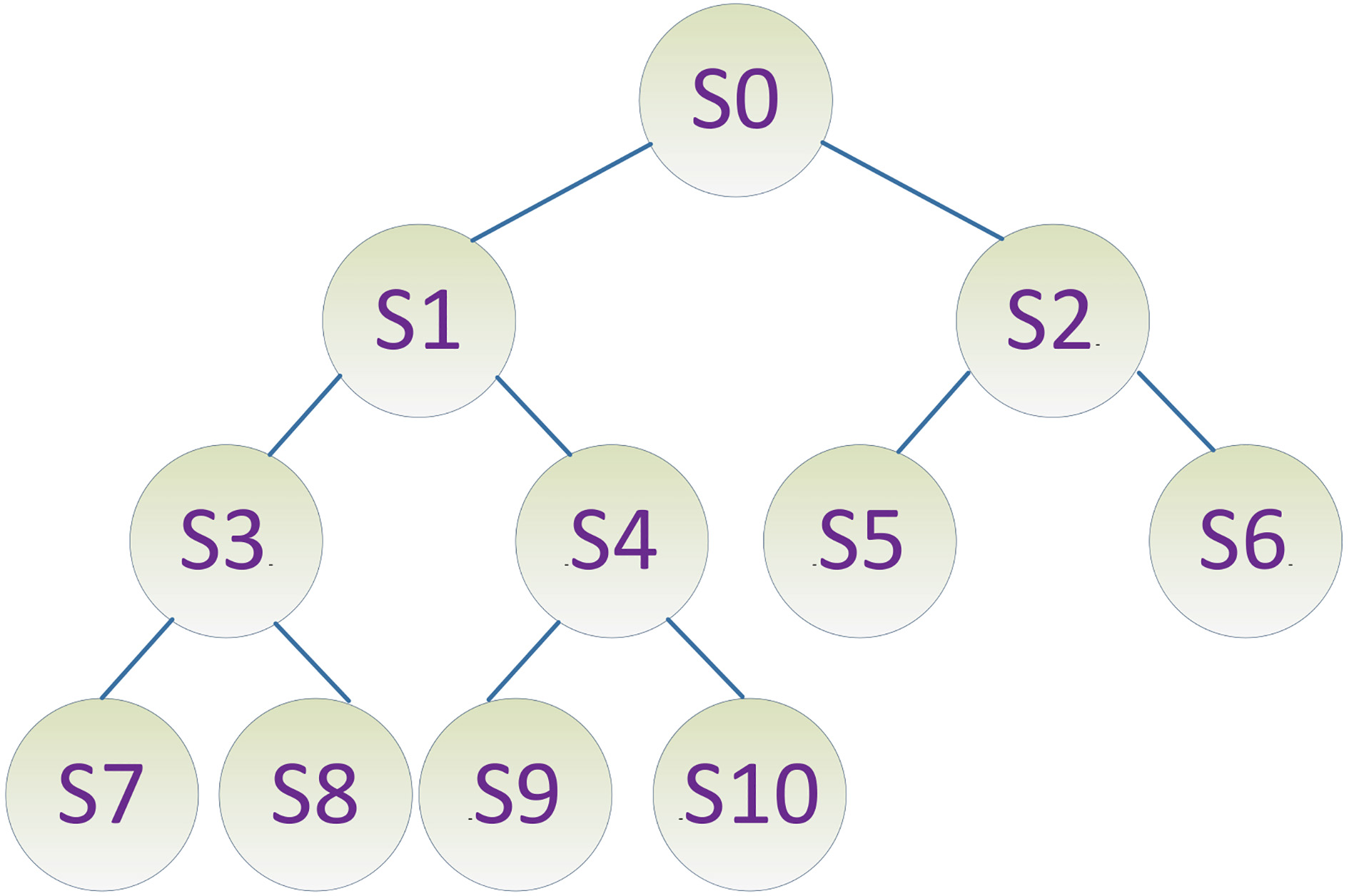
As shown in Fig. 4, the root node of the tree is S0, which is a collection of all data points.
This paper presents a probabilistic optimal projection partition
Algorithm
The main steps of the algorithm are summarized as follows.
The original data are read into the memory in a two-dimensional vector and saved in a two-dimensional array. The root of the KD tree and the partitioned node queue are created. The root node is added to the queue. Each node in the queue is inspected to determine whether it satisfies the When the partition queue is not empty, the head node of the queue is fetched. Suppose the head node is a At point Each leaf node is traversed. We obtain the equivalent clusters in each leaf node and anonymize each cluster. An anonymous table
Links between the four proposed algorithms.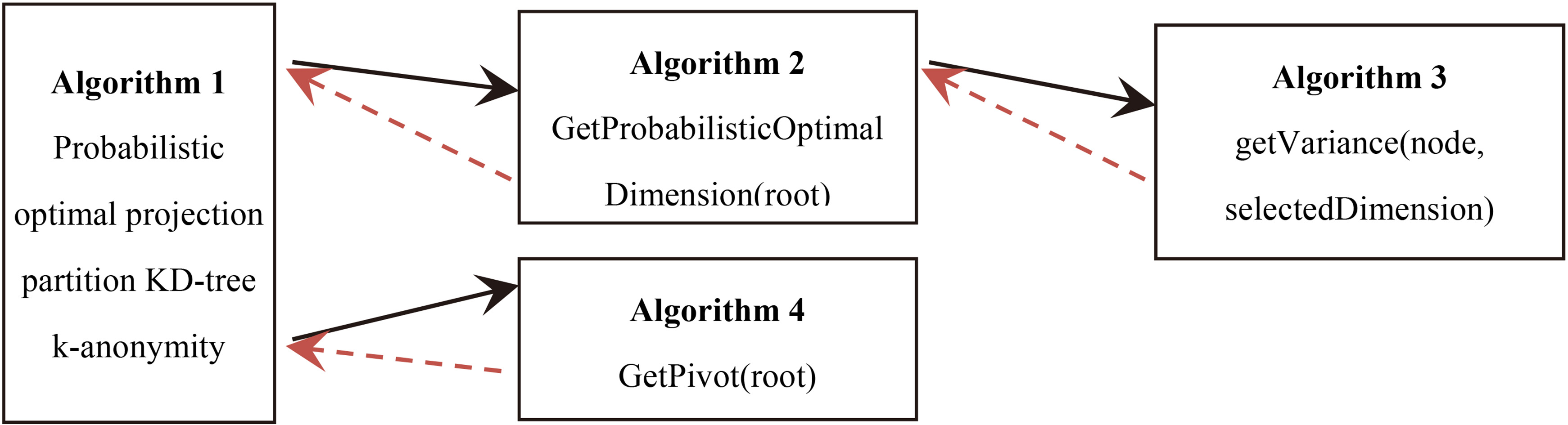
Algorithm 1 lists the pseudocode of the proposed algorithm described in the previous section. Algorithms 2 and 3 list the pseudocode for the function in Algorithm 1 that find the optimal projection dimension. Moreover, Algorithm 4 lists the pseudocode for the function in Algorithm 1 that finds the optimal partition point on the projection. The links between the four proposed algorithms is shown in Fig. 5.
First, Algorithm 1 reads the original data into a two-dimensional array (line 1), initializes the root node of the KD tree (line 2), creates the KD tree with the root (line 3), and creates a queue to store the data in the root node (line 4). Then, it adds the root node to the queue (line 5). While nodeQueue is not empty, each element in the queue is divided (line 6). The top element of nodeQueue (line 8) is processed to determine whether it meets the requirements of anonymity (line 9). If the number of elements in the node is greater than 2
In Algorithm 2, the fifth line obtains the discrete values of each dimension. The pseudocode for this step is listed in Algorithm 3.
In Algorithm 2, a certain number of attributes are randomly selected from all dimensions (line 1), and the candidate dimension set is generated (line 2). The algorithm then traverses each selected attribute (lines 3 to 11) and calculates each variance of the projected dimension (lines 5 to 10) to find the optimal dimension. The node is then divided along the hyperplane perpendicular to the optimal dimension (lines 12 to 13). This method of local optimization ensures division in the locally optimal dimension, maximizing the aggregation of the original data and reducing the loss of information, thus improving the quality of the anonymous data. In addition, the KD tree generated by this division is more balanced and the data distribution is more uniform. Moreover, compared with global dimension optimization, the probabilistic dimension optimization method improves the speed of the algorithm at the expense of a small amount of data quality loss. Thus, a better balance between data availability and calculation speed can be achieved.
In Algorithm 4, the selected dimensions of all projection points are sorted (line 1). Then, the upper bounds of bbv1 and bbv2 and lower bounds of tbv1 and tbv2 are calculated (lines 3 to 6) for both intervals and merged as the division point determination interval (line 7). Partition coefficient set pmset is then initialized (line 8). For each point in the interval [bbv, tbv], the partition coefficient
Proof:
When When
Proof: By Theorem 1, we can see that when the data is processed by this algorithm, the data after anonymization consist of
In the worst case, the maximum size of the anonymous equivalence cluster of the leaf node in the KD tree satisfies
The average number of anonymous clusters of all leaf nodes satisfies
In summary, under nontrivial conditions, a
Proof: If an anonymous equivalent cluster X satisfies the
Assuming that
Suppose that
Algorithm space complexity analysis
The maximum memory consumption of the algorithm is used to create the queues for partitioning. The extra memory space needed is
Experimental results and analysis
In this section, we analyze the performance of probabilistic optimal projection partition
Experimental data
The experiment used the UCI multifeature digit dataset called mfeat-fac.1
http://archive.ics.uci.edu/ml/machine-learning-databases/.
The following metrics were used to evaluate the results:
Data quality (Dq), which is the logarithm of Adr, given in Definition 4, and is used because the value of Adr is large when the dimensions of the attributes are large. It is calculated using Eq. (10).
The execution time of the algorithm over the dataset. Information loss, which is mainly measured by the data generalization scope and the upper and lower bounds of the data.
Data quality comparison of three algorithms on mfeat-fac_20 for (a) 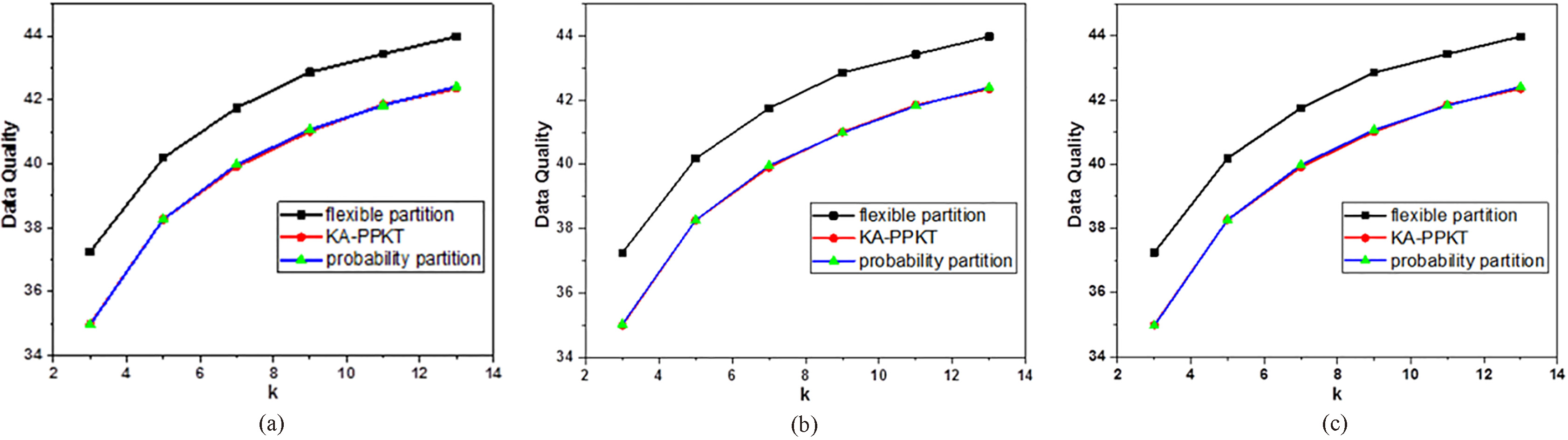
Data quality comparison of three algorithms on mfeat-fac_107 for (a) 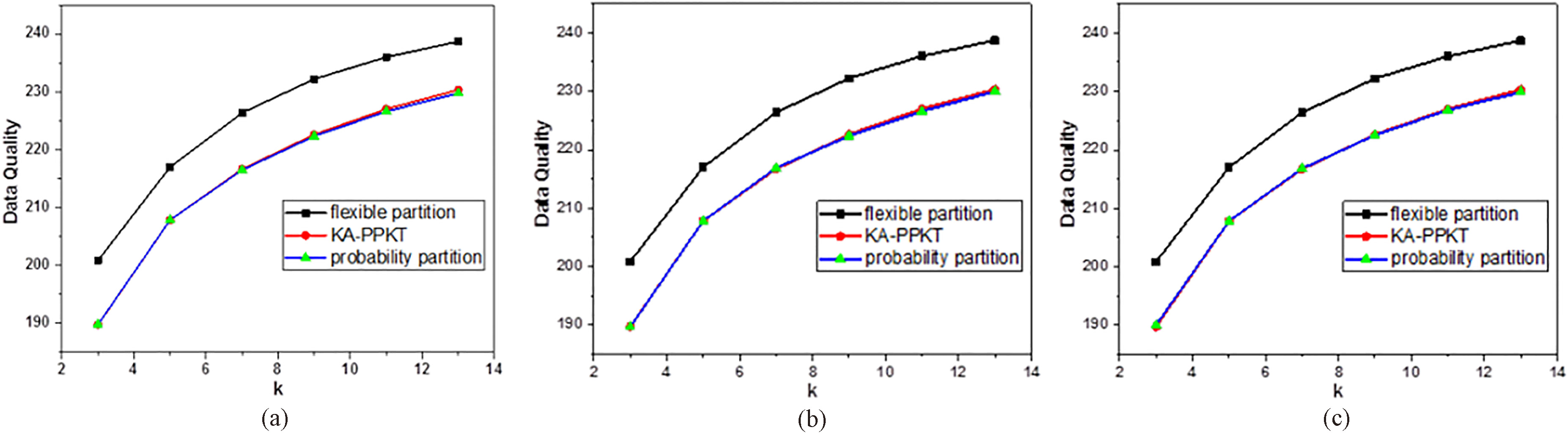
Figures 6 and 7 compare the data quality obtained by the algorithms for probabilistic partitioning (proposed method), KA-PPKT, and flexible partitioning for different datasets. Figure 6a–c compare the results for mfeat-fac_20 and Fig. 7a–c compare the results for mfeat-fac_107. Overall, the data quality of the proposed probabilistic partitioning algorithm is better than that of the flexible partitioning algorithm and close to that of the KA-PPKT algorithm. Moreover, the proposed algorithm is very stable on the high-dimensional dataset mfeat-fac_107. This is because the algorithm selects the optimal dimensions. Compared with random partitioning, locally optimized dimension selection is helpful for improving the quality of partitioning. Relative to the KA-PPKT algorithm with its globally optimal partitioning, although the random choice of dimensions to be considered reduces the data quality, the algorithm adopts the double point selection interval division to make up for this disadvantage, in practice obtaining a data quality that is similar to that of the optimal partition.
Execution time on mfeat-fac_20 (s)
Execution time on mfeat-fac_20 (s)
Tables 2 and 3 show the running time results of the experiments on mfeat-fac_20. Table 2 shows that when
Ratio of the time efficiency of the probabilistic partitioning algorithm to KA-PPKT algorithm on mfeat-fac_20
Ratio of the time efficiency of the probabilistic partitioning algorithm to KA-PPKT algorithm on mfeat-fac_20
Figure 8 shows the runtime results of the probabilistic partitioning algorithm for different probability values. Figure 8a shows the change in runtime of this algorithm on the mfeat-fac_20 dataset along with the
Execution time comparison of the proposed algorithm on (a) mfeat-fac_20 and (b) mfeat-fac_107.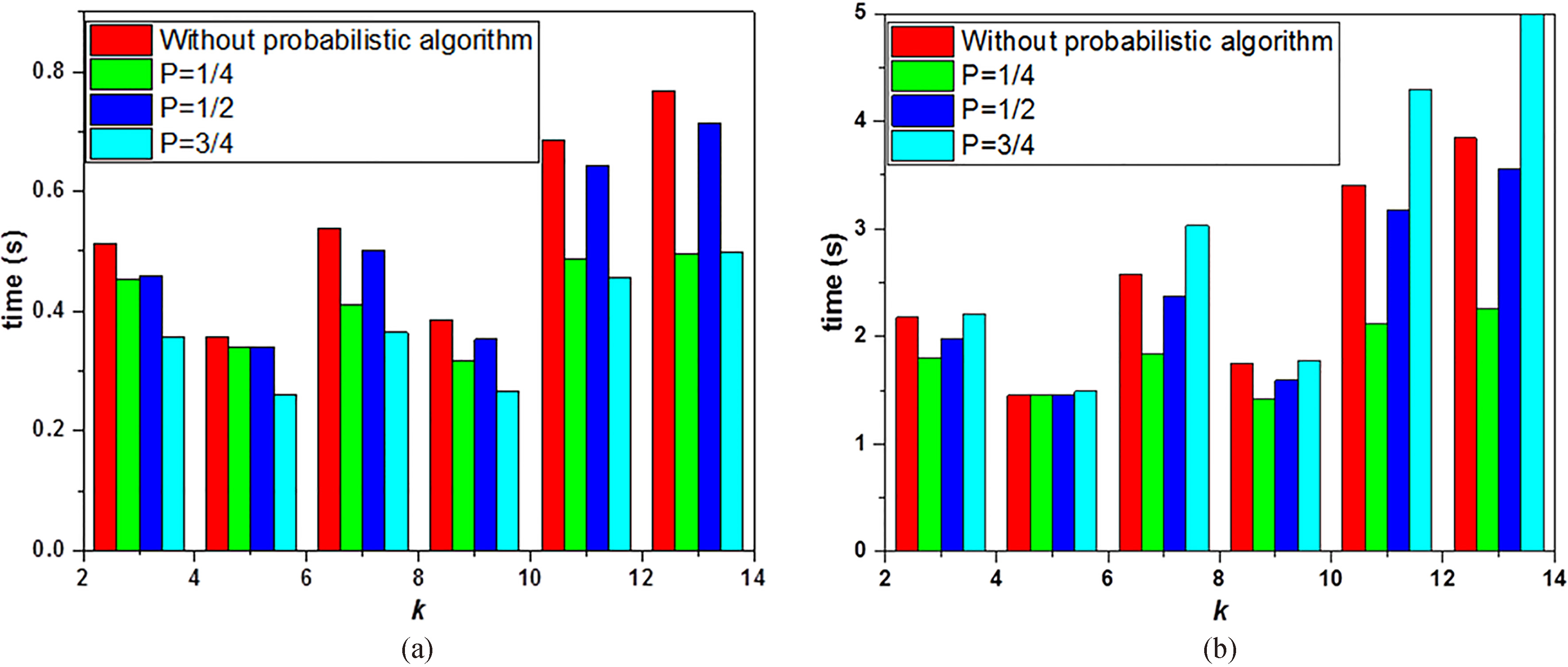
Figure 8 shows that the probabilistic partitioning algorithm has a better overall running time. There are some fluctuations, mainly caused by dual-interval partitioning, as many points can fall within the two zones to be checked. Hence, the algorithm takes some time to process them, and the runtime time will fluctuate somewhat. However, on the whole, the speed of the algorithm is substantially improved.
Figure 8 further shows that the overall performance of the proposed probabilistic partitioning algorithm is better than the algorithm that does not use it. There is some fluctuation in the running time, mainly due to the influence of the dual-interval partitioning. When the number of data points in the two intervals is relatively high, it will take a certain amount of time to determine each partition point, so the time will fluctuate slightly. However, on the whole, the time efficiency of this algorithm is obviously substantially improved.
Data range obtained by the three algorithms in each dimension on mfeat-fac_20 for (a) 
Data range obtained by the three algorithms in each dimension on mfeat-fac_107 for (a) 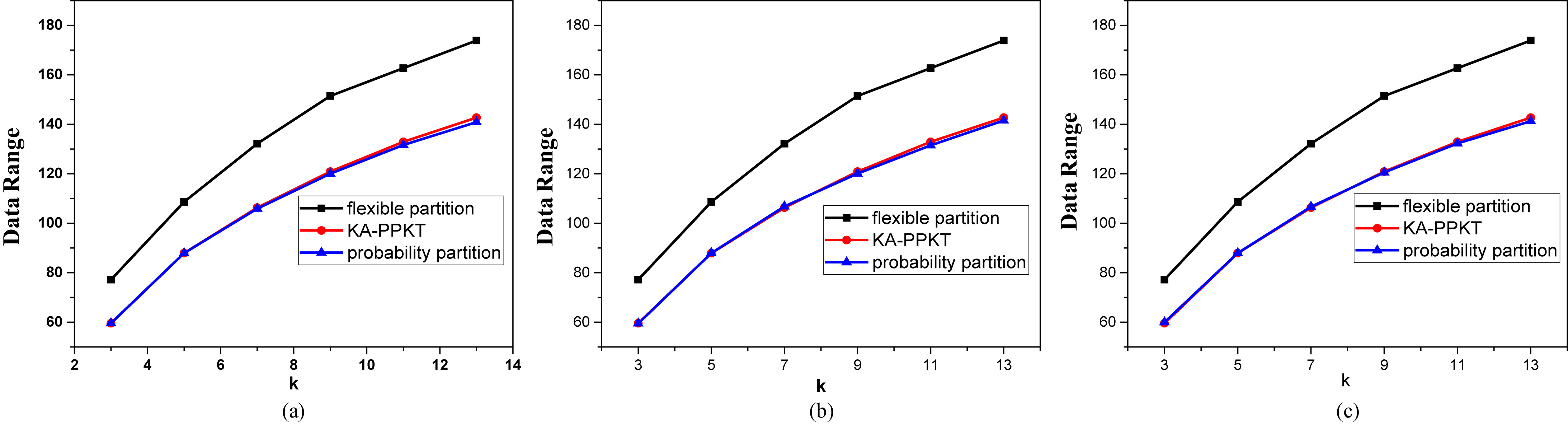
Comparison of the data range ratio for the probabilistic partitioning and flexible partitioning algorithms in each dimension on mfeat-fac_20 (
Data range
Figure 9 compares the data generalization range of the three algorithms when the probabilities are 0.25, 0.50, and 0.75 on the mfeat-fac_20 dataset. The experimental results show that the data range obtained by the proposed algorithm is better than that obtained by the flexible partitioning algorithm and the data range of the KA-PPKT algorithm is almost the same as that of the full probabilistic algorithm. To further verify the performance of the algorithm, the experiment was repeated on the high-dimensional dataset mfeat-fac_107 and the experimental results are shown in Fig. 10. Figures 9 and 10 both show that the proposed algorithm performs well and is stable on both datasets, especially the high-dimensional dataset. This is because we consider the influence of local probability on the result of spatial division and extend the division range to improve its quality. Therefore, the data quality is close to that obtained by the globally optimal dimension selection method. However, the proposed algorithm is more efficient.
The ratio of the data range Rdr is the ratio of the data point generalization of the two algorithms and is calculated using Eq. (11).
If Rdr
Comparison of the data range ratio for the probabilistic partitioning and flexible partitioning algorithms in each dimension on mfeat-fac_107 (
Figure 11 shows that in 20 dimensions, the probabilistic partitioning algorithm and flexible partitioning have an Rdr in the vicinity of 0.8, indicating that probabilistic partitioning algorithm has a generalization range of 80% of that of the flexible partitioning algorithm generalization. In contrast, the probabilistic partitioning algorithm and KA-PPKT algorithm have an Rdr close to one, indicating that these algorithms have approximately the same information loss. Figure 12 shows that the performance of the algorithm is still stable in 107 dimensions. Moreover, it is superior to the data quality of the flexible partitioning algorithm and comparable to that of the KA-PPKT algorithm. Figure 12 shows that the high-dimensional data quality improves slightly, which indicates that this algorithm is superior for data in 107 dimensions.
The ratio of the average data range Radr is the average value of the data point generalization of the two algorithms, as calculated using Eq. (12).
If Radr
Comparison of the average data range ratio for the three algorithms in each dimension on mfeat-fac_20 for (a) 
Comparison of the average data range ratio for the three algorithms on mfeat-fac_107 for (a) 
Figures 13 and 14 show the Radr in each dimension along with the change in
Assume that the upper boundary of the generalization data points obtained by the two algorithms are denoted by
Average ratio of the (a) lower boundary and (b) upper boundary of the probabilistic partitioning algorithm and flexible partitioning algorithm on mfeat-fac_20 (
Average ratio of the (a) lower boundary and (b) upper boundary of the probabilistic partitioning algorithm and flexible partitioning algorithm on mfeat-fac_107 (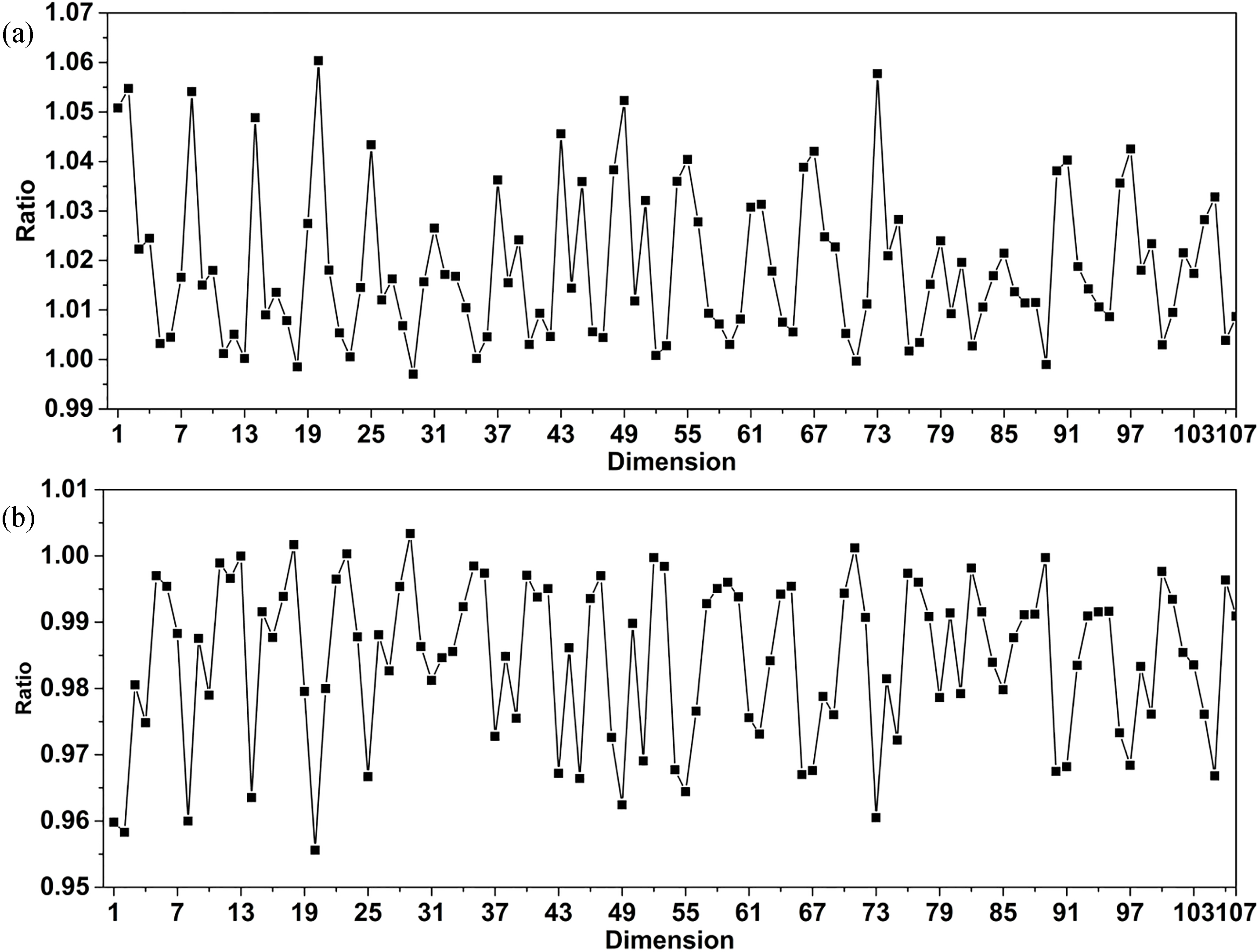
If Rubr
Moreover, assume that the upper boundary of the generalization data points obtained by the two algorithms are denoted by
If Rlbr
Figures 15 and 16 respectively show the upper and lower data bounds for each dimension after the probabilistic partitioning and flexible partitioning algorithms have anonymized the data of mfeat-fac_20 and mfeat-fac_107. The ratios in Figs 15a and 16a are mostly less than one, indicating that the algorithm in this paper has a smaller upper bound. The ratios in Figs 15b and 16b are mostly greater than one, indicating that this algorithm has a larger lower bound. The smaller upper bound and larger lower bound indicate that the anonymized data has a smaller scope and the quality of the data is higher.
This paper presents an improved KD tree probabilistic
We can improve its speed by probabilistically selecting some dimensions for the global search to find the best dimension. This method can also increase the quality of data by searching for the best partition points by increasing the search interval of the points. The data quality of this algorithm is similar to that of the globally optimum partitioning method KA-PPKT, but the time efficiency is improved by 8% to 32%. The proposed method preserves data quality, loses little information, and is fast to compute. Moreover, the algorithm shows good stability at high dimensions and for large datasets.
In the future, we will consider simulation studies using artificial data with changeable parameters in order to gain a deeper insight into the behavior of the algorithm. We will also deeply explore the effects of noise and missing values in the data sets. Finally, we plan to study how to dynamically find the optimal probability value based on the relationship between data quality, execution time, and privacy protection.
Footnotes
Acknowledgments
The authors would like to thank the reviewers for their useful comments and suggestions for this paper. This work was supported by the Key Project of Academic Support for the Top Talents in Anhui Universities (Grant No. gxbjZD2016011), National Natural Science Foundation of China (Grants No. 61370050, No. 61672039, and No. 61702010) and the Novation Foundation of Anhui Normal University (Grant No. 2017XJJ93).