
Abstract
The Internet of Things (IoT) has shown rapid growth in recent years. However, it presents challenges related to the lack of standardization of communication produced by different types of devices. Another problem area is the security and privacy of data generated by IoT devices. Thus, with the focus on grouping, analyzing, and classifying existing data security and privacy methods in IoT, based on data anonymization, we have conducted a Systematic Literature Review (SLR). We have therefore reviewed the history of works developing solutions for security and privacy in the IoT, particularly data anonymization and the leading technologies used by researchers in their work. We also discussed the challenges and future directions for research. The objective of the work is to give order to the main approaches that promise to provide or facilitate data privacy using anonymization in the IoT area. The study’s results can help us understand the best anonymization techniques to provide data security and privacy in IoT environments. In addition, the findings can also help us understand the limitations of existing approaches and identify areas for improvement. The results found in most of the studies analyzed indicate a lack of consensus in the following areas: (i) with regard to a solution with a standardized methodology to be applied in all scenarios that encompass IoT; (ii) the use of different techniques to anonymize the data; and (iii), the resolution of privacy issues. On the other hand, results made available by the k-anonymity technique proved efficient in combination with other techniques. In this context, data privacy presents one of the main challenges for broadening secure domains in applying privacy with anonymity.
Introduction
The Internet of Things (IoT) is on the rise. Daily, it connects objects, the Internet, and local networks. It interacts with itself, humans and animals. IoT consists mainly of sensors responsible for capturing the most varied types of data in the environment and actuators that perform tasks according to what was captured by the sensors. Therefore, IoT can connect devices and incorporate them into the communication system to intelligently process their specific information and make autonomous decisions [48]. Figure 1 shows how the interaction between the components of the IoT works.
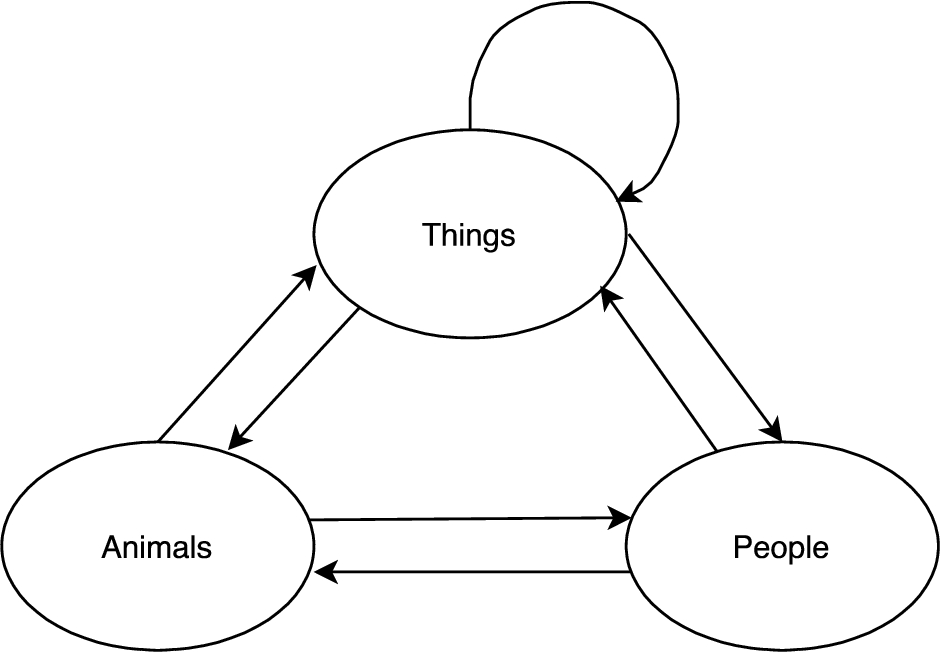
Interaction in the Internet of Things.
According to Borgia [7], the application of IoT encompasses three major domains: (i) the industrial domain, (ii) the smart cities domain, and (iii) the health and wellbeing domain. Therefore IoT has enormous potential for the development of new intelligent applications. It has an improved capacity to detect situations (for example, to collect information about natural phenomena, medical parameters, or users’ habits) – information ideal for offering personalized services. In this context, the IoT is designed to provide a better quality of life for people, impacting the economy and society.
Not all IoT applications currently have attained the same level of maturity [7]. Some applications, especially the most straightforward and intuitive ones, are already part of our daily lives. Many others are still at the experimental stage, as they require greater coordinated efforts among numerous actors. Finally, others are more futuristic and are at an early stage of development. An application considered promising for the IoT lies in the future of our homes: Smart Homes.
Smart Homes have sensors and controllers throughout various locations to provide considerable energy savings, home automation, and other expense controlling benefits for convenience and cost-effectiveness [7,43]. The devices capture information from daily routine, useful for the most diverse purposes. This information can be used to improve the functionality of these devices according to their profile, and it can also help offer products more suited to users’ tastes [55].
However, this information can be sold to third parties or even used by a malicious person to harm users. Even though there is a wide variety of possibilities for personal information, some things may inflict harm in place of offering advantages for users. To harm, a system identifying whether there are people at home or not or what times people usually leave can benefit burglars. Consequently, there are countless possibilities for using this information to benefit and harm users of devices and the people around them.
The IoT’s challenges are related to the lack of standardization across the communication of different types of devices, alongside the devices’ heterogeneity. Data security and privacy are implicit in these challenges [1,16]. These phenomena increase the need for certain requirements concerning hardware capacity (processing capacity, storage, and power capacity), placing limits upon conventional encryption used in local applications or Web applications due to the increasing amount of data. The data used in numerous services originate in location, search history on the site, and energy usage data. However, this data cannot be used to enhance efficiency for secondary purposes due to privacy issues. Thus, anonymity is the usual solution for privacy protection in applying these data to secondary uses [16].
According to the literature, it is possible to observe several types of data privacy solutions in the IoT [44]. Such solutions demand new services that provide an increase in information, since information should not be provided to third parties without the preservation of privacy [45]. Among the solutions available in the literature, the one that stands out significantly is the anonymization of data [24,34,35,45]. The anonymization of data permits the utilization of possibly sensitive material only if it can be securely published where information is disclosed. It is the most unique and distinctive resource for anonymity, different from other cryptography methods of service provision. Data can be delivered to third parties to provide services for secondary use. Even if anonymized data leaks, the impact on users will be significantly reduced compared to when the original data is disclosed [24,35,45].
Conventional data flow anonymization approaches have been employed for a single data flow, dealing with a fixed number of attributes. Intelligent scenarios that use IoT devices can detect, compute, and act in the environment. An individual user can use multiple IoT devices at any time – for example, smartwatches, fitness tracking, home monitoring sensors, etc. In this scenario, one object can produce several data flows with missing values, restricting the conventional anonymity of the data flow and algorithms for publishing IoT streaming data for analytical or sharing purposes [34].
There are some solutions involving data anonymization that are welcomed by the community with a stake in data privacy [6,12,14,41,47]. In relation to the IoT, there are several acceptable anonymization techniques. Until now, we have been unable to identify any work that analyzes each method’s main advantages and weaknesses. Therefore, this work aims to analyze the solutions based on anonymization for data privacy in IoT and propose a direction for developing new approaches that can meet the IoT’s current needs concerning users’ data privacy.
In order to achieve this, we conducted a Systematic Literature Review (SLR) based on a methodological framework proposed by [22]. This research method encompasses a set of stages that follow a predefined protocol. This SLR offers an in-depth understanding of both state-of-the art solutions, as well as currently used privacy solutions, using the anonymization approach, highlighting their main characteristics (for example, scenarios and potential implementation problems). Another contribution is that this SLR can identify trends for the future, develop research and share challenges for open research. Another factor to be highlighted is that our SLR provides the details necessary to replicate it or expand its reach in the future. Our original contributions are threefold:
To provide an in-depth understanding of the state of the art of the main data anonymization techniques used to provide privacy in the context of the IoT, highlighting the main characteristics of each one and presenting where each is most used;
To identify trends and key challenges related to the use of data anonymization in the IoT along with issues and challenges for research; and
To provide the details necessary to replicate it or expand its scope in the future.
The article is organized as follows. Section 2 presents the description of technologies related to the IoT, e.g., privacy and data anonymization. Section 3 details the protocol stages and the strategies for retrieving the evidence to allow this SLR to be reproduced by other researchers. Section 4 describes the research process resulting from the SLR’s execution and the results obtained with the data extraction. Section 5 details a taxonomy for data anonymization and the analysis of implementations found in the researched literature. Section 6 presents the description of the results obtained and the lessons learned in this review. Section 7 lists the open challenges of developing solutions for anonymizing data in IoT and directions for future research. Section 8 describes the related works. Finally, Section 9 concludes this article.
This section presents the main concepts and definitions covered in this article. Section 2.1 describes the IoT, its architecture, and its applications. Section 2.2 contextualizes data privacy for IoT. Section 2.3 describes the anonymity and your characteristics. Finally, Section 2.4 defines Data Anonymization and presents the main techniques applied in IoT scenarios.
Internet of Things
It is possible to find several definitions for the term the Internet of Things (IoT) in the literature. However, there is still no consensus regarding this concept. In the course of this work, some of the definitions found in the literature will be presented.
The Internet of Things (IoT) consists of ubiquitous smart devices and objects with embedded sensors/actuators. According to Ashton [5], the term IoT was mentioned for the first time in 1999 as the title of a presentation that he made at Procter & Gamble (P & G). The paradigm provides for a world where everything is connected and can be monitored and controlled remotely. It is possible to improve efficiency and reduce costs if relevant data is collected and analyzed [11,54].
In Santos [42], the IoT consists of an extension of the current Internet to provide everyday objects (whatever they may be), connect to the Internet, and allow the things themselves to be accessed by service providers. One of IoT’s significant characteristics and challenges is the communication between heterogeneous devices (devices with different processing capacities) with varying forms of connection (Wi-Fi, Bluetooth, 4G). The lack of standardization is one of the most striking characteristics of IoT today, besides security and privacy issues [4,15,19,27,29].
The implementation of IoT requires an open, multi-layered architecture to maximize interoperability between heterogeneous systems and distributed resources. There are several research articles on studies of different instances of IoT architecture [1,17,21,51,53]. For this research, we will adopt the architecture proposed by Wu et al. [53] that better explains the resources and connotations of the IoT. This definition is widely accepted in the area literature, dividing the IoT into five layers: the business layer, the application layer, the processing layer, the transport layer, and the perception layer.
Composition of the IoT
In [2], the authors describe the IoT as being composed of 6 components: Identification; Detection; Communication; Computing; Services, and Semantics. The definition and purpose of each of these components will be presented:
IoT application areas
As stated earlier, [7] classifies the application of the IoT in three domains, which will be detailed below:
Logistic and product lifetime management;
Agriculture and breeding; and
Industrial processes.
Smart mobility and smart tourism;
Smart grid;
Smart home/building; and
Public safety and environmental monitoring.
Medical and healthcare; and
Independent living.
[2] states that “IoT offers a great market opportunity for equipment manufacturers, Internet service providers, and application developers”.
Data privacy
The idea behind privacy is to guarantee the confidentiality of data related to a person’s private life. Thus, this feature ensures that personal data is not readable except by the owner or entities with explicit authorization. Moreover, the processing and use of the data collected by the user must be regulated and must not be sold, under any circumstances, to interested parties for marketing, targeted advertising, or used to pressure and blackmail [6].
The preservation of privacy is defined as tolerance to prevent information leakage caused by combining published data with other data. The anonymization methods must be tolerant when merging with other data [32]. According to a risk analysis presented by [6], each solution to preserve privacy must guarantee the confidentiality of data related to users and their private life. Whereas not maintaining privacy means that the recipient of the information can access data to identify its owner. Meanwhile, access control and authentication are implemented against direct disclosures and do not guarantee privacy preservation by themselves.
Anonymity
Anonymity can be characterized as the property that certain records or transactions are not attributable to an individual [39]. The author in [50] says a sender may be anonymous only within a set of potential senders, his/her sender anonymity set, which itself may be a subset of all subjects worldwide who may send messages from time to time. The recipient can be anonymous within a set of potential recipients, which form his/her recipient anonymity set. An example of anonymity is an anonymous call; we received the information but could not identify the sender. According [37], to enable anonymity of a subject, there always has to be an appropriate set of subjects with potentially the same attributes.
Methods for data anonymization
Anonymizing data removes or replaces information, thus preventing an attacker from interfering with a user’s privacy. Therefore, anonymization allows individuals to remain hidden from potential threats when their data is published for analytical or commercial purposes. Confidential details or information that can identify a person, which should not be published in the public domain, is called personal information [24].
Anonymization approaches are classified into two main classes: static data and data flow. The anonymization of static data works with a set of pre-recorded data. Data flow anonymization processes data as quickly as it arrives. The anonymization’s quality of data flow is defined by an exchange between updating and usability of data [35].
In [16], the authors developed a work related to the energy area; they created three anonymizing data methods. For them, these methods are suitable for anonymizing energy usage data. Both methods focus on k-anonymity. These methods are (i) disturbance, (ii) k-member grouping, and (iii) a combination of k-member grouping with Gaussian distribution. Appropriate anonymity satisfies a certain level of anonymity, causing minimal data modification, and this is desirable to achieve privacy preservation and effective secondary use of data [32].
Conventional anonymization methods add great noise to the data due to the difficulty of defining anonymity, which does not facilitate practical use. Furthermore, different anonymity degrees are necessary since the required privacy protection levels vary according to individuals or purposes. For example, some people do not hesitate to reveal their age, while others do not like to expose their age. However, conventional methods do not consider these differences between individuals [32]. Therefore, the purpose of anonymization algorithms is to find the best way to obscure/hide data in a way that guarantees the privacy of users’ data, maximizing the usefulness of the data and protecting the identity of its owner [27].
It is possible to find several methods to omit or even hide personal data in the literature. Thus, there are several methods available in the literature to anonymize data. There are also methods with a wider scope, which can be applied in various contexts, both in the IoT scenario as in other areas. Some methods were developed exclusively for the IoT. They can be used in the multiple contexts of IoT applications. Others were created for more specific purposes, such as the method proposed by [48] created to anonymize the user’s location.
Data obfuscation
Obfuscation is a technique used to protect privacy, such as the user’s location. In this technique, the user’s original location is slightly changed to another place. In this way, the person’s original location is hidden from the opponent. Several techniques have been proposed to protect the site’s privacy, namely dispersion techniques, randomization techniques, perturbation techniques, the semantic glare technique, etc., but none of them paid attention to the balance between privacy and utility. The user can obtain a good result from the privacy perspective but cannot efficiently get the necessary service [48].
K-anonymity
K-anonymity is a typical method of preserving privacy, considering the level of anonymity. Before explaining k-anonymity, it is worthwhile to understand the definition of the data table, index, attribute, identifier, and quasi-identifier:
In [46], the concept of k-anonymity proposes that a data release with this property implies that each person’s information cannot be distinguished from at least
For [33], k-anonymity is the process of anonymizing records. Therefore, k individuals are indistinguishable from each other. This mechanism protects the record from identity disclosure; and from the lashing out of attacks from a remote position. Thus, Attachment or Identity Disclosure can offer the opportunity for an attacker to disclose the value of a person’s sensitive attributes with known values. This mechanism is prone to some of the frequent attacks. Some examples include homogeneity attack, similarity attack, background knowledge attack, and probabilistic inference attack [33]. The purpose of the original k-anonymity algorithm is to ensure that no individual can be uniquely identified within a group of k people [26].
Generalization and disturbance
Generalization is a technique for replacing attribute values with a broader category. The method includes sampling, global recoding, and local recoding [45]. Disturbance is a technique for disturbing data using multiplicative or additive noise. Randomized processes are also a popular method of disturbance. Such a technique can be completed only by performing a simple operation on the data and has advantages over the required resources [45].
Sliding window
The Sliding Window technique is used to anonymize the most recent data tuples and publish a recently received data flow. There are two main types of Sliding Window: based on time and count. In the Sliding Window based on the count, the round of anonymization is invoked when the size of the Sliding Window reaches a specific limit. On the other hand, in the Sliding Window based on time, anonymity is controlled by the time received from a tuple in the Sliding Window [24].
Mixing
Mixing is a mechanism for randomizing the sequence of a batch of data so that the output remains indistinguishable from the input. The following are two approaches developed by Chaum that use Mixing, which are Mixnet [9] and DCnet [8].
For [9], the Mixnet is a network that consists of a chain of servers, called mixing nodes. Each mixing node receives a batch of encrypted messages, then decrypts or re-encrypts individual messages performs a random permutation, and forwards the batch to the next mixing node. The final output is unlinkable to the input when at least one of the mixing node’s permutations remains secret. Shuffling is the composition of permutations along the chain of the mixing nodes. Shuffling is verifiable if there is a mechanism to prove the correctness of the output sequence. Mixnet relies on the cryptographic-primitives, for example, factorization or computational discrete logarithm problem. Therefore, verifiable Mixnets incur the additional cost of communication and computation [30].
In another work, Chaum [8] intended the DCnet for anonymous communication. DCnet is free of cryptographic-primitives and eliminates the traffic analysis problem. DCnet is primarily designed for honest people. Unfortunately, DCnet suffers from collision and interference attacks [30].
Pseudonyms
Pseudonyms include the mechanism for renaming entities with alternative random identities. A digital pseudonym is a public key used to verify signatures made by the anonymous holder of the corresponding private key. A roster, or list of pseudonyms, is created by an authority that decides which applications for pseudonyms to accept, but is unable to trace the pseudonyms in the completed roster. For example, the applications may be sent to the authority anonymously, by untraceable mail, or they may be provided in some other way [9].
Each application received by the authority contains all the information required for the acceptance decision and a special unaddressed digital letter (whose message is the public key K, the applicant’s proposed pseudonym). In the case of a single mix, these letters are of the form
Systematic literature review planning
This section describes the planning for conducting the Systematic Literature Review (SLR). In this context, we present the research questions and the procedures adopted to select research sources for the studies and the studies themselves. It is worth mentioning that, to conduct this SLR, we will follow the Guideline proposed by [22].
Research questions
Specifying research questions (RQ) is a crucial part of planning an SLR. These questions are capable of guiding the review process and provide a basis for deciding: (i) which primary studies will be included in the review (directing the search strategy), (ii) what data will be extracted, and (iii) how the data will be synthesized to answer the research questions [23].
The RQs must be answered to achieve the objectives listed in this study, thus being a way of developing solutions using data anonymization for data privacy in the IoT. Therefore, to conduct this research, we have defined the following research question: What are the main approaches for the IoT area that promise or can provide data privacy using anonymization? From the main question of this research stem the following research sub-questions:
These questions seek clarification on how data anonymization techniques are used to address data privacy in the context of IoT. It is necessary to make a classification of these works to answer these questions. In order to do this, a subset of characteristics will be used to classify the studies. These characteristics include: Design of the technique/approach; Area of application; Methods used; Metrics used in the evaluation of anonymization.
At the end of this Systematic Literature Review, we classify the differences between these studies based on the type of target environment, that is, where these techniques applied to data anonymization for IoT are used, what they were created for, and point out the main advantages and disadvantages in the scenario addressed.
Sources selection
The strategy for conducting this review is to use both manual and automatic searches jointly. Thus, the search and selection of studies were defined based on the research questions and their sub-questions. The search string used for the automatic search refers to the terms and synonyms used to find the search engines studies.
The search string was elaborated based on what was found in the manual search. After performing the tests to verify the string’s scope, we performed tests on the chosen bases. Subsequently, we did tests interactively and incrementally to arrive at a string that met our research’s objectives. After several attempts, we arrived at the final version of the string:
Bases used for automatic search
Bases used for automatic search
Table 2 shows the search strings per web search engine and the number of studies returned by each one. It is worth mentioning that we also filtered articles written between 2009 and 2021. This search was carried out on 03/19/2021. Furthermore, the search engine that found the most studies was SpringerLink, with 295 works. At the end of the searches, a total of 523 works were returned.
List of search strings by search engine
We have established some inclusion and exclusion criteria to assist in selecting studies relevant to this SLR. For a study to be included, it must satisfy at least one of the inclusion criteria set out below. On the other hand, for a given study to be eliminated, this same study must be related to at least one of the exclusion criteria. Below are the inclusion and exclusion criteria used for selecting the studies:
Studies presenting concepts, theories, methods, tools, reference models, guidelines, lessons learned, and experience reports on the application of data anonymization in IoT.
Editorials, abstracts, tutorials, keynote, workshop reports, opinions, conference summaries, theses, dissertations, technical reports, books;
Secondary or tertiary studies;
Primary studies that do not explicitly present the application of data anonymization;
Articles that are not accessible via the web;
Duplication of publications (Indexed);
Articles not written in English; and
Articles that are not associated with the areas of Computer Science and Engineering.
The SRL was divided into four phases to select the works considered relevant for this SLR. They are described below.
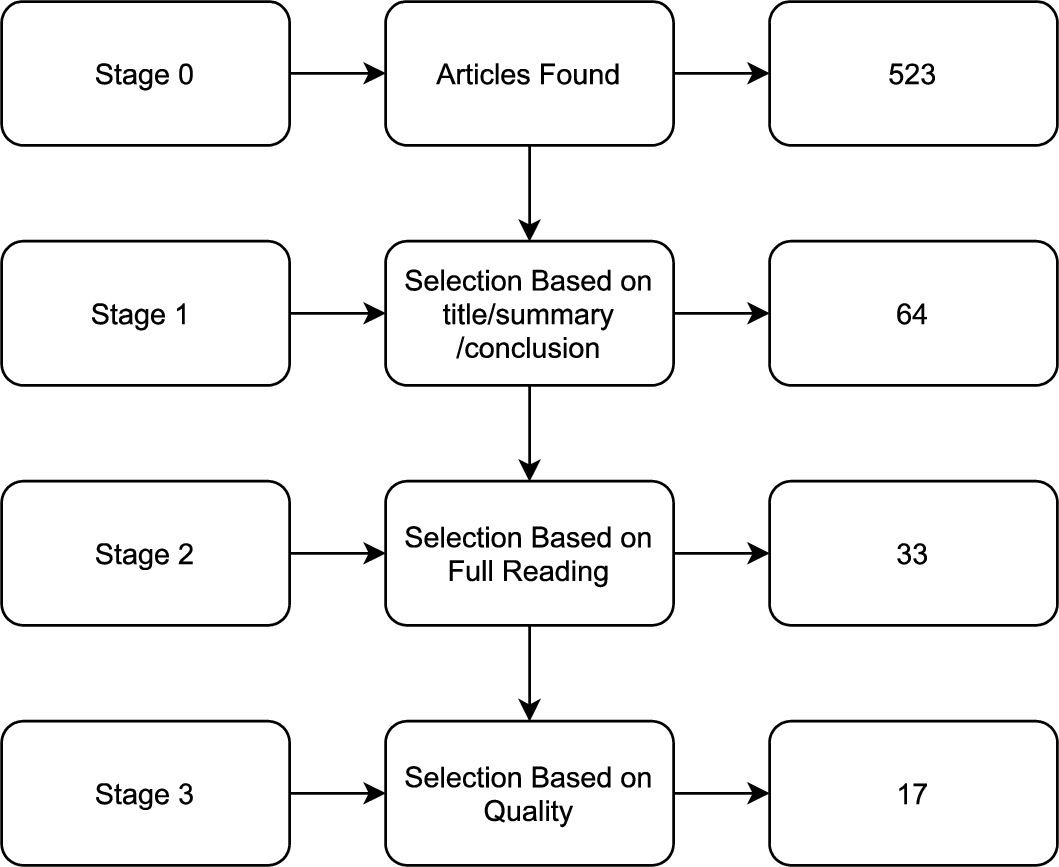
Selection process for SLR articles.
In Fig. 2, it is possible to observe the results of each of the four Stages performed to select the works in the SLR developed in this research. After Stage 0, we proceed to the second analysis (Stage 1). 64 studies were pre-selected. In this analysis, the reviewers read the title, abstracts, and conclusions of all studies returned in the search stage. Then, in Stage 2, 33 articles were selected. In Stage 3, the Quality Analysis was carried out (see Section 3.4). Then, the papers were read in full and classified according to their relevance, resulting in a final number of seventeen selected articles.
In Stage 3, we prioritized the articles previously selected for the execution of the Quality Analysis. In order to do this, we read the entire content of the studies. The Quality Analysis process was carried out based on [13]. For this analysis, nine criteria were used, divided into four categories: (i) regarding the quality of the report, (ii) rigour, (iii) credibility, and (iv) relevance of the study. These are presented in Table 3. Next, we evaluated the quality of papers of different types using the same checklist. For this, we use a Likert-based scale with the following intervals: −2 (totally disagree), −1 (partially disagree), 1 (partially agree), and 2 (totally agree).
Criteria for quality analysis
Criteria for quality analysis
We decided to exclude primary studies classified as low quality for the synthesis process. However, before performing the exclusion, verifying the exclusion’s impact on the mapping is necessary. The remaining articles, which were not excluded in the Quality Analysis, were analyzed in subsequent stages. The level of agreement reached in the Quality Analysis using values for the number of questions considered appropriate, and the average score for each article, will be measured using Pearson’s correlation coefficient [36]. These Inclusion criteria were applied in phase III, described in Section 3.3. After the Quality Analysis, seventeen studies were selected to perform the next stage, data extraction.
The form used for data extraction was built based on the work of [13]. It is essential that mapping is carried out between the items to be extracted and the research questions to guide the extraction process and facilitate the data analysis and synthesis process. Table 4 presents the form used for data extraction, which was built based on the work of [13].
Data extraction form
Data extraction form
Data extracted from selected articles during the review process (SRL)
In the data extraction process, all works were fully read and reread by performing a careful analysis, previously described, so that the information that could support the answers to the research questions related in Section 3.1 could be extracted. Table 5 presents the data extracted from the articles selected in the review; it is also important to highlight that some data (objectives) were omitted to respect the document’s designation of spacing limits. However, it is possible to find these data/objectives in the synthesis section.
Observing Table 5, we can identify that the researchers from Keio University in Japan stand out from other universities. Out of the seventeen studies analyzed, three come from Keiko [16,32,45]. Researchers developed one of the works from “IBM T. J. Watson Research Center / Cardiff University” [27]. Almost all the other works were relevant in some way. Only paper [6] from the National Institute of Posts and Telecommunications STRS Lab did not undergo evaluation.
Figure 3 illustrates the graphical distribution of the works returned by automatic search with the year in which they were published. Of the seventeen works analyzed, the years 2016, 2019, and 2021 had two each; 2017 and 2018 amount to eight of the works analyzed. For 2020, three of the works were analyzed. Therefore, of the seventeen works analyzed, fifteen of them made Quantitative evaluations. However, only [6] did not provide for an evaluation. The method was proposed in this case, but no experiment was carried out. [12] had already made a Qualitative evaluation. And all works implemented at least one algorithm to test their proposal.
Below is a summary of the seventeen papers previously selected for this (SRL) analysis review, as previously presented and explained in Table 5. In this subsection, the strengths and weaknesses of each of the selected approaches will be tested.

Quantitative of the works analyzed and their respective years of publication (2016–2021).
According to [48], the things/devices connected in our homes, shopping malls, streets, and recreational spaces continuously send information over the Internet. These recordings and also the recording of all user movements lead us to several privacy concerns. In light of this, these two authors have proposed an Enhanced Semantic Overshadowing Technique (ESOT), which is designed to preserve the privacy of general IoT device locations.
This technique is based on the semantics of the user or device location. Their primary concern is hiding from the opponent’s IoT device localization, which may want to find a real location to violate privacy. In this scenario, the authors, as mentioned earlier, propose to protect the user’s location from the Localization Based Service (LBS), since LBS is not a reliable component. Therefore, Hiding’s use is recommended. Hiding is a technique used to protect the privacy of the user’s location. In this technique, the user’s original location is slightly changed to another location. In this way, the person’s original location is hidden from the opponent. ESOT achieves better performance in terms of site privacy and service utility compared to the Semantic Overshadowing Technique (SOT).
An anonymization protocol for the Internet of Things
In [12] one sees an anonymity protocol explicitly designed for Machine to Machine IoT and Social Internet of Things (SIoT) communications. The proposed anonymity system is based on the Tor routing concept, but unlike Tor, SIoT is completely datagram-oriented, with less protocol and cryptographic overload. Moreover, path selection is made by a package to increase the overall level of anonymity. Two different anonymity path modes are designed to easily support end-to-end and source-to-output node anonymization models.
In [12], one sees an anonymity protocol explicitly designed for Machine to Machine IoT and Social Internet of Things (SIoT) communications. The proposed anonymity system is based on the Tor routing concept, but unlike Tor, SIoT is completely datagram-oriented, with less protocol and cryptographic overload. Moreover, path selection is made by a package to increase the overall level of anonymity. Two different anonymity path modes are designed to support easily end-to-end and source-to-output node anonymization models.
The anonymity protocol has been implemented as a user anonymity datagram layer that expands upon the standard UDP layer (Java DatagramSocket). This implementation allowed for simple and easy integration into any UDP-based application, such as the CoAP clients and servers used. It was only a matter of replacing the standard UDP layer (Java DatagramSocket) with the new anonymity datagram layer.
Still, according to the authors [12], the main scope of this implementation was to validate the design principles and the protocol’s correctness. Nevertheless, 100 (virtual) IoT objects, which were run on two Raspberry Pi devices (50 virtual nodes per single device), were added. That is to say, the evaluation did not use real objects; they were simulated.
Anonymization method based on sparse coding for power usage data
For [16], a method for anonymizing energy demand data is proposed, in which sparse coding is used to solve the three problems that affect the conventional method. The proposed method can anonymize time series data and allows the data to be analyzed at the chosen time. The proposed method was used to anonymize energy use data at the Urban Design Center of Misono (UDCMi). The experimental error rate decreased when compared to the conventional method. The dictionary produced using the proposed method represents the data from the electrical appliance.
Furthermore, [16] reveals three different privacy standards: k-anonymity, l-diversity, and t-closeness. The proposed method by the authors focuses on k-anonymity. This method achieves the following three main objectives: first, the proposed method allows time-series data to be anonymized; the next goal tells us that the error rate (ER) is reduced compared to conventional methods, and finally, usage information acquired in household appliances can be stored in an anonymous environment.
Hardware for accelerating anonymization transparent to network
[45] proposes data anonymization hardware that obtains transparent anonymization of data flows from IoT devices. The architecture is implemented in a field-programmable gate array (FPGA). The proposed hardware is allocated in the intermediate location of a network to capture the packet of IoT devices. The captured packet is anonymized by hardware and forwarded to the next node while the header is modified without influencing its routing. The anonymization process does not affect the communication protocol or packet routing, and the proposed hardware obtains transparent network anonymization, similar to a communication cable. Transparency allows an anonymization function to be installed on all devices, including IoT devices, but without modifying the devices. The proposed mechanism has achieved lower power consumption and higher throughput than software processing. Besides this, through our investigation we confirm that the FPGA has realized the anonymity of transparent packets to the network.
As described by [45], k-anonymity can be adopted. However, in this study, the authors [45] implemented noise nuisance, which is a simple method of anonymization that requires adding pseudo-random numbers to numerical values. The target values to be anonymized were the energy use data recorded by an intelligent meter. The unauthorized use of energy use data violates the privacy of people living in their homes. Therefore, the preservation of the privacy of energy use data is necessary. The format of the energy use data was a matrix of numerical values with the was previously provided noise range. The authors [45] focused on the transparency of the proposed hardware, a simple method of anonymization and data format being employed.
Although the authors [45] stated that the technique could be used on other IoT devices, they only implemented it in two types of devices and a controlled scenario. The evaluation could be broader, using more data and using different connections to see the behaviour.
K-VARP: K-anonymity for varied data flow via partitioning
[35] proposes the K-VARP (K-anonymity for VARied data flow via partitioning) to anonymize numerous data flows. The goal is to anonymize and publish a variety of data flow, minimizing delay and loss of information. The K-VARP algorithm uses partitioning and marginalization methods to anonymize varied data flow in a time-based Slider Window.
The results demonstrate the effectiveness of K-VARP, as it uses R-similarity to identify similar partitions in the merge. In addition, a combination of marginalization and flexible reuse has a significant impact on the anonymity of varying data flow. K-VARP anonymizes varied data flow with 3% to 9% less information loss and 10% to 20% less information loss in PM 2.5, compared to two of the other compared algorithms, utilizing a similar time span for the calculation. The K-VARPś data usability is better than the other two algorithms because our proposed algorithm does not assign missing values, and belated anonymity is impractical.
Learning light-weight edge-deployable privacy models
According to [27], Apache Spark creates an implementable anonymization model at the edge quickly. Once a model is created, the structure allows even users or cutting-edge IoT devices to overshadow their records without significant computational overheads or knowledge of the data in its entirety to reflect the varying characteristics of data over time. The framework also provides a verification function to validate whether an anonymization model meets the desired data privacy restrictions. Therefore, data administrators do not need to continuously calculate the anonymization model for incoming records. They only retrain an anonymization model when a current model does not pass the validation procedure.
Yet in this article, they [27] implement and evaluate the scalable data anonymization structure and lead to the proposed anonymization function’s flexible deployment. According to the authors [27], the structure speeds up the learning process of anonymization rules by applying parallel computing and generates viable models to be implemented in the latest generation devices. The authors [27] also investigated several factors that affect the performance of anonymization, as well as parallelization. The resultś experimental show that the structure is capable of reducing the time to build anonymization models. The evaluations show that the framework learns anonymization models up to 16 times faster than a sequential anonymization approach and still preserves enough information in anonymized data for data-oriented applications.
Mobile sensor data anonymization
[29] proposes a transformation in the sensor data device to be shared for specific applications, such as monitoring selected daily activities, without revealing information that allows user identification. The authors formulated the anonymization problem using a theoretical approach to knowledge and proposed a new multi-objective loss function for in-depth self-coding training. This loss function helps to minimize user identity information and data distortion to preserve the application-specific utility.
According to [29], to remove the user identifiable features included in the data, not only the neural network model feature extractor (encoder) was considered, but also the reconstructor (decoder) was forced to shape the final output independently of each user in the training set. Hence, the trained final model is a generalized model that can be used by a new invisible user. The authors’ proposal ensures that the transformed data is minimally disturbed so that an application can still produce accurate results, for example, for activity recognition. The solution proposed by [29] is essential to ensure the anonymity of participatory detection when individuals contribute data recorded by their devices for health and wellbeing data analysis.
Privacy and utility preserving data clustering for data anonymization and distribution on Hadoop
[33] proposes a cluster-based anonymization algorithm resilient to similarity attacks and probabilistic inference attacks. The anonymized data is distributed in the Hadoop Distributed File System. The algorithm achieves a better compromise between privacy and utility. Performance is measured in terms of accuracy and FMeasure against different classifiers.
In this work, k-anonymity is employed to preserve data privacy in a distributed environment. The authors claim that they proposed a grouping algorithm to achieve k-anonymization and l-diversity resilient to the attack of similarity and probabilistic inference. Later, privacy preserved anonymized datasets are distributed in Hadoop.
According to [33], data owners can securely distribute the data by applying the proposed cluster algorithms to any distributed structure. The sensitive information in the data is protected against link attacks, homogeneity attacks, similarity attacks, and probabilistic inference attacks using the proposed cluster algorithms.
Privacy preservation in the Internet of Things
What is analyzed by [6] is privacy in the IoT based on a case study that proposes mechanisms to improve security and preserve privacy. This analysis also considers the economic advantages related to the use of IoT as a new business opportunity without the disclosure of personal data.
The paper contributes to the user’s privacy field in IoT by presenting an in-depth risk analysis of the threat to privacy and proposes two approaches to preserving privacy. The first is recommendations for user application developers and the IoT. The second employs the use of anonymization techniques to hide recorded data that can be used as a threat to violate privacy.
The framework and algorithm for preserving user trajectory while using location-based services in IoT-cloud systems
The work of [26], focuses mainly on the solution of two problems: (i) preservation of location privacy for a single query; (ii) preservation of trajectory privacy for continuous consultations. They proposes an efficient algorithm based on the k-anonymity technique to protect the privacy of the user path in location-based services. And to better preserve the privacy of the location and reduce the complexity of time, the proposed k-anonymity mechanism is based on Sliding Window. According to the authors [26], the k Sliding Window selects fictitious locations, and the Trajectory Selection Mechanism (TSM) selects false paths. The simulation results show that the algorithm reduces time complexity compared to existing solutions for a single query, and effectively preserves user path privacy for continuous queries.
TMk-anonymity: Perturbation-based data anonymization method for improving effectiveness of secondary use
In [32], a solution to the privacy problems for disclosed data was developed. The authors defined the TMk-anonymity and proposed three different methods of anonymity, (i) the condensation method, (ii) the addition of noise method, and (iii) the addition of condensation and noise method (CoNoA), which combines the two methods.
TMk-anonymity may be more practical from the perspective that it can give different degrees of anonymity to different individuals compared to the conventional k-anonymity. Furthermore, the rootmean-square error (RSME) of the proposed anonymization methods was approximately 0.7% compared to the conventional Pk-anonymization. This process of retaining resources is since the CoNoA method uses the noise addition method, adding noise according to the original data, and the condensation method that allows lower RMSE anonymity of the data when compared to the other methods.
Toward anonymizing IoT data streams via partitioning
[34] present IoT’s anonymity for a new algorithm that published IoT data flow generated from various IoT devices under the k-anonymity privacy model, and to achieve this anonymity, the time-based Slider Window technique was used to manipulate IoT streams by partitioning tufts based on their description. This preliminary operation helped form the cluster faster by locating tuples and supporting partition merging when needed. The proposed algorithm outperformed the conventional approach of anonymizing the modified data flow to anonymize IoT data flow.
The experiment demonstrated that conventional flow anonymity could not be applied directly to IoT streaming data and required significant research and development. According to the authors [34], it would be interesting to investigate new privacy models to group anonymously with missing data.
Data anonymization: A novel optimal k-anonymity algorithm for identical generalization hierarchy data in IoT
In their research, [28] present a novel optimal k-anonymity algorithm for identical generalization hierarchy (IGH) data which is the main data type in the IoT environment. The authors proposed a novel method to provide a globally optimized k-anonymity solution for the IGH datasets. The proposed algorithms determine an optimal solution based on identical generalization hierarchy (IGH) data characteristics by visiting and evaluating only essential nodes of the generalization lattice that satisfy the k-anonymity. Since the k-anonymization problem is of the NP-hard type, it was shown that the algorithm could efficiently find optimal k-anonymity solutions by exploiting special characteristics of the IGH data, i.e., the optimality between nodes at different levels of the generalization lattice. From the experimental results, according to the authors, it is evident that the algorithm is much more efficient than the comparative algorithms, demanding less searching on the given lattice.
According to [28], the key idea of the algorithm is to analyze only necessary nodes, which are those at the lowest level of generalization, found as k-anonymous nodes, in contrast to other algorithms in the literature where one has to examine all nodes. The algorithm first finds the routes from the root node of the generalization lattice, i.e., (000), to the highest-level node using the pre-order traversal method. The k-anonymity determines all nodes in the routes starting from the node at the lowest level. The k-anonymous nodes are to be tagged, and the lowest level found k-anonymous, called k-anonymous level, is set. The algorithm traverses to the other routes and visits only the nodes at the lower-than-k-anonymous level until all nodes in the lower-than-k-anonymous level have been found and tagged.
Cooperative privacy-preserving data collection protocol based on delocalized-record chains
The authors [40] introduce a novel mechanism of collaborative anonymous communication aimed at multi-user environments, named delocalized-record chain. The proposal is characterized by being an autonomous solution adapted to the distributed nature of an IoT environment, in which the users interested in getting anonymity work in synergy to anonymize their data transmissions. Because the solution lacks third-party intermediaries, it is particularly appropriate for private networks, such as private IoT networks.
The new data collection generates a protocol by the name of Cooperative Privacy-Preserving Data Collection protocol (cPPDC) that offers privacy-preserving conditions in both data collection and publication without limiting Privacy-Preserving Data Collection (PPDC). This method can be used to k-anonymize the data set. This protocol is resistant to network traffic analysis attacks by using the delocalized-record chain as a data transmission medium in the collection phase. This protocol can generate k-anonymous datasets in IoT environments, protecting, at its source, the personal data that a set of devices sends to a central collector. To extend the privacy requirement to the data collection phase, the protocol uses a new mechanism of collaborative anonymous communication named delocalized-record chain. Since the protocol does not require third-party anonymous communication channels, its application is especially relevant in IoT environments deployed on private networks [40].
Data anonymization for privacy protection in fog enhanced smart homes
This paper [38] presents the architecture of a fog-enhanced smart home environment for preserving the privacy of individuals when data from their smart homes is shared with third parties. A Km data anonymization technique is employed to prevent privacy breaches by individuals. The proposed architecture and technique are evaluated on a real-world data set, and the results indicate their effectiveness in the preservation of privacy.
In the proposed architecture for [38], the privacy preservation module (PPM) is placed on the fog layer. The sensitive data collected from smart homes in a community or smart apartment complex is fed to the PPM. The PPM applies a slicing technique [25] to the aggregated data. It removes the linkage between the constituent fields of user records. This remotion anonymizes the data, and consequently, it is not possible to associate a data record with a particular user or home. This impossibility protects the user data from privacy breaches.
A robust privacy preserving approach for electronic health records using multiple dataset with multiple sensitive attributes
[20] formalized an adversary’s behaviour, performing identity and attribute disclosures on a balanced p+-sensitive k-anonymity model with the help of adversarial scenarios, since the balanced p+-sensitive k-anonymity model is not sufficient for 1 to M with multiple sensitive attributes (MSAs) 1 datasets in terms of privacy preservation. The authors coined an extended privacy model called “1: M MSA-(p, l)-diversity” for 1: M dataset with MSAs.
They then performed formal modelling and verification of the proposed model using High-Level Petri Nets (HLPN) to confirm privacy attack invalidation. Experimental results show that the proposed “1: MMSA-(p, l)-diversity model” is efficient and provides enhanced data utility of published data [20].
[20] proposes an approach based on datasets containing MSAs and multiple records of a single patient (1: M) in EHRs. It is done to classify the privacy scenarios for identity and sensitive attribute disclosure on a balanced p+ sensitive k-anonymity model and proposed an improved version called “1: M MSA-(p, l)-diversity” to anonymize EHRs data.
Distributed l-diversity using Spark-based algorithm for large resource description frameworks data
In this work, [18] proposes an l-diversity anatomy de-identification method that can overcome the limitations of k-anonymity and guarantee stronger privacy protection than k-anonymization. Further, as this data anonymization process is computationally time-intensive, Spark distributed computing to provide rapid re-identification to enhance its utility. Preservation of l-diversity was also proposed for dynamically evolving RDF datasets. Experimental results show that the proposed distribution of the l-diversity algorithm processes the data more efficiently than conventional approaches.
Main anonymization techniques used
In Table 6, a classification of the selected works is made, considering which technique the works use to provide data privacy, remembering that all the methods used in the works perform the anonymization of data in some way.
Main anonymization techniques
Main anonymization techniques
It is important to note that the topic anonymization is intended for works that have not specifically categorized which technique was adopted to execute their respective proposals. In addition to the jobs selected in the automatic search, four more jobs were added [8,9,24,30] selected through a manual search. The works marked as k-anonymity mean that either they used the method without modification or they used it as a basis to make an improved version, that is, they used it indirectly. After the analysis of the twenty-one papers selected in the review, we identified that eleven among them [16,20,26–28,32–35,40,45] use the technique “k-anonymity,” of those works that use “k-anonymity” two [26,35] use “k-anonymity” plus another technique. The other three papers [6,12,18] use anonymization to provide data privacy. The same authors only specify that they use anonymization and do not determine whether they use some of the techniques in Table 6 or another method, so these works were classified in the anonymization category. The Sliding Window technique was used in three papers [24,26,34]. Of the twenty one papers analyzed, four [26,27,35,45] use two techniques simultaneously.
From the elaboration/realization of this research until now, no anonymization technique has been applied in the researched IoT scenarios. Most of the analyzed works use different techniques to anonymize the data or make a combination of more than one technique. Still, it is worth pointing out that the technique that stands among the numerous works is k-anonymity; this technique is used in most of the analyzed works, even when used combined with another technique or modifications made to k-anonymity.
Given the data extracted in this review, it was possible to demonstrate that data anonymization provides a promising solution in its privacy delivery to data generated by IoT devices. Several techniques are currently being used to provide anonymization in the context of IoT; the k-anonymity method was the most used. For [6], the factors that lead to the use of K-Anonymy is that it can guarantee the privacy of data from the following aspects: “(i) The sensitive data must not reveal information that was redacted in the generalized columns; (ii) The value of sensitive columns are not all the same for a particular group of k; (iii) The dimensional of the data must be sufficiently low”. These aspects cited are essential factors that lead to the choice of this technique for protecting data privacy in various research, both in the area of IoT and other sectors of computing.
In Table 7, we made a comparative analysis between the selected works, considering the application area of each study. The objective of this comparative analysis between the works is to identify which areas are being more studied for data privacy that the devices generate and which areas are researching and developing solutions for the problems related to data security and privacy in the IoT.
Classification of selected jobs according to the IoT domains
Classification of selected jobs according to the IoT domains
The domains are analyzed according to the division proposed by [7]. Since some works do not specify where their application is or where they tested their techniques, we added a fourth category (iv) Undefined Domain (“Not defined”). The latter category is intended for works that were not allocated or directed to some domain due to a lack of information data used in the tests.
According to the analysis of the works, it was possible to identify that the Smart city domain and Health Well-being Domain both had four and three works respectively that developed some mechanism to treat privacy using anonymization. With the information present in the researched works, it was not possible to identify any that had developed something for the Industrial Domain. Fourteen of the works were classified as undefined Domain because, in the works, they did not have information that classified them in any domain. This analysis enabled us to observe that most of the works are generic; firstly, they were developed for IoT as a whole, and the authors do not focus on any area of IoT; another hypothesis is that they did not put enough information due to regulated space in their respective works.
In this subsection, we present a comparative analysis between the anonymization techniques presented in Table 6 and the IoT application domains, taking into account the division of the IoT proposed by [7], which is presented in Table 7. In this way, we discuss the anonymization techniques and in which areas each one is more applied according to the results obtained in this Systematic Literature Review.
According to the information provided in the analyzed works, it was not possible to identify any work that used any anonymization technique applied to the industrial domain. In Smart City Domain, we identified that the work of [48] used Obfuscation, [16] used k-anonymity, [24] used Sliding Window, and [38] used an anonymization approach based on the Generalization technique. In this scenario, we identified that each job uses a different anonymization technique.
In the HealthWell-Being Domain, we identified that the k-anonymity technique was used in two of the three works returned in this research [26] and [20]. Only the work by [29] uses Disturbance to anonymize the data, and there is still another work [45] that uses this technique. Still, it was not possible to identify which domain it belonged to the data available in the work did not identify which IoT domain it was applied to. The search of [26], in addition to using k-anonymity, also uses SlidingWindow to anonymize the data. k-anonymity stands out as the anonymization technique that was applied in more works and almost all domains, with the exception of the industrial domain, where no work was identified.
IoT anonymization processing flow
This section provides support for answering the fifth research question: “What are the categories related to metrics, techniques, methods, tools and technologies applied to data anonymization for IoT?” In this way, we describe a flow for organizing the various levels of decision making for anonymizing data in IoT, taking into account the origin of the data, whether they are in continuous flow (data transmitted in real-time) or be they static data (data that is stored in some database). The main challenge of continuous flow is capturing the data in real-time and anonymizing it without interrupting the system’s flow. The main challenge of static data is to prevent unauthorized entities from having access to these data that are stored in some database and jeopardize users’ privacy.
First, one understands how the collection and analysis of data generated by IoT devices work without using anonymization. The data is generated and sent to be stored in some database of the company that developed the devices. They can be analyzed and then used to improve the quality of the device or service offered or sold to third parties; this process is represented in Fig. 4.

Process of data generation.
Not anonymizing the data puts at risk the privacy of the users of the devices because unauthorized entities may have access to this data. For example, this data may be stolen or even sold, and this may put the identity security of the owner of the data at risk, which can cause much damage to a person’s image, or even his or her life, because this data may offer different information about a person’s daily life. To solve this problem, before the data is analyzed, it can be anonymized to be later analyzed and stored; in Fig. 5, the process is illustrated in detail.
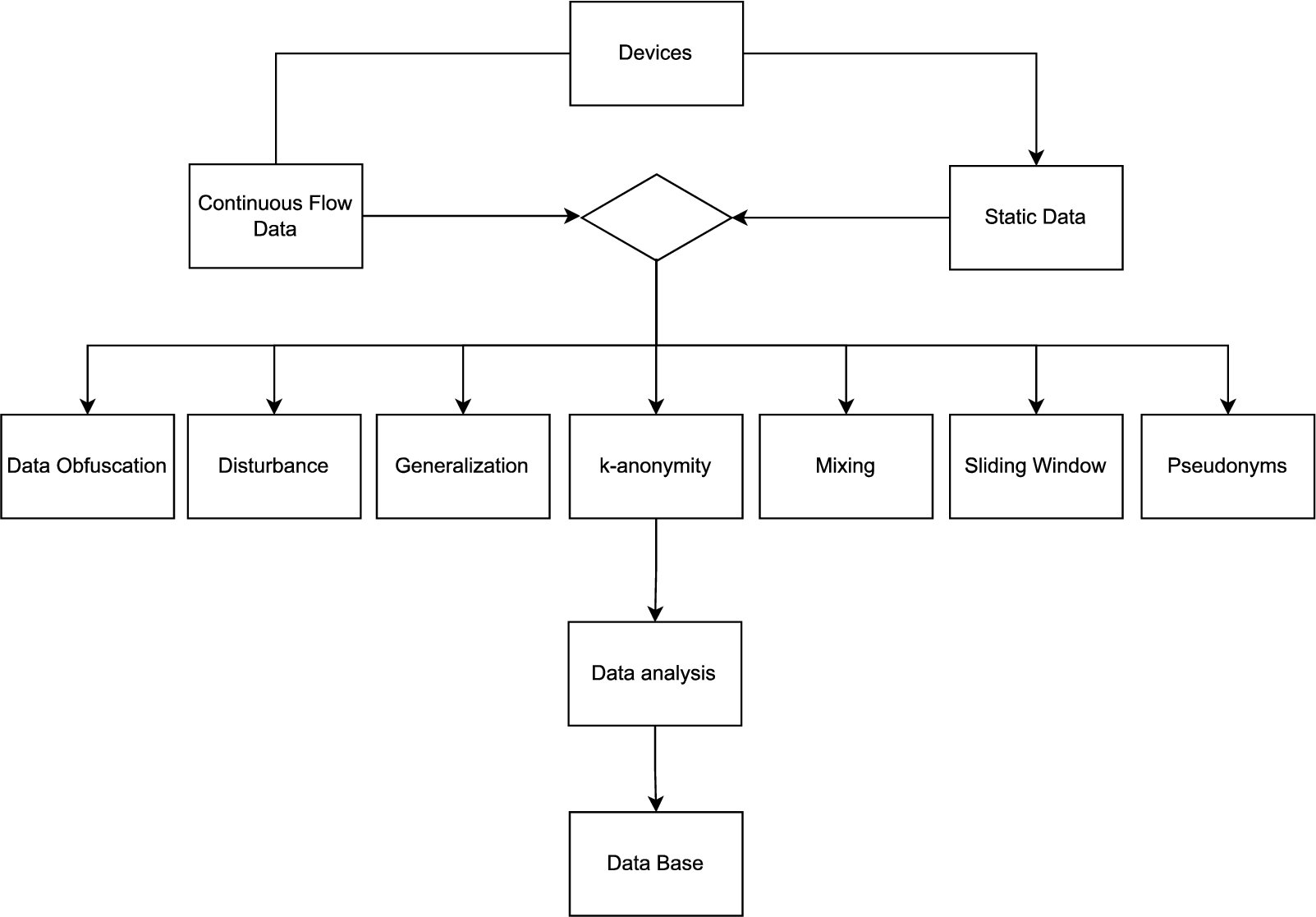
Flow for data anonymization.
The data are generated by IoT devices (these devices can be of various types); this data can be classified into two types: (i) continuous flow and (ii) static data. According to the type of data, it will be anonymized by one of the algorithms and then analyzed and later stored; this process protects the identity of the data owner and allows it to be analyzed without losing the quality of the analysis.
While IoT devices provide valuable data to service providers to offer services contextually, these devices can detect confidential information that can violate the privacy of users of these devices. Anonymity provides a solution to this problem by transforming the data and preventing attackers from linking published data to the data source, i.e., the owner of the data [34].
IoT applications bring numerous benefits to our daily lives. At the same time, they can put our privacy at risk; this is due to applications’ providing some service that makes our lives more comfortable. IoT applications need to collect a set of information to analyze it and, in the face of this analysis, provide the service according to each user’s profile. From the moment our data is collected, our privacy is at risk because third parties may be having access to our information, and besides using our information to provide us with some service, our data may be used for other purposes, and this may put our privacy at risk.
There are two approaches to data anonymization, (i) static data anonymization and (ii) data flow anonymization. The approaches based on static data anonymization are the most discussed in the works under analysis. This approach works with a set of data that are generated and stored in a database to execute the anonymization of this data. The anonymization approaches of data flow, on the other hand, are the least discussed, perhaps because analyzing the data in continuous flow is a more complex task due to the massive flow of data that are generated and transmitted instantly.
Given the set of researched and used works, it was possible to identify that most of these works developed comprehensive solutions. For example, they did not focus on specific areas of IoT. Most of the works do not worry about where they will be applied; they only worry about anonymizing a data set without considering their origin or destination.
Moreover, according to the analyses performed in the works, it was found that among the anonymization techniques in the selected works, the k-anonymity technique was the most used. The intention was to provide privacy. A very common approach in some works was to adopt more than one technique to provide privacy. So, two techniques could be combined to improve their effectiveness. This combination was made through the use of k-anonymity and another technique.
Because of what has been exposed, an important question arises. To what extent are people willing to give up their information to receive some service? Would they be happy to know that their data is being used for something other than providing the service of interest to them, for example, being sold to third parties?
If, on the one hand, we give up our data to acquire a service/product for our convenience, on the other hand,our data may expose our personal information. To what extent is it worthwhile to allow the collection of our data?
Future research directions: Opportunities and challenges
We have analyzed the selected studies to get a clear picture of directions for future research efforts. We have identified some challenges in designing and implementing privacy in the IoT. According to [27], there is a significant concern about anonymized data. However, anonymizing data using these privacy metrics raises several concerns:
For [26], privacy issues have not been solved regarding sensors, devices, cars, appliances, drones, and other emerging IoT applications that must reach and use location data and personal data (in all their magnitude). Another point is that the identification of location data leads to different types of crime. One of the most critical privacy settings is the right to control the flow of personal data. According to the author, the pertinent areas for research to consider include:
Location-based privacy;
Cloud computing data privacy;
Effective privacy settings, including some specific domain privacy settings;
Effective monitoring of social group interactions;
Some aspects of privacy-driven policies and software development paradigms;
Accountability measures owing to privacy violations;
Techniques and mechanisms for tracking the flow of information and controlling that flow; and
Techniques in the analysis of privacy data based on large-scale location.
Among the techniques presented, there is another essential factor to be highlighted in the analyzed works. All of them are evaluated using specific data, i.e., no proposal is broad enough to be used in all IoT scenarios; the solutions are proposed, developed, and applied in some cases of particular use. Usually, the evaluations are made in data sets. Most cases are not used in practice; it means an experiment is not developed in a real IoT environment with several devices generating data, sending it to be anonymized, running the analysis of them, and comparing the same scenario without the use of anonymization. The running of this analysis could be done to verify the algorithm’s performance, taking into account the resource consumption of the device that it is running and verifying the effectiveness of data analysis in both scenarios.
With the exponential growth in the uses of the IoT in people’s daily lives, numerous types of devices are multiplying (often for personal use). The connection of devices also arises in the context of the Smart Grid, in a Smart Home to serve a family, in public places (sensors used in a shopping mall) and ultimately in the context of Smart Cities. Many cases of devices are used indirectly by large groups of different population segments in a day. Each of these scenarios where IoT devices are involved brings a background of different types and volumes of data with it.
So, faced with this scenario, some questions arise: how should we treat the anonymization of this data coming from different contexts, indifferent, and in heterogeneous quantities? And how can anonymization algorithms identify which data should or should not be anonymized according to its origin?
In this scenario, where several types of IoT devices used in people’s daily lives are present, there is an infinity of continuously generated data, which can be of several types. These data can be classified into three main categories, preserving their owners’ privacy and their usefulness for extracting information and knowledge. Understanding the characterization and operation is essential for correct conduct in treating these data to protect their owners. They are (i) Identifiers, (ii) Quasi-Identifiers, and (iii) Non-Identifiers, described below:
Many algorithms only anonymize the Identifier‘s data (directly related to a person’s identity, as previously presented). Still, there is little concern for the rest of the data. Data that depending on the context, can become Near Identifiers (this data does not directly identify an individual, but when combined with other data, can lead to the identification of the individual, as explained above).
The question arises as to how to treat Quasi-Identifiers, faced with this framework involving Identifiers and Quasi-Identifiers while allowing the data analysis to bring some relevant (useful)information to those who are analyzing them or even those who are interested in buying them.
Another direction that can mitigate data privacy problems will be a combination of approaches or a mapping/classification of the data types that can be anonymized by each approach, pointing towards a better indication of when to choose certain security measures.
In addition to the various approaches discussed in this paper, other technologies are considered promising to address data privacy in IoT. According to an ad-hoc search conducted to enrich this Systematic Literature Review, it was possible to identify that among these technologies that stand out, approaches based on the differential privacy technique are promising and viable opportunities to be conducted in future research on data privacy enforcement in the IoT.
Related works
In this section, we present similar analyses that have been portrayed in the literature to identify problems and open issues.
The work of [49] presents state of the art in privacy preservation mechanisms for CS (Crowdsensing) systems. After a general description of CS systems and their main components, this work addresses the most important issues to be considered in the design, implementation, and evaluation of privacy preservation mechanisms.
In [52], the growing need for appropriate regulatory and technical actions is highlighted to bridge the gap between automated surveillance by IoT devices and the rights of individuals who are often unaware of the potential privacy risk to which they are exposed. According to the author, as a result of his research, new legal approaches to privacy protection need to be developed.
In [1], as IoT systems become so widespread that they become ubiquitous, a number of security and privacy issues are likely to arise. Thus, this work has discussed the vision of IoT, the existing security threats, and the open challenges in IoT. Likewise, the current state of research on IoT security requirements is discussed, and future research instructions regarding IoT security and privacy are presented.
[31] provide an overview of security risks in the IoT industry. Specific security mechanisms adopted by the most popular IoT communication protocols are discussed. Some of the attacks against real IoT devices reported in the literature are then reported and analyzed to point out the current security deficiencies of commercial IoT solutions and note the importance of considering security as an integral part of the design of IoT systems. The paper concludes with a reasoned comparison of the considered IoT technologies to a set of qualified security attributes such as integrity, anonymity, confidentiality, privacy, access control, authentication, authorization, and resilience.
In [3], he researched recent security advances to overcome IoT limitations using blockchain. This article discusses attempts to use blockchain to overcome IoT limitations related to cybersecurity, which have been classified into four categories, (i) end-to-end traceability; (ii) data privacy and anonymity; (iii) identity verification and authentication; and (iv) confidentiality, data integrity, and availability, contributing as guidelines for future research.
In short, the central advance of this research, compared to the other works listed above, is the analysis of the main works available in the literature that use anonymization techniques. According to the literature, these techniques are currently on the rise in order to preserve data privacy within the context of the IoT. Our analysis presents the main advantages and weaknesses of each technique. Classification is also made of which works use each technique and combine more than one technique to preserve data privacy. Finally, the work has also indicated directions for future research related to data anonymization in the IoT.
Concluding remarks
The IoT is increasingly present in our daily life and generates a large amount of data. This vast amount of data can be used to provide services for our convenience, but this generates a great concern about the privacy of the data. On the one hand, beneficial services are offered; on the other hand, our data can be exposed to third parties because the data is collected and analyzed and then can be stored to be analyzed in the future for various purposes. However, it is not clear to what extent people are willing to cede their information to enjoy some service.
Due to the context of insecurity through the scenario presented, this work proposed a Systematic Literature Review (SLR) to understand the leading data privacy solutions for the IoT that use the technique of data anonymization in an orderly and systematic way. The objective is mainly to identify current trends in this field. For this purpose, a total of seventeen articles were selected, according to our predefined SLR protocol, later four more works were added that address techniques used for anonymization. They were studied in depth. Moreover, through a detailed analysis and comprehensive interpretation of the data collected, the panorama presented indicates a lack of consensus on using the techniques concerning methodologies and usage patterns. Through the results achieved in this work, the k-anonymity technique proved to be very useful, used alone and in combination with other techniques mentioned in the researched works. Therefore, its use is an extremely promising challenge.
Through the analysis of the research unveiled, the objective was reached. After its completion, we were able to identify and order the main categories, applied techniques, and methods of anonymization of data used in the context of IoT, such as: (i) Data obfuscation; (ii) Generalization, (iii) Disturbance; (iv) k-anonymity, (v) Sliding Window and (vi) Mixing, as well as the questions initially made about the amount of studies focused on data anonymization for IoT in a time window of the last ten years, i.e., between 2009 and 2021, which came to a final number of seventeen papers. These individuals and organizations are the most active in research based on anonymization of data for the IoT. In this particular case, we have only worked with information found through the first question. The question of the data that can and cannot be disclosed, i.e., the categories related to preserving the privacy of their owners, since the anonymity of the individual may be harmed (or may not fall in harm’s way), and finally the challenges that resulted in directions and opportunities regarding future research in this area.
Footnotes
Acknowledgments
We thank the Centro de Informática (CIN) and the Universidade Federal de Pernambuco (UFPE) for offering all the necessary infrastructure for us to conduct this research. We also thank the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (Capes) for the financial support and the Instituto National de Engenharia de Software (INES 2.0).