
Abstract
In sentiment analysis, the high dimensionality of the feature vector is a key problem because it can decrease the accuracy of sentiment classification and make it difficult to obtain the optimum subset of features. To solve this problem, this study proposes a new text feature selection method that uses a wrapper approach, integrated with ant colony optimization (ACO) to guide the feature selection process. It also uses the k-nearest neighbour (KNN) as a classifier to evaluate and generate a candidate subset of optimum features. To test the subset of optimum features, algorithm dependency relations were used to find the relationship between the feature and the sentiment word in customer reviews. The output of the feature subset, which was derived using the proposed ACO-KNN algorithm, was used as an input to identify and extract sentiment words from sentences in customer reviews. The resulting relationship between features and sentiment words was tested and evaluated to determine the accuracy based on precision, recall, and F-score. The performance of the proposed ACO-KNN algorithm on customer review datasets was evaluated and compared with that of two hybrid algorithms from the literature, namely, the genetic algorithm with information gain and information gain with rough set attribute reduction. The results of the experiments showed that the proposed ACO-KNN algorithm was able to obtain the optimum subset of features and can improve the accuracy of sentiment classification.
Keywords
Introduction
Information is being continuously added to websites and the amount of data is increasing every second. All sorts of information can be found on various social media platforms, such as Facebook and Twitter, in postings, blogs, discussion forums, and in emails. Such information could help individuals or organizations make decisions about the selection, production, or improvement of quality products, or help in business transactions and product purchases. However, with more data being added to the web every day, a technology is needed to analyse all these information with accuracy and precision. A technology that could help consumers or organizations acquire accurate and useful information in this respect is known as sentiment analysis.
Sentiment analysis combines the fields of text mining, natural language processing, and computer intelligence. In the past few years, sentiment analysis has become the focus of attention of many researchers in these fields [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]. There are three basic problems in sentiment analysis: feature selection, identifying sentiment words, and sentiment classification [10, 11, 12, 13]. Features or aspects are the topics that users comments about or give opinions on. Features are important; failing to identify the features present in the sentences or comments made by users will make it hard to identify the sentiments. Thus, the main problem or challenge in sentiment analysis is to improve the quality of feature selection by finding a way to identify and remove features that are irrelevant or overlapping and to effectively deal with a large feature space [6, 7, 8].
Machine learning is widely used in sentiment classification. According to [8], machine learning can overcome problems of high dimensionality of the feature space by applying a feature selection technique to eliminate irrelevant and noisy features. Indeed, the main problems or challenges in sentiment analysis are the large size of the feature space, as well as irrelevant and overlapping features [6, 7, 8]. Researchers are trying to find a suitable technique to identify and choose the best subset of features from the original feature space to reduce dimensionality and increase the accuracy of the classification process. Feature selection involves finding effective features from a large number of total features in a high-dimension space. This problem remains a challenge for researchers in the field of machine learning for sentiment analysis.
According to [14], it is important to select an optimum subset of features that could represent the actual subset of features to reduce feature size and increase classification accuracy. In [15], a metaheuristic algorithm was used as the feature selection technique to determine the optimum subset of features. This is because feature selection problem is an NP-hard combinatorial problem that requires an effective and appropriate algorithm for the feature selection process [15, 16, 17, 18]. Previous studies [19, 20, 21, 22] have shown that using the metaheuristic approach for feature selection can solve problems of feature selection and feature reduction in large-size datasets that contain noisy, overlapping, and irrelevant data. Various techniques have been suggested for feature selection, including metaheuristic approaches, such as the genetic algorithm (GA), ant colony optimization (ACO), and particle swarm optimization (PSO). These techniques have produced good results in obtaining optimum feature subset.
In [15], a modified discrete PSO algorithm was presented for solving the problem of feature subset selection. The study showed that the proposed discrete PSO algorithm was competitive in terms of classification accuracy and computation performance. On the other hand [19, 21], implemented ACO and the GA as feature selection techniques for text classification. The results of these two studies showed that ACO was more advantageous compared to GA in terms of its efficiency and competence in the convergence process, and its strong ability to find the problem space and to successfully obtain the optimum subset of features. Moreover, ACO is a very simple concept and it is computationally inexpensive in terms of memory requirement and speed. Based on these advantages, this paper proposes an integrated text feature selection algorithm based on ACO and KNN to obtain a subset of optimum features and to improve the accuracy of sentiment classification.
The remainder of this paper is organized as follows: Section 2 discusses the existing works on feature selection and the basic concept of ACO. Then, Section 3 presents an overview of the methodology adopted in this study, while Section 4 describes the proposed hybrid ACO and KNN algorithm for feature selection in sentiment analysis. Section 5 discusses the experimental results and Section 6 concludes the paper.
Related works
Various feature selection techniques have been suggested and implemented to identify product features that are discussed among users. In [6], the authors proposed a feature extraction method that used both syntactic and stylistic features. Syntactic features include word n-grams, part-of-speech (POS) tags, punctuation, and phrase patterns. These are usually used as a set of features for sentiment analysis. Stylistic features include lexical and structural features, but these types of features have limited usage in sentiment analysis. Their method of selecting a feature involved using a combination of information gain (IG) and GA techniques. The combination of these two algorithms is known as the entropy weighted genetic algorithm (EWGA). In the initial stage of the EWGA, the unigram features would be extracted from the document. The next stage involved feature selection using the IG technique to determine the importance of the features contained in the document.
However, the IG technique has two main weaknesses: first, it must determine the threshold value in advance, and second, it does not consider features that overlaps [9]. To overcome these drawbacks [9], combined IG with the rough set attribute reduction (RSAR) technique. This technique can reduce the number of noisy and irrelevant features. In addition, it has the advantage of being able to consider overlapping features. However, if RSAR is used on its own, it would take a long time to obtain the optimal feature subset. Therefore, by combining IG and RSAR [9], was able to reduce the number of overlapping features, as well as obtain the minimum feature subset more quickly, which can reduce time complexity during sentiment classification.
In a comprehensive study [23] showed that ACO-based feature selection achieved a very promising result. The authors used ACO to search the feature space and select an ‘appropriate’ subset of features. The proposed algorithm used mutual information evaluation information (MIEF) to measure the local importance of a given feature. In their work, ACO was applied in the classification of speech segments. The Texas instrument and Massachusetts Institute of Technology (TIMIT) database were used and an artificial neural network (ANN) was applied to classify the features. For this classification, the performance of the proposed ACO in selecting the features was compared with that of the GA and of sequential forward selection (SFS). The authors found that the proposed ACO algorithm achieved 84.22% for classification accuracy, which was better than the GA and SFS, which only achieved 83.49% and 83.19% accuracy, respectively. Thus, ACO gave superior outcomes compared to the GA and SFS.
In [24], the performance of a proposed ACO algorithm for feature selection in a face recognition system was investigated. The authors used the classifier performance and the length of the selected feature vector as heuristic information. The proposed algorithm was tested using the Olivetti Research Laboratory (ORL) greyscale face image database that contains 400 facial images of 40 individuals. They used two different sets of features, namely, the pseudo Zernike moment invariant (PZMI) and the discrete wavelet transform (DWT) coefficients as a feature vector. In the first step, the PZMI and DWT coefficients were extracted from each facial image and in the second step, the proposed ACO algorithm was used to select the optimal feature subsets. A nearest-neighbour classifier was used to classify the selected features and obtain the mean squared error (MSE), which was used as a performance measure. Overall, the study indicated that the proposed ACO algorithm achieved better performance compared to other tested algorithms.
Meanwhile [19, 21] showed that ACO can be used to solve problems of feature selection for text categorization. In these works, classifier performance and feature subset length were used to evaluate every feature. The ACO algorithm was applied to the so-called ‘bag of words’, which is a document containing a set of words or phrases. Every feature in the text was represented as a vector of term weights. A classification algorithm was used to evaluate and sort the selected subsets of features based on the performance of the classifier and the subset length. In these experiments, the authors assumed that classifier performance was more important than feature subset length. In their proposed algorithms, the value of the pheromone was updated based on the performance of the measured classifier and feature subset length. The performance of the algorithm as a text feature selection technique was compared with that of a GA and two statistical methods (IG and chi-square analysis). For these experiments, they used the Reuters-21578 dataset and the results of the experiment showed that ACO had outstanding capabilities and was more efficient than the GA, IG, and chi-square analysis.
In [25], the authors conducted an experiment to explore ACO as a suitable feature selection technique for a bioinformatics dataset. They used classifier performance and the length of the selected feature subset as the parameters to evaluate the performance of their proposed ACO algorithm. In their experiment, the proposed ACO algorithm was compared with the standard binary PSO algorithm. The ACO algorithm, when using only a small subset of selected features, achieved better classification accuracy than the PSO algorithm. The study showed that ACO has higher intelligence, is easy to implement, faster computation time, has the ability to converge quickly, has a strong search capability in the problem space, and efficient in finding the minimum subset of features [25]. In another investigation into ACO algorithms [26], found that ACO can select the optimum feature subset when applied to a web page classification problem. The authors used a naïve Bayesian algorithm to measure classification performance. In [27], a two-stage feature selection process was described. During stage one, the position of the terms in documents was determined using the IG technique. Stage two consisted of feature extraction using a principal component analysis (PCA) technique, where a GA functioned as the feature selection technique. The aim was to increase the effectiveness of the text categorization process by applying these two stages to identify only the important terms. The study proved that dimension reduction can be achieved using GA and PCA, with the help of IG, in determining the importance of features, thus increasing the success of the text categorization process.
In [28], a binary PSO was combined with KNN to select a feature set in an Arabic-language document. The results showed that the combination of these two techniques could increase the accuracy of text classification. In [29], a combination of ACO with trace-oriented feature analysis (TOFA) was proposed. The advantage of ACO, which uses ants to search for the optimum subset of features in the search space, was combined with the ability of TOFA to analyse large-scale text data. The authors claim that previous studies have proven that TOFA is effective in reducing dimension size. The experimental results showed that the suggested approach could reduce the size of the feature space to a smaller dimension and increase the accuracy of text classification. In [30], a novel heuristic algorithm for feature selection, known as the chaos genetic feature selection optimization (CGFSO), was suggested. The authors proposed a hybrid of the GA and chaos optimization (CO) for feature selection in text categorization. Their results confirmed that the association of the GA and CO was effective and superior to other compared algorithms for the text categorization problem. In [31], a combination of ACO for feature selection and a neural network (NN) as a classifier was proposed. The authors utilized the concept of a hybrid search technique to select outstanding features using a subset size determination schema. The study looked at the performance of a variety of hybrid techniques on eight benchmark classification datasets and one gene expression dataset. Their results showed that 98.91% of average accuracy was achieved by their proposed algorithm.
In [19], ACO showed higher classification performance compared to GA, IG, and chi-square when used as a feature selection technique in text classification. Based on a literature review conducted by [32] and the experiment in [19], ACO has been proven to have several advantages. First, it can rapidly find the optimum solution, even with numerous iterations. Second, it is efficient in creating the minimum feature subset, and third, it has a powerful exploration capability during a gradual search process towards the optimum solution.
Therefore, this current study has chosen ACO as the feature selection technique for sentiment classification of customer product reviews, which is different than in normal text classification. Sentiment classification functions to classify the feature subset acquired from feature selection into groups of positive or negative sentiments. This classification is related to the sentiments expressed by customers when they evaluate each feature of a product they have purchased.
Based on the successes of the methods in [19], a metaheuristic algorithm is proposed in this study for text feature selection based on the characteristics of the words in customer reviews to improve the accuracy of sentiment classification. In this study, the classifier performance and the length of the selected feature subset were taken as heuristic information for ACO. Therefore, the proposed algorithm did not require prior knowledge of features. The proposed ACO-KNN algorithm was applied to the text features of the bag-of-words model in which a document is considered as a set of words, or phrases (called terms). Additionally, each position in the input feature vector corresponds to a given term in the original document.
Methodology
Generally, the methodology for sentiment analysis is designed to obtain the optimum feature subset and to classify sentiments accurately. In this study, it comprises of five phases, namely, text preprocessing, feature selection, detection of the relationship between the features and sentiment words, sentiment classification and testing, evaluation, and analysis, as depicted in Fig. 1. The working principles of these phases are explained in the following subsections.
Methodology of the proposed algorithm.
This section briefly explains the phases in methodology as applied in this study. First, each sentence present in the dataset went through a
Next, a transformation process was applied to convert the feature list into a feature vector because the feature list was in text form, which cannot be interpreted by a classifier. The resulting feature vector was used in the
The optimum feature subset obtained by the feature selection process was used
Next, in the
Phase 1: Text preprocessing
The customer review datasets went through a cleaning process to edit the review sentences written by users. This is because the comments were written by regular users who are not language experts. Therefore, the datasets were likely to contain spelling errors, grammatical errors, such as punctuation mistakes and the wrong use of capital letters, slang words that do not exist in dictionaries, and abbreviations or acronyms for common terms. The cleaning process can be performed using standard word processing software, such as Microsoft Word to correct spelling errors, to amend the first letter of each sentence to a capital letter where necessary, and to ensure that each sentence ends with the correct punctuation, such as a full stop (.), question mark (?), or exclamation mark (!). An example of a sentence written by a user, before and after cleaning, is given below:
In the above sentence, the first letter was a lowercase ‘t’, which was changed to an uppercase or capital ‘T’ to denote the start of the sentence; the error in the spelling of the word ‘settting’, with an extra ‘t’ was corrected to ‘setting’; and the repeated exclamation marks (‘! ! !’) were amended to appear only once (‘!’). Once the cleaning process was completed, the POST process was performed for each sentence to identify the noun, adjective, adverb, verb, and determiner. This study used the noun, verb, and adjective to identify the features present in sentences, whereas the adjective, noun, verb, and adverb were used to identify the sentiment words. The list of features was extracted from the sentences and placed in a table. Next, this feature list was changed, or transformed into numerical values, which was performed through a feature weighting calculation process. For this study, term frequency-inverse document frequency (tf-idf) [33] was used to calculate the weight for each feature.
Feature extraction
In this study, feature extraction consisted of two steps, namely, part-of-speech tagging and a transformation process.
Part-of-speech tagging
This study was focused on the features of products that the reviewers commented on. Hence, the term feature refers to a product’s features, such as camera, size, screen, button, picture, design, and weight. Next, the feature set was extracted from the cleaned review sentences. However, prior to feature extraction, every sentence was parsed using Stanford Parser tools to build the grammatical structure. This process is known as part-of-speech tagging, or POST. Through this process, each word in the sentence was marked according to certain categories and divisions, such as noun, adjective, adverb, verb, determiner, conjunction, pronoun, preposition, and number. An example of a sentence before and after the POST process is shown below:
Before POST:
“The screen is very easy to read.” After POST: “The/DT screen/NN is/VBZ very/RB easy/JJ to/TO read/VB ./.”
Based on a previous study by [2], the normally occurring nouns (NN) and noun phrases (NP) were preserved as features, while the adjective (JJ) or adverb (RB) modifiers describing them were preserved as sentiment words.
Transformation process
A text document cannot be directly read and interpreted by a classifier. Therefore, an indexing process that maps the text document into a representation, known as a feature vector was performed. The indexing procedure that maps the text document into a compact representation of its contents must be equivalently applied to the documents.
Equation (1) shows how a text
where
where
and #(
The tf-idf is the function frequently used to represent terms that are present in documents. The tf-idf also considers each term’s relationship in the whole document llection [34]. Each dataset contains comment sentences related to particular products, such as cameras, mobile phones, and similar items. Each sentence in the dataset is broken down to form a document, with each document containing a sentence. Each document represents a vector and is considered to be the word, or term ‘bag’. Figure 2 shows the process of transforming the dataset into a tf-idf representation. Table 1 shows an example set of features for a set of documents.
Example set of features for a set of documents
Steps to create tf-idf representation.
In Table 2, the matrix has a dimension of N
Illustration of feature vector in matrix form
Illustration of tf-idf representation in tabular form
Feature selection is one of the most important aspects of solving a classification problem because it removes irrelevant features to decrease the computational cost [10]. Feature selection is a process of assessing and selecting features to obtain the feature subset that best represents the actual feature list, without changing or affecting the feature quality. Several evaluation criteria need to be considered to obtain the optimum feature subset [19]. According to [35], there are four steps in selecting features, namely, subset generation, subset evaluation, application of stopping criteria, and validation of results. The generation of a subset involves a search procedure to create a suitable feature subset for the assessment process and is based on a search strategy. Each subset is assessed and compared with the previous best one based on several particular evaluation criteria. If the new subset is better, then it replaces the older subset. This process is repeated until the generated subset meets the stopping criteria. The best newly acquired feature subset will then go through a validation process based on prior knowledge, or be subjected to different tests using synthetic and/or real-world datasets [35].
According to [35, 36, 37], three feature selection techniques can be used for the classification process, which are the filter technique, the wrapper technique, and the embedded or hybrid technique. The filter technique is a processing step that is independent of a machine learning algorithm. During the filter process, the relevant score for each feature is calculated and features with low scores are removed. The acquired feature subset is the input for the classification algorithm [37]. In the wrapper technique, the induction algorithm is used to evaluate feature selections to find the best feature subset [18]. Meanwhile, the hybrid technique is a combination of the filter and the wrapper techniques [39, 42], which can be used to handle a large-size dataset [42, 43]. The combined technique can produce the optimum feature subset using a standard optimization technique, such as GA, PSO, and ACO [40]. The feature subset selection process is an NP-hard problem [16, 45]. Therefore, a thorough search process is often required to obtain the optimum solution. The metaheuristic approach is suitable because there is no need to explore the entire solution space thoroughly [42]. The experiment reported in this study used a hybrid technique that combined ACO and KNN to obtain the optimum subset of features.
K-nearest neighbour (KNN)
The KNN is the easiest and simplest machine learning algorithm. KNN groups new data based on the shortest distance between
The MSE value derived from the classification process was used to assess the classification performance. The MSE values for two nodes (A node and B node) were compared with the MSE value for the previous subset (A node). A decreased MSE value meant that the performance value has increased. Thus, the B node was chosen and placed in the training data subset list. Subsequently, the ants moved to the next node, which was the C node and was considered as the test dataset. The distances between node C and node A, and between node C and node B in the training dataset, were calculated. Then, the MSE value for the groups of A, B, and C nodes were calculated. If the MSE value is lesser than the previous MSE value, the C node would be selected and placed in the training data subset list. Otherwise, the C node would not be selected and the ants would have to continue on their journey to the next node. The process was repeated until the ants have visited all the nodes.
Ant colony optimization for feature selection in sentiment analysis
Ants are insects that help one another to look for food and bring them back to their nest. The ants have the ability to find the best routes to get food by producing pheromone. This chemical substance sticks on soil, thus serving as a route marker and as the medium of communication among ants. Ants also use this marker to find their way back to their nest. They can also use the marker to determine which route is the best one to use for transporting food to the nest.
This natural phenomenon was the inspiration for the development of the algorithm, known as the artificial colony of ants [43]. This algorithm is a metaheuristic approach that can be used to solve various combinatorial optimization problems. Ant colony optimization (ACO) is a popular algorithm used for solving optimization problems, such as the travelling salesman problem (TSP), work scheduling, the travelling vehicle problem, the quadratic load problem, feature selection, and bioinformatics [19, 20, 25, 32, 33, 34]. In the TSP, ACO was used to find the shortest route between cities [32, 34].
Feature selection is an important step in finding the optimum feature subset because it produces high classification accuracy and is able to maintain the original feature set. The definitions of the terminologies used in the ACO algorithm are as follows [24]:
Expression of the problem in graph form: The problem must be designed as a graph with a set of nodes and edges between nodes. Heuristic value: This value is used to measure the movement of the ants between the nodes in the graph. Pheromone update rule: A rule for updating the pheromone levels on the edges is required as well as a corresponding evaporation rule. There are two types of pheromone update rule, namely, a local pheromone update rule and a global pheromone update rule. Probabilistic transition rule: This rule is used to determine the probability of an ant traversing from one node to the next node in the graph.
To apply an ACO algorithm for feature selection in sentiment analysis, three main issues must be addressed [19]. These are explained in the following subsections.
Expression of the problem in graph form
The feature selection goal needs to be expressed in a format that is suitable for ACO, thereby, ACO needs a problem to be symbolized as a graph [19, 33]. Thus, the nodes in the graph represent features, where the edges between them indicate the start of the next feature. The search for the optimal feature subset is made by an ant traversing the graph and visiting a minimum number of nodes that satisfies the traversal stopping criteria [19].
Figure 3 provides an example of this process, where the ant is currently at node
Representation of subset construction by ACO for feature selection.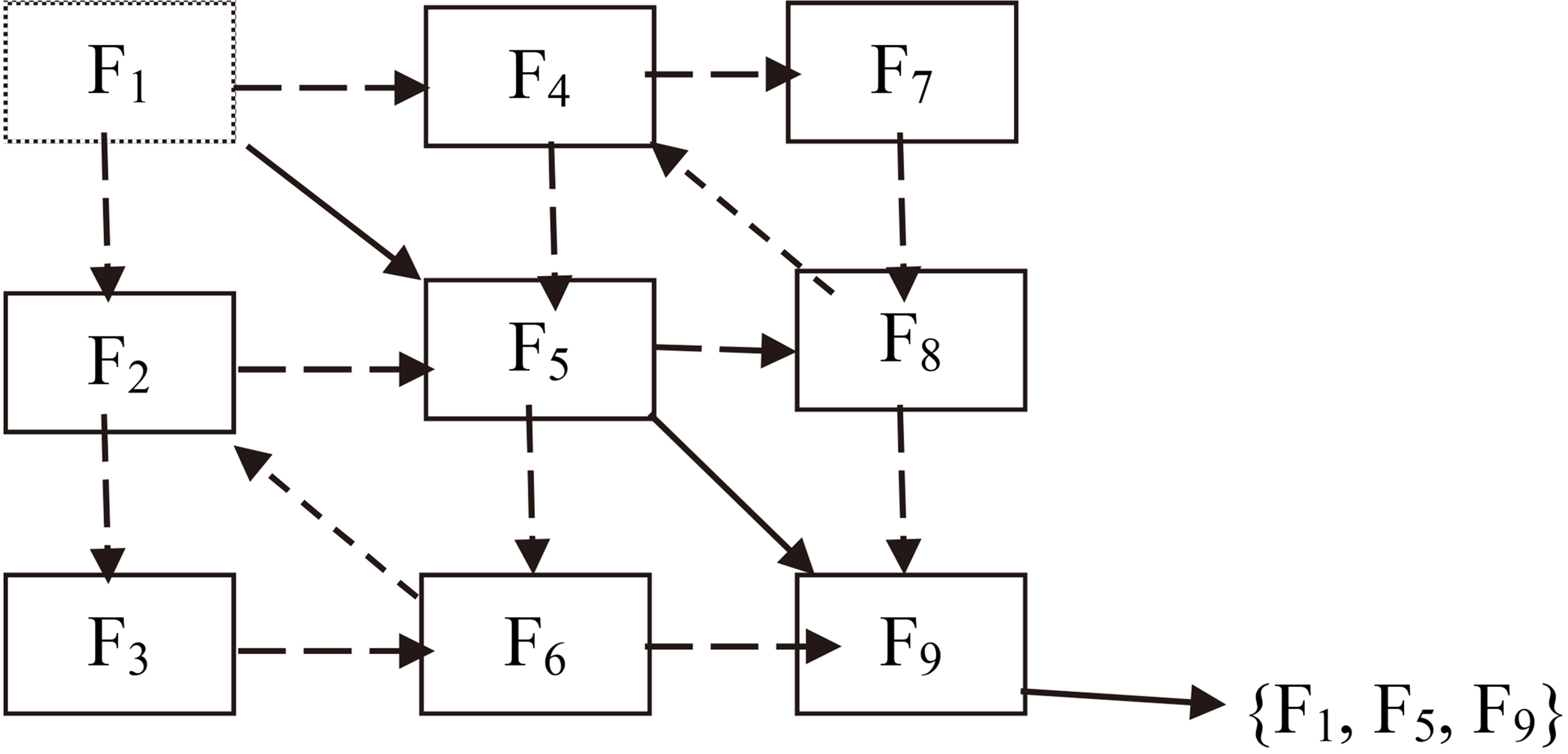
Heuristic value
A heuristic value is also called heuristic information or, as in [19], heuristic desirability. A heuristic value is optional, but is often needed for an algorithm to achieve high performance [47]. A heuristic value,
According to [47], in most studies on ACO algorithms, the probabilities for selecting the next nodes are called transition probabilities. In this study, ants were placed in
where:
The PTR value is a combination of the heuristic value and the pheromone value, which is related to feature
Pheromone update rule
The pheromone update rule in the ACO algorithm is the most important aspect of the feature selection process. This study used two types of pheromone update rule [31]: (a) local pheromone update rule that is applied by each ant while constructing solutions; and (b) a global update rule that refers to the global-best ant, i.e., the ant that made the best route from the start of the search in the current iteration.
Every time an ant visits a node, it adjusts the pheromone level by using the local pheromone update rule, shown by Eq. (5):
where:
Once all the ants have created their routes, only the overall best ant that has created the shortest route from the visit starting point was allowed to update the pheromone by using the global pheromone update rule shown by Eq. (6):
where:
Equation (7) was used for all nodes, where
where:
The main purpose of pheromone evaporation is to avoid stagnation, which is a condition that requires ants to build similar solutions. This can give the optimum solution from the ants’ exploration to obtain the optimum feature subset.
The general ACO-KNN feature selection process applied in this study is depicted in Fig. 4. The process started by declaring all the variable values used in the ACO-KNN algorithm. Next, a number of ants were placed randomly on the graph. The chances were that the total number of ants on the graph is the same as the number of features in the dataset. Then, the ants would start to chart their routes from their original positions and go to all the nodes until they meet the stopping criteria that have been set. If the stopping criteria are not met, the pheromone value needs to be updated and the process is repeated again with a newly created set of ants. The function of ACO is to guide the feature selection process, while KNN functions as a classifier to evaluate the candidate subsets of features.
Phase 3: Detection of relationship between the features and sentiment words
After the optimum feature subset has been obtained, the next step was to identify the relationship between each feature in the optimum feature subset and the sentiment word in a customer review sentence. This study used the hybrid role of typed dependency relations (TDR) and part-of-speech tagging (POST) algorithm [49], which was designed to identify the relationships between the words present in a sentence. This approach used the Stanford Typed Dependencies to obtain grammatical relationships in a sentence. In [49], a list of combination rules was created using TDR and POST to identify the relationship between the feature and sentiment word present in a sentence, as shown in Table 4.
Rules for typed dependency relations and POST for NSUBJ (adopted from [49])
Rules for typed dependency relations and POST for NSUBJ (adopted from [49])
Overall process of proposed ACO-KNN algorithm.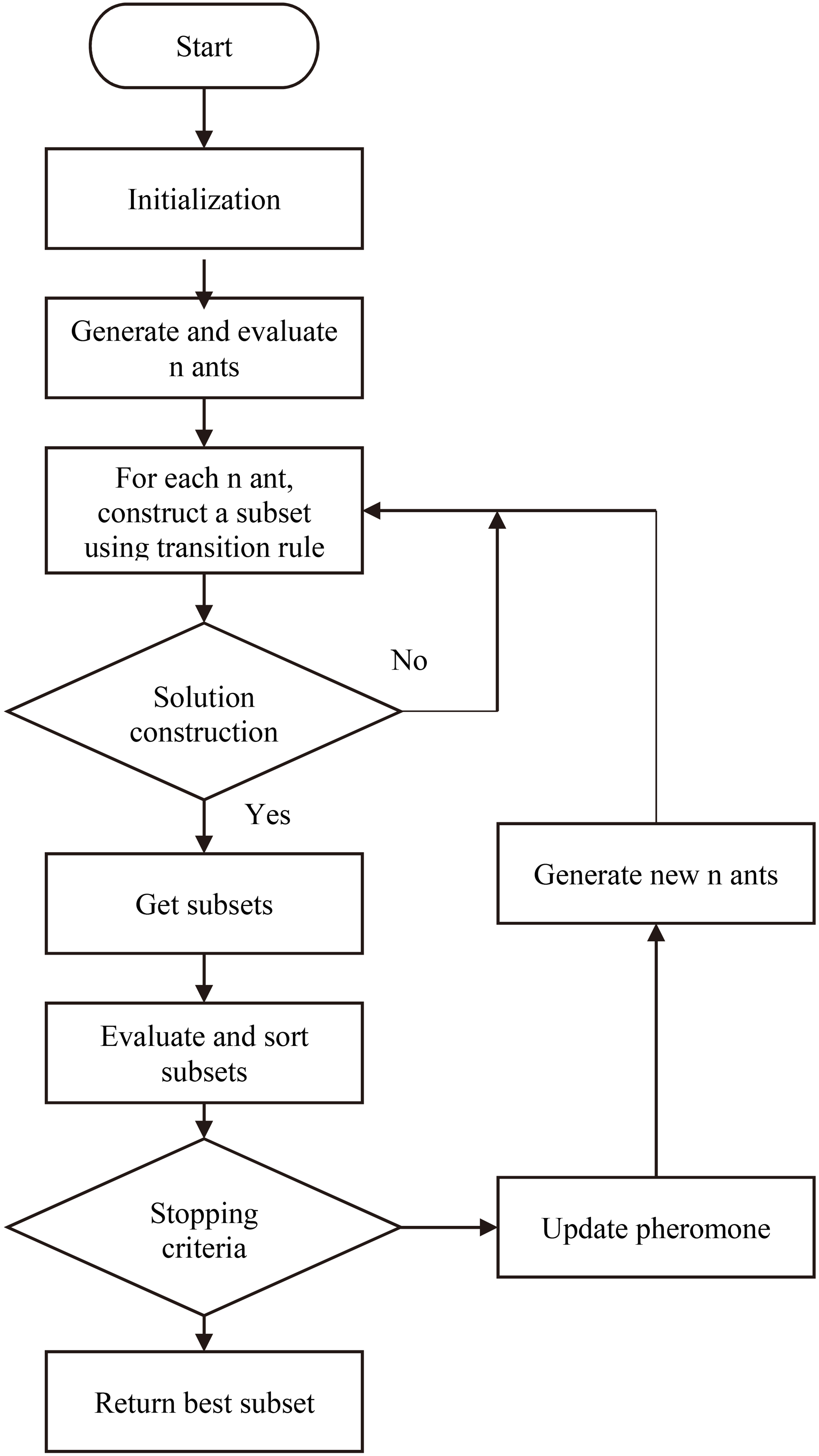
The algorithm developed by [49] was able to detect up to five TDR layers when identifying features and sentiment word relations based on the analysed results of the proposed algorithm. For example, the relationship between a word and another word in a sentence is defined as ‘one layer TDR’. Additionally, the relationship between more than one TDR layer is known as ‘multiple layer TDR’.
The following describes the process of identifying the relationship between a feature (F) and a sentiment word (S), in one layer and in multiple layers.
Example:
One layer:
The dependency relationship for the sentence: This recorder is perfect.
Sentence 1
Dependency relationship
The word “recorder” is the feature. The word “perfect” is the sentiment word. The “recorder” is a noun, which is the subject. The word “perfect” is the complement of the copular verb. In this relationship, the TDR layer is NSUBJ(perfect/JJ
ii) Multiple layers:
The dependency relationship for the sentence: The video quality works excellent.
Figure 6 shows a combination of three (TDR AMOD-NSUBJ-XCOMP) layers, which is categorized as the ‘multiple TDR layers’ (video/JJ
In this study, sentiment classification was manually checked. Output from phase 3, which was the pair list (feature, sentiment word), was manually checked against the information present in the customer review dataset. Checking has to be done to ensure that the previously extracted features and sentiment words are similar to the information present in the existing dataset.
Phase 5: Testing, evaluation, and analysis
Dataset
The data used in this study were from customer review datasets that have been used in [1, 2]. The customer review datasets were from the Amazon website and covered five different types of electronic products (see Table 5). Each review consisted of a review title, product features, and opinion strength. There were also review sentences that did not have any features in them. This research had only focused on review sentences that contained product features and opinion words. The datasets were manually annotated by [1]. For example, the sentence, “This camera is perfect for an enthusiastic amateur photographer” would receive a tag “camera [
Summary of product features in customer review datasets
Summary of product features in customer review datasets
The five electronic product datasets in Table 5 were used for comparisons and to evaluate the effectiveness of the proposed algorithm. The prepared experimental data were divided according to certain percentages. Generally, based on the data mining approach, a dataset would be split into two groups, namely, training data (90%) and test data (10%). To avoid any discrepancy that might arise due to the selection of only certain samples, this data allocation process was repeated 10 times using random sample selection, so that the training data and the test data became interchangeable. These data were represented in 10 training datasets and 10 test datasets, with a 90% training and 10% test allocation without overlap between the two. This process is known as 10-fold cross-validation. The value 10 shows that the data have been tested comprehensively and are a suitable representation for generating the best error prediction [50]. The overall customer review dataset consisted of five electronic product datasets. Each dataset has 10 divisions based on different percentages, which were 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, and 100%. Each percentage contained a different dataset that did not overlap. This means that the proposed ACO-KNN algorithm and the baseline algorithms (IG-GA and IG-RSAR) had to be run 10 times for each dataset, with different data percentages.
For the two baseline algorithms, a combination of IG and GA, and a combination of IG and RSAR were chosen for the following reasons:
The GA is a metaheuristic technique that has been proven to be an effective feature selection technique in [6] for sentiment analysis. Furthermore, IG was combined with GA in [6] and was found to be able to filter and choose quality features. Therefore, the combination of the GA and IG techniques was deemed effective. Thus, this combination was considered to be potentially useful as a baseline algorithm in this study. By comparing the proposed ACO-KNN algorithm with the IG and GA hybrid, the effectiveness and ability of the ACO metaheuristic and that of the GA as a feature selection technique for analytical research on sentiments could be evaluated. The RSAR was merged with IG in [9] as a feature selection technique for sentiment analysis. The experimental results showed that the combination of IG and RSAR was able to produce a good classification accuracy that ranged between 78.1% and 87.7%. The combined techniques were able to reduce redundant features and produced a minimum set of features of good quality. Thus, this combination was also thought to be suitable as a baseline algorithm to test the effectiveness of the proposed ACO-KNN algorithm as a hybrid feature selection technique in sentiment analysis.
For the evaluation, all the reviews were read and evaluated by human beings. An optimum feature subset was extracted from the reviews using the ACO-KNN algorithm. Similarly, the sentiment words in the reviews were extracted and identified as either positive or negative sentiments using the DR algorithm, as described in Section 3.4. The effectiveness of the proposed algorithm was measured according to three metrics, namely, precision (
where true positive (TP) is the number of reviews from which the algorithm correctly extracts the right feature and right sentiment words, false positive (FP) is the number of reviews from which the algorithm falsely extracts the wrong features and wrong sentiment words, while false negative (FN) is the number of reviews from which the algorithm fails to identify any features or sentiment words.
The ACO algorithm has been suggested as a feature selection technique because it is effective in exploring the entire search space and can reduce the dimension of the overall feature space. On the other hand, the KNN algorithm works well as a classifier to evaluate the candidate feature subsets by using MSE as a heuristic value. In other words, this study had utilised a wrapper approach because the ACO had wrapped the classifier to guide the search during the feature selection [18]. Thus, the combination of the two algorithms should be able to produce the optimum feature subset. The proposed ACO-KNN algorithm is explained in Fig. 7.
Experimental set-up
A series of experiments was conducted to show the utility of the proposed feature selection algorithm. All experiments were run on a machine with an Intel Core 2.10 GHz CPU and 512 MB RAM. The proposed ACO-KNN algorithm, and the IG-GA and IG-RSAR baseline algorithms, were implemented in JAVA programming language. The conducted testing and evaluation did not take into consideration the implementation time needed to create a feature subset. Testing only took into account the capability of the ACO-KNN algorithm to create a feature subset that is both relevant and of high quality. The combined algorithm should also be able to use the feature subset to identify the relationship between the feature and sentiment word present in a customer review sentence. The output was the pairing of a feature and a sentiment word. To test the accuracy of the created output, it was evaluated using precision (
ACO parameter settings
ACO parameter settings
Algorithm 1: ACO-KNN algorithm.
The capability of ACO-KNN as an effective feature selection technique in creating the optimum feature subset was tested through an evaluation of classification performance based on precision (
To show the utility of the proposed ACO-KNN algorithm, it was compared with IG-RSAR [9] and IG-GA [6]. This section presents the performance results of ACO-KNN as a text feature selection method for sentiment analysis. The algorithm was evaluated for three performance metrics, namely, precision (
The proposed algorithm had achieved the highest performance with the parameters in Table 6. However, to ensure that these values were optimum and suitable, a follow-up study was conducted to verify them.
Table 7 shows the parameter settings for the IG-GA algorithm, as stated in [6]. The EWGA was used for the feature selection process. The EWGA used the IG heuristic to weight the various sentiment features. The IG values were then integrated into the two basic parameters of the GA, which are crossover and mutation operators [6]. The IG heuristic was used to select features based on the threshold value. Then, the IG heuristic was applied in the EWGA crossover procedure to improve the quality of the newly generated solution. The mutation operator was used to factor the attribute IG into the mutation probability and the mutation probability of a bit was set to mutate from 0 to 1 based on the feature’s IG [6].
IG-GA parameter settings.
IG-GA parameter settings.
The IG-RSAR algorithm did not require additional parameter settings. However, for IG, all features with a value of greater than 0 were selected [9].
Table 8 shows the experimental results of the proposed algorithm, in terms of precision (
Performance (precision, recall, and F-score) of ACO-KNN, IG-GA, and IG-RSAR on customer review datasets
Table 8 clearly shows that the proposed ACO-KNN algorithm has the ability to obtain higher precision and recall values compared to the IG-GA and IG-RSAR algorithms.
Figures 8–10 show the average for precision, recall, and F-score values, respectively, for the three algorithms. From Figs 8 and 9, the average values for precision and recall of IG-GA were 74.1% and 76% (Nikon), 73.3% and 61.6% (Nokia), 63% and 60.5% (Apex), 78.8% and 83.4% (Canon), and 82.6% and 84.5% (Creative). Figures 8 and 9 show that the average values for precision and recall of IG-RSAR were 72.3% and 84% (Nikon), 62.8% and 61% (Nokia), 62.4% and 60.5% (Apex), 76.2% and 85.3% (Canon), and 78.3% and 80.2% (Creative). Therefore, the combination of IG and GA was generally more effective than the combination of IG and RSAR because the former has better average precision and recall values. However, it showed a slightly lower performance for precision, recall, and F-score on the Apex dataset.
Comparison of average precision for ACO-KNN, IG-GA, and IG-RSAR.
Comparison of average recall for ACO-KNN, IG-GA, and IG-RSAR.
Nonetheless, the proposed algorithm had outperformed both of these algorithms in terms of precision and recall for all five datasets. Thus, it is clear that ACO-KNN has the ability to choose the best features from real-value datasets, even those that contain a mixture of irrelevant or redundant features.
Comparison of average F-score for ACO-KNN, IG-GA, and IG-RSAR.
Moreover, Fig. 10 shows that the proposed algorithm was able to achieve a higher F-score compared to the other two algorithms. This result indicates that ACO-KNN was effective in extracting features and superior to the baseline algorithms.
This section provides the results of Experiment 2, which was conducted to evaluate the performance of ACO-KNN, IG-GA, and IG-RSAR in selecting features for the feature subset. The purpose of conducting Experiment 2 was to investigate whether the number of features in the feature subset would affect the sentiment classification performance. Figures 11–13 and Table 9 show the results of the comparison between the classification performances of ACO-KNN, IG-GA, and IG-RSAR for five types of customer review dataset in terms of average precision, recall, and F-score against the number of features selected.
Figure 11 clearly shows that the proposed algorithm (ACO-KNN) was able to produce the best solution between five to nine features and a high classification performance based on precision, recall, and F-score values, of 71% to 92%.
Comparison of average for precision, recall, and F-score and the number of features selected by ACO-KNN.
In contrast, as shown in Fig. 12, the average classification performance of IG-GA is between 60.5% and 85.3% when an average of six to eleven features was selected. Moreover, Fig. 13 shows that ACO-KNN was better than IG-RSAR, which has a classification performance of between 60% and 85% when six to 11 features were selected. Thus, the ACO-KNN algorithm was deemed capable of selecting a smaller number of features that are of good quality, so it can produce a better classification performance compared to the IG-GA and IG-RSAR algorithms.
The following Table 9 displays the comparison of the overall average for the ACO-KNN, IG-GA, and IG-RSAR algorithms. It was clear that the ACO-KNN algorithm was capable of acquiring, on average, the minimum number of features (i.e., six) compared to the other two algorithms. It was able to achieve a high classification performance of 81.5% of precision, 84.2% of recall, and 82.7% of F-score. In contrast, the IG-GA algorithm had only achieved 74.4% of precision, 73.2% of recall, and 73.1% of F-score with nine features. IG-RSAR was able to obtain 70.4% of precision, 74.2% of recall, and 71.8% of F-score with nine features. Thus, Experiment 2 had proven that the ACO-KNN algorithm is capable of acquiring the minimum number of features with high classification performance.
Average values of performance and number of features selected by ACO-KNN, IG-GA and IG-RSAR
Comparison of average for precision, recall, and F-score and a number of features selected by IG-GA.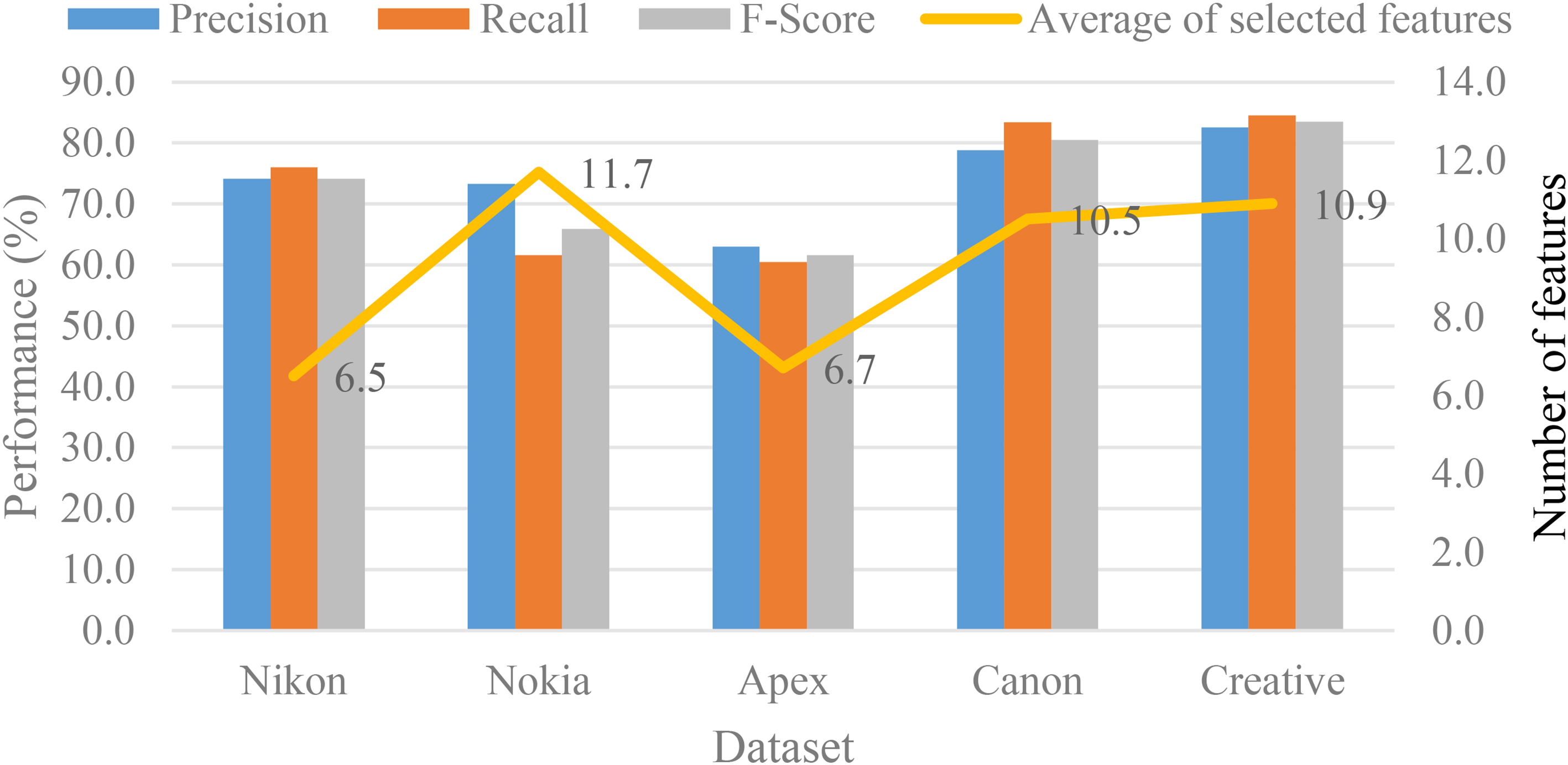
Comparison of average for precision, recall, and F-score and number of features selected by IG-RSAR.
Significantly, it can be said that using ACO-KNN for feature selection had improved the performance of classification, with the minimum number of features. As previously explained, the feature selection process is a very important task in choosing the best features.
This study showed the capability and efficiency of the proposed ACO-KNN algorithm, which was suggested as a suitable feature selection technique for sentiment analysis. To determine its effectiveness, the performance of ACO-KNN was compared with that the performance of two other hybrid algorithms, IG-GA and IG-RSAR. The results have shown that ACO-KNN could achieve the highest performance with the parameters, as shown in Table 6. The values of these parameters were appropriate for the experiments that were conducted. However, the experiments were not designed to investigate whether these parameters would be the optimum values for ACO. Therefore, an in-depth investigation was necessary to determine the optimum parameter values needed to implement the ACO as a feature selection technique in sentiment analysis research. The parameter values can help in obtaining the minimum, optimum, and high-quality feature subsets.
The natural phenomenon of ants looking for the shortest route between their nest and food source is the main basis of the ACO algorithm. This idea was used as the guideline for the ants to look for the correct path, which is critical for high-quality problem solving. Thus, ACO was able to provide a guideline for ants during the feature subset building process by determining the subset size. When applied to the search space, the ACO algorithm has the capacity to produce a feature subset. Furthermore, a heuristic function can be used to assess the quality of the features that the ants visit. A good heuristic function could help in solving the problem of feature selection by ACO. This study used the KNN algorithm as the heuristic function for each feature that the ants visit. Each feature has its own heuristic value that helps the ants decide which node to choose.
Several experiments were conducted to assess the capability of the ACO-KNN algorithm when applied to five different datasets (see Table 1). Based on the results in Sections 5.1 and 5.2, ACO-KNN was found to be highly competitive with the baseline algorithms, has the ability to converge quickly, has a strong search process in the problem space, and was efficient in searching for the minimum and optimum feature subset.
This study had implemented the wrapper approach in the feature selection process. The KNN algorithm was used as a classifier to select and evaluate the candidate features using MSE as a heuristic value. The ACO algorithm was used to guide the search in the feature selection process. In other words, ACO had wrapped KNN in the feature selection process.
In ACO, if the optimum feature subset is not acquired, a pheromone update process would take place, a set of new ants would be created and the process would be repeated in further iterations. The search for the optimum feature subset is done through the ants’ traversal of the graph. When an ant traverses a path and has selected a feature, the feature is not selected again for the same path. This limitation was implemented in the ACO algorithm in this study to avoid selecting the same feature again. Therefore, the selected feature subset will have different features.
The advantages of the ACO algorithm, such as its powerful ability to explore the feature space, its robustness, and the ease with which it can be combined with other classifiers, such as KNN, nearest neighbour, the entropy-based measure, or the rough set dependency measure, could enable it to create the best feature subset to facilitate the search for the optimum quality feature subset. The role and advantages of ACO in assessing and selecting high-quality, optimum feature subsets, can produce good sentiment classification, as shown by the results presented in Sections 5.1 and 5.2.
Based on the results, using ACO-KNN combination in searching for and assessing features was possible with algorithms that are competitive in producing optimum, minimum, and high-quality feature subsets to increase classification accuracy.
Conclusion
This paper suggests the use of a wrapper approach, in which an ACO algorithm was wrapped around a KNN algorithm as a classifier, to evaluate the candidate subset features using the MSE value as the heuristic value. In other words, the proposed ACO-KNN algorithm had guided the feature selection process and used KNN to evaluate the candidate subset of features. Extensive experiments were conducted to evaluate the performance of the proposed ACO-KNN in finding noticeable features in different datasets. In the proposed hybrid algorithm, the MSE value of classification and the feature subset length were considered as suitable measures to evaluate the performance of the algorithm. Based on the results, this algorithm was able to select the optimal feature subset without prior knowledge of the features. The computational results have indicated that the proposed ACO-KNN algorithm could achieve good performance with a smaller number of features. The main contribution of this paper is that to the best of the authors’ knowledge, this is the first work that used ACO in this way for feature selection in sentiment analysis. The advantages of using ACO are that it is fast and efficient in searching for the optimum solution to obtain the minimum length of feature subset. Additionally, ACO is a good feature selection method that can be used to guide the selection process. Thus, it can be applied quite readily, in combination with another algorithm that acts as a classifier to find a good solution. The hybrid ACO-KNN algorithm had shown promising performances in terms of precision, recall, and F-score. It had performed better than IG-GA and IG-RSAR, except in the case of the Apex dataset. Therefore, it is necessary to find parameter settings that are more suitable for the ACO part of the hybrid algorithm to guide the ants to find the best subset of features.
Footnotes
Acknowledgments
The authors gratefully acknowledge Universiti Pertahanan Nasional Malaysia and Ministry of Education Malaysia, as well as the Fundamental Research Grant Scheme for supporting this research project through grant no. FRGS/1/2016/ICT02/UKM/01/2.