
Abstract
The rapid growth in web development has transformed today’s communication. The combination of features and corresponding sentiment words (SWs) can help produce accurate, meaningful, and high-quality sentiment analysis (SA) results. There are some basic matters in the study of SA that must be understood, namely, the objects or entities that form a key part of the discussion, the characteristics or features of the object, the SWs, and the connection between the features of the object and the SWs. Failure to identify these basic matters can reduce the accuracy and meaning of the SA results. The main objective of this review is to offer an overview of the role and techniques of feature selection (FS), SWs detection, and the identification of the relationship between features and SWs. The main contributions of this review are its sophisticated categorisations of a large number of recent articles related to FS techniques and the detection of SWs. It also highlights the recent trends in the field of SA research. This review will also look at the metaheuristic approach as a FS technique in SA, identify the strengths and weaknesses of existing FS techniques, and analyse the potential of the metaheuristic approach for solving problems that exist in the selection of features in SA.
Keywords
Introduction
Analysis of consumer comments on a website is important in helping consumers find information or for companies to reformulate ideas for marketing products. Nowadays, most consumers buy groceries and daily necessities using online shopping portals. Consumers also express their satisfaction or dissatisfaction about purchased products through websites, such as Facebook and Twitter, or in forum discussions or blogs. This leads to a collection of information that contains consumers’ opinions, and this collection is increasing in size. There should be a method for collecting consumers’ opinions or comments that can summarise the expressed information so that the essence of a product and the advantages or disadvantages expressed by consumers can be identified. In this way, manufacturers or producers can gain knowledge of the advantages and shortcomings of their products. Such information would enable them to improve the quality of their products. In the past, if an individual is curious about the advantages or disadvantages of a product, they would have to ask their friends or family who had purchased the product. Meanwhile, producers or manufacturers who wanted to get consumer feedback about their products would have to conduct surveys. However, things have currently changed with the development of sophisticated information technology. Social media, such as Facebook, blogs, Twitter, and forum discussions play various roles in providing information to both consumers and manufacturers. Thus, there is a need for a method that can analyse the information available in the said social media. However, due to the large volume of information, it may be difficult to gather accurate information that can assist in decision making. Sentiment analysis (SA) attempts to address this need. SA is a type of text analysis that falls under the broad heading of text mining, which involves natural language processing (NLP) and computational intelligence. However, three fundamental problems must be considered when developing an effective SA method, namely, feature selection (FS), identification of sentiment words (SWs), and sentiment classification [1, 2].
Therefore, the purpose of this review is to present recent studies in this field that would be useful for researchers in developing effective methods for SA. This review is important for the following reasons:
This review provides a sophisticated categorisation of a large number of recent articles based on FS techniques, and in identifying SWs and the relationships between the features and the SWs. These categories can be useful for researchers who are familiar with certain SA techniques, to use and choose the most applicable technique for certain applications. The various SA techniques are categorised with brief details of the algorithms and their originating references. This review offers a panoramic view of the current state of play in this entire field of research to researchers who are new to the SA field. This review highlights the role of different FS methods in identifying SWs, as well as the advantages and disadvantages of each technique. It identifies the limitations in the existing FS techniques. Finally, this review discusses the challenges in identifying features and SWs in SA, and the more specific challenges that are encountered in the SA research. Therefore, the overall aim of this study is to provide information and guidelines on the components of SA, namely, FS, identification of SWs, and analysis of the relationships between words that have been derived from previous researches, including the latest work in this field.
This research field has grown, as shown by the publication of several survey papers in the past few years. In this review, these papers have been categorised according to the sub-tasks in SA. These categories include FS, identifying SWs and the relationships between them, and the challenges faced in identifying features and SWs in SA. Each section of this article presents the results of a comprehensive literature review on each sub-task.
To achieve the above-mentioned goals and identify the methods selected by previous researchers, the result assessment method, and the advantages and limitations of each technique used for selection of features in SA were analysed based on the following research questions (RQs):
RQ 1: What are the main goals of the researcher being reviewed? RQ 2: What is the proposed and appropriate approach for FS in SA? RQ 3: What are the proposed and appropriate approaches for identifying SWs? RQ 4: What are the proposed approaches to identify pairing between feature and SW in sentences?
The remainder of this article is organised as follows: Section 2 discusses the previous studies on FS in SA. In Section 3, the definition and components of SA are explained, and several related articles on FS techniques in SA are discussed. In Section 4, the identification of SWs is defined and the methods used to identify them are explained. A discussion on the challenges in identifying features and SWs is also presented in this section. Section 5 discusses several suggestions to improve the limitations of the current method. Finally, Section 6 concludes this review and offers several directions for future work.
Previous literature has conducted explicit systematic studies on the overall descriptive observations and challenges of SA. In [3], an overview of the fundamental features of SA was reported, which explained the techniques and approaches related to the process of classification, extraction, and summarisation. They also assessed issues pertaining to privacy, manipulation, and economic impacts on developing an information database service with customer-review-oriented information. Additionally, they offered a guideline on the dataset used for experiments, campaign assessments, lexical sources and tutorials, and bibliographies in their study.
In [4], the authors discussed, in general, the selection techniques, semantic orientations of texts, sentiment classifications, and common issues in SA. A study by [5] presented a more elaborated discourse on sentiment classification techniques, FS techniques, and sentiment identification tools in social networking sites. Their study had also analysed the functions of negative words in customer review, apart from reviewing the effectiveness of the suggested techniques based on the sources of dataset. Their findings led to the conclusion that a combined classification approach could overcome the limitations of singular approaches in sentiment classification, where a longitudinal research is necessary. In [6], the components of SA are explained by highlighting subjectivity and polarity classification, opinion target extraction, opinion source identification, opinion summarisation, and the issues and challenges encountered in SA. Extensive explanations on the techniques used in each component were also presented. In terms of data collection, they collected the personal opinions of social media and web blog users. The data were used to test the validity of the opinion representation model, to develop new models and components of SA, and to identify problems related to SA.
A survey was conducted by [7] on relevant literature published from 2010 to 2013, to get an overall view of the techniques used in SA. Among these techniques were the FS technique, sentiment classification technique, which includes machine learning technique and lexicon approach, and other relevant techniques. Their paper also included a narrative review on external fields related to SA, such as emotion detection, building resources, and transfer learning. An analysis on different algorithmic patterns, dataset representations, and analytical methods used in SA were also conducted by covering the aspects of classification techniques, polarity strength calculations, and other analytical methodologies. Several graphs were extrapolated based on certain criteria, such as the algorithmic categorisation of articles based on sentiment counts, numerical analysis of sentiments in different domains (i.e., customer reviews, web blogs, and news), and numerical analysis of sentiments in different languages. They also considered the research gaps in previous SA studies, which included errors in data sets, barriers in language, and inappropriate tools for natural language processing (NLP).
The main purpose of this current review is to determine the prospects of using metaheuristic approaches as a FS technique. Additionally, this review paper is also aimed at identifying the relationship between feature and SWs, with its related problems. Thus, published studies from 2003 to 2016 were reviewed and can be summarised as follows:
This paper put forth extensive discussions on FS techniques in SA studied by previous scholars. The fundamental objective of this review was to identify the limitations, advantages, problems, and gaps of each technique. In addition, the frequency in which a metaheuristic approach was used in this topic was also determined. The appropriateness of metaheuristic approach for FS technique in SA was also reviewed, apart from conducting comparative analysis with traditional text classification. To note, both sentiment classification and traditional text classification apply text dataset. Detailed explanations are provided in Sections 3.4 and 3.5. This paper has also discussed different techniques for identifying the relationships between features and SWs. The advantages and limitations of each technique were also discussed. Additionally, the relationship between feature and SWs in customer reviews was thoroughly examined. This could provide clearer directions for future researches on what particulars should be given attention to while implementing the process of feature and SW matching. This review was only focused on opinion sentences (review sentences that contain opinions for product features).
Definition of sentiment analysis
SA is an increasingly important technology for analysing consumers’ opinions and for producing simple information that can represent these opinions as a whole. According to [8], SA is also known as opinion mining, which is defined as a type of research that analyses opinions, comments, thoughts, attitudes, and assessments of human emotions towards entities, such as products, services, organisations, politics, current issues, events and people, and the features that exist in these entities.
Components of sentiment analysis
Based on previous researches [1, 8, 9, 10, 11, 12], SA is composed of the following six main components (see Fig. 1):
Components of SA.
Data preprocessing is a process of removing words that do not give any meaning or are not required, which improves the accuracy of the search for important word(s) in each sentence. Available ways to preprocess data based on text include removing stop words, tokenization, sentence splitting, word stemming, misspelled words, and part of speech tagging (POST). Data transformation is a process of transforming text data into feature vectors. It is used because SA focuses on text documents. These data cannot be directly interpreted by a classifier. Therefore, text documents must be transformed into a format that the computer can identify, and the vector space model is the favoured method to do this. This model transforms a document into a multi-dimension vector, and the features selected from the dataset are dimensions of this vector. Feature vectors represent the data objects in the feature space. FS is a process of identifying and eliminating redundant and irrelevant features from a list of features to reduce feature dimensions and to improve classification accuracy. FS is important in SA as the selected feature subsets need to accurately represent the features of the objects commented on by consumers. Sentiment word identification is a step to identify sentiment words that can be linked to a feature in a sentence. Based on several studies [1, 11, 12, 13, 14, 15], the word in a sentence that is tagged with JJ/JJR/JJS is an adjective, which usually represents a SW. Determining the feature-sentiment word relationship is an important process because such relationship(s) could be rather complex, if the sentence contains more than one feature or SW. Sentiment classification is a process that looks at the document, sentence, or feature level to determine which documents, sentences, or features express a positive, negative, or neutral sentiment. Testing and Evaluation is a process of testing the accuracy of the relationship between the feature and the SW. Evaluation is conducted to test the accuracy of the relationship between the feature and the SW, as well as the accuracy of different types of sentiments for comments that are either positive or negative.
A feature is an aspect that users comment about in relation to products, politics, services, organisations, events, and/or individuals. SA deals with information in the form of documents that contain a group of sentences in text format. When dealing with data in text format, it is usually represented by a feature vector, which is a group of words, or also known as the set-of-words approach [16]. Features are categorised into two main types [17]:
A list of words in a document, which can be in the form of a unigram, bi-gram, or tri-gram. As POS tags, which are used to identify each word in the document, i.e., whether it is a noun, adjective, verb, adverb, preposition, or determiner.
The type of feature commonly used in SA is the n-gram [18, 19]. According to [19], the large size of the n-gram feature set requires a suitable FS technique, and they suggested two categories for the n-gram feature, namely, fixed and variable. The fixed n-gram is a sequence occurring at the character, or at the token level, whereas the variable n-gram is a pattern extraction that represents a more advanced linguistic phenomenon. There are various types of fixed variables that can be used in SA, such as word, POS, character, legomena, syntactic, and semantic n-grams. Examples in the form of words include bag-of-words (BOW), bi-gram, and tri-gram. An n-gram character is a sequence of letters. For example, the word “like” can be represented by two or three sequences of letters, such as “li”, “ik”, “ke”, “lik”, and “ike”. Earlier studies have used the n-gram character to classify emotions in texts [20]. The n-gram legomena refers to collocations that are used to replace words that only occur once in a corpus. For example, the tri-gram sentence, “I hate JIM” can be replaced with “I hate HAPAX”, provided that “JIM” occurs only once in the corpus, or it is a unique word [21]. There are two ways of handling a feature in SA, namely, feature extraction and FS.
A. Feature extraction
Researches by [8, 11, 12, 22, 23, 24] have extensively used feature extraction. According to [25, 26], feature extraction is the identification process of the features of a product as commented by users. Meanwhile, [27] stated that feature extraction functions by selecting candidate features from noun phrases in sentences and extracting relevant opinions as information. Additionally, [8] argued that feature extraction can be seen as an information task.
B. Feature selection (FS)
FS has been differently defined to fit the different perspectives of the authors concerned. The problem of selecting the right features is often discussed in relation to its functions involving supervised and unsupervised machine learning, such as classification, clustering, regression, and time-series prediction. The definition by [28] stressed that the aim of a FS technique is to improve the accuracy of the prediction, or to reduce the size of the structure by selecting a feature subset without significantly reducing the accuracy of the classifier prediction that was built using the selected features. According to [29], FS is a set of feature lists from which the classification system can select a subset of the best features. Meanwhile, [30] showed that the problem with FS lies in selecting an
Consideration of all the subsets possible for Selecting the subset with a big value for the classification step.
This is contrary to the definition by [15], whereby FS was defined as a process to select a minimum feature subset from a list of original features, based on a number of specific selection criteria. Similarly, according to [31], FS can be done by selecting features based on a specific metric measurement, and irrelevant features are removed based on a specified threshold value. The reduced number of features might increase the effectiveness of the training and assessment procedures, and enhances the classification performance. In [32], the authors stated that FS involves selecting a suitable feature subset, which could help create a good prediction model. Several studies [33, 34, 35] have defined that FS is for selecting irrelevant and excessive features. They also found that the best FS technique would be to apply an algorithm that interacts with large-sized data, including irrelevant features, to create a subset of relevant features with a suitable target class. Meanwhile, according to [35], FS is a process of identifying and eliminating excessive and irrelevant features that could be present in the feature list.
The definitions by [17, 36] suggested that FS could reduce the dimension space of features. According to [36], FS can be defined as a method of reducing a large-sized feature space, for example, by eliminating the less relevant features to create a set of suitable features. According to [17], FS is a way of selecting important features by removing irrelevant features. Only a few published studies [17, 19, 37] have examined how reducing feature vectors containing only irrelevant features could speed up the calculation process and improve classification accuracy.
To avoid confusion and to standardise the terminologies used in this paper, the term “feature selection” is generally used to explain the techniques in feature extraction. Additionally, the term “feature selection” is also understood as it was used in previous studies [31, 38, 39], with regards to SA. Thus, in the context of this review, FS is a process of identifying and eliminating excessive and irrelevant features from the feature list to reduce the size of the feature dimension space and helps to improve the accuracy of sentiment classification.
This study was focused on two types of FS techniques. The first type was FS techniques using the NLP approach that refers to feature extraction. The second was FS techniques that use combinations of NLP and non-NLP approaches (which will eventually use machine learning algorithms). NLP and text mining are investigative approaches that aim to gather rich knowledge resources through the abstraction and retrieval of thoughts or features from unstructured text. Figure 2 shows the FS categories in SA.
FS categories in SA.
The following are some examples of FS techniques using the NLP approach:
Parts of speech tagging (POST): Known as grammatical tagging, or word-category disambiguation, POST is the process of marking up a word in a text (corpus) as equivalent to a specific part of speech. In POST, each term in a document or in sentences is allocated a tag or label that represents its position in the grammatical context. For example, “This camera is very good and perfect,” becomes, “This/DT camera/NN is/VBZ very/RB good/JJ and/CC perfect/JJ,” after POST. The nouns and adjectives in this sentence can be identified from this tagging process, and these can be used for selecting features and as sentiment indicators.
Opinion words and target relations: The relationship between the feature and the opinion words can be exploited to extract the feature. This relationship can be shown by the dependency parser, which is used to identify the dependency relation for a selection of features.
Topic modelling: In this method, a generative probability model that uses a distribution of vocabulary was applied to discover topics from a large collection of text documents [40]. Topic modelling is an unsupervised learning method and its function is to identify the mixture of topics in each document [8]. The output from this method is a group of words. For example, in a collection of documents on comments about a camera, the relevant topics would include memory card, battery, megapixels, viewfinder, weight, and price.
Negation word: This is also an important feature to take into consideration because it can change the sentiment’s orientation. For example, “not bad” corresponds to “good”.
Rules of opinions: These are terminologies or language structures that can be used to describe sentiments and opinions.
In [12, 14], the NLP approach was applied to identify the features in comment sentences. POST was used to assess each sentence, and the words in the sentences that were tagged as NN/NNS/NNP/NNPS were identified as nouns or noun phrases, namely, features. The association rule mining [41] was used to determine frequent features, which are sets of commonly used words or phrases. In their studies, [12] assumed that features can be divided into two types: frequent and infrequent. They argued that an infrequent feature could lead to problems in identifying SWs because it might contain nouns or noun phrases that have no connection to the product. They also argued that infrequent features only have a minor impact of 15%–20% on their proposed system. Therefore, only the frequent features were considered in their studies. They used the concept of the “nearby adjective” in identifying SWs. Thus, if a word is tagged with JJ/JJR/JJS, the word is an adjective, thereby, it represents a sentiment word that is the nearest to the frequent feature. In an investigation into FS, [15] used POST to generate the POS tag of each word (to identify nouns, verbs, adverbs, and adjectives), and an n-gram was used to produce shorter segments from long ones.
In a more recent study, [23] used POST to parse each sentence and generate a POS tag for each word in the sentence. After the POS tagging process was completed, they extracted and identified the nouns and noun phrases in the sentences using the concept of “pattern knowledge”. Eight patterns of knowledge were generated in identifying features in sentences. Meanwhile, the extracted SWs had tagging of adjective/JJ, or adverb/RB and were the closest to the extracted feature. According to [24], there are three steps in the process of extracting features of sentences. In the first step, input documents are converted into tagged documents using the POS tagging software. In the second step, evaluative expressions are extracted using the combined pattern-based noun phrases (cBNP) technique. Lastly, this algorithm extracts product features that are usually represented by noun phrases. In their study, [24] used a list of opinion lexicons for identifying sentiment-hood.
Meanwhile, [11] proposed the “Know-It-All” system to extract explicit features from parsed review data. This system is known as OPINE and works recursively in identifying the “parts” and “properties” of product classes. The process stops if there is no “candidate” to be identified. The system searches a concept that has a connection and extracts the said “parts” as well as the “properties”. The system would also extract noun phrases and retains the noun phrase that has a frequency value of greater than the specified threshold value. The process of evaluating the acquired noun phrase is based on a Pointwise Mutual Information (PMI) score between a phrase and a meronymy discriminator that has a connection with the product class. The process of identifying SWs uses explicit features, but is based on syntactic dependencies identified by a MINIPAR parser. Based on the extracted rules, OPINE will search the lexical heads for potential SW phrases. The system identifies the semantic orientation of each lexical head that has a semantic orientation with a positive or negative feature and retains this as the opinion phrase.
In their study, [18] had successfully used term presence compared to term frequency in their sentiment classification of movie reviews. They applied a unigram (BOW) as the feature type to classify movie reviews into two classes, namely, positive and negative. In [42], the authors investigated the differential impact of classifying product reviews using n-grams, bi-grams, and tri-grams. In their research, they obtained good performances for classification using bi-grams and tri-grams.
In [9], “linguistic filtering patterns” and a “general inquirer dictionary” were used for extracting a list of product features. Their process of identifying SWs was based on dependency analysis, which was divided into a dependency tree and a dependency path. Dependency analysis involves identifying an asymmetric binary relationship between words, known as the “head or governor”, or in other words, the “modifier or dependent”. The authors introduced and adopted six types of syntactic relationships to identify the connection between features and SWs.
In [1], it was pointed out that an “unsupervised model” and language-independent model can identify explicit and implicit features from reviews. An unsupervised model does not require a set of pre-labelled training data. Therefore, this was to their advantage because the model can easily be transferred between domains or languages. They used a graph-based approach to identify implicit features in comments. The graph was drawn based on the use of a polarity lexicon and a list of specified features. SWs from the polarity lexicon were used as nodes connected to each feature that had a connection. The authors gave an initial weight to each connection and to add more precision to the identification of implicit features, they defined a function to measure the strength of the connection between the features and SWs. Table 1 provides a summary of the FS and SW identification techniques.
FS (NLP approach) and SWs techniques
Non-NLP is an approach that is closely related to the machine learning approach. Previous studies have reported using a hybrid FS technique, which is a combination of an NLP approach with a non-NLP approach. Non-NLP approaches include the genetic algorithm (GA), information gain (IG), rough set theory (RST), decision tree, and minimum redundancy maximum relevance (mRMR). FS techniques can be generally categorised as either univariate methods or multivariate methods based on the conditions for evaluating the features. Univariate methods analyse a single variable at a time, while multivariate methods analyse more than one variable at a time. Wrapper and hybrid techniques are included in the multivariate category. There are generally three FS techniques for machine learning tasks, namely, filter, wrapper, and hybrid [34, 43, 44], which are briefly described as follows:
The filter technique is independent of any machine learning algorithm. During the filtering process, the relevant score for each feature is calculated, and the features with low scores are removed. The resulting feature subset becomes the input for the classification algorithm [45]. The wrapper technique needs a machine learning algorithm and uses it as part of the evaluation function. The hybrid technique, as the name implies, is a combination of the filter and the wrapper techniques.
A. Filtering techniques
A few conclusions can be drawn from the review of previous studies. The advantage of utilising a univariate filtering technique is that it is simple and fast, with a short processing time. However, there are also limitations to this technique; there is no interaction or dependency between features and no interaction with the machine learning algorithm. Feature evaluation is performed individually and usually, the features are listed based on their predictability. As such, the dependency between features would be ignored. Table 2 provides a summary of the advantages and limitations identified in previous studies that used the univariate and multivariate methods.
Summary of advantages and limitations of the univariate and multivariate methods
B. Hybrid techniques
The hybrid technique is a combination of the filter and wrapper techniques that was used by [15, 53]. The hybrid technique can be used to manage a large-sized dataset [44, 53, 54]. This combination of two techniques could create an optimum feature subset by using standard optimising techniques, or a metaheuristic approach, such as the GA, particle swarm optimization (PSO), and ant colony optimization (ACO) [55]. Table 3 provides a summary of the advantages and limitations of using hybrid methods for SA, as identified from the literature review.
Summary of the advantages and limitations of hybrid techniques
The FS technique and SWs are the main determinants of the accuracy of sentiment classification. SA is based on the machine learning approach and there is normally a large-sized feature space. A number of studies on SA have combined filtering and wrapper techniques to overcome the limitations that exist in each individual technique. For example, [10, 37] used the IG technique to identify important features for sentiment classification. According to [37], IG was used to measure uncertainty reduction when identifying the feature class character once the feature value has been identified. The most important features were selected to reduce the size of the feature vector and come up with a better classification. They also reported that IG is the best filtering technique because it is able to determine the importance of the features in a document. However, the IG has several limitations, such as the threshold value has to be set in advance; the method does not take into consideration the problem of excessive features; and there is no communication among the features [37, 45].
In [10], the IG filtering technique was combined with the Entropy Weighted Genetic Algorithm (EWGA) metaheuristic technique, which had successfully increased sentiment classification accuracy and produced an optimum feature subset. However, the study has its limitation in that the data was in the form of document data. Document data only considers sentiments based on the whole document without refining the content. In [57], the authors also found that SA at the feature level would thoroughly consider the feature and SWs that exist in a document. The initial stage involved conducting the process of extracting the unigram features of the document. The next stage was the process of FS using the IG technique to determine the importance of the features in the document. However, one weakness of the IG technique is that it must determine the threshold value in advance and it does not consider features that overlap [37].
To overcome this problem, [37] combined IG with RST. This technique can reduce the number of noisy and irrelevant features. The advantage of this hybrid approach is that it can consider overlapping features, as well as obtain minimum feature sets that can reduce time complexity during sentiment classification. However, [10, 37] did not clearly state the methods they used to identify SWs. However, the support vector machine (SVM) technique was used for the sentiment classification process by [10], while [37] utilised the SVM and naive bayes (NB) in the sentiment classification process to identify positive and negative sentiments in the documents. In [56], the authors proposed using a GA to extract feature collections from semantic features of emotional collections. In their work, a conditional random field (CRF) was developed for labelling web-page classifications for different types of comments, such as positive comments, negative comments, and objective comments. They did not mention the identification and the relationship between SW and feature.
Table 4 provides an overview of the available techniques for FS and SW identification.
Techniques for FS (NLP
C. Other techniques
i. Rough set theory with filtering technique
In [37], the IG technique was combined with the RST technique. The RST was used to reduce the number of irrelevant, excessive, and noisy features. The advantage of using RST is that it can take into account the combined dependency among the features [58]. However, the RST has two limitations, one of which was the difficulty of obtaining an optimum reduction in the feature subset. This was a non-deterministic polynomial-time hard (NP-hard) problem, thus a heuristic algorithm was suggested to resolve it [37]. The second limitation was its long processing time [37, 59, 60]. Thus, only a few studies have explored the metaheuristic approach for FS in SA research. Table 5 provides a summary of the advantages and limitations of using RST combined with a univariate filtering technique.
Summary of advantages and limitations of the RST method, combined with a univariate filtering technique
ii. Neural network
In [61], the authors compared three types of neural networks, namely, the probabilistic neural network (PNN), the back propagation neural network (BPN), and the homogeneous ensemble of PNN (HEN). The comparison was performed using varying levels of word granularity as a form of feature for feature level sentiment classification based on a dataset of product reviews collected from the Amazon review website. The hybrid combination of sentiment classification methods, which were based on the PNN and the principal component analysis (PCA), acted as a feature reduction analysis to reduce training time and increase the performance of the classification process. These neural networks were developed to effectively incorporate the supervision from sentiment polarity of text.
A research by [62] proposed a method to learn sentiment-specific word embedding (SSWE) by integrating sentiment information into the loss functions of the three neural networks. Additionally, large scale training corpora were acquired by learning SSWE from massive distant-supervised tweets composed by positive and negative emoticons. To evaluate the effectiveness of SSWE, a dataset from SemEval 2013 was used as the benchmark. The verification process was done by computing word similarities in the embedding space for sentiment lexicons. The results indicated that the integration of SSWE with sentiment information of sentences was able to achieve a good performance in the experiments.
Meanwhile, [63] proposed the use of recursive neural tensor networks (RNTN) to calculate the representations of compositional vector for phrases of variable lengths and syntactic types. They had also developed the Stanford Sentiment Treebank corpus, which contains label parse trees. The label parse trees allow a complete analysis on the compositional effects of sentiments in language. Ultimately, their experiment showed that compared to previous models, the RNTN was able to achieve 80.7% accuracy when applied on fine-grained sentiment prediction across all phrases. RNTN can also capture negations of different sentiments.
iii. Metaheuristic
Several metaheuristic approaches were also applied as FS methods in SA. Table 10 displays a summary of metaheuristic approaches that can be used for selecting features in SA based on dataset, and performance evaluation (accuracy, precision (P), recall (R), and F1 Score).
In [64], a two-stage prediction algorithm was presented. In the first stage, the classifier learned the conditional dependencies among words and encoded them into a Markov Blanket Directed Acyclic Graph for the sentiment variable. In the second stage, a metaheuristic strategy was used to fine-tune the algorithm to yield a higher cross-validated accuracy. Two collections of online movie reviews from IMDB and three collections of online news were used, whereby the algorithm in the dataset was then compared with SVM, NB, and maximum entropy (ME). It was illustrated that this method, in comparison to other methods, was able to identify a parsimonious set of predictive features and obtained better prediction results on sentiment orientations. Results from the experiments suggested that sentiments were generally captured by conditional dependencies among words, keywords, or high-frequency words.
In another context, [65] implemented genetic-based machine learning (GBML) for the purpose of subjectivity detection. In their study, GBML was tested with both English and Bengali news, movie reviews, and blog domains. Results displayed the precision values of 90.22% and 93.00%, respectively, for English news and movie review corpora. Meanwhile, the precision values for Bengali news and blog corpora were 87.65% and 90.6%, respectively. These experiments have proven that GBML can automatically identify the best feature set based on the principle of natural selection and survival of the fittest. In a comparative study by [66], information gain and genetic algorithm were proposed as feature reduction analysis. In their experiment, multidomain and movie review datasets were used for opinion mining. Five classification algorithms, which consisted of naive bayes (NB), logistic regression (LR), support vector machine (SVM), and two ensemble methods (bagged SVM (BSVM) and bayesian NB (BNB)) were used to compare the performance with the proposed hybrid method. Additionally, McNemar’s test was used to compare the level of significance of the classifiers. The results showed that the hybrid method had outperformed other approaches.
The authors in [67] were engaged in a comparative study on different FS techniques in SA. They found that metaheuristic techniques have been widely used for selecting features in text classification problems. Based on their review, metaheuristic techniques were able to obtain optimum feature subsets and increase the performance of sentiment classification. Therefore, they believed that metaheuristic can be potentially used as an FS technique in SA. Additionally, [68] proposed a two-step technique for text classification sentiment. During the first step of this technique, co-clustering was used on words and documents to reduce the dimensional space of SWs. During the second step, genetic algorithm was used in text classification to calculate the weights of the SWs in the text. Reviews of movies, books, and cameras were used from the ROMIP_2011 seminar as datasets. Thus, the findings from these two studies serve as proofs that the current proposed method is better than other classifiers, such SVM and lexical.
In [69], a novel multi-swarm particle swarm optimization (MPSO) algorithm was proposed to be used as an FS technique in selecting emotional features in course reviews. The researchers used a sentiment recognition concept to understand the emotions and feelings of learners. The effectiveness of the MPSO algorithm was evaluated using baseline algorithms, such as IG, mutual information (MI), Chi-square statistic, GA, and single swarm-particle swarm optimization (SSPO). From the experimental results, the MPSO algorithm was found to be effective in reducing the redundancy of text features and in recognising discriminative features. The MPSO algorithm obtained over 88% of micro F-measure and was able to reduce the dimension of initial feature space from 10,000 to 3,000 dimensions.
FS in SA using the metaheuristic approach
As previously mentioned, FS is an NP-hard problem, so it requires an efficient algorithm to solve it, such as a metaheuristic algorithm [43, 70, 71, 72]. Researches on SA require a realistic application for effective and accurate analysis as SA is a field that analyses various opinions or feelings about a variety of topics, and these can be derived from different types of information sources. Therefore, an optimum solution would be impossible to find, unless the search process was conducted thoroughly in the solution space. The metaheuristic approach could be used to find an excellent solution without having to explore the whole solution space. As in any approach, the quality of the solution depends on the methods used. Metaheuristic-based methods have already been shown to be able to solve optimization problems. However, in reality, an application would only need to find a good solution within an appropriate time frame rather than finding the optimum solution.
According to [8, 37], sentiment classification is also a text classification problem. Traditional text classification involves classifying documents into various topics, such as politics, science, and sports. It is done according to topics related to features, with words related to important topics. In contrast, classification in SA is conducted based on SWs in the document or sentences. Examples of SWs are “good”, “bad”, “excellent”, and “amazing”. These SWs denote the user’s opinion about certain objects, such as products and services, or other matters and show whether the user has made a positive, or a negative comment. In this review, the use of FS techniques based on metaheuristics in previous SA studies was compared with the use of metaheuristics in normal text classification studies. This comparison was made because both SA and normal text classification deal with the same data format, namely, text data. Thus, the advantages and limitations of each metaheuristic technique were identified in this review, for resolving the FS problem.
The metaheuristic approach is a high-level strategy and an iterative generation process, which guides the exploration of the search space by using different techniques, such as ACO, GA, and PSO [73, 74]. Table 7 provides a summary of several studies that applied metaheuristic-based FS methods to classify traditional text and sentiments. The advantages and disadvantages of these methods are summarised in Table 8.
FS techniques in text classification (traditional) using the metaheuristic approach
FS techniques in text classification (traditional) using the metaheuristic approach
The advantages and disadvantages of metaheuristic approaches
Metaheuristic techniques, such as ACO and GA have been used as the FS techniques in traditional text classification process [76, 77, 88]. Particle swarm optimization has only been used for traditional text classification in the Chinese [84] and Arabic [85] languages. Research by [77] found that only ACO was capable of obtaining the optimum feature subset. The advantages of ACO are as follows [77]:
Speed of convergence, Good search capability in the problem space, and Efficient in searching for the minimum feature subset.
However, the ACO’s processing time could be affected by the dimension problem (total number of features) and data size [77]. This problem can be resolved by combining ACO and RST [89, 90]. RST is a technique that can reduce the size of the feature by eliminating all overlapping features [58]. In another SA study by [37], in which the RST was combined with IG, one disadvantage with RST is that it struggled to obtain the optimum feature subset. Therefore, it was suggested that RST should be combined with a metaheuristic algorithm to obtain the optimum feature reduction [59, 60]. As such, the metaheuristic algorithm is seen as a potential FS technique in SA to obtain an optimum feature set. Tables 9 and 10 show the results of the various FS methods described in this review. The summary is based on different datasets and the different performance criteria that were used in the previous studies.
Based on the discussions in Section 3.4 and the comparisons listed in Table 6, GA has been widely used as a FS technique in SA. Conversely, the study by [77] and the comparative analysis in Table 8 showed that ACO has more potential than GA in producing optimal subset of features and can improve the performance of sentiment classification.
Different classifiers for FS in SA (% accuracy) adopted from Sharma and Dey [47]
Based on this review, SA technology has become a necessity because it provides many benefits to the public. SA has also become an interesting and challenging research field in this era. However, SA technology has some challenges to overcome due to the diverse information that exists on websites. Some of the factors that could be considered challenges in the field of SA are described as follows [6, 40, 57].
Accuracy: Numerous SA studies were conducted in relation to products, politics, and social media. However, SA services that are commercially available for simplifying consumers’ comments are still limited because such services require accurate and correct information to be channelled to the consumers. Failure to provide accurate information could lead to impaired quality of service. Most of the tasks in SA are done manually (i.e., with the help of humans). Companies that provide commercial services related to SA are concerned about having highly accurate information. However, there are difficulties in understanding the language used in the comments. The use of complex sentences and expressions often cause SA to generate inaccurate information [40]. This problem is literally and closely associated with gaining a more detailed and clear understanding of NLP, with regards to context dependency, semantic relatedness, and ambiguity [6]. To overcome the challenges in SA, it is obvious that each step of the process should be refined and improved [40]. A clear understanding of the process may help to improve the accuracy.
Scalability: SA technology is mostly implemented in the form of web applications. The main purpose of SA technology is to develop a fast, accurate, and efficient online information search engine that can provide sentiment summaries of the information provided by the consumers regarding products and services. It should be possible to access the search engine anytime and anywhere. Nevertheless, the huge size of data on websites, the increasing volume of information, the limited speed of the Internet, and the high data dimensionality are all challenges that need to be addressed to improve this technology. These can be overcome by applying a more complex version of NLP. In [40], the authors proposed that algorithm development is done in parallel so that the segregation of duties within SA is balanced in order for text processing to become faster. They also suggested that cloud, or grid computing should be adapted for the SA web service due to their technological advantages in terms of scalability.
Standards for dataset and evaluation criteria: The use of datasets in SA should follow a certain predetermined standard to control its output quality. Some researchers have used their own datasets [12, 13, 14]. However, there are currently no proper specifications to outline the standards of datasets that should be
Summary of survey on various FS methods
Summary of survey on various FS methods
used in this field of study [40]. The reason for this is because different standards exist in different studies for their respective assessment measurements and datasets. This often results in complicated decision-making to what would be the best methodology to be used. Previous studies [12, 49, 91, 92] used different datasets and measurements, which makes it difficult to judge which is the best technique. Since it is noticeable that each study had used different datasets and evaluation criteria, a standard specification for datasets and evaluation measurement should be introduced to enable a fair comparison between the different methods [40].
Quality of review data: Most of the data required in SA are obtained from various sources, such as the web, social media, forums, and Twitter. Most of these sources can be accessed by anyone. The information contained in these sources may also be unreliable because consumers might deliberately give misleading opinions. Thus, the quality of the comments or opinions about products can be questionable. In addition, there may be spamming problems with the information available on the website. This can affect the output quality generated by SA. Therefore, it is necessary to identify spam in customers’ reviews [93, 94, 95]. Thus, a solution that can evaluate the quality of the reviews that appear in social media must be developed to ensure that the results generated from SA are of quality, reliable, and highly accurate.
Short form words: Comments on websites may also contain words in their short form, such as “pics” for pictures, and “res” for resolution. This can make it difficult to interpret the actual meaning the user wished to convey. It could also have an adverse effect on feature identification and sentiment type, and cause a problem in the classification process. This could be resolved with the help of a linguistic expert, who could advise on the correct and precise language used.
Object identification: Identifying the object in each review is very important in SA. Failure to recognise the intended object in a user’s comment would make the comment useless. Researchers should be able to distinguish between related and unrelated objects in a user’s comment.
Feature extraction and FS: Based on previous studies, various approaches on feature extraction have been introduced in SA. Researchers need to understand the difference between feature extraction in SA and FS in machine learning. Lately, more researches have combined the process of feature extraction and FS to obtain good subset features and to improve the performance of sentiment classification.
Synonym words: Researchers should also consider the functions of synonym words in SA. In [96], it was argued that synonym words need to be identified and grouped together. Additionally, [97] extensively discussed the function of synonym words. They identified that a lot of distinctive features contain synonyms. Consequently, they concluded that the issue of synonym words in SA is a complex one. Thus, it requires a more detailed research. The author in [8] also argued that the process of grouping synonym words in SA is challenging. Meanwhile, [15] claimed that many synonyms are domain dependent. Different synonyms are used in different senses, and thus, not all synonym words can be generalised since this practice will promote more errors [15]. For example, for the domain “movie”, the words “movie” and “picture” are synonymous. However, for the domain “camera”, the word “picture” is synonymous to the word “photo”. Additionally, the word “movie” is more likely to be synonymous to the word “video”. Most feature expressions are multi-word phrases, and thus, they cannot be easily selected from dictionaries [8]. The author also argued that while most aspects of expressions are describing one similar feature, the case is not applicable in the same domain. For example, “expensive” and “cheap” can both indicate the feature “price”, but they are not synonymous (the two are antonyms).
The previously discussed challenges still prevail in the SA h field. However, this study has critically reviewed and discussed findings from previous studies to identify the advantages and limitations of the various FS techniques applied in SA. The advantages and limitations of FS techniques for normal text classification that apply metaheuristic approaches were also reviewed. The potential of using this type of approach as a FS technique in SA was then considered, and the limitations that could be overcome by using a metaheuristic approach were identified.
Classification of the cross-domain sentiment: The problem of cross-domain is equally challenging and need to be taken into consideration in terms of the sentiment classification process. The same words may have different sentiment polarities in different domains. For example, the word “hot” in “The room is very hot” relays a negative sentiment in the domain “house”. However, in the sentence “The shower had great hot water,” “hot” has a positive sentiment in the domain “hotel”. The problem with cross-domain can affect the performance of sentiment classification if it is not rectified. According to [98], the main four problems with cross-domain are:
Sparsity – occurs when words or phrases in the target domain do not exist in the source domain. Polysemy – the meaning of a word changes depending on whether it is in the target domain or in the source domain. This condition makes it difficult to test the accuracy of feature representation. Feature divergence or feature mismatch refers to the mismatch between the domain-specific word/feature [98]. Polarity divergence – a feature that has different sentiment polarity in different domains.
In [98], a combination of the deep learning method and word embedding was suggested to overcome the problems with cross-domain. In their study, [99] were able to develop a sentiment-related index that could determine the association between different lexical elements in specific domains. Then, the SentiRelated algorithm was developed based on this index. This algorithm functions by adding features from the target domain to feature vectors that were extracted from the source domain. This algorithm was capable of reducing the difference between the target domain and the source domain. Nonetheless, numerous solutions were proposed by previous studies to solve the problems with cross-domain. Several factors need to be taken into consideration, such as the different languages used, the cultural factor, linguistic variations, and the different contexts and noises in the data.
Definition of a SW
The most important elements to consider in SA are “sentiment words”, which can act as indicators of sentiment. SWs are also known as “opinion words”. These words can be used to express positive or negative sentiments. For example, words that convey a positive sentiment may include “good”, “great”, and “excellent”, while negative SWs may include “bad”, “annoying”, and “angry”. A SW can also be represented by phrases and idioms, e.g., “It costs me an arm and a leg”. The identification of SWs and phrases is crucial for the success of SA. A list of such words and phrases is called a “sentiment lexicon” or “opinion lexicon” [8].
The importance of SW in SA
SW is an integral element in sentiment classification because it enables words, sentences, or documents to be categorised into positive or negative sentiments. In [18], it was stated that on a documental level, the entire content of a document is identified with either a positive or a negative sentiment. Meanwhile, on a sentential level, the first step in classifying sentences is to classify them into either a subjective or an objective sentence. An objective sentence expresses factual information, while a subjective sentence expresses subjective views and opinions [8]. To note, both levels of analysis (documental and sentential) do not indicate users’ preferences. The author further argued that a finer-grained analysis can only be achieved through an analysis on a feature level. In a feature level analysis, object identification, identification of features in an object, and identification of expression sentiments from users on features are crucially important. Additionally, a SW is important in determining the expression sentiments from users regarding their level of satisfactions.
SWs can also help users assess an object, or a product for sale per day by skimming through the results of the sentiment classification analysis from social media. Nonetheless, the amount of information in social media is overwhelming, which makes it slow and difficult for users to assess a product. Therefore, the SA technology can assist users to automatically process SWs contained in the customer review datasets. Among the steps in SA are text preprocessing, FS, feature and SW matching process, and sentiment classification. Lastly, the outputs from the sentiment classification process could give an overall view on product features; whether it falls under the positive or negative category.
Methods to identify the relationship between feature and SW
A. Nearby adjective
The concept of nearby adjective was used by [14] to identify SWs or opinion words. The authors used adjective words as opinion words. A nearby adjective means that the adjacent adjective can amend nouns or noun phrases that are frequent features. This method was applied when the distance between the feature and the SW was close. But what if they are distant from each other? What if there are more than one feature and sentiment word in the same sentence? How should the matching process between feature and multiple sentiment words be performed? This condition will make it difficult to produce an exact match.
B. Pattern knowledge
Pattern knowledge was used by [23] to extract features and find the nearest SWs to an adjective or adverb. Table 11 shows the list of patterns of extracted phrases. The authors used the Stanford-POS tagger to parse each sentence to identify the noun, noun phrase, or verb group for feature extraction. They collected a set of SWs (adjectives) to determine the opinion orientation (negative or positive) of each sentence. If an adjective appeared to be close to a product feature in a sentence, then it was considered as an opinion word.
Patterns of extracted phrases (adopted from [23])
Patterns of extracted phrases (adopted from [23])
The following are some examples of sentences to illustrate how the pattern knowledge process works:
Sentence 1: This camera is perfect for an enthusiastic amateur photographer. Sentence 2: It is light enough to carry around all day without being cumbersome.
In Sentence 1, the feature “camera” is close to the SW “perfect”. In this sentence, the nearby adjective can be extracted as the SW because this sentence contains the feature. However, Sentence 2 does not contain a feature (camera), but it does contain the SW “light”. Thus, the feature in this sentence is known as an implicit feature. The weakness of this pattern knowledge process is that it cannot extract the SW in Sentence 2 because the sentence contains an implicit feature.
C. Dependency relationship
The authors in [9] proposed the concept of dependency analysis to extract product features and to identify SWs related to these features. The authors used the Stanford-typed dependencies to represent a simple description of the grammatical relation in a sentence. These typed dependencies contained 50 grammatical relations [100, 101]. The grammatical relations were represented in a hierarchy form that had a head and were dependent between words. Figure 3 shows an example of the dependency relationship for a sentence.
They used the Stanford lexicalised parser to compute the syntactic parse tree. There is a huge selection of linguistic structures that could express the relationships between features and SWs. The shortest dependency path and syntactic relationship were combined to develop six syntactic relationships between the product feature and the SW, as shown in Table 12.
Six syntactic relationships (adopted from [9])
Example of a dependency relationship in a sentence.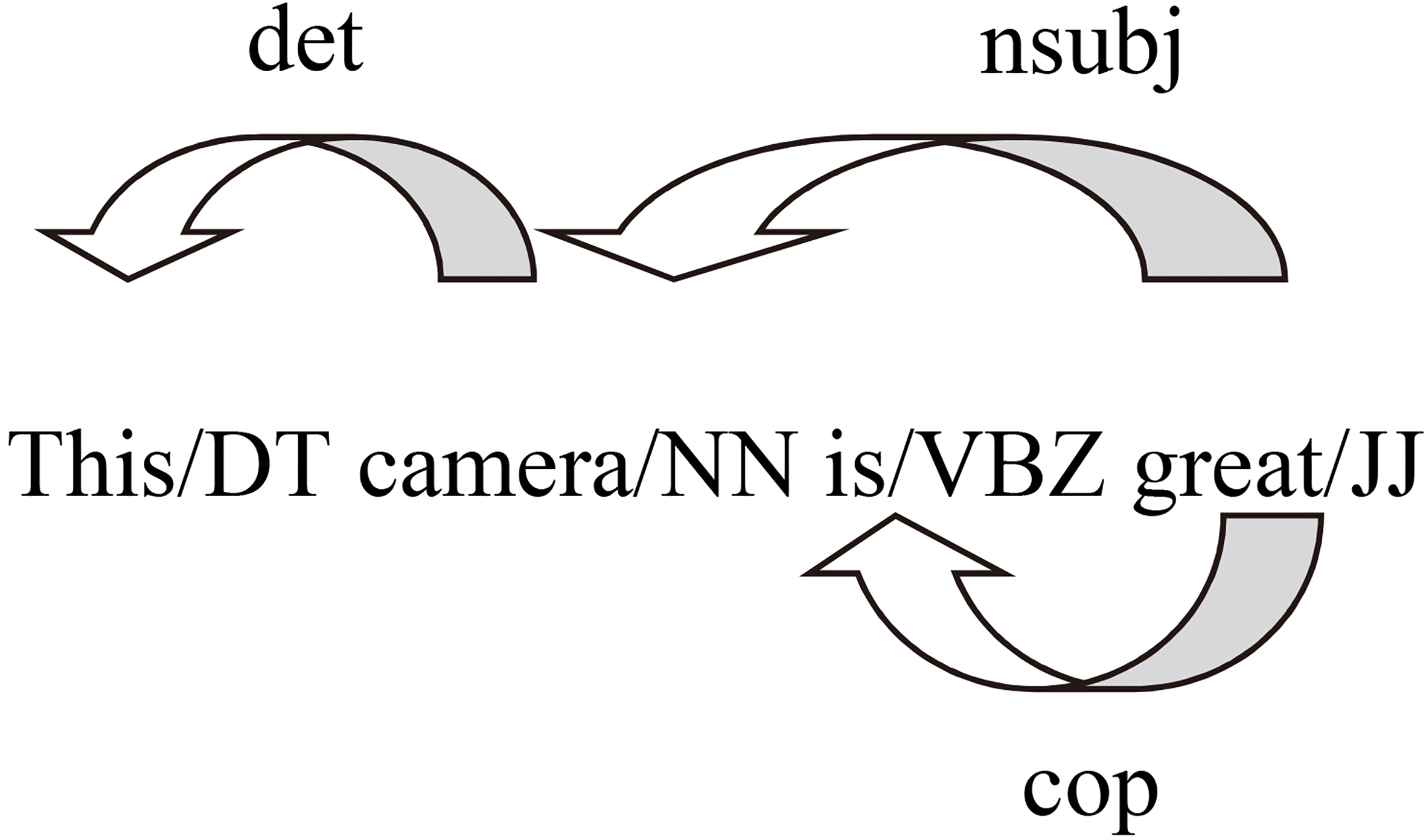
D. Typed dependency relations
In [102], the author used three types of typed dependency relations (TDR) parameters, namely, ACOMP, XCOMP, and ADVMOD, to identify sentiment sentences and their relations with related features. The author also attempted to draw the relationship between features and SWs in a customer review data set by showing that the number of TDR relations involved was more than three, which was more than the typical quantity used. According to [101], TDR in Stanford Parser has approximately 50 grammatical relations.
TDR is clear because it involves a direct link between one word and another in the same sentence. Apart from that, TDR has a closed link, with simple and easy to understand semantic relationships, which facilitate the next interpretation process [100, 103, 104]. TDR also uses Standard English grammatical relationships [103]. They ultimately suggested that this approach is capable of identifying features and SWs in longer and more complex sentences found in customer reviews. Thus, this approach should be explored further.
E. Dependency relations
Similarly, [105] used typed dependency relations in their study to identify the relationship between features and SWs. They were able to identify the two stages in the process of identifying the relationships between features and SWs, known as the word stage and the phrase stage. In this context, fuzzy measurements were used to calculate sentiment phrasal words and opinion degree intensifiers. Each SW has a weightage based on fuzzy measurement, while the weightage for customer review used fuzzy operation. The frequency of a feature SW occurring in each review and the fuzzy weightage value for each sentiment are the two main aspects in determining the weightage value for each customer review. Datasets from different products, namely, Canon camera, Casio watch, and Nike shoes were used to test the proposed algorithm. Based on the datasets, a test that consisted of five main stages (sentiment classification, orientation evaluation and prediction, FS, sentiment word extraction, and the extraction of feature and SW relation) were carried out to validate the method. Consequently, the proposed method has performed well compared to its equivalent algorithm. However, according to [105], this method has a few drawbacks, listed as follows:
The proposed algorithm could not generate dependency relation for long sentences and was unable to extract feature and sentiment words. No strategies to accurately calculate the polarity value of ironic and subjunctive expressions in customer reviews. The use of WordNet dictionary was the most appropriate solution to externally correct wrongly spelled words.
F. Walk and Learn
In [106], a novel two-stage method, named Walk and Learn was proposed. In the first stage, the authors proposed the Sentiment Graph Walking algorithm to cope with the problem of false opinion relation. The sentiment graph was combined with random walking to estimate the pattern of confidence. Therefore, the terms that have low confidence were the terms that were extracted using low-confidence patterns. This condition could improve the accuracy of the extraction. Based on the results from the first phase, the following problems had to be taken into consideration:
False opinion target – there are expressions of opinions that contain non-target terms, such as “good thing”, “nice people” in the review. Low degree of long-tail opinion targets in a Sentiment Graph.
Hence, they used self-learning strategies during the second phase to filter false opinion target and extract long-tail opinion targets from the first stage.
G. A word vector and matrix factorisation
In [107], the author argued that most existing extraction methods use dictionaries. The main weakness of using diaries is the difficulty in identifying domains that rely on sentiment words. Meanwhile, a corpus-based method is dependent on sentiment seed words, but has limited sentiment information, without taking into account the context information. To address this problem, they developed a word vector and a matrix factorisation-based method for extracting opinion lexicon. The results showed that the proposed method had achieved the highest accuracy in identifying sentiment polarities of opinion words.
The three main characteristics that need to be identified from consumers’ comments are entities or objects, characteristics or feature of an object, and SWs that are associated with each object feature. The process of identifying the actual feature in a document or sentence is very important because it plays a major role in determining the actual objects being reviewed or commented on by the consumers. Once the feature is identified in a sentence, the next step is to identify the SW that is associated with the feature of the sentence. However, if the identification of the actual feature and SW fails, this could result in an inaccurate SA output. Inaccurate analysis output could have a poor impact, and the results of the analysis may not help consumers to obtain the actual information regarding matters that concern them, such as products, services, and politics. The relationship between feature and SWs should be accurate so that the SA can generate accurate results. Nonetheless, problems may arise if there is more than one feature and SW in the same sentence. Appropriate methodologies are required to generate a corresponding relationship between feature and SW.
According to [8, 96, 105], the task of identifying features, the SWs they express, and the relationships between features and sentiment expressions from the sentence are very challenging. These challenges must be taken into account when developing a system related to SA, which are discussed in the following subsections.
A. SW has different meanings
A SW that has the same terminology can carry different meanings, polarity, and orientation depending on the context of use. Examples of sentences that have the same terminology, for example, “small” are:
Sentence 1: The camera has a small size; (size
Sentence 1 has a positive orientation because it describes a small-sized camera that can be carried anywhere easily. However, Sentence 2 has a negative orientation because it describes the camera as having a short battery life, thus, the battery needs to be charged or replaced regularly. In addition, the use of negation words, such as “not” and “but” could also affect the orientation and polarity of a sentence, for example:
Sentence 1: The sound is clear. Sentence 2: The sound is not clear.
Sentence 1 illustrates a positive orientation, whereas Sentence 2 has a negative orientation. This difference is due to the use of the negation word, “not”, in Sentence 2. A negation word can modify the sentence from a positive to a negative orientation and vice versa. Several studies have discussed the use of negation words. In [108], the roles of negation words in SA and the various approaches to handle negation words were presented. Additionally, [3, 108] stated that negation words in ironic and sarcastic sentences are difficult to identify. The complications related to negation words are because negations are not only confined to common negation words, such as “not”, “never”, and “no”, they also encompass lexical units, such as phrasal verbs. To note, the word “lexical” denotes the meaning of relating to the vocabulary of a language. Consequently, to handle negation words, every researcher must be well-versed in the type of sentences in datasets, grammar structures, lexical knowledge, semantic relations, and syntactic patterns [109]. Additionally, the factor of reliable identification of genuine polar expressions in specific contexts must be considered in SA [108]. Thus, these conditions must be taken into account when generating a detailed and meaningful output.
B. Implicit SW
SW can also be categorised as explicit or implicit. The sentence, “Orange tastes great” clearly describes the explicit SW, “great”. In comparison, this sentence, “I bought the mattress a week ago, and a valley has formed” has implicit SWs. According to [8], it is difficult to identify an implicit SW, and most previous studies have focused only on sentences that have explicit SWs.
C. Different words to describe a feature
According to [110], consumers use different words to describe the features of a product. For example, both “picture” and “photo” refer to the same feature of a camera. A synonym is a word that has a similar meaning to another word. Synonyms can be found in some dictionaries. Researchers in the field of SA use a lexicon, which is similar to a dictionary. Examples of lexicons are WordNet and SentiWordNet, which have been used in various studies [14, 97, 111, 112] to check for synonyms that are used in the dataset. There are several constraints in the process of identifying a feature when synonyms are involved:
Most of the non-synonymous words in the lexicon literally refer to the same feature in the application domain. “Appearance” and “design” are examples of non-synonymous words, but refer to the same feature of “design” [110]. Many synonyms are dependent on the domain, for example, “movie” and “picture” are examples of synonyms used in a film review. However, the use of these words is different for a camera review, where “picture” is more synonymous with “photo”, whilst “movie” is more synonymous with “video”.
Therefore, according to [110], there is a need for SA to have a group of features that contains a list of the same features of an object or product. In addition, they also recommended the use of the Expectation-Maximisation (EM) algorithm as a semi-supervised learning method to classify all features into several topics according to consumers’ opinions. To meet the needs of consumers, they labelled the data for each topic. Then, the system functioned according to the semi-supervised learning method for categorizing the feature list. In [113], EM was used and two assumptions were established for producing good results:
The lists of features that share words with similar terminologies are gathered in the same group, for example, “battery life” and “battery power”. The lists of features that have similar synonyms in the dictionary are considered as originating from the same group, for example, “movie” and “picture”.
These assumptions could facilitate the classification process when using a better EM technique. However, [2] used the concept of constrained-latent Dirichlet allocation (LDA) to categorise the features. In this technique, two expressions were used in identifying features in the sentences:
If two expressions of a feature share one or more words, they are known as “Must-Link”, where the expressions appear in topics with similar categories, for example, “battery power” and “battery life”. If two expressions of a feature appear in one sentence, they are known as “Cannot-Link”. This is because there is no possibility of reiteration of the same feature in a sentence, for example, “I like the picture quality, battery life, and zoom of this camera”.
D. Implicit feature
According to [14], features can be divided into two categories, namely, explicit and implicit features. An explicit feature leads to a clearer expression in a sentence, for example, “The movie quality of this video is great”. This sentence has clearly described the “movie quality” (noun/noun phrase) as the feature, and “great” as the SW. However, if a sentence contains an implicit feature, the sentence does not have any noun or noun phrase for describing the feature of an object, such as a camera. An example of a sentence that contains an implicit feature is “This camera is light”. This sentence vaguely describes the weight, which is the feature of the camera. Only the adjective word “light” is used to represent the feature of the object, the camera. In addition, an adverb, verb, or verb phrase can be used to represent an implicit feature [8]. It is crucial to identify the actual implicit feature commented on by consumers because the feature in the sentence is implicit or hidden.
E. Pronouns
A word that replaces the noun in a sentence is called a pronoun. The use of pronouns makes it challenging to identify the actual feature that represents the noun in the sentences of users’ comments. In [114], the authors studied and analysed the importance of pronouns in sentences and their effect on sentiment classification. A mechanism or approach is needed to identify the feature represented by the pronouns in sentences. For example, “This one was rated very highly by several people, who checked out this site and epinions.com” has the word “one”, which was used as a pronoun to replace the noun “camera” as the feature.
This review was conducted to determine the prospects of applying the metaheuristic approach as a FS technique in SA. To achieve this objective, research articles on FS techniques from 2003 to 2016 were studied. This review has concluded that FS techniques in sentiment classification can be divided into two categories: i) based on natural language processing; and ii) based on a combination of NLP and machine learning techniques. This review has also identified the research gaps in previous literature based on the positive and negative criteria of each FS technique.
Additionally, the differences in domains have also been reviewed in implementing metaheuristic approach as a FS technique. As explained in Section 3.5, a traditional text classification topically classifies the topics contained in a document, whereas a sentiment classification classifies the features, sentences, or documents into positive or negative sentiments. The similarity of these domains is that the datasets are presented in the form of textual data. It was observed that metaheuristic approaches have been extensively used as FS techniques in traditional text classification. Thus, a review of previous literature was conducted to identify the weaknesses and limitations of metaheuristic approaches. Based on Table 6, genetic algorithm is one of the widely used metaheuristic approaches as a FS technique in SA. However, findings from the literature in Sections 3.4 and 3.5 have shown that ACO possesses a better exploration capability, stronger search capability in problematic space, and higher efficiency in producing minimum subset feature compared to the GA approach [77]. Likewise, this review opines that metaheuristic approaches have the potential to be used as FS techniques in SA. It is inarguable that the domains for sentiment classification and traditional text classification are different. Nonetheless, both classification techniques are still closely linked to text classification.
The technique for detecting the relationships between features and SWs is an important aspect in SA. Failure to accurately detect feature, SW, and the relationship between the two could adversely affect the sentiment classification process. Consequently, the efficiency of the classification process would greatly decrease. The followings are a few suggestions to improve the limitations of the current method:
A more systematic FS technique that is able to perform search processes more efficiently should be used, for example, the metaheuristic approach. In [77], the authors have proven that the metaheuristic approach is able to produce optimum and high-quality feature subset. In the initial stage, customer review datasets have to undergo a data cleaning process to fix spelling and grammatical errors. The use of word processing software, such as Microsoft Word, could help in ensuring that the words are grammatical and correctly spelled [115]. This process is important to ensure that speech tagging and building typed dependency relation, which will come in later stages, are not affected. Failure to execute this process might affect the performance of sentiment classification. The algorithm of feature-SW relation could directly interact with Stanford API to generate and produce POS tags for each word, and formulate typed dependency relations between one word and another in sentences. This situation could help create a dependency for long sentences and automate the process of labelling the grammar in sentences. This process could also help to identify features and sentiments that are present in sentences. Features represented by pronouns and implicit words would need a NLP approach to have them correctly identified.
This paper has critically reviewed the functions of FS and SWs, as well as the relationship between FS techniques and SW in SA. It has also looked at various FS techniques that have been implemented to select the features in SA. The functions of the feature and SW in SA are very important, as mistakes made in selecting features or the actual SWs expressed in user comments could lead to wrong interpretations when the sentiments in the sentence are analysed. This review has also identified a number of studies that have combined NLP and non-NLP techniques, where this combination was able to increase the accuracy of sentiment classification. The selection of suitable NLP or non-NLP techniques should be carefully considered and matched with the problems at hand so that the solution can improve the classification result. This review of the literature in the SA domain has also identified the metaheuristic approach as a potential FS technique for SA, but a limited number of studies have utilised it in their work. This finding was revealed by comparing metaheuristic approaches that were implemented for selecting features in SA, and with those that were used in normal text classification. After analysing numerous articles, this review found that there is clearly a lot of room for research on the FS implementation process and on improving the metaheuristic approach for utilisation in SA.
Footnotes
Acknowledgments
The authors gratefully acknowledge Universiti Pertahanan Nasional Malaysia, the Ministry of Education Malaysia, and the Fundamental Research Grant Scheme for supporting this research project through grant no. FRGS/1/2016/ICT02/UKM/01/2.