
Abstract
Finding coherent topics in Twitter data is difficult task because of the sparseness and informal language. Tweets also provide rich contextual and auxiliary metadata which can be used to supervise the topic modeling to get more coherent topics. In this paper, a novel topic model is proposed which extends Author Topic Model for twitter. Standard Author Topic Model cannot be used on Twitter data as every tweet has exactly one author. The proposed User Graph Topic Model (UGTM) considers the semantic relationships among tweet users based on the contextual information like hashtags, user mentions and replies to make a user graph. Related users of author of a tweet are found and used in tweet generation process. Related user information from the user graph is used to obtain the dirichlet prior for user generation. Empirical results show that the proposed UGTM outperforms standard Author Topic Model (ATM) on experimental data.
Introduction
In the age of Big Data, analyzing large collections of flat text data is a challenging task. Unstructured nature of textual data make analysis difficult. Topic Models [1] have been proven useful for analyzing and discovering important statistical pattern in large collection of text documents. Topic models are probabilistic models which discover the latent semantic structure hidden in the large text data. They have wide spectrum of text mining applications such as multi-document summarization [2–5], Sentiment analysis [6, 7], opinion mining [8], social network analysis [9], machine translation [10] etc.
Topic models have obtained success in analyzing topics in long flat documents i.e. scientific documents, news articles, literary documents etc. but they fail to produce good results for short text data like tweets [11]. Tweets are very short containing maximum of 140 characters. The reason for unsatisfactory results for short text is their noisy and sparse nature because Topic Models implicitly capture the word co-occurrence relationships in the documents which are very sparse in short documents [12]. Moreover, Tweets contains informal language construct like slangs, abbreviations which increases the size of dictionary and ambiguity. Several methods are proposed for improving topic model results for short text-By extending short text, by adding additional terms [13–15], by aggregating similar tweets [11, 16–18], by designing special topic models that suit short text [19–21].
Although conventional topic models are designed for the flat text documents, they can utilize the meta-data of the text documents to supervise the topic modelling [22]. Tweets have rich contextual information. In addition to the actual text, tweets also have hashtags, URLs, user mentions in the tweet body which provides additional semantics to the tweets. Hashtags are added by users to categorize and highlight topics of the tweets. URLs provides additional information to the tweets. User mentions and replies provide communication relationships among the tweet users. Furthermore, tweet meta-data also contains auxiliary data like user profile, timestamp, reply, location etc. These contextual and auxiliary information of tweets can be used to weekly-supervise topic modelling to get additional word co-occurrence relationship among the tweets. Several works have focused on using these contextual and auxiliary tweet data to enhance topic modeling on tweets [23–29]. Most of these works focused on using hashtags for supervising topic models. The drawback of these works is that they can be used only when tweets has some hashtags. If a tweet does not contain any hashtag then either hashtag based topic modelling cannot be applied or that tweet does not contribute to topic modeling. For this reason, all hashtag based topic modeling methods use only those tweets which contains hashtags for training and testing.
In Author Topic Model [30], set of authors of the document are treated as document tags. Each author of the document has some contribution to the content of the document. ATM has some drawbacks. First, ATM does not improve topic modeling if there is exactly one author for each document in the corpus. For this reason, ATM cannot be used for tweet data because each tweet has exactly one author. Second, ATM does not consider the impact of those users who are not the author of the document. In a social network like Twitter, the content of text documents is affected by a group of users who are closely communicating on a topic. The group of users communicating on a topic are reflected by using a set of hashtags and URLs, mentioning each other using user mentions and replying to each other on twitter. Such communicating users have a kind of mutual relationships among them, which can be used to model the role of users on tweet generation. For example, consider the following four tweets shown in the first column of table 1, which were tweeted by four different users but they mentioned the same user ‘@elisewho’. There is no hashtag in these tweets. But since the author of these tweets have mentioned to the same user ‘@elisewho’, the authors of these tweets topic are related to the topics of the user ‘@elisewho’. The second column of table 1 shows tweets posted by ‘@elisewho’, which are related to the topics of the tweets shown in the first column of Table 1.
Relationship among mentioning and mentioned users
Relationship among mentioning and mentioned users
In this paper, a probabilistic topic model, User Graph Topic Model (UGTM), is proposed that takes the relationships among the tweet users into account and use it to model the effect of users on tweets generation. The proposed UGTM model uses user and their relationships based on hashtags, URLs and mentions. UGTM alleviates the problem faced by hashtag based approches discussed above. Since every tweet has a user, UGTM can be used with every tweet whether that tweet contains hashtag or not. UGTM also improves Author Topic Model by also considering the contribution of those users in tweet generation who are not the author of tweet.
In the proposed model, to generate a word of a tweet, a user is first generated probabilistically using the user relationships. The generated user may be different from the actual author of the tweet. A word is generated then from the generated user’s topic distribution over words. So, a word in a tweet may generated by a user whose topic distribution is related to the tweet content but is not the author of tweet. The contribution of the proposed model is summarized as follows: The proposed model tackles the sparsity problem of short text by using user relationship based on the tweet contextual information. Unlike Author Topic Model, the proposed model considers the effect of non-author users on topic modeling. The user relationship information is used as dirichlet prior for generating user in the generative process. The proposed model performs effectively on tweet data on clustering and topic quality task.
Remainder of the paper is organized as follows. Next section describes related work. Section 3 presents the proposed model. Section 4 presents experiments and results. Section 5 concludes and discusses future work.
Topic Modelling have been a popular method to analyze the latent semantic structures of large text collections. Topic modelling algorithms finds latent topics in the documents by using a probabilistic generative process to generate hidden topics. Latent Dirichlet Allocation (LDA) [31] is the first approach in this direction which is the extension of probabilistic latent semantic analysis (pLSA) [32]. LDA is generalization of pLSA and is similar to it when a uniform dirichlet prior is used instead of sparse dirichlet prior. LDA introduces dirichlet priors for multinomial distribution of documents over topics. Several extensions of LDA have been proposed. Correlated Topic Model (CTM) [33] finds topic relations in the documents. Dynamic Topic Model (DTM) [34], Relational Topic Model (RTM) [35] and Hierarchical Topic Model (HTM) [36] are some other variants of LDA. LDA and its variants produce excellent results on long documents but they fail on short documents like tweets which are noisy, sparse and short.
Topic modelling for short texts
Several approaches have been proposed for topic modeling to handle short and noisy data. In one approach, short texts have been extended by appending additional words from external knowledge bases Word-Net, Wikipedia or World Wide Web. Additional words are also added from the document corpus itself using co-occurrence word relationships. Co-frequency Expansion (CoFE) [37] framework added the words in the corpus which co-occur frequently with the document words, assuming that co-occurring words have high probability of falling in the same topic. A distributed representation based expansion (DREx) framework [15] is designed which is based on the concept of word embedding to model word similarities.
Another approach of tackling the short text problem is to aggregate the related short documents into longer documents. The relation among the short documents is based on some heuristics. For example, hashtags [16], users [11] and conversations [17] have been used for tweet aggregation. Hong et al. [11] applies the standard LDA on the aggregated document of all the tweets authored by a single user. Mehrotra [16] et al proposes tweet pooling based on burst-score, timestamp and hashtag, which combines tweets on the basis of tweet bursts (i.e. high number of tweets in unit time), time period (e.g. hour) and tweet hashtags respectively. Hashtag based tweet pooling scheme perform better than standard LDA but burst-score and timestamp based pooling does not improve the results. Alvarez-Melis [17] proposes conversa-tion based pooling which combines those tweets which are part of the same twitter conversation. Author claims that conversation based pooling scheme performs better than hashtag based pooling scheme. Other works have also used other tweet contextual information like URL, mentions for tweet pooling. The drawback of these pooling schemes is that the contextual information like hashtags, replies, URLs are not always available in all the tweets. These pooling schemes can be used only when the contextual information is available for aggregation. Self-Aggregation based Topic Model (SATM) [38] uses clustering methods along with topic modelling to provide a general framework for document aggregation.
Another approach for tackling short text is to design special topic modelling algorithm that are suited for sparse and noisy nature of short texts. Bi-term topic Model (BTM) [19] considers all bigrams instead of words in the entire corpus to reduce the sparsity problem. Twitter-LDA [20] models solves the data sparsity problem by assuming that short text contains exactly one topic. This assumption provides better result and is reasonable for the short text. GPU-DMM topic model [39] enriches short text by using auxiliary word embedding from large text collections. It uses Generalized Polya Urn Model to promote semantically related words during the sampling process. Word network Topic Model (WNTM) [21] works upon the pseudo documents created for each word using word graph. The group of words found in the generative process are treated as latent topics in the corpus.
Supervised topic models
Supervised topic models uses contextual information available with semi structured text documents for guiding the generative models. Blei proposes Supervised LDA (sLDA) [22] for labelled documents to accommodate a variety of response types that limits the topics to a pre-defined set with their distributions provided a priori. Labelled-LDA [40] uses one to one correspondence between topics and document tags to learn word-tag relations. Labelled-LDA restricts a documents topics to the labels assigned to it. Ramage et al [41] uses labelled-LDA to pick hyper-parameters corresponding to the tweet labels restricting tweet topics to its labels.
Several works have been proposed to use tag information associated with the documents to supervise the topic modelling. Hashtag Graph Topic Model (HGTM) [23], Tag-topic model [24], TagLDA [25], Behaviour-LDA [27], tag-Weighted Dirichlet Allocation (TWDA) [26], hashtag-LDA [28], Tag-Latent Dirichlet Allocation [29] models uses the tags associated with the documents to restrict the topics guided by tags. Y Wang [23] proposes HGTM to utilize hashtag relationship from a hashtag graph to model semi structured tweets. HGTM directly models the influence of those words which does not appear in the document itself through the use of hashtag relationships. Tsai presents Tag-topic model [24] for blog mining, which is based on the Author-Topic model and Latent Dirichlet Allocation. The tag-topic model determines the most likely tags and words for a given topic in a collection of blog posts. TagLDA [25] extend Latent Dirichlet Allocation model by replacing the unigram word distribution with a factored representation conditioned on both the topic and the tag structure of the document. TWDA [26] provides a framework that leverages both the tags and words in each document to infer the topic components for the documents. This allows not only to learn the document-topic and topic-word distributions, but also to infer the tag-topic distributions for text mining. Behavior-LDA [27] uses tweet behavior (reply, retweet, post etc.) as document tags and uses it to guide topic learning. Hashtag-LDA [28] studies the influence of tweet hashtags on the topic distribution by jointly modeling the words and hashtags in tweets. Tag-Latent Dirichlet Allocation (TLDA) [29] presents a topic modeling approach that extends Latent Dirichlet Allocation by incorporating the observed hashtags in the generative process. In TLDA, a hashtag is mapped into the form of a mixture of shared topics. This representation further enables the analysis of the relationships between the hashtags. Author Topic Model (ATM) [30] is another supervised topic model which uses author information for influencing topic modelling that models both document content and author interests. In fact, Tag-Topic model is a variant of ATM, in which tags of the blog documents instead of au-thors are used for supervision.
The proposed work is similar to the Author Topic Model in the respect that it also models the author influence on document generation. The advantage of the proposed model is that it can model those document collections in which there is only one author for each document. Performance of ATM is same as standard LDA in this situation. The proposed model is also similar to the Labelled-LDA in the respect that it modifies dirichlet hyper-parameters to model the author influence on topic distribution. Labelled-LDA uses a set of binary switches to select dirichlet hyper-parameters for selecting the topics related to the tags of the documents. Whereas the proposed model obtains dirichlet hyper-parameter values from the relationships among all the users. The proposed work is related to Word Network topic Model (WNTM) and Hashtag Graph topic Model (HGTM) in the respect that the proposed model also uses a graph of users as WNTM uses word graph and HGTM uses hashtag graph.
User graph based topic model
In this section, the proposed user graph topic model (UGTM) is presented. Firstly, a brief overview of latent dirichlet allocation (LDA) and one of its variant Author Topic Model (ATM), on which the proposed topic model is built, are described, then proposed topic model is presented.
Latent Dirichlet Allocation (LDA) and Author Topic Model (ATM)
Latent Drichlet allocation has been widely applied for topic modelling of text documents. In LDA, each document in the corpus is supposed to be a mixture of multiple topics. Each word of the document is sup-posed to come from a different topic. Each document has a multinomial distribution over a fixed number of topics and each topic has a multinomial distribution over a fixed vocabulary words. To generate a word in a document, the generative process of LDA first generates a topic according to the probability distribution of the document over topics and then generates a word according to the probability distribution of the selected topic over vocabulary words.
Author Topic Model (ATM) extents LDA by considering the authorship information of the documents. ATM is used for the documents when there are multiple authors for a single document. In ATM, each author of the document, instead of the document itself, has a multinomial distribution over topics and each topic has a multinomial distribution over words. In ATM, document is modeled as distribution over topics that is a mixture over distributions over authors. Clearly, ATM is same as LDA when each document has exactly one author.
Proposed user graph topic model
ATM does not improve the performance substantially on documents which has exactly one authors. There are documents like tweets which has exactly one author. Due to the social nature of twitter a tweet by one author is also affected by other authors. ATM fails to model the influence of other users on the tweet generation. UGTM assumes that the words of a document may also be generated by the topic distribution of other users who are not the author of the document. User Graph Topic Model (UGTM) is a probabilistic topic model that describes a generative process to model the collaborative influence of authors on documents. The block diagram of UGTM is shown in Fig. 1.

Block Diagram of UGTM.
Let the corpus has N documents. Each document has N d words wd1, wd2, …, w dN d . The author of the document d is u d .
Traditional LDA assumes a fixed number of hidden topics K in the whole corpus. To generate words in a document, it first generates a latent topic and then generates word from that topic. UGTM uses two la-tent variables for the generation of a word. It first generates a latent user variable using the author’s multinomial distribution over all users. Each user has multinomial distribution over topics. UGTM then generates a latent topic variable from the generated user’s topic distribution and then generates word from the generated topic’s word distribution.
UGTM supervises user latent variable generation. Supervision information is taken from user graph which specifies the relationships among users. A user graph is an undirected weighted graph in which nodes are users and edges are obtained from some relationship among users. One relationship between user u i and u j is the usage of common hashtags by them in the entire corpus, which shows a kind of semantic relationship between user u i and u j . The weight of the edge (u i , u j ) is the number of common hashtags between u i and u j . Several of such relationship can be defined using tweet contextual information e.g. URLs, replies, mentions etc. User graph is represented as two dimensional matrix GU×U where U is the number of users in the corpus. Let G u be the row of the matrix G for user u.
UGTM uses dirichilet-multinomial distribution pair to model user, topic and word generation. Dirichilet distribution is the conjugate prior of the multinomial distribution. The effect of using dirichlet distribution as prior for multinomial distribution is the addition of dirichilet prior count to the multinomial counts in the posterior distribution. For this reason dirichlet prior counts are also called pseudo-counts, which provides a smoothing effect on multinomial parameters and exhibits the polya-urn’s rich get richer behavior [42].
In UGTM, user graph is used to find the dirichlet prior for the user generation. In traditional LDA and its other variants, usually a symmetric dirichlet prior is used which uses a single vale for all dirichlet parameters. UGTM uses supervision information from user graph to find the dirichlet prior for user latent variable generation. In the user graph G, each row G u describes the relationships between the user u and all other users. This relationship information for user u i.e. row G u of user graph can be used as prior information for guiding to find the other related users who may affect the generation of the document. The user graph matrix row G u is used to find the dirichlet prior parameters for user latent variable generation. The values in row G u normalized by the largest value in that row are used as dirichlet prior parameters for multinomial distribution of user latent variable.
Note that there is no loops i.e. an edge from a user node to itself in the user graph, resulting in the zero prior value for the author itself. But prior value for the author must be largest. A parameter π is introduced to make the dirichlet priors correct. Let S u be the sum of all values in the original row G u and guu′ be the relationship value between u and u’ in that row. The prior for the author u is kept as π × S u . The prior for other users u’ are kept as (1 - π) × guu′. This increases the prior belief that most of the words in the document are generated by the author of the document.
To choose the value of π, experiments are conducted for different values of π. Large values of π (>0.9) will reduce the effect of user graph and make UGTM close to Author Topic Model. Low values of π will take the effect of other users more than the actual user of the tweet. Any value of π greater than 0.5 give preference to the author of the tweets. The value 0.7 is empirically chosen because it gives best results.
Generative process of tweets in UGTM
Let the author of the document d be u d . For each word position w d i in document d, user u d i and topic z d i latent variables are generated. First, user u d i of the word w d i is generated. User u d i is generated by drawing from the u d ’s multinomial distribution ψ u d over all users with dirichlet hyper-parameter γ u d . Each user has a multinomial distribution over topics with dirichlet hyper-parameter α. Topic z d i is drawn from user u d i ’s topic distribution. Each topic has a multinomial distribution over terms with dirichlet hyper-parameter β. Finally, Word w d i is drawn from topic z d i ’s term distribution. By assigning a user latent variable, each user has a contribution to the topic distribution of the document. The plate notation of graphical model of UGTM is depicted in Fig. 1.
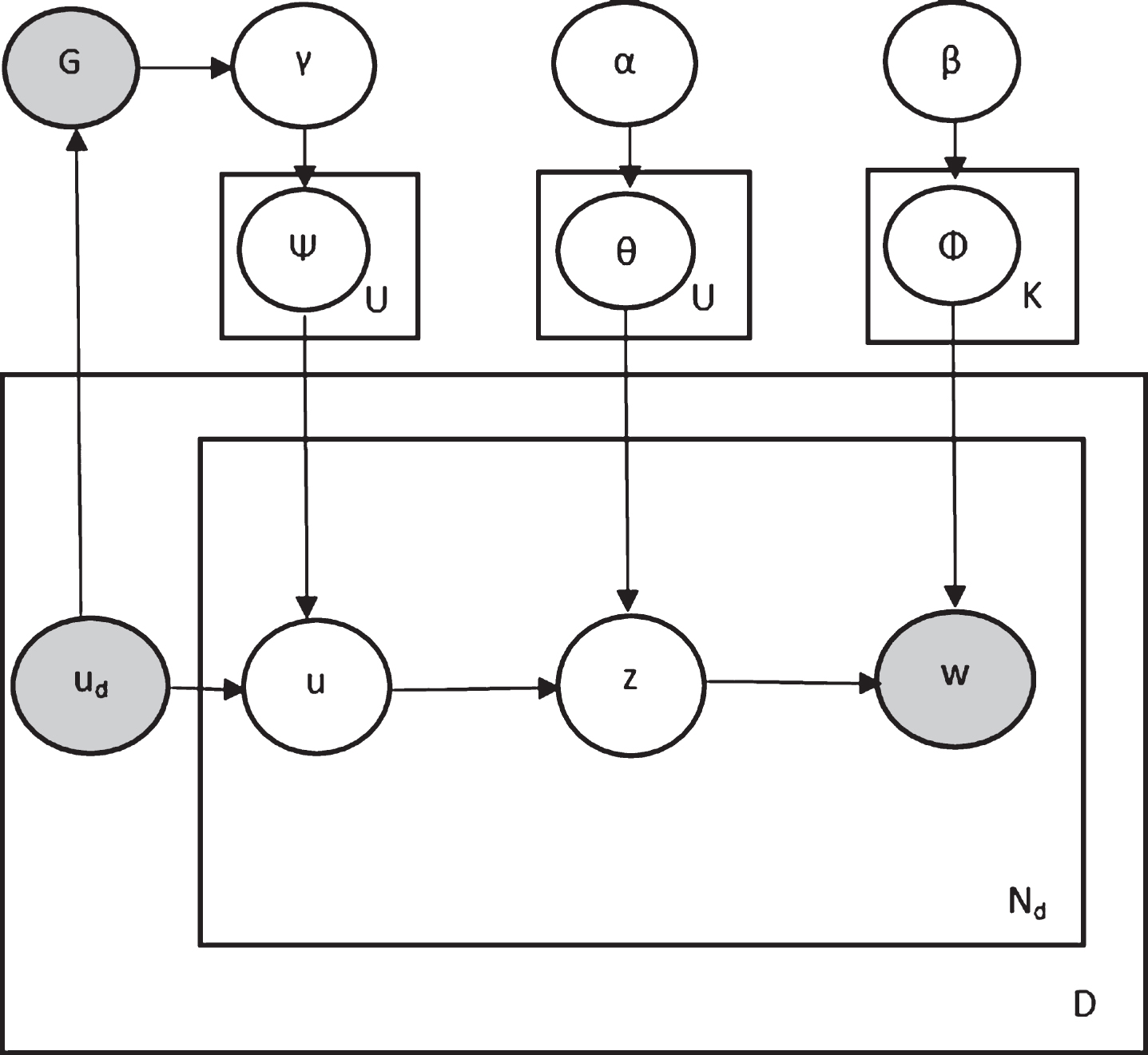
Plate Notation of graphical Model of UGTM.
The generative process for UGTM is described as follows: Φ ∼Dirichlet(β)
θ ∼ Dirichlet(α)
ψ u d ∼ Dir(γ u d )
u| u d ∼Multinomial(ψ u d )
z ∼Multinomial(θ u )
w ∼ Multinomial(Φ
z
) Dirichlet hyper-parameters α, β are predefined. Dirichlet hyper-parameter γ is derived from the user graph G (Section 3.2.1). Let γ
u
be the dirichlet prior for user u. Number of topics K and number of users U are fixed. For each of the user u = 1: U, draw ψ
u
∼Dir(γ
u
) For each of the user u = 1: U, draw θ
u
∼Dir(α) For each of the topic z = 1: K, draw Φ
z
∼Dir(β) For each document d = 1: N, draw document length N
d
Let u
d
be the author of document d and dirichlet hyper-parameter for user u
d
i
be γ
u
d
i
. For each word w
di
i = 1: N
d
of document d: Draw u
d
i
for w
di
, u
d
i
∼Multinomial(ψ
u
d
| γ
u
d
) Draw z
di
for u
di
, z
di
∼Multinomial(θ
u
d
i
) Draw w
di
for z
di
, w
di
∼Multinomial(Φ
z
d
i
)
UGTM is a probabilistic model that describes the generation of documents as defined in Fig. 2. The author u
d
and words w
d
of the document are observed. The Dirichlet hyper-parameters γ
u
for each user u is derived from the user graph G. For each word in each document, a user and topic latent variables are sampled according to latent multinomial distribution parameters ψ and θ respectively. Now the task is to infer all the hidden variables based on the observed variables. Assuming all words of all the documents are drawn independently, the probability of generating the whole corpus is given by:
Here, N is the number of documents in the corpus. Since all the words of a document are drawn independently, the probability of generating document d is given by:
Here, U is the number of users and K is the number of topics.
The exact inference of the above probability distribution s intractable. An approximate inference method called Gibbs Sampling is used for the solution. Gibbs Sampling [43] is a special case of Markov Cain Monte Carlo (MCMC) [44] simulation and provides simple algorithm for approximate inference in complex models. A collapsed Gibbs sampler is used which integrates out some of the parameters for model inference. In this application, model parameters Φ, θ and ψ are integrated out.
Adopting the process as described in [45], the full conditionals for the hidden variables z di and u di are derived after integrating out other parameters, the sample posterior distributions for z di and u di can be written as:
After sufficient number of sampling iteration, the Gibbs sampling chain converges. The parameters Φ, θ and ψ can be obtained using following equations:
The Gibbs sampling algorithm is described in Algorithm 1.
Algorithm 1 Gibbs sampling algorithm for UGTM
Once the parameters has been inferred, a new documents topic distribution can also be inferred using the estimated parameters. For a new document with its author and words known, its topics can be inferred using the same sampling algorithm using the parameters learned by algorithm 1. The algorithm to infer the topics of a new document is shown in Algorithm 2:
This section describes the evaluation methods and experimental re-sults.
Datasets
The dataset is collected using Twitter Streaming API [46] during April, 2018. Twenty disjoint trending topics are selected to fetch tweets from twitter. For each of the trending topic, certain number of tweets are fetched. Total number of tweets in the dataset is around 193K after discarding retweets. The trending topic of each tweet is assigned as class label of that tweet. The dataset is randomly divided into 80% training set and 20% test set. Topic label distribution in both training and test set is preserved.
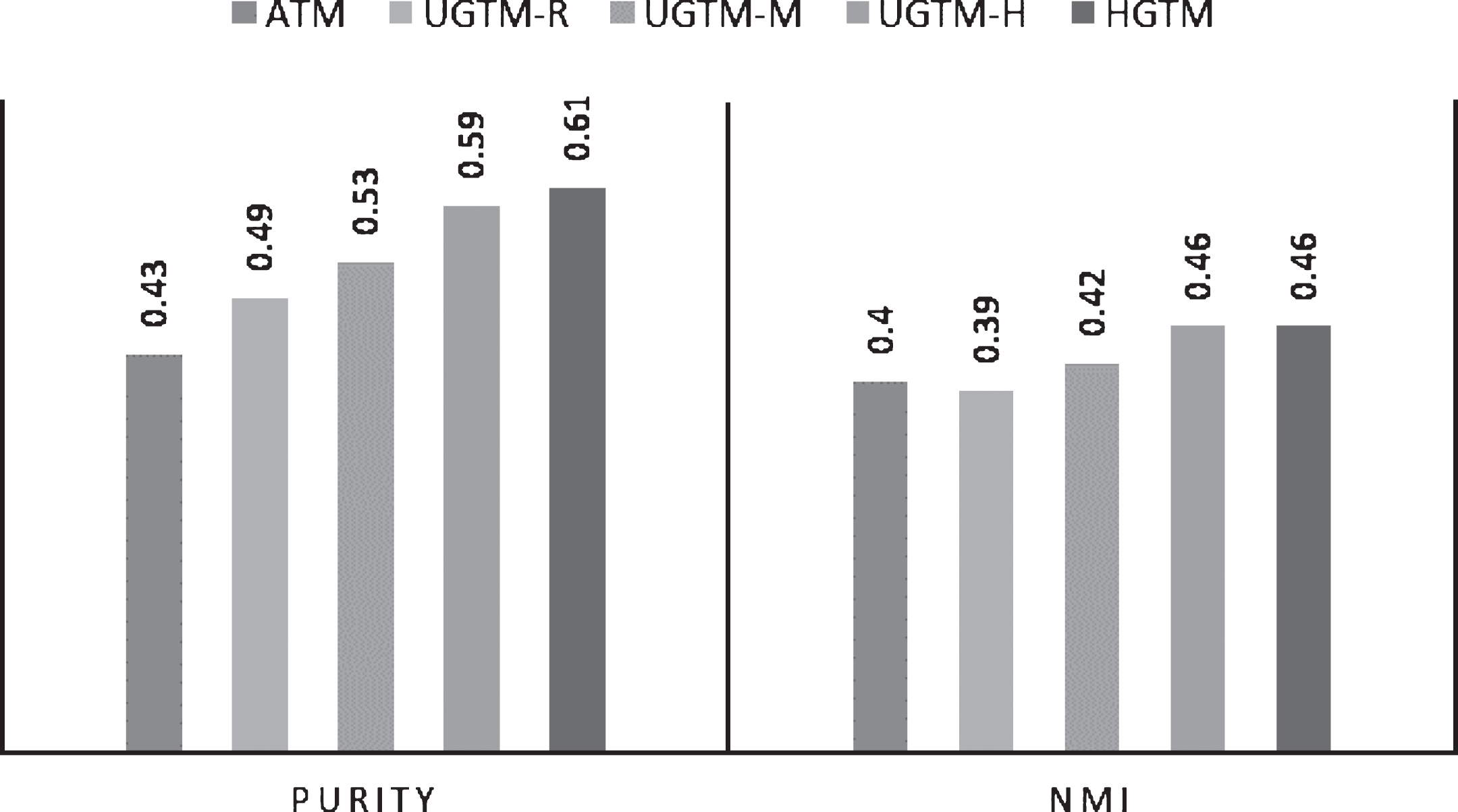
Purity and NMI Score.
Firstly, the data collected from Twitter are processed to remove the quirks of the social nature of Twitter. A raw tweet may have any sort of slangs, punctuations and hyphenation. After tokenizing, all stop-words, expressions, mentions and URLs are removed in the Tweet text. HTML characters are escaped and slangs are modified using a slang dictionary. Only those tweets are retained which has more than 3 tokens after preprocessing.
Evaluation criterion
The proposed model is evaluated on two tasks. First task is tweet clustering. The performance of proposed model is evaluated on how well it clusters the tweets. Since the true labels of the tweets are available, Purity and Normalized Mutual Information (NMI) [47] are used for clustering evaluation. Clustering quality is good if value of Purity and NMI are large. H-Score [19] measure is also used which is the ratio of intra-cluster distance to the inter-cluster distance. Lesser the H-score values, better the performance.
For Purity and NMI, Each topic is considered as a cluster. To assign a tweet to a cluster, cosine similarity is calculated between vector space model representation of the tweet and topic words distribution. Each tweet is assigned to exactly one cluster with maximum similarity.
For H-score calculation, each tweet’s word-topic count vector is found and normalized to make it a vector. For H-score calculation, we select 20 popular hashtags and each hashtag’s tweet-set is considred as a topic. Note that, one tweet may be in more than one topic if it has more than one selected hashtags. Second task is evaluation of topic quality, which is measured using Pointwise Mutual Information (PMI) score [48], which agrees with human-judged topic coherence. PMI score uses point wise mutual information using an external knowledge-base. In our experiment, English Wikipedia of size 3.1 M articles is used for calculating PMI score. Top twenty words of each topic are considered for the evaluation of PMI-score.
Results & discussion
Results for both the evaluation tasks are presented in the following sub-sections. Three kind of user relationships have been used to construct user graph. The proposed model is denoted as UGTM-H when hashtags are used to construct user graph. The model is denoted as UGTM-M and UGTM-R when user mentions and replies are used for graph construction respectively.
UGTM results are compared with ATM [30] and HGTM [23]. HGTM uses hashtag relationship among tweets to model the tpoics. Work in [23] shows that it outperforms all hashtag based topic models on tweet and hashtag clustering tasks. We have implemented HGTM-T algorithm as described in [23].
Tweet Clustering
The Purity, NMI and H-score results for the dataset are shown in Figs. 4 and 5. The empirical results shows that all variants of UGTM perform better than ATM on all three evaluation measures purity, NMI and H-score. Among the three UGTM variants, UGTM-H perform better than UGTM-M which performs better than UGTM-R. It shows that hashtag based co-occurrence relationship shows stronger semantic relationship among users than relationship based on user mentions and tweet replies. One reason for this is that the experimental dataset is collected using hashtag based keywords and most of the users have used the popular hashtags and are related with each other based on those hashtags. Also the number of tweets mentioning users (41.1 %) and replying other tweets (14.8 %) are much less than the number of tweets having hashtags (53.3 %). UGTM-M and UGTM-R are outperformed by HGTM. but the performance of UGTM-H is at par with HGTM. In fact, UGTM-H performs slightly better than HGTM on H-Score. Note that HGTM is trained on only those tweets which has at least one hashtag and tested on entire test set which also includes tweets that does not include any hashtags. When HGTM is tested on only those test tweets which has some hashtags, the purity, NMI and H-Score values comes out to be 0.65, 0.51 and 0.41 respectively.

H-Score.

PMI Score.
Top Twenty Words for Each Algorithm
The PMI for the dataset is shown in Fig. 5. Results shows that all variants of UGTM outperforms ATM on PMI-score. PMI-score for UGTM-H and UGTM-M are better than ATM whereas UGTM-R results are comparable to ATM. UGTM-R and ATM discovers almost similar topic words. The performance UGTM-H is same as HGTM on PMI-Score. When HGTM is tested on only those test tweets which has some hashtags, the PMI-Score comes out to be 1.05.
The top twenty words for each algorithm for five selected topics are shown in table 2. Study of topical words presented in table 2 shows that words discovered by UGTM-H and UGTM-M are more coherent than UGTM-R and ATM. UGTM-R and ATM discovered mostly unrelated words for some topics.
Conclusion
Tweet topic modelling requires extra effort due to the sparsity and informality problem. But it allows the contextual and auxiliary data available with tweets to be used to semi-supervise the topic modelling. In this paper, a user graph topic model is presented which uses the user relationships from a user graph which is obtained by finding the relationship among tweet users based on hashtags, user mentions and replies. The proposed topic model, differently from the Author Topic Model, describes the effect of those users on a tweet generation who are not the author of tweet. The paper also shows that the dirichlet prior can be obtained from the user graph to supervise the user generation so that it is restricted to only related users. We also compare proposed UGTM algorithm with state of the art HGTM algorithm. HGTM outperforms UGTM-M and UGTM-R. The performance of UGTM-H is comparable to HGTM. Note that we have used a smaller training dataset containing only those tweets which has atleast one hashtag for executing HGTM. For this reason, hashtag relationships is rich in HGTM and it performs well. Only UGTM-H provides at par results with HGTM. Nevertheless, our goal was to model the effect of users on topics which UGTM fulfills as it provides better results than ATM. User graph topic model enhances semantic relationships among tweet users which is reflected in semantic relationships among tweets in the tweet generation process. Empirical results show that the proposed topic model outperforms standard ATM on tweet clustering and topic coherence evaluation.