
Abstract
Recently how to recommend celebrities to public has become an interesting problem in real social network applications. In this problem, a matrix of users’ following actions is usually very sparse. Therefore, it causes conventional collaborative filtering based methods to degrade significantly in recommendation performance. To address the sparsity problem, side information could be rendered. Collaborative social topic regression (CSTR) is an appealing new method, which combines the matrix of general users’ following actions, content information and a social network of celebrities. However, this method is limited by using the topic model latent Dirichlet allocation (LDA) as the critical component. The learned content representation may not be compact and effective enough. Moreover, the social network of general users also exists, which is helpful for recommendation. In this paper, we employ a deep learning component to learn more effective feature representation and incorporate social network information of general users by adding social regularization terms. We propose a novel hierarchical Bayesian model named collaborative social deep learning (CSDL), which jointly handles deep learning for the content information and collaborative filtering for general users’ following actions, the social network of celebrities and that of general users. Experiments on two real-world datasets show the effectiveness of our proposed model.
Introduction
Nowadays, social network websites such as Twitter and Tencent MicroBlog have become popular for users to connect friends and share opinions online. There are some special users, such as celebrities, famous organizations, and well-known groups, who spread newest ideas and are always followed by a number of other users. More and more users regard social network websites as an appealing media to gain the up to date information from authorities and elites [11]. The public have become more interested in celebrities and famous organizations. Celebrities and organizations have already realized the enthusiasm of common people to get the newest ideas and opinions which they are interested in, and signed up their own accounts to propagate their opinions in succession [5].
In social network websites, celebrities are a small part of all users, but the scale of them is relatively large, which can flood users with a huge number of information and hence put them at risk of information overload. Therefore, how to recommend celebrities (items) whom general users are truly interested in to follow, becomes an interesting problem [42]. In this issue, we can only observe users’ following actions from microblogs, and unfollow actions do not mean they are not interested. The following actions can be seen as positive samples. This class of collaborative filtering with only positive samples is also called one-class collaborative filtering (OCCF) [21]. Therefore, conventional collaborative filtering (CF), which automatically predicts the interest of a particular user based on the collective behavior records of similar users or items [10, 29], cannot be directly applied to solve this celebrity recommendation problem. What’s more, traditional CF-based models suffer from the sparsity problem and imbalance of rating data, especially for new and infrequent users. To deal with the major weaknesses of traditional CF-based recommendation systems, many models have been proposed to explore side information, such as items’ content information [1, 31] and users’ social network [9, 17]. For instance, collaborative topic regression (CTR) [31] is a state-of-the-art model, which naturally incorporates content information by latent Dirichlet allocation (LDA) [2] into a collaborative filtering framework. Trustwalker [9] is a social network-based CF model, which finds the user’s like-minded neighbors to address the rating sparsity limitation. But very few attempts have been made to focus on utilizing both content and social network information [22].
CSTR [5] is a recently proposed hybrid method. It is a probabilistic graphical model that seamlessly integrates a topic model and probabilistic matrix factorization (PMF) [25] which factorizes following records and social information. To our best knowledge, it is the first model to explore whether celebrities’ social network has an effect on improving the performance and efficiency of recommending celebrities. However, this model learns the features of side information associated with items by LDA. Therefore it is not effective enough to learn the latent representation especially when side information is very sparse [33]. Fortunately, deep learning as a set of feature-learning method is a perfect alternative. It could model multiple levels of representation of raw input by composing simple but non-linear modules. Each module transforms the representation at one level into a slightly more abstract style at a higher-level [12]. Deep learning has attracted a lot of attention because of its promising performance to learn representation on various tasks [7, 20]. Recently, collaborative deep learning (CDL) [33] was proposed, by tightly coupling deep learning and matrix factorization to improve recommendation performance and efficiency.
Meanwhile, CSTR only considers the social network of celebrities. Since the social network information of general users also exists and is available, it is desirable to incorporate this kind of side information into celebrity recommendation models. But the social network of general users and that of celebrities are greatly different [5]: (i) the social network of general users is huge and sparse, but that of celebrities is small and dense; (ii) to a certain extent, celebrities’ social network can be regarded as the relationships among different kinds of interests, and the social network of general users may mainly indicate friendship; (iii) celebrities are followed by plenty of other users in their social network, but general users are not.
In this paper, we propose a hierarchical Bayesian model called collaborative social deep learning (CSDL) for celebrity recommendation. It incorporates deep learning for content information, matrix factorization for both celebrities’ social network and users’ interest matrix, and social regularization terms for the social network of general users. We connect content, the social network of celebrities and general users’ interests these three data sources by using the shared item latent feature space. The matrix factorization of celebrities’ social network and general users’ interests will learn the low-rank item latent feature space, while a deep learning method named Stacked Denoising Autoencoders (SDAE) provides a content representation of the items in the item latent feature space, in order to make better recommendation performance. As for the social network of general users, we first adopt Jaccard’s coefficient, a feature intrinsic to the network topology, to compute node similarity [18]. Then, CSDL incorporates it by adding social regularization terms to constrain the taste difference between a general user and others. Note that, although our method employs SDAE for feature representation, as a generic framework it can also admit other deep learning methods, such as convolutional neural networks and recurrent neural networks.
The main contributions of this study in celebrity recommendation in social websites can be summarized as follows.
We propose a hierarchical Bayesian framework, named CSDL, which combines deep feature learning of item content, celebrities’ social network, general users’ social network and general users’ preferences to improve the performance and efficiency of celebrity recommendation. We introduce the social network of general users by adopting Jaccard’s coefficient to compute a user similarity value, which can be utilized to constrain the taste difference between a general user and others. Even if a new user has followed only one celebrity, CSDL can alleviate the data sparsity problem in CF by using the social network of celebrities and social information of general users, which will consequently improve the recommendation performance. Even though the content information is very sparse, CSDL can achieve desired performance by employing a deep learning component in an attempt to learn more effective feature representation. And by integrating multiple information sources into one model, CSDL can also improve the recommendation accuracy even the social network matrix of celebrities is sparse. We conduct experiments on two real-world datasets to evaluate the effectiveness of CSDL. Experimental results show CSDL outperforms other state-of-the-art methods in terms of Recall and Average Precision under different sparsity level settings.
The rest of the paper is organized as follows. We review the related works in Section 2. And then explain the details of our method in Section 3. Experimental settings and results are provided in Section 4. Finally, Section 5 concludes the paper and discusses future work.
In general, our work is closely related to the following topics: latent factor models, latent factor models associated with social network, and latent factor models based on deep learning.
Latent factor models
Traditional recommender systems are mostly based on collaborative filtering and there are two widely used approaches. In neighborhood methods [10, 28], the similarity between users based on the content they have consumed and rated is the basis of a new recommendation. Most effective recommendation methods are latent factor models [24, 25], which provide better recommendation results than the neighborhood methods [31]. Among latent factor methods, matrix factorization (MF) works well [31]. It allows us to discover the latent factors of user-item interactions by factorizing the feedback matrix into a joint latent space of user and item features respectively. Many MF-based methods have been proposed. Existing works usually build some assumptions on the latent factors. Probabilistic matrix factorization [24, 25] provides an assumption that both the prior probability distribution of the latent factors and the probability of the observed ratings given the latent factors follow a Gaussian distribution. MF-based models such as non-negative matrix factorization (NMF [13]) and maximum margin matrix factorization (MMMF [28]) are usually used to reduce the dimensions of user-item matrix and smooth out the noise information. All of them are helpful to algorithm scalability, but cannot be directly applied to the case in which ratings have only two states: observed and not observed. To handle such problem, Hu et al. [8] introduce different confidences for observed items and unobserved items. In our model, we adopt PMF for both the social network of celebrities and general users’ following records. And we regard those unfollow actions as unobserved data and model them as negative samples with low confidence.
Latent factor models associated with social network
Recently, some works have studied the effectiveness of social network to help recommendation performance improvement. [22, 38] explore social network of common users to better understand common users’ interest. Social matrix factorization [17, 22] incorporates social relationships into MF to improve recommendation performance. Shen and Jin [27] study varieties of users’ social relationships. Cheng et al. [4] utilize users’ social relationships to mine users’ preferences on locations and make favorite recommendation. Guo et al. [6] study social trust information and prove that both explicit and implicit influence of trust should be taken into consideration in a recommendation model. [37] considers trust relationships to more accurately reflect users’ reciprocal influence on the formation of their own opinions for high-quality recommendations. [3, 5] are the most relevant works with ours. They incorporate LDA with social matrix factorization to gain powerful learning feature. The difference between these two works is that the topic model in [3] functions not only user interest but also celebrities’ social network, while the topic model in [5] only plays a part in user interest matrix factorization. However, Ding et al. [5] only consider the social network of celebrities. In our model, besides the social network of celebrities, we also focus on how the social network of general users would have an effect on the task of celebrity recommendation.
Latent factor models based on deep learning
The idea of combing deep learning models with collaborative filtering is just proposed in recent years. As we best know, Salakhutdinov et al. [26] are the first to apply deep learning into the task of collaborative filtering. They modify the restricted Boltzmann machines for the task of collaborative filtering and achieve good performance. Recently, some deep learning models are proposed to learn latent factors from content information, such as raw features of audio and text [7, 20]. X. Wang and Y. Wang [36] utilize deep belief nets (DBN) for music recommendation, and unify feature extraction and recommendation of songs in a joint framework. This framework automatically learns the feature vectors of songs using a deep belief network, which is a generative probabilistic graphical model. Differently, Oord et al. [19] address the music recommendation problem using the convolutional neural networks (CNN) rather than DBN. They conduct a weighted matrix factorization to obtain latent factors for all songs, after that they use deep learning to map audio content to those latent factors. Most recently, Wang et al. [33] propose a hierarchical Bayesian model (CDL) which tightly couples SDAE and MF. To our best knowledge, CDL is the first hierarchical Bayesian model to bridge the gap between state-of-the-art deep learning models and recommender system. This work is much close to our work but differs from ours. Because CDL does not incorporate social network to improve performance, which is very important in celebrity recommendation as discussed before. A deep learning model is adopted to learn latent features from content information and model it with a latent factor model in our model.
The graphical model for the PMF model.
In this section, we first discuss probabilistic matrix factorization. Then, we review stacked denoising autoencoders. After that, we present CSDL in detail.
Probabilistic matrix factorization
In our model, we conduct PMF. Similar to previous work [24, 25], we provide Gaussian priors on the latent factors. Note that, we employ PMF to factorize the social network of celebrities and general users’ following records simultaneously, and they share the item latent feature space. The graphical model is shown in Fig. 1. Let
We assume the following generative process:
For each user
For each item
For each celebrity
For each user-item pair
where For each celebrity’s social network pair
Note that,
In many practical recommendation scenarios, users rarely express their explicit behaviors, while implicit ones are very popular (e.g. clicking and browsing history). This class of collaborative filtering with only positive samples is called OCCF [21]. In that work, the authors introduce different confidence parameters
where
where
where
A 1-layer SDAE with 
To recover the clean input, SDAE [30] learns a compressed representation from randomly corrupted input through a feedforward neural network. We define a
where
Assuming that the corrupted input
For each layer
For each column
Draw the bias vector For each row
For each item , draw a clean input,
Where
(a) shows the graphic model of CSDL. The part inside the dashed rectangle shows an example of SDAE with 
A simple social network. 
Figure 3(a) shows the graphic model of CSDL. Next, we describe a general framework that integrates matrix factorization, social regularization and deep feature learning in detail. The generative process of CSDL is described as follows:
For each layer
For each column For each row
For each item (celebrity)
Draw a clean input Draw a latent item offset vector
For each celebrity
For all users, draw latent user vector set,
For each user-item pair, draw a following action
For each social network pair, draw a relationship
Note that, the middle layer
In order to further improve recommendation accuracy, our model also considers the social information of general users. The social network of general users differs from that of celebrities as discussed before, so we adopt a different but more effective strategy to handle it. Figure 4 shows a simple following topology structure in social network websites. Following action will generate a tie. For example, there exists a tie when user
We adopt Jaccard’s coefficient, a simple measure that effectively captures common neighborhood, to compute nodes’ similarity values. Then, we incorporate the social network of general users by assigning a different prior to each user, which is based on the similarity values between the general users and their friends as Eq. (1) shows. We denote the similarity matrix between general users by
where
Note that, this work can be up-scaled to other applications. For example, when recommending scientific articles for users in CiteULike, users’ reference libraries, the citation relations between articles and co-author between users are available, the proposed model can be adjusted to up-scaled to this recommendation task easily.
In our model, we develop an EM-style algorithm to learn the maximum posterior (MAP) estimates (because of our model’s Bayesian nature, fully Bayesian methods can also be applied [33]). We denote
Analogous to the generalized SDAE, to reduce computational complexity, we can also take
As discussed in the previous section,
Similar to [5, 33], we optimize the objective function using coordinate ascent. Given current
where
Based on current
The above steps will be repeated until the model converges to a steady state. In order to learn more robust feature representation, we adopt dropout strategy. And some generally utilized techniques can be adopted to alleviate local optimum issue, for instance, we add momentum term in our model. Finally, we obtain the latent factors
After learning the optimal parameters
Note that, when any new celebrity
Experiments
In this section, we design several experiments on two real-world datasets, and compare performance between CSDL and three state-of-the-art algorithms. The experiments are designed to answer the following questions:
To what degree does CSDL outperform the state-of-the-art methods, especially when the data is extremely sparse? To what degree does the different data sparsity setting level of celebrity network affect recommendation performance? How is the recommendation performance affected by the social parameter
Statistics of the user-item matrix
Statistics of the matrix of celebrities’ social network
Data sparsity of general users’ following actions.
Data sparsity of celebrities’ social relations.
To effectively illustrate the performance of CSDL, we use the same Tencent MicroBlog and Twitter datasets used in [5]. We only sample a subset of 10,000 users from the whole set of users, which do not consider the noisy data that users who follow less than 5 celebrities. To show the effectiveness of the social network of celebrities, we use the full social network of celebrities. In Tencent MicroBlog dataset, there are 4,183 celebrities, 10,000 users, 288,491 user following action records, thus, the sparsity is 0.68%. For celebrities’ social network, there are 152,284 edges, the sparsity is 0.87%. Twitter dataset has 900 celebrities, 10,000 users, 198243 user following action records, thus, the sparsity is 2.2%. And there are 129510 edges, the sparsity is 15.99%. The descriptions of celebrities contain the keywords extracted from the corresponding MicroBlog profile of celebrities. The vocabulary size
Next, we take Tencent MicroBlog dataset as an example to analyze the dataset statistic feature. The statistics of the following actions matrix of general users and the social network of celebrities are summarized in Tables 1 and 2, respectively. The data sparsity of general users’ following actions and celebrities’ social relations are shown in Figs 5 and 6, respectively. The y-axis is the value of number of general users, x-axis denotes the number of general users’ following actions in Fig. 5. And the y-axis is the value of celebrities, x-axis denotes the number of directed edges in Fig. 6.
Evaluation metrics
The same as [33], we randomly choose
The information of following action records is the form of implicit feedback, a zero entry may be owing to the fact that the user is not interested in the item, or that the user is not aware of its existence. So, precision is not a suitable performance measure. Recall and Average Precision (AP) are commonly used evaluation metrics in top-M recommendation with implicit feedback. Similar to [5], we employ Recall and Average Precision (AP) to quantize the performance of recommendation,
where rel(m) is a 0-1 binary variable, which indicates the user follows a celebrity or not. For both Recall and AP, the final result is the average over all users.
Baselines and experimental settings
Our comparison models include three state-of-the-art hybrid recommendation algorithms as follows,
In the experiments, we first use a validation set to find the optimal parameters for CTR, CDL, and CSTR. When
For CSDL, we directly set
AP@M when the matrix of general users’ following actions is sparse and dense
AP@M when the matrix of general users’ following actions is sparse and dense
Recall@M when the matrix of general users’ following actions is sparse.
Recall@M when the matrix of general users’ following actions is dense.
In order to compare the quality of recommendation in the stated methods experimentally, the Recall and AP of each method were measured. The curves in the graph indicate that as the number of recommended items M increases, Recall values tend to increase. Figures 7 and 8 show the results about Recall of algorithms CSDL, CDL, CSTR, CTR. Our experiment uses the real-world datasets from Tencent MicroBlog and Twitter under both
From Fig. 8, we find that CDL, CSTR and CTR can achieve extremely close performance, when the matrix of general users’ following action records is dense
For the ranking metric AP, CSDL also achieves the best performance, as shown in Table 3 under
AP@M when the matrix of celebrities’ social relations is sparse and dense
AP@M when the matrix of celebrities’ social relations is sparse and dense
Recall@M when the matrix of celebrities’ social relations is sparse.
Recall@M when the matrix of celebrities’ social relations is dense.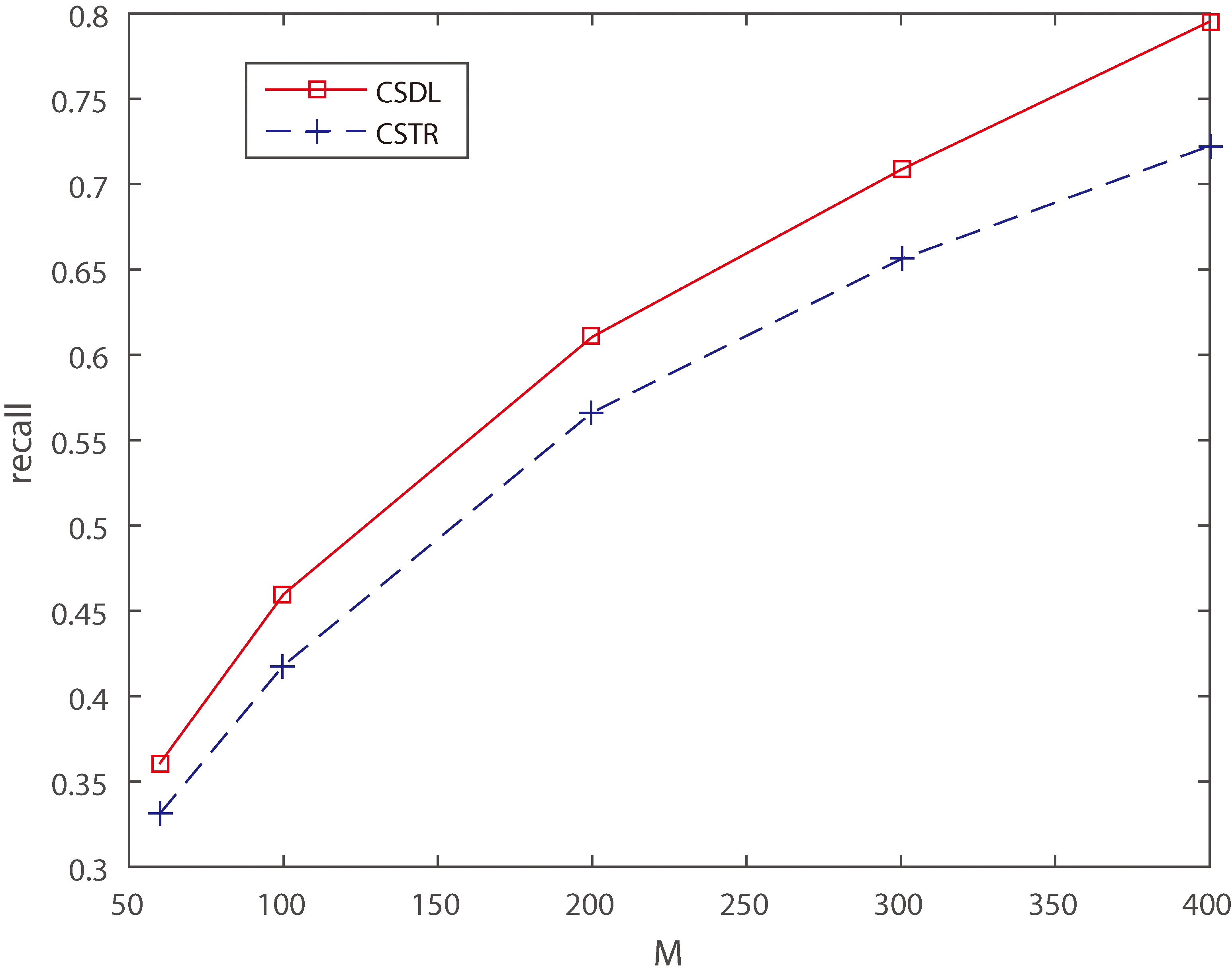
Both CSDL and CSTR integrate the social network of celebrities into models to improve the performance in celebrity recommendation. Thus, to explore the effectiveness of the social network of celebrities, we use different data sparsity setting levels of celebrity network in Tencent MicroBlog dataset. We set up two cases:
randomly select 2 edges associated with each celebrity from celebrities’ social network to set sparse social network; randomly select 20 edges associated with each celebrity from celebrities’ social network to set dense social network.
Figures 9 and 10 illustrate the Recall under sparse and dense social network, when
Moreover, the larger M, the more highly CSDL outperforms CSTR. From this phenomenon, we can draw a conclusion that CSDL has a higher stability.
Recall@M when the matrix of general users’ following actions is sparse and 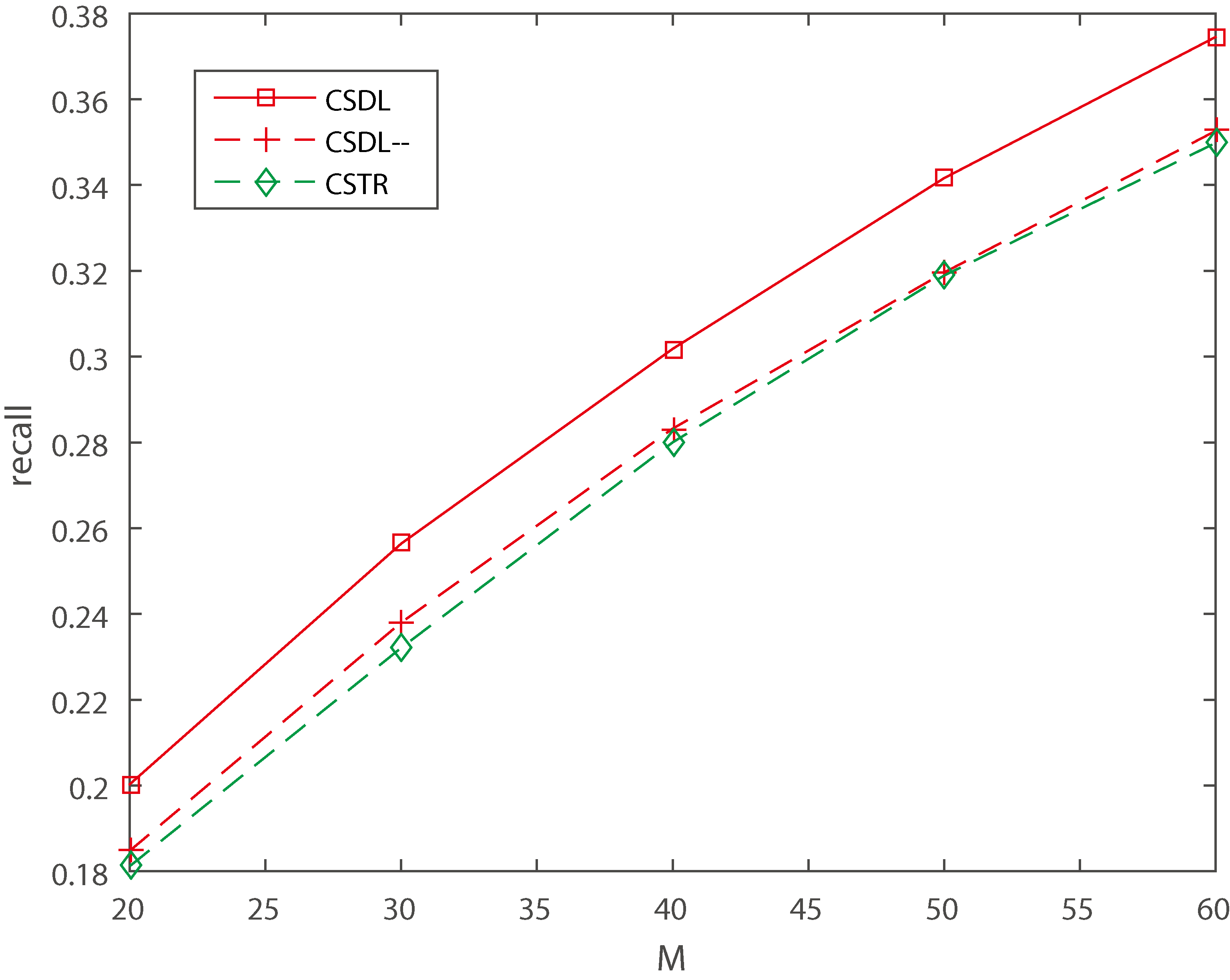
Recall@M when the matrix of general users’ following actions is dense and 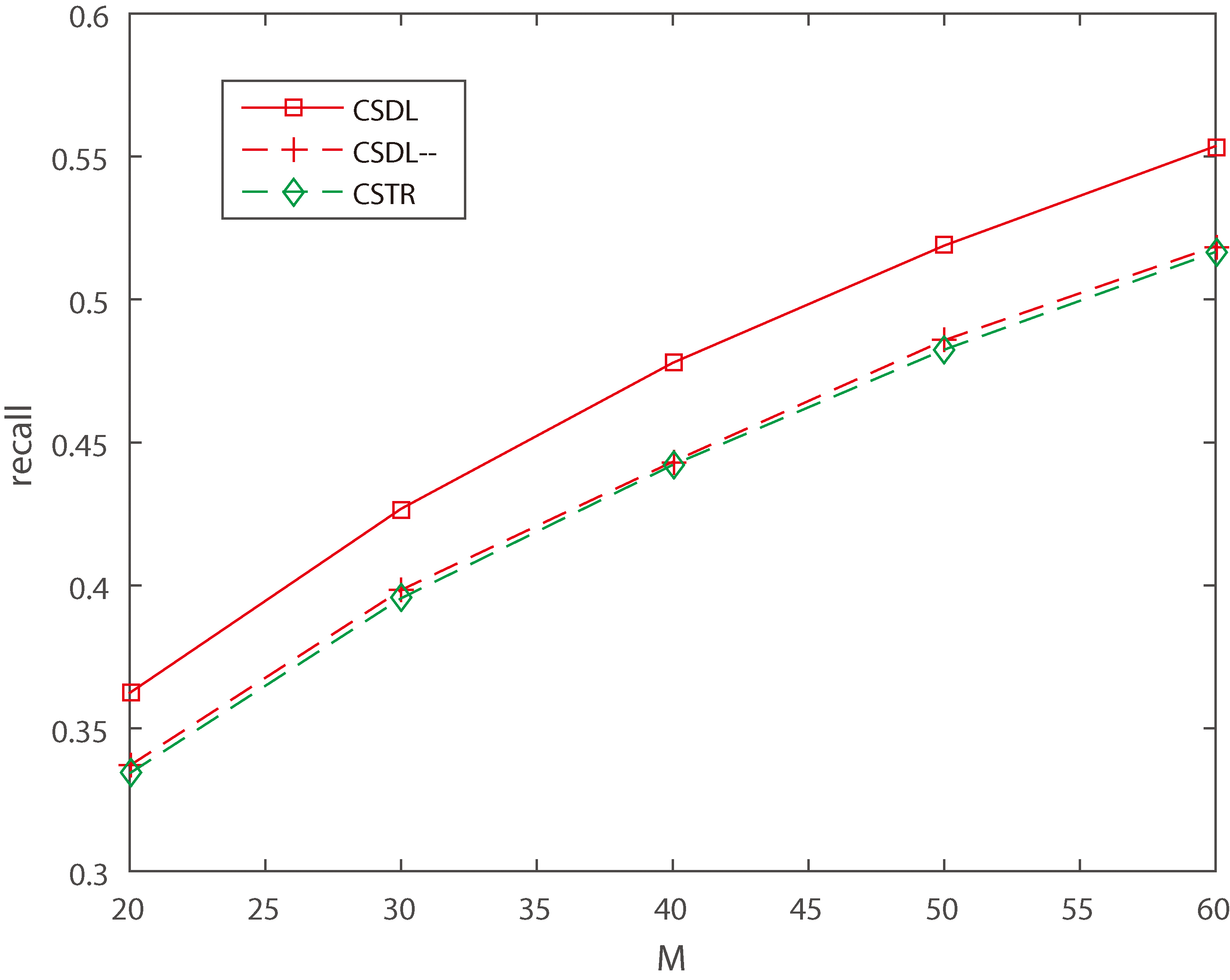
In this part, we will analyze the parameters impact in Tencent MicroBlog dataset.
Social parameter
The social parameter
Extreme cases of
As discussed before, whether
Recall@60 when the matrix of general users’ following actions is sparse and dense
Recall@60 when the matrix of general users’ following actions is sparse and dense
Recall@M when change 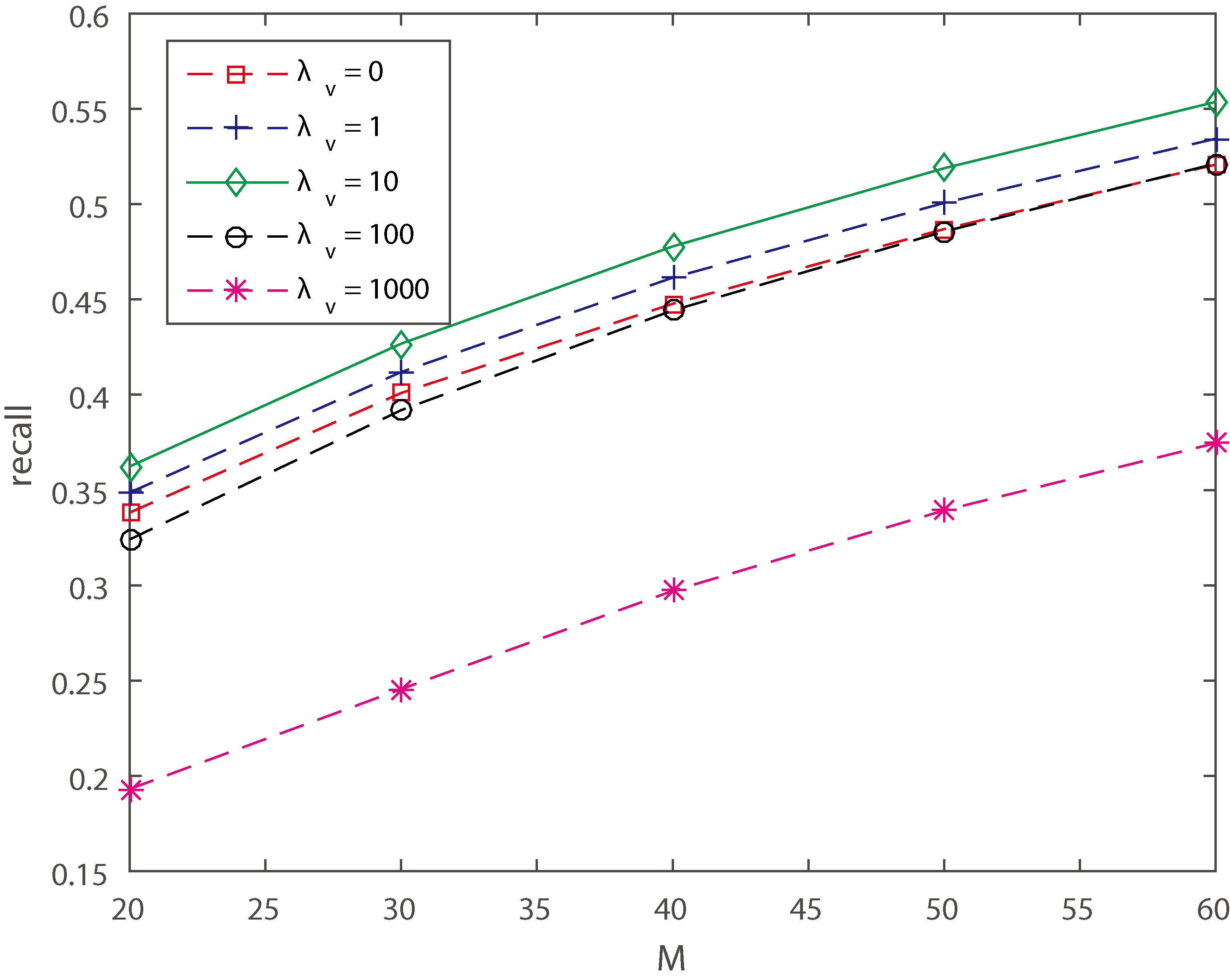
We use SDAE, which is a deep learning method, to learn a deep representation of content. SDAE transforms the representation at one level into slightly more abstract style at a higher-level. Therefore, we study the effect of the layers of SDAE. Table 5 shows the Recall@60 results when CSDL is set with different number of layers under both the sparse general users’ following action records and the dense general users’ following action records. As we can see, CSDL will overfit when it exceeds two layers.
Algorithm complexity
In order to update
Conclusion
In this paper, we have developed a novel hierarchical Bayesian model called CSDL for celebrity recommendation in the context of social network websites. CSDL can seamlessly integrate general users’ following action records, celebrities’ content information and social network information into one principled model. In CSDL, social network information includes both the relationships of celebrities and that of general users. In addition, CSDL uses side information and deep feature learning to alleviate the sparsity problem faced by traditional CF methods and CSTR. The experimental results on two real-world datasets show that our approach outperforms other state-of-the-art algorithms under different sparsity level settings.
In the future, we will try other deep learning methods to further improve performance of our hierarchical Bayesian framework. One promising choice is recurrent neural network (RNN), which can consider the context and order of words to improve the performance. We will also further explore the social information to improve recommendation performance.
Footnotes
Acknowledgments
This work is supported by the National Key Research and Development Program of China under grant 2016YFB1000901, the National Natural Science Foundation of China (NSFC) under grant No. 61202227 and Provincial Natural Science Foundation of Anhui Higher Education Institution of China under grant No. KJ2018A0013.