
Abstract
As a combinatorial optimization problem, feature selection has been widely used in machine learning and data mining. In this paper, a feature selection method using forest optimization algorithm based on contribution degree is proposed. The proposed method uses a contribution degree strategy which is embedded in forest optimization algorithm. The goal of the contribution degree is to guide the search process of the forest optimization algorithm to select features according to high class correlation and low redundancy between features. The proposed algorithm is verified on some data sets from the UCI repository and the experiments show that the proposed method improves the classification accuracy compared with some other methods.
Introduction
With the development of big data, datasets with a large number of instances and features have brought a great challenges to machine learning. This challenge consists mainly of two aspects: firstly, a large number of redundant and irrelevant features have negative effects on classifier performance [13]. Secondly, calculating a large data set would be time consuming and computationally expensive. Therefore, feature selection is inevitable to deal with this problem by removing irrelevant and redundant features. Feature selection is a common dimensionality reduction technique in many fields such as machine learning, data mining and pattern recognition [18, 31, 12, 6, 38, 43, 49]. The purpose of feature selection is to select salient feature subset and construct the classification model to achieve satisfying prediction accuracy.
Feature selection is usually formulated as a searching optimization problem. For a n-dimension set of feature, there are
The filter methods use mathematical statistics to analyze the feature set which does not rely on any learning algorithm. The filter-based feature selection methods can be classified into univariate and multivariate methods [5]. In the univariate methods, the relevance of a feature is evaluated individually according to the specific criterion. The univariate algorithms include Information gain [21], Gain Ratio [42], Gini index [20], symmetrical uncertainty [17], Fisher Score (F-Score) [36] and Laplacian Score (L-Score) [46]. The univariate methods do not take the dependencies between the features in the feature selection process into account, and the multivariate approachs are the opposite. Thus, multivariate methods require more computational resources than univariate methods, but their performance is superior to univariate methods. There are numerous well-known multivariate filter methods, such as minimal redundancy-maximal-relevance [14], mutual correlation [27], random subspace method [5] and relevance-redundancy feature selection (RRFS) [2].
The wrapper methods have been widely used since it can achieve higher quality of the feature subsets. Wrapper methods assess the quality of feature subsets by using the classification performance of a specific classifier. The wrapper-based methods can be categorized into sequential and random search methods [28]. The sequential algorithms include Sequential Forward Selection (SFS), Sequential Backward Selection (SBS), sequential forward floating selection (SFFS), sequential backward floating selection (SBFS) and “plus l take away r method” [40]. SFS and SBS are two kinds of hill climbing methods. SFS starts from an empty set of features and at each step a feature is added to the feature set. After meeting the requirement, the feature set obtained is selected as the feature selection result. In fact, at each step of the algorithm, a feature is added to the current set, making the feature selection criterion the largest. The computational complexity of this algorithm is relatively small, but it does not take full account of the correlation between features. But, SBS starts from the full set of features and deletes a feature with the smallest contribution of the evaluation function at each step, until the number of remaining features meet the requirements. Its superiority lies in the full consideration of the relevant characteristics between the features. “plus l take away r method” is actually a compromise between SBS and SFS. Its operation speed is faster than SBS and its operation effect is better than SFS. Moreover, the floating search method uses the floating step to adaptively update the values of l and r. This is a very practical improvement mechanism. On the other hand, the random search method attempts to embed randomness into its search process to avoid local optimal solutions. For example, particle swarm optimization (PSO) [47], genetic algorithm (GA) [37], ant colony optimization (ACO) [33], artificial bee colony (ABC) [11] and forest optimization algorithm (FOA) [26] have been used to solve feature selection problems.
The embedded approach is intended for feature selection as part of the model building process. Thus, the method is associated with a particular learning algorithm, which means that the search for a good subset of features has been performed by a learning algorithm [50]. Support vector machine (SVM) [29], naïve Bayes (NB) [30], and decision tree algorithm [35] are well-known algorithms which are used to construct a learning model in the embedded approach. Therefore, the hybrid model combines a filter and a wrapper model to achieve the best possible performance.
The hybrid model combines the filter and wrapper method together. In the first step, a filter model is applied to reduce the original feature set. Then in the second step, this mode uses wrapper approach to select the optimal feature subset on the reduced feature set. Examples of hybrid approaches include a hybrid genetic algorithm for feature selection wrapper based on mutual information [19], a maximum relevance minimum redundancy feature selection method based on swarm intelligence for support vector machine classification [3] and a filter model for feature subset selection based on genetic algorithm [24].
In general, filter-based methods are usually faster than the wrapper-based ones due to lack of computational cost of the learning model. However, the filter-based methods usually return a relatively low quality. Moreover, the wrapper methods apply a given learning model to evaluate the quality of candidate feature subsets in each iteration. Although the wrapper methods usually achieve better the quality of feature subsets, it needs be at the expense of high computational costs for high dimensional data sets. On the other hand, the goal of the hybrid method is to take advantage of both the filter and the wrapper methods. The embedded approach seeks to subsume feature selection as part of the model building process. In other words, the filter-based feature selection methods usually take the computational time into account. While wrapper, embedded and hybrid approaches are usually concerned with the quality of the selected features. Therefore, a trade-off between these two issues has become an important and necessary goal to providing a good search method.
In this paper, we propose a contribution degree strategy based on forest optimization algorithm, which aims to achieve a high quality approximate solution within an acceptable computational time. We use contribution degree strategy to select some better trees as neighbor trees according to high class correlation and low redundancy between features. This strategy is able to effectively identify and remove the irrelevant and redundant features. We choose features instead of simply sorting the features according to the redundancy of the feature. In the process of searching the optimal solution, we select the features from two aspects: Firstly, in local and global seeding stage, our proposed algorithm randomly will select some features in each iteration. We use normalized mutual information as a metric to assess the correlation between the selected feature and other features. If the correlation is greater than a given threshold (Section 4.1), we consider the feature to be a redundant feature, and the feature will be filtered out. On contrary, we consider this feature as an irrelevant feature that is exactly what we need. For class correlation, if the correlation between the selected feature and class variable is greater than a given threshold, this means that the feature is class correlation, and the feature will be selected. Otherwise, the feature will be discarded. Secondly, In population limited stage, all feature subsets in the forest are sorted by their fitness value. The fitness function assesses the classification accuracy and the quality of the feature subsets. The quality of feature subsets depends on feature redundancy and class correlation. In other words, when the classification accuracy is roughly equal, only those feature subsets whose every feature has higher class correlation and lower redundancy between each other possess higher fitness values. This also means that these feature subsets will not be eliminated. The design of this fitness function removes the irrelevant and redundant features to some extent. In addition, we propose a distance adaptive strategy to effectively and quickly guide the search process to select features according to distance between the current tree and the current global optimal tree. This strategy accelerates the convergence speed of the algorithm. Finally, in order to further improve the performance of the algorithm, we adjust the fitness function. By applying our proposed fitness function, we make sure that each selected feature subset from candidate population satisfies the higher classification accuracy, and ensure that each of their features has higher class correlation and lower redundancy between each other.
The rest of this paper is organized as follows. Section 2 presents related work. Section 3 presents a brief overview of forest optimization algorithm for feature selection. Section 4 presents our method, called FSFOACD. In Section 5 we compare the experimental results of the proposed method to those of other feature selection algorithms. Finally, Section 6 presents the conclusion.
Related work
In this paper, the proposed algorithm is a hybrid-based approach. As mentioned above, the goal of the hybrid-based methods is to take advantage of the computational efficiency of the filter model and the proper performance of the wrapper methods. In which, the proposed contribution strategy is the filter model, which is based on information theory. Mutual information as one of filter methods is used to measure the quality of feature by assessing the correlation and redundancy of feature, which possesses a solid theoretical foundation. To date, the combination of mutual information, “relevance” and “redundancy” is widely used for feature selection. For example, Peng et al. [14] used the mutual information as a metric to measure the relationship between the features and class by minimum-Redundancy-Maximum-Relevancy (mRMR) analysis. However, their proposed algorithm is only suitable for interaction between two variables. To identify more complicated variable interactions, some solutions have been proposed. Such as, Bennasar et al. [23] proposed two new feature selection methods based on information theory: Joint Mutual Information Maximisation (JMIM) and Normalised Joint Mutual Information Maximisation (NJMIM). The two methods are designed to address the problem of choosing redundant and irrelevant features in certain circumstance. Vinh et al. [32] proposed a principled approach for deriving new higher-dimensional MI based feature selection approaches by relaxing the identified assumptions, and systematically investigated the issues of employing high-order dependencies for mutual information based features selection. Feature selection based on the relevant redundancy trade-off criteria has become a very popular method in the field of data mining. But the existing feature selection algorithms based on mutual information still have some limitations on common feature selection in practice. This type feature selection methods have the problem of overestimation or underestimation of feature significance. To overcome these limitations, Che et al. [18] proposed a novel mutual information feature selection method based on the normalization of the maximum relevance and minimum common redundancy (N-MRMCR-MI).
On the other hand, Forest optimization algorithm (FOA) is a wrapper model, which was firstly proposed by Ghaemi and Feizi-Derakhshi [26] to solve continuous search space problems. To date, FOA has been applied and developed. For example, Haindl et al. [27] proposed a discrete binary version of the FOA to solve the discrete problems. Yang et al. [37] used FOA to find the best answer for the multidimensional knapsack problem using low number of iterations and low computational effort. Truc [8] used FOA with discrete variables combined with local search to solve the Order Acceptance and Scheduling problem in single-machine environment so that producers gain the maximum profit based on available resources. Moreover, he developed discrete FOA combined with min-max algorithm and local search to solve the independent job scheduling on computational grids with the goal of minimizing makespan[9]. Moreover, FOA is an evolutionary algorithm that has been applied to feature selection. Ghaemi and Feizi-Derakhshi [25] used FOA to cope with discrete search space problems like feature selection and achieved satisfactory results. In addition, he combined FOA with a gradient method to improve the fuzzy c-means (FCM) algorithm [1].
Forest optimization algorithm for feature selection
FOA is inspired by the procedure of a few trees in the forests. FOA is an evolutionary algorithm, which is proposed to solve continuous search space problems. Then, FOA is used in discrete search space problems like feature selection. Forest optimization algorithm for feature selection (FSFOA) involves five main stages: (1) initialize trees, (2) local seeding, (3) population limiting, (4) global seeding and (5) update the best tree.
Initialize trees
The forest is initialized by generating trees randomly. At first, each feature of a tree is randomly generated by ‘0’ or ‘1’. In a dataset with n features, the size of each tree will be (
Some neighbors of each tree aged 0 are added into the forest in this stage. For each tree aged 0, some features are selected randomly (“Local Seeding Changes” (LSC) parameter determines the number of the selected features and also means the number of neighbor trees to be added). Then, the selected features change to the opposite values. This procedure is considered as local search by adding and removing those features ahead of learning algorithm. Once the local seeding stage finished, the “Age” of each tree except newly generated ones will be added by 1. Figure 1 shows an example of local seeding operator on one tree aged 0, where the dimension of the dataset is 5 and the value of “LSC” is assigned to 2.
An example of local seeding operation on one tree with “LSC” 
There are two series of trees that will be omitted from the forest to form the candidate population: (1) trees older than “life time” parameter (“life time” means the maximum allowed “Age” of a tree in the forest) and (2) the extra trees out of the “area limit” parameter after sorted by their fitness value (“area limit” represents the largest number of the trees in the forest). These trees then be migrated to the candidate population and soon afterwards used in global seeding.
Global seeding
For each selected tree from the candidate population, a set of features are selected randomly (“Global Seeding Changes” (GSC) parameter determines the number of the selected features). Similar to the local seeding, the value of these selected features will be reversed (changing from 0 to 1 or vice versa). But this time, all features are simultaneously considered to be added or deleted and not just one feature at a time. Figure 2 shows an example of global seeding operator on one tree, where the value of “GSC” is assigned to 3.
An example of global seeding operation on one tree with “GSC” 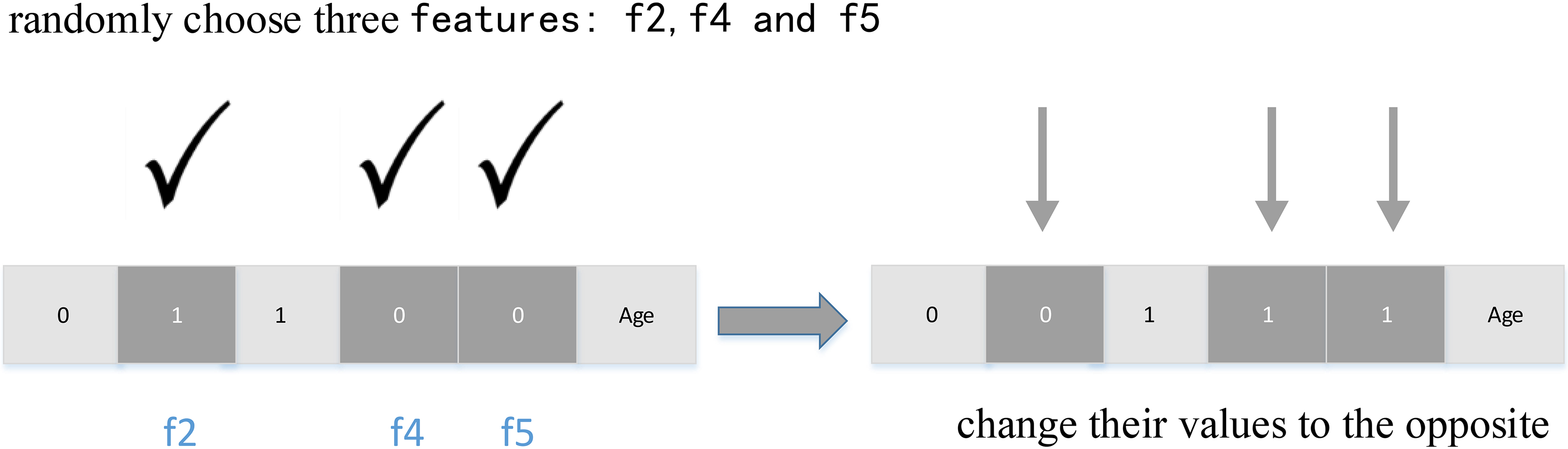
The classification accuracy from KNN classifier was selected as the fitness function. For feature selection validation, classification accuracy is an effective measure and it is defined as Eq. (2).
In the last stage, after sorted by the fitness value, the best tree will arise with the highest classification accuracy and its “Age” will be set to ‘0’. The above stages are iteratively performed until the stop condition is satisfied. The pseudo code of FSFOA is illustrated as Algorithm 1.
FSFOA (life time, transfer rate, area limit, LSC, GSC)
Method
Although FSFOA has achieved satisfactory results compared with some other feature selection methods, but there are some shortcomings. Firstly, in local seeding, some features of tree aged 0 are randomly selected and changed and does not consider the class correlation and redundancy between features. Which leads to poor quality of trees in the forest and reduce the search efficiency of FSFOA. Secondly, the number of neighbor trees to be added in each iteration always depends on the number of the features of the dataset and neglects the relationship between the current tree and the current global optimal tree. For some trees close to the optimal tree, adding a lot of neighbor trees will result in a large number of unnecessary calculations and the convergence of the algorithm becomes slower. Thirdly, FSFOA only used the classification accuracy as a fitness function and did not take the contribution of a single feature to the entire feature subset into account. In other words, just using classification accuracy as a fitness function only reflects the performance of the entire feature subset, and cannot reflect the performance of each feature in the feature subset. This deficiency can easily lead to a local optimal solution. In order to solve the above shortcomings, we propose the following solutions.
Contribution degree
Every mature season in the nature, the grown-up trees produce some seeds that will fall into the mud beside them. Local seeding simulates this process of nature. This operator is mainly manifested in trees with age 0 and adding some neighbor trees around each tree aged 0 in the forest. Due to the limitation of total number of trees, some seeds with enough living space, water, nutrient and sunshine will have a better opportunity to grow up to a young tree. On contrary, they will finally be eliminated in the competition with other seeds. In our work, the neighbor trees are not completely randomly generated any longer, but selected on the basis of how many survival resources they have. The more living resources the tree have, the higher the selected rate will be. Each neighbor tree represents a new location in the feature space. To this end, we propose a contribution degree strategy to assess the quality of the seed. We update the location by choosing one feature of the feature subset and change the value of the feature. The updating formula is as follows:
Where
Where C_correlation(
In Eq. (5), AvgMI(
Where
In Eq. (9),
From Eq. (10), it follows that the MI between two random variables is bounded above by the minimum of their entropies. Since the entropy between features may vary greatly, this measure should be normalized. Therefore, normalized mutual information is defined as follows:
In Eq. (11), The NMI is a kind of correlation measure, which takes values in [0,1]. The relative strength of mutual information and correlation can be divided into weakly relevant, relevant and strongly relevant, which is respectively corresponding to the value of NMI belonging to [0, 0.4), [0.4, 0.6) and [0.6, 1] in our method. In feature selection, we are usually interested in features with high class correlation and low redundancy between features. Therefore, only those features whose value of NMI of the C_correlation over 0.6 and value of NMI of the AvgMI below 0.4 have a better opportunity to be selected, and which will be taken into Eq. (5) for calculation. It is worth noting that this assessment is only used for feature selection of local seeding and global seeding stage, and is not used in fitness function calculations.
The additional details of the contribution degree strategy are illustrated with an example as shown in Fig. 3. This strategy is able to effectively identify and remove the irrelevant and redundant features. To a certain extent, we make sure that each tree in the forest selects the features with minimum redundancy while it maximizes the dependency on the target class.
Illustration of the contribution degree strategy of the proposed method.
In the process of finding the optimal tree, over time, all the trees tend to get closer to the optimal position, eventually, all the trees will remain around the optimal tree. In FSFOA, the number of new neighbor tree added is affected by the “LSC” parameters in local seeding. The “GSC” parameter determines the location of some trees that are migrated to the candidate population and soon afterwards used in global seeding. In each iteration, “LSC” and “GSC” parameters depend on the number of the features of each dataset. Which results in a large number of unnecessary calculations and reduces the efficiency of algorithm search.
In our work, we believe that the number of neighbor trees added in each iteration to find the optimal tree should be related to the distance between the current tree and the current global optimal tree. Therefore, we propose a distance adaptive strategy. We determine the number of neighbor trees to be added based on the distance between the current tree and the global optimal tree. For the trees far from the optimal tree, we need more neighbor trees to speed up space searches. For some tree near by the optimal tree, we only need a small number of neighbor trees to approximate the optimal tree.
The distance here refers to the number of different bits between the current tree and the current global optimal tree. In other words, the “LSC” and “GSC” parameters no longer depend on the number of features of each dataset, but depend on the distance between the current tree and the global optimal tree in each iteration. This distance adaptive strategy can effectively and quickly guide the algorithm to search the optimal tree and accelerate the convergence speed of the algorithm. An illustration of the distance adaptive strategy of the proposed method is shown as Fig. 4. The distance formula is defined as follows:
Where Tree means the current tree, BestTree is current global optimal tree. For example, Tree
An illustration of the distance adaptive strategy of the proposed method.
In population limited stage, all trees in the forest are sorted by their fitness value. Then, some trees with the lower fitness value are moved to the candidate population and soon afterwards used in global seeding. Just using classification accuracy as a fitness function only reflects the performance of the entire feature subset, and cannot reflect the performance of each feature in the feature subset. This deficiency is easy to lead to the whole algorithm into the local optimal solution. Therefore, we hope that each feature subset in candidate population satisfies the higher classification accuracy, and ensures that each of their features has higher class correlation and lower redundancy between each other. We define the fitness function as follows:
Where Scores(Tree) is used to measure the importance of the current tree (the current feature subset) by evaluating the correlation and redundancy of each selected feature. Accuracy(Tree) denotes the classification accuracy of the current feature subset on the classifier.
[h] FSFOACD (life time, transfer rate, area limit)
In order to verify the efficiency of the proposed method, several experiments are performed on 10 benchmark datasets obtained from the UCI Machine Learning Repository. We compare FSFOACD with several other feature selection algorithms, including Feature selection using Forest Optimization Algorithm(FSFOA)[25], Unsupervised probabilistic feature selection using ant colony optimization (UPFS) [4], Integration of graph clustering with ant colony optimization for feature Selection(GCACO) [34] and Unsupervised FS algorithm based on ACO(UFSACO) [41]. All the experiments are implemented using Matlab on an Intel Core-i3 CPU (2.40 GHz) with 4 GB of RAM. Moreover, in our work, SMO, IBK and J48 in WEKA are embedded into Matlab for implementing SVM, KNN and DT.
Characteristics of the datasets used in the experiments
Characteristics of the datasets used in the experiments
Performance evaluation of FSFOACD on the average accuracy of SVM, KNN and J48 classifiers on the whole datasets according to different values of parameter (average over 10 independent runs)
In the experiments, we select several benchmark datasets with different properties to evaluate the performance of the feature selection methods, including Glass, Heart-statlog, Wine, Vehicle, Parkinsons, Ionosphere, Dermatology, SpamBase and Sonar datasets. The datasets can be distributed into three types: small, medium and large in accordance with their feature sizes. In the feature selection problem, the datasets with the number of features belonging to [0, 19], [20, 49] or [50,
Performance evaluation of FSFOACD on the average accuracy of SVM, KNN and J48 classifiers on the whole datasets according to different values of “area limit”. The value of “life time” and “transfer rate” are considered to 6 and 10%, respectively (average over 10 independent runs)
Performance evaluation of FSFOACD on the average accuracy of SVM, KNN and J48 classifiers on the whole datasets according to different values of “area limit”. The value of “life time” and “transfer rate” are considered to 6 and 10%, respectively (average over 10 independent runs)
Performance evaluation of FSFOACD on the average accuracy of SVM, KNN and J48 classifiers on the whole datasets according to different values of “transfer rate”. The value of “area limit” and “life time” are considered to 50 and 6, respectively (average over 10 independent runs)
Performance evaluation of FSFOACD on the average accuracy of SVM, KNN and J48 classifiers on the whole datasets according to different values of “life time”. The value of “area limit” and “transfer rate” are considered to 50 and 5%, respectively (average over 10 independent runs)
Before conducting the experiment, we need to set the parameters of the proposed method. Based on domain expert experience, the number of trees in the forest is initialized to 30–50, which is satisfied for most data sets [25, 26]. Meanwhile, we have also done experiments to prove this. From the results of experiments in Tables 3 and 4, we find that the values of “area limit” and “transfer rate” have little effect on the performance of our algorithm. The appearance of this phenomenon is understandable. The value of the “transfer rate” parameter indicates that a certain number of trees will be migrated to the candidate population and soon afterwards used in global seeding. The purpose of this operation is to avoid the algorithm to fall into the local optimal solution. The fitness value of these trees is relatively low. So only a relatively small number of these trees need to be added at each iteration of the algorithm. “Life time” means the maximum allowed “Age” of a tree in the forest. Once a tree’s “Age” is greater than the “life time” parameter, it will be omitted is omitted from the forest and added to the candidate population. If we choose a big number for this parameter, the forest will be full of old trees, which will affect the performance of the algorithm. On contrary, if we choose a very small value for this parameter, the trees will get old very soon and they will be eliminated soon. So this parameter affects the performance of the algorithm. We have done experiments on the optimal value of “life time” parameter and the related results are presented in Table 5. In order to reach the best performance, the value of “life time” parameter, “transfer rate” and “area limit” are set to 15, 5% and 50, respectively. The value of “LSC” and “GSC” parameters are no longer determined by the number of the feature of each dataset, but are evaluated by Eq. (12).
Average classification accuracy and standard deviation on each dataset using SVM classifier under 10-fold cross validation. The best result for each dataset between all feature selection algorithms is shown in bold face. The last row of the table shows the average value of each algorithm over the whole datasets
Average classification accuracy and standard deviation on each dataset using SVM classifier under 10-fold cross validation. The best result for each dataset between all feature selection algorithms is shown in bold face. The last row of the table shows the average value of each algorithm over the whole datasets
The average accuracy of proposed algorithms and other wrapper-based algorithms on the whole datasets using SVM classifier under 10-fold cross validation.
In the experiments, we used different classifiers to evaluate the performance of the proposed method, including k-nearest neighbor (KNN), decision tree (J48) and support vector machine (SVM). In order to obtain fair results, 10-fold cross validation are introduced to measure the accuracy of feature selection algorithms. Tables 6–8 report the average and the standard deviation of classification accuracy over 10 independent runs for FSFOA, UPFS, GCACO, UFSACO and FSFOACD methods using SVM, KNN and J48 classifiers.
Average classification accuracy and standard deviation on each dataset using KNN classifier under 10-fold cross validation. The best result for each dataset between all feature selection algorithms is shown in bold face. The last row of the table shows the average value of each algorithm over the whole datasets
Average classification accuracy and standard deviation on each dataset using KNN classifier under 10-fold cross validation. The best result for each dataset between all feature selection algorithms is shown in bold face. The last row of the table shows the average value of each algorithm over the whole datasets
Average classification accuracy and standard deviation on each dataset using J48 classifier under 10-fold cross validation. The best result for each dataset between all feature selection algorithms is shown in bold face. The last row of the table shows the average value of each algorithm over the whole datasets
The average accuracy of proposed algorithms and other wrapper-based algorithms on the whole datasets using KNN classifier under 10-fold cross validation.
Table 6 compares the mean and standard deviation of classification accuracy (average over 10 independent runs) of our proposed FSFOACD method with other wrapper based methods over SVM classifier. It is clear from Table 6 and Fig. 5 that FSFOACD achieved the highest average classification accuracy compared to other feature selection methods on the most of datasets. But for Parkinsons dataset, our proposed algorithm obtained the second place with the classification accuracy of 89.56%, and the GCACO achieved first rank with the classification accuracy of 91.52%. Parkinsons dataset is the only dataset where the difference between the features is extremely small. This makes it difficult to select the proper features for prediction. In addition, our proposed algorithm has significantly improved the accuracy of the classification compared with other algorithms when applied on Vehicle and Sonar datasets.
The average accuracy of proposed algorithms and other wrapper-based algorithms on the whole datasets using J48 classifier under 10-fold cross validation.
Table 7 reported similar results over the KNN classifier. It can be concluded from Table 7 and Fig. 6 that our proposed FSFOACD method outperforms the other feature selection methods on the most of datasets. For example, for datasets Glass, Heart-Statlog, Wine, Vehicle, Hepatitis, Ionosphere, Dermatology, SpamBase and Sonar, the proposed algorithm returned the highest average classification accuracy. Unfortunately, in the case of Parkinsons dataset, the proposed algorithm did not show good performance. Because as we mentioned before, the difference between the characteristics of the Parkinsons dataset is extremely small, resulting in poor classification. For Glass, Vehicle and Sonar datasets, our proposed algorithm has significantly improvement. It achieved the average classification accuracy 89.82% on all the datasets and lies on the first place among the methods.
Average classification accuracy on all datasets, with respect to the wrapper-based methods for classifiers SVM, KNN and J48.
Table 8 shows the mean and standard deviation of classification accuracy of the J48 classifier of the proposed algorithm. As can be seen from the Table 8 and Fig. 7, the proposed method achieved the best classification accuracy compared with other methods in each dataset. In addition, the standard deviation of the proposed method is the lowest among all the methods. That means that our proposed method produced robust results. This is due to the fact that the contribution degree strategy of FSFOACD result in selecting more discriminative and high class correlation features and removing irrelevant and redundant features in local and global seeding stage.
Figure 8 provides the average accuracy of SVM, KNN and J48 classifiers on the whole datasets for the proposed algorithm and wrapper-based methods including FSFOA, UPFS, GCACO and UFSACO. For SVM classifier, our proposed method with 0.8874% average accuracy is superior to other methods and the GCACO algorithm obtained 0.8416% average accuracy ranked second. The same result for the KNN and J48 classifiers is shown, where the proposed method outperformed all other algorithms with the average accuracy of 0.8982% and 0.8904%, respectively. While the FSFOA method won the second place with the average accuracy of 0.8659% and 0.8659%, respectively.
Feature selection using forest optimization algorithm based on contribution degree was proposed in this paper. This method introduces a contribution degree strategy which is embedded in forest optimization algorithm. The goal of the contribution degree technique is to guide the search process of forest optimization algorithm to select features according to high class correlation and low redundancy between features. To measure performance, SVM, KNN and DT classifiers were applied to some well-known datasets from the UCI repository including Glass, Heart-statlog, Wine, Vehicle, Parkinsons, Ionosphere, Dermatology, Spam Base and Sonar datasets. In addition, the proposed method was compared with some wrapper-based algorithms including FSFOA, UPFS, GCACO and UFSACO. Our results show that the proposed algorithm outperforms those wrapper-based algorithms on 10 benchmark datasets.
Footnotes
Acknowledgments
This work was supported in part by National Science Foundation of China (No. 61572259), supported by the National Social Science Foundation of China (No. 16ZDA054), Special Public Sector Research Program of China (No. GYHY201506080), and was also supported by PAPD.