Model selection in spectral clustering consists in estimating the ground truth number of clusters . We propose a novel probabilistic framework to address this problem in a principled manner. The spectral clustering pipeline relies on a latent representation over which a mixture model with components is eventually fitted. However the dimensionality of the latent representation varies alongside : this setting is uncommon in the literature on mixture model selection. This raises issues regarding probabilistic modelling, and leads to the ineffectiveness of classical criteria such as the Bayesian Information Criterion (BIC). Alternatively, we propose an adapted Gaussian likelihood expression, and use it to derive a probabilistic model selection criterion for spectral clustering. We give theoretical arguments and empirical evidence suggesting the proposed criterion mitigates the peculiarities observed with classical criteria in an effective way. The performance of the method is evaluated on real and synthetic data sets, and compared to concurrent approaches from the literature.
Clustering is pervasive in data-intensive practices. Basically, this class of techniques automatically extracts homogeneous groups from unlabeled data, which is often useful in exploratory stages of an analysis, or for preprocessing data before a supervised learning task. Relevant applications include the identification of health care trends from medical records [26], the processing of hyperspectral images to identify novel objects in the sky [30], speaker identification and speech processing [16].
A limitation of the most common clustering techniques such as k-means is the inability to extract non-convex clusters, i.e., those that lie on non-linear low-dimensional manifolds within a higher dimensional space. Spectral clustering proceeds by unfolding such clusters to a transformed space where they can more easily be extracted. Most spectral clustering variants assume the number of clusters is known in advance, which is seldom the case in exploratory data analysis.
This model selection problem has been addressed in various ways in the literature. In the range of non-parametric models adapted to non-convex clusters, Self-Organizing Maps let the user choose the number of clusters using visual cues, as facilitated by the low-dimensional mapping of the data they produce [23]. It is chosen automatically in DBSCAN, solely influenced by a threshold parameter [17]. This parameter is set heuristically using the distribution of pairwise distances among elements of the data set. Similarly, Mean Shift determines the number of clusters automatically, but it is ultimately linked to a bandwidth parameter, also set heuristically [14]. In the affinity propagation technique proposed by [20], the clusters emerge iteratively from exemplars. To the contrary of previously mentioned techniques, its damping factor parameter is data-independent.
Elaborate procedures for model selection exist in the context of parametric mixture models. Beyond the traditional Bayesian Information Criterion (BIC) [31], more recently variational methods [3] and Dirichlet mixture models [28] have been proposed. Heuristics specially crafted to spectral clustering have also been proposed in the literature [42, 39]. Yet the ultimate step of the spectral clustering processing pipeline relies on a mixture model formalism, and to our knowledge little has been made to leverage parametric mixture selection methods such as [31] or [3] in this context.
Our contributions
As the model selection problem is quite general, and often addressed in model-specific ways, we focus our review of related work to model selection for spectral clustering in Section 2. We show traditional mixture model selection criteria such as BIC are not adapted to the structure underlying the spectral clustering problem in Section 3. In response, we propose a Dimensionality-Independent Gaussian likelihood expression as an adapted probabilistic scheme. We conduct a detailed theoretical and empirical analysis of the properties of this expression. A novel Dimensionality-Independent criterion for spectral clustering model selection is built upon this expression. Section 4 compares its performance to related methods from the literature.
Related work
The spectral clustering algorithm
Let us consider a -dimensional numerical data set of elements , with . is the dimensionality of the data in its initial space. Alternatively the data elements can be seen as the vertices of a graph, with edges weighted by the similarities between pairs of elements. The graph is implemented by the matrix , with the similarity between and . Several methods can convert -dimensional data to a graph: for example, [38] builds a k-NN graph by setting iif elements et both belong to their respective nearest neighbors, 0 else. In this paper, we use the Radial Basis Function (RBF) [27], most commonly used when there is little prior knowledge about the data:
yielding similarities ranging in . Let be the diagonal matrix such that , i.e., featuring the node degrees on its diagonal. In the literature, is called the Laplacian of graph . Normalized variants have been proposed in the literature, among which the most widely used is the symmetric Laplacian [18, 42].
Spectral clustering proceeds with the eigenvalue decomposition of the Laplacian, written as . The columns of matrix and the diagonal of are the eigenvectors and eigenvalues of the Laplacian, respectively. An explicit relationship between the last columns of and the optimum of the relaxed minimal graph cut of matrix in connected components has been established [33, 38], and is summarized by Proposition 1:
.
Let us assume exhibits clusters as the result of a relaxed minimal graph cut. Then:
the last columns of are associated to the eigenvalue 0,
the range of the last eigenvectors of L and has vectors as basis,
with the indicator vector of cluster . In practice, Proposition 1 implies that membership of data element to one of the clusters can be deduced by inspecting the row of the last columns of matrix . As the range of these columns is the set of indicator vectors, each row is assigned with 1 out of distinct -dimensional vectors, each characterizing a cluster.
The RBF, on which the computation of ultimately relies, has one free parameter: in Expression (1). In the empirical density estimation literature it is often known as the bandwidth [32], as it controls the width of an unnormalized Gaussian. This parameter is often set to a constant without further discussion [20, 25, 40]. [42] proposed a local bandwidth parametrization, which uses a distinct bandwidth parameter for each data element:
[42, 22] empirically set with the Euclidean distance of element to its and nearest neighbor, respectively. In a recent study, additional observations support this parametrization, and a generalization depending on the quantiles of the empirical pairwise distance distribution is proposed [10]. There it is shown that the 2% quantile yields the best results, independently of the data set at hand. In the remainder of the paper, the RBF as stated in Eq. (2) is used, along with the 2% quantile.
Most spectral clustering implementations directly decompose instead of the actual symmetric Laplacian. The solution is then associated to eigenvalue 1, which is itself associated to the major eigenvectors of - identical to those of up to the sign and the reversed order [18]. More options for efficient partial decomposition are available for the major order (e.g., Lanczos methods [4]): in the remainder of the paper, decompositions are thus implicitly made with reference to this variant. For convenience, we also refer to the first columns of as .
We refer to the coordinates (i.e., line) of as the latent coordinates of element . The -dimensional space in which these coordinate vectors take values is then called latent space of the Laplacian. This denomination is to contrast with the initial space in which data is represented, i.e., to which the RBF is applied.
The motivation for spectral clustering is to formalize clusters in terms of neighborhood in a graph, materialized by the transformation of the initial space to a simplified latent space following Proposition 1. As the columns in are rank- linear combinations of indicator vectors (see Proposition 1), latent coordinate vectors take 1 out of distinct canonical positions in the latent space, therefore greatly facilitating their processing by the k-means algorithm. The dimensionality of the initial space then becomes implicit to the similarities, and the complexity of k-means is shifted from to , usually small in clustering applications.
Model selection in spectral clustering
As implied by Proposition 1, there is a link between the number of clusters and the multiplicity of eigenvalue 0 (or 1 if major order is used) in the respective Laplacian. Assuming the ground truth number of clusters is , the eigenvalue is then significantly smaller than one, i.e. the eigengap is large. Monitoring this gap is the most classical procedure to determine , the estimate of .
The first eigenvalues seldom strictly equal 1 in realistic settings, so an approximation is necessary. A simple heuristic has been to find an inflexion point in the curve of eigenvalues ordered in decreasing order [12]. Recently a variant of Bartlett’s test for equal variances has also used this curve of eigenvalues [11].
As the distribution in the latent space is theoretically concentrated on a set of canonical positions, [42] perform model selection by estimating the divergence from such a configuration.
[13] use the Approximation Set Coding framework to estimate the that strikes a trade-off between stability and informativeness. They rely on the kernel trick in order to avoid the varying dimensionality of the latent space identified in Sections 2.1. [34] assume an upper bound to , and use a dimensionality reduction approach. The link between and the latent subspace dimensionality is not used explicitly then.
Some spectral clustering approaches completely avoid the use of Laplacians and eigendecompositions, and use inflation and contraction operators to directly estimate maximal subgraphs [37, 25]. This procedure claims to automatically estimate the number of clusters as a by-product. It has a single parameter that influences the granularity of solutions, i.e., to weight emphasis on small compact clusters.
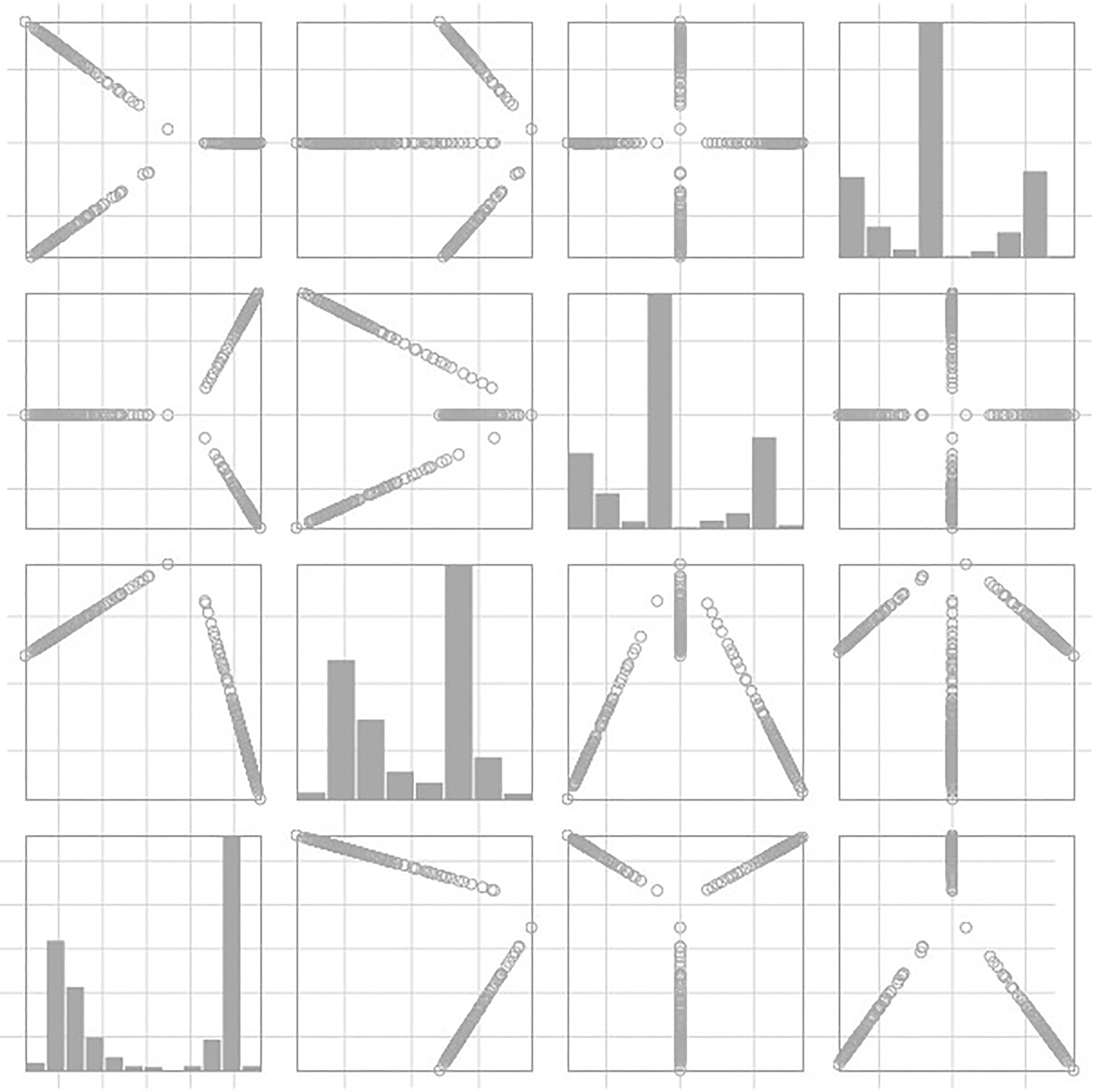
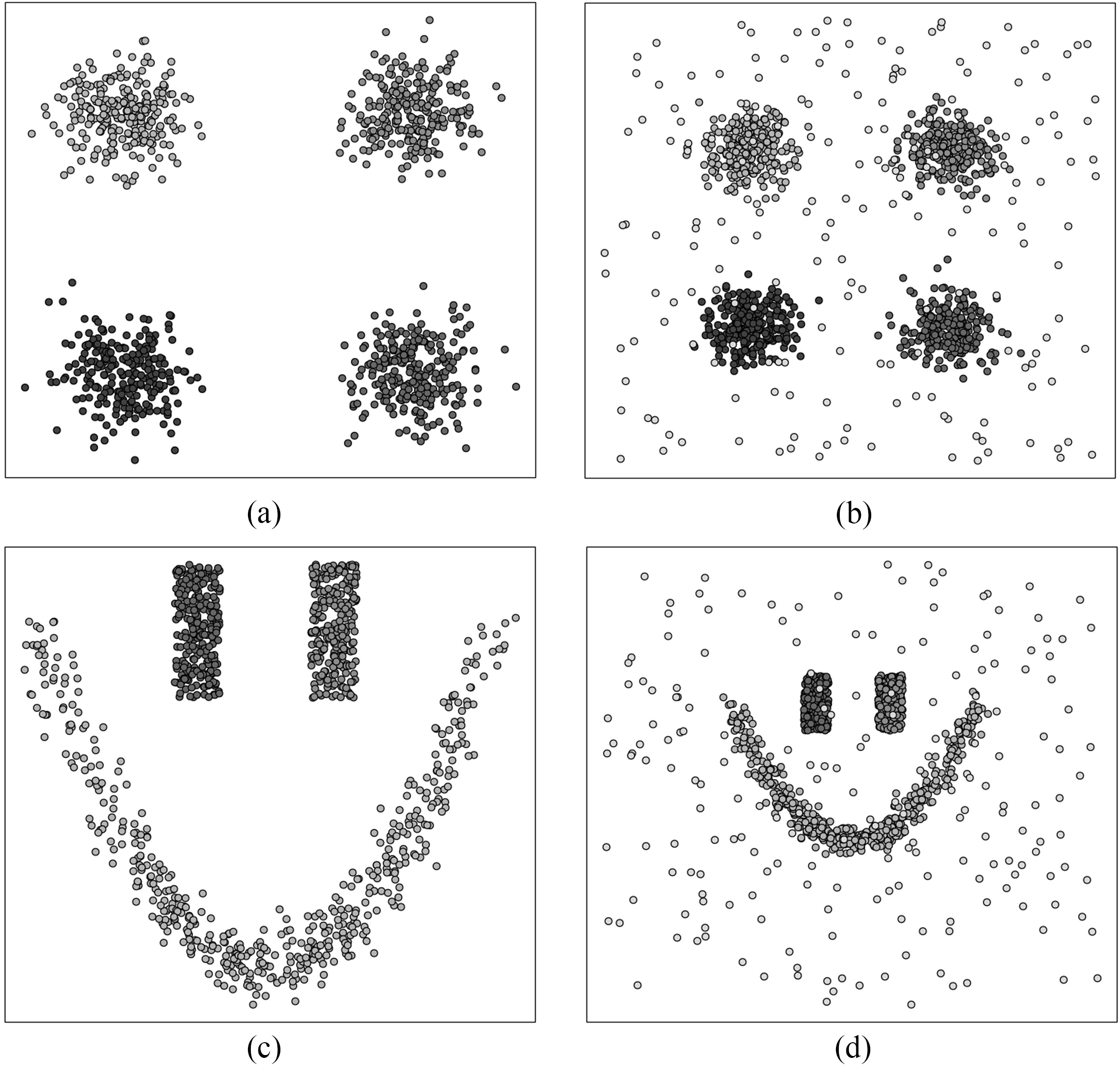
Scatterplot matrix of the latent space obtained with data set synth1 (see description in Table 1). The third and fourth eigenvectors are redundant then, and cluster-specific linear manifolds are rotated in the 2D planes involving the two other dimensions. This still conforms to Proposition 1, and clusters remain easy to delineate in the latent space. However, bimodal distributions would fit poorly to any latent dimension.
The contribution by Xiang and Gong [39] is based on the assumption – not necessarily verified, as shown in Fig. 1 – that each eigenvector should characterize a cluster. This is translated to a greedy search of the latent subspace size, that uses a threshold on the relevance of fitting a bimodal distribution against a single distribution on each dimension of the latent space. This way of proceeding is presented as more robust than expecting a strict fit to a canonical system or analyzing the spectrum, where decisions are not stable enough. The size found for the subspace defines an upper bound to the number of clusters. It is then reduced using BIC [31] as a model comparison criterion.
Proposed technique
A dimensionality-independent gaussian likelihood
The final step of spectral clustering is to apply k-means to the latent representation introduced in Section 2.1. As the model underlying k-means is essentially a Gaussian mixture model (constrained to hard assignments, equal weights and spherical covariance matrices), model selection, i.e., estimating the ground truth number of clusters , could in principle be carried out by choosing the that minimizes the BIC criterion [31]:
with mixture weights , means , covariance matrices , and the number of parameters in the model, increasing with . Model selection is then performed by learning mixture models with various , and selecting the one that minimizes BIC. Basically, as grows, more components are used to fit the same data, which mechanically increases the associated likelihood, hence decreases the first term in Eq. (3). The optimal model complexity can then be thought as a balance between model fit and complexity.
Minimizing Eq. (3) favors accurate density estimation, which might differ from finding good clustering models, i.e. where components in the mixture are compact and well separated. The Integrated Classification Likelihood (ICL) was introduced in view of this distinction [7]. In the context of k-means, [8] gives a limit formulation of ICL in which the weight vanishes from the first term:
with .
[39] use BIC in a post-processing step. However, in our paper the selection procedure is fully integrated to the problem structure with varying dimensionality as described by Proposition 1. In this context, the mixture model step in the spectral clustering algorithm differs from classical mixture settings by the dimensionality of the latent subspace varying along with the number of components .
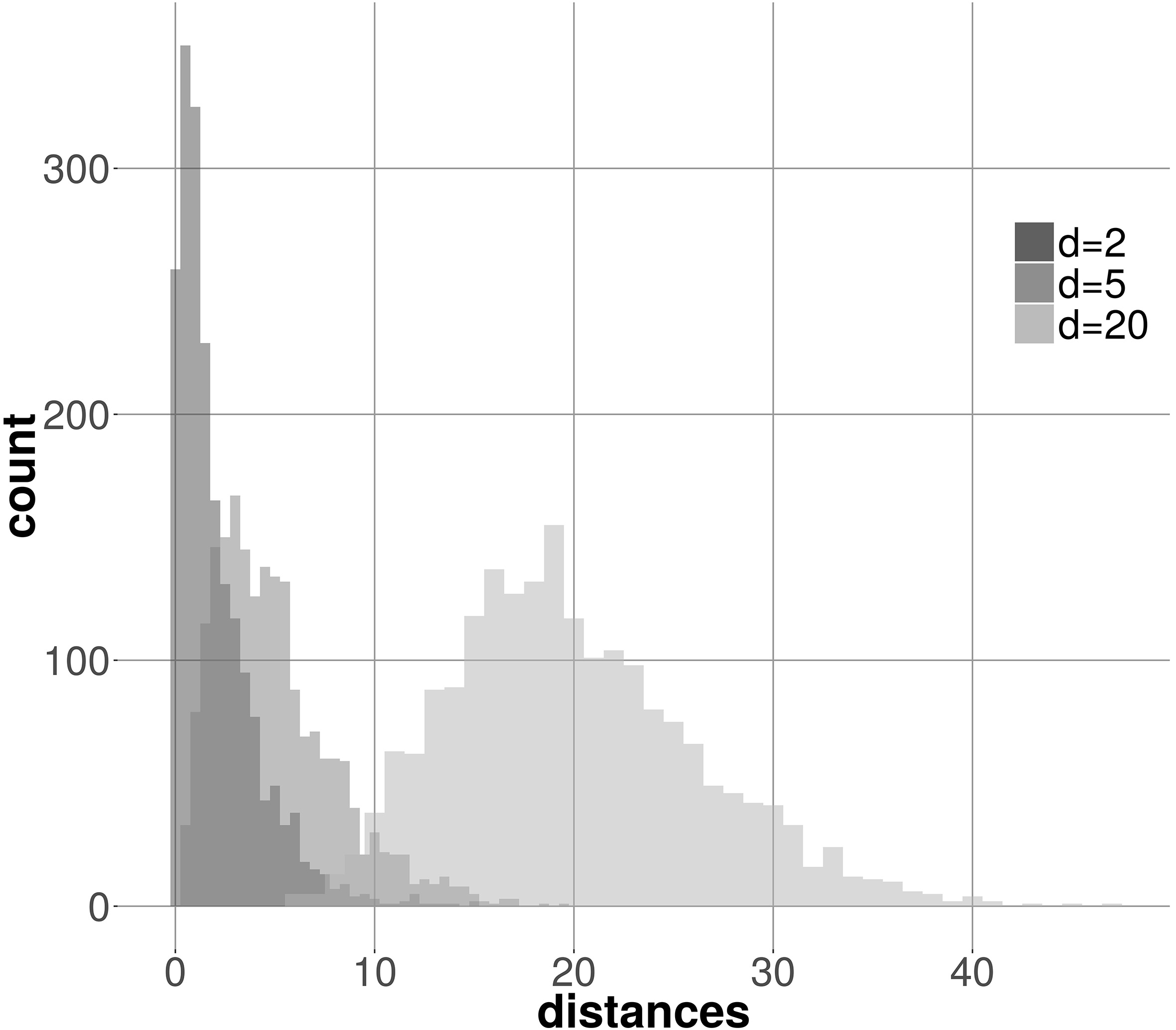
Figure 2 shows the empirical distribution of the square of the Euclidean distance between standard (i.e. ) -dimensional Gaussian samples and the origin. Assuming a diagonal covariance with a constant extent (e.g., 1 for ), it can be seen that this distance squared is expected to increase with .
Distributions of the square of the distance between -dimensional Gaussian samples ( 2000) and their respective origin for 2 (dark grey), for 5 (medium grey) and for 20 (light grey).
As the Gaussian density is a function of the square of a distance, according to the observation in Fig. 2 the distribution of its values is influenced by , the dimensionality of the data. BIC and ICL use the Gaussian density in their first term in Eqs (3) and (4), respectively. In common mixture settings, is the dimensionality of the initial space, therefore constant, so the dependence goes unnoticed.
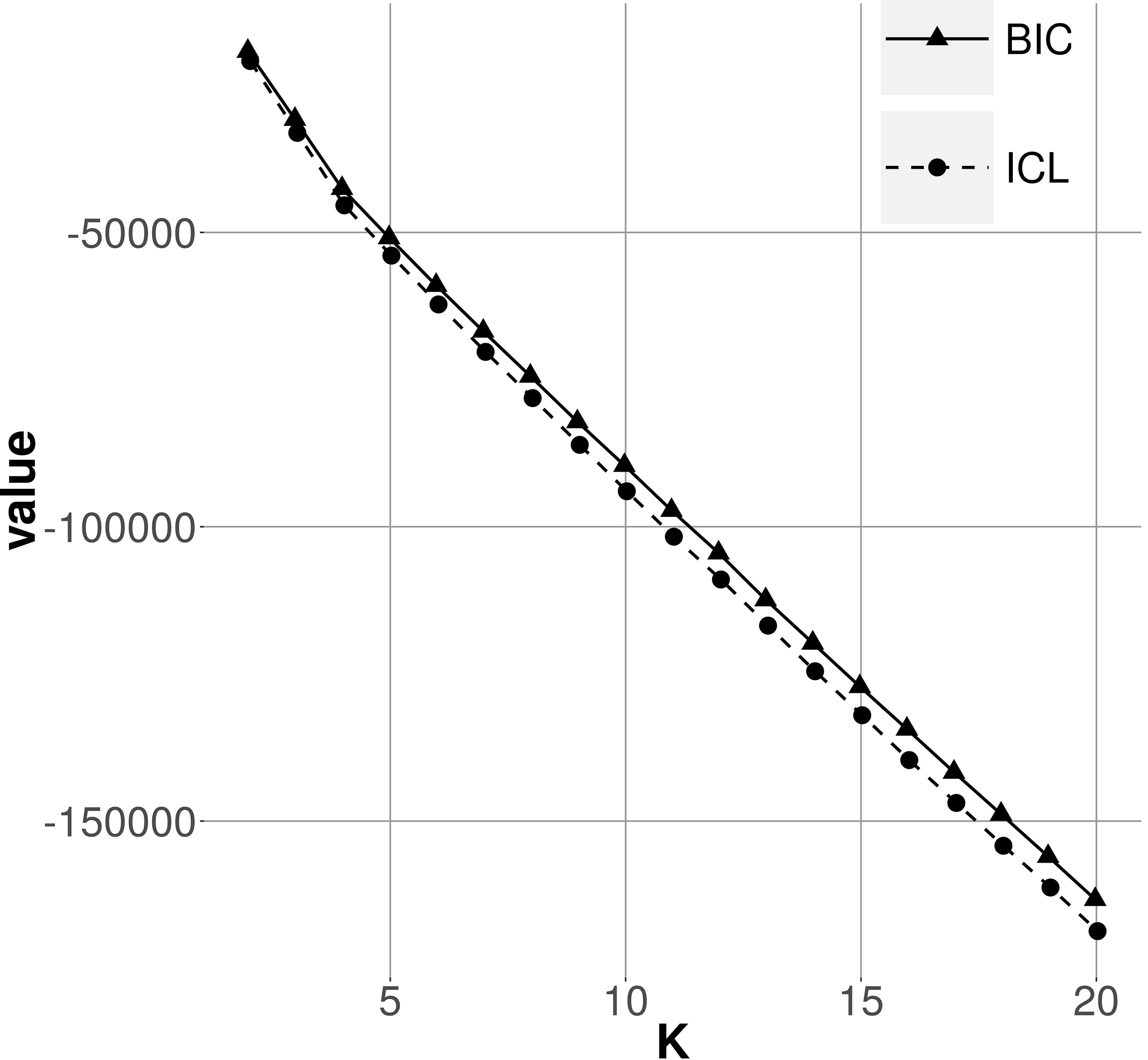
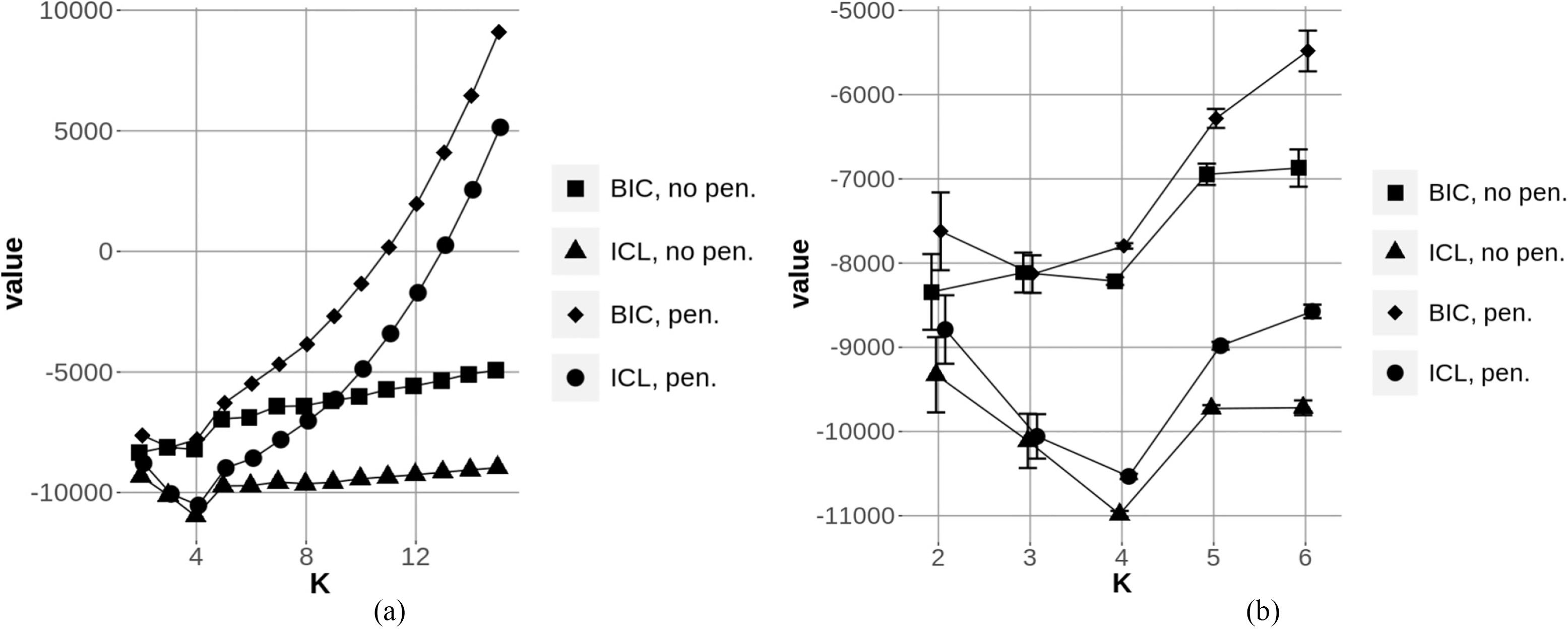
Curves for BIC and ICL criteria as a function of , with latent representations obtained from the synth1 data generating process. Each value is averaged over 20 independent experiments.
Figure 3 shows the curves for BIC and ICL obtained with latent representations extracted from data generated according to the synth1 process (see definition in Section 4). We see that both criteria are monotonically decreasing functions of , instead of reaching a minimum at . This discrepancy is a consequence of the latent space dimensionality variation w.r.t. .
To mitigate this problem, an alternative to the Gaussian density is needed as a plugin to BIC and ICL expressions. We propose a Dimensionality-Independent (DI) likelihood for this purpose:
.
Let . We define the Dimensionality-Independent (DI) likelihood as:
with the cumulative distribution function of , its quantile function, the dimensionality of and an arbitrary constant integer.
Let and be two multidimensional Gaussian laws, with means and , covariances and , and dimensionalities and , respectively. Let and . Let us assume and have equal extent, i.e. . Then, if , we have : in other words, is insensitive to , the dimensionality of the data.
The proof can be found in Appendix B. Intuitively, the exponential term in Eq. (5) remaps squared distances of any dimensionality to their counterparts in a common dimensionality . Corollaries given in Appendix C show that preserves the order implied by the Gaussian density function over varying dimensionality and extent (see Appendix A for the extent definition).
We explicitly refer to Expression (5) as a likelihood (instead of a density) as it does not integrate to 1 anymore. Appendix D provides empirical evidence of the effectiveness of the proposed likelihood expression. The same evidence also shows that , the only free parameter in Expression (5), should be set to 2 for reliable model selection: this value is used in the remainder of this paper.
A novel model selection criterion
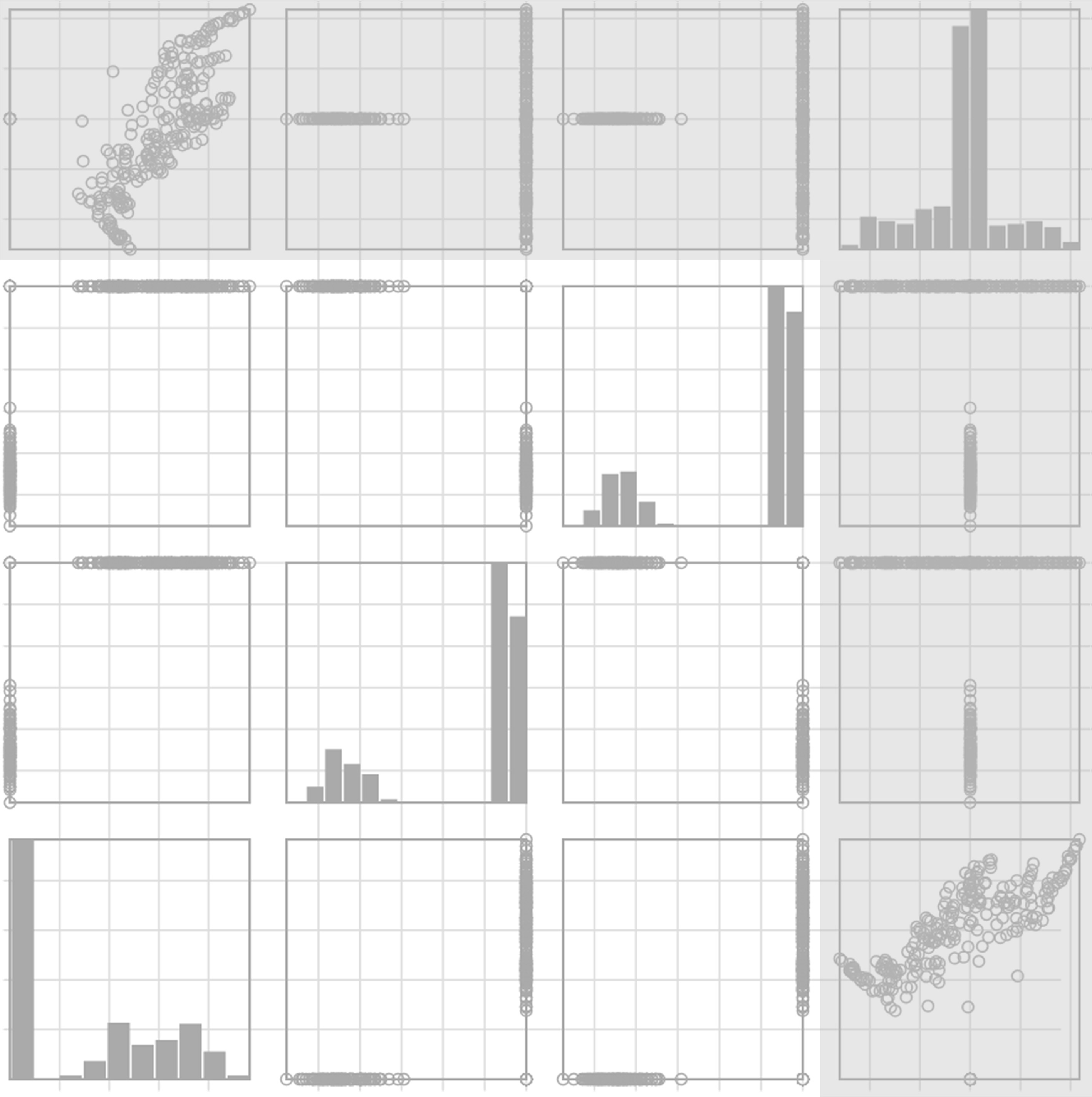
At constant , the second term in Eqs (3) and (4) favors mixture models with minimal . However, with spectral clustering, the mixture complexity is tied to the dimensionality of the latent space (see Section 2.1). In practice, if is not big enough, then a small number of components does not exhibit satisfactory fit. When , penalty occurs naturally when spurious dimensions are added to the latent space (see Fig. 4).
Scatterplot matrix of the latent space obtained with data set synth2 (see description in Table 1). The subspace matching the ground truth number of clusters is unshaded. Dimensions beyond this subspace (here the is shaded in grey) do not contribute to delineated linear manifolds, leading to poorly fitted mixture models.
This suggests that a penalty term would be naturally embedded in the spectral clustering model selection problem, possibly leading to the removal of the second term in Expressions (3) and (4). Figure 5 shows the result of experiments mirroring those reported in Fig. 3, when substituting to in Eqs (3) and (4).
Curves for BIC and ICL criteria as a function of , with latent representations obtained from the synth1 data generating process. Criteria with or without penalty are considered. Each value is averaged over 20 independent experiments. The curve in a) is magnified for in b).
Figure 5a shows the difference between modified criteria, with or without the explicit penalty term. The ground truth for synth1 features 4 clusters (see Section 4), so curves in Fig. 5 are expected to reach a minimum at .
The penalized versions of BIC and ICL exhibit a clear quadratic tendency for higher values of . This is quite natural, as the number of parameters in a mixture model grows quadratically with . Also, we see that criteria without penalty exhibit a linear tendency as increases: this confirms that the first term in Eqs (3) and (4) already embeds an implicit penalty when using .
The same curves are magnified for low values of in Fig. 5b. Error bars reflect the variance of criterion values. Firstly, BIC appears as inadequate for the model selection task at hand, as the criterion values for lie in the confidence intervals for and 3, either with or without the penalty term. This means that depending on the specific generated data set and initialization, or 3 might be selected. For the penalized version of ICL, the value at is also close to the confidence interval for . This leaves the ICL criterion without penalty, for which the optimal value clearly stands out.
Integrating these observations to the ICL criterion in Eq. (4) yields the DI-ICL criterion, that simply maximizes the sum of log-DI-likelihoods of Gaussian components to which data elements are assigned by the k-means procedure:
where is the cluster assignment of element by k-means. Algorithm 5 uses the DI-ICL criterion in Eq. (6) to cluster a data set, and select the appropriate number of clusters automatically, without additional user parametrization.
Leftleft Thisthis Upup UnionUnion FindCompressFindCompress Inputinput Outputoutput A data set A set of labels with // is an hard-coded upper bound to computed according to Eq. (2) diagonal computed s.t. set as solving first columns of , sample means and covariances resulting from applying k-means to the rows of DI-ICL() according to Eq. (6) crit labels resulting from applying k-means with Spectral clustering with automatic determination of
Experiments
In this study, we introduce synthetic data generating processes synth1 and synth2, that generate noisy replicas of 2D data sets as shown in Fig. 6a and c. Samples of 1000 elements are used in this section. synth1 is the reference case with no specific difficulties for clustering (i.e. well-separated spherical clusters). synth2 is inspired by [42], and features non-convex cluster shapes that k-means or EM typically fail at processing. As means to estimate the impact of background clutter to clustering performance, these synthetic data sets can be augmented by a portion (i.e. 0 to 500 additional data points), generated from a uniform distribution (see Fig. 6b and d). ISOLET, PENBASED and OPTICAL data sets have been released by [15, 1, 2] respectively. Table 1 summarizes the data sets used to illustrate this study.
Clustering results will be qualified according to the relevance of the estimated , the adjusted Rand index [21], and the Normalized Mutual Information (NMI) [35]. We avoid the use of unsupervised quality indexes (i.e., that do not need the ground truth classes of elements), as they all assume convex clusters. Also, we do not report the purity of obtained clusters, as the clustering error is then under-estimated when the number of clusters is unknown (e.g. 1 cluster per data point yields a purity of 1 in the limit).
List of data sets used in the experiments, characterized by their nature, size , dimensionality and number of ground truth classes
Name
Nature
synth1
Synthetic
1000
2
4
synth2
Synthetic
1000
2
3
ISOLET vowels
Real
1800
617
6
PENBASED
Real
10992
16
10
OPTICAL
Real
5620
64
10
Scatterplots of a) synth1 and c) synth2. The ground truth class of glyphs is emphasized using grey shades. Noisy samples, featuring background clutter, can also be generated for synth1 and synth2 (b and d, respectively).
Although theory expects the alignment of coordinates in the latent space to a basis, in practice linear manifolds are observed irrespective of the Laplacian used (see Figs 1 and 4). As k-means performs badly on ellipsoidal clusters, some authors suggest to normalize the coordinate vectors (i.e., divide coordinate vectors by ), letting clusters concentrate on the expected discrete positions in the latent space [29, 38]. Alternatively we can use the original latent representation without normalizing the coordinate vectors, along with a variant of k-means that estimates ellipsoidal clusters. Elliptical k-means (Ek-means in the remainder) proceeds as the usual k-means, except that a Mahalanobis metric is updated at each step [36] using cluster-wise sample covariances. The distance function for assignments incorporates as means to favor clusters with balanced shapes. In practice we found better results when rescaling covariance matrices by at each step. Each component is regularized by a prior with large variance, ensuring that DI-ICL is well-behaved when .
Comparative performance of DI-ICL based model selection, with (k-means) or without (Ek-means) coordinate vector normalization. The results are averaged over 20 independent experiments. The performances of ZMP [42] and DBSCAN [17] are also reported. For each metric, the best performing method is bold-faced
Adjusted rand index
synth1
Ek-means
1.00 0.00
1.00 0.00
1.00 0.00
1.00 0.00
k-means
0.99 0.06
1.00 0.00
0.97 0.09
0.98 0.03
ZMP
0.97 0.13
0.92 0.16
0.80 0.25
0.73 0.25
DBSCAN
0.86 0.02
0.86 0.02
0.87 0.02
0.88 0.02
NMI
0.0
0.1
0.2
0.5
Ek-means
1.00 0.00
1.00 0.00
1.00 0.00
1.00 0.00
k-means
0.99 0.03
1.00 0.00
0.98 0.05
0.98 0.03
ZMP
0.99 0.06
0.95 0.09
0.89 0.14
0.84 0.15
DBSCAN
0.85 0.01
0.85 0.02
0.85 0.01
0.86 0.01
0.0
0.1
0.2
0.5
Ek-means
4.00 0.00
4.00 0.00
4.00 0.00
4.00 0.00
k-means
3.95 0.22
4.00 0.00
4.00 0.00
5.20 1.54
ZMP
4.45 2.01
4.15 1.09
5.50 3.99
7.15 4.93
DBSCAN
6.80 1.15
6.75 1.45
7.30 1.59
8.50 1.91
Adjusted rand index
0.0
0.1
0.2
0.5
synth2
Ek-means
1.00 0.00
1.00 0.00
1.00 0.00
0.95 0.16
k-means
1.00 0.00
1.00 0.00
1.00 0.00
0.95 0.11
ZMP
1.00 0.00
1.00 0.00
1.00 0.00
0.98 0.11
DBSCAN
0.67 0.08
0.69 0.10
0.71 0.10
0.70 0.09
NMI
0.0
0.1
0.2
0.5
Ek-means
1.00 0.00
1.00 0.00
1.00 0.00
0.97 0.10
k-means
1.00 0.00
1.00 0.00
1.00 0.00
0.97 0.06
ZMP
1.00 0.00
1.00 0.00
1.00 0.00
0.99 0.06
DBSCAN
0.80 0.04
0.81 0.04
0.82 0.05
0.81 0.05
0.0
0.1
0.2
0.5
Ek-means
3.00 0.00
3.00 0.00
3.00 0.00
3.15 0.49
k-means
3.00 0.00
3.00 0.00
3.00 0.00
3.35 0.93
ZMP
3.00 0.00
3.00 0.00
3.00 0.00
2.95 0.22
DBSCAN
9.10 1.65
7.90 1.25
8.15 1.73
8.45 1.88
This latter variant is compared to using regular k-means and coordinate vector normalization in a model selection task in Table 2. In the same table we also compare to two reference methods from the literature: one based on spectral clustering by Zelnik-Manor and Perona [42] (referred to as ZMP hereafter1
Implementation available at http://www.vision.caltech.edu/lihi/Demos/SelfTuningClustering.html.
Implementation available at https://cran.r-project.org/web/packages/dbscan/index.html.
Experiments are repeated 20 times for each synthetic data generating process. The same samples are reused for all methods.
In Table 2 we see that Ek-means performs always better than the k-means variant. For both data sets, it is very robust to the addition of background clutter. ZMP yields little improvement to the Ek-means results on synth2, but is highly affected by the addition of clutter in synth1 experiments. Like our Ek-means variant, DBSCAN is not much sensitive to the background clutter, but it heavily overestimates the number of clusters, and yields results consistently worse than all other tested methods. In the remainder, the Ek-means variant is used as the default DI-ICL implementation.
We also apply DI-ICL, ZMP and DBSCAN to the real-world high dimensional ISOLET, PENBASED and OPTICAL data sets. In order also to evaluate the sensitivity of the tested methods, 50% of each data set was subsampled 20 times at random, and fed to DI-ICL, ZMP and DBSCAN. The respective results are averaged, and reported in Table 3.
ZMP and DI-ICL both perform reasonably well on all three data sets. ZMP and DI-ICL both identify the ground truth number of clusters for ISOLET, with a slightly better Rand index and NMI for DI-ICL. is slightly better for DI-ICL on OPTICAL (8.95, against 8.40 for ZMP, when in this experiment), with also an advantage in terms of Rand index and NMI.
Comparative performance of DI-ICL and ZMP on real data sets. Best performing methods are bold-faced for each data set
Rand
NMI
ISOLET
DI-ICL
0.93 0.02
0.93 0.01
6.00 0.00
ZMP
0.90 0.02
0.89 0.01
6.00 0.00
DBSCAN
0.11 0.01
0.37 0.02
3.80 0.89
PENBASED
DI-ICL
0.49 0.02
0.66 0.01
7.05 0.22
ZMP
0.64 0.04
0.75 0.02
10.9 1.07
DBSCAN
0.30 0.08
0.64 0.04
21.0 2.22
OPTICAL
DI-ICL
0.63 0.04
0.74 0.02
8.95 0.51
ZMP
0.57 0.05
0.70 0.03
8.40 1.85
DBSCAN
0.05 0.05
0.28 0.16
4.70 1.56
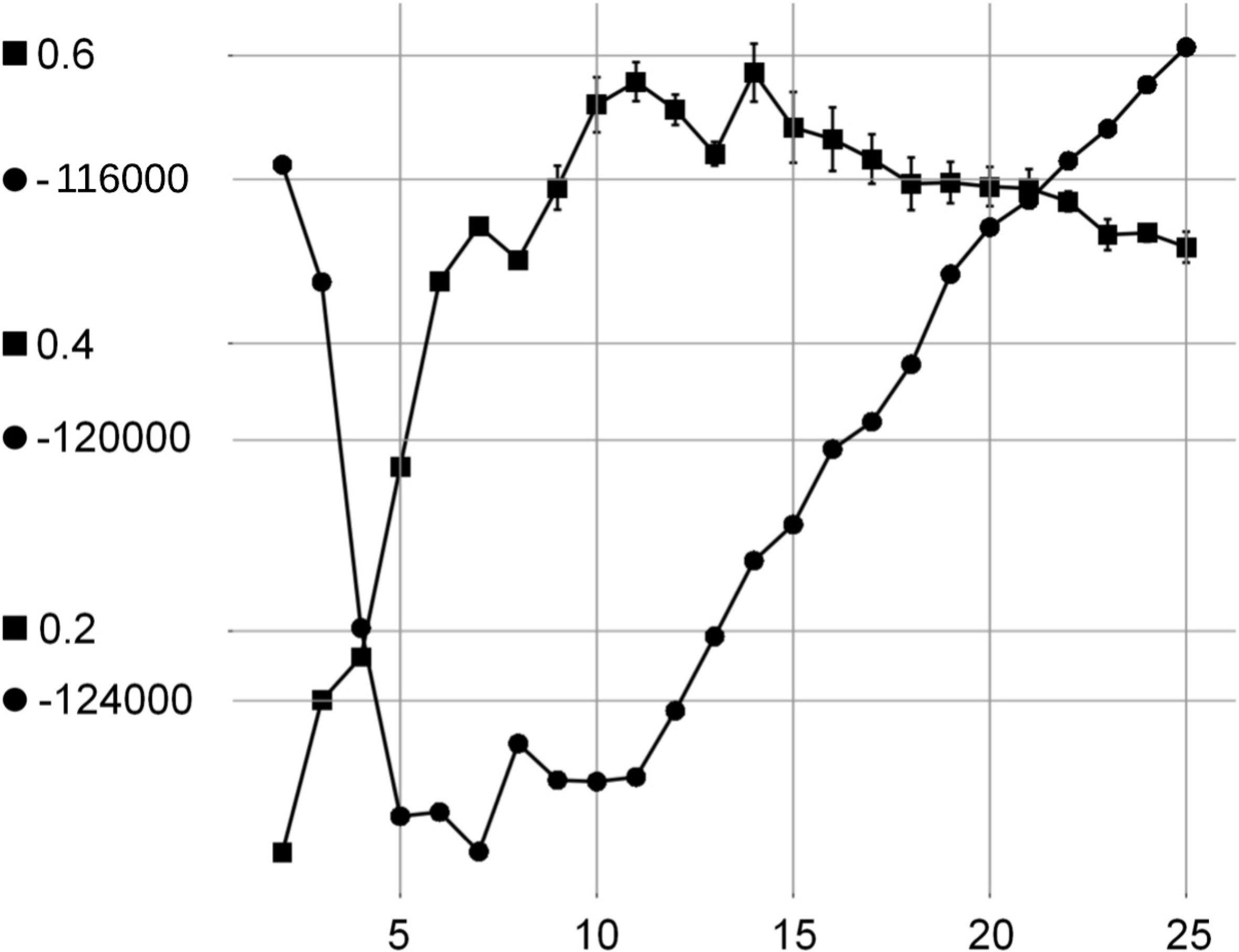
Super-imposed plots of the DI-ICL criterion (discs) and Rand index (squares) w.r.t. for the PENBASED data set. The displayed values average the results of 20 independent experiments.
Conversely, DI-ICL is outperformed by ZMP for the PENBASED data set, even though the number of clusters and Rand index obtained by DI-ICL are reasonably good. DBSCAN is significantly outperformed by both DI-ICL and ZMP for all data sets, in terms of clustering error and estimated number of clusters. In particular, is heavily over-estimated with PENBASED, and under-estimated with ISOLET and OPTICAL.
In Fig. 7, we expand the DI-ICL criterion w.r.t. for the PENBASED data set. Globally, the graph shows that DI-ICL is fairly well (negatively) correlated to the Rand index. It is thus a reasonable proxy to the clustering error in an unsupervised context. Looking first at the DI-ICL criterion curve, we see that before exhibiting its linear increasing tendency as grows, the criterion values plateau between 5 and 11. Three local minima lie in this interval: at 5, 7 and 10. 10 is the ground truth for PENBASED. Also, the significant increase of DI-ICL between 7 and 8 is exactly associated to a degradation of the Rand index. Hence, beyond merely outputting a point estimate of the selected number of clusters, plotting the DI-ICL curve helps identify a range of satisfactory values. This can be seen as an improvement over ZMP, that outputs a point estimate for .
Discussion
Due to the need to compute the eigenvectors of a square similarity matrix, the naive algorithm is : it is brought down to using a Lanczos decomposition method, as clustering generally implies .
The power iteration algorithm proposes a more efficient decomposition algorithm to tackle this eigenvector analysis [24]. Specifically, they claim that intermediate states of an iterative estimation procedure of the major eigenvector summarize the complete clustering structure, instead of requiring vectors as in our development. Specifically, Boutsidis et al. show that the power iteration method approximates the major eigenvectors in a meaningful way for k-means [9]. However both contributions do not address the automatic determination of , and the framework developed in our paper is hardly adaptable to their method.
For experiments in this paper a naive implementation has been used, that recomputes k-means afresh for each possible in a range (typically ). Yet the problem has optimal substructure, i.e. up to a rotation factor the first eigenvectors do not depend on the . This feature is used extensively by Lanczos methods [4]. An analogous heuristic could be used in order to speed-up the k-means processes, as the first dimensions of seeds can be initialized with the previous solution.
The eigendecomposition of large matrices can be made even more efficient with the Nyström matrix completion [18]. Approximate similarity computation could also decrease the overall execution time of the algorithm [41]. However potential interactions between these approximation methods and our algorithm should be studied closely.
The Ek-means variant has been established as the best performing option in Section 4. However it has complexity, when baseline k-means is . Execution time can then become prohibitive for the highest candidate values for . This problem could be partly mitigated by exploiting the substructure identified above, or spacing out the covariance matrix updates.
Conclusion
From the acknowledged ineffectiveness of classical probabilistic model selection methods in the context of spectral clustering, we derived a Dimensionality Independent Gaussian likelihood expression that restores their applicability. Thorough inspection of the properties of this expression showed that with appropriate parametrization, it yields a relevant model selection criterion.
After experimental validation on synthetic data sets, our method was applied to real-world high-dimensional data sets, and compared to the literature. The proposed technique performs well, and occasionally outperforms the reference methods from the literature. In addition, its probabilistic foundations make it viable for a more qualitative usage, such as identifying a suitable range for rather than a point estimate, as shown by the end of Section 4.
The naive implementation used in the paper has high complexity, but Section 5 highlighted fairly straightforward keys for improvement. Other relevant perspectives certainly lie in combining such spectral clustering schemes with feature selection or metric learning techniques [6]. The proposed criterion and algorithm operate mostly in the latent space of the similarity matrix. Their generality is hence not limited a priori by the similarity function used – chosen as the RBF in Section 2.1. For example, in [39], depending on the data set at hand, experimental results using either the RBF or a similarity function specially adapted to video behavior analysis are given. Experimental confirmation using alternative similarity functions (e.g. cubic, k-NN, exponential) could be part of future work, though.
So far we did not investigate the relative quality of clusters, based on monitoring their shapes and densities. Cluster ranking approaches [5] focus on these features, and will also be considered in future work.
Multivariate gaussian properties
Let us recall the expression of the density of the -dimensional multivariate Gaussian distribution :
In this appendix we investigate how Eq. (7) behaves as increases. First we focus on the term in the exponent:
.
Let . Then .
Proof..
As , and .
can be factorized using the Cholesky decomposition as , with an upper triangular matrix. Let , so that . The following holds:
Hence , and is simply the sum of squares of independent zero-mean unit-variance Gaussian random variables: in other words . ∎
and are and respectively: in other words, the squared Mahalanobis distance of a -dimensional multivariate Gaussian sample to its respective center appearing in the exponent of Eq. (7) is expected to be , as perceived intuitively in Fig. 2.
The actual scale and shape of Eq. (7) is controlled by the term. Lemma 2 establishes the link between and :
.
Let be a positive semi-definite (PSD) matrix. At constant geometric mean of its eigenvalues, is exponentially increasing with d.
Proof..
Let be the eigenvalues of . Then . The geometric mean of the is defined as . We trivially get . Setting as a constant closes the proof. ∎
can be understood as the radius of a hyper-sphere whose volume equals that of the hyper-ellipsoid parametrized by the . In this paper, is referred to as the extent of the respective component, and serves as basis for comparing models determined on latent subspaces of varying dimension.
Proof for the DI likelihood theorem
Proof..
Taking the definition of random variable from Lemma 1, we have that , and . Hence, if , then a change of variables to polar coordinates yields . Terms within the exponent are then equal.
Lemma 2 established the exponential tendency of w.r.t. . Here, we have and . Hence the first terms of and both equal . The in Eq. (7) is dropped as it bears no dependence on the data. ∎
Corollaries to the DI likelihood theorem
.
Let be a multidimensional Gaussian with density , and . If then . In other words, Theorem 1 preserves the order w.r.t. .
Proof..
Both and in Eq. (5) are monotonically increasing. ∎
.
Let and be two multidimensional Gaussian laws of equal dimensionality, with respective densities and , and extents and , so that . We also have and . If then and also . Hence Theorem 1 preserves the order w.r.t. .
Proof..
If , at constant Theorem 1 shows terms in the exponent in Eqs (7) and (5) are equal. The order is then fully determined by the term. ∎
Empirical study of the DI gaussian likelihood
In this appendix, we evaluate the ability of Expression (5) to fulfill its intended effect: at constant extent, DI likelihoods of Gaussian samples should be independent of . To do so we consider a set of dimensionalities taken as . In the experiment, this parameter varies jointly with the extent in and the constant in (defined in Theorem 1, see Eq. (5)). For each possible resulting experimental condition, we sample 1000 data elements from , and compute the associated sum of log-DI-likelihoods using Eq. (5), by analogy to the first terms of the BIC and ICL criteria (Eqs (3) and (4), respectively). The experiment for each condition is repeated 20 times. The joint influence of parameters , and is investigated with the ANOVA model. Results are displayed in Table 4.
Summary of ANOVA applied to sums of log-DI-likelihoods. Joint effects of parameters are also analyzed (lines 4–6). Significance codes: o non-significant, *** high significance
df
F
p-value
significance
1
0.94
o
1
***
1
***
1
0.2
0.63
o
1
0.3
0.61
o
1
0.2
0.62
o
As expected, log-DI-likelihoods are not affected by the dimensionality , neither alone nor in conjunction with or . The latter, quite naturally, affect the results (). However they have independent effects, as is not significant. Variations in log-DI-likelihoods w.r.t. are then most likely due to stochastic sampling noise, or in other words, at constant extent the DI-likelihood is insensitive to .
Let us consider a collection of data items so that . We then study the consistency of the DI-likelihood expression (5), i.e. whether the following implication holds:
with and the sample mean and sample covariance, respectively, of the . Considering , ideally we would obtain the Maximum Likelihood (ML) estimator via calculus using . However closed-form estimators cannot be obtained from Expression (5). Yet we can see that both and are strictly increasing functions of : hence each term is maximized by , supporting the relevance of as the ML estimator of w.r.t. . For , there is no equivalent qualitative argument.
To further investigate the behaviour of in the context of parameter inference, we perform simulations relying on the numerical optimization of w.r.t. and . The first experiments, reported in Fig. 8, estimate the bias of the ML estimators and of for and varying in and respectively. The true means, denoted as , are sampled uniformly in an identical range of for all dimensions. The diagonals of the respective are sampled in , and off-diagonals in . Even if this process has reasonable chances to yield non-degenerate covariance matrices, a projection on the PSD cone is also performed. They are then rescaled so that their extent equals 1. Each optimization uses sets of 1000 elements sampled independently from . The experiment for each joint configuration of and is repeated 20 times with independent covariance matrices, and averaged in Fig. 8.
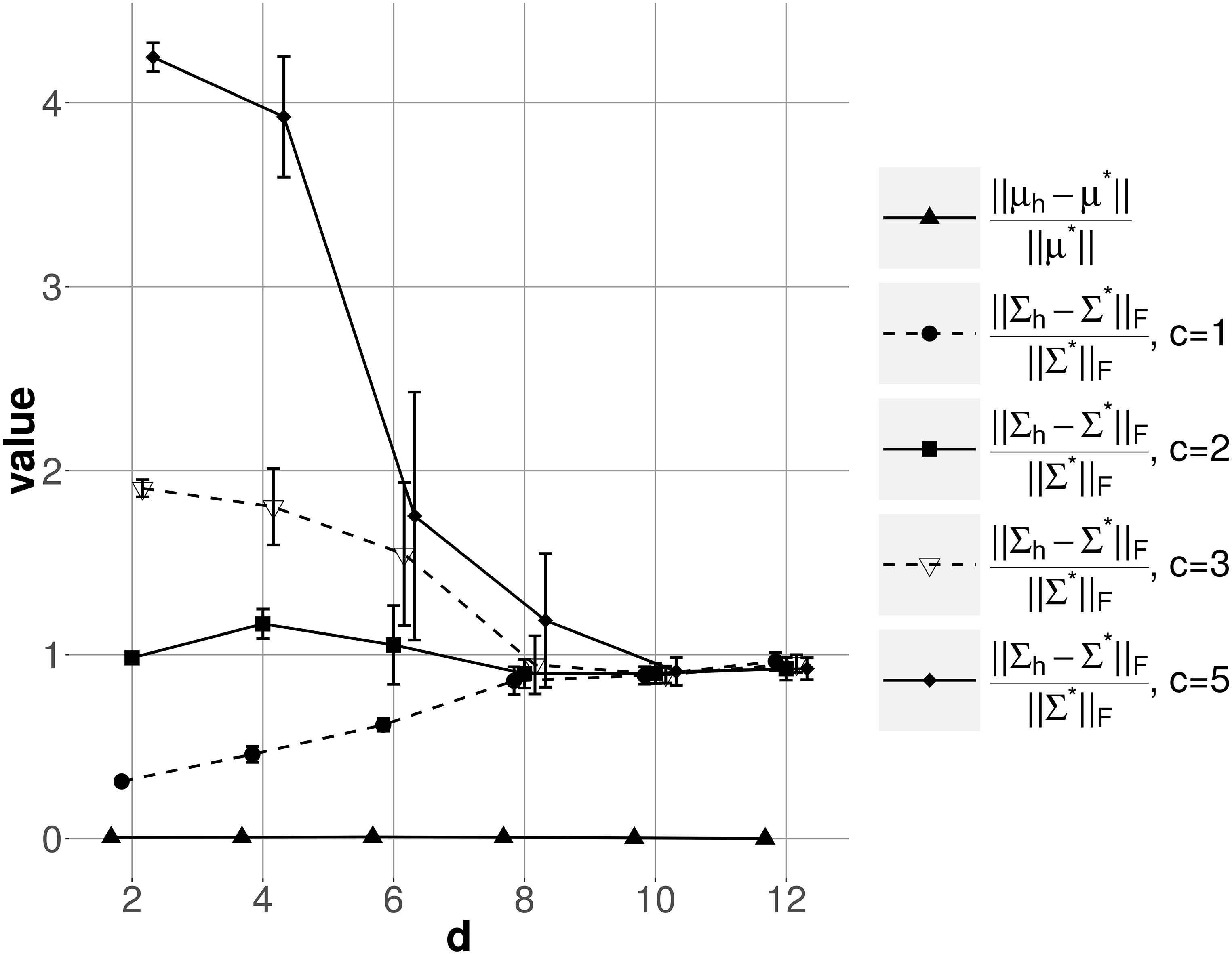
Norm deviations of ML estimators and w.r.t. and . Each measure is obtained by averaging 20 independent simulations. Confidence intervals are reflected by error bars.
In the figure the quality of is estimated by the scale-corrected deviation in L2-norm , similarly for and the scale-corrected deviation in Frobenius norm . As expected, the consistency of is revealed as satisfactory, irrespective of and (the curve for is plotted in Fig. 8).
As confirmed by monitoring the respective scale-corrected deviations of , the latter systematically over-estimates . Expression (5) should thus not be used for maximum likelihood estimation of parameters. In Fig. 8 we see that has an incidence on the variation of this bias w.r.t. . With 1, it is initially small but goes increasing, whereas 3 or more yields very high bias for low . The bias is almost constant with 2. However for a model selection purpose, consistency is not needed as long as:
orders induced by Gaussian density are preserved by respective . This is guaranteed by Corollary 1 (see Appendix C).
At constant and the bias of is constant, i.e. orders between models w.r.t. are preserved over variations of . Reading Fig. 8, this property is true only for 2. This value parametrizes Eq. (5) for the remainder of the paper.
At constant and , the bias is constant w.r.t. , i.e. model orders w.r.t. do not depend on model extent. This is guaranteed by Corollary 2 (see Appendix C).
Footnotes
Appendix
References
1.
AlimogluF. and AlpaydinE., Methods of combining multiple classifiers based on different representations for pen-based handwritten digit recognition, In TAINN, 1996.
2.
AlpaydinE. and KaynakC., Cascading classifiers, Kybernetika34(4) (1998), 369–374.
3.
AttiasH., A variational Bayesian framework for graphical models, Advances in Neural Information Processing Systems12(1-2) (2000), 209–215.
Bar-YossefZ.GuyI.LempelR.MaarekY. and SorokaV., Cluster ranking with an application to mining mailbox networks, Knowledge and Information Systems14(1) (2008), 101–139.
6.
BelletA.HabrardA. and SebbanM., A survey on metric learning for feature vectors and structured data, CoRR, abs/1306.6709, 2013.
7.
BiernackiC.CeleuxG. and GovaertG., Assessing a mixture model for clustering with the integrated completed likelihood, IEEE Transactions on Pattern Analysis and Machine Intelligence22(7) (2000), 719–725.
8.
BishopC.M., Pattern recognition and machine learning, Springer, 2006.
9.
BoutsidisC.GittensA. and KambadurP., Spectral clustering via the power method – provably, In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015, pages 40–48.
10.
BruneauP. and OtjacquesB., Observations on latent distributions of graph Laplacians, In EGC, 2016, pages 93–104.
11.
BruneauP.ParisotO. and OtjacquesB., A Heuristic for the Automatic Parametrization of the Spectral Clustering Algorithm, In Proceedings of the 22nd International Conference on Pattern Recognition, 2014, pages 1313–1318.
12.
CattellR.B., The scree test for the number of factors, Multivariate Behavioral Research1(2) (1966), 245–276.
13.
ChehreghaniM.BusettoA. and BuhmannJ., Information theoretic model validation for spectral clustering, In AISTATS, 2012, pages 495–503.
14.
ComaniciuD. and MeerP., Mean shift: A robust approach toward feature space analysis,IEEE PAMI24(5) (2002). 603–619.
15.
DietterichT.G. and BakiriG., Error-correcting output codes: A general method for improving multiclass inductive learning programs, In Proceedings of the 9th National Conference on Artificial Intelligence (AAAI), 1991, pages 572–577.
16.
DupuyG.MeignierS.DelégliseP. and EsteveY., Recent improvements on ILP-based clustering for broadcast news speaker diarization, In Odyssey, 2014.
17.
EsterM.KriegelH.SanderJ. and XuX., A density-based algorithm for discovering clusters in large spatial databases with noise, In ACM SIGKDD, 1996, pages 226–231.
18.
FowlkesC.BelongieS.ChungF. and MalikJ., Spectral grouping using the Nystrom method, IEEE Transactions on Pattern Analysis and Machine Intelligence26(2) (2004), 214–225.
19.
FowlkesC.BelongieS. and MalikJ., Efficient spatiotemporal grouping using the Nyström method, In IEEE Conference on Computer Vision and Pattern Recognition, volume 1, 2001, pages 231–238s.
20.
FreyB. and DueckD., Clustering by passing messages between data points, Science315(5814) (2007), 972–976.
21.
GordonA.D., Classification, Chapman and Hall, 1999.
22.
KaratzoglouA.SmolaA.HornikK. and ZeileisA., kernlab – an S4 package for kernel methods in R, Journal of Statistical Software11(9) (2004), 1–20.
23.
KohonenT., Essentials of the self-organizing map, Neural Networks37 (2013), 52–65.
24.
LinF. and CohenW.W., Power iteration clustering, In Proceedings of the 27th International Conference on Machine Learning, 2010, pages 655–662.
25.
LiuH.LateckiJ. and YanS., Fast Detection of Dense Subgraphs with Iterative Shrinking and Expansion, IEEE Transactions on Pattern Analysis and Machine Intelligence35(9) (2013), 2131–2142.
26.
MarlinB.M.KaleD.C.KhemaniR.G. and WetzelR.C., Unsupervised pattern discovery in electronic health care data using probabilistic clustering models, In ACM SIGHIT International Health Informatics Symposium, 2012, pages 389–398.
27.
NabneyI.T., NETLAB: Algorithms for Pattern Recognition, Springer, 2002.
28.
NealR.M., Markov chain sampling methods for Dirichlet process mixture models, Journal of Computational and Graphical Statistics9(2) (2000), 249–265.
29.
NgA.Y.JordanM.I. and WeissY., On spectral clustering: Analysis and an algorithm, In Advances in Neural Information Processing Systems, 2002, pages 849–856.
30.
PieperM.ManolakisD.TruslowE.CooleyT. and LipsonS., Performance evaluation of cluster-based hyperspectral target detection algorithms, In Proceedings of the 19th IEEE International Conference on Image Processing, 2012, pages 2669–2672.
31.
SchwarzG., Estimating the dimension of a model, The Annals of Statistics6(2) (1978), 461–464.
32.
SheatherS.J. and JonesM.C., A reliable data-based bandwidth selection method for kernel density estimation, Journal of the Royal Statistical SocietyB(53) (1991), 683–690.
33.
ShiJ. and MalikJ., Normalized cuts and image segmentation, IEEE Transactions on Pattern Analysis and Machine Intelligence22(8) (2000), 888–905.
34.
SocherR.MaasA. and ManningC., Spectral Chinese Restaurant Processes: Nonparametric Clustering Based on Similarities, In AISTATS, 2011, pages 698–706.
35.
StrehlA. and GhoshJ., Cluster ensembles-a knowledge reuse framework for combining multiple partitions, JMLR3 (2002), 583–617.
36.
SungK. and PoggioT., Example-based learning for view-based human face detection, IEEE Transactions on Pattern Analysis and Machine Intelligence20(1) (1998), 39–51.
37.
van DongenS., Graph clustering via a discrete uncoupling process, SIAM Journal on Matrix Analysis and Applications30(1) (2008), 121–141.
38.
von LuxburgU., A tutorial on spectral clustering, Statistics and Computing17(4) (2007), 395–416.
39.
XiangT. and GongS., Spectral clustering with eigenvector selection, Pattern Recognition41(3) (2008), 1012–1029.
40.
YanD.HuangL. and JordanM., Fast approximate spectral clustering, In ACM SIGKDD, 2009, pages 907–916.
41.
YianilosP.N., Data structures and algorithms for nearest neighbor search in general metric spaces, In Proceedings of the ACM-SIAM Symposium on Discrete Algorithms, 1993, pages 311–321.
42.
Zelnik-ManorL. and PeronaP., Self-tuning spectral clustering, Advances in Neural Information Processing Systems17 (2005), 1601–1608.