
Abstract
We propose models based on SVM, Naïve Bayes and deep learning to solve the consumption intention classification problem. Applying consumption intention mining to prediction tasks in social media. This paper discusses consumption intention towards a certain kind of product, i.e. movie, and uses movie consumption intention as an important feature in box office prediction. We combine consumption intention with traditional features used in the problem of box office prediction, and achieve a outperforms previous work of this problem We build a system based on linear regression which automatically predicts movies’ total box office and opening weekend box office one day prior to the movie’s release date.
Introduction
The rapid growth of natural language sentence query brings great challenges to traditional search engines. Most of the traditional search engines mainly rely on keyword matching technology to perform fast search and return to user search results. Considering the natural language sentence query as described above, without understanding the semantic intent of the query, the search engine may return only the document that matches the user’s query keyword, rather than returning the information that the user really wants to find. However, when it is known that the user queries semantic intent (e.g. restaurant search) and at the same time knows the specific meaning of each query component (e.g. “French restaurant” is the search core word, “best” is a constraint). Then the search engine can search the query according to a specific pattern and return the most relevant and necessary results to the user, not only returning the results of some of the related words in the query. Therefore, one of the necessary factors for the further development and improvement of the search engine system is the query intent understanding. In recent years, the problem of query semantic intent understanding has gradually attracted more and more attention. The work of this paper focuses on the semantic intent understanding of natural language queries for the field of map search.
For business intent recognition on Query, the method used in this paper is to use Query itself, search engine search result interface and other content as the data source, and then translate the problem into a business intent recognition problem on the web page. Later, Derek Hao Hu [1–3] and others conducted further research on the identification of commercial intent on Query. Considering that Honghua Kai’s work only analyzes Query itself without considering the user’s individual needs, they proposed the POINT algorithm (personalized online business intent detection). The algorithm combines the user’s query with the user’s profile (including the user’s search history, etc.) based on the conditional random field. In addition, Ashcan and Clarke [4–6] and others use the user’s click-through behavior, and Guo and Agichtein [7–9] use the user’s mouse click and scroll to perform online business intent recognition. However, the above work is based on the data in the search engine, and is essentially different from the consumer intent recognition on Weibo. There are many research work on online business intent recognition (OCI). In 2006, the concept of online commercial advertising was first proposed by Honghua Kai [10–13] and others.
Kröll and Strohmaier [14–16] first defined a new concept: Intent Analysis, which is intent analysis. In the 2009 article, they argued that intent analysis is a problem that is somewhat similar to sentiment analysis and treats it as a multivariate classification problem. Later in the 2013 article, Hollerit and Kröll [17–19] and others studied the consumption intentions on Weibo. Their defined consumption intentions need to include at least one consumer intent keyword, such as auction, buy, cheap, etc., which is closer to the category of “explicit consumption intentions containing consumer intent triggers” in this classification system. Later, the consumption intention classification was carried out by methods such as SVM and Naïve Bayes, and finally achieved an accuracy of about 57%. In 2013, Zhiyuan Chen [20–23] and others proposed the concept of “intentional text mining in online forums”. They conducted intent mining in an online forum, for example: “I want to buy a camera.” Their definition of intent is similar to the explicit consumption intention of a consumer intention trigger as defined in this article. They propose different expressions of intentions for different fields, and based on this idea, propose an intent mining algorithm based on migration learning. In this paper, their proposed algorithms are implemented and compared with the deep learning-based consumer intent mining algorithm. In addition, Jinpeng Wang [24–26] and others proposed the problem of mining trend-related products from Weibo. They define “trends” as topics that are heatedly discussed by users on Weibo. For example, if someone says on Weibo that “the air in Beijing is very bad recently”, they hope to dig out products related to air purifiers, masks, etc. from the trend of poor air. Therefore, their work unearths a product related to a certain trend, and the consumption intention of the product, can be considered as a special case of the consumption intention research in this paper.
Conditional random field model
The Conditional Random Field Model (CRF) was first proposed by Lafferty et al. [27–28], which is an undirected graph model, that is, a set of output random variables under the given set of input random variables. The conditional probability distribution model, which assumes that the output random variables constitute Markov random fields, has applications in named entity recognition, Chinese word segmentation, annotation and other natural language processing tasks, and has good performance.
This section mainly introduces the conditional random field theory, including the definition of the conditional field, and various representation methods.
Definition of conditional random field model
Let X and Y be random variables, and.P (Y|X) is the conditional probability distribution of Y under the given X condition. If the random variable Y constitutes a Markov random field represented by the undirected graph G = (V, E),
For any node v to be established, the conditional probability distribution is called coincidence. P (Y|X) is a conditional random field. Where ω ∼ υ denotes that G = (V,E) is all nodes w connected to the node v in the graph G, ω ≠ υ denotes all nodes except the node v, and Y υ and Y ω are the nodes v and the random variable corresponding to w.
In reality, it is generally assumed that X and Y have the same graph structure, and the linear chain shown in the following two figures is used.
Then, assuming that P(Y, X) is a linear chain condition random field, the conditional probability that the random variable Y takes the value of y has the following form under the condition that the random variable has a value of x:
Where t k a feature function is defined on the edge, called a transition feature, depending on the current and previous position, and s l is a feature function defined on the node, called a state feature, depending on the current position. Both t k and s l depend on the position and are local feature functions. Generally, the feature functions t k and s l have a value of 1 or 0, and when the feature condition is satisfied, the value is 1, and otherwise it is 0. The conditional random field is completely determined by the weights λ k and u l of the characteristic functions t k , s l .
This section discusses the problem of estimating the conditional random field model parameters for a given training data set, i.e. the conditional random field learning problem. The conditional random field model is actually a log-linear model defined on time series data, and its learning methods include maximum likelihood estimation and regularized maximum likelihood estimation. The specific optimization implementation algorithm has improved iterative scale method IIS, gradient descent method and quasi-Newton method. We choose the BFGS algorithm of the proposed Newton method for a brief introduction.
The conditional random field model learning can apply the Newton method or the quasi-Newton method. For the conditional random field model.
The objective function of learning is:
The gradient function is:
The BFGS algorithm of the Newton method is as follows:
Input: features function f1, f2, …, f
n
, Empirical distribution is
Output: Optimal parameter value Initially selected point ω0, taking B0 as a positive definite symmetry matrix, set k = 0; Compute g (k) = ω
k
, if g (k) =0, stop, else turn to (3); Obtain p
k
from B
k
p
k
= - g
k
; One-dimensional search: obtain λ
k
when Set ω(k+1) = ω(k) + λkp
k
; Compute gk+1 = g (ω(k+1)), if g
k
= 0, stop, or obtain Bk+1 by:
Where, y
k
= gk+1 - g
k
, δ
k
= ωk + 1 - ω(k) Set k = k+1, turn to (3).
This section describes the representation of semantic intents based on natural language sentences. Firstly, the semantic intent representation of natural language sentence query is introduced. Then, the grammar of generating semantic intent is introduced. Finally, the analysis of natural language sentence query intent is transformed into structural prediction problem, and the corresponding learning algorithm is given. In general, the task defined in this chapter is to map natural language sentence queries into corresponding semantic intent representations. Note that we are a grammar based on a specific search context definition. By redefining the grammar that suits the desired situation, the method proposed in this paper can be generalized to other search scenarios.
Structured SVM-based learning algorithm
In general, the measure of the correctness of a predictive parse tree is the F1 value (for example, Johnson’s work [29]). Specifically, the harmonic mean of the correct rate and the recall rate is calculated based on the nodes that overlap between the trees. We will use this type of loss function and introduce a standard 0-1 loss function as a measure of the benchmark. Suppose z and z
i
are two output parse trees, and |z| and |z
i
| are the number of brackets in z and z
i
, respectively. Let n be the same number of brackets in both trees. Then the loss function of trees z and z
i
can be calculated as follows:
Note that the learning function can be calculated by looking for the structure y ∈ Y by the maximal algorithm such that F (x ; y ; ω) =〈 ω, δω i (y) 〉 is maximal. To do this, we use the CKY parser developed by Mark Johnson and integrate it into our algorithm.
Results and analysis
This section will introduce the semantic intent of the natural language sentence query proposed in this paper to indicate the validity of the learning method. We conducted two sets of comparative experiments. The first set of experiments was used to demonstrate the performance of the learning method proposed in this paper, including three evaluation indicators: correct rate, recall rate and F1 value. The second set of experiments was used to explore the effects of related kernel functions on learning outcomes. The results using cross-test on the MSItent dataset is analyzed as Table 1.
Analyze results using cross-test on the MSItent dataset
Analyze results using cross-test on the MSItent dataset
In addition, the structured SVM may produce some “NULL” value output on the test set, probably because the grammar generated by the structured SVM does not derive the sentence. But in general, the method we proposed has a higher recall rate.
This chapter attempts to explore the semantic meaning of natural language sentence query from a new perspective, that is, the natural language sentence query is parsed into the corresponding semantic intent representation. Firstly, we introduce a hierarchical structure to represent the semantic intent of natural language sentence query. Then, an automatic learning method for natural language sentence query semantic intent expression is proposed, and the natural language sentence query and corresponding are constructed manually. The corpus of semantic intent representations. The experimental results on the annotated corpus show that our method achieves very good performance in terms of accuracy and F1 values. Therefore, we can infer that the structured support vector machine is very suitable for the semantic intent learning problem of natural language sentence query. We also use the conditional random field model to obtain semantic annotation results with high accuracy, which brings benefits to the query semantic intent representation learning preprocessing.
The main drawback of the proposed method is the limitation of querying the sequence of words in natural language sentences. We note that although it applies to the query semantic intent modeling of this task, it may be more beneficial to ignore these restrictions. This issue will be one of the directions for our future development. Another interesting and very important issue for future research is to extend fully supervised SVM learning to semi-supervised SVM learning. In this way, the semantic intent of natural language queries can be learned by processing the annotated and unlabeled data, which greatly saves manpower and material resources.
In the previous chapter, we implemented the SVM-based consumer intent classifier and further improved the performance of the classifier by introducing external corpus for migration learning. However, by observing the classification results, we found that the SVM classifier does not implement the mining of semantic level information, which leads to the poor classification of SVM for those microblogs that do not have explicit consumption intention trigger words. In order to solve this problem, we introduce a deep learning-based classification model of consumption intentions, and combine it with distributed word representation to achieve a deeper understanding of Weibo text.
Distributed word representation model
In Chapter 2, the SVM-based consumer intent classification model, we use the word bag model to represent words. This model represents each word as a vector of length equal to the length of the dictionary, and only one dimension in the vector is 1, and all other dimensions are 0, which we call a One-hot representation. The advantage of the One-hot representation is that it is very concise, but its disadvantage is that it does not represent any semantic features itself, and the words and words are completely isolated. Due to problems with the One-hot representation, Hinton [30] et al. proposed a distributed word representation (Word Embedding or Distributed Word Representation) model in 1986. This distributed word vector represents each word as a real-value word vector of the same dimension (such as 100 dimensions), so it can represent much more information than the One-hot representation, and can express some semantic level. Characteristics.
Introduction to deep learning
Deep Learning is a new direction in the field of machine learning. Its main idea is to learn deep representation and abstraction from text, image, speech and other data. Commonly used models for deep learning include Auto encoder, Denoising Auto encoder(DAE) [31–34], Stacked Denoising Auto encoder (SDAE) [35–37], Recursive Auto encoder, Deep Belief Network, Deep Boltzmann Machine, Recurrent Neural Network and so on. At present, deep learning has achieved very good results in a large number of natural language processing tasks. For example, in language models, part-of-speech tagging, word segmentation, named entity recognition, sentiment analysis, and other tasks, deep learning-based models reach or approach the state-of-the-art level [38, 39].
The consumption intention classification and sentiment analysis tasks in this paper have certain similarities. In the field of sentiment analysis, most of the research work is based on the word bag model, and uses a large number of artificially constructed resources (such as emotional word dictionary, etc.). However, in recent years, some research work using distributed word representation and deep learning models has emerged and achieved good results.
Classification of consumption intentions based on distributed word representation and SDAE
Denoising Auto Encoder (DAE) was proposed by Bengio et al. [11] and is an improvement of the Auto Encoder model. DAE introduces “destruction” of the input vector to force the hidden layer in Auto Encoder to learn more powerful features. Usually, in order to destroy the input vector, we can randomly set some inputs to 0. The DAE first encodes the input and then attempts to recover the original input vector from the corrupted input vector. In this way, the DAE can learn the implicit associations between multiple samples.
Stacked Denoising Auto encoder (SDAE) is a stack of multiple DAEs. The training of SDAE is divided into two steps: Perform Pre-training, train DAE layer by layer from the first layer, and use the output of the kth layer as the input of the k+1th layer. This step is unsupervised. Perform Fine-tuning to further adjust the parameters in each layer. We use the output of the last layer as input to a logistic regression layer and add supervisory information to the logistic regression layer (obtained by previous manual annotation). After that, we train the entire SDAE and adjust the parameters in all hidden layers.
The SDAE model framework used in this chapter is shown as Fig. 1:
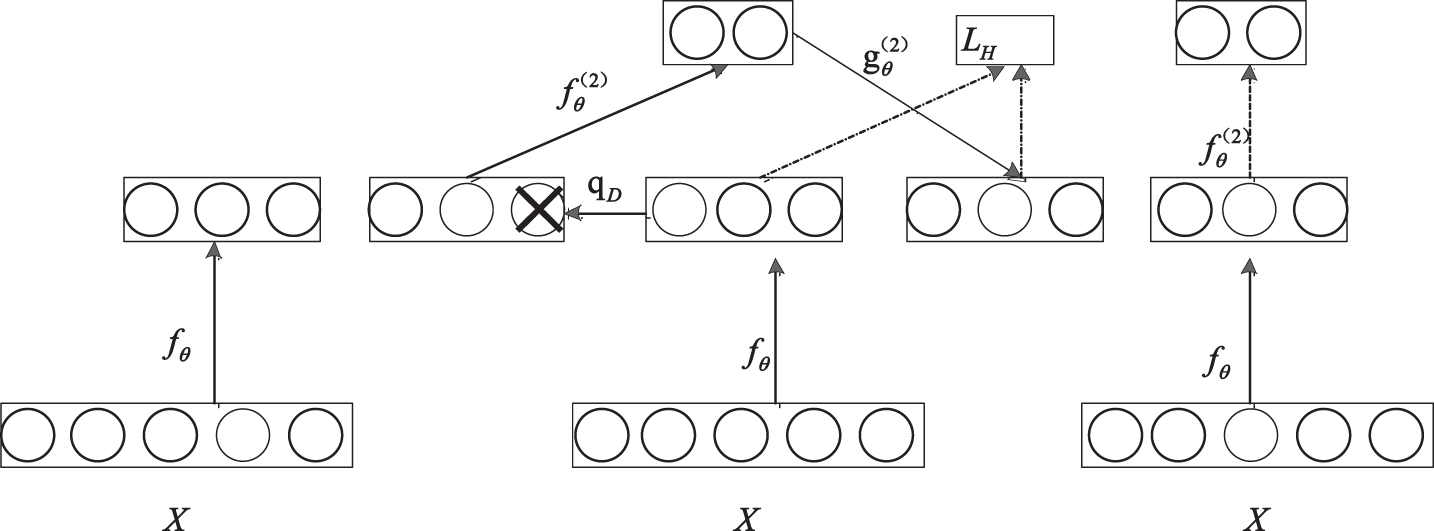
SDAE schematic.
We first train the first auto encoder in the left picture, which receives the original input vector and gets an encoding function c. After that, we use the output of the first encoder as the input of the second encoder to get the encoding function
The experimental corpus in this section is still the microblog corpus in Section 2.6. We compared the following models: Word Embedding+SDAE+Logistic Regression (WE+DAE+LR), SDAE+ Logistic Regression (DAE+LR), Word Embedding+ Logistic Regression (WE+LR), and Word Embedding+SVM (WE+SVM), and the three models in Chapter 2. The experimental results are shown in the Table 2:
Consumer intent classification experiment results
Consumer intent classification experiment results
As can be seen from the above table, the introduction of Word Embedding can significantly improve the classification results, and the SDAE model is significantly better than SVM and Naïve Bayes. The combination of WE+SDAE+LR achieved the highest F-measure.
This chapter first points out the problem of the word bag model used in Chapter 2, the SVM/Naïve Bayes model, and then proposes a solution to these problems using Word Embedding and Stacked Denoising Autoencoder. The experimental results show that both Word Embedding and Stacked Denoising Autoencoder can improve the classification of consumption intentions, and the model combination of Word Embedding+StackedDenoisingAutoencoder+Logistic Regression achieves the best classification of consumption intentions.
Opinion mining gains more comprehensive consumer opinions for consumers and businesses through the collection and processing of online product reviews. The opinions in the comments have an impact on the consumer’s intention to consume, avoid blind consumption, and reduce the risk in consumption. At the same time, it also facilitates real-time tracking of customer opinions by customers, and adjusts product quality issues and service satisfaction issues to improve customer satisfaction. However, most of the current opinion mining work is directed at English text processing. In the Chinese text processing, it often has a lower accuracy rate and recall rate. This paper mainly studies Chinese online commentary mining. Based on hotel reviews, book reviews, and computer reviews, text mining techniques are used to extract words of interest in comments. On the basis of the research of existing methods, the methods of extracting feature word extraction, comment word extraction and merging synonym in Chinese product review are improved. This paper introduces the current situation of product comment opinion mining and common feature extraction and synonym merging methods, and analyzes the advantages and disadvantages of these methods, and clarifies the research significance and practical application value of product review text mining. The natural language processing of Chinese comment texts is completed based on the natural language processing platform. According to the natural language analysis, the review texts are divided into four categories. In view of the phenomenon that the product product text mining has poor effect on Chinese product review feature extraction, the research focuses on the product text feature extraction method. On the basis of this, an improved Chinese product comment feature word and opinion word extraction algorithm is proposed. By combining the conjunction word with the newly defined feature word and opinion word, the feature word and opinion word are comprehensively extracted, and the product review is verified through experiments. The validity of the feature word and opinion word extraction method. On the basis of the analysis and implementation of the existing synonym merging method, in order to meet the requirements of extracting the briefness of the information, the product comment feature words and opinion words are combined based on the synonym word forest extension. The experiment proves that the method can effectively improve the briefness of information.
Footnotes
Acknowledgment
This work was supported by Natural Science Foundation of Hubei Province of China(Grant No. 2018CFB681).