
Abstract
As an efficient sampling algorithm for latent dirichlet allocation SparseLDA uses cache strategy to improve the time and space efficiency of its standard gibbs sampling algorithm (StdGibbs) by recycling previous computation. However, SparseLDA cannot further improve the time-efficiency of StdGibbs, since the amount of recycled computation is limited. This is because the word types of two adjacent tokens are usually different and the previous computation cannot be further recycled easily. To solve this problem, in this paper we propose a new algorithm named Efficient SparseLDA (ESparseLDA) based on SparseLDA. The main idea of ESparseLDA is to first rearrange the tokens within one text according to the word types so that the tokens of the same word type are aggregated together and then recycle more computation while making no approximation and ensuring the exactness. In this paper, we make detailed theoretical explanations and comparative experimental analyses on the correctness, exactness and time-efficiency of ESparseLDA. In detail, the statistical significance tests on perplexities strictly show that ESparseLDA is correct and exact. In addition, the running time results show that the time-efficiency of ESparseLDA is the higher than SparseLDA in varying degrees from 5.06% to 31.85% on the different datasets used in experiments.
Introduction
Latent dirichlet allocation (LDA) has been studied extensively and deeply in recent years. As a type of graphical model it is well known as “topic model” [1, 26, 32, 37] nowadays. Initially LDA was proposed as an unsupervised method to deal with the text data which have no label information [3, 4]. Since then researchers from different fields have conducted extensive and in-depth research on LDA. In view of application LDA have been widely used in text mining [8, 11, 19, 23, 25], dimensionality reduction [7, 18], speech recognition [15, 16, 17], sentiment analysis [14, 21, 22, 33, 34], social network analysis [5, 6], image recognition [9, 28], scene recognition [27, 36] and other tasks [2]. Moreover, from a theoretical point of view both the generative process [30] and inference process [31] of LDA has been studied. In these studies researchers have made different expansions and improvements on LDA according to the diverse characteristics of the problems from various fields.
Concretely considering the problem that standard gibbs sampling algorithm [12] (shortened as “StdGibbs”) usually takes a long time (about hours on a medium size dataset) [38] to infer the topics of the tokens, the topic sampling process of StdGibbs for LDA has been studied intensively. Up to now there are two main inference methods for LDA, variational inference methods [4] and sampling inference methods [12]. Compared with variational inference methods, sampling inference methods have an advantage that they usually aim at the true posterior probability distribution in the topic inference process [24]. However, sampling inference methods have a problem that they usually take a long time to get closer to the true posterior probability. As a result of this problem, the application range of LDA is limited to a certain extent.
In order to solve this problem, some researchers have optimized the topic sampling process of StdGibbs for LDA to improve its time-efficiency and expand the adaptation of LDA. Accordingly some improved algorithms have been proposed successively. Typically these improved algorithms include FastLDA [29], SparseLDA [38], ECGS [35], AliasLDA [20] and LightLDA [39] (see Section 2 Related works). In these methods ECGS and AliasLDA are approximate algorithms which make some approximations in the optimization of StdGibbs, while FastLDA and SparseLDA are precise algorithms which do not make any approximation in the optimization of StdGibbs.
Among those precise optimization methods, SparseLDA is the most efficient. However, it still has a “recycle computation” problem (see Section 4.1 Problem statement). This problem is caused by a fact that usually the word types of two adjacent tokens are different. Consequently the word type changes frequently along with the token switching from one to another on the token sequence. Just because of this problem SparseLDA cannot recycle more computation by caching the results which have already been calculated before in the topic sampling process. Therefore the time complexity of SpareLDA cannot be further reduced (see Section 3.2 SparseLDA).
Aiming at this issue, this paper proposes a more efficient algorithm named “Efficient SparseLDA” (ESparseLDA) on the basis of SparseLDA. The main idea to solve the “recycle computation” problem in ESparseLDA includes two points. 1) The first point is to make a token rearrangement operation on the token sequence so that the tokens of the same word type within texts are aggregated together. 2) The second point is to recycle more computation by caching the results which have already been calculated so that the total amount of computation is reduced.
In particular, as the main contribution of this paper ESparseLDA has three distinguishing features as follows.
Simplicity: The idea of ESparseLDA is simple and easy to understand and implement. The idea of ESparseLDA is to first make a token rearrangement operation on the token sequence and then use cache strategy to optimize the calculation in the topic sampling process (see Subsection 4.1 Intuitive ideas). Exactness: The sampling results of ESparseLDA are consistent with SparseLDA and StdGibbs. In other words, ESparseLDA is an optimization and improvement of SparseLDA while ensuring the exactness of the sampling results (see Subsection 4.5 Verification of ESparseLDA, Subsection 5.3.1 Correctness verification and Subsection 5.3.2 Exactness verification). Time-efficiency: ESparseLDA is more efficient compared with SparseLDA. The time complexity of SparseLDA is approximately O(DNK
For a brief presentation we summarize these three characteristics of the proposed algorithm ESparseLDA in Table 1.
Three characteristics of the proposed algorithm ESparseLDA
The rest of this paper is organized as follows. Section 2 discusses the related works. Section 3 describes StdGibbs and SparseLDA which are the important bases of this paper. Section 4 presents our proposed algorithm ESparseLDA in detail, including the framework description, time complexity analysis and theoretical illustration of its features. Section 5 conducts experimental validation to verify the features of ESparseLDA. Section 6 concludes the paper and points to future work.
Aiming at the problem that the topic sampling process of StdGibbs for LDA usually takes a long time to infer the topics of the tokens, researchers have proposed a series of optimized methods based on StdGibbs including FastLDA [29], SparseLDA [38], ECGS [35], AliasLDA [20] and LightLDA [39]. These modified methods use different strategies to improve and optimize StdGibbs from different perspectives. In this section we discuss the relationship between them, since these studies are highly related to the method proposed in this paper.
Notation description
Notation description
The main problem of StdGibbs is that in general it takes a long time for inferring the topics. For instance, on a medium sized dataset (1.0
Finally, these optimizations can be divided into two categories according to the exactness of the sampling results. 1) The first category includes ECGS, AliasLDA and LightLDA. These three methods make some approximations in the optimization of StdGibbs in order to improve much more time-efficiency. 2) The second category includes FastLDA and SparseLDA. These two methods are exact and make no approximation. In other words, these methods correctly and exactly samples from the same true total topic distribution as StdGibbs. As a precise optimization of StdGibbs which is relatively more efficient than or comparative with other refined methods, SparseLDA still has a “recycle problem” which controls its time complexity. That means as the most efficient algorithm among those precise optimization methods SparseLDA cannot further improve the time-efficiency of StdGibbs (see Section 4.1 Problem statement), since the amount of recycled computation is limited. Concretely, this is because the word types of two adjacent tokens are usually different and the previous computation cannot be further recycled easily (see Section 3.2 SparseLDA). Hence, in this paper we analyze the “recycle computation” problem of SparseLDA and propose a new algorithm ESparseLDA under the condition of ensuring its exactness. Comparatively, ESparseLDA is more time-efficient than SparseLDA and makes no approximation compared with ECGS, AliasLDA and LightLDA (see Section 4 Proposed method).
In this section we first give a brief introduction of StdGibbs, including its algorithm framework and time complexity. Then based on this, we make a detailed analysis of SparseLDA, because it is an important related work of this paper and the original paper [38] does not present too much specific information about it. Concretely, the detailed analysis of SparseLDA includes its core ideas and key points in addition to its algorithm framework and time complexity. These contents are the key foundation of the method proposed in this paper.
StdGibbs
LDA contains two main processes, the generative process and the inference process. The generative process of LDA assumes that each text is a mixture over latent topics, and each topic is a distribution over word types. After the generation process, in the inference process of LDA the main problem is to infer the topic of each token. Using StdGibbs the probability that one token
The notations are summarized in Table 2. In this paper, this probability is also called “topic probability segment” shortened as “segment”. For each token, there are
According to the granularity of relevant data, SparseLDA divided Eq. (1) used in StdGibbs into three buckets as shown in Eq. (2), and each of these three buckets is a sum of
In original paper, these three blocks respectively are called the “smoothing only” bucket, the “document topic” bucket and the “topic word” bucket, but in this paper these three buckets are called “S item”, “R item” and “Q item”. To improve the time-efficiency of StdGibbs, SparseLDA uses “cache strategy” to compute S item and R item and uses “sparse strategy” to compute Q item according to the different changes of these three items in the topic sampling process.
Time complexity for calculating S item in SparseLDA
Time complexity for calculating R item in SparseLDA
Time complexity for calculating Q item in SparseLDA
In summary, for all tokens of the entire dataset the time complexity of the calculation process is O(DNK
Time complexity of the search process in SparseLDA for one token
Based on this there is another point should be noted about the segments of the Q item, which further influences the time complexity of the search process. When the sampling point falls into the Q item, the time complexity of the search process for one token can even be approximated as O(1), since in SparseLDA the segments of Q item is ordered from large to small and the proportion of the first largest segment is usually more 90%. In summary, for one token the time complexity of the search process is approximately O(1) and for all tokens in the entire dataset the total time complexity of the search process is approximately O(DN).
In this section, we first describe the “recycle computation” problem of SparseLDA and introduce our intuitive ideas to solve this problem. Then, we propose our method ESparseLDA modified on SparseLDA and present the details of ESparseLDA, mainly including its algorithm framework and time complexity. Finally, we explain the features (correctness, exactness and time-efficiency) of ESparseLDA from the theoretical point of view.
Problem statement
Intuitive ideas
In order to improve the time-efficiency of SparseLDA, it is necessary to solve the “recycle computation” problem in calculating the segments of Q item in SparseLDA. To solve this problem the general idea of this paper is to firstly rearrange the token sequence within each document according to word types and secondly compute Q item by caching and recycling the previous results. Obviously, the general idea includes two parts. The first part aims to create conditions by rearranging the token sequence for the second part to utilize cache strategy. Following are the description and illustration of the contents and details of these two parts.
In order to solve this associated problem, this paper considers such a reality that usually in one text there will be more than one token belonging to the same word type. Based on this reality, this paper has produced an intuitive idea, the idea of token rearrangement, to solve this associated problem. The main motive of this intuitive idea is that for the same text if the tokens of the same word type are grouped together, then the word type will not change so frequently along with the token switch in the topic sampling process, and Q item can be calculated through cache strategy by recycling the previous computational results.
Below the operation of this idea is described through an example. Suppose there are two sentences from an article [4] as follows:
Accordingly, assume that a token sequence is obtained from this sentence as follows after stop word removal and other pretreatment on this sentence.
Based on this token sequence, another sequence is obtained as below after the token rearrangement operation.
Comparing these two token sequences, it can be seen that the tokens with the same word type in the latter token sequence are placed together. For the two tokens of the word type “foundation”, they are not adjacent before, but after the token rearrangement operation they are adjacent. Similarly, the situation is the same for the two tokens of the word type “center”.
Briefly, it is because cache strategy needs less computation and can reduce the time complexity to a greater extent compared with the sparse strategy. In detail, cache strategy utilizes the previous intermediate results to accomplish most of the later computation, while sparse strategy utilizes the sparsity of count matrices and needs to compute all the nonzero elements. Concretely, in the same text when the topic sampling process switches from one token to another token with the same word type, only two segments (O(1)) in Q item (
Below the operation of this idea is explained by carrying on the previous example. Take the previous token sequence obtained after the token rearrangement operation as an example, the corresponding strategy, sparse strategy or cache strategy, used to compute Q item for each token is shown as follows.
It can be seen that for the first token of the word type “center” its Q item is computed by the sparse strategy, while for the second token of the word type “center” its Q item is computed by the cache strategy. The situation is the same for the two tokens of the word type “foundation”.
In summary, before the token rearrangement operation all the Q items are calculated using sparse strategy only, but after the token rearrangement operation, some changes have happened; that is, some Q items are still calculated using sparse strategy, but the other Q items are calculated using cache strategy. Specifically, it is divided into two kinds of situations: 1) If the current token has the same word type as the previous token, then the Q item of the current token is calculated using cache strategy. 2) Otherwise, the Q item of the current token is calculated using sparse strategy as before in SparseLDA.
In practice, there will much more Q items computed by cache strategy. For example, in view of the datasets used in this paper on average about 25–60% tokens are repetitive within one text. Thus their Q items are all computed by cache strategy. Especially, the repetition ratio will be higher for the documents which in general repeat similar content again and again, such as fictions, patents and dissertations.
ESparseLDA
Based on these two intuitive ideas introduced in the previous section, we propose a new algorithm named “Efficient SparseLDA” (ESparseLDA) in this section. ESparseLDA accomplishes the same task as SparseLDA but is more time-efficiency than SparseLDA, since the “recycle computation” problem of SparseLDA has been solved in ESparseLDA. The main idea of ESparseLDA to solve the “recycle computation” problem in ESparseLDA is as follows: 1) First it rearranges the tokens in the same text according to the word type. This step makes the tokens of the same word type within texts aggregated together. 2) Second it calculates some of the Q items using the cache strategy by recycling the computational results which have already been calculated. This step reduces the amount of computation required by Q item.
2) The other part of the calculations (Algorithm 11, line 8 and 9) after the topic sampling of the current token is as follows:
In this way, the time complexity of the calculations for Q item in ESparseLDA is reduced from O(
Time complexity of ESparseLDA
Like SparseLDA, ESparseLDA mainly comprises two processes, the calculation process and the search process. In the following, we separately analyze the time complexities of these two processes.
The calculation process of Q item can be divided into two cases according to the two strategy used (cache strategy or sparse strategy) for computing. In short, the single time complexity for compute one Q item is O(1) (Algorithm 11, line 3) in cache case and is O(
Time complexity for calculating Q item in ESparseLDA
Time complexity for calculating Q item in ESparseLDA
In summary, the time complexities of the three calculation processes for all S item, R item and Q item are respectively O(DN), O(DN) and O(RDNK
In addition, it needs to be explained that the token rearrangement operation is just a preprocessing step. This step is completed in conjunction with other preprocessing steps. It does not affect the time complexity of ESparseLDA.
ESparseLDA has three important points needed to be explained and verified. In short, these three points are the 1) correctness, 2) exactness and 3) time-efficiency of ESparseLDA. In detail, 1) correctness-refers to the rationality of the token rearrangement operation which is performed before the topic sampling process, 2) the second point, exactness, refers to the consistency between the training results of ESparseLDA and SparseLDA, 3) the third point, time-efficiency, refers to the time-efficiency of ESparseLDA compared with SparseLDA. In this subsection, these three points are explained from the theoretical point of view, and in the next section (Section 5 Experiments) they are verified from the experimental point of view.
From the viewpoint of sufficient statistics, the token rearrangement operation has no impact on the quality of the LDA, since it does not affect the main sufficient statistics of LDA. In detail, LDA mainly considers the statistical information about the number of each topic within each text and the number of each word type within each topic. It does not concern about the statistical information about the order of tokens and topics. The main sufficient statistics of LDA are the two counting matrices,
Considering the property of gibbs sampling, the token rearrangement operation is equivalent to change changing the sampling order of gibbs sampling algorithm. Since gibbs sampling algorithm has a property that random permutations of the sampling order does not affect the sampling results [10], from this viewpoint the token rearrangement operation also has no influence on the quality of LDA. Moreover, it is worth to note that gibbs sampling algorithm contains a number of random factors because it is a kind of stochastic algorithm. Although these random factors will affect the specific sampling results, this will not affect the quality of the overall results of gibbs sampling algorithm.
However, in reality compared with SparseLDA the amount of computation reduced by ESparseLDA is
Experiments
In this section, we verify the correctness, exactness and time-efficiency of ESparseLDA from the experimental point of view. The experimental design, results and analysis is the core content of this section. In addition, this section also describes the datasets, evaluation criteria, parameter setting and implementation details of the experiments.
Statistical information of the original datasets
Statistical information of the original datasets
Datasets
To be explained, “TTR” is the abbreviation of “Type Token Ratio”2
The variety of the word types increases as the value of TTR increases. In addition, TTR
Statistical information of the extended datasets
In this paper, we need to verify the correctness, exactness and time-efficiency of ESparseLDA. The validation of the correctness and exactness needs to evaluate the ability of LDA. And the validation of the time-efficiency needs to evaluate the time used for training LDA. For this purpose, the typical evaluation criteria, perplexity [4, 20],5
Perplexity is a criterion commonly used in natural language processing to measure the generalization ability of language models [4]. Algebraically it is defined as the reciprocal geometric mean of the likelihood of a held-out test dataset given the results of models. The results of LDA are the count matrices, including the document-topic count matrix
where
Perplexity is a monotonically decreasing function and a lower perplexity value indicates better generalization ability. In our experiments, the test set ratio is set to 10% which means that 90% of the dataset is used for training LDA and 10% of the dataset is used to compute the perplexity for LDA. It should be noted that SparseLDA and ESparseLDA are compared on the same dataset partition in order to eliminate the effect of dataset partition on perplexity values and running times and the experiment results in this paper is averaged over five runs for each algorithm on each dataset. For the reason that the values of error bars are relatively too small compared with the values of perplexities and running times, the error bars which show the standard deviation of the experiment results over five runs are not plotted.
In this experiment the number of topics
In this paper, SparseLDA is used as the contrast algorithm to analyze the performance of ESparseLDA. Implementation of SparseLDA is achieved from an open source code on GitHub6
All the experiments in this paper were conducted on a laptop with 4 GB memory and an Intel i5-4210M processor with 2.6 GHz clock rate. In addition, the program was carried out on Microsoft Visual Studio 2013 development platform (VS2013) under Windows7 64 bit operating system. Since VS2013 is not fully support for C++11, we made a proper modification on the open source code, and this modification does not affect the core algorithms and data structures in SparseLDA and ESparseLDA.
According to the different contents to be verified the whole experiment is divided into three parts as follows. 1) “Correctness verification” verifies the correctness of the token rearrangement operation. 2) “Exactness verification” verifies the consistency between the training results of ESparseLDA and SparseLDA. 3) “Time-efficiency verification” verifies the time-efficiency of ESparseLDA compared with SparseLDA. Since the token arrangement operation is the prerequisite of ESparseLDA, this experiment firstly verifies the correctness and then verifies the exactness and time-efficiency of ESparseLDA.
Correctness verification
The correctness of token arrangement operation has been explained from the perspective of theoretical analysis in the previous section (see Section 4.5 Verification of ESparseLDA). From the experimental point of view, verifying the correctness of token arrangement operation is to verify that changing the sampling order of token sequence within texts before sampling does not affect the quality of LDA trained by the same sampling algorithm.
From Fig. 1 it can be seen that on each dataset the perplexities of these two LDA models (“Unordered”, “Ordered”) roughly converge to the same value. Moreover, the convergence processes of these two LDA models are also generally consistent. In addition to the visual inspection we make a statistical significance test on each pair of the perplexities of these two LDA models (“Unordered”, “Ordered”). Table 10 shows the means and standard deviations of the perplexities of these two LDA models (“Unordered”, “Ordered”) after convergence in five running for the three datasets. Intuitively, it can be observed that the means of the perplexities of these two LDA models (“Unordered”, “Ordered”) on each dataset are very close and they are the same until the first or the second decimal place. Strictly, we make a statistical significance test on each pair of perplexities in the same dataset to check whether the difference between them is significant or not. The p-value shows that from a statistical point of view the exactness of the results of these two LDA models (“Unordered”, “Ordered”) have no differences and only changing the sampling order of the token sequence within texts does not affect the ability of LDA model. Thus the correctness of the token rearrangement operation is verified.
Means and standard deviations of the perplexities of these two LDA models (“Unordered”, “Ordered”) after convergence in five running for the three datasets
Means and standard deviations of the perplexities of these two LDA models (“Unordered”, “Ordered”) after convergence in five running for the three datasets
Perplexity as a function of the number of iterations. Unordered vs Ordered: (a) dataset Kos, (b) dataset Nips, (c) dataset Enron.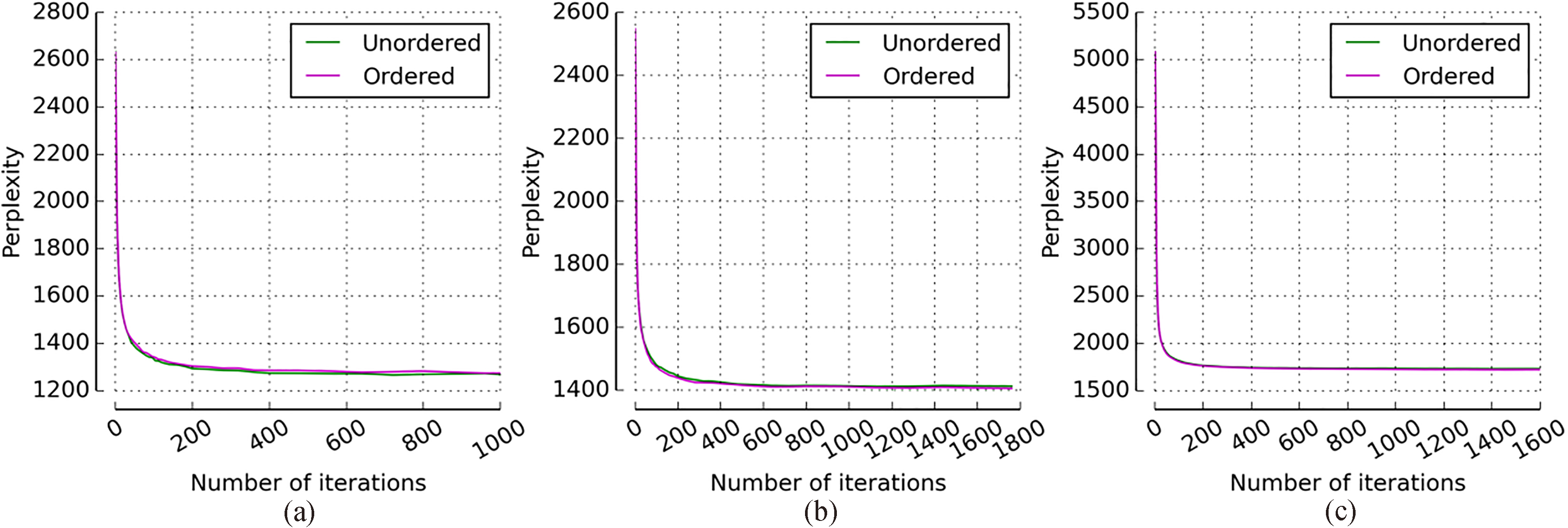
Theoretically the exactness of ESparseLDA refers to the consistency between the training results of ESparseLDA and SparseLDA. In experiment verifying the exactness of ESparseLDA is to verify that the abilities of two LDA models respectively trained by ESparseLDA and SparseLDA on the same token sequence are consistent.
From Fig. 2 it can be seen that the perplexities of these two LDA models (“SparseLDA”, “ESparseLDA”) obtained in each dataset roughly converge to the same value. Moreover, the convergence processes of these two LDA models are also generally consistent. In addition to the visual inspection we also make a statistical significance test on each pair of the perplexities of these two LDA models (“SparseLDA”, “ESparseLDA”). Table 11 shows the means and standard deviations of the perplexities of these two LDA models (“SparseLDA”, “ESparseLDA”) after convergence in five running for the three datasets. The p-value shows that from a statistical point of view the exactness of the results of these two LDA models (“SparseLDA”, “ESparseLDA”) have no differences and using ESparseLDA instead of SparseLDA for training has no change on the ability of LDA model. Thus the exactness of ESparseLDA is verified.
Means and standard deviations of the perplexities of these two LDA models (“SparseLDA”, “ESparseLDA”) after convergence in five running for the three datasets
Means and standard deviations of the perplexities of these two LDA models (“SparseLDA”, “ESparseLDA”) after convergence in five running for the three datasets
Perplexity as a function of the number of iterations. SparseLDA vs ESparseLDA: (a) dataset Kos, (b) dataset Nips, (c) dataset Enron.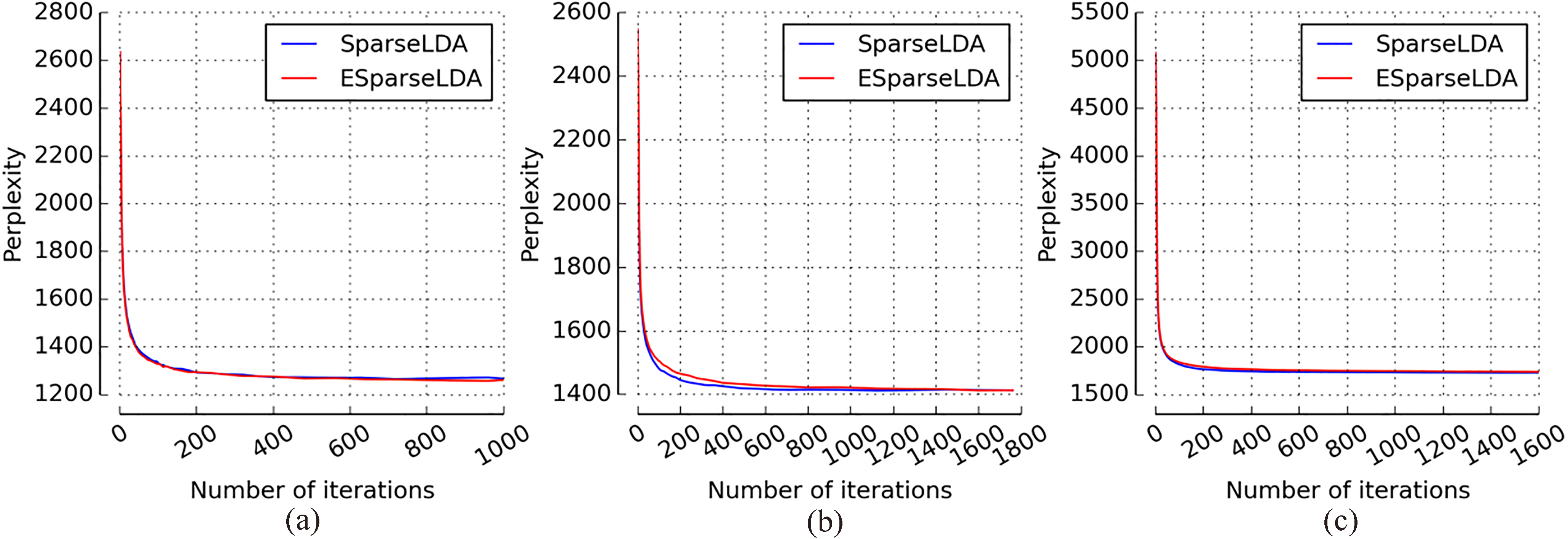
Meanwhile, combining the correctness verification and exactness verification it can be seen that the method proposed in this paper which first rearranges the token sequence and then uses ESparseLDA for training will not change the ability of LDA.
Verifying the time-efficiency of ESparseLDA is to verify that compared with SparseLDA ESparseLDA needs less running time to train LDA model on the rearranged token sequence. It is important to note that in verifying the time-efficiency of ESparseLDA it is necessary to first verify that the token rearrangement operation will not change the running time of SparseLDA, since ESparseLDA requires this operation in its preprocessing.
Comparison of running time for one iteration after convergence between SparseLDA (LDA-1) and ESparseLDA (LDA-3) on dataset Kos, Nips and Enron
Comparison of running time for one iteration after convergence between SparseLDA (LDA-1) and ESparseLDA (LDA-3) on dataset Kos, Nips and Enron
Seconds of one iteration as a function of the number of iterations. LDA-1 vs LDA-2: (a) dataset Kos, (b) dataset Nips, (c) dataset Enron. LDA-1 vs LDA-3: (d) dataset Kos, (e) dataset Nips, (f) dataset Enron.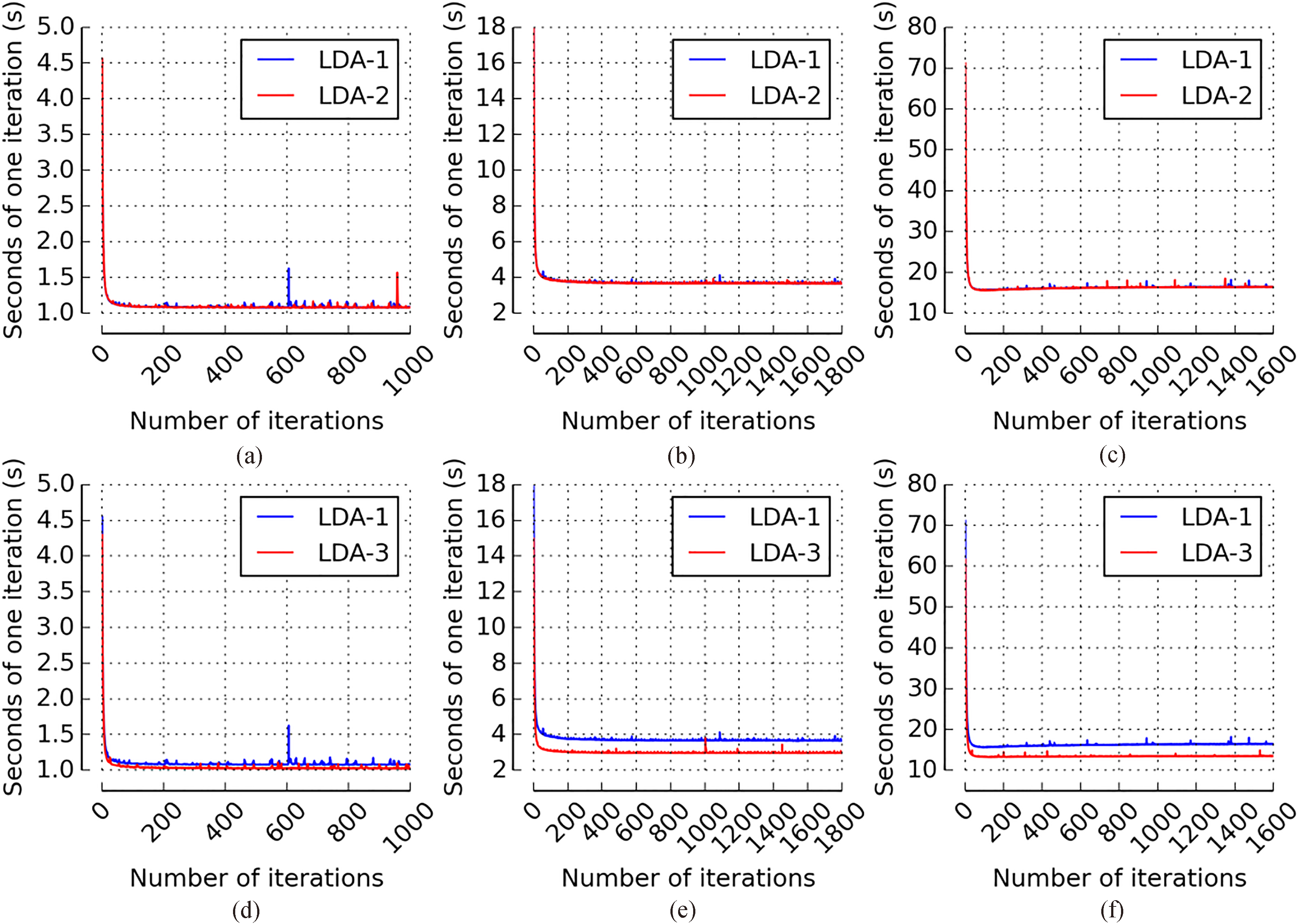
Seconds of one iteration as a function of 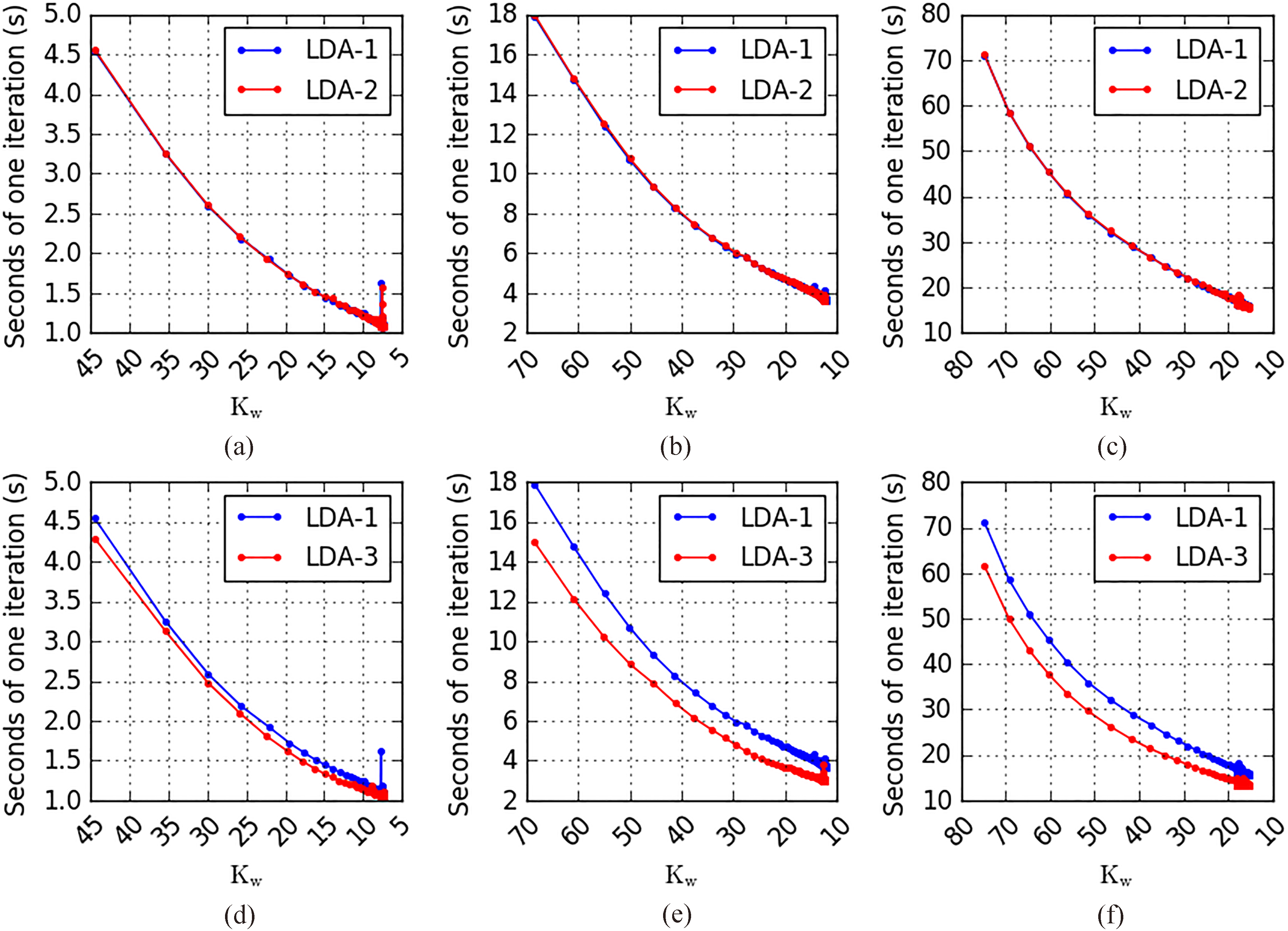
Furthermore, on the same
Comparison of running time for one iteration at initial stage between SparseLDA (LDA-1) and ESparseLDA (LDA-3) on dataset Kos, Nips and Enron
Time-efficiency improvement as a function of 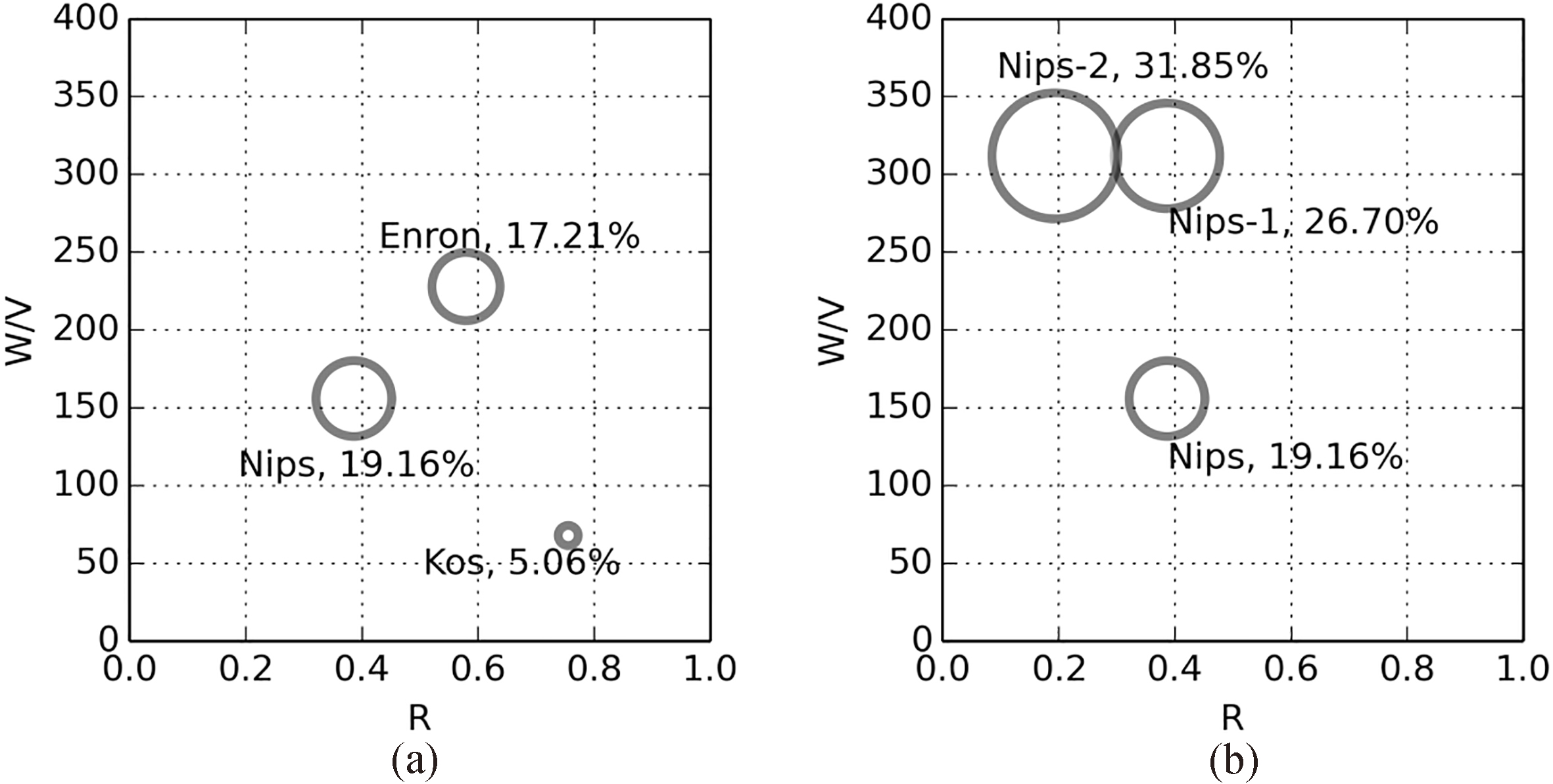
Figure 5 is the experimental results of the third part in time-efficiency verification. In each subfigure of Fig. 5, the horizontal axis represents the value of
Time-efficiency improved by ESparseLDA compared with SparseLDA on dataset Kos, Nips and Enron
Theoretically it can be inferred that when
In addition, in this case it can be seen that the time-efficiency improved by ESparseLDA is comparative with AliasLDA. Theoretically ESparseLDA performs better on the dataset with small value of
In summary, in this subsection we verify the time-efficiency of ESparseLDA by conducting comparative experiments, and actually the experimental results show that ESparseLDA is more time-efficient than SparseLDA. Concretely, the time-efficiencies improved by ESparseLDA on SparseLDA varies from 5.06% to 31.85% on the different datasets used in experiments. Moreover, the experimental results also validate our previous theoretical analysis of the impact of
In this paper, we proposed a more efficient gibbs sampling algorithm, ESparseLDA, based on SparseLDA. ESparseLDA is also used in LDA for inferring the topics and accomplishes the same task as SparseLDA. It improves the time-efficiency of SparseLDA by recycling more computation while ensuring the exactness of SparseLDA. In other words, ESparseLDA makes no approximation in the optimization of SparseLDA. The core idea of ESparseLDA is combining token rearrangement and cache strategy for recycling more computation so as to improve the time-efficiency of SparseLDA. In this paper we verified the correctness, exactness and time-efficiency of ESparseLDA both from theoretical analysis and experimental validation. Theoretically the percentage of the time-efficiency improved by ESparseLDA is
Future work will try to optimize the sampling inference algorithms of other LDA-based topic models using the core idea of ESparseLDA, since the core idea is general and is not limited to LDA. Theoretically, this idea can be applied to AliasLDA which can reduce the time complexity from O(
Footnotes
Acknowledgments
This work was supported by National Nature Science Foundation of China (NSFC) under the Grant No. 61602204, 61472157, 61170092, 61133011 and 61103091.