
Abstract
A fundamental problem in machine learning is ensemble clustering, that is, combining multiple base clusterings to obtain improved clustering result. However, most of the existing methods are unsuitable for large-scale ensemble clustering tasks owing to efficiency bottlenecks. In this paper, we propose a large-scale spectral ensemble clustering (LSEC) method to balance efficiency and effectiveness. In LSEC, a large-scale spectral clustering-based efficient ensemble generation framework is designed to generate various base clusterings with low computational complexity. Thereafter, all the base clusterings are combined using a bipartite graph partition-based consensus function to obtain improved consensus clustering results. The LSEC method achieves a lower computational complexity than most existing ensemble clustering methods. Experiments conducted on ten large-scale datasets demonstrate the efficiency and effectiveness of the LSEC method. The MATLAB code of the proposed method and experimental datasets are available at https://github.com/Li-Hongmin/MyPaperWithCode.
Keywords
Introduction
Ensemble clustering, also known as consensus clustering, is a classic problem in machine learning, and it aims to combine multiple base clusterings through improved consensus clustering [28, 22, 9, 17, 32, 26, 36, 14, 15, 25, 24, 12, 11, 42, 43]. Owing to its suitable performance, ensemble clustering plays a pivotal role in many research areas, such as community detection [29] and bioinformatics [18, 33].
There are two critical steps in ensemble clustering: ensemble generation and consensus function. Ensemble generation aims to generate multiple base clusterings on the same datasets. In the early stage,
Co-association matrix-based ensemble clustering method [9, 17, 35, 34] is one of the most widely used ensemble clustering strategies. A typical example is the evidence accumulation clustering method [9], that counts the frequency of the pairwise co-occurrence of the same cluster between a pair of data points according to base clusterings. After treating the co-association matrix as a similarity matrix, a hierarchical agglomerative clustering algorithm is applied to obtain the consensus clustering. Iam-On et al. [17] extended the EAC method by constructing a co-association matrix-based on common neighborhood information between clusters. Tao et al. [30] proposed a robust spectral ensemble clustering method to learn a robust representation for the co-association matrix by capturing noise and conducting spectral clustering to realize consensus clustering. Huang et al. [15] also enhanced the co-association matrix-based on similarity mapping from the cluster level to the object level and achieved ensemble clustering via fast propagation of cluster-wise similarities. However, co-occurrence matrix-based methods often lead to high computational costs that has become a bottleneck for large-scale clustering tasks. Therefore, most co-association matrix-based methods can function efficiently in small-scale datasets, but do not complete large-scale clustering tasks within acceptable time.
Graph partitioning-based ensemble clustering methods [28, 7, 13, 19] aim to transform the ensemble clustering problem into a graph partitioning problem to realize consensus clustering. Strehl and Ghosh [28] constructed a hypergraph representation by exploring base clusterings and proposed three graph partitioning-based ensemble clustering methods. Huang et al. [13] developed a sparse graph with a small number of probably reliable links from base clusterings and realized consensus clustering based on probability trajectory analysis. Li et al. [19] applied the spectral clustering method on base clusterings; they considered the graph Laplacian matrices of base clusterings as input, thereafter learnt a consensus representation by optimizing the graph Laplacians of consensus clustering and base clusterings simultaneously, and finally conducted spectral clustering to realize consensus clustering. Although graph partitioning-based methods have successfully improved clustering quality, they still have limitations regarding large-scale datasets.
Recently, a few studies have made progress in the application of large-scale data for ensemble clustering. Wu et al. [36] proposed a
In this paper, we propose a large-scale ensemble spectral clustering (LSEC) method to alleviate the problem of the application of ensemble clustering for large-scale data. A spectral clustering-based ensemble generation method is designed to efficiently handle nonlinear datasets and provide high-quality base clusterings. The ensemble generation process is further accelerated by reusing
The main contributions of this study are as follows:
An efficient spectral clustering-based ensemble generation method is designed to handle large-scale datasets and provide high-quality base clusterings via a divide-and-conquer-based large-scale spectral clustering method. Two accelerating approaches are proposed: 1) the computation of similarity among multiple base clusterings is accelerated by reusing the The proposed method efficiently generates base clusterings and conducts bipartite graph partitioning to realize consensus clustering. The computational and space complexites are dominated by
In this section, we briefly discuss the existing work relevant to the current study.
Spectral clustering
Given a dataset
Although spectral clustering has shown priority performance on complex data, it is often limited in its application to large-scale datasets because of its
Ensemble clustering
Ensemble clustering, which aims to integrate various base partitions into a consensus partition, consists of two steps: the ensemble generation and consensus function. In the ensemble-generation step, a clustering algorithm is usually employed to produce various base partitions with different parameters. In the consensus function step, all base partitions are integrated into a consensus partition using a certain objective function. Ensemble clustering methods often demonstrate advantages in improving the clustering accuracy and robustness. However, most ensemble clustering methods are not suitable for large-scale clustering tasks owing to efficiency bottlenecks.
EAC [9] is a classic ensemble framework which considers the co-occurrence of the same cluster between two objects in a base clustering as evidence that the two objects should belong to the same cluster. Thus, EAC accumulates the “evidence” by counting the frequency of co-occurrence to construct a co-association matrix and conduct the single-link method to obtain a final clustering result. However, the co-association matrix-based ensemble framework has a high time complexity and is not scalable. To improve the scalability of ensemble clustering, KCC [36] and SEC [24] consider transformations to a modified
Preliminaries
Ensemble clustering
Let
Divide-and-conquer-based large-scale spectral clustering
DnC-SC has been proposed as an effective method for large-scale clustering tasks [21]. It first constructs an approximate similarity matrix via a divided-and-conquer-based landmark selection and approximates the
Let
where
The recursive Eqs (3) and (4) are used to divide the optimization problem into small sub-problems that are easier to solve.
The parameter
Similarities between each
where the Gaussian kernel is used to measure the similarity and
The similarity matrix
where
To improve the scalability of ensemble clustering, we propose the LSEC method that complies with the large-scale spectral clustering-based formulation and aims to overcome the efficiency bottleneck of previous algorithms. The LSEC method consists of two steps: (1) Large-scale spectral clustering-based ensemble generation: we designed a new framework that applies the state-of-the-art large-scale spectral clustering algorithm to product base clusterings and further accelerate the process by reusing the
Ensemble generation based on large-scale spectral clustering
The ensemble generation step aims to produce diverse
Overview of proposed method. Given a dataset, 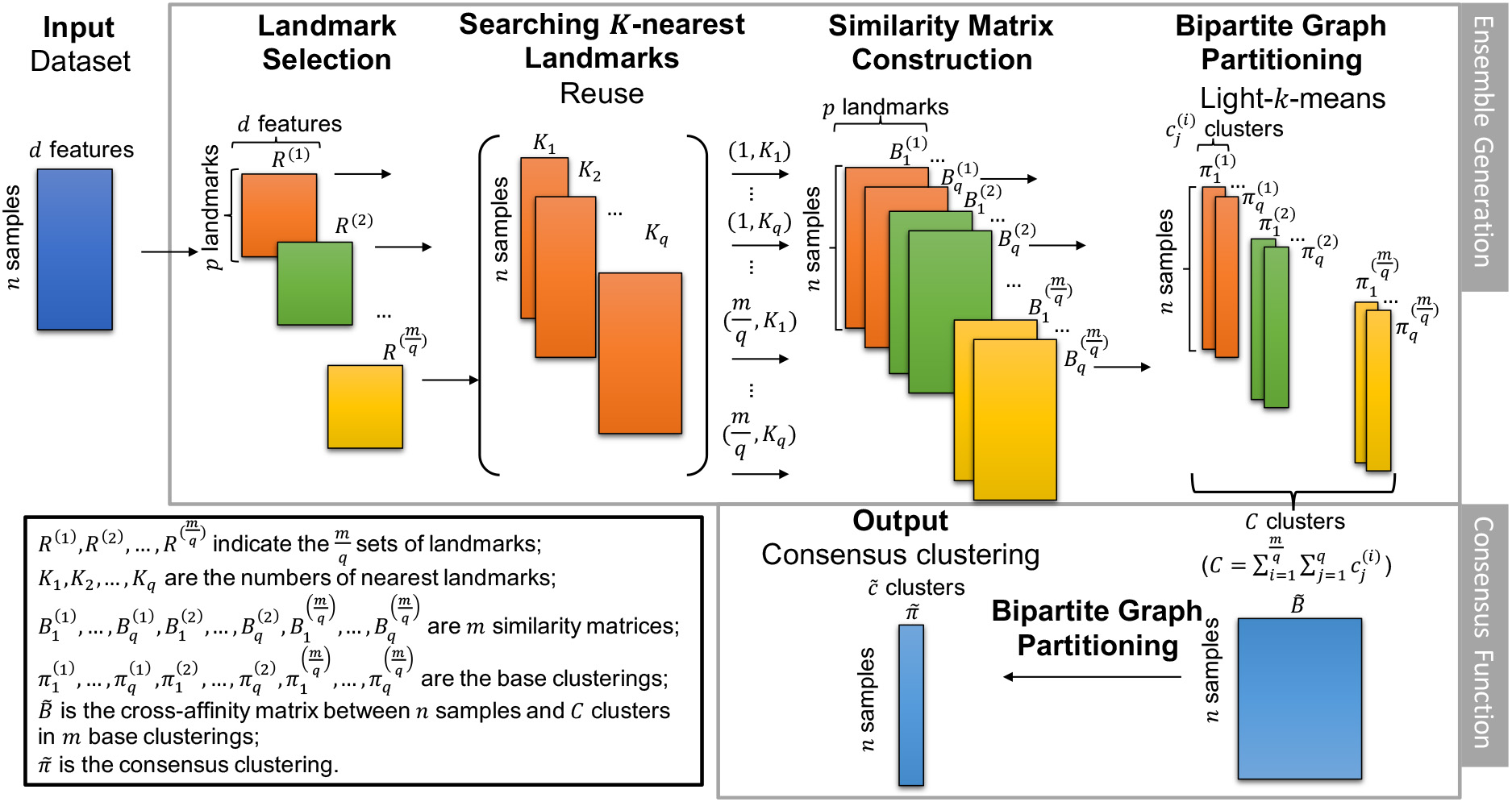
First, the
where
To construct a sparse similarity matrix with
Let
That is,
The sparse similarity matrix between
where
After obtaining
where
The obtained
where
Proposed ensemble generation processDataset
Solve (1) by recursively applying (3) and (4) to obtain
After ensemble generation, the base clusterings are combined according to a consensus function to obtain the consensus partition. We treat this problem as a bipartite graph partition problem and provide a solution similar to that in Section 3.2.
The cluster indicator matrix
The cluster indicator matrix
To define the bipartite graph, we first collect all clusters from the base clusterings using Eq. (13), and we denotes the clusters in Eq. (14) for clarity.
where
where
Having defined of
where
As shown in Table 1 shows, the sum of each row of
For this modified bipartite graph
Comparison of the computational complexity between LSEC and U-SPEC
Then we have a generalized eigenproblem of
where
where
The
Large-scale ensemble spectral clusteringDataset
Computational complexity analysis
In this section, we summarize the computational costs of the proposed method. The ensemble generation of the LSEC algorithm has a computational cost of
Relations with other methods
As a large-scale spectral ensemble clustering method, the proposed method is closely related to the U-SENC method [16]. We compare the proposed method with the U-SENC to discuss the improvements in the proposed method.
First, we compare them to the ensemble generation methods in term of diversity. In U-SENC, base clusterings are directly generated by the large-scale spectral clustering U-SPEC with different numbers of clusters. As a large-scale spectral clustering method, the U-SPEC method also uses the landmark selection technique. Thus, the diversity of base clusterings of U-SENC is based on two facts: the different landmarks and the number of clusters of ensemble generation. However, the
Secondly, we compare them with the ensemble generation methods in term of efficiency. Because the different
Overall, LSEC redesigns the ensemble generation framework based on a more efficient clustering method (that is, DnC-SC) and accelerates the process by reusing the
Experiments
In this section, we conduct experiments on five real and five synthetic datasets to evaluate the performance of the proposed LSEC method. The comparison experiments against six state-of-the-art spectral clustering methods confirmed improved clustering quality and efficiency of the LSEC methods. In addition, the parameters were analyzed. For each experiment, the test method was repeated 20 times, and the average performance was reported. All experiments were conducted in MATLAB R2020a on a Mac Pro with 3 GHz 8-Core Intel Xeon E5 with 16 GB of RAM.
Datasets and evaluation measures
Properties of the real and synthetic datasets
Properties of the real and synthetic datasets
Illustration of five synthetic datasets. Note that only 0.1% samples of each dataset are plotted.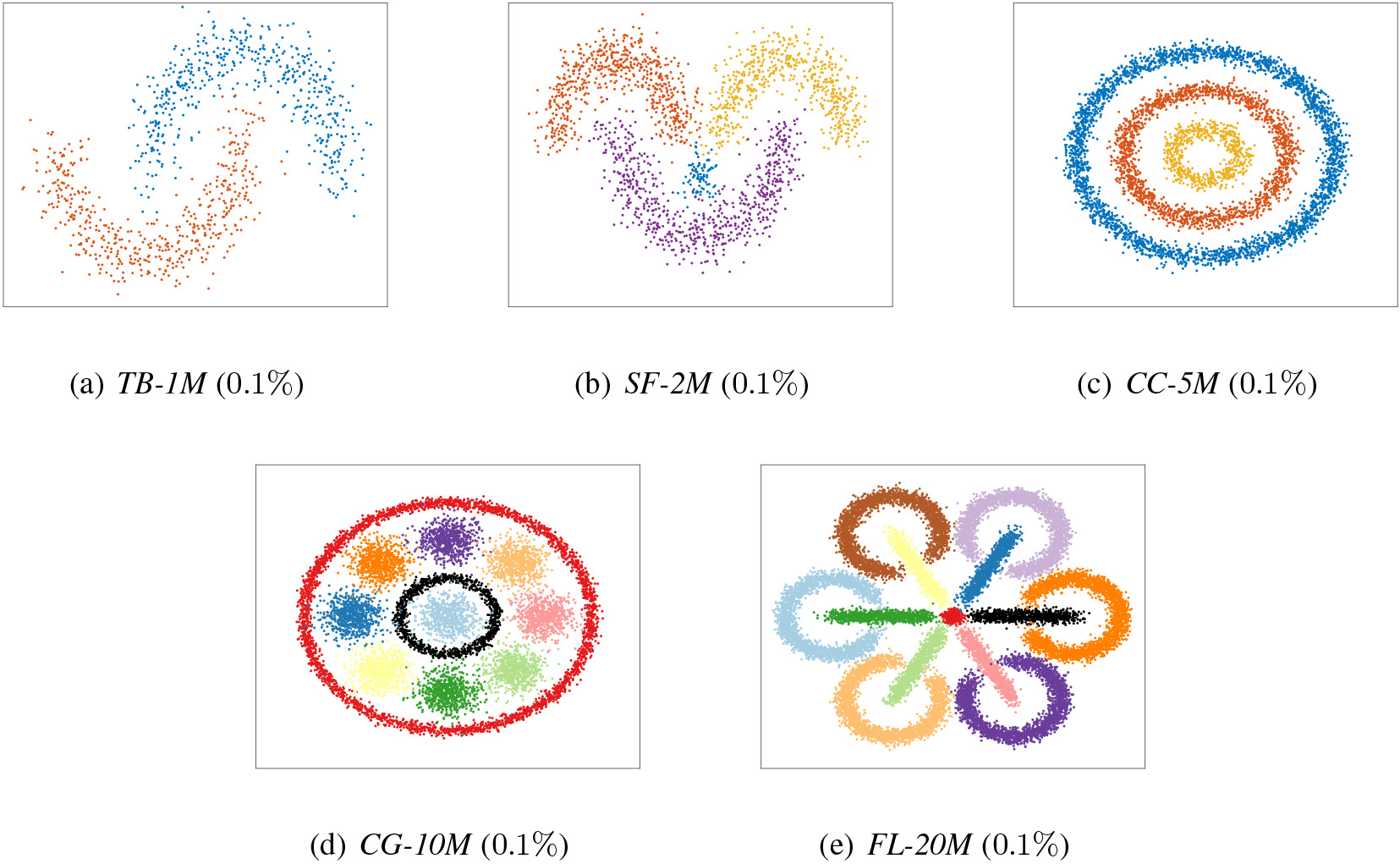
Our experiments were conducted on ten large-scale datasets, varying from 9,000 to 20 million data points. Specifically, the five real datasets are PenDigits [1],1
To evaluate the clustering results, we adopt two widely used evaluation metrics, that is, Normalized Mutual Information (NMI) [27] and Accuracy (ACC) [38]. Let
where
The NMI is the normalization of mutual information by the joint entropy:
A better clustering result will provide a larger value of NMI/ACC. Both NMI and ACC are in the range of [0, 1].
In this experiment, we compare the proposed method with a baseline clustering method, that is, the divide-and-conquer based large-scale spectral clustering (DnC-SC) [21], as well as six state-of-the-art ensemble clustering methods. The spectral clustering methods compared are as follows:
There are several common parameters among the methods mentioned above. We set these parameters as follows:
We set the number of landmarks as Base clustering is generated by We set the There are some unique parameters The DnC-SC method has a unique parameter The true number of classes on each dataset is used to conduct all experiments. Other parameters in the baseline methods are set as suggested in the existing literature.
The experimental comparison results are presented in Tables 4–6. Note that DnC-SC is not an ensemble clustering algorithm; its clustering results are provided for reference only. As shown in Tables 4 and 5, the LSEC algorithm realizes the highest ACC and NMI scores on most of datasets. In terms of the average score across the ten datasets, LSEC achieves the best average ACC (%) and NMI (%) scores of 77.01 and 77.21, respectively. The second-best ensemble clustering method (that is, U-SENC) achieves average ACC (%) and NMI (%) scores of 72.59 and 74.78, respectively. The EAC, KCC, PTGP, SEC, and LWGP methods use the
ACC (%) scores (over 20 runs) realized by the proposed method and the baseline ensemble clustering methods (The best score in each row is shown in bold)
ACC (%) scores (over 20 runs) realized by the proposed method and the baseline ensemble clustering methods (The best score in each row is shown in bold)
NMI (%) scores (over 20 runs) realized by the proposed method and the baseline ensemble clustering methods (The best score in each row is shown in bold)
Time costs(s) of the proposed method and the baseline ensemble clustering methods
The time costs of different ensemble clustering methods are provided in Table 6. The proposed LSEC method achieves the lowest time costs on nine datasets and the second-lowest time cost on a single dataset. Except PenDigits dataset, LSEC is 2.4 (FL-20M) to 5.75 (CC-5M) times ahead of the second-best method in time consumption. The LSEC method has shown significant advantages over other ensemble clustering methods, particularly on large-scale datasets.
To further analyze the experimental results in Tables 4–6, we use the
We conduct a parameter analysis experiment to demonstrate the performance of the proposed method, varying different parameter values of
Clustering performance (ACC (%), NMI (%), and time costs(s)) for different methods obtained by varying the number of base clusterings
Clustering performance (ACC (%), NMI (%), and time costs(s)) for different methods obtained by varying the number of base clusterings

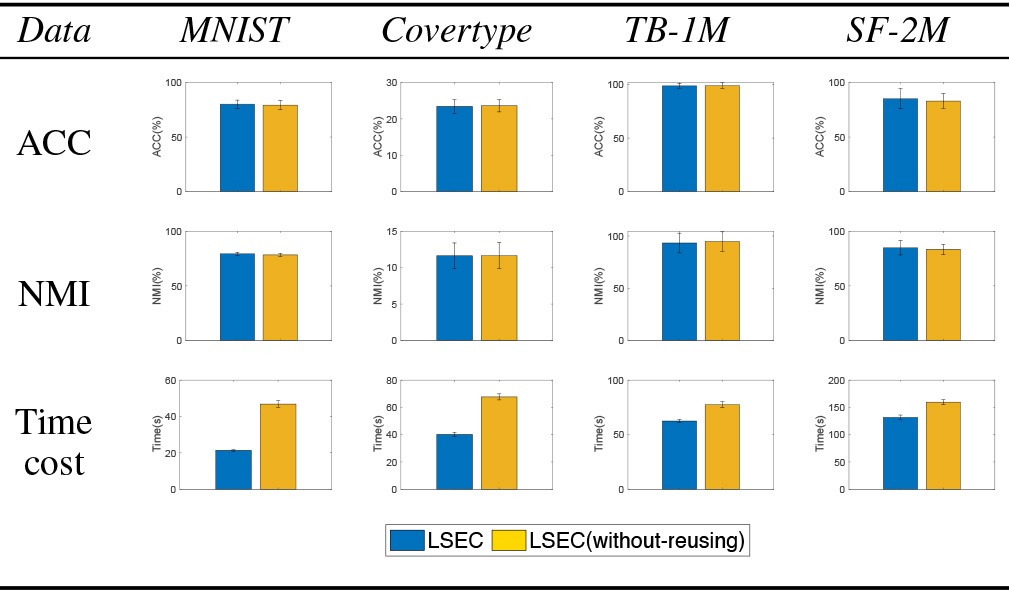
Clustering performance (ACC (%), NMI (%), and time costs(s)) for LSEC with or without reusing the nearest landmarks
Clustering performance (ACC (%), NMI (%), and time costs(s)) for LSEC using light-

The number of times that proposed method is (significantly better than/comparable to/significantly worse than) a baseline method by statistical test (
In this section, we compare the performances of the proposed method with and without reusing the nearest landmarks, denoted as LSEC and LSEC-without-reusing. The experimental results are shown in Table 8. As mentioned, the reuse of nearest landmarks results in improved efficiency in searching the
Influence of light-
-means
In this section, we compare the performances of the proposed method using light-
Conclusion
In this paper, we propose the LSEC method to balance between the efficiency and effectiveness of ensemble clustering on large-scale datasets. We design an efficient ensemble generation framework to produce base clusterings by applying divide-and-conquer large-scale spectral clustering to determine high-quality base clusterings. In the ensemble generation of the proposed method, we accelerate the process of searching
Footnotes
Acknowledgments
This study was supported by the New Energy and Industrial Technology Development Organization (NEDO) Grant (ID:18065620) and JST COI-NEXT.